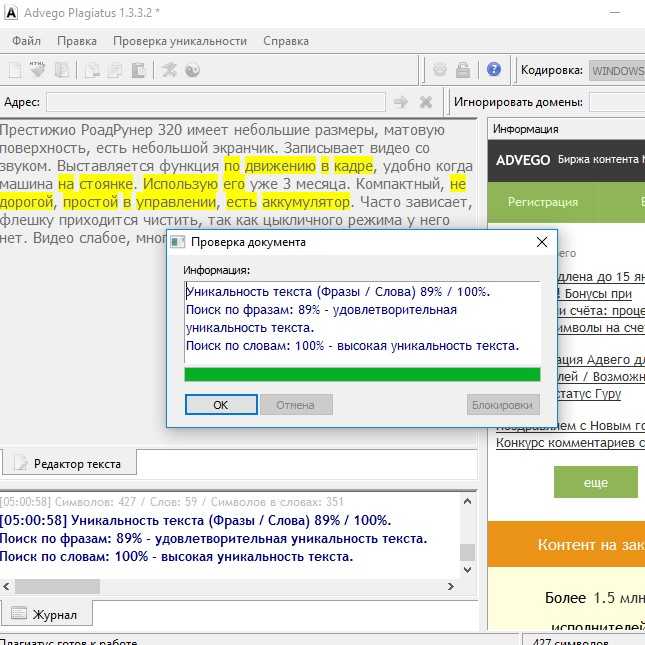
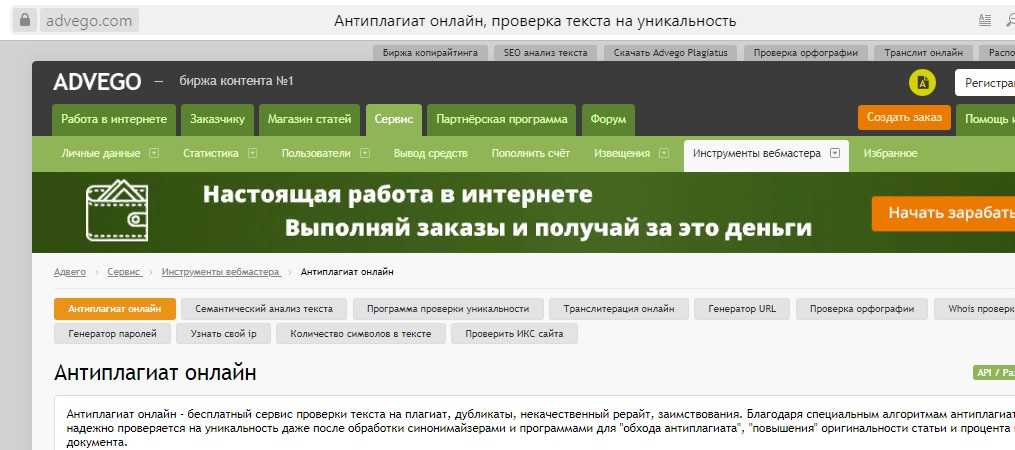
Проверка на уникальность
Здравствуйте.
Сегодня хотим рассказать о новой возможности, которая появилась в новой версии конструктора веб-форм, а именно о проверке данных в форме на уникальность. Раньше для этого в настройках нужного элемента был специальный чекбокс «Уникальное поле».
Установив этот чекбокс, форму нельзя было отправить дважды с одинаковыми данными. Например, если для элемента формы email или телефон, включить этот чекбокс, то тогда пользователь не сможет 2 раза отправить веб-форму с одинаковым email адресом или телефоном.
Но иногда этого функционала не хватает. Так недавно к нам обратился клиент с просьбой помочь сделать форму заявок, в которой клиент не мог бы отправить две заявки, пока прежняя не будет обработана. Получается проверку на уникальность нужно делать по нескольким полям.
Нам показалось, что этот функционал будет полезным для многих пользователей и мы решили доработать проверку на уникальность.
Форма будет состоять из следующих полей: имя, email адрес, текст заявки и статус заявки. Статус заявки имеет 3 значения: новая, одобрена и обработана.
Стоит обратить внимание на элемент формы «Статус заявки». Это служебное поле, которое должно выводиться при редактировании заявки в разделе «Статистика» и не должно выводится в форме. Чтобы этого добиться необходимо перейти в редактировании данного элемента и включить опцию «Доступно только для админа в режиме редактирования»:
Все новые заявки должны создаваться со статусом «Новая». Для этого нужно установить значение по умолчанию:
Настройка проверки на уникальность
По условиям нашей задачи пользователь может отправить заявку при условии что до этого он еще не подавал заявок, либо все предыдущие заявки уже обработаны. Если есть хоть одна заявка со статусом «Новая» или «Одобрена», то необходимо запретить отправку формы.
