
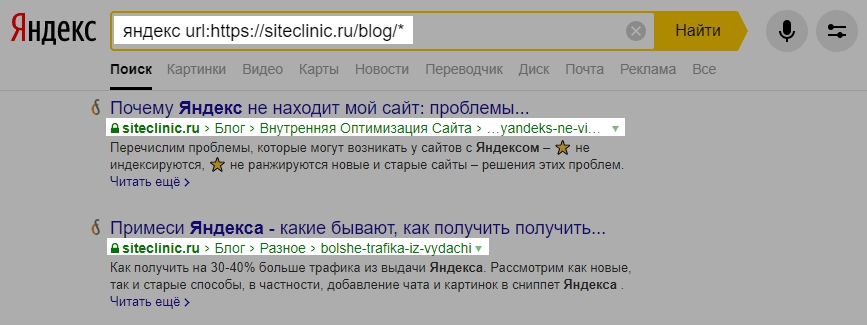
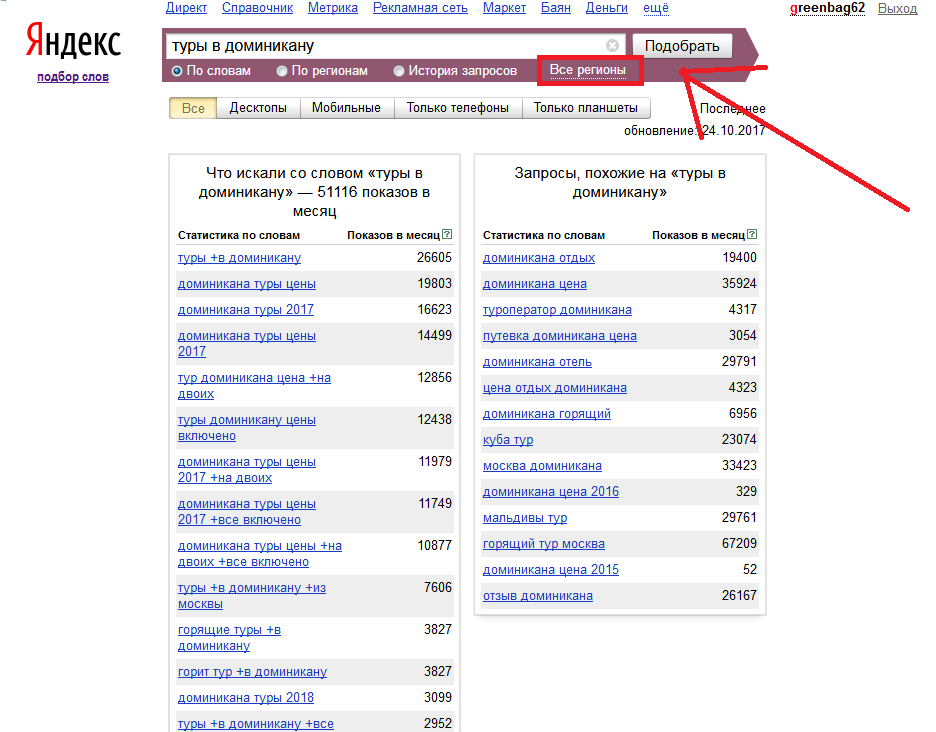
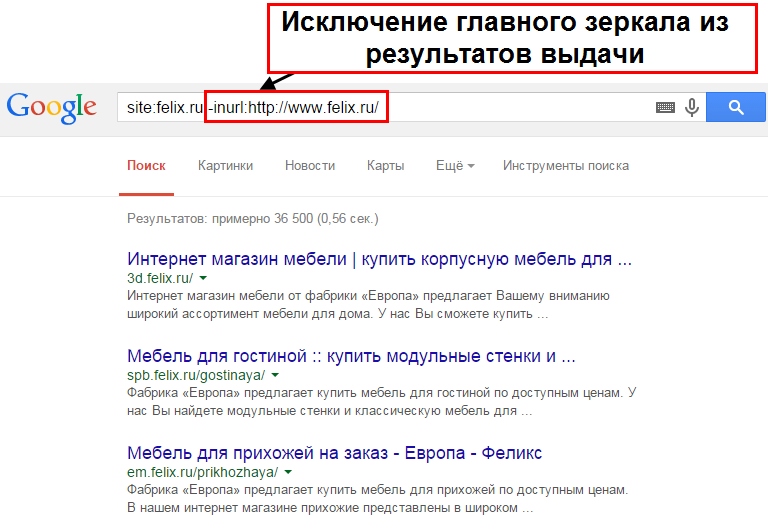
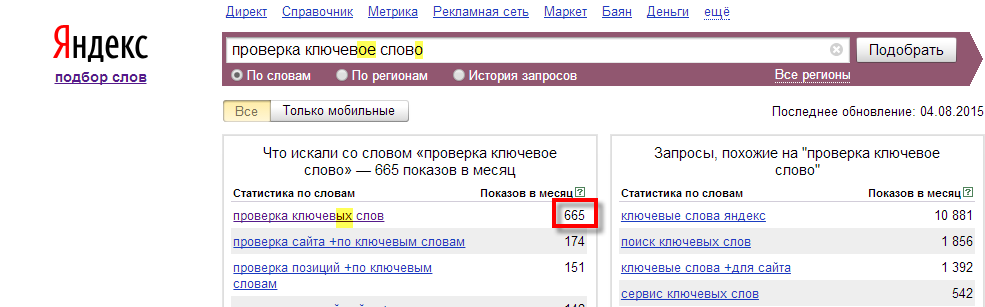
10.1.3. Язык запросов. Яндекс для всех
10.1.3. Язык запросов. Яндекс для всехВикиЧтение
Яндекс для всех
Абрамзон М. Г.
Содержание
10.1.3. Язык запросов
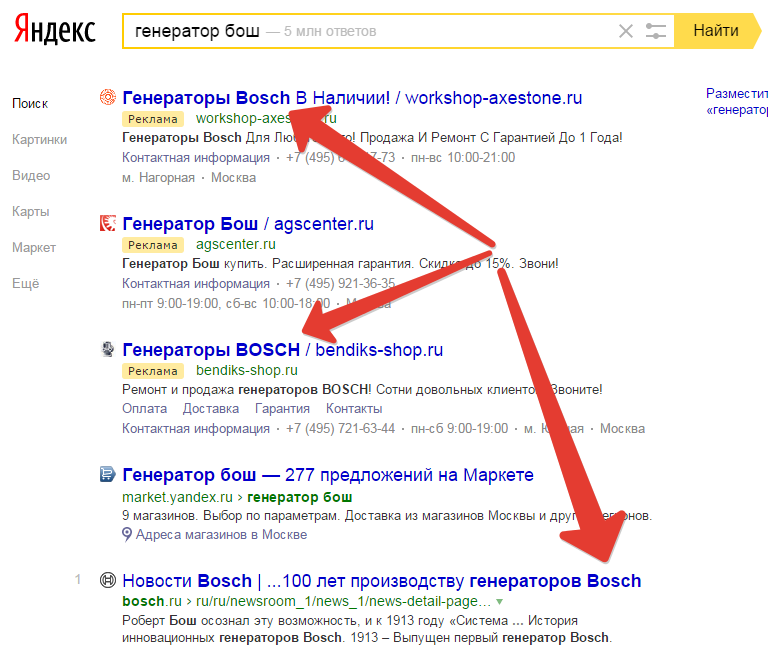
Язык запросов, используемый в Яndex.Server, в полной мере соответствует языку запросов, с которым работает поисковая система Яндекс. Поэтому все, что можно использовать для поиска в Интернете, новостях, среди картинок, поддерживается и в версии программы, предназначенной для установки на сайте. Такой подход удобен для пользователей — если он знаком с возможностями формирования запросов на Яндексе, то без проблем сможет искать информацию и на вашем сайте.
Задавать вопросы можно и на естественном языке, и используя логические операторы (расширенные возможности Яндекса). Часть расширенных возможностей реализована в виде поисковой страницы, на которую можно перейти по ссылке Расширенный поиск

С заданием запросов на естественном языке справится любой, поэтому здесь остановимся кратко на использовании логических операторов, позволяющих в одном запросе задать несколько условий поиска. Такой вариант удобен, когда есть возможность выделить для запроса ключевые слова, определить возможные синонимы, задать слова, которые не должны попадать в результаты.
Языковый модуль, входящий в состав программы, обеспечивает поиск всех форм заданного слова. Но если требуется найти документы, в которые входят лишь точная форма слова в запросе, перед этим словом в запросе нужно поставить восклицательный знак. Два восклицательных знака действуют иначе — ведется поиск всех производных слов от заданного.
Как и в поиске на Яндексе, здесь также поддерживается поиск синонимов, поиск слов, находящихся на определенном расстоянии друг от друга, поиск словосочетаний.
Поиск в зонах документа и их атрибутах будет полезен, на мой взгляд, в первую очередь даже не для посетителей вашего сайта.
