Чем опасны дубли страниц и как с ними бороться?
Оглавление
- Как выявить дубли страниц?
- Ручной способ
- Применение Яндекс.Вебмастер
- Почему возникают дублированные страницы
- Применение CMS
- Технические ошибки
- Человеческий фактор
- Чем опасны дубли страниц?
- Виды дубликатов
- Полные
- Неполные
- Как избавиться от дубликатов?
- Редирект 301
- Каноническая страница
- Запрет индексации
- Вывод
Сейчас все хотят привлечь клиентов в интернете. Делают оптимизацию, мучаются с ней. После этого хочется выдохнуть и забыть об отладке. К сожалению, так не работает.
Каждый сайт нуждается в постоянных проверках. Посетители приходят — вот информация о трафике. Тематические ресурсы оставляют ссылки на вас — появляются контакты с внешним миром. Нужно проверять, что оптимизация работает корректно.
Добавление новой информации, актуализация старых статей повышает авторитет вашего ресурса.
Допустим, была статья по теме. После обновления она стала доступна по двум разным URL. Это дубль. Поисковая система считает страницы разными из-за неодинаковых адресов.
Она недоумевает, потому что видит две страницы со схожим содержимым. Требования к уникальности у поисковиков высокие. В результате оцениваются дубли неадекватно и не могут пробиться в топ.
Здесь мы расскажем о том, как справиться с лишними зеркалами и предотвратить их появление.
Как выявить дубли страниц?
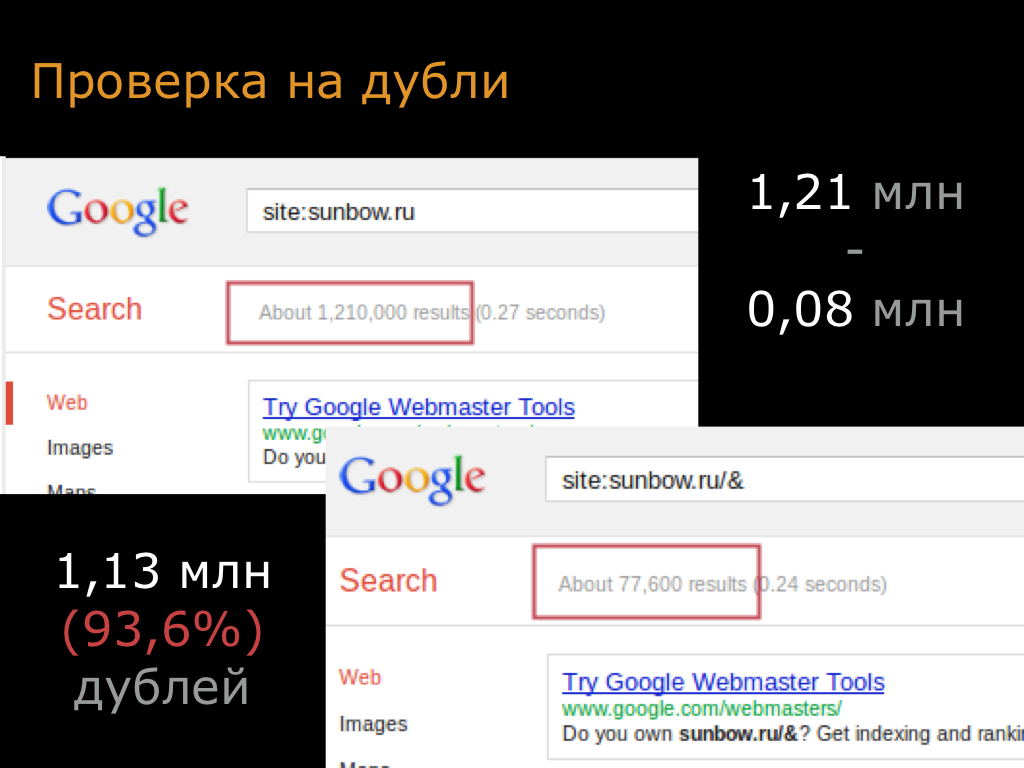
Чтобы определить, что перед вами дубль, достаточно просто взглянуть на адрес. У зеркал URL выглядит по-разному. А страничка открывается одна и та же.
Для улучшения работы сайта таких знаний недостаточно. Придётся выяснять откуда дубли взялись, как устранить уже существующие и не наплодить новых.
Найти дубли помогут поисковые системы. При сканировании роботом доступных страниц сайта, помечаются одинаковые.
Если индексация еще не произошла, то прибегать следует к помощи других инструментов. Как поступать в этом случае мы также разберем.
Как поступать в этом случае мы также разберем.
Ручной способ
Самый простой и интуитивно понятный путь — это ручной. Если поисковая система индексирует похожие страницы и это создает проблемы, то логичнее всего искать их с её помощью.
Делается это следующим образом:
site: your-adress.com/catalog — выдает перечень всех страниц.
Для проверки каждой группы дублей можно использовать:
site: your-adress.com inurl: target-page-pattern — это позволяет искать по схожим элементам адреса.
Надо помнить, что поиск в системах Яндекс и Google дает неодинаковые результаты. Это происходит из-за разных алгоритмов ранжирования. Лучше проверять в обеих системах.
Преимущества метода — это прямой способ проверки. Удобен, когда нужно посмотреть конкретную группу дубликатов. Для тотальной проверки ручной метод не подходит. Невозможно получить статистику по всему сайту.
Применение Яндекс.Вебмастер
Если проверить нужно весь сайт и времени на делать это вручную нет, сильно упрощает задачу использование вебмастера. Алгоритм для Яндекса представлен ниже:
Алгоритм для Яндекса представлен ниже:
- Предупреждение в разделе “Диагностика” говорит о переизбытке дублей. Обновляются данные не сразу. Нужно подождать 2-3 дня, а потом уже проверять.
- Дальше нужно перейти в раздел “Индексирование”, и кликнуть на “Страницы в поиске”. Это откроет доступ к списку проиндексированных страниц.
- После этого перейти в “Исключённые”
- Теперь можно скачать данные в виде таблицы
- В отчете нас интересует графа статус со значением “DUPLICATE”
Информация, предоставленная вебмастером, может быть неполной. Часть одинаковых страниц не получит пометку “DUPLICATE”. К этому могут привести случайные изменения в тексте. Но убирать такие страницы тоже нужно. Тут поможет ручная проверка.
