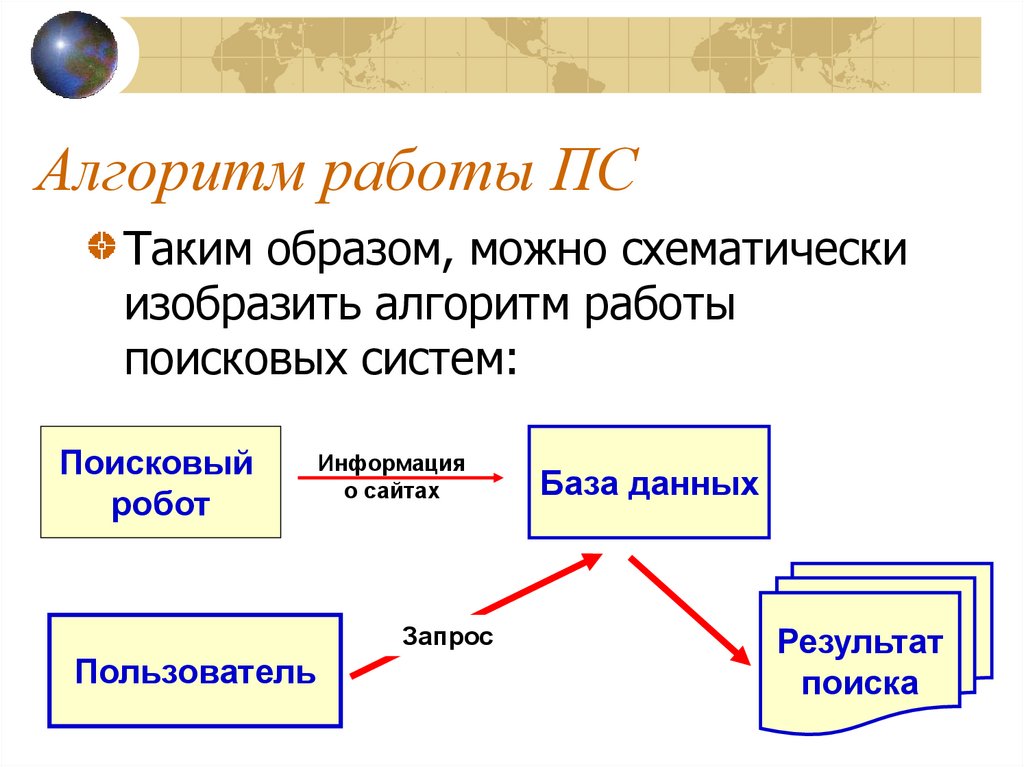
Работа поисковых систем: общие принципы работы поисковиков
Игорь СеровSEO учебникyahoo, анализировать сайт, база данных, бот, механизм поисковой оптимизации, поисковый паук, поисковый робот, поисковых роботов, программа seo анализа, работа поисковиков, ссылкаВступление
Каждая поисковая система имеет свой алгоритм поиска запрашиваемой пользователем информации. Алгоритмы эти сложные и чаще держатся в секрете. Однако общий принцип работы поисковых систем можно считать одинаковым. Любой поисковик:
- Сначала собирает информацию, черпая её со страниц сайтов и вводя её в свою базы данных;
- Индексирует сайты и их страницы, и переводит их из базы данных в базу поисковой выдачи;
- Выдает результаты по поисковому запросу, беря их из базы проиндексированных страниц;
- Ранжирует результаты (выстраивает результаты по значимости).
