
Как работают поисковые системы: особенности работы Яндекса
Приветствую всех читателей блога int-net-partner.ru. А вы никогда не задумывались о том, «Как работают поисковые системы?», «Что такое сниппет?», интересно? Тогда читайте статью до конца!
Я решил написать полезную всем статью как начинающим, так и «бывалым» пользователям Интернета, блоггерам. Как многие уже знают, что основная доля трафика идёт с Яндекса и Гугла, и следовательно, чтобы этот трафик шёл к нам, нужно подружиться с ними, узнать «чем они дышат» :).
Что такое сниппет?
Так что же такое сниппет для сайта и почему для оптимизатора его содержимое очень важно?
data-ad-client=»ca-pub-8243622403449707″
data-ad-slot=»1319308473″
data-ad-format=»auto»>
Сниппет — это описание статьи, которое находится под ссылкой на найденный документ.
Если текст из ссылки на статью берётся из мета -тега Title, то сниппет формируется автоматически из статьи ( берутся куски, отдельные фразы), в зависимости от поискового запроса. Какие фрагменты статьи брать — решает поисковик, специально разработанный алгоритм. Интересно ещё и то, что при разных поисковых запросах сниппеты будут разные!
Из вышесказанного можно сделать вывод, что сниппет нужен для того, чтобы можно было понять какую информацию несёт страница статьи в зависимости от поиска, не переходя на неё.
Также содержимое тега Description иногда может быть использовано в качестве сниппета. Это может произойти, если слова в поисковом запросе совпадут с ключевыми словами в дискрипшене.
Для того, чтобы заполнить содержимое тега Description, Title, используйте плагин All in One SEO Pack, как с ним работать я писал здесь.Основные принципы работы поисковиков
Цель оптимизации — поднять статью в топ выдачи поисковых систем, т.е. сделать страницу релевантной данному поисковому запросу.
Это и есть работа оптимизаторов. Пока алгоритмы поисковых систем не совершенны, оптимизаторы будут «помогать» поисковикам поднять страницу в топ. Но зачастую такая «помощь» мешает алгоритму сделать выдачу, релевантную данному запросу.
Вот оптимизаторы и стараются улучшить релевантность страниц, путём внутренней и внешней оптимизации, чтобы их продвигаемый запрос вышел в топ Яндекса и Google.
Но прежде чем оптимизировать те или иные страницы сайта по нужный нам запрос, необходимо знать как работают поисковики, чтобы в дальнейшем знать их поведение от того или иного изменения.
Конечно, весь принцип работы поисковиков мы разобрать не сможем, так как многая информация не доступна обычному оптимизатору и не подлежит разглашению, но основные принципы мы разберем.
Итак, приступим. В чём же всё — таки заключается принцип работы поисковых систем? Принцип работы у всех поисковых систем одинаковый: собирается информация со всевозможных страниц, особым образом обрабатывается, чтобы можно было удобно вести поиск. Ну, это если совсем в общих чертах.
Давайте внесём такой термин как документ.
Документ — это страница сайта. При этом документ должен иметь свой url (уникальный адрес), также хеш — ссылки не приводят к появлению нового документа.
А теперь остановимся на способах (алгоритмах) поиска информации в собранной поисковиками базе страниц сайтов (документов).
Способы прямых и обратных индексов
Метод прямого индекса (поиска) — это метод простого перебора страниц, которые хранятся в базе. Этим методом можно найти информацию наверняка, все мелкие детали, ничего не пропустив. Но оптимальным его нельзя назвать, так как он не предназначен для поиска информации с большим объёмом данных, потому что поиск займёт слишком длительное время.
Поэтому для работы с большим объёмом данных был разработан способ инвертированных (обратных) индексов. Также следует добавить, что этот способ используют все крупные поисковые системы в мире.
При использовании способа обратных индексов документы преобразовываются в текстовые файлы, которые содержат список всех слов, имеющихся в документе.
Слова в этих файлах располагаются по алфавиту, рядом с ними в виде координат указаны места расположения их на странице. Кроме этого имеются и другие параметры, которые определяют значение этих слов.
Всё это расположение немного напоминает список терминов в технической литературе, который расположен на последней странице. Там написан термин и указана страница, где его можно найти. Всех слов этот список не включает, но как пример, я думаю понятен. Вот так строятся индекс-файлы с помощью инвертированных индексов.
Поисковики ищут информацию не в прямых индексах (они нужны для составления сниппетов), а в обратных индексах, обработанных ими документов (вебстраниц), об этом мы с вами говорили в начале статьи.
На данный момент алготритм обратных индексов используется всеми поисковыми системами, так как позволяет ускорить процесс поиска информации, в отличие от алгоритма прямых индексов. Следует заметить, что при преобразовании документа в индекс-файл, неизбежны потери информации, за счёт искажений при преобразовании.