Если есть хоть одна заявка со статусом «Новая» или «Одобрена», то необходимо запретить отправку формы.
Поиск клиента будет производиться по полю «E-mail адрес». Именно для него мы и будем настраивать проверку на уникальность. Давайте перейдем в режим редактирования e-mail адреса и установим чекбокс «Уникальное поле»:
Как видно на изображении выше, после включения чекбокса «Уникальное поле», ниже появилась кнопка «Настроить параметры уникальности». Давайте кликнем на неё:
Перед нами откроется всплывающее окно, где мы можем добавить связанные поля, которые будут участвовать в поиске дублей. Так как нам нужно вместе с «E-mail адресом» учитывать еще и статус заявки, то в этом окне нам нужно добавить связанное поле «Статус заявки». Для этого необходимо нажать на ссылку «Добавить связанное поле»:
Так как нам нужно учитывать еще значение статуса заявки, то нам необходимо их указать. Для этого необходимо нажать на ссылку «Добавить варианты ответа», где мы укажем значение статуса «Новая» и «Одобрена»:
Для этого необходимо нажать на ссылку «Добавить варианты ответа», где мы укажем значение статуса «Новая» и «Одобрена»:
Теперь необходимо сохранить наши параметры нажав на кнопку «Сохранить». На этом настройка нашей формы закончена и можно проверять работу.
Если сейчас открыть форму, то мы увидим, что в ней не выводится поле «Статус заявки»:
Если мы впервые отправим форму, то заявка успешно будет создана со статусом «Новая». Если после этого попробовать отправить форму с тем же самым email адресом, то мы увидим сообщение об ошибке и заявка не будет создана. Только после того, как мы в разделе «Статистика» изменим статус заявки на «Обработана», можно будет повторно создать новую заявку с тем же самым email адресом.
На сегодня это все. Удачного дня!
Проверка на уникальность с Sets
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
На сегодняшний день любой бизнес активно использует аналитику, чтобы развивать свои продукты. На основе данных можно лучше понимать пользователей и их потребности. Одна из базовых метрик, использующаяся повсеместно, — это количество уникальных посетителей страницы. Представим, что есть необходимость хранить такие данные в Redis.
На основе данных можно лучше понимать пользователей и их потребности. Одна из базовых метрик, использующаяся повсеместно, — это количество уникальных посетителей страницы. Представим, что есть необходимость хранить такие данные в Redis.
Прежде всего, стоит определить, как данные будут использоваться. Важно эффективно выполнять 2 условия:
- получать количество уникальных посетителей страницы
- проверять, что пользователь уже есть в списке посетителей, чтобы не записать дважды
Прикинем несколько вариантов решения.
Обычные ключи
Для начала можно попробовать хранить каждое посещение отдельным ключом с форматом page:{page_path}:user:{user_id}:
127.0.0.1:6379> set page:/courses:user:22 1 OK 127.0.0.1:6379> set page:/courses:user:33 1 OK 127.0.0.1:6379> exists page:/courses:user:22 (integer) 1 127.0.0.1:6379> keys page:/courses:user:* 1) "page:/courses:user:33" 2) "page:/courses:user:22"
Хотя проверка на существование пользователя в списке будет происходить быстро, этот вариант не подходит, потому что получение количества уникальных пользователей займет O(N) (N — количество ключей в Redis).
Redis Lists
Второй вариант — использовать тип данных Lists для хранения уникального списка ID пользователей:
127.0.0.1:6379> lpush page:/courses 22 33 44 (integer) 3 127.0.0.1:6379> llen page:/courses (integer) 3
В данном случае размер списка можно получить очень быстро за O(1), но вставка будет происходить неэффективно, так как перед вставкой необходимо делать поиск по всему списку для проверки существования.
Redis Hashes
Можно использовать структуру Hashes. Ключом будет страница, а значения будут в формате {user_id}: 1:
127.0.0.1:6379> hset page:/courses 11 1 22 1 33 1 (integer) 3 127.0.0.1:6379> hlen page:/courses (integer) 3
Это решение удовлетворяет обоим требованиям:
- Получение списка уникальных пользователей происходит за O(1) с командой
hlen - Вставка происходит за O(1) с проверкой уникальности пользователя
Но имеются и недостатки:
- Хранится много лишних данных из-за единиц для каждого идентификатора юзера
- Hashes не позволяют посчитать пересечения списков: например, количество пользователей, которые посетили 3 определенные страницы
Redis Sets
Для решения задачи с уникальными посетителями в Redis есть структура данных Sets. Sets — это список уникальных элементов, поддерживающий быстрые функции вставки, проверки на уникальность и пересечений.
Sets — это список уникальных элементов, поддерживающий быстрые функции вставки, проверки на уникальность и пересечений.
