создание, настройка, проверка и индексация сайта
Здравствуйте!
В SEO мелочей не бывает. Иногда на продвижение сайта может оказать влияние всего лишь один небольшой файл — Robots.txt. Если вы хотите, чтобы ваш сайт зашел в индекс, чтобы поисковые роботы обошли нужные вам страницы, нужно прописать для них рекомендации.
«Разве это возможно?», — спросите вы. Возможно. Для этого на вашем сайте должен быть файл robots.txt. Как правильно составить файл роботс, настроить и добавить на сайт – разбираемся в этой статье.
Что такое robots.txt и для чего нужен
Robots.txt – это обычный текстовый файл, который содержит в себе рекомендации для поисковых роботов: какие страницы нужно сканировать, а какие нет.
Важно: файл должен быть в кодировке UTF-8, иначе поисковые роботы могут его не воспринять.
Зайдет ли в индекс сайт, на котором не будет этого файла? Зайдет, но роботы могут «выхватить» те страницы, наличие которых в результатах поиска нежелательно: например, страницы входа, админпанель, личные страницы пользователей, сайты-зеркала и т. п. Все это считается «поисковым мусором»:
п. Все это считается «поисковым мусором»:
Если в результаты поиска попадёт личная информация, можете пострадать и вы, и сайт. Ещё один момент – без этого файла индексация сайта будет проходить дольше.
В файле Robots.txt можно задать три типа команд для поисковых пауков:
- сканирование запрещено;
- сканирование разрешено;
- сканирование разрешено частично.
Все это прописывается с помощью директив.
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova.
Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика 🙂 Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Где должен находиться файл Robots
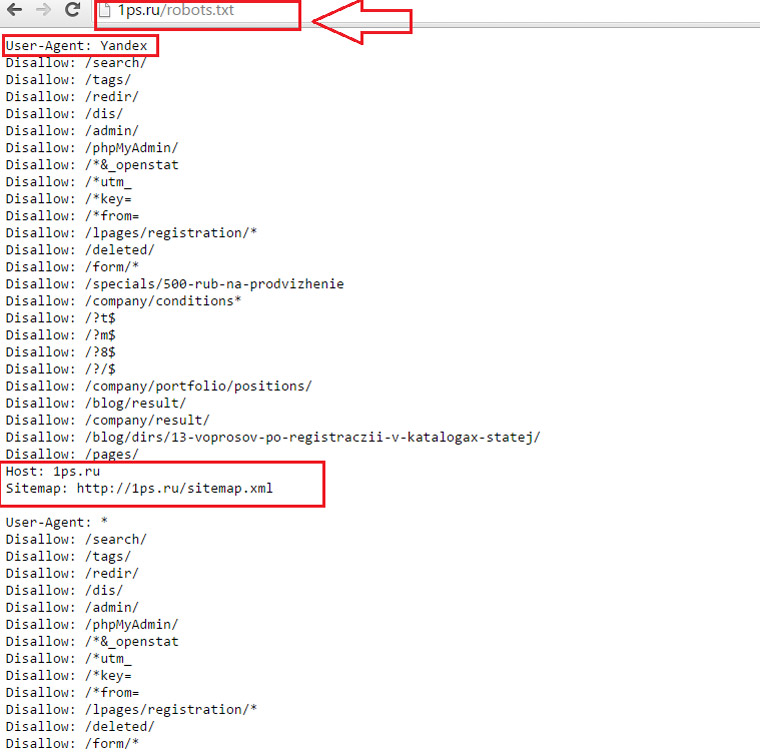
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:
Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt. Вам откроется вот такая страничка (если файл есть):
Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop. Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS. Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Читайте также: Как найти и удалить дубли страниц на сайте
Настройка файла Robots.
 txt: индексация, главное зеркало, диррективы
txt: индексация, главное зеркало, диррективыКак вы уже видели на скриншоте, первой идет директива User-agent. Она указывает, для какого поискового робота будут идти правила ниже.
User-agent: * — правила для всех поисковых роботов, то есть любой поисковой системы (Google, Yandex, Bing, Рамблер и т.п.).
User-agent: Googlebot – указывает на правила для поискового паука Google.
User-agent: Yandex – правила для поискового робота Яндекс.
Для какого поискового робота прописывать правила первым, нет никакой разницы. Но обычно сначала пишут рекомендации для всех роботов.
