
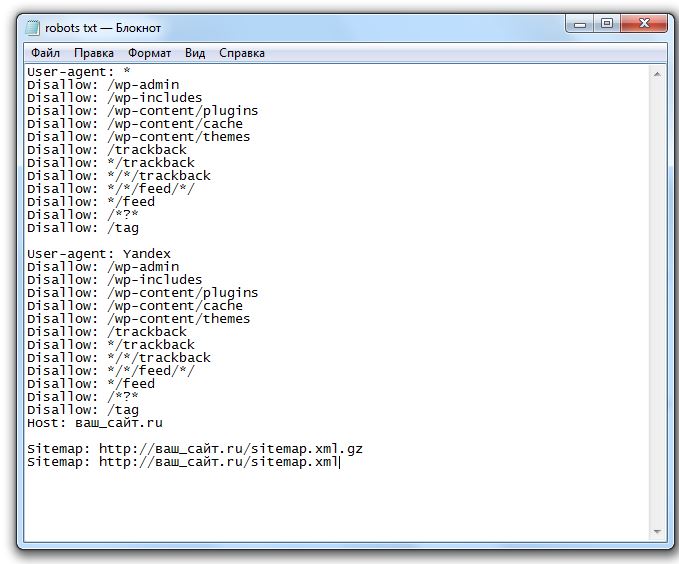
Проверка работы robots.txt на сайте
Файл robots.txt предназначен для роботов поисковых систем и должен быть составлен по определенной структуре для корректной обработки. В этом файле веб-мастер может указать параметры индексирования своего сайта как для всех роботов сразу, так и для каждой поисковой системы по отдельности.
Проверка запрета индексации технических страниц (разделов)
В поисковый индекс могут попасть технические страницы сайта [http://<домен>/]. Нахождение указанных типов страниц в поисковом индексе нежелательно и может негативно повлиять на скорость попадания в поисковый индекс страниц с полезным содержимым (например, продвигаемых страниц).
Для исключения технических страниц из индекса поисковых систем, а так же, предотвращения попадания их в индекс, необходимо внести соответствующие директивы в файл robots.txt:
Disallow: /cart/
Пояснения:
1. /cart/ — раздел корзины
Пример страницы:
[http://<домен>/]cart/
*Окончательный вариант файла robots.
txt делает ваш вебмастер.
 txt делает ваш вебмастер.
txt делает ваш вебмастер.Проверка запрета индексации технических дублей страниц
Технические дубли являются частичными дубликатами основных страниц сайта. Попадание данных страниц в поисковый индекс повлечет за собой проблемы с определением релевантности целевых страниц поисковыми системами и понижение позиций документов сайта в поисковой выдаче.
Для исключения технических дублей страниц из поискового индекса необходимо внести соответствующие директивы в файл robots.txt:
Disallow: /*sort=
Пояснения: /*sort= — параметр сортировки
Пример страницы:
[http://<домен>/| http://www.<домен>/]category/?sort=price
Проверка запрета индексации URL с параметрами по маске
URL-адреса, содержащие параметры, являются полными дубликатами основных страниц сайта. Попадание данных страниц в поисковый индекс повлечет за собой наложение санкций со стороны поисковых систем и понижение позиций документов сайта в поисковой выдаче.
Примеры URL с параметрами:
- [Пример 1] [Дубликат 1], [Дубликат 2], [Дубликат 3] и т.д.
Для исключения полных дублей страниц из поискового индекса необходимо внести соответствующие директивы в файл robots.txt:
Disallow: /*utm_
Пояснения: /*utm_ — URL-адреса, содержащие utm-метки
Пример страницы:
[http://<домен>/]category/?utm_source=yandex&utm_medium=cpc&utm_campaign=action
Проверка правильности записи основного зеркала
Вариант 1. На данный момент основное зеркало сайта указано корректно. Необходимо оставить директорию в файле без изменений:
Host: [<основной хост>]
Вариант 2. На данный момент основное зеркало отсутствует в файле robots.txt. Для того, чтобы указать поисковому роботу Яндекса основное зеркало сайта, необходимо прописать директиву Host с его указанием, непосредственно после директив ‘Disallow'(‘Allow’):
Host: [<основной хост>]
Поделиться с друзьями:
Твитнуть
Поделиться
Плюсануть
Поделиться
Отправить
Класснуть
Линкануть
Запинить
Adblock
detector
Что такое robots.
 txt и какие инструменты для его проверки существуют?
txt и какие инструменты для его проверки существуют?Содержание
- Что такое Robots.txt и зачем он нужен?
- Из чего же, из чего же сделан robots.txt?
- Не правилами едиными…
- Чем проверить robots.txt?
- Какие ошибки часто возникают при работе с индексным файлом?
- Не так просто как кажется
Впервые о файле robots.txt (его ещё называют индексным) услышали в 1994 году. За 26 лет его существования изменилось многое, кроме одного – большинство владельцев сайтов до сих пор ничего о нём не знают. Почему стоит познакомиться с robots.txt вашего сайта? Почему так важна его грамотная настройка? Какие ошибки обычно возникают при работе с robots.txt? И как понять, что в файл пора вносить правки? Давайте разбираться.
Robots.txt по праву можно назвать помощником поисковых роботов. Этот файл подсказываем им, какие разделы есть на сайте, какие страницы стоит посмотреть, а на какие заглядывать нет никакой необходимости.
В рамках SEO файл robots.txt тщательно анализируют с помощью инструментов для его проверки. Почему это так важно? Потому что всего одна ошибка в содержимом этого помощника поисковых роботов может стоить вам бюджета продвижения. Заглянем внутрь этого файла и изучим его подробнее.
Чтобы изучить индексный файл своего сайта, откройте его. Для этого зайдите на главную страницу своего ресурса, в адресной строке после адреса сайта поставьте слэш, а затем введите название файла, который вам нужен (robots.txt). Загрузите страницу. Перед вами тот самый индексный файл. Первая часть нашего robots.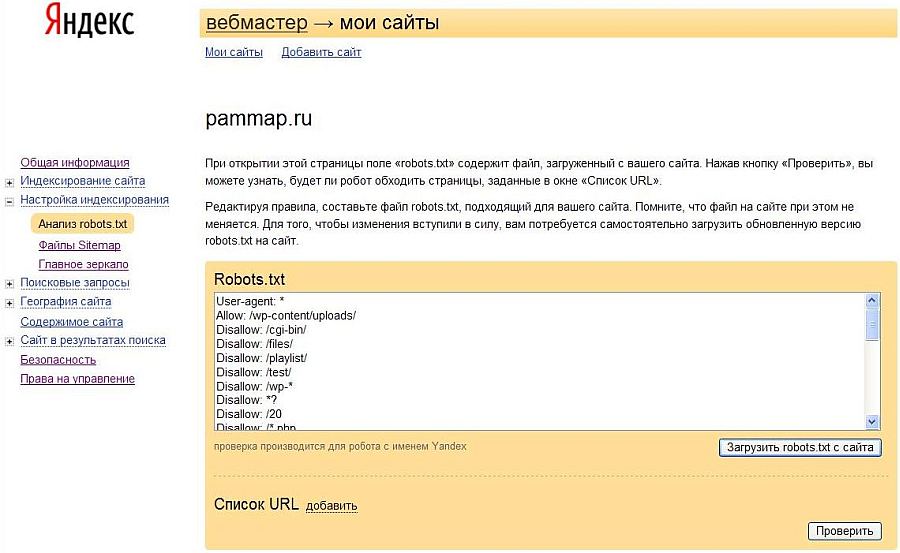
Ваш robots.txt сильно отличается? Не спешите расстраиваться.