В отличие от других правил формирования запросов, операторы зонноатрибутивного поиска зависят от настроек, примененных при создании индексных файлов. А именно, в них используются имена поисковых зон и атрибутов, заданные в конфигурационных файлах парсеров. Имена документных атрибутов также могут быть заданы в конфигурационном файле источника данных. В табл. 10.3 приведено краткое описание операторов запросов, связанных с поиском по зонам и атрибутам.
И последнее, что связано с языком запросов. Формирование списка результатов выполняется с учетом релевантности найденного документа поисковому запросу. Релевантность определяется по сложным формулам и зависит от множества факторов, в том числе от частотных характеристик слов в поисковом выражении, веса слова или выражения, близости слов в тексте документа.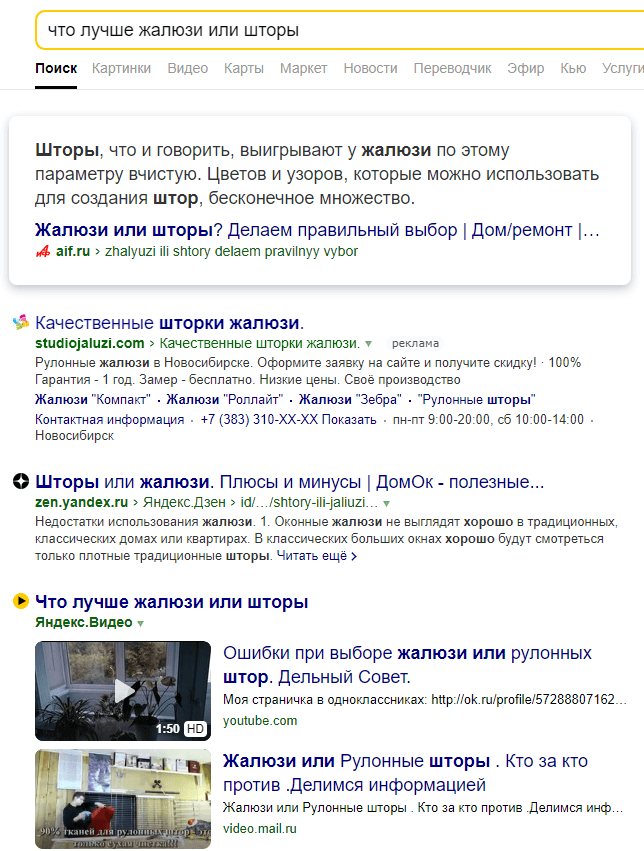
Вес слова или выражения определяется числом. Это число ставится через двоеточие после слова (или выражения) в строке запроса. Например, если поисковый запрос выглядит так: экспериментальные:4 модели, то? хотя будут найдены те же документы, что и по запросу экспериментальные модели, но вот в начало списка будут выведены те результаты (документы), в которых слово «экспериментальные» встречается чаще.
Аналогично, если в запрос будет добавлено уточняющее слово, то в начало списка результатов будут выведены те документы, которые содержат как основное слово или выражение, так и уточняющее.
Данный текст является ознакомительным фрагментом.
Очереди запросов
Очереди запросов
Для блочных устройств поддерживаются очереди запросов (request queue), в которых хранятся ожидающие запросы на выполнение операций блочного ввода-вывода. Очередь запросов представляется с помощью структуры request_queue, которая определена в файле <linux/blkdev.h>.
Очередь запросов представляется с помощью структуры request_queue, которая определена в файле <linux/blkdev.h>.
Количество DNS-запросов
Количество DNS-запросов Система DNS устанавливает соответствие имен хостов их IP-адресам, точно так же как телефонный справочник позволяет узнать номер человека по его имени. Когда вы набираете «www.yahoo.com» в адресной строке браузера, преобразователь DNS, к которому обратился
Обработка запросов с помощью PHP
Обработка запросов с помощью PHP Основы клиент-серверных технологийВ самом начале курса мы уже говорили о том, что PHP – это скриптовый язык, обрабатываемый сервером. Сейчас мы хотим уточнить, что же такое сервер, какие функции он выполняет и какие вообще бывают серверы.
Предсказывающий регулятор запросов
Предсказывающий регулятор запросов
В большинстве реляционных баз данных присутствует регулятор запросов (query governor) гарантирующий, что единичный запрос не будет выполняться слишком долго. По истечении заданного времени такой регулятор останавливает выполнение
По истечении заданного времени такой регулятор останавливает выполнение
Формирование запросов
Формирование запросов Если вы не хотите углубляться в детали техники поиска, то можете просто задать поисковой машине вопрос так же, как задали бы его человеку, у которого хотите получить совет. Например, «как быстро похудеть», «есть ли жизнь на Марсе», «где раки зимуют»
Приложение № 1 Язык запросов
Приложение № 1 Язык запросов Мощный язык запросов позволяет контролировать малейшие нюансы поведения «Яндекса» при поиске (в том числе при поиске по блогам). Для использования наиболее востребованных команд не обязательно запоминать операторы: можно воспользоваться
7.6 Сообщения запросов ICMP
7.6 Сообщения запросов ICMP
Не все сообщения ICMP сигнализируют об ошибках.
15.5 Работа с дубликатами запросов RPC
15.5 Работа с дубликатами запросов RPC Если служба основана на протоколе TCP, запросы и ответы будут доставляться надежно. TCP берет на себя обеспечение целостности доставляемых данных.Если RPC базируется на UDP, то, в зависимости от требований конкретного приложения, клиент и
1.3.3. Язык запросов
1.3.3. Язык запросов Для того чтобы Яндекс корректно понимал запросы, состоящие из нескольких слов, был разработан специальный язык запросов. Отдельные его элементы мы уже рассмотрели — это и специальные символы, используемые в обычном поиске, и дополнительные параметры,
10.
 1.3. Язык запросов
1.3. Язык запросов10.1.3. Язык запросов Язык запросов, используемый в Яndex.Server, в полной мере соответствует языку запросов, с которым работает поисковая система Яндекс. Поэтому все, что можно использовать для поиска в Интернете, новостях, среди картинок, поддерживается и в версии программы,
Создание запросов TOP PERCENT
Создание запросов TOP PERCENT Можно писать запросы, возвращающие записи, количество которых определяется заданным процентом от общего количества записей в таблице. Например, если у вас есть таблица с 1000 записей и необходимо возвратить один процент первых записей, то, как
6.2. Оптимизация запросов
6.2. Оптимизация запросов Основным способом повышения производительности запросов являются индексы. Определить, действительно ли созданные вами индексы используются запросом, позволяет командаEXPLAIN <Текст запроса>; Набор данных, выводимый командой EXPLAIN, содержит
Планы запросов
Планы запросов
Перед выполнением запроса комплект программ подготовки — известный как оптимизатор- начинает анализировать столбцы и операции запроса для вычислен? самого быстрого способа выполнения. Подготовка начинается с просмотра индексов таблицы и используемых
Подготовка начинается с просмотра индексов таблицы и используемых
Типы запросов
Типы запросов Запрос SQL – это запрос, создаваемый при помощи инструкций SQL [15] .Запросы являются основным средством просмотра, изменения и анализа информации, которая содержится в одной или в нескольких таблицах базы данных. В этой главе, а также в главах 10 и 12,
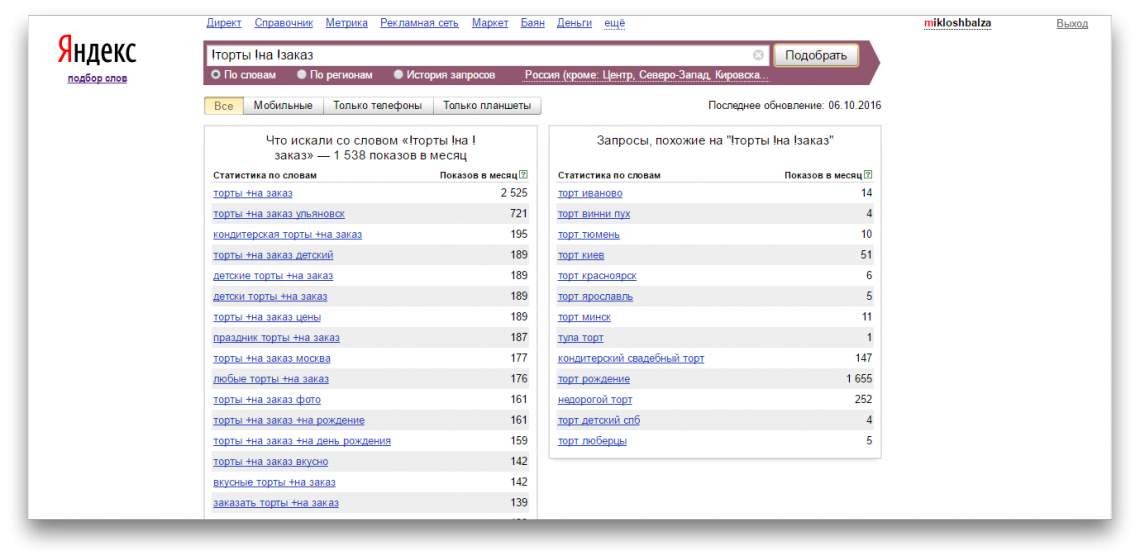
Язык запросов Яндекс — языки запросов различных браузеров
Поисковая система
Яндекс. Укажем в ней необходимые слова и нажмем на клавиатуре
клавишу <Enter> или же щелкнем мышью на кнопке «Найти», размещенной возле строки
поиска. На Web-странице с результатами сразу под поисковой строкой будет расположена статистика по нашему запросу. Здесь будет указано, сколько по нему найдено Web-страниц и Web-сайтов. Внизу страницы Вы также можете узнать, насколько часто пользователи Яндекса ищут то же, что искали мы. После статистических данных размещаются ссылки на Web-сайты, найденные по нашему запросу. По умолчанию на одной Web-странице Яндекс отображает только 10 таких ссылок, поэтому для ознакомления с полными результатами поиска необходимо будет листать Web-страницы с помощью цифр-ссылок. Каждый обнаруженный ресурс в результатах поиска
представлен названием Web-страницы и текстом ссылки. Кроме того, в большинстве
случаев поисковая система демонстрирует небольшой фрагмент текста,
содержащегося на той или иной найденной Web-странице, в котором обнаружено совпадение
с текстом вашего запроса. Внизу Web-страницы, на которой отображена итоговая сводка по обработанному запросу, находится дополнительный блок ссылок, где среди множества предложений наибольший интерес представляет строка «в других поисковых системах». Рядом с этими словами имеются ссылки на несколько других популярных поисковых систем. Поиск информации в Яндексе можно осуществлять в простом и расширенном поисковом режиме. О том, что представляют собой эти виды, речь пойдет ниже. Простой поиск Перед тем как начинать вводить в строку поиска