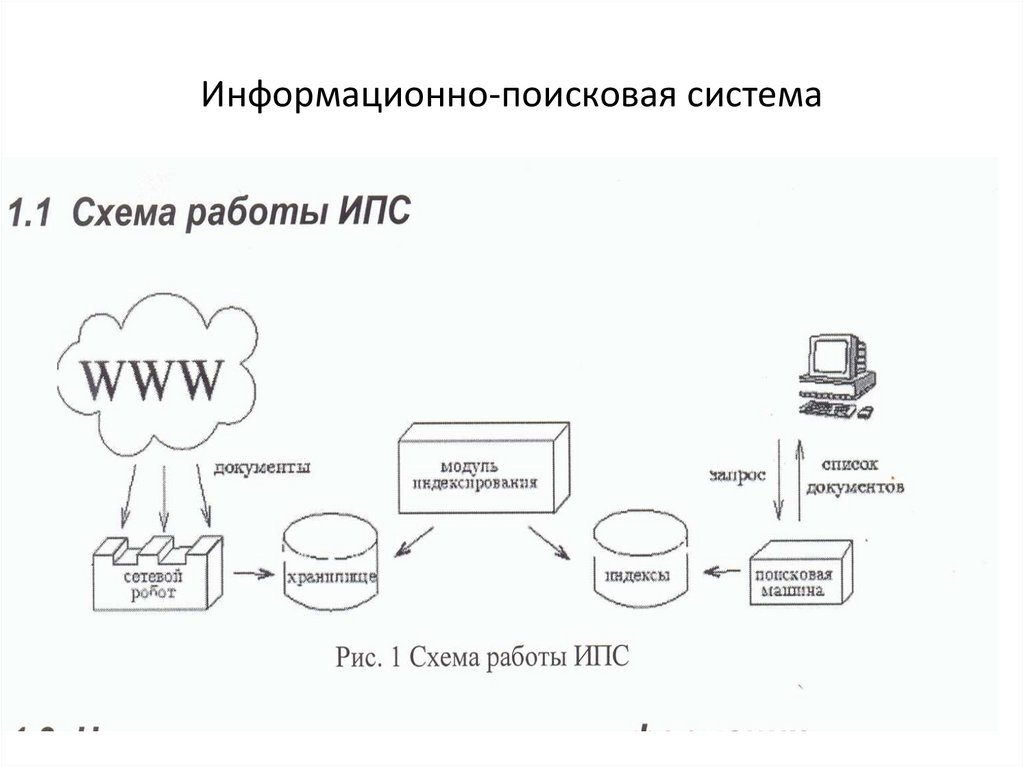
Работа поисковых систем – общие принципы
Вся работа поисковых систем выполняют специальные программы и комбинации этих программ.
Перечислим основные составляющие алгоритмов поисковых систем:
- Spider (паук) – это браузероподобная программа, скачивающая веб-страницы. Заполняет базу данных поисковика.
- Crawler (краулер, «путешествующий» паук) – это программа, проходящая автоматически по всем ссылкам, которые найдены на странице.
- Indexer (индексатор) – это программа, анализирующая веб-страницы, скачанные пауками. Анализ страниц сайта для их индексации.
- Database (база данных) – это хранилище страниц. Одна база данных это все страницы загруженные роботом. Вторая база данных это проиндексированные страницы.
- Search engine results engine (система выдачи результатов) – это программа, которая занимается извлечением из базы данных проиндексированных страниц, согласно поисковому запросу.
- Web server (веб-сервер) – веб-сервер, осуществляющий взаимодействие пользователя со всеми остальными компонентами системы поиска.


Реализация механизмов поиска у поисковиков может быть самая различная. Например, комбинация программ Spider+ Crawler+ Indexer может быть создана, как единая программа, скачивающая и анализирующая веб-страницы и находящая новые ресурсы по найденным ссылкам. Тем не менее, нижеупомянутые общие черты программ присущи всем поисковым системам.
Программы поисковых систем
Spider
«Паук» скачивает веб-страницы так же как пользовательский браузер. Отличие в том, что браузер отображает содержащуюся на странице текстовую, графическую или иную информацию, а паук работает с html-текстом страницы напрямую, у него нет визуальных компонент. Именно, поэтому нужно обращать внимание на ошибки в html кодах страниц сайта.
Crawler
Программа Crawler, выделяет все находящиеся на странице ссылки. Задача программы вычислить, куда должен дальше направиться паук, исходя из заданного заранее, адресного списка или идти по ссылках на странице. Краулер «видит» и следует по всем ссылкам, найденным на странице и ищет новые документы, которые поисковая система, пока еще не знает. Именно, поэтому, нужно удалять или исправлять битые ссылки на страниц сайта и следить за качеством ссылок сайта.
Именно, поэтому, нужно удалять или исправлять битые ссылки на страниц сайта и следить за качеством ссылок сайта.
