
Читайте про Дубли страниц в нашем словаре SEO терминов
Дубли страниц — различные интернет-страницы конкретного ресурса с максимально схожим или полностью идентичным контентом. Бытует мнение, что дубликаты являются совершенно безобидными. Это относится лишь к пользователям, для которых присутствие таких страниц не играет особой роли. Но в отношении продвижения и ранжирования сайтов поисковиками они способны создать негативный эффект.
Отрицательные факторы влияния дублей:
- Индексация. Дублирующийся контент заставляет ботов поисковых систем терять драгоценный краулинговый бюджет на такие страницы. При этом действительно важная информация сайта может остаться без индексации.
- Понижение процента общей уникальности контента, размещенного на портале.
- Внешние ссылки продвигаемых интернет-страниц теряют вес. Это происходит, когда посетитель делится ссылкой на страницу-дубликат.
- Неуникальный контент.
 Поисковые системы могут применить санкции в отношении сайта из-за повторяющихся текстовых материалов.
Поисковые системы могут применить санкции в отношении сайта из-за повторяющихся текстовых материалов. - Возможность продвижения нерелевантной интернет-страницы. Поисковик способен отображать в результатах выдачи совершенно не ту страницу, которую оптимизатор пытается продвинуть.
 Поисковые системы могут применить санкции в отношении сайта из-за повторяющихся текстовых материалов.
Поисковые системы могут применить санкции в отношении сайта из-за повторяющихся текстовых материалов.Страничные дубли являются частичными, либо же полными. В полных дублях контент абсолютно идентичен, в частичных – контент похож. При этом более безопасными и безобидными считаются частичные дубли, ведь они не дают сайту сильно пострадать из-за своего присутствия. Хотя постепенное понижение в ранжировании все равно может происходить. Что касается полных дубликатов, то подобные страницы зачастую обнаруживаются в интернет-магазинах (карточки и описание товаров).
Почему же появляются дубли? Например, они в состоянии автоматически генерироваться движком сайта. Либо же речь может идти о корректировке структуры портала. В этом случае старые адреса не только сохраняются, но и дополнительно получают новые адреса.
Поиск страниц-дублей на сайте
Далее будут представлены самые эффективные способы поиска дублей интернет-страниц.
Сканирование ресурса благодаря специализированным приложениям
Выявлять дубликаты можно с помощью особых программ (например, Screaming Frog Seo Spider, NetPeak Spider), которые являются платными или бесплатными. Такие приложения умеют довольно быстро сканировать ресурс, чтобы найти дубли. В этих программах возможно осуществить выгрузку списка URL-адресов. Есть возможность отсортировать результаты по тегам Description и Title. Это позволяет оперативно находить повторяющийся текстовый контент.
Вебмастер Google или Yandex
Вот как происходит поиск дублей в соответствующей консоли Google:
- открываем панель инструментов;
- нажимаем на пункт «Вид в поиске»;
- выбираем «Оптимизация HTML».
Теперь дубликаты можно увидеть в разделе «Повторяющиеся заголовки».
Ищем дубли страниц в Яндексе:
- находим пункт «Страницы в поиске», который располагается в сервисе Яндекс.Вебмастер;
- переходим в «Исключенные страницы»;
- сейчас нам нужна «Сортировка: Дубль»;
- не забываем применять действия;
- система осуществит выдачу повторяющихся страниц.
Если это необходимо, то всегда можно выгрузить готовый список для собственных нужд.
Ручной поиск
Профессиональный вебмастер способен отыскать дубли вручную. Как правило, для этих целей используется url-адрес ресурса. Он многократно вводится с помощью различных вариаций (например, добавляются какие-то знаки или символы).
Оператор «site:»
Открываем поисковую строку, чтобы ввести «site:site_name.ru». В выдаче появятся все страницы вашего ресурса, прошедшие индексацию. Такой метод дает возможность отыскать не только страницы-дубли, но и «мусорный» контент.
Удаляем дубли страниц
Нет желания постоянно заниматься выявлением дублей страниц, а также их закрытием от поисковиков? Тогда лучше раз и навсегда от них избавиться.
Файл .htaccess и 301 редирект
Если дубли появились абсолютно случайно (к примеру, был использован двойной пробел), то можно воспользоваться обычной настройкой 301 редиректа. Для этого нужно установить необходимое перенаправление при помощи файла .htaccess.
Запрет индексации страниц-дублей через robots.txt
Есть возможность закрыть некоторые интернет-страницы от роботов поисковых систем. В файле robots.txt прописываем:
User-agent: *
Disallow: /page-name
Такой способ будет максимально эффективен в отношении служебных страниц, повторяющих контент главной страницы площадки. Если же интернет-страница уже присутствует в индексе, тогда данный метод может не работать.
