
Как найти и удалить дубли страниц
Дубль – страница, которая полностью или частично дублирует контент другой страницы. Одна из причин потери трафика из поисковых систем – наличие дублей страниц на сайте.
Принципы определения дублей поисковыми системами
Поисковые системы (далее «ПС») имеют свои алгоритмы проверки и определения дублей страниц.
Основные параметры, которые учитывают ПС при определении дублей:
- Мета-теги;
- Заголовки h2-H6;
- Текст страницы.
Способы определения дублей страниц на сайте
Статус «Дубль» присваивается поисковым роботом соответствующей поисковой системы при сканировании страниц сайта. Воспользуйтесь Вебмастерами поисковых систем, чтобы определить наличие дублей. Или воспользуйтесь специализированными программами для ручного поиска дублей.
Способ 1: Дубли страниц в Яндекс.Вебмастер
В поисковой системе Яндекс увидеть дубли страниц можно в Яндекс.Вебмастер, в разделе Индексирование -> Страницы в поиске -> Исключенные страницы -> Статус «Дубль».
 Дубли страниц в Яндекс.Вебмастер
Дубли страниц в Яндекс.ВебмастерСпособ 2: Дубли страниц в Google Search Console
В поисковой системе Google увидеть дубли страниц можно в Google Search Console, в разделе «Покрытие» -> «Исключено».
 Дубли страниц в Google Search Console
Дубли страниц в Google Search ConsoleСпособ 3: Через программы для комплексного анализа сайтов
Поисковые системы не всегда корректно распознают дубли. Используя различные программы сканирования сайтов можно определить наличие дублей на сайте. Например, программа Screaming Frog позволяет это сделать.
Чтобы найти дубли с помощью Screaming Frog используйте те же самые основные параметры поиска:
-
Поиск одинаковых Title. Вкладка «Page Titles» -> Filter «Duplicate»
 Список страниц с одинаковыми Title в программе Screaming Frog
Список страниц с одинаковыми Title в программе Screaming Frog -
Одинаковые заголовки h2, h3. Вкладка «h2» или «h3» -> Filter «Duplicate»Список страниц с одинаковыми h2 в программе Screaming Frog
 Список страниц с одинаковыми Title в программе Screaming Frog
Список страниц с одинаковыми Title в программе Screaming Frog Список страниц с одинаковыми h2 в программе Screaming Frog
Список страниц с одинаковыми h2 в программе Screaming FrogПодобным образом можно найти дубли во вкладке Description, h3.
Способ 4: Ручной поиск – проверка типичных ошибок
Дубли сайта формируются на основании технических особенностей систем, на которых пишутся сайты.
Основные ручные проверки, которые необходимо провести:
- Доступность страницы с добавлением index.php / index.html / index.htm для каждой страницы после слеша. Например, есть страница https://site.ru, нужно проверить доступность страницы по адресам:
- https://site.ru/index.php
- https://site.ru/index.html
- https://site.ru/index.htm
- Доступность страницы по HTTP и HTTPS страницы: https://site.ru и http://site.ru. Если страница доступна по разным протоколам, то необходимо настроить 301 редирект с HTTP на HTTPS.
- Доступность страницы по разным зеркалам. Адреса с «www» и без «www»: http://www.site.ru и http://site.ru
- Доступность страницы с разным регистром в URL: http://site.ru/example/ и http://site.ru/EXAMPLE/
- Доступность одной и той же страницы по разным URL: http://site.ru/catalog/tovar1/ и http://site.ru/tovar1/
- Доступность страницы со слешами («/», «//», «///») и без них в конце: http://site.ru/example, http://site.ru/example// и http://site.ru///example/
- Доступность страницы-дубля через пагинацию: > http://site.ru/catalog/ и http://site.ru/catalog/page1
Как избавиться от дублей страниц
- Установить тег canonical. Установить тег в <head>: <link rel=»canonical» href=»ссылка на каноничную страницу» />.
- Изменить контент страницы. Изменить мета-теги, заголовки h2-h6, текст, учитывая особенности контента, расположенного на странице. Используйте в случае необходимости индексирования страницы-дубля.
- Удалить страницу.
- Установить 301 редирект с дубля на оригинальную страницу. Попадая на страницу дубль, пользователь будет переадресован на нужную страницу.
- Запретить индексирование в robots.txt. Указать поисковому роботу, что добавлять в индекс такие страницы не нужно.
- Установить
Влияние дублей страниц на поисковое продвижение
- Любой поисковая система имеет лимит на сканирование страниц для одного сайта. При появлении дублей, увеличивается общее количество страниц на сайте. При большом количестве страниц-дублей, поисковой робот может вовсе пропустить важные страницы.
- Изменение релевантности страницы. Поисковой робот может решить, что страница-дубль отвечает на запрос лучше, чем оригинальная страница и в поисковой выдаче будет показывать страницу-дубль.
- Потеря ссылочной массы оригинальной страницы и посетители станут попадать на страницы-дубли.
454080, Россия, Челябинская, Челябинск, Энтузиастов 2
ComparseR проверит сайт на дубли страниц
Дубли страниц ресурса – это доступность одной или нескольких страниц сайта по разным адресам. Нахождение и удаление дублей является одним из первоочередных действий SEO-оптимизатора при продвижении сайта. Подобное действие архиважное, поскольку наличие дублей страниц делает сайт неуникальным, а это значит, что поисковые системы рано или поздно пессимизируют его, как следствие, раскрутка станет временно невозможной. Рекомендуем воспользоваться специальной SEO программой для поиска дублей страниц сайта «ComparseR». Описание программы, видеообзор и ссылка на скачивание внизу этой страницы.
Полные и неполные дубли страниц сайта
Различают полные и неполные дубли страниц. Полный дубль – это 100% повторение одной страницы содержания другой. На неполных дублях материал повторяется частично: к ним относится дублирование анонсов новостей в ленте сайта, сквозные пункты меню и так далее.
Самое главное правило – не допустить индексации дублей страниц. Однако зачастую SEO-специалисты обнаруживают дубли страниц непосредственно в процессе продвижения.
Основные причины появления дублей страниц:
- присутствие параметров в URL-адресах страниц;
- адреса сайта с приставкой «www» и без нее не склеены и доступны в двух вариантах;
- не склеены адреса страниц без слеша на конце и с ним.
Для того чтобы проверить сайт на дубли страниц, нужно взять любой сайт, например, ваш_сайт_ру со слешем на конце, и перейти по нему, затем ввести его же, только без слеша в конце. Если браузер открывает страницу со слешем и во втором случае, то это свидетельствует о том, что страницы склеены, 301 редирект работает, как следствие, дублей нет. Точно так же проверяют сайты на дубли с приставкой «www» и без нее.
Поиск дублей страниц сайта в Яндексе
Поисковая система Яндекс также помогает определить наличие дублей с помощью поиска контента на сайте. Для этого нужно воспользоваться расширенным поиском. Сначала в строке расширенного поиска нужно ввести предложение с интересующего сайта и заключить его в кавычки. Затем в графе «На сайте» ввести адрес сайта. В случае нахождения Яндексом только одной страницы – можно успокоиться, так как дублей у ресурса нет. Сервис поддерживает все доменные зоны, включая зону рф.
Поиск дублей в Google
Google также предлагает схожий сервис. Для того чтобы им воспользоваться, также нужно в строке поиска ввести предложение в кавычках, а после него через пробел ввести команду site:ваш_сайт_ру. Если в результатах поиска выдается только один сайт, то дублей у него нет. Google также поддерживает все доменные зоны, в том числе и домены на кириллице.
Удаление дублей
При обнаружении дублей оптимизатор, как правило, удаляет их в панели Яндекс Вебмастер, там есть специальный сервис по удалению URL, и можно быстро избавиться от дублей страниц в выдаче, тоже самое есть и в панели Google webmasters.
Удаление страниц из выдачи Яндекса
Удаление страниц из выдачи Google
Для успешного продвижения сайта оптимизатору еще на начальной стадии нужно обязательно обнаружить и удалить имеющиеся дубли, поскольку они могут серьезно навредить продвижению и свести на «нет» все усилия веб-мастера.
Сервис по поиску дублей страниц сайта
Для автоматического поиска дублей заголовков «title» и описаний «description» очень удобно пользоваться специальной программой «ComparseR», разработанной в веб-студии «АлаичЪ и Ко». Программу можно скачать тут.
Автор программы предусмотрел демо-режим, который вполне годится для небольших сайтов. Проверить 150 страниц сайта на дубли и ошибки можно совершенно бесплатно.
Посмотрите видеообзор программы «ComparseR»
Прочитано раз: 3 072
Пост написан: 07.11.2014. Последнее изменение: 16.09.2019
Поиск и устранение дублей сайта. Настройка правильной индексации сайта в поисковых системах
- Причины появления дублей
- Поиск дублей
- Устранение дублей
- Ответы на вопросы
Для начала посмотрим, в чем же заключается опасность дублирующих страниц на сайте, попробуем найти дубли на ресурсе и их устранить для того, чтобы в будущем они не появлялись.
Опасность дублей на сайте
Перед тем как говорить о дублях, хочется дать определение, что же такое дублирующая страница сайта. Под дублями мы понимаем несколько страниц одного ресурса, который содержит в достаточной мере идентичный текстовый контент. Хочу обратить ваше внимание, что речь мы ведем только об одном ресурсе и говорим о текстовом контенте в том плане, что подразумеваем, что робот при определении дублирующих страниц смотрит только на текстовое содержимое страниц вашего сайта. Он не проверяет дизайн, либо изображение на данных страничках, а смотрит только на текст. В большинстве случаев дублирующие страницы – это одна и та же страница сайта, доступная по нескольким адресам.
Причины появления дублей
Причин появления дублей на сайте огромное количество.

