
HTML5 | Простой документ
134
Веб-программирование — HTML5 — Простой документ HTML5
Рассмотрим один из простейших документов HTML5. Он начинается с указания типа документа с помощью специального кода описания типа документа (значение этого кода объясняется в следующем разделе), после чего задается кодировка и название документа, а потом идет его содержимое. В данном случае содержимое состоит из одного абзаца текста:
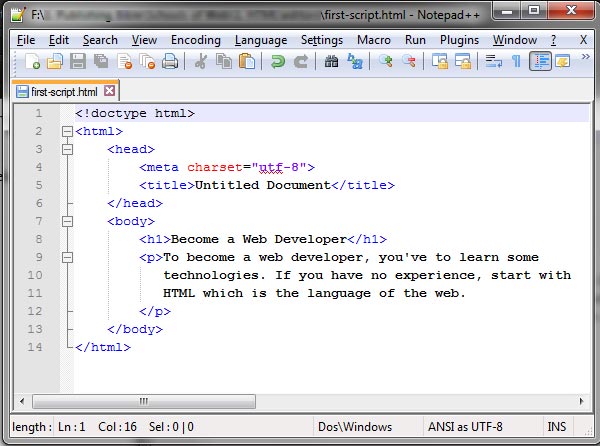
<!DOCTYPE HTML> <meta charset="utf-8"> <title>Крошечный документ HTML5</title> <p>Дадим встряску браузеру в стиле HTML5!</p>
Этот простой документ можно упростить еще больше. Например, конечный тег </р> вообще-то не является обязательным в стандарте HTML5, т. к. браузеры знают, как закрывать все открытые элементы в конце документа (а стандарт HTML5 узаконивает это поведение). Но подобное срезание углов вместо упрощения делает разметку более сложной для понимания и может вызвать неожиданные ошибки.
Большинство веб-разработчиков придерживается мнения, что использование традиционных разделов <head> и <body> полезно для облегчения восприятия документа, т.к. они четко разделяют информацию о странице (заголовок страницы) и само содержимое (основная часть страницы). Такая структура особенно полезна, когда к странице добавляются сценарии, таблицы стилей и метаэлементы:
<!DOCTYPE HTML> <head> <meta charset="utf-8"> <title>Крошечный документ HTML5</title> </head> <body> <p>Дадим встряску браузеру в стиле HTML5!</p> </body>
Наконец, весь документ (за исключением строки doctype) можно облачить в традиционный элемент <html>, как показано в следующем листинге:
<!DOCTYPE HTML> <html> <head> <meta charset="utf-8"> <title>Крошечный документ HTML5</title> </head> <body> <p>Дадим встряску браузеру в стиле HTML5!</p> </body> </html>
Вплоть до HTML5 в каждой версии официальной спецификации HTML требовалось использование элемента <html>, несмотря на то, что наличие этого элемента никаким образом не влияет на обработку браузером остального кода страницы. В HTML5 использование этого элемента оставлено полностью на личное усмотрение разработчика.
В HTML5 использование этого элемента оставлено полностью на личное усмотрение разработчика.
Использование элементов <html>, <head> и <body> является просто вопросом стиля. Страница без этих элементов будет работать отличнейшим образом даже на старых браузерах, которые и слыхом не слыхивали ни о каком HTML5. Фактически, браузер автоматически предполагает наличие этих элементов. Поэтому, если посмотреть на модель DOM (набор программных объектов, представляющих страницу) страницы с помощью сценария JavaScript, она будет содержать объекты для элементов <html>, <head> и <body>, даже если разработчик и не использовал их.
На данном этапе этот пример страницы является чем-то средним между самым простым HTML5-документом и расширенной отправной точкой практической веб-страницы HTML5. В последующих разделах мы добавим к нему остальные необходимые элементы и копнем глубже в разметку.
Описание типа документа HTML5
В первой строке каждого HTML5-документа всегда дается описание типа документа. Это описание ясно указывает, что далее следует HTML5-содержимое, и выглядит следующим образом:
Это описание ясно указывает, что далее следует HTML5-содержимое, и выглядит следующим образом:
<!DOCTYPE HTML>
Первое, что бросается в глаза в описании типа документа HTML5 — это его поразительная простота. Сравните его, например, с неуклюжим описанием типа документа, который требуется использовать веб-разработчикам при работе со строгим XHTML 1.0:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0
Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">Даже профессиональные веб-разработчики были вынуждены вставлять описание типа документа XHTML методом копирования и вставки из другого документа. А описание типа документа HTML5 короткое, четкое и легко вводится вручную.
Описание типа документа HTML5 также примечательно тем, что оно не содержит номера официальной версии HTML (5 для HTML5). В нем просто указывается, что страница является HTML-страницей. Это соответствует новой концепции HTML5 как живого языка. Добавленные в HTML новые возможности автоматически доступны для размещения на странице, не требуя для этого изменений в описании типа документа.
Все это порождает непростой вопрос: если HTML5 — живой язык, то зачем тогда для страницы вообще нужно описание типа документа?
Ответ на этот вопрос таков: описание типа документа продолжает использоваться по историческим причинам. При обработке страницы с отсутствующим описанием типа документа большинство браузеров (включая Internet Explorer и Firefox) переходят в режим совместимости (quirks mode). В этом режиме они пытаются отобразить страницу с учетом ошибок в правилах, которые использовались в более ранних версиях. Проблема с этим состоит в том, что режим совместимости одного браузера может отличаться от режима совместимости другого браузера, вследствие чего страницы, разработанные для одного браузера, на другом браузере будут, скорее всего, отображаться с ошибками, такими как неправильный размер шрифта, нарушенная структура оформления и т.п.
