
Почему страницы сайта выпадают из индекса — Маркетинг на vc.ru
В этой статье специалист Mello затронет следующие вопросы:
2423 просмотров
- Как проверить индексацию страницы сайта в Яндексе и в Google
- С помощью каких сервисов можно проверить информацию об исключенных URL
- Причины выпадения страниц из индекса и что делать в такой ситуации
Одиночное выпадение страниц из индекса поисковых систем
Вебмастер может заметить, что трафик, присутствовавший на некогда популярной странице услуги, исчез, звонки прекратились, а продажи упали до нуля. В этом случае следует проверить – не выпала ли данная страница из индекса поисковых систем, особенно если единственным каналом продвижения этой услуги в интернете был органический поиск.
Как проверить не выпала ли страница из индекса Яндекса:
В Яндекс Вебмастере. Вкладка «Индексирование — Проверить статус URL». Вводим URL нужной страницы, нажимаем кнопку “Проверить” и ждём. Если в результате написано, что страница обходится роботом и находится в поиске, значит все хорошо:
Вводим URL нужной страницы, нажимаем кнопку “Проверить” и ждём. Если в результате написано, что страница обходится роботом и находится в поиске, значит все хорошо:
Через оператор url. В поисковой строке Яндекса вводим запрос по формуле [url:URL_документа]. Пример:
Если страница присутствует в индексе, Яндекс ее выведет.
Пример с отсутствующим в поиске URL:
Как проверить не выпала ли страница из индекса Google:
Проверить индексацию страницы в Гугле можно через сервис Google Search Console. Вставляем URL в строку проверки, нажимаем Enter:
Выводится информация о странице. В данном случае нас интересует информация о том, что URL присутствует в индексе Google.
Массовое выпадение страниц из индекса поисковых систем
Необходимо регулярно проверять свой сайт на количество исключенных из поиска страниц, так как целевые страницы могут выпасть из индекса в любой момент.
Как проверить информацию об исключенных страниц в Яндексе:
С помощью Вебмастера Яндекса можно узнать всю необходимую информацию об индексации страниц. Вкладка «Индексирование -> Страницы в поиске».
Вкладка «Индексирование -> Страницы в поиске».
Всегда проверяйте исключенные URL, особенно если видите, что раньше страниц в поиске было заметно больше. Здесь вы можете увидеть информацию о дате и причине исключения URL из индекса.
Как проверить информацию об исключенных страницах в Google:
В Google Search Console также можно посмотреть информацию об исключенных URL. Для этого перейдем во вкладку «Покрытие»:
Здесь нам показывают:
- Страницы с ошибками – Google не смог их проиндексировать
- Без ошибок, есть проблемы — проиндексированные страницы, но, возможно, имеющие ошибку с нашей стороны (например запрещены нужные нам URL в файле robots.txt)
- Без ошибок
- Исключенные
По каким причинам страницы выпадают из индекса
Причин, по которым страницы могут исключить из индекса, целое множество. Мы разделим их на две группы: технические причины и причины, зависящие от контента.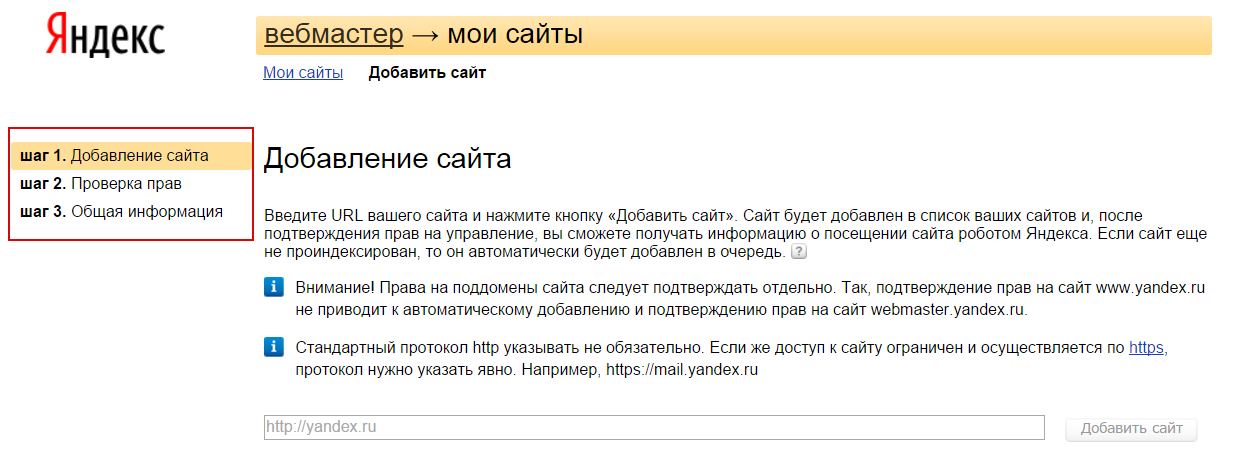
Технические причины
Редиректы
Поисковые системы исключают из индекса страницы, которые перенаправляют пользователя на другие страницы. При этом сама конечная страница (на которую идет перенаправление) зачастую не исключается (если нет другой причины).
Типичный пример исключения страницы, перенаправляющей пользователя на другую страницу (301 редирект):
Конечная страница осталась в поиске:
Так как конечная страница остается в поиске, то ничего страшного в данной ситуации нет, но желательно минимизировать кол-во ненужных 301 редиректов на сайте, если есть такая возможность.
404
Страницы с 404 ошибками также выпадают из индекса:
Если страница удалена по ошибке, то конечно необходимо ее восстановить. Если страница больше не нужна, то нужно удалить все ссылки на сайте, ведущие на нее.
Файл Robots.txt и мета-тег Robots
Вебмастер может рекомендовать поисковым системам не включать в индекс нужные ему URL с помощью файла robots.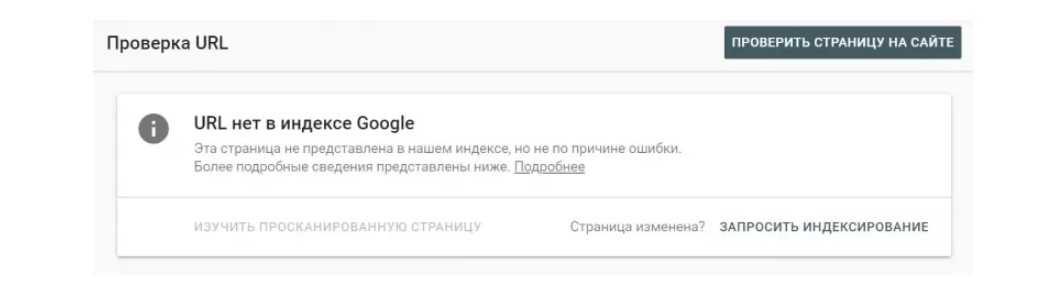 txt или с помощью мета-тега Robots:
txt или с помощью мета-тега Robots:
Проверьте файл robots.txt, нет ли там нужных вам страниц. Также проверьте мета-тег Robots. Если вы видите, что у атрибута “name” задано значение “robots”, а у атрибута “content” присутствует значение “noindex”, это означает, что сканирование страницы запрещено для всех поисковых роботов:
Более подробно про данный мета-тег можете почитать в справке Google.
Страница обнаружена, но не проиндексирована
В Google Search Console есть исключенные из индекса URL со статусом «Страница просканирована, но пока не проиндексирована»:
Это означает, что поисковый робот нашел вашу страницу, но не добавил ее в индекс. В данном случае нужно просто подождать и страница будет добавлена в поиск.
Причины, зависящие от контента
Дубли
Страницы полностью или частично дублирующие другие могут быть исключены из поиска.
Если страницы-дубли не нужны, то лучшим решением будет их удалить. Если нужны, то можно установить тег “rel=canonical” в этих страниц.
Если нужны, то можно установить тег “rel=canonical” в этих страниц.
Например:
Также можно настроить 301 редирект со страницы-дубля на каноническую страницу.
Если обе похожие друг на друга страницы должны присутствовать не только на сайте, но и в поиске (например, две страницы карточек товара), то их нужно сделать уникальными (изменить мета-теги, текст на странице, фото и т.д.).
Недостаточно качественные страницы
Сюда относятся страницы, несоответствующие запросу и неcпособные удовлетворить потребности пользователя.
Необходимо сделать страницу более качественной. Если это страница блога, то сделать уникальный и полезный читателю контент. Если это страница карточки товара в интернет-магазине, то товар должен быть в наличии (или должна присутствовать возможность заказать со склада), содержать описание, краткие характеристики товара и т.д.
Переоптимизированный контент
Тексты, сделанные для поисковиков, а не для людей. Их отличает большое количество вхождений ключевых слов. В случае, если у вас на сайте много переоптимизированного контента, поисковики могут наложить фильтр на сайт и целое множество страниц выпадет из индекса.
Их отличает большое количество вхождений ключевых слов. В случае, если у вас на сайте много переоптимизированного контента, поисковики могут наложить фильтр на сайт и целое множество страниц выпадет из индекса.
Как написано выше — делайте контент в первую очередь для пользователей. И не забывайте про фактор переоптимизации.
Накрутка поведенческих факторов
Поисковые системы накладывают санкции за использование различных методов так называемого «черного» SEO. Одним из таких методов и является попытка накрутить поведенческие факторы искусственным путем.
Не стоит использовать в своей работе сомнительные сервисы и программы по накрутке поведенческих факторов.
Неестественный ссылочный профиль
Если на сайте расположено множество покупных ссылок, а естественных ссылок очень мало, на него может наложиться фильтр поисковых систем (Минусинск у Яндекса и Пингвин у Гугла).
Аффилированность
Если два сайта одной компании борются за место в выдаче, то поисковые системы показывают страницу только одного сайта (как правило показывается наиболее подходящий запросу).
Как проверить находится ли сайт под фильтром
В Яндексе
Зайдите в раздел «Диагностика -> Безопасность и нарушения» в Яндекс Вебмастере:
Если ваш сайт получил фильтр, то информация об этом отобразится в данном разделе.
В Google
В Google Search Console это можно проверить в разделах «Меры принятые вручную» и «Проблемы безопасности»:
Вывод
Если вы попали ситуацию с кучей выпавших из индекса URL, проанализируйте:
- Заказывали ли вы ссылки, какие и сколько
- Все ли тексты на вашем сайте качественные и уникальные
- Удобен ли ваш сайт для пользователя, нет ли там излишней рекламы
- Какие страницы запрещены с помощью файла Robots.txt и мета-тега robots
- Присутствуют ли на сайте страницы-дубли
и исходя из итогов анализа устраните причину.
Если же вам не удалось установить причину исключения URL из индекса, или вы устранили все возможные ошибки, а страницы так и не попали в поиск, попробуйте обратиться в техподдержку поисковой системы.
Автор: специалист SEO- отдела в Mello, Павел Шевченко.
Как узнать сколько страниц проиндексировано в Яндекс и Google? – Проверить индексацию страниц поисковиками
Определить количество проиндексированных страниц в Яндекс или Google можно несколькими способами: с помощь специального запроса или посмотреть статистику в панели вебмастера
Tilda Publishing
Главная > Статьи > Как определить количество страниц в поиске?
Как узнать количество проиндексированных страниц с помощью запроса
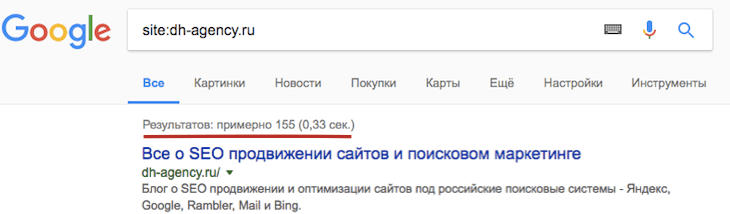
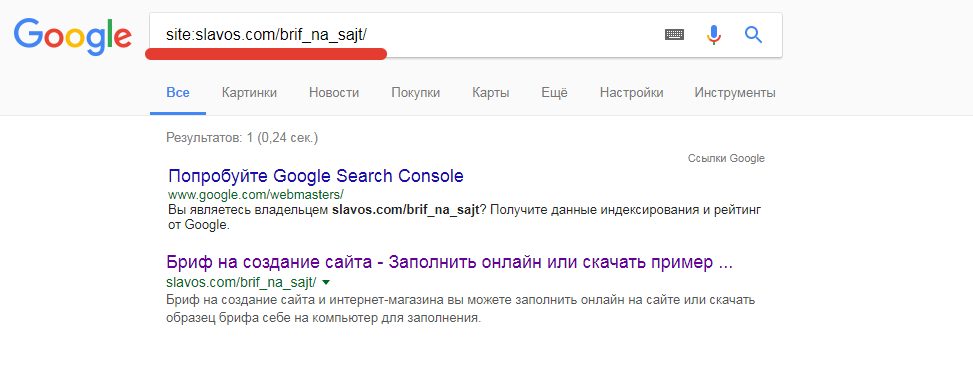
В поисковой строке Яндекс или Гугл нужно набрать запрос следующего типа: site:домен.рф, где домен.рф – это адрес интересующего вас сайта. Например:
Проверка количества страниц в поисковой выдаче Яндекс с помощью запроса
Такой же запрос действует и в Google:
Проверка количества проиндексированных страниц в Goggle с помощью специального запроса
Гугл обычно показывает в поиске больше результатов. Это связано с тем, что Google быстрее добавляет новые страницы в поисковую выдачу.
Это связано с тем, что Google быстрее добавляет новые страницы в поисковую выдачу.
Статистика индексирования в консоли вебмастера Яндекс и Google
Статистику индексирования и количество страниц можно посмотреть в консоли вебмастера:
Проверка количества проиндексированных страниц в консоли вебмастера
По данным консоли в поиске Яндекс 126 страниц, а с помощью запроса мы обнаружили 129. По данным техподдержки Яндекса – значение, которое мы видим в поиске – достовернее. А разница в количестве страниц может зависеть от настроек браузера, типа устройства и проведения работ на стороне Яндекса.
Также можно обратить внимание, что поисковой системой загружено больше страниц, чем добавлено в поиск. Загруженные страницы – это все страницы сайта, о которых известно поисковой систем, страницы в поиске – это все, что выводится в поиск.
Страницы, которые не попадают в поиск:
- Дубликаты,
- Заспамленные страницы,
- Закрытые от индексирования.

- Содержащие бесполезный контент.
Также страницы могут не попадать в индекс по техническим ошибкам на стороне Яндекса. Если вы уверены, что на сайте ошибок нет, страница качественная, а в поиск она все никак не попадает – пишите в поддержку.
Как проверить проиндексированность конкретной страницы?
В Яндексе можно использовать поисковый оператор «url:». После двоеточия нужно указать полную ссылку страницы:
Как узнать проиндексирована ли страница в Яндексе?
В Яндексе оператор URL позволяет также проверять проиндексированность отдельных разделов сайта. Для этого нужно набрать в строке поиска такую конструкцию – url:домен.рф/раздел1/* — звездочка обозначает любое количество любых символов, поэтому в ответ на такой запрос Яндекс отобразить все страницы, ссылки которых начинаются на домен.рф/раздел1/, т.е. отобразить все проиндексированные страницы в первом разделе.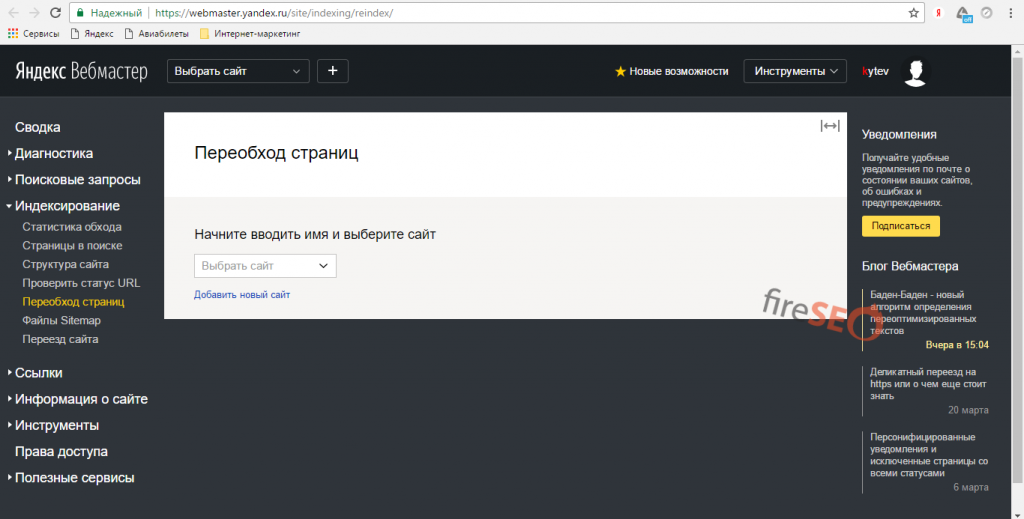
Чтобы определить проиндексирована ли страница в Google, нужно воспользоваться оператором «site:», а после двоеточия указать полную ссылку на страницу:
Проверка индексации страницы в Google
Следите за тем, чтобы количество страниц в поиске Яндекс и Google было примерно одинаковым. Поисковые системы использую разные алгоритмы, поэтому разница в индексе может достигать 10-15%. Если у вас разница больше, нужно провести SEO-аудит и выяснить причину.
