
Как попасть в поисковые подсказки «Яндекса»
25.11.2022Подробно о секретном SEO-инструменте, который вызывает много споров, но все равно работает.
Хотим что-то найти — идем в поисковые системы. Они ответят на любые вопросы: как продвинуть бизнес, где найти работу и что ждет Россию. С “Яндекса” начинается наш интерес, там же он и заканчивается. Из чего состоит страница поисковой выдачи (SERP)? Если на бытовом языке, то:
- Коммерческий трафик: туда попадают те, кто платит за контекстную рекламу.
- Органический трафик: туда попадают те, кто, по мнению алгоритмов, популярнее и полезнее.
- “Колдунщики” — спецэлементы “Яндекса”, которые дают релевантный ответ на вопрос пользователя. Это шорткаты (быстрые ответы), адреса, карты, граф знаний, картинки, видео и данные из сервисов.
- Поисковые подсказки (на айтишном языке “саджест”) — похожие запросы, которые по данной теме вводили другие пользователи.

Бизнес редко задумывается, но подсказки систем создают первое впечатление еще до того, как пользователь видит ссылки. Они направляют, меняют мнение, приводят к конкретному бренду или месту. Это тоже инструмент влияния. Только чей?
- Можно тратить большие бюджеты на контекст, но систематично упускать клиентов из-за поисковых подсказок.
Разбираемся, что это такое и как бизнесу их применять.
ЧТО ТАКОЕ ПОИСКОВЫЕ ПОДСКАЗКИ?
Поисковые подсказки — список похожих запросов под поисковой строкой “Яндекса”. Чаще всего это 5-10 словосочетаний, автоматически подобранных системой. Когда пользователь начинает вводить первые символы, алгоритм тут же выводит самые высокочастотные запросы в продолжении того слова, которое ввел человек.
К примеру, поисковые подсказки на вопрос “Как?”
Виды поисковых подсказок:
- Полные. Они словно “дополняют” мысль пользователя. Он вводит слово — алгоритм предлагает закончить фразу с помощью актуальных запросов.
- Навигационные. Помогают пользователю сориентироваться. Если система четко понимает, куда нужно человеку, вместе с подсказкой она дает ссылку на сайт.
- Фактоиды. Высвечиваются, если пользователь спрашивает о простых фактах: пробках, погоде, датах. Это короткие ответы в строке подсказок.
- Персональные. Основаны на истории поиска. Если человек уже вводил некий запрос, алгоритм его запоминает и выдает в приоритете.
- Коммерческие. В 2020 году вышло обновление, с которым контекстную рекламу можно запускать непосредственно в подсказках. CTR такого баннера, по средним оценкам, — 16%.
 Он вводит слово — алгоритм предлагает закончить фразу с помощью актуальных запросов.
Он вводит слово — алгоритм предлагает закончить фразу с помощью актуальных запросов.“Помимо текста, в поисковые подсказки также может попасть конкретная ссылка. Если поисковая система сочтет, что логичным ответом на запрос является определенный сайт, подсказка со ссылкой на него будет показана первой.
Милена Худякова,
ведущий менеджер проектов агентства Markway
С недавних пор в поисковых подсказках в ответ на информационные запросы все чаще появляются ссылки на популярные статьи в “Дзене”. Это дополнительный инструмент продвижения.
КАК СОРТИРУЮТСЯ ПОИСКОВЫЕ ПОДСКАЗКИ?
Что влияет на отображение подсказок в “Яндексе”:
- Геолокация. Алгоритм предлагает варианты похожих запросов, исходя из конкретного города присутствия. Для Москвы и Костромы список подсказок будет разным.
- История поиска. “Яндекс” следит за нами и при подборе подсказок ориентируется на темы, которыми посетитель интересовался ранее. Частые запросы будут обозначаться другим цветом.
- Релевантность. Система самостоятельно определяет ценность похожих запросов.
- Частота. Чем чаще что-то спрашивали другие пользователи, тем чаще похожий запрос показывается нам. “Яндекс” считает это маркером популярности. Редкие фразы попадают в список, только если запрос пользователя длинный и состоит из нескольких слов. К примеру, “Как установить на машину автозапуск”.
- CTR. Чем чаще кликают на саджесты, тем лучше.
- Содержание. Система многое не пропускает. Подсказки с нецензурной лексикой, призывами к жестокости и упоминаниями порнографии найти не получится.
 “Яндекс” считает это маркером популярности. Редкие фразы попадают в список, только если запрос пользователя длинный и состоит из нескольких слов. К примеру, “Как установить на машину автозапуск”.
“Яндекс” считает это маркером популярности. Редкие фразы попадают в список, только если запрос пользователя длинный и состоит из нескольких слов. К примеру, “Как установить на машину автозапуск”.- “Яндекс” обновляет набор подсказок каждые 30 минут.
Система анализирует контент с большим охватом. Так, в подсказки попадают сегодняшние события, которые быстро становятся трендами. Например, в апреле и октябре 2022 года в подсказки по Илону Маску попала фраза “Илон Маск купил Твиттер” из-за аномального всплеска запросов — 13 и 9 тысяч соответственно. Со временем подсказка станет неактуальной и отсеется.
ПОЧЕМУ ПОДСКАЗКИ УДОБНЫ ПОЛЬЗОВАТЕЛЮ?
По средним оценкам, такой фичей пользуются 90% посетителей.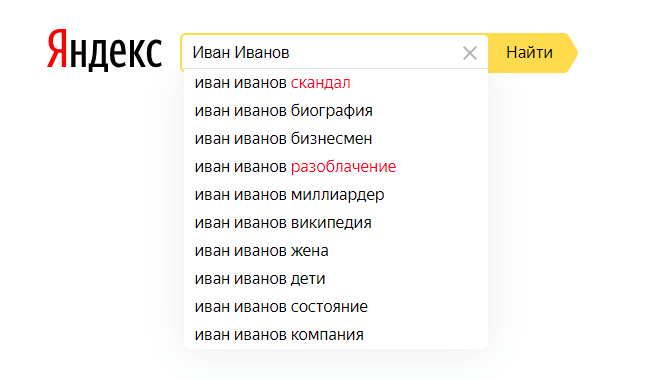 Почему такой высокий интерес? Все просто — обыкновенная человеческая лень.
Почему такой высокий интерес? Все просто — обыкновенная человеческая лень.
- “Яндекс” рассчитал, что в среднем человек при запросе вводит около 19 символов.
Получается, пользователь совершает 19 лишних кликов. Алгоритм подсказок уменьшает это число до 10-11. Команда “Яндекса” подсчитала, что они экономят людям около 60 лет. Масштабно.
