Как проверить дубли страниц на сайте
Дубли страниц на сайте могут возникать автоматически, а могут появляться из-за человеческого фактора. В любом случае дубль негативно сказывается на ранжировании сайта. Поэтому важно на моменте разработки убедиться, что дублей нет, или настроить имеющиеся так, чтобы они не индексировались как отдельные страницы с таким же контентом. В статье рассказываем, как это сделать.
Что такое дубли страниц и какие они могут быть
Дубли страниц — это любые страницы сайта, которые по содержанию копируют другую. Например, если вы заходите на страницу товара в интернет-магазине, но выбираете иной цвет одежды, и вас перенаправляют на другую страницу. Сами урлы изменяются незначительно — у них меняется набор символов. Также изображения разные, хоть товар один и тот же, но разного цвета. Текст к товару идентичен, но он скрыт от пользователя, пока он его не откроет.
Вот так выглядит это в реальности — товар магазина Sela разных цветов:
По сути, страницы одинаковые, и они дублирующиеся. Если бы вебмастер не позаботился о сокрытии текста, изменении картинок, то тогда эти страницы были бы неявными дублями. То есть это дубли, но их отредактировали так, чтобы для роботов они выглядели уникально.
Если бы вебмастер не позаботился о сокрытии текста, изменении картинок, то тогда эти страницы были бы неявными дублями. То есть это дубли, но их отредактировали так, чтобы для роботов они выглядели уникально.
И подобных примеров много — давайте разберем самые частые из них:
- страница доступна под разными протоколами — есть страница для https:/ и для http:/;
- страница для www и без www — то есть пользователь попадает по этим адресам на одну страницу, но их всего две;
- со слешем и без слеша — если к урлу добавить слеш, откроется та же самая страница, но это будет дубль;
- один товар доступен по разным адресам — например, в одном урле есть название товара, в другом к нему добавили и название категории, но при этом открывается один и тот же товар;
- страницы с GET-параметрами — это когда есть один вариант урла страницы, а также такая же страница по адресу типа www.что-то.ru/news?hfkznsm;
- страницы версии для печати тоже копируют контент и доступны по тому же адресу, что и оригинал.


Это основные виды явных дублей, но они могут быть и неявными. Например, если в разделе статей вы открываете доступ к комментариям. И каждый новый комментарий или ответ на него доступен почти по такому же адресу, что и страницы со статьей, но с добавлением номера или GET-параметров.
Типичный пример — это dtf, где часто можно увидеть древовидные комментарии. Также дублями могут быть страницы одного товара, которые доступны по разным адресам. Под это подходит наш пример с одеждой в Sela — если бы не настройка вебмастера, то страницы с разными цветами товаров дублировали бы оригинал. Другой вариант — это страницы пагинации, когда перечисляют пул товаров. И каждая последующая страница немного меняет свой урл — появляется дополнение в виде порядкового номера или категории товара. Но их контент остается неизменным.
Причины появления дублей — это ошибка вебмастера, автоматическое появление в зависимости от движка, ошибки в директивах robot.
Почему нужно работать с дублями страниц
Хоть и стало понятней, почему эти дубли появляются, до сих неясно, зачем от них избавляться. Давайте рассмотрим, почему дубли негативно влияют на сайт.
- Поисковик индексирует страницу-оригинал неправильно — предположим, что у вас два урла, которые приводят пользователя на одну страницу. Вы продвигаете один из них, и все вроде хорошо. Но потом поисковик находит дубль и индексирует его, но этот урл не продвигается, поэтому и охватов получает меньше.
- Индексация длится слишком долго — как правило, поисковый робот индексирует страницы сайта не так долго. Но если дублей много, индексация идет дольше — поисковик просто не успевает за определенное время добраться до вашего контента.
- Ограничения со стороны поисковой системы — хоть дубли не нарушают никаких правил, поисковый робот может подумать, что вы специально их создаете. Тогда органическое продвижение сайта замедляется. Это происходит, если у вас есть дубли, и вы с ними ничего не делаете.
- Сложности в устранении — когда с дублями не работают, со временем их число может расти. Тогда-то и придется на их устранение потратить огромное время и ресурсы.
 Тогда органическое продвижение сайта замедляется. Это происходит, если у вас есть дубли, и вы с ними ничего не делаете.
Тогда органическое продвижение сайта замедляется. Это происходит, если у вас есть дубли, и вы с ними ничего не делаете.То есть основная причина в том, что дубли проблемны, — это плохое ранжирование сайта поисковой системой.
Как выявить дубли страниц сайта
Чтобы выявить дубль страницы, необязательно вручную сидеть и искать их — это довольно энергозатратно и долго. Но такой вариант все равно присутствует, если вы знаете, как искать и не можете использовать другие способы. Если не знаете, мы на всякий случай подскажем — достаточно в поисковую строку ввести команду «site: {домен} inurl1: {часть урла}». Вместо части урла нужно указать тот, по которому, вероятно, есть дубль. Например, если это GET-параметры, то можно попробовать ввести знак вопроса — именно по такой логике создаются урлы GET-параметров. Или введите слово page и номер — подойдет для поиска страниц пагинации.
Или введите слово page и номер — подойдет для поиска страниц пагинации.
Есть вероятность, что вы просто не введете нужную часть урла. То есть дубль создается нетипичный — это будет просто набор рандомных цифр или слов. В этих ситуациях можно использовать другие способы поиска дублей — всего их три.
Через Яндекс.Вебмастер. Обычно в первую очередь дубли находит именно поисковый робот, и он может об этом сообщить. Достаточно зайти в Яндекс.Вебмастер и пройти в раздел диагностики сайта. Всю информацию по ошибкам система загрузит в раздел Индексирования, «Страницы в поиске» — чтобы вся информация была перед глазами во время работы, можно загрузить таблицу с урлами в формате XLS или CSV.
Google Search Console. В вебмастере Google тоже можно искать дубли — это необходимо, ведь та информация, что вы нашли в Яндекс. Вебмастере касается только поисковика Яндекса. Чтобы узнать о дублях, которые отображаются в Google, нужна Google Search Console — просто зайдите в раздел «Вид в поиске» и потом «Оптимизация HTML». Там и покажут все дубли страниц по заголовкам и мета-описаниям, а также битые ссылки.
Вебмастере касается только поисковика Яндекса. Чтобы узнать о дублях, которые отображаются в Google, нужна Google Search Console — просто зайдите в раздел «Вид в поиске» и потом «Оптимизация HTML». Там и покажут все дубли страниц по заголовкам и мета-описаниям, а также битые ссылки.
Приватный VIP-клуб для SEO-специалистов. Никакой воды, коллективное решение проблем и эксклюзивный контент!
Использовать парсеры или программы. Можно автоматизировать процесс поиска — даже если вы загружаете таблицу через Вебмастер, искать-то придется все равно вручную, хоть и в списке. Поэтому можно использовать различные парсеры и программы, которые полностью автоматизируют процесс.