Поисковая оптимизация сайта на WIX
Продвижение сайта на WIX вполне реально. Конструктор соответствует минимальным требованиям для базовой оптимизации. При правильном подходе возможно вывести сайт на WIX в топ
Какую CMS лучше выбрать для интернет-магазина?
Выбор правильного движка для интернет-магазина отразиться на работе сайта, поисковой оптимизации, удобстве проекта для пользователей и бюджете на разработку
Что такое движок сайта?
Движок сайта – это программное обеспечение, которое позволяет управлять контентом сайта без знания языков программирования
Что такое посадочная страница?
Посадочная страница – это страница входа посетителей на ваш сайт, спроектированная таким образом, чтобы получать максимум заявок от посетителей
Базовый аудит рекламных кампаний в Яндекс Директ
Быстрый аудит рекламных кампаний в Яндекс Директе можно использовать в качестве проверки профессионализма агентства или фрилансера, который настраивал рекламу
Настройка корректировки ставок в системе контекстной рекламы Яндекс Директ
Корректировка ставок в Яндекс Директ позволяет уменьшать или увеличивать стоимость клика в зависимости от признаков целевой аудитории. Правильная корректировка ставок в Директе
Правильная корректировка ставок в Директе
Бесплатная консультация
Мы создаем и раскручиваем сайты, ведем аналитику и размещаем рекламу в интернете. Задайте нам вопрос по любой из этих тем
| Написать |
как краулер сканирует сайт и методы улучшения индексирования – Блог iSEO
В этой статье вы узнаете, что такое индексация сайтов, как индексируют сайты Google и Яндекс, как можно ускорить индексацию вашего сайта и какие проблемы встречаются чаще всего.
Кому полезна статья?
Начинающим SEO-специалистам и маркетологам, веб-разработчикам и владельцам сайтов, желающим разобраться в принципах индексирования и методиках его улучшения.
Оглавление
- Индексирование сайта — что это и для чего необходимо?
- Сканирование и индексация сайта — как протекает процесс?
- Наиболее популярные ошибки
- Сайт или страницы закрыты в robots.txt
- Бот не получает код ответа 200
- Бот не может получить код страницы
- Страницы закрыты метатегом robots или заголовком X-Robots-Tag
- Как управлять сканированием и индексацией?
- Файл robots. txt
- Метатег robots
- HTTP-заголовок X-Robots-Tag
- Тег и HTTP-заголовок canonical
- HTTP-код ответа сервера, отличный от 200
- Удаление страниц в Яндекс.Вебмастере и Google Search Console
- Как отправлять страницы на индексацию/переиндексацию?
- Файл robots.
- Как улучшить сканирование и индексацию?
- Используйте XML-карту сайта
- Оптимизируйте перелинковку
- Внедрите поддержку IndexNow и Google Indexing API
- Анонсируйте новый контент в социальных сетях
- Выводы
 txt
txtИндексирование сайта — что это и для чего необходимо?
Прежде чем касаться вопроса индексации, необходимо вспомнить о целях любой поисковой системы. Главная задача поиска — ответ на запрос пользователя. Чем точнее и качественнее он будет, тем чаще пользователи будут пользоваться поисковиком.
Поисковая система ищет подходящую информацию в своей базе данных, куда сайты попадают после их индексирования, а значит, только корректное индексирование может обеспечить попадание в выдачу.
Процесс можно разделить на 3 этапа:
Из схемы можно увидеть, что процесс сканирования и индексирования — это база для ранжирования любого сайта. Если возникают существенные проблемы на любом из указанных этапов, то можно забыть о высоких позициях, росте трафика и лидов. Рассмотрим эти этапы детальнее.
Сканирование и индексация сайта — как протекает процесс?
Сканирование сайта (или crawling) — процесс, при котором поисковые роботы обходят сайт и загружают страницы с целью определения внутренних ссылок и контента.
Источники, из которых поисковые системы могут узнавать о новых страницах на сайте:
- Из XML-карт сайта — ссылки на них, как правило, есть в robots.txt.
- Из данных счетчиков — Яндекс.Метрика, Google Analytics.
- Из данных браузеров — Яндекс.Браузер, Google Chrome.
- Из сервисов для веб-мастеров — отправка на переобход в Яндекс.Вебмастере, запрос на индексацию URL в Google Search Console.
- Из RSS-фида — XML-файл в специальном формате.
- По протоколу IndexNow.

Уже просканированные страницы сайтов боты поисковых систем периодически переобходят для выявления изменений, способных повлиять на их ранжирование.
Алгоритм сканирования сайтов следующий:
После сканирования поисковые роботы добавляют страницы в поисковый индекс. Сама по себе индексация представляет собой процесс, при котором поисковые системы упорядочивают информацию перед поиском, чтобы обеспечить максимально быстрый ответ пользователю на запрос.
Каждый из этапов сканирования важно контролировать, так как любые ошибки могут критически влиять на индексацию страниц.
Наиболее популярные ошибки
При работе с сайтом каждый оптимизатор или маркетолог сталкивались с проблемами индексирования сайтов. Далее разберем примеры самых частых проблем.
Сайт или страницы закрыты в robots.txt
Наиболее популярная проблема, встречающаяся у всех типов сайтов.
Файл robots.txt — это текстовый документ, содержащий разрешающие и запрещающие директивы для ботов поисковых систем.
Если ваш robots.txt содержит строку «Disallow: /», это повод проверить, видит ли ваш сайт поисковый бот. Сделать это можно с помощью инструмента https://webmaster.yandex.ru/tools/robotstxt/.
Бот не получает код ответа 200
Вторая наиболее часто встречающаяся проблема индексирования — наличие кодов ответа 4XX или 5XX.
Примеры ошибок:
| Код ответа | Ошибка | Описание |
|---|---|---|
| 400 | Неверный запрос / Bad Request | Запрос не может быть понят сервером из-за некорректного синтаксиса. |
| 401 | Неавторизованный запрос / Unauthorized | Для доступа к документу необходимо вводить пароль или быть зарегистрированным пользователем. |
| 402 | Необходима оплата за запрос / Payment Required | Внутренняя ошибка или ошибка конфигурации сервера. |
| 403 | Доступ к ресурсу запрещен / Forbidden | Доступ к документу запрещен. Если вы хотите, чтобы страница индексировалась, необходимо разрешить доступ к ней. Если вы хотите, чтобы страница индексировалась, необходимо разрешить доступ к ней. |
| 404 | Ресурс не найден / Not Found | Документ не существует. |
| 405 | Недопустимый метод / Method Not Allowed | Метод, определенный в строке запроса (Request-Line), не дозволено применять для указанного ресурса, поэтому робот не смог его проиндексировать. |
| 406 | Неприемлемый запрос / Not Acceptable | Нужный документ существует, но не в том формате (язык или кодировка не поддерживаются роботом). |
| 407 | Требуется идентификация прокси, файервола / Proxy Authentication Required | Необходима регистрация на прокси-сервере. |
| 408 | Время запроса истекло / Request Timeout | Робот не передал полный запрос в течение установленного времени, и сервер разорвал соединение. |
| 410 | Ресурс недоступен / Gone | Затребованный ресурс был окончательно удален с сайта.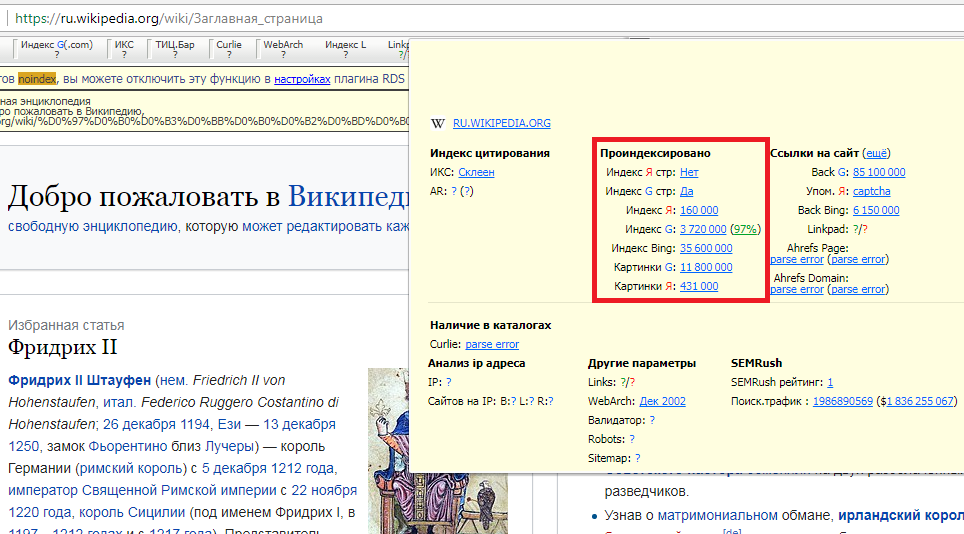 |
| 500 | Внутренняя ошибка сервера / Internal Server Error | Сервер столкнулся с непредвиденным условием, которое не позволяет ему выполнить запрос. |
| 501 | Метод не поддерживается / Not Implemented | Сервер не поддерживает функциональные возможности, требуемые для выполнения запроса. |
| 502 | Ошибка шлюза / Bad Gateway | Сервер, действуя в качестве шлюза или прокси-сервера, получил недопустимый ответ от следующего сервера в цепочке запросов, к которому обратился при попытке выполнить запрос. |
| 503 | Служба недоступна / Service Unavailable | Возникла ошибка из-за временной перегрузки или отключения сервера. |
| 504 | Время прохождения через межсетевой шлюз истекло / Gateway Timeout | Сервер при работе в качестве внешнего шлюза или прокси-сервера своевременно не получил отклик от вышестоящего сервера. |
Наличие HTTP-кодов ответа сервера, отличных от 200, может стать серьезной проблемой на пути сканирования и индексации сайта.
Проверить ответ сервера вы можете с помощью внутренних инструментов поисковых систем: https://webmaster.yandex.ru/tools/server-response/ и https://search.google.com/search-console/. Или с помощью внешних сервисов, например https://bertal.ru/.
Бот не может получить код страницы
Главное для поисковика — наличие исходного HTML-кода, который он сможет прочесть. С развитием JavaScript технологий сайты стали функциональнее и быстрее, однако из-за фреймворков может происходить их некорректная индексация и снижение трафика.
Основная проблема JS-фреймворков в том, что они развиваются быстрее поисковых систем. Особенно это было заметно в Яндексе, где у сайтов на JavaScript часто возникали проблемы с индексированием контента (но есть надежда, что в ближайшем будущем ситуация изменится).
Да и у Google процесс сканирования и индексирования JS-сайтов несколько отличается от обработки классического HTML. В процесс индексирования включается этап «отрисовки» (rendering), увеличивающий время индексирования:
Поскольку рендеринг требует гораздо больше вычислительных ресурсов, чем разбор HTML, то возникают следующие проблемы:
- Этап рендеринга может длиться значительно дольше, чем индексация HTML-страницы. Он может занять несколько недель.
- Не все страницы сайта в принципе могут дойти до этапа рендеринга.
 Он может занять несколько недель.
Он может занять несколько недель.При работе с JS-сайтами учитываете требования поисковиков: https://yandex.ru/support/webmaster/yandex-indexing/rendering.html и https://developers.google.com/search/docs/advanced/javascript/javascript-seo-basics?hl=ru.
Проверить, как индексируется ваш сайт и настроен ли корректно рендринг, вы можете:
Используя сервис https://bertal.ru/ или аналогичный, выставив настройки «отображать HTML-код» и подходящий тип поискового робота:
Анализируя текстовую сохраненную копию страницы в выдаче Яндекса и Google. В случае, если вы наблюдаете проблемы с видимостью страниц на JS-фреймворках, проверьте сохраненную текстовую копию страницы прямо из выдачи:
Анализируя страницы непосредственно в сервисах Яндекса и Google для веб мастеров — Яндекс.Вебмастере и Google Search Console.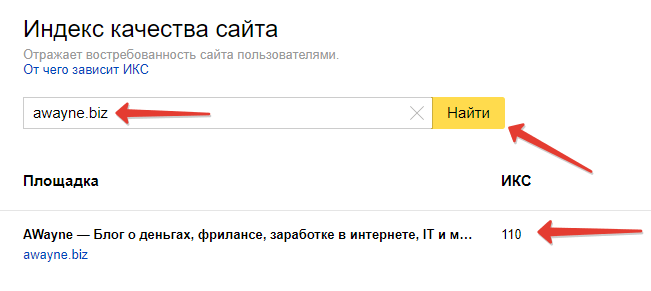 Рекомендуем обращать внимание не только на те страницы, что попали в индекс, но и на те, что не попали. Важно понять, должны ли эти страницы индексироваться и если должны, то по какой причине этого не происходит.
Рекомендуем обращать внимание не только на те страницы, что попали в индекс, но и на те, что не попали. Важно понять, должны ли эти страницы индексироваться и если должны, то по какой причине этого не происходит.
Страницы закрыты метатегом robots или заголовком X-Robots-Tag
Кроме файла robots.txt, поисковик может не получить доступ к конкретной странице, если на ней указан метатег robots, запрещающий её индексацию:
<meta name="robots" content="noindex, nofollow" />
Данный тег размещается внутрь тега…и дает поисковику команду не индексировать страницу (noindex) и не переходить по ее внутренним ссылкам (nofollow).
Аналогом метатега может быть блокировка сканирования страниц с помощью HTTP-заголовка X-Robots-Tag.
Проверить доступность страниц вы можете в инструментах для веб мастеров, например https://webmaster.yandex.ru/tools/server-response/, либо с помощью парсинга сайта программами Screaming Frog SEO Spider, Netpeak Spider и т.
 д.
д.Отметим, что отсутствие вышеперечисленных ошибок не может гарантировать корректного сканирования и индексирования сайта. Негативно могут влиять:
- мусорные страницы — например, страницы результатов сортировок или работы фильтров;
- дубли страниц — один и тот же контент, доступный по разным URL;
- технические/служебные страницы без полезного для пользователей контента;
- дубли страниц в формате PDF и т. д.
Как управлять сканированием и индексацией?
Для того чтобы сайт индексировался корректно, необходимо контролировать, как поиск видит сайт и расходует краулинговый бюджет.
Краулинговый бюджет — это квота страниц сайта, подлежащих индексированию в рамках одного обращения робота к сайту. Например, если краулер вместо целевых и полезных страниц ходит по мусорным документам, то индексация ухудшается, новые страницы не попадают в поиск, а потенциал трафика уменьшается.
Чтобы направлять краулер туда, куда необходимо, важно использовать следующие методы управления индексацией.
Файл robots.txt
Самый простой метод управления индексацией — текстовый файл robots.txt в корневой папке сайта. Как мы уже отметили ранее, поисковые роботы всегда обращаются к содержимому файла для понимания, какие страницы доступны к добавлению в поисковый индекс, а какие нет. Вы можете использовать файл для блокировки тех страниц, которые вы считаете неважными и ненужными к индексированию.
Пример:
Disallow: /folder-you-want-to-block/
Плюсы
- Как правило, легко внедрять корректировки.
- Быстро принимается и учитывается поиском.
- Есть возможность проверки файла с помощью Яндекс.Вебмастера и Google Search Console.
Минусы
- Google может проигнорировать директивы в robots.txt и добавить страницы в индекс. Google считает, что файл robots.txt управляет только сканированием сайта, а не его индексацией.
- Ссылки на страницы, закрытые в robots.txt, расходуют т. н. «статический вес» страниц (PageRank, ВИЦ и подобные алгоритмы).
- С заблокированных страниц не передается вес на другие страницы сайта.

Важный факт. Для Яндекса существует полезная директива «Clean-param», где вы можете указать параметры URL, которые поиск должен игнорировать. Например, результаты сортировки или работы фильтра товаров. Плюс такого решения — передача сигналов ранжирования (например поведенческих метрик) на страницы без параметров, что очень важно для Яндекса.
Метатег robots
Метатег robots позволяет эффективнее блокировать страницы к индексированию. В частности, для Google это более важный сигнал, чем инструкции в файле robots.txt.
<meta name="robots" content="noindex, nofollow" />
Внедрив тег на страницу, вы сможете без участия файла robots.txt заблокировать её индексацию.
Плюсы
- Может эффективнее работать для блокировки страниц в Google, чем robots.txt.
- Хорошо воспринимается поисковыми ботами.
Минусы
- Более трудоемко, чем блокировка в robots. txt, если нужно заблокировать много страниц.
- Применим только для HTML-страниц.
- Ссылочный вес не передается на другие страницы.
 txt, если нужно заблокировать много страниц.
txt, если нужно заблокировать много страниц.При использовании метатега robots обращайте внимание на содержимое robots.txt. Чтобы Google увидел метатег robots на странице, она не должна быть заблокирована в файле robots.txt.
Аналог метатега robots. Вы можете использовать тот или иной метод.
Плюсы
- Может эффективнее работать для блокировки страниц в Google, чем robots.txt.
- Хорошо воспринимается поисковыми ботами.
Минусы
- Более трудоемкая реализация, чем использование файла robots.txt или метатега robots.