Рекомендации для каждого робота, как я уже писала, отделяются отступом.
Disallow: Запрет на индексацию
Чтобы запретить индексацию сайта в целом или отдельных страниц, используется директива Disallow.
Например, вы можете полностью закрыть сайт от индексации (если ресурс находится на доработке, и вы не хотите, чтобы он попал в выдачу в таком состоянии). Для этого нужно прописать следующее:
User-agent: *
Disallow: /
Таким образом всем поисковым роботам запрещено индексировать контент на сайте.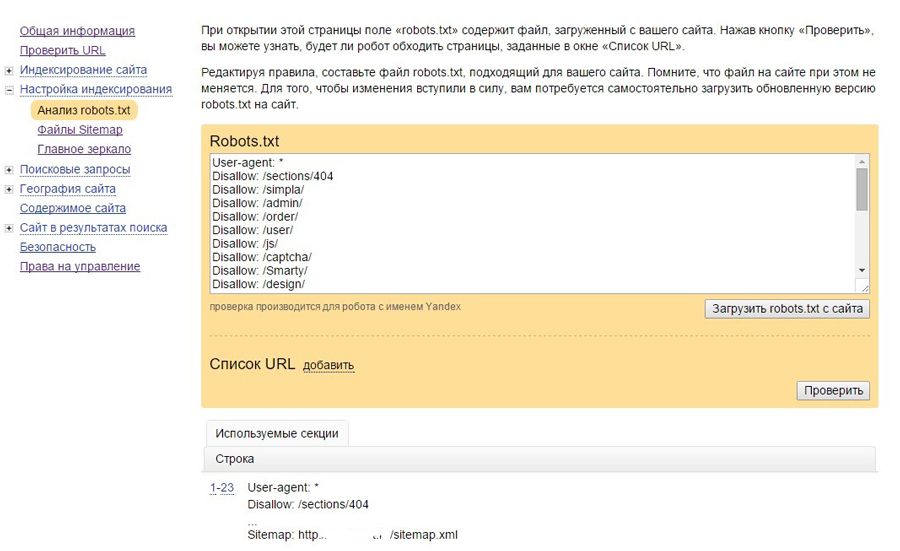
А вот так можно открыть сайт для индексации:
User-agent: *
Disallow:
Потому проверьте, стоит ли слеш после директивы Disallow, если хотите закрыть сайт. Если хотите потом его открыть – не забудьте снять правило (а такое часто случается).
Чтобы закрыть от индексации отдельные страницы, нужно указать их адрес. Я уже писала, как это делается:
User-agent: *
Disallow: /wp-admin
Таким образом на сайте закрыли от сторонних взглядов админпанель.
Что нужно закрывать от индексации в обязательном порядке:
- административную панель;
- личные страницы пользователей;
- корзины;
- результаты поиска по сайту;
- страницы входа, регистрации, авторизации.
Можно закрыть от индексации и отдельные типы файлов. Допустим, у вас на сайте есть некоторые .pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
Закрыть их от индексации можно следующим образом:
User-agent: *
Disallow: /*. pdf$
Как отрыть сайт для индексации
Даже при полностью закрытом от индексации сайте можно открыть роботам путь к определённым файлам или страницам. Допустим, вы переделываете сайт, но каталог с услугами остается нетронутым. Вы можете направить поисковых роботов туда, чтобы они продолжали индексировать раздел. Для этого используется директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Главное зеркало сайта
До 20 марта 2018 года в файле robots.txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект.
Что такое главное зеркало? Это какой адрес вашего сайта является главным – с www или без. Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Карта сайта: robots.txt sitemap
После того, как прописаны все директивы для роботов, необходимо указать путь к Sitemap. Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Sitemap: site.ru/sitemap.xml
Когда робот будет обходить сайт, он будет видеть, какие изменения вносились в этот файл. В итоге новые страницы будут индексироваться быстрее.
Директива Clean-param
В 2009 году Яндекс ввел новую директиву – Clean-param. С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
Прописать эту директиву можно в любом месте файла robots.txt.
Параметры, которые роботу не нужно учитывать, перечисляются в первой части значения через знак &:
Clean-param: sid&sort /forum/viewforum. php
php
Эта директива позволяет избежать дублей страниц с динамическими адресами (которые содержат знак вопроса).
