23 KPI для IT кроме uptime + пример системы показателей
KPI для ИТ не должны ограничиваться uptime-ом! Если мы хотим отслеживать ИТ и получать ранние предупреждения о потенциальных проблемах, нам необходимо иметь четко определенный и сбалансированный набор показателей. В этой статье мы рассмотрим некоторые примеры ИТ-KPI, способных стать основой вашей системы показателей.
Основные темы:
- Согласование ИТ со стратегией компании
- Финансовые KPI
- KPI клиентов
- KPI внутренних процессов
- KPI обучения и роста
Прежде чем мы углубимся в детали: иногда ИТ-отдел живет в компании своей собственной жизнью. Это означает, что front end оценивается очень субъективно, а измерение внутренних процессов ограничивается отслеживанием uptime-а. Другие показатели являются слишком техническими и/или не имеют ничего общего с реализацией стратегии компании.
Хорошим решением проблемы является определение SLA между подразделениями бизнеса, однако это лишь первый шаг.
- Финансы: отслеживание и управление расходами на ИТ;
- Клиенты: отслеживание и улучшение опыта внутренних и сторонних пользователей;
- Внутренние процессы: проактивное предотвращение технических проблем и проблем безопасности;
- Обучение: поддержка ИТ-систем; улучшение процесса обучения на основе решения прошлых ошибок.
ИТ не генерирует прибыль напрямую, однако с точки зрения финансов имеет смысл отслеживать некоторые расходы. Здесь представлены примеры KPI этого типа:
- Процент затрат на ИТ от общих затрат, %. Управление внутренними бизнес-системами и поддержка сайта не входят в число ваших прямых компетенций и не приносят прибыль напрямую.
 В структуре затрат должна быть отражена следующая идея: выделение средств, достаточных для поддержания системы в хорошем состоянии, но не для гонки за новейшими технологиями.
В структуре затрат должна быть отражена следующая идея: выделение средств, достаточных для поддержания системы в хорошем состоянии, но не для гонки за новейшими технологиями. - Затраты на сотрудников, $/сотрудник. С одной стороны, вы должны снабдить команду необходимыми инструментами, с другой, нужно понимать, когда стоит остановиться. Сравните свои данные с показателями по отрасли и сделайте выводы.
- Затраты на поддержку одного пользователя, $/пользователь. Этот показатель похож на предыдущий. Большие затраты на поддержку (по сравнению со средними данными в отрасли или вашими историческими данными) могут указывать на потенциальную проблему. Например, сотрудники могут слишком часто связываться с ИТ-отделом из-за отсутствия ясных руководств или потому, что они не были обучены работе в информационных системах.
 В структуре затрат должна быть отражена следующая идея: выделение средств, достаточных для поддержания системы в хорошем состоянии, но не для гонки за новейшими технологиями.
В структуре затрат должна быть отражена следующая идея: выделение средств, достаточных для поддержания системы в хорошем состоянии, но не для гонки за новейшими технологиями.Используя эти или похожие финансовые показатели, вы должны четко понимать, для чего вы это делаете. Если в данный момент понимания нет, не тратьте ресурсы на измерение того, что не является важным для вашей организации.
- Узнать больше о финансовой перспективе ССП.
Существует два типа клиентов ИТ-отдела:
- Внутренние пользователи (сотрудники компании) и
- Внешние пользователи (конечные пользователи продукта, посетители сайта и т.д.)
Мы рекомендуем разделить показатели на две соответствующие группы.
KPI для ИТ
Необходимо учитывать также и то, что сегодняшний ИТ-отдел не только исправляет связанные с компьютерами проблемы, но и обеспечивает получение пользователями наилучшего опыта. Поэтому необходимо также отслеживать соответствующие показатели.
- Время ответа на запросы, часы. Показатель является показателем действия для бизнес-целей, связанных со взаимодействием сотрудников и пользователей. Чем быстрее ИТ-команда отвечает на запросы, тем выше уровень вовлеченности.
- Использование бизнес-системы, %. Возьмите бизнес-систему, используемую в компании (CRM, ERP или BI), определите интервал времени (например, 7 дней) и рассчитайте процент пользователей, которые использовали систему в течение этого промежутка. Это хороший показатель результата, оценивающий вовлеченность пользователей в сравнении с историческими данными: если вы установили первоклассное ПО, но его никто не использует, то это повод задуматься.
- Количество критических проблем, о которых сообщил пользователь. Проблемы возникают каждый день, однако важно знать, какие критические проблемы были обнаружены и предотвращены внутренней командой, а о каких проблемах сообщили конечные пользователи (= проблемы, затронувшие ваш бренд).
Чтобы продолжить работу с клиентами, опишите типичные случаи использования, связанные с взаимодействием клиентов и ИТ, и найдите ключевые моменты, влияющие на качество обслуживания клиентов. Например, открывает ли ИТ-отдел учетную запись для всех новых сотрудников, обеспечивает ли простоту и прозрачность всего процесса. Возможны соответствующие показатели:
Возможны соответствующие показатели:
- Время на регистрацию новой учетной записи, минут
- Показатель успешности создания аккаунта, %.
Узнайте больше о клиентской перспективе в ССП.
KPI внутренних процессовКак правило, основные проблемы возникают с определением показателей внутренних бизнес-процессов. Рекомендуется отдельное отслеживать простои, связанные с проблемами безопасности, и создание соответствующего плана предотвращения.
- Средняя наработка на отказ (MTBF). Среднее время между сбоями.
- Среднее время ремонта (MTTR). Сравните этот показатель с данными по отрасли. Если ваш поставщик услуг тратит слишком много времени на ремонт, возможно, кто-то другой выполнит эту работу быстрее.
- Доступность (период исправного состояния) рассчитывается как MTBF/(MTBF + MTTR). Применяется к внутренним системам, сетям, вебсайту и т.д.
- Сбои, связанные с проблемами безопасности. Показатель результата инициатив ИТ-безопасности. В качестве плана улучшения можно запланировать регулярный экспертный аудит систем безопасности.
 Показатель результата инициатив ИТ-безопасности. В качестве плана улучшения можно запланировать регулярный экспертный аудит систем безопасности.
Показатель результата инициатив ИТ-безопасности. В качестве плана улучшения можно запланировать регулярный экспертный аудит систем безопасности.KPI для ИТ
С точки зрения управления, необходимо понять, работает ли ИТ-отдел в стиле поиска и решения проблем, или он способен учиться на своих ошибках. Хорошим началом могут стать следующие показатели.
- Количество повторяющихся проблем (упрощенная версия: процент вновь открытых обращений в тех поддержку). Это хороший индикатор результата улучшения службы: если команда хорошо справляется с задачей с первого раза, проблема не возникнет вновь.
- Уровень восстановления системы. Сымитируйте сбой системы, отследите % восстановленных данных и время восстановления. Подобная эмуляция поможет создать план действий по улучшению ИТ-системы.

Узнайте больше о перспективе обучения и роста в ССП.