Довольно редко происходит обратная ситуация. Непохожие страницы помечаются “DUPLICATE”. Таких надо отслеживать.
Аналогами проверки через вебмастер можно считать использование краулеров, таких как Xenu. Они подойдут, если с обновления прошло мало времени и информация об индексировании не успела обновиться.
Почему возникают дублированные страницы
Чтобы убрать ошибку — надо знать, где она произошла. Чтобы узнать — нужен примерный план проверки. Ниже обсудим основные места возникновения ошибок, приводящих к дупликации.
Применение CMS
CMS сильно упрощает жизнь создателю сайта. Однако, для корректной работы сайта движок должен быть правильно настроен. Иначе он будет источником проблем.
Движок создаёт ссылки и работает в том числе на поддержание внутренней иерархии. Системы очень разные, у каждой свои особенности работы. При изменении правил создания URL могут возникать дубли. Пример: если при переходе на ЧПУ не убрать старый вариант, то появятся зеркала.
Полезную информацию о системах управления содержимым и создании сайта с нуля можно найти в нашей статье.
Технические ошибки
Проблемы могут возникать из-за неправильных настроек сайта. Самые банальные — ненастроенные редиректы и канонические страницы.
Часто встречается индексация служебных выражений в составе адреса вроде UTM-меток. В норме, какая метка выводится в URL не важно. Индексируется одна страница. При неправильной настройке возникает огромное количество зеркал.
Другой пример — это признание дублями страниц, не имеющих общего содержимого. Мы уже упоминали выше, что такое возможно. Причина — сбой кода ошибки. Из-за него временно недоступные страницы индексируются как идентичные. Тут необходимо совпадение времени проверки сайта и появления ошибки.
Человеческий фактор
При добавлении новых страниц, организации внутренних ссылок может происходить дублирование статей. Ошибка в этом случае допущена человеком. Проверять надо не только за CMS и настройками сайта.
Пример — это некорректное указание ссылки. Достаточно упомянуть при организации внутренней перелинковки не основной домен, а с добавлением www.
При структурных перестройках обычно остаются старые страницы. Место в иерархии они будет занимать другое, но из-за человеческой ошибки могут вызываться и по старому адресу.
Чем опасны дубли страниц?
Теперь стоит поговорить, к чему приводит большое количество зеркал. Основной повод для беспокойства — неправильная индексация. Вместо одной страницы появляется несколько очень похожих. В результате поисковик снижает общие оценки сайта.
Что именно не нравится поисковой системе:
- Наполнение больше не уникально
- Падает значимость источника
- Похоже на спам — так как появляется переизбыток ключевых слов определённой группы.
О важности уникальности контента можно узнать в нашей статье.
Очень большое количество дублей приводит к бану от поисковой системы. Она считает такое попыткой оккупировать несколько мест в выдаче. Поэтому нельзя запускать проблему с дублями. Но надо отметить, что санкции — штука редкая, поисковые системы не бьют тревогу сразу.
Как поисковик обходится с дублями: он чистит выдачу от зеркал — то есть не дает одновременно в поиске выпадать одинаковым станицам. Однако, может меняется выпадающая в выдаче станица — вчера было одно зеркало, сегодня другое. Такие флуктуации приводят к размазываю трафика между зеркалами.
Как это работает. У нас есть две или больше страницы с идентичным содержимым. Для посетителя сайта текст URL значит мало, так что он не заметит разницы. Заходит он на ту, что раньше появляется в выдаче. Если бы станица была одна, то весь этот трафик бы суммировался и шёл на неё. Тут же их 2 или больше — трафик на каждую сильно ниже, чем в случае отсутствия зеркал. А ранжируется каждый дубликат отдельно.
Ссылки на зеркала усугубляют ситуацию — они мешают их сокрытию и не способствуют увеличению трафика на канонической странице. Чем дольше существует дубль, тем сильнее он обрастает ссылками. И тем сложнее всё исправить и склеить зеркала.
Из-за дублей появляются лишние страницы.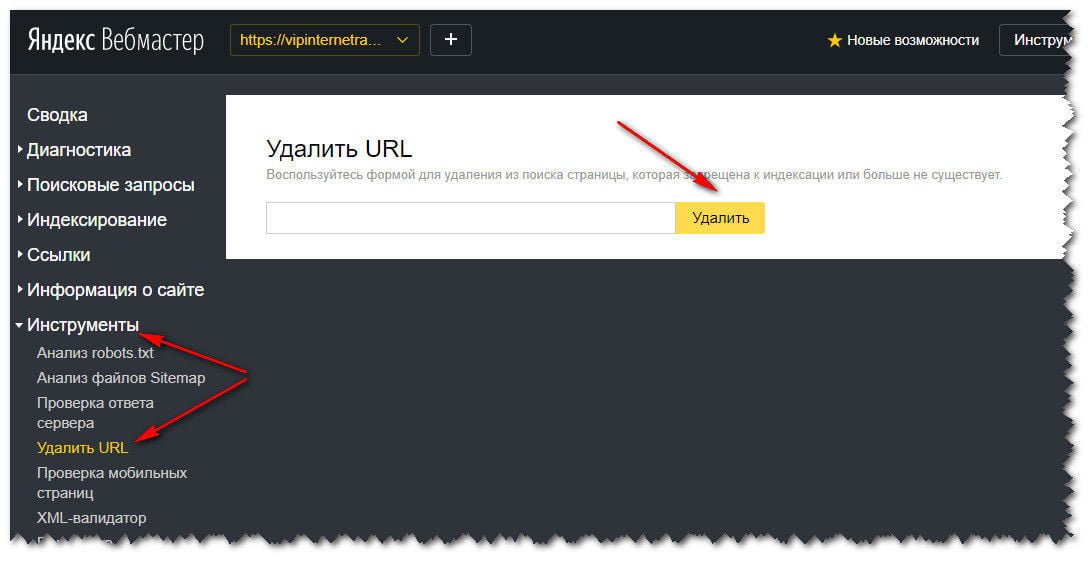 Таким образом растет количество работы для робота. В один заход он может проверить только определенное количество страниц. Получается, что чем больше дублей, тем дольше идет индексация.
Таким образом растет количество работы для робота. В один заход он может проверить только определенное количество страниц. Получается, что чем больше дублей, тем дольше идет индексация.
Кроме того, хуже работает вебмастер. На него сильнее нагрузка. И невозможно пользоваться бесплатными версиями краулеров. У них есть ограничение на количество проверенных страниц.
