
Дубли страниц: все, что необходимо знать
Дубликаты страницы – это копии, которые содержат полностью идентичный или повторяющийся контент. Зачастую именно из-за наличия таких копий сайт находится на низких позициях в поиске. Именно поэтому важно знать, что представляют собой дубли, откуда они берутся и как от них избавиться.
Полные копии появляются тогда, когда существует несколько адресов одной страницы. Устранить эту проблему можно, настроив редирект 404 или выбрав главное зеркало сайта. Нередко они создаются в автоматическом порядке системой управления сайтов.
Частичные копии страниц могут быть результатом багов в системе, также причиной данного дефекта может быть специфика самой CMS. Нередко нежелательными дублями становятся служебные страницы, не закрытые от индексации.
Какой вред для SEO?
Если на сайте есть много дублей одной страницы, они начинают между собой соперничать. Поисковые системы хранят несколько копий, но выводят в результаты только одну из них. И если ею окажется не основная страница, а ее копия, то позиции сайта резко упадут. Наличие дублей отрицательно сказывается на факторах поведенческих, а большое количество одинаковых страниц вовсе может привести к неполной индексации. Также следует знать, что роботы поисковых систем реже переходят на сайты с дубликатами, что в свою очередь, также плачевно сказывается на поисковом продвижении.
И если ею окажется не основная страница, а ее копия, то позиции сайта резко упадут. Наличие дублей отрицательно сказывается на факторах поведенческих, а большое количество одинаковых страниц вовсе может привести к неполной индексации. Также следует знать, что роботы поисковых систем реже переходят на сайты с дубликатами, что в свою очередь, также плачевно сказывается на поисковом продвижении.
Как определить дубли страниц на сайте?
Это можно делать несколькими способами.
- Сервисы для вебмастеров. В Гугле это Google Search Console, а в Яндексе – Яндекс.Вебмастер. К дублям можно отнести страницы с совпадающими метатегами и метаописанием. В сервисе Яндекс.Вебмастер подобные страницы можно найти во вкладке «Инексирование» в категории дублей.
- Специальные инструменты. В интернете существуют специализированные платформы, которые также позволяют определить копии страниц по совпадающим метатегам. К популярным инструментам, который позволит быстро справиться с данной проблемой, относится Screaming Frog.

- Расширенные операторы Google – site и inurl. С их помощью можно найти перечень повторяющихся страниц, проиндексированных поисковой системой Google.
- Ручной поиск. Данный способ подходит, если речь идет о небольшом сайте.
- Инструменты веб-аналитики. Один из популярных сервисов – Serpstat.

Удаление дублей страниц
Устранить копии страниц, которые препятствуют продвижению сайта в органическом поиске, можно разными путями:
- Удалить все статические страницы, в которых копируется контент. Также необходимо убрать все внутренние ссылки.
- Запретить сканирование дубликатов. Поставить запрет на сканирование и индексацию можно в файле robots.txt. Таким образом можно убрать копии, связанные с поиском и фильтрами.
- Настроить редиректы в конфигурационном файле htaccess. Это позволит избавиться от копий главной страницы и реферальных ссылок.
- Атрибут rel=“canonical” – его можно разместить на html-странице между любыми тегами. С помощью этого атрибута можно указать приоритетность страницы. Именно её поисковые системы будут отображать на странице результатов поиска, она будет приоритетной среди одинаковых страниц.
- Помощь разработчика – если правильно настроить движок или систему управления сайтом, то можно навсегда избавиться от нежелательных копий.
 С помощью этого атрибута можно указать приоритетность страницы. Именно её поисковые системы будут отображать на странице результатов поиска, она будет приоритетной среди одинаковых страниц.
С помощью этого атрибута можно указать приоритетность страницы. Именно её поисковые системы будут отображать на странице результатов поиска, она будет приоритетной среди одинаковых страниц.24 февраля 2021
Интересные и полезные публикации написанные профессионалами
Мы пишем интересные статьи про SEO продвижение и создание сайтов, рекламу, маркетинг и другие темы. Подпишитесь на наш канал в Яндекс.Дзен и получайте только лучшие материалы!
Яндекс.ДзенКак не попасть под фильтр из-за дублей страниц на сайте
Дубликаты: в чем опасность?Опасность возникновения дублей можно показать на простом отвлеченном примере: посмотрите на картинку справа и скажите, какой из 2-х изображенных плодов наиболее релевантен запросу «красное яблоко».