Запись
Для записи значений используется команда sadd key member [member ...]:
127.0.0.1:6379> sadd page:/courses 11 22 33 44 (integer) 4
Если набора не существовало, то он будет создан. После записи возвращается количество добавленных элементов. Если попытаться добавить существующий элемент, то вернется 0:
127.0.0.1:6379> sadd page:/courses 22 (integer) 0
Чтение и проверка на уникальность
Получить количество уникальных пользователей страницы можно с помощью команды scard key:
127.0.0.1:6379> scard page:/courses (integer) 4
Команда sismember key member проверяет, что пользователь посещал данную страницу:
127.0.0.1:6379> sismember page:/courses 33 (integer) 1 127.0.0.1:6379> sismember page:/courses 12222 (integer) 0
Удаление
Удалить пользователя из набора можно командой srem key member [member .: ..]
..]
127.0.0.1:6379> srem page:/courses 44 (integer) 1 127.0.0.1:6379> smembers page:/courses 1) "11" 2) "22" 3) "33"
Пересечения
Допустим, что есть 3 страницы: /courses, /courses/java и /courses/php. Нужно получить уникальных пользователей, которые посетили все 3 страницы. Задача решается одной командой sinter key [key ...]:
127.0.0.1:6379> sadd page:/courses 1 2 3 4 5 6 7 8 9 10 (integer) 10 127.0.0.1:6379> sadd page:/courses/java 1 2 3 4 5 6 7 (integer) 7 127.0.0.1:6379> sadd page:/courses/php 5 6 7 8 9 (integer) 5 127.0.0.1:6379> sinter page:/courses page:/courses/java page:/courses/php 1) "5" 2) "6" 3) "7"
Резюме
- уникальные значения в Redis можно хранить с помощью Hashes, но тогда хранятся лишние данные и отсутствуют некоторые функции
- структура данных Sets идеально подходит для списков уникальных значений. Вставка и проверка на уникальность происходят за O(1).
 Также присутствуют функции для расчета пересечений/разницы
Также присутствуют функции для расчета пересечений/разницы - добавить элемент в набор можно командой
sadd
 Также присутствуют функции для расчета пересечений/разницы
Также присутствуют функции для расчета пересечений/разницыОткрыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Электронная почта *
Отправляя форму, вы принимаете «Соглашение об обработке персональных данных» и условия «Оферты», а также соглашаетесь с «Условиями использования»
Наши выпускники работают в компаниях:
Глава 3 Доступность и уникальность
В этой главе показано, как проверить, доступны ли записи и/или полным в отношении набора ключей, и являются ли они уникальными. Описанные здесь проверки обычно полезны для данных в «длинном» формате, где один столбец содержит значение, а все остальные столбцы определяют это значение.- Для проверки отсутствующих значений в отдельных переменных см. также 2.2.
- Чтобы проверить, заполнены ли записи или их части, см. 4.1.
 также 2.2.
также 2.2.Данные
В этой главе используется набор данных samplonomy , который поставляется с проверкой упаковка.
библиотека (подтвердить) данные (самплономия) head(samplonomy, 3)
## регион частота период значение измерения ## 1 Agria A 2014 г.в.п. 600000 ## 2 Agria A 2014 импорт 210000 ## 3 Agria A 2014 export 222000
3.1 Длинные данные
Набор данных выборки структурирован в «полной форме». Это означает, что каждый
запись имеет сингл
головка(самплономия,3)
## регион частота период значение измерения ## 1 Agria A 2014 г.в.п. 600000 ## 2 Agria A 2014 импорт 210000 ## 3 Agria A 2014 export 222000
Набор данных содержит несколько временных рядов для нескольких показателей
вымышленной страны Самплония. Есть временные ряды для нескольких
субрегионы Самплонии.
Есть временные ряды для нескольких
субрегионы Самплонии.
Данные длинного формата обычно используются в качестве транспортного формата: они могут массовая загрузка данных в системы баз данных на основе SQL или для передачи данных между организации однозначно.
Данные в длинной форме, как правило, гораздо сложнее проверить и обработать для статистической цели, чем данные в широком формате, где каждая переменная хранится в отдельный столбец. Причина в том, что в длинноформатных отношениях между различные переменные разбросаны по записям, и эти записи не обязательно упорядочены каким-либо особым образом перед обработкой. Это делает интерпретация валидации по своей сути терпит неудачу для длинных данных, чем для широкоформатных данных.