А обнаружив на странице описание типа документа, браузер знает, что обработку этой страницы требуется выполнять, следуя более строгим правилам
режима стандартов (standards mode), который обеспечивает единообразное форматирование и структуру страницы при ее отображении любым современным браузером. За некоторыми исключениями, браузеру совершенно безразлично, какой именно тип документа указан в описании. Он просто проверяет, что страница имеет какое-либо описание типа документа. Описание типа документа HTML5 просто самое короткое действительное описание типа документа, которое задействует режим стандартов браузера.
За некоторыми исключениями, браузеру совершенно безразлично, какой именно тип документа указан в описании. Он просто проверяет, что страница имеет какое-либо описание типа документа. Описание типа документа HTML5 просто самое короткое действительное описание типа документа, которое задействует режим стандартов браузера.Кодировка символов
Кодировка — это стандарт, указывающий компьютеру, каким образом преобразовывать текст в последовательность байтов при записи текста в файл (а также, как выполнять обратное преобразование при открытии файла). По историческим причинам в мире существует множество разных кодировок. В настоящее время практически на всех веб-сайтах используется компактная и быстрая кодировка UTF-8, поддерживающая все символы других алфавитов, которые вам когда-либо могут потребоваться.
Веб-серверы часто настраивают, чтобы сообщать посещающим их браузерам, что предлагаемые сервером страницы имеют определенную кодировку. Но нельзя быть уверенным, что веб-сервер, на котором вы планируете разместить свой веб-сайт, будет настроен таким образом (если только это не ваш собственный сервер). Кроме этого, попытка браузера в таком случае предположить наиболее вероятную используемую кодировку может претерпеть неудачу по причине какого-либо малоизвестного вопроса безопасности. По этим причинам всегда следует вставлять информацию об используемой кодировке в разметку страницы.
Кроме этого, попытка браузера в таком случае предположить наиболее вероятную используемую кодировку может претерпеть неудачу по причине какого-либо малоизвестного вопроса безопасности. По этим причинам всегда следует вставлять информацию об используемой кодировке в разметку страницы.
HTML5 делает эту задачу легкой. Для этого нужно лишь вставить элемент <meta> в самом начале блока <head> (или, если элемент <head> не используется, сразу же после кода описания типа документа):
<!DOCTYPE HTML> <head> <meta charset="utf-8"> <title>Крошечный документ HTML5</title> </head>
Инструменты для веб-разработки, такие как Dreamweaver или Expression Web, вставляют этот элемент автоматически при создании страницы. Эти инструменты также обеспечивают сохранение файлов в кодировке UTF. Но при создании веб-страницы с помощью обычного текстового редактора, чтобы обеспечить сохранение файлов в правильной кодировке, может потребоваться выполнить дополнительные шаги.
Язык
Считается хорошим тоном указывать естественный язык веб-страницы. Эта информация может быть иногда полезной для других, например, поисковые движки могут использовать ее для фильтрации результатов поиска, чтобы возвратить только страницы на указанном языке.
Чтобы указать язык для какого-либо содержимого, используется атрибут lang в любом элементе разметки с заданием кода требуемого языка. Код для русского языка — ru, а для английского — en. Коды для других языков можно узнать на странице people.w3.org/rishida/utils/subtags.
Вставить в веб-страницу информацию о языке легче всего через элемент <html>:
<html lang="ru">
Информация о языке также может быть полезной, если страница содержит текст на разных языках, который нужно прочитать с помощью программы чтения экранного текста. В таком случае атрибут lang с кодом соответствующего языка вставляется в нужном месте документа, например, в элементы <div>, охватывающие текст на разных языках.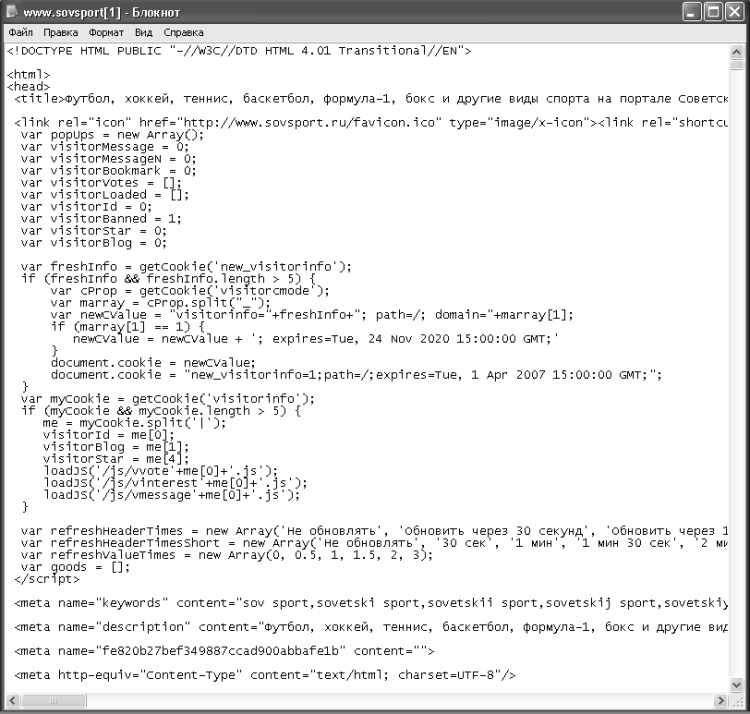 Таким образом, программа чтения экранного текста способна определить, какой текст она может читать.
Таким образом, программа чтения экранного текста способна определить, какой текст она может читать.
