
10 инструментов для работы с текстом — bool.dev
Так или иначе мы сталкиваемся с написанием текстов. Будто технические статьи или рабочие документы. В этой статье разбираем 10 инструментов для работы с текстом, которые помогут писать тексты грамотно, лаконично и структурировано.
1. Главред
https://glvrd.ru/
Сервис помогает проверить текст на соответствие принципам «чистого текста» который был описан в книге «пиши, сокращай».
Что может главред?
Главред помогает очистить текст от словесного мусора
Проверяет на соответствие информационному стилю.
2. Балабола
https://yandex.ru/lab/yalm
Сервис от яндекса для генерации текста. Иногда в поисках идеи «как стартануть» свою статью проходит много времени, в таких случаях Балаболка, которая поможет сгенерировать более-менее «осмысленный текст».
У сервиса доступно несколько вариантов стилизации сгенерированного текста:
- Без стиля
- Балабоба х
- Теории заговора
- ТВ-репортажи
- Тосты
- Народные мудрости
- Пацанские цитаты
- Рекламные слоганы
- Короткие истории
- Подписи в Instagram
- Короче, Википедия
- Синопсисы фильмов
- Гороскоп
3.
 LanguageTool
LanguageToolhttps://languagetool.org/ru
Возможности:
- Можно проверить грамматику, орфографию и стилистику текста.
- Есть расширение для Chrome, Firefox, Microsoft Office, Google Docs и др
- В бесплатной онлайн версии имеется лимит на проверку 20 тыс. символов
- Поддержка более 20 языков
4. Text.ru
https://text.ru/
Инструмент проверяет орфографию и анализирует контент по следующим критериям:
- Проверка текста на уникальность;
- Проверка орфографии
- Seo анализ текста
- Подбирает синонимы к словам
5. Типограф
https://www.typograf.ru/
Инструмент проверяет орфографию и анализирует контент:
- Оформляет текст по правилам типографии.
- Расставляет «правильные» кавычки, убирает лишние пробелы, исправляет «дефис» на «тире».
- Указывает на орфографические ошибки
6.
 Deepl
Deeplhttps://www.deepl.com/translator
Deepl – переводчик, который умеет переводить как онлайн, так и в word документах. У дипла есть выбор стиля перевода (платно), что помогает переводить различные тексты ближе к «сленгу» в котором они написаны.
7. Свежий Взгляд
https://workspace.google.com
Свежий Взгляд — это экстеншн для хрома. Свежий Взгляд ищет в тексте места, подозрительные на предмет паронимии или «нечаянной тавтологии» — расположенных близко по тексту фонетически и морфологически сходных слов. Например: «каким *образом* из бесконечного *многообразия* идей», «*вместо* нее это *место* занял», «оказался *довольно* дорогим *удовольствием*».
8. Grammarly
https://app.grammarly.com/
Расширение для Chrome проверяет тексты на английском языке на ошибки и печатки, что помогает делать тексты на английском грамотнее.
9. Emojipedia
emojipedia
В современном мире трудно представить текст без emoji, этот ресурс поможет найти необходимый вам эмодзи для ваших текстов.
10. Hemingway App
https://hemingwayapp.com/
Еще один инструмент для проверки текстов на английском. Hemingway помогает структурировать мысль и изложить текст в понятном стиле.
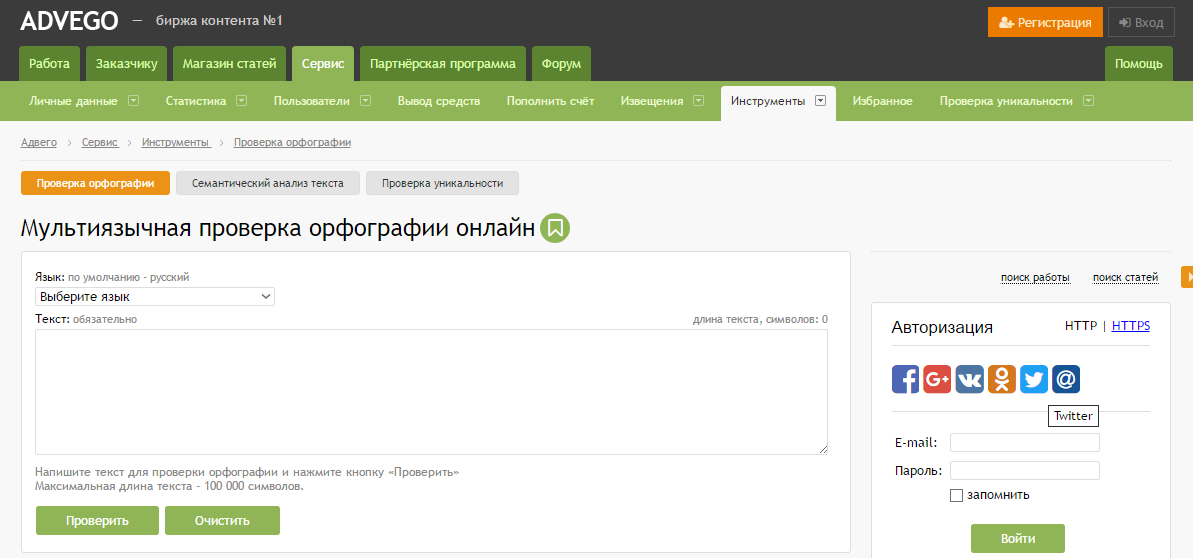
Проверка текста на орфографию и на уникальность с помощью Text.ru
Проверка текста на орфографию и пунктуацию «лучший инструмент».
Здравствуйте дорогие посетители, Вы копирайтер? Или студент? Вам нужен качественный текст с минимальным количеством ошибок? Вам нужна проверка орфографии онлайн и исправление ошибок за короткое время? Если да — то вы попали по адресу и в данной статье вы узнаете, как проверить свой текст на наличие ошибок. Проверка текста на орфографию и пунктуацию очень важный аспект для копирайта и Вебмастера, так что не нужно игнорировать данный инструмент.
Проверка текста на орфографию онлайн — немного о сайте Text.ru
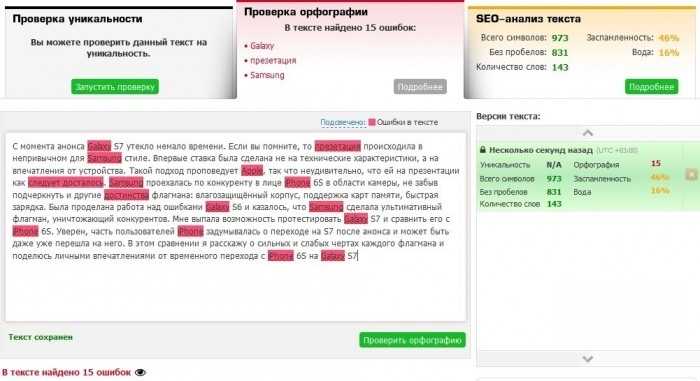
Как вы уже наверняка поняли text.ru сможет помочь в том случае, если вам нужна проверка текста на орфографию онлайн. Но сайт умеет проводить проверку не только на орфографию, при проверке текста на данном сервисе вы также узнаете уникальность текста и такие SEO показатели, как водность и заспамленность.
Но сайт умеет проводить проверку не только на орфографию, при проверке текста на данном сервисе вы также узнаете уникальность текста и такие SEO показатели, как водность и заспамленность.
Проверка текста на уникальность онлайн с помощью текст ру
Как выше писалось, здесь хорошая проверка текста на уникальность в режиме онлайн другими словами онлайн проверка текста на плагиат, но есть задержки в зависимости от загрузки сервиса.
Что касается репутации и надежности сайта, то можно сказать, что он один из лучших между другими подобными сервисами. Так как он пользуется огромной популярностью, как между исполнителями, так и между заказчиками. И в то же время данный сервис осуществляет анализ намного лучше и понятнее, чем Advego.
Как пользоваться сервисом Text.ru
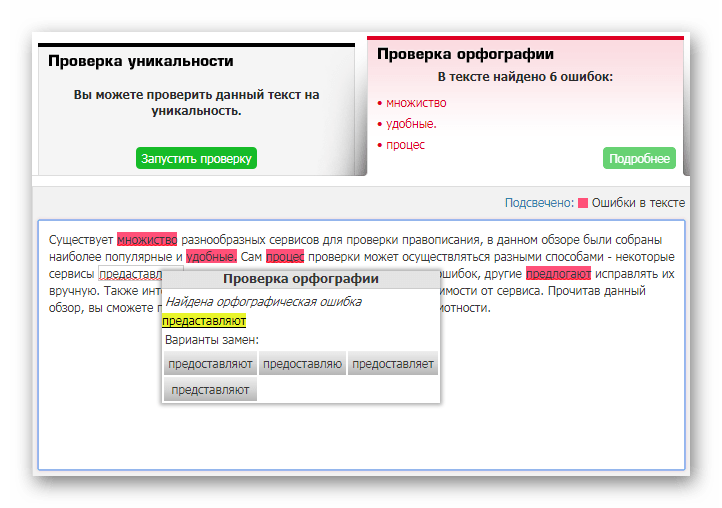
Итак, мы подошли к основному вопросу: как осуществить проверку орфографии или проверить текст на уникальность данным сайтом? Сначала вам нужно перейти по адресу данного сайта и потом желательно зарегистрироваться (это нужно для того, чтобы проверка ваших текстов производилась быстрее и сохранялись тексты «это бывает ой, как кстати»). Регистрироваться здесь несложно. Вот так выглядит сам интерфейс сайта и поле регистрации:
Регистрироваться здесь несложно. Вот так выглядит сам интерфейс сайта и поле регистрации:
Теперь жмем на кнопку проверка орфографии.
И вставляем в появляющееся поле собственно наш текст, проверка осуществляется довольно быстро, но иногда бывают задержки (зависит от числа пользователей, проверяющих в данный момент текст).
После чего вы увидите информацию о своем тексте и сможете сразу исправить ошибки.
Как Вы видите по изображению выше, имеется три пункта:
Нажав на любой пункт можно увидеть слова с ошибками «пройдемся од первого до последнего пункта», №1(не уникальные места в тексте), №2 (водные предложения или слова, которые имеют орфографические ошибки), №3 (заспамлёность текста), ещё подробнее вы сможете понять по видео или перейдя на сам сайт и практиковаться.
Результаты проверки сохраняются на сервисе и вы всегда сможете их зафиксировать, что уменьшит риск недопонимания между заказчиком и исполнителем.
Плюсы и минусы Texta.
 ru
ruДля исполнителя:
Плюсы:
- Быстрая и бесплатная проверка текста;
- Удобный и понятный интерфейс;
- Проверка на данном сайте справедлива и более лояльна, чем на других подобных сервисах;
- Проверка орфографии онлайн и исправление ошибок практически моментально;
- Сайт предлагает вариант замены слова с ошибкой и точно указывает, в чем заключается ошибка;
- Отсутствие различных captcha, что тоже существенно повышает скорость работы;
- Возможность осуществлять проверку без регистрации в проекте. Но она будет ещё длительней, чем для зарегистрированных пользователей
Минусы
- Иногда нагрузки на сайт растут и ваш текст может проверятся немного дольше чем обычно.
Для заказчика:
Плюсы:
- Минимальный риск попасть на мошенника, сдавшего чужой текст;
- Точный процент уникальности;
- Много различной информации о тексте;
- Сайт очень тяжело обмануть, поэтому заказчик может доверять результатам проверки;
- Данный сайт замечает очень много ошибок в словах, предложениях, в расстановке запятых и т.
 д.
д.
 д.
д.Также был создан раздел, где вы сможете найти сайты на которых вы сможете произвести другие анализы с текстом «подробнее смотрите в этом разделе«.
Минусы: не замечено.
Заключение.
Хорошая проверка текста на орфографию и пунктуацию, а также имеется онлайн проверка текста на плагиат.
- Textus pro — как проверить плотность ключевых слов + Видео.
- ТОП 3 сервиса для анализа сайта и контента.
- Заработать на биржах комментариев 4 САЙТА + Видео.
- Дополнительный заработок в интернете на капчах ТОП 4.
Проверка орфографии | Проверка орфографии для кода!
Базовая проверка орфографии, которая хорошо работает с кодом в стиле camelCase.
Цель этого средства проверки орфографии — помочь выявить распространенные орфографические ошибки, одновременно снижая количество ложных срабатываний.
Поддержите дальнейшее развитие
- Станьте Патреоном!
- Поддержка через
Управляйте запросами на вытягивание и проводите проверки кода в своей среде IDE с полным контекстом исходного дерева. Комментируйте любую строку, а не только различия. Используйте переход к определению, ваши любимые сочетания клавиш и интеллектуальный анализ кода, расширяя рабочий процесс.
Комментируйте любую строку, а не только различия. Используйте переход к определению, ваши любимые сочетания клавиш и интеллектуальный анализ кода, расширяя рабочий процесс.
Узнать больше
Функциональность
Загрузить файл TypeScript, JavaScript, текст и т. д. Слова, отсутствующие в словарных файлах, будут подчеркнуты волнистой линией.
Пример
Подсказки
Чтобы увидеть список подсказок:
После установки курсора в слово, любое из следующих действий должно отобразить список подсказок:
- Нажмите на 💡 (лампочку) в левом поле.
-
Quick FixКоманда действия редактора:- Mac:
⌘+.илиCmd+. - ПК:
Ctrl+.
- Mac:
Установить
См.:
- Средство проверки орфографии кода — Visual Studio Marketplace
- Средство проверки орфографии кода — Открыть Реестр VSX
Открыть вверх VS Code и нажмите F1 и введите ext выберите установить и введите код проверки орфографии нажмите Enter и перезагрузите окно, чтобы включить.
Поддерживаемые языки
- Английский (США)
- Английский (GB) — включите, изменив
"cSpell.language": "en"на"cSpell.language": "en-GB"
Дополнительные языковые словари
- Каталонский
- Чешский
- Датский
- Голландский
- Французский
- Французский Réforme 90
- Немецкий 9 0009 греческий
- иврит
- Итальянский
- Персидский
- Польский
- Португальский (Бразилия)
- Португальский
- Русский
- Словенский
- Испанский
- Шведский 90 010
- Турецкий
- Украинский
Дополнительные специализированные словари
- Медицинские термины
Включенные типы файлов
- AsciiDoc
- C, C++
- C#
- css, меньше, scss
- Dart
- Elixir
- Go
- Html
- Java
- JavaScript
- JSON / JSONC
- LaTeX
- Markdown
- PHP
- PowerShell
- Pug/Jade
- Python
- reStructuredText
- Rust
- Scala
- Text
- TypeScript
- YAML
Включить/выключить типы файлов
До Включить или Выключить проверка орфографии для типа файла:
- Нажмите на статус проверки орфографии в строке состояния:
- На экране информации нажмите ссылку Включить .
Как это работает с camelCase
Принцип прост: разделите слова в CamelCase, прежде чем проверять их по списку известных английских слов.
- camelCase -> camel case
- HTMLInput -> ввод html — обратите внимание, что
Iсвязан сВвод, а не сHTML - змея_case_words -> слова змеиного регистра
- camel2snake -> верблюжья змея – (2 игнорируется)
Особый случай со словами ЗАГЛАВНЫМИ БУКВАМИ
Есть несколько особых случаев, чтобы помочь с общепринятой практикой правописания для слов, НАПИСАННЫХ ЗАГЛАВНЫМИ БУКВАМИ.
Завершающие s , ing , ies , es , ed сохраняются с предыдущим словом.
- CURLs -> curls — завершающий
s - CURLedRequest -> изогнутый запрос — завершающий
ed
На что следует обратить внимание
- Эта проверка орфографии er нечувствителен к регистру. Он не будет обнаруживать ошибки, такие как английский язык, который должен быть английским.
- Средство проверки орфографии использует локальный словарь слов. Он ничего не отправляет за пределы вашей машины.
- Слова в словаре могут содержать и содержат ошибки.
- Пропущены слова.
- Проверяются только слова длиннее 3 символов. «jsj» подходит, а «jsja» — нет.
- Все символы и знаки препинания игнорируются.
 Он не будет обнаруживать ошибки, такие как английский язык, который должен быть английским.
Он не будет обнаруживать ошибки, такие как английский язык, который должен быть английским.В настройках документа
В исходный код можно добавить настройки проверки орфографии. Это поможет решить проблемы с файлами, которые могут быть неприменимы ко всему проекту.
Все настройки имеют префикс cSpell: или проверка орфографии: .
-
отключить— отключить проверку орфографии для участка кода. -
включить– включить проверку орфографии после того, как она была выключена. -
игнорировать– указать список слов, которые будут игнорироваться. -
слов– укажите список слов, которые будут считаться правильными и появятся в списке предложений. -
ignoreRegExp— Любой текст, соответствующий регулярному выражению, НЕ будет проверяться на орфографию. -
включитьRegExp— Проверяться будет только текст, соответствующий набору includeRegExp. -
enableCompoundWords/disableCompoundWords– Разрешить/запретить такие слова, как: «stringlength».
Включить/отключить проверку разделов кода
Есть возможность отключить/включить проверку орфографии, добавив комментарии к вашему коду.
Отключить проверку
-
/* cSpell:disable */ -
/* проверка орфографии: отключить */ -
/* проверка орфографии: отключить */ -
/* cspell: отключить-строку */ -
/* cspell: отключить-следующую строку */ 900 13 -
/ * cSpell:enable */ -
/* проверка орфографии: включить */ -
/* проверка орфографии: включить */
Включить проверку
Пример
// cSpell:disable const wackyWord = ['zaallano', 'wooorrdd', 'zzooommmmmmmm']; /* cSpell:включить */ // Отключение/включение гнезда не поддерживается // проверка орфографии: отключить // Теперь он отключен.
 вар лип = 1;
/* cspell: отключить */
// Он по-прежнему отключен
// cSpell:включить
// Теперь он включен
const str = 'goededag'; // <- будет помечено как ошибка.
// проверка орфографии: включить <- ничего не делает
// cSPELL:DISABLE <-- тоже работает.
// если разрешения нет, правописание отключено до конца файла.
const str = 'goedemorgen'; // <- НЕ будет помечено как ошибка.
вар лип = 1;
/* cspell: отключить */
// Он по-прежнему отключен
// cSpell:включить
// Теперь он включен
const str = 'goededag'; // <- будет помечено как ошибка.
// проверка орфографии: включить <- ничего не делает
// cSPELL:DISABLE <-- тоже работает.
// если разрешения нет, правописание отключено до конца файла.
const str = 'goedemorgen'; // <- НЕ будет помечено как ошибка.
Игнорировать
Игнорировать позволяет вам указать список слов, которые вы хотите игнорировать в документе.
// cSpell:игнорировать zaallano, wooordd // cSpell:игнорировать zzooommmmmmmm const wackyWord = ['zaallano', 'wooorrdd', 'zzooommmmmmmm'];
Примечание. слов, определенных с помощью ignore , будут игнорироваться для всего файла.
Words
Список слов позволяет вам добавлять слова, которые будут считаться правильными и будут использоваться в качестве предложений.
// cSpell:words woorxs sweetbeat const companyName = 'woorxs sweetbeat';
Примечание: слов, определенных с помощью слов , будут использоваться для всего файла.
Включить/выключить составные слова
В некоторых языках программирования принято склеивать слова.
// cSpell:enableCompoundWords символ * сообщение об ошибке; // Все в порядке с cSpell:enableCompoundWords целочисленный номер ошибки; // Тоже нормально.
Примечание: Проверка составных слов не может быть включена/выключена в одном и том же файле. Последний параметр в файле определяет значение для всего файла.
Исключение и включение текста для проверки.
По умолчанию проверяется правописание всего документа. cSpell:disable / cSpell:enable выше позволяет блокировать разделы документа. ignoreRegExp и includeRegExp дают вам возможность игнорировать или включать шаблоны текста. По умолчанию добавляются флаги gim , если флаги не заданы.
Проверка орфографии работает следующим образом:
- Найти все совпадения текста
includeRegExp - Удалить все совпадения текста
excludeRegExp - Проверить оставшийся текст. \1]*?\1/g
# только комментарии и блочные строки будут проверены на правописание.
def sum_it (я, последовательность):
"""Это проверяется на орфографию"""
переменная = 0
alinea = 'это не проверено'
для числа в последовательности:
# Локальное состояние 'value' будет сохраняться между итерациями
переменная += число
переменная доходность
Предопределенные выражения RegExp
Шаблоны исключения
-
URL-адреса1 — Соответствует URL-адресам -
HexValues — Соответствует общему шестнадцатеричному формату, например # aaa, 0xfeef, \u0134 -
EscapeCharacters1 — специальные совпадения символы: ‘\n’, ‘\t’ и т.д. -
Base641 – соответствует base64 блокам текста длиннее 40 символов. -
Электронная почта— соответствует большинству адресов электронной почты.
Включить шаблоны
-
Все1 — По умолчанию мы сопоставляем весь документ и удаляем исключения. -
string— Соответствует общепринятым форматам строк, таким как ‘…’, «…» и `…` Строки PHPHereDoc.
1. Эти шаблоны являются частью списка включения/исключения по умолчанию для каждого файла.
Настройка
Конфигурацией проверки орфографии можно управлять с помощью настроек VS Code или
файла конфигурации cspell.json.Порядок приоритета:
- Папка рабочей области
cspell.json - Папка рабочей области
.vscode/cspell.json - Настройки VS Code
c Заклинаниераздела.
Добавление слов в словарь рабочей области
У вас есть возможность добавлять собственные слова в словарь рабочей области. Самый простой способ — навести курсор на слово, которое вы хотите добавить, когда загорится лампочка, нажмите 9.0039 Ctrl+. (Windows) /
Cmd+.(Мак). Вы получите список предложений и возможность добавить слово.Вы также можете ввести слово, которое хотите добавить в словарь:
F1добавить слово– выберитеДобавить слово в словарьи введите слово, которое хотите добавить.cspell.json
Слова, добавленные в словарь, помещаются в файл
cspell.jsonв папке workspace . Обратите внимание, настройки вcspell.jsonпереопределит эквивалентные настройки cSpell в VS Codesettings.json.Пример
cspell.json файл// Настройки cSpell { // Версия файла настроек. Всегда 0,2 "версия": "0.2", // язык - текущий активный язык правописания "язык": "ан", //words - список слов, которые всегда считаются правильными "слова": [ "мкдирп", "цмерге", "githubusercontent", "уличное программное обеспечение", "vsmarketplacebadge", "визуальная студия" ], // flagWords - список слов, которые всегда будут считаться неправильными // Это полезно для оскорбительных слов и распространенных орфографических ошибок.
// Например, "hte" должно быть "the"
"флагВордс": [
"хте"
]
}
Настройки конфигурации кода VS
//-------- Конфигурация проверки правописания кода -------- // Локальный язык для использования при проверке орфографии. «en», «en-US» и «en-GB» в настоящее время поддерживаются по умолчанию. "cSpell.language": "ru", // Контролирует максимальное количество орфографических ошибок в документе. "cSpell.maxNumberOfProblems": 100, // Управляет количеством отображаемых предложений. "cSpell.numSuggestions": 8, // Минимальная длина слова перед проверкой по словарю. "cSpell.minWordLength": 4, // Указываем типы файлов для проверки орфографии. "cSpell.enabledLanguageIds": [ "кшарп", "идти", "джаваскрипт", "javascriptреагировать", "уценка", "пхп", "простой текст", "машинопись", "реакция на машинопись", "имл" ], // Включить/выключить проверку орфографии. "cSpell.enabled": правда,
// Отображать статус проверки орфографии в строке состояния.
"cSpell.showStatus": правда,
// Слова для добавления в словарь для рабочей области.
"cSpell.words": [],
// Включить / отключить составные слова, такие как «сообщение об ошибке»
"cSpell.allowCompoundWords": ложь,
// Слова, которые следует игнорировать и не предлагать.
"cSpell.ignoreWords": ["поведение"],
// Пользовательские слова для добавления в словарь. Должно быть только в настройках пользователя.
"cSpell.userWords": [],
// Указываем пути/файлы для игнорирования.
"cSpell.ignorePaths": [
"node_modules", // это будет игнорировать все, что находится в каталоге node_modules
"**/node_modules", // то же самое для этого
"**/node_modules/**", // то же самое для этого
"node_modules/**", // В настоящее время не работает из-за того, как определяется текущий рабочий каталог.
"vscode-расширение", //
".git", // Игнорировать каталог .Словари
Средство проверки орфографии включает набор словарей по умолчанию.
General Dictionaries
- wordsEn — Произведено из Hunspell американских английских слов.
- wordsEnGb — Произведено из английских слов Hunspell GB.
- компаний — Список известных компаний
- Условия использования программного обеспечения — Термины и понятия программного обеспечения, такие как «сопрограмма», «отказ от дребезга», «дерево» и т. д.
- разное — Термины, которых нет в других словарях.
Словари языков программирования
- typescript — ключевые слова для Typescript и Javascript
- node — термины, связанные с использованием nodejs.
- php — php ключевые слова и библиотечные методы
- go — go ключевые слова и библиотечные методы
- python — 9019 4 питона ключевые слова
- powershell — powershell ключевые слова
- html — html связанные ключевые слова
- css — css 9019 5 , меньше и scss связанные ключевые слова
Прочие словари
- шрифты — длинный список шрифтов — для помощи с css
В зависимости от языка программирования будут загружены разные словари.
Вот правила по умолчанию: «*» соответствует любому языку.
"local"используется для фильтрации на основе настройки"cSpell.language"{ "cSpell.languageSettings": [ { "languageId": '*', "local": 'en', "словари": ['wordsEn'] }, { "languageId": '*', "local": 'en-US', "словари": ['wordsEn'] }, { "languageId": '*', "local": 'en-GB', "словари": ['wordsEnGb'] }, { "languageId": '*', "словари": ['компании', 'softwareTerms', 'разное'] }, { "languageId": "python", "allowCompoundWords": правда, "словари": ["python"]}, { "languageId": "перейти", "allowCompoundWords": правда, "словари": ["перейти"] }, { "languageId": "javascript", "словари": ["typescript", "node"] }, { "languageId": "javascriptreact", "словари": ["typescript", "node"] }, { "languageId": "машинопись", "словари": ["машинопись", "узел"] }, { "languageId": "typescriptreact", "словари": ["typescript", "node"] }, { "languageId": "html", "словари": ["html", "шрифты", "машинопись", "css"] }, { "languageId": "php", "словари": ["php", "html", "шрифты", "css", "typescript"] }, { "languageId": "css", "словари": ["шрифты", "css"] }, { "languageId": "меньше", "словари": ["шрифты", "css"] }, { "languageId": "scss", "словари": ["шрифты", "css"] }, ]; }Как добавить собственные словари
Глобальный словарь
Чтобы добавить глобальный словарь, вам необходимо изменить настройки пользователя.
Определение словаря
В настройках пользователя вам нужно будет указать программе проверки орфографии, где найти список слов.
Пример добавления медицинских терминов, чтобы можно было найти такие слова, как акантоптеригический .
// Список словарных определений. "cSpell.dictionaryDefinitions": [ { "name": "medicalTerms", "path": "/Users/guest/projects/cSpell-WordLists/dictionaries/medicalterms-en.txt"}, // Чтобы указать путь относительно папки рабочей области, используйте ${workspaceFolder} или ${workspaceFolder:Name} { "имя": "companyTerms", "путь": "${workspaceFolder}/../company/terms.txt"} ], // Список словарей для использования при проверке файлов. "cSpell.словари": [ "медицинские условия", "Условия компании" ]Объяснение: В этом примере мы указали средству проверки орфографии, где найти файл со списком слов. Так как это находится в пользовательских настройках, мы должны использовать абсолютные пути.
После определения словаря. Нам нужно сообщить программе проверки орфографии, когда ее использовать. Добавление его к
cSpell.dictionariesсоветует программе проверки орфографии всегда включать медицинские термины при проверке орфографии.Примечание: Добавление больших файлов словаря для постоянного использования замедлит создание предложений.
Словарь проекта/рабочей области
Чтобы добавить словарь на уровне проекта, он должен находиться в файле
cspell.json. Этот файл может находиться либо в корне проекта, либо в каталоге .vscode.Пример добавления медицинских терминов, где термины зарегистрированы в проекте, и мы хотим использовать его только для файлов .md.
{ "словарьопределений": [ { "имя": "medicalTerms", "путь": "./dictionaries/medicalterms-en.txt"}, { "имя": "города", "путь": "./dictionaries/cities.txt"} ], "словари": [ "города" ], "языковые настройки": [ { "languageId": "markdown", "словари": ["medicalTerms"] }, { "languageId": "открытый текст", "словари": ["medicalTerms"] } ] }Объяснение: В этом примере были определены два словаря: города и медицинские термины .
Пути указаны относительно расположения файла cSpell.json . Это позволяет словарям возвращаться в проект.Словарь городов используется для каждого типа файлов, потому что он был добавлен в список словарей . Словарь medicalTerms используется только при редактировании уценки или файлы открытого текста .
FAQ
См. FAQ
pyspellchecker — документация pyspellchecker 0.7.2
Pure Python Проверка орфографии на основе Peter Сообщение в блоге Norvig о настройке простой алгоритм проверки орфографии.
Используется расстояние Левенштейна алгоритм для поиска перестановок в пределах расстояния редактирования 2 от оригинальное слово. Затем он сравнивает все перестановки (вставки, удаления, замены и транспозиции) на известные слова в словесной частоте список. Те слова, которые чаще всего встречаются в частотном списке, скорее правильные результаты.
pyspellcheckerподдерживает несколько языков, включая английский, испанский, немецкий, французский, португальский, арабский и баскский. Для получения информации о том, как словари
созданы и как их можно обновить и улучшить, см. Dictionary Creation and Update раздел readme!pyspellcheckerподдерживает Python 3pyspellcheckerпозволяет настроить расстояние Левенштейна (до двух) для проверки. Для более длинных слов настоятельно рекомендуется использовать расстояние 1, а не по умолчанию 2. См. краткое руководство, чтобы узнать, как можно изменить параметр расстояния.Установка
Самый простой способ установки — с помощью pip:
pip install pyspellchecker
Для сборки из исходников:
git clone https://github.com/barrust/pyspellchecker.git cd pyspellchecker python -m сборка
Для поддержки python 2.7 установите выпуск 0.5.6 но обратите внимание, что никакие будущие обновления не будут поддерживать python 2 .
pip установить pyspellchecker == 0.5.6
Быстрый запуск
После установки с помощью
pyspellcheckerдолжен быть довольно прямым вперед:из импорта проверки орфографии SpellChecker заклинание = Проверка орфографии () # найти те слова, которые могут быть написаны с ошибками с опечаткой = заклинание.
неизвестно (['что-то', 'есть', 'происходит', 'здесь'])
для слова с ошибкой:
# Получить один «наиболее вероятный» ответ
печать (орфография. исправление (слово))
# Получить список «вероятных» вариантов
печать (заклинание.кандидаты (слово))
Если список частот слов вам не нравится, вы можете добавить дополнительные текст, чтобы создать более подходящий список для вашего варианта использования.
из импорта проверки орфографии SpellChecker Spell = SpellChecker() # загружает список частот слов по умолчанию заклинание.word_frequency.load_text_file('./my_free_text_doc.txt') # если я просто хочу убедиться, что некоторые слова не помечены как написанные с ошибками spell.word_frequency.load_words(['Microsoft', 'Apple', 'Google']) spell.known(['microsoft', 'google']) # теперь вернет и то, и другое!Если слова, которые вы хотите проверить, длинные, рекомендуется уменьшить расстояние к 1. Это можно сделать либо при инициализации заклинания проверить класс или постфактум.
из импорта проверки орфографии SpellChecker Spell = SpellChecker(distance=1) # устанавливается при инициализации # поработайте над более длинными словами Spell.distance = 2 # вернуть параметру расстояния значение по умолчанию
Неанглийские словари
pyspellcheckerподдерживает несколько словарей по умолчанию как часть словаря по умолчанию упаковка. Каждый из них прост в использовании при инициализации словаря:из импорта проверки орфографии SpellChecker english = SpellChecker() # по умолчанию английский (language='en') spanish = SpellChecker(language='es') # используйте словарь испанского языка russian = SpellChecker(language='ru') # использовать русский словарь arabic = SpellChecker(language='ar') # используйте арабский словарь
В настоящее время поддерживаются следующие словари:
- Английский — «en»
- Испанский — «es»
- Французский — ‘fr’
- Португальский — «pt»
- Немецкий — «де»
- Русский — ru
- Арабский — «ар»
- Баскский — «ЕС»
- Латышский — «lv»
Создание и обновление словарей
Создание словарей, к сожалению, не является точной наукой.
Я предоставил сценарий, который с учетом текстового файла предложений (в данном случае из
OpenSubtitles), он сгенерирует список частоты слов на основе слов, найденных в тексте. Затем сценарий пытается выполнить *очистить* частоту слов, например, удалив слова с недопустимыми символами (обычно из других языков), удалив термины с малым количеством слов (орфографические ошибки?) и попытавшись применить доступные правила (не более одного ударения в слове в Испанский язык). Затем он удаляет слова из списка известных слов, которые должны быть удалены. Затем он добавляет в словарь слова, которые, как известно, отсутствуют или были удалены из-за слишком низкой частоты.Сценарий можно найти здесь:
scripts/build_dictionary.py`. Исходный список частот слов, проанализированный из OpenSubtitles, можно найти в папке`scripts/data/`вместе с текстовыми файлами включения и исключения каждого языка.Очень желательна любая помощь в обновлении и поддержании словарей.
Для этого
можно начать обсуждение на GitHub или добавить запросы на обновление файлов включения и исключения.Дополнительные методы
Доступна онлайновая документация; ниже приведена версия некоторых доступных функций в виде заметок:
исправление(слово): Возвращает наиболее вероятный результат для слово с ошибкойкандидатов(слово): Возвращает набор возможных кандидатов для слово с ошибкойизвестные([слова]): Возвращает те слова, которые находятся в частоте слова listunknown([words]): Возвращает те слова, которые не входят в частоту listword_probability(word): Частота данного слова из всех слов в частотном спискеСледующие данные вряд ли понадобятся пользователю, но доступны:
edit_distance_1(word): Возвращает набор всех строк в строке Расстояние до единицы на основе алфавита выбранного языкаedit_distance_2(word): Возвращает набор всех строк на уровне Левенштейна. -
 \1]*?\1/g
# только комментарии и блочные строки будут проверены на правописание.
def sum_it (я, последовательность):
"""Это проверяется на орфографию"""
переменная = 0
alinea = 'это не проверено'
для числа в последовательности:
# Локальное состояние 'value' будет сохраняться между итерациями
переменная += число
переменная доходность
\1]*?\1/g
# только комментарии и блочные строки будут проверены на правописание.
def sum_it (я, последовательность):
"""Это проверяется на орфографию"""
переменная = 0
alinea = 'это не проверено'
для числа в последовательности:
# Локальное состояние 'value' будет сохраняться между итерациями
переменная += число
переменная доходность 
 // Например, "hte" должно быть "the"
"флагВордс": [
"хте"
]
}
// Например, "hte" должно быть "the"
"флагВордс": [
"хте"
]
}
 "cSpell.enabled": правда,
// Отображать статус проверки орфографии в строке состояния.
"cSpell.showStatus": правда,
// Слова для добавления в словарь для рабочей области.
"cSpell.words": [],
// Включить / отключить составные слова, такие как «сообщение об ошибке»
"cSpell.allowCompoundWords": ложь,
// Слова, которые следует игнорировать и не предлагать.
"cSpell.ignoreWords": ["поведение"],
// Пользовательские слова для добавления в словарь. Должно быть только в настройках пользователя.
"cSpell.userWords": [],
// Указываем пути/файлы для игнорирования.
"cSpell.ignorePaths": [
"node_modules", // это будет игнорировать все, что находится в каталоге node_modules
"**/node_modules", // то же самое для этого
"**/node_modules/**", // то же самое для этого
"node_modules/**", // В настоящее время не работает из-за того, как определяется текущий рабочий каталог.
"vscode-расширение", //
".git", // Игнорировать каталог .
"cSpell.enabled": правда,
// Отображать статус проверки орфографии в строке состояния.
"cSpell.showStatus": правда,
// Слова для добавления в словарь для рабочей области.
"cSpell.words": [],
// Включить / отключить составные слова, такие как «сообщение об ошибке»
"cSpell.allowCompoundWords": ложь,
// Слова, которые следует игнорировать и не предлагать.
"cSpell.ignoreWords": ["поведение"],
// Пользовательские слова для добавления в словарь. Должно быть только в настройках пользователя.
"cSpell.userWords": [],
// Указываем пути/файлы для игнорирования.
"cSpell.ignorePaths": [
"node_modules", // это будет игнорировать все, что находится в каталоге node_modules
"**/node_modules", // то же самое для этого
"**/node_modules/**", // то же самое для этого
"node_modules/**", // В настоящее время не работает из-за того, как определяется текущий рабочий каталог.
"vscode-расширение", //
".git", // Игнорировать каталог .
 д.
д.


 Пути указаны относительно расположения файла cSpell.json . Это позволяет словарям возвращаться в проект.
Пути указаны относительно расположения файла cSpell.json . Это позволяет словарям возвращаться в проект. Для получения информации о том, как словари
созданы и как их можно обновить и улучшить, см. Dictionary Creation and Update раздел readme!
Для получения информации о том, как словари
созданы и как их можно обновить и улучшить, см. Dictionary Creation and Update раздел readme! неизвестно (['что-то', 'есть', 'происходит', 'здесь'])
для слова с ошибкой:
# Получить один «наиболее вероятный» ответ
печать (орфография. исправление (слово))
# Получить список «вероятных» вариантов
печать (заклинание.кандидаты (слово))
неизвестно (['что-то', 'есть', 'происходит', 'здесь'])
для слова с ошибкой:
# Получить один «наиболее вероятный» ответ
печать (орфография. исправление (слово))
# Получить список «вероятных» вариантов
печать (заклинание.кандидаты (слово))
 Я предоставил сценарий, который с учетом текстового файла предложений (в данном случае из
OpenSubtitles), он сгенерирует список частоты слов на основе слов, найденных в тексте. Затем сценарий пытается выполнить *очистить* частоту слов, например, удалив слова с недопустимыми символами (обычно из других языков), удалив термины с малым количеством слов (орфографические ошибки?) и попытавшись применить доступные правила (не более одного ударения в слове в Испанский язык). Затем он удаляет слова из списка известных слов, которые должны быть удалены. Затем он добавляет в словарь слова, которые, как известно, отсутствуют или были удалены из-за слишком низкой частоты.
Я предоставил сценарий, который с учетом текстового файла предложений (в данном случае из
OpenSubtitles), он сгенерирует список частоты слов на основе слов, найденных в тексте. Затем сценарий пытается выполнить *очистить* частоту слов, например, удалив слова с недопустимыми символами (обычно из других языков), удалив термины с малым количеством слов (орфографические ошибки?) и попытавшись применить доступные правила (не более одного ударения в слове в Испанский язык). Затем он удаляет слова из списка известных слов, которые должны быть удалены. Затем он добавляет в словарь слова, которые, как известно, отсутствуют или были удалены из-за слишком низкой частоты. Для этого
можно начать обсуждение на GitHub или добавить запросы на обновление файлов включения и исключения.
Для этого
можно начать обсуждение на GitHub или добавить запросы на обновление файлов включения и исключения.