поисковой системы запрос, тщательно его сформулируйте. Чем более расплывчатой
и нечеткой будет выбранная формулировка, тем больше ненужных Вам Web-сайтов предложит в результатах
поиска поисковая система. Предположим, мы хотим найти обзор футбольного матча между командами Ювентус и Реал. (Работаем в Интернете). В этом случае не стоит вводить в строку поиска слова вроде «футбол» или «матч» — в Интернет эти слова встречаются чересчур часто, и маловероятно, что поисковая система предложит нам подходящие ссылки. Лучше всего подойдет следующий вариант: Ювентус Реал. Все очень просто. Если поисковая система найдет на одной Web-странице рядом или на расстоянии нескольких слов упоминание введенных нами слов, с большой долей вероятности можно утверждать, что это будет именно та информация, которая нам нужна. Расширенный поиск Все популярные поисковые системы располагают
специальными возможностями для расширенного поиска ресурсов. Чтобы попасть на Web-страницу, предоставляющую такие
возможности, необходимо воспользоваться ссылкой с названием вроде «Расширенный
поиск». А теперь подробнее о логическом языке запросов, который позволяет в режиме обычного поиска вводить в строку поиска дополнительные служебные команды, уточняющие ваши требования. Для каждой поисковой системы существуют свои языки
запросов. Мы познакомимся с языком запросов для Яндекса (Для тех, кто желает
более подробно познакомиться с логическим языком запросов, можно
порекомендовать: Открыв «расширенный поиск» в любой поисковой системе, щелкнув
на «Памятку по использованию языка запросов», Вы найдете для себя не только эту
памятку, но и раздел «Как пользоваться поиском?» (Поиск – помощь)). Памятка по использованию языка запросов
|
 Получив такую команду, Яндекс просмотрит всю свою базу данных и
попытается найти в ней Web-страницы, где встречается введенное нами слово или
словосочетание. При этом нужно заранее учитывать, что чем обширнее наш запрос,
тем меньшее количество Web-страниц будет ему
соответствовать.
Получив такую команду, Яндекс просмотрит всю свою базу данных и
попытается найти в ней Web-страницы, где встречается введенное нами слово или
словосочетание. При этом нужно заранее учитывать, что чем обширнее наш запрос,
тем меньшее количество Web-страниц будет ему
соответствовать. При этом слова, которые мы ввели для поиска, в этих
фрагментах будут выделены полужирным начертанием. Чтобы открыть в новом окне Web-обозревателя один из найденных Web-сайтов, щелкнем на Web-странице с результатами поиска
на его ссылке.
При этом слова, которые мы ввели для поиска, в этих
фрагментах будут выделены полужирным начертанием. Чтобы открыть в новом окне Web-обозревателя один из найденных Web-сайтов, щелкнем на Web-странице с результатами поиска
на его ссылке. Поэтому очень важно четко себе представить, какой
именно текст может находиться на требуемых нам Web-сайтах, и ввести в строку поиска
именно его.
Поэтому очень важно четко себе представить, какой
именно текст может находиться на требуемых нам Web-сайтах, и ввести в строку поиска
именно его. (Работаем в Интернете).
Перейдя по этой ссылке, мы увидим большую поисковую форму, в которой можно
указать множество параметров. Известная поисковая система Яндекс позволяет настраивать
параметры поиска слов на Web-странице в зависимости от их
расположения (рядом, в одном предложении, на одной странице) и формы. Кроме
того, она может искать Web-страницы по их языку (русский, украинский,
белорусский и т.д.), по дате последнего изменения и даже по формату файла Web-страницы. Наконец, с помощью
Яндекса информацию можно искать на каком-то конкретном Web-сайте. Это бывает полезно в том
случае, если на нужном вам Web-сайте нет встроенной поисковой
системы или если она есть, но функционирует некорректно.
(Работаем в Интернете).
Перейдя по этой ссылке, мы увидим большую поисковую форму, в которой можно
указать множество параметров. Известная поисковая система Яндекс позволяет настраивать
параметры поиска слов на Web-странице в зависимости от их
расположения (рядом, в одном предложении, на одной странице) и формы. Кроме
того, она может искать Web-страницы по их языку (русский, украинский,
белорусский и т.д.), по дате последнего изменения и даже по формату файла Web-страницы. Наконец, с помощью
Яндекса информацию можно искать на каком-то конкретном Web-сайте. Это бывает полезно в том
случае, если на нужном вам Web-сайте нет встроенной поисковой
системы или если она есть, но функционирует некорректно. .
. 

используйте в Wordstat И Яндекс Директ
Динамический коллтрекинг
Стоимость
8 800 555 55 22
Google Телепорт: полное руководство
Google в 2017 году разработал сервис, который способен решить задачу по переносу или дубляжу готовой рекламной кампании из одного аккаунта в другой практически в автоматическом режиме. Телепорт поможет перенести рекламную кампанию из Яндекс.Директ в AdWords за 15-30 минут и 6 простых шагов…
Пошаговая инструкция по настройке Google Adwords
Из из этого руководства ниже вы узнаете, как пошагово создать, настроить и улучшить эффективность рекламной компании в Google Adwords
Оглавление
Виртуальная АТС
- Голосовое меню (IVR)
- Запись разговоров
- Интеграция с LDAP
- Конференцсвязь
- Многоканальные номера
- Поддержка
- Подключение
- Статистика и мониторинг
Коллтрекинг
- О продукте
- Как подключить
- Решения
- Возможности
- Стоимость
- Сквозная аналитика
- Мультиканальная аналитика
Контакт-центр
- Исходящий обзвон
- Оценка эффективности работы
- Поддержка
- Подключение
- Управление клиентским сервисом
Решения
- IP-Телефония
- Телефонизация офиса
- Бесплатный вызов 8-800
- Для стартапов
- Объединение филиалов
- Дополнительные линии
- Диспетчеризация ЖКХ ТСЖ и УК
 org/SiteNavigationElement»>
org/SiteNavigationElement»>Бизнес-кейсы
Партнерам
Поддержка
О компании
Почему MANGO OFFICE
Наша команда
Наши достижения
Карьера
Пресс-центр
Блог «Бизнес-рецепты»
Мероприятия
Наши клиенты
Отзывы
Заказать звонок
Выберите интересующий вас вопрос:
- Покупка услуг
- Обслуживание
- Техподдержка
Хотите себе такой же виджет? Узнайте, как подключить!
Отправляя заявку, вы даете согласие с Политикой обработки персональных данных
airflow.
 providers.yandex.operators.yandexcloud_dataproc — apache-airflow-providers-yandex Документация
providers.yandex.operators.yandexcloud_dataproc — apache-airflow-providers-yandex Документация- Главная
-
airflow.providers.yandex -
airflow.провайдеры.яндекс.операторы -
airflow.providers.yandex.operators.yandexcloud_dataproc
Классы
| Данные для действия инициализации, которое должно выполняться при запуске кластера DataProc. |
| Создает кластер Yandex.Cloud Data Proc. |
| Базовый класс для операторов DataProc, работающих с данным кластером. |
| Удаляет кластер Yandex. |
| Запускает задание Hive в кластере Data Proc. |
| Запускает задание Mapreduce в кластере Data Proc. |
| Запускает задание Spark в кластере Data Proc. |
| Запускает задание Pyspark в кластере Data Proc. |
 Cloud Data Proc.
