Robots txt: что это за файл
Файл текстового формата robots.txt содержит информацию, необходимую для индексации сайта поисковиками. Он размещается в корневом каталоге и разбит на директории, содержащие команды, при помощи которых ботам поисковиков открывается доступ к определенным местам на веб-ресурсе и закрывается. Причем роботы разных поисковиков обрабатывают этот файл при помощи собственных алгоритмов, у которых могут быть свои специфические особенности. Работа со ссылками с других площадок проводится независимо от того, как настроен robots.
Основные задачи robots.txt
У «роботс» главное назначение – это содержать правила, которые помогают ботам правильно индексировать ресурс. Основные из таких директив – Allow (разрешение индексировать раздел или конкретный файл), Disallow (обратная команда, то есть запрет на такую процедуру) и User-agent (адресация команд Allow и Disallow, то есть определение, какие боты должны им следовать). Следует учитывать, что содержащиеся в «роботс» инструкции имеют характер рекомендаций, а не обязательных предписаний. Поэтому роботы могут в разных ситуациях как использовать, так и игнорировать их.
Поэтому роботы могут в разных ситуациях как использовать, так и игнорировать их.
Создание и размещение «роботс»
Файл должен быть исключительно текстовым, то есть иметь расширение txt, и находиться в корневом каталоге соответствующего сайта. Размещение осуществляется при помощи клиента FTP. Дальше проводится проверка файла на предмет его доступности. С этой целью необходимо перейти на страницу site.com/robots.txt. Причем этот адрес должен отображаться в браузере полностью.
Требования к файлу
Следует учитывать, что при отсутствии «роботс» в корневом каталоге или неправильной его настройке есть риск того, что сайт не будет доступен в поисковике и его посещаемость будет низкой. В файле не может использоваться кириллица, поэтому , если домен кириллический, применяют Punycode. Важно при этом, чтобы поддерживалось соответствие между кодировкой страниц и структурой ресурса.
Дополнительные директивы
Кроме основных команд Allow, Disallow и User-agent, присутствующих в каждом файле «роботс», есть ряд директив специального назначения, которые используются в особых случаях.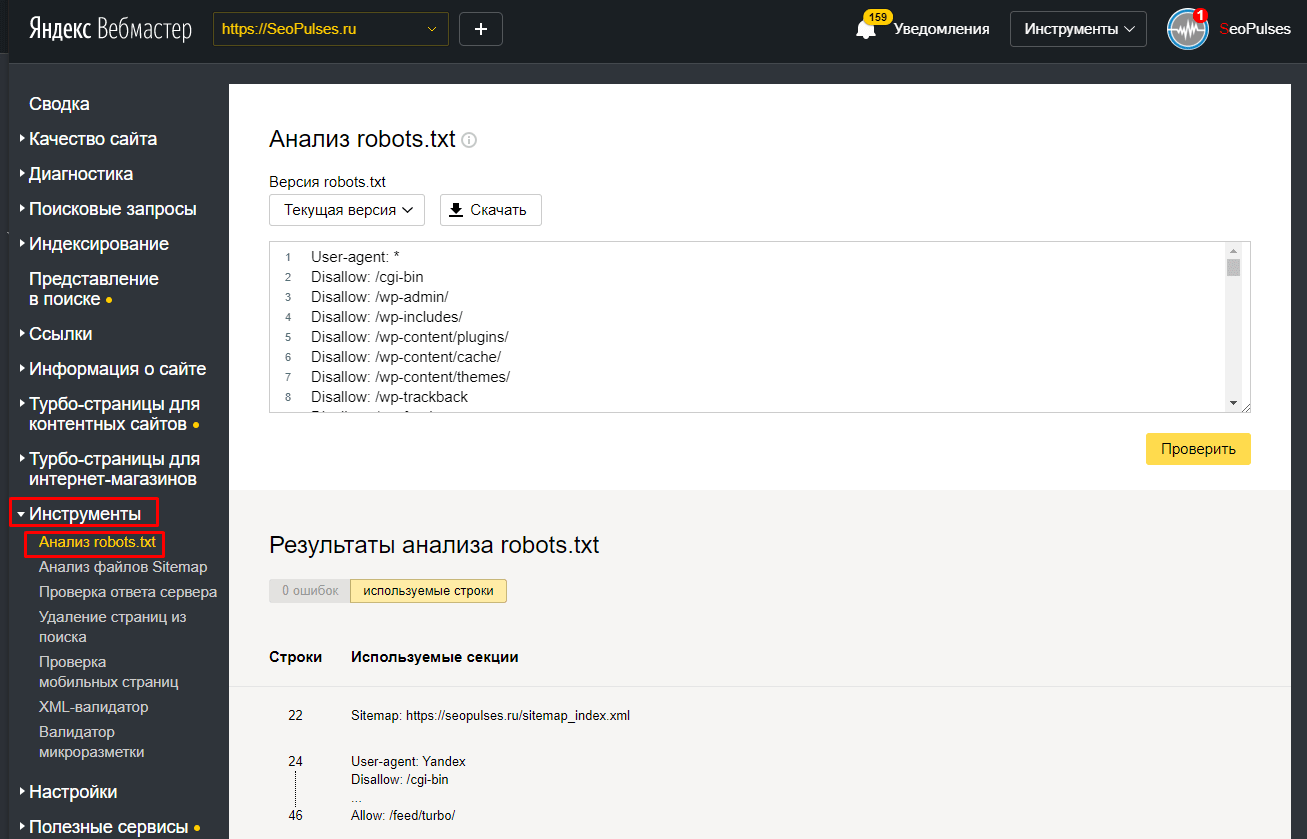
Crawl-delay
Если роботы поисковых систем слишком сильно нагружают сервер, поможет эта директива. Она содержит информацию о минимальном интервале между завершением загрузки одной страницы и переходом бота к обработке следующей. Этот промежуток времени указывается в секундах. Причем робот «Яндекса» без проблем считывает не только значения в целых числах, но и дробные, к примеру 0,7 секунды. Но роботы поисковика Google директиву Crawl-delay пока не учитывают.
Clean-param
Эта директива используется поисковыми ботами «Яндекса». Структура названий сайтов может быть сложной, и нередко системы, управляющие контентом, создают в них динамические параметры. Они могут передавать дополнительные сведения о сессиях пребывания на сайте пользователей, реферерах и т. п. Директива Clean-param имеет такой синтаксис:
s0[&s1&s2&..&sn] [path].
Здесь два поля, в первом из которых перечисляются параметры, учитывать которые поисковые роботы не должны. Их необходимо разделять при помощи символа &. Во втором поле указываются адреса тех страниц, на которые распространяется данное правило. В качестве примера использования такой директивы можно привести форум, на котором при посещении пользователем страниц формируются ссылки с длинными названиями такого образца: http://forum.com/index.php?id=788987&topic=34. При этом у страниц одинаковое содержание, но у всех пользователей собственные идентификаторы. Чтобы предотвратить индексацию поисковыми роботами всего массива дублирующихся страниц с разными id, директива Clean-param должна выглядеть так: id /forum.com/index.php.