Модель ранжирования
Поиск по обратным индексам осуществляется при помощи математической модели ранжирования, которая упрощает процесс обнаружения нужных вебстраниц (по введённому запросу) и упрощает определение релевантности всех документов, найденных по этому запросу. Соответственно чем больше найденный документ соответствует определённому запросу, тем он релевантнее, а следовательно, выше должен стоять в поисковой выдаче.
Задача математической модели ранжирования заключается в поиске страниц в своей базе обратных индексов, которые соответствуют определённому запросу, затем сортировка их по релевантности данному запросу в порядке убывания.
Простая логическая модель ранжирования (поиск по фразе) нам не подойдёт, так как в Интернете огромное количество вебстраниц, имеющих какую-либо фразу и выдаваемых на рассмотрение пользователю.
Следует заметить, что математическая модель не идеальна в плане сортировки страниц по определённому запросу (по релевантности) и этим неплохо пользуются оптимизаторы, оказывая влияние на ранжирование документов в поисковой выдаче.
Математическая модель ранжирования относится к классу векторных моделей, где используется такое понятие как вес документа относительно заданного пользователем запроса.
Для расчёта веса документа по заданному запросу в базовой векторной математической модели ранжирования используются 2 параметра: частота, с которой в документе встречается данное слово (TF — term frequency) и то, насколько редко встречается данное слово во всех страницах, известных поисковой системе (IDF — inverse document frequency).
А умножив эти параметры друг на друга, получим вес документа (вебстраницы) по данному поисковому запросу.
Конечно, кроме этих двух параметров TF и IDF поисковики используют ещё множество коэффициентов, но суть остаётся прежней: чем чаще слово из поиска встречается на странице и чем реже на всех остальных проиндексированных вебстраницах поисковиком, тем вес её будет больше. Но здесь следует заметить, что слишком частое количество повторений поискового слова в документе может быть расцениваться спамом.
Асессоры. Оценка качества работы формулы
Как вы уже поняли, что формирование поисковой выдачи по тем или иным запросам производится по формуле. Но над формулой должен производиться контроль как и над самой математической моделью ранжирования.
Вот именно для контроля математической модели ранжирования и существуют люди — асессоры, которые просматривают поисковую выдачу определённой поисковой системы (которая их наняла) и оценивают качество работы формулы.
Асессоры вносят замечания, а люди, которые отвечают за за настройку математической модели ранжирования уже, в свою очередь, редактируют формулу, в результате чего поисковик работает более качественно.
А вот видео, из которого вы можете подробнее узнать об асессорах Яндекса:
Основные критерии оценки работы формулы:
- Точность выдачи поисковой системы — процент документов, соответствующих запросу (релевантных). Т.е. чем меньше страниц, не соответствующих запросу присутствует — тем лучше.
- Полнота выдачи поисковой системы — это отношение релевантных вебстраниц по данному запросу к общему количеству релевантных документов, находящихся в коллекции (совокупности страниц, находящихся в поисковой системе). Например, если во всей коллекции релевантных страниц больше, чем в поисковой выдаче, то это означает неполноту выдачи. Это произошло из-за того, что некоторая часть релевантных вебстраниц попала под фильтр.
- Актуальность выдачи поисковой системы — это соответствие вебстраницы тому, что написано в сниппете. Например, документ может сильно отличаться или вовсе не существовать, но в выдаче присутствовать. Актуальность выдачи напрямую зависит от того, как часто сканирует поисковый робот документы из своей коллекции.
Сбор коллекции (индексация страниц сайта) осуществляется специальной программой — поисковым роботом. Поисковый робот получает список адресов для индексации, копирует их, далее содержимое скопированных вебстраниц отдаёт на обработку алгоритму, который преобразует их в обратные индексы.
Поисковый робот, также может переходить по ссылкам с вебстраниц, которые находятся в списке индексации и индексировать их. Таким образом можно сделать вывод, что робот ведёт себя как обычный пользователь.
Сколько страниц может проиндексировать Яндекс?
Яндекс, как никто другой, заинтересован, чтобы пользователь получал разнообразную информацию. Но Яндекс допускает в выдаче второго документа с того же Интернет — ресурса. Это является исключением из правил, но если страница уж очень «хороша» или по-другому релевантна, то и исключение можно сделать. Поэтому возможен случай, когда две страницы одного и того же сайта попадут в топ по определённому поисковому запросу. Вот так.
Яндекс старается индексировать равномерно все сайты, но как быть, если нужно проиндексировать не одну, а сто, тысячу, или несколько десятков тысяч страниц?
Для этого Яндекс поставил ограничение на количество документов, которое может быть проиндексировано с одного сайта.
Так для доменов второго уровня, например, int-net-partner.ru, максимальное число страниц, которое Яндекс может проиндексировать находится в диапозоне от 100 до 150 тысяч (в зависимости от отношения к данному домену).
Для доменов третьего уровня от 10 до 30 тысяч вебстраниц.
А что делать, если вам нужно будет проиндексировать, например, 500000 страниц? Я думаю, единственным выходом будет создание множества поддоменов.