Директива Crawl-delay
Эта директива придёт на помощь тем, у кого слабый сервер.
Приход поискового робота – это дополнительная нагрузка на сервер. Если у вас высокая посещаемость сайта, то ресурс может попросту не выдержать и «лечь». В итоге робот получит сообщение об ошибке 5хх. Если такая ситуация будет повторяться постоянно, сайт может быть признан поисковой системой нерабочим.
Представьте, что вы работаете, и параллельно вам приходится постоянно отвечать на звонки. Ваша продуктивность в таком случае падает.
Так же и с сервером.
Вернемся к директиве. Crawl-delay позволяет задать задержку сканирования страниц сайта с целью снизить нагрузку на сервер. Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
Crawl-delay: 2
Комментарии в robots.
 txt
txtБывают случаи, когда вам нужно оставить в файле комментарий для других вебмастеров. Например, если ресурс передаётся в работу другой команде или если над сайтом работает целая команда.
В этом файле, как и во всех других, можно оставлять комментарии для других разработчиков.
Делается это просто – перед сообщением нужно поставить знак решетки: «#». Дальше вы можете писать свое примечание, робот не будет учитывать написанное:
User-agent: *
Disallow: /*. xls$
#закрыл прайсы от индексации
Как проверить файл robots.txt
После того, как файл написан, нужно узнать, правильно ли. Для этого вы можете использовать инструменты от Яндекс и Google.
Через Яндекс.Вебмастер robots.txt можно проверить на вкладке «Инструменты – Анализ robots.txt»:
На открывшейся странице указываем адрес проверяемого сайта, а в поле снизу вставляем содержимое своего файла. Затем нажимаем «Проверить». Сервис проверит ваш файл и укажет на возможные ошибки:
Также можно проверить файл robots.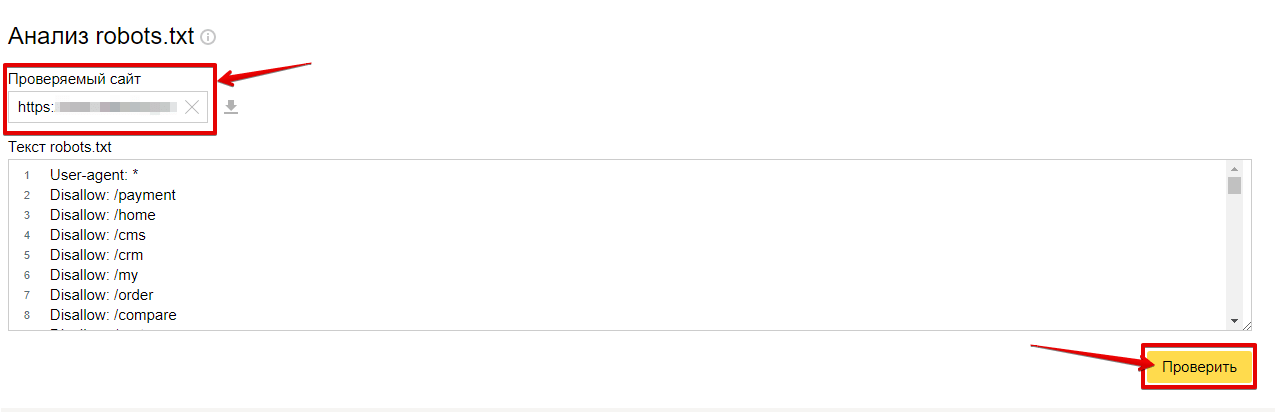 txt через Google Search Console, если у вас подтверждены права на сайт.
txt через Google Search Console, если у вас подтверждены права на сайт.
Для этого в панели инструментов выбираем «Сканирование – Инструмент проверки файла robots.txt».
На странице проверки вам тоже нужно будет скопировать и вставить содержимое файла, затем указать адрес сайта:
Потом нажимаете «Проверить» — и все. Система укажет ошибки или выдаст предупреждения.
Останется только внести необходимые правки.
Если в файле присутствуют какие-то ошибки, или появятся со временем (например, после какого-то очередного изменения), инструменты для вебмастеров будут присылать вам уведомления об этом. Извещение вы увидите сразу, как войдете в консоль.