Их необходимо разделять при помощи символа &. Во втором поле указываются адреса тех страниц, на которые распространяется данное правило. В качестве примера использования такой директивы можно привести форум, на котором при посещении пользователем страниц формируются ссылки с длинными названиями такого образца: http://forum.com/index.php?id=788987&topic=34. При этом у страниц одинаковое содержание, но у всех пользователей собственные идентификаторы. Чтобы предотвратить индексацию поисковыми роботами всего массива дублирующихся страниц с разными id, директива Clean-param должна выглядеть так: id /forum.com/index.php.
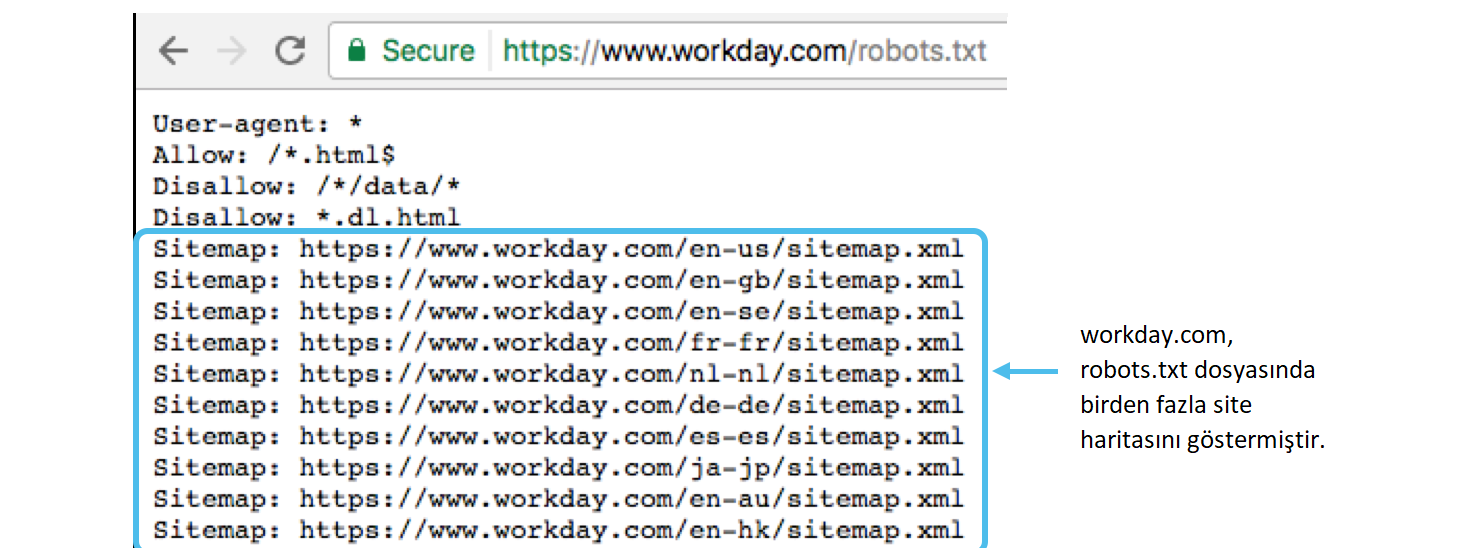
Sitemap
Чтобы сайты индексировались правильно и быстро, создается Sitemap – файл (или несколько) с картой ресурса. Соответствующая директива прописывается в любом месте файла «роботс» и учитывается поисковыми ботами независимо от расположения. Однако, как правило, она находится в конце документа. Обрабатывая директиву, бот запоминает информацию и проводит ее переработку. Именно полученные таким образом данные становятся основой для проведения последующих сессий, в процессе которых для индексации загружаются страницы веб-ресурса.
Именно полученные таким образом данные становятся основой для проведения последующих сессий, в процессе которых для индексации загружаются страницы веб-ресурса.
Host
Боты всех поисковиков руководствуются этой директивой, которая позволяет прописать зеркало веб-ресурса, которое при индексации будет восприниматься как главное. Так можно избежать включения в индекс нескольких зеркал, то есть дублирования одного сайта в выдаче поисковой системы. Если значений Host несколько, робот, осуществляющий индексацию, принимает во внимание только первое, а все остальные игнорирует.
Специальные символы
Необходимо учитывать, что в конце каждой директивы по умолчанию прописывается специальный символ *. Его назначение – расширить зону действия правила на весь сайт, то есть на все его страницы или разделы, названия которых начинаются с определенного сочетания символов. Для отмены операции, которая проводится по умолчанию, используется символ $. По стандарту формирования «роботс» рекомендуется после каждого набора указаний User-agent прописывать пустую строку с переводом. Причем для комментирования используется символ #. Информацию, размещенную после него и до пустого перевода, поисковые боты не учитывают.
Причем для комментирования используется символ #. Информацию, размещенную после него и до пустого перевода, поисковые боты не учитывают.
Запрет индексации ресурса или отдельных разделов
Чтобы весь сайт, определенные разделы или страницы не индексировались, можно использовать указание Disallow. Если проставить здесь символ /, будет заблокирован для индексации весь ресурс, а «/ bin» закроет доступ к тем страницам, названия которых начинаются с этого сочетания знаков.
Проверка robots.txt
Когда в файл «роботс» вносятся какие-либо изменения, его необходимо проверить. Это операция, которая проводится в обязательном порядке, так как ошибка в расстановке символов может вызвать немало проблем. Минимальную проверку можно провести при помощи инструментов веб-мастера от Google и «Яндекса». Для их использования следует пройти регистрацию и внести информацию о своем ресурсе.
Настройка файла robots.txt
В служебном файле robots.txt содержатся инструкции для поисковых роботов. С помощью данного файла можно запретить или ограничить доступ поисковых роботов к определенным страницам или всему сайту. Также можно указывать ограничения для разных типов поисковых роботов. Снижение допустимой частоты запросов поисковых роботов к сайту позволяет уменьшить нагрузки на сайт и на сервер. С другой стороны, полное ограничение может привести к ухудшению позиций сайта в выдаче поисковых систем. Поэтому очень важно корректно настроить robots.txt. Данный файл размещается в корневом каталоге сайта: /public_html/robots.txt.
С помощью данного файла можно запретить или ограничить доступ поисковых роботов к определенным страницам или всему сайту. Также можно указывать ограничения для разных типов поисковых роботов. Снижение допустимой частоты запросов поисковых роботов к сайту позволяет уменьшить нагрузки на сайт и на сервер. С другой стороны, полное ограничение может привести к ухудшению позиций сайта в выдаче поисковых систем. Поэтому очень важно корректно настроить robots.txt. Данный файл размещается в корневом каталоге сайта: /public_html/robots.txt.
Формат robots.txt
Рекомендуется проверять файл robots.txt в специальных сервисах, например, Yandex, Google.
Используемые директивы
User-agent
Каждый блок начинается с директивы User-agent. Здесь указывается робот, для которого используется данное правило.