На практике X-Robots-Tag применяется реже, чем предыдущие два метода. При этом данный метод отлично работает для документов, отличных от HTML. К примеру, с помощью X-Robots-Tag можно легко блокировать PDF и другие документы, изображения и скрипты, что метатег сделать не может.
Тег и HTTP-заголовок canonical
Метатег, применяемый для указания среди двух или более одинаковых страниц одной канонической, которую поисковик должен проиндексировать и добавить в поиск, при этом другие страницы будут признаны неканоническими и добавляться в индекс не будут. Пример тега:
<link rel="canonical" href="https://www.iseo.ru/blog/" />
По сравнению с другими методами, тег canonical не является блокирующим. Вы можете поменять каноническую страницу или полностью удалить тег.
Плюсы
- Передает сигналы ранжирования (например ссылочные факторы) с неканонических на каноническую страницу. Аналогично 301-му редиректу.
- Позволяет бороться с дублями страниц внутри сайта.
- Может быть использован для указания скопированного контента, если вы размещаете один и тот же контент на нескольких доменах. Но некоторые поисковые системы могут не поддерживать межхостовый canonical.
- Легко обратим, если править теги canonical позволяет ваша CMS.
Минусы
- Тег носит рекомендательный характер. Если страницы заметно различаются, то поисковый бот может сменить каноническую страницу и добавить в индексе не ту копию, что вам нужна.
- Не экономит краулинговый бюджет. Бот реже обходит неканонические URL, но не прекращает это делать.
Чтобы тег canonical работал, страницы-дубли не должны быть закрыты в robots.txt или метатегом robots, в противном случае он будет проигнорирован. Также не следует помещать на одну страницу два или более тегов canonical.
В качестве альтернативы тегу canonical можно использовать HTTP-заголовок. В частности, для указания канонических документов (не HTML-страниц). Пример:
Link: <http://www.iseo.ru/downloads/some-file.pdf>; rel="canonical"
HTTP-код ответа сервера, отличный от 200
Альтернативным решением по исключению страниц из индекса является настройка HTTP-кодов ответа сервера отличных от 200.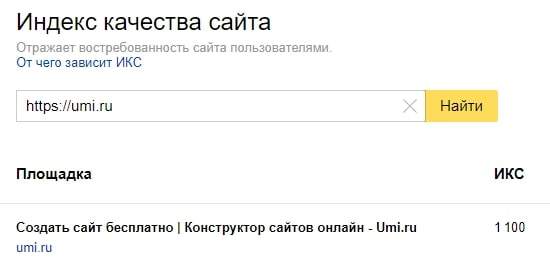
К примеру, у вас большое количество мусорных страниц или страниц дублей, созданных по ошибке. Они не имеют ни трафика, ни ссылок. Для таких страниц можно настроить код ответа сервера 404 или 410.
Или же на сайте были созданы две похожих по интенту страницы, мешающих друг другу ранжироваться. В таком случае для сохранения ссылочного веса и передачи прочих сигналов ранжирования (например поведенческих факторов) вы можете использовать 301-ый редирект. Таким образом, одна из страниц со временем будет удалена из выдачи.
Частный случай этого метода — закрытие доступа к сайту, папке или странице/файлу с помощью пароля. При этом боты будут получать код ответа 403. Например, таким образом можно закрыть от индексации новую версию сайта на тестовом домене.
Плюсы
- Высокая эффективность. В отличии от метатегов и директив в robots.txt, код ответа сервера воспринимается ботом всегда, а значит, вы наверняка сможете предотвратить появление лишних страниц в индексе.
- Возможность сохранить внешние ссылки при использовании 301-х редиректов.
- Высокая скорость индексирования изменений. В отличии от индексации тегов, поисковые роботы, как правило, очень быстро принимают и учитывают новый код ответа сервера.

Минусы
- Потеря веса внешних ссылок в случае настройки 5ХХ или 4ХХ ответов сервера.
- Долгая обратимость. В случае, если вы ошибетесь при настройке, возврат 200-го кода ответа сервера может не гарантировать возврат страницы на старые позиции, а значит, может быть потерян трафик.
Удаление страниц в Яндекс.Вебмастере и Google Search Console
Для ускорения удаления страниц из поиска вы можете воспользоваться инструментами Яндекса и Google для веб мастеров:
- Для Яндекса — https://webmaster.yandex.ru/site/tools/del-url/
- Для Google — https://search.google.com/search-console/removals
Плюсы
- Высокая оперативность. К примеру, из Google страницы удаляются в течение двух дней.
Минусы
- Страницы блокируются от индексации не навсегда. Блокировка возникает на 6 месяцев для Google или на время присутствия запрещающих директив или кодов 403/404/410 для Яндекса.
- Есть разница в работе функционала. Для Google страница должна быть доступна для сканирования. При коде ответа 404, 502 или 503 блокировка отключается, а это значит, что если страница позже появится с кодом 200, то она может быть снова добавлена в поиск. Для Яндекса же наоборот, удаление может коснуться только тех страниц, что заблокированы в robots.txt или имеют код ответа 403, 404 или 410. Если страница отдает код 200 и открыта в robots.txt, запрос будет отклонен.
- Возможен расход краулингового бюджета на переобход заблокированных страниц.
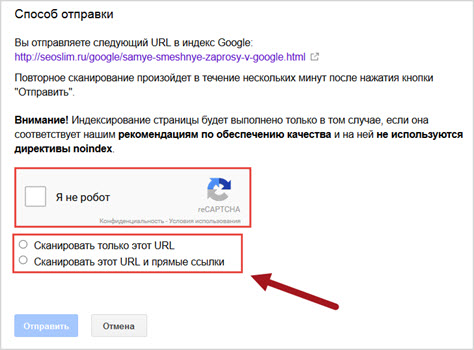
Как отправлять страницы на индексацию/переиндексацию?
Можно не только удалять мусорные страницы, но и ускорять индексацию приоритетных. Воспользуйтесь Яндекс.Вебмастером и Google Search Console, чтобы сообщить поиску о новых страницах на вашем сайте или о появлении новых.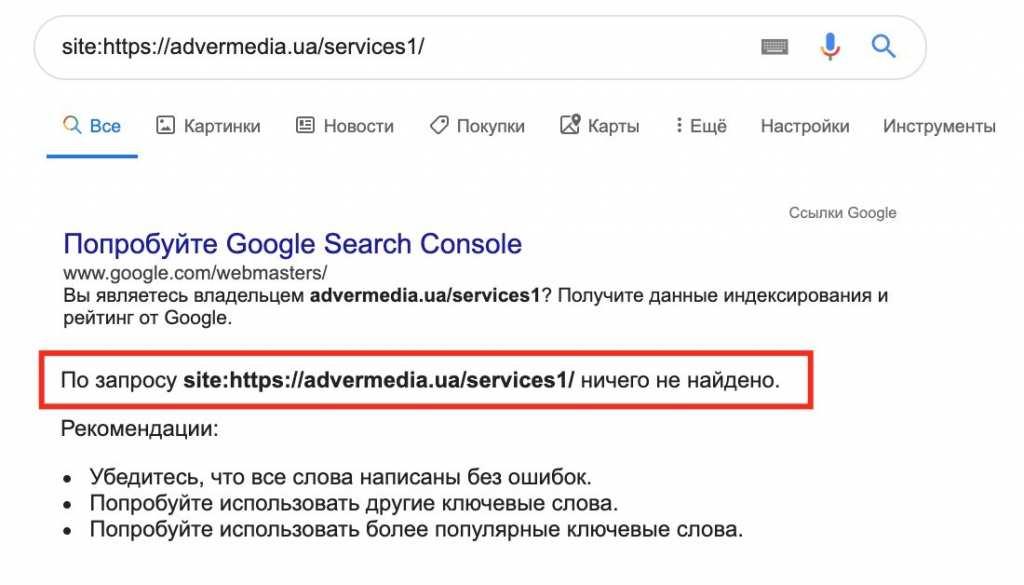
Для Яндекса — https://webmaster.yandex.ru/site/indexing/reindex/.
Добавьте URL в список страниц и отправьте его на переобход. Обратите внимание: для каждого сайта предусмотрен свой дневной лимит.
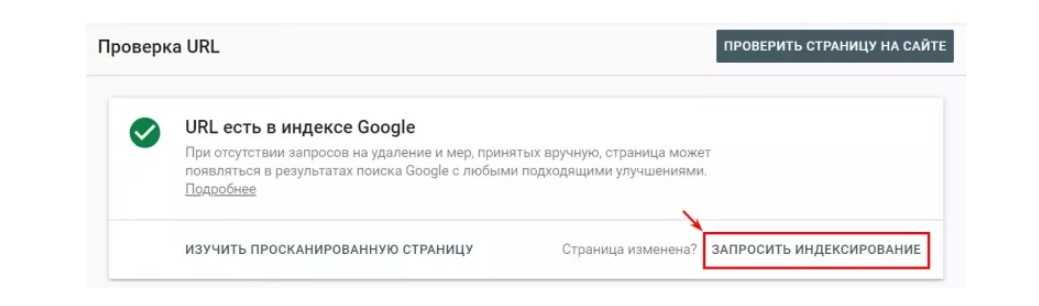
Для Google — https://search.google.com/u/3/search-console/inspect.
Добавьте адрес страницы в строку и запросите индексирование:
Используя данные инструменты, вы сможете:
- Оперативно уведомлять поисковые системы о появлении новых страниц, не дожидаясь обхода краулера.
- Сообщать ботам об изменениях на странице с целью ускоренной переиндексации контента.
Как улучшить сканирование и индексацию?
Добавление вручную страниц в консолях веб мастеров — хорошее решение для небольших сайтов. Но если у вас крупный сайт, лучше довериться поисковым роботам и упростить им работу за счет следующих решений.
Используйте XML-карту сайта
XML-карта сайта — это файл со ссылками на все страницы, которые необходимо индексировать поисковым системам.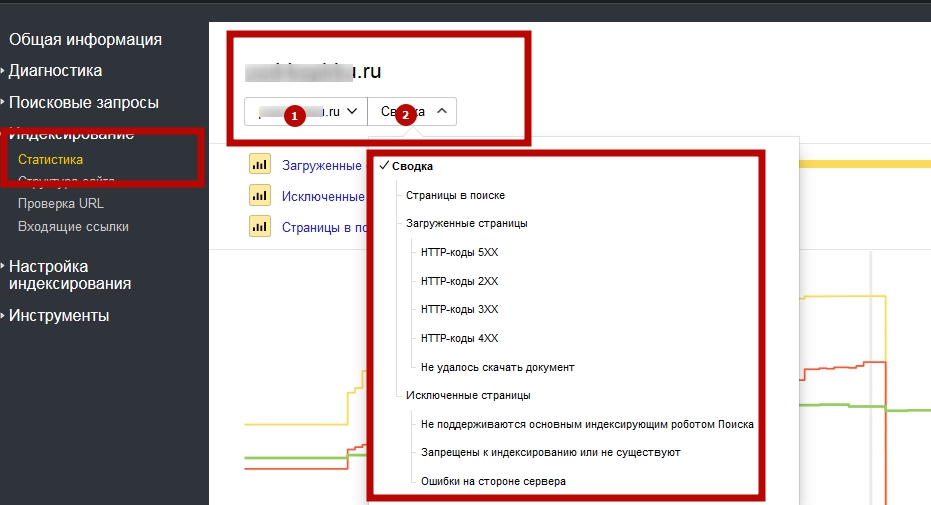
Поисковые системы разрабатывают алгоритмы, по которым краулеры узнают о сайтах и новых страницах, к примеру, переходя по внутренним и внешним ссылкам. Но иногда боты могут пропустить какие-то страницы, или же на целевые страницы мало или нет ссылок. XML-карта решает такие проблемы, отдавая полный список URL, доступных к индексации.
Рекомендации по использованию файлов XML-карт сайта:
- Не размещайте ссылки на закрытые от индексирования страницы.
- Не размещайте ссылки на страницы с кодом ответа сервера, отличным от 200.
- Используйте кодировку UTF-8.
- Не размещайте более 50 000 ссылок в одном файле. Если страниц больше, используйте индексный файл.
- Файл с XML-картой должен отдавать код 200 и быть доступным к обходу в robots.txt.
- Укажите ссылку на XML-карту сайта в robots.txt. Либо добавьте ссылку на XML-карту в инструменты для вебмастеров Яндекса и Google.
После создания файла sitemap.xml следует отправить его на индексацию в Яндекс. Вебмастер и Google Search Console.
Вебмастер и Google Search Console.
Оптимизируйте перелинковку
Внутренние ссылки — это главная артерия любого сайта. Именно по гиперссылкам переходят краулеры поисковых систем, оценивая ссылочный вес и релевантность страниц, а пользователи совершают внутренние переходы, улучшая поведенческие показатели. Далее приведем несколько примеров перелинковки.
HTML-карта сайта
Это аналог sitemap.xml, но с некоторыми отличиями:
- В HTML-карте не всегда выводят ссылки на все страницы. Иногда только на самые важные. Например, если у вас большой интернет-магазин, то имеет смысл вывести ссылки на основные листинги товаров (категории, подборки и т. п.), но не на страницы товаров.
- В отличие от XML-карты сайта, HTML-карта передает по ссылкам сигналы ранжирования (PagRank и т. п.). Также учитываются анкоры ссылок.
- Сокращается вложенность страниц. Все страницы, на которые ссылается карта сайта, становятся доступны в два клика от главной страницы.
Пример небольшой карты сайта: https://www.iseo.ru/sitemap/.
Хлебные крошки
Навигационная цепочка, показывающая путь в структуре сайта от главной страницы к текущей. Пример со страницы https://shop.mts.ru/product/smartfon-apple-iphone-12-pro-max-256gb-tikhookeanskij-sinij:
Хлебные крошки решают следующие задачи:
- Передают статический вес страницам более высокого уровня.
- Улучшают юзабилити за счет понятного расположения страницы в иерархической структуре сайта.
- Могут быть размечены с помощью Schema.org и улучшить сниппет.
Ссылки на похожие товары или статьи
Блок перелинковки похожего контента — один из вариантов ускорения индексирования новых карточек товаров, статей и новостей.
Пример блока: https://www.iseo.ru/clients/internet-magazin-mts/
Чаще всего данный блок работает автоматически. В контенте уже добавленных в индекс страниц выводятся ссылки на новые страницы. На это обращает внимание краулер и совершает их обход.
На это обращает внимание краулер и совершает их обход.
Ссылки с главной страницы
Как правило, главная страница обладает самым большим статическим весом по мнению поиска, так как чаще всего на нее ведет самое большое количество ссылок. Поэтому внедрение элементов перелинковки на главной странице имеет следующие плюсы:
- Высокая ценность таких ссылок. Страницы со ссылками с главной часто ранжируются лучше аналогичных без них.
- Ускорение индексации новых страниц.
Рекомендуем вам пользоваться главной страницей по максимуму при построении схем перелинковки.
Внедрите поддержку IndexNow и Google Indexing API
Кроме классических решений по ускорению индексации, вы можете подключить дополнительные протоколы типа IndexNow для Яндекса или Google Indexing API.
С их помощью вы можете не дожидаться, пока бот обнаружит все ваши страницы с помощью sitemap.xml или внутренней перелинковки. Вы сами можете уведомлять поисковики об обновлении, создании новых или удалении старых страниц.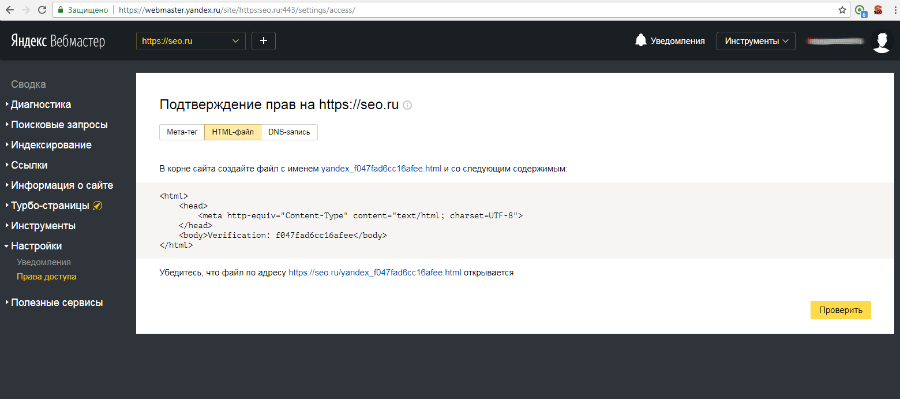 Причем делать это тысячами, не расходуя лимиты и время. Однако внедрение поддержки этих протоколов, скорее всего, потребует дополнительной разработки на стороне вашего сайта.
Причем делать это тысячами, не расходуя лимиты и время. Однако внедрение поддержки этих протоколов, скорее всего, потребует дополнительной разработки на стороне вашего сайта.
Подробнее о технологиях:
- Справка Яндекса по IndexNow — https://yandex.ru/support/webmaster/indexing-options/index-now.html
- Протокол IndexNow — https://www.indexnow.org/locale/ru_ru/index
- Справка по Google Indexing API — https://developers.google.com/search/apis/indexing-api/v3/using-api?hl=ru
Еще одним решением по ускорению индексации являются соцсети.