Indexer
Программа Indexer (индексатор) делит страницу на составные части, далее анализирует каждую часть в отдельности. Выделению и анализу подвергаются заголовки, абзацы, текст, специальные служебные html-теги, стилевые и структурные особенности текстов, и другие элементы страницы. Именно, поэтому, нужно выделять заголовки страниц и разделов мета тегами (h2-h5,h5,h6), а абзацы заключать в теги <p>.
Database
База данных поисковых систем хранит все скачанные и анализируемые поисковой системой данные. В базе данных поисковиков хранятся все скачанные страницы и страницы, перенесенные в поисковой индекс. В любом инструменте веб мастеров каждого поисковика, вы можете видеть и найденные страницы и страницы в поиске.
Search Engine Results Engine
Search Engine Results Engine это инструмент (программа) выстраивающая страницы соответствующие поисковому запросу по их значимости (ранжирование страниц). Именно эта программа выбирает страницы, удовлетворяющие запросу пользователя, и определяет порядок их сортировки. Инструментом выстраивания страниц называется алгоритм ранжирования системы поиска.
Именно эта программа выбирает страницы, удовлетворяющие запросу пользователя, и определяет порядок их сортировки. Инструментом выстраивания страниц называется алгоритм ранжирования системы поиска.
Важно! Оптимизатор сайта, желая улучшить позиции ресурса в выдаче, взаимодействует как раз с этим компонентом поисковой системы. В дальнейшем все факторы, которые влияют на ранжирование результатов, мы обязательно рассмотрим подробно.
Web server
Web server поисковика это html страница с формой поиска и визуальной выдачей результатов поиска.
Повторимся. Работа поисковых систем основана на работе специальных программ. Программы могут объединяться, компоноваться, но общий принцип работы всех поисковых систем остается одинаковым: сбор страниц сайтов, их индексирование, выдача страниц по результатам запроса и ранжирование выданных страниц по их значимости. Алгоритм значимости у каждого поисковика свой.
©SeoJus.ru
Другие уроки SEO учебника
Похожие записи:
Принципы работы поисковых указателей
Принципы работы поисковых указателейВсе поисковые системы Интернета основаны на гиперссылках. Их можно
рассматривать как обширные коллекции гиперссылок, но принцип доступа к
гиперссылкам в различных поисковых системах
Их можно
рассматривать как обширные коллекции гиперссылок, но принцип доступа к
гиперссылкам в различных поисковых системах
Популярные предметные каталоги
- Yahoo! (www.yahoo.com)
- Общественный проект Open Directory ( www.dmoz.org)
- Lii.org Тематический Интернет-каталог для библиотекарей Libririans’Index to the Internet(www.lii.org)
В России
- List.Ru (www.list.ru)
- «Созвездие Интернет» (www.stars.ru )
- Russia on the Net (www. ru)
 ru)
ru)Обычно поисковые каталоги формируются вручную. Отсюда их достоинства и недостатки. К достоинствам следует отнести предварительный просмотр и отбор сайтов человеком редактором.
Развивается идея интеграции поискового указателя с предметным
каталогом, например портал «Яндекс» (
www.yandex.ru)
«Яндекс» можно отнести к поисковым системам типа автоматический индекс.
Автоматический индекс навещает все известные ему сайты,переписывает тексты
всех доступных страничек и хранит эти тексты вместе с их адресами в своей базе
данных.
Как любой автоматический индекс, «Яндекс» состоит из двух частей: база данных и
программа поиска нужного слова.
Главная разница между катаогом и поисковой системой:
Каталог (например List.Ru) содержит только адреса и краткие описания сайтов,
а роисковые системы (например «Яндекс») хранит содержимое всех известных ему сайтов.
Принципы работы поисковых указателей
Четыре этапа
- Сканирование Web-пространства. Поисковая система с помощью специальных программ просматривает доступное пространство Web и копирует к себе все встреченные страницы.
- Индексация ресурсов.Эти страницы обрабатываются специальными программными средствами и из них составляется специальная база данных, именуемая указателем.
- Поиск по запросу. Система анализирует ключевые слова, введенные пользователем в запросе, и, согласно указателю, отбирает ссылки на те ресурсы, которые запросу соответствуют — их может получиться очень много.