Частые ошибки в заполнении файла robots.txt
Какие же ошибки чаще всего допускают вебмастера или владельцы ресурсов?
1. Файла вообще нет. Это встречается чаще всего, и выявляется при SEO-аудите ресурса. Как правило, на тот момент уже заметно, что сайт индексируется не так быстро, как хотелось бы, или в индекс попали мусорные страницы.
2. Перечисление нескольких папок или директорий в одной инструкции. То есть вот так:
Allow: /catalog /uslugi /shop
Называется «зачем писать больше…». В таком случае робот вообще не знает, что ему можно индексировать. Каждая инструкция должна иди с новой строки, запрет или разрешение на индексацию каждой папки или страницы – это отдельная рекомендация.
3. Разные регистры. Название файла должно быть с маленькой буквы и написано маленькими буквами – никакого капса. То же самое касается и инструкций: каждая с большой буквы, все остальное – маленькими. Если вы напишете капсом, это будет считаться уже совсем другой директивой.
4. Пустой User-agent. Нужно обязательно указать, для какой поисковой системы идет набор правил. Если для всех – ставим звездочку, но никак нельзя оставлять пустое место.
5. Забыли открыть ресурс для индексации после всех работ – просто не убрали слеш после Disallow.
6. Лишние звездочки, пробелы, другие знаки. Это просто невнимательность.
Лишние звездочки, пробелы, другие знаки. Это просто невнимательность.
Регулярно заглядывайте в инструменты для вебмастеров и вовремя исправляйте возможные ошибки в своем файле robots.txt.
Удачного вам продвижения!
как его создать и правильно настроить
Robots.txt – это текстовый файл, в котором указаны рекомендации для роботов поисковых систем относительно индексации сайта. Расположен данный файл в корневом каталоге сайта и среди его основных функций мы можем выделить следующие:
- Указание главного зеркала сайта;
- Указание пути к карте сайта для роботов;
- Создание необходимых правил обхода страниц поисковым краулером.
Помимо возможности давать рекомендации поисковыми системам по индексации сайта, роботс тхт максимально удобен в редактировании. Для этого через доступ FTP файл можно открыть через любой текстовый редактор, внести необходимые правки и загрузить обновленный файл в корень сайта с заменой старого документа. При этом некоторые CMS обеспечивают возможность редактирования без необходимости скачивать файл.
При этом некоторые CMS обеспечивают возможность редактирования без необходимости скачивать файл.
Важно отметить, что директивы robots txt могут не работать даже при правильном их составлении. Зачастую это связано со следующими синтаксическими ошибками:
- Итоговый размер файла превышает максимально допустимое значение для Яндекса в 500 килобайт и Гугла в 500 кибибайт;
- В процессе создания вы использовали кодировку, которая отличается от UTF-8, что актуально именно для Google;
- Расширение файла не txt или в его названии содержатся недопустимые символы;
- К файлу по определенным причинам нет доступа на сервере.
Исходя из всех вышеперечисленных пунктов можно отметить необходимость регулярно делать анализ robots txt, проверяя его на работоспособность.