Поддомены для домена второго уровня выглядят так: seo.int-net-partner.ru. Их количество, которое может проиндексировать Яндекс находится в диапозоне от 200 до 1000. Поэтому этим способом можно загнать несколько миллионов страниц сайта.
Отношение Яндекса к сайтам, не находящемся в зоне RU,SU, UA
В первую очередь, если вы только создали домен, Яндекс индексирует русскоязычные домены, это домены в зонах ru, su, ua. Все остальные домены индексируются не ранее чем через месяц.Доменная зона только влияет на время, которое потребуется, до начала первой индексации страницы. На частоту индексации доменная зона влияния не оказывает.
Вот приблизительно как работает поисковая система в плане частоты индексации:
- Робот находит страницу, индексирует её, заходит на неё на следующий день.
- Робот сравнивает её с тем, что было вчера и если не находит отличий, то зайдёт на неё через три дня.
- И если на этот раз изменений в странице робот не найдёт, то зайдёт на неё через неделю и т.д.
Ну вот и всё, что я хотел вам рассказать (итак много получилось), теперь вы знаете как работают поисковые системы.
P.S.
Как вам статья? Рекомендую получать свежие статьи блога на e-mail, чтобы не пропустить много новой интересной информации!
С уважением, Александр Сергиенко
Общие принципы работы поисковых систем
При оптимизации и продвижении сайта в Интернете необходимо знать по какому принципу работают поисковые системы. Известно, что поисковые системы работают по определенным алгоритмам, зная их можно предпринимать соответствующие меры по оптимизации сайта с целью улучшения позиций по тем или иным запросам. В данном уроке мы рассмотрим общие принципы работы ПС, разберем их основные компоненты.

В состав ПС входят следующие основные компоненты:
1. Spider (паук) — это программа на подобии браузера пользователя, которая скачивает веб-страницы. Паук работает с HTML-кодом страницы.
2. Crawler (краулер) — программа, которая переходит по всем размещенным на веб-странице ссылкам. Краулер, основываясь на ссылках, определяет, куда дальше должен идти паук. Таким образом, краулер исследует все ссылки и находит новые веб-страницы (документы), которые до этого не были известны поисковой системе.
3. Indexer (индексатор) — специальная программа, которая разбивает документ на отдельные части и анализирует их по отдельности.
4. Database (база данных) — база данных хранит все скачанные и обработанные документы. Базу данных, применительно к поисковым системам, также называют индексом поисковых систем.
5. Search engine results engine (система выдачи результатов) — эта система предназначена для извлечения результатов поиска из базы данных с целью ранжирования веб-страниц. Система выдачи результатов определяет релевантность страниц по определенным запросам, после чего решает в каком порядке их необходимо отсортировать в результатах выдачи поисковой системы. Ранжирование происходит согласно внутренним алгоритмам поисковой системы. У каждой поисковой системы эти алгоритмы свои. Для улучшения позиций сайта в выдаче поисковика по определенным запросам следует подстраиваться под эти алгоритмы.
6. Web server (веб-сервер) — веб-сервер является, своего рода, интерфейсом, с помощью которого происходит взаимодействие между пользователем и поисковой системой. Пользователь вводит в форму поиска соответствующий запрос, в результате веб-сервер выдает определенный результат в виде веб-страницы.
Таким, образом мы рассмотрели общие принципы работы поисковых систем. Как говорилось ранее, при оптимизации следует знать по какому принципу работают «поисковики». Кроме того, правильная оптимизация контента на веб-странице может обеспечить хорошие позиции в поисковой выдаче по определенным запросам.
Понравилось? Поделитесь с друзьями!
Поисковые системы
Основные поисковые системы
На заре своего существования Интернет еще не обладал большим объемом информации. Количество пользователей Сетью было тоже совсем невелико. Однако со временем возникла необходимость в оптимизации доступа к информации, содержащейся в Интернете, благодаря чему в 1994 году на свет появился проект под названием Yahoo. Данный проект подразумевал создание каталогов сайтов, в которых ссылки на сайты были сгруппированы по различным темам. Однако этот проект еще совсем мало был похож на современные поисковые системы. Первой поисковой системой в привычном для нас понимании стала WebCrawler.
На сегодняшний день основными мировыми поисковиками являются Google, Yahoo, MSN Search.
В российском Интернете этот список представлен следующими поисковыми системами: Яндекс, Google, Mail.ru, Aport, Rambler, KM.ru.
Бесспорно, самыми популярными из них являются Яндекс и Google.
Структура поисковых систем
Различные поисковые системы содержат одинаковый состав входящих в них основных элементов, а именно, поле поиска, кнопка поиска, список найденных результатов.
Структура поисковой системы представлена комплексом следующих программ.
- Робот spider (паук) , целью которого является просмотр страниц сайтов, предназначенных для индексации.
- Робот crawler (путешествующий паук). Его функция заключается в поиске новых и неизвестных системе ссылок и добавление их в список индексации.
- Индексатор обрабатывает страницу очереди, стоящей на индексацию.