Делитесь свежим контентом с пользователями в социальных сетях. Такие ссылки поисковики замечают быстрее, а значит, и контент будет проиндексирован раньше. Бонусом здесь выступает трафик, который вы можете получить из социальных сетей.
Выводы
Индексация — это отправная точка для органического трафика и продаж любого сайта. Если вы знаете, что у вас есть проблемы с индексированием, то исправляйте ошибки очень аккуратно и перепроверьте трижды результаты ваших решений.
А если вам нужна помощь экспертов, обращайтесь в нашу компанию за SEO-аудитом или поисковым продвижением вашего сайта.
Денис Яковенко
Руководитель группы SEO-специалистов
что это такое, как рассчитывается, как повысить
Яндекс всё больше старается заботиться о пользовательском опыте. Логично, что сайты, которые выше всего находятся в выдаче, должны нравиться многим пользователям и удовлетворять их нужды. Именно для того, чтобы это оценивать, и ввели индекс качества.
В статье расскажем, что такое ИКС и на что он влияет? Как считают показатель? Какой уровень считается хорошим? Какой максимальный индекс может быть у сайта?
А в конце дадим несколько советов о том, как поднять ИКС сайта в Яндексе.
Что такое ИКС сайта в Яндексе?
ИКС расшифровывается как индекс качества сайта. Яндекс оценивает, насколько ваш ресурс полезен и интересен для аудитории. Чем больше людей могут найти у вас то, что им нужно — тем более высокий показатель у вас будет.
Если у сайта есть зеркало или поддомен, ИКС для них будет такой же, как и для главного ресурса. Но только если доменные имена зеркал одинаковые. Если разные — индекс качества может отличаться.
ИКС — это фишка, которую сейчас использует только Яндекс. Раньше у Google тоже был подобный показатель — Page Rank (PR). Но в 2016 году его просто отменили.
Индекс качества Яндекс ввёл не так давно — в 2018 году. До этого его место занимал ТИЦ — тематический индекс цитирования. Он использовался почти 20 лет (с 1999 года), и на его уровень влияли только внешние ссылки. То есть качество сайта определяли по тому, какие ресурсы на него ссылаются. Этим показателем было довольно легко манипулировать: достаточно закупить побольше ссылок — и вот уровень ТИЦ вырос.
Сейчас ситуация в SEO изменилась, и Яндекс стал больше ориентироваться на удобство сайтов для аудитории. Поэтому и показатель качества пришло время поменять. Да и сами ссылки сейчас уже не так сильно влияют на место сайта в выдаче, как это было несколько лет назад.
Да и сами ссылки сейчас уже не так сильно влияют на место сайта в выдаче, как это было несколько лет назад.
Что учитывают при расчёте индекса качества?
Для расчёта Яндекс берёт информацию из своих сервисов. В первую очередь это, конечно, Метрика и поиск. Но важны также Карты, Дзен, Маркет и другие ресурсы. В справке написано, что при расчёте ИКС играет роль:
- Посещаемость ресурса
- Степень удовлетворённости аудитории
- Уровень доверия людей и самого Яндекса к сайту
- Другие критерии
То есть все показатели, которые влияют на ИКС, Яндекс до конца не раскрывает. А ещё предупреждает, что в любой момент может изменить алгоритм расчёта и не предупреждать об этом пользователей.
В любых ситуациях, когда система не раскрывает алгоритмы расчёта какого-то показателя, специалисты пытаются вычислить их сами. С ИКС то же самое. Считается, что помимо тех критериев, что даёт Яндекс, на него влияют ещё:
- Количество проиндексированных страниц
- Возраст сайта
- Количество брендовых запросов
- Присутствие в социальных сетях (оцениваются группы и аккаунты в соцсетях, ссылки на которые есть на сайте)
- Возврат к результатам поиска
- Количество полезной информации о сайте на сервисах Яндекса
- Внешние ссылки (как и в ТИЦ, но теперь они играют гораздо меньшую роль)
ИКС постоянно пересчитывают.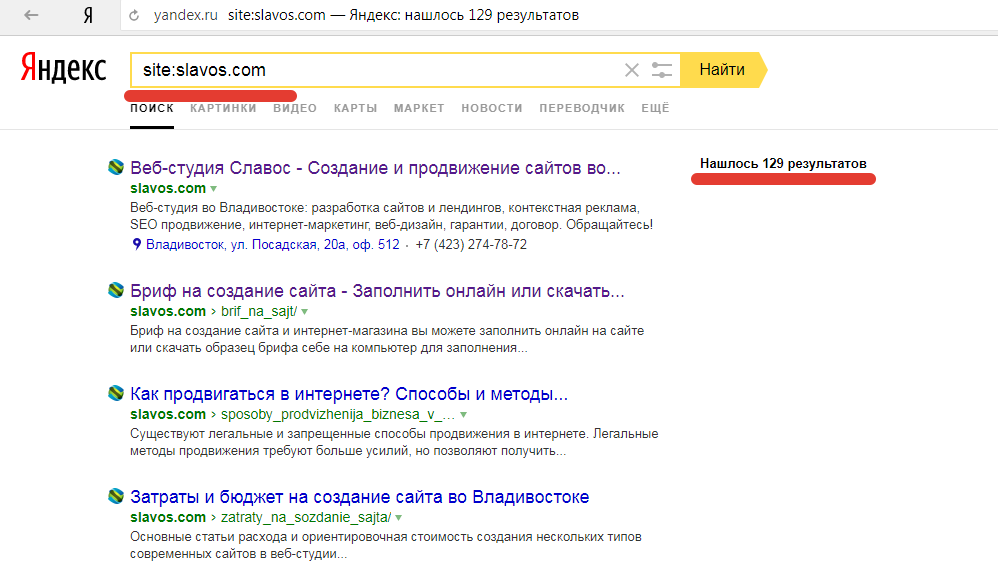 Обычно это происходит раз в месяц. Но иногда Яндекс вносит какие-то изменения в алгоритм расчёта индекса качества сайта. Показатели в таком случае могут изменяться чаще. Чтобы не пропустить момент, когда ИКС для вашего сайта обновится, можно настроить уведомления.
Обычно это происходит раз в месяц. Но иногда Яндекс вносит какие-то изменения в алгоритм расчёта индекса качества сайта. Показатели в таком случае могут изменяться чаще. Чтобы не пропустить момент, когда ИКС для вашего сайта обновится, можно настроить уведомления.
На что влияет индекс качества сайта?
Важно понимать, что индекс напрямую не влияет на место сайта в выдаче. Точнее влияет, но не только он один.
На первом месте в выдаче необязательно будет сайт с самым высоким ИКС. Но при этом у всех сайтов из ТОП-10, индекс обычно достаточно высокий. Но это не значит, что в ТОП их вывел именно он. Чем дальше от первой страницы выдачи мы уходим, тем ниже в среднем будет показатель.
За два года, которые существует ИКС, проводилось уже много исследований. Все они пытались понять взаимосвязь индекса и результатов выдачи. И все они приходят к одному: величина ИКС почти никак не соотносится с базовыми факторами, которые влияют на ранжирование сайта.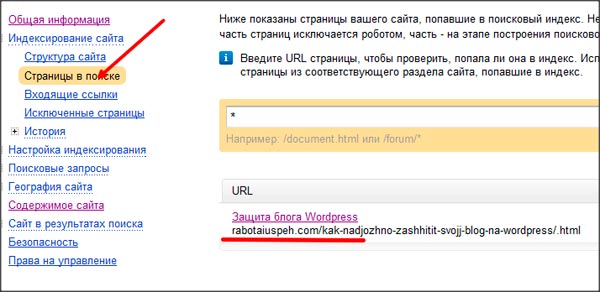
Зачем же тогда вообще думать об ИКС? Раз никакой особой роли он не играет. Индекс помогает быстро сравнить ваш ресурс с конкурентами. А если ваш индекс выше, его можно разместить в футере сайта. Это даёт небольшое, но всё-таки преимущество для вашей репутации. Чтобы сделать ваш индекс видимым для пользователей, нужно зайти в настройки Вебмастера, выбрать “Иконка ИКС”, скопировать сформированный код и добавить его на сайт.
А если вы вдруг решите продавать домен, индекс качества будет одним из самых важных показателей, по которому оценивается качество ресурса. Если смотреть на него в совокупности с другими SEO-метриками, можно увидеть нестыковки, которые чаще всего говорят о накрутках или санкциях со стороны поисковиков. Если данные в Яндекс.Метрике (отказы, глубина просмотра, посещаемость и т.д.) нормальные, но при этом ИКС подозрительно низкий, это повод более внимательно изучить изнанку. То же самое и наоборот.
Как узнать индекс качества сайта для конкретного ресурса?
Сделать это можно через Вебмастер. Нужно зайти в раздел “Качество сайта”, а потом найти “Показатели качества”.
Нужно зайти в раздел “Качество сайта”, а потом найти “Показатели качества”.
Чтобы проверить ИКС сайта в Яндексе у чужого ресурса, нажимаем на три точки рядом со ссылкой в поисковой выдаче и из выпадающего списка выбираем “Информация о сайте”. Так Вебмастер покажет данные о любом ресурсе, даже если вы не его владелец. Индекс нельзя посмотреть только у сервисов самого Яндекса.
Есть и другие сервисы, с помощью которых можно проверить индекс качества сайта в Яндексе. Например, в бесплатной версии PR-CY, помимо других SEO-показателей, видно в том числе и ИКС.
Вообще за индексом можно следить с помощью многих платных сервисов для SEO-аудита. Например:
- Пиксель Тулс (от 950 руб/мес)
- SE Ranking (от 350 руб/мес)
- SEO Reports (от 880 руб/мес)
Индекс качества сайта в Яндексе: какой должен быть?
Показатель ИКС всегда кратен 10.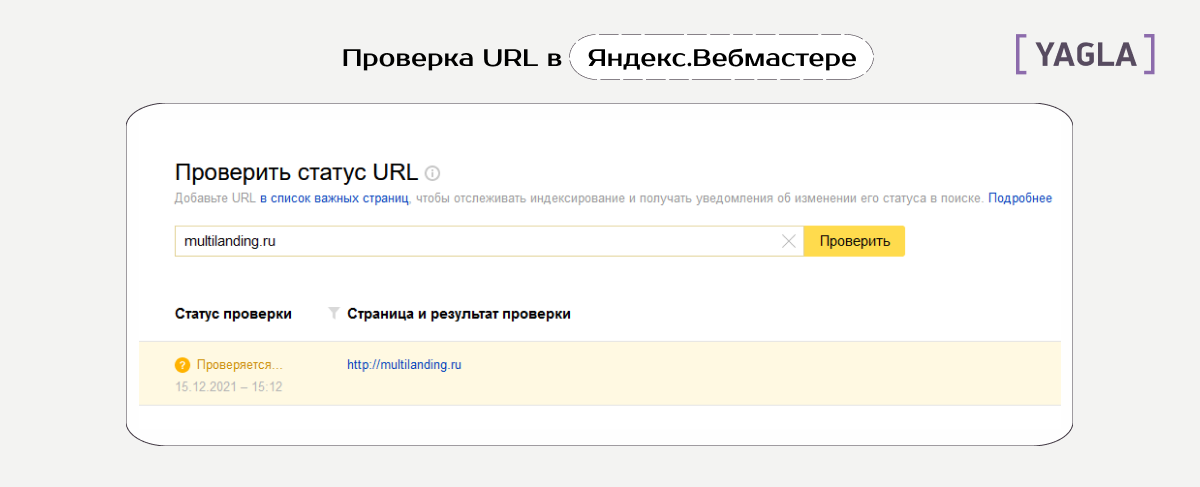 То есть он не может быть 275 или 1526. Только 270 или 1530. Максимальное значение индекса качества сайта не ограничено. Пока что рекорд принадлежит YouTube — 342 000.
То есть он не может быть 275 или 1526. Только 270 или 1530. Максимальное значение индекса качества сайта не ограничено. Пока что рекорд принадлежит YouTube — 342 000.
Индекс всегда зависит от сферы, в которой вы работаете. То есть сайту компании-установщика окон в Воронеже нет смысла сравнивать себя с условной Википедией.
- Индекс от 0 до 100 считается довольно низким. Но если сайт молодой или это просто небольшой коммерческий ресурс, то показатель 60-100 может быть вполне нормальным.
- Показатели ИКС в Яндексе от 100 до 10 000 — это хороший уровень, который говорит о том, что сайт полезный и посещаемый.
- ИКС больше 10 000 обычно получают только крупные ресурсы: большие маркетплейсы, СМИ или соцсети. Например, значения ИКС в Яндексе для google.com — 135 000, а у Ozon — 62 000.
Почему ИКС может снижаться?
Как мы уже выяснили, больше всего ИКС в Яндексе зависит от объёма трафика (особенно, поискового).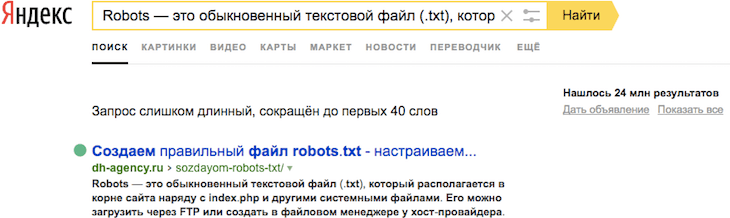 А значит, если вы в последнее время удаляли или скрывали с сайта какие-то страницы, которые притягивали на ваш ресурс большое количество трафика, возможно дело в этом.
А значит, если вы в последнее время удаляли или скрывали с сайта какие-то страницы, которые притягивали на ваш ресурс большое количество трафика, возможно дело в этом.
Ещё вариант — Яндекс просто изменил алгоритм расчёта индекса, и по новым показателям ваш ресурс стал выглядеть для системы чуть хуже. Что именно не так, точно узнать не получится. Поэтому вариант всегда один — делать сайт всё лучше и лучше для пользователей.
Если Вебмастер пишет, что у него нет данных об ИКС вашего сайта, это может значить, что:
- Вы сделали опечатку в адресе ресурса
- Ваш сайт не ранжируется в поиске
- Сайт ещё слишком новый, и Яндекс не успел посчитать для него индекс
Как повысить индекс качества сайта (ИКС)?
Как повысить показатель, если он ниже, чем вам бы хотелось?
- Делайте ставку на качественный, уникальный и читабельный контент. Он поможет привлечь на ваш ресурс больше заинтересованного трафика. Можно добавлять дополнительные фишки, которые повышают полезность страницы: инфографику, онлайн-калькуляторы, шаблоны, тесты и т.д.
- Добавьте свой ресурс в Яндекс.Справочник. Тогда он появится сразу и на Картах, и в Поиске (организация будет отображаться сбоку от результатов выдачи)
- Добавьте социальные сети. Если у вас есть аккаунты или группы, разместите ссылки на них на сайте
- Используйте внутреннюю перелинковку. То есть размещайте на своём ресурсе больше ссылок, которые ведут на другие страницы сайта. Например, в конце информационной статьи можно порекомендовать пользователю почитать что-то ещё
- Соревнуйтесь с конкурентами. Если у вас на сайте будет видео, а у них нет, есть шанс, что пользователям больше понравитесь вы
- Размещайте внешние ссылки. Да, ссылки для ИКС гораздо менее важны, чем для его предшественника, тИЦ. Но наращивание ссылочного профиля всё равно имеет значение. Просто закупать ссылки в 2021 году уже не имеет смысла. Гораздо лучше работает, например, гостевой постинг. Вы размещаете контент на других авторитетных ресурсах, где есть ваша аудитория. И трафик получаете, и плюсик в карму (то есть в ИКС)
- Повышайте кликабельность ресурса. Для этого нужно заполнить title и description вашего сайта. Если пользователь видит заголовок, который прямо отвечает на его вопрос, то с большей вероятностью кликнет на него
 Можно добавлять дополнительные фишки, которые повышают полезность страницы: инфографику, онлайн-калькуляторы, шаблоны, тесты и т.д.
Можно добавлять дополнительные фишки, которые повышают полезность страницы: инфографику, онлайн-калькуляторы, шаблоны, тесты и т.д. Гораздо лучше работает, например, гостевой постинг. Вы размещаете контент на других авторитетных ресурсах, где есть ваша аудитория. И трафик получаете, и плюсик в карму (то есть в ИКС)
Гораздо лучше работает, например, гостевой постинг. Вы размещаете контент на других авторитетных ресурсах, где есть ваша аудитория. И трафик получаете, и плюсик в карму (то есть в ИКС)
Поднять ИКС с помощью покупки платного трафика не получится. Это был бы слишком лёгкий путь: кто потратил больший бюджет на рекламу, у того индекс качества лучше. Но нет, всё не так просто. Владельцам сайтов важно больше сосредоточиться на привлечении органического трафика: переходов из социальных сетей, поиска и других ресурсов.
С накруткой ИКС тоже лучше не экспериментировать. Да, это может дать какой-то кратковременный эффект. Но зачем он вам, если в итоге сайт может попасть под санкции? Тогда около года вы вообще не будете получать никакого трафика из поиска.
А что в итоге?
