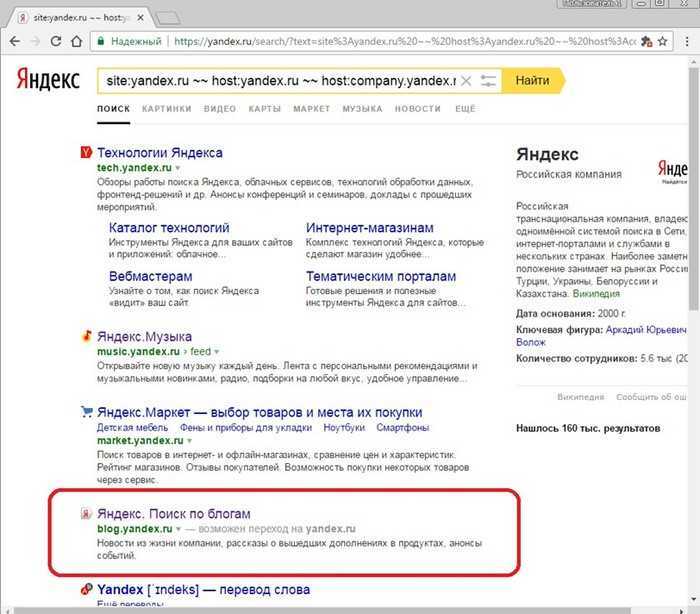
Поисковый алгоритм Королев — новый алгоритм Яндекса
Сегодня был запущен новый алгоритм поиска в Яндексе, который с помощью нейронной сети сопоставляет смысл запросов и вебстраниц — это позволяет Яндексу точнее отвечать на сложные пользовательские запросы и выдавать более релевантные результаты. Как мы писали ранее — алгоритм базируется на категорийном бустинге: то есть способен учитывать так называемые категориальные признаки — признаки, которые принимают одно из конечного количества значений.
Запуск нового алгоритма «Королев»
Презентация нового алгоритма поиска проводилась в Московском планетарии, что как бы намекает на «изменения космического масштаба». Ведущие презентации прямо на сцене нажали на «красную кнопку», ознаменовав тем самым запуск нового алгоритма, название которого — «Королев».
Искусственный интеллект все ближе к человеку
Первый шаг к поиску по смыслу Яндекс сделал в прошлом году, когда был представлен поисковый алгоритм «Палех». В его основе лежит нейронная сеть. Нейросети показывают отличные результаты в задачах, с которыми люди традиционно справлялись лучше машин: скажем, распознавание речи или объектов на изображениях.
В его основе лежит нейронная сеть. Нейросети показывают отличные результаты в задачах, с которыми люди традиционно справлялись лучше машин: скажем, распознавание речи или объектов на изображениях.
Запуская «Палех», Яндекс научил нейронную сеть преобразовывать поисковые запросы и заголовки веб-страниц в группы чисел — семантические векторы. Важное свойство таких векторов состоит в том, что их можно сравнивать друг с другом: чем сильнее будет сходство, тем ближе друг к другу по смыслу запрос и заголовок.
Как работает новый алгоритм «Королёв»
Поисковый алгоритм «Королёв» сравнивает семантические векторы поисковых запросов и веб-страниц целиком — а не только их заголовков. Как и в случае с «Палехом», тексты веб-страниц в семантические векторы преобразует нейросеть. «Королёв» высчитывает векторы страниц не в режиме реального времени, а заранее, на этапе индексирования. Когда вы задаете запрос, алгоритм сравнивает вектор запроса с уже известными ему векторами страниц.
Данная схема позволяет начать подбор документов, соответствующих запросу по смыслу, еще на ранних стадиях ранжирования. В алгоритме «Палех» смысловой анализ — один из завершающих этапов, через который проходят всего 150 документов. В «Королёве» смысловой анализ производится для 200 тысяч документов — в тысячу с лишним раз больше! При этом — «Королёв» не только сравнивает текст веб-страницы с запросом, но и обращает внимание на другие запросы, по которым пользователи переходят на страницу из поиска, что позволяет установить дополнительные смысловые связи между запросами и страницей.
Кто обучает нейронную сеть
Нейронная сеть алгоритма «Королёв» обучается на обезличенной поисковой статистике. Системы сбора статистики учитывают — на какие страницы пользователи переходят по различным запросам и сколько времени проводят на них. Если пользователь открыл веб-страницу и провел на ней много времени — можно предположить, что он получил ответ на свой вопрос — то есть страница хорошо отвечает на его запрос.
Чтобы поиск развивался, люди должны постоянно давать оценку его работе. Еще не так давно оценкой поиска занимались только сотрудники Яндекса — асессоры. Но с развитием технологий и проектов — количества асессоров стало катастрофически нехватать. Поэтому Яндекс решил привлечь к этому всех желающих и запустил сервис Яндекс.Толока.
Сейчас в сервисе зарегистрировано более миллиона пользователей: они анализируют качество поиска и участвуют в улучшении других сервисов Яндекса. За два с лишним года существования сервиса толокеры дали около двух миллиардов оценок.
В основе современного поиска лежат очень сложные алгоритмы, которые придумывают разработчики, а учат их — миллионы пользователей Яндекса. Любой запрос — это анонимный сигнал, который помогает машине всё лучше понимать людей.
Как Яндекс отправил котов в космос — смотрите в записи презентации из Московского планетария.