Синтаксис и директивы файла Robots.txt для сайта
Настройка robots txt для сайта предполагает создание директив, которые можно разделить на обязательные и необязательные.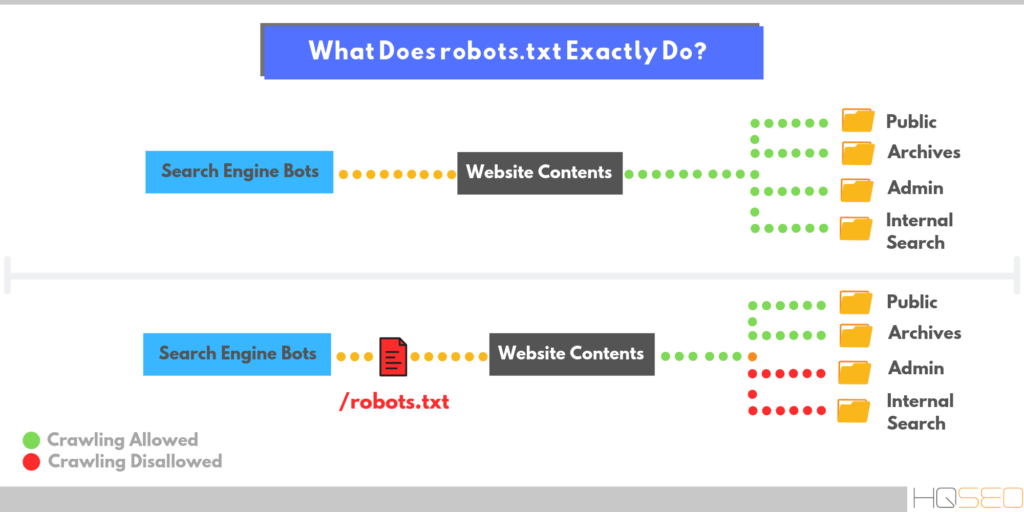 Размещение данных директив также должно быть в определенном порядке, что позволи краулерам поисковых систем нормально их воспринимать. Стандартно первой директивой должна быть User Agent, после следует запрет на индексацию Disallow, затем разрешение индексации Allow и окончательным этапом указывается основное зеркало сайта через директиву Host. Во избежания ошибок в процессе настройки Robots.txt мы рекомендуем обратить внимание на следующие правила работы с синтаксисом:
Размещение данных директив также должно быть в определенном порядке, что позволи краулерам поисковых систем нормально их воспринимать. Стандартно первой директивой должна быть User Agent, после следует запрет на индексацию Disallow, затем разрешение индексации Allow и окончательным этапом указывается основное зеркало сайта через директиву Host. Во избежания ошибок в процессе настройки Robots.txt мы рекомендуем обратить внимание на следующие правила работы с синтаксисом:
- В одной строке прописывается одна директива;
- Любая новая директива прописывается с новой строки;
- В начале строки и между строками не допускаются пробелы;
- Описываемый параметр нельзя переносить в новую строку;
- Перед всеми страницами сайта в директории обязательно нужно ставить слэш (/).
Важно отметить, что все директивы должны быть прописаны только латинскими символами. Правильный robots txt содержит в себе ряд директив, которые стоит рассмотреть более детально.
User-agent
Это обязательная директива файла, которая прописывается в первой строке. Основная цель данной директивы – это обращение к поисковому роботу, соответственно, существуют следующие ее варианты:
- User-agent: *
- User-agent: Yandex
- User-agent: Googlebot
Первый вариант предполагает обращение ко всем поисковым роботам, а остальные к конкретной поисковой системе.
Disallow
Директива указывает поисковому роботу на запрет индексации конкретной части сайта. При сочетании с директивой User-agent можно обеспечить запрет индексации для всех роботов или для конкретного поискового краулера.
Allow
Директива разрешает поисковым роботам индексацию всех страниц сайта или разделов, которые включают в себя данные страницы.
Crawl-Delay
Директива позволяет задать временной период, через который робот будет индексировать страницы. При заданном параметре Crawl-delay: 5 краулер будет индексировать следующую страницу через 5 секунд.
Host
Благодаря данной директиве можно указать главное зеркало сайта с www или без www.
Sitemap
Можно указать путь к карте сайта, а сама директива выглядит следующим образом Sitemap: mysite.com/sitemap.xml.