- База данных хранит различную информацию необходимую для выведения результатов поиска.
- Система обработки запросов и выдачи результатов. Алгоритм ее работы сводится к следующему: во-первых, принять от пользователя запрос на поиск какой-либо информации, во-вторых, обратиться с этим запросом к базе данных, в-третьих, вывести пользователю полученный результат.
Фильтры поисковых систем
Рассмотрим отдельно фильтры, применяемые поисковой системой Google и системой Яндекс. Однако следует понимать, что такое разграничение имеет весьма зыбкие границы, так как в той или иной степени большинство из нижеперечисленных фильтров частично присутствует в каждой из этих двух поисковых систем.
Фильтры, предусмотренные системой Google.
- Фильтр “Песочница” (Sandbox). Под этот фильтр попадают все новые сайты и могут находиться, в так называемой “песочнице”, от трех месяцев до нескольких лет. Страницы таких новообразованных сайтов не выводятся в результатах поиска по высокочастотным запросам. Однако по запросам с низкой частотностью могут выдаваться поисковой системой. Одной из особенностей этого фильтра является то, что сайты из “песочницы” выводятся не по отдельности, а целыми группами. Достаточно быстрый вывод сайта из “песочницы” может быть обеспечен благодаря большому количеству ссылок на этот интернет-ресурс.
- Фильтр “Дополнительные результаты”. Те страницы сайта, которые попали под данный вид фильтра, будут выводиться в результатах поиска только лишь в тех случаях, когда не будет хватать основных, так называемых, “хороших” страниц.
- Фильтр “Bombing”. Под этот фильтр сайты попадают по причине неуникальности анкоров в ссылках.
- Фильтр “Bowling”. Опасность попадания сайтов под этот тип фильтров может угрожать исключительно интернет-ресурсам, TrustRunk которых низкий. Попадание сайта под этот фильтр может быть умышленно спровоцировано конкурентами.
- Фильтр “Возраст домена”. Причина попадания под фильтр – недоверие поисковой системы новым доменам.
- Фильтр “Дублирующийся контент”. Для сайта очень важно наличие на своих страницах уникального контента. Если на интернет-ресурсе используется большое количество краденой информации, то есть скопированной с других ресурсов, то сайт окажется под данным фильтром.
- Фильтр-30. Этот фильтр получил свое название благодаря тому, что понижает сайт на тридцать позиций в том случае, если на веб-ресурсе применяются черные методы продвижения (дорвеи, редиректы с помощью JavaScript).
- Фильтр “Опущенные результаты”. Сайт может оказаться под фильтром из-за скопированного с других ресурсов контента, из-за недостаточного числа входящих ссылок, дублирующихся заголовков и других meta-тегов. Кроме того, дополнительной причиной может являться недостаточная внутренняя перелинковка страниц сайта.
- Фильтр “Социтирование”. Причиной действия этого фильтра на интернет-ресурс может являться то, что на него ссылаются сайты совершенно иной тематики.
- Фильтр “Links”. Чтобы избежать действия данного фильтра, не следует заводить у себя на сайте страницу, предназначенную для обмена ссылками с партнерами. Это не поможет повысить сайт в результатах выдачи поисковой системы, а только нанесет вред.
- Фильтр “Много ссылок сразу”. Чтобы миновать данный фильтр, необходимо воздержаться от приобретения для сайта большого количества ссылок за достаточно короткий период времени.
- Фильтр “Чрезмерная оптимизация”. Причина попадания сайта под фильтр является использование на нем чрезмерного количества ключевых фраз с высокой степенью плотности.
- Фильтр ”Битые ссылки”. Избежать действия фильтра можно при условии, что ссылки не будут вести на страницы, которых не существует.
- Фильтрация страниц по времени загрузки. Как уже понятно из названия, фильтрация в данном случае обусловлена слишком долгой загрузкой страницы.
- Общий фильтр “Степень доверия” (Google Trust Rank). Фильтр учитывает такие факторы, как качество перелинковки, число исходящих ссылок, количество и авторитетность входящих ссылок, возраст домена и др. Для повышения позиций сайта в выдаче поисковой системы необходимо повышать Trust Rank.
Фильтры, предусмотренные системой Яндекс.
- АГС. Благодаря этому фильтру из поисковой системы исключаются сайты, предназначение которых заключается в поисковом спаме.
- Непот-фильтр. Интернет-ресурс может пострадать от этого фильтра за ведение торговли ссылками с сайта, из-за чего сайт засоряется большим количеством таких ссылок.
- Редирект фильтр. Этот фильтр наказывает сайты за применение javascript редиректов.
- Фильтр плотности ключевых слов. Чтобы избежать действия фильтра, необходимо избегать чрезмерной концентрации ключевых слов и фраз на сайте.
- Фильтр “Ты последний”. Причина действия фильтра лежит в обнаружении поисковой системы дубля страницы.