KPI для ИТ
Заключение
Мы обсудили несколько важных показателей для ИТ. Они будут более эффективны, если вы согласуете их со стратегией и конкретными задачами бизнеса. Это прекрасная возможность пересмотреть KPI и сосредоточиться на тех, отслеживать которые нужно регулярно.
Возникли вопросы о KPI, посетили интересные идеи? Поделитесь ими в комментариях.
Другие примеры Сбалансированны Систем Показателей
Цитирование: Aleksey Savkin, «23 KPI для IT кроме uptime + пример системы показателей», BSC Designer, 21 мая, 2020, https://bscdesigner.com/ru/it-kpi.htm.
This website uses cookies to improve your experience. We’ll assume you’re ok with this, but you can opt-out if you wish. Cookie settingsOK
Ключевые показатели ИТ-департамента — Cleverics
Возможно, вы консультант или вновь назначенный ИТ-менеджер или просто очень любознательный сотрудник ИТ-департамента, который хочет разобраться, как работает управление ИТ в организации.
 Эти метрики помогут быстро составить впечатление от ИТ-департамента вашей организации и наметить следующие шаги.
Эти метрики помогут быстро составить впечатление от ИТ-департамента вашей организации и наметить следующие шаги.Важные предостережения:
Это не показатели для ежедневного контроля – значения большинства их них не меняются существенно даже на отрезке года.
Метрики в основном не годятся в качестве KPI ИТ-подразделения или ИТ-директора – большинству из них нельзя задать целевое значение.
Это не чеклист для обследования ИТ-департамента, а лишь база для дальнейшего анализа.
Большинство метрик уместно использовать и для измерения коммерческого провайдера ИТ-услуг, но все же фокус этой статьи – внутренний ИТ-департамент организации, бизнес которой не связан с информационными технологиями.
Вот эти метрики:
Доля ИТ-затрат в общих операционных затратах организации
Уровень доступности
Incident rate
Своевременность обработки запросов
Доля численности ИТ-персонала в развитии
Размер бэклога (разработки)
Доля времени разработчиков на эксплуатацию
Удовлетворенность потребителей услуг
Анализ представленных показателей позволят быстро и на основе цифр составить портрет ИТ-департамента, подскажут путь дальнейшего анализа, посветят области, требующие внимания и приложения усилий. Разберем каждый из них.
Разберем каждый из них.
Доля ИТ-затрат
Говорят, что технологии уже пронизывают каждую функцию организации и оказывают критическое влияние на все аспекты бизнеса. Но возможно конкретной организации – еще не до цифровой трансформации. Метрика наглядно показывает, насколько значимы ИТ для бизнеса и задает контекст для трактовки остальных показателей. Если возможно, хорошо бы взглянуть на метрику в первую очередь.
Почему важен
Позволяет оценить, насколько значимы ИТ для организации.
Как измерять
Определить общие операционные затраты, включая оплату труда ИТ-персонала, амортизацию ОС (основные средства) и НМА (нематериальные активы), оплату труда ИТ-персонала, оплаты по договорам оказания услуг и прочие операционные затраты (расходные материалы и малоценные активы).
Поделить на общие операционные затраты организации.
Если организация не выполняет аллокацию ИТ-затрат, то быстрое получение доступа к данным о фактических затратах может быть затруднительно. В этом случае, можно использовать бюджет.
В этом случае, можно использовать бюджет.
Как использовать
Если первичные данные и модель аллокации ИТ-затрат позволяет, можно пойти в анализе чуть дальше и:
Рассчитать долю затрат на персонал. По нашему опыту, при численности персонала 150-500 человек, ожидаемые значения – 25-50%. То есть зарплаты ИТ-специалистов могут составлять четверть всех ИТ-затрат предприятия. Когда речь о цифре порядка полумиллиарда, это создает совсем другой уровень интереса к анализу того, как построена работа этих специалистов и как ее сделать эффективной (процессные метрики, персональные KPI, система мотивации).
Рассчитать долю затрат на амортизацию оборудования. Наибольший интерес представляет не сама доля затрат (по нашему опыту, она колеблется в широком диапазоне 8-32%), а объем неутилизированных мощностей. Значения выше 12% должны настораживать. Коридор “нормальных” значений – 8-12%. Все, что ниже, означает огромные успехи в оптимизации использования ресурсов (менее вероятно) или неточное выполнение аллокации ИТ-затрат (более вероятно).
Уровень доступности
Доступность – первое, что приходит в голову, когда говорят о качестве ИТ-услуг. Уровень доступности – важнейший показатель потому, что отражает, как много бизнес теряет (точнее: может потерять) в связи со сбоями ИТ. Особенно важно, что ИТ-организация умеет измерять, оценивать и отчитываться о доступности ИТ-услуг.
Почему важен
Позволяет оценить бизнес-риски, связанные со сбоями ИТ.
Как измерять
Процент доступности – общепринятый показатель для измерения надежности ИТ-инфраструктуры, но он не годится для измерения доступности ИТ-услуг, предоставляемых ИТ-подразделением организации.
Первая сложность связана с обсуждением показателя. Доступность определена как 99,9%. Вроде неплохо. Но 0,1% в год равен почти 9 часам (при режиме эксплуатации 24×7). А в месяц – это почти 45 минут. А в неделю – чуть более 10 минут. Так какие 99,9% имел в виду бизнес-заказчик? А ИТ-менеджмент?
Однако значительно более существенен следующий нюанс: показатель довольно неточно отражает негативное влияние на бизнес. Что если все без малого 9 часов за год случились разом? Или услуга становилась недоступна потребителям по две минуты, но 15 раз за один день? Как это будет выражено в процентах?.. Поэтому, например, ITIL вводит такие показатели, как MTRS (Mean time to restore service), MTBF (Mean time between failures).
Что если все без малого 9 часов за год случились разом? Или услуга становилась недоступна потребителям по две минуты, но 15 раз за один день? Как это будет выражено в процентах?.. Поэтому, например, ITIL вводит такие показатели, как MTRS (Mean time to restore service), MTBF (Mean time between failures).
Вернемся в начало координат и зададимся вопросом: зачем мы вообще вводим показатели доступности? Почему бизнес предъявляет требования к доступности услуг? Почему сервис-провайдер должен обеспечивать высокую доступность и отчитываться по ее фактическим значениям? Ответ прост: бизнес несет потери вследствие простоев ИТ-услуг. Значит, идеальным для бизнеса показателем доступности, вероятно, была бы метрика «Потери вследствие простоев ИТ-услуг»?
Произвести расчет такой метрики возможно в основном для ИТ-услуг, непосредственно связанных с получением прибыли (продажи, кредитный конвейер и так далее). Таким образом, мы должны определить другие показатели, не забывая о том, что в совокупности они должны нести информацию о бизнес-влиянии (фактическом или потенциальном).
От чего зависят потери бизнеса вследствие простоев?
Чем меньше за отчетный период услуга была в uptime, тем больше потери. Используем показатель «Суммарное время простоев».