Виды дубликатов
Оценка внешнего вида — эффективный способ подбора решения для избавления от дубля. Ниже мы рассмотрим, какие они бывают.
Полные
Так называются страницы с идентичным содержимым. Естественно, при этом у них совпадают еще и метатеги Title & Description.
Ошибки и изменения в тексте URL, возникающие при автогенерации или ошибочном ручном введении могут быть разными. Самые распространенные:
- Замена http на https
- Слеш на конце (не имеет значения, если это главная страница)
- Добавление/утрата www
Менее частые, но тоже возможные искажения — это смена регистра:
CAPS на caps
и замена дефисов на подчеркивания:
like_that на like-that.
Также могут появляться лишние символы в адресе:
www.domain.ru/target будет www.domain.ru/target3f47
или меняться уровни вложенности: теряться или меняться местами.
www.domain.ru/target/page0 будет www.domain.ru/page0/target
Отдельно упомянем динамические параметры. Они в норме индексируются единожды. При нарушениях — порождают зеркала.
Неполные
Причинами возникновения неполных копий могут быть такие удобные для пользователя функции, как:
- Поиск
- Пагинация
- Мобильная версия, смена языка или региона
- Фильтры
Все они делают в конце адреса служебные пометки. По этому свойству их легко узнать и объединить в одну группу.
Почему так важно знать, полная ли копия? Есть инструменты избавления от дублей, которые работают только на тождественные страницы и бесполезны для неполных замен.
Отдельно поговорим про карточки похожих товаров — это разные страницы, но если различие только в размере или цвете, то описания будут похожи. Из-за этого страницы будут признаны дублями.
Исправлять это с помощью методов избавления от дублей неправильно. Обычно в этих случаях реорганизовывают каталог, склеивают вместе такие товары и делают общую карточку. Другой путь — уникализировать описания на каждой странице.
Как избавиться от дубликатов?
Мы разобрали основные типы зеркал. Теперь обсудим, что с ними делать. Инструментов несколько и применять нужно наиболее подходящий.
Редирект 301
Он позволяет не убирать дубликат из индексации. На первый взгляд может показаться, что плохо — так как мы не добиваемся своей цели. Мы не уничтожаем дубль. Он остаётся, а пользователя перекидывает на основную страницу. Постепенно снижается положение зеркала в выдаче.
Это на самом деле полезное свойство, если на дублирующую страницу были ссылки в сторонних источниках. В этом случае уничтожить зеркало значит лишиться ссылки.
В этом случае уничтожить зеркало значит лишиться ссылки.
Редирект оформляется в теле страницы. Исключение — использование Apache. У таких сайтов есть .htaccess, в котором можно прописать указания регулярными выражениями.
Избавляясь от дублей не прибегайте к временному редиректу 302. Он, в отличие от 301, не будет вообще передавать вес ссылок и трафик на основную страницу (при 301ом передаётся часть). Также для страницы с 302м редиректом не будет снижения позиции в выдаче.
Избыток перенаправлений не улучшит положение: будет перегружен сервер. Так нельзя убрать индексируемые страницы с динамическими параметрами.
Каноническая страница
Есть способ пометить правильное зеркало, не делая редиректов. То есть посетителя не перекинет автоматически на основную страницу. Такая пометка показывает, что нужно индексировать в первую очередь и передает полный вес.
Оформляется в коде заголовка страницы следующим образом:
<link rel=»canonical» href=”https://www. domain.ru/target/”>
domain.ru/target/”>
Ограничение этого способа: дубль с атрибутом «canonical» и каноническая страница должны быть одинаковы. Иначе команда не сработает. Такой способ стоит применять для динамических параметров.
Google нравятся редиректы и канонические страницы. Он считает их лучшими способами борьбы с дублями. Описанные ниже способы — не жалует.
Запрет индексации
Здесь поговорим о методах склеивания зеркал, рекомендуемые Яндексом. Тут принципиально другая идея. Мы не показываем, где искать основную страницу. Мы убираем из поиска лишние.
Как этого можно добиться? Проще всего — не показывать роботам дубли страниц. Это можно сделать через robots.txt. Без прохождения проверки невозможно оказаться в выдаче поисковика.
Оформляется регулярными выражениями через директиву “Disallow”.
Есть другой вариант, применяемый при работе с GET-параметрами. Это что-то среднее между атрибутом «canonical» и директивой “Disallow”: даёт ссылку на канонический вариант и при этом запрещает индексацию.
Используется другая директива всё в том же файле. Называется она “Clean-param”. Если канон не был проиндексирован, то это повысит шансы, что его проиндексируют в ближайшее время.
Третий способ — использование мета-тега “robots”. Его прописывают в заголовке страницы. В сочетании с параметром “noindex” он делает то же самое, что и “Disallow”.
Можно использовать и другой параметр. Если “noindex” закрывает двери для входа на страницу, то “nofollow” — для выхода. Робот не сканирует исходящие ссылки. То есть он не может совершить переход вглубь сайта.
Нельзя посылать роботам противоречивые команды. В приоритете у них директивы из robots.txt.
Заполнение файла с указаниями для всего сайта — дело сложное. Например, если после директивы “Disallow” и слеша не написать ничего, то робот не зайдёт никуда.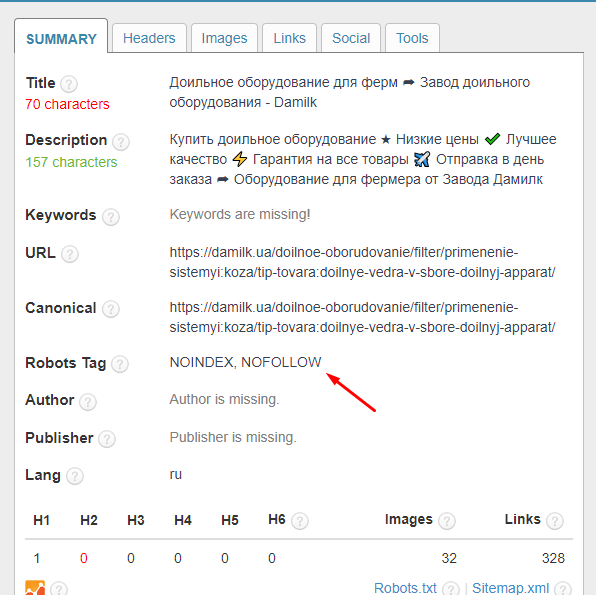 Сайт будет полностью недоступен ему. Поэтому мета-теги могут быть удобнее.