Сложно, не правда ли? Ведь оба плода на картинке — это яблоки, и оба они красные.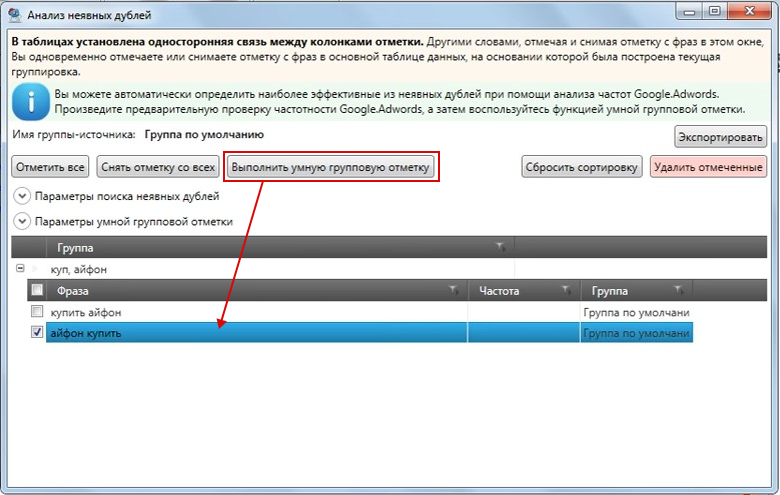 То есть, они одинаково релевантны запросу, а выбрать нас просят один, максимально точно соответствующий.
То есть, они одинаково релевантны запросу, а выбрать нас просят один, максимально точно соответствующий.
Возвращаясь к сайтам: в той же ситуации оказывается и поисковая система, когда ей нужно выбрать из двух одинаковых страниц одну и показать ее в результатах выдачи.
Конечно, поисковик учитывает и другие параметры при ранжировании, такие как внешние и внутренние ссылки, поведение пользователей, но факт остается фактом: из 2-х одинаково красных яблок, Google или Yandex должны выбрать одно. В этом-то и состоит вся трудность.
Возникновение такой дилеммы может привести к различным негативным последствиям:
1. Снижению релевантности основной посадочной страницы, а, значит, и снижению позиций ключевых слов.
2. «Скачкам» позиций ключевых слов за счет постоянной смены релевантной привязки с одной страницы на другую.
3. Общему понижению в ранжировании, когда проблема приобретает масштабы не отдельных URL, а всего сайта.
Именно подобная опасность вынуждает SEO-оптимизаторов обращать особое внимание на поиск и устранение страниц-дубликатов на этапе внутренней оптимизации.
Какими бывают дубли?
Перед тем, как начать процесс поиска дублей, нужно определиться с тем, что они бывают 2-х типов, а значит, процесс поиска и борьбы с ними будет несколько отличным. Так, в частности, выделяют:
- Полные дубли — когда одна и та же страница размещена по 2-м и более адресам.
- Частичные дубли — когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
Полные дубликаты — откуда они берутся?
1. Одна и та же страница по адресу с «www» и без «www».
Такую проблему еще часто называют: «Не выбрано главное зеркало сайта».
2. Дубли главной страницы по адресам:
- http://mysite.com/index/
- http://mysite. com/index.php
- http://mysite.com/index.php/
- http://mysite.com/index.html
- http://mysite.com/index.html/
 com/index.php
com/index.phpОдин из этих URL может быть адресом главной страницы по умолчанию.
3. Дубли, сгенерированные реферальной ссылкой.
Когда пользователь приходит по URL адресу с параметром «?ref=…», должно происходить автоматическое перенаправление на URL без параметра, что, к сожалению, часто забывают реализовать разработчики.
4. Ошибки, связанные с иерархией URL, приводящие к возникновению дублей.
Так, например, один и тот же товар может быть доступен по четырем разным URL-адресам:
- http://mysite.com/catalog/dir/tovar.php
- http://mysite.com/catalog/tovar.php
- http://mysite.com/tovar.php,
- http://mysite.com/dir/tovar.php
5. Некорректная настройка страницы 404 ошибки, приводящая к возникновению «бесконечных дублей» страниц вида:
http://mysite.com/olololo-test-olololo
где текст, выделенным синим — это любой набор латинских символов и цифр.
6. Страницы с utm-метками и параметрами «gclid».
Данные метки нужны для того, чтобы передавать некоторые дополнительные данные в системы контекстной рекламы и статистики. Несмотря на то, что, по идее, они не должны индексироваться поисковыми системами, частенько можно встретить полный дубль страницы с utm-меткой в выдаче.
Полные дубли представляют серьезную опасность с точки зрения SEO, так как критично воспринимаются поисковыми системами и могут привести к серьезным потерям в ранжировании и даже к наложению фильтра, пессимизирующего весь сайт.
Как и в случае с полными дублями, частичные возникают, в первую очередь, из-за особенностей CMS сайта, но значительно труднее обнаружаются. Кроме того, от них сложнее избавиться, но об этом чуть ниже, а пока наиболее распространенные варианты:
1. Страницы пагинации, сортировок, фильтров
Как правило, каким-то образом меняя выводимый товарный ассортимент на странице категории магазина, страница изменяет свой URL (фактически все случаи, когда вывод не организован посредством скриптов). При этом SEO-текст, заголовки, часто и мета-данные — не меняются. Например:
При этом SEO-текст, заголовки, часто и мета-данные — не меняются. Например:
http://mysite.com/catalog/category/ — стартовая страница категории товаров
http://mysite.com/catalog/category/?page=2 — страница пагинации
При том, что URL адрес изменился и поисковая система будет индексировать его как отдельную страницу, основной SEO-контент будет продублирован.