Например, чтобы задать правило для индексирующего бота Яндекса, введите:
User-agent: YandexBot
Чтобы правило применялось ко всем ботам Яндекса и Google, введите:
User-agent: YandexUser-agent: Googlebot
Чтобы правило применялось ко всем роботам:
User-agent: *Disallow и Allow
Директивы Disallow и Allow разрешают или запрещают доступ к разделам сайта.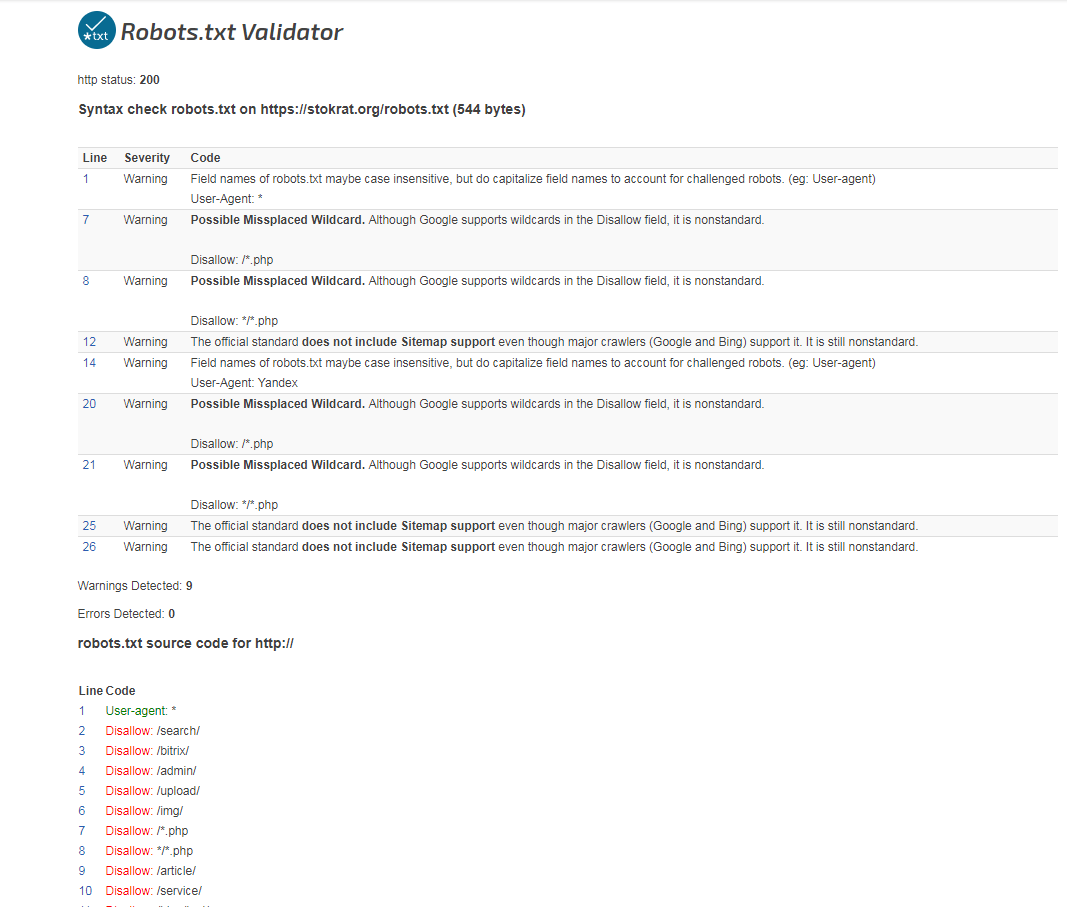
Например, чтобы запретить доступ ко всему сайту, введите:
Disallow: /
Чтобы при этом одновременно разрешить доступ к каталогу сайта catalog1, введите:
Allow: /catalog1
Если необходимо запретить индексацию страниц /catalog1/*, но разрешить для страниц /catalog1/catalog12, введите:
User-agent: * #или имя_ботаDisallow: /catalog1
Allow: /catalog/catalog12
Каждое правило записывается с новой строки и может включать только одну папку. Для каждой новой папки необходимо указать отдельное правило.
Рекомендуется ограничивать доступ к сайту определенных ботов. Это позволяет снизить нагрузку на сайт. Например, сервис majestic.com использует поисковый бот MJ12bot, ahrefs.com – AhrefsBot. Для запрета доступа нескольких ботов введите:
User-agent: MJ12bot #правило работает для бота MJ12botUser-agent: AhrefsBot #правило работает для бота AhrefsBot
User-agent: DotBot #правило работает для бота DotBot
User-agent: SemrushBot #правило работает для бота SemrushBot
Disallow: / # запрет доступа к всему сайту
- Disallow: — пустая директива, т.
 е. ничего не запрещает.
е. ничего не запрещает. - Allow: / — директива разрешает всё.
- $ — обозначает строгое соответствие параметра. Например, директива Disallow: /catalog$ запрещает доступ только к этому каталогу. Доступ к каталогам catalog1 или catalog-best будет разрешен.
 е. ничего не запрещает.
е. ничего не запрещает.Sitemap
Если для описания структуры сайта используется файл sitemap.xml, Вы можете указать путь к нему:
User-agent: *Disallow:
Sitemap: https://domain.com/путь-к-файлу/sitemap.xml
Host
Данная директива указывает роботам Яндекса расположение зеркала сайта.
Например, если сайт также располагается на домене https://domain2.com, введите:
User-agent: YandexBotDisallow:
Host: https://domain2.com
Робот воспринимает только первую указанную в файле директиву Host, остальные не учитываются.
Если используется http, зеркало можно указать без протокола – domain2.com. Если используется https, необходимо указывать протокол — https://domain2. com.
com.
Директива Host указывается после Disallow и Allow.
Crawl-delay
Директива Crawl-delay устанавливает минимальный интервал, с которым роботы могут обращаться к сайту. Это позволяет снизить нагрузку на сайт.
Значение указывается в секундах (разделитель — точка).
User-agent: YandexDisallow:
Crawl-delay: 0.6
Директива Crawl-delay указывается после Disallow и Allow.
Для Яндекса максимальное значение 2. (В Яндекс.Вебмастер можно установить большее значение).
Частота обращений Google-бота устанавливается в Search Console.
Clean-paramДанная директива предназначена для Яндекса и позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах. Так робот не будет повторно индексировать содержимое страниц и создавать дополнительную нагрузку.