Запись презентации Янедкса
 com/embed/7rCKBf2dBwc» frameborder=»0″ allowfullscreen=»»>
com/embed/7rCKBf2dBwc» frameborder=»0″ allowfullscreen=»»> Сравниваем выдачу: Яндекс vs Google
Яндекс – безоговорочный лидер по аудитории стационарных компьютеров, то Google – захватил львиную долю мобильной аудитории (по данные TNS). В феврале 2015 года мобильными сервисами Google воспользовались 13,5 млн. человек. Как отмечают представители компании, росту популярности Google помогают голосовой поиск и голосовые команды. Но основная причина успеха обусловлена предустановленными приложениями Google на мобильных устройствах Android. В сентябре этого года ФАС уже признал, что подобные действия Google нарушают закон о конкуренции. Посмотрим, повлияет ли это на дальнейший рост популярности Google, или Яндекс найдет иные способы (кроме судебных) заполучить мобильную аудиторию. Мы же в нашей статье сравним качество поиска Яндекс и Google со стационарного ПК.
Интерфейс поиска
Начнем мы свое сравнение с внешнего вида страницы поиска.
Яндекс уже на главной странице довольно навязчиво предлагает свои сервисы, обильно сдобрив их рекламой. Возможно, это особенность российских компаний, так как поиск Mail и Rambler имеют аналогичный вид.
Кому-то наоборот кажется удобным возможность уже на стартовой странице узнать свежие новости, прогноз погоды, загруженность дорог и пр.
Функционал
По функционалу оба поисковика предлагают примерно одинаковый набор инструментов: поиск по картам, видео, новостям, картинкам и прочему, есть фильтр расширенного поиска с более тонкой настройкой. На мой взгляд, у Яндекса более понятный и визуально приятный интерфейс.
У Google, в отличие от Яндекса, есть голосовой поиск не только на мобильном, но и на стационарном ПК. Тут же на странице поиска Google можно отключить персональный результат (с учетом истории предыдущего поиска для зарегистрированных пользователей), в Яндексе эта функция отключается в настройках, что потребует больше времени и усилий.
Тут же на странице поиска Google можно отключить персональный результат (с учетом истории предыдущего поиска для зарегистрированных пользователей), в Яндексе эта функция отключается в настройках, что потребует больше времени и усилий.
Реклама в Яндекс и Google
В Google больше рекламы. В зависимости от запроса она занимает не только первые три позиции, но и всю правую колонку, включая как текстовые объявления, так и баннеры.
В Яндексе реклама сосредоточена в поисковой выдаче и занимает три первых и последних места на странице, а также располагается справа в виде медийно-контекстного баннера.
Механизм поиска
Сегодня механизм поиска довольно сложный, и позволяет за считанные секунды определять, что именно ищет пользователь, и находить наиболее релевантный ответ. Для этого поисковые системы все время совершенствуют свои алгоритмы поиска.
Для этого поисковые системы все время совершенствуют свои алгоритмы поиска.
Сравним механизм работы двух систем. Мощности Google достаточно, чтобы индексировать сайты практически в режиме реального времени. Именно поэтому апдейты выдачи Google происходят ежедневно. Для пользователей это означает, что Google способен предоставлять самую актуальную информацию.
Например, по запросу «турция» (так как сейчас это самая горячая новостная тема в связи со сбитым российским истребителем) Google на первых строках выдает текущие новости по ситуации с Турцией.
В Яндексе по аналогичному запросу новости появляются только ближе к середине страницы выдачи.
Google лучше Яндекса подходит для поиска на других языках, так как является международным продуктом и работает по всему миру. Но тут есть и обратная сторона, отечественный Яндекс выдает гораздо более качественный результат по региональному запросу.
Мощностей серверов Яндекса не достаточно для моментальной обработки данных, поэтому большая часть поисковых запросов кэшируется, и пользователь получает заранее заготовленную страницу выдачи. Такая технология позволяет быстро и качественно формировать выдачу на запрос пользователя, только ответ этот будет не всегда актуальным. Периодичность, с которой боты Яндекса обходят сайты, зависит от их тематики, и для некоторых ресурсов может составлять несколько дней и более. Для новостных и информационных порталов, социальных сетей, twitter используются специальные быстророботы, которые индексируют сайты каждый час. Метод кеширования страниц позволяет получать более качественные сайты в выдаче. Но с введением «Минусинска» выдача по некоторым запросам начала обновляться практически ежедневно и ее качество ухудшилось.
Качество поиска
Приступаем к самому важному пункту сравнения – качеству поиска. Основным показателем качества является удовлетворенность пользователя, то есть получил ли он ответ на свой вопрос, и как быстро. Для этого сравним выдачу по трем запросам разного типа: информационному, коммерческому и региональному.
Для этого сравним выдачу по трем запросам разного типа: информационному, коммерческому и региональному.
1. Начнем с коммерческого запроса «купить apple iphone 6».
Пользователь хочет приобрести определенную модель телефона и ищет подходящий магазин.