- Формирование результирующей страницы. Система формирует динамическую Web-страницу
Ранжирование результатов поиска
- Ранжирование по каталогу.
- Ранжирование по рейтинговой системе.
- Ранжирование по цитируемости.

Проверка указателя
Проверить объем того или иного указателя нетрудно.
Во-первых, большинство указателей сами сообщают о себе такие данные,
особенно если им есть чем гордиться. Если же таких данных нет, можно
воспользоваться классическим запросом to be or not to be.
Согласно такому запросу система должна выдать страницы, содержащие слова
to be ИЛИ НЕ содержащие слова to be, то есть вообще
все, что у нее есть. Правда этот прием не везде срабатывает.
Относительную оценку того или иного указателя можно получить, проведя несколько поисков по какому-нибудь широко распространенному слову, например: компьютер, человек, машина, — но к полученному результату надо отнестись осторожно.
Гораздо интереснее проверить актуальность данных, собранных поисковой
системой.
 Это может быть какое-либо
событие, например атака террористов, объект, например
всемирный торговый центр, или, скажем, продукт, например
Windows XP.
Это может быть какое-либо
событие, например атака террористов, объект, например
всемирный торговый центр, или, скажем, продукт, например
Windows XP.
Смутное время
Одним из направлений развития пространства Web в 1997-1998 годах
стала централизация поиска в сочетании с децентрализацией обслуживания
запросов.
Смысл идеи состоит в следующем. Создается мощная система, богато
оснащенная вычислительной техникой и занимающаяся только сбором
информации из WWW, но не обслуживанием конечных пользователей.
В частности такой системой стала Inktomi
(www.inktomi.com)
. Работой с пользователями занимаются другие компании, которые
принимают запросы на поиск и передают их Inktomi на обработку.
У разных партнеров разная политика ранжирования, поэтому в результате
поиска результаты не будут идентичными.
Централизация поиска вы этот период привела к быстрому
развитию концепции порталов — небольших служб, предоставляющих
множество справочных услуг, в том числе и поисковых.
В период 1998-1999 годах стали развиваться средства
метапоиска (заказ на поиск принимает одна служба ,
которая потом размещает его на разных указателях, после чего
собирает от них результаты, ранжирует и рафинирует их по своему
усмотрению и передает пользователю).
Именно по этому принципу работают метапоисковые системы.
Однако любая метапоисковая система использует только малую часть адресов,
выданных отдельным каталогом или индексом. На большее нет времени — ведь необходимо
опросить несколько систем. В результате могут быть пропущены важные документы.
Возврат в начало страницы Возврат на главную страницу сайта
Хостинг от uCoz
Общие принципы поисковой системы | НиГрафик
Представлено Нимой Мехрабани
в пн, 20. 07.2020 — 13:28
07.2020 — 13:28
Все стремятся повысить прибыльность, но достичь этого в Интернете очень сложно, отнимает много времени, а если выбрать неправильную SEO-компанию, то дорого. Наше цифровое агентство с полным спектром услуг предлагает квалифицированный интернет-маркетинг, SEO и оптимизированные для мобильных устройств веб-сайты, чтобы воплотить ваши онлайн-цели в реальность. Получите первое место в рейтинге Google и оставайтесь на нем!
Чтобы понять сео, нужно знать архитектуру поисковых систем. Все они содержат следующие основные компоненты:
Spider — браузероподобная программа, загружающая веб-страницы.
Crawler – программа, которая автоматически переходит по всем ссылкам на каждой веб-странице.
Индексатор — программа, которая анализирует веб-страницы, загруженные поисковым роботом и поисковым роботом.
База данных – хранилище загруженных и обработанных страниц.
Система результатов – извлекает результаты поиска из базы данных.
Веб-сервер – сервер, отвечающий за взаимодействие между пользователем и другими компонентами поисковой системы.
Конкретные реализации механизмов поиска могут различаться. Например, группу компонентов Spider+Crawler+Indexer можно реализовать как единую программу, которая загружает веб-страницы, анализирует их и затем использует их ссылки для поиска новых ресурсов. Покупайте трафик для своего сайта и увеличивайте продажи! Однако перечисленные компоненты присущи всем поисковым системам, а принципы SEO-инструментов одинаковы.