Набор данных samplonomy имеет особенно неприятную структуру. Он содержит оба
годовые и квартальные временные ряды ВВП, импорта, экспорта и баланса
Торговля (экспорт минус импорт). Таким образом, столбец периода содержит как ежеквартальные
и годовые этикетки.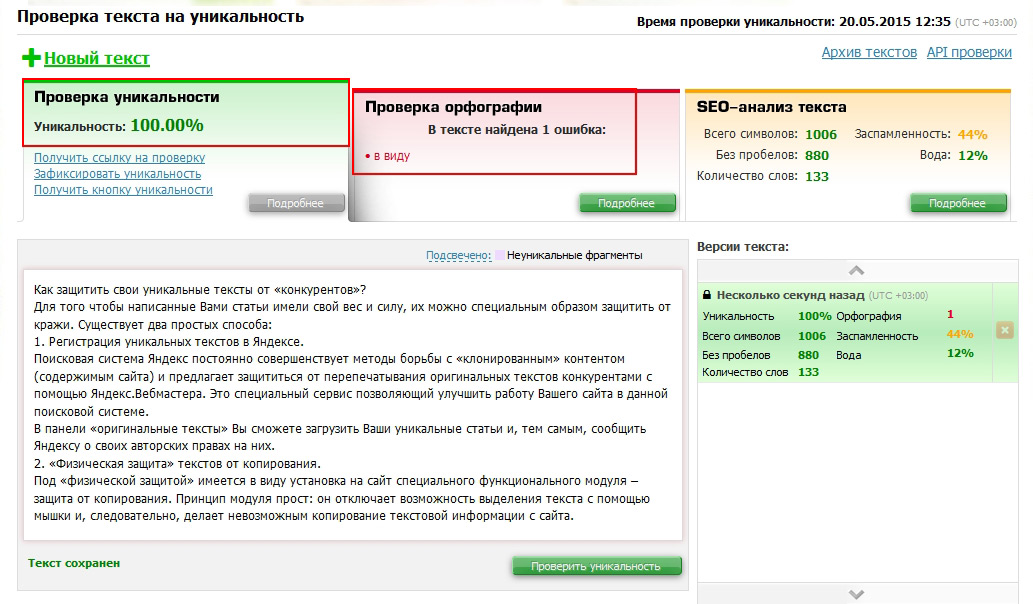 Кроме того, существуют временные ряды для всего
Самплония (регион Самплония), для каждой из двух его провинций (регионы Агрия и
Индастон) и для каждого из его районов в Агрии (Уитон и Гринхэм) и
Индастон (Смокли, Мадуотер, Ньюбей и Окдейл).
Кроме того, существуют временные ряды для всего
Самплония (регион Самплония), для каждой из двух его провинций (регионы Агрия и
Индастон) и для каждого из его районов в Агрии (Уитон и Гринхэм) и
Индастон (Смокли, Мадуотер, Ньюбей и Окдейл).
Естественно, мы ожидаем, что комбинации клавиш уникальны, что все временные ряды непрерывны и полны, что торговый баланс равен экспорту за вычетом импорта. везде значения этих районов складываются с провинциями, и эта провинция значения складываются в общую сумму Samplonia. Наконец, квартальные временные ряды должны в сумме соответствовать годовым значениям.
3.2 Уникальность
Функция is_unique() проверяет, являются ли комбинации переменных (обычно
ключевые переменные) однозначно идентифицируют запись. Он принимает любое положительное число
имена переменных и возвращает ЛОЖЬ для каждой записи, которая дублируется с
относительно обозначенных переменных.
Здесь мы проверяем, однозначно ли регион, период и показатель определяют значение в
набор данных samplonomy .
правило <- validator(is_unique(регион, период, мера)) out <- конфронтация (самплономия, правило) # показываем 7 столбцов вывода для удобочитаемости summary(out)[1:7]
## name items pass failed nNA error warning ## 1 V1 1199 1197 2 0 ЛОЖЬ ЛОЖЬ
2 сбоя. После извлечения личности
значения для каждой записи, мы можем найти дубликаты, используя
функция удобства от подтвердите .
нарушение(самплономия, выход)
## регион частота период значение измерения ## 870 Induston Q 2 кв. 2018 экспорт 165900 ## 871 Induston Q 2018Q2 export 170000
При интерпретации уникальности следует помнить о двух тонкостях. первое связано с пропущенными значениями, а второе связано с группировкой. Чтобы начать с проблемы пропущенного значения, взгляните на следующие две записи. кадр данных.