Казалось бы, если ИКС — это показатель, который оценивает качество вашего сайта, на него и стоит ориентироваться при оптимизации. Но далеко не он один играет роль. Индекс качества — это, скорее, следствие всех ваших усилий по продвижению и оптимизации сайта.
Если вы будете делать ваш ресурс удобным для пользователей, создавать полезный и интересный контент, привлекать на сайт органический трафик — ИКС также будет расти.
Как удалить сайт из поиска «Яндекс» и Google
Для удаления страницы из индекса можно использовать разные методы, и все они заметно различаются по принципу действия. Какой из них выбрать в вашем случае и как не навредить сайту, пытаясь удалить страницу из SERP? Узнаем сегодня.
Зачем удалять страницу из индекса
Удаление страниц из результатов поиска целесообразно проводить в следующих случаях:
- страница содержит устаревший контент;
- страница содержит персональные данные;
- страница с дублированным контентом;
- страница с неуникальным контентом;
- удаление технических / служебных страниц;
- страницы с ограниченным доступом.

Хостинг: как выбрать и на какие технические возможности обратить внимание
Крайне редко владельцам бизнеса удается самостоятельно выявить эти ошибки и принять меры по их устранению. Если вы не уверены, что ваш сайт работает идеально, – обратитесь аудитом и внутренней оптимизацией ресурса к «Текстерре». Выявим и устраним ошибки, сделаем сайт удобным для поиска, увеличим поисковый трафик и подготовим план дальнейшего продвижения.
Проверяем индексацию страницы
Прежде чем удалять страницу, необходимо проверить, находится ли она в индексе вообще. Отдельно проверяем индексацию в Google и отдельно – в «Яндекс». Начнем с первого.
Запускаем инструмент Index Coverage Report.
Откроется Google Search Console. Мы должны выбрать домен, на котором размещается проверяемая страница:
Вводим полный адрес интересующей веб-страницы и нажимаем Enter:
Если проблемная веб-страница уже «выпала» из индекса Google, вы получите такое сообщение:
Это значит, что проблемная веб-страница в настоящий момент не может присутствовать в поиске.
Как увеличить конверсию рекламных кампаний: боремся с низким CTR и отказами
Еще один способ проверить индексацию любой веб-страницы в Google (и, кстати, в «Яндексе» тоже) – ввести ее полный URL в поисковую строку:
Да, так просто. Если искомая веб-страница уже проиндексирована, вы увидите соответствующий результат:
Пример проиндексированной веб-странице в SERP Google
Пример проиндексированной страницы в «Яндексе»
Проверить индексацию любой веб-страницы в «Яндексе» можно при помощи инструментов «Яндекс.Вебмастер». Просто открываем его и в разделе «Индексация» выбираем пункт «Проверить статус URL». Можно проверять индексацию только у тех веб-страниц, которые относятся к подтвержденным доменам (у вас должны быть права на сайт, чтобы вы могли «стереть» URL). Если веб-страница находится в индексе отечественного поисковика, вы увидите у нее соответствующий статус:
Почему не стоит проверять индексацию оператором site:
Проблема оператора site: заключается в том, что показывает не только страницы в индексе, но и URL с перенаправлением или с настроенным каноникал. Если в прошлом сайт был перенесен на другой домен, то через site: вы можете увидеть страницу с абсолютно другим заголовком / описанием.
Если в прошлом сайт был перенесен на другой домен, то через site: вы можете увидеть страницу с абсолютно другим заголовком / описанием.
Шаблон или уникальный дизайн: что выбрать для сайта
Как удалить страницу сайта из поиска Google
Не срочное удаление страницы
Мне нужно удалить контент веб-страницы или всю страницу целиком, но не срочно. Например, контент перестал быть актуальным. Я согласен, если еще какое-то время (пару недель) она продолжит «болтаться» в кэше Google (значит, иногда появляться в SERP).
В вышеуказанном случае можно порекомендовать просто удалить содержимое страницы целиком.
Удаление веб-страницы немного отличается в каждой CMS. Например, в WordPress необходимо открыть страницу в редакторе и выбрать пункт «Удалить в корзину»:
Удаленная страница со временем начнет отдавать ошибку 404. Через несколько дней краулеры Google автоматически исключат такую страницу из индекса.
Страница 404: самые креативные, смешные и лаконичные варианты
Объединение нескольких страниц и указание главной
У меня есть несколько версий одной страницы. Я хочу объединить все эти страницы и перенести их на единый URL. Контент на этих страницах является практически не отличается.
Я хочу объединить все эти страницы и перенести их на единый URL. Контент на этих страницах является практически не отличается.
В таком случае нужно использовать единый каноникал-тег. О том, как указать каноническую страницу – в справке Google.
Учите, что rel canonical указывает на веб-страницу, которая является главной, а не второстепенной.
Здесь следует иметь в виду, что каноникал-тег не является прямой директивой. Соответственно, краулеры могут его игнорировать.
Кстати, кроме тега можно использовать перенаправление (лучше 301-ое) и параметры после URL (параметры следуют сразу после знака «?»). О том, как блокировать обход дублированного контента, содержащего параметры, —в справке Google Search Console.
Каноникализацию можно сделать несколькими способами. Выбирайте тот инструмент, которым владеете лучше.
Срочное удаление страницы из результатов поиска
Мне нужно как можно быстрее удалить страницу из индекса. У меня нет времени возиться с канониклами / ограничением доступа / метатегами. Речь идет о конфиденциальных данных или об исполнении решения суда.
Речь идет о конфиденциальных данных или об исполнении решения суда.
В этом случае нужно использовать «Инструмент удаления URL». Открываем инструмент и выбираем сайт:
Создаем запрос:
Указываем полный URL страницы, которую нужно скрыть:
Что должно быть в вашей CRM: ключевые возможности для бизнеса и сотрудников
Кстати, здесь же можно удалить все URL с текущим префиксом и скрыть кэшированную копию страницы. Подтверждаем запрос:
Инструмент не удаляет страницу из индекса в буквальном смысле, а лишь убирает ее оттуда на 6 месяцев, после чего вы должны принять финальное решение: удалить все содержимое страницы целиком либо ограничить доступ к странице.
Инструмент действует не мгновенно: скрывает проблемную страницу в течение 24-х часов.
Это самый быстрый способ показать Google, что страница должна быть удалена из результатов поиска.
Страницу нужно удалить из поиска, но она должна быть доступной
Мне нужно удалить всю страницу из индекса, но после этого она должна быть доступна определенным посетителям сайта.
В этом случае нужно использовать ограничение доступа к странице. Сервисов и инструментов для этого много, но чаще всего используется ограничение по IP или организация доступа к странице по паролю. Здесь, опять же, сложно советовать что-то конкретное, так как ваши конечные цели сложно предугадать. По сложности внедрения оба способа примерно одинаковые.
Ограничение доступа по IP или вход по паролю – отличный сценарий для тестовых этапов разработки сайта (например, при внедрении нового функционала) или для внутренних сетей. Страницы с ограниченным доступом никогда не попадут в индекс «Яндекс» и Google.
Ограничить доступ к определенной странице можно при помощи учетных записей на сайте, но это трудоемкий способ.
Ограничить доступ к странице всем пользователям и сохранить его для некоторых посетителей можно при помощи мета-тега robots. Для этого необходимо добавить в него директиву noindex. На практике выглядит такой тег следующим образом:
При помощи директивы noindex в robots вы даете понять краулеру: выбранная страница не должна находиться в SERP.
Удаление изображения из результатов поиска
Мне нужно удалить картинку из результатов поиска / «Google Картинок»
Здесь я рекомендую использовать атрибут disallow, который нужно указать в robots.txt. Никаких сложностей с этим точно не возникнет.
Как запустить вирусную видеорекламу: 7 составляющих вирального ролика
Вы можете ограничить обход как одной, так и сразу всех картинок. Все, что нужно для этого, – знать имя краулера. Это Googlebot – Image.
Например, мы хотим удалить картинку, значит, прописываем такой атрибут:
Удаление ссылки на страницу с контентом, защищенным копирайтом
Я хочу удалить материалы, нарушающие мои или чужие авторские права
Вам необходимо создать заявление в специальном инструменте для вебмастеров Google (называется DMCA).
Выбираем пункт «Создать новое заявление» и заполняем всю контактную информацию:
Указываем персональные данные, электронную почту, название компании и страну проживания:
Заполняем контактную информацию
«Подписываем» заявление
Как видим, потребуется описать произведение, защищенное копирайтом, и указать ссылку, где оно размещается легально. Потребуется указать и точное расположение материалов (в виде ссылки), ущемляющих ваши авторские права:
Потребуется указать и точное расположение материалов (в виде ссылки), ущемляющих ваши авторские права:
Не забываем отметить чекбоксы и дать согласие на то, что эта форма заполняется «под присягой»:
Составление семантического ядра: 5 типичных ошибок
Удаление ссылки на страницу, содержащую персональные данные
Я хочу удалить персональные данные, которые появились на определенном сайте в интернете.
Для этого используйте инструмент «Удаления конфиденциальности». Он создан специально для ЕС, но мне известны как минимум 2 случая, когда он помогал удалить персональные данные и граждан РФ.
Понадобится заполнить страну проживания, фамилию и имя, электронную почту. Можно отправить запрос от имени родственника / члена семьи / друга / клиента. В этом случае понадобится указать степень родства (если речь идет о родственнике):
Далее указываем ссылки на действующие веб-страницы, содержащие ваши персональные данные:
Указываем поисковую фразу (в этом случае – имя и фамилия), по которой в результатах поиска выводятся ссылки на веб-страницы, содержащие персональные данные (ваши или доверенного лица):
Читаем соглашение Google о ПДн, отмечаем чекбоксы и подписываем документ:
Как удалить / стереть страницу из результатов поиска «Яндекс»
Теперь о том, что предлагает «Яндекс» для удаления URL из поиска.
Для эффективного удаления URL навсегда отечественный поисковик советует использовать уже знакомую директиву disallow. Ее следует указывать прямо robots-файле.
Второй способ. На удаляемой странице нужно прописать метатег robots (не забываем про директиву noindex).
Взламываем «Яндекс» с помощью тега noindex: что это, зачем и как использовать
Здесь стоит отметить, что бот-краулер отечественного поисковика первым делом анализирует именно robots-файл и только потом начинает сканировать саму веб-страницу. Убедитесь, что robots.txt содержит корректные указания. Для этого вы можете использовать специальный инструмент:
Еще один вариант – настроить HTTР-статус (он должен быть настроен у самой удаляемой веб-страницы). В последнем случае вы должны настроить точное перенаправление (404-ый или же 403-ий редирект).
Индексирование в поисковиках: что это такое и как работает
Если вы сделали прямое запрещение на сканирование веб-страницы в системной файле robots, краулеры перестанут сканировать проблемную веб-страницу примерно спустя 24 часа (или быстрее).
Другой сценарий. Вы «сотрете» веб-страницу при помощи robots-тега (или же сразу настроите редирект http-статусом), а краулер продолжит сканирование проблемной веб-страницы (точно сказать нельзя, но в течение нескольких дней). Страница и спустя пару дней остается недоступной и не обновляется? Значит, она будет автоматически удалена из SERP «Яндекса » в ближайшее время.
Как ускорить удаление URL в «Яндексе»
Вы можете повлиять на скорость удаления URL. Первым делом уничтожьте веб-страницу через админку используемой CMS (URL должна отдавать 404-ой код). Вы можете удалить и целую группу URL, если в этом возникает необходимость.
Кстати, «Яндекс» позволяет удалить страницу из поиска даже в том случае, если вы не являетесь владельцем сайта и у вас отсутствуют права на домен (где размещается страница, которую вы хотите удалить) в «Яндекс.Вебмастере». Откройте инструмент и укажите проблемный URL:
Этот инструмент может помочь вам, только если для удаления URL есть какие-либо основания. К ним можно отнести 403-ий / 404-ый / 410-ый коды, прямое ограничение индексирования в robots.txt или запрещение метатегом noindex.
К ним можно отнести 403-ий / 404-ый / 410-ый коды, прямое ограничение индексирования в robots.txt или запрещение метатегом noindex.
Если права на сайт в «Я.В» у вас подтверждены, вы сразу сможете стереть до пятисот URL в сутки.
Это все способы, при помощи которых Вы можете удалить страницу из индекса «Яндекс» и Google. Теперь предлагаю рассмотреть самые распространенные ошибки, которые могут возникнуть при удалении страниц.
Как не надо удалять страницу из поиска
Nofollow – только рекомендация
Использование Nofollow, когда требуется исключить страницу из индекса.
Этот способ вообще не работает, так как nofollow – всего лишь рекомендация для краулера и он, скорее всего, не будет ее соблюдать.
Тег noindex уже не работает
Использование тега noindex для запрещения индексации через robots.txt.
Раньше этот способ частично работал, но еще в 2019 году Google объявил, что отныне noindex в robots.txt не поддерживается.
Каноникал на другой URL
Страница с каноикл-тегом, которая ведет на иной URL.
Каноникал используется для указания главной страницы, требующей индексации. Noindex же говорит краулерам, что страница не должна находиться в индексе. Тут возникает конфликт. Поэтому не используйте страницы с каноникл-тегом, указывающие на другие URL.
Оптимизация сайта под «Яндекс»: топ-9 факторов для интернет-магазинов в 2021 году
Блокировка поисковых роботов в robots.txt
Блокировка краулеров через файл robots.txt.
Так вы лишь рекомендуете краулеру не обходить страницу, но он все равно может ее просканировать по своему усмотрению и даже включить ее в SERP.
Канониклы настраиваем в тех случаях, когда проблемная страница нужна в рамках сайта. Когда не нужна, настраиваем 301-ое / 404-ое перенаправление.
Быстрая индексация страниц в поисковых системах с помощью инструмента URL Submission.
Протестировать инструмент
Вы тратите много ресурсов на обновление и оптимизацию своих страниц, но поисковики неделями «не замечают» изменений?
Если вы работаете с Bing и Яндекс и хотите ускорить индексацию своего сайта, Serpstat URL Submission мгновенно уведомит поисковые системы об обновлениях. Загружайте до 10 000 страниц одновременно и максимально ускорьте индексацию Яндекса и Bing.
Загружайте до 10 000 страниц одновременно и максимально ускорьте индексацию Яндекса и Bing.
Почему сайт не индексируется
Вы обновляете сайт и заметили, что они долго индексируются? Вы постоянно срываете сроки своих проектов из-за медленной индексации? Проблема в том, что поисковые системы довольно редко сканируют каждый URL.
Поэтому обновление сайта в Bing и Яндексе может занять от нескольких дней до нескольких недель.
С помощью инструмента отправки URL от Serpstat вы можете мгновенно сообщать об изменениях в поисковые системы. Затем системы немедленно узнают об изменениях URL-адресов и помещают их в список с наивысшим приоритетом для индексации. Таким образом, вы можете ограничить органическое сканирование для обнаружения нового контента.
Частые проблемы с индексацией сайта
Вы часто сталкиваетесь с проблемами с индексацией сайта? Для этого может быть ряд причин. Проверьте:
Проверьте:
Средство отправки URL-адресов может помочь решить проблемы, связанные с медленным обнаружением сайтов или документов. Это аналог аддурилки, которая позволяет добавлять информацию об обновлениях на сайте, чтобы поисковые системы Яндекс и Bing могли их моментально увидеть.
сайт добавлен в черный список;
поисковая система не нашла сайт или документ;
объект полностью или частично недоступен для робота;
допущена техническая ошибка;
плохое качество отдельных страниц или разделов.
Способы ускорения индексации страниц сайта
Хотите как можно быстрее увидеть результаты обновлений поисковых систем и узнать, как ускорить индексацию страниц?
Использовать отправку URL:
Ваши страницы теперь будут иметь приоритет при сканировании страниц роботом. В ближайшее время обновления страницы будут проиндексированы Яндексом и Bing.
Введите домен;
Добавить список URL-адресов (до 10 000 единиц), которые изменились;
Добавить ключ API Index Now;
Нажмите «Добавить список URL».
Задачи, которые можно решить с помощью отправки URL Serpstat
Ускорение индексации новых и обновленных страниц в поисковых системах Яндекс и Bing
Массовая подача страниц в индексацию — до 10 000 страниц за раз
Стабильный рейтинг сайта в поисковых системах без пауз при индексации
Крупнейшие данные Google SERP и собственный ссылочный индекс:
Ключевые преимущества Serpstat
домены
1,69 В
28,86 М
ключевые слова
базы данных Google
ссылающиеся домены
Не ждите несколько недель, пока поисковый бот проверит ваши страницы. С Serpstat вы можете быстрее проверить свой сайт поисковыми роботами и получить целый набор инструментов продвижения.
Готовы попробовать?
Записаться на консультацию
Увеличьте скорость индексации сайта с помощью инструмента отправки URL
Часто задаваемые вопросы об индексации сайта и инструменте отправки URL
1. Влияет ли хостинг на индексацию страницы сайта?