Сайт будет полностью недоступен ему. Поэтому мета-теги могут быть удобнее.
Описанные в этом разделе способы не нравятся Google. Если есть внешние ссылки, то страница может выпадать в поиске. В рекомендациях по избавлению от дублей просят не убирать их из индексации, так это ограничивает возможности анализа. Скрытые страницы считаются уникальными по умолчанию. Таким образом мы вводим в заблуждение алгоритмы.
Поисковым системам нравятся разные подходы. Можно и нужно попытаться угодить всем целевым. Тогда в robots.txt придётся указывать отдельно все параметры для каждой. “По умолчанию” в этом случае будут игнорироваться.
Не следует пугаться фразы про необходимость что-то писать в коде страницы. Залезть в тело каждой не нужно. Всё, кроме
robots.txt, редактируется через CMS для всего сайта.
Вывод
Дубли страниц вредны: усложняют работу сервера, ухудшают ранжирование, не дают пробиться в топ и привлечь посетителей. От зеркал необходимо избавляться. Нельзя запускать — это усугубит ситуацию.
От зеркал необходимо избавляться. Нельзя запускать — это усугубит ситуацию.
Чеклист по тому, как это делать:
- Найдите зеркала вручную или через вебмастер
- Какие у них особенности?
- Почему они появились?
- Что можно с ними сделать?
- Какие поисковые системы устроит ваше решение?
Хотите почистить сайт от дублей?
Получить помощь SEO-специалистаЧто такое дубли страниц, как их найти и как с ними бороться
Дубли на сайте — это страницы, которые повторяют контент друг друга частично или полностью.
Условно внутренние дубли на сайте можно разделить на 3 типа:
- Полные дубли — полностью одинаковые страницы со 100-процентно совпадающим контентом и метатегами, доступные по разным адресам.
- Частичные дубли — страницы, контент которых дублируется частично. Например, страницы пагинации в интернет-магазине: метатеги, заголовки и текст одинаковые, но список товаров меняется.

- Семантические дубли — страницы, которые наполнены разным контентом, но оптимизированы под одни и те же либо похожие запросы.

Какие негативные последствия могут принести дубли страниц
Наличие дублей на сайте в большинстве случаев некритично для пользователей. Но с точки зрения поисковой оптимизации есть следующие негативные последствия:
-
Помехи качественному ранжированию, так как поисковые системы не могут однозначно определить, какой URL релевантен запросу. Как результат, в выдаче может отображаться не та страница, на которой проводились работы. Или релевантная страница в выдаче будет постоянно изменяться вместе с занимаемой позицией.
-
Нецелевое расходование краулингового бюджета и снижение скорости индексации значимых страниц, так как значительная часть краулингового бюджета поисковых систем будет тратиться на переиндексацию нецелевых страниц при наличии большого количества дублей.
-
Потеря потенциальной ссылочной массы на продвигаемые страницы. Естественные внешние ссылки могут быть установлены на страницы-дубли, в то время как продвигаемая страница естественных ссылок получать не будет.
Причин появления дублей страниц не очень много. Для удобства разделим дубли на три группы — полные, частичные, семантические — и рассмотрим причины появления для каждой.
Полные дубли
-
Передача кода ответа 200 страницами неглавных зеркал.
Например, у сайта с главным зеркалом https://site-example.info есть 3 неглавных зеркала:
http://site-example.info;
http://www.site-example.info;
https://www.site-example.info.
Если с неглавных зеркал не был настроен 301-й редирект на главное, их страницы могут быть проиндексированы и признаны дублями главного зеркала.
Решение: настроить прямые редиректы со всех страниц неглавных зеркал на соответствующие страницы главного зеркала.
https://www.site-example.info/
301 →
https://site-example.info/
http://site-example.info/catalog/
301 →
https://site-example.info/catalog/.
-
Передача кода ответа 200 страницами с указанием index.php, index.html, index.htm в конце URL:
https://site-example.info/index.php,
https://site-example.info/index.html и другие.
Решение: настроить прямые 301 редиректы со всех страниц с указанными окончаниями в URL на страницы без них:
https://site-example. info/index.php → https://site-example.info/,
info/index.php → https://site-example.info/,
https://site-example.info/catalog/index.html → https://site-example.info/catalog/.
-
Передача кода ответа 200 страницами со множественными слешами «/» в конце URL либо со множественными слешами в качестве разделителя уровня вложенности страницы:
https://site-example.info/catalog///////,
https://site-example.info/catalog///category///subcategory/.
Решение: настроить прямые 301 редиректы по правилу замены множественных слешей на одинарный:
https://site-example.info/catalog/////// 301 → https://site-example.info/catalog/,
https://site-example.info/catalog///category///subcategory/ 301 → https://site-example.info/catalog/category/subcategory/.
-
Передача кода ответа 200 несуществующими страницами (отсутствие корректной передачи кода ответа 404):
https://site-example. info/catalog/category/qwerty123123/,
info/catalog/category/qwerty123123/,
https://site-example.info/catalog/category/471-13-2/ и другие.
Решение: настроить корректную передачу кода ответа 404 несуществующими страницами.
-
Написание URL в разных регистрах:
https://site-example.info/catalog/,
https://site-example.info/Catalog/,
https://site-example.info/CATALOG/.
Решение: заменить все внутренние ссылки страницами с URL в нижнем регистре (при наличии таких ссылок) и настроить прямые 301 редиректы со страниц с другим типом написания URL.