Чем дольше разовый простой, тем больше потери. Нередко потери не являются постоянной во времени величиной и зависят от длительности прерывания экспоненциально. В первый отрезок времени ущерб складывается из несовершенных транзакций, потерь продуктивности персонала и затрат на восстановление, но с определенного момента длительный простой угрожает бизнесу штрафами, санкциями, уроном репутации и так далее. Об этом расскажет показатель «Максимальный разовый простой».
Ряд бизнес-процессов, напротив, «чувствительны» не к единичным длительным простоям, а к частым прерываниям. Это особенно важный фактор для процессов, в рамках которых происходят длительные вычисления, которые в случае прерывания требуется перезапускать. Таким образом, должно быть обеспечено как можно меньшее количество прерываний за период. Не лишним будет показатель «Количество нарушений».
Не лишним будет показатель «Количество нарушений».
Альтернативной (или дополнительной) метрикой, отражающей тот же аспект, но с акцентом на периоде спокойной работы пользователей, может быть показатель «Минимальная (или средняя) продолжительность работы без нарушений».
Итого, в зависимости от ИТ-услуги возможно использовать один или несколько показателей:
Суммарный показатель простоев
Максимальный разовый простой
Минимальная продолжительность работы без нарушений
Кол-во нарушений за период
Как использовать
Нередко для оценки деятельности ИТ-департамента показатели доступности услуг агрегируют для расчета общего KPI. Но чтобы получить представление о том, как ИТ справляется с управлением доступностью, нужно смотреть на них в “развернутом” виде – для этого будет достаточно взгляда га нескольких (до 5-6) ключевых ИТ-услуг, которые обеспечивают функционирование бизнеса, за 3-4 месяца. Особое внимание нужно уделить трендам и единичным провалам – они зададут направления для следующих шагов.
Incident rate
Incident rate также характеризует надежность ИТ. В отличие от уровня доступности он значительно менее требователен к средствам измерения и методике оценки (если есть ITSM-система, в которой регистрируются инциденты).
Кроме того, метрика косвенно показывает, насколько реактивно ИТ-подразделение и сколько ресурсов тратит на «тушение пожаров» вместо плановой работы.
Почему важен
показывает, насколько надежны применяемые ИТ-решения
показывает, сколько ресурсов тратится на «тушение пожаров»
Как измерять
Incident rate = количество запросов категории «Инцидент», поступивших за один месяц, в расчете на одного активного сотрудника организации – пользователя ИТ.
Лучше брать выборку за год в разбивке по месяцам, чтобы исключить сезонность. Из пользователей лучше исключить уволенных сотрудников и различные технические учетные записи.
Значение показателя может сравниваться с отраслевой статистикой. Она показывает, что значения этой метрики колеблются в довольно узком диапазоне – 0. 4 — 2.3. Причем данный диапазон слабо зависит от размера организации и в основном определяется отраслью (например, в банках значения выше, чем в энергетике). Отраслевая специфика – это следствие влияния сложности применяемых информационных технологий и частоты их изменений.
4 — 2.3. Причем данный диапазон слабо зависит от размера организации и в основном определяется отраслью (например, в банках значения выше, чем в энергетике). Отраслевая специфика – это следствие влияния сложности применяемых информационных технологий и частоты их изменений.
Как использовать
У IR два направления для применения:
анализ потока, чтобы, например, определить ориентиры по повышению доступности за счёт сокращения текущего (известного) количества инцидентов
прогноз потока, чтобы оценить количество инцидентов при организации процесса управления инцидентами
Своевременность обработки запросов
Метрика связана с ключевым обязательством ИТ-департамента перед бизнесом. В организации может не быть каталога услуг и SLA, но целевое время решения запросов пользователей задано и отслеживается везде. Решение запросов пользователей связано с коммуникацией, поэтому своевременное и результативное решение пользовательских запросов в существенной степени формирует общее восприятие ИТ.
Почему важен
ключевое обязательство ИТ-департамента перед бизнесом
значимый фактор удовлетворенности работой ИТ
Как измерять
На первый взгляд, своевременность обработки запросов измерить несложно: количество своевременно обработанных запросов нужно поделить на общее количество запросов, обработанных за некоторый период времени.
Однако за простотой этой формулы скрывается существенный недостаток – такое определение метрики своевременности не учитывает, на сколько был нарушен срок обработки запроса. Обычно пользователю не все равно, был ли его запрос просрочен на 5 минут или на неделю.
Отразить в метрике, насколько нарушен срок, можно следующим образом: количество своевременно обработанных запросов поделить на коэффициент Wi (вместо общего количества запросов). При этом Wi:
равен 1, если i-ое обращение решено в срок
равен ti/Ti, где ti – фактическое время решения i-ого обращения, Ti – нормативное время решения, если обращение просрочено
Тогда чем сильнее просрочен i-тый запрос, тем больше его вес Wi, снижающий значение метрики (поскольку ti > Ti).
Подробнее о показателе – в книге “Управление услугами на основе измерений”.
Как использовать
Оценить показатель для процесса в целом.
Оценить показатели TPI для групп поддержки – определить, какие группы поддержки являются узким местом процесса. Проанализировать возможные причины низкой своевременности решения.
Оценить «хвост» – количество нерешенных обращений в предыдущем периоде, перешедших в текущий.
Первый показатель, который мы предложили, – доля ИТ-затрат – касается роли ИТ в бизнесе организации. Последующие три – уровень доступности, Incident Rate, своевременность выполнения обращений – касаются эксплуатации. Следующие три показателя – про развитие.
Доля численности ИТ-персонала в развитии
Метрика доли ИТ-затрат показывает роль ИТ в бизнесе в целом. Метрика ‘Доля численности ИТ-персонала в развитии’ уточняет, насколько много ресурсов компания тратит на развитие информационных технологий. И соответственно, какое внимание ей следует уделять применению релевантных подходов и их развитию (agile, devops и так далее).
Почему важен
Показывает, насколько важна разработка для организации.
Как измерять
Если компания работает в режиме инсорсинга, расчет может быть проведен через численность персонала – как доля персонала в подразделениях развития в общей численности ИТ-персонала организации. Компании, делающих ставку на ИТ, и особенно в ИТ-зависимых областях (банки, ритейл) склонны возвращать разработчиков в инсорс, поэтому такой расчет для них может быть приемлем.
В ситуации активного использования аутсорса корректнее оценивать этот показатель через долю затрат на разработку от общих затрат ИТ-подразделения по ФОТ и услугам.
Как использовать
Если есть возможность, сравнить со значениями данного показателя с референсными компаниями (например, основными конкурентами или с компаниями-ориентирами). В компаниях с серьёзной внутренней разработкой данный показатель имеет значения 50-60% и выше.