Добавление таблицы стилей
Практически в каждой странице должным образом разработанного профессионального веб-сайта используются таблицы стилей. Для указания требуемой таблицы стилей используется элемент <link>
<head> <meta charset="utf-8"> <title>Крошечный документ HTML5</title> <link href="style.css" rel="stylesheet"> </head>
Этот способ похож на указание таблиц стилей в традиционных HTML-документах, но немного проще. Так как существует единственный язык каскадных таблиц стилей — CSS, то в добавлении атрибута type=»text/css», который требовался ранее, больше нет надобности.
Добавление JavaScript-кода
Язык сценариев JavaScript изначально создавался как средство для трудоемкого способа придания блеска и обаяния скучным веб-страницам. В настоящее время основная область применения JavaScript сместилась с разработки прибамбасов интерфейса на разработку нестандартных веб-приложений, включая сверхэффективных клиентов электронной почты, текстовых редакторов и картографических движков, которые исполняются непосредственно в браузере.
В настоящее время основная область применения JavaScript сместилась с разработки прибамбасов интерфейса на разработку нестандартных веб-приложений, включая сверхэффективных клиентов электронной почты, текстовых редакторов и картографических движков, которые исполняются непосредственно в браузере.
Код JavaScript вставляется в документ HTML5 по большому счету таким же способом, как и в традиционную HTML-страницу. В следующем листинге приводится пример вставки в веб-документ кода JavaScript по ссылке на внешний файл:
<head> <meta charset="utf-8"> <title>Крошечный документ HTML5</title> <script src="script.js"></script> </head>
Атрибут language=»JavaScript» не является обязательным, т. к. если не указан какой-либо другой язык сценариев (а поскольку JavaScript — единственный широко-поддерживаемый язык сценариев для HTML, то вероятность такого развития ничтожно мала), браузеры автоматически предполагают, что используется JavaScript. Но даже ссылаясь на внешний файл с кодом JavaScript, все равно нужно помнить о закрывающем теге </script>. Если упустить этот тег по недосмотру или при попытке укоротить код, используя синтаксис пустых элементов, то страница не будет работать должным образом.
Но даже ссылаясь на внешний файл с кодом JavaScript, все равно нужно помнить о закрывающем теге </script>. Если упустить этот тег по недосмотру или при попытке укоротить код, используя синтаксис пустых элементов, то страница не будет работать должным образом.
Если вы уделяете много времени тестированию своих страниц с JavaScript в Internet Explorer, может быть полезным добавление метки MOTW (Mark of the Web — метка особенности сети) в блок <head> сразу же после строки кодировки. Делается это таким образом:
<head> <meta charset="utf-8"> <!-- saved from url=(0014)about:internet --> <title>Крошечный документ HTML5</title> <script src="script.js"></script> </head>
Эта строка кода указывает Internet Explorer обрабатывать страницу таким образом, как будто бы она была загружена с удаленного веб-сайта. В противном случае IE переключается в особый режим блокировки, выводит предупреждение безопасности в строке сообщений и отказывается исполнять любой код JavaScript до тех пор, пока вы не нажмете кнопку «Разрешить заблокированное содержимое».
Все другие браузеры не обращают внимания на метку MOTW и используют одни и те же настройки безопасности как для страниц, загружаемых с удаленных веб-сайтов, так и для локальных файлов HTML.
Как утащить простой сайт за 5 минут
Когда начинаешь практиковаться в вёрстке сайтов, может быть очень полезно разобраться, как устроены сайты у других ребят. Вот как это сделать.
👉 Всё, что мы делаем в этой статье, мы делаем в учебных целях. Если вы просто скопируете себе чужой сайт и будете выдавать его за свой, это может плохо кончиться.
💡 На самом деле всё сказанное в этой статье нужно для тех, кто боится отключения интернета и хочет сохранить у себя на компьютере самую важную информацию. Но эта мысль бредовая сразу на стольких уровнях, что мы стесняемся её произносить вслух. Разве что шёпотом.
В чём идея
Мы будем копировать чужой сайт, чтобы его можно было запустить на своём сервере или на домашнем компьютере. Задача — не просто открыть сайт в браузере и посмотреть его код, а забрать из него все важные файлы — и стили, и скрипты, и изображения. Чтобы было проще, мы будем практиковаться на одностраничном сайте, но всё то же самое будет работать и на многостраничном.
Чтобы было проще, мы будем практиковаться на одностраничном сайте, но всё то же самое будет работать и на многостраничном.
❌ Мы не сможем утащить чужие PHP-скрипты и страницы, связанные с данными пользователя (например, не сможем утащить из интернет-магазина рабочую версию корзины с покупками). Для этого нужен доступ к файлам сервера, а этого у нас нет.
Главный принцип этой работы: когда ваш браузер запрашивает страницу чужого сайта, веб-сервер отправляет ему эту страницу, в буквальном смысле. То же с картинками, стилями и скриптами: каждый раз, когда вы посещаете сайт, вы как будто делаете его копию у себя на компьютере. Браузер получает страницу от сервера и выводит её копию на экран, а в памяти держит исходный код. Разве что он не сохраняет эту страницу на диск, чтобы вы могли её редактировать.
Вот этот последний этап мы и исправим: теперь мы будем сохранять чужие сайты к себе на диск.
Весь процесс покажем на примере сайта ux-posters.ru – простом одностраничном сайте, где есть картинки, стили и скрипты. Автору этого текста пришлось помогать авторам этого сайта с похожей задачей, так что пример свеженький.
Автору этого текста пришлось помогать авторам этого сайта с похожей задачей, так что пример свеженький.
Быстрый путь: грабберы
Есть категория программ под названием «веб-грабберы», или «веб-рипперы». Они работают так:
- Ты говоришь программе, на какую страницу сайта зайти.