Овнеры магазинов ФБ акков про свой бизнес и тренды в арбитраже. ФБ аккаунты для арбитража трафика
PromoPult — позволяет анализировать все данные урлов из Вебмастера. Мы уже сказали, что придется самостоятельно идти по списку таблицы и проверять дубли. Чтобы этого не делать, можно загрузить готовую таблицу в PromoPult и начать поиск дублей. Также сервис позволяет проанализировать данные не только из Яндекса, но из Google — это поможет понять, какие урлы дублируются и в каких поисковых системах. Так легче и подобрать сам способ настройки этих страниц. Кроме того, на сервисе можно и заказать услугу по аудиту сайта от специалистов — они сами подобьют информацию по дублям и в целом по оптимизации.
Чтобы этого не делать, можно загрузить готовую таблицу в PromoPult и начать поиск дублей. Также сервис позволяет проанализировать данные не только из Яндекса, но из Google — это поможет понять, какие урлы дублируются и в каких поисковых системах. Так легче и подобрать сам способ настройки этих страниц. Кроме того, на сервисе можно и заказать услугу по аудиту сайта от специалистов — они сами подобьют информацию по дублям и в целом по оптимизации.
Apollon — это полноценный онлайн-парсер, который быстро и бесплатно найдет все дублированные страницы. Можно выгрузить таблицу с Вебмастера, скопировать до пяти ссылок оттуда и вставить в поле на сайте. После обработки запроса перед вами откроется таблица со страницами и адресами. Если адрес один и тот же, то вы нашли дубль — осталось решить, что с ним делать.
Seoto — сервис находит все ошибки, которые мешают продвижению сайта.
Siteliner — бесплатный онлайн-сервис, который помогает найти быстро все битые ссылки и дублированные страницы. Но есть ограничение — бесплатно только до 250 страниц.
ScreamingFrog — это программа для компьютера, которая является частично бесплатно. Некоторые про-функции нужно оплачивать. Принцип работы программы простой — достаточно вбить нужный сайт и начать его анализ. Если ваш сайт действительно большой или у вас несколько сайтов, то понадобится про-версия — утилита может сканировать бесплатно только до 500 ссылок.
Xenu — это полностью бесплатная программа, причем она анализирует сайты, которые Яндекс еще не проиндексировал. Даже если создать сайт и сразу же проверить его через программу, она все равно соберет все ошибки и дубли страниц — то есть не нужны данные из инструментов вебмастеров. Весь поиск дублей происходит через мета-описания и заголовки страниц.
Даже если создать сайт и сразу же проверить его через программу, она все равно соберет все ошибки и дубли страниц — то есть не нужны данные из инструментов вебмастеров. Весь поиск дублей происходит через мета-описания и заголовки страниц.
Как избавиться от неявных и явных дублей
Мы выяснили, как можно обнаружить все дубли страниц. Теперь давайте разбираться, что с ними делать. Скажем сразу — это зависит от вида вашего дубля.
Если проблема возникла из-за наличия или отсутствия слешей в урле. В этом случае можно настроить редирект 301 — он будет перенаправлять юзеров с дубля на целевую страницу. Стандартную команду нужно добавить в файл .htaccess — в ней будет такое содержание:
Redirect 301 /урл, с которого идет перенаправление
http://доменное имя/новый урл, на который нужно перенаправить
Если нужно сделать редирект с домена без WWW на домен с WWW. (.*)$ http://домен.ru/$1
(.*)$ http://домен.ru/$1
[R=301, L]
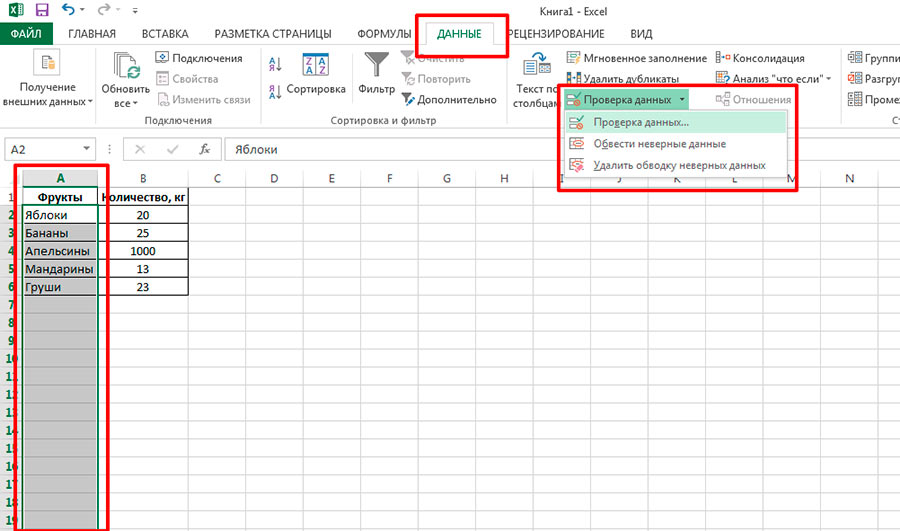
Запрет на индексацию дублей в файле robot.txt. Способ самый простой — нужно просто запретить индексирование страницы-дубля для поискового робота, чтобы он игнорировал адрес. Для этого в файл нужно добавить следующее содержание:
User-agent: __
Disallow: /ваш урл, который не нужно индексировать
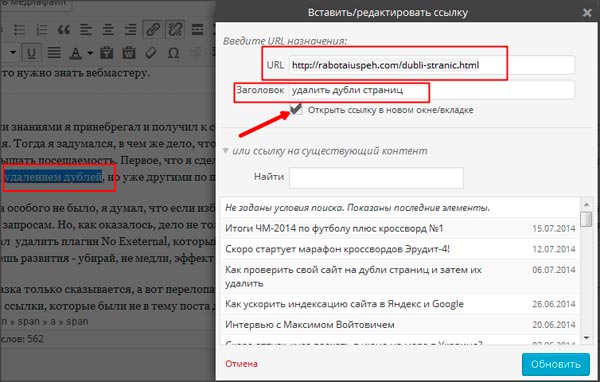
Если у вас несколько страниц с товарами, то есть страницы пагинации. В таком случае можно в коде обозначить каноническую страницу — то есть «материнскую». Для этого в коде канонической страницы вбиваем в теге & It;link& + rel=canonical href=href=”адрес канонической страницы”>адрес канонической страницы/>. Теперь все дочерние страницы будут ссылаться на каноническую — они не будут считаться дублями.
Чтобы не индексировать страницу и не переходить/переходить по ссылкам. Для этой команды можно ввести специальный мета-тег на страницу-дубль. Если ввести мета-тег & It;meta name=robots content=noindex, nofollow& qt, тогда робот не будет индексировать страницу и допускать переход по ссылкам на нее. Если ввести мета-тег & It;meta name=robots content=noindex, follow& qt, то страница не будет индексироваться, однако перейти на нее будет возможность.
Для этой команды можно ввести специальный мета-тег на страницу-дубль. Если ввести мета-тег & It;meta name=robots content=noindex, nofollow& qt, тогда робот не будет индексировать страницу и допускать переход по ссылкам на нее. Если ввести мета-тег & It;meta name=robots content=noindex, follow& qt, то страница не будет индексироваться, однако перейти на нее будет возможность.