Размер бэклога (разработки)
Если компания прикладывает значительные усилия на развитие, то следующая метрика, на которую имеет смысл посмотреть, – это величина бэклога, очереди запросов, которые требуют реализации силами разработчиков.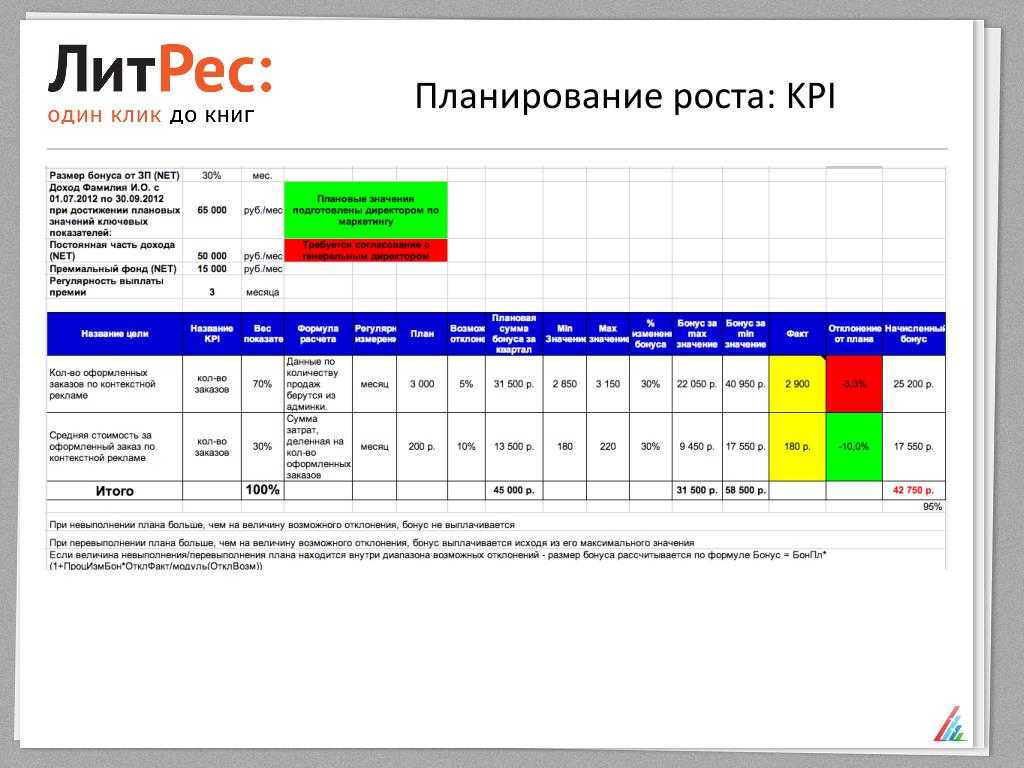
Почему важен
Показывает баланс спроса на развитие ИТ и предложения.
Как измерять
Наилучший способ оценить очередь – посчитать суммарный объем трудозатрат на реализацию запросов на изменения во входной очереди. Такой показатель расскажет, сколько дней (недель, месяцев) займет реализация уже принятых запросов, если прием новых запросов прекратить (при неизменных ресурсах).
Если существенная доля запросов на изменения не имеет оценки трудозатрат, можно выполнить приблизительную оценку как произведение количества запросов на изменение в бэклоге на средние трудозатраты по одному запросу (на основании данных прошлых периодов).
Как использовать
Чем выше показатель, тем меньше ресурсное обеспечение разработки соответствует спросу внутренних заказчиков организации. Значения больше трех месяцев могут означать нехватку ресурсов и/или скорости реализации, которая определяется продуктивностью разработчиков.
Чтобы сделать корректные выводы на основании величины бэклога, целесообразно сразу пойти немного дальше и выполнить анализ задач в бэклоге:
По видам (развитие, тех. долг, …)
долг, …)
По группам исполнителей
По этапу обработки (входная очередь на оценку, выходная очередь на реализацию)
По «возрасту» (например, задачи с возрастом более года могут уже утратить свою актуальность)
Если существенная доля запросов на изменения не имеет оценки трудозатрат, полезно провести анализ практики / скорости оценки запросов в бэклоге.
Доля времени разработчиков на эксплуатацию
Чем менее качественный код, тем больше разработчикам приходится отвлекаться на эксплуатацию и в частности поддержку. Мы уже ввели выше показатель Incident Rate, который помимо прочего показывает, насколько много ресурсов компания направляет на “тушение пожаров”. Этот показатель уточняет, как много разработчиков в составе “пожарных бригад”.
Почему важен
Маркер качества разработки и способности разработки решать новые запросы, не занимаясь текущими вопросами эксплуатации.
Как измерять
Для расчета метрики нужно выделить трудозатраты разработчиков за некоторый период времени на развитие (анализ и реализацию новых запросов на изменения) и поделить на общий бюджет рабочего времени разработчиков за тот же период времени.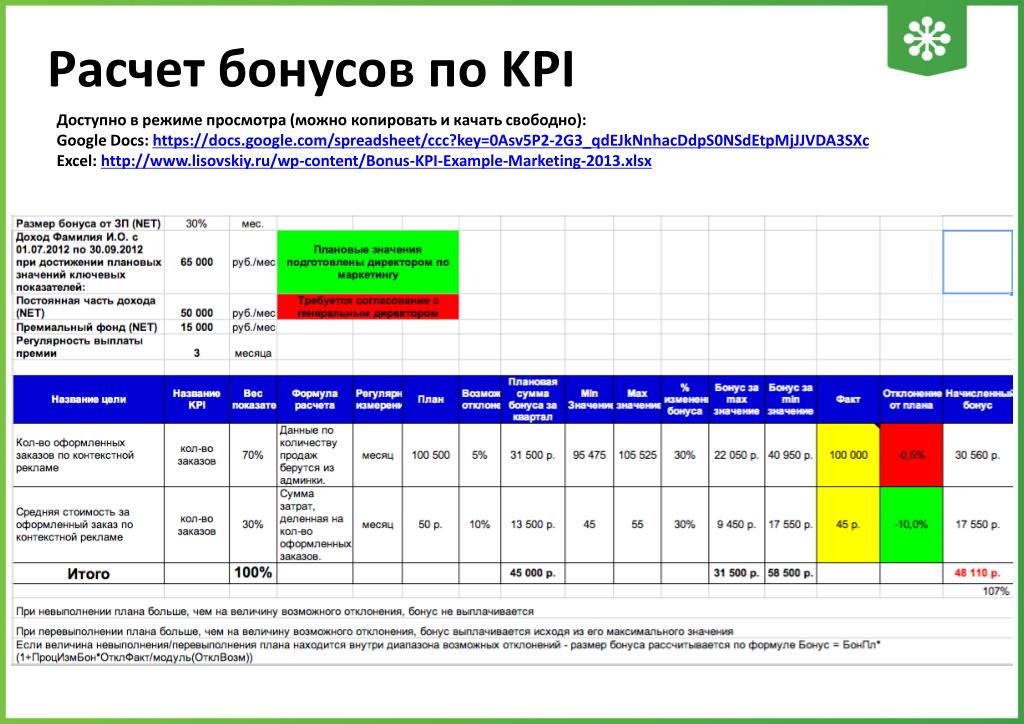
Расчет можно выполнить на основании данных учетных систем разработки (Jira, RedMine, …). При отсутствии объективных данных можно опираться на экспертную оценку руководителей отделов / групп разработчиков.