- Программа собирает все ссылки с этой страницы, переходит по этим ссылкам и строит себе виртуальную карту сайта — то есть пытается понять, сколько на этом сайте страниц и как они связаны.
- Потом граббер начинает ползать по этим страницам подряд, запрашивать их у сервера, получать ответы и сохранять ответы на вашем жёстком диске.
- В какой-то момент граббер останавливается, потому что он скачал все доступные ему страницы с этого сайта.
После работы граббер оставляет у вас на диске гору файлов, которые представляют собой статичный отпечаток чужого сайта. Эту гору можно загрузить на собственный сервер, и издалека это будет похоже на чужой сайт.
✅ Плюсы: граббер может быстро охватить много страниц и скачать из них огромное количество стилей, картинок и всего подряд. Работа очень быстрая и хорошо автоматизирована.
Работа очень быстрая и хорошо автоматизирована.
❌ Минусы: часто он качает всё без разбора, оставляя на диске много дублей. Также он бессилен с сайтами, в которых контент выводится динамически или имеет нестандартную систему адресации.
💡 В целом грабберы можно использовать, чтобы скачивать сайты библиотек, архивов и других мест, где документов много и всё устроено логично. Например, с помощью граббера можно скачать какую-нибудь классическую книгу из онлайн-библиотеки.
Вот ссылки на грабберы для разных платформ:
- HTTrack — старый интерфейс из нулевых, но свою задачу выполняет полностью. Бесплатный и надёжный, работает везде.
- Getleft — мультиплатформенный граббер, который пытается выкачивать всё, до чего дотянется, включая PHP-скрипты.
- Cyotek WebCopy — для тех, кто любит только Windows, тоже бесплатный.
Сложный путь: ручное сохранение
Допустим, мы хотим сохранить какую-то отдельную страницу сайта или конкретные её части (например, картинки). Но эти картинки как-то так хитро встроены, что вы не можете просто нажать «Сохранить картинку как…». Тогда потребуется ручной метод.
Но эти картинки как-то так хитро встроены, что вы не можете просто нажать «Сохранить картинку как…». Тогда потребуется ручной метод.
Заходим на страницу и нажимаем в браузере Ctrl + I (в Виндоус) или ⌥ + ⌘ + I (если у вас мак). Появляется окно «Инспектора», где видна внутренняя структура страницы:
Мы видим, что текущий документ в браузере состоит:
- из страницы index.html;
- скрипта likely.js;
- четырёх таблиц стилей;
- шрифтов, подключённых через сервис Google;
- папки с картинками.
Шрифты нам скачивать необязательно — сайт и так их подключит с сервера гугла, а всё остальное скачать нужно. Чтобы не создавать хаос на компьютере, создадим сначала папку ux-posters — в ней будет храниться наш сайт. Потом в эту папку сохраняем все файлы таким способом:
- Нажимаем правой кнопкой мыши на очередной файл.
- Выбираем пункт Save as, или «Сохранить как».
- Пишем имя и расширение файла — точно так, как указано в списке.

- Если лень писать самому — скопируйте перед этим название файла, нажав правую кнопку мыши и выбрав Copy file name, или «Скопировать имя файла».
- Чаще всего название файла подставится само, но если нет — смотрите пункт 4.

Исключения в названии файлов два:
- (index) — это index.html.
- В любом файле знак вопроса и всё, что после него, писать не нужно.
Скачать можно всё, а можно только то, что вам нужно для работы и экспериментов. Например, если вам нужны только стили и код страницы, сохраняйте файлы .css и (index). Если нужны картинки, заходите в папку pics и сохраняйте всё оттуда.
Щёлкаем на очередном файле и выбираем «Сохранить как»Выбираем нашу папку для сохранения и пишем имя файлаЧто в итоге
Если мы пройдёмся по всем папкам и сохраним в них всё нужное нам, у нас получится локальный слепок сайта. Теперь можно:
- Изучить, как он устроен, что-то отредактировать и увидеть результат у себя на компьютере.
- Открыть файл index. html в браузере, и будет ощущение, что вы зашли на сайт, но с локального компьютера. Сайт откроется по протоколу file:// — это так браузер говорит нам, что файл взялся с нашего компьютера, а не из интернета.
- Запустить MAMP и завести на нём локальную копию сайта для экспериментов. Тогда браузер будет думать, что ходит за этим сайтом в интернет. Можно написать какие-нибудь php-скрипты и оживить сайт.
 html в браузере, и будет ощущение, что вы зашли на сайт, но с локального компьютера. Сайт откроется по протоколу file:// — это так браузер говорит нам, что файл взялся с нашего компьютера, а не из интернета.
html в браузере, и будет ощущение, что вы зашли на сайт, но с локального компьютера. Сайт откроется по протоколу file:// — это так браузер говорит нам, что файл взялся с нашего компьютера, а не из интернета. Что нужно поставить на компьютер, чтобы делать сайты
💡 Важно понимать, что перед нами именно «слепок» — то, что мы бы увидели, если бы сервер сегодня ответил на наш запрос. Если завтра сервер будет отвечать по-другому, мы этого в своей локальной копии не увидим.
Когда ещё это пригодится
Защитить сайт перед наплывом пользователей. С помощью грабберов можно быстро создать неубиваемую статическую копию сайта и временно подменить ей динамическую версию сайта. Это полумера, но может сработать. А вообще вместо этого есть специальные надстройки, которые делают почти то же самое, но более умно, — поищите слово «кеширование».
Делаем неубиваемый сайт: статика и динамика
Сделать копию своего блога, личного сайта или ещё чего-то важного вам, если вы потеряли к нему доступ, но сайт всё ещё на ходу.