Какие метрики определяют качество подсказок для пользователя (тоже от команды “Яндекса”):
- Expected Actions Count (EAC) — число действий, которые пользователь совершит в строке до использования подсказки.
- Guess Probability (GP) — отношение “удачных” использованных подсказок к их общему количеству.
Показатели влияют друг на друга. Чем больше EAC, тем меньше GP. И, соответственно, наоборот.
ПОЧЕМУ ПОДСКАЗКИ ВЛИЯЮТ НА БИЗНЕС?
А здесь начинается самое интересное. Первое — подсказки действительно способны повысить трафик и лояльность. Второе — бизнес может на них повлиять.
Второе — бизнес может на них повлиять.
В каких случаях подсказки действуют на репутацию:
- Информационные запросы. Подсказки неосознанно формируют коммерческий интерес. Мы видим упоминание компании и кликаем на него.
- Продуктовые запросы. Подсказывают, какой именно бренд популярен в данном сегменте. Продуктам, которые пользуются спросом, мы склонны доверять больше.
- Коммерческие запросы. Направляют к конкретной компании, которая может удовлетворить запрос на покупку/заказ.
- Брендовые запросы. Могут сформировать негативное впечатление, если есть упоминания о скандале.
- Репутационные запросы. оздают репутацию еще до того, как клиент посмотрит отзывы.
МОЖНО ЛИ ПОВЛИЯТЬ НА ПОИСКОВЫЕ ПОДСКАЗКИ?
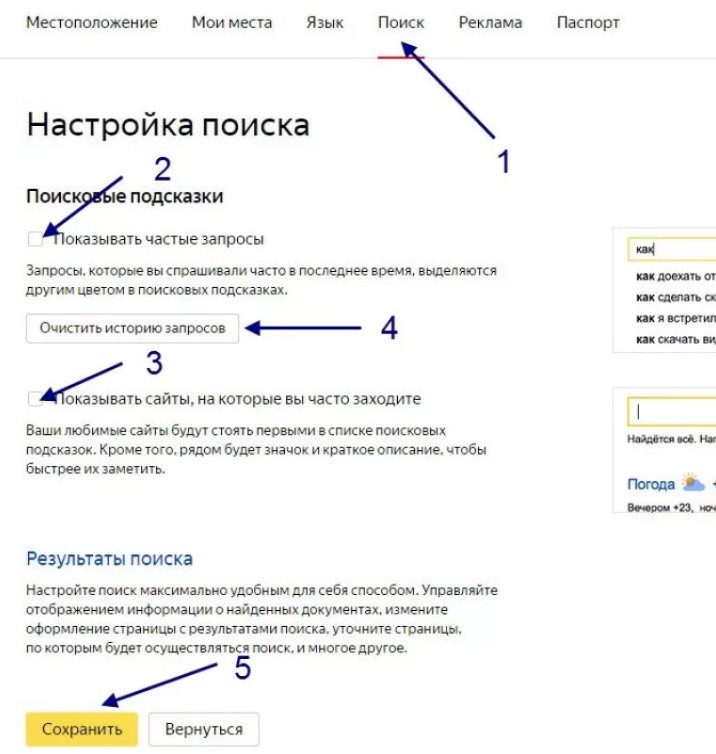
Бизнес должен отслеживать свое присутствие в поисковых подсказках. Есть шанс увидеть неприятность, которая будет отталкивать пользователей. Кроме того, нужно следить за конкурентами, которые могут показать аномальную активность.
Кроме того, нужно следить за конкурентами, которые могут показать аномальную активность.
- Если по названию вашего бренда в похожих запросах неожиданно появились конкуренты, значит, они ведут накрутку поисковых подсказок. С этим нужно бороться.
Причем необязательно, чтобы поисковый запрос с названием бренда был таким же популярным, как и общий запрос. В примере ниже частотность отличается в среднем в 464 раза. Но это не мешает “Леруа Мерлен” появляться в поисковых подсказках.
Повлиять на поисковые подсказки можно двумя способами — белыми и теневыми.
- Белые методы.
Продуманная рекламная кампания в контексте, которая создает спрос на конкретный товар. Чем чаще пользователи спрашивают о ней с упоминанием бренда, тем быстрее нужная фраза бесплатно появится в подсказках. Лайфхак: как только запрос появляется в саджестах, на него кликают чаще, и он становится еще популярнее.
- Теневые методы.

Искусственно созданный интерес к определенным запросам. Продвижение поисковых подсказок здесь ведется с помощью большой базы агентов влияния. Самостоятельно заниматься этим сложно, потому как запросы с одного IP-адреса не учитываются, а подсказки просто удалятся. Лучше обращаться к опытным специалистам.
- Важно: повлиять на подсказки проще по среднечастотным и низкочастотным запросам. И делать это нужно регулярно, не менее раза в месяц.
В управлении репутацией не бывает мелочей. Важен каждый инструмент продвижения, который может изменить мнение клиента. Пользуйтесь всем, что вам доступно.
МИЛЕНА ХУДЯКОВА
Руководитель отдела ORM
Поделиться
интернет-маркетингСделайте репутацию
источником продаж!
Чтобы мы начали готовить для вас комплекс продвижения, заполните заявку или закажите обратный
звонок. Ваш персональный менеджер подготовит специальное коммерческое предложение и сформирует
маркетинговую стратегию.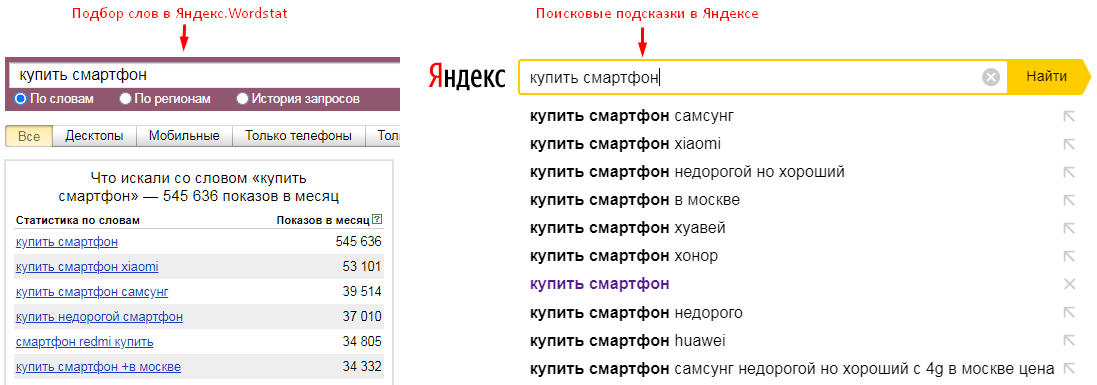
Получить книгу
Регистрация на вебинар
Как мы научились предсказывать запрос пользователя и ускорили загрузку поисковой выдачи / Хабр
Поисковые подсказки (саджест) — это не только пользовательский сервис, но ещё и очень мощная языковая модель, хранящая миллиарды поисковых запросов, поддерживающая нечёткий поиск, персонализацию и многое другое. Мы научились использовать саджест для того, чтобы предугадывать итоговый запрос пользователя и загружать поисковую выдачу до нажатия кнопки «Найти».