Вот так выглядит выдача поисковиков
ТОП | Яндекс | |
| 1 | Страница Apple iPhone 6 16Gb на Яндекс.Маркете https://market.yandex.ru/product/11031621?clid=703 | Сайт официального производителя Apple http://www.apple.com/ru/shop/buy-iphone/iphone |
| 2 | Страница Apple iPhone 6 64Gb на Яндекс.Маркете https://market.yandex.ru/product/11031663?clid=703 | Страница Apple iPhone 6 64Gb на Яндекс.Маркете https://market.yandex.ru/product/11031663 |
| 3 | Посадочная страница интернет-магазина Apple4G https://apple-4g. ru/iphone/6/ ru/iphone/6/ | Страница Apple iPhone 6 16Gb на Яндекс.Маркете https://market.yandex.ru/product/11031621 |
| 4 | Посадочная страница интернет-магазина Luck-shop.ru http://luck—shop.ru/catalog/apple-iphone-6s- | Раздел каталога товаров с iPhone 6 «В Связном» http://www.svyaznoy.ru/catalog/phone/225/apple/iphone-6 |
| 5 | Страница товара интернет-магазина Apple-ru http://apple—ru.ru/catalogue/phones/iphone/apple-iphone-6/apple-iphone-6-64gb-space-grey/ | Раздел каталога товаров с iPhone 6 в Re-store http://www.re-store.ru/apple-iphone/iphone-6/ |
Выдача Google выглядит более качественной, так как предлагает пользователю официальные магазины данного продукта. Сниппеты также более информативные, в них представлена цена, есть возможность перейти сразу на страницу с конкретной моделью.
В выдаче Яндексе на первой странице нет сайта производителя, как и официальных дилеров бренда.
Вывод: Выдача в обоих поисковиках пересекается по двум ссылкам на Яндекс.Маркет,
в остальном более качественные и надежные интернет-магазины были предложены Google.
2. Информационной запрос «Севилья»
Google сразу дает понять, что знает по этому запросу больше Яндекса (8,6 млн ответов, против 4 млн в Яндексе). Проверим, насколько эта информация более ценная для пользователя. Ведь по запросу не понятно, что именно мы ищем. Это может быть испанский город, его достопримечательности, одноименный футбольный клуб и т.д.
Сравним выдачу.
| ТОП | Яндекс | |
| 1 | Ссылка на Википедию. | Ссылка на Википедию. |
| 2 | Русскоязычный сайт футбольного клуба «Севилья» http://sevillafc.ru/. | Путеводитель по Севилье на сайте «Тонкости туризма».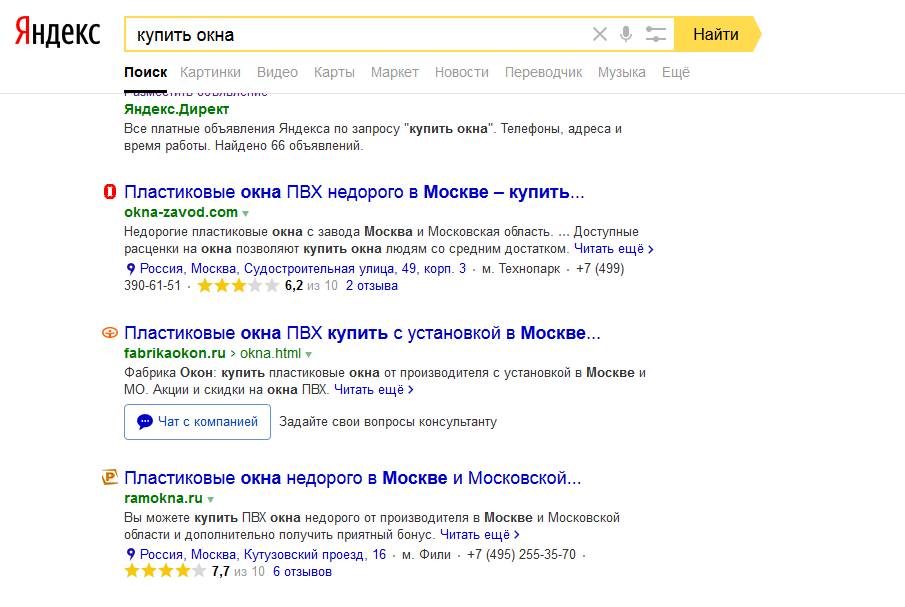 |
| 3 | Путеводитель по Испании. | Новости футбольного клуба «Севилья» на Sports. |
| 4 | Путеводитель по Севилье. | Турнирная таблица футбольного клуба (Украинский домен). |
| 5 | Новости футбольного клуба «Севилья» в спортивном издании Sports. | Сайт об Испании. |
И снова одно совпадение – оба ресурса поставили на первое место ссылку на Википедию. Дальше есть пересечение по ссылке на спортивное издание Sports.
Выдача Яндекса по информационному запросу выглядит иначе, чем по коммерческому. Меньше рекламы (в основном в низу страницы), есть подборка WikiData с кратким описанием города, в выдаче есть ссылки на карты, подборку картинок и видео.
Вывод: Google не до конца понимает, что именно мы искали, и на всякий случай дает равнозначную выдачу и по городу, и по ФК. Яндекс более уверен, что речь идет именно о городе, поэтому в основном предлагает путеводители, отели и прочую информацию для туристов.
Яндекс более уверен, что речь идет именно о городе, поэтому в основном предлагает путеводители, отели и прочую информацию для туристов.
3. Региональный запрос «доставка воды в Красноярске»
Яндекс нашел 5 млн. запросов, в то время в Google по данному запросу всего 338 тыс. страниц.
Выводы: Оба поисковика предлагают примерно одинаковую выдачу по данному запросу. Но Яндекс предлагает более информативные сниппеты, а в Google есть наглядная карта со всей контактной информацией по каждой компании.
Проанализировав выдачу обоих поисковых систем, становится понятно, что они отличаются друг от друга. И речь идет не только об особенностях ранжирования сайтов, но и о предоставлении информации и взаимодействии с пользователем. Складывается впечатление, что сейчас из-за частой ротации в выдаче Яндекса, Google выглядит более качественным ресурсом. И, тем не менее, каждый ресурс подходит под решение определенных задач, Google – для поиска актуальной информации, а также запросов на других языках, Яндекс неплохо справляется с региональным поиском товаров и услуг.