Качество хостинга является важным фактором скорости индексации сайтов. Рассмотрим некоторые причины, по которым скорость индексации может снижаться из-за медленного хостинга: Показатель работоспособности веб-ресурса в идеале должен иметь значение 99,98%. Если из-за проблем с хостингом время работы вашего сайта ниже, есть вероятность, что сайт может быть недоступен при следующем заходе поискового робота. Поэтому индексация будет производиться только при следующем посещении сайта ботом, а это может быть даже через несколько недель. Рейтинг этого сайта в поисковых системах падает. Для стабильного поддержания и роста ранга рекомендуется использовать платные хостинги:
Для стабильного поддержания и роста ранга рекомендуется использовать платные хостинги:
- Им больше доверяют поисковые системы;
- У них более высокая скорость передачи данных.
Влияние бесплатного/слабого хостинга на индексацию будет наиболее заметно для больших многостраничных сайтов.
2. Сколько времени требуется для индексации новой страницы?
Примерный срок индексации новых страниц и сайтов в Google около 1 недели, в Яндексе 2-3 недели. Bing проиндексирует новую страницу примерно за 2 дня. Важно помнить, что эти цифры являются оценочными, и нет никакой гарантии, что индексация произойдет в эти сроки.
3. Если сайт настроен правильно, как быстро он отображает изменения?
Вы обновляете сайт и хотите сообщить Google о новой странице? Прежде всего, убедитесь, что все настройки верны. О том, как проверить позиции сайта и оценить юзабилити, вы можете узнать из статей на блоге Serpstat.
После проверки добавьте отправку URL в инструмент, а затем:
- Введите домен;
- Добавить ключ API Index Now;
- Добавить список URL-адресов (до 10 000 единиц), которые изменились;
- Нажмите «Добавить список URL».
Обычное время индексации сайтов в Яндексе и Гугле составляет до трех недель, но после использования URL Submission это значительно сократится, так как поисковый бот повысит приоритет проверки вашей страницы.
4. Как проверить, увидел ли Google изменения на странице?
Чтобы проверить, проиндексировал ли Google и распознал ли поисковик изменения на странице, введите в строке поиска следующую команду: site: [адрес страницы]. Таким образом, вы увидите все страницы сайта, которые были проиндексированы. Вы можете проверить дату последнего сканирования сайта ботами поисковых систем. Для этого введите в кэш команд: [адрес проверяемой страницы]. Чтобы проверить индексацию отдельной страницы, введите site: [адрес страницы] в строке поиска. Этот метод проверки будет работать для Google, Yandex или Bing.
Этот метод проверки будет работать для Google, Yandex или Bing.
Проверка индекса Google — инструмент SEO
Получите 100% точные данные об индексации вашего
страницы в гугле и яндексе с космической скоростью
Попробуйте бесплатно
Первые 7 дней бесплатно.
Кредитная карта не нужна!
Основные
функции индексации сайтаFast Indexation Check
- Позволяет проверить индексацию 100 000 страниц за 10 минут
- Космическая скорость для Google и Yandex
Удобные форматы загрузки страниц
- Просто укажите список URL для проверки или загрузки файла Excel – быстро и удобно
- Не хотите собирать список URL? Просто предоставьте ссылку на файл Sitemap. xml, и мы сами получим все URL-адреса, даже если у вас есть несколько вложений Sitemap
- У вас большой сайт, и вам нужно часто проверять его индексацию? Получайте данные в реальном времени через API
 xml, и мы сами получим все URL-адреса, даже если у вас есть несколько вложений Sitemap
xml, и мы сами получим все URL-адреса, даже если у вас есть несколько вложений Sitemap Любое количество страниц
- Большой сайт? Нет проблем — проверим индексацию даже 1 000 000 страниц
- Проверить индексацию в интерфейсе платформы или получить данные через API в вашей системе аналитики
Дополнительные
функции индексирования сайтаУ нас есть экспертные возможности для проверки статуса индекса Google любого сайта в Google
Мощный API
Получайте данные об индексации вашего сайта в режиме реального времени с помощью API
.Учет косой черты «/»
Мы знаем, как проверить индексацию URL-адресов с косой чертой в конце
и без нее.Проверка индексации URL-адресов в верхнем и нижнем регистре
Если на вашем сайте есть URL-адреса как в верхнем, так и в нижнем регистре, у нас есть специальная опция для их проверки
.

Как это работает
Современный рынок требует новых технологий и подходов к решению задач SEO.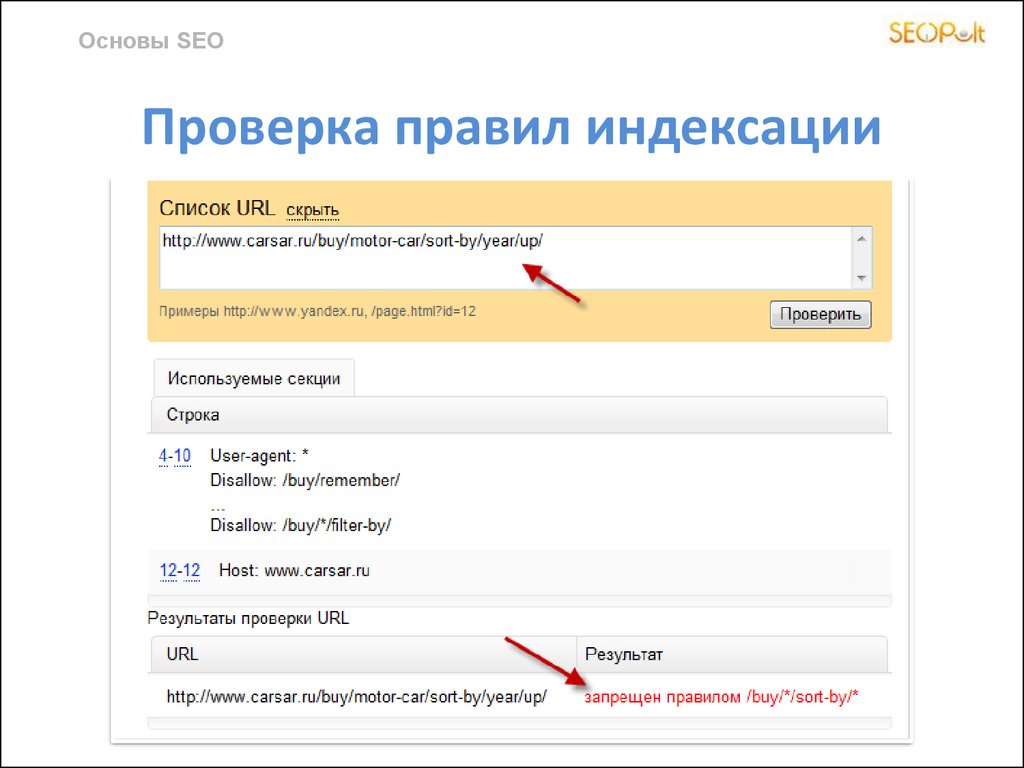
Добавить URL для проверки индексации
Любым способом: перечислите, загрузите файл Excel или предоставьте ссылку на файл Sitemap.xml
Выберите поисковик
Проверяем индексацию в Гугле и Яндексе одинаково быстро и качественно
Получить готовый к использованию отчет об индексации
Через несколько минут вы получите статус каждой страницы, независимо от того, проиндексирована ли она Google или нет
Начните использовать Rush Analytics сегодня
Получите 7-дневный бесплатный пробный доступ ко всем инструментам.
Кредитная карта не нужна!
Попробуйте бесплатно
Что о нас говорят экспертыПопользовавшись Rush Analytics пару месяцев, могу сказать, что это один из лучших трекеров на рынке. Он может очень быстро проверять позиции ключевых слов, даже для 100 000+ ключевых слов. Отличный инструмент для ваших нужд SEO.
Rush Analytics — самый важный инструмент SEO, который я использую.
Мне больше всего нравится трекер рангов и оптимизатор контента, они дают мне реальные данные, которые помогают догнать и обогнать конкурентов.
в соответствии с вашими потребностями
Старт
19 9 долларов США0003
- Количество сайтов
- Количество потоков API
- Гостевой доступ
Подписывайся Подписаться
Pro
49
- долларов США Количество сайтов
- Количество потоков API 1
- Гостевой доступ
Подписывайся Подписаться
Команда
169
- долларов США Количество сайтов
- Количество потоков API 20
- Гостевой доступ
Подписывайся Подписаться
Выберите план подписки
Получите 7-дневный бесплатный пробный доступ ко всем инструментам.

Подберите правильные ключевые слова из предложений Google, YouTube и Яндекса
Попробуйте бесплатно
Дополнительные функцииКаковы самые большие различия между Google и Яндекс SEO?
Вы когда-нибудь слышали о «Яндексе»? Если да, то, возможно, вы уже имели дело или планируете иметь дело с российским интернет-рынком. В то время как Google является доминирующей поисковой системой в мире, Яндекс, безусловно, является крупнейшей поисковой системой в России: более 57% россиян полагаются на нее как на свою основную поисковую систему, и в настоящее время она занимает первое место в рейтинге интернет-компаний в стране.
Хотя большинство фундаментальных принципов продвижения сайтов в Google применимы и к Яндексу, есть несколько ключевых отличий, о которых нужно знать, если ваша целевая аудитория базируется в России и вы планируете освоить Яндекс SEO.
Если сайт не имеет серьезных технических проблем, имеет полезный контент, правильно оптимизирован и имеет естественно растущий портфель обратных ссылок, он обычно хорошо ранжируется как в Яндексе, так и в Google.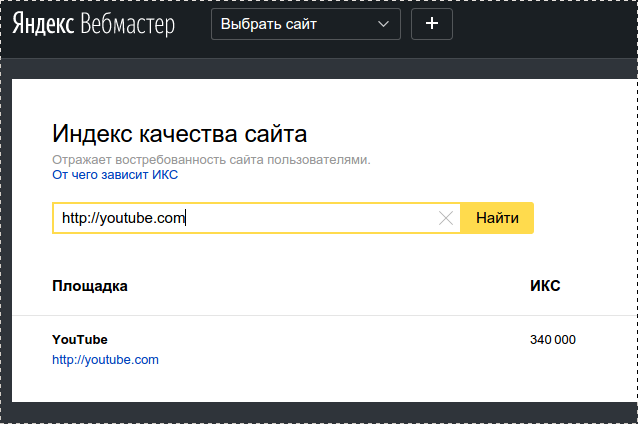 При этом между алгоритмами каждой поисковой системы существуют довольно существенные различия:
При этом между алгоритмами каждой поисковой системы существуют довольно существенные различия:
Продвижение в Яндексе
Одним из основных факторов ранжирования в Яндексе является региональность. В Яндексе локальный поиск играет гораздо большую роль, чем в Google. Таким образом, в основном, если вы находитесь в Сибири и в вашем запросе нет слова местоположения, то будут отображаться наиболее релевантные местные результаты. Google, с другой стороны, придает большее значение популярности источника.
Это означает, что ваш сайт может ранжироваться по-разному в зависимости от местоположения искателя. Это будет зависеть от следующего:
- Как пользователи из разных мест реагируют на ваш контент, т. е. насколько он полезен для них
- Локальный NAP на сайте
- Цитатится ли ваш сайт в справочнике Яндекса и на карте
- Содержит ли ваш сайт название вашего местоположения в доменном имени. Многие российские SEO-специалисты склонны придерживаться стратегии создания нескольких локальных поддоменов, поскольку дублированный контент не является проблемой для Яндекса, в то время как, как мы знаем, это категорически не рекомендуется для Google. Пример: www.domain.kiev.ua/
- Яндекс отдает предпочтение сайтам с локальными IP адресами серверов
- Страна, указанная в вашем TLD, играет роль
- Домен .ru лучше всего подойдет для продвижения в России
 Пример: www.domain.kiev.ua/
Пример: www.domain.kiev.ua/Индексирование
Говорят, что Яндекс индексирует страницы медленнее, чем Google. Однако можно отправить новый сайт на индексацию через свою учетную запись Яндекс Вебмастер. В отличие от Google, Яндекс не позволяет вам загружать свои страницы и заставлять ботов пересканировать их. Боты Яндекса будут повторно сканировать ваши новые страницы со своей скоростью и дадут вам знать, как только это будет сделано в вашей учетной записи веб-мастера.
Имейте в виду: если ваш сайт был проиндексирован одной из двух поисковых систем, это не значит, что он был проиндексирован другой.
Свежий контент — Google
Говорят, что Яндекс меньше заботится о свежести вашего контента и о том, сколько раз он обновлялся в прошлом, в то время как Google положительно относится к сайтам, контент которых регулярно обновляется свежей информацией.
Повышение цитируемости
Повышение цитируемости в хорошо зарекомендовавших себя каталогах, таких как Top100.rambler, Yandex, Yahoo и Yelp, положительно повлияет на ваш рейтинг в обеих поисковых системах (при условии, что у вас есть качественный веб-сайт, не являющийся задействованы в каких-либо манипулятивных схемах).
Качественный контент
Качественный контент продвинет вас далеко вперед в обеих поисковых системах. При этом следите за тем, чтобы не переоптимизировать свой контент, поскольку обе поисковые системы имеют алгоритмы искусственного интеллекта, которые все больше и больше фокусируются на общем значении вашей страницы и используемых синонимах, чтобы представить страницы, которые лучше всего соответствуют намерениям пользователей. а не точное ключевое слово, введенное пользователем в панели поиска.
Объем контента
Объем качественного контента, необходимый для высокого рейтинга в Google, выше, чем у Яндекса. Топ-10 результатов Google обычно содержат много «долго читаемых» фрагментов контента, тогда как в Яндексе вы можете получить хороший рейтинг с гораздо меньшим количеством текста.
Топ-10 результатов Google обычно содержат много «долго читаемых» фрагментов контента, тогда как в Яндексе вы можете получить хороший рейтинг с гораздо меньшим количеством текста.
Behavior Metrics
Яндекс уделяет большое внимание количеству посетителей и тому, сколько времени они проводят на сайте. Чем больше тем лучше. Google меньше заботится об этом. В результате многие российские SEO-специалисты покупали фальшивых посетителей сайта для увеличения этих показателей (эта практика устаревает по мере усложнения алгоритма). Разумеется, такая тактика приведет к штрафам со стороны Яндекса. Метрики, на которые следует обратить внимание: посещения, глубина страницы, показатель отказов, прилипание и время на сайте.
Штрафы
У каждой поисковой системы есть собственный алгоритм наказания веб-сайтов. Говорят, что Минусинск от Яндекса намного строже, чем Пингвин от Google.
Инструменты Яндекса
Сообщается, что Яндекс активно использует данные о каждом сайте из списка инструментов поисковой системы. Поэтому желательно иметь аккаунты на Я.Маркет, Я.Справочник, Я.Каталог, 2ГИС и т.д. Во многих случаях сайт с очень небольшим количеством обратных ссылок может занимать первые места в результатах поиска Яндекса. Этого можно добиться на Яндексе за счет внутренней оптимизации, устранения технических неполадок, обеспечения логичной и удобной навигации по сайту, наполнения всего сайта качественным контентом и т. д.
Поэтому желательно иметь аккаунты на Я.Маркет, Я.Справочник, Я.Каталог, 2ГИС и т.д. Во многих случаях сайт с очень небольшим количеством обратных ссылок может занимать первые места в результатах поиска Яндекса. Этого можно добиться на Яндексе за счет внутренней оптимизации, устранения технических неполадок, обеспечения логичной и удобной навигации по сайту, наполнения всего сайта качественным контентом и т. д.
Ниже приведена таблица, из которой видно, что на 70% сайтов, входящих в топ-10 Яндекса по «ремонту lenovo», очень мало ссылок (сайты с большим количеством ссылок выделены красным):
Яндекс говорит по-русски
Говорят, что Google сложнее интерпретировать запросы на русском языке, чем Яндекс, который более продвинут, когда дело доходит до анализа запросов на русском языке и преодоления языковых препятствий (включая CrazyFont, который является практикой написания на русском языке). слова с использованием латиницы).
Какие поисковые системы индексируют содержимое Javascript?
Это эксперименты, чтобы увидеть, какие поисковые роботы правильно индексируют содержимое Javascript. Мы тестируем Google, Bing (и Yahoo), Yandex и Baidu.
Мы тестируем Google, Bing (и Yahoo), Yandex и Baidu.
Введение
В продолжение наших предыдущих экспериментов и с целью проверки технических концепций нашей платформы персонализации Unless.com, вот результаты серии экспериментов, чтобы увидеть, что будет индексироваться, а что нет, если Javascript используется для вставки контента на вашу страницу.
Летом 2018 года мы тестировали Google, Bing (и Yahoo), Яндекс и Baidu.
Метод эксперимента
Каждый эксперимент состоит из предложения с уникальной строкой, которая вводится Javascript с использованием нескольких различных методов. После индексации поисковыми ботами вы можете использовать эту строку, чтобы проверить, отображаются ли связанные результаты поиска или нет, просто выполнив поисковый запрос в каждой поисковой системе, что подтверждает возможности индексирования Javascript каждой из них.
Мы провели эксперимент несколько недель, и вот результаты. Вы также можете скачать исходный код, чтобы повторить его самостоятельно.
Внедрение до загрузки DOM
Этот эксперимент синхронно записывает строку в элемент DIV с помощью Javascript. Чтобы тест прошел успешно, следующий контент должен быть проиндексирован.