Внедрение этой технологии – пререндера – потребовало многих интересных решений в мобильной разработке, разработке поискового рантайма, логов, метрик. И, конечно, нам нужен был крутой классификатор, определяющий, нужно ли загружать поисковый запрос заранее: этот классификатор должен соблюдать баланс между ускорением загрузки, дополнительным трафиком и нагрузкой на Поиск. Сегодня я расскажу о том, как нам удалось создать такой классификатор.
1.
 Сработает ли идея?
Сработает ли идея?В исследовательских задачах редко заранее бывает очевидно, что хорошее решение существует. И в нашем случае мы тоже изначально не знали, какие данные необходимы для того, чтобы построить достаточно хороший классификатор. В такой ситуации полезно начать с нескольких очень простых моделей, которые позволят оценить потенциальную пользу от разработки.
Самой простой идеей оказалась следующая: будем загружать выдачу по первой подсказке из поискового саджеста; когда подсказка меняется, мы выкидываем предыдущую загрузку и начинаем скачивать уже нового кандидата. Оказалось, что такой алгоритм работает неплохо и почти все запросы удаётся предзагрузить, однако соответственно возрастает нагрузка на поисковые бекенды и соответственно же возрастает пользовательский трафик. Ясно, что такое решение внедрить не получится.
Следующая идея тоже была достаточно простой: необходимо загружать вероятные поисковые подсказки не во всех случаях, а только тогда, когда мы в достаточной степени уверены, что они и правда нужны. Самым простым решением будет классификатор, работающий прямо в рантайме по тем данным, которые и так есть у саджеста.
Самым простым решением будет классификатор, работающий прямо в рантайме по тем данным, которые и так есть у саджеста.
Первый классификатор был построен с использованием всего десяти факторов. Эти факторы зависели от распределения вероятностей по множеству подсказок (идея: чем больше «вес» первой подсказки, тем более вероятно, что именно она и будет введена) и длины ввода (идея: чем меньше букв осталось ввести пользователю, тем безопасней предзагружать выдачу). Прелесть этого классификатора была ещё и в том, что для его построения не нужно было ничего релизить. Нужные факторы для кандидата можно собрать, сделав один http-запрос в саджестовый демон, а таргеты строятся по простейшим логам: кандидат считается «хорошим», если итоговый запрос пользователя полностью с ним совпадает. Собрать такой пул, обучить несколько логистических регрессий и построить диаграмму рассеяния оказалось возможным буквально за несколько часов.
Метрики для пререндера устроены не совсем так, как в обычной бинарной классификации. Важны всего два параметра, но это не точность и не полнота.
Важны всего два параметра, но это не точность и не полнота.
Пусть — общее количество запросов, — общее количество всех пререндеров, — общее количество удачных пререндеров, т.е. таких, которые в итоге совпали с пользовательским вводом. Тогда две интересные характеристики вычисляются следующим образом:
Скажем, если совершается ровно один пререндер на один запрос, а успешными оказывается половина пререндеров, то эффективность пререндера составит 50%, и это означает, что удалось ускорить загрузку половины запросов. При этом для тех запросов, в которых пререндер сработал успешно, дополнительный трафик не был создан; для тех запросов, в которых пререндер сработал неуспешно, пришлось задать один дополнительный запрос; так что общее количество запросов в полтора раза больше исходного, «лишних» запросов 50% от исходного количества, поэтому .
В этих координатах я и нарисовал первый scatter plot. Он выглядел вот так:
Эти значения содержали изрядное количество допущений, но по крайней мере было уже понятно, что, скорее всего, хороший классификатор получится: ускорять загрузку для нескольких десятков процентов запросов, увеличивая нагрузку на несколько десятков процентов — интересный размен.
Интересно было наблюдать за тем, как срабатывает классификатор. Действительно, оказалось, что очень сильным фактором является длина запроса: если пользователь уже почти ввёл первую подсказку, и она при этом достаточно вероятна, можно осуществить префетч. Так что предсказание классификатора резко возрастает к концу запроса.
margin prefix candidate -180.424 м майл -96.096 мо мос ру -67.425 мос мос ру -198.641 моск московское время -138.851 моско московское время -123.803 москов московское время -109.841 московс московское время -96.805 московск московское время -146.568 московска московская олимпиада школьников -135.725 московская московская олимпиада школьников -125.448 московская московская олимпиада школьников -58.
 615 московская о московская олимпиада школьников
31.414 московская об московская область
-66.754 московская область московская область карта
1.716 московская область з московская область запись к врачу
615 московская о московская олимпиада школьников
31.414 московская об московская область
-66.754 московская область московская область карта
1.716 московская область з московская область запись к врачуПререндер будет полезен, даже если он произошёл в момент ввода самой последней буквы запроса. Дело в том, что пользователи всё-таки тратят некоторое время на то, чтобы нажать на кнопку «Найти» после ввода запроса. Это время тоже можно сэкономить.
2. Первое внедрение
Через некоторое время удалось собрать полностью работающую конструкцию: приложение ходило за поисковыми подсказками в демон саджеста. Тот присылал, среди прочего, информацию о том, нужно ли предзагружать первую подсказку. Приложение, получив соответствующий флаг, скачивало выдачу и, если пользовательский ввод в итоге совпадал с кандидатом, осуществляло рендеринг выдачи.
Классификатор к этому моменту обзавёлся новыми факторами, а моделью была уже не логистическая регрессия, а вполне себе CatBoost. Изначально мы выкатили достаточно консервативные пороги для классификатора, однако даже они позволили мгновенно загружать почти 10% поисковых выдач. Это был очень удачный релиз, т.к. нам удалось значительно сместить младшие квантили скорости загрузки выдачи, а пользователи заметили это и начали статистически значимо возвращаться в поиск: существенное ускорение работы поиска сказалось на том, как часто пользователи совершают поисковые сессии!
Изначально мы выкатили достаточно консервативные пороги для классификатора, однако даже они позволили мгновенно загружать почти 10% поисковых выдач. Это был очень удачный релиз, т.к. нам удалось значительно сместить младшие квантили скорости загрузки выдачи, а пользователи заметили это и начали статистически значимо возвращаться в поиск: существенное ускорение работы поиска сказалось на том, как часто пользователи совершают поисковые сессии!