Паук. Эта программа загружает веб-страницы так же, как веб-браузер. Разница в том, что браузер отображает информацию, представленную на каждой странице (текст, графика и т. д.), в то время как паук не имеет никаких визуальных компонентов и работает непосредственно с базовым HTML-кодом страницы. Возможно, вы уже знаете, что в стандартных веб-браузерах есть возможность просмотра исходного HTML-кода.
Гусеничный. Эта программа находит все ссылки на каждой странице. Его задача — определить, куда должен идти паук, либо путем оценки ссылок, либо по заранее заданному списку адресов. Сканер переходит по этим ссылкам и пытается найти документы, еще не известные поисковой системе.
Эта программа находит все ссылки на каждой странице. Его задача — определить, куда должен идти паук, либо путем оценки ссылок, либо по заранее заданному списку адресов. Сканер переходит по этим ссылкам и пытается найти документы, еще не известные поисковой системе.
Индексатор. Этот компонент анализирует каждую страницу и различные элементы, такие как текст, заголовки, структурные или стилистические особенности, специальные теги HTML и т. д.
База данных. Это область хранения данных, которые поисковая система загружает и анализирует. Иногда его называют индексом поисковой системы.
Механизм результатов. Система результатов ранжирует страниц. Он определяет, какие страницы лучше всего соответствуют запросу пользователя и в каком порядке страницы должны быть перечислены. Это делается в соответствии с алгоритмами ранжирования поисковой системы. Из этого следует, что рейтинг страницы является ценным и интересным свойством, и любой специалист по поисковой оптимизации больше всего заинтересован в нем, когда пытается улучшить результаты поиска по своему сайту. В этой статье мы подробно обсудим SEO-факторы, влияющие на рейтинг страницы.
В этой статье мы подробно обсудим SEO-факторы, влияющие на рейтинг страницы.
Веб-сервер. Веб-сервер поисковой системы обычно содержит HTML-страницу с полем ввода, где пользователь может указать интересующий его поисковый запрос. Веб-сервер также отвечает за отображение результатов поиска пользователю в виде HTML-страницы .
поисковая система
SEO
Основы поисковой системы | Дистиллированный U
Основы поисковой системы [720p].mov
- Из чего состоит Всемирная паутина;
- История и назначение поисковых систем;
- Краткий обзор сканирования, индексации и ранжирования;
- Последние разработки поисковой системы.
Чтобы стать эффективным SEO-специалистом, вам нужно не только понимать принципы внутренних и внешних факторов, но также понимать пользователей и то, как работает Интернет. Это понимание дает вам твердое представление о том, как работает поиск и как пользователи взаимодействуют с Интернетом.
Из чего состоит Всемирная паутина?
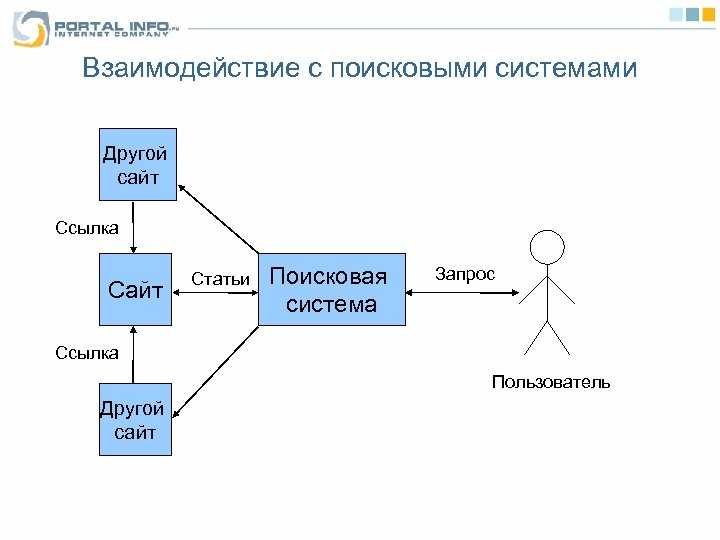
Интернет представляет собой набор страниц и файлов, связанных между собой сложным набором гиперссылок. Эти гиперссылки позволяют пользователям и поисковым системам перемещаться по сети в поисках нового контента. До появления поисковых систем единственным способом ориентироваться в Интернете было ввести точный адрес нужной страницы или щелкнуть гиперссылку, которая привела бы вас на разные страницы.