Подсистемы помощи в поиске динамически внедряемого контента, и это доказательство: WrPekZCDMg
Результаты
Гугл
Бинг
Яндекс
Байду
Внедрение после загрузки DOM
После загрузки DOM этот эксперимент записывает строку в элемент DIV с помощью Javascript. Чтобы тест прошел успешно, следующий контент должен быть проиндексирован.
Механизмы справки находят содержимое Javascript, которое вводится после загрузки DOM, и это является доказательством: 0ieQgguBQp
Результаты
Бинг
Яндекс
Байду
Асинхронная инъекция
По истечении времени в 1000 миллисекунд эксперимент записывает строку в элемент DIV. Чтобы тест прошел успешно, следующий контент должен быть проиндексирован.
Чтобы тест прошел успешно, следующий контент должен быть проиндексирован.
Асинхронно внедряемый контент можно найти в результатах поиска, и это доказательство: 7Cw6GVRR7p
Результаты
Бинг
Яндекс
Байду
Внедрение после httpRequest
Этот эксперимент загружает файл JSON, а затем функция обратного вызова вставляет DIV со строкой, используя его данные. Чтобы тест прошел успешно, следующий контент должен быть проиндексирован.
Даже с помощью httpRequest() вы можете получить содержимое. Помогите двигателям найти его. Доказательство: Jgv0PGmZRL
Результаты
Бинг
Яндекс
Байду
Внедрение метаэлементов
Синхронно метаописание было заменено другим, содержащим уникальную строку. Чтобы тест прошел успешно, следующий контент должен быть проиндексирован и отображаться как описание в поисковой выдаче. Сравните уникальную строку. Примечание: следующий эксперимент может отменить этот.
Чтобы тест прошел успешно, следующий контент должен быть проиндексирован и отображаться как описание в поисковой выдаче. Сравните уникальную строку. Примечание: следующий эксперимент может отменить этот.
Индексируют ли поисковые системы метаэлементы, внедренные Javascript? Посмотрите на 5ZW1D7Fmvk для доказательства
Результаты
Бинг
Яндекс
Байду
Внедрение метаэлементов, асинхронное
С помощью функции тайм-аута метаописание было заменено новым, содержащим уникальную строку. Чтобы тест прошел успешно, следующий контент должен быть проиндексирован и отображаться как описание в поисковой выдаче. Сравните уникальную строку. Если этот эксперимент окажется удачным, предыдущий тоже сработает.
Индексируют ли поисковые системы метаэлементы, асинхронно внедряемые Javascript? Посмотрите на GMuPPfM0lw доказательство
.
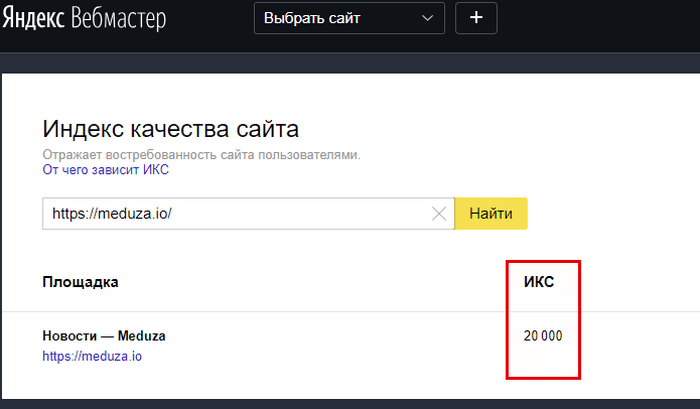
Результаты
Бинг
Яндекс
Байду
Бонус: внедрение варианта Unless
Этот эксперимент загружает вариант Unless, содержащий уникальную строку. Мы предпочитаем, чтобы следующий контент не индексировался — т.к. варианты Unless не должны показываться поисковым ботам. Посмотрим.
Если поисковые системы проиндексируют вариации, вы увидите GFgfT64FKk в поисковой выдаче.
Результаты
Бинг
Яндекс
Байду
Заключение
Google показал лучшие результаты в сканировании и индексировании динамического контента. Весь контент индексируется, будь то синхронный или асинхронный, или через http-запрос, или с задержкой иным образом. Как и ожидалось, вариант Unless не отображается — это сделано специально, поскольку он показывает персонализированный контент людям, а не поисковым системам.
Весь контент индексируется, будь то синхронный или асинхронный, или через http-запрос, или с задержкой иным образом. Как и ожидалось, вариант Unless не отображается — это сделано специально, поскольку он показывает персонализированный контент людям, а не поисковым системам.
Bing
Мы можем быть краткими. Bing (или его младший брат Yahoo) не показывает динамический контент на страницах результатов поисковой системы.
Яндекс
Яндекс неплохо справляется со сканированием и индексированием javascript-текста. Однако он не сможет распознать метаэлементы, такие как заголовок страницы и описание, если вы установите это из скрипта. Как и ожидалось, он не показывает персонализированный контент Unless.
Baidu
Baidu, похоже, не распознает контент, который был внедрен с помощью javascript.
Часто задаваемые вопросы
Как Unless справляется с SEO?
Персонализация предназначена для предоставления наиболее релевантного контента людям, а не ботам. Таким образом, мы не показываем ботам какой-либо персонализированный контент, за исключением AdsBot (чтобы вы могли превратить свои существующие страницы в рекламные лендинги). Вместо этого поисковые роботы увидят ваш оригинальный контент.
Таким образом, мы не показываем ботам какой-либо персонализированный контент, за исключением AdsBot (чтобы вы могли превратить свои существующие страницы в рекламные лендинги). Вместо этого поисковые роботы увидят ваш оригинальный контент.
Тестовая страница для API индексирования Google и Bing
Это тестовая страница (это тестовое дополнение раздела описания) для API индексирования различных поисковых систем, таких как Bing, Yandex и Google. Indexing API — это интерфейс приложения, позволяющий поисковым системам узнавать о новых веб-страницах или обновлениях на новых страницах для изменения их индексов. Эта тестовая страница создана с низким качеством специально для проверки мощности сигнала пингов индексации API. Существует ли другой порог или процесс деиндексации и индексации изменится в зависимости от методологии индексации?
Это результат теста Indexing API через 74 секунды после первого запроса. При обслуживании кэша Bing не кэширует страницу сразу.
Тест Indexing API будет продолжен. На следующий день был написан следующий раздел теста Indexing API для Bing и Google.
Когда Google индексирует веб-страницу, если она отправляется в API индексирования?
Google Indexing API предназначен только для публикации вакансий и трансляции событий с видеообъектом на веб-странице. Таким образом, неясно, будет ли тест правильно работать с Google Indexing API или нет. В этом контексте Google проиндексировал веб-страницу через 6 часов, чем Bing. Чтобы иметь возможность увидеть разницу между приоритетами индексации Google от Indexing API и процессом индексации запросов Google Search Console, я выполню для него новый запрос индексации.
Bing все еще не кэшировал веб-страницу, которую мы сделали проиндексированной, которая является этой веб-страницей. Но Google кэшировал веб-страницу с первой версией. И в этом разделе стоит сказать еще пару слов об использовании Indexing API. Google кэшировал первую версию веб-страницы. Не обновленная версия. Сделав запрос к Google Indexing API, я добавил один дополнительный абзац и изображение, показывающее результаты индексирования в Bing и Google. Это сигнал о том, что Google сделал снимок моего первого запроса на первую версию веб-страницы. Отметка времени в кэше Google также показывает 21:35:12.
Не обновленная версия. Сделав запрос к Google Indexing API, я добавил один дополнительный абзац и изображение, показывающее результаты индексирования в Bing и Google. Это сигнал о том, что Google сделал снимок моего первого запроса на первую версию веб-страницы. Отметка времени в кэше Google также показывает 21:35:12.
Я написал этот пост в 21:28 с этой версией. И сделал запрос в 21:29. Это означает, что Google сделал снимок сразу после моего запроса на собственный кеш. Но индексация или обслуживание веб-страницы из проиндексированной произошло позже. Причина этой задержки может быть оценена веб-страницей, или кеширование и индексация могут иметь разные приоритеты и системы, которые не связаны друг с другом на стороне Google.
Позже я добавлю несколько обращений к файлу журнала для проверки этой области. И, в качестве сравнения дизайна фрагмента, вы можете проверить ниже.
Bing показывает дату публикации содержимого в области даты с маленькой точкой. Google показывает дату публикации, говоря «Х часов до», в этом случае он показывает 24 часа с большим разделителем, например «-». Bing помещает больше информации для описания веб-страницы, в то время как Google помещает меньше информации для описания. Оба они использовали заголовок, который я написал.
Bing помещает больше информации для описания веб-страницы, в то время как Google помещает меньше информации для описания. Оба они использовали заголовок, который я написал.
Для измерения их рефлексов я изменил название веб-страницы, не добавляя описания. Я хочу увидеть, будут ли они выбирать предложения ниже или первые предложения для представленного резюме веб-страницы.
API индексирования поисковой системы используется для уведомления алгоритмов и систем сканирования, индексирования и обслуживания об обновлении индексов для различных запросов. Google и Bing имеют разные системы индексации. У Bing есть протокол IndexNow, в то время как Google все еще тестирует протокол IndexNow, он использует свой собственный API индексирования. API индексирования Google подходит не для всех типов веб-страниц. Но тем не менее из файлов журнала видно, что Google Indexing API работает для того, чтобы робот Googlebot сканировал веб-страницу. Другими словами, Google не может увидеть цель использования Indexing API, не видя содержимого веб-страницы. Это показывает, что он не классифицировал источники, чтобы увидеть, является ли это веб-сайтом новостей, рекламы вакансий или вещания. Потому что каждый веб-сайт может использовать эти жанры контента. В этом контексте Google Indexing API нужно будет использовать осторожно, но тем не менее это не означает, что Google откажется от продвижения веб-сайта. Через некоторое время он может отфильтровать источник, если есть чрезмерный запрос. Или команда разработчиков Google также может использовать эти запросы в качестве источника данных. Тест Indexing API для Google и Bing будет продолжен.
Это показывает, что он не классифицировал источники, чтобы увидеть, является ли это веб-сайтом новостей, рекламы вакансий или вещания. Потому что каждый веб-сайт может использовать эти жанры контента. В этом контексте Google Indexing API нужно будет использовать осторожно, но тем не менее это не означает, что Google откажется от продвижения веб-сайта. Через некоторое время он может отфильтровать источник, если есть чрезмерный запрос. Или команда разработчиков Google также может использовать эти запросы в качестве источника данных. Тест Indexing API для Google и Bing будет продолжен.
«Последний мод» тестовой веб-страницы API индексирования показывает изменения, сделанные в последний раз. Вы можете увидеть это выше. Структурированные данные этой веб-страницы показывают дату публикации и дату изменения, как показано ниже.
Даты публикации, изменения и атрибута lastmod карты сайта, а также время из истории изменений панели CMS WordPress будут использоваться для сравнения API-интерфейсов индексирования обеих поисковых систем (Google и Bing).
11 ноября 2021 г., 11:15 GMT+3 — время окончания этого абзаца.
Тест Indexing API будет продолжен.
Отдает ли Bing приоритет источникам, использующим IndexNow?
IndexNow — это протокол, который используется поисковыми системами, чтобы позволить создателям контента уведомлять себя об обновлении своего контента. IndexNow может снизить стоимость индексации и сканирования, поскольку вместо сканирования веб-сайтов для поиска нового контента веб-сайты могут вызывать сканеры, когда у них появляется новый контент. IndexNow — это репрезентативная версия совместной работы издателя контента и поисковых систем контента. В этом контексте поисковая система может отдавать приоритет источникам, которые легко понять, сканировать или индексировать. И индекс Bing меньше, чем у Google, а это означает, что их ресурсы намного более ограничены, чем у Google. Таким образом, поисковая система может отдавать приоритет источникам, которые сотрудничают с ней. В этом контексте первое предложение этого предложения Indexing API было ранжировано в избранном фрагменте в Bing.
Видно, что «тестовый аддон» для метаописания там не виден. Потому что Bing еще не обновил свой индекс. Это означает, что когда вы используете IndexNow с Bing, они не проверяют веб-страницу в ближайшее время для обновления своего контента. Это предложение было написано после того, как Bing проиндексировал эту веб-страницу, 17 часов. Когда я поделюсь файлами журнала, это будет более ясно.
Google и Bing используют разные системы для индексации, но они также используют разные методологии сопряжения ответов и вопросов. Если вы зададите тот же вопрос в Google, вы увидите, что они будут использовать извлечение информации, а не поиск.
Вы видите два разных ракурса при извлечении информации. Во всяком случае, этот раздел немного ранжирования и ассоциации. Но тема этого теста другая. Моя цель здесь на самом деле обновить веб-страницу новыми улучшениями, чтобы проверить, как они изменят их восприятие. Чтобы увидеть это, я возьму изображение из избранного фрагмента Bing и буду использовать его как точную копию.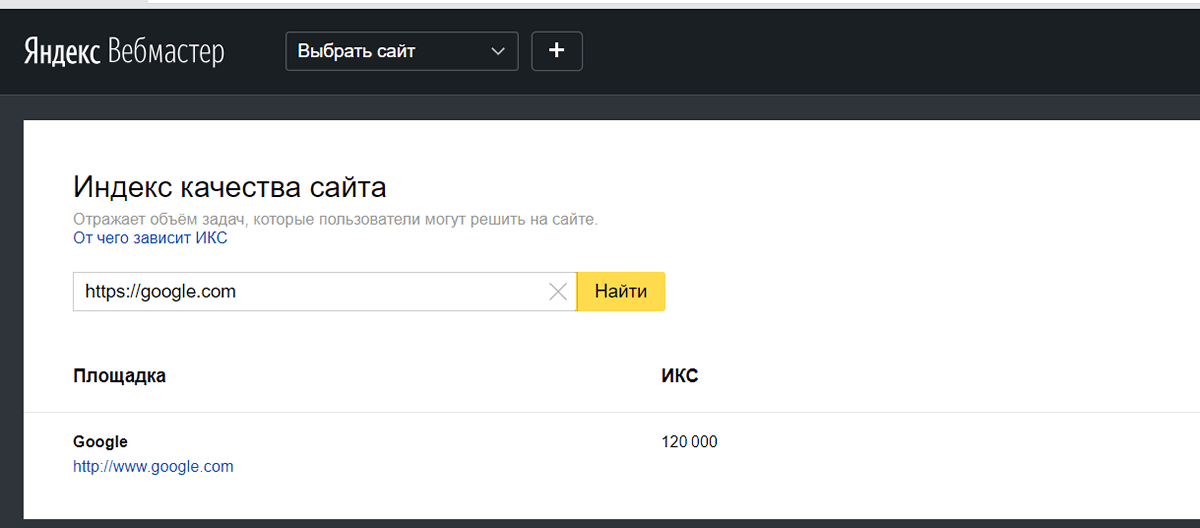 Сначала выложу сюда, потом в другой раздел. Давайте добавим контекст для поисковых систем.
Сначала выложу сюда, потом в другой раздел. Давайте добавим контекст для поисковых систем.
Системы Indexing API и IndexNow имеют разные статусы и время отклика API. API для индексирования может давать быстрые ответы пользователю или задерживать индексирование. Indexing API может использовать хорошие, средние, неработоспособные, очень нездоровые, опасные статусы с пороговыми значениями временной шкалы 0–50, 51–100, 101–200, 201–300 и >301. Ниже вы можете увидеть изображение, которое объясняет возможную задержку API индексирования Bing и Google.
Наглядный ответ на вопрос «Что такое Indexing API».Также интересно видеть, что изображение, которое Bing использует в избранном фрагменте, не с защищенного веб-сайта, согласно Google Chrome, Microsoft Edge и Internet Explorer.
Этот раздел добавлен 11 ноября 2021 года в 19:45 по Гринвичу +3.
Тест Indexing API будет продолжен.
Удаляет ли Google штамп «X часов до» через 24 часа?
12 ноября 2021 года, спустя 42 часа после публикации первой версии контента, Google удалил из фрагмента штамп «X часов до». Это может быть сигналом того, что время показа свежести контента может потерять свою значимость после 24-часового рабочего дня.
Это может быть сигналом того, что время показа свежести контента может потерять свою значимость после 24-часового рабочего дня.
Другое дело, что Google обновил кешированную версию веб-страницы.
Но Google не включил все изменения, которые я сделал. Например, это изменило вступительное предложение, которое я создал, как указано выше. Он реализовал «(это тестовый аддон раздела описания), но, как вы можете видеть, он не изменил вид фрагмента. Тем не менее, фрагмент веб-страницы показывает четкую версию того же текста. Это может быть связано с тем, что сервер фрагментов Google может отличаться от сервера кеша. Или Google считает, что старое предложение все еще может правильно определить и обобщить содержание. Другой раздел, который не включен в кеш, приведен ниже.
Я добавил этот дополнительный раздел 11 ноября в 16:46 по Гринвичу +3. И Google обновил свой кеш за 5 часов и 30 минут до моего изменения.
И, как видите, он еще не проиндексирован.
Таким образом, 24 часа могут быть своего рода порогом времени спада для свежести, а также кеш-сервера и обновления индекса для поисковой системы Google. Тем не менее, для стороны Bing веб-сайт не кэшируется.
Тем не менее, для стороны Bing веб-сайт не кэшируется.