3. Дальнейшие улучшения
Хотя внедрение и оказалось удачным, решение было всё ещё крайне несовершенным. Внимательное изучение логов срабатываний показало, что есть несколько проблем.
Классификатор нестабилен. Например, может так оказаться, что по префиксу «янд» он предсказывает запрос «яндекс», по префиксу «янде» он не предсказывает ничего, а по префиксу «яндек» он снова предсказывает запрос «яндекс». Тогда наша первая прямолинейная реализация делает два запроса, хотя вполне могла обойтись и одним.
Пререндер не умеет обрабатывать пословные подсказки. Клик по пословной подсказке приводит к появлению в запросе дополнительного пробела. Например, если пользователь ввёл «яндекс», его первой подсказкой будет запрос «яндекс»; но если пользователь воспользовался пословной подсказкой, вводом будет уже строка «яндекс », а первой подсказкой — «яндекс карты». Это приведёт к плачевным последствиям: уже загруженный запрос «яндекс» будет выкинут, вместо него загрузится запрос «яндекс карты». После этого пользователь нажмёт на кнопку «Найти» и… будет дожидаться полной загрузки выдачи по запросу «яндекс».
В некоторых случаях у кандидатов нет никаких шансов стать успешными. В саджесте работает поиск по неточному совпадению, так что кандидат может, например, содержать только одно слово из введённых пользователем; либо пользователь может совершить опечатку, и тогда первая подсказка никогда не совпадёт в точности с его вводом.

Конечно, оставлять пререндер с такими несовершенствами было обидно, пусть даже он и полезен. Особенно мне было обидно за проблему с пословными подсказками. Я считаю внедрение пословных подсказок в мобильном поиске Яндекса одним из лучших своих внедрений за всё время работы в компании, а тут пререндер не умеет с ними работать! Позор, не иначе.
Особенно мне было обидно за проблему с пословными подсказками. Я считаю внедрение пословных подсказок в мобильном поиске Яндекса одним из лучших своих внедрений за всё время работы в компании, а тут пререндер не умеет с ними работать! Позор, не иначе.
В первую очередь мы исправили проблему нестабильности классификатора. Решение выбрали крайне простое: даже если классификатор вернул негативное предсказание, мы не прекращаем загрузку предыдущего кандидата. Это помогает экономить дополнительные запросы, поскольку, когда этот же кандидат вернётся в следующий раз, не нужно будет качать соответствующую выдачу заново. В то же время, это позволяет загружать выдачи быстрее, так как кандидат скачивается в тот момент, когда классификатор впервые сработал для него.
Затем настал черед пословных подсказок. Саджестовый сервер является stateless-демоном, так что в нём тяжело реализовать логику, связанную с обработкой предыдущего кандидата для того же пользователя. Осуществлять поиск подсказок одновременно для запроса пользователя и для запроса пользователя без концевого пробела означает фактически удвоить RPS на саджестовый демон, так что это тоже не было хорошим вариантом. В итоге мы сделали так: клиент передаёт специальным параметром текст кандидата, который загружается прямо сейчас; если этот кандидат с точностью до пробелов похож на пользовательский ввод, мы отдаём его, даже если кандидат для текущего ввода поменялся.
В итоге мы сделали так: клиент передаёт специальным параметром текст кандидата, который загружается прямо сейчас; если этот кандидат с точностью до пробелов похож на пользовательский ввод, мы отдаём его, даже если кандидат для текущего ввода поменялся.
После этого релиза наконец-то стало можно вводить запросы при помощи пословных подсказок и наслаждаться префетчем! Довольно забавно, что до этого релиза префетчем пользовались только те пользователи, что заканчивали ввод своего запроса при помощи клавиатуры, без саджеста.
Наконец, с третьей проблемой мы разобрались при помощи ML: добавили факторов про источники подсказок, совпадение с пользовательским вводом; кроме того, благодаря первому запуску мы смогли собрать побольше статистики и обучиться по месячным данным.
4. Что в итоге
Каждый из этих релизов давал рост количества мгновенно загружаемых выдач на десятки процентов. Самое приятное в том, что нам удалось улучшить показатели пререндера более чем в два раза, практически не трогая часть про machine learning, а лишь улучшая физику процесса. Это важный урок: зачастую качество классификатора не является самым узким местом в продукте, зато его улучшение является самой интересной задачей и поэтому разработка отвлекается именно на него.
Это важный урок: зачастую качество классификатора не является самым узким местом в продукте, зато его улучшение является самой интересной задачей и поэтому разработка отвлекается именно на него.
К сожалению, мгновенно загруженные выдачи — это ещё не полный успех; загруженную выдачу нужно ещё отрендерить, что происходит не мгновенно. Так что нам ещё предстоит работать над тем, чтобы лучше конвертировать мгновенные загрузки данных в мгновенные отрисовки поисковых выдач.
К счастью, сделанные внедрения уже позволяют говорить о пререндере как о достаточно стабильно работающей фиче; мы дополнительно проверили внедрения, описанные в пункте 2: они все вместе тоже приводят к тому, что пользователи сами по себе начинают чаще совершать поисковые сессии. Отсюда ещё один полезный урок: значительные улучшения в скорости работы сервиса могут статистически значимо влиять на его retention.
На видео ниже можно посмотреть, как сейчас работает пререндер на моём телефоне.
какая из следующих не является поисковой системой – au
3 мин
какая из следующих не является поисковой системой
Утвержденный ответВ чем разница между веб-сервером веб-сайта…
Поисковая система — это особый тип веб-сайта, который помогает пользователям находить веб-сайты с других веб-сайтов. Есть множество Google Bing, Yandex DuckDuckGo и многие другие. Некоторые из них являются общими, другие специализируются на определенных темах.
Основы Интернета с использованием поисковых систем — GCFGlobal.org
edu.gcfglobal.org › использование поисковых систем › 1 Основы Интернета с использованием поисковых систем — GCFGlobal.org edu.gcfglobal.org › использование поисковых систем › 1 Кэширование Как искать предложения для поиска в Интернете Уточните параметры поиска Поиск по содержаниюРекламаВы можете использовать множество разных инструментов, но самые популярные из них включают Google Yahoo! и Бинг. Чтобы выполнить поиск, вы должны зайти в поисковую систему в своем веб-браузере и ввести одно или несколько ключевых слов, также известных как условия поиска, а затем нажать Enter на клавиатуре. Ищите рецепты в этом примере. После того, как вы начнете поиск… См. полный список на edu.gcfglobal.org Если вы не найдете то, что ищете, с первой попытки, не волнуйтесь! Поисковые системы хорошо находят информацию в Интернете, но они не идеальны. Вам часто придется пробовать различные условия поиска, чтобы найти то, что вы ищете. Если у вас возникли проблемы с вводом новых условий поиска, вы можете вместо этого использовать поисковые подсказки. Обычно они выглядят как… Полный список можно найти на сайте edu.gcfglobal.org. Если вам все еще не удается найти именно то, что вам нужно, вы можете использовать специальные символы для уточнения поиска. Например, если вы хотите исключить слово из поиска, вы можете ввести тире (-) в начале слова. Поэтому, если вы хотите найти рецепты печенья без шоколада, вы можете поискать рецепты печенья-шоколада… См. полный список на edu.gcfglobal.org Иногда вам может понадобиться что-то более конкретное, как изображение в новостной статье или видео. Большинство поисковых систем имеют ссылки в верхней части страницы, которые позволяют выполнять эти уникальные поиски.