Указание канонической старницы
Мы можем задать каноническую страницу для последующего индексирования используя тег rel=»canonical».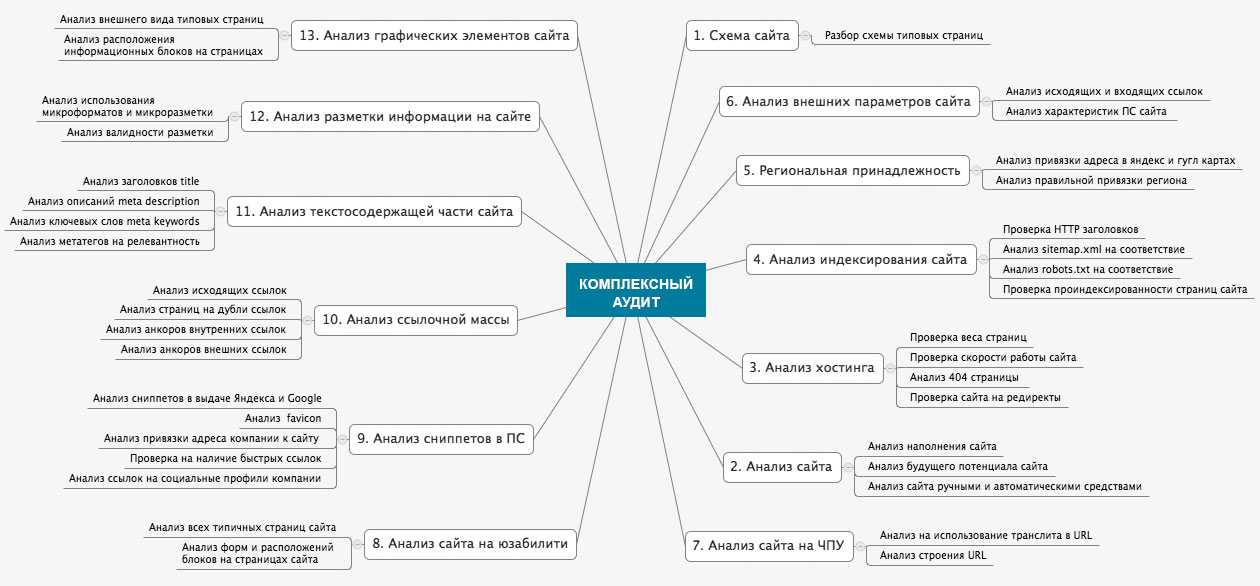 При этом она будет открыта для просмотра. Это очень полезно для различных фильтров, а также страниц-сортировок. Нужно лишь указать соответствующий атрибут canonical в теге <link>. Причем делается это в коде HTML текущей интернет-страницы.
При этом она будет открыта для просмотра. Это очень полезно для различных фильтров, а также страниц-сортировок. Нужно лишь указать соответствующий атрибут canonical в теге <link>. Причем делается это в коде HTML текущей интернет-страницы.
Мета-тег
Есть возможность насильно запретить роботам поисковиков индексировать определенные документы при помощи тега noindex. Благодаря этому специальные боты не будут переходить по ссылкам. Сам тег располагается в блоке <meta name=»robots» content=»noindex, nofollow> или <meta name=»robots» content=»noindex, follow>
Данный вариант очень часто применяется, когда речь заходит о вкладках с пользовательскими отзывами о том или ином товаре или услуге.
Когда повторяющийся контент будет удален (или скрыт), то рекомендуется осуществить повторную проверку ресурса. Причем делать это нужно регулярно, чтобы случайно не выпасть из рейтинга поисковых систем. Важно, чтобы количество страниц с дублирующимися материалами было сведено к минимуму, либо же вообще равнялось нулю.
Дубли страниц на сайте — что это такое. Поиск и удаление
Дубли страниц, что это такое, какое влияние они оказывают на поисковое продвижение сайта и как можно избежать этих дублей. Все эти вопросы по понятным причинам волнуют сайтостроителей.
Содержание:- Что такое дубли страниц
- Поиск дублей
- Поиск на сервисах и удаление
Если открыть главную страницу блога, то, как обычно, увидим анонсы последних записей. Часто бывает так, что если набрать в поисковой строке адрес домена/page/1, то есть страница первая, то можно увидеть здесь то же самое содержимое, что и на главной странице сайта.
Это явление и называется дубли контента, то есть страницы с частично или полностью повторяющимся содержимым.
То, что дубли страниц не приносят ничего хорошего сайту, можно догадаться ничего больше не зная о них. Таких дублей на самом деле может быть очень много.
Каждая страница сайта обладает каким-то статическим весом, что непосредственно напрямую влияет на ее позиции в выдаче. Если на том же самом хосте появляется дубликат страницы, то статический вес страницы размывается.
Контент на странице становится для поисковых систем не уникальным, и они задерживают или занижают позиции страниц в выдаче. Поэтому нужно как можно раньше начать бороться с проблемой наличия дублей на сайте.
Откуда дубли вообще берутся? В большинстве случаев они генерируются самой системой WordPress. Это различные категории, метки, результаты поиска, комментарии и другое.
Не будем говорить, что виновата в этом система движка. Скорее всего, вина исходит от того, кто настраивал или наоборот не настраивал ее.
Первое, что нужно проверить, настроен ли редирект со второстепенного зеркала сайта на главное. Для этого перед URL главной страницы сайта введем тройное www.
Если открывается та же самая страница, значит редирект на главное зеркало не настроен, поэтому страницы с www и без www являются полными дублями.
Таким образом, все страницы сайта, по сути, дублируются. Это конечно нехорошо и надо все исправить. Исправить это можно либо в настройках web-сервера, либо в файле .htaccess.txt. Проверить также нужно страницы index.php и index.html.
Для этого на главной странице сайта в адресной строке введем https://webentrance.ru/index.php. Снова открывается та же самая страница. Проверим https://webentrance.ru/index.html, здесь такой страницы не существует.