User-agent
Если напротив User-agent в вашем индексном файле прописан Googlebot или Yandex, значит правила задаются только для указанного робота. Звездочка, использованная в примере ниже, показывает, что правила действуют для всех поисковых роботов без исключения. Ошибки в этом правиле можно найти и без инструмента для проверки файла robots.txt.
Disallow
Если на сайте нет страниц, которые нужно закрывать от сканирования, robots.txt может выглядеть вот так:
Если сайт полностью закрыт от индексации, то запись будет отличаться всего на один символ:

Allow
Тогда как предыдущее правило запрещает индексирование определенного контента, то это, наоборот, разрешает. Когда его использовать? Например, вы хотите показывать только те страницы, которые располагаются в разделе «Каталог». Все остальные страницы в таком случае закрываются от индексации с помощью правила Disallow.
Host
Это правило используется для показа роботу главного зеркала сайта, которое нужно индексировать. Если сайт работает на HTTPS, протокол обязательно прописывается в индексном файле. Если на HTTP, название протокола можно опустить. Выяснить, верно ли прописано это правило на вашем сайте, можно и не используя инструмент для проверки файла robots.txt. Достаточно найти строку со словом host и сравнить её с образцом.
Sitemap
С помощью этого правила вы показываете роботам поисковых систем, где можно посмотреть все урлы вашего сайта, которые он должен проиндексировать. Чтобы их найти, роботу придётся прогуляться по адресу типа https://site.ua/sitemap.xml. Всё это вписывается в индексный файл. У нас это сделано вот так:
Чтобы их найти, роботу придётся прогуляться по адресу типа https://site.ua/sitemap.xml. Всё это вписывается в индексный файл. У нас это сделано вот так:
Crawl-delay
Правило стоит использовать, если у вашего ресурса слабый сервер. Оно позволяет увеличивать длину промежутка загрузки страниц. Параметр по умолчанию измеряется в секундах.
Clean-param
Это правило призвано бороться с дублированием контента, связанным с динамическими параметрами. Из-за сортировок, разных id сессий и других причин на сайте одна и та же страница может быть доступна по нескольким адресам. Чтобы поисковый робот не расценил такое явление как дублирование, его прописывают в robots.txt. Если страница отвечает по адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
www.site. com/catalog/get_phone.ua?ref=page_2&phone_id=1,
com/catalog/get_phone.ua?ref=page_2&phone_id=1,
то правило выглядит следующим образом:
Прежде чем познакомиться с инструментами для проверки файла robots.txt рассмотрим символы, применяемыми в нем.
Чаще всего в robots.txt используются следующие символы:
- Звездочка
Необходима для обозначения любой последовательности. Например, с её помощью можно спрятать от робота все файлы с расширением gif, хранящиеся в папке catalog. - Слэш
Ставится для обозначения местонахождения файла в корневом каталоге, а также в тех случаях, когда нужно закрывать от индексации весь сайт. - Знак доллара
Этот символ показывает, где перестает действовать звездочка. В примере на скриншоте мы закрываем от индексации содержимое папки каталог, но при этом урлы, в которых содержится элемент catalog, индексировать разрешено. - Решётка
Используется значительно реже, чем все остальные символы, потому как нужна только для комментариев. После решётки можно написать любую подсказку, которая поможет в работе вам или веб-мастеру, работающему с сайтом.

В интернете можно найти добрую сотню сервисов, разбирающих по косточкам индексные файлы сайтов. Мы доверяем только тем, которые учитывают все изменения в алгоритмах поисковых систем. А таких сервисов всего 2: Google Webmaster Tools и «Анализ robots.txt» от Яндекса. Покажем, как работать с каждым из них.
Google Webmaster Tools
Чтобы начать пользоваться этим инструментом, нужно войти в свой Google-аккаунт, а потом открыть эту ссылку.
Если это ваше первое знакомство с Google Webmaster, придётся добавить сайт и подтвердить свои права на него. Сделать это можно несколькими способами. Самый простой из них – закачка файлов.
После подтверждения прав на сайт вы получите полный доступ к инструменту для проверки файла robots.txt. Выберите этот сервис в панели меню, затем укажите, что хотите проанализировать индексный файл своего сайта. И получите результаты проверки. Выглядеть это будет примерно так:
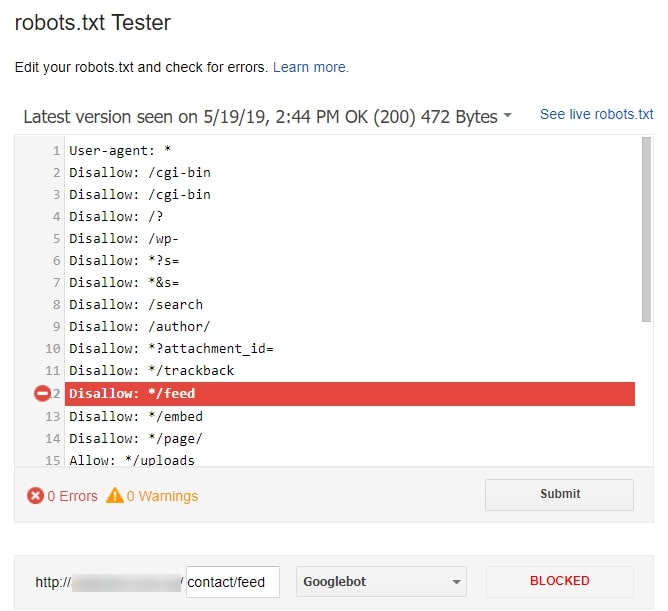
Красным прямоугольником мы выделили строку, на которую вам нужно обратить своё внимание в первую очередь. Здесь показывается, есть ли ошибки в robots.txt. Если инструмент нашёл ошибки, пролистайте содержимое файла с помощью бегунка и найдите значок белый крест в красном круге на полях. В тех строках, где есть такие значки, что-то написано неправильно. К сожалению, Google ещё не научился сразу же говорить, что именно не так, и предлагать исправления. Поэтому с ошибками придётся разбираться самостоятельно. Или обращаться за советом к профессионалам.
Новая версия этого инструмента для проверки файла robots.txt даёт возможность смотреть, открыты ли для индексации новые страницы. Она также позволяет вносить изменения в индексный файл сразу же после нахождения ошибок. Для этого больше не нужно открывать robots.txt в отдельной вкладке. Ещё одна фишка обновления – просмотр старых версий индексного файла. Вы можете посмотреть не только, что вы меняли в robots.txt, но и как на это реагировали роботы.