Ищите рецепты в этом примере. После того, как вы начнете поиск… См. полный список на edu.gcfglobal.org Если вы не найдете то, что ищете, с первой попытки, не волнуйтесь! Поисковые системы хорошо находят информацию в Интернете, но они не идеальны. Вам часто придется пробовать различные условия поиска, чтобы найти то, что вы ищете. Если у вас возникли проблемы с вводом новых условий поиска, вы можете вместо этого использовать поисковые подсказки. Обычно они выглядят как… Полный список можно найти на сайте edu.gcfglobal.org. Если вам все еще не удается найти именно то, что вам нужно, вы можете использовать специальные символы для уточнения поиска. Например, если вы хотите исключить слово из поиска, вы можете ввести тире (-) в начале слова. Поэтому, если вы хотите найти рецепты печенья без шоколада, вы можете поискать рецепты печенья-шоколада… См. полный список на edu.gcfglobal.org Иногда вам может понадобиться что-то более конкретное, как изображение в новостной статье или видео. Большинство поисковых систем имеют ссылки в верхней части страницы, которые позволяют выполнять эти уникальные поиски.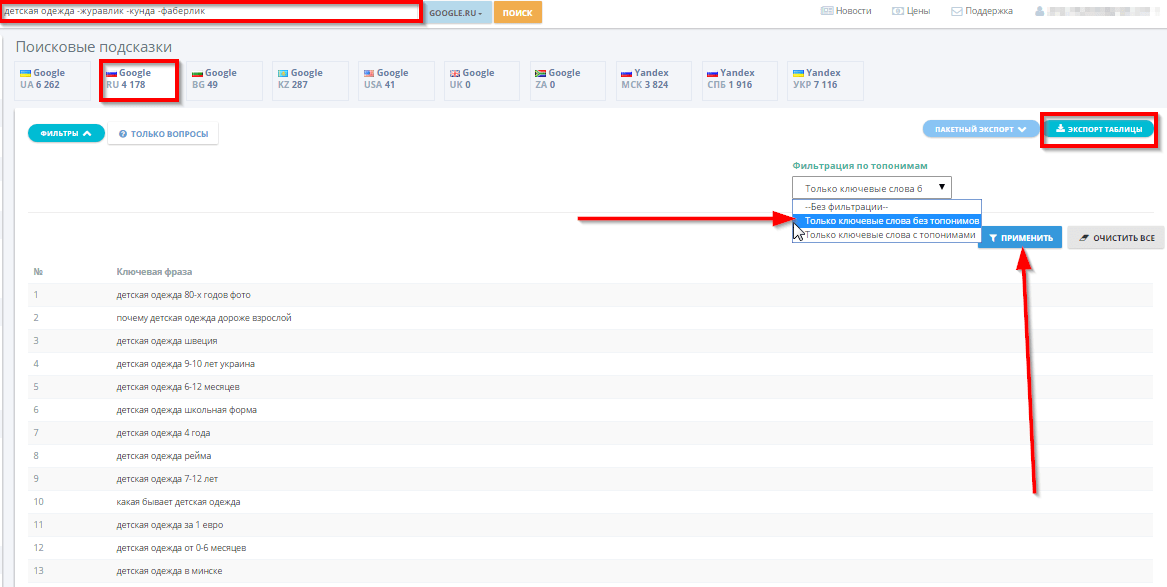 В приведенном ниже примере мы использовали те же условия поиска для поиска изображений вместо веб-страниц. Если вы видите изображение, которое вам нравится, вы можете нажать на него… Посмотреть полный список на edu.gcfglobal.org И последнее, на что следует обратить внимание. Большинство поисковых систем включают рекламу в свои результаты поиска. Например, вы можете увидеть рекламу в верхней части результатов поиска ниже. Эти объявления основаны на ваших поисковых запросах и часто похожи на другие результаты поиска. Хотя в некоторых случаях они могут быть полезны, обычно полезнее сосредоточиться на действии… Полный список см. на edu.gcfglobal.org
В приведенном ниже примере мы использовали те же условия поиска для поиска изображений вместо веб-страниц. Если вы видите изображение, которое вам нравится, вы можете нажать на него… Посмотреть полный список на edu.gcfglobal.org И последнее, на что следует обратить внимание. Большинство поисковых систем включают рекламу в свои результаты поиска. Например, вы можете увидеть рекламу в верхней части результатов поиска ниже. Эти объявления основаны на ваших поисковых запросах и часто похожи на другие результаты поиска. Хотя в некоторых случаях они могут быть полезны, обычно полезнее сосредоточиться на действии… Полный список см. на edu.gcfglobal.org
Что из перечисленного не является поисковой системой? — Toppr
Вопрос Что из перечисленного не является поисковой системой? A Google B Yahoo C Bing D Easy Windows Solution проверено Toppr Правильный вариант: D) Google Yahoo и Bing — это поисковые системы, а Windows — это операционная система Был ли этот ответ полезен? 0 0 Похожие вопросы HTML и XML являются языками разметки Решения Medium View >
Основы Интернета Основы Интернета — Оценка VII — Викторина
Что из перечисленного НЕ является поисковой системой? (Yahoo Chrome Bing Google) Образовательные учреждения. Что из следующего использует домен верхнего уровня .edu ( Предприятия Государственные учреждения Образовательные учреждения Организации) Zoom.
Что из следующего использует домен верхнего уровня .edu ( Предприятия Государственные учреждения Образовательные учреждения Организации) Zoom.
Testbank Вопросы Поиск информации в Интернете — Quizlet
Что из нижеперечисленного НЕ является типом альтернативной поисковой системы? A. Система поиска работы B. Система поиска ключевых слов C. Система поиска блогов D. Система поиска людей
Что из перечисленного не является поисковой системой? — ВЫ БЫЛИ
Знания можно найти и перечислить во всемирной паутине. Предоставляемые Google Yahoo и Bing являются примерами поисковых систем. Но Windows — это операционная система. Поисковый движок. Название поисковой системы означает, что она ищет информацию, которая нужна пользователю.