Cloud Data Proc.- класс airflow.providers.yandex.operators.yandexcloud_dataproc.InitializationAction[источник]
Данные для действия инициализации, которое должно выполняться при запуске кластера DataProc.
- uri :str [источник]
- args :Sequence[str] [источник]
- тайм-аут : целое число [источник]
- class airflow.
 providers.yandex.operators.yandexcloud_dataproc.DataprocCreateClusterOperator( * , folder_id=None , cluster_name=None , cluster_description=» version_ , 0127, ssh_public_keys=Нет , subnet_id=Нет , services=(‘HDFS’, ‘YARN’, ‘MAPREDUCE’, ‘HIVE’, ‘SPARK’) , s3_bucket=Нет 6, ru-central1-b’ , service_account_id=None , masternode_resource_preset=None , masternode_disk_size=None , masternode_disk_type=None , datanode_resource_preset=None , datanode_disk_size=None , datanode_disk_type=None , datanode_count=1 , computenode_resource_preset=None , computenode_disk_size=None , computenode_disk_type=None , computenode_count=0 , computenode_max_hosts_count=None , computenode_measurement_duration=None , computenode_warmup_duration=None , computenode_stabilization_duration = Нет , Computenode_preemptible = Ложь , Computenode_cpu_utilization_target = Нет , computenode_decommission_timeout=None , connection_id=None , properties=None , enable_ui_proxy=False , host_group_ids=None , security_group_ids=None , log_group_id=None , initialization_actions=None , * *kwargs )[источник]
providers.yandex.operators.yandexcloud_dataproc.DataprocCreateClusterOperator( * , folder_id=None , cluster_name=None , cluster_description=» version_ , 0127, ssh_public_keys=Нет , subnet_id=Нет , services=(‘HDFS’, ‘YARN’, ‘MAPREDUCE’, ‘HIVE’, ‘SPARK’) , s3_bucket=Нет 6, ru-central1-b’ , service_account_id=None , masternode_resource_preset=None , masternode_disk_size=None , masternode_disk_type=None , datanode_resource_preset=None , datanode_disk_size=None , datanode_disk_type=None , datanode_count=1 , computenode_resource_preset=None , computenode_disk_size=None , computenode_disk_type=None , computenode_count=0 , computenode_max_hosts_count=None , computenode_measurement_duration=None , computenode_warmup_duration=None , computenode_stabilization_duration = Нет , Computenode_preemptible = Ложь , Computenode_cpu_utilization_target = Нет , computenode_decommission_timeout=None , connection_id=None , properties=None , enable_ui_proxy=False , host_group_ids=None , security_group_ids=None , log_group_id=None , initialization_actions=None , * *kwargs )[источник] Базы:
airflow. models.BaseOperator Создает кластер Yandex.Cloud Data Proc.
- Параметры
folder_id ( str | None ) — ID папки, в которой должен быть создан кластер.
имя_кластера ( str | Нет ) — имя кластера. Должен быть уникальным внутри папки.
cluster_description ( str | Нет ) — Описание кластера.
cluster_image_version ( str | None ) — версия образа кластера. По умолчанию.
ssh_public_keys ( str | Iterable [ str ] | None ) – List of SSH public keys that will be deployed to created compute instances.
subnet_id ( str | None ) – идентификатор подсети.
Все узлы кластера Data Proc будут использовать одну подсеть.services ( Iterable [ str ] ) — список служб, которые будут установлены в кластер. Возможные варианты: HDFS, ПРЯЖА, MAPREDUCE, HIVE, TEZ, ZOOKEEPER, HBASE, SQOOP, FLUME, SPARK, SPARK, ZEPPELIN, OOZIE
s3_bucket ( str | None ) — корзина Yandex.Cloud S3 для хранения логов кластера. Задания не будут работать, если ведро не указано.
zone ( str ) — Зона доступности для создания кластера. В настоящее время существуют ru-central1-a, ru-central1-b и ru-central1-c.
service_account_id ( str | None ) — идентификатор учетной записи службы для кластера. Учетная запись службы может быть создана внутри папки.
masternode_resource_preset ( str | Нет ) — Предустановка ресурсов (конфигурация CPU+RAM) для основного узла кластера.
masternode_disk_size ( int | None ) — размер хранилища Мастерноды в ГиБ.
masternode_disk_type ( str | Нет ) — Тип хранилища Мастерноды. Возможные варианты: сеть-ssd, сеть-hdd.
datanode_resource_preset ( str | Нет ) — Предустановка ресурсов (конфигурация CPU+RAM) для узлов данных кластера.
datanode_disk_size ( int | None ) — размер хранилища Datanodes в ГиБ.
datanode_disk_type ( str | None ) — Тип хранилища Datanodes. Возможные варианты: сеть-ssd, сеть-hdd.
Computenode_resource_preset ( str | None ) — предустановка ресурсов (конфигурация CPU+RAM) для вычислительных узлов кластера.
Computenode_disk_size ( int | None ) — размер хранилища вычислительных узлов в ГиБ.
Computenode_disk_type ( str | None ) — тип хранилища вычислительных узлов. Возможные варианты: сеть-ssd, сеть-hdd.
connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
Computenode_max_count — максимальное количество узлов подкластера автоматического масштабирования вычислений.
Computenode_warmup_duration ( int | None ) — время прогрева экземпляра в секундах. В течение этого времени, трафик отправляется на инстанс, но метрики экземпляра не собираются. В секундах.
вычисление_стабилизации_длительности ( целое число | Нет ) – Минимальное время в секундах для мониторинга до Группы экземпляров могут уменьшить количество экземпляров в группе.
За это время размер группы не уменьшается,
даже если новые значения метрик указывают на то, что это необходимо. В секундах.calculatenode_preemptible ( bool ) — Выгружаемые экземпляры останавливаются не реже одного раза в 24 часа, и могут быть остановлены в любое время, если их ресурсы потребуются вычислительным ресурсам.
Computenode_cpu_utilization_target ( int | None ) — определяет правило автомасштабирования на основе средней загрузки ЦП группы экземпляров. в процентах. 10-100. По умолчанию не задано и используется стратегия автомасштабирования по умолчанию.
Computenode_decommission_timeout ( int | Нет ) — тайм-аут для корректного вывода узлов из эксплуатации во время уменьшения масштаба. В секундах
свойства ( dict [ str , str ] | Свойства переданы основному узлу.
Документы: https://cloud.yandex.com/docs/data-proc/concepts/settings-listenable_ui_proxy ( bool ) — включить функцию UI Proxy для перенаправления веб-интерфейсов компонентов Hadoop. Документы: https://cloud.yandex.com/docs/data-proc/concepts/ui-proxy
host_group_ids ( Iterable [ str ] | None ) — выделенные группы хостов для размещения виртуальных машин кластера. Документы: https://cloud.yandex.com/docs/compute/concepts/dedicated-host
security_group_ids ( Iterable [ str ] | None ) — группы безопасности пользователей. Документы: https://cloud.yandex.com/docs/data-proc/concepts/network#security-groups
log_group_id ( str | None ) — идентификатор группы журналов для записи журналов.
По умолчанию журналы будут отправлены в группу журналов по умолчанию.
Чтобы отключить отправку облачного журнала, установите свойство кластера dataproc:disable_cloud_logging = true
Документы: https://cloud.yandex.com/docs/data-proc/concepts/logsinitialization_actions ( Iterable [ InitializationAction ] | Нет ) — Набор инициализирующих действий, выполняемых при запуске кластера. Документы: https://cloud.yandex.com/docs/data-proc/concepts/init-action
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
- свойство идентификатор_кластера [источник]
 providers.yandex.operators.yandexcloud_dataproc.DataprocCreateClusterOperator( * , folder_id=None , cluster_name=None , cluster_description=» version_ , 0127, ssh_public_keys=Нет , subnet_id=Нет , services=(‘HDFS’, ‘YARN’, ‘MAPREDUCE’, ‘HIVE’, ‘SPARK’) , s3_bucket=Нет 6, ru-central1-b’ , service_account_id=None , masternode_resource_preset=None , masternode_disk_size=None , masternode_disk_type=None , datanode_resource_preset=None , datanode_disk_size=None , datanode_disk_type=None , datanode_count=1 , computenode_resource_preset=None , computenode_disk_size=None , computenode_disk_type=None , computenode_count=0 , computenode_max_hosts_count=None , computenode_measurement_duration=None , computenode_warmup_duration=None , computenode_stabilization_duration = Нет , Computenode_preemptible = Ложь , Computenode_cpu_utilization_target = Нет , computenode_decommission_timeout=None , connection_id=None , properties=None , enable_ui_proxy=False , host_group_ids=None , security_group_ids=None , log_group_id=None , initialization_actions=None , * *kwargs )[источник]
providers.yandex.operators.yandexcloud_dataproc.DataprocCreateClusterOperator( * , folder_id=None , cluster_name=None , cluster_description=» version_ , 0127, ssh_public_keys=Нет , subnet_id=Нет , services=(‘HDFS’, ‘YARN’, ‘MAPREDUCE’, ‘HIVE’, ‘SPARK’) , s3_bucket=Нет 6, ru-central1-b’ , service_account_id=None , masternode_resource_preset=None , masternode_disk_size=None , masternode_disk_type=None , datanode_resource_preset=None , datanode_disk_size=None , datanode_disk_type=None , datanode_count=1 , computenode_resource_preset=None , computenode_disk_size=None , computenode_disk_type=None , computenode_count=0 , computenode_max_hosts_count=None , computenode_measurement_duration=None , computenode_warmup_duration=None , computenode_stabilization_duration = Нет , Computenode_preemptible = Ложь , Computenode_cpu_utilization_target = Нет , computenode_decommission_timeout=None , connection_id=None , properties=None , enable_ui_proxy=False , host_group_ids=None , security_group_ids=None , log_group_id=None , initialization_actions=None , * *kwargs )[источник] models.BaseOperator
models.BaseOperator  Все узлы кластера Data Proc будут использовать одну подсеть.