2. Страницы отзывов, комментариев, характеристик
Достаточно часто можно встретить ситуацию, когда при выборе соответствующей вкладки на странице товара, происходит добавление параметра в URL-адрес, но сам контент фактически не меняется, а просто открывается новый таб.
3. Версии для печати, PDF для скачивания
Данные страницы полностью дублируют ценный SEO-контент основных страниц сайта, но имеют упрощенную версию по причине отсутствия большого количества строк кода, обеспечивающего работу функционала. Например:
http://mysite.com/main/hotel/al12188 — страница отеля
http://mysite.com/main/hotel/al12188/print — ЧБ версия для печати
http://mysite. com/main/hotel/al12188/print?color=1 — Цветная версия для печати.
com/main/hotel/al12188/print?color=1 — Цветная версия для печати.
Выдача Google:
Выдача Yandex:
4. Html слепки страниц сайта, организованных посредством технологии AJAX
Найти их можно заменив в оригинальном URL-адресе страницы «!#» на «?_escaped_fragment_=». Как правило, в индекс такие страницы попадают только тогда, когда были допущены ошибки в имплементации метода индексации AJAX страниц посредством перенаправления бота на страницу-слепок и робот обрабатывает два URL-адреса: основной и его Html-версию.
Основная опасность частичных дублей в том, что они не приводят к резким потерям в ранжировании, а делают это постепенно и незаметно для владельца сайта. То есть найти их влияние сложнее и они могут систематически, на протяжении долгого времени «отравлять жизнь» оптимизатору.
C помощью каких инструментов искать дубли
Существует несколько инструментов для поиска дублей:
Мониторинг выдачи посредством оператора «site:»
Отобразив на странице SERP все проиндексированные URL участвующие в поиске, можно визуально детектировать повторы и разного рода «мусор».
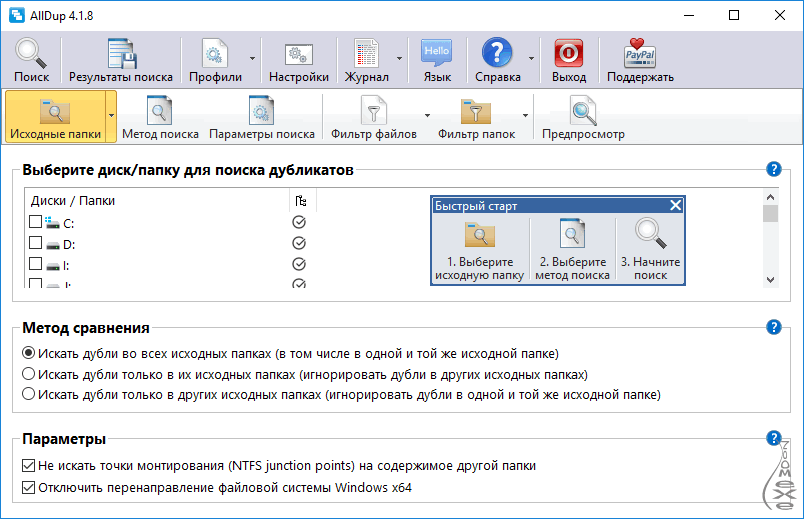
Десктопные программы-парсеры
Могу порекомендовать три удобные и информативные программы: Screaming Frog Seo Spider, Netpeak Spider, Xenu. Запуская собственных ботов к вам на сайт, программы выгружают полный список URL-адресов, который можно отсортировать по совпадению тега «Title» или «Description», и таким образом, выявить возможные дубли.
Пример отчета по выявлению потенциальных дублей из Netpeak Spider
В Serpstat также можно найти потенциальные дубли. Он находит страницы с дублирующимися Title и Description.
Поисковая консоль Google
В Google Search Console во вкладке «Оптимизация Html» можно посмотреть список страниц с повторяющимися мета-описаниями, т.е. список потенциальных дублей.
Ручной поиск непосредственно на сайте
Опытные веб-мастера способны вручную выявить большинство дублей в течение пары минут, просто попробовав различные вариации URL-адресов в обозначенных выше проблемных местах.
Как побороть и чем?
Способов борьбы с дубликатами не так уж и много, но все они потребуют от вас привлечения специалистов-разработчиков, либо наличия соответствующих знаний. По факту же арсенал для «выкорчевывания» дублей сводится к:
1. Их физическому удалению — хорошее решение для статических дублей.
2. Запрещению индексации дублей в файле «robots.txt» — подходит для борьбы со служебными страницами, частично дублирующими контент основных посадочных.
3. Настройке 301 редиректов в файле-конфигураторе «.htacces» — хорошее решение для случая с рефф-метками и ошибками в иерархии URL.
4. Установке тега «rel=canonical» — лучший вариант для страниц пагинации, фильтров и сортировок, utm