Затем можно зайти в какой-либо раздел, например, Windows-7. Нужно проверить, есть ли редирект со страниц со слешем. То есть, если приставить к адресу страницы слеш и открывается та же самая страница, то так же необходимо сделать редирект через настройки веб-сервера.
Откроем любую страницу и посмотрим, что изменится, если к адресу ввести .html или .php. Открывается та же самая страница. Введем в адрес страницы случайные символы. Если открывается та же страница, то это значит, что не работает на сайте перенаправление на страницу с 404 ошибкой.
Еще несколько вещей, которые могут привести к дублям на вашем сайте. Это страницы с сортировкой, группировкой или фильтром какого-то товара. Все они имеют различные приставки к URL в виде различных параметров. Эти параметры собственно и создают дубликаты страниц.
Нужно помнить, что любой URL, который отличается от текущего, является другой страницей. Пусть даже их содержание абсолютно идентично. Поэтому такие страницы нужно закрывать в файле robots.txt, чтобы поисковый робот их не видел. И чтобы они ни в коем случае не попадали в индекс поисковых систем.
Вот основные причины, по которым появляются дубликаты страниц. Здесь может быть, как уже говорилось, два решения:
1. Закрыть их в robots.txt.
2. Решить проблему с помощью файла .htaccess.txt.
Ищем дубли страницЕсть два способа для поиска дублей страниц. Во-первых, копируем URL и пишем в Яндексе команду site:webentrance.ru без http.
Таким образом, Яндекс покажет нам все страницы, которые есть на данный момент в индексе.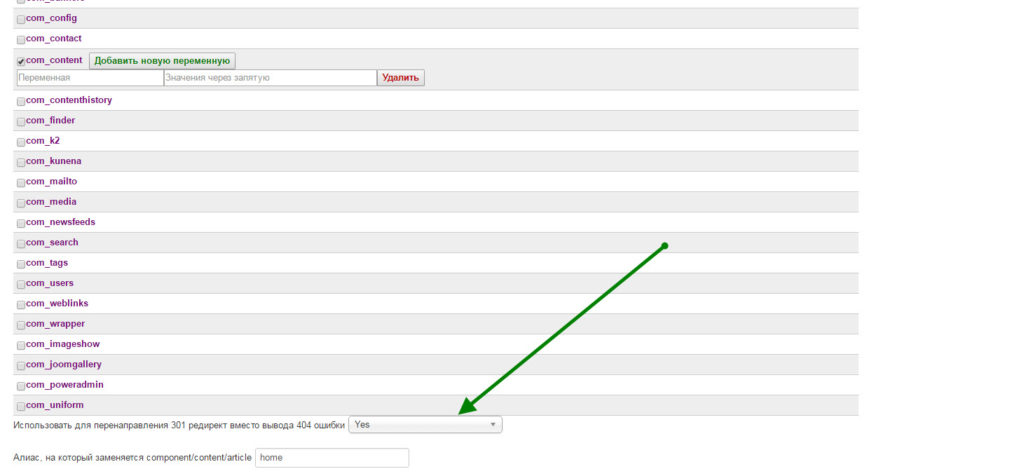
Наша задача просмотреть в выдаче все URLы и найти подозрительные. То есть просматриваем сайт и ищем несоответствие. Возможны ошибки URL и т. д. и здесь очень просто найти дубли страниц.
Поиск дублей страниц с помощью сервисовВторой способ это софт и различные сервисы, например, Google веб-мастер. Заходим в него и во вкладке Оптимизация, выбираем Оптимизация html. Нам показывают те страницы, на которых есть одинаковые мета-теги.
Скорее всего, они и являются дубликатами. Как уже было сказано, самый простой способ избавиться от дубликатов, это закрыть их в файле robots.txt.
Произойдет это конечно не сразу, но через какое-то время можно будет заметить, что дубли выбыли из индекса. Вскоре можно будет заметить эффект в позициях ресурса в поиске и трафике, поэтому это необходимо сделать.
Для определения дублей страниц, уже проиндексированных поисковыми системами, можно перейти в Яндекс.Вебмастер, перейти в раздел Индексирование сайта и проверить, какие страницы ресурса находятся в поиске поисковой системы.
Здесь надо увидеть главную страницу блога, где адресом является просто домен. Затем должны быть все страницы, которые доступны в верхнем меню и все до одной статьи.
Если сайт небольшой, порядка 100 страниц, то его можно без труда просмотреть и понять, какие именно страницы находятся в индексе и ничего лишнего здесь быть не должно.
Не должно быть никаких page, категорий, никаких тегов. Здесь же можно посмотреть исключенные страницы и документы, запрещенные файлом robots.txt. Это обычно все результаты поиска и т. д.