Все узлы кластера Data Proc будут использовать одну подсеть.

 За это время размер группы не уменьшается,
даже если новые значения метрик указывают на то, что это необходимо. В секундах.
За это время размер группы не уменьшается,
даже если новые значения метрик указывают на то, что это необходимо. В секундах. Документы: https://cloud.yandex.com/docs/data-proc/concepts/settings-list
Документы: https://cloud.yandex.com/docs/data-proc/concepts/settings-list По умолчанию журналы будут отправлены в группу журналов по умолчанию.
Чтобы отключить отправку облачного журнала, установите свойство кластера dataproc:disable_cloud_logging = true
Документы: https://cloud.yandex.com/docs/data-proc/concepts/logs
По умолчанию журналы будут отправлены в группу журналов по умолчанию.
Чтобы отключить отправку облачного журнала, установите свойство кластера dataproc:disable_cloud_logging = true
Документы: https://cloud.yandex.com/docs/data-proc/concepts/logs- класс airflow. providers.yandex.operators.yandexcloud_dataproc.DataprocBaseOperator( * , yandex_conn_id=Нет , cluster_id=Нет , **kwargs )[8] 900
Базы:
airflow.models.BaseOperatorБазовый класс для операторов DataProc, работающих с данным кластером.
- Параметры
- template_fields :Sequence[str] = [‘cluster_id’] [источник]
- абстрактный выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
 providers.yandex.operators.yandexcloud_dataproc.DataprocBaseOperator( * , yandex_conn_id=Нет , cluster_id=Нет , **kwargs )[8] 900
providers.yandex.operators.yandexcloud_dataproc.DataprocBaseOperator( * , yandex_conn_id=Нет , cluster_id=Нет , **kwargs )[8] 900- класс airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocDeleteClusterOperator( * , connection_id=нет , cluster_id=нет , **kwargs )[источник]
Базы:
DataprocBaseOperatorУдаляет кластер Yandex.
Cloud Data Proc.- Параметры
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
 Cloud Data Proc.
Cloud Data Proc.- class airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateHiveJobOperator( * , query=None , query_file_uri=None , script_variables=None , continue_on_failure=False , properties=None , name=’Hive job’ , cluster_id=None , connection_id=None , **kwargs )[источник]
Оснований:
DataprocBaseOperatorЗапускает задание Hive в кластере Data Proc.
- Параметры
запрос ( str | Нет ) — запрос Hive.
query_file_uri ( str | None ) — URI скрипта, содержащего запросы Hive. Можно разместить в HDFS или S3.
свойств ( dict [ стр , стр ] | Нет ) — сопоставление имен свойств со значениями, используемое для настройки Hive.
Script_Variables ( DICT [ STR , STR ] | ). NAYALIAL . NAIS .
continue_on_failure ( bool ) — продолжать ли выполнение запросов в случае сбоя запроса.
имя ( стр ) – Название задания. Используется для маркировки.
cluster_id ( str | None ) — идентификатор кластера, в котором выполняется задание.
Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
 Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)
Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)- класс airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateMapReduceJobOperator( * , main_class=Нет , main_jar_file_uri=Нет , jar_file_uris = none , archive_uris = none , file_uris = none , args = none , . Нет , **kwargs )[источник]
Базы:
DataprocBaseOperatorЗапускает задание Mapreduce в кластере Data Proc.
- Параметры
main_jar_file_uri ( str | None ) — URI jar-файла с заданием. Можно разместить в HDFS или S3. Можно указать вместо main_class.
main_class ( str | None ) — Имя основного класса задания. Можно указать вместо main_jar_file_uri.
file_uris ( Iterable [ str ] | Нет ) — URI файлов, используемых в задании. Можно разместить в HDFS или S3.
archive_uris ( Iterable [ str ] | None ) — URI архивных файлов, используемых в задании. Можно разместить в HDFS или S3.
jar_file_uris ( Iterable [ str ] | None ) — URI файлов JAR, используемых в задании.
Можно разместить в HDFS или S3.свойства ( dict [ str , str ] | Свойства для работы.
args ( Iterable [ str ] | None ) — аргументы для передачи в задание.
имя ( стр ) – Название задания. Используется для маркировки.
cluster_id ( str | None ) — идентификатор кластера, в котором выполняется задание. Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)
connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора.
Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.Дополнительные сведения см. в get_template_context.

 Можно разместить в HDFS или S3.
Можно разместить в HDFS или S3. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.- class airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateSparkJobOperator( * , main_class=None , main_jar_file_uri=None , jar_file_uris=None , archive_uris=None , file_uris=None , args=None , properties=None , name=’Spark job’ , cluster_id=None , connection_id=Нет , пакетов=Нет , репозиториев=Нет , exclude_packages=Нет , **kwargs )[источник]
Базы:
DataprocBaseOperatorЗапускает задание Spark в кластере Data Proc.
- Параметры
main_jar_file_uri ( str | None ) — URI файла jar с заданием.
Можно разместить в HDFS или S3.main_class ( str | None ) — Имя основного класса задания.
file_uris ( Iterable [ str ] | None ) — URI файлов, используемых в задании. Можно разместить в HDFS или S3.
archive_uris ( Iterable [ str ] | Нет ) – URI архивных файлов, используемых в задании. Можно разместить в HDFS или S3.
jar_file_uris ( Iterable [ str ] | None ) — URI файлов JAR, используемых в задании. Можно разместить в HDFS или S3.
свойства ( dict [ str , str ] | Свойства для работы.
args ( Iterable [ str ] | None ) — аргументы для передачи в задание.
имя ( стр ) – Название задания. Используется для маркировки.
cluster_id ( str | None ) — идентификатор кластера, в котором выполняется задание. Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)
connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
packages ( Iterable [ str ] | None ) — список maven-координат классов jar для включения в драйвер и исполнитель.
репозитории ( Iterable [ стр ] | Нет ) — Список дополнительных удаленных репозиториев для поиска координат maven дается с —packages.
exclude_packages ( Iterable [ str ] | None ) — Список groupId:artifactId, чтобы исключить зависимости при разрешении зависимостей предоставляется в –packages, чтобы избежать конфликтов зависимостей.
- выполнить( контекст )[источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
 Можно разместить в HDFS или S3.
Можно разместить в HDFS или S3.
- class airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreatePysparkJobOperator( * , main_python_file_uri=Нет , python_file_uris=Нет , jar_file_uris = none , archive_uris = none , file_uris = none , args = none , Свойства = , Имя = ‘Pyspark Job’ , , name = ‘pyspark job’ , , name = ‘pyspark job’ , , name = ‘pyspark job’ , , . , пакетов = нет , репозиториев = нет , exclude_packages = нет , **kwargs )[источник]
Базы:
DataprocBaseOperatorЗапускает задание Pyspark в кластере Data Proc.
- Параметры
main_python_file_uri ( str | None ) — URI файла Python с заданием. Можно разместить в HDFS или S3.
python_file_uris ( Iterable [ str ] | None ) — URI файлов python, используемых в задании. Можно разместить в HDFS или S3.
file_uris ( Повторяемый [ стр ] | Нет ) — URI файлов, используемых в задании. Можно разместить в HDFS или S3.
archive_uris ( Iterable [ str ] | None ) — URI архивных файлов, используемых в задании. Можно разместить в HDFS или S3.
jar_file_uris ( Iterable [ str ] | Нет ) — URI файлов JAR, используемых в задании.
Можно разместить в HDFS или S3.свойства ( dict [ str , str ] | Свойства для работы.
args ( Iterable [ str ] | None ) — аргументы для передачи в задание.
имя ( стр ) – Название задания. Используется для маркировки.
cluster_id ( str | None ) — идентификатор кластера, в котором выполняется задание. Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)
connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
packages ( Iterable [ str ] | None ) — список maven-координат jar для включения в пути к классам драйвера и исполнителя.
repositories ( Iterable [ str ] | None ) — Список дополнительных удаленных репозиториев для поиска m-координат дается с —packages.
exclude_packages ( Iterable [ str ] | None ) — Список groupId:artifactId, чтобы исключить при разрешении зависимостей предоставляется в –packages, чтобы избежать конфликтов зависимостей.
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.

 Можно разместить в HDFS или S3.