Все они связаны с различными ошибками. Например, ошибки в содержимом страниц, когда некорректно указаны относительные ссылки, ошибки, связанные с отсутствием, либо недостаточным количеством текста на страницах, некорректные настройки 404 кода ответа, либо доступность служебных страниц сайта, либо особенности работы CMS, которую вы используете. Это большое количество дублирующих страниц зачастую гнетет вебмастеров, и они откладывают работу над дублями в долгий ящик и не хотят этим заниматься.
Проблемы, к которым приводят дубли
Но на самом деле делать этого не стоит, поскольку наличие дублей может привести к различным проблемам. Их можно разделить на три большие группы:
- Во-первых, это смена релевантной страницы в результатах поиска.
- Во-вторых, обход роботом большого количества дублирующих страниц вместо того, чтобы индексировать нужные странички сайта.
- И, в-третьих, это проблема со сбором статистики на вашем ресурсе.
Давайте рассмотрим более подробно каждую проблему.
Смена релевантной страницы

Я взял сразу пример из практики. На сайте есть страничка с бухгалтерскими услугами, которая доступна по двум адресам. Первый адрес находится в разделе «услуги», а второй адрес – это страничка в корне сайта. Контент данных страничек абсолютно одинаков. Поскольку робот не хранит в своей базе сразу несколько идентичных документов, он выбирает самостоятельно страницу для включения в поисковую выдачу. Кажется, что, по сути, не должно произойти ничего плохого, ведь странички абсолютно похожи между собой. Но вы же опытные вебмастера и знаете, что позиции конкретной страницы по запросам рассчитываются на основании нескольких сотен показателей. Поэтому при смене страницы в поисковой выдаче ее позиции могут измениться.

Как произошло и в нашем случае. По конкретному запросу «услуги бухгалтерского отчета» видно, что в середине июня произошло проседание позиций. Это как раз связано с тем, что сменилась релевантная страница в поисковой выдаче и спустя несколько дней, в районе 19 сентября, позиции восстановились, поскольку в поиск вернулась нужная страница сайта, который участвовал в выдаче до этого. Согласитесь, даже такое небольшое изменение позиций сайта может очень сильно повлиять на трафик, на ваш ресурс.
Обход дублирующих страниц

Вторая причина, по которой необходимо бороться с дублями, связана с тем, что робот начинает посещать большое количество дублирующих страниц. Поскольку количество запросов со стороны индексирующего робота ограничено, например, производительностью вашего сервера или CMS, вами с помощью директивы Crawl-delay, а также роботом, то при большом количестве дублирующих страниц начинает скачивать именно их вместо того, чтобы индексировать нужные вам страницы сайта.

В результате, в поисковой выдаче могут показываться неактуальные данные, и пользователи, переходя на ваш ресурс, не будут видеть информацию, которую вы размещали на сайте.

Тоже пример из практики по обходу дублирующих страниц. Очень большой интернет-магазин, где видно, что до конца мая робот каждый день скачивал чуть меньше 1 миллиона страниц с сайта. После обновления ресурса и внесения изменений на сайт видно, что робот резко увеличил нагрузку на ресурс и начал скачивать несколько миллионов страниц. Огромные цифры.

Если посмотреть, что именно скачивает индексирующий робот, то можно увидеть, что большое количество – этот желтый пласт, несколько десятков миллионов – это как раз дублирующие страницы. Их примеры можно будет посмотреть ниже:

Это страницы с некорректными параметрами, get параметрами в URL-адресе. Такие странички появились из-за некорректного обновления CMS, используемой на сайте.
Затруднение сбора статистики

И третья проблема, к которой могут привести дублирующие страницы – это проблемы со сбором статистики на вашем сайте. Например, в Яндекс. Вебмастере, либо в Яндекс. Метрике.

Если говорить о Яндекс. Вебмастере, то в разделе «Страницы в поиске» вы можете наблюдать такую картину. При каждом обновлении поисковой базы количество страниц в поиске остается практически неизменным, но видно, что робот на верхнем графике при каждом добавлении, добавляет и удаляет примерно одинаковое количество страниц. Происходит процесс, постоянно что-то добавляется/удаляется, но при этом в поиске количество страниц остается неизменным. Странная ситуация.
Смотрим раздел «Статистика обхода»:

Ежедневно робот посещает несколько тысяч новых страниц сайта. Это только новые страницы. При этом данные страницы при поисковой выдаче, как видно на графике ниже, опять-таки не попадают. Это опять же связано с обходом дублирующих страниц, которые потом в поисковую выдачу не включаются.