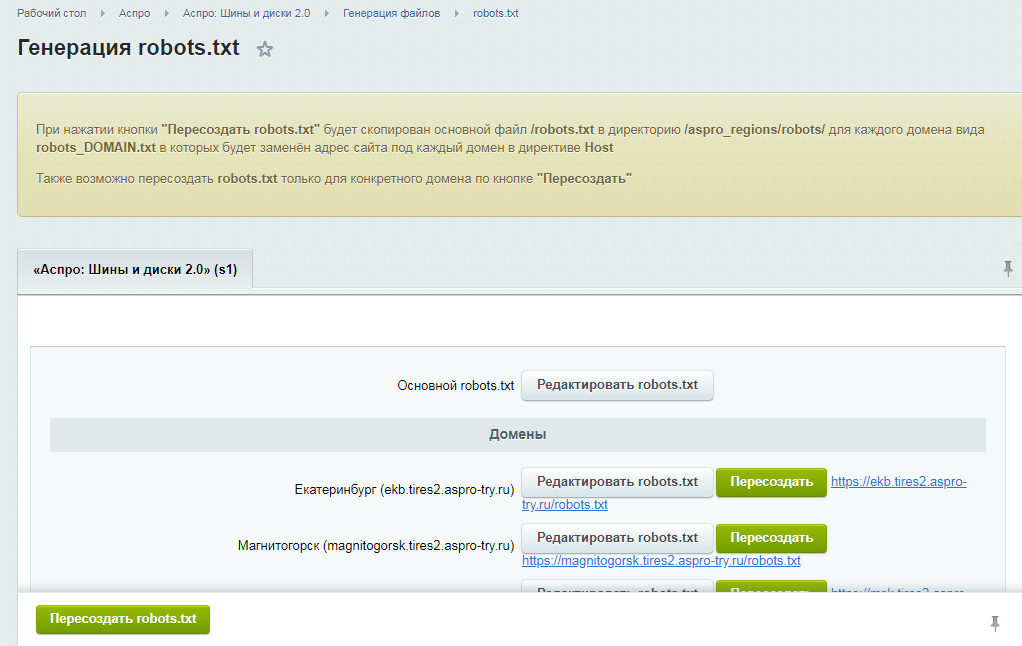
Как сделать Robots.txt
Правильный файл robots txt можно создать вручную, используя необходимые вам вышеперечисленные директивы в зависимости от особенностей вашего сайта. Если вы не можете самостоятельно создать роботс для сайта или боитесь допустить ошибки, можно использовать один из следующих генераторов онлайн:
- PR-CY;
- Seolib;
- Media Sova.
Любой из вышеперечисленных сервисов обеспечивает автоматическую генерацию файла, поэтому проблем с тем, как как сделать robots txt для сайта у вас не возникнет. Важно отметить, что содержимое файла robots txt отличается не только в зависимости от конкретного сайта, но и в зависимости от CMS.
Проверка файла robots.txt
Когда мы уже рассмотрели как создать robots txt и сгенерировали текстовый файл, его необходимо проверить на работоспособность. Для этого мы рекомендуем воспользоваться одним из множества онлайн сервисов.
Для этого мы рекомендуем воспользоваться одним из множества онлайн сервисов.
Google Search Console и Яндекс.Вебмастер
Стандартные сервисы поисковых систем, которые в своем функционале предлагают возможность проверки файла роботс на правильность и отсутствие ошибок.
Website Planet
На главной странице сайта доступны все инструменты сервиса, среди которых есть проверка файла robots. После ввода адреса сайта мы получаем не только наличие ошибок или их отсутствие, но и любые предупреждения по файлу.
Данный сервис можно с уверенностью назвать самым информативным для анализа роботс.
Tools.descript.ru
Проверка осуществляется стандартным методом через инструменты, которые предлагает Tools.descript. В окне для проверки просто вводим URL сайта и получаем детальный отчет.
Ключевой особенностью сервиса можно отметить возможность выбора не только целевого краулера определенной поисковой системы, но и выбор конкретной CMS. Это позволяет проверить правильность создания Robots для любого движка сайта.
Это позволяет проверить правильность создания Robots для любого движка сайта.
Возьмем на себя все заботы по продвижению и раскрутке сайта:
> Создание сайта > SEO продвижение > Контекстная реклама в Яндекс и Google
Подпишись на рассылку, чтобы не пропустить ничего интересного!
Бесплатная консультация
Массовая проверка Robots.txt: бесплатный инструмент тестирования
URL-адресов доменов для тестирования (МАКС. 50) ↓ Капча: обновить
|
Что делает инструмент Test Robots.Txt?
Наш чекер robots.txt сможет массово проверять наличие файла robots.txt в списке веб-сайтов.
Просто вставьте адреса ваших сайтов, нажмите «Проверить», и наш инструмент автоматически проверит наличие и правильность файла robots. txt, а также отобразит все данные в отчете.
txt, а также отобразит все данные в отчете.
Что такое файл robots.txt?
Robots.txt — это файл в вашем домене (some-site.com/robots.txt), который указывает, могут ли определенные программы или боты сканировать различные страницы вашего веб-сайта. Инструкции по сканированию указываются путем «запрета» или «разрешения» сканирования страниц вашего сайта различными поисковыми роботами.
Robots.txt Testing Tool >>
0 комментариев
Вы должны войти, чтобы оставить комментарий.