Если вы едете туда, где не будет интернета, а вам нужна информация с сайта (например, путеводитель по чужой стране). Помните, что динамические карты и видеоролики так не сохранятся.
Сделать собственный «веб-архив» — это сервис, который ползает по сайтам и делает их «слепки» для истории. Благодаря этому сервису можно посмотреть, как выглядели ваши любимые сайты много лет назад — например, Яндекс.
Текст:
Михаил Полянин
Редактор:
Максим Ильяхов
Художник:
Даня Берковский
Корректор:
Ирина Михеева
Вёрстка:
Кирилл Климентьев
Соцсети:
Олег Вешкурцев
Простая HTML-страница для начинающих. Не спорю, HTML является самым основным и… | by Akande Olalekan Toheeb
Photo by Florian Olivo on Unsplash Не спорю, HTML — самый простой и простой язык из существующих.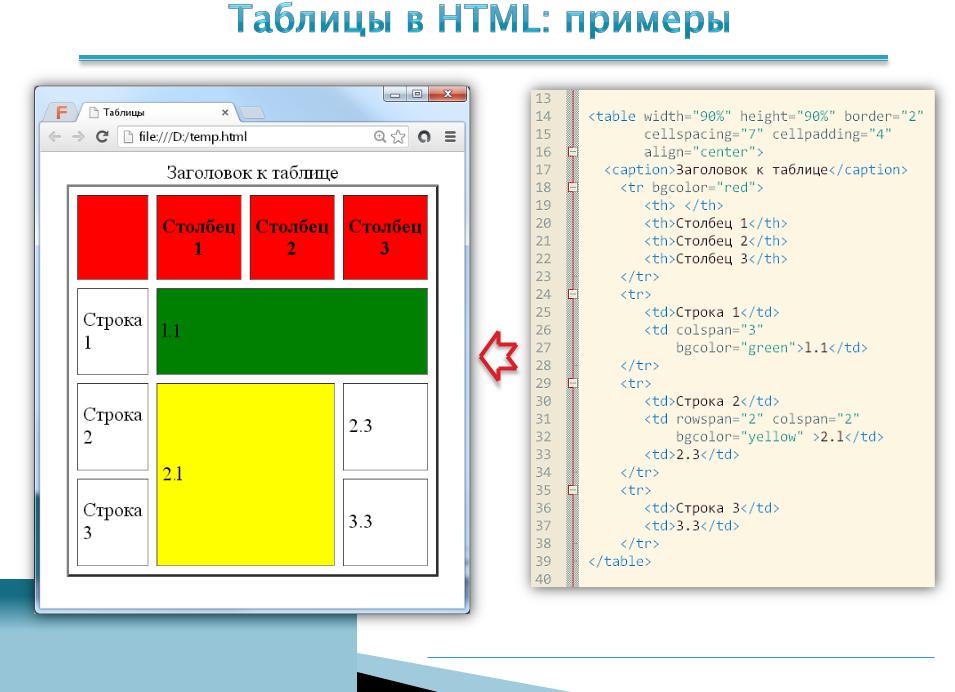 Как новичок, вы должны понимать, что такое веб-языков , как их использовать при разработке желаемого веб-сайта и взаимосвязь между ними. В этой статье я объясню концепцию веб-языка, HTML и как создать простую HTML-страницу. Эта статья написана в трех частях, чтобы сделать ее понятной следующим образом:
Как новичок, вы должны понимать, что такое веб-языков , как их использовать при разработке желаемого веб-сайта и взаимосвязь между ними. В этой статье я объясню концепцию веб-языка, HTML и как создать простую HTML-страницу. Эта статья написана в трех частях, чтобы сделать ее понятной следующим образом:
- Концепция языков веб-программирования .
- Введение в HTML .
- Пошаговое руководство по созданию простой страницы HTML .
Концепция веб-языков
Веб-разработка — обширная отрасль, требующая многих навыков и знаний (см. статью 1). Одним из навыков/знаний, необходимых для того, чтобы стать квалифицированным разработчиком, является кодирование и знание веб-языков 9.0004 .
Веб-программирование относится к написанию, разметке, кодированию, связанному с веб-разработкой. Это включает в себя веб-контент, сетевую безопасность и сценарии веб-клиента и сервера.
С момента создания Интернета создано множество языков. У каждого языка есть своя функция и место, где он подходит для каждого аспекта веб-разработки. Некоторые из них используются в дизайне, некоторые — в структуре, а некоторые — в адаптивности веб-сайта. Это связано с их функциями. От веб-разработчика не ожидается, что он будет знать все языки, а только должен выучить язык, который ему нужен, чтобы стать экспертом на пути, который он выбрал.
HTML CODING CSS CODING Введение в HTML-язык гипертекстовой разметки HTML означает язык гипертекстовой разметки. It — это простой язык, описывающий структуру веб-страницы с использованием разметки . HTML также был создан в 1991 году, и многие версии создаются и доступны для изучения. Некоторые изменения, внесенные в старые версии, порождают новые версии, и это делается для улучшения структуры и отзывчивости наших веб-сайтов, а также для облегчения веб-разработки для начинающих. Ниже приведен список версий с момента создания сети в 19 г.91:-
Ниже приведен список версий с момента создания сети в 19 г.91:-
Элементы HTML являются строительными блоками HTML-страниц и представлены тегами. Тег заключен в угловые скобки и обычно идет парами (начальный и конечный теги). Конечный тег пишется так же, как и начальный, но с косой чертой, вставленной перед именем тега. Начальный тег, содержимое и конечный тег составляют элемент.