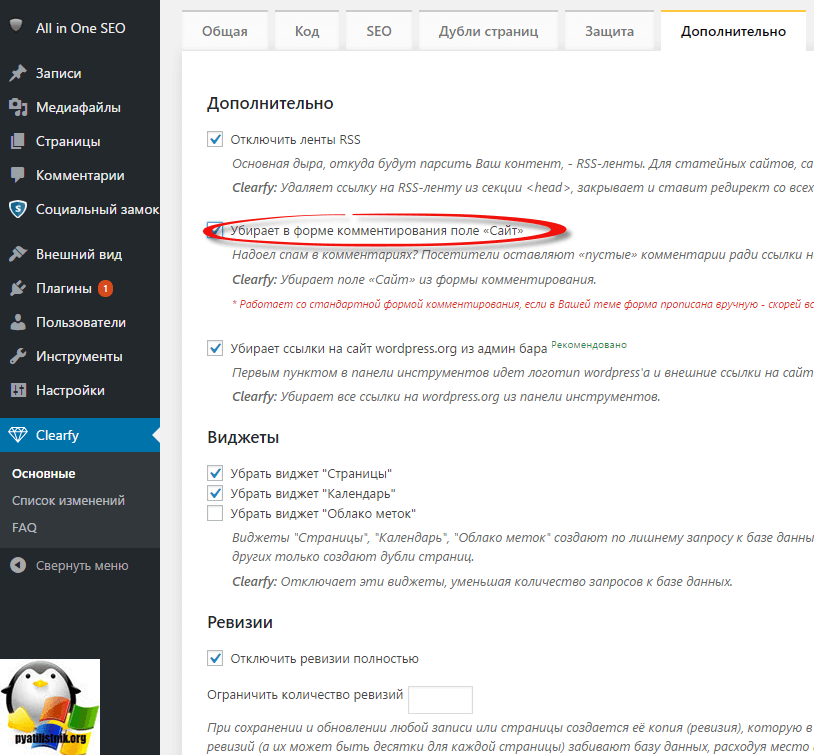
Перейдем в настройки плагина All in SEO Plugin Options и ставим галочки Использовать параметр ‘noindex’ для рубрик, для архивов, для архива меток.
Чтобы посмотреть файл robots.txt, достаточно набрать после домена через слеш robots.txt. Здесь особо ничего закрывать не надо, кроме каких-то служебных файлов.
В результате этой работы в поиске должны остаться только необходимые страницы, которые будут быстрее индексироваться поисковыми системами.
Средство проверки дублирующегося контента / Средство обнаружения плагиата
Средство проверки дублирующегося содержимого / Обнаружение плагиата.
Используйте средство проверки дублированного контента, чтобы найти внутренний и внешний дублированный контент для определенной веб-страницы. Дублированный контент является важной проблемой SEO, потому что поисковые системы стараются отфильтровать как можно больше дубликатов, чтобы обеспечить наилучшие условия поиска. Этот инструмент способен обнаруживать два типа (текстового) дублированного контента.
Наконечник: Нужно ежедневно проверять дубликатов контента на наличие дополнительных веб-сайтов? Попробуйте API →
Дублирование типов контента
Почему важно предотвращать дублирование контента?
Как упоминалось выше, поисковые системы не любят дублированный контент / плагиат, потому что пользователям не интересно просматривать страницу результатов поиска, содержащую несколько URL-адресов, содержащих более или менее одинаковый контент. Чтобы этого не произошло, поисковые системы пытаются определить первоисточник, чтобы показать этот URL по релевантному поисковому запросу и отфильтровать все дубликаты. Как мы знаем, поисковые системы довольно хорошо фильтруют дубликаты, но определить исходную веб-страницу по-прежнему довольно сложно. Это может случиться, когда один и тот же блок текста появляется на нескольких веб-сайтах, алгоритм решит, что страница с наивысшим авторитетом / наибольшим доверием будет отображаться в результатах поиска, даже если это не первоисточник. В случае, если Google обнаружит дублированный контент с целью манипулирования рейтингом или обмана пользователей, Google внесет коррективы в рейтинг ( Panda filter ), иначе сайт будет полностью удален из индекса Google и результатов поиска.
Чтобы этого не произошло, поисковые системы пытаются определить первоисточник, чтобы показать этот URL по релевантному поисковому запросу и отфильтровать все дубликаты. Как мы знаем, поисковые системы довольно хорошо фильтруют дубликаты, но определить исходную веб-страницу по-прежнему довольно сложно. Это может случиться, когда один и тот же блок текста появляется на нескольких веб-сайтах, алгоритм решит, что страница с наивысшим авторитетом / наибольшим доверием будет отображаться в результатах поиска, даже если это не первоисточник. В случае, если Google обнаружит дублированный контент с целью манипулирования рейтингом или обмана пользователей, Google внесет коррективы в рейтинг ( Panda filter ), иначе сайт будет полностью удален из индекса Google и результатов поиска.
Как работает средство проверки дублированного контента?
- Поиск проиндексированного дублированного контента с помощью ввода URL или ТЕКСТА.
- Используйте ввод URL для извлечения основного содержания статьи / текста, найденного в теле веб-страницы. Элементы навигации удалены, чтобы уменьшить шум (иначе многие страницы будут ошибочно идентифицированы как внутренние дубликаты).
- Используйте ввод текста, чтобы лучше контролировать ввод.
- Используйте ввод URL для извлечения основного содержания статьи / текста, найденного в теле веб-страницы.
- Аналогичный контент извлекается, возвращается и помечается как: входной URL, внутренний дубликат, внешний дубликат.
- Экспорт результатов в .CSV. и используйте электронную таблицу Excel / Open Office для просмотра, редактирования или отчета о ваших результатах.
 Элементы навигации удалены, чтобы уменьшить шум (иначе многие страницы будут ошибочно идентифицированы как внутренние дубликаты).
Элементы навигации удалены, чтобы уменьшить шум (иначе многие страницы будут ошибочно идентифицированы как внутренние дубликаты).Как использовать эти результаты?