О чем важно помнить после всех настроек и проверок
Если вы исправили проблему с дублями, и кажется, что все хорошо — все равно убедитесь в этом. Хорошо, если вы специалист и можете самостоятельно выявлять проблемы с оптимизацией. Тогда достаточно сделать повторную проверку сайта.
Но если вы еще новичок или просто делали сайт по заказу, и сейчас вам необходима профессиональная помощь, то проще всего прогнать сайт через сервисы и программы проверок и анализа. В других случаях — можно заказать аудит от специалиста. В этом больше преимуществ, ведь вебмастер сможет полностью и точно проанализировать настройки и оптимизацию, а также исправить проблемы.
В этом больше преимуществ, ведь вебмастер сможет полностью и точно проанализировать настройки и оптимизацию, а также исправить проблемы.
Главное правило — проверять эти данные регулярно, ведь может быть так, что движок сам будет создавать дубли страниц, а вы о них даже не узнаете. Зато пропадет органический трафик.
Какие еще могут быть проблемы с технической оптимизацией сайта
Дубли влияют на ранжирование сайта, но они — не единственная возможная проблема. Мы разберем еще несколько ошибок, которые могут влиять на продвижение в поисковике:
- Отсутствие файла robot.txt — это частая проблема среди новичков. Если у сайта нет этого файла, то возникают проблемы с индексацией — поисковый робот просто не видит этого файла и проверяет все страницы подряд, в том числе и служебные. Поэтому важно проверить наличие этого файла — просто введите в поисковую строку домен/robot.txt. Если страница открылась, то файл в наличии.
- Нет страницы 404 — это страница, которая всплывает у пользователя при проблемах с вводом домена. Смысл этой страницы в том, что она перенаправляет пользователя на каноническую. Так трафик теряется меньше. Если страницы ошибки нет, то пользователь может просто покинуть ресурс.
PBN-сети и дроп-домены по выгодной цене! Все включено на 12 месяцев: хостинг, домен, CDN и Private Person — получи скидку по промокоду PARTNERKIN10
- Отсутствие микроразметки — эта деталь необязательна, но она вызывает больше доверия у робота. Кроме того, это позволяет делать прикольные сниппеты в соцсетях, а также органично смотреться в поиске. Например, для многих рецептов делают микроразметки — при их поиске робот выбивает микроразметку с началом рецепта в отдельный блок, что привлекает внимание пользователей лучше.
- Проблемы с прогрузкой сайта — не секрет, что сайты иногда получаются очень тяжелыми. Из-за габаритности они дольше грузятся и могут погружаться некорректно. Лучше заранее это проверить через сервисы вроде Google Pagespeed Insights и увеличить скорость.
- Отсутствие протокола HTTPS — большинство пользователей уверены, что этот протокол равно безопасный сайт. Поэтому можно потерять часть трафика, если его не добавить — в браузерной строке просто не будет пометки безопасности, и пользователи могут отсеяться.
 Из-за габаритности они дольше грузятся и могут погружаться некорректно. Лучше заранее это проверить через сервисы вроде Google Pagespeed Insights и увеличить скорость.
Из-за габаритности они дольше грузятся и могут погружаться некорректно. Лучше заранее это проверить через сервисы вроде Google Pagespeed Insights и увеличить скорость.Вывод
Дубли страниц — не критично, но важно о них позаботиться, чтобы с ранжированием не было проблем. Для поиска дублей можно использовать различные сервисы и программы — о них рассказали в статье. Способы решения проблемы зависят от того, что это за дубль, — иногда достаточно настроить редирект, но в других случаях лучше просто запретить роботу считывать и индексировать страницу. После решения проблемы с дублями страниц проверяйте их появление регулярно, а также заботьтесь в целом о качестве оптимизации.
А вам приходилось работать с дублями?
0 голосов
Нет Да, надоело уже
как проверить и найти дубли страниц на сайте
Одной из частых проблем, мешающих SEO-продвижению, являются дубли страниц. Они содержат одинаковое с оригиналом содержание, но при этом у них отличаются URL. Почему они возникают, как их искать – читайте в этой статье.
Что такое дублированный контент и его виды
Под данным термином подразумевается идентичное наполнение страниц с разными урлами. Они могут быть расположены как на одном, так и на нескольких доменных именах. Появляются они не только из-за копирования содержимого. Дубли страниц также возникают в результате невозможности исключения тестовой версии сайта из индексации или невыполненной переадресации.
В зависимости от объема скопированного контента их делят на:
- полные;
- частичные.
Первые содержат 100 % идентичного материала. Обычно к полным относятся зеркала ресурсов, адрес которых может содержать или не содержать www, дубли main page и реферальных программ. Еще сюда относятся веб-страницы, связанные с некорректной иерархией, содержащие в URL множественные символы // или ///. Возникают полные дубли и по причине неправильно выполненного переезда на протокол SSL. Их обязательно нужно удалить и как можно быстрее.
Еще сюда относятся веб-страницы, связанные с некорректной иерархией, содержащие в URL множественные символы // или ///. Возникают полные дубли и по причине неправильно выполненного переезда на протокол SSL. Их обязательно нужно удалить и как можно быстрее.
Частичные дублируют контент не полностью, а только какую-то его часть. Это web-страницы пагинации, сортировки. Чаще всего их возникновение обусловлено нюансами CMS. Узнать такие можно по параметру get. К частичным дублям могут относиться и другие типы страниц: отзывов, свойств товара, фильтрации или копии, созданные при помощи AJAX.
Проблемы внутреннего и внешнего дублирования
Особенность страниц с идентичным содержанием в том, что они могут возникать не только на каком-то одном сайте, но и сразу на нескольких. Называются они, соответственно, внутренними и внешними. Остановимся на нюансах детальнее.
Внутреннее дублирование
Так называют страницы, содержащие идентичное наполнение, расположенные на одном ресурсе, но по разным адресам.
Внутреннее дублирование приводит к каннибализации фраз. При такой ситуации минимум пара подстраниц одного доменного имени может отображаться для одного ключа.
Если внутреннее дублирование не устранить, то позиции начнут «прыгать» в выдаче. Почему? Все просто – поисковая система не сможет определить, какую из страниц показать, поэтому демонстрироваться они будут по очереди. Из-за этого алгоритмы Google расценят их как некачественные, и приоритет в ранжировании будет отдаваться другим сайтам.
Рекомендуем также почитать о том, как выполняется продвижение сайта, и принципах ранжирования.
Хотите получить комплексный анализ вашего сайта?Адрес сайта
Внешнее дублирование
Так называют идентичный контент, который расположен на разных веб-ресурсах. Случается такое в основном по двум причинам:
- воровство;
- размещение контента-копии со своего сайта на других площадках.
Дубли страниц в поддоменах тоже относятся к этой категории. Если же одинаковый текст размещен на нескольких доменных именах, то поисковик Google на высокой позиции будет отображать ту страницу, оптимизация которой выполнена лучше, создана ранее или линк на нее размещен на большом количестве площадок-доноров.