df <- data.frame(x = c(1,1), y = c("A",NA))
df ## х у ## 1 1 А ## 2 1
Как определить, уникальны ли эти две записи? Заманчивый вариант такой
сказать, что первая запись уникальна, и вернуть NA для второй записи
поскольку он содержит пропущенное значение: R имеет привычку возвращать NA из
расчеты, когда входное значение равно NA .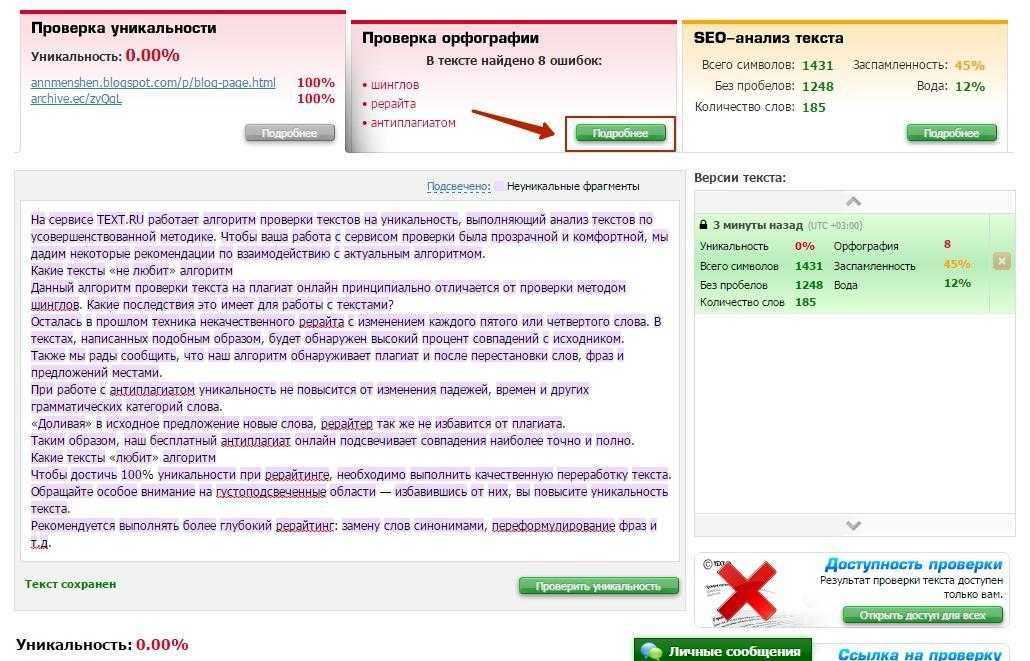 Этот выбор не является недействительным, но он
будет иметь последствия для определения того, является ли первая запись уникальной, поскольку
хорошо. В конце концов, можно заполнить значение в отсутствующем поле, например
что две записи дублируются. Следовательно, если бы кто-то вернул
Этот выбор не является недействительным, но он
будет иметь последствия для определения того, является ли первая запись уникальной, поскольку
хорошо. В конце концов, можно заполнить значение в отсутствующем поле, например
что две записи дублируются. Следовательно, если бы кто-то вернул NA для
вторая запись, правильно будет также вернуть NA для первой
записывать. В R выбор сделан для обработки NA как фактического значения при проверке
для дубликатов или уникальных записей (см. — дубликат из базы R). Чтобы увидеть это
проверьте следующий код и вывод.
df <- data.frame(x=rep(1,3), y = c("A", NA, NA))
is_unique(df$x, df$y) ## [1] TRUE FALSE FALSE
Вторая тонкость связана с группировкой. Вы можете проверить, является ли
столбец уникален, учитывая одну или несколько других переменных. Соблазнительно думать
что для этого требуется подход «разделить-применить-объединить», при котором набор данных сначала
разделить по одной или нескольким группирующим переменным, проверить уникальность
столбец в каждой группе, а затем объедините результаты.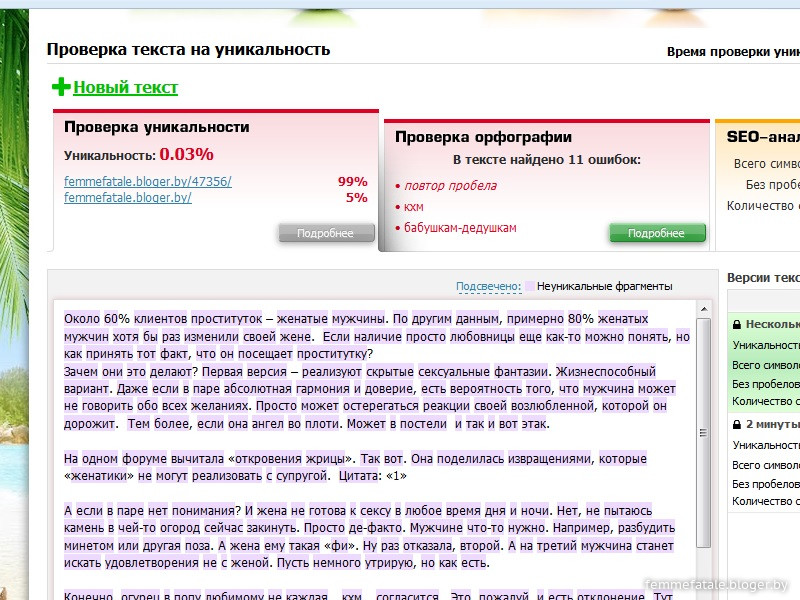 Однако такой подход
в этом нет необходимости, так как вы можете просто добавить группирующие переменные в список
переменные, которые вместе с должны быть уникальными.