Можно разместить в HDFS или S3.
Была ли эта запись полезной?
Использование правил запросов для создания более естественного поиска | Siddharth Kothari
Демонстрационный магазин appbase. io, продвигающий продукт Samsung по поисковому запросу iphone
io, продвигающий продукт Samsung по поисковому запросу iphoneПосле двух десятилетий поисковых инноваций технологических гигантов сегодня потребители возлагают большие надежды, когда сталкиваются с поиском. Для предприятий электронной коммерции и SaaS, где обнаружение контента имеет решающее значение для бизнеса, удовлетворение ожиданий потребителей может стать конкурентным преимуществом.
В этом посте мы расскажем о правилах запросов, о том, чем они отличаются от стратегии релевантности поиска, и покажем 10 основных вариантов использования правил запросов.
Проще говоря, правила запросов (также известные как бизнес-правила) позволяют улучшить существующую стратегию релевантности поиска, предоставляя авторский интерфейс для создания правил стиля «если это, то это». Вот несколько примеров:
- Интернет-магазин может рекламировать недавно выпущенный телефон «Samsung», когда пользователь ищет «One Plus» или «iphone».
- Магазин электронной коммерции хотел бы показывать фильтры по ОЗУ, размеру диска и размеру устройства, когда пользователь ищет «ноутбук». И показывать фильтры для Материалов и Случаев, когда пользователь вместо этого ищет «сумку».
 И показывать фильтры для Материалов и Случаев, когда пользователь вместо этого ищет «сумку».
И показывать фильтры для Материалов и Случаев, когда пользователь вместо этого ищет «сумку».Правила запросов можно использовать для создания баннера сезонной распродажи (правило, основанное на времени), реагирования на намерения пользователя, изменения настроек поиска для внесения разнообразия в результаты, когда поисковый запрос слишком специфичен. Правила запросов также позволяют писать полностью настраиваемую бизнес-логику, охватывающую любой сценарий, выходящий за рамки того, что возможно с пользовательским интерфейсом администратора.
Стратегия релевантности поиска (S.R.S) — это ваша обобщенная формула для предоставления релевантных результатов. Поисковые системы, такие как Elasticsearch и Solr, начинают с BM25 или TF/IDF в качестве алгоритма релевантности, который можно дополнительно настроить, настроив поля для поиска, назначив веса полей, веса поискового запроса, уровень допуска опечаток, способ учета синонимов. Дело в том, что релевантность поиска — это самостоятельный зверь, и правила запросов не следует рассматривать как замену S.![]() R.S.
R.S.
Правила запросов лучше всего рассматривать как дополнение к SRS (отображение различных фасетных фильтров на боковой панели в зависимости от категории поиска, реагирование на намерения пользователя) или решение крайних случаев, когда ваша SRS не может предоставить релевантные результаты поиска. Однако, в отличие от S.R.S., создание правил запросов не требует понимания технологии поисковых систем. Это требует только понимания вашего бизнес-прецедента.
В следующем видео показано, как создавать правила запросов на панели управления appbase.io.
Далее мы рассмотрим 10 основных случаев использования, в которых могут быть полезны правила запросов.
Продвижение результатов
Это часто называют поисковым продвижением или поисковым мерчандайзингом. Это включает в себя повышение позиции определенных продуктов в результатах поиска, что дает им больше шансов на конвертацию. Searchandising с использованием правил запросов позволяет оптимизировать релевантность поиска совершенно по-новому.
Допустим, наш магазин хочет провести акцию с участием нового Samsung Galaxy Note 10 в наличии. Бегло взглянув на данные поисковой аналитики, мы определили, что «примечание 10» — популярный термин для установки правила запроса. Вот что видят в магазине поисковые пользователи до того, как мы настроим акцию.
И вот как мы можем создать это правило запроса.
Теперь, после настройки правила запроса, Galaxy Note будет автоматически продвигаться в результатах поиска магазина. Когда мы повторим тот же поиск, вот что мы увидим.
Скрыть результаты
Что произойдет, если у вас закончатся товары, которых не будет в наличии в течение некоторого времени? Возможно, вы удалили объявление из своего магазина, но оно все еще может быть проиндексировано в вашем поиске. Скорее всего, пользователь может найти его и оказаться на странице с ошибкой 404 и выйти с вашего сайта. Вы сможете предотвратить этот сценарий, настроив правило запроса для внесения записей в черный список по имени и предоставления релевантных результатов поиска.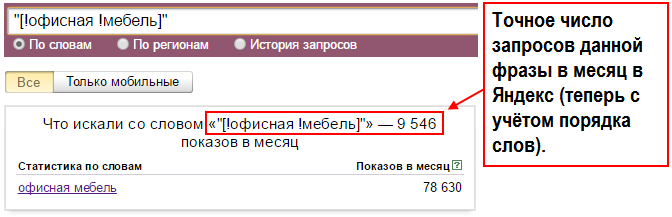
Вернувшись в наш магазин, мы видим, что в магазине закончились запасы «DeLonghi — Эспрессо-машина — Нержавеющая сталь». Но этот элемент по-прежнему отображается на нашей странице результатов поиска как лучший результат для «эспрессо-машины».
Все, что нам нужно сделать, это добавить название продукта в список «Скрыть результат», когда поисковым запросом является «эспрессо-машина».
Мы установили правило запроса, чтобы скрыть только этот результат, в то время как все остальные результаты по-прежнему будут отображаться на странице результатов поиска.
Пользовательские данные
Допустим, вы хотите добавить некоторую дополнительную информацию, такую как купоны, фильтры или баннеры, которые будут отображаться при определенных поисковых запросах. Любая дополнительная информация о внешнем интерфейсе, подобная этой, упрощает принятие решения о покупке, поэтому пользователь должен легко просматривать ее. Используя это правило запроса, вы сможете применить это и многие другие пользовательские взаимодействия.
Например, мы хотим добавить новый фильтр, который автоматически открывается, когда наши поисковые пользователи используют навигацию по категориям для перехода к нашей странице категории «Музыка». Вот что они увидят до того, как мы настроим правило запроса.
С помощью этой дополнительной информации пользователи смогут быстрее найти то, что им нужно. Это все, что мы должны добавить.
Теперь, с нашим новым фильтром, вот что получат наши пользователи.
Заменить слова
Предположим, вы заметили, что популярный поисковый запрос дает нерелевантные результаты. Что происходит в фоновом режиме, так это то, что в магазине так много записей, использующих ключевое слово, что они снижают релевантность поиска для определенных результатов. Здесь нужно создать исключение, которое сработает только в том случае, если часть поискового запроса содержит это ключевое слово. Это правило запроса не изменит поисковый запрос для пользователя, оно заменит слово для вашей поисковой системы, чтобы она могла возвращать релевантные результаты.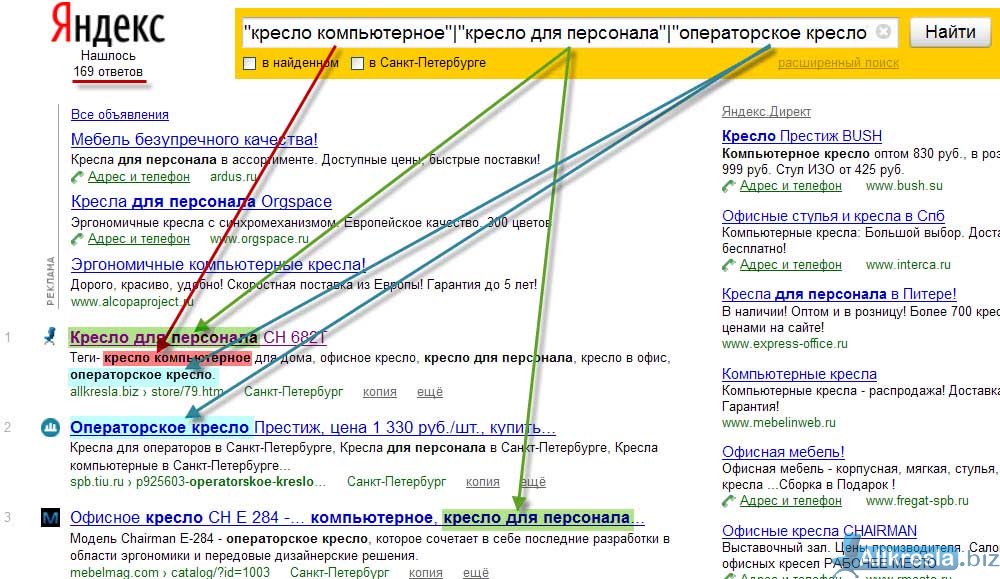
Мы заметили, что наш магазин выдает нерелевантные результаты для «деревянных скамеек», хотя у нас было много перечисленных товаров.
Мы можем настроить правило запроса, чтобы если поисковый запрос начинался со слова «деревянный», только затем он заменялся на «Simpli Home», наш мебельный бренд.
Теперь с помощью того же поиска мы сможем получить лучшие результаты, не влияя на другие поиски слова «деревянный».