Что из перечисленного не является поисковой системой? — Toppr
Укажите следующее — поисковая система в Интернете, использующая информацию из многих источников. — Габриэль Вайнберг нашел его. — Это поисковая система, ориентированная на конфиденциальность, которая показывает всем своим пользователям одинаковые результаты по заданному поисковому запросу.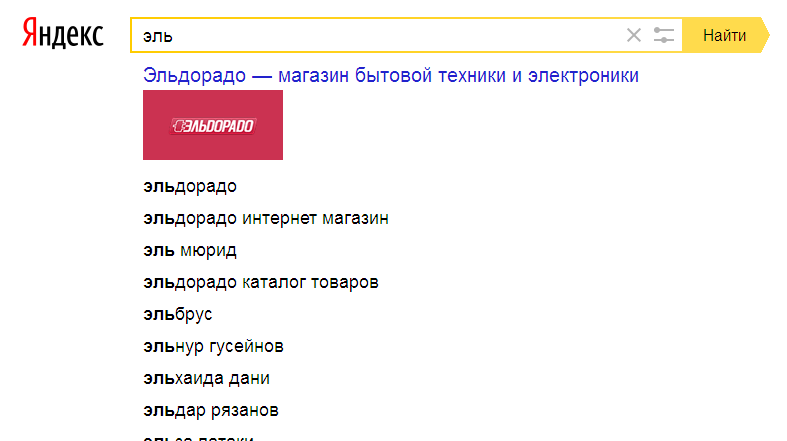
Что из перечисленного не является поисковой системой? — Testbook.com
Скачать решение в формате PDF. Хром НЕ правильный. Chrome не является поисковой системой, потому что это…
Отвечено Что из следующего не является поисковой системой…
Экспертно проверенный ответ на вопрос. Хром неправильный. Chrome на самом деле не поисковая система; это веб-страница, которая использует поисковую систему для извлечения и отображения информации с веб-страниц, размещенных на веб-серверах. Название поисковой системы говорит о том, что она ищет данные, которые нужны пользователю.
Ответ Что из следующего не является поисковой системой?
Chrome не является поисковой системой. Chrome — это веб-браузер, который использует поисковую систему для поиска и отображения информации с веб-страниц, хранящихся на веб-серверах, поэтому он не является поисковой системой. Почему Chrome не поисковик Сергей Брин и Ларри Пейдж — основатели.
Поисковая система | Определение История Оптимизация Индексация.
 ..
..Даже крупнейшие общие поисковые системы, такие как Google (безусловно, самая популярная поисковая система), Bing (которая также поддерживает поиск Yahoo!), российская Яндекс и китайская Baidu, не могут идти в ногу с распространение веб-сайтов, каждый из которых оставляет открытыми большие участки Интернета.
Диапазон источников данных Supermetrics, API и окна обновления
Группа поддержки сайта SupermetricsДата изменения: пн, 16 января 2023 г., 11:28
Ниже перечислены различные ограничения для исторических диапазонов, задержек API и рекомендуемых периодов обновления данных, доступных из разных источников данных.
Стандартная лицензия Supermetrics поддерживает столько истории, сколько позволяет каждый источник данных (за исключением лицензий на хранилище данных, облачное хранилище и озеро данных с возможностью обновления на 2 года).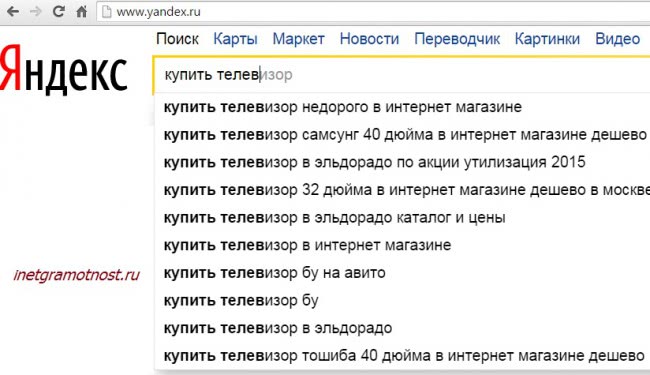
Обратите внимание, что этот список не является исчерпывающим. Если для источника данных не указано рекомендуемое окно обновления, хорошей отправной точкой будет 3 дня.
Источник данных | Исторический диапазон (HR), задержка API и рекомендуемое окно обновления, если доступно 3 | HR : Зависит от выбранных данных источники — см. исторические диапазоны для конкретных источников данных. |
| Adform | HR : Данные за последние 397 дней. | |
| Adobe Analytics | HR : неограниченный срок действия, но Adobe лучше всего извлекать исторические данные, регулярно увеличивая их, а не запрашивая весь набор данных сразу. | |
| Adobe Analytics 2.0 | HR : На весь срок службы, но Adobe лучше всего извлекать исторические данные, регулярно увеличивая их, а не запрашивая весь набор данных сразу. | |
| AdRoll | HR : API AdRoll не предоставляет данные старше 01.01.2012. | |
| Ahrefs | HR : Только даты первого, последнего и предыдущего сканирования ссылок. | |
| Apple Search Ads | HR :
| |
| BigQuery | HR : зависит от данных в хранилище данных. | |
| Инструменты Bing для веб-мастеров | HR : Максимальный доступный период набора данных — 6 месяцев. | |
| CallRail | HR : Срок действия учетной записи. | |
| Criteo | HR : Последние 2 года. | |
| База данных (сценарий Google Apps) | HR : Исторические ограничения будут основываться на том, какие данные доступны в базе данных. | |
| Facebook Ads | Facebook Ads API не предоставляет: — данные старше 28. — демографические данные старше 01.01.2013 — Данные устройства старше 2014 года- 07-03 — Данные статистики рекламы старше 37 месяцев (ссылка) Окно обновления: Установите максимальное количество окон атрибуции на платформе. | |