И изменения, которые я сделал вчера, не индексируются.
Эти разделы добавлены в 11:34 по Гринвичу +3 12 ноября 2021 года. Тест индексирования API продолжится удалением и обновлением URL-адресов.
Почему Google деиндексировал и проиндексировал веб-страницу?
Google деиндексировал «тестовую веб-страницу API индексирования» после 2 дней индексации. 15 ноября 2021 года Google проиндексировал эту веб-страницу. Это может быть из-за трех разных причин.
- Обновление алгоритма Broad Core за ноябрь 2021 г. При наличии обновления алгоритма Broad Core Google сталкивается с предотвращением индексации или даже деиндексации. Таким образом, когда возникает своего рода ошибка индексации, они также не обновляют отчет о покрытии Google Search Console. Из лог-файлов видно, что они попали по конкретному URL за 15 ноября 2021 года. Но, тем не менее, они удалили его из индекса.
- Использование Indexing API: Indexing API Google предназначен только для размещения вакансий и веб-сайтов вещания. Когда веб-сайт использует его для другой цели, Google может деиндексировать конкретную веб-страницу, даже если она индексируется на первом этапе. Таким образом, Google может попытаться отменить индексацию через Indexing API для обслуживания веб-страницы с правильной вертикали или хранилища в своей системе обслуживания индексов.
- Нарушенный контекст на веб-странице: на странице тестирования API индексирования нет даже подходящего изображения. Он был написан случайным языком. Таким образом, у поисковой системы может не быть надлежащей оценки достоверности для индексации конкретной веб-страницы. Индексация и деиндексация, переиндексация могут сигнализировать об изменении доверия поисковой системы к контенту, который находится в серой зоне для присвоения качества.
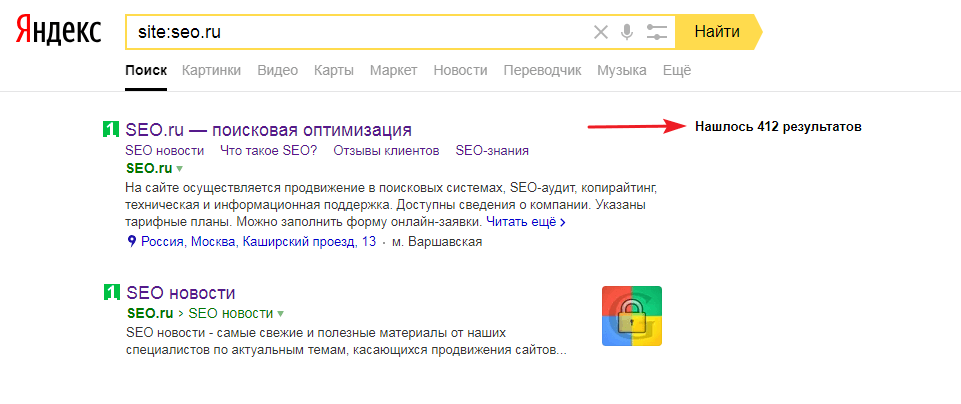 Когда веб-сайт использует его для другой цели, Google может деиндексировать конкретную веб-страницу, даже если она индексируется на первом этапе. Таким образом, Google может попытаться отменить индексацию через Indexing API для обслуживания веб-страницы с правильной вертикали или хранилища в своей системе обслуживания индексов.
Когда веб-сайт использует его для другой цели, Google может деиндексировать конкретную веб-страницу, даже если она индексируется на первом этапе. Таким образом, Google может попытаться отменить индексацию через Indexing API для обслуживания веб-страницы с правильной вертикали или хранилища в своей системе обслуживания индексов.Ниже вы можете видеть, что Google деиндексировал веб-страницу.
Когда Bing добавляет кэш URL?
Microsoft Bing начал показывать кэшированную версию веб-страницы 15 ноября 2021 года. Но дата, которую Microsoft Bing показывает для кэшированной версии веб-страницы, не соответствует действительности.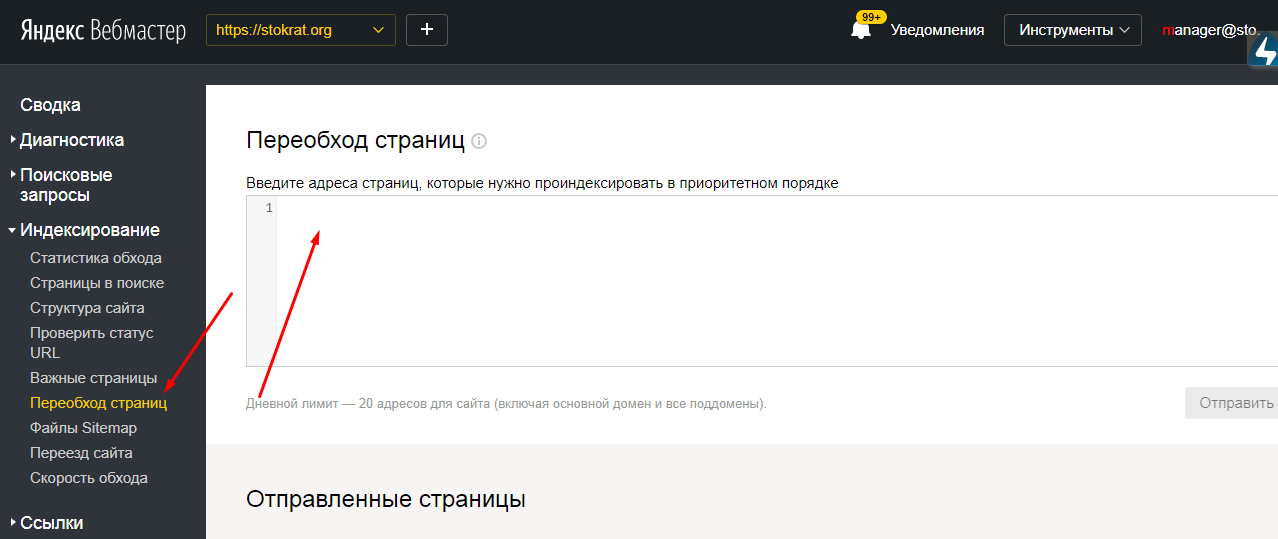 Я опубликовал эту веб-страницу 10 ноября. И я добавил последний раздел этой веб-страницы 15 ноября. Они говорят, что показывают версию от 10 ноября, которая является датой первого попадания от Bingbot. Но они показывают части контента, добавленные 15 ноября. Это означает, что Microsoft Bing показывает «Дату создания» документа в качестве своего первого попадания, и они публикуют обновленную версию содержимого в своем кеше без предоставления конкретной информации, связанной с датой обновления.
Я опубликовал эту веб-страницу 10 ноября. И я добавил последний раздел этой веб-страницы 15 ноября. Они говорят, что показывают версию от 10 ноября, которая является датой первого попадания от Bingbot. Но они показывают части контента, добавленные 15 ноября. Это означает, что Microsoft Bing показывает «Дату создания» документа в качестве своего первого попадания, и они публикуют обновленную версию содержимого в своем кеше без предоставления конкретной информации, связанной с датой обновления.
Microsoft Bing начал показывать правильный ответ на вопрос «Что такое Indexing API». И, в качестве другой функции SERP, они также начали показывать окно видео на боковой панели с дополнительной информацией. Люди также задают вопросы, которые существуют в поисковой выдаче с таким же названием. Вскоре, чтобы протестировать его более агрессивно, я попытаюсь изменить больше вещей на веб-странице.
И Bing по-прежнему сохраняет веб-страницу как проиндексированную, говоря, что она датирована 10 ноября 2021 года. Потому что дата статей упоминает об этом.
Потому что дата статей упоминает об этом.
Это дополнение было добавлено в 2021 году, 15 ноября. Тест Indexing API будет продолжен.
- Автор
- Последние сообщения
Корай Тугберк ГУБЮР
Владелец и основатель Holistic SEO & Digital
Корай Тугберк ГУБЮР является генеральным директором и основателем компании Holistic SEO Science, Web Data Consultancy, в которой он занимается разработкой цифровых данных. , веб-дизайн и услуги по поисковой оптимизации со стратегическим руководством для клиентских проектов агентства по поисковой оптимизации. Koray Tuğberk GÜBÜR регулярно проводит SEO A/B-тесты, чтобы понять Google, Microsoft Bing и Yandex, как алгоритмы поисковых систем и внутреннюю повестку дня. Koray использует науку о данных, чтобы понять пользовательские кривые кликов и деревья решений алгоритмов детских поисковых систем. Тугберк использовал множество веб-сайтов для написания различных тематических исследований SEO. Он опубликовал более 10 тематических исследований SEO с более чем 20 веб-сайтами, чтобы объяснить поисковые системы. Корай Тугберк начал свою карьеру в области SEO в 2015 году в индустрии казино и перешел в индустрию SEO-оптимизации. Koray работал с более чем 300 компаниями над их SEO-проектами с 2015 года. Koray использовал SEO для улучшения взаимодействия с пользователем и коэффициента конверсии, а также узнаваемости бренда онлайн-бизнеса из разных вертикалей, таких как розничная торговля, электронная коммерция, партнерство и b2b. или b2c сайты. Ему нравится изучать веб-сайты, алгоритмы и поисковые системы.
Корай Тугберк начал свою карьеру в области SEO в 2015 году в индустрии казино и перешел в индустрию SEO-оптимизации. Koray работал с более чем 300 компаниями над их SEO-проектами с 2015 года. Koray использовал SEO для улучшения взаимодействия с пользователем и коэффициента конверсии, а также узнаваемости бренда онлайн-бизнеса из разных вертикалей, таких как розничная торговля, электронная коммерция, партнерство и b2b. или b2c сайты. Ему нравится изучать веб-сайты, алгоритмы и поисковые системы.
Последние сообщения Koray Tuğberk GÜBÜR (посмотреть все)
- Важность объема поиска по ключевым словам для SEO — 29 июня 2022 г.
- Сложность ключевых слов: определение, примеры, использование и важность для SEO — 19 июня 2022 г.
- Google Авторский рейтинг: как Google узнает, какой контент принадлежит какому автору? — 31 мая 2022 г.
Поисковая оптимизация — отправка вашего сайта в поисковые системы > Блог Webnode
Поисковые системы, такие как Google, Bing или Yandex, используют своих роботов-индексаторов для просмотра случайных веб-сайтов и записи их контента.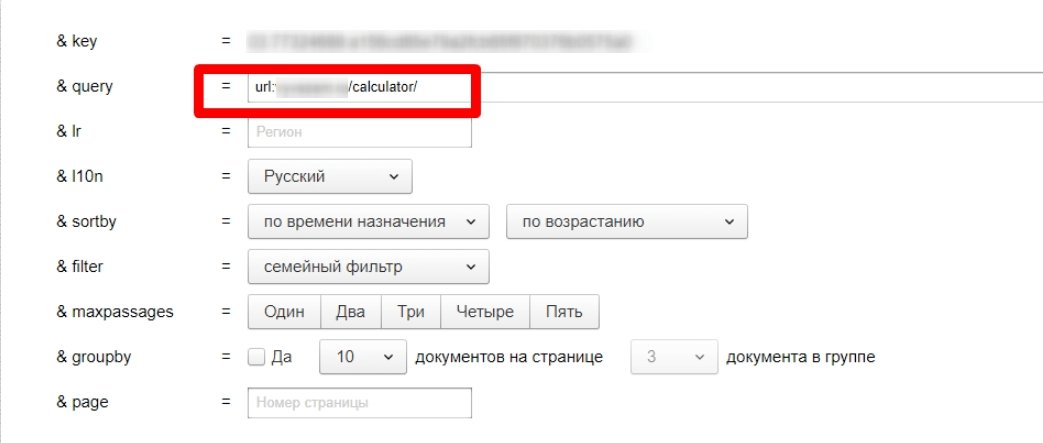 Этот процесс происходит автоматически, поэтому, если вы специально не запретите поисковым системам индексировать ваш сайт, они в конечном итоге его найдут. Однако это может занять некоторое время.
Этот процесс происходит автоматически, поэтому, если вы специально не запретите поисковым системам индексировать ваш сайт, они в конечном итоге его найдут. Однако это может занять некоторое время.
При том, что каждую минуту создается около 380 новых веб-сайтов, даже предполагаемое количество веб-сайтов, создаваемых каждый день, огромно, а процесс их индексации занимает месяцы. Также нет гарантии, что роботы найдут все страницы.
Тем не менее, не стоит отчаиваться – есть способы сообщить поисковым системам, что ваш веб-сайт существует, и даже есть простые решения для добавления вашего веб-сайта непосредственно в их индекс.
Чтобы быстро сообщить поисковым системам о существовании вашего веб-сайта, просто выполните поиск «URL-адрес добавления Google» или «URL-адрес добавления Bing». Среди первых нескольких результатов вы найдете все необходимые ссылки.
Все же гораздо эффективнее подключить свой сайт напрямую к выбранной поисковой системе через ее собственный сервис. Для Google используйте их бесплатный и удобный инструмент Google Search Console.
Для Google используйте их бесплатный и удобный инструмент Google Search Console.
Что делать с Search Console
Вы можете настроить все, выполнив всего четыре простых шага:
1. Зарегистрируйтесь в Search Console и создайте ресурс для своего веб-сайта.
2. Войдите в свой конструктор веб-сайтов Webnode и добавьте HTML-код из Search Console 9.0334 в шапку вашей домашней страницы.
3. Подтвердите подключение в Search Console.
4. Добавьте карту сайта в Search Console , чтобы упростить индексацию будущих страниц.
В нашей базе знаний вы можете найти подробное руководство, которое проведет вас через весь процесс. Search Console предлагает несколько удобных функций, которые окупятся дополнительной работой:
Это поможет сделать ваш сайт удобным для Google
Вы можете увидеть, есть ли какие-либо страницы с ошибками, которые необходимо исправить, или страницы, которые по какой-то причине не работают. не могут быть просканированы роботами Google.
не могут быть просканированы роботами Google.
Вы можете попросить Google проверить конкретный URL-адрес, чтобы узнать, был ли он уже проиндексирован, просканирован или оптимизирована ли страница для мобильных устройств. Используйте этот «инструмент проверки URL» всякий раз, когда вы создаете новую страницу, чтобы убедиться, что ее заметят, но не раньше, чем вы убедитесь, что она полна отличного контента. Вы же не хотите, чтобы у Google сложилось плохое мнение о новой странице.
Если Google подозревает, что с вашим сайтом происходит что-то подозрительное, что может причинить вред другим (например, вредоносное ПО, попытки фишинга, взломанный сайт), вы увидите уведомление об этом в Search Console.
Если вы начали работать над созданием внутренних ссылок после прочтения нашей статьи о важности ссылок на вашем веб-сайте, Search Console покажет вам страницы, на которые чаще всего ссылаются, и количество внутренних ссылок, ведущих на них. Чтобы отслеживать внешние ссылки, вы можете проанализировать список ссылок, ведущих на ваш сайт, и проверить самые популярные сайты.
Это многое говорит о производительности веб-сайта
Используйте консоль поиска для анализа производительности вашего веб-сайта WebnodeВозможно, это лучшая из функций Search Console. Вы можете увидеть, по каким ключевым словам ваш сайт отображается в результатах поиска, количество показов, кликов и среднюю позицию страниц в этих результатах. Вы можете значительно улучшить производительность своего веб-сайта, если будете регулярно следить за этими данными и действовать в соответствии с ними.
Пока мы пишем эту статью, Search Console также экспериментирует с отчетом, который покажет вам, является ли скорость загрузки ваших страниц медленной, умеренной или быстрой. Объедините это с Google PageSpeed Insights, и вам не придется беспокоиться о потере посетителей из-за медленного времени отклика.
Где еще зарегистрироваться Помимо поисковых систем, существуют также различные онлайн-каталоги, где люди могут просматривать списки компаний или веб-сайты схожей тематики. Их обычно называют каталогами веб-сайтов. Поскольку некоторые из них одобрены или даже созданы поисковыми системами, регистрация на них может принести вам большое количество новых посетителей.
Их обычно называют каталогами веб-сайтов. Поскольку некоторые из них одобрены или даже созданы поисковыми системами, регистрация на них может принести вам большое количество новых посетителей.
Упомянем хотя бы два основных:
Google My Business
Bing Places for Business
Существуют также сотни небольших и локальных каталогов. Если вы хотите зарегистрироваться у них, убедитесь, что они хорошего качества. В противном случае может показаться, что ваш сайт следует тем же сомнительным стандартам.
О чем следует помнить
Активно информируйте поисковые системы о новых и обновленных страницах вашего сайта, чтобы убедиться, что они заметят все изменения. Если вы объедините это с регулярной проверкой данных, собранных в Google Search Console, вы уже на пути к успешному веб-сайту.
- Введение
- Основные принципы и рекомендации
- С чего начать? (контент, целевая группа, конкуренты, собственный домен)
- SEO-настройки в конструкторе сайтов Webnode
- Ссылки на вашем сайте
- Размещение вашего сайта в поисковых системах
- SEO и социальные сети
- Анализ данных (изучение посетителей)
- Первая мобильная индексация
Хотите знать, как сделать SEO? У нас есть для вас подробная инструкция.