Внутренние дубликаты В большинстве случаев вы начнете решать проблемы с внутренними дубликатами. Потому что эти проблемы существуют в вашей собственной контролируемой среде (вашем веб-сайте). Для удаления внутренних дубликатов можно использовать различные методы, в зависимости от характера проблемы. Некоторые примеры:
Внешние дубликаты Внешние дубликаты могут быть совсем другой историей, потому что вы не можете просто внести коррективы в свой собственный сайт и решить проблему. Несколько примеров того, как вы можете удалить внешние дубликаты:
Несколько примеров того, как вы можете удалить внешние дубликаты:
Ограничения инструмента
- Этот инструмент автоматически извлекает текст из веб-страницы, чтобы использовать его в качестве входных данных для обнаружения дублированного контента. Это не всегда тот блок текста, который вы хотите проверить на наличие дубликатов. В этом случае лучше использовать поле ввода текста.
- Новое содержимое необходимо проиндексировать, прежде чем оно сможет быть возвращено этим инструментом. Если странице/контенту меньше 2 дней, шансы на получение каких-либо результатов невелики.
- Не все дубликаты, найденные в Интернете, возвращаются этим инструментом. Но по сравнению с другими инструментами он возвращает довольно большую сумму.
Внешние ресурсы:
- Google, https://support.google.com/webmasters/answer/66359?hl=en
- Search Engine Land, http://searchengineland.com/library/google/google- панда-обновление
Зачем и как проверять наличие дубликатов
Большинство профессиональных писателей знают, что Google и другие поисковые алгоритмы не приветствуют дублированный контент.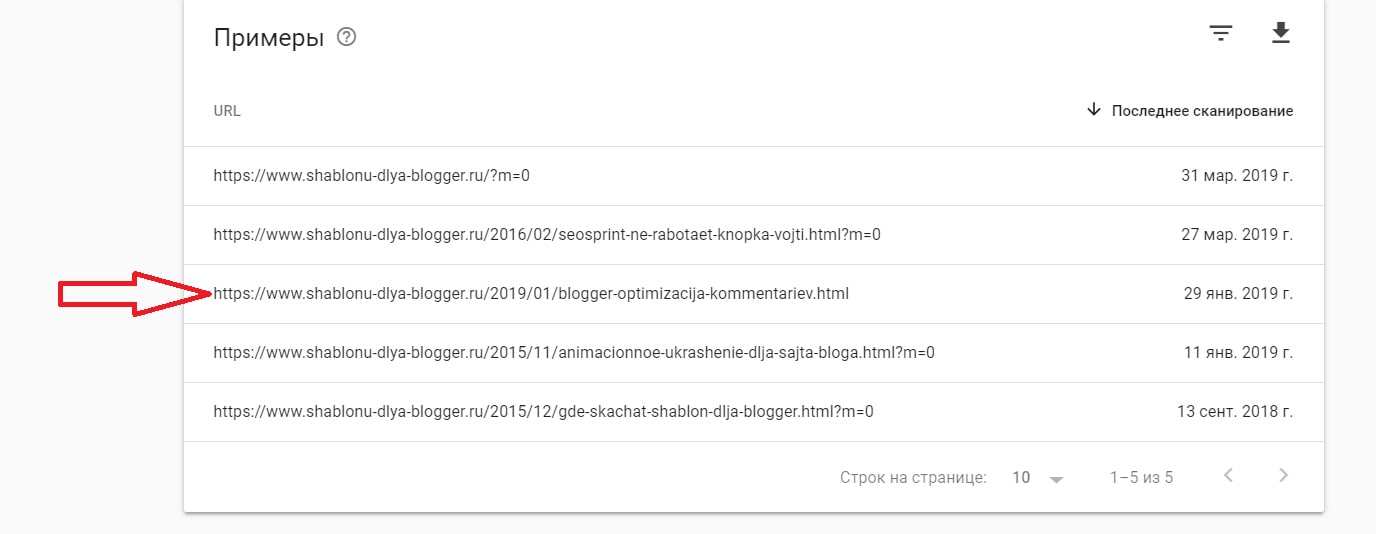 Золотым стандартом является свежее, высококачественное письмо, которое следует превосходным методам поисковой оптимизации и приносит новую информацию. Даже когда вы пишете статью, которая представляет ту же информацию в другом свете, важно избегать копирования — или даже восприятия копирования — работы, которая была написана до вас.
Золотым стандартом является свежее, высококачественное письмо, которое следует превосходным методам поисковой оптимизации и приносит новую информацию. Даже когда вы пишете статью, которая представляет ту же информацию в другом свете, важно избегать копирования — или даже восприятия копирования — работы, которая была написана до вас.
Есть несколько причин, по которым важно помнить об этом, и почему важно выполнять проверку дубликатов контента, прежде чем нажимать кнопку «Опубликовать». Эти причины варьируются от ориентированности на поисковую оптимизацию до создания бренда и этического желания избежать обвинений в плагиате или краже.