Она также позволяет вносить изменения в индексный файл сразу же после нахождения ошибок. Для этого больше не нужно открывать robots.txt в отдельной вкладке. Ещё одна фишка обновления – просмотр старых версий индексного файла. Вы можете посмотреть не только, что вы меняли в robots.txt, но и как на это реагировали роботы.
В связке с этим инструментом стоит использовать просмотр сайта глазами Googlebot. Применяя эту функцию, вы сможете проанализировать, понравится ли роботу поисковых систем ваш сайт или нет.
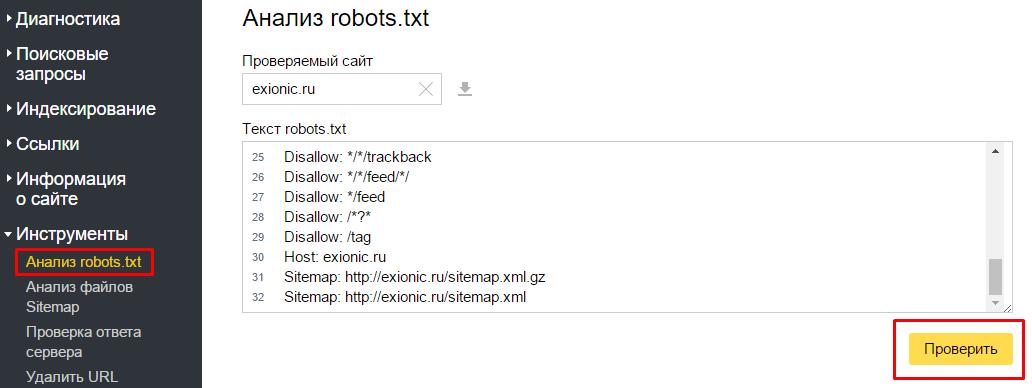
«Анализ robots.txt»
С этим сервисом всё проще, хотя бы потому что он приспособлен для русскоязычного пользователя. Прежде чем приступить к непосредственной работе с инструментом для проверки robots.txt, придется пройти те же этапы, что и с Google Webmaster Tools. Когда получите доступ к сервису, загляните в боковое меню и найдите в нём интересующий нас сервис.
На этой странице вы увидите результаты анализа индексного файла.
В разделе «Анализ robots.txt» также можно узнать, индексируются ли определённые страницы сайта или нет. Для этого урлы вносят в нижнее окно и отправляют на проверку.
Правильная настройка robots.txt напрямую влияет на то, какие страницы сайта попадут в индекс и будут выводиться в поиске, а какие никогда там не окажутся. Поэтому так важно свести риск возникновения ошибок в работе индексного файла к минимуму. Вот самые частотные:
- В файле прописано правило, закрывающее весь сайт от индексации, например, Disallow со значком слэш;
- Для индексации открыты страницы с ID-сессий и страницы с UTM-метками;
- Sitemap указан некорректно;
- Применяются только стандартные правила и не прорабатываются каталоги, страницы, технические папки и другие категории. Как результат, роботы индексируют всё подряд.
 Как результат, роботы индексируют всё подряд.
Как результат, роботы индексируют всё подряд.Думали, что разберетесь с robots.txt за 5 минут и тут же внесете в него правки, но что-то пошло не так? Не расстраивайтесь. Специалисты Студии ЯЛ решат вашу проблему. Позвоните нам и мы дадим профессиональный совет. Ну а если вы не хотите разбираться с индексным файлом, поручите это нам. В рамках оптимизации и SEO-продвижения сотрудники Студии ЯЛ приведут в порядок ваш robots.txt и не только.
Другие материалы:
- Настройка цели в Google Analytics для нажатия на кнопку. Пошаговая инструкция
- Таргетированная реклама в Инстаграм (признана экстремистской организацией, деятельность которой запрещена в Российской Федерации): виды и правила настройки
- Тильда: возможности и преимущества, недостатки и нюансы
🤖 Анализ и тестирование файлов robots.txt в больших масштабах — Python
Несмотря на крошечный размер, файлы robots. txt содержат важные инструкции.
которые могут заблокировать основные разделы вашего сайта, что они и должны
делать. Только иногда вы можете совершить ошибку, заблокировав не тот раздел.
txt содержат важные инструкции.
которые могут заблокировать основные разделы вашего сайта, что они и должны
делать. Только иногда вы можете совершить ошибку, заблокировав не тот раздел.
Поэтому очень важно проверить, доступны ли определенные страницы (или группы страниц). заблокирован для определенного user-agent определенным файлом robots.txt. В идеале вы хотел бы запустить ту же проверку для всех возможных пользовательских агентов. Даже больше в идеале вы хотите иметь возможность запускать проверку большого количества страниц с помощью все возможные комбинации с пользовательскими агентами.
Чтобы преобразовать файл robots.txt в удобный для чтения формат, вы можете использовать robotstxt_to_df() , чтобы получить его в DataFrame.
импортировать рекламные инструменты как рекламу
amazon = adv.robotstxt_to_df('https://www.amazon.com/robots.txt')
Амазонка
директива | содержание | etag | robotstxt_last_modified | robotstxt_url | дата_загрузки | |
|---|---|---|---|---|---|---|
0 | Агент пользователя | * | «а850165д925дб701988даф7еад7492д3» | 28. | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
1 | Запретить | /exec/obidos/аккаунт-доступ-логин | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
2 | Запретить | /exec/obidos/change-style | «а850165д925db701988daf7ead7492d3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
3 | Запретить | /exec/obidos/flex-вход | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www. | 2022-02-11 19:33:03.200689+00:00 |
4 | Запретить | /exec/obidos/handle-buy-box | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
… | … | … | … | … | … | … |
146 | Запретить | /hp/video/mystuff | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 11 февраля 2022 г. 19:33:03.200689+00:00 |
147 | Запретить | /gp/видео/профили | «а850165д925дб701988даф7еад7492д3» | 28. | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
148 | Запретить | /hp/video/профили | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
149 | Агент пользователя | ЭтаоСпайдер | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
150 | Запретить | / | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon. | 2022-02-11 19:33:03.200689+00:00 |
 10.2021 17:51:39+00:00
10.2021 17:51:39+00:00 amazon.com/robots.txt
amazon.com/robots.txt 10.2021 17:51:39+00:00
10.2021 17:51:39+00:00 com/robots.txt
com/robots.txtВозвращенный DataFrame содержит столбцы для директив, их содержимое, URL файла robots.txt, а также дату его загрузки.
директива : Основные команды. Разрешить, Запретить, Карта сайта, Задержка сканирования, Пользователь-агент и так далее.
содержание : Детали каждой из директив.
robotstxt_last_modified : Дата последней публикации файла robots.txt модифицировано, если указано (согласно заголовку ответа Last-modified).
etag : Тег сущности заголовка ответа, если он предоставлен.
robotstxt_url : URL-адрес файла robots.txt.
download_date : Дата и время загрузки файла.