Причины внутреннего дублирования
Рассмотрим причины, которые наиболее часто приводят к проблеме. Это важно, поскольку такое дублирование контента на сайте случается буквально у каждого владельца ресурса. Чтобы понимать, почему так произошло, читайте дальше.
Дубль товара по разным URL
Варианты продукта, которые размещены на нескольких подстраницах, – явление нередкое. Если бы постоянно использовались уникальные описания, то проблема не возникла. Но далеко не всегда соблюдается это правило, особенно если в продаже есть много позиций товара с небольшими отличиями (модель туфель в разных цветах, к примеру) и тратиться на оригинальные описания нет времени и лишних средств. Это, кстати, один из частых приемов маркетинга. Из-за такого подхода и возникает дублирование контента на сайте, влекущее за собой проблемы с продвижением.
Это, кстати, один из частых приемов маркетинга. Из-за такого подхода и возникает дублирование контента на сайте, влекущее за собой проблемы с продвижением.
Оставлять ситуацию так нельзя, нужно устранить проблему. Это необходимо, чтобы интернет-ресурс не потерял позиции в рейтинге.
Поиск дублированных страниц
Найти проблему можно несколькими способами. Расскажем детальнее, как найти дубли страниц на сайте.
С помощью специальных программ и сервисов
Обнаружить дубли страниц можно при помощи:
- Xenu;
- NetPeak Spider;
- Screaming Frog SEO Spider.
Эти и подобные им программы находят веб-страницы с идентичным содержимым, проверяя совпадение метатегов.
Еще можно применить инструмент Гугл Search Console. Он поможет выявить на сайте дубли и даст рекомендации, как их устранить.
Использование поисковых операторов
К таким относятся «inurl» и «site». Операторы анализируют URL и при обнаружении адресов с одинаковым контентом выдают их списком.
Как найти дубли страниц при помощи поисковых операторов? Нужно просто в поле поиска ввести оператора перед адресом сайта. Например:
site:https:// название ресурса.com — site:https:// название ресурса.com/&
В этой формуле первое определение показывает страницы вашего веб-ресурса, которые содержатся в общем индексе системы Google. Второе – странички, которые задействованы в поиске.
Как бороться с проблемой дублирования контента
Бывает, что писать уникальные тексты для однотипных товаров не всегда есть возможность. Но и дублирование контента – не выход. Избежать проблемы поможет специальный тег, который ведет к базовой версии – rel=canonical. Такая ссылка указывает роботам поисковика предпочтительные страницы для подстраниц похожего типа. Прибегать к нему нужно, если тексты повторяются на нескольких урлах.
Еще один способ, который поможет избежать такой проблемы, как дублированный контент – создавать на похожие товары уникальные карточки с опцией выбора нужного варианта.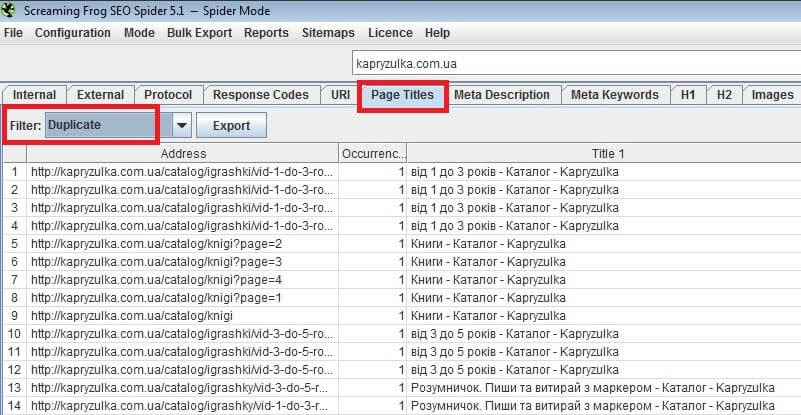 Но следует учесть, чтобы при таком подходе URL не менялся. Прочие подстраницы нужно перенаправить на главную.
Но следует учесть, чтобы при таком подходе URL не менялся. Прочие подстраницы нужно перенаправить на главную.
В ситуациях, если на каждый тип товара уже подобраны ключи и создан контент, необходимо создать индивидуальные адреса URL. Таким образом, получится добиться оптимизации товара под отличительные черты, что улучшит видимость в выдаче. Ключи с хвостами помогут привлечь большее количество клиентов – состоявшихся или потенциальных.
Сайт доступен по многим адресам
Причин такого явления довольно много. Среди наиболее распространенных:
- Индексирование тест-версии ресурса. Процесс создания или редактирования имеющегося сайта влечет за собой появление версии, которая при правильном раскладе должна оставаться доступной лишь разработчикам. Но если от индексации она не скрыта, то робот просканирует и ее, в результате появятся дубли страниц на сайте.
- Отображение home page сразу по нескольким урлам. Некоторые из движков могут создавать адреса в разных версиях с небольшими отличиями в написании: со слешем или без, с «index. php» или «index.html». Подобное указывает, что одинаковые тексты отображаются на нескольких страницах, возникает дублирование контента. Подобного результата можно избежать, если указать поисковику на оригинал сайта, перенаправив на него адреса-копии.
- Неправильное подключение SSL-стандарта. Дублирование контента на сайте может возникать и по причине отсутствия редиректа. Его обязательно следует настроить подключением SSL. Поисковик страницы http и https воспринимает как разные, то есть будет считать их за две версии ресурса. Чтобы не возникло дублей, следует выполнить несколько действий:
 php» или «index.html». Подобное указывает, что одинаковые тексты отображаются на нескольких страницах, возникает дублирование контента. Подобного результата можно избежать, если указать поисковику на оригинал сайта, перенаправив на него адреса-копии.
php» или «index.html». Подобное указывает, что одинаковые тексты отображаются на нескольких страницах, возникает дублирование контента. Подобного результата можно избежать, если указать поисковику на оригинал сайта, перенаправив на него адреса-копии.- настроить редирект для подстраниц;
- удалить внутренние ссылки, содержащие http без подключенного стандарта SSL. Сделать это можно, если проверить канонические ссылки, а также файлы с графическим изображением;
- выполнить обновление sitemap.xml. Но перед этим следует создать файл по текущему адресу.
Еще нужно позаботиться о добавлении версии ресурса с SSL в Search Controle поисковой системы Google, отправить sitemap. xml обновленного типа.
xml обновленного типа.
Неоптимизированные страницы сортировки и фильтрации
Дубли страниц на сайте еще могут возникать и по причине неправильно выполненной оптимизации таких функций, как фильтрация и сортировка. Почему? Дело в том, что настройка данных функций меняет лишь определенную часть ресурса, ту, на которой размещены товары. При этом содержимое не меняется. А вот когда в процессе перезагрузки добавляются параметры фильтра и сортировки, то появляются копии.
Решить эту проблему поможет тег, о котором мы уже упоминали – rel=canonical. Но даже так странички будут отображаться в выдаче. Чтобы удалить их, потребуется метатег – noindex.
Можно еще позаботиться о том, чтобы не отображался процесс индексирования фильтрации и сортировки в robots.txt. Помочь в этом может директива, блокирующая доступ поисковику к ряду страниц. Подобный метод также эффективно экономит бюджет, выделенный на краулинг.