Например, на сайте есть страницы:
www.domain1.com/news.html?&parm1=1&parm2=2www.domain1.com/news.html?&parm2=2&parm3=3
Фактически это две одинаковые страницы с разным динамическим содержимым.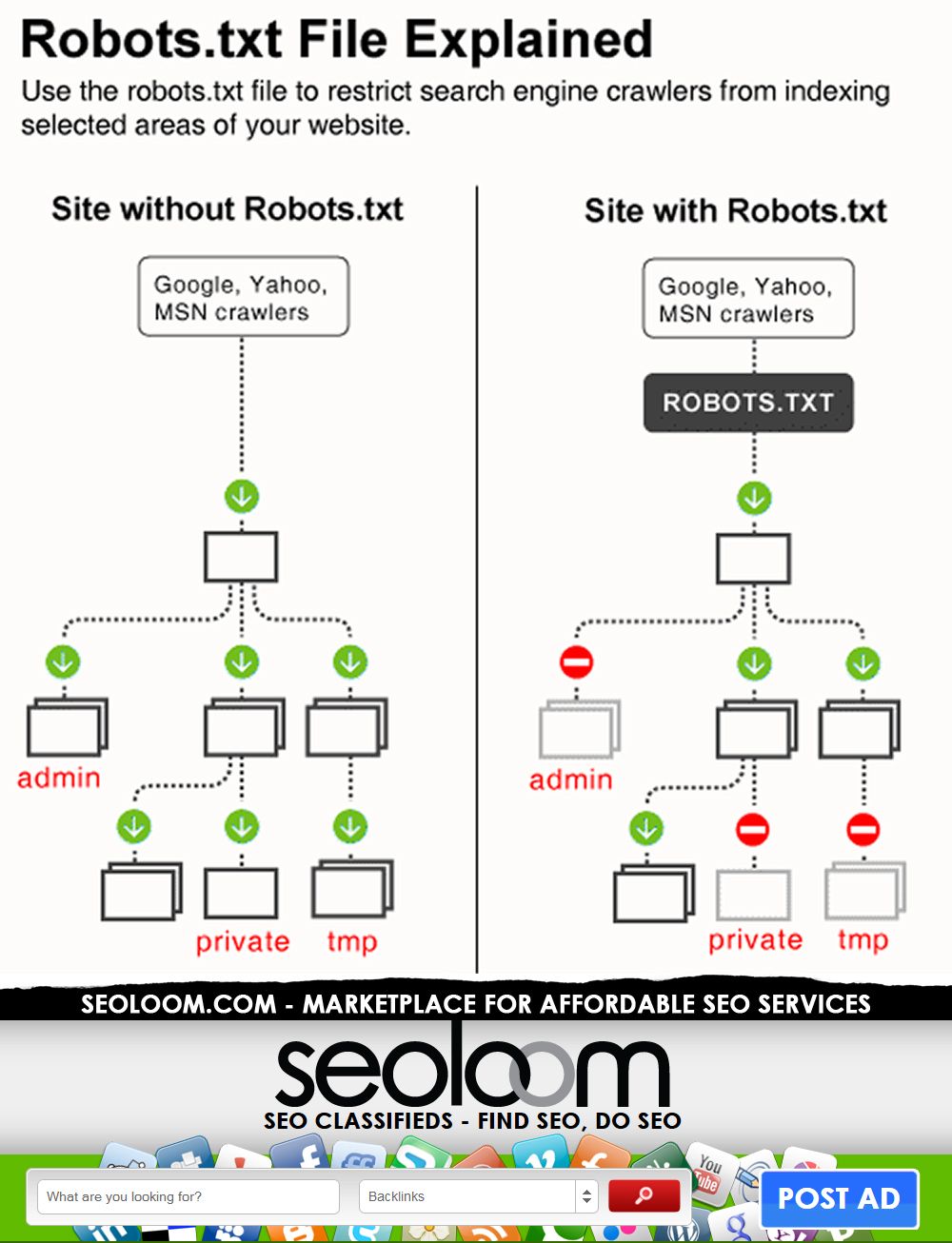 Чтобы Яндекс не индексировал каждую копию этой страницы, введите директиву:
Чтобы Яндекс не индексировал каждую копию этой страницы, введите директиву:
User-agent: YandexDisallow:
Clean-param: parm1&parm2&parm3 /news.html
Через & перечисляются параметры, которые не учитывает робот. Затем указывается страница, для которой применяется данная директива.
В справочнике Яндекса Вы можете ознакомиться с подробной инструкцией по настройке данной директивы.
Если у Вас остались вопросы — создайте тикет в техподдержку.
Robots.txt и SEO — Полное руководство от экспертов
Ваш файл robots.txt, один из самых важных файлов на вашем веб-сайте, — это файл, который позволяет роботам поисковых систем знать, следует ли им сканировать веб-страницу или оставить ее в покое.
Одной из основных целей файла robots.txt является обеспечение того, чтобы серверы вашего веб-сайта не были перегружены ботами поисковых систем, сканирующими ваш веб-сайт в любое время дня, но знаете ли вы, что есть также преимущества, связанные с SEO, которые дает правильно оптимизированный файл robots?
Продолжайте читать это руководство, чтобы узнать больше о файле robots. txt, передовых методах и о том, как это помогает SEO-оптимизации вашего веб-сайта.
txt, передовых методах и о том, как это помогает SEO-оптимизации вашего веб-сайта.
Что делает файл robots.txt?
Распространенным заблуждением является то, что файл robots.txt препятствует индексации страницы поисковыми системами.
Неправда.
Google говорит: «Если другие страницы указывают на вашу страницу с описательным текстом, Google все равно может проиндексировать URL-адрес, не посещая страницу». Если Google проиндексирует страницу, запрещенную файлом robots.txt, у нее не будет описания, поскольку им не разрешено посещать эту страницу.
Если вы хотите запретить индексацию страницы, используйте тег noindex. Либо заблокируйте страницу паролем, чтобы Google не индексировал личную информацию.
По умолчанию сканеры могут сканировать, индексировать и ранжировать все страницы вашего веб-сайта, если только они не заблокированы директивой disallow (дополнительная информация приведена ниже в разделе о синтаксисе и форматировании therobots. txt). Таким образом, если файл robots.txt не существует или недоступен, поисковые системы будут сканировать, индексировать и ранжировать каждую страницу, которую они могут найти на вашем веб-сайте, как если бы не было никаких ограничений.
txt). Таким образом, если файл robots.txt не существует или недоступен, поисковые системы будут сканировать, индексировать и ранжировать каждую страницу, которую они могут найти на вашем веб-сайте, как если бы не было никаких ограничений.
Синтаксис и форматирование Robots.txt
Стандарт исключения роботов (также известный как Robots.txt) должен следовать набору правил, чтобы быть действительным и использоваться сканерами поисковых систем.
Структура файла robots.txt включает:
- Группа : Имена агента пользователя и директивы, которым он должен следовать. В файле robots.txt может быть столько групп, сколько вы хотите, но большинство пользовательских агентов будут следовать только первым группам, которые к ним относятся.
- User-Agent : Идентификация сканера. Именование пользовательского агента в robots.txt пользовательского агента, установленного для них директивами. Например, вы можете назвать Googlebot одним пользовательским агентом, а бота Pinterest — другим.
- Директивы : Это инструкции, которым должен следовать каждый пользовательский агент, названный в той же группе.
- Карта сайта XML : В файлах robots.txt возможно и часто упоминается карта сайта, потому что поисковые роботы могут легко найти файл.

Сканеры обычно обрабатывают группы сверху вниз, но Googlebot и Bingbot по умолчанию используют наиболее конкретные правила, поскольку они обычно менее строгие.