Кроме того, вы можете предоставить список URL-адресов роботов, если хотите скачать
их все за один раз.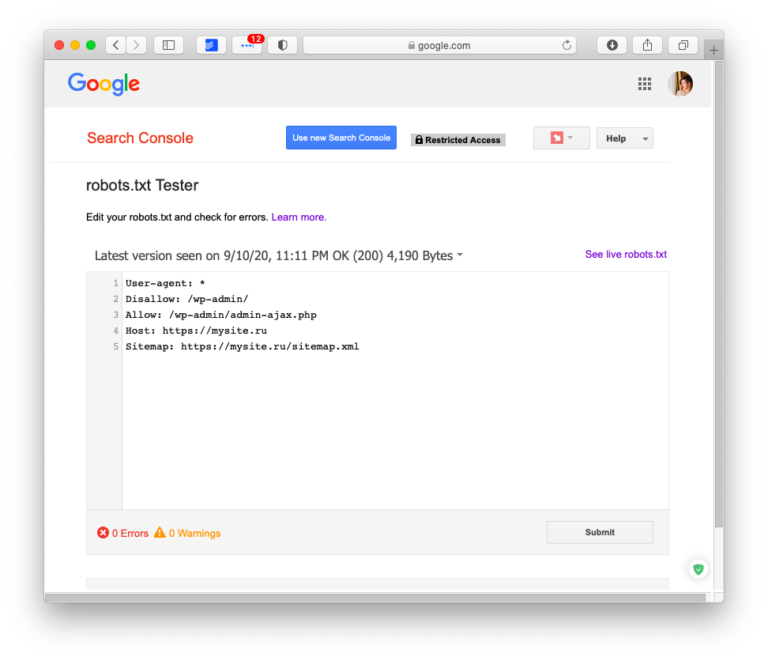 Это может быть интересно, если:
Это может быть интересно, если:
Вы анализируете отрасль и хотите следить за множеством различных сайты.
Вы анализируете веб-сайт со множеством поддоменов и хотите получить все файлы robots вместе.
Вы пытаетесь понять компанию, у которой много веб-сайтов под разными названиями. домены и поддомены.
В этом случае вы просто предоставляете список URL-адресов вместо одного.
robots_urls = ['https://www.google.com/robots.txt',
'https://twitter.com/robots.txt',
'https://facebook.com/robots.txt']
googtwfb = adv.robotstxt_to_df(robots_urls)
# Сколько строк в каждом файле robots?
googtwfb.groupby('robotstxt_url')['директива'].count()
robotstxt_url https://facebook.com/robots.txt 541 https://twitter.com/robots.txt 108 https://www.google.com/robots.txt 289 Имя: директива, dtype: int64
# Показать первые пять строк каждого из файлов robots: googtwfb.
 groupby('robotstxt_url').head()
groupby('robotstxt_url').head()
директива | содержание | robotstxt_last_modified | robotstxt_url | дата_загрузки | |
|---|---|---|---|---|---|
0 | Агент пользователя | * | 2022-02-07 22:30:00+00:00 | https://www.google.com/robots.txt | 2022-02-11 19:52:13.375724+00:00 |
1 | Запретить | /поиск | 2022-02-07 22:30:00+00:00 | https://www.google.com/robots.txt | 2022-02-11 19:52:13.375724+00:00 |
2 | Разрешить | /поиск/о | 2022-02-07 22:30:00+00:00 | https://www.google. | 2022-02-11 19:52:13.375724+00:00 |
3 | Разрешить | /поиск/статический | 2022-02-07 22:30:00+00:00 | https://www.google.com/robots.txt | 2022-02-11 19:52:13.375724+00:00 |
4 | Разрешить | /search/howsearchworks | 2022-02-07 22:30:00+00:00 | https://www.google.com/robots.txt | 2022-02-11 19:52:13.375724+00:00 |
289 | комментарий | Робот поисковой системы Google | НаТ | https://twitter.com/robots.txt | 2022-02-11 19:52:13.461815+00:00 |
290 | комментарий | НаТ | https://twitter.com/robots.txt | 2022-02-11 19:52:13. | |
291 | Агент пользователя | Гуглбот | НаТ | https://twitter.com/robots.txt | 2022-02-11 19:52:13.461815+00:00 |
292 | Разрешить | /?_escaped_fragment_ | НаТ | https://twitter.com/robots.txt | 2022-02-11 19:52:13.461815+00:00 |
293 | Разрешить | /*?язык= | НаТ | https://twitter.com/robots.txt | 2022-02-11 19:52:13.461815+00:00 |
397 | комментарий | Примечание. Сбор данных на Facebook с помощью автоматизированных средств | НаТ | https://facebook.com/robots.txt | 2022-02-11 19:52:13.474456+00:00 |
398 | комментарий | запрещено, если у вас нет письменного разрешения от Facebook | НаТ | https://facebook. | 2022-02-11 19:52:13.474456+00:00 |
399 | комментарий | и может проводиться только для ограниченной цели, указанной в указанном | НаТ | https://facebook.com/robots.txt | 2022-02-11 19:52:13.474456+00:00 |
400 | комментарий | разрешение. | НаТ | https://facebook.com/robots.txt | 2022-02-11 19:52:13.474456+00:00 |
401 | комментарий | См.: http://www.facebook.com/apps/site_scraping_tos_terms.php | НаТ | https://facebook.com/robots.txt | 2022-02-11 19:52:13.474456+00:00 |
 com/robots.txt
com/robots.txt 461815+00:00
461815+00:00 com/robots.txt
com/robots.txtМассовая
robots.txt Тестер Этот тестер предназначен для работы в больших масштабах.
robotstxt_test() функция запускает тест для заданного файла robots.txt, проверяя, какой из
при условии, что пользовательские агенты могут получить, какой из предоставленных URL-адресов, путей или шаблонов.
импортировать рекламные инструменты как рекламу
adv.robotstxt_test(
robotstxt_url='https://www.amazon.com/robots.txt',
user_agents=['Googlebot', 'baiduspider', 'Bingbot'],
urls=['/', '/hello', '/some-page.html'])
В результате вы получаете DataFrame со строкой для каждой комбинации (пользовательский агент, URL), указывающий, может ли этот конкретный пользовательский агент получить указанный URL.
Некоторые причины, по которым вы можете это сделать:
SEO-аудит: особенно для крупных веб-сайтов с множеством шаблонов URL и правила для разных юзер-агентов.