Но прежде чем применять способ, следует проверить, как он скажется на трафике, не упадет ли посещаемость? Если снизится, то можно попробовать оптимизировать эту часть аудитории под ключи с хвостами.
Внутренний поиск и копии
Проблемы могут возникать и по причине плохой реализации опции поиска на ресурсе. Ее применение порой провоцирует появление новой веб-страницы, которая по сути будет копией. Решить такую проблему можно добавлением в robots.txt несколько директив, закрывающих доступ для роботов к страничкам внутреннего поиска.
Неоптимизированные страницы пагинации
Пагинация помогает разделять содержимое и размещать эти части на подстраницах. В качестве контента могут использоваться список категорий, товары и пр.
Если пагинация выполнена неверно, она сопровождается рядом проблем:
- копия первой страницы;
- отсутствие различия в заголовках тегов;
- идентичное наполнение.
Работая над пагинацией, сразу нужно мониторить, чтобы не образовывались дубли страничек.
Неправильная реализация языковых версий
Отсутствие переводов на каждой странице тоже является причиной возникновения дублей. Избежать рисков можно, если выполнить перевод текстов на тот язык, который соответствует стране продвижения. Еще поможет указание на страницах атрибутов hreflang. Так, поисковики поймут, что на ресурсе реализовано несколько языковых версий.
Еще поможет указание на страницах атрибутов hreflang. Так, поисковики поймут, что на ресурсе реализовано несколько языковых версий.
Как создается внешнее дублирование
Такие ситуации не всегда возникают из-за воровства контента. Причины могут быть разными.
Копирование описаний товаров с сайтов производителей
Так называемый копипаст используется широко. Но не все в курсе, что подобные методы влекут за собой проблемы. Если есть множество товаров, и нет возможности для каждого создать уникальный контент, то необходимо подготовить тексты хотя бы для позиций, которые определены приоритетными.
Оригинальность наполнения ценится поисковиками. Поэтому шансы подняться в рейтинге у ресурса с уникальным контентом тоже выше.
Создание нескольких похожих или одинаковых сайтов
Дубли на сайте появляются, если есть субдомен. Так называют версии ресурса, созданные под определенные регионы. Чтобы не допускать появления дублей, при разработке субдоменов следует уделить внимание написанию новых текстов.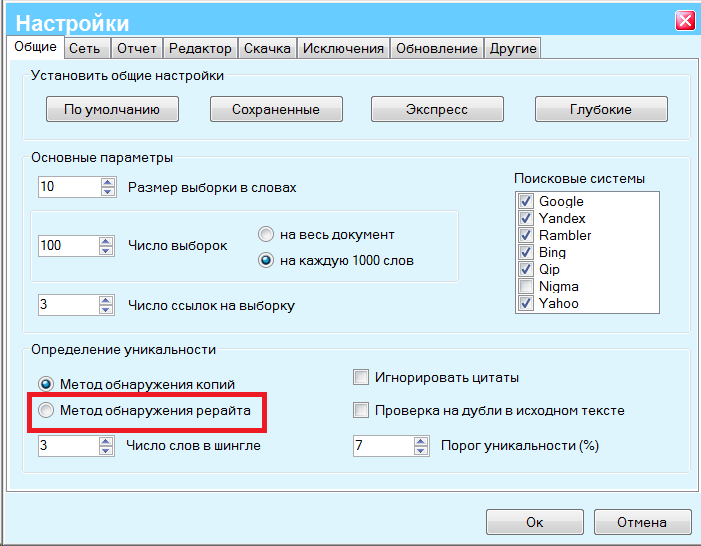
Выводы
Дублирование контента на сайте – проблема распространенная. Порой к ее появлению приводят неожиданные факторы, поэтому важно мониторить ресурс, чтобы выявить их как можно раньше и быстро устранить. Также следует принять меры по предотвращению появления дублей. Для этого необходимо каждую страницу наполнить полезным и уникальным контентом.
Мы, команда Elit-Web, при продвижении сайтов уделяем особое внимание этому аспекту. Чтобы снизить риски образования дублей, веб-ресурс клиента наполняется только уникальным оптимизированным контентом, который создают наши авторы. Ответственный подход к созданию текстов позволяет обеспечивать гарантированный результат и успешное поисковое продвижение сайтов.
КОМПЛЕКСНЫЙ АУДИТ САЙТА
Профессиональный комплексный аудит сайта — глобальный анализ вашего проекта ✔ Подробный отчет с перечнем ошибок и рекомендаций для улучшения ✔ Увеличение конверсий
Получить консультацию
Наш менеджер свяжется с Вами в ближайшее время
Как найти URL-адреса с повторяющимися заголовками страниц?
Аналитика
Заголовок страницы — это короткий текст, описывающий страницу, который можно увидеть на вкладке браузера посетителя и в поиске Google (или других поисковых системах). Это важная часть информации, которая позволяет роботу Googlebot ранжировать страницу и помогает посетителю перемещаться по результатам поиска.
Это важная часть информации, которая позволяет роботу Googlebot ранжировать страницу и помогает посетителю перемещаться по результатам поиска.
Название страницы должно быть уникальным для каждой страницы и каждого URL-адреса страницы. Если один и тот же заголовок страницы используется для многих страниц, это влияет на SEO и приводит посетителей в замешательство. Это как если бы несколько книг имели одинаковое название и разное содержание. Вы бы не смогли различить их с первого взгляда.
Так что хорошо бы, чтобы заголовки ваших страниц были уникальными и не дублировались. Теперь, если вам нужно проверить наличие дубликатов, вы можете использовать настраиваемые отчеты в Piwik PRO.
Найти повторяющиеся заголовки страниц
Чтобы найти повторяющиеся заголовки, выполните следующие действия:
- Перейдите в Меню > Аналитика .
- Перейдите к Пользовательские отчеты .
- Нажмите Добавить новый отчет .
- Выберите следующий тип отчета: Проводник . Мы используем этот тип, потому что нам нужно создавать вложенные таблицы.
- Назовите отчет.
- Выберите параметр Видимость : Автор или Все пользователи . Параметр Все пользователи позволяет поделиться этим отчетом с другими участниками команды.
- Выберите следующие параметры: название страницы и URL страницы . Перетащите элементы из меню аттракциона в левую точку сброса.
- Добавьте несколько показателей, например сеансов и просмотров страниц .
- В Измерения фильтра установите следующий фильтр:
Тип события — Просмотр страницы.Примечание: Мы добавляем этот фильтр, чтобы убедиться, что в отчет включены только страницы, записанные с просмотрами страниц.
- Нажмите Создать отчет .
- Теперь выберите диапазон данных для отчета.
- Посмотрите список заголовков страниц.
- Щелкните заголовок страницы.
- Просмотр URL-адресов страниц, связанных с заголовком страницы.
В нашем случае у нас есть две URL-адреса страниц,
/product-tourи/blog/product-tourдля заголовка одной страницы,Product Tour. Похоже, кто-то создал запись в блоге с названием страницыОбзор продукта, которое также используется для страницы с описанием продукта. Как только мы это узнаем, мы можем исправить заголовок страницы для сообщения в блоге и убрать дубликаты. - Проверьте заголовки других страниц в этом отчете.