Пользовательские агенты могут следовать только за одной группой, и вам следует избегать противоречивых директив для одного и того же пользовательского агента. Если группа директив нацелена на пользовательский агент более одного раза, они, скорее всего, проигнорируют ее, следуя только первой группе, найденной в файле robots.txt.
Вы также можете использовать файл исключения robots на поддоменах (например, www.mydomain.com/robots.txt или blog.mydomain.com/robots.txt ) или нестандартные порты ( mydomain. com:8181/robots.txt ).
com:8181/robots.txt ).
Основные правила файла robots.txt:
- Должен быть в кодировке UTF-8.
- Должен называться «robots.txt».
- Должен находиться в корне домена.
- Он будет действителен только для того же протокола (HTTP или HTTPS) и субдомена (например, с www или без www), где он расположен.
- Следует использовать только относительные пути (кроме карты сайта).
- В каждой строке должна быть только одна директива.
- Директивы чувствительны к регистру.
- Комментарии начинаются с # и не читаются поисковыми роботами.
Директивы Robots.txt
Поисковые роботы различных поисковых систем, будь то Googlebot или Bingbot, например, будут следовать каждой директиве, относящейся к ним, в файле robots.txt, чтобы убедиться, что они понимают, на какие страницы веб-сайта им разрешено переходить. Это позволяет им понять, какие страницы на веб-сайте можно сканировать, индексировать и ранжировать.
Стоит отметить, что не все поисковые роботы поддерживают одни и те же директивы или даже интерпретируют синтаксис директив одинаково.
Googlebot — один из тех пользовательских агентов, которые не поддерживают все директивы. Но прежде чем объяснять их подробно, давайте сначала посмотрим список всех директив:
- Карта сайта.
- Запретить.
- Разрешить.
- Задержка сканирования.
- Без индекса.
- Нет подписки.
Все директивы, кроме карты сайта, поддерживают подстановочные знаки из RegEx для всей строки, префикса или суффикса. Директивы должны начинаться с косой черты («/») при обращении к странице и заканчиваться «/» при обращении к каталогу.
Директива карты сайта
Директива карты сайта показывает URL-адрес, по которому находится XML-карта сайта веб-сайта, что упрощает их поиск поисковыми роботами. Эта директива поддерживается как внутри, так и вне групп. Если у вас нет конкретной карты сайта для конкретного бота, лучше объявить ее в начале файла robots. txt, чтобы ее могли использовать все поисковые роботы.
txt, чтобы ее могли использовать все поисковые роботы.
Как упоминалось в нашем руководстве по файлам Sitemap в формате XML, они не являются обязательными, и если вы уже отправили их в Google Search Console, эта директива может быть избыточной. Однако объявление XML-карты сайта не повредит вам и упростит ее поиск другим пользовательским агентам, таким как Bingbot.
Пример, показывающий использование директивы Sitemap:
Карта сайта: https://mydomain.com/sitemap.xml
User-agent: *
Disallow: /admin
Disallow Directive
Директива disallow сообщает сканерам, что им не разрешено посещать URL-адрес или соответствующее выражение (при использовании RegEx). Эту директиву вы будете чаще использовать в файле robots.txt, поскольку по умолчанию нет ограничений на количество страниц, которые могут посещать боты.
В приведенном ниже примере директива disallow не позволяет ботам сканировать административные страницы на сайте WordPress, и это будет выглядеть так:
User-agent: *
Disallow: /wp-admin/ не хотят, чтобы ссылки на их области входа в систему были проиндексированы и ранжированы. Вы видите проблему, которую это может вызвать, верно?
Вы видите проблему, которую это может вызвать, верно?
Директива Allow
Директива allow сообщает поисковым роботам, что они могут посещать и сканировать URL-адрес или соответствующее регулярное выражение. Это правило в основном используется для перезаписи директивы disallow, когда вы хотите, чтобы боты сканировали страницу из заблокированного каталога.
Примером может быть разрешение сканерам посещать страницу входа, но не все страницы администрирования сайта WordPress.
Агент пользователя: *
Запретить: /admin/
Разрешить: /admin/login
Директива задержки сканирования
Директива Crawl-delay ограничивает частоту посещения краулерами URL-адресов, чтобы избежать перегрузки серверов. Не все сканеры поддерживают эту директиву, и они могут по-разному интерпретировать значение задержки сканирования.
Пример:
User-agent: *
Crawl-delay: 1
В приведенном выше примере Bingbot интерпретирует, что ему следует подождать 1 секунду перед сканированием URL-адреса. Одна из самых больших проблем, возникающих при неправильной настройке этой директивы, заключается в том, что конкретный сканер поисковой системы, такой как, например, Bingbot, может вызвать слишком большую нагрузку на сервер вашего веб-сайта и привести к сбою всего вашего веб-сайта.
Одна из самых больших проблем, возникающих при неправильной настройке этой директивы, заключается в том, что конкретный сканер поисковой системы, такой как, например, Bingbot, может вызвать слишком большую нагрузку на сервер вашего веб-сайта и привести к сбою всего вашего веб-сайта.
Директива Noindex
Директива noindex в файле robots.txt предотвращает индексацию URL-адресов. Однако Google прекратил его поддержку в 2019 году, так как он никогда не документировался. Гэри Иллиес упомянул, что одной из причин удаления было то, что веб-сайты «наносили себе вред» с помощью noindex.
Не верите? Я видел множество примеров, когда веб-сайты не индексировали целые разделы своих веб-сайтов, из-за чего они (почти во всех случаях) не ранжировались в конкретной поисковой системе.
Одной из основных причин этого являются промежуточные веб-сайты. Естественно, пока веб-сайт создается в тестовой среде, почти все страницы не индексируются, чтобы Google и другие поисковые системы не трогали их во время сборки. Как только веб-сайт заработает, вполне возможно, что кто-то забудет отредактировать файл robots.txt и оставить для разделов веб-сайта значение noindex.
Как только веб-сайт заработает, вполне возможно, что кто-то забудет отредактировать файл robots.txt и оставить для разделов веб-сайта значение noindex.
Да. Это действительно худший кошмар SEO-специалиста!
На практике эта директива работала аналогично тегу noindex. Разница в том, что эта директива централизованно хранила инструкции в одном месте (robots.txt) вместо того, чтобы создавать тег noindex на каждой странице.
В этом примере файл robots.txt требует от сканеров не индексировать страницу about:
Агент пользователя: *
Noindex: /about
Директива Nofollow
Директива nofollow предписывает сканерам не переходить по ссылкам в URL. Это похоже на то, что делает тег nofollow, но вместо того, чтобы делать это для ссылки, он применяется к каждому URL-адресу на странице. Google не поддерживает эту директиву, как они объявили в 2019 году (то же объявление, что и noindex выше).
Кроме того, сотрудники Google задолго до этого объявления предупреждали людей не использовать эту директиву.
В этом примере файл robots.txt требует от сканеров не переходить по ссылкам на странице about:
User-agent: *
Nofollow: /about
Поддерживаемые директивы Robots.txt от Google Crawlers
Googlebot поддерживает только следующие файлы robots.tx t директивы:
- User-agent.
- Запретить.
- Разрешить.