А вы какой поиск предпочитаете?
Яндекс запускает персонализированный поиск в реальном времени
Иммануэль Симонсен 30 мая 2013 г.
Сегодня Яндекс объявил об итерации своих результатов персонализированного поиска, в которых лидер российского поиска добавляет новое измерение в режиме реального времени к функциям персонализации, запущенным в декабре 2012 года. в среднесрочной и долгосрочной перспективе, а затем «перетасовывать» результаты, чтобы они соответствовали более постоянным интересам данного пользователя.
Однако до сих пор, если пользователь выполнял поиск о чем-то, что он никогда не искал в прошлом, Яндекс отключал персонализацию из-за отсутствия данных. Но сейчас это меняется.
С сегодняшнего дня Яндекс начнет анализировать поисковые сессии в режиме реального времени и мгновенно реагировать на запросы по мере их возникновения. Согласно данным comScore Media Metrix, эта итерация затронет всех ее 93 млн пользователей в месяц и, по сути, позволит российскому поисковому лидеру предоставлять персонализированные результаты поиска даже для пользователей, у которых нет предыдущей истории поиска.
По данным Яндекса, более половины всех поисковых запросов на его платформах связаны с чем-то, что интересует пользователя в данный момент и перестает интересовать его через мгновение.
Личные интересы не могут ограничиваться несколькими ключевыми темами. Наряду с более или менее устойчивыми интересами существуют преходящие, сиюминутные. Они приходят и уходят. Они не длятся дольше 24 часов. Более половины всех интересов недолговечны.
Полагаясь только на среднесрочный и долгосрочный интерес, пользователь, проявляющий большой интерес к книгам, например, будет постоянно видеть «Великий Гэтсби» Фитцджеральда в верхней части результатов поиска при вводе «великого». Но что, если бы тот же пользователь только что искал «списки фильмов», а затем через мгновение ввел «великие»? Не будет ли более вероятным, что он/она, несмотря на то, что в целом отдает предпочтение книгам, а не фильмам, на самом деле ищет недавнюю голливудскую интерпретацию бестселлера Фитцджеральда «19». 25 роман? Как показано на рисунке ниже, новая функция позволяет Яндексу учитывать этот элемент давности и соответствующим образом корректировать результаты.
25 роман? Как показано на рисунке ниже, новая функция позволяет Яндексу учитывать этот элемент давности и соответствующим образом корректировать результаты.
Работает ли он точно так же, как «предыдущий запрос» Google?
Google персонализирует результаты поиска на основе предыдущего запроса пользователя с 2008 года, хотя это происходит лишь для очень небольшой доли от общего числа запросов (0,3 %, по словам Мэтта Каттса из Google). Яндекс тоже использовал один предыдущий запрос, чтобы повлиять на следующий результат — правда, с 2010 года.
Однако с сегодняшним шагом ведущий российский поисковик, похоже, делает еще один шаг вперед, уделяя гораздо больше внимания краткосрочным намерениям пользователей. С момента вступления в силу в декабре персонализации поиска Яндекс персонализировал около 60% запросов для 30% своей пользовательской базы. Эти «относительно» низкие цифры связаны с тем, что персонализация (когда полагаешься только на среднесрочную/долгосрочную историю поиска) сработает только для пользователей, которые предоставили достаточно информации, чтобы обоснованно определить свои более глубоко укоренившиеся интересы. Теперь, когда к уравнению добавлен фактор давности, Яндекс рассчитывает персонализировать результаты для 85% запросов для ВСЕХ своих пользователей, сообщил нам представитель компании.
Теперь, когда к уравнению добавлен фактор давности, Яндекс рассчитывает персонализировать результаты для 85% запросов для ВСЕХ своих пользователей, сообщил нам представитель компании.
Кроме того, хотя поисковая команда Яндекса не хочет раскрывать точное количество действий, подсчитанных в рамках данной поисковой сессии, компания заявляет, что будет хранить поисковую сессию в течение двух часов. Например, если вы часто совершаете покупки в Интернете и недавно набрали «путешествие в Бразилию», а затем ввели поиск «Амазонка», вполне вероятно, что, скажем, статья в Википедии о реке Амазонка превзойдет популярную в Интернете статью. одноименный торговый сайт. Однако если вы прервете сеанс поиска и через три часа вернетесь к Яндексу и снова наберете Amazon, позиции, скорее всего, изменятся.
Сосредоточение внимания на неотложных потребностях особенно имеет смысл в эпоху мобильных устройств
Хотя у меня еще не было возможности поиграть с этим, имеет смысл придавать большее значение непосредственным намерениям. Я считаю, что одной из причин этого является непрерывный переход от настольных компьютеров к мобильным. В этом отношении мобильные поиски имеют тенденцию быть значительно более ориентированными на решение/цель и менее информативными. Находясь в дороге, вы чаще всего ищете решения конкретной проблемы, с которой столкнулись прямо здесь и сейчас (которая вполне может быть изолирована от ваших постоянных интересов). Google, кстати, проделывает потрясающую работу с «Google Now», который проактивно обслуживает карточки с релевантной контекстной информацией, и вам даже не нужно ее явно искать.