Время от времени запускайте этот отчет, чтобы содержание вашего веб-сайта было хорошо организовано и оптимизировано для поисковой оптимизации и посетителей. Хорошая практика, удачи.
Была ли эта статья полезной?
Да НетТехническая поддержка
Если у вас остались вопросы, посетите наше сообщество. Всегда есть кто-то, кто готов помочь!
Как найти повторяющийся контент
Обновлено: 16 апреля 2023 г.
Узнайте, как найти дублированный контент на своем веб-сайте с помощью JetOctopus.
В этом руководстве я покажу вам , как найти дублированный контент на вашем веб-сайте и объясню, почему важно быть в курсе любых потенциальных проблем.
Хотя дублирование контента не всегда является проблемой, полезно следить за ним и оценивать, нужно ли его устранять.
Я также предоставлю некоторые решения для устранения проблем с дублирующимся контентом и включу раздел часто задаваемых вопросов, который охватывает ряд тем, связанных с дублирующимся контентом.
К концу у вас будет четкое представление о том, как сохранить уникальность контента вашего сайта и оптимизировать его для SEO.
Давайте погрузимся в это!
TL;DR: как финансировать дублированный контент на вашем сайте
Что такое дублированный контент?
А как насчет штрафа за дублирование контента?
Начните работу с JetOctopus бесплатно
Как найти дублированный контент на вашем сайте с помощью JetOctopus
Обзор дублирования
Повторяющиеся заголовки
Повторяющиеся мета-описания
Дублировать h2
Дублировать h3
Дублированный контент
Знать, когда дублированный контент не является проблемой
Как исправить проблемы с дублированием контента
Внедрить канонические теги
Создавайте уникальный контент для похожих страниц
Перенаправить, объединить или удалить дубликаты страниц
Часто задаваемые вопросы о дублирующемся контенте
Заключительные слова мудрости
TL;DR: Как финансировать дублированный контент на вашем веб-сайте
Чтобы быстро определить, есть ли на вашем веб-сайте дублированный контент , просто просканируйте его с помощью поискового робота, такого как JetOctopus. После завершения сканирования перейдите к Дублирование Сообщите и просмотрите проблемы с дублированием контента на вашем веб-сайте.
После завершения сканирования перейдите к Дублирование Сообщите и просмотрите проблемы с дублированием контента на вашем веб-сайте.
Что такое дублированный контент?
Дублирующееся содержимое относится к содержимому, которое либо точно такое же, либо очень похожее и появляется более чем на одной веб-странице. Это может вызвать проблемы у поисковых систем, когда они пытаются решить, какую версию ранжировать или отображать в результатах поиска.
Существуют различные типы дублированного контента, о которых вам следует знать:
- Точные дубликаты — это когда содержимое полностью идентично на нескольких страницах. Это может произойти из-за копирования и вставки или технических проблем, таких как наличие одного и того же контента на разных URL-адресах.
- Прямые дубликаты — это когда содержание почти такое же, но с небольшими вариациями, такими как переформулировка или изменение порядка абзацев. Это может произойти, когда несколько страниц охватывают одну и ту же тему, но не совпадают в точности.
 Это может произойти, когда несколько страниц охватывают одну и ту же тему, но не совпадают в точности.
Это может произойти, когда несколько страниц охватывают одну и ту же тему, но не совпадают в точности.Конечно, дублирование влияет не только на основной контент вашего веб-сайта; это также может повлиять на важные элементы SEO на странице, такие как:
- Мета-заголовки: Мета-заголовок — это интерактивный заголовок, отображаемый на страницах результатов поисковой системы (SERP) для данной веб-страницы.
Помогает пользователям и поисковым системам понять тему вашей страницы. Дублирование мета-заголовков может сбить с толку поисковые системы и негативно повлиять на ваш рейтинг, поскольку они могут с трудом различать страницы с одинаковыми заголовками.
Конечно, Google очень любит переписывать мета-заголовки, но это очень важный сигнал для поисковых систем о том, о чем страница на самом деле.
- Мета-описания: Мета-описание — это краткое изложение содержания веб-страницы, которое появляется под мета-заголовком в поисковой выдаче.

Уникальное и хорошо написанное мета-описание может улучшить показатель кликабельности (CTR), побуждая пользователей переходить на вашу страницу.
Повторяющиеся метаописания могут ввести в заблуждение поисковые системы и пользователей и потенциально снизить воспринимаемую релевантность нашей страницы.
Google также очень любит переписывать метаописания, а метаописания не являются фактором ранжирования, но по-прежнему рекомендуется делать их уникальными для каждой страницы.
- Теги h2: Тег h2 является основным заголовком веб-страницы и обычно является заголовком или основной темой контента. Это имеет решающее значение для SEO на странице, поскольку помогает поисковым системам определить фокус страницы.
Дублирование тегов h2 на разных страницах может затруднить поисковым системам понимание структуры вашего сайта и определение того, какие страницы должны иметь приоритет в поисковом рейтинге.
- Теги h3: Теги h3 — это подзаголовки, используемые для организации вашего контента в более мелкие, легко усваиваемые разделы. Они также помогают поисковым системам понять структуру и иерархию вашего контента.
Подобно тегам h2, повторяющиеся теги h3 могут вызвать путаницу у поисковых систем и негативно повлиять на SEO вашего сайта.
 Они также помогают поисковым системам понять структуру и иерархию вашего контента.
Они также помогают поисковым системам понять структуру и иерархию вашего контента.Как насчет штрафа за дублирование контента?
Существует распространенный миф о «штрафе за дублирование контента», но правда в том, что Google не наказывает напрямую за дублирование контента t.
Если штрафа нет, то каковы возможные негативные последствия дублирования контента?
- Когда поисковые системы сталкиваются с дублирующимся контентом, они изо всех сил пытаются определить, какую версию индексировать и отображать в результатах поиска. Это может привести к тому, что предпочитаемая вами версия не будет отображаться.
- Дублированный контент может уменьшить ваш ссылочный вес, поскольку обратные ссылки, указывающие на разные версии одного и того же контента, распределяются между этими версиями. Объединение этих ссылок в одну страницу значительно повысит авторитет вашей страницы и шансы на более высокий рейтинг.
- Наличие дублированного контента на вашем веб-сайте может привести к ухудшению взаимодействия с пользователем. Пользователи могут быть сбиты с толку или разочарованы, если они столкнутся с одним и тем же контентом на нескольких страницах, что приведет к увеличению показателя отказов и снижению вовлеченности пользователей.
- Поисковые системы выделяют определенный краулинговый бюджет для каждого веб-сайта, который определяет, сколько страниц они будут сканировать в течение определенного периода времени. Дублированный контент может привести к трате вашего краулингового бюджета, так как поисковые системы будут тратить время на сканирование и индексацию повторяющихся страниц вместо того, чтобы обнаруживать новый уникальный контент на вашем сайте.