- Карта сайта (при упоминании вне группы).
Согласно документации Google, все Adsbot должны быть явно названы пользовательскими агентами. Таким образом, использование подстановочного знака (*) не будет включать Google Adsbot.
Как Google интерпретирует директивы robots.txt
Компания Google располагает обширной документацией о том, как ее поисковые роботы интерпретируют директивы из файлов robots.txt.
Сводка интерпретации директив Googlebot:
- Файл robots.txt должен быть в кодировке UTF-8 и иметь размер менее 500 КБ.
- Файл robots.txt будет считаться действительным только для того же домена (тот же протокол, субдомен, хост или номер порта).
- Они не проверяют robots.txt в подкаталогах при сканировании корневого домена. Например, когда они смотрят на www.amazingcompany.com они не будут смотреть на
- Когда robots.txt возвращает коды 4XX, отличные от 429, Google считает, что ограничений на сканирование нет.
- Для кодов 5XX и 429 Google считает сайт запрещенным, но будет пытаться «просканировать файл robots.txt до тех пор, пока не получит код состояния HTTP, не являющийся ошибкой сервера». Если по прошествии 30 дней файл по-прежнему будет недоступен, они будут считать, что ограничений нет.
- Когда Google считает, что сайт настроен на отправку ошибок 503 для местоположения robots.txt вместо 404, когда файл не существует, они интерпретируют 503 как 404.
- Google будет игнорировать недопустимые строки в файле, «включая метку порядка байтов Unicode (BOM)».
- Пробелы в начале и конце каждой строки игнорируются. Однако их рекомендуют «улучшать читабельность».
- Робот Googlebot будет автоматически игнорировать комментарии.
- Робот Googlebot будет игнорировать директивы без пути.
- URL-адреса должны указываться относительно папки файла robots.txt (т. е. корня).
- Директива XML Sitemap должна использовать абсолютный путь.
- URL-пути чувствительны к регистру.
- Разрешено упоминать более одной директивы карты сайта XML.
- Робот Googlebot пытается выполнить наиболее конкретную группу директив. Если существует более одной действительной группы, пользовательский агент сгруппирует ее. «Специальные группы пользовательского агента и глобальные группы (*) не объединяются».
- Robots.txt будет обращать внимание только на разрешения, запреты и пользовательский агент внутри групп.
- В случае противоречивых правил Google использует наименее ограничительную директиву.



Подробные примеры с порядком приоритета этих правил см. в документации.
Robots.txt Example Rules
Хотя вполне возможно создать много правил в одном файле robots.txt, некоторые правила гораздо полезнее других! В этом разделе мы сосредоточимся на некоторых наиболее ценных правилах, которые вам необходимо усвоить.
Запретить сканирование каталога
Агент пользователя: *
Запретить: /grandma-recipes/
В этом примере файл robots.txt запрещает ботам сканировать все страницы в папке grandma-recipes.
Заблокировать доступ к одному сканеру
Агент пользователя: надоедливый бот
Запретить: /
В этом примере агент пользователя по имени надоедливый бот не может сканировать ни одну страницу на сайте. Пожалуйста, помните, что поисковые роботы не обязаны следовать этим директивам, но уважаемые будут.
Запретить сканирование одной страницы
Агент пользователя: *
Запретить: /best-grandma-cookies
В этом примере ни одному сканеру не разрешено посещать страницу под названием «Лучшие бабушкины куки». Также стоит отметить, что это будет работать так же, как директива каталога, которую мы объяснили немного ранее, поэтому любая страница по этому пути также будет заблокирована.
Также стоит отметить, что это будет работать так же, как директива каталога, которую мы объяснили немного ранее, поэтому любая страница по этому пути также будет заблокирована.
Блокировать все изображения на вашем сайте из Google Images
Агент пользователя: Googlebot-Image
Запретить: /
Эта группа запрещает роботу изображений Google посещать любую страницу на вашем веб-сайте, поэтому это невероятно полезно, если вы не хотите, чтобы изображения на вашем веб-сайте появлялись в Google Images. Имейте в виду, однако, что это исключительно сканер изображений Google, поэтому он не помешает ботам изображений из других поисковых систем посещать ваши изображения и, возможно, ранжировать их.
Блокировка определенного изображения из Google Картинок
Агент пользователя: Googlebot-Image
Запретить: /images/cookies.jpg
Можно заблокировать только определенные изображения от сканирования ботами. Для этого используйте директиву disallow и путь к файлу на сервере.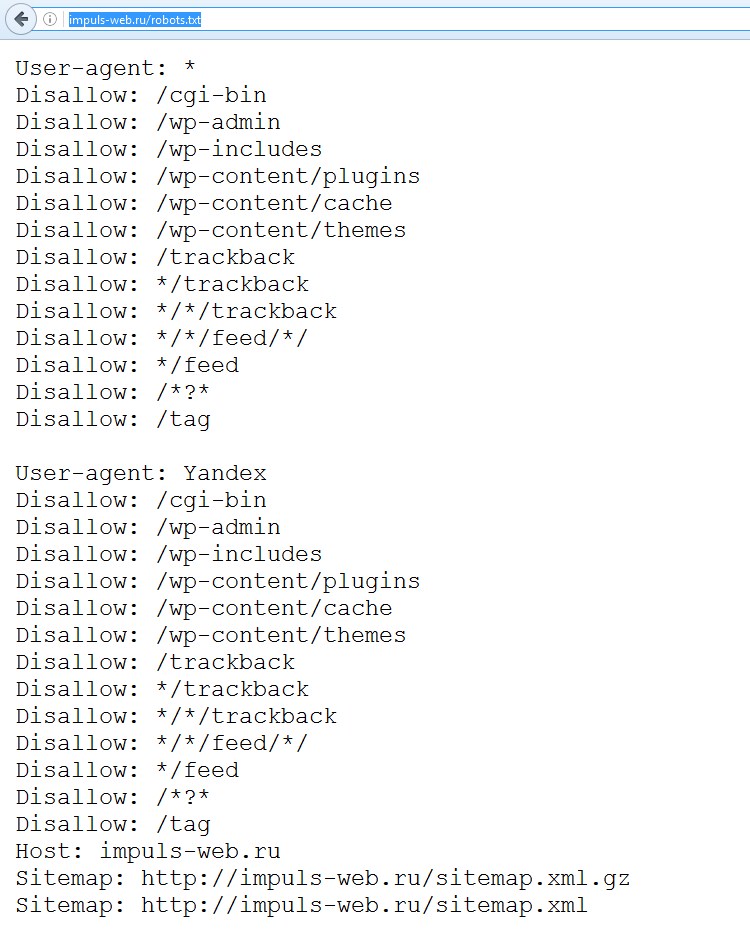 Отлично, если на определенных изображениях отображается информация, которую вы не хотите отображать в Google Images, но все в порядке с другими изображениями на вашем веб-сайте, которые индексируются.
Отлично, если на определенных изображениях отображается информация, которую вы не хотите отображать в Google Images, но все в порядке с другими изображениями на вашем веб-сайте, которые индексируются.