| Facebook Insights | HR: Хотя это нигде не регистрируется, значения органического охвата не отслеживаются до октября 2017 года (и, возможно, раньше, это может быть скользящее окно). Insights сохраняет данные только за последние 2 года, более старые данные подлежат удалению. Задержка API: 0–4 дня Окно обновления : 5 дней Из-за ограничения постов в Graph API будет возвращено примерно 600 ранжированных, опубликованных постов в год. | |
| Google Ad Manager | HR : данные за последние 3 года. | |
| Google AdSense | HR : Последние 3 года. | |
| Google Ads | HR : ограничений нет, предполагается, что это срок действия учетной записи. Окно обновления: Установите максимальное количество окон атрибуции на платформе. | |
| Google Analytics | HR : Для большинства данных после 01. 01.2005 ограничений нет. 01.2005 ограничений нет. | |
| Google Analytics 4 | HR : данные на уровне пользователя, включая конверсии, удаляются через 14 месяцев, а данные о возрасте, поле и интересах — через 2 месяца. Для всех других данных о событиях вы можете выбрать срок хранения 2 или 14 месяцев. Подробнее | |
| Google Campaign Manager 360 | HR : 2 года для большинства данных; 60 дней для отчетов Floodlight, отчетов по многоканальным последовательностям и отчетов о пути к конверсии. 31 день для данных ключевых слов. Задержка API : 1 день Окно обновления : 3 дня | |
| Google Display & Video 360 | 9 0307 По умолчанию: Данные за последние 2 года Отчет Floodlight: Последние 2 месяца данных | |
| Google My Business | HR : данные за последние 18 месяцев. Задержка API : 2 дня Окно обновления : 4 дня | |
| Google Search Ads 360 | HR : Данные за последние 2 года. | |
| Google Search Console | HR : данные за последние 16 месяцев. Задержка API : 2 дня Окно обновления : 4 дня | |
| Google Trends | HR : Возвращает данные с 2004 года и только за последний 31 день для Daily Trends. | |
| HubSpot | HR : Срок действия учетной записи. | |
| Статистика Instagram | HR : Истории исчезают через 24 часа. Данные метрик хранятся до 2 лет. Конечная точка мультимедиа получает не более 10 000 самых последних созданных объектов. Задержка API : 0-4 дня Окно обновления : 5 дней | |
| Общедоступные данные Instagram 2 | HR: Сообщения в профиле до 2 лет; Истории исчезают из результатов через 24 часа.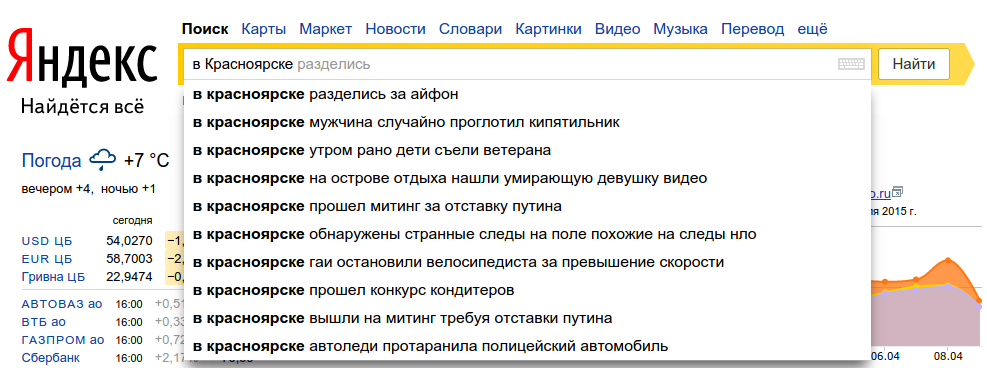 Поиск сообщений выбирает сообщения, опубликованные за последние 24 часа, до 250 сообщений. Поиск сообщений выбирает сообщения, опубликованные за последние 24 часа, до 250 сообщений. | |
| JSON/CSV/XML | HR : Исторические ограничения зависят от API/веб-сервиса, к которому вы подключаетесь. Пожалуйста, ознакомьтесь с документацией исходной системы. | |
| LinkedIn Ads | HR : Доступны недемографические данные за последние 10 лет. Ежедневная демографическая аналитика доступна за последние 6 месяцев, а все остальные детализированы за 2 года. Окно обновления: Установите максимальное количество окон атрибуции на платформе. | |
| Страницы компаний LinkedIn | HR : Доступны недемографические данные за последние 10 лет. | |
| Mailchimp | HR : ограничений нет, предполагается, что это срок действия учетной записи | |
| Microsoft Advertising | HR : данные максимум за 3 года, но зависит от типа отчета. Дополнительные сведения см. в документах Microsoft Advertising API. Окно обновления: Установите максимальное количество окон атрибуции на платформе. | |
| млн унций | HR : В API нет исторических данных.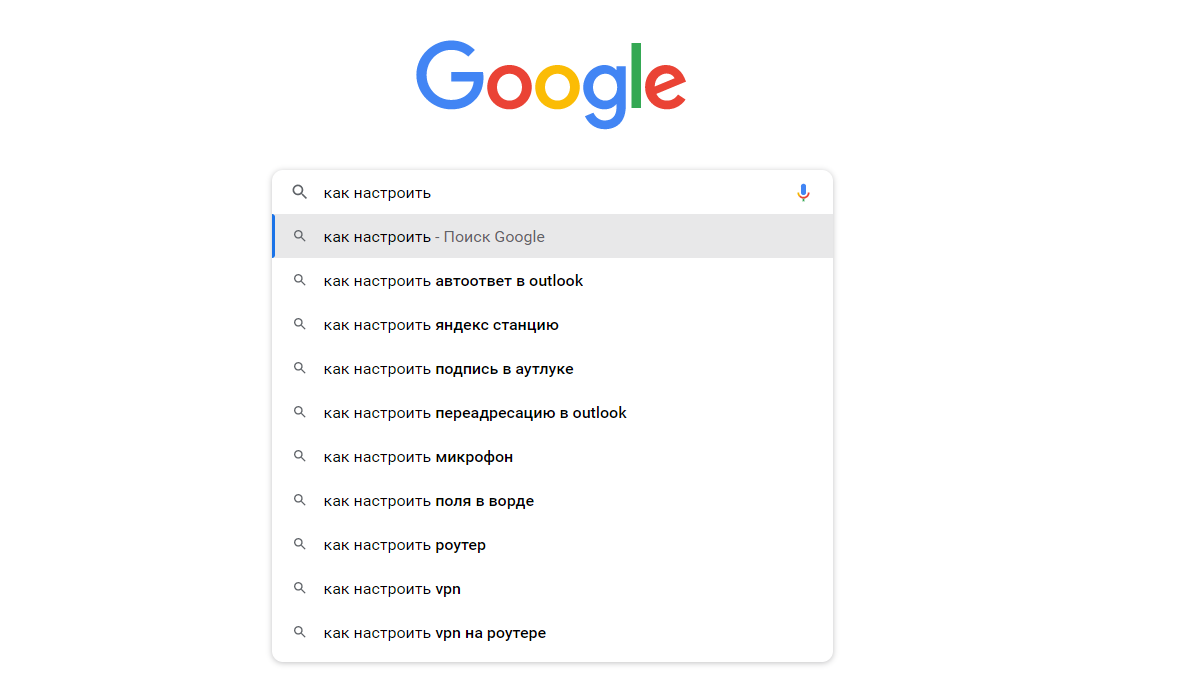 Все данные актуальны. Все данные актуальны. | |
| Optimizely | HR : Срок службы проекта. | |
| Outbrain Amplify | HR : Срок действия учетной записи. | |
| PayPal | HR : Срок действия учетной записи. | |
| Pinterest Ads | HR : в отчетах пользовательского интерфейса доступны данные только за последние 25 месяцев, в некоторых случаях могут быть данные за год до текущей даты. API позволяет использовать данные за 30 месяцев для не почасовой разбивки. API позволяет использовать данные за 30 месяцев для не почасовой разбивки.Окно обновления: Установите максимальное количество окон атрибуции на платформе. | |
| Pinterest Organic | HR : можно получать данные за период до года назад. Для метрик пинов и досок за последние 6 месяцев. | |