Как использовать
Значения выше 15-20% говорят о серьезном отвлечении разработчиков от вопросов развития. В совокупности с большим бэклогом это говорит о наличии проблемы с качеством реализации изменений.
Дальнейшие действия могут включать в себя:
Анализ показателя в разрезе по группам исполнителей
Анализ корреляции с размером бэклога в разрезе по группам исполнителей
Изучение видов и трудоёмкость работ, на которые отвлекаются разработчики
Мы рассмотрели еще три показателя, которые касаются разработки. Наконец, перейдем к заключительному показателю, который покажет насколько результативны усилия ИТ-департамена с точки зрения потребителей.
Удовлетворенность потребителей услуг
Заключительный показатель в списке, который показывает итоговое восприятие работы ИТ-подразделения – насколько ИТ соответствуют тем ожиданиям, которые есть у потребителей ИТ-услуг организации.
Почему важен
Показывает ИТ глазами потребителей услуг.
Как измерять
Есть множество способов померить удовлетворенность потребителей. Они в основном не специфичны для ИТ:
Средний балл по результатам опроса потребителей услуги
Количество или доля пользователей, которые не продлили подписку после пробного периода
Коэффициент оттока клиентов (процент потребителей, которые перестали потреблять услугу за отрезок времени)
Индекс готовности рекомендовать (NPS – Net promoter score) – отражает лояльность потребителей и как много из них “работают” агентами услуги
Так или иначе, оценку удовлетворенности можно получить из целевого опроса или путем извлечение информации из текущей оперативной деятельности – в зависимости от отношений бизнеса и ИТ и доступных данных уместно использовать один или другой или оба способа.
Как использовать
Средний показатель по компании вряд ли расскажет что-то интересно, поэтому нужно сразу установить наименее удовлетворенные группы пользователей и на что жалуются.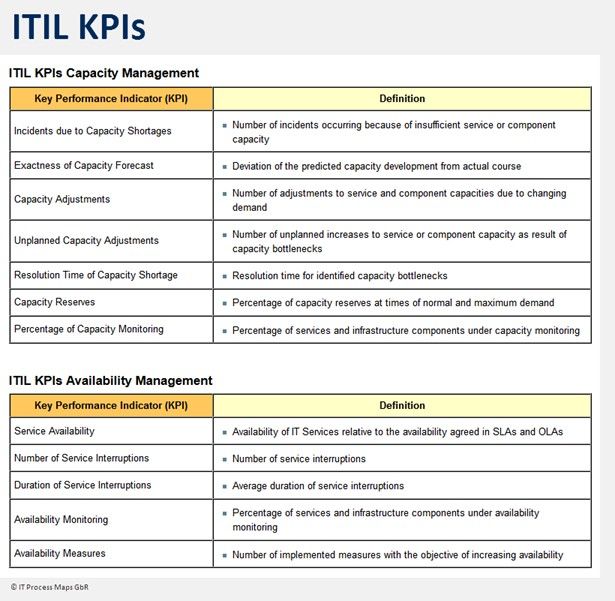 Если для сбора данных используется опросник, уместно туда включить утверждения и предложить указать степень согласия, например:
Если для сбора данных используется опросник, уместно туда включить утверждения и предложить указать степень согласия, например:
Я понимаю, как работать в информационных системах, в том числе после обновлений функциональности. Проводится обучение, инструкции и руководства содержат ответы на мои вопросы.
Мне легко найти на портале нужную категорию заявки.
В случае обращений в поддержку сотрудники ДИТ обычно делают все возможное, чтобы помочь.
Как правило, мне понятно, за какое время будет решена моя заявка.
Как правило, меня устраивает время решения заявок.
Проанализировать связь между низкими оценками конкретных групп потребителей и:
Уровнем качества предоставляемых их услуг, в первую очередь уровнем доступности
Уровнем поддержки по соответствующим категориям обращений, в первую очередь своевременность решения обращений
Функциональностью систем, в которых работает группа пользователей
Мы рассмотрели восемь основных показателей, которые помогут получить первое впечатление от ИТ-департамента. Напомним, что на их основе некорректно делать выводы об качестве работы ИТ или эффективности менеджмента – они лишь расставляют акценты и намечают дорогу для дальнейшего анализа. Это дорогу мы постарались наметить.
Напомним, что на их основе некорректно делать выводы об качестве работы ИТ или эффективности менеджмента – они лишь расставляют акценты и намечают дорогу для дальнейшего анализа. Это дорогу мы постарались наметить.
Все показатели можно сгруппировать следующим образом. Естественный, но не обязательный порядок анализа:
Значимость ИТ для организации: доля ИТ-затрат в общих операционных затратах организации
Разработка: доля численности ИТ-персонала в развитии, величина бэклога, доля времени разработчиков на эксплуатацию
Эксплуатация и поддержка: уровень доступности, Incident Rate, своевременность обработки запросов
Результаты ИТ: удовлетворенность потребителей ИТ-услуг
Восемь – не какая-то волшебная цифра, каждую группу показателей можно дополнить для получения более детальной и точной картины (например, блок “Результаты ИТ” можно дополнить метрикой, связанной с успешностью проектов, а в “Эксплуатацию и поддержку” также включить метрики производительности и непрерывности). И напротив, если для расчета показателя данные недоступны, метрику соответствующей области можно заменить интервью или экспертной оценкой. Помните, что измерения и метрики – не единственный инструмент управленца, хотя, как правило, выводы, сделанные на основе цифр заслуживают большего доверия.
И напротив, если для расчета показателя данные недоступны, метрику соответствующей области можно заменить интервью или экспертной оценкой. Помните, что измерения и метрики – не единственный инструмент управленца, хотя, как правило, выводы, сделанные на основе цифр заслуживают большего доверия.
По этой теме
Case Study
Sportmaster
Спортмастер. Взаимодействие с бизнесом
Case Study
Sportmaster
Спортмастер. Команды архитекторов (FAST)
Примеры ключевых показателей эффективности информационных технологий | Стратегии паука
Основы
Примеры ключевых показателей эффективности
Информационные технологии
Раскройте весь потенциал своего ИТ-отдела с помощью нашего исчерпывающего списка ключевых показателей эффективности (KPI). От времени безотказной работы и безопасности до удовлетворенности пользователей и производительности — отслеживайте и измеряйте производительность, чтобы внедрять инновации и добиваться выдающихся результатов.
От времени безотказной работы и безопасности до удовлетворенности пользователей и производительности — отслеживайте и измеряйте производительность, чтобы внедрять инновации и добиваться выдающихся результатов.