Принципы ранжирования в поисковых системах
Ранжирование – это вывод сайтов на страницах поисковых систем в определенной последовательности в ответ на какой-либо запрос пользователя. Принято выделять внутренние и внешние принципы ранжирования. Рассмотрим каждую группу по отдельности.
Внутренние принципы ранжирования. Внутренние принципы ранжирования подчинены действиям владельца сайта. Они учитывают:
- объем информации на странице сайта;
- количество, плотность и расположение ключевых слов и фраз на странице интернет-ресурса;
- стилистику представленного на странице текста;
- наличие ключевых слов в теге Title и в ссылках;
- содержание ключевых слов в мета-тегах Description;
- общее количество страниц сайта.
Внешние принципы ранжирования учитывают:
- Индекс цитирования (оценивает популярность сайта).
- Ссылочный текст (внешние ссылки, которые ведут на сайт).
- Релевантность ссылающихся страниц (оценка информации ссылающейся страницы).
- Google PageRank (теоретическая посещаемость страницы).
- Тематический индекс цитирования Яндекс (авторитетность сайта относительно других близких ему интернет-ресурсов).
- Добавление информации о сайте (самбит) в каталоги общего назначения, каталог DMOZ, Каталог Яндекса.
- Обмен ссылками между сайтами.
Таким образом, мы представили некоторую информацию, касающуюся специфики работы поисковых систем. Однако следует учесть тот факт, что алгоритм их работы претерпевает различные изменения, поэтому информация о поисковых системах является весьма динамичной и требует постоянного анализа со стороны seo-специалистов.
Поиск в Интернет. Каталоги. Информационно-поисковые системы. Механизмы поиска в Интернет.
ИПС (информационно-поисковая система) – это система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска.
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска сформулированному запросу.
Далее мы будем, в основном, рассматривать ИПС для всемирной паутины (WWW). Основными показателями ИПС для WWW являются пространственный масштаб и специализация.
По пространственному масштабу ИПС можно разделить на локальные, глобальные, региональные и специализированные. Локальные поисковые системы могут быть разработаны для быстрого поиска страниц в масштабе отдельного сервера.
Региональные ИПС описывают информационные ресурсы определенного региона, например, русскоязычные страницы в Интернете. Глобальные поисковые системы в отличие от локальных стремятся объять необъятное – по возможности наиболее полно описать ресурсы всего информационного пространства сети Интернет.
Кроме того, ИПС также могут специализироваться по поиску различных источников информации, например, документов WWW, файлов, адресов и т.д.
Рассмотрим подробнее основные задачи, которые должны решить разработчики ИПС. Как следует из определения, ИПС для WWW проводят поиск в собственной базе (индексе) с описанием распределенных источников информации.
Следовательно, сначала нужно описать информационные ресурсы и создать индекс. Построение индекса начинается с определения начального набора URL источников информации. Затем проводится процедура индексирования.
Индексирование – описание источников информации и построение специальной базы данных (индекса) для эффективного поиска.
В некоторых информационно-поисковых системах описание источников информации проводится персоналом ИПС, то есть, людьми, которые составляют краткую аннотацию на каждый ресурс. Затем, как правило, проводится сортировка аннотаций по темам (составление тематического каталога). Конечно, описание, составленное человеком, будет совершенно адекватно источнику. Правда, в этом случае процедура описания занимает значительный период времени, поэтому формируемый индекс имеет, как правило, ограниченный объем. Зато поиск в подобной системе можно будет проводить так же легко, как в тематических каталогах библиотек.
В ИПС второго типа процедура описания информационных ресурсов автоматизирована. Для этого разрабатывается специальная программа-робот, которая по определенной технологии обходит ресурсы, описывает их (проводит индексирование) и анализирует ссылки с текущей страницы для расширения области поиска. Как может описать документ программа? Чаще всего просто составляется список слов, которые встречаются в тексте и других частях документа, при этом учитывается частота повторения и местоположение слова, то есть, слову приписывается своеобразный весовой коэффициент в зависимости от его значимости. Например, если слово находится в названии Web-страницы, робот пометит этот факт для себя. Поскольку описание автоматизировано, затраты времени невелики, и индекс может оказаться очень большим по размеру.
Следовательно, следующей задачей для ИПС второго типа является разработка робота-индексировщика. Для поиска в системах данного типа пользователю придется научиться составлять запросы, в простейшем случае состоящие из нескольких слов. Тогда ИПС будет искать в своем индексе документы, в описаниях которых встречаются слова из запроса. Для проведения более качественного поиска необходимо разрабатывать специальный язык запросов для пользователя. В зависимости от особенностей построения модели индекса и поддерживаемого языка запросов разрабатывается механизм поиска и алгоритм сортировки результатов поиска. Поскольку индекс имеет значительный объем, количество найденных документов может оказаться достаточно большим. Следовательно, чрезвычайно важно, как поисковая машина проведет поиск и отсортирует его результаты.