Разработчик или владелец сайта собирается внести большие изменения
Интерес к стратегиям некоторых компаний
Пользовательские агенты
На самом деле есть только две группы пользовательских агентов, о которых вам нужно беспокоиться о:
Пользовательские агенты, перечисленные в файле robots.
txt: для каждого из них вам необходимо
проверить, заблокированы ли они для получения определенного URL-адреса
(или узор).*все остальные пользовательские агенты:*включает в себя все другие пользовательские агенты, поэтому проверка применимых к нему правил должна позаботиться обо всем остальном.
 txt: для каждого из них вам необходимо
проверить, заблокированы ли они для получения определенного URL-адреса
(или узор).
txt: для каждого из них вам необходимо
проверить, заблокированы ли они для получения определенного URL-адреса
(или узор).robots.txt Подход к тестированию
Получите интересующий вас файл robots.txt
Извлечь из него пользовательские агенты
Укажите URL-адреса, которые вы хотите протестировать
Запустить функцию
robotstxt_test()
fb_robots = adv.robotstxt_to_df('https://www.facebook.com/robots.txt')
fb_robots
директива | содержание | robotstxt_url | дата_загрузки | |
|---|---|---|---|---|
0 | комментарий | Примечание: Сбор данных на Facebook с помощью автоматизированных средств | https://www. | 2022-02-12 00:48:58.951053+00:00 |
1 | комментарий | запрещено, если у вас нет письменного разрешения от Facebook | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
2 | комментарий | и может проводиться только для ограниченной цели, указанной в указанном | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
3 | комментарий | разрешение. | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
4 | комментарий | См.: http://www.facebook.com/apps/site_scraping_tos_terms.php | https://www. | 2022-02-12 00:48:58.951053+00:00 |
… | … | … | … | … |
536 | Разрешить | /ajax/pagelet/generic.php/PagePostsSectionPagelet | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
537 | Разрешить | /карьера/ | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
538 | Разрешить | /проверка безопасности/ | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
539 | Агент пользователя | https://www. | 2022-02-12 00:48:58.951053+00:00 | |
540 | Запретить | / | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
 facebook.com/robots.txt
facebook.com/robots.txt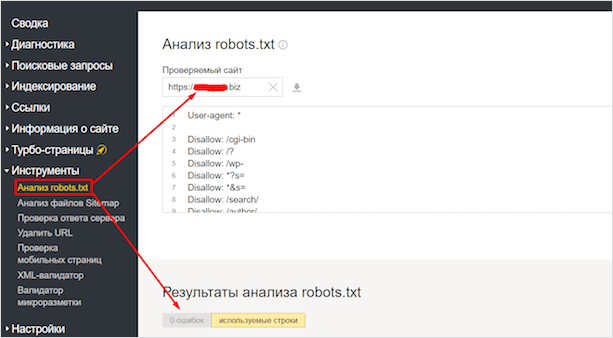 facebook.com/robots.txt
facebook.com/robots.txt facebook.com/robots.txt
facebook.com/robots.txtТеперь, когда мы загрузили файл, мы можем легко извлечь список пользовательские агенты, которые он содержит.
fb_useragents = (fb_robots
[fb_robots['директива']=='Агент пользователя']
['контент'].drop_duplicates()
.к списку())
fb_useragents
['Applebot', 'байдуспайдер', 'Бингбот', «Дискорбот», 'facebookexternalhit', 'гуглбот', 'Googlebot-Изображение', 'ia_archiver', 'LinkedInBot', мснбот, «Навербот», 'Pinterestbot', 'сезнамбот', 'Хлеб', 'теома', 'ТелеграмБот', «Твиттербот», 'Яндекс', 'Йети', '*']
Довольно длинный список!
В качестве небольшого и быстрого теста мне интересно проверить домашнюю страницу, случайный
страница профиля (/bbc), страницы групп и хэштегов.
urls_to_test = ['/', '/bbc', '/groups', '/хэштег/']
fb_test = robotstxt_test('https://www.facebook.com/robots.txt',
fb_useragents, urls_to_test)
fb_test
robotstxt_url | пользователь_агент | url_path | can_fetch | |
|---|---|---|---|---|
0 | https://www.facebook.com/robots.txt | * | / | Ложь |
1 | https://www.facebook.com/robots.txt | * | /ББК | Ложь |
2 | https://www.facebook.com/robots.txt | * | /группы | Ложь |
3 | https://www.facebook. | * | /хэштег/ | Ложь |
4 | https://www.facebook.com/robots.txt | Эпплбот | / | Правда |
… | … | … | … | |
75 | https://www.facebook.com/robots.txt | сезнамбот | /хэштег/ | Правда |
76 | https://www.facebook.com/robots.txt | теома | / | Правда |
77 | https://www.facebook.com/robots.txt | теома | /ББК | Правда |
78 | https://www.facebook.com/robots.txt | теома | /группы | Правда |
79 | https://www. | теома | /хэштег/ | Правда |
 com/robots.txt
com/robots.txt facebook.com/robots.txt
facebook.com/robots.txtДля двадцати пользовательских агентов и четырех URL-адресов каждый мы получили в общей сложности восемьдесят тестовых Результаты. Сразу видно, что все юзер-агенты, не указанные в списке (обозначаются * не разрешено получать ни один из предоставленных URL-адресов).
Посмотрим, кому разрешено, а кому нет доступа к домашней странице.
fb_test.query('url_path== "/"')
robotstxt_url | пользователь_агент | url_path | can_fetch | |
|---|---|---|---|---|
0 | https://www.facebook.com/robots.txt | * | / | Ложь |
4 | https://www. | Эпплбот | / | Правда |
8 | https://www.facebook.com/robots.txt | Бингбот | / | Правда |
12 | https://www.facebook.com/robots.txt | Дискордбот | / | Ложь |
16 | https://www.facebook.com/robots.txt | Гуглбот | / | Правда |
20 | https://www.facebook.com/robots.txt | Googlebot-изображение | / | Правда |
24 | https://www.facebook.com/robots.txt | LinkedInBot | / | Ложь |
28 | https://www. | Навербот | / | Правда |
32 | https://www.facebook.com/robots.txt | Pinterestbot | / | Ложь |
36 | https://www.facebook.com/robots.txt | Хлеб | / | Правда |
40 | https://www.facebook.com/robots.txt | TelegramBot | / | Ложь |
44 | https://www.facebook.com/robots.txt | Твиттербот | / | Правда |
48 | https://www.facebook.com/robots.txt | Яндекс | / | Правда |
52 | https://www. | Йети | / | Правда |
56 | https://www.facebook.com/robots.txt | байдуспайдер | / | Правда |
60 | https://www.facebook.com/robots.txt | facebookexternalhit | / | Ложь |
64 | https://www.facebook.com/robots.txt | ia_archiver | / | Ложь |
68 | https://www.facebook.com/robots.txt | msnbot | / | Правда |
72 | https://www.facebook.com/robots.txt | сезнамбот | / | Правда |
76 | https://www. | теома | / | Правда |
 facebook.com/robots.txt
facebook.com/robots.txt facebook.com/robots.txt
facebook.com/robots.txt facebook.com/robots.txt
facebook.com/robots.txt facebook.com/robots.txt
facebook.com/robots.txtЯ оставлю это вам, чтобы выяснить, почему LinkedIn и Pinterest запрещены. сканировать домашнюю страницу, но Google и Apple, потому что я понятия не имею!