<имя тега> ….. здесь находится содержимое….
Элемент HTMLПростой документ HTML записывается в следующей форме:-
заголовок страницы …. содержание….
…. содержание….
Вот анализ приведенной выше структуры
- Объявление определяет этот документ как HTML5.
- 9Элемент 0004 — это корневой элемент HTML-страницы.
- Элемент содержит метаинформацию о документе.
- Элемент
</strong> указывает заголовок документа.</li><li> Элемент <strong><body> </strong> содержит видимое содержимое страницы.</li><li> Элемент <strong><h2></h2></strong> <strong> </strong> определяет большой заголовок.</li><li> Элемент <strong><p> </strong> определяет абзац.</li></ul><p> <strong> Примечание </strong> — <strong> Заголовки HTML </strong> определяются тегами от<h2><span class="ez-toc-section" id="i-10"> до </span></h2><h6><span class="ez-toc-section" id="i-11">. </span></h6><strong><h2></h2></strong> определяет самый важный заголовок. <strong><h6></h6></strong> определяет <strong> </strong> наименьший заголовок.</p><ul><li><h2><span class="ez-toc-section" id="i-12"> Это самый большой заголовок </span></h2></li><li><h3><span class="ez-toc-section" id="i-13"> Это самый большой заголовок </span></h3></li><li><h4><span class="ez-toc-section" id="i-14"> Это большой заголовок </span></h4></li><li><h5><span class="ez-toc-section" id="i-15"> Это маленький заголовок </span></h5></li><li><h5><span class="ez-toc-section" id="i-16"> Это заголовок меньшего размера </span></h5></li><li><h6><span class="ez-toc-section" id="i-17"> Это самый маленький заголовок </span></h6></li></ul><h3><span class="ez-toc-section" id="_HTML"> Пошаговое руководство по созданию простой HTML-страницы веб-страницы веб-сайта.</span></h3><img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/cf2.ppt-online.org/files2/slide/r/RJu0Ml31xFysP4BdSEnHGZLzKO6pbQh2wtkcNrovm/slide-49.jpg' /><noscript><img loading='lazy' src='/800/600/https/cf2.ppt-online.org/files2/slide/r/RJu0Ml31xFysP4BdSEnHGZLzKO6pbQh2wtkcNrovm/slide-49.jpg' /></noscript> Эта веб-страница требует следующих шагов;</p><p> <strong> Шаг 1. </strong> Получение текстового редактора, в котором вы вводите коды для получения желаемого результата. <strong> Блокнот (ПК), Visual Studio Code (VS Code) и TextEdit (Mac) </strong> являются примерами текстового редактора. Я рекомендую текстовый редактор VS Code из-за его эффективности. Вы можете просто найти Блокнот или TextEdit на своем ноутбуке.</p> <strong> VISUAL STUDIO CODE </strong><p> <strong> Шаг 2. </strong> Объявление файла. Это можно сделать двумя (2) способами.</p><p> Во-первых, откройте новую папку на своем компьютере и назовите ее с расширением HTML. Например, index.html.</p> <strong> Новая папка, сохраненная с расширением .html </strong><p> Второй способ — открыть редактор (рекомендуется VS Code), открыть новый файл и выбрать язык как HTML, затем нажать кнопку «Сохранить» или CTRL + S и назвать файл с любым желаемым именем, он обязательно будет сохранен с расширением «html».</p><p> щелкните здесь, чтобы посмотреть короткое видео</p><p> <strong> Шаг 3.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/ru-static.z-dn.net/files/d1a/1ab15d14d30dea69d5011c952361b00b.png' /><noscript><img loading='lazy' src='/800/600/https/ru-static.z-dn.net/files/d1a/1ab15d14d30dea69d5011c952361b00b.png' /></noscript> </strong> Начните писать код, объявив его в HTML 5, как было объяснено ранее. Это делается с помощью объявления HTML 5</p><pre> <!DOCTYPE html> </pre><p> Примечание: VS Code предоставляет возможный ввод, как только вы начинаете писать, и это очень упрощает вашу работу.</p> <strong> Код VS, всплывающий при возможном результате ввода </strong><p> <strong> Шаг 4. </strong> Щелкните следующую строку или нажмите клавишу ввода после шага 3, затем введите начальный и конечный теги HTML, которые будут выглядеть следующим образом:</p><pre> <html></html> </pre><p> <strong> Примечание: </strong> 1. VS Code автоматически закрывает все теги после ввода начального тега, если только тег не имеет только начальный тег (не требует конечного тега), потому что не все теги требуют конечный тег.</p><p> 2. Все остальные теги должны находиться между начальным и конечным тегами HTML, который был введен ранее, например:</p><p> <strong> Шаг 5. </strong> Введите тег<head>. Тег head содержит метаинформацию о документе.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/fs.znanio.ru/d5af0e/9c/f1/5e857dd6bb99e431c60ced40ed35e22ed1.jpg' /><noscript><img loading='lazy' src='/800/600/https/fs.znanio.ru/d5af0e/9c/f1/5e857dd6bb99e431c60ced40ed35e22ed1.jpg' /></noscript> Например, теги заголовка, стили CSS находятся между начальным и конечным тегами заголовка.</p><p> Содержимое тегов заголовков будет отображаться как заголовок веб-страницы</p><p> <strong> Шаг 6. </strong> Введите тег<body>. Элемент body содержит все элементы, которые будут отображаться на вашей веб-странице.</p><pre> <body></body> </pre><p> <strong> Шаг 7. </strong> Теперь вы можете начать писать что угодно внутри своей страницы, используя элементы от<h2><span class="ez-toc-section" id="i-18"> до </span></h2><h6><span class="ez-toc-section" id="i-19"> и теги </span></h6><p>, к нашему удовлетворению.