Я считаю, что одной из причин этого является непрерывный переход от настольных компьютеров к мобильным. В этом отношении мобильные поиски имеют тенденцию быть значительно более ориентированными на решение/цель и менее информативными. Находясь в дороге, вы чаще всего ищете решения конкретной проблемы, с которой столкнулись прямо здесь и сейчас (которая вполне может быть изолирована от ваших постоянных интересов). Google, кстати, проделывает потрясающую работу с «Google Now», который проактивно обслуживает карточки с релевантной контекстной информацией, и вам даже не нужно ее явно искать.
Кроме того, поисковые запросы на мобильных устройствах обычно короче из соображений удобства использования. Так что, если вам действительно приходится самостоятельно вводить запрос (обратите внимание на небольшую иронию), возможно, более вероятно, что вы будете вводить «великий Гэтсби» или «списки фильмов» в качестве отдельных запросов, чем «великий фильм Гэтсби». списки» все в одном.
Хорошее дополнение, которое поможет не быть «запертым» в собственных интересах
Когда Яндекс впервые объявил о персонализации поиска на конференции в Москве, заместитель технического директора компании Григорий Бакунов сказал, что Яндекс получил очень обнадеживающие результаты от соответствующий уровень персонализации, например, повышение CTR на 37 % в персонализированном топ-результате. Я выделил «соответствующие», потому что собственное исследование Яндекса показало, что пользователи считают полностью персонализированные результаты менее релевантными. Пользователи просто не хотели замыкаться в своих интересах. И сегодняшнее объявление об измерении в реальном времени поможет избежать этого.
Я выделил «соответствующие», потому что собственное исследование Яндекса показало, что пользователи считают полностью персонализированные результаты менее релевантными. Пользователи просто не хотели замыкаться в своих интересах. И сегодняшнее объявление об измерении в реальном времени поможет избежать этого.
Дополнительную информацию о новой функции персонализации можно найти здесь или посмотреть в этом видео. Или, в качестве альтернативы, если вы хотите узнать об эволюции персонализированного поиска и о том, куда он движется, я сделал довольно длинную статью после объявления Яндекса еще в декабре.
Следующие две вкладки изменяют содержимое ниже.
- Биография
- Последние сообщения
Как менеджер по исследованиям многоязычного агентства веб-маркетинга Webcertain, Иммануэль возглавляет деятельность компании по исследованию глобального рынка и крупным проектам контент-маркетинга. Он является автором нескольких отчетов и руководств, в том числе «The Essential Guide to Rel-Alternate-Hreflang» и «The Webcertain Global Search and Social Report 2013». Помимо того, что он является преподавателем в Международной школе маркетинга, которая обучает профессионалов онлайн-маркетинга бизнес-возможностям по всему миру, Иммануэль регулярно выступает на International Search Summit, ведущей серии мероприятий, посвященных многоязычному поиску и маркетингу в социальных сетях.
Помимо того, что он является преподавателем в Международной школе маркетинга, которая обучает профессионалов онлайн-маркетинга бизнес-возможностям по всему миру, Иммануэль регулярно выступает на International Search Summit, ведущей серии мероприятий, посвященных многоязычному поиску и маркетингу в социальных сетях.
Эволюция структур данных в Яндекс.Метрике
Яндекс.Метрика принимает поток данных о событиях, которые произошли на сайтах или в приложениях. Наша задача сохранить эти данные и представить их в анализируемом виде. Настоящая проблема заключается в том, чтобы попытаться определить, в какой форме следует сохранять обработанные результаты, чтобы с ними было легко работать. В процессе разработки нам несколько раз приходилось полностью менять подход к организации хранения данных. Мы начали с таблиц MyISAM, затем использовали LSM-деревья и, в конце концов, придумали столбцовую базу данных ClickHouse.
Метрика создавалась как ответвление сервиса поисковых объявлений Яндекс. Директа. Таблицы MySQL с движком MyISAM использовались в Директе для хранения статистики, и было естественно использовать такой же подход в Метрике. Изначально в Яндекс.Метрике для сайтов было более 40 «фиксированных» типов отчетов (например, отчет по географии посетителей), несколько инструментов внутристраничной аналитики (например, карты кликов), Вебвизор (инструмент для детального изучения действий отдельных пользователей), а также отдельный конструктор отчетов. Но со временем, чтобы не отставать от бизнес-целей, система должна была стать более гибкой и предоставлять больше возможностей для настройки для клиентов. В настоящее время Метрика вместо использования фиксированных отчетов позволяет свободно добавлять новые параметры (например, в отчете по ключевым словам можно дополнительно разбить данные по целевым страницам), сегментировать и сравнивать (между, скажем, источниками трафика для всех посетителей и посетителей из Москва), изменить набор метрик и т. д. Эти функции потребовали совершенно другого подхода к хранению данных, чем тот, который мы использовали с MyISAM, мы далее обсудим этот переход с технической точки зрения.
Директа. Таблицы MySQL с движком MyISAM использовались в Директе для хранения статистики, и было естественно использовать такой же подход в Метрике. Изначально в Яндекс.Метрике для сайтов было более 40 «фиксированных» типов отчетов (например, отчет по географии посетителей), несколько инструментов внутристраничной аналитики (например, карты кликов), Вебвизор (инструмент для детального изучения действий отдельных пользователей), а также отдельный конструктор отчетов. Но со временем, чтобы не отставать от бизнес-целей, система должна была стать более гибкой и предоставлять больше возможностей для настройки для клиентов. В настоящее время Метрика вместо использования фиксированных отчетов позволяет свободно добавлять новые параметры (например, в отчете по ключевым словам можно дополнительно разбить данные по целевым страницам), сегментировать и сравнивать (между, скажем, источниками трафика для всех посетителей и посетителей из Москва), изменить набор метрик и т. д. Эти функции потребовали совершенно другого подхода к хранению данных, чем тот, который мы использовали с MyISAM, мы далее обсудим этот переход с технической точки зрения.