Если вы используете Яндекс. Метрику для сбора статистики посещаемости конкретной страницы, то может возникнуть следующая ситуация. Данная страница показывалась ранее по конкретному запросу и на нее были переходы из результатов поиска. Но видно, что в начале мая данные переходы прекратились. Страничка перестала показываться по запросам посетителей, пользователей поисковой системы перестали переходить по ней. Что же произошло на самом деле? В поисковую выдачу включилась дублирующая страница и пользователи поиска переходят именно на нее, а не на нужную страницу, за которой вы наблюдаете с помощью Яндекс. Метрики.
Проблемы, к которым приводят дубли
В результате три больших проблемы, к которым могут привести дублирующие страницы вашего сайта:
- Это смена релевантной страницы.
- Обход дублирующих страниц вместо нужных.
- Проблемы со сбором статистики
Согласитесь, три больших проблемы, которые должны вас как-то мотивировать к работе над дублирующими страницами сайта. Но чтобы что-то предпринять, сначала нужно найти дубли найти. Об этом следующий раздел.
Поиск дублей
Если немножко изменить довольно-таки популярный диалог, получилось бы следующее: «Видишь дублирующие страницы? – Нет. – И я нет, а они есть». Так же на самом деле, практически на каждом ресурсе в Интернете есть дублирующие страницы, осталось их только найти.
Источник для поиска дублей «Страницы в поиске»
Начнем с самого простого способа, будем искать дубли с помощью раздела «Страницы в поиске» в Яндекс. Вебмастере.

Всего 4 клика, с помощью которых можно увидеть все дублирующие страницы на вашем ресурсе. Первый клик – заходим в раздел «Страницы в поиске», переходим на вкладку «Исключенные страницы»:

Выбираем сортировку и нажимаем кнопку «применить»:
В результате чего на нашем экране видны все страницы, которые исключил робот из поисковой выдачи, поскольку посчитал дублирующими.
Согласитесь, очень легко, 4 клика, быстро, понятно и вот все дублирующие страницы с вашего ресурса удалены.
Если таких дублирующих страниц много, как в нашем случае их несколько десятков тысяч, можно полученную таблицу скачать в Excel’евском формате, либо CSV’шном и дальше использовать в своих интересах. Например, собрать какую-то статистику, посмотреть списком все страницы, которые исключил индексирующий робот.
Источник для поиска дублей «Статистика обхода»

Второй способ – это раздел «Статистика обхода». Соседний раздел, переходим в него, смотрим, что посещает индексирующий робот.

Внизу раздела можно включить сортировку по 200 коду и видно, какие страницы доступны для робота и какие страницы посещает робот. В этом разделе можно увидеть не только дублирующие страницы, но и различные служебные страницы сайта, которые так же индексировать не хотелось бы.
Источник для поиска дублей «Ваша фантазия»

Третий способ посложнее и вам нужно будет применить свою фантазию. Берем любую страницу на вашем сайте и добавляем к ней произвольный get-параметр. В данном случае к странице добавили параметр test со значением 123. Используемый инструмент – «проверка ответа сервера», нажимаем кнопку «Проверить» и смотрим код ответа от данной страницы. Если такая страница доступна, как в нашем случае, отвечает кодом ответа 200, это может привести к появлению дублирующих страниц на вашем сайте. Например, если робот найдет такую ссылку где-то в Интернете, он проиндексирует и потенциально страница может стать дублирующей, что не очень хорошо.
Источник для поиска дублей «Проверить статус URL»

И четвертый способ, с которым я надеюсь вы никогда не столкнетесь после сегодняшнего вебинара – это инструмент «Проверить статус URL». В ситуации, если нужная вам страница уже пропала из результатов поиска, вы можете использовать этот инструмент, чтобы посмотреть по каким причинам это произошло. В данном случае видно, что страница была исключена из поисковой выдачи, поскольку дублирует уже представленную в поиске страницу сайта, и вы видите соответствующую рекомендацию.
Источник для поиска дублей

Четыре простых способа, которые может использовать каждый вебмастер, каждый владелец сайта с помощью сервиса Яндекс. Вебмастер. Кажется, все очень легко и просто, я думаю, что никаких проблем у вас не возникнет. Но помимо этих четырех способов вы можете использовать свои способы, например, посмотреть логи вашего сервера, к каким страницам обращается робот и посетители, посмотреть статистику Яндекс. Метрики, а также поисковую выдачу. Возможно, там получится найти дублирующие страницы вашего ресурса.
После того, как мы нашли дубли, с ними нужно что-то делать, каким-то образом работать. Об этом следующий раздел.
Устранение дублей

Все дубли можно разделить на две большие группы:
- Это явные дубли. Это страницы одного сайта, которые содержат абсолютно идентичный контент.
- Это неявные дубли. Это страницы с похожим содержимым одного сайта.
Внутри этих больших групп представлено огромное количество видов конкретных дубей. Сейчас мы с вами обсудим каким образом можно их устранить.
Дубли: со слэшом в конце и без

Самый простой вид дублей – это страницы со слэшом в конце адреса и без слэша, как указано в нашем примере. Самый простой вид дублей и, естественно, простое их решение, устранение этих дублей. Для таких дублирующих страниц мы советуем использовать 301 серверное перенаправление с одного типа адресов на другой тип страниц. Вы спросите, а какие страницы нужно оставить для робота?
Здесь решение принимать только вам. Вы можете посмотреть результаты поиска и увидеть какие именно страницы вашего сайта присутствуют в поисковой выдаче на данный момент. Если сейчас индексируются и участвуют в поиске страницы без слэша, соответственно, со страниц со слэшом можно установить перенаправление на нужные вам. Это прямо укажет роботу на то, какие именно страницы нужно индексировать и включать в поисковую выдачу. Настроить редирект можно разными способами – с помощью служебного файла htaccess, либо в настройках CMS выбрать формат адресов.
Дубли: один товар в двух категориях

Второй вид дублей – это один и тот же товар, который находится в нескольких категориях. В данном случае у нас товар – мяч, он доступен по адресу с категорией, игрушки/мяч и доступен так же в корневой папке вашего сайта. Для робота, поскольку эти страницы абсолютно одинаковые, это как раз дубли. В такой ситуации я советую вам использовать атрибут rel=” canonical” с указанием адреса канонической страницы, ту страницу, которую необходимо включать в поисковую выдачу. Это будет прямое указание для робота, и в поиске будет участвовать именно нужный вам адрес.
Какой адрес выбирать? В такой ситуации стоит подумать о посетителях вашего сайта. Посмотрите, какой формат адресов будет удобен и поможет им лучше ориентироваться на вашем сайте при просмотре адресов, понимать, в какой категории, например, они находятся.
Дубли: версии для печати
Следующий пример дублирующих страниц – это страницы «Версии для печати»:

В качестве примера я взял страницу одного сайта, в котором собраны тексты песен. Видно, что с левой стороны у нас версия для обычных пользователей с дизайном, с фоном, со стилями, а с правой стороны – версия для печати для того, чтобы было удобно распечатать эту страничку на принтере. Поскольку данные страницы доступны по разным адресам, потенциально для робота они тоже дублирующие, потому что текстовое содержимое данных страниц абсолютно похожее.

Для подобных страниц, для того, чтобы дублирование в случае их наличия не возникло, я вам советую использовать запрет в файле robots.txt. Например, как в нашем случае запрет Disallow: /node_print.php* укажет роботу на то, что все страницы по подобным адресам индексировать нельзя. Одно простое правило позволит вам избежать проблем с дублирующими страницами.
Дубли: незначащие параметры
Следующий вид дублей – это страницы с незначащими параметрами.