Начните работу с JetOctopus бесплатно
Вы можете использовать различные инструменты SEO-сканирования, чтобы помочь вам найти дублированный контент на веб-сайте, например JetOctopus , Semrush Site Audit, Screaming Frog , Sitebulb , Ahrefs Site Audit и т. д.
д.
Я использую JetOctopus и приглашаю вас использовать его, который предлагает бесплатную 7-дневную пробную версию.
Зарегистрироваться в JetOctopus очень просто.
- Зайдите на их веб-сайт и нажмите кнопку «Бесплатная 7-дневная пробная версия».
- Заполните необходимую информацию и создайте учетную запись. Для бесплатной пробной версии кредитная карта не требуется, поэтому вы можете попробовать ее без каких-либо обязательств.
- После регистрации нажмите «Добавить новый веб-сайт».
- Затем подключите свой веб-сайт, следуя приведенным там инструкциям. Первое сканирование начнется автоматически.
Готово? Давайте теперь проверим дублированный контент.
Как найти дублированный контент на вашем веб-сайте с помощью JetOctopus
Затем выполните следующие шаги, чтобы найти дублированный контент на вашем веб-сайте.
- Щелкните только что созданный проект. В моем случае это «SEOSLY SITE» для целей этого руководства.

- Щелкните последнее сканирование из списка сканирования .
- Перейдите на вкладку Duplication (в отчете Crawler ).
- Этот отчет организован по различным категориям, чтобы помочь вам определить точный тип обнаруженного дублирования:
Обзор дублирования
Вкладка Обзор содержит сводку обо всех проблемах дублирования на вашем сайте, таких как повторяющиеся заголовки, метаописания, h2, h3 и основной текст.
Он также позволяет фильтровать страницы с дублирующимся содержимым по индексируемости, нахождению в определенной подпапке (например, /blog), посещению роботом GoogleBot или посещению роботом GoogleBot.
Повторяющиеся заголовки На этой вкладке отображается список страниц с одинаковыми или похожими заголовками. Вы также можете отфильтровать их так же, как вы могли отфильтровать страницу в отчете Обзор .
На этой вкладке вы найдете страницы с повторяющимися или почти повторяющимися метаописаниями.
Дубликат h2
Если у вас есть страницы с одинаковыми тегами h2, они будут отображаться на этой вкладке.
Дубликат h3
Аналогично, вкладка Дубликат h3 показывает страницы с дубликатами тегов h3.
Повторяющееся содержимое
Наконец, на этой вкладке выделяются страницы с точным или почти повторяющимся содержимым в основном тексте.
Как понять, что дублированный контент не является проблемой
Хотя дублированный контент может вызвать проблемы с SEO вашего сайта, бывают ситуации, когда это не проблема.
Вот три сценария, в которых дублированный контент не представляет угрозы для SEO вашего веб-сайта:
- Канонизированные страницы: Точно так же, если у вас есть дублированный контент на страницах с каноническим тегом, указывающим на первоисточник, поисковые системы будут понимать, что дублирование является преднамеренным и будет индексировать и ранжировать только исходную, каноническую версию.
Имейте в виду, что Google воспринимает
rel="canonical"как подсказку и может выбрать другую каноническую версию страницы, отличную от той, которую вы указали.В JetOctopus и большинстве сканеров веб-сайтов канонизированные страницы попадают в категорию неиндексируемых страниц.
- Страницы, которые вы не хотите ранжировать: Иногда у вас может быть дублированный контент на страницах, которые не предназначены для ранжирования в результатах поиска, например правовые оговорки, политики конфиденциальности или условия.
В этих случаях дублированный контент не вызывает беспокойства, поскольку он не влияет на вашу SEO-стратегию или цели.
В моем случае это выпуски SEO-бюллетеней и заметки о SEO-подкастах. Они индексируются, но меня не волнует дублирование контента.
Как исправить проблемы с дублированием контента
Чтобы устранить проблемы с дублированием контента на вашем веб-сайте, рассмотрите следующие решения:
Внедрите канонические теги
Используйте канонические теги, чтобы указать поисковым системам на исходную предпочтительную версию страницы. Хотя Google рассматривает канонические теги как подсказку и может выбрать другой канонический URL-адрес, все же рекомендуется использовать их.
Хотя Google рассматривает канонические теги как подсказку и может выбрать другой канонический URL-адрес, все же рекомендуется использовать их.
Проверьте Инструмент проверки URL в Google Search Console, чтобы увидеть каноническую ссылку, которую Google выбрал для данного URL. Это гарантирует, что исходная страница будет проиндексирована и ранжирована, а дубликаты будут объединены.
Создавайте уникальный контент для похожих страниц
Убедитесь, что каждая страница вашего веб-сайта имеет определенное назначение и уникальный контент. Переориентируйте дубликаты страниц на другие ключевые слова, чтобы сделать их уникальными и ценными для пользователей. Это не только улучшает взаимодействие с пользователем, но и помогает поисковым системам различать страницы и ранжировать их соответствующим образом.
Перенаправление, объединение или удаление повторяющихся страниц
Если у вас есть несколько страниц с одинаковым содержимым, рассмотрите возможность использования перенаправления 301, чтобы направлять пользователей и поисковые системы к предпочтительной версии. Вы также можете объединить дубликаты страниц вместе, объединив их содержимое и добавив переадресацию 301 с удаленных страниц на объединенные.
Вы также можете объединить дубликаты страниц вместе, объединив их содержимое и добавив переадресацию 301 с удаленных страниц на объединенные.
Можно также удалить дубликаты страниц. Это поможет поисковым системам сканировать и индексировать ваш сайт более эффективно. Однако перед удалением страниц обязательно ознакомьтесь с моим руководством о том, вредят ли ошибки 404 SEO.
Часто задаваемые вопросы о дублирующемся контенте
Вот наиболее часто задаваемые вопросы о дублирующемся контенте. Они должны забить тему дублирования контента до смерти.
Что такое дублированный контент и почему это проблема для SEO моего сайта?Дублированный контент — это идентичный или почти идентичный контент, который появляется на нескольких страницах вашего веб-сайта. Это может негативно повлиять на SEO вашего сайта, запутав поисковые системы и снизив ваши шансы на высокий рейтинг.
Какие бывают типы дублированного контента? Существует два основных типа дублированного контента: точные дубликаты (полностью идентичный контент) и почти дубликаты (почти одинаковый контент с небольшими вариациями).
Дублированный контент может сбить с толку поисковые системы и снизить шансы вашего сайта на высокий рейтинг, поскольку они могут с трудом различать страницы с одинаковыми элементами SEO на странице, такими как мета-заголовки, мета-описания, теги h2 и h3.
Существует ли штраф за дублирование контента со стороны Google?Google не наказывает напрямую за дублирование контента. Однако дублированный контент может негативно повлиять на рейтинг вашего сайта и его видимость в результатах поиска.
Каковы негативные последствия дублирования контента на моем веб-сайте? Негативные последствия наличия дублированного контента включают трудности для поисковых систем с определением, какую версию индексировать, размытый вес ссылок, плохое взаимодействие с пользователем и потраченный впустую краулинговый бюджет.