| Общедоступные данные Pinterest | HR : только отчеты о показателях за все время существования. Можно получить только 50 пинов на пользователя. | |
| Quora Ads | HR : Quora Ads имеет ограничение в 2000 запросов в час. Узнайте больше в документации Quora. Узнайте больше в документации Quora.Окно обновления: Установите максимальное количество окон атрибуции на платформе. | |
| Общедоступные данные Reddit | HR : Получает только текущее состояние платы/пользователя/и т. д. Нет исторических данных | |
| Salesforce | HR : ограничений нет. | |
| Searchmetrics | HR : есть некоторые исторические выборки, но ограничения зависят от типа отчета. Дополнительные сведения см. в документации по Searchmetrics.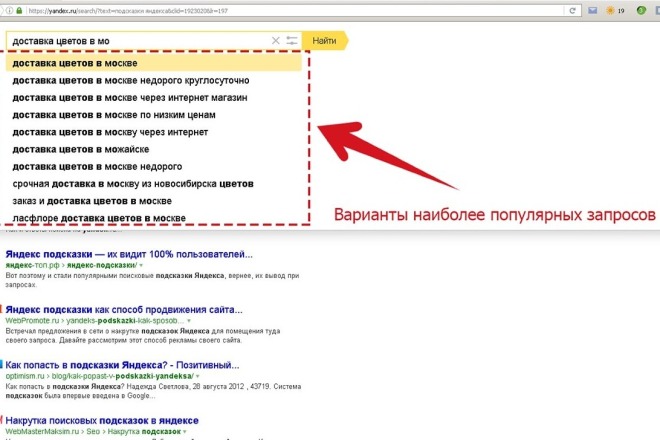 | |
| Semrush Analytics | HR : может извлекать данные из баз данных США с 2012 г., исторический диапазон других местоположений может быть меньше. Пользователи могут извлекать текущие данные (сегодня), а некоторые типы отчетов позволяют извлекать данные за прошлые месяцы — обратите внимание, что это стоит больше кредитов. | |
| Semrush Projects | HR : Может извлекать данные из баз данных США с 2012 года, исторический диапазон других местоположений может быть меньше. Пользователи могут извлекать текущие данные (сегодня), а некоторые типы отчетов позволяют извлекать данные за прошлые месяцы — обратите внимание, что это стоит больше кредитов. | |
| Shopify | HR : Документально не ограничено, но применяются практические ограничения (стоимость запроса). См. документы Shopify API для получения дополнительной информации. Ежедневная демографическая аналитика доступна только за последние 6 месяцев. | |
| Snapchat Marketing | HR : ограничений нет. Задержка API : 2 дня Окно обновления : 4 дня | |
| Снежинка | HR : Исторические ограничения будут основываться на том, какие данные доступны в хранилище данных. | |
| StackAdapt | HR : ограничения неизвестны, предполагается, что это время жизни учетной записи. | |
| Stripe | HR : ограничений нет, предполагается, что это срок действия учетной записи. | |
| Taboola | HR : Ограничения неизвестны, предполагается, что это срок действия учетной записи. | |
| Торговая стойка | HR : API может извлекать только данные, созданные 20 июня 2017 г.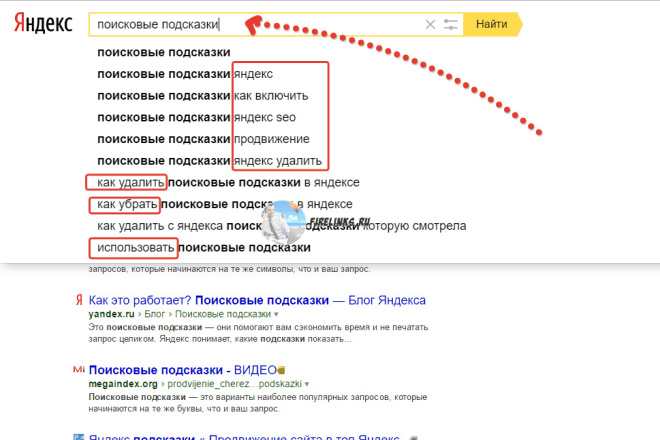 или позднее. Supermetrics поддерживает последние 180 дней с момента первого входа клиента. или позднее. Supermetrics поддерживает последние 180 дней с момента первого входа клиента.Например, если вы впервые подключаете The Trade Desk к Supermetrics 1 января 2022 года, самая ранняя дата, за которую вы можете получить данные, — это 180 дней до этой даты. Это останется неизменным до тех пор, пока вы используете этот разъем. | |
| Публичные данные Tumblr | HR : получает только текущее состояние блога. Никаких исторических данных, кроме извлечения старых сообщений. | |
| Реклама в Твиттере | HR : Срок действия учетной записи, хотя рекомендуется получать данные в течение 30 дней. Задержка API : 2 дня Окно обновления: Установите максимальное количество окон атрибуции на платформе. | |
| Twitter Premium | HR : Данные о показах и взаимодействиях за последние 90 дней. Лимит 3200 твитов, включая ретвиты и ответы. См. также ограничения Twitter Premium и лимиты скорости. | |
| Общедоступные данные Twitter | HR : будет получено прибл. последние 2000 твитов (включая ретвиты и ответы), начиная с указанной даты окончания и двигаясь назад. | |
| Общедоступные данные Vimeo | HR : Ограничения неизвестны. | |
| Публичные данные ВКонтакте | HR : Получает только текущее состояние доски/пользователя/и т. д. Исторические данные отсутствуют. д. Исторические данные отсутствуют. | |
| Yahoo DSP | HR : Может получать данные за период до 2 лет; более старые данные удаляются и не могут быть запрошены. | |
| Yahoo Native Ads | HR : Последние 400 дней | |
| Яндекс.Директ | HR : Статистика доступна за последние 3 года. | |
Яндекс. |
 09.2012
09.2012
 Ежедневная демографическая аналитика доступна за последние 6 месяцев, а все остальные детализированы за 2 года.
Ежедневная демографическая аналитика доступна за последние 6 месяцев, а все остальные детализированы за 2 года.