-
Страницы с UTM-метками в URL:
http://site-example.info/catalog?utm_source=test&utm_medium=cpc,
http://site-example.info/catalog?utm_medium=target,
http://site-example.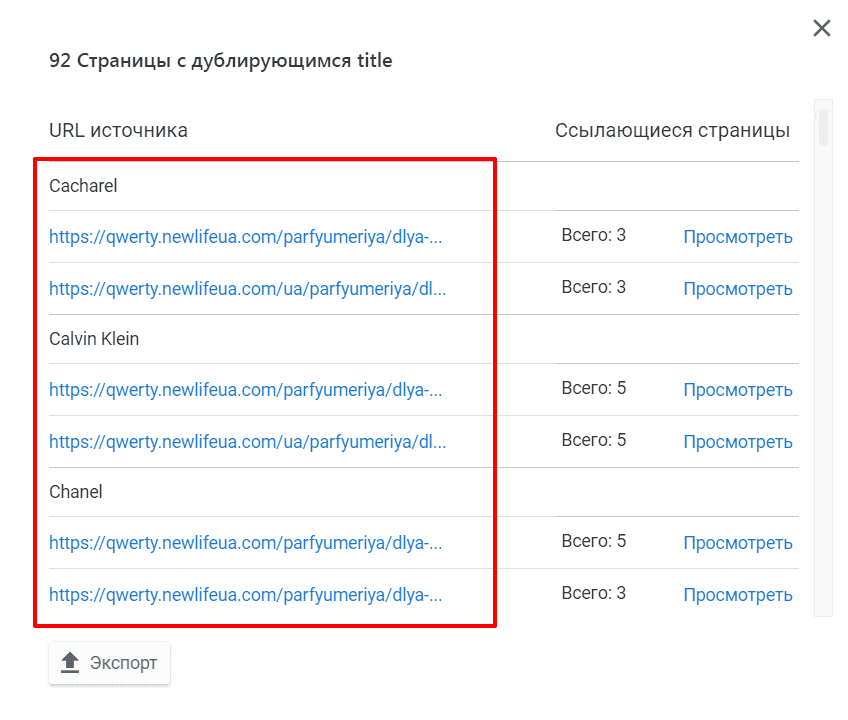 info/catalog?sort=price и другие.
info/catalog?sort=price и другие.
Решение: указать поисковым системам на параметры в URL, которые не изменяют содержимое страниц.
Для ПС «Яндекс»: используя директиву Clean-param в файле robots.txt. Например:
User-agent: Yandex,
Clean-param: utm_campaign&utm_content&utm_medium&utm_source.
Для ПС Google: в разделе «Параметры URL», в GSC установить значение «Нет, параметр не влияет на содержимое страницы».
-
Страницы с одинаковым контентом, но доступные по разным адресам.
Наиболее яркий пример таких страниц — размещение одного товара в разных категориях:
https://site-example.info/category_14/product_page/,
https://site-example.info/category_14/product_page/,
https://site-example. info/category_256/product_page/.
info/category_256/product_page/.
Решение: настроить работу сайта таким образом, чтобы при размещении товара в дополнительных категориях адрес страницы самого товара не изменялся и был привязан только к одной категории.
Частичные дубли
-
Дублирование контента на страницах пагинации:
https://site-example.info/catalog/category/,
https://site-example.info/catalog/category/page_2/.
Решение: уникализировать страницы пагинации, чтобы они не мешали ранжированию основной страницы раздела.
-
Уникализировать метатеги title и description, добавив в них информацию о странице: «title_страницы_каталога — страница {номер_страницы_пагинации}».
-
Разместить основной заголовок <h2> на страницах пагинации с помощью тега <div>.
-
Скрыть текстовый блок со страниц пагинации.

Альтернативным решением является создание отдельной страницы, на которой будут отображаться все товары/материалы, и последующее закрытие от индексации страниц пагинации.
Однако в случае наличия большого количества товаров подобная реализация может быть неприемлемой — скорость загрузки такой страницы будет значительно медленнее, чем у страницы с небольшим количеством товаров.
-
Дублирование контента на страницах фильтрации каталога:
https://site-example.info/catalog/category/,
https://site-example.info/catalog/category/filter_color-black/.
Решение: уникализировать страницы фильтрации, чтобы они не мешали ранжированию основной страницы раздела и позволяли получать поисковый трафик по запросам с вхождением значения примененного фильтра.
-
Уникализировать заголовок h2, тег title и метатег description, включив в них информацию о параметре фильтрации.
-
При необходимости — разместить текстовый блок с уникальным текстом.
-
Дублирование контента на страницах каталога с измененной сортировкой (при наличии статичных страниц сортировки):
https://site-example.info/catalog/category/sort-price-low/
Решение: поскольку страницы с измененной сортировкой не являются значимыми для продвижения, рекомендуем закрыть их от индексации, разместив в коде тег <meta name="robots" content="noindex" />.
-
Дублирование контента в версиях страниц для печати.
Например: https://site-example.
 info/print.html.
info/print.html.
Решение: установить на таких страницах тег <link rel="canonical" href="ссылка_на_основную_страницу" />.
Семантические дубли страниц
Семантическое дублирование страниц может происходить только при одновременной оптимизации нескольких страниц под одинаковые или похожие запросы.
В таком случае необходимо определить более подходящую страницу — ту, что отличается лучшей технической оптимизацией, лучше ранжируется поисковыми системами и более посещаема. Затем установить с дублирующих страниц прямой 301 редирект.
Как найти дубли страницДублированные страницы в рамках одного сайта можно найти несколькими методами. Мы рекомендуем использовать их все для получения более качественных результатов:
- Проверка через сервис «Я.Вебмастер».
Если дубли страниц уже просканированы ПС «Яндекс», значительная часть из них будет исключена из индекса по причине дублирования. Такие страницы легко увидеть в разделе «Индексирование — страницы в поиске», вкладка «Исключенные страницы».
Такие страницы легко увидеть в разделе «Индексирование — страницы в поиске», вкладка «Исключенные страницы».
- Проверка через сервис Google Search Console.
Аналогично панели «Яндекс.Вебмастер» в GSC можно увидеть список страниц, исключенных по причине дублирования. Переходим в раздел «Покрытие» на вкладку «Исключено», причина: «Страница является копией. Канонический вариант не выбран пользователем».
Отметим, что сервис Google Search Console может предоставить данные только по 1 тыс. исключенных страниц.
- Использование программ для сканирования сайта, например Screaming Frog SEO Spider Tool или Netpeak Spider.
После сканирования сайта необходимо проверить страницы на предмет дублирования тегов title, description, keywords и h2. Отсутствие перечисленных тегов также может стать сигналом существования дублей.
Метод позволяет обнаружить только полные дубли страниц.
- Использование сервисов для проверки позиций сайта. Рекомендуем для поиска семантических дублей.
После проведения проверки необходимо проанализировать каждую группу запросов на предмет наличия страниц, которые ранжируются по каждому запросу из группы.
Если по одной группе запросов ранжируются разные страницы, необходимо провести ручную проверку этих страниц на предмет сходства контента.
Если релевантные страницы по одному запросу периодически изменяются, рекомендуем проверить эти страницы.