Однако такой подход
в этом нет необходимости, так как вы можете просто добавить группирующие переменные в список
переменные, которые вместе с должны быть уникальными.
В качестве примера рассмотрим вывод следующих двух подходов.
# y уникален при данном x. Но не сам по себе df <- data.frame(x=rep(буквы[1:2],каждый=3), y=rep(1:3,2)) # подход "разделить-применить-объединить" unsplit(tapply(df$y, df$x, is_unique), df$x)
## [1] TRUE TRUE TRUE TRUE TRUE TRUE
# комбинированный подход is_unique(df$x, df$y)
## [1] ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА
3.3 Доступность записей
Этот раздел находится на проверке на наличие полных записей. Тестирование для отдельных пропущенные значения (NA) рассматривается в 2.2.
Мы хотим убедиться, что для каждого региона и каждой переменной периоды 2014,
2015, \(\ldots\), 2019 присутствуют. Используя contains_at_least , мы можем установить
этот.
правило <- валидатор(
содержит_по крайней мере(
ключи = data.frame(период = as.character(2014:2019))
, by=список(регион, мера))
)
out <- конфронтация (самплономия, правило)
# показываем 7 столбцов вывода для удобочитаемости
итог(выход)[1:7] ## элементы имени не проходят проверку, предупреждение об ошибке nNA ## 1 V1 1199 1170 29 0 FALSE FALSE
Функция contains_at_least разбивает набор данных samplonomy на блоки
по значениям регион и мерка . Далее проверяется, что в каждом
блок переменной период содержит как минимум значения 2014–2019.
Возвращаемое значение представляет собой логический вектор, в котором количество элементов равно
количество просматриваемых строк в наборе данных. это ИСТИНА для каждого блока
где присутствуют все годы, и ЛОЖЬ для каждого блока, где один из
лет отсутствует. В этом случае 29 записей помечены как FALSE. Эти
можно найти следующим образом.
Эти
можно найти следующим образом.
головка(нарушение(самплономия, выход))
## регион частота период значение измерения ## 1 Agria A 2014 г.в.п. 600000 ## 5 Agria Q1 2014Q1 ВВП 60000 ## 9 Agria Q2014 Q2 ВВП 120000 ## 13 Agria Q 2014Q3 ВВП 300000 ## 17 Agria Q4 2014Q4 ВВП 120000 ## 204 Agria Q1 2015Q1 ВВП 58200
Проверка этих записей показывает, что в этом блоке для Agria ВВП
для "2015" отсутствует.
Мы можем выполнить более строгую проверку и проверить, все ли для каждой меры кварталы "2014Q1" \(\ldots\) "2019Q4" присутствуют для каждой провинции ( Agria и Индастон ). Сначала создайте набор ключей для тестирования.
лет <- as.character(2014:2019)
четверти <- paste0("Q",1:4)
набор ключей <- expand.grid(
регион = c("Агрия", "Индастон")
, период = sapply (годы, paste0, кварталы))
головка(набор ключей) ## регион период ## 1 Агрия 2014Q1 ## 2 Индастон 2014Q1 ## 3 Агрия 2 кв.
 2014 г.
## 4 Индастон, 2 кв. 2014 г.
## 5 Агрия 3 кв. 2014 г.
## 6 Induston 2014Q3
2014 г.
## 4 Индастон, 2 кв. 2014 г.
## 5 Агрия 3 кв. 2014 г.
## 6 Induston 2014Q3 Этот набор ключей будет указан в правиле и передан против в качестве ссылки
данные.
правило <- валидатор(
содержит_по крайней мере (ключи = минимальные_ключи, по = мера)
)
out <- конфронтация(самплономия, правило
, ссылка = список (минимальные_ключи = набор ключей))
# показываем 7 столбцов вывода для удобочитаемости
итог(выход)[1:7] ## элементы имени не проходят проверку, предупреждение об ошибке nNA ## 1 V1 1199 899 300 0 FALSE FALSE
300 ошибок. Проверяя набор данных, как указано выше, мы
см., что для Induston export отсутствует в "2018Q3" .
Наконец, мы проводим строгий тест, чтобы проверить, что для каждого измерения все периоды и
сообщаются все регионы. Мы также требуем, чтобы не было больше и не меньше
записей, чем для каждой отдельной меры. Для этого функция contains_exactly можно использовать.
Сначала создайте набор ключей.