Дублированный контент не является проблемой, если он относится к неиндексируемым или канонизированным страницам или если он появляется на страницах, которые вы не хотите ранжировать, например, юридические заявления об отказе от ответственности или политики конфиденциальности.
Как реализовать канонические теги для решения проблем с дублированием контента? Чтобы реализовать канонические теги, добавьте тег rel="canonical" к страницам-дубликатам, указывающий на исходную предпочтительную версию страницы. Это помогает поисковым системам понять, какую страницу индексировать и ранжировать.
Чтобы создать уникальный контент для похожих страниц, убедитесь, что каждая страница служит определенной цели, и переориентируйте повторяющиеся страницы на разные ключевые слова. Это поможет поисковым системам различать страницы и улучшить взаимодействие с пользователем.
Это поможет поисковым системам различать страницы и улучшить взаимодействие с пользователем.
Для устранения повторяющихся страниц вы можете использовать переадресацию 301, чтобы направлять пользователей и поисковые системы к предпочтительной версии, объединять повторяющиеся страницы, объединяя их содержимое и добавляя переадресацию 301 с удаленных страниц к объединенным, или удалять дубликаты страниц, чтобы облегчить поиск. поисковые системы сканируют и индексируют ваш сайт более эффективно. Перед удалением страниц обязательно проверьте потенциальное влияние на SEO и убедитесь, что вы не вызываете ненужных ошибок 404.
Как дублированный контент влияет на трафик и конверсии моего веб-сайта? Дублированный контент может привести к ухудшению видимости в результатах поиска, поскольку поисковым системам может быть сложно определить наиболее релевантную страницу для ранжирования. Это может привести к снижению органического трафика и, как следствие, снижению конверсии. Кроме того, дублированный контент может ухудшить взаимодействие с пользователем, поскольку посетители могут разочароваться, увидев один и тот же контент на нескольких страницах. Это может привести к увеличению показателей отказов и снижению вовлеченности пользователей, что негативно скажется на общей производительности вашего сайта.
Это может привести к снижению органического трафика и, как следствие, снижению конверсии. Кроме того, дублированный контент может ухудшить взаимодействие с пользователем, поскольку посетители могут разочароваться, увидев один и тот же контент на нескольких страницах. Это может привести к увеличению показателей отказов и снижению вовлеченности пользователей, что негативно скажется на общей производительности вашего сайта.
Внутренние ссылки могут сыграть роль в решении проблем с дублированием контента, помогая поисковым системам понять иерархию и структуру вашего сайта. Тщательно структурируя свои внутренние ссылки, вы можете направлять поисковые системы на самые важные страницы и выделять связи между вашим контентом. Это может помочь поисковым системам определить наиболее релевантные и уникальные страницы на вашем сайте, уменьшая влияние дублированного контента. Однако внутренние ссылки не являются самостоятельным решением проблем дублирования контента, и вам все же следует рассмотреть возможность использования канонических тегов, создания уникального контента и объединения или перенаправления дубликатов страниц по мере необходимости.
Однако внутренние ссылки не являются самостоятельным решением проблем дублирования контента, и вам все же следует рассмотреть возможность использования канонических тегов, создания уникального контента и объединения или перенаправления дубликатов страниц по мере необходимости.
Если вы используете описания продуктов от производителей, существует высокая вероятность того, что многие другие веб-сайты используют тот же контент. Чтобы избежать проблем с дублированием контента, вы можете переписать описания продуктов, чтобы создать уникальный контент для своего веб-сайта. Сосредоточьтесь на предоставлении дополнительной ценности вашим посетителям, подчеркивая особенности и преимущества продукта, решая потенциальные проблемы клиентов и добавляя релевантные ключевые слова для улучшения SEO.
Если я использую цитаты или выдержки с других веб-сайтов, будет ли это считаться дублирующимся содержанием? Использование цитат или выдержек из других источников может быть приемлемым при условии, что вы правильно указываете авторство первоисточника и сопровождаете цитируемый контент своими собственными уникальными идеями или комментариями. Однако, если вы в значительной степени полагаетесь на цитируемый контент или если цитаты составляют значительную часть вашей страницы, поисковые системы все равно могут считать это дублирующим контентом. Чтобы свести к минимуму риск, убедитесь, что вы добавили на свои страницы существенный оригинальный контент вместе с цитатами или выдержками.
Однако, если вы в значительной степени полагаетесь на цитируемый контент или если цитаты составляют значительную часть вашей страницы, поисковые системы все равно могут считать это дублирующим контентом. Чтобы свести к минимуму риск, убедитесь, что вы добавили на свои страницы существенный оригинальный контент вместе с цитатами или выдержками.
Если другие веб-сайты копируют ваш контент без разрешения, это может привести к проблемам с дублированием контента, которые потенциально могут повлиять на SEO вашего веб-сайта. Поисковые системы могут испытывать трудности с определением того, какую версию контента ранжировать и отображать в результатах поиска. В некоторых случаях скопированный контент может опережать исходный контент, что может привести к потере органического трафика. Чтобы защитить свой контент и поддерживать рейтинг в поисковых системах, рассмотрите возможность использования таких инструментов, как Copyscape или Google Alerts, для отслеживания в Интернете случаев дублирования контента. Если вы обнаружите, что ваш контент используется без разрешения, вы можете попросить веб-сайт, нарушающий авторские права, удалить этот контент или предоставить надлежащую атрибуцию через обратную ссылку на ваш сайт.
Если вы обнаружите, что ваш контент используется без разрешения, вы можете попросить веб-сайт, нарушающий авторские права, удалить этот контент или предоставить надлежащую атрибуцию через обратную ссылку на ваш сайт.
Хотя дубликаты изображений не так сильно влияют на SEO, как дублирование текстового контента, все же рекомендуется использовать уникальные изображения, когда это возможно. Поисковые системы предпочитают свежий и оригинальный контент, поэтому использование уникальных изображений может улучшить взаимодействие с пользователем и потенциально улучшить ваш рейтинг.
Приводит ли использование стандартного текста к проблемам с дублированием содержимого? Стандартный текст, такой как нижние колонтитулы, заявления об отказе от ответственности или юридическая информация, как правило, не рассматривается поисковыми системами как дублирующий контент. Однако убедитесь, что шаблонный текст не является основным элементом страницы и что на каждой странице достаточно уникального контента, чтобы отличать ее от других.
Внутреннее дублированное содержимое, которое появляется на вашем собственном веб-сайте, как правило, менее вредно, чем внешнее дублированное содержимое, обнаруженное на нескольких веб-сайтах. Тем не менее, по-прежнему важно устранять внутренний дублированный контент, чтобы избежать размывания ссылочного капитала, траты краулингового бюджета и путаницы поисковых систем.
Есть ли разница между дубликатом и неполным содержимым? Дублированное содержимое относится к идентичному или почти идентичному содержимому, появляющемуся на нескольких страницах, в то время как неполноценное содержимое относится к страницам, практически не имеющим ценности или содержания. Хотя оба типа могут негативно повлиять на SEO, дублированный контент в первую очередь влияет на индексацию и ранжирование поисковой системы, в то время как слабый контент может привести к ухудшению пользовательского опыта и снижению показателей вовлеченности.