ВыводНаличие дублей на сайте — серьезная ошибка, которая может значительно ухудшить качество индексации и ранжирования сайта, особенно если дублей много. Исправление этой ошибки критически важно для обеспечения хороших результатов в продвижении сайта любой тематики и с любым количеством страниц.
Важно отметить, что мы рекомендуем проверять сайт на наличие дублей не только при первоначальном аудите, но и в рамках регулярных проверок технического состояния сайта.
Как проверить наличие дублированного контента для улучшения поисковой оптимизации вашего сайта
Публикация оригинального контента на вашем веб-сайте, безусловно, имеет решающее значение для расширения вашей аудитории и улучшения SEO.
Преимущества уникального и оригинального контента двояки:
- Оригинальный контент обеспечивает превосходное взаимодействие с пользователем.
- Исходный контент помогает гарантировать, что поисковые системы не будут вынуждены выбирать между несколькими вашими страницами с одинаковым контентом.
Однако при случайном или преднамеренном дублировании контента поисковые системы не будут обмануты и могут соответственно оштрафовать сайт с более низким рейтингом в поиске. К сожалению, многие компании часто публикуют повторяющийся контент, не подозревая об этом. Вот почему аудит вашего сайта с помощью средства проверки дублированного контента так ценен, поскольку помогает сайтам распознавать и заменять такой контент по мере необходимости.
Эта статья поможет вам лучше понять, что считается дублирующимся контентом, и шаги, которые вы можете предпринять, чтобы убедиться, что это не мешает вашим усилиям по поисковой оптимизации.
Как Google определяет «дублированный контент»?
Дублированный контент описывается Google как контент, «внутри домена или между доменами, который либо полностью соответствует другому контенту, либо заметно похож». Контент, соответствующий этому описанию, может повторяться либо на нескольких страницах вашего сайта, либо на разных веб-сайтах. Обычные места, где может скрываться этот дублированный контент, включают дублирование копии на целевых страницах или в сообщениях блога, или области, которые труднее обнаружить, такие как метаописания, которые повторяются в коде веб-страницы. Дублированный контент может быть ошибочно создан несколькими способами: от простого повторного размещения существующего контента по ошибке до предоставления доступа к одному и тому же контенту страницы через несколько URL-адресов.
Когда посетители заходят на вашу страницу и начинают читать то, что кажется недавно опубликованным контентом, только для того, чтобы понять, что они читали его раньше, этот опыт может снизить их доверие к вашему сайту и вероятность того, что они будут искать ваш контент в будущем. . Поисковые системы одинаково запутываются, когда сталкиваются с несколькими страницами с похожим или идентичным содержанием, и часто реагируют на вызов, присваивая более низкие поисковые рейтинги по всем направлениям.
В то же время существуют сайты, которые намеренно дублируют контент в злонамеренных целях, собирая контент с других сайтов, которые им не принадлежат, или дублируя контент, который, как известно, обеспечивает успешную SEO-оптимизацию в попытке обмануть алгоритмы поисковой системы. Однако чаще всего дублированный контент просто публикуется по ошибке. Существуют также сценарии, в которых допустима повторная публикация существующего контента, например гостевые блоги, синдицированный контент, преднамеренные изменения копии и т. д. Эти методы следует использовать только в сочетании с лучшими практиками, помогающими поисковым системам понять, что этот контент публикуется намеренно (описано ниже).
д. Эти методы следует использовать только в сочетании с лучшими практиками, помогающими поисковым системам понять, что этот контент публикуется намеренно (описано ниже).
Источник: Alexa.com SEO Audit
Инструмент автоматической проверки дублированного контента может быстро и легко помочь вам определить, где такой контент существует на вашем сайте, даже если он скрыт в коде сайта. Такие инструменты должны отображать каждый URL-адрес и метаописание, содержащие дублирующийся контент, чтобы вы могли методично выполнять работу по решению этих проблем. Хотя наиболее очевидной практикой является либо удаление повторяющегося контента, либо добавление оригинальной копии в качестве замены, есть несколько других подходов, которые могут оказаться полезными.
Как проверить дублирующийся контент
1. Использование тега rel=canonical
Эти теги могут сообщать поисковым системам, какой конкретный URL следует рассматривать как основную копию страницы, тем самым устраняя любую путаницу с дублирующимся содержанием точка зрения поисковых систем.
Ресурсы
2. Использование переадресации 301
Они предлагают простой и удобный для поисковых систем метод перенаправления посетителей на правильный URL-адрес, когда необходимо удалить повторяющуюся страницу.
3. Использование метатегов «noindex»
Они просто говорят поисковым системам не индексировать страницы, что может быть выгодно при определенных обстоятельствах.
4. Использование инструмента Google URL Parameters
Этот инструмент помогает запретить Google сканировать страницы с определенными параметрами. Это может быть хорошим решением, если ваш сайт использует параметры как способ доставки посетителю контента, который в основном представляет собой тот же контент с небольшими изменениями (например, изменения заголовка, изменения цвета и т. д.). Этот инструмент позволяет легко сообщить Google, что ваш дублированный контент является преднамеренным и не должен рассматриваться в целях SEO.
Источник: Алекса. направлены на свежий контент, который заставляет их возвращаться снова и снова.
направлены на свежий контент, который заставляет их возвращаться снова и снова.
Есть какие-нибудь эффективные советы о том, как бороться с дублированием контента на сайте? Поделитесь ими в комментариях.
Ким Косака — директор по маркетингу Alexa.com.
Дополнительная литература:- Как оптимизировать местный бизнес для голосового поиска
- Как воспользоваться последними обновлениями Google Search Console
- Руководство покупателя: Корпоративные инструменты SEO
- Практический пример SEO: как Venngage превратила поиск в свой основной источник потенциальных клиентов
Подробнее о:
Зачем и как проверять наличие дубликатов
Большинство профессиональных писателей знают, что Google и другие поисковые алгоритмы не приветствуют дублированный контент. Золотым стандартом является свежий, высококачественный текст, который следует превосходным методам поисковой оптимизации и предлагает новую информацию. Даже когда вы пишете статью, которая представляет ту же информацию в другом свете, важно избегать копирования — или даже восприятия копирования — работы, которая была написана до вас.
Даже когда вы пишете статью, которая представляет ту же информацию в другом свете, важно избегать копирования — или даже восприятия копирования — работы, которая была написана до вас.