лет <- as.character(2014:2019)
четверти <- paste0("Q",1:4)
набор ключей <- expand.grid(
регион = с(
"Агрия"
, "Краудон"
, "Гринхэм"
, "Индастон"
, "Грязевая вода"
, "Ньюбэй"
, "Окдейл"
, "Самплония"
, "Смокли"
, "Уитон"
)
, период = с (годы, период (годы, паста0, кварталы))
)
головка (набор ключей) ## регион период ## 1 Агрия 2014 ## 2 Краудон 2014 ## 3 Гринхэм 2014 ## 4 Индастон 2014 ## 5 Грязевая вода 2014 ## 6 Ньюбэй 2014
Набор ключей передается правилу в качестве справочных данных с использованием и .
правило <- валидатор (содержит_точно (все_ключи, по = мере))
out <- конфронтация(самплономия, правило
, ссылка = список (all_keys = набор ключей))
# показываем 7 столбцов вывода для удобочитаемости
summary(out)[1:7] ## name items pass failed nNA error warning ## 1 V1 1199 0 1199 0 FALSE FALSE
Чтобы найти, где находятся ошибки, мы сначала выбираем записи с ошибкой и
затем найдите уникальные меры, встречающиеся в этих записях.
ошибочные_записи <- нарушение(самплономия, вне) unique(erroneous_records$measure)
## [1] "gdp" "import" "export" "balance"
Итак, здесь в блоках, содержащих GDP и Export, отсутствуют целые записи.
3.4 Пробелы в (временных) рядах
Для временных рядов или, возможно, других рядов желательно, чтобы существует постоянное расстояние между каждыми двумя элементами ряда. Математический термин для такого ряда называется линейной последовательностью . Вот несколько примеров линейных рядов.
- Натуральные числа: \(1,2,3,\ldots\)
- Четные натуральные числа \(2, 4, 6, \ldots\)
- Кварталы:
"2020Q1","2020Q2", \(\ldots\) - лет (это просто натуральные числа): \(2019, 2020, \ldots\)
проверка функций is_linear_sequence и in_linear_sequence проверка
представляет ли переменная линейный ряд, возможно, в блоках, определяемых
категориальные переменные.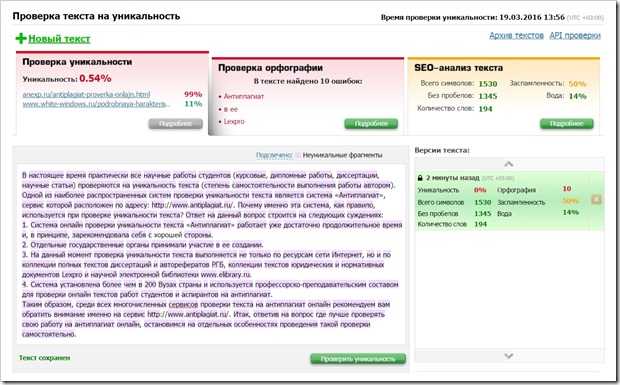 Они могут использоваться интерактивно или, как правило, в
объект валидатора. Сначала мы покажем, как работают эти функции, а затем дадим
пример с 9Набор данных 0015 samplonomy .
Они могут использоваться интерактивно или, как правило, в
объект валидатора. Сначала мы покажем, как работают эти функции, а затем дадим
пример с 9Набор данных 0015 samplonomy .
is_linear_sequence(c(1,2,3,4))
## [1] TRUE
is_linear_sequence(c(8,6,4,2))
## [1] TRUE
is_linear_sequence( c(2,4,8,16))
## [1] FALSE
Для символьных данных функция способна распознавать определенные форматы для периодов времени.
is_linear_sequence(c("2020Q1","2020Q2","2020Q3","2020Q4")) ## [1] TRUE
См. ?is_linear_sequence для полной спецификации поддерживаемых
форматы даты и времени.
Нет необходимости сортировать данные, чтобы их можно было распознать как линейная последовательность.
is_linear_sequence(c("2020Q4","2020Q2","2020Q3","2020Q1")) ## [1] TRUE
Можно также задать начальную и/или конечную точку последовательности.
is_linear_sequence(c("2020Q4","2020Q2","2020Q3","2020Q1")
, begin = "2020Q2") ## [1] FALSE
Наконец, можно разделить переменную по одному или нескольким другим столбцам и
проверьте, представляет ли каждый блок линейную последовательность.
ряд <- с(1,2,3,4,1,2,3,3)
блоки <- rep(c("a","b"), каждый = 4)
is_linear_sequence(series, by = blocks) ## [1] FALSE
Теперь этот результат не очень полезен, так как теперь неизвестно, какой блок
не является линейным рядом. Здесь на помощь приходит функция in_linear_sequence .
in_linear_sequence(series, by = blocks)
## [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE
Есть некоторые тонкости. Отдельный элемент также является линейной последовательностью (длины 1).
is_linear_sequence(5)
## [1] TRUE
Это может привести к сюрпризам в случае блоков длиной 1.