Заменить поисковый запрос
Теперь, возможно, вы хотите увеличить масштаб и заменить весь запрос. Может быть, вы замечаете, что неприятный поисковый запрос с длинным хвостом часто появляется в вашем отсутствии результатов. Возможно, пользователи ищут фразу или описание, которые вы не сопоставили с набором данных. Затем используйте это правило запроса, чтобы перехватить эти запросы и заменить их, чтобы повысить релевантность поиска.
Например, в нашем магазине была проведена рекламная кампания со скидкой 30% на механические клавиатуры. Но мы заметили, что значительное количество поисковых запросов использовали код скидки нашей кампании в качестве поискового запроса вместо «механическая клавиатура».
Но мы заметили, что значительное количество поисковых запросов использовали код скидки нашей кампании в качестве поискового запроса вместо «механическая клавиатура».
Итак, мы установили правило запроса, которое заменит «clackety clack 30» на «механические клавиатуры».
После этого наши поисковые пользователи увидят правильные результаты по обоим ключевым словам.
Удалить слова
Говоря о ключевых словах с длинным хвостом, вот еще один способ сделать их намного проще для вашей поисковой системы, чтобы понять, что пользователь пытается найти. Иногда все, что нужно сделать, чтобы сделать эти запросы понятными для поиска, — это удалить из них нерелевантные слова. Используя это правило запроса, вы сможете удалить определенные слова из заданных длинных запросов, чтобы функция поиска предоставляла результаты только по жизненно важным ключевым словам.
Возвращаясь к набору данных нашего магазина, мы видим, что это то, что наши поисковые пользователи получают, когда они ищут «план страхования от несчастных случаев для смартфонов».
Итак, чтобы решить эту проблему, мы создаем правило запроса, которое удалит из запроса «смартфон» и «страхование», чтобы наш поиск давал релевантные результаты.
А вот и новый поисковый опыт.
Настройки поиска
Вы знаете, что ваши настройки поиска определяют релевантность поиска. Но что произойдет, если эта настройка помешает продаже популярного товара? Нет смысла переворачивать весь алгоритм поиска, чтобы приспособиться к некоторым пограничным случаям. Даже небольшое изменение может привести к потере общей релевантности поиска. Здесь наличие правила запроса для работы с этими пограничными случаями будет иметь большое значение для повышения вашего удобства поиска.
Например, стратегия релевантности поиска нашего магазина придает одинаковый вес всем полям поиска. Но это означает, что именно это видят многие пользователи нашего поиска, когда ищут «apple iphone».
Мы можем обойти это, придав больший вес полю «Производитель устройства» при поиске по этому запросу.
Теперь наши пользователи увидят более релевантную страницу результатов.
Заменить поисковый запрос
Теперь предположим, что вы хотите еще больше контролировать определенные поисковые запросы. Возможно, у вас есть физическая торговая точка, где ваши сотрудники отдела продаж используют настраиваемый поисковый интерфейс для проверки наличия, запасов или характеристик некоторых ваших предложений. Очевидно, что они будут искать по артикулам, а не по названиям продуктов. Используя это правило запроса, вы сможете настроить триггерное выражение, чтобы ваши сотрудники также могли выполнять поиск на основе других сопоставленных полей. Но из-за повышенной гибкости это правило запроса требует некоторого понимания синтаксиса строки запроса Elasticsearch.
Добавить фильтры
Вы ищете способ уточнить поисковые запросы для ваших пользователей без добавления каких-либо дополнительных входных данных с их стороны? Используйте это правило запроса, чтобы автоматически применять предустановленные фильтры и создавать бесшовный путь поиска.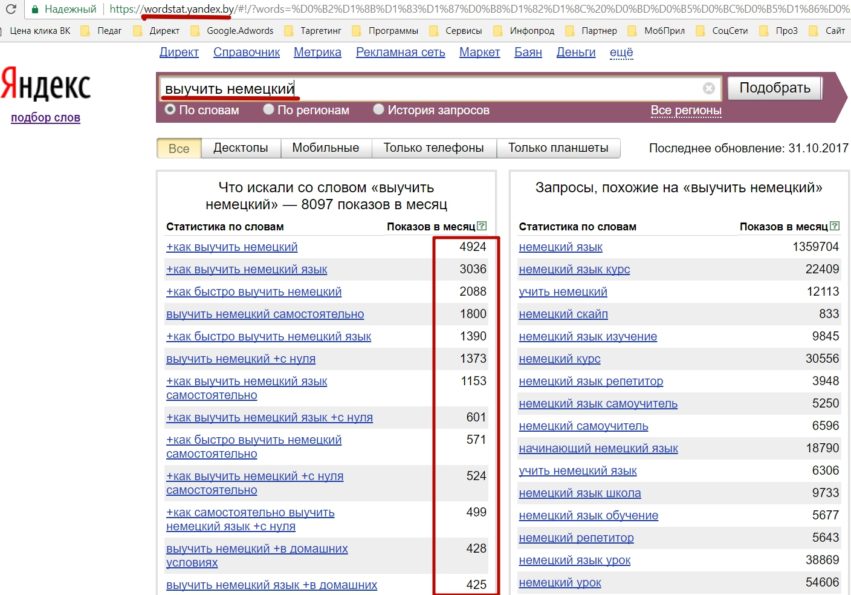 Вместо того, чтобы тратить время на поиск наиболее релевантной категории для своего поиска, ваши поисковые пользователи смогут просматривать больше вашего магазина и быть ближе к совершению покупки.
Вместо того, чтобы тратить время на поиск наиболее релевантной категории для своего поиска, ваши поисковые пользователи смогут просматривать больше вашего магазина и быть ближе к совершению покупки.
Допустим, наш магазин после изучения своей поисковой аналитики выяснил, что после поиска «лего звездные войны» пользователи почти всегда выбирают фильтр «Игрушки». Это означает, что у нашего магазина есть возможность упростить это взаимодействие. В настоящее время это то, что увидит пользователь поиска.
А вот и правило, которое мы добавим для применения фильтра.
Вот что увидят наши поисковые пользователи.
Функции
Представьте, что вы хотите запустить маркетинговую кампанию, которая каждый час будет продвигать разные продукты по одному и тому же поисковому запросу. Или вы хотите выделить различные аксессуары в зависимости от того, какие устройства используют ваши посетители. Одним из способов может быть настройка нескольких правил запросов, созданных для этих пограничных случаев, но это будет утомительный процесс.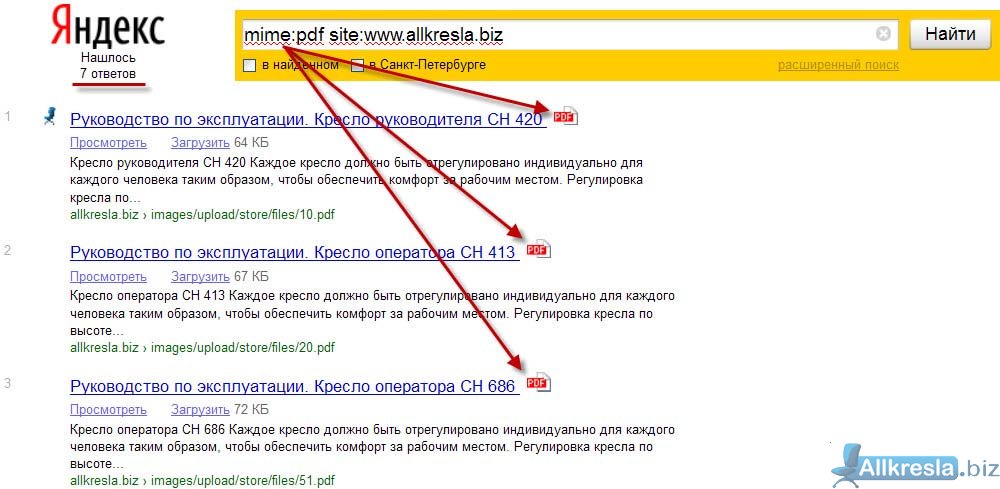 Вместо этого вы можете реализовать даже самые амбициозные проекты с помощью настраиваемых функций.
Вместо этого вы можете реализовать даже самые амбициозные проекты с помощью настраиваемых функций.
Appbase.io поможет вам включить эти функции в правила запросов, чтобы вы могли обеспечить феноменальную релевантность поиска.
Вы можете просмотреть эту демонстрацию, чтобы лучше понять, как можно определить функцию.В этом посте мы объяснили, что такое правила запросов, чем они отличаются от стратегии релевантности поиска, и рассмотрели 10 основных вариантов использования правил запросов.