Файлы могут быть различными, включая:
- Изображения
- Видео
- PDF-файлы
- Javascript
Эти файлы можно использовать для улучшения веб-страниц, чтобы они представляли собой нечто большее, чем просто текст. В первые дни существования Интернета эти файлы было очень трудно сканировать поисковым системам, не говоря уже о понимании и индексировании. Отчасти это произошло из-за того, что технология сканирования не была очень продвинутой, но также и потому, что сканирование и индексирование файлов, отличных от обычного текста и изображений, требовало много ресурсов, которых поисковые системы просто не имели или не могли себе позволить в то время.
Благодаря улучшению своих ресурсов и технологий, а также внедрению высокоскоростных интернет-соединений, веб-страницы стали намного богаче типами контента, которые они могут предоставлять.
Однако поисковые системы все еще могут испытывать трудности со сканированием и индексированием определенных типов контента. Они все время совершенствуются и внесли значительные улучшения, но прямо сейчас вам нужно знать, с чем они борются. Мы рассмотрим это более подробно ниже в разделе «Потенциальные проблемы для поисковых систем».
Как SEO-специалисту, вам необходимо знать об этих типах файлов, чтобы вы могли обогащать веб-сайты, с которыми вы работаете, что в конечном итоге может улучшить работу пользователей. В то же время вам нужно знать, как эти типы файлов могут вызвать проблемы.
История и назначение поисковых систем
Всемирная паутина была широко распространена около 30 лет и за это время феноменально выросла. В начале 1990-х годов, когда Интернет был молод, обычному пользователю было гораздо сложнее создать свой собственный веб-сайт. Веб-сайты в основном размещались технически подкованными компаниями или любителями.
Веб-сайты в основном размещались технически подкованными компаниями или любителями.
В те дни не существовало такого понятия, как «поисковая система» — веб-сайты обнаруживались из уст в уста или на одной из немногих страниц типа «Что нового в Интернете?», на которых перечислялись новые сайты. Это было не очень эффективно с самого начала, но по мере того, как сеть росла в течение следующих нескольких лет, стало ясно, что необходимо решение.
В течение 1993-1994 годов появились первые поисковые системы, за которыми в течение следующих нескольких лет последовало множество коммерческих систем, включая Excite, AltaVista и Yahoo!. Количество веб-страниц и пользователей выросло до такой степени, что поиск искомого контента был просто невозможен с помощью централизованного списка.
Сам Google появился в 1996 году и назывался BackRub, когда над ним начали работать Ларри Пейдж и Сергей Брин. Они были первой поисковой системой, которая осознала силу и потенциал гиперссылок как сигнала доверия и авторитета. Они подробно рассказали об этом в своей университетской статье, опубликованной в 1997 году. релевантность и качество их результатов.
Они подробно рассказали об этом в своей университетской статье, опубликованной в 1997 году. релевантность и качество их результатов.
Всемирная паутина в настоящее время состоит из миллиардов веб-страниц, а поисковые системы являются частью повседневной жизни большинства людей.
Чтобы узнать по-настоящему всестороннюю историю поисковых систем, технически восходящую к 1945 году, мы рекомендуем взглянуть на историю поисковых систем.
3 шага поисковых систем: сканирование, индексирование и ранжирование.
При изучении поисковых систем нужно понимать 3 основные области: сканирование, индексирование и ранжирование. Мы подробно рассмотрим их в ходе этого модуля, но их можно резюмировать:
- Сканирование — это процесс, который поисковые системы используют для обнаружения нового контента. У них есть сложные программы, которые посещают веб-страницы и переходят по ссылкам на них, чтобы найти новые страницы.
- Индексирование. Поисковые системы сохраняют копии содержимого всех веб-страниц, которые они посетили. Этот индекс хранится на большом количестве компьютеров таким образом, что его можно очень быстро найти.