Незначащие параметры – это те get-параметры в URL-адресе ваших страниц, которые совсем не меняют их содержимое. Посмотрим пример, который я взял. У нас есть страница без параметров – это страничка page, есть вторая страница с utm-метками, например, они используются в рекламных компаниях и есть страничка с параметрами идентификатора сессии, например, если у вас Foon. Поскольку эти параметры абсолютно не меняют контент страницы, для робота это дублирующие страницы сайта.
Для таких ситуаций у нас есть специальная директива Clean-param. Она так же располагается в файле robots.txt и в ней можно перечислить все незначащие параметры, которые используются на вашем сайте. В данном случае у нас два параметра: utm_source и sid. Указали их в директиве Clean-param. Эта директива поможет роботу не только указать на то, что данные параметры являются незначащими, но и укажет роботу на то, что на вашем сайте есть страницы по чистому адресу, без данных get-параметров. Если она была роботу ранее неизвестна, он придет и специально скачает страничку по чистому адресу и включит ее в поисковую выдачу.
Такая сложная логика, но эта логика позволит вам избежать проблем и ситуаций, а нужные вам странички по чистым адресам будут всегда присутствовать в поисковой выдаче. Чего не будет происходить, если вы используете запрет, как указано в примере ниже. В данном случае робот не узнает, что на вашем сайте есть такие страницы по чистым адресам. Поэтому для незначащих параметров используйте директиву Clean-param.
Дубли: страницы действий
Очень близко по смыслу это страницы действий на вашем сайте.

Например, если пользователь на вашем ресурсе добавляет товар в корзину, либо сравнивает его с другими товарами, возможно, перемещается по страницам с комментариями, добавляются дополнительные служебные параметры, которые характеризуют действия на вашем сайте. При этом контент на таких страницах может совсем не меняться, либо может меняться совсем незначительным способом.
Чтобы робот совсем не посещал такие страницы, не добавлял их в свою базу, для данных случаев советую использовать запрет в файле robots.txt. Вы можете перечислить в директиве Disallow по отдельности каждый из параметров, который характеризует действия на сайте, либо, если совсем не хотите, чтобы страницы с параметрами индексировались, используйте правила, которые указаны ниже. Одно такое правило позволит сразу избежать возможных проблем из-за наличия таких страниц действий.
Дубли: некорректные относительные адреса

В случае, если на вашем сайте, как в примере, о котором ранее я говорил, в интернет-магазине появились некорректные относительные адреса, то, примерно, у вас возникнет следующая ситуация. У вас одна и та же страничка, например, как наш мячик, будет находиться в разделе игрушки/мяч, так и станет доступна по большому количеству вложенностей этой категории. В данном случае – несколько раз повторяется категория «игрушки» и потом «мяч». И в конце обычные пользователи, и роботы видят товар, который находится на исходном адресе.
Во-первых, чтобы побороть такие страницы, стоит разобраться с причинами их появления. Просмотреть исходный код страниц вашего сайта и проверить, корректно ли вы используете относительные ссылки на вашем ресурсе. После того, как ошибку нашли, настройте возврат 404 кода на запрос индексирующего робота к таким страницам. Это сразу позволит избежать дублирования информации.
Дубли: похожие товары
Следующий вид дублей, он же относится и к неявным дублирующим страницам – это похожие товары.

Как правило, в интернет-магазинах один и тот же товар доступен в нескольких вариантах. Например, разного размера, цвета, мощности, все, что угодно. В большинстве случаев такие товары доступны по отдельным URL-адресам. Что, естественно, затрудняет работы индексирующего робота, поскольку, по сути, эти странички практически ничем не отличаются, поэтому для таких страниц я советую использовать один URL-адрес, по которому сразу можно выбрать варианты исполнения данного товара, размер, либо цвет.
Это позволит не только роботу хорошо ориентироваться на вашем ресурсе и позволит избежать дублирования информации, но и облегчит посетителям переходы по страничкам. Не нужно будет возвращаться обратно в каталог, выбирать нужный вариант, вы можете установить селектор, и ваши пользователи на одной странице смогут сразу выбрать тот вариант, который им нужен.
Если такой возможности нет, нет возможности разместить этот селектор, вы можете добавить на такие страницы, на страницы с вариантами, дополнительное какое-то описание, расписать, почему такая мощность и для каких вариантов она подходит, почему такой цвет лучше, чем другой цвет, может быть, оттенками отличается. Добавить различные отзывы покупателей, которые купили именно тот или иной вариант цвета. Так же вы можете закрыть с помощью тега noindex служебные текстовые части страниц. Это укажет роботу на то, что контентная страница на самом деле отличается и нужно в поисковую выдачу включать оба или несколько вариантов страниц.
Дубли: фото без описания
Очень похожие по смыслу – эт
Дубликаты страниц сайта. Простой поиск дублей
Проверка сайта на дубликаты страниц
Ваш сайт продвигается слишком медленно? Постоянно случаются откаты на более низкие позиции? И это при том что внутренняя и внешняя оптимизация веб-ресурса выполнена на высшем уровне?
Подобное случается по нескольким причинам. Самая частая из них –дубликаты страниц на сайте, имеющих разные адреса и полное или частичное повторение содержания.
Чем опасны дубли страниц на сайте
Дубликаты страниц на сайте делают текст, размещенный на них неуникальным. К тому же снижается доверие к подобному веб-ресурсу со стороны поисковых систем.
Чем же еще опасны дубли страниц на сайте?
- Ухудшение индексации. Если веб-ресурс достаточно объемный и по каким-либо причинам регулярно происходит дублирование контента на сайте (бывают случаи, когда у каждой страницы существует по 4–6 дублей), это достаточно негативно влияет на индексацию поисковиками.
Во-первых, из-за того, что роботы поисковиков расходуют время при индексации лишних страничек.
Во-вторых, поисковики постоянно выполняют поиск дублей страниц. При обнаружения таковых они занижают позиции веб-ресурса и увеличивают интервалы между заходами своих роботов на его страницы.
- Ошибочное определение релевантной страницы. На сегодняшний день алгоритмы поисковых систем обучены распознавать дублирование контента на сайте, который индексируется. Но выбор поисковых роботов не всегда совпадает с мнением владельца веб-ресурса.
В итоге в результатах поиска может оказаться совсем не та страничка, продвижение которой планировалось. При этом внешняя ссылочная масса может быть настроена на одни странички, а в выдачу будут попадать дубликаты страниц на сайте.
В результате ссылочный профиль будет неэффективным и поведенческие факторы будут колебаться из-за распределения посетителей по ненужным страницам. Другими словами, будет путаница, которая крайне негативно скажется на рейтинге Вашего сайта.
- Потеря естественных ссылок. Посетитель, которому понравилась информация с Вашего веб-ресурса, может захотеть кому-нибудь ее рекомендовать. И если эту информацию он почерпнул на странице- дубликате, то и ссылку он будет распространять не ту, которая требуется.
Такие ценные и порой дорогие естественные ссылки будут ссылаться на дубли страниц на сайте, что в разы снижает эффективность продвижения.

Дублирование контента на сайте. Причины
Чаще всего дубли страниц на сайте создаются по одной из причин:
- Не указано главное зеркало сайта. То есть одна и та же страница доступна по разным URL — с www. и без.
- Автоматическая генерация движком веб-ресурса. Такое довольно часто происходит при использовании новых современных движков. Поскольку у них в теле заложены некоторые правила, которые делают дубликаты страниц на сайте и размещают их под другими адресами в своих директориях.
- Случайные ошибки веб-мастера, вследствие которых происходит дублирование контента на сайте. Результатом таких ошибок часто становится появление нескольких главных страничек, имеющих разные адреса.
- Изменение структуры сайта, которое влечет за собой присваивание новых адресов старым страницам. При этом сохраняются их копии со старыми адресами.