</p> <strong> Вход </strong><p> <strong> Выход </strong></p><p> Спасибо за прочтение.</p><p> Не стесняйтесь обращаться ко мне в следующих социальных сетях: Twitter, Facebook, Instagram или WhatsApp.</p><p> <em> Больше контента на </em> <em> plainenglish.io </em> <em> . Подпишитесь на нашу бесплатную еженедельную рассылку </em> <em> </em> <em>. Получите эксклюзивный доступ к возможностям письма и советам в нашем </em> <em> сообществе Discord </em> <em>. </em></p><h2><span class="ez-toc-section" id="_2022"> Элементы и пример кодирования [издание 2022 г.</span></h2><img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/xn--90abhccf7b.xn--p1ai/800/600/https/ds03.infourok.ru/uploads/ex/0bd1/000032e0-b5fb8468/img16.jpg' /><noscript><img loading='lazy' src='/800/600/https/xn--90abhccf7b.xn--p1ai/800/600/https/ds03.infourok.ru/uploads/ex/0bd1/000032e0-b5fb8468/img16.jpg' /></noscript> ]</h2><p> Макет HTML — это схема, используемая для организации веб-страниц четко определенным образом. Он прост в навигации, прост для понимания и использует теги HTML для настройки элементов веб-дизайна. Крайне важно для любого веб-сайта, макет HTML, использующий правильный формат, легко улучшит внешний вид веб-сайта. Кроме того, поскольку макеты HTML обычно адаптивны по умолчанию, они также будут правильно отформатированы для мобильных устройств.</p><h3><span class="ez-toc-section" id="_HTML-2"> Что такое макет HTML? </span></h3><p> Макет страницы определяет внешний вид веб-сайта. Макет HTML — это структура, которая помогает пользователю легко перемещаться по веб-страницам. Это способ, которым вы можете создавать веб-страницы, используя простые теги HTML.</p><h3><span class="ez-toc-section" id="HTML"> HTML-элементы макета </span></h3><p> HTML содержит различные элементы, определяющие структуру веб-страницы:</p><p></p><ul><li><header>: определяет заголовок для веб-страницы</li><li><nav>: определяет контейнер для навигационных ссылок</li><li><section>: определяет раздел на веб-странице</li>.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/cdn.freelance.ru/img/portfolio/pics/00/36/15/3544557.jpg?mt=7a8ed06f' /><noscript><img loading='lazy' src='/800/600/https/cdn.freelance.ru/img/portfolio/pics/00/36/15/3544557.jpg?mt=7a8ed06f' /></noscript><li><article>: это основной элемент, содержащий информацию о веб-странице</li>.<li><aside>: содержимое<aside> часто помещается в качестве боковой панели в документе</li><li> <нижний колонтитул>: определяет нижний колонтитул для документа или раздела</li><li> <details>: используется для определения дополнительных сведений</li><li> <summary>: определяет заголовок для элемента <details></li></ul><p> <strong> Читайте также: Что такое HTML (язык гипертекстовой разметки)? </strong></p><h3><span class="ez-toc-section" id="_HTML-3"> Пример кодирования макета HTML </span></h3><p> Давайте разберемся с макетом веб-страницы HTML на примере.</p><p></p><p></p><p> Это приведет к следующему результату:</p>.<p></p><blockquote> Освойте интерфейсные и серверные технологии и продвинутые аспекты в нашей программе последипломного образования в области полнофункциональной веб-разработки. Раскройте свою карьеру в качестве опытного разработчика полного стека. Свяжитесь с нами СЕЙЧАС!</blockquote><h3><span class="ez-toc-section" id="i-20"> Заключение </span></h3><p> HTML-элементы макета играют важную роль в разработке веб-страниц и позволяют разрабатывать хорошо структурированные веб-страницы.<img class="lazy lazy-hidden" loading='lazy' src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/cf2.ppt-online.org/files2/slide/d/DP5ailRtAxBukeYb6KUdsXrZmW9oqOpT0j7gCL4GS/slide-1.jpg' /><noscript><img loading='lazy' src='/800/600/https/cf2.ppt-online.org/files2/slide/d/DP5ailRtAxBukeYb6KUdsXrZmW9oqOpT0j7gCL4GS/slide-1.jpg' /></noscript></div><footer class="entry-footer"> <span><i class="fa fa-folder"></i> <a href="https://russia-dropshipping.ru/category/raznoe" rel="category tag">Разное</a></span><span><i class="fa fa-link"></i><a href="https://russia-dropshipping.ru/raznoe/prostaya-stranicza-na-html-prostejshaya-html-stranicza-struktura-html-dokumenta-html-academy.html" rel="bookmark"> permalink</a></span></footer></article><nav class="navigation post-navigation clearfix" role="navigation"><h1 class="screen-reader-text">Post navigation</h1><div class="nav-links"><div class="nav-previous"><a href="https://russia-dropshipping.ru/raznoe/tz-kak-sostavit-kak-sostavit-tz-instruktsiya-kak-pisat-tehnicheskoe-zadanie-i-chto-dlya-etogo-nuzhno.html" rel="prev"><i class="fa fa-long-arrow-left"></i> Тз как составить: Как составить ТЗ – инструкция, как писать техническое задание и что для этого нужно</a></div><div class="nav-next"><a href="https://russia-dropshipping.ru/sozdan-2/sozdanie-sajta-web-poshagovaya-instrukcziya-etapy-i-stoimost.html" rel="next">Создание сайта web: пошаговая инструкция, этапы и стоимость <i class="fa fa-long-arrow-right"></i></a></div></div></nav><div id="comments" class="comments-area"><div id="respond" class="comment-respond"><h3 id="reply-title" class="comment-reply-title">Добавить комментарий <small><a rel="nofollow" id="cancel-comment-reply-link" href="/raznoe/prostaya-stranicza-na-html-prostejshaya-html-stranicza-struktura-html-dokumenta-html-academy.html#respond" style="display:none;">Отменить ответ</a></small></h3><form action="https://russia-dropshipping.ru/wp-comments-post.php" method="post" id="commentform" class="comment-form" novalidate><p class="comment-notes"><span id="email-notes">Ваш адрес email не будет опубликован.