Примеры KPI для информационных технологий
- Время работы сети
- Среднее время отклика
- Удовлетворенность сотрудников
- Успешное создание учетной записи
- Успешное удаление учетной записи
- Индекс производительности Active Directory
- Соотношение количества предупреждений и заявок
- Средняя доступность центра обработки данных
- Доступность АТС колл-центра
- Доступность кампусной АТС
- Эффективность подключения клиента
- Потребляемая мощность центра обработки данных
- Доступность почтового клиента
- Доступность сервера Exchange
- Инциденты из-за изменения
- Производительность интернет-прокси
- Доступность сети — сайты высокой доступности
- Доступность сети — стандартные сайты
- Количество успешных кибератак
- Проблем не обнаружено/дубликаты тикетов
- Процент успешного резервного копирования филиала
- Процент каналов, превышающих целевое использование
- Процент управляемых ИТ-серверов, исправленных к крайнему сроку
- Процент рабочих серверов, соответствующих стандартам конфигурации программного обеспечения
- Процент перезапусков обновлений безопасности в период обслуживания
- Процент успешных подключений к серверу удаленного доступа (RAS)
- Уровень обслуживания ответа на телефонный звонок
- Сетевые инциденты с приоритетом 1 и приоритетом 2, соответствующие SLA
- Статус принятия продукта и соответствие требованиям
- Коэффициент успешного восстановления
- Скорость роста сервера
- Индекс управляемости сервера
- Удовлетворенность клиентов службы поддержки — процент недовольных
- Уровень разрешения службы поддержки 1
- Время службы поддержки для эскалации
- Время службы поддержки для решения
- Доступность службы хранилища
- Использование утилиты хранения
- Интервал подготовки виртуальной машины
- Доступность утилиты виртуального сервера
- Доступность веб-сервера
Зачем использовать ключевые показатели эффективности в вашем ИТ-отделе?
Когда ИТ-отдел начинает отслеживать ключевые показатели эффективности, это может реально повлиять на общий успех организации. Используя «шаблон ключевого показателя эффективности ИТ», компании могут воспользоваться несколькими преимуществами, которые помогут улучшить их ИТ-операции и добиться общего успеха.
Используя «шаблон ключевого показателя эффективности ИТ», компании могут воспользоваться несколькими преимуществами, которые помогут улучшить их ИТ-операции и добиться общего успеха.
Во-первых, шаблон ключевых показателей эффективности ИТ поможет вам сосредоточиться на своих целях. Имея четко определенные цели, ИТ-отделы знают, чему расставить приоритеты, что помогает убедиться, что вся команда работает синхронно для достижения общих целей.
Отслеживание KPI также позволяет лучше принимать решения. Когда у вас есть точные данные для анализа, гораздо проще определить области, которые нуждаются в улучшении или оптимизации. Это позволяет вашему ИТ-отделу принимать обоснованные решения и предпринимать стратегические действия.
Кроме того, использование шаблона ключевых показателей эффективности ИТ способствует прозрачности и подотчетности. Имея измеримые цели, члены команды понимают свои обязанности и могут нести ответственность за свою работу. Это поощряет культуру постоянного совершенствования, когда каждый стремится достичь своих целей или превзойти их.
Наконец, мониторинг ключевых показателей эффективности может повысить вовлеченность и мотивацию сотрудников. Когда ИТ-персонал может видеть прямое влияние своей работы на успех своей организации, он с большей вероятностью возьмет на себя ответственность за свои задачи и почувствует чувство выполненного долга. Это создает позитивную рабочую среду, в которой сотрудники мотивированы и вовлечены.
Использование шаблона ключевого показателя эффективности ИТ для отслеживания ключевых показателей эффективности ИТ-отдела позволяет сфокусироваться, улучшить процесс принятия решений, повысить прозрачность, подотчетность и повысить вовлеченность сотрудников. Таким образом, компании могут оптимизировать свои ИТ-операции и внести заметный вклад в общий успех.
Самые популярные КПЭ ИТ
Эти КПЭ чаще всего используются, чтобы помочь организациям понять, достигают ли они своих целей в области ИТ, а если нет, то что им нужно сделать для их улучшения.
- Время безотказной работы системы : этот KPI измеряет процент времени, в течение которого ИТ-системы доступны и работают бесперебойно. Организации отслеживают время безотказной работы системы, потому что они хотят убедиться, что их клиенты и сотрудники имеют надежный опыт работы с цифровыми услугами. Минимизация времени простоя может повысить производительность и удовлетворенность клиентов.
- Время реагирования на инцидент : это среднее время, которое требуется ИТ-команде для подтверждения и начала работы над проблемой после того, как о ней было сообщено. Чем быстрее время отклика, тем лучше ИТ-команда справляется с проблемами, которые могут нарушить бизнес-операции. Отслеживание этого ключевого показателя эффективности помогает организациям гарантировать, что их ИТ-команда гибка и быстро реагирует на проблемы.
- Среднее время решения (MTTR) : MTTR представляет собой среднее время, необходимое для устранения проблемы с момента сообщения о ней до ее решения. Организации отслеживают этот KPI для измерения эффективности своих процессов ИТ-поддержки. Сокращение MTTR означает уменьшение влияния инцидента на бизнес и повышение удовлетворенности клиентов.
- Показатель разрешения первого обращения : этот ключевой показатель эффективности измеряет процент запросов на поддержку, разрешенных во время первого взаимодействия между пользователем и вашей группой ИТ-поддержки. Организации отслеживают этот KPI, чтобы увидеть, насколько эффективно их команда поддержки решает проблемы быстро и точно. Высокий показатель разрешения проблем при первом контакте указывает на знающую и квалифицированную группу поддержки, которая может справиться с большинством проблем без их эскалации.
- Затраты на ИТ в процентах от дохода : этот KPI отслеживает сумму вашего дохода, которая тратится на расходы на ИТ, такие как оборудование, программное обеспечение и персонал. Организации отслеживают этот KPI, чтобы убедиться, что они инвестируют в ИТ таким образом, который соответствует их общим бизнес-целям. Хорошо управляемый ИТ-бюджет может способствовать внедрению инноваций, повышению эффективности и поддержке роста, в то время как неэффективный бюджет может привести к перерасходу и пустой трате ресурсов.
 Организации отслеживают время безотказной работы системы, потому что они хотят убедиться, что их клиенты и сотрудники имеют надежный опыт работы с цифровыми услугами. Минимизация времени простоя может повысить производительность и удовлетворенность клиентов.
Организации отслеживают время безотказной работы системы, потому что они хотят убедиться, что их клиенты и сотрудники имеют надежный опыт работы с цифровыми услугами. Минимизация времени простоя может повысить производительность и удовлетворенность клиентов.
KPI Software
Узнайте, как программное обеспечение воплощает в жизнь ваши KPI с помощью информационных панелей, отчетов и предупреждений о производительности.
Помощь от экспертов
Если ваша организация не определила свои ключевые показатели эффективности, мы сотрудничаем с экспертами мирового уровня, чтобы ускорить разработку вашей стратегии.