Как найти дубликаты страниц
Проверить сайт на дубли страниц поможет один из несложных методов:
- Анализ данных в сервисах поисковых систем для вебмастеров. Добавляя свой веб-ресурс в сервис Google Webmaster, Вы получаете доступ к данным раздела «Оптимизация HTML». В нем по дублируемым мета-данным можно найти страницы, на которых есть дублирование контента.
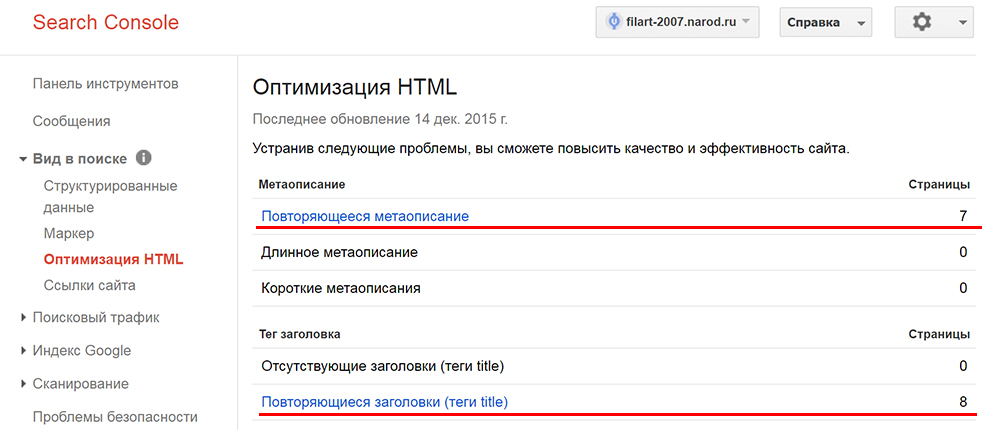
В Яндекс.Вебмастере дубли страниц можно проверить в разделе «Индексирование» > «Вид в поиске». На этой странице сделайте сортировку «Исключенные страницы» > «Дубли».
- Анализ проиндексированных страниц. Для получения их списка используется специальные операторы поисковых систем:
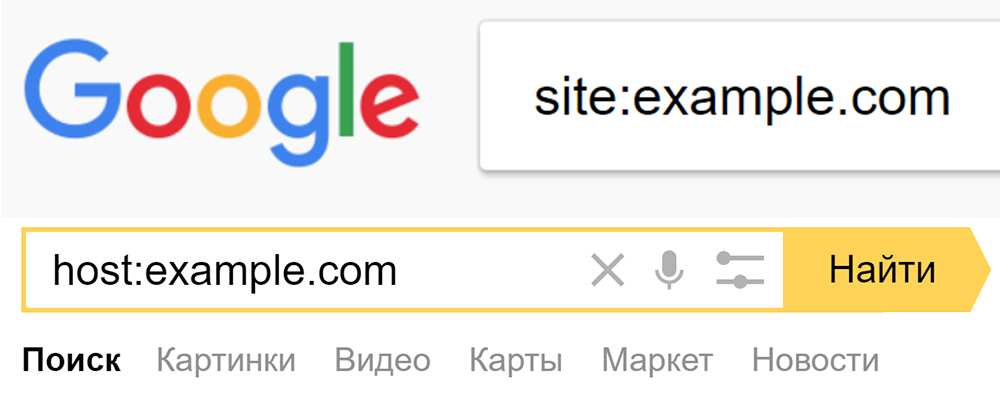
Полученная в результате выдача поможет проверить сайт на дубли страниц, у которых будут повторяться заголовки и сниппеты.
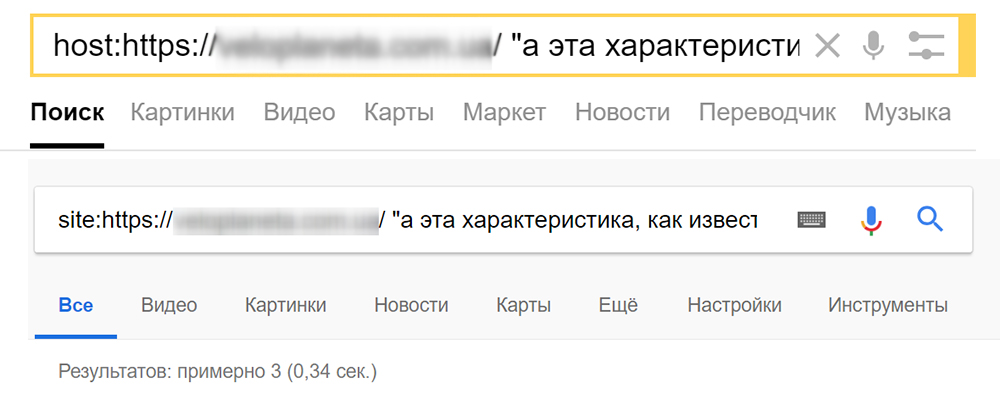
3. Поиск дублей фрагментов текста. Для получения их списка используются уже знакомые операторы (site: — для Google и hosh: — для Яндекса) , после которых указываем адрес сайта и в кавычках фрагмент текста. В результате мы можем получить либо полные дубли страниц, либо же частичное дублирование контента.
4. С помощью специальных программ и сервисов. Например, воспользовавшись программой Netpeak Spider, можно определить дубликаты страниц, текста, мета-тегов и заголовков. Все обнаруженные дубли необходимо будет удалить.
Если вы не хотите покупать десктопную программу Netpeak Spider, найти дубли страниц поможет многофункциональная seo-платформа Serpstat, которая работает онлайн + есть мобильная версия.
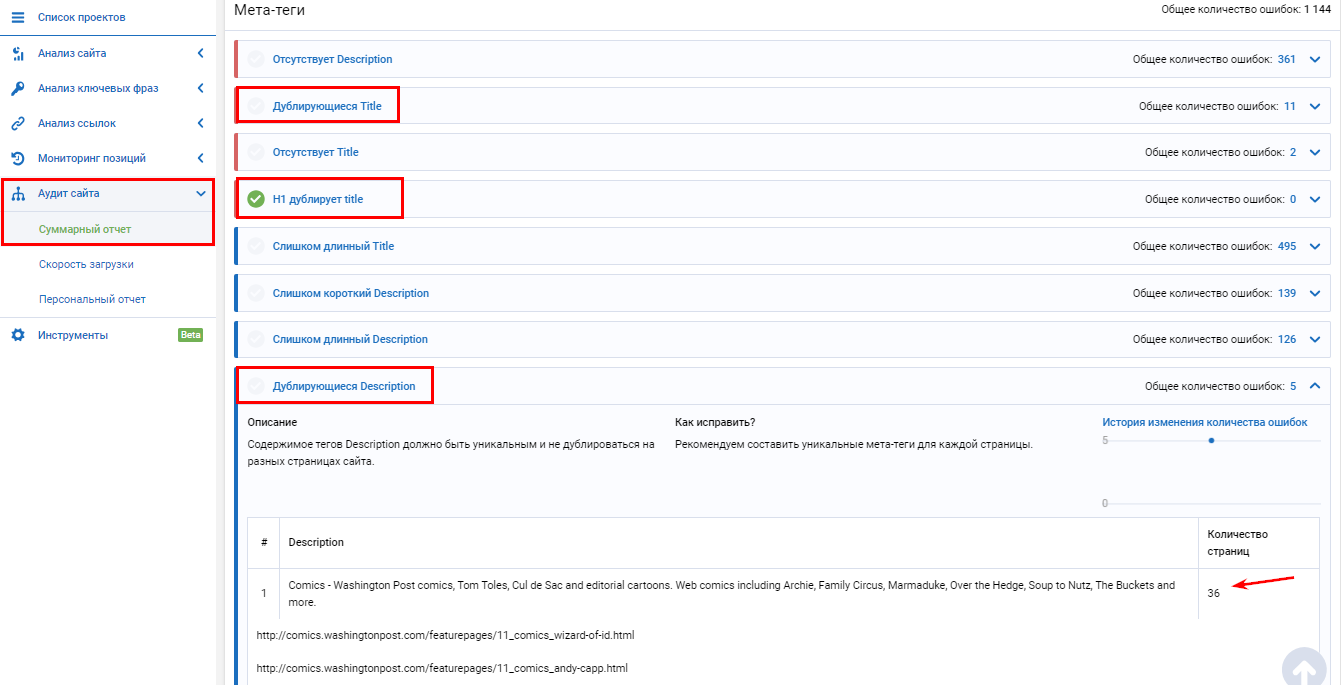
Сервис находит дублирующиеся тайтлы, дескрипшны, h2 дубль тайтла, больше чем 1 тайтл на странице, больше чем 1 заголовок h2 на странице.