</span> <span class="required-field-message">Обязательные поля помечены <span class="required">*</span></span></p><p class="comment-form-comment"><label for="comment">Комментарий <span class="required">*</span></label><textarea id="comment" name="comment" cols="45" rows="8" maxlength="65525" required></textarea></p><p class="comment-form-author"><label for="author">Имя <span class="required">*</span></label> <input id="author" name="author" type="text" value="" size="30" maxlength="245" autocomplete="name" required /></p><p class="comment-form-email"><label for="email">Email <span class="required">*</span></label> <input id="email" name="email" type="email" value="" size="30" maxlength="100" aria-describedby="email-notes" autocomplete="email" required /></p><p class="comment-form-url"><label for="url">Сайт</label> <input id="url" name="url" type="url" value="" size="30" maxlength="200" autocomplete="url" /></p><p class="form-submit"><input name="submit" type="submit" id="submit" class="submit" value="Отправить комментарий" /> <input type='hidden' name='comment_post_ID' value='71955' id='comment_post_ID' /> <input type='hidden' name='comment_parent' id='comment_parent' value='0' /></p></form></div></div></main></div><div id="secondary" class="widget-area" role="complementary"><aside id="search-2" class="widget widget_search"><form role="search" method="get" class="search-form" action="https://russia-dropshipping.ru/"> <label> <span class="screen-reader-text">Найти:</span> <input type="search" class="search-field" placeholder="Поиск…" value="" name="s" /> </label> <input type="submit" class="search-submit" value="Поиск" /></form></aside><aside id="categories-3" class="widget widget_categories"><h3 class="widget-title">Рубрики</h3><ul><li class="cat-item cat-item-7"><a href="https://russia-dropshipping.ru/category/seo">Seo</a></li><li class="cat-item cat-item-15"><a href="https://russia-dropshipping.ru/category/instrument-2">Инструмент</a></li><li class="cat-item cat-item-9"><a href="https://russia-dropshipping.ru/category/instrument">Инструменты</a></li><li class="cat-item cat-item-16"><a href="https://russia-dropshipping.ru/category/program-2">Програм</a></li><li class="cat-item cat-item-4"><a href="https://russia-dropshipping.ru/category/program">Программы</a></li><li class="cat-item cat-item-14"><a href="https://russia-dropshipping.ru/category/prodvizh-2">Продвиж</a></li><li class="cat-item cat-item-5"><a href="https://russia-dropshipping.ru/category/prodvizh">Продвижение</a></li><li class="cat-item cat-item-3"><a href="https://russia-dropshipping.ru/category/raznoe">Разное</a></li><li class="cat-item cat-item-13"><a href="https://russia-dropshipping.ru/category/semant-2">Семант</a></li><li class="cat-item cat-item-8"><a href="https://russia-dropshipping.ru/category/semant">Семантика</a></li><li class="cat-item cat-item-17"><a href="https://russia-dropshipping.ru/category/sovet-2">Совет</a></li><li class="cat-item cat-item-11"><a href="https://russia-dropshipping.ru/category/sovet">Советы</a></li><li class="cat-item cat-item-12"><a href="https://russia-dropshipping.ru/category/sozdan-2">Создан</a></li><li class="cat-item cat-item-6"><a href="https://russia-dropshipping.ru/category/sozdan">Создание</a></li><li class="cat-item cat-item-18"><a href="https://russia-dropshipping.ru/category/sxem-2">Схем</a></li><li class="cat-item cat-item-10"><a href="https://russia-dropshipping.ru/category/sxem">Схемы</a></li></ul></aside></div></div><div id="sidebar-footer" class="footer-widget-area clearfix" role="complementary"><div class="container"></div></div><footer id="colophon" class="site-footer" role="contentinfo"><div class="site-info"><div class="container"> Copyright © 2025 <font style="text-align:left;font-size:15px;"><br> Дропшиппинг в России.<br> Сообщество поставщиков дропшипперов и интернет предпринимателей.<br>Все права защищены.<br>ИП Калмыков Семен Алексеевич. ОГРНИП: 313695209500032.<br>Адрес: ООО «Борец», г. Москва, ул. Складочная 6 к.4.<br>E-mail: mail@russia-dropshipping.ru. <span class="phone-none">Телефон: +7 (499) 348-21-17</span></font></div></div></footer></div> <noscript><style>.lazyload{display:none}</style></noscript><script data-noptimize="1">window.lazySizesConfig=window.lazySizesConfig||{};window.lazySizesConfig.loadMode=1;</script><script async data-noptimize="1" src='https://russia-dropshipping.ru/wp-content/plugins/autoptimize/classes/external/js/lazysizes.min.js'></script> <!-- noptimize --> <style>iframe,object{width:100%;height:480px}img{max-width:100%}</style><script>new Image().src="//counter.yadro.ru/hit?r"+escape(document.referrer)+((typeof(screen)=="undefined")?"":";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+";h"+escape(document.title.substring(0,150))+";"+Math.random();</script> <!-- /noptimize --></body></html>