MyISAM
Большинство запросов SELECT, извлекающих данные для отчетов, выполняются с условиями, ГДЕ CounterID = AND Date МЕЖДУ min_date И max_date. Иногда также есть фильтр по региону, поэтому имело смысл использовать сложный первичный ключ, чтобы превратить его в прочитанный диапазон первичного ключа. Итак, схема таблицы для Метрики выглядит так: CounterID, Date, RegionID -> Visits, SumVisitTime и т. д. Теперь посмотрим, что происходит, когда он приходит.
Таблица MyISAM состоит из файла данных и индексный файл. Если из таблицы ничего не удалялось и строки при обновлении не менялись по длине, то файл данных будет состоять из сериализованных строк, расположенных последовательно в том порядке, в котором они были добавлены. Индекс (включая первичный ключ) представляет собой B-дерево, листья которого содержат смещения в файле данных. Когда мы читаем данные диапазона индекса, многие смещения в файле данных берутся из индекса. Затем выполняется чтение для этого набора смещений в файле данных.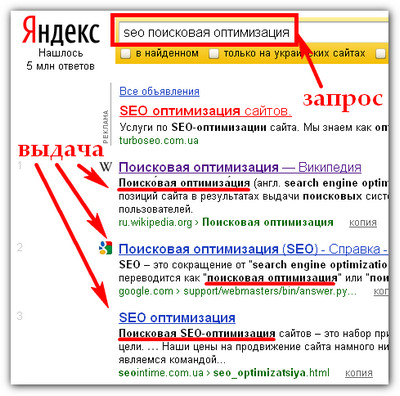
Рассмотрим реальную ситуацию, когда индекс находится в оперативной памяти (кэш ключей в MySQL или системный кеш страниц), но данные таблицы не кэшируются. Предположим, что мы используем жесткие диски. Время, необходимое для чтения данных, зависит от объема данных, которые необходимо прочитать, и от того, сколько операций Seek необходимо выполнить. Количество операций поиска определяется расположением данных на диске.
Местоположение данных показано:
События Метрики поступают практически в том же порядке, в котором они происходили на самом деле. В этом входящем потоке данные с разных счетчиков разбросаны совершенно хаотично. Другими словами, входящие данные являются локальными по времени, но не локальными по CounterID. При записи в таблицу MyISAM данные с разных счетчиков также размещаются довольно хаотично. Это означает, что для чтения отчета с данными вам потребуется выполнить примерно столько случайных чтений, сколько строк в таблице нам нужно.
Типичный жесткий диск со скоростью вращения 7200 об/мин может выполнять от 100 до 200 случайных операций чтения в секунду. RAID, при правильном использовании, может обрабатывать ту же сумму, умноженную на количество дисков в нем. Один пятилетний SSD может выполнять 30 000 случайных операций чтения в секунду, но мы не можем позволить себе хранить наши данные на SSD. Так что в этом случае, если бы нам нужно было прочитать 10 000 строк для отчета, это заняло бы более 10 секунд, что было бы совершенно неприемлемо.
RAID, при правильном использовании, может обрабатывать ту же сумму, умноженную на количество дисков в нем. Один пятилетний SSD может выполнять 30 000 случайных операций чтения в секунду, но мы не можем позволить себе хранить наши данные на SSD. Так что в этом случае, если бы нам нужно было прочитать 10 000 строк для отчета, это заняло бы более 10 секунд, что было бы совершенно неприемлемо.
InnoDB намного лучше подходит для чтения диапазонов первичных ключей, поскольку использует кластеризованный первичный ключ (т. е. данные хранятся упорядоченным образом в первичном ключе). Но InnoDB было невозможно использовать из-за низкой скорости записи. Если это напоминает вам о TokuDB, то читайте дальше.
Чтобы Яндекс.Метрика работала на MyISAM, потребовалось много уловок, таких как сортировка периодических таблиц, сложные схемы ручного разделения и хранение данных в поколениях. У этого подхода также было много операционных недостатков, например медленная репликация, непротиворечивость, ненадежное восстановление и т..png) д. Тем не менее, по состоянию на 2011 год мы хранили более 580 миллиардов строк в таблицах MyISAM.
д. Тем не менее, по состоянию на 2011 год мы хранили более 580 миллиардов строк в таблицах MyISAM.
Metrage и OLAPServer
Metrage — это реализация LSM Tree, довольно распространенной структуры данных, которая хорошо работает для рабочих нагрузок с интенсивным потоком записей и в основном чтением первичного ключа, как в Яндекс.Метрике. В 2010 году LevelDB не существовало, а TokuDB в то время была собственностью.
В Metrage произвольные структуры данных (зафиксированные во время компиляции) могут использоваться как «строки». Каждая строка представляет собой пару ключ-значение. Ключ — это структура с операциями сравнения на равенство и неравенство. Значение представляет собой произвольную структуру с операциями обновления (добавления чего-либо) и слияния (агрегирования или объединения с другим значением). Короче говоря, это CRDT. Данные расположены довольно локально на жестком диске, поэтому чтение диапазона первичного ключа выполняется быстро. Блоки данных эффективно сжимаются даже при использовании быстрых алгоритмов из-за упорядоченности (в 2010 году мы использовали QuickLZ, с 2011 года — LZ4). Систематическое хранение данных позволяет нам использовать разреженный индекс.