Выводы
Желательно время от времени выполнять вышеперечисленные проверки, чтобы дублирование контента на сайте не стало неожиданной причиной падения его рейтингов. При этом нужно не забывать, что полные дубликаты страниц не являются единственной проблемой.
Дублирующиеся h2, title, description, а также некоторые части контента вроде отзывов и комментариев также очень нежелательны.
Надеемся, что эта статья была для Вас полезной. Не забудьте поделиться ссылкой на нее с теми, кому она также может быть интересной!
Поиск дублей страниц и их устранение
Дубли страниц могут присутствовать на любых сайтах, независимо от того сколько им лет и из скольких страниц они состоят. Для обычного посетителя они не представляют абсолютно никаких неудобств, такие страницы содержат необходимую ему информацию, а больше ему ничего и не нужно.
Если же посмотреть на URL адреса таких страниц, то можно заметить, что они отличаются. Поэтому поисковые системы и воспринимают их как абсолютно разные страницы, со всеми вытекающими отсюда негативными последствиями. В этой статье мы рассмотрим, как производить поиск дублей страниц, какие инструменты и методы их поиска существуют и как от них избавиться.
Наличие дублей страниц может негативно сказаться на ранжировании этих же страниц в поисковых системах.
Потому как эти страницы являются по сути одинаковыми, то теряется их уникальность, а это уже большой минус. Поисковая система не может понять какая из них более релевантная и какую из них нужно ранжировать выше. Поэтому высокие позиции в поисковой выдаче таким страницам занять очень тяжело.
Тот ссылочный вес который планировалось передать данной странице может просто напросто «размыться», а может даже оказаться на той странице, которой, изначально его никто не собирался передавать.
Среди некоторых SEO специалистов бытует мнение, что небольшое количество страниц, не оказывает негативного воздействия, но наличие на сайте 40 — 50 % страниц которые дублируются может создать некоторые трудности.
Из своего опыта могу сказать, что при появлении дубля той или иной страницы в индексе Яндекса значительно снижаются позиции данной страницы по продвигаемому запросу. Именно поэтому я считаю, что эта проблема очень актуальна и сколько бы дублей страниц у вас не было нужно регулярно проверять сайт на дубли страниц и устранять их.
Разновидности и причины появления дублей страниц
В целом можно выделить 2 разновидности дублей страниц это полные дубли (четкие) и неполные (нечеткие).
Полные дубли — это страницы с абсолютно одинаковым содержимым но с разными URL адресами. URL адреса могут отличаться расширением.
Например:
http://webmastermix.ru/uroki-i-stati.html http://webmastermix.ru/uroki-i-stati.htm http://webmastermix.ru/uroki-i-stati.php
Или иметь различные индентификаторы сесий и параметры.
Например:
http://webmastermix.ru/uroki-i-stati.html?start=5
Причины появления:
1. В большинстве случаев полные дубли появляются из за различных технических недоработок CMS, на которых создаются сайты. Причем такие недоработки встречаются как у популярных так и менее популярных движков. Способы устранения таких дублей будут зависеть от вида CMS, используемых плагинов и расширений и для каждого сайта их необходимо рассматривать в отдельности.
2. Следующей причиной появления четких дублей может быть произведенный редизайн, смененная структура сайта или смена используемого движка сайта на новый. Получается, что страницы поменяли свои адреса, но и по старым URL адресам могут выдаваться определенные страницы, но совсем не те, что были по ним доступны ранее.
3. Еще одной причиной возникновения четких копий может быть не внимательность веб-мастера, контент менеджера или администратора ресурса.
Примером могут быть дубли главной страницы вида:
http://webmastermix.ru/ http://webmastermix.ru/index.html http://webmastermix.ru/default.html
Нечеткие дубли — это страницы содержимое кторых очень похоже или содержит большие части текста из других страниц.
Такие страницы возникают в следующих случаях:
1. Самый распространенный вариант, когда основное содержимое страницы сайта настолько мало, что содержимое его сквозных частей, таких как футер, хедер и боковые колонки, превышает его. В качестве примера можно привести страницы галереи, карточки товаров в интернет магазине имеющие описание в 1 — 2 предложения.
2. Страницы на которых полностью или только частично повторяются определенные части текста в любых последовательностях. Примером таких страниц могут быть страницы рубрик, где текст анонса статьи присутствует как на странице рубрики или нескольких рубрик, так и в полной версии статьи. Еще в качестве примера можно привести страницы с результатами поиска по сайту, а так же страницы различных фильтров поиска, например товаров в интернет магазинах.
Методы определения и поиска дублей страниц
Разновидности и причины появления дублей мы рассмотрели, теперь рассмотрим как найти дубли страниц и какие способы для этого существуют.
Поиск по фрагментам текста
Такая проверка очень проста и сводится к тому, чтобы вы скопировали небольшую часть текста страницы, вставили ее в поисковую строку и произвести поиск по своему сайту. Для этого можно взять 10 — 15 первых слов текста страницы, которую необходимо проверить. Слишком большой текст не берите, потому как в поисковиках есть определенное ограничение по символам, которые можно вводить для поиска.
Для поисковой системы Яндекс, зайдите в расширенный поиск, в поле «Я ищу» укажите текст, а в поле «На сайте» адрес вашего сайта и произведите поиск.
После этого визуально просмотрите результаты поиска и найдите те страницы на которых точно повторяется этот текст. Я нашел 2 таких страницы:
В данном случае у меня нашлись нечеткие дубли двух категорий на которых расположен один и тот же анонс материала. Как вы видите саму страницу с данным материалом, тоже показало, но полного повторения данного текста на ней нет. Все потому, что я всегда пишу специальный текст который и является анонсом к статье и не использую в качестве анонса введение к статье.
Такой же поиск можно произвести и в Google. Для этого текст который нужно проверить вставьте в кавычках и через пробел укажите область поиска: site:vash-sait.ru
Естественно если сайт состоит из большого числа страниц, то проверить их все будет очень сложно и долго по времени. Чтобы ускорить весь этот процесс можно воспользоваться специальной программой, которая известна многим оптимизаторам — это Xenu’s Link Sleuth.
Проверка дублей при помощи программы Xenu’s Link Sleuth
Скачать программу можно на сайте разработчика: http://home.snafu.de/tilman/xenulink.html#Download
Установите и запустите программу. После этого перейдите в пункт меню File >> Check URL, введите адрес вашего сайта и нажмите кнопку «ОК».
После этого программа начнет ходить по ссылкам вашего сайт и находить все указанные на его страницах ссылки, не зависимо от того рабочие они или нет. Кроме этого она определит тип документов, его заголовки, description и еще много всего. В зависимости от размера сайта, программа может работать продолжительное время, у меня были случаи до 30 — 40 минут. После окончания работы перед вами будет список всех ссылок вашего сайта.
Дубли можно искать двумя способами по найденным URL адресам страниц и по найденным заголовкам страниц.
Чтобы искать по URL адресам кликните по табулятору «Address» и отсортируйте все найденные адреса по алфавиту. Найдите в списке ссылки именно своего сайта и визуально просматривая их найдите, те которые выглядят иначе, чем обычные адреса сайта. Если на сайте используется ЧПУ, можно искать URL адреса содержащие и отличающиеся наличием и отсутствием идентификаторов и параметров.
На приведенном скриншоте я выделил страницы, которые в принципе могут быть дублями страницы: http://webmastermix.ru/web-design.html. Но именно вот эти страницы закрыты от индексации у меня на сайте.
Чтобы искать страницы по заголовку, нужно кликнуть по табулятору «Title» и отсортировать заголовки по алфавиту. Теперь задача найти одинаковые заголовки. Потому как страницы с четкими дублями, о которых шла речь выше, будут иметь одинаковые заголовки.
Недостатком применения данной программы является то, что она показывает все предполагаемые дубли не зависимо от того, есть они в индексе поисковиков или нет. Поэтому каждый раз необходимо проверять на предмет индексации найденные страницы. Но есть еще один способ проверить дубли страниц и он позволяет проверять и видеть только те страницы, которые находятся в индексе той или иной поисковой системы.
Анализ всех проиндексированных страниц
Данный метод основан на том, чтобы просмотреть все старницы определенного сайта которые есть в индексе той или иной поисковой системы. Чтобы увидеть все страницы вашего сайта необходимо в поисковой строке Яндекса указать: host:vash-sait.ru | host:www.vash-sait.ru или Google указать: site:vash-sait.ru | site:www.webmastermix.ru
Полученную выдачу необходимо исследовать на предмет наличия всяких не типичных ссылок. Опять же если на сайте используется ЧПУ, то можно искать такие ссылки которые заканчиваются различными идентификаторами сессий и параметрами.
Но такой способ тоже имеет свои недостатки, потому как все представленные страницы не будут упорядочены, чтобы их упорядочить по URL или заголовку можно применить языки запросов.
Использование языков запросов для анализа проиндексированных страниц
Поиск дублей осуществляется так же как и в прошлом примере, но здесь мы можем вывести проиндексированные статьи по содержимому определенных слов или словосочетаний в Title или URL адресе страницы. Выше я уже упоминал, что именно заголовок и URL является одинаковым у полных дублей.
Что бы произвести поиск по содержимому заголовка, необходимо в поисковой строке указать следующее:
Для Яндекса: site:vash-sait.ru title:(уроки html)
Для Google: site:vash-sait.ru intitle:уроки html
— где «уроки html» полный Title определенной страницы или отдельные слова из Title определенной страницы.
Так же можно производить поиск в URL адресах страниц сайта. Для этого в поисковой строке необходимо прописать, как для Яндекса так и для Google следующее: site:vash-sait.ru inurl:lessons-joomla
— в данном случае будут выведены все URL в которых присутствует — lessons-joomla.
Избавляемся от дублей страниц
Способы избавления от дублей страниц зависят от того, что это за страницы и каким образом они попали в индекс поисковой системы. Есть ряд мероприятий применив которые можно избавиться от дублей страниц. В некоторых случаях достаточно будет применить одно из них в других же понадобится комплекс мероприятий. В целом можно произвести следующее мероприятия:
1. Если та страница которая является дублем была создана вами вручную, то также в ручную вы можете ее удалить.
2. При помощи файла Robots.txt можно управлять индексацией всего сайта. Для запрета индексации определенных страниц или каталогов используется директива: «Disallow». Таким способом хорошо избавляться от дублей тех страниц, которые лежат в определенной директории сайта.
Например, чтобы закрыть от индексации страницы тегов URL которых содержит: /tag/, нужно в фале robots.txt указать следующее:
Еще таким способом хорошо избавляться от дублей адреса которых содержат идентификатор сессии и в них используется знак «?». Чтобы запретить индексацию все страниц в адресах которых содержится вопросительный знак «?», достаточно в фале robots.txt прописать следующее:
3. Использование 301 редиректа. При помощи редиректа 301 можно производить автоматическую переадресацию посетителей сайта и роботов поисковых систем с одной страницы сайта на другую. Данный редирект дает понять роботам поисковых систем, что данная страница навсегда перенесена на другой адрес и больше по данному адресу не доступна.
В результате поисковыми системами производится склеивание страниц доступных по двум или более адресам, в страницу доступную только по одному адресу указанному при настройке 301 редиректа. Подробнее о 301 редиректе читайте в статье: «Как настроить 301 редирект в htaccess и в скриптах — более 18 примеров использования».
4. Использование атрибута rel=»canonical». Данный атрибут, употребленный на определенных страницах сайта, которые имеют одинаковое или очень мало отличимое содержимое дает понять какую страницу считать основной из множества похожих документов. понимают данный атрибут ПС Яндекс и Google.
Чтобы его задать необходимо в HTML код страницы между тегами <head>…</head> поместить следующее:
<link href="http://webmastermix.ru/seo-optimization.html" rel="canonical" />
— где http://webmastermix.ru/seo-optimization.html является канонической ссылкой и если у данной страницы будут присутствовать дубли вида:
http://webmastermix.ru/seo-optimization.html?start=5 http://webmastermix.ru/seo-optimization.html?start=6 http://webmastermix.ru/seo-optimization.html?start=7
Но на всех этих страницах будет указан атрибут rel=»canonical», пример которого приведен выше, то за основную страницу будет считаться именно страница с адресом: http://webmastermix.ru/seo-optimization.html
Во многих популярных CMS, например WordPress или Joomla данный атрибут генерируется сразу при создании страниц.
Самые распространенные причины автоматического появления дублей и избавление от них
Страницы пагинации
В рубриках и категориях сайта выводить большое количество материалов на одной странице не удобно. Поэтому как правило их выводят в виде многостраничных каталогов, где каждая страница имеет свой адрес, но содержимое этих страниц может дублироваться.
Чаще всего дублируются мета теги описаний и анонсы статей. Особенно плохо когда анонсы статей или описания товаров большие по объему и берутся непосредственно из начальной части статьи. Т. е. они будут фигурировать и на страницах пагинации и в полной версии статьи.
Избавиться от такого типа дублей можно одним из следующих способов:
1. Запретить индексацию страниц в файле Robots.txt — для Яндекса данный метод работает отлично, но вот Google может игнорировать robots.txt и все равно индексировать такие страницы, как от этого избавится читайте ниже, где будет идти речь о страницах с результатами поиска и фильтров.
2. Использовать атрибут rel=»canonical», в котором указать основной адрес для всех этих страниц — в некоторых CMS он используется по умолчанию.
3. Что касается частичных дублей, то анонсы статей необходимо делать уникальными, а не брать текст из вводной части статьи.
Страницы поиска и применения фильтров
Поиск присутствует на любом сайте и поэтому страницы с результатами поиска, на которых так же частично дублируется контент, могут легко попасть в индекс ПС.
Фильтры, как правило используются когда нужно отсортировать материалы или товары в интернет магазине по определенным параметрам.
Страницы результатов поиска и сортировки имеют динамических URL и создаются автоматически. Все это может порождать большое количество копий.
Избавится от таких клонов можно одним из следующих способов:
1. Закрыть от и индексации в robots.txt. Можно закрыть все страницы сайта содержащие определенные параметры. Как вариант можно закрыть все страницы, адреса которых содержат вопросительный знак «?». Как это сделать мы рассматривали выше. Этого будет вполне достаточно для ПС Яндекс, но может оказаться мало для Google и он продолжит их индексировать. Поэтому переходим к следующему способу.
2. Использование инструментов Google Webmaster. Если в панели Google Webmaster перейти в пункт «Сканирование» >> «Параметры URL» и кликнуть по ссылке «Настройка параметров URL». Перед вами появится ряд параметров, которые присутствуют в адресах страниц вашего сайта.
И здесь у вас есть возможно запретить для индексации адреса тех страниц сайта, которые содержат определенный параметр. Для этого, на против нужного вам параметра кликните по ссылке «Изменить». Затем в выпадающем списке выбираете пункт «Нет, параметр не влияет на содержание страницы». Кликнув по «Показать примеры URL» откроются все ссылки которые содержат этот параметр и будут запрещены к индексации.
Как только удостоверились, что это именно те страницы которые вы хотели закрыть, нажимаете на кнопку «Сохранить».
Дубли возникающие из-за различных технических особенностей CMS
Ввиду некоторых технических особенностей формирования URL адреса каждой страницы все CMS могут автоматически создавать различные дубли. Например в Joomla это происходит из-за того, что одна и та же страница может быть получена несколькими способами. Если включены ЧПУ, такие страницы сразу видно. Потому, что если у вас есть страница с URL: http://ваш-сайт.ru/stranica.html, а помимо ее присутствует еще и страница: http://ваш-сайт.ru/stranica.html?view=featured, то она является копией первой страницы.
Способы борьбы:
1. Часть таких копий убирается средствами самой CMS, а те что остаются можно убрать одним или несколькими из предложенных выше способов.
2. Кроме этого в некоторых случаях придется использовать 301 редирект, чтобы склеить одни страницы с другими — все зависит от CMS.
Рекомендуем ознакомиться:
- Подробности
Опубликовано: 12 Ноябрь 2013
Обновлено: 30 Ноябрь 2013
Просмотров: 17038
Как найти дубли страниц на сайте? Как удалить дубли страниц
Приветствую Вас! В этой статье разберемся, как найти и удалить дубли страниц на сайте WordPress. Не так давно я узнал, что на сайте могут появляться дубли страниц, что не очень-то меня обрадовало. Решил я проверить, в каком состоянии мой сайт, и обнаружил множество дублирующих страниц, от которых надо незамедлительно избавляться. Сейчас я расскажу все по-порядку.
Вы можете подумать: ну и пусть себе появляются дубли, мне-то какая разница? Оказывает все не так просто, как может показаться на первый взгляд.
Читайте так же по теме как этой статье: как удалить сопли Google и как удалить дубли картинок на сайте WordPress
Поиск дублей страниц на сайте и удаление
Дубли плохо влияют на индексацию блога. Польза от перелинковки и внешних ссылок значительно теряет вес. Чаще всего дубли страниц формируются у CMS WordPress, Joomla и др.
Возможно, небольшое количество дублей и не повредит сайту, но если их очень много, тогда с сайтом могут начаться реальные проблемы. Для поиска дублей существует несколько способов.
Один из способов поиска дублей страниц на сайте
Введите вначале в поисковике Яндекс команду: host:вашсайт.ru, а потом в Гугл, и посмотрите на результат выдачи, какое количество в Яндекс, и какое в Гугл.
В Google у меня показало 3470 ответа, а в Яндексе всего 130. Так вот, если число страниц в Яндекс и Гугл будет значительно отличаться, то это уже подозрительно.
Еще один способ
С каждой страницы скопируйте отрывок текста, примерно 15 слов и вставьте в поисковую строку браузера. Если будет появляться в выдаче более одной страницы, значит, существуют дубли.
Ну а если Ваш сайт имеет достаточно много страниц, тогда можно воспользоваться программой Xenu`s Link Sleuth. Скачать программу можно по этой ссылке http://home.snafu.de/tilman/XENU.ZIP
Программа Xenu’s Link Sleuth — инструкция
Скачайте и установите программу на ПК. Запустите ее, а затем перейдите «file» -> “Check URL…»,

введите адрес своего сайта и нажмите ОК.

Начнется долгий процесс проверки. Это программа будет находить страницы, битые ссылки, ссылки на картинки и прочее. Любые ошибки будут выделяться красным цветом, поэтому их будет сложно не заметить.
По результатам проверки моего ресурса, похвастаться нечем. Весь сайт набит каким-то HTML-мусором. Один плагин мне вообще весть сайт чуть не загубил. Пропало несколько статей, а также куча картинок.
После того, как проверка закончится, нужно все содержимое на экране скопировать и вставить в любой текстовый редактор. Там уже можно спокойно искать дубли страниц.
Но проверить дубли на сайте можно не только с помощью этой программы, но и воспользоваться инструментами Яндекc и Google
Удаление дублей страниц
Все ненужные ссылки, которые индексирует Яндекс, можно удалять здесь https://goo.gl/JUdQFd
Также надо удалить ссылки, которые индексирует Гугл. Переходите в Google Webmaster по этой ссылке https://www.google.com/webmasters/tools/, а затем выберите сайт, который который хотите проверить.

Далее, с левой стороны, надо выбрать «Индекс Google», а потом «Удалить URL-адреса». После этого надо кликнуть по серому прямоугольнику, который называется «Создать новый запрос на удаление».
Теперь откройте новую вкладку в браузере и введите в адресной строке google.com. Нам нужен поисковик от Гугл.
Наберите в поисковой строке site:vashsait.ru. Появиться список всех страниц, которые есть на сайте, и если есть дубли, то они тоже появятся.

Теперь находите дубли страниц, и если они есть, то копируйте адреса этих страниц и вставляйте в другой вкладке браузера в окошко «Создать новый запрос на удаление». Я выделил рамочкой, чтобы Вы понимали где адреса страниц копировать.

Вот таким образом Вы избавитесь от всех ненужных копий.
Таким способом можно избавиться от дублей, если у Вас маленький сайт. Но если на сайте достаточно много страниц, то дубли можно удалять с помощью редиректа 301 или закрытия этих страниц от индексации в файле robots.txt.
Файл robots.txt нужно правильно составить, еще в самом начале создания сайта. О файле robots.txt я писал в статье как правильно составить файл robots.txt
Посмотрите видео, как можно удалить дублирующие страницы с сайта, с помощью программы «Xenu Link Sleuth».