Независимо от того, являетесь ли вы копирайтером, онлайн-редактором или другим профессионалом, создающим контент в Интернете, очень важно, чтобы вы знали, как проверять дублированный контент. Давайте посмотрим, что это такое, где это происходит, почему это проблема и как не допустить этого в вашей работе с помощью современной передовой технологии защиты от плагиата.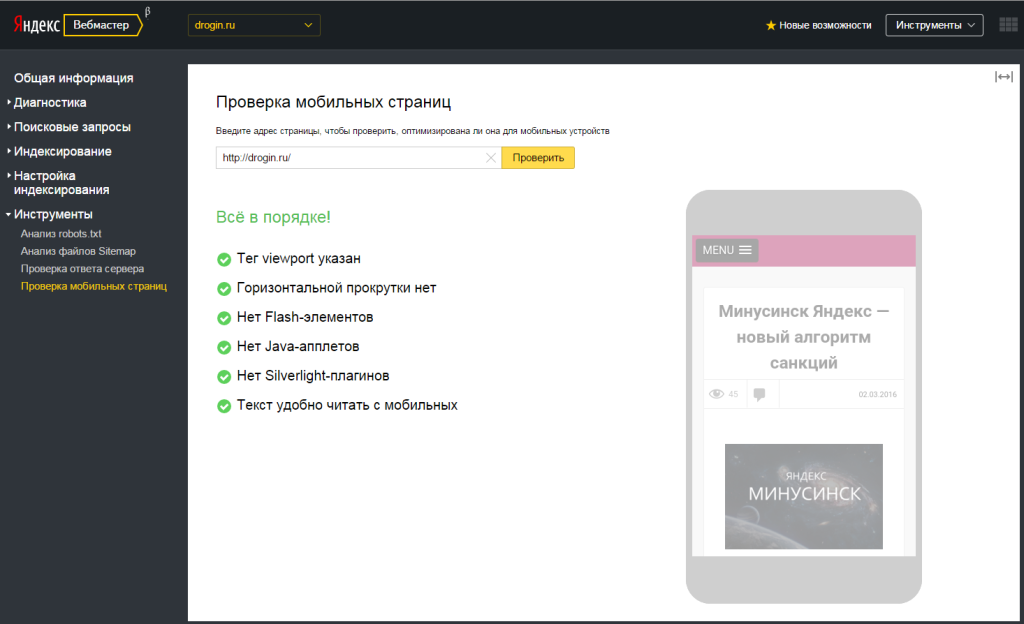
Что такое дублированный контент?
Дублированный контент — это именно то, на что это похоже: фрагмент контента, который можно найти более чем в одном месте. Обратите внимание, что это не ограничивается дословным текстом с одинаковыми заголовками и форматированием, найденным на двух разных веб-сайтах. Дублированный контент по-прежнему считается, если он равен:
- Внутренние и найденные на двух или более страницах одного и того же сайта
- Переставлено в лоскутное одеяло — что все равно является плагиатом, если работа не ваша, — или самоплагиатом, то есть вы должны были создать новый контент для публикации, а не
- Публикуется с другими заголовками или форматированием
- Только фрагменты оригинальной работы
Важно отметить, что внутреннее дублирование контента, которое не является чем-то фантастическим с точки зрения SEO (обсуждено вкратце), гораздо менее вредно, чем внешне дублированная работа. Это связано с тем, как поисковые системы организуют, ранжируют и возвращают различные фрагменты контента интернет-пользователям, когда они вводят ключевые слова в поле поиска.![]()
Как Google решает, какой контент ранжировать?
Вот как это работает. Google сравнивает дубликаты документов, чтобы найти тот, который, по его мнению, наиболее актуален для его аудитории. Что касается ботов, необходим только один фрагмент контента. Он оценивает обе части по типичным алгоритмическим показателям релевантности и ранжирует одну из них в индексе Google, в то время как другая фактически архивируется, чтобы она не отображалась в результатах поиска. Та, которая ранжируется, является «канонической» страницей и отныне будет подтягиваться алгоритмами по этим ключевым словам.
Важно отметить, что Google не делает различий между оригинальным контентом и последующим. Если боты считают, что неоригинальный контент лучше — из-за ссылок, структуры, заголовков и форматирования, метаданных и других показателей успеха — они присвоят этому рейтингу и отныне будут поднимать его в результатах поиска.
Дублированный контент и удобство поиска
Люди часто принимают это за «наказание». Они предполагают, что одна часть работы задержана, а другие порезаны и сожжены. Не так. Google просто должен выбрать, какой результат вернуть в поисковом рейтинге. Если бы это было не так, алгоритм существовал бы в постоянном состоянии выбора, на какой похожий веб-адрес отправлять людей по разным ключевым словам. Это означало бы разделение трафика каждого, разбавление ценности всех ссылок меньшим входящим трафиком и, как правило, снижение влияния всех задействованных веб-страниц.
Они предполагают, что одна часть работы задержана, а другие порезаны и сожжены. Не так. Google просто должен выбрать, какой результат вернуть в поисковом рейтинге. Если бы это было не так, алгоритм существовал бы в постоянном состоянии выбора, на какой похожий веб-адрес отправлять людей по разным ключевым словам. Это означало бы разделение трафика каждого, разбавление ценности всех ссылок меньшим входящим трафиком и, как правило, снижение влияния всех задействованных веб-страниц.
По общему признанию, предотвращение этого сценария обеспечивает лучший пользовательский опыт. Вы ограничиваете идентичный контент, возвращаете поисковикам высококачественные результаты в рамках заданных параметров, повышаете функциональность и обеспечиваете отличные результаты поисковой выдачи (страницы результатов поисковой системы). Отбрасывая похожий контент, скопированный контент, внутренний дублированный контент и менее оптимизированный контент веб-сайта, Google делает свои страницы результатов более чистыми и удобными для пользователя.