Систематическое хранение данных позволяет нам использовать разреженный индекс.
Поскольку чтение выполняется не очень часто (даже несмотря на то, что при этом считывается много строк), увеличение задержки из-за большого количества фрагментов и распаковки блока данных не имеет значения. Чтение дополнительных строк из-за разреженности индекса также не имеет значения.
После переноса отчетов из MyISAM в Metrage мы сразу увидели увеличение скорости интерфейса Метрики. Если раньше 90% отчетов о заголовках страниц загружались за 26 секунд, то с Metrage они загружались за 0,8 секунды (общее время, включая время на обработку всех запросов к базе данных и последующие преобразования данных). Время, затрачиваемое самим Метражем на обработку запросов (по всем отчетам), в процентном отношении выглядит следующим образом: среднее = 6 мс, 90tile = 31 мс, 99tile = 334 мс.
Мы используем Metrage уже пять лет, и это решение оказалось надежным. По состоянию на 2015 год мы хранили в Metrage 3,37 триллиона строк и использовали для этого 39 * 2 серверов.
Его преимущества заключались в простоте и эффективности, что делало его гораздо лучшим выбором для хранения данных, чем MyISAM. Хотя у системы все еще был один огромный недостаток: она действительно эффективно работает только с фиксированными отчетами. Metrage агрегирует данные и сохраняет агрегированные данные. Но для этого вы должны заранее перечислить все способы, которыми вы хотите агрегировать данные. То есть, если мы делаем это 40 разными способами, значит, Метрика будет содержать 40 типов отчетов и не более.
Чтобы смягчить это, нам пришлось какое-то время сохранять отдельное хранилище для мастера настраиваемых отчетов под названием OLAPServer. Это простая и очень ограниченная реализация столбцовой базы данных. Он поддерживает только один набор таблиц во время компиляции — таблицу сеансов. В отличие от Metrage, данные обновляются не в режиме реального времени, а несколько раз в день. Единственный поддерживаемый тип данных — это числа фиксированной длины от 1 до 8 байт, поэтому он не подходил для отчетов с другими видами данных, например URL-адресами.
ClickHouse
С помощью OLAPServer мы поняли, насколько хорошо СУБД, ориентированные на столбцы, справляются с задачами специальной аналитики с неагрегированными данными. Если вы можете получить любой отчет из неагрегированных данных, то возникает вопрос, нужно ли данные вообще агрегировать заранее, как мы сделали с Metrage.
С одной стороны, предварительное агрегирование данных может уменьшить объем данных, которые используются в момент загрузки страницы отчета. С другой стороны, однако, агрегированные данные не решают всего. Вот почему:
- вам нужно заранее иметь список отчетов, которые нужны вашим пользователям; другими словами, пользователь не может составить пользовательский отчет
- при агрегации большого количества ключей объем данных не уменьшается и агрегация бесполезна; когда отчетов много, слишком много вариантов агрегации (комбинаторный взрыв)
- при агрегировании ключей высокой мощности (например, URL) количество данных уменьшается ненамного (менее чем вдвое) за счет этого объем данных может не уменьшаться, а фактически расти при агрегации
- пользователи не будут просматривать все отчеты, которые мы для них рассчитываем (другими словами, многие расчеты оказываются бесполезными)
- трудно поддерживать логическую согласованность при хранении большого количества различных агрегатов
Как видите, если ничего не агрегировать и работать с неагрегированными данными, то возможно объем вычислений даже сократится. Но только работа с неагрегированными данными предъявляет очень высокие требования к эффективности системы, выполняющей запросы.
Но только работа с неагрегированными данными предъявляет очень высокие требования к эффективности системы, выполняющей запросы.
Значит, если мы агрегируем данные заранее, то делать это нужно постоянно (в реальном времени), но асинхронно по отношению к запросам пользователей. Мы действительно должны просто агрегировать данные в режиме реального времени; большая часть получаемого отчета должна состоять из подготовленных данных.
Если данные не агрегируются заранее, вся работа должна выполняться в момент запроса пользователем (т. е. в ожидании загрузки страницы отчета). Это означает, что в ответ на запрос пользователя необходимо обработать многие миллиарды строк; чем быстрее это можно сделать, тем лучше.
Для этого нужна хорошая столбцовая СУБД. На рынке не было колоночно-ориентированных СУБД, которые достаточно хорошо справлялись бы с задачами интернет-аналитики в масштабах Рунета (русского интернета) и не требовали бы запредельно дорогих лицензий.
В последнее время в качестве альтернативы коммерческим столбцовым СУБД стали появляться решения для эффективной оперативной аналитики данных в распределенных вычислительных системах: Cloudera Impala, Spark SQL, Presto и Apache Drill. Хотя такие системы могут эффективно работать с запросами для внутренних аналитических задач, их сложно представить в качестве бэкэнда для веб-интерфейса аналитической системы, доступного внешним пользователям.
Хотя такие системы могут эффективно работать с запросами для внутренних аналитических задач, их сложно представить в качестве бэкэнда для веб-интерфейса аналитической системы, доступного внешним пользователям.
В Яндексе мы разработали, а затем выложили в открытый доступ собственную колоночно-ориентированную СУБД — ClickHouse. Давайте рассмотрим основные требования, которые мы имели в виду, прежде чем приступить к разработке.