блоков[8] <- "c" data.frame(серия = серия, блоки = блоки)
## блоки серии ## 1 1 а ## 2 2 а ## 3 3 а ## 4 4 а ## 5 1 б ## 6 2 б ## 7 3 б ## 8 3 c
in_linear_sequence(серии, блоки)
## [1] ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА
Теперь у нас есть три линейных ряда, а именно
- Для
"а":1,2,3,4 - Для
"б":1,2,3 - Для
"с":3.

Мы можем обойти это, задав явные границы.
in_linear_sequence(серия, блоки, начало = 1, конец = 4)
## [1] ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ЛОЖЬ ЛОЖЬ ЛОЖЬ ЛОЖЬ ЛОЖЬ
Теперь вернемся к набору данных samplonomy . Мы хотим проверить это для
каждая мера и каждая область, временные ряды являются линейными рядами. С тех пор
являются временными рядами разных частот, нам нужно разделить данные по частоте
также.
правило <- валидатор(
in_linear_sequence (период
, по = список (область, частота, мера))
)
out <- конфронтация (самплономия, правило)
summary(out)[1:7] ## name items pass failed nNA error warning ## 1 V1 1199 1170 29 0 FALSE FALSE
Блоки, в которых записи идут не по порядку, можно найти следующим образом (выводить не напечатано здесь для краткости).
нарушение(выборка, вне)
Проверка выбранных записей показывает, что для Agria ВВП за 2015 г.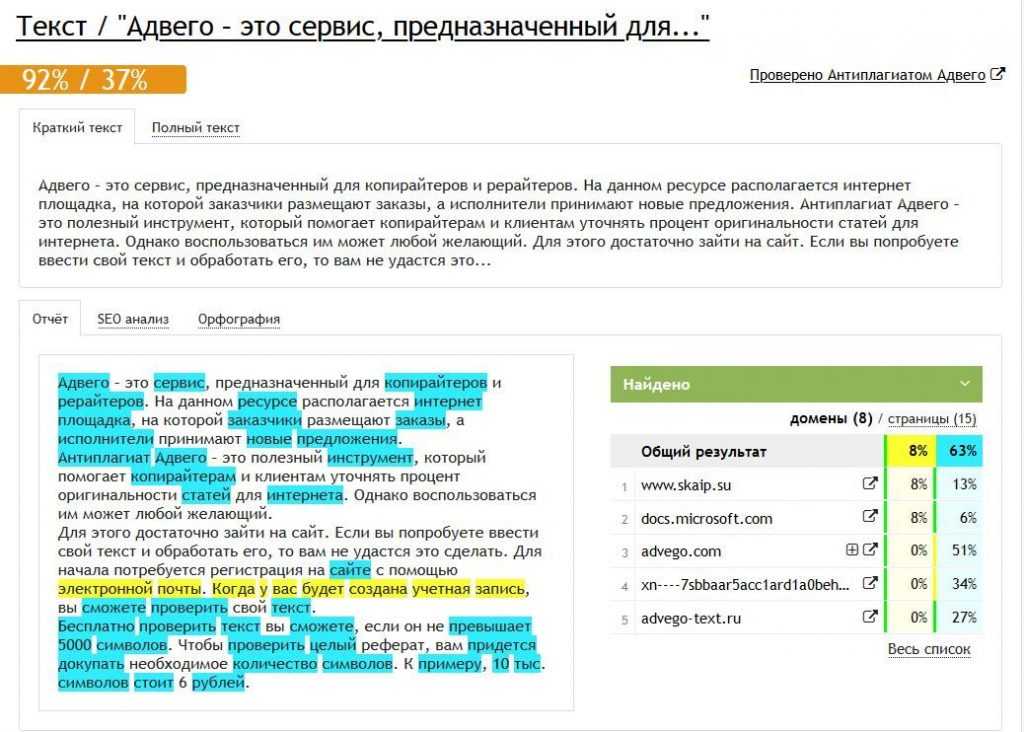 отсутствует, а для Induston экспорт за 2018Q3 отсутствует, а экспорт
для 2018Q2 встречается дважды (но с разными значениями)
отсутствует, а для Induston экспорт за 2018Q3 отсутствует, а экспорт
для 2018Q2 встречается дважды (но с разными значениями)
— проверка MySQL на уникальность набора атрибутов?
Задавать вопрос
спросил
Изменено 1 год, 1 месяц назад
Просмотрено 202 раза
Что я пытаюсь сделать, так это выполнить проверку уникальности. Однако я не просто проверяю "если имя iggy уже существует в БД?" . Мне нужно проверить уникальность набора атрибутов.
Вот что я имею в виду под проверкой уникальности набора атрибутов. Допустим, мне нужно проверить уникальность столбцов/атрибутов: type , partNum и name .