Обратите внимание, что это не означает, что исходный контент теряет свое место в Интернете. Например, неканонический контент:
- Остается на сайте, где он был опубликован, и не может быть удален Google
- Все еще могут быть внутренние ссылки на другие веб-сайты или через них
- Будет представлен в поиске через Wayback Machine или другие цифровые архивы
Тем не менее, как только первоначальный фрагмент контента был вытеснен новым фрагментом контента, в первую очередь возникают серьезные последствия для человека или организации, которые создали этот контент. На данный момент самый простой способ понять это — изучить пример.
Дублированный контент: пример использования сыра
Допустим, вы написали в блоге статью под названием «Овладение искусством дегустации голландского сыра». Это был один из самых популярных постов, написанных фуд-блогером в начале 2000-х, и какое-то время он привлекал много трафика, но сейчас он немного надоел. Вы больше не обновляете свой сайт и не добавляете новые статьи. В наши дни не так много людей ссылаются на оригинальный пост. Тем не менее, это ваше, и это приводит к приличному трафику, который приносит вам партнерский доход.
Вы больше не обновляете свой сайт и не добавляете новые статьи. В наши дни не так много людей ссылаются на оригинальный пост. Тем не менее, это ваше, и это приводит к приличному трафику, который приносит вам партнерский доход.
Введите гигантский кулинарный блог и писателя, который оставил свой моральный компас где-то в Греции около 10 лет назад. Они берут «Овладение искусством дегустации голландского сыра», переделывают его с другими заголовками и красивым эффектом пэчворка, добавляют несколько фотографий и фирменную цветовую схему и загружают в WordPress. Им бессовестно не удается запустить проверку дубликатов контента, и они нажимают «Опубликовать».
Немедленно они получают много попаданий. Кроме похлопываний по плечу от начальства, впечатленного трафиком. Пост, который всегда был хорошо написан, получил много любви в социальных сетях и много раз был опубликован. На него ссылаются в текущих блогах о еде, и он даже упоминается в New York Times. В конце концов, конечно, правда всплывает на поверхность… но к тому времени последствия SEO для исходного плаката уже наступили, и потребуется время, чтобы исправить эту ошибку.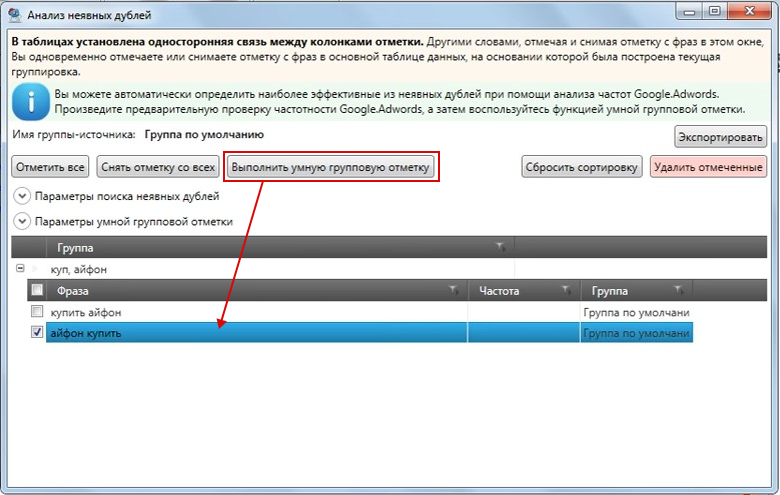
Естественно, это не норма. Но бывает и не редко. Давайте рассмотрим некоторые из наиболее распространенных причин непреднамеренного дублирования контента.
Причины дублирования контента
Большинство людей также предполагают, что проблемы с дублированием контента возникают, когда злоумышленник крадет часть оригинального контента и размещает его на своей веб-странице. Хотя прямой плагиат действительно имеет место, это не самая распространенная форма плагиата.
Чаще всего это происходит, когда человек смотрит на работу другого при создании своего контента. При профессиональной работе в Интернете не применяются те же правила, что и при написании бумажной работы в классе. Например, дублированный контент часто создается, когда блоггеры цитируют из других блогов, даже с надлежащей атрибуцией. Дело в том, что не имеет значения, насколько вы отдаете должное другому сайту, если вы: а) берете так много контента, что это заставляет Google думать, что существуют дубликаты, или б) заимствуете контент, который появляется во фрагменте (в в верхней части страницы результатов поиска), что имеет решающее значение для SEO и, следовательно, несправедливо по отношению к организации, занявшей первое место.
Это также может произойти, когда люди цитируют контент веб-сайта в сообщениях в социальных сетях. Каждая публикация в социальных сетях в Instagram, Twitter, Facebook, Pinterest, TikTok и т. д. рассматривается как отдельный уникальный URL-адрес. Скопированный контент является скопированным контентом, и Google будет рассматривать эти URL-адреса как таковые, а затем принимать решение о том, какой из них является каноническим.
Дублирование контента также может быть вызвано идентификаторами сеанса, несколькими URL-адресами одного и того же контента, версиями веб-страниц только для печати и другими более невинными причинами.