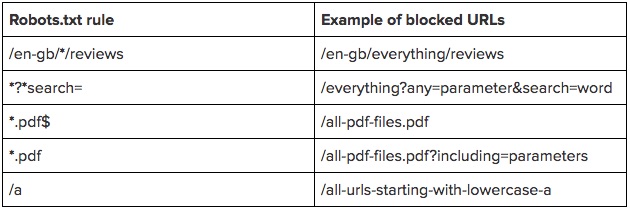
Запретить сканирование файлов определенного типа
Агент пользователя: *
Запретить: /*.pdf$
Также возможна блокировка определенных типов файлов. Например, чтобы заблокировать 1 тип файла на сайте, используйте регулярное выражение с подстановочным знаком (*), укажите расширение файла (в данном случае PDF) и завершите выражение знаком доллара ($). Знак доллара указывает на конец URL-адреса.
Передовой опыт
Мой совет: вам следует следовать стандартной структуре и форматам robots.txt, упомянутым в этом руководстве, но ниже приведены несколько советов по более эффективному использованию robots.txt.
Использование регулярных выражений для упрощения директив
Файл robots.txt поддерживает использование регулярных выражений. Это упростит объявление инструкций в файле, потому что вы можете сгруппировать инструкции в одно выражение вместо того, чтобы писать одну директиву для каждого URL.
Практический пример — параметры поиска на сайте. Без RegEx вы бы написали следующие директивы:
Агент пользователя: *
Запретить: /cookies/chocolate?
Запретить: /cookies/крем?
Запретить: /торты/клубника?
Запретить: /cakes/vanilla?
С RegEx файл robots.txt будет выглядеть примерно так:
Агент пользователя: *
Запретить: /cookies/*?
Запретить: /торты/*?
В этом примере подстановочный знак (*) будет включать все страницы каталогов файлов cookie и тортов. Для веб-сайтов с несколькими каталогами было бы обременительно поддерживать документ, поэтому использование RegEx более эффективно.
Использовать каждый пользовательский агент только один раз
Большинство сканеров читают robots.txt сверху вниз и следуют первой подходящей группе для своего пользовательского агента, а эти пользовательские агенты будут следовать только одной группе директив. Если вы упомянете сканер более одного раза, он проигнорирует одну из групп. Это не относится к Google и Bingbot, поскольку они следуют более конкретным правилам, а в случае с Google они объединяют группы так, как будто это только одна.
Это не относится к Google и Bingbot, поскольку они следуют более конкретным правилам, а в случае с Google они объединяют группы так, как будто это только одна.
Однако, во избежание путаницы, лучше перечислить конкретные пользовательские агенты вверху, а группу с подстановочным знаком для всех неупомянутых сканеров внизу.
Будьте точны с директивами
Точность в файле robots.txt окупается и предотвращает непреднамеренные последствия, когда боты не сканируют важные разделы вашего сайта.
Представьте, что вы не хотите, чтобы боты сканировали папку cookie , и вы создаете следующее правило запрета:
User-agent: *
Запретить: /cookies
Это правило запрета («/cookies») также предотвратит сканирование ботами следующих URL-адресов:
/cookies-recipes.html
/cookies-best-recipes-for-download.pdf
Решением будет исправление директивы и упоминание /cookies/, например: 07 Нужно ли вам использовать robots. txt?
txt?
Robots.txt не является фактором ранжирования или требованием для получения хороших органических результатов, и большинство веб-сайтов не заметят никакой разницы, если они не используют его.
Однако использование файла robots.txt становится все более важным по мере роста веб-сайта и увеличения количества страниц. Так что для крупных веб-сайтов файл robots.txt имеет большее значение и может иметь значительное влияние!
Как упоминалось выше, файл robots.txt поможет управлять трафиком сканеров, управляя бюджетом сканирования (внутренняя ссылка) или предотвращая перегрузку сервера.
Каковы ограничения файла robots.txt?
Основные ограничения robots.txt следующие:
- Не все сканеры поисковых систем поддерживают одни и те же директивы.
- Разные программы-обходчики по-разному интерпретируют синтаксис в файле.
- Запрещенные страницы все еще могут быть проиндексированы.
- Боты с плохим поведением могут игнорировать инструкции robots. txt.
 txt.
txt.Что произойдет, если вы не используете robots.txt?
Если вы не используете файл robots.txt, поисковые роботы сочтут, что нет ограничений на страницы, которые они могут посещать и индексировать с вашего сайта. Это поведение по умолчанию при отсутствии файла robots.txt.
Как упоминает Google в своей документации, если файл robots.txt недоступен, они будут действовать так, как будто файл не существует, и сканировать каждую страницу веб-сайта.
Проще говоря, если на вашем веб-сайте есть страницы, которые вы не хотите, чтобы роботы поисковых систем посещали и сканировали, вам необходимо убедиться, что все они перечислены в файле robots.txt.
Что произойдет, если вы запретите страницу с тегом noindex?
Google не увидит страницу с тегом noindex, если она запрещена файлом robots.txt. Таким образом, комбинируя disallow и noindex, вы говорите Google, что не хотите, чтобы они посещали страницу, но поскольку они не могут посетить страницу, они не увидят вашего указания не индексировать ее.
Если вы не хотите, чтобы страница индексировалась, лучше использовать тег noindex, поскольку инструкция более специфична для вашей цели.
Как найти ошибки в файле robots.txt в Google Search Console?
Посетите отчет о покрытии в Google Search Console, чтобы найти ошибки или заблокированные страницы, которые в настоящее время проиндексированы. Страницы с ошибками будут находиться в статусе «Исключено» по адресу «Заблокировано robots.txt». Вы должны посмотреть здесь, чтобы увидеть, не были ли какие-либо страницы непреднамеренно заблокированы.
Вы по-прежнему найдете «Проиндексировано, но заблокировано robots.txt» в статусе «Действительно с предупреждением». Это потенциально страницы, которые вы не хотите индексировать в Google. Решение состоит в том, чтобы разрешить сканирование страниц и использовать тег noindex. Чтобы исправить это решение быстрее, вручную попросите Google просканировать страницу после добавления на нее тега noindex.
Shopify Robots.
 txt: как его редактировать (и зачем!)
txt: как его редактировать (и зачем!){{ebook-chapter}}
После долгих лет ожидания мы наконец-то можем редактировать файл Robots.txt в наших магазинах Shopify (как стандартных, так и Shopify Plus).
Вот как его редактировать, когда его следует настраивать и чем это полезно для поисковой оптимизации.
{{potential-cta}}
Что такое Robots.txt?
Robots.txt — это файл, содержащий правила доступа роботов/краулеров к вашему сайту. Примером правила может быть «запретить», когда вы устанавливаете конкретный каталог или URL-адрес как запрещенный, чтобы указать, что все роботы не имеют доступа к нему.
Этот файл всегда находится по адресу:yourwebsite.com/robots.txt
Наличие правил в файле Robots.txt не обязательно «заставляет» ботов их соблюдать, но большинство хороших ботов, включая googlebot, ahrefsbot, bingbot, duckduckbot и т. д., проверяют этот файл перед сканированием.