Популярные инструменты SEO / Все инструменты
Релевантность текста | Текст Семантика | Средство проверки переадресации | Детектор CMS | Заголовок и шашка h2 | Найти поддомены | Массовое индексирование сайта |
URL Код состояния HTTP | Генератор карты сайта | Программа проверки robots. | Проверка возраста домена | Text Unique Checker | Генератор УУЛЕ | Извлекатель звеньев |
SiteAnalyzer |

<< Назад
Проверить Robots.txt бесплатно 2023
Бесплатные инструменты SEO
Бесплатно
Бесплатные инструменты SEO
txt Tester
Инструмент для тестирования robots.txt это утилита, используемая для проверки содержимого файла robots.txt веб-сайта, который указывает поисковым роботам, какие страницы или разделы сайта не следует индексировать.
БЕСПЛАТНО
Бесплатный инструмент SEO-аудита
Бесплатный инструмент SEO-аудита анализирует внутренние и внешние элементы веб-сайта, такие как ключевые слова, метатеги и обратные ссылки, для выявления технических и связанных с содержанием проблем, которые могут мешать видимость и ранжирование в поисковых системах.
БЕСПЛАТНО
Бесплатно Google SERP Checker
Инструмент Google SERP Checker позволяет пользователям проверять позицию своего веб-сайта или определенных страниц на страницах результатов поисковой системы Google (SERP) по целевым ключевым словам.
БЕСПЛАТНО
Бесплатная программа проверки поисковой выдачи Bing
Бесплатный инструмент проверки поисковой выдачи Bing похож на подзорную трубу для оценки эффективности вашего веб-сайта в поисковых системах, позволяя вам следить за своим положением на страницах результатов поисковой системы Bing и корректировать свою стратегию SEO. соответственно.
БЕСПЛАТНО
Бесплатный инструмент для проверки обратных ссылок
Бесплатные инструменты для проверки обратных ссылок подобны картам сокровищ для создания ссылок вашего веб-сайта, помогая вам находить новые возможности для ссылок и перемещаться по морям Интернета, чтобы улучшить видимость и рейтинг вашей поисковой системы.
БЕСПЛАТНО
Бесплатное исследование ключевых слов
Бесплатные инструменты исследования ключевых слов SEO подобны компасу для стратегии содержания вашего веб-сайта, направляя вас к ключевым словам и фразам, которые помогут вам ориентироваться в ландшафте поисковых систем и достигать своей целевой аудитории.
БЕСПЛАТНО
Page Crawl Test
Бесплатный инструмент сканирования для SEO похож на фонарик в темноте, освещая закоулки и закоулки вашего веб-сайта, которые поисковые системы не могут найти, и помогая вам оптимизировать способность сканирования и видимость вашего сайта. .
БЕСПЛАТНО
Тест мобильной поддержки
Бесплатный инструмент тестирования мобильной поддержки похож на личного помощника для вашего веб-сайта. Он обеспечивает удобную навигацию и использование на крошечных экранах мобильных устройств, а также позволяет оптимизировать ваш сайт для мира, который становится все более ориентированным на мобильные устройства.
БЕСПЛАТНО
URL HTTP Header Test
Бесплатный инструмент проверки заголовков для SEO похож на детектива, просматривающего код вашего веб-сайта, чтобы проверить правильность ваших заголовков и убедиться, что они правильно отформатированы и оптимизированы для помощи поисковым системам. лучше понять ваши страницы.
БЕСПЛАТНО
Тест скорости веб-сайта
бесплатный инструмент для проверки скорости веб-сайта похож на секундомер для измерения производительности вашего веб-сайта, измеряя скорость загрузки страниц и предоставляя информацию об улучшении взаимодействия с пользователем и видимости в поисковых системах.
БЕСПЛАТНО
Проверка внутренних ссылок
Инструмент анализа внутренних ссылок похож на путеводитель по вашему веб-сайту, помогая вам перемещаться по различным страницам и разделам и гарантируя, что ваши посетители и сканеры поисковых систем смогут легко найти то, что они представляют. находясь в поиске.
БЕСПЛАТНО
Плотность ключевых слов
Бесплатный инструмент плотности ключевых слов для SEO подобен микроскопу для содержания вашего веб-сайта, предоставляя информацию о частоте используемых ключевых слов и фраз, что позволяет оптимизировать ваш контент как для пользователей, так и для поисковых систем.