- robotstxt_test( robotstxt_url , user_agents , URL )[источник]
Учитывая
robotstxt_url, проверьте, какой изuser_agentsявляется разрешено получать, какой изURL-адресов.Все комбинации
user_agentsиURL-адресабудут проверено, и результаты возвращаются в одном кадре данных.>>> robotstxt_test('https://facebook.com/robots.txt', ... user_agents=['*', 'Googlebot', 'Applebot'], ... urls=['/', '/bbc', '/groups', '/hashtag/']) robotstxt_url user_agent url_path can_fetch 0 https://facebook.com/robots.txt * / Ложь 1 https://facebook. com/robots.txt * /bbc Ложь
2 https://facebook.com/robots.txt * /groups Ложь
3 https://facebook.com/robots.txt * /хэштег/ Ложь
4 https://facebook.com/robots.txt Applebot/True
5 https://facebook.com/robots.txt Applebot/bbc Правда
6 https://facebook.com/robots.txt Applebot/группы Правда
7 https://facebook.com/robots.txt Applebot /hashtag/ Ложь
8 https://facebook.com/robots.txt Googlebot / Правда
9https://facebook.com/robots.txt Googlebot/bbc Правда
10 https://facebook.com/robots.txt Googlebot /groups Верно
11 https://facebook.com/robots.txt Googlebot /hashtag/ Ложь
- Параметры
robotstxt_url ( url ) — URL файла robotx.txt
user_agents ( str , список ) — Один или несколько пользовательских агентов
URL-адреса ( str , list ) — Один или несколько путей (относительных) или URL-адресов (абсолютных) к чек
- Возврат DataFrame robotstxt_test_df
 com/robots.txt * /bbc Ложь
2 https://facebook.com/robots.txt * /groups Ложь
3 https://facebook.com/robots.txt * /хэштег/ Ложь
4 https://facebook.com/robots.txt Applebot/True
5 https://facebook.com/robots.txt Applebot/bbc Правда
6 https://facebook.com/robots.txt Applebot/группы Правда
7 https://facebook.com/robots.txt Applebot /hashtag/ Ложь
8 https://facebook.com/robots.txt Googlebot / Правда
9https://facebook.com/robots.txt Googlebot/bbc Правда
10 https://facebook.com/robots.txt Googlebot /groups Верно
11 https://facebook.com/robots.txt Googlebot /hashtag/ Ложь
com/robots.txt * /bbc Ложь
2 https://facebook.com/robots.txt * /groups Ложь
3 https://facebook.com/robots.txt * /хэштег/ Ложь
4 https://facebook.com/robots.txt Applebot/True
5 https://facebook.com/robots.txt Applebot/bbc Правда
6 https://facebook.com/robots.txt Applebot/группы Правда
7 https://facebook.com/robots.txt Applebot /hashtag/ Ложь
8 https://facebook.com/robots.txt Googlebot / Правда
9https://facebook.com/robots.txt Googlebot/bbc Правда
10 https://facebook.com/robots.txt Googlebot /groups Верно
11 https://facebook.com/robots.txt Googlebot /hashtag/ Ложь
- robotstxt_to_df( robotstxt_url , output_file=None )[источник]
Загрузить содержимое
robotstxt_urlв DataFrameВы также можете использовать его для загрузки нескольких файлов robots, передав список URL-адреса.
>>> robotstxt_to_df('https://www.twitter.com/robots.txt') содержание директивы robotstxt_url download_date 0 Пользователь-агент * https://www.twitter.com/robots.txt 2020-09-27 21:57:23.702814+00:00 1 Запретить / https://www.twitter.com/robots.txt 2020-09-27 21:57:23.702814+00:00>>> robotstxt_to_df(['https://www.google.com/robots.txt', ... 'https://www.twitter.com/robots.txt']) содержание директивы robotstxt_last_modified robotstxt_url download_date 0 Агент пользователя * 2021-01-11 21:00:00+00:00 https://www.google.com/robots.txt 2021-01-16 14:08:50.087985+00:00 1 Disallow /search 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00 2 Разрешить /search/about 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00 3 Разрешить /search/static 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00 4 Разрешить /search/howsearchworks 11-01-2021 21:00:00+00:00 https://www. google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
283 User-agent facebookexternalhit 11.01.2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
284 Разрешить /imgres 2021-01-11 21:00:00+00:00 https://www.google.com/robots.txt 2021-01-16 14:08:50.087985+00:00
285 Карта сайта https://www.google.com/sitemap.xml 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08 :50.087985+00:00
286 User-agent * NaT https://www.twitter.com/robots.txt 2021-01-16 14:08:50.468588+00:00
287 Disallow / NaT https://www.twitter.com/robots.txt 2021-01-16 14:08:50.468588+00:00
В исследовательских целях и если вы хотите скачать более ~500 файлов, вам возможно, вы захотите использовать
output_fileдля сохранения результатов по мере их загрузки. Расширение файла должно быть «.jl», к нему добавляются файлы robots. файл, как только они будут загружены, на случай, если вы потеряете соединение или может ваше терпение!>>> robotstxt_to_df(['https://example.
com/robots.txt',
... 'https://example.com/robots.txt',
... 'https://example.com/robots.txt'],
... output_file='robots_output_file.jl')
Чтобы открыть файл как DataFrame:
>>> импортировать панд как pd >>> robotsfiles_df = pd.read_json('robots_output_file.jl', lines=True)- Параметры
robotstxt_url ( url ) — Один или несколько URL-адресов файлов robots.txt
output_file ( str ) — Необязательный путь к файлу для сохранения файлов robots.txt, в основном полезно для загрузки > 500 файлов. файлы добавляются, как только они загружаются. Поддерживаются только расширения «.jl».
- Возвращает DataFrame robotstxt_df
DataFrame, содержащий директивы, их содержание, URL и время загрузки

 google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
283 User-agent facebookexternalhit 11.01.2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
284 Разрешить /imgres 2021-01-11 21:00:00+00:00 https://www.google.com/robots.txt 2021-01-16 14:08:50.087985+00:00
285 Карта сайта https://www.google.com/sitemap.xml 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08 :50.087985+00:00
286 User-agent * NaT https://www.twitter.com/robots.txt 2021-01-16 14:08:50.468588+00:00
287 Disallow / NaT https://www.twitter.com/robots.txt 2021-01-16 14:08:50.468588+00:00
google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
283 User-agent facebookexternalhit 11.01.2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
284 Разрешить /imgres 2021-01-11 21:00:00+00:00 https://www.google.com/robots.txt 2021-01-16 14:08:50.087985+00:00
285 Карта сайта https://www.google.com/sitemap.xml 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08 :50.087985+00:00
286 User-agent * NaT https://www.twitter.com/robots.txt 2021-01-16 14:08:50.468588+00:00
287 Disallow / NaT https://www.twitter.com/robots.txt 2021-01-16 14:08:50.468588+00:00
 com/robots.txt',
... 'https://example.com/robots.txt',
... 'https://example.com/robots.txt'],
... output_file='robots_output_file.jl')
com/robots.txt',
... 'https://example.com/robots.txt',
... 'https://example.com/robots.txt'],
... output_file='robots_output_file.jl')
Как проверить и протестировать файл robots.txt с помощью Python или нет доступа. Благодаря файлам robots.
 txt владельцы веб-сайтов могут контролировать сканеры поисковых систем, чтобы они могли индексировать только необходимую информацию на своем веб-сайте. Кроме того, они могут управлять эффективностью сканирования и бюджетом сканирования. Любая ошибка в файле Robots.txt может смертельно повлиять на проект SEO. Таким образом, важно проверить файл Robots.txt на наличие различных путей и URL-адресов. В этой статье мы увидим, как проверить файл robots.txt для различных типов пользовательских агентов и путей URL с помощью Python и Adertools.
txt владельцы веб-сайтов могут контролировать сканеры поисковых систем, чтобы они могли индексировать только необходимую информацию на своем веб-сайте. Кроме того, они могут управлять эффективностью сканирования и бюджетом сканирования. Любая ошибка в файле Robots.txt может смертельно повлиять на проект SEO. Таким образом, важно проверить файл Robots.txt на наличие различных путей и URL-адресов. В этой статье мы увидим, как проверить файл robots.txt для различных типов пользовательских агентов и путей URL с помощью Python и Adertools.Если у вас недостаточно информации, прежде чем продолжить, вы можете прочитать соответствующие рекомендации.