Зачем предотвращать дублирование контента
На вопрос «Почему следует избегать дублирования контента?» есть два ответа. Во-первых, вы можете попасть в серьезные неприятности из-за плагиата чужой работы. Это неэтично и вызывает неодобрение в академическом, научном и писательском сообществах, где ценится оригинальная работа. В некоторых случаях вы можете оказаться на неправильном конце судебного процесса. Это также может привести к негативным последствиям SEO для вашего сайта, когда вы дублируете контент внутри. Вы разбавляете ценность своих собственных страниц, снижая свой веб-рейтинг в Google и влияя на свои собственные места размещения в поисковой выдаче.
Это также может привести к негативным последствиям SEO для вашего сайта, когда вы дублируете контент внутри. Вы разбавляете ценность своих собственных страниц, снижая свой веб-рейтинг в Google и влияя на свои собственные места размещения в поисковой выдаче.
Последняя причина, по которой вам следует предотвращать дублирование контента, заключается в том, что это может привести к серьезным последствиям для кого-то другого.
Обратная сторона дублированного контента для оригинальных создателей
Если кто-то пишет контент для оптимизации, использование дублированного контента также может негативно повлиять на его поисковую оптимизацию.
К сожалению, хотя парсеры (боты, сканирующие контент) хорошо справляются с потребностями пользователей, они не могут сказать, кто что написал. Они просто выстраивают контент и отмечают, «заметно ли он похож». Затем они, основываясь на различных показателях, выбирают один для ранжирования и отбрасывают другие. Когда алгоритм архивирует исходный фрагмент контента, то есть отбрасывает чью-то тяжелую работу, это серьезная проблема.
Это означает, что первоначальный автор или веб-мастер может потерять заработанный кредит, если его страница будет заархивирована и больше не будет отображаться в результатах поиска. Это также означает, что вторая часть контента появляется в поисковом рейтинге как исходная часть контента. Это имеет ряд последствий, в том числе:
- Потеря любого будущего потенциала обратных ссылок, потому что дублированный контент теперь с большей вероятностью будет получать ссылки из других источников
- Уменьшение потенциала электронной коммерции архивных дубликатов страниц
- Напрасная трата времени и ресурсов компании, которая усердно работала над оптимизацией оригинального контента (теперь считающегося «дублированным») с помощью правильных форматов, внутренних ссылок, структуры HTML, метатегов и т. д.
- Превращение оригинального создателя в плагиатора
По очевидным причинам, только последнее делает дублирование контента огромной проблемой. Большинство людей, конечно, благородны и не хотели бы этого делать. (Те, кто заметят, что такие инструменты, как средства проверки на плагиат и Google Search Console, теперь значительно усложняют задачу по предотвращению кражи интеллектуальной собственности в Интернете.)
Большинство людей, конечно, благородны и не хотели бы этого делать. (Те, кто заметят, что такие инструменты, как средства проверки на плагиат и Google Search Console, теперь значительно усложняют задачу по предотвращению кражи интеллектуальной собственности в Интернете.)
Если вы хотите оставаться в чистоте, вы всегда должны создавать уникальный контент, используя свои слова. Если вы беспокоитесь о дублировании, вы можете провести SEO-аудит или использовать множество других инструментов SEO, чтобы убедиться, что вы всегда создаете что-то новое, привлекательное и значимое для ваших читателей. Это лучший способ увеличить аудиторию и в то же время держать нос в чистоте.
И, конечно же, средства проверки контента.
Как проверить дублирующийся контент
Очевидно, что как профессионал вы не хотите, чтобы вас считали копирующим чужую работу. Хотя вы можете запустить средство проверки дублирующегося контента, чтобы сравнить свою работу с другой — так же, как вы сравниваете два документа Word, — лучшей альтернативой будет использование средства проверки на плагиат для поиска каждого фрагмента когда-либо написанного контента и предотвращения случайного дублирования.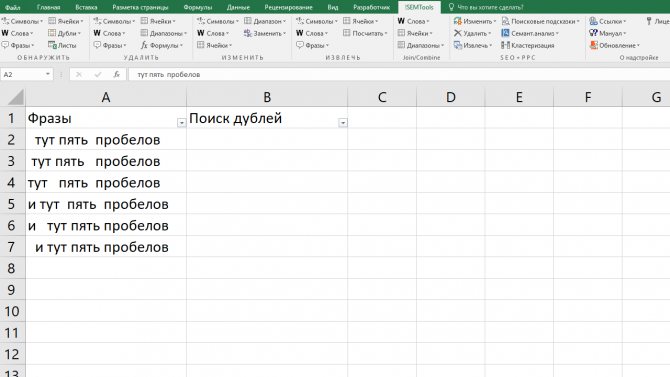
Кроме того, помните о следующих рекомендациях:
- По возможности используйте чужие идеи для вдохновения, в лучшем случае перефразируя их работу
- Если не цитировать автору оригинала будет плохой услугой и если он не включает его фрагмент Google, вы можете вырезать и вставить одну или две строки контента из другого источника с указанием авторства .
- Старайтесь использовать как можно больше источников при создании собственных историй и информационных статей
- Всегда отдавайте должное фотографиям, графике, музыке или другим видам искусства
- Никогда не цитируйте данные без указания авторства
- Даже с номерами постарайтесь переработать контент, чтобы он не вызывал дублирования
В дополнение к средству проверки дублирующегося контента вы также можете копировать разделы своего письма, которые, как вы беспокоитесь, могут быть слишком близкими, и вставлять их в поле поиска Google. Если он подтягивает источник, который вы использовали, ваш текст все еще слишком близок к оригиналу.