Испытайте Spider Impact бесплатно
Запланируйте демонстрацию в реальном времени или получите бесплатную 30-дневную пробную версию. Мы готовы либо продемонстрировать Spider Impact, либо бесплатно превратить ваши данные в прототип.
Заказать демо Попробуй бесплатно
20 ключевых показателей эффективности и показателей ИТ, которые следует отслеживать для повышения производительности
Руководители, не являющиеся техническими специалистами, долгое время и несправедливо рассматривали ИТ как функцию центра обработки вызовов. Однако мы (в ИТ-отрасли), конечно, знаем, что ИТ на самом деле является стратегической функцией бизнеса. Этот разрыв между воспринимаемой ценностью и фактической ценностью связан с тем, что ИТ исторически не устанавливали и не отслеживали многие ключевые показатели эффективности (KPI).
Однако мы (в ИТ-отрасли), конечно, знаем, что ИТ на самом деле является стратегической функцией бизнеса. Этот разрыв между воспринимаемой ценностью и фактической ценностью связан с тем, что ИТ исторически не устанавливали и не отслеживали многие ключевые показатели эффективности (KPI).
Поскольку мы потенциально приближаемся к рецессии, никогда не было так важно определить ключевые показатели эффективности, установить базовые уровни, измерить текущую производительность, оценить тенденции, сообщить о своих успехах и принять меры, когда это необходимо. Это касается как внутренних, так и внешних поставщиков ИТ-услуг. Внутренние ИТ-команды должны защищать как свою численность персонала, так и бюджеты. С другой стороны, MSP должны убедиться, что их клиенты понимают ценность, которую они предоставляют, чтобы уменьшить отток клиентов и обеспечить наличие каналов дополнительных продаж.
Что такое ключевые показатели эффективности ИТ?
KPI или ключевой показатель эффективности — это мера того, насколько эффективно конкретный отдел в организации достигает своих основных бизнес-целей. Как следует из названия, ключевые показатели эффективности ИТ используются для оценки производительности внутренних ИТ-отделов и MSP.
Как следует из названия, ключевые показатели эффективности ИТ используются для оценки производительности внутренних ИТ-отделов и MSP.
Ключевые показатели эффективности ИТ отслеживают все критические аспекты качества, связанные с ИТ-проектами, и помогают реализовать их наиболее эффективно, своевременно и в рамках выделенного бюджета. Это достигается путем отслеживания, анализа и оптимизации различных критических параметров, связанных с ИТ, таких как управление затратами на ИТ, решение проблем и управление заявками.
Почему важно отслеживать ключевые показатели эффективности ИТ?
Отслеживание ключевых показателей эффективности ИТ помогает:
- контролировать состояние ИТ-отдела/MSP
- отслеживать ход выполнения текущих ИТ-проектов
- использовать возможности и решать проблемы успехи и неудачи
- Повышение ответственности между отдельными членами команды
20 ключевых показателей эффективности и показателей ИТ для отслеживания
Мы разделили различные КПЭ и показатели ИТ на четыре категории в зависимости от различных показателей успеха, которые они отслеживают, а именно финансовые показатели, операционные показатели, системные показатели и показатели безопасности. Давайте подробно рассмотрим все эти показатели ниже:
Давайте подробно рассмотрим все эти показатели ниже:
Финансовые показатели
Отслеживание эффективности ИТ-инициативы необходимо для понимания ценности вложенных ресурсов. Финансовые показатели помогают оценить финансовую эффективность ИТ-проектов и инициатив и сократить разрыв между их предполагаемой и фактической ценностью. Некоторые из наиболее важных финансовых показателей:
1. Расходы на ИТ по сравнению с планом
Этот финансовый показатель помогает отслеживать ваши расходы на ИТ и анализировать, насколько эффективно вы расходуете выделенный вам ИТ-бюджет. Вы тратите весь бюджет? Вы постоянно экономите деньги на своих ИТ-инициативах? Хорошо ли организована ваша функция? Эта метрика помогает ответить на эти вопросы, связанные с финансами, и многое другое.
2. Деньги, сэкономленные на переговорах
С помощью этого финансового показателя вы можете узнать, удалось ли вам сэкономить на каких-либо дополнительных расходах на переговорах. Он отслеживает экономию за счет сокращения неиспользуемых рабочих мест, объединения нескольких инструментов в единое решение, перехода на более дешевое решение или перехода на более долгосрочный контракт с более дешевой годовой ставкой.
Он отслеживает экономию за счет сокращения неиспользуемых рабочих мест, объединения нескольких инструментов в единое решение, перехода на более дешевое решение или перехода на более долгосрочный контракт с более дешевой годовой ставкой.
3. Окупаемость инвестиций в ИТ
Этот показатель помогает оценить фактическую окупаемость инвестиций (ROI) для долларов, потраченных на ИТ-проекты и инициативы. Успешные организации обычно стремятся к рентабельности инвестиций 3:1, чтобы получить максимальную отдачу от своих инвестиций в ИТ. Вы можете рассчитать рентабельность инвестиций в ИТ, разделив преимущества вашей ИТ-программы на стоимость инвестиций.
Операционные показатели
Операционные показатели используются для отслеживания эффективности организации в режиме реального времени или за определенный период времени. При рассмотрении ИТ-отдела операционные показатели сосредоточены на измерении производительности ИТ-функций и ресурсов, таких как услуги, технологии и рабочая сила, используемых для выполнения бизнес-операций. К общим операционным показателям относятся:
К общим операционным показателям относятся:
4. Показатель успешности проекта
Этот операционный показатель помогает измерить процент успешно завершенных ИТ-проектов, а также процент проектов, успешно завершенных вовремя.
5. Уровень соответствия SLA
Для расчета уровня соответствия SLA внутренние ИТ-команды и MSP согласовывают цифры с точки зрения производительности и качества и измеряют их ежемесячно или ежеквартально, чтобы увидеть, выполняются ли соглашения об уровне обслуживания. доставлено. Вы можете рассчитать процент билетов с ранее согласованным соглашением об уровне обслуживания.
6. Коэффициент разрешения первого контакта
С помощью этого показателя можно рассчитать процент обращений, разрешенных при первом контакте. Это важная мера того, насколько эффективно ИТ-команда работает над устранением инцидентов.
7. Заявки за период
Большинство ИТ-отделов используют этот показатель для отслеживания количества заявок, создаваемых ежедневно или еженедельно. Отслеживание этой операционной метрики полностью зависит от того, что нужно знать вашему руководителю или клиентам.
Отслеживание этой операционной метрики полностью зависит от того, что нужно знать вашему руководителю или клиентам.
8. Количество автоматизированных задач
Этот показатель всегда должен отражать увеличение в годовом исчислении. Общие задачи, которые можно автоматизировать для повышения эффективности, — установка исправлений, подключение пользователей и автоматическое исправление общих тикетов. Если ваше решение RMM или управление конечными точками не помогает вам автоматизировать общие ИТ-процессы, вам следует перейти на лучшее в своем классе решение, которое поможет вам автоматизировать повседневные задачи.