- Подробнее о том, как создавать правила запросов с помощью appbase.io, можно прочитать здесь: https://docs.appbase.io/docs/search/rules/
- Вы можете узнать о соответствующем поисковом продукте appbase.io здесь: https://appbase.io/product/search
Правила запросов appbase.io можно использовать с существующим кластером Elasticsearch или с облачным продуктом appbase.io.
| Redaktionelle Informationen bereitgestellt von DB-Engines | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Name | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Kurzbeschreibung | Native high-speed multi-model DBMS for relational and key -value хранить данные, одновременно доступные через API SQL и NoSQL. | Гибридная СУБД с распределенным графом, работающая в памяти в первую очередь, обеспечивающая высокую производительность при выполнении аналитических и транзакционных рабочих нагрузок в масштабе предприятия Совместимый с DynamoDB API | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Базовая модель банка данных | Хранилище ключей и значений Реляционная СУБД | Графическая СУБД | Хранилище документов Реляционная СУБД | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Веб-сайт | www.faircom.com/products/faircom-d | Memgraph.com | Cloud.yAndex.com/Services/LICLICES183333339. /ydb ydb.tech | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Техническая документация | Learn.faircomcorp.com/developers/documentation_directory | docs.memgraph.com | cloud.tech/ | cloud.tech/ | managed-y en/docs | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Social network pages | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Entwickler | FairCom Corporation | Memgraph Ltd | Yandex | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Erscheinungsjahr | 1979 | 2017 | 2019 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Aktuelle Version | V12, November 2020 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Lizenz Коммерческий или с открытым исходным кодом | kommerziell Доступна бесплатная версия с ограничениями | kommerziell Доступна бесплатная лицензия | Apache 2. 0 с открытым исходным кодом; Коммерческая лицензия доступна 0 с открытым исходным кодом; Коммерческая лицензия доступна | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ausschließlich Ein Cloud-Service Nur Als Cloud-Service Verfügbar | NEIN | NEIN | NEIN | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DBAAS ANGEBOTE (GESPONSERTE LINKIDSABSERTE SERVIDESABSERTE DALEDSABSERTE DALEDSABSERTE). быть перечисленным. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Руководство по внедрению | ANSI C, C++ | C и C++ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Server Betriebssysteme | AIX FreeBSD HP-UX Linux NetBSD OS X QNX SCO Solaris VxWorks Windows easily portable to other OSs | Linux | Linux | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Datenschema | schema бесплатно, схема необязательна, схема обязательна, частичная схема, | схема и схема необязательно | Гибкая схема (определенная схема, частичная схема, схема свободна) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Typisierung vordefinierte Datentypen, z.B. float oder date float oder date | ja, ANSI Standard SQL Types, JSON, типизированные двоичные структуры | ja | ja | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| XML Unterstützung Verarbeitung von Daten in XML Format, beispielsweise Xerathtungersungsung von XML-Stodrukturenung , XSLT | nein | nein | nein | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sekundärindizes | ja | ja | SQL Support of SQL | yes, ANSI SQL with proprietary extensions | nein | SQL-like query language (YQL) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| APIs und andere Zugriffskonzepte | ADO.NET Direct SQL JDBC JPA ODBC RESTful HTTP/JSON API RESTful MQTT/JSON API RPC | Протокол Bolt Язык запросов Cypher | RESTful HTTP API (совместимый с DynamoDB) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Unterstützte Programmiersprachen | .Net C C# C++ Java JavaScript (Node.js and browser) PHP Python Visual Basic | . Net Net C C++ Elixir Go Haskell Java JavaScript PHP Python Ruby Scala | Go Java JavaScript (Node.js) PHP Python | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Server-seitige Scripts Stored Procedures | ja .Net, JavaScript, C/C++ | nein | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Triggers | ja | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Partitionierungsmechanismen Methoden zum Speichern von unterschiedlichen Daten auf unterschiedlichen Knoten | File partitioning, horizontal partitioning, sharding Customizable business rules for table partitioning | Sharding dynamic graph partitioning | Sharding | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Replikationsmechanismen Methoden zum redundanten Speichern von Daten auf mehreren Knoten | yes, настраиваемый для параллельного или последовательного, синхронного или асинхронного, однонаправленного или двунаправленного, ACID-совместимого или окончательно согласованного (с пользовательским разрешением конфликтов).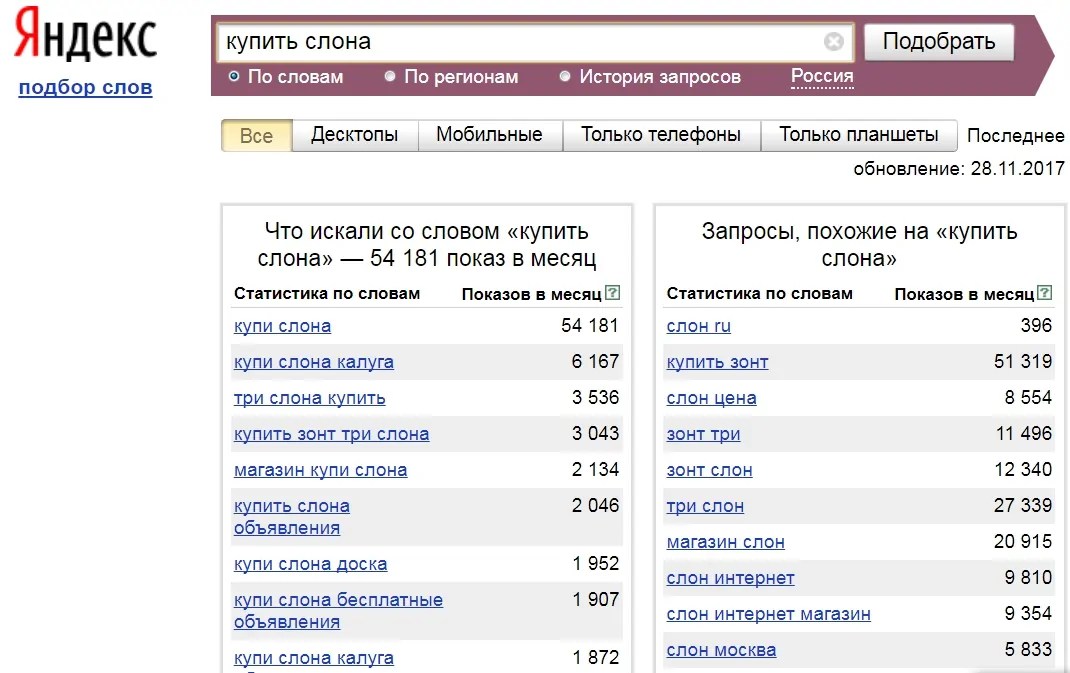 | Multi-source replication using RAFT | Active-passive shard replication | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MapReduce Bietet ein API für Map/Reduce Operationen | nein | nein | nein | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Konsistenzkonzept Methoden zur Sicherstellung der Konsistenz in einem verteilten Система | Согласованность в конечном итоге Немедленная согласованность Настраиваемая согласованность для каждого сервера, базы данных, таблицы и транзакции | Немедленная согласованность | Immediate Consistency | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fremdschlüssel referenzielle Integrität | ja | ja relationships in graphs | nein | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Transaktionskonzept Unterstützung zur Sicherstellung der Datenintegrität bei nicht-atomaren Datenmanipulationen | tunable from ACID to Eventually Consistent | ACID with изоляция моментальных снимков | ACID | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Concurrency Unterstützung von gleichzeitig ausgeführten Datenmanipulationen | и | да, многоверсионный контроль параллелизма (MVCC) | и | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Durability Dauerhafte Speicherung der Daten | Да, перестраиваемый от устойчивого к отложенному и периодическому снимку состояния7 с сохранением в памяти | и | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| In-Memory Unterstützung Gibt es Möglichkeiten einige oder alle Strukturen nur im Hauptspeicher zu halten | ja | NEIN | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| BERECHTIGUNGSKONZEPT Zugriffskontrolle | Права с мелким покрытием. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Особые характеристики | Достижение сотен тысяч транзакций в секунду на одном сервере базы данных… » Подробнее | Memgraph напрямую подключается к вашей потоковой инфраструктуре, поэтому вы и ваша команда… » Дополнительно | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Конкурентные преимущества | Основные функции SQL Key-value хранилище и навигация NoSQL API Индексированные двоичные объекты… » mehr | Лицензия Business Source гарантирует будущее алгоритма MAGE сообщества Memgraph… » mehr | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Типичные сценарии применения | Решения для обработки транзакций в реальном времени используют базу данных FairCom, потому что это NoSQL… » больше | Графовые алгоритмы в биоинформатике Анализ социальных сетей Криптовалютная сеть… » больше | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ключевые клиенты | Microsoft, UPS, Verizon, Motorola, Commvault, Thomson Reuters, ACI, BNY Mellon, Rockwell. .0032 .0032 | Так же, как технические аспекты базы данных FairCom являются гибкими для удовлетворения эксплуатационных требований,… » mehr | Вы можете ознакомиться с нашей моделью ценообразования и лицензиями на веб-сайте компании. » mehr | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wir laden Vertreter der Systemhersteller ein uns zu kontaktieren, um die Systeminformationen zu aktualisieren und zu ergänzen, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wir laden Vertreter von Anbietern von zugehörigen Produkten ein uns zu kontaktieren, um hier Informationen über ihre Angebote zu präsentieren. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Weitere Ressourcen | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Erwähnungen in aktuellen Nachrichten | Graph database company Memgraph raises $9.34M Memgraph Launches Streaming Graph Algorithms to the Masses; объявляет $ 90,34 млн. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