Не последнее значение имеет внешний вид поисковой системы, предстающий перед пользователем, поэтому одной из задач является разработка удобного и красивого интерфейса. Наконец, исключительно важна форма представления результатов поиска, поскольку пользователю необходимо узнать как можно больше о найденном источнике информации, чтобы принять правильное решение о необходимости его посещения.
Для обращения к поисковому серверу пользователь использует стандартную программу-клиент для всемирной паутины, то есть браузер. По адресу домашней страницы ИПС пользователь работает с интерфейсом поисковой системы, который служит для общения пользователя с поисковым аппаратом системы (системой формирования запросов и просмотра результатов поиска).
6 Принципы работы метапоисковых систем. Механизмы поиска в интернет. Язык запросов.
При работе метапоисковой системы из полученного от поисковых систем множества документов необходимо выделить наиболее релевантные, то есть соответствующие запросу пользователя.
Простейшие метапоисковые системы реализуют стандартный подход, представленный на рис. 1. В таких системах анализ полученных описаний документов не производится, что может поставить нерелевантные документы, идущие первыми в одной поисковой системе, выше релевантных в другой, чем существенно понизить качество самого поиска.
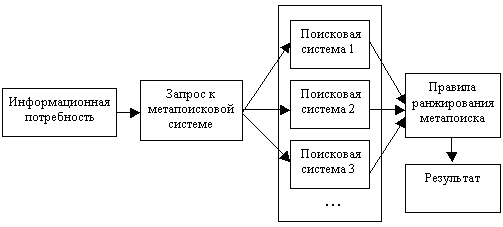
Рис.1 Стандартная метапоисковая система
При разработке следующего поколения метапоисковых систем были учтены недостатки, присущие стандартным метапоисковым системам. Были созданы системы с возможностью выбора тех поисковых машин, в которых, по мнению пользователя, он с большей вероятностью может найти то, что ему нужно (рис. 2)
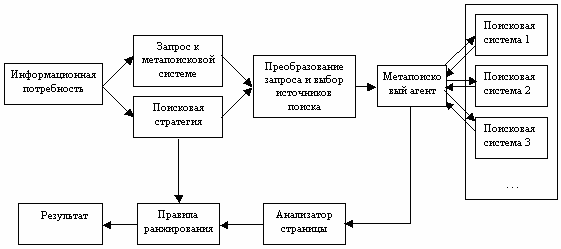
Рис. 2. Следующее поколение метапоисковых систем
Кроме этого, такой подход позволяет уменьшить используемые вычислительные ресурсы метапоискового сервера, не перегружая его слишком большим объемом ненужной информации и серьезно сэкономить трафик. Здесь нужно отметить, что в любой системе метапоиска наиболее узким местом в основном является пропускная способность канала передачи данных, так как обработка страниц с результатами поиска, полученными от нескольких десятков поисковых серверов не является слишком трудоемкой операцией, потому что затраты времени на обработку информации на порядки меньше времени прихода страниц, запрошенных у поисковых серверов.
Как пример систем, имеющих подобную организацию, можно назвать Profusion, Ixquick, SavvySearch, MetaPing.
Примером метапоисковой системы является Nigma (Нигма. РФ) — российская интеллектуальная метапоисковая система.
Программа ускоренного поиска – это программа с возможностями метапоисковой системы, устанавливаемая на локальном компьютере.
Принципиальным отличием метапоисковых систем и программ ускоренного поиска от ИПС является отсутствие своего собственного индекса. Зато они превосходно умеют использовать результаты работы других поисковых систем.
Механизмы поиска
Обобщенная технология поиска состоит из следующих этапов:
Пользователь формулирует запрос
Система проводит поиск документов (или их поисковых образов)
Пользователь получает результат (сведения о документах)
Пользователь совершенствует или реформирует запрос
Организация нового поиска…
Как правило, поисковые машины поддерживают два режима: режим простого поиска и режим расширенного поиска. Рассмотрим обобщенные возможности.
Формирования запроса в режиме простого поиска. Можно просто вводить через пробел одно или несколько слов; поиск слов со всевозможными окончаниями моделируется символом * в конце слова. Многие системы позволяют искать словосочетания или фразу, для этого необходимо ее заключить в кавычки. Возможно обязательное включение или исключение определенных слов.
Основная проблема поиска по примитивно составленному запросу (в виде перечисления ключевых слов) заключается в том, что поисковая машина найдет все страницы, на которых указанные слова встречаются в любой части документа. Как правило, количество найденных страниц будет слишком велико.
Для улучшения качества поиска в режиме простого поиска допустимо использование логических операторов и операторов, позволяющих ограничить область поиска, а также выбор определенной категории документов из представленного списка.
Многие поисковые системы включают в свой язык составления запросов специальные операторы, позволяющие проводить поиск в определенных зонах документа, например, в его заголовке, или искать документ по известной части его адреса.
Режим расширенного или детального запроса в разных системах реализован индивидуально, но чаще всего это бланк, в котором упомянутые операторы и ключевые элементы реализуются простой установкой соответствующих флажков или выбором параметров из списка.