9. Конечные точки на одного специалиста
Этот конкретный показатель будет сильно различаться в зависимости от того, являетесь ли вы внутренним ИТ-отделом или MSP. Эта метрика помогает вам оценить количество конечных точек, за которые отвечает каждый из ваших технических специалистов. Лучшее в своем классе решение RMM может легко поддерживать соотношение 500 конечных точек к 1 техническому специалисту, не перегружая технических специалистов из-за отсутствия автоматизации.
10. Коэффициент удержания персонала
С помощью этого показателя вы можете измерить, как долго вы удерживаете своих сотрудников. В случае высокой текучести кадров вы можете отслеживать затраты на обучение, время, необходимое для обучения нового сотрудника, или время, необходимое для найма нового персонала. При измерении коэффициента удержания вы должны исключить сотрудников, уволенных за плохую работу.
Системные показатели
Системные показатели направлены на обеспечение надежной работы всех ИТ-систем, таких как оборудование и приложения. Эти показатели помогают организациям оценивать историческую производительность системы и, соответственно, прогнозировать будущую производительность. Системные метрики предоставляют ИТ-командам информацию, необходимую для масштабирования их бизнеса, а также для использования новых возможностей, которые в значительной степени зависят от стабильной ИТ-инфраструктуры.
11. Всего ИТ-активов
С помощью этого KPI вы можете отслеживать и записывать количество ИТ-активов в вашей ИТ-инфраструктуре.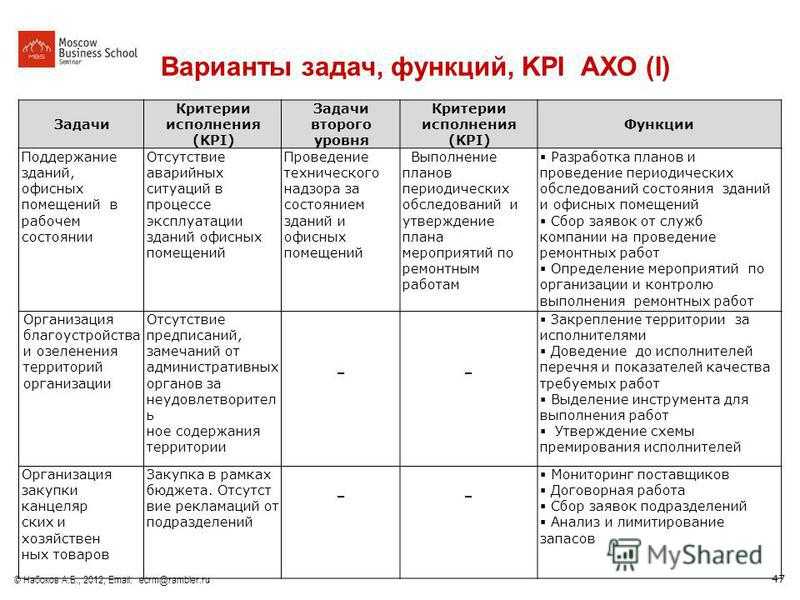 Вы также можете сегментировать эту информацию об активах на основе типа ИТ-актива, такого как количество настольных компьютеров, ноутбуков, телефонов и серверов.
Вы также можете сегментировать эту информацию об активах на основе типа ИТ-актива, такого как количество настольных компьютеров, ноутбуков, телефонов и серверов.
12. Доступность системы (время безотказной работы)
Другим важным KPI системы, который необходимо отслеживать, является доступность системы или время безотказной работы, то есть процент времени, в течение которого конечные пользователи могут работать с вашими ИТ-системами. Чтобы адекватно измерить этот KPI, вы должны обратиться к правилу 9с. Вы должны стремиться к минимуму 99,9% времени безотказной работы, что составляет около 9 часов в год или 10 минут в неделю.
13. Доступность сервера (время безотказной работы)
Доступность сервера измеряется как процент времени, в течение которого серверы в вашей сети работают. Вы можете рассчитать время безотказной работы сервера, вычтя общее время простоя из общего времени и разделив результат на общее количество времени за определенный период. Подобно доступности системы, время безотказной работы сервера более 99,9% считается благоприятным.
Подобно доступности системы, время безотказной работы сервера более 99,9% считается благоприятным.
14. Использование сервера и/или облака
Использование сервера — еще один важный показатель, который помогает контролировать и отслеживать производительность системы. С помощью этой метрики вы можете отслеживать время, в течение которого сервер занят. Некоторые организации также отслеживают использование облака как способ измерения производительности своей системы.
15. Совокупное использование рабочих станций
Использование рабочих станций — еще один важный KPI, служащий мерой производительности системы. Он отслеживает процент от общего объема памяти рабочей станции, используемой в организации.
Показатели безопасности
Показатели безопасности — это важнейший ключевой показатель эффективности ИТ, предназначенный для измерения того, насколько эффективно ваши усилия по обеспечению безопасности обеспечивают защиту ваших систем и сетей от угроз безопасности. Отслеживание показателей безопасности имеет решающее значение для поддержания целостности вашей ИТ-инфраструктуры и внесения регулярных корректировок, чтобы вы всегда были в курсе своих усилий по обеспечению безопасности.
Отслеживание показателей безопасности имеет решающее значение для поддержания целостности вашей ИТ-инфраструктуры и внесения регулярных корректировок, чтобы вы всегда были в курсе своих усилий по обеспечению безопасности.
16. Развертывание антивируса/антивредоносного ПО
Этот показатель отслеживает состояние развертывания антивируса/антивредоносного ПО в ваших системах. В качестве важного показателя безопасности этот KPI в идеале должен составлять 100 %, чтобы ваша ИТ-инфраструктура работала наиболее эффективно и безопасно.
17. Количество открытых уязвимостей
С помощью этой метрики ИТ-специалисты и MSP могут отслеживать количество открытых уязвимостей как для компьютеров, так и для серверов в своей сети. Это помогает отслеживать подверженность вашей ИТ-инфраструктуры потенциальным угрозам и позволяет разрабатывать стратегии для укрепления уровня ИТ-безопасности вашей компании за счет более быстрого устранения инцидентов.
18. Доля успешных исправлений
Мониторинг доли успешных исправлений имеет решающее значение для обеспечения того, чтобы ваши системы были правильно исправлены и обновлены. Метрика успешного развертывания исправлений фиксирует процент развернутых исправлений и помогает отслеживать ход процесса развертывания исправлений вашим ИТ-отделом.
19. Дней с момента последнего инцидента
С помощью этого показателя вы можете рассчитать количество дней, прошедших с момента последнего инцидента в вашей ИТ-инфраструктуре. Это помогает ИТ-командам и MSP оценивать эффективность любых стратегических и технологических изменений, которые они могли внести для снижения вероятности инцидентов. В идеале разрыв между двумя инцидентами должен постоянно увеличиваться для учета обновлений безопасности.
20. Коэффициент успешного резервного копирования
Еще одна отличная метрика безопасности, которая может помочь отслеживать и улучшать состояние вашей безопасности.