- Как анализировать и сравнивать файлы Robots.txt с помощью Python
- Что такое файл Robots.txt
В нашем руководстве мы будем использовать Advertools, еще одну библиотеку Python, специально предназначенную для SEO, SEM и анализа текста для цифровых Маркетинг. Прежде чем продолжить, я рекомендую вам подписаться на Элиаса Даббаса, создателя Advertools, в Twitter.
Как выполнить проверку файла Robots.txt с помощью Python?
В нашей последней статье о Python и SEO, связанной с анализом Robots.txt, мы использовали файлы robots.txt «Washington Post» и «New York Times» для сравнения. В этой статье мы продолжим использовать их файлы robots.txt для тестирования. Связанная и необходимая функция от Advertools — «robotstxt_test». Благодаря функции «robotstxt_test» мы можем мгновенно протестировать более одного URL-адреса для более чем одного агента пользователя.
из рекламных инструментов импорта robotstxt_test
robotstxt_test('https://www.nytimes.com/robots.txt', user_agents=['*'], urls=['/ads/']) - Мы импортировали нужную функцию из Advertools.
- Мы провели тест с помощью функции «robotstxt_test».
- Первый параметр — это URL проверенного файла robots.txt.
- Второй параметр предназначен для определения пользовательских агентов, которые будут тестироваться.
- Третий параметр предназначен для определения пути URL-адреса, который будет проверен в соответствии с пользовательскими агентами на основе определенного файла robots. txt.
 txt.
txt.Вы можете увидеть результат проверки файла robots.txt ниже.
Мы выполнили проверку Robots.txt и User-agent через Python.- Первый столбец «robotstxt_url» показывает URL-адрес robots.txt, в соответствии с которым мы тестируем.
- В столбце «user-agent» показаны пользовательские агенты, которые мы тестируем.
- «url_path» показывает фрагмент URL, который мы тестируем.
- «can_fetch» принимает только значения «true» или «false». В этом примере это «False», что означает, что это запрещено.
Давайте рассмотрим пример посложнее.
robotstxt_test('https://www.nytimes.com/robots.txt', user_agents=['Googlebot', 'Twitterbot', 'AhrefsBot', 'Googlebot-Новости', 'SemrushBot-BA'], urls= ['/', 'amp', 'search']) Если мы выполним «Тестирование Robots.txt» с более чем одним URL-адресом и пользовательскими агентами, функция будет выполнять изменения для каждой комбинации и создавать фрейм данных для нас.
Robots. txt Тестирование для нескольких пользовательских агентов.
txt Тестирование для нескольких пользовательских агентов.Вы можете просто сразу увидеть, какой User-agent может достичь какого URL-пути. В нашем примере файлы PDF из New York Times запрещены для всех тестируемых пользовательских агентов, за исключением Googlebot и Googlebot-News. Twitterbot, Ahrefsbot и SemrushBot-BA (Semrush Backlink Bot) не могут его получить.
Мы также можем провести тест для Washington Post, чтобы увидеть похожий ландшафт.
wprobots = 'https://www.washingtonpost.com/robots.txt' robotstxt_test(wprobots, user_agents=['Googlebot', 'Googlebot-Новости', 'Twitterbot', 'AhrefsBot', 'SemrushBot-BA'], urls=['/', '/amphtml/', 'ads'])
Мы присвоили URL-адрес Washington Post Robots.txt в виде строки переменной «wprobots», а затем выполнили наш тест. Вы можете увидеть результат ниже:
Robots.txt тест для Washington Post через Python Мы видим, что только Twitterbot не может получить URL-путь «/amphtml/», а остальные URL-адреса разрешены для разных URL-путей. Если вы хотите протестировать больше URL-путей, вы можете использовать функцию «robotstxt_to_df()», чтобы вы могли видеть URL-пути для их массового тестирования. Вы можете увидеть пример ниже:
Если вы хотите протестировать больше URL-путей, вы можете использовать функцию «robotstxt_to_df()», чтобы вы могли видеть URL-пути для их массового тестирования. Вы можете увидеть пример ниже:
robotstxt_to_df('https://www.google.com/robots.txt')
ВЫВОД>>>
INFO:root:Getting: https://www.google.com/robots.txt Robots.txt можно превратить в Dataframe с помощью Advertools.Здесь мы видим файл robots.txt веб-объекта Google. Вы можете легко просматривать разделы веб-объектов Google благодаря их файлу Robots.txt. Кроме того, вы можете увидеть, что они скрывают от поисковых роботов или сколько у них разделов веб-сайта, о которых вы не знаете. Давайте проведем еще один тест только для файла Google robots.txt. Во-первых, мы извлечем пользовательских агентов в их файл Robots.txt.
googlerbts[googlerbts['директива'].str.contains('.gent',regex=True)]['content'].drop_duplicates().tolist() Мы извлекли только уникальный «пользовательский агент » через значения регулярных выражений из столбца «директива». Если вам интересно узнать больше об этом разделе, вам следует прочитать нашу статью об анализе файла Robots.txt с помощью Python. Вы можете увидеть результат ниже.
Если вам интересно узнать больше об этом разделе, вам следует прочитать нашу статью об анализе файла Robots.txt с помощью Python. Вы можете увидеть результат ниже.
У них есть только четыре разных объявления пользовательского агента. Это означает, что они запрещают или разрешают некоторые специальные области содержимого только для этих пользовательских агентов.
googlerbts[googlerbts['content']=='Twitterbot']
Мы проверяем порядковый номер строки «Twitterbot» в столбце «content».
Мы отфильтровали определенный пользовательский агент из файла robots.txt.Теперь мы должны проверить требуемое пространство индекса, чтобы увидеть, какие изменения сделаны для Twitterbot с точки зрения запрета или разрешения.
googlerbts.iloc[278:296]
Вы можете увидеть результат ниже:
Мы использовали метод «iloc» для фильтрации определенных строк. Google разрешает ботам Twitter и Facebookexternalhit сканировать их папку «изображения». Я предполагаю, что они блокируют некоторые подпапки этого пути URL.
Я предполагаю, что они блокируют некоторые подпапки этого пути URL.
googlerbts[googlerbts['content'].str.contains('.mgres', regex=True)] Вы можете увидеть результат ниже:
Мы отфильтровали специальный URL-путь с помощью регулярного выражения.Мы обнаружили заметку, в которой говорится, что «мы разрешили некоторым определенным сайтам социальных сетей сканировать папки «imgres». Теперь мы можем выполнить наш тест.
robotstxt_test('https://www.google.com/robots.txt', user_agents=['Googlebot', 'Twitterbot', 'Facebookexternalhit', 'Ahrefsbot', 'SemrushBot-BA'], urls=[' /', '/imgres', '/search', '/search/о нас']) Мы проводим тест Robots.txt для «Googlebot», «Twitterbot», «Facebookexternalhit», «Ahrefsbot» и «SemrushBot-BA» для путей URL «/», «/imgres», «/search», и «/поиск/о нас». Вы можете увидеть результат ниже.