Есть несколько причин, по которым важно помнить об этом, и почему важно выполнять проверку дубликатов контента, прежде чем нажимать кнопку «Опубликовать». Эти причины варьируются от ориентированности на поисковую оптимизацию до создания бренда и этического желания избежать обвинений в плагиате или краже.
Независимо от того, являетесь ли вы копирайтером, онлайн-редактором или другим профессионалом, создающим контент в Интернете, очень важно, чтобы вы знали, как проверять дублированный контент. Давайте посмотрим, что это такое, где это происходит, почему это проблема и как не допустить этого в вашей работе с помощью современной передовой технологии защиты от плагиата.
Что такое дублированный контент?
Дублированный контент — это именно то, на что он похож: фрагмент контента, который можно найти более чем в одном месте. Обратите внимание, что это не ограничивается дословным текстом с одинаковыми заголовками и форматированием, найденным на двух разных веб-сайтах. Дублированный контент по-прежнему считается, если он равен:
Обратите внимание, что это не ограничивается дословным текстом с одинаковыми заголовками и форматированием, найденным на двух разных веб-сайтах. Дублированный контент по-прежнему считается, если он равен:
- Внутренние и найденные на двух или более страницах одного и того же сайта
- Переделано в лоскутное одеяло — что все равно является плагиатом, если работа не ваша, — или самоплагиатом, то есть вы должны были создать новый контент для публикации, а не
- Публикуется с другими заголовками или форматированием
- Только фрагменты оригинального произведения
Важно отметить, что внутренний дублированный контент, который не является чем-то фантастическим с точки зрения SEO (обсуждено вкратце), наносит гораздо меньший вред, чем внешний дублированный контент. Это связано с тем, как поисковые системы организуют, ранжируют и возвращают различные фрагменты контента интернет-пользователям, когда они вводят ключевые слова в поле поиска.
Как Google решает, какой контент ранжировать?
Вот как это работает. Google сравнивает дубликаты документов, чтобы найти тот, который, по его мнению, наиболее актуален для его аудитории. Что касается ботов, то необходим только один фрагмент контента. Он оценивает обе части по типичным алгоритмическим показателям релевантности и ранжирует одну из них в индексе Google, в то время как другая фактически архивируется, чтобы она не отображалась в результатах поиска. Та, которая ранжируется, является «канонической» страницей и отныне будет подтягиваться алгоритмами по этим ключевым словам.
Google сравнивает дубликаты документов, чтобы найти тот, который, по его мнению, наиболее актуален для его аудитории. Что касается ботов, то необходим только один фрагмент контента. Он оценивает обе части по типичным алгоритмическим показателям релевантности и ранжирует одну из них в индексе Google, в то время как другая фактически архивируется, чтобы она не отображалась в результатах поиска. Та, которая ранжируется, является «канонической» страницей и отныне будет подтягиваться алгоритмами по этим ключевым словам.
Важно отметить, что Google не делает различий между оригинальным контентом и последующим. Если боты считают, что неоригинальный контент лучше — из-за ссылок, структуры, заголовков и форматирования, метаданных и других показателей успеха — они присвоят этому рейтингу и отныне подтягивают его в результатах поиска.
Дублированный контент и возможности поиска
Люди часто принимают это за «наказание». Они предполагают, что одна часть работы задержана, а другие порезаны и сожжены. Не так. Google просто должен выбрать, какой результат вернуть в поисковом рейтинге. Если бы это было не так, алгоритм существовал бы в постоянном состоянии выбора, на какой похожий веб-адрес отправлять людей по разным ключевым словам. Это означало бы разделение трафика каждого, разбавление ценности всех ссылок меньшим входящим трафиком и, как правило, снижение влияния всех задействованных веб-страниц.
Не так. Google просто должен выбрать, какой результат вернуть в поисковом рейтинге. Если бы это было не так, алгоритм существовал бы в постоянном состоянии выбора, на какой похожий веб-адрес отправлять людей по разным ключевым словам. Это означало бы разделение трафика каждого, разбавление ценности всех ссылок меньшим входящим трафиком и, как правило, снижение влияния всех задействованных веб-страниц.
По общему признанию, предотвращение этого сценария обеспечивает лучший пользовательский опыт. Вы ограничиваете идентичный контент, возвращаете поисковикам высококачественные результаты в рамках заданных параметров, повышаете функциональность и обеспечиваете отличные результаты поисковой выдачи (страницы результатов поисковой системы). Отбрасывая похожий контент, скопированный контент, внутренний дублированный контент и менее оптимизированный контент веб-сайта, Google делает свои страницы результатов более чистыми и удобными для пользователя.
Обратите внимание, что это не означает, что исходный контент теряет свое место в сети. Например, неканонический контент:
Например, неканонический контент:
- Остается на сайте, где он был опубликован, и не может быть удален Google
- Все еще могут быть связаны внутренними ссылками с другими веб-сайтами или другими веб-сайтами
- Будет представлен в поиске через Wayback Machine или другие цифровые архивы
Тем не менее, как только исходный фрагмент контента будет вытеснен новым фрагментом контента, в первую очередь это повлечет за собой серьезные последствия для человека или организации, создавших этот контент. На данный момент самый простой способ понять это — изучить пример.
Дублированный контент: тематическое исследование сыра
Допустим, вы написали в блоге статью под названием «Овладение искусством дегустации голландского сыра». Это был один из самых популярных постов, написанных фуд-блогером в начале 2000-х, и какое-то время он привлекал много трафика, но сейчас он немного надоел. Вы больше не обновляете свой сайт и не добавляете новые статьи. В наши дни не так много людей ссылаются на оригинальный пост. Тем не менее, это ваше, и это приводит к приличному трафику, который приносит вам партнерский доход.
В наши дни не так много людей ссылаются на оригинальный пост. Тем не менее, это ваше, и это приводит к приличному трафику, который приносит вам партнерский доход.
Введите гигантский кулинарный блог и писателя, который оставил свой моральный компас где-то в Греции около 10 лет назад. Они берут «Овладение искусством дегустации голландского сыра», переделывают его с другими заголовками и красивым эффектом пэчворка, добавляют несколько фотографий и фирменную цветовую схему и загружают в WordPress. Им бессовестно не удается запустить проверку дубликатов контента, и они нажимают «Опубликовать».
Немедленно они получают много попаданий. Кроме похлопываний по плечу от начальства, впечатленного трафиком. Пост, который всегда был хорошо написан, получил много любви в социальных сетях и много раз был опубликован. На него ссылаются в текущих блогах о еде, и он даже упоминается в New York Times. В конце концов, конечно, правда всплывает на поверхность… но к тому времени последствия SEO для исходного плаката уже наступили, и потребуется время, чтобы исправить эту ошибку.