Возможность работы с большими наборами данных. В текущей Яндекс.Метрике для сайтов ClickHouse используется для хранения всех данных для отчетов. По состоянию на ноябрь 2016 года база данных состоит из 18,3 трлн строк. Он состоит из неагрегированных данных, которые используются для получения отчетов в режиме реального времени. Каждая строка в самой большой таблице содержит более 200 столбцов.
Система должна масштабироваться линейно. ClickHouse позволяет увеличивать размер кластера, добавляя новые серверы по мере необходимости. Например, основной кластер Яндекс.Метрики за три года увеличился с 60 до 426 серверов. В целях отказоустойчивости наши серверы разбросаны по разным дата-центрам. ClickHouse может использовать все аппаратные ресурсы для обработки одного запроса. Таким образом можно обрабатывать более 2 терабайт в секунду.
Например, основной кластер Яндекс.Метрики за три года увеличился с 60 до 426 серверов. В целях отказоустойчивости наши серверы разбросаны по разным дата-центрам. ClickHouse может использовать все аппаратные ресурсы для обработки одного запроса. Таким образом можно обрабатывать более 2 терабайт в секунду.
Высокая эффективность. Мы особенно гордимся высокой производительностью нашей базы данных. По результатам внутренних тестов ClickHouse обрабатывает запросы быстрее, чем любая другая система, которую мы могли бы приобрести. Например, ClickHouse работает в среднем в 2,8-3,4 раза быстрее, чем Vertica. В ClickHouse нет единственной серебряной пули, которая заставляет систему работать так быстро.
Функциональности должно быть достаточно для инструментов веб-аналитики. База данных поддерживает диалект языка SQL, подзапросы и JOIN (локальные и распределенные). Существует множество расширений SQL: функции для веб-аналитики, массивы и вложенные структуры данных, функции высшего порядка, агрегатные функции для приближенных вычислений с использованием скетчинга и т. д. Работая с ClickHouse, вы получаете удобство реляционной СУБД.
д. Работая с ClickHouse, вы получаете удобство реляционной СУБД.
ClickHouse изначально разрабатывался командой Яндекс.Метрики. Кроме того, нам удалось сделать систему достаточно гибкой и расширяемой, чтобы ее можно было успешно использовать для решения различных задач. Хотя база данных может работать на больших кластерах, ее можно установить на один сервер или даже на виртуальную машину. Сейчас в нашей компании более десятка различных приложений ClickHouse.
ClickHouse хорошо оснащен для создания всевозможных аналитических инструментов. Только подумайте: если система справится с задачами Яндекс.Метрики, можете быть уверены, что ClickHouse справится с остальными задачами с большим запасом производительности.
ClickHouse хорошо работает в качестве базы данных временных рядов; в Яндексе он обычно используется в качестве бэкенда для Graphite вместо Ceres/Whisper. Это позволяет нам работать с более чем триллионом показателей на одном сервере.
ClickHouse используется аналитикой для внутренних задач. По нашему опыту в Яндексе, ClickHouse работает примерно на три порядка быстрее, чем традиционные методы обработки данных (скрипты на MapReduce). Но это не просто количественная разница. В том-то и дело, что имея такую высокую скорость вычислений, можно позволить себе применять кардинально разные методы решения задач.
По нашему опыту в Яндексе, ClickHouse работает примерно на три порядка быстрее, чем традиционные методы обработки данных (скрипты на MapReduce). Но это не просто количественная разница. В том-то и дело, что имея такую высокую скорость вычислений, можно позволить себе применять кардинально разные методы решения задач.
Если аналитик должен составить отчет, и он компетентен в своей работе, он не будет просто строить один отчет. Скорее, они начнут с поиска десятков других отчетов, чтобы лучше понять природу данных и проверить различные гипотезы. Часто бывает полезно посмотреть на данные под разными углами, чтобы выдвинуть и проверить новые гипотезы, даже если у вас нет четкой цели.
Это возможно только в том случае, если скорость анализа данных позволяет проводить онлайн-исследования. Чем быстрее выполняются запросы, тем больше гипотез можно проверить. Работая с ClickHouse, даже возникает ощущение, что они способны думать быстрее.
Образно говоря, в традиционных системах данные подобны мертвому грузу. Манипулировать им можно, но это занимает много времени и неудобно. Однако если ваши данные находятся в ClickHouse, они гораздо более податливы: вы можете изучать их в разных срезах и детализировать до отдельных строк данных.
Манипулировать им можно, но это занимает много времени и неудобно. Однако если ваши данные находятся в ClickHouse, они гораздо более податливы: вы можете изучать их в разных срезах и детализировать до отдельных строк данных.
Выводы
Яндекс.Метрика стала второй по величине системой веб-аналитики в мире. Объем данных, которые принимает Метрика, вырос с 200 млн событий в день в 2009 году.до более чем 25 миллиардов в 2016 году. Чтобы предоставить пользователям широкий спектр возможностей, не отставая от растущей рабочей нагрузки, нам приходилось постоянно изменять наш подход к хранению данных.
Эффективное использование оборудования очень важно для нас. По нашему опыту, когда у вас есть большой объем данных, лучше не беспокоиться о том, насколько хорошо масштабируется система, а вместо этого сосредоточиться на том, насколько эффективно используется каждая единица ресурса: каждое ядро процессора, диск и твердотельный накопитель, ОЗУ и сеть. В конце концов, если в вашей системе уже используются сотни серверов, и вам нужно работать в десять раз эффективнее, маловероятно, что вы сможете просто установить тысячи серверов, какой бы масштабируемой ни была ваша система.