- Ранжирование. Это та область поисковых систем, которая больше всего интересует SEO. Когда пользователь выполняет поиск в любой поисковой системе, ей нужен «рецепт» (известный как алгоритм), который он может использовать для оценки страниц в своем индексе, чтобы определить, какие из них наиболее релевантны, и, таким образом, определить, в какой позиции (рейтинге) они возвращаются пользователю.
 Этот индекс хранится на большом количестве компьютеров таким образом, что его можно очень быстро найти.
Этот индекс хранится на большом количестве компьютеров таким образом, что его можно очень быстро найти.Чтобы дать вам немного больше общего ознакомления с этим процессом, вот полезное видео от Google, которое довольно хорошо объясняет это. Хотя мы не всегда думаем, что видео от Google полезны для практиков, они иногда создают хорошие видео, подобные этому, которые дают отличное представление о том, как они думают:
Последние разработки в поисковых системах какие страницы были наиболее релевантны для данного запроса, основываясь исключительно на содержании этих страниц и на том, как на них ссылались другие страницы в Интернете.
 Вся информация, которую поисковые системы исследовали для определения релевантности, была инкапсулирована в самой сети.
Вся информация, которую поисковые системы исследовали для определения релевантности, была инкапсулирована в самой сети.Любой, кто ищет определенное слово или поисковую фразу, получит те же результаты, что и все остальные, кто выполняет поиск в той же стране.
Однако за последние несколько лет это изменилось благодаря персонализированному поиску.
Индивидуальный поиск дает пользователям возможность просматривать различные результаты в зависимости от ряда факторов:
История поиска, основанная на предыдущих поисковых запросах Google.
Устройство, используемое для поиска.
Ваше местоположение/IP-адрес.
Независимо от того, вошли ли вы в свою учетную запись Google. Если вы вошли в свою учетную запись Google во время поиска чего-либо, поисковая система сохранит ваши данные, чтобы помочь уточнить ваш поиск на основе прошлого поведения.
Взаимодействие в социальных сетях. Если вы используете социальные сети для демонстрации своего поведения, Google будет использовать эту информацию для персонализации вашего поиска.
И последнее, но не менее важное: настройки поиска

Предлагая персонализированные результаты, Google стремится предоставить наиболее полезный и актуальный контент на основе вашего поиска.
В последние годы произошли и другие важные события, изменившие способ поиска людей. Google, в частности, стал намного более продвинутым в использовании машинного обучения и пользовательских данных для прогнозирования наилучших результатов для данного запроса. Есть несколько функций Google, которые демонстрируют эту способность и демонстрируют достигнутые ими успехи:
- Google Suggest — запущенный в августе 2008 года, Google Suggest использует передовые алгоритмы и машинное обучение для прогнозирования того, что вы ищете. Когда вы начинаете вводить свой запрос, Google предлагает вам ключевые слова, это позволяет вам уточнять свой запрос по мере его продвижения и получать идеи о том, что вы можете захотеть.
- Google Instant — запущенный в сентябре 2010 года, Google Instant значительно изменил то, как люди выполняют поиск, создавая динамические результаты по мере того, как пользователь вводит свой запрос. Результаты будут обновляться «вживую», и пользователю даже не придется нажимать клавишу ввода.
- Избранные фрагменты и поля для ответов — запущенные в 2014 году и пересмотренные в 2020 году — расширенные фрагменты и поля для ответов предназначены для того, чтобы дать пользователям мгновенный ответ на их поисковый запрос. Это означает, что им никогда не придется посещать веб-страницу. Ящики для ответов также могут предоставлять ответы на поисковые запросы на голосовых устройствах, таких как Alexa и Siri.
- Составные запросы — запущенные в апреле 2015 года, составные запросы позволяют пользователям объединять поисковые запросы для уточнения результатов поиска.
 Когда вы начинаете вводить свой запрос, Google предлагает вам ключевые слова, это позволяет вам уточнять свой запрос по мере его продвижения и получать идеи о том, что вы можете захотеть.
Когда вы начинаете вводить свой запрос, Google предлагает вам ключевые слова, это позволяет вам уточнять свой запрос по мере его продвижения и получать идеи о том, что вы можете захотеть.