Естественно, это не норма. Но бывает и не редко. Давайте рассмотрим некоторые из наиболее распространенных причин непреднамеренного дублирования контента.
Причины дублирования контента
Большинство людей также предполагают, что проблемы с дублированием контента возникают, когда злоумышленник крадет часть оригинального контента и размещает его на своей собственной веб-странице. Хотя прямой плагиат действительно имеет место, это не самая распространенная форма плагиата.
Чаще всего это происходит, когда человек смотрит на работу другого при создании своего контента. При профессиональной работе в Интернете не применяются те же правила, что и при написании бумажной работы в классе. Например, дублированный контент часто создается, когда блоггеры цитируют из других блогов, даже с надлежащей атрибуцией. Дело в том, что не имеет значения, насколько вы отдаете должное другому сайту, если вы: а) берете так много контента, что это заставляет Google думать, что присутствуют дубликаты, или б) заимствуете контент, который появляется во фрагменте (в в верхней части страницы результатов поиска), что имеет решающее значение для SEO и, следовательно, несправедливо по отношению к организации, занявшей первое место.
Это также может произойти, когда люди цитируют контент веб-сайта в сообщениях в социальных сетях. Каждая публикация в социальных сетях в Instagram, Twitter, Facebook, Pinterest, TikTok и т. д. рассматривается как отдельный уникальный URL-адрес. Скопированный контент является скопированным контентом, и Google будет рассматривать эти URL-адреса как таковые, а затем принимать решение о том, какой из них является каноническим.
Дублирование контента также может быть вызвано идентификаторами сеанса, несколькими URL-адресами одного и того же контента, версиями веб-страниц только для печати и другими более невинными причинами.
Зачем предотвращать дублирование контента
Есть два ответа на вопрос «Почему я должен стараться избегать дублирования контента?» Во-первых, вы можете попасть в серьезные неприятности из-за плагиата чужой работы. Это неэтично и вызывает неодобрение в академическом, научном и писательском сообществах, где ценится оригинальная работа. В некоторых случаях вы можете оказаться на неправильном конце судебного процесса. Это также может привести к негативным последствиям SEO для вашего сайта, когда вы дублируете контент внутри. Вы разбавляете ценность своих собственных страниц, снижая свой веб-рейтинг в Google и влияя на свои собственные места размещения в поисковой выдаче.
В некоторых случаях вы можете оказаться на неправильном конце судебного процесса. Это также может привести к негативным последствиям SEO для вашего сайта, когда вы дублируете контент внутри. Вы разбавляете ценность своих собственных страниц, снижая свой веб-рейтинг в Google и влияя на свои собственные места размещения в поисковой выдаче.
Последняя причина, по которой вы должны предотвратить дублирование контента, заключается в том, что это может привести к серьезным последствиям для кого-то другого.
Обратная сторона дублированного контента для оригинальных создателей
Если кто-то пишет контент для оптимизации, использование дублированного контента также может негативно повлиять на его поисковую оптимизацию.
К сожалению, хотя парсеры (боты, сканирующие контент) хорошо справляются с потребностями пользователей, они не могут сказать, кто что написал. Они просто выстраивают контент и отмечают, «заметно ли он похож». Затем они, основываясь на различных показателях, выбирают один для ранжирования и отбрасывают другие. Когда алгоритм архивирует исходный фрагмент контента, то есть отбрасывает чью-то тяжелую работу, это серьезная проблема.
Это означает, что первоначальный автор или веб-мастер может потерять заработанный кредит, если его страница будет заархивирована и больше не будет отображаться в результатах поиска. Это также означает, что вторая часть контента появляется в поисковом рейтинге как исходная часть контента. Это имеет ряд последствий, в том числе:
- Потеря любого будущего потенциала обратных ссылок, потому что дублированный контент теперь с большей вероятностью будет получать ссылки из других источников
- Снижение потенциала электронной коммерции архивных дубликатов страниц
- Напрасная трата времени и ресурсов компании, которая усердно работала над оптимизацией оригинального контента (теперь считающегося «дубликатом») с помощью правильных форматов, внутренних ссылок, структуры HTML, метатегов и т. д.
- Создатель оригинала выглядит как плагиатор
По понятным причинам, только последнее создает огромную проблему для дублирования контента. Большинство людей, конечно, благородны и не хотели бы этого делать. (Те, кто заметят, что такие инструменты, как средства проверки на плагиат и Google Search Console, теперь значительно усложняют задачу по предотвращению кражи интеллектуальной собственности в Интернете.)
Если вы хотите оставаться в чистоте, вы всегда должны создавать уникальный контент, используя свои слова. Если вы беспокоитесь о дублировании, вы можете провести SEO-аудит или использовать множество других инструментов SEO, чтобы убедиться, что вы всегда создаете что-то новое, привлекательное и значимое для ваших читателей. Это лучший способ увеличить аудиторию и в то же время держать нос в чистоте.
И, конечно же, средства проверки контента.
Как проверить дублирующийся контент
Очевидно, что как профессионал вы не хотите, чтобы вас считали копирующим чужую работу. Хотя вы можете запустить средство проверки дублирующегося контента, чтобы сравнить свою работу с другой — так же, как вы сравниваете два документа Word, — лучшей альтернативой будет использование средства проверки на плагиат для поиска каждого фрагмента когда-либо написанного контента и предотвращения случайного дублирования.
Кроме того, помните о следующих рекомендациях:
- По возможности используйте чужие идеи для вдохновения, в лучшем случае перефразируя их работу
- Если не цитировать автору оригинала будет плохой услугой и если он не включает его фрагмент Google, вы можете вырезать и вставить одну или две строки контента из другого источника с указанием авторства .
- Старайтесь использовать как можно больше источников при создании собственных историй и информационных статей
- Всегда отдавайте должное фотографиям, графике, музыке или другим видам искусства
- Никогда не цитируйте данные без указания авторства
- Даже с номерами постарайтесь переработать контент, чтобы он не вызывал дублирования
В дополнение к средству проверки дублирующегося контента вы также можете копировать разделы своего письма, которые, как вы беспокоитесь, могут быть слишком близкими, и вставлять их в поле поиска Google. Если он подтягивает источник, который вы использовали, ваш текст все еще слишком близок к оригиналу.