Ниже в качестве примера приведены сведения из раздела помощь поисковой системы Yandex: окно расширенного поиска, язык запросов, искать в найденном.
Искать в найденном Если в результате запроса Яндекс нашел много документов, но по более широкой теме, чем вам хочется, вы можете сократить этот список, уточнив запрос. Еще один вариант — включить флажок в найденном в форме поиска, задать дополнительные ключевые слова, и следующий поиск будет вестись только по тем документам, которые были отобраны в предыдущем поиске.
Основные принципы работы поисковых систем (стр. 1 из 11)
Основные принципы работы поисковых систем.
Не зря наше время называют веком информационных технологий. От того, насколько быстро и точно будет найдена та или иная информация, насколько она будет соответствовать потребности человека, желающего получить или найти её, очень часто зависит успех в бизнесе и не только.
Поиск информации до недавнего времени представлял из себя сложную и длительную процедуру, ее возможно было найти только в книгах, газетах и других средствах массовой информации. Сегодня, когда огромным хранилищем разнообразной информации является интернет, ее поиск стал и проще, и в то же самое время значительно сложнее.
Сложность поиска информации в интернете обусловлена ее огромным объемом, количеством, многочисленностью и разбросанностью ресурсов, на которых она расположена. Осуществлять поиск информации в интернете без использования специальных методов и приемов — сложное, а порой даже невозможное занятие.
Именно в связи с этим для облегчения работы по поиску информации пользователями сети интернет были созданы специальные поисковые машины или поисковики, которые осуществляют поиск необходимой информации во всемирной сети, используя принципы поиска по ключевым словам и фразам, которые задаются пользователями сети, осуществляющими поиск необходимой им информации различного плана.
Принцип работы поисковой системы достаточно несложен, по нему работают все известные поисковые системы, число которых в интернете превышает миллион: заданное пользователем в специальной строке поиска, слово или словосочетание, соответствующее характеру необходимой информации, анализируется поисковой системой и по нему находятся соответствия в интернете, наиболее подходящие под условия поиска. Работа поисковой системы, таким образом, заключается в нахождении подобных заданным, слов и словосочетаний на многочисленных сайтах, расположенных в сети Интернет.
Активное развитие сети Интернет, произошедшее в последнее десятилетие, привело к тому, что результатами поиска необходимой информации, могли стать десятки тысяч интернет-страниц и сайтов, содержащих слово или фразу, внесенную пользователем в строку запроса. При этом совсем необязательно, что эти страницы или сайты могли соответствовать по смыслу той информации, которую искал пользователь сети.
Эти обстоятельства привели к тому, что разработчиками современных поисковых систем, стали использоваться абсолютно новые принципы поиска, заложенные в поисковые машины, использующие логические и морфологические инструменты построения предложений и фраз. Работающие по таким принципам поисковые системы, имеют возможность отсеивать ненужную информацию, выбирать из найденной информации действительно полезную и выдавать в качестве результатов поиска, преимущественно ту информацию, в которой испытывает потребность пользователь Интернета, осуществляющий поиск.
Как правило, принципы работы поисковых систем, являются ноу-хау их разработчиков, занимающихся постоянным совершенствованием своих поисковых машин.
1.Введение
2.Сроки
3.Сниппеты
4.Интернет-магазины
5.Что выбрать?
6.Ошибки запросов
7.Ключевые слова
8.Релевантность
9.Ссылки
10.Раскрутка
11.Методы раскрутки
12.ИЦ и PR
13.Непот-фильтр
14.Мифы оптимизации
15.Ошибки в SEO
16.Мета-теги
17.Cистемы и каталоги.
18.Обмен ссылками
19.Бесплатная раскрутка
20.Фреймы
21.Черные методы
22.Бан сайта
23.Интернет-реклама
24.Гарантии
25.Принципы поиска
26.Аудит рынка
27.Исследование конкурентов
28.Интернет-маркетинг
29.Продвижение форума
30.Выбор домена
31.Партнерские программы
Введение
Интернет уже давно перестал быть простым источником информации и превратился в глобальную зону деловой активности и торговли. Темпы роста оборотов интернет коммерции просто поражают воображение и заставляют многие компании задуматься об использовании таких обширных возможностей для поиска новых клиентов и партнеров, реализации товаров и услуг, автоматизации обслуживания и поддержки покупателей.
Активный рост количества интернет сайтов различных компаний из всех сфер бизнеса постепенно привел к росту конкуренции практически во всех областях бизнеса. Поэтому многие компании стали все серьезнее задумываться о том, как можно выделить свой сайт среди конкурентов и привлечь на него как можно больше заинтересованных пользователей.
Поэтому спрос на SEO (Search Engine Optimization) услуги и рекламу в сети Интернет в настоящее время резко возрос. Сегодня любой владелец сайта хорошо понимает большую важность поисковой оптимизации и продвижения сайта в поисковых системах, так как именно поисковики распределяют значительную долю сетевого трафика.
Однако серьезная конкуренция и техническая сложность качественной оптимизации привели к увеличению стоимости SEO-услуг. Поэтому далеко не каждая компания, а тем более рядовой пользователь сети Интернет, может позволить себе потратится на профессиональную раскрутку сайта и его дальнейшую поддержку.
Многие стараются сократить расходы на оптимизацию за счет самостоятельного выполнения работ, обращения к фрилансерам, автоматическим программным средствам продвижения. К сожалению, в таких ситуациях эффективность работы резко снижается из-за недостатка информации и опыта в SEO сфере.
Поэтому эта серия статей предназначена для того, что бы дать основные понятия об оптимизации и уберечь начинающих веб мастеров от часто допускаемых ошибках при выполнении оптиматизации и раскрутке своего сайта.
Оптимальные сроки продвижения сайта.
Один из самых острых вопросов, возникающих при заказе оптимизации и раскрутки сайта, это, безусловно, сроки. Вполне понятно, что в этом пункте интересы заказчиков и оптимизаторов расходятся. Заказчик жаждет поскорее ощутить реальные результаты продвижения своего сайта, а оптимизатору необходимо немного времени для того, чтобы спокойно и качественно провести весь комплекс работ по продвижению сайта заказчика, не нервничая при этом из-за сжатых сроков. Кроме того, рассуждая о сроках продвижения, не нужно забывать про то, что в этом процессе задействована и третья сторона – поисковые системы, которые не зависят ни от заказчика, ни от оптимизатора и могут в любой момент внести свои непредсказуемые коррективы в результаты раскрутки.
Попробуем разобраться в этом вопросе. Во-первых, вполне логично, что универсального подхода в определении сроков продвижения сайта нет. Каждый сайт по-своему индивидуален, он ориентирован на определенную целевую группу пользователей, имеет свою базу ключевых слов, свою тематику и специфику работы. Как известно, добиться хороших результатов по популярным запросам на распространенные темы довольно сложно и требуется немало времени и усилий, в то же время продвинуть узкоспециализированный сайт с небольшим количеством точных ключевых фраз сравнительно проще, хотя это также требует времени. В среднем, на то, чтобы занять высокие позиции в результатах поиска по ключевым запросам и получить реальные результаты продвижения, необходимо 2-3 месяца.
Для людей далеких от оптимизаторской деятельности срок в 2-3 месяца может показаться пугающим, но проследив весь цикл работ по продвижению сайта, становится ясно, что обещания «мгновенных результатов» это чистой воды мошенничество.
После того, как договор подписан, оптимизаторская компания начинает работу. Проводится тщательный анализ ситуации по выбранной тематике, изучается напряженность конкуренции и интересы пользователей. Используя накопленный опыт, статистику поисковых систем и комплекс профессионального программного обеспечения, оптимизаторы проводят подбор базы ключевых запросов (семантическое ядро) и поисковую оптимизацию сайта. Эти действия позволяют повысить привлекательность сайта для поисковых роботов, он быстрее индексируется, повышается весомость ресурса для поисковых систем. В зависимости от размера и наполнения сайта на это уходит около двух недель.
Далее одним из самых значимых этапов продвижения является формирование и наращивание ссылочной базы сайта. Формируются тексты ссылок, проводится их размещение. Успех и скорость этой работы во многом ограничиваются регулярностью апдейтов поисковиков, частота которых колеблется от одной до двух недель.
Даже после исполнения полного комплекса работ (анализа и оптимизации сайта, наращивания ссылочной базы, размещения информации и статей в интернете и т.д.) и апдейта поисковой системы, далеко не всегда удается достигнуть цели. Как правило, приходится кропотливо работать и ждать, наращивая и совершенствуя результаты продвижения сайта с каждым апдейтом поисковика. И чем сложнее и популярнее тематика сайта, тем длиннее будет его путь к вершинам выдачи, хотя первые результаты работ будут видны уже через 1-1,5 месяца.
Отдельно нужно отметить новые изменения в поисковом алгоритме Яндекса в 2008 году, в результате которых срок продвижения для сайтов, созданных и запущенных совсем недавно, немного увеличился. Для новых сайтов срок достижения лидирующих позиций составляет 3-4 месяца.
Сниппеты и их роль в поисковой оптимизации.
Понятие «сниппет» мало кому знакомо из обычных людей, однако практически каждый пользователь сети Интернет ежедневно множество раз сталкивается со сниппетами. Слово снипет произошло от английского snippet, что в переводе означает – отрывок, часть, фрагмент. Это небольшой отрывок текста страницы сайта, который показывает пользователю поисковая машина, как описание ссылки в итогах поиска по тому или иному запросу. Сниппеты включают контекст, в котором было найдено искомое ключевое слово и, как правило, состоят из заголовка, текста описания или ссылки, адреса найденной страницы, размера страницы и некоторой дополнительной информации, в зависимости от использующейся поисковой машины. Так, например, Яндекс-снипет дополнительно содержит наименование рубрики Яндекс-каталога, в которой зарегистрирована найденная страница и ее последнюю копию.