Robots.txt Тестирование нескольких пользовательских агентов и URL-адресов. Здесь мы видим, что Ahrefsbot не может добраться до папок «/imgres» и «/search», но может добраться до путей «/» и «/search/about». Мы также видим, что боты Twitterbot и Facebookexternalhit могут добраться до папки «/imgres», как сказано в комментарии Google. Вы можете просканировать веб-сайт или получить все данные из отчета об охвате Google Search Console, чтобы выполнить тест для различных моделей и шаблонов URL, чтобы увидеть, запрещены ли они или разрешены для определенных типов пользовательских агентов.
Мы также видим, что боты Twitterbot и Facebookexternalhit могут добраться до папки «/imgres», как сказано в комментарии Google. Вы можете просканировать веб-сайт или получить все данные из отчета об охвате Google Search Console, чтобы выполнить тест для различных моделей и шаблонов URL, чтобы увидеть, запрещены ли они или разрешены для определенных типов пользовательских агентов.
Чтобы узнать больше о Python SEO, вы можете прочитать соответствующие рекомендации:
- Как массово изменить размер изображений с помощью Python
- Как выполнить обратный просмотр DNS благодаря Python
- Как выполнить анализ TF-IDF с помощью Python
- Как сканировать и анализировать веб-сайт с помощью Python
- Как выполнять анализ текста с помощью Python
- Как сравнивать и анализировать файл robots.txt с помощью Python
- Как анализировать структуру содержимого веб-сайта с помощью файлов Sitemap и Python
Как выполнить тест Robots.
 txt с помощью модуля «urllib» Python
txt с помощью модуля «urllib» PythonПрежде чем продолжить, мы должны сообщить вам, что есть два других варианта тестирования файлов Robots.txt с помощью Python. Это «urllib». Вы можете найти блок кода, который выполняет тест для того же файла robots.txt, что и пример, через «urllib».
импорт urllib.robotparser
robots_url = urllib.robotparser.RobotFileParser(url='https://www.nytimes.com/robots.txt')
robots_url.read()
rrate = robots_url.request_rate("*")
robots_url.crawl_delay("*")
robots_url.can_fetch("*", "https://www.nytimes.com/wirecutter/*?s=") - Первая линия импортирует нужный нам класс модуля.
- Вторая строка анализирует определенный URL-адрес Robots.txt.
- Третья строка считывает проанализированный файл Robots.txt.
- Мы пытаемся перехватить параметр «request-rate» из файла Robots.txt.
- Мы пытаемся проверить, есть ли параметр «crawl-delay» в файле Robots.txt или нет.
- Мы пытаемся получить запрещенный шаблон URL.

Вы можете увидеть результаты ниже:
Анализ образца через urllib.robotparser.По сути, это говорит о том, что параметры «скорость сканирования» или «задержка сканирования» отсутствуют, и запрошенный URL-адрес не может быть получен для определенной группы агента пользователя. Файлы robots.txt могут иметь параметры «скорость сканирования» и «задержка сканирования» для управления пропускной способностью сервера, даже если алгоритмы Google не заботятся об этих параметрах, они могут потребоваться для проверки. Также вы можете столкнуться с более конкретными и уникальными параметрами, такими как «Indexpage».
Как протестировать файлы robots.txt с помощью библиотеки Reppy
Reppy — это библиотека Python, созданная Moz, одним из крупнейших в мире программ для SEO, созданным «Dr. Пит Мейер». Reppy построен на базе репозитория Google Robots.txt, изначально созданного на C++. Мы также можем выполнить некоторые тесты с помощью простой в использовании библиотеки Reppy. Вы можете увидеть пример использования ниже.
Вы можете увидеть пример использования ниже.
из импорта reppy.robots Роботы
роботы = Robots.fetch('https://www.nytimes.com/robots.txt')
robots.allowed('https://www.nytimes.com/wirecutter/*?s=', "*")
агент = robots.agent('googlebot')
agent.allowed('https://www.nytimes.com/news')
robots.agent('Googlebot').delay
robots.sitemaps - Первая строка предназначена для импорта необходимой функции класса.
- Вторая строка предназначена для получения целевого файла robots.txt.
- Третья строка предназначена для проверки определенных пользовательских агентов ситуаций «разрешить и запретить» для данного URL-адреса.
- Четвертая строка предназначена для определения специального пользовательского агента.
- Пятая строка предназначена для проверки различных сценариев только для этого пользовательского агента.
- Шестая строка предназначена для проверки параметра Crawl-delay агента пользователя.
- Седьмая строка предназначена для перечисления всех карт сайта.
Вы можете увидеть результаты ниже:
Пример тестирования robots.txt с помощью пакета reppy.robbots.Существуют и другие типы возможностей проверки файла Robots.txt через Python, но пока этих трех основных вариантов будет достаточно для данного руководства. Я считаю, что из всех этих вариантов лучшим является Advertools. Он проще в использовании, а также имеет больше ярлыков, а также позволяет использовать методы фильтрации и обновления «Pandas» для результатов.
Последние мысли о тестировании и проверке Robots.txt с помощью Python
Мы провели короткие и краткие три различных теста для файлов Robots.txt с помощью Python. Он включает в себя немного аналитического мышления и навыков интерпретации, но, тем не менее, благодаря улучшенным функциям Advertools, мы можем тестировать более одного пути URL для более чем одного агента пользователя в одной строке кода. Это невозможно для инструмента Google для тестирования файла robots.txt или других инструментов проверки robots. txt. Из-за этой ситуации знание Python может сэкономить целостное SEO для многих задач. Вы можете создать для себя простой шаблон тестирования файла robots.txt, чтобы реализовать аналогичные коды для разных SEO-проектов с точки зрения проверки Robots.txt даже за более короткое время.
txt. Из-за этой ситуации знание Python может сэкономить целостное SEO для многих задач. Вы можете создать для себя простой шаблон тестирования файла robots.txt, чтобы реализовать аналогичные коды для разных SEO-проектов с точки зрения проверки Robots.txt даже за более короткое время.
Наша статья о тестировании файла Robots.txt с помощью Python со временем будет улучшаться. Если у вас есть какие-либо идеи или предложения, сообщите нам об этом.
- Автор
- Последние сообщения
Корай Тугберк ГУБЮР
Владелец и основатель Holistic SEO & Digital
Корай Тугберк ГУБЮР является генеральным директором и основателем компании Holistic SEO Science, Web Data Consultancy, в которой он занимается разработкой цифровых данных. , веб-дизайн и услуги по поисковой оптимизации со стратегическим руководством для клиентских проектов агентства по поисковой оптимизации. Koray Tuğberk GÜBÜR регулярно проводит SEO A/B-тесты, чтобы понять Google, Microsoft Bing и Yandex, как алгоритмы поисковых систем, и внутреннюю повестку дня.