д., проверяют этот файл перед сканированием.
Как редактировать Robots.txt в Shopify
- Откройте панель инструментов Shopify
- Перейти в интернет-магазин > Темы
- В разделе Живая тема нажмите Действия > Код редактирования
- В разделе шаблоны нажмите «Добавить новый шаблон» 9003 4
- Изменить «Создать новый шаблон для» на
Robots.txt - Нажмите «Создать шаблон»
Будет создан Robots.tx t.liquid со следующим кодом:
Этот файл шаблона напрямую изменяет файл Robots.txt, а этот код по умолчанию добавляет все стандартные правила, которые Shopify использует по умолчанию.
Примечание: Я настоятельно рекомендую не удалять эти правила, большинство из них хорошо оптимизированы Shopify
Теперь у нас есть файл, мы можем настроить его по своему усмотрению.
Настройка Robots.txt.liquid
Есть 3 настройки, которые мы можем внести в этот файл:
- Добавить новое правило в существующую группу
- Удалить правило из существующей группы
- Добавить пользовательские правила
Группа относится к набору правил для определенных поисковых роботов.
Добавить новое правило в существующую группу
Вот файл, измененный для включения нескольких правил по умолчанию, которые мы обычно используем для клиентов:
Этот код говорит, что если user_agent (имя робота) равно *, что применяется ко всем роботам, то запрещается следующее:
-
/collections/all— блокирует коллекцию по умолчанию, содержащую список всех товаров. -
/collections/vendors*?*q=— это заблокирует обход коллекций поставщиков по умолчанию -
/collections/types*?*q=— это заблокирует сканирование коллекций типов по умолчанию -
/collections/*?*constraint*– это заблокирует другой параметр для поставщиков и типов -
/collections/*/*– это заблокирует сканирование тегов продуктов 6 ( ПРИМЕЧАНИЕ: будьте осторожны с этим, это может помешать сканированию продуктов, даже если вы не настроите внутренние ссылки ) -
/collections/*?*filter*— блокирует сканирование общих параметров фильтра -
/collections/*?*pf_*— блокирует сканирование общего параметра фильтра -
/collections/*?*view*— блокирует параметр для изменения количества отображаемых продуктов. 0035 -
/collections/?page=*— это заблокирует сканирование пагинации коллекции по умолчанию. -
/blogs/*/tagged— это заблокирует сканирование тегов блога./collections/anything?constraint=anythingбудет заблокирован.Удаление правила по умолчанию из существующей группы
Хотя это и не рекомендуется, при необходимости правила по умолчанию можно удалить из файла
Robots.txt.Вот стандартный Shopify
Robots.txtи правила для справки:Допустим, мы хотим удалить правило, блокирующее
/policies/, вот пример кода для этого: не показывать это. Или, точнее, показать все правила, кроме этого.Добавить пользовательские правила
Если вы хотите применить правила, которые не применяются к группе по умолчанию (*, adsbot-google, Nutch, AhrefsBot, AhrefsSiteAudit, MJ12bot и Pinterest), вы можете добавить их в конец файла шаблона.
Например, если вы хотите заблокировать WayBackMachine, вы можете добавить следующее:
Или, если вы хотите добавить дополнительную карту сайта, вы можете добавить это:
{{potential-cta}}
Как узнать, работает ли мой файл Robots.txt?
Может быть трудно определить, правильно ли настроен файл Robots.txt и разрешено ли поисковым системам сканировать ваш сайт.
С помощью нашего инструмента тестирования Robots.txt вы можете легко протестировать конкретный URL-адрес с помощью пользовательского агента, чтобы узнать, доступен ли он для сканирования или заблокирован Robots.txt. Если вы тестируете магазин Shopify, мы также порекомендуем правила, основанные на наших рекомендациях выше.
Зачем настраивать Robots.txt?
Если вы не оптимизатор, вам может быть интересно, почему это вообще имеет значение. Позволь мне объяснить.
Это сводится к обоим:
- Бюджет сканирования
- Тонкий контент
Бюджет сканирования
Существует техническая концепция SEO, известная как Бюджет сканирования , это термин, описывающий объем поиска ресурсов двигатели выделяют для сканирования каждого веб-сайта.
Короче говоря:
Поисковые системы не могут регулярно сканировать каждую страницу всего Интернета (их слишком много!). Поэтому они используют алгоритмы, чтобы решить, сколько ресурсов выделить каждому веб-сайту.
Если вашему веб-сайту требуется больше ресурсов, чем ему выделено, тогда страницы будут регулярно пропускать сканирование .
Для SEO вы хотите, чтобы поисковые системы, такие как Google, регулярно сканировали ваш сайт, чтобы отслеживать ваши улучшения. Если они не сканируют эти страницы, они понятия не имеют, как они изменились или улучшились, поэтому вы не увидите никаких улучшений рейтинга.
Это имеет значение, когда страницы низкого качества сканируются, а важные игнорируются.
Таким образом, когда SEO-специалисты обсуждают «кроулинг-бюджет», они имеют в виду, как лучше всего использовать краулинг-бюджет, который у нас есть.
Используя
Robots.txt, мы можем специально заблокировать ботов от сканирования определенных страниц или каталогов, что сокращает потраченный впустую бюджет сканирования. До этого единственным решением, которое у нас было, была настройка страниц на
noindex, что помогает для тонкого контента (следующий раздел) , но по-прежнему требует, чтобы роботы сканировали страницы.Тонкий контент
Тонкий контент — это термин SEO, относящийся к контенту, который не добавляет никакой ценности для пользователей поисковых систем.
Если вы перейдете на
YOURSTORE.COM/collections/vendors?q=BRAND, вы увидите страницу по умолчанию, созданную для всех поставщиков, которых вы установили на панели управления Shopify.На этой странице нет ни содержания, ни описания, и ее нельзя каким-либо образом настроить. Не говоря уже об уродливом URL.
Мы бы назвали это «тонким контентом», вряд ли он будет занимать какое-либо место в Google со всеми этими недостатками.
Лучшим решением было бы удалить или заблокировать эту страницу, а затем вручную создать новую коллекцию Shopify для этого поставщика/торговой марки, которую можно полностью настроить.
Прежде чем мы смогли отредактировать
Robots.txt, нашим единственным решением было установить для этих страниц значениеnoindex, follow. По сути, просите поисковые системы переходить по ссылкам на этой странице, но не добавляйте эту страницу в результаты своих поисковых систем.Этот работал , но это все равно приводило к потенциальному сканированию сотен страниц в первую очередь.
Теперь мы можем полностью запретить их сканирование, что уменьшит объем некачественного контента и сэкономит бюджет сканирования.
Заключение
Надеюсь, последний раздел никого не потерял, это может стать довольно техническим.
Shopify, наконец, доверяет нам редактировать наш собственный файл
Robots.txt— это огромное обновление для магазинов Shopify, однако я призываю к осторожности тех, кто не занимается SEO и не является разработчиком, делая это.Вполне возможно заблокировать весь ваш веб-сайт и создать серьезные проблемы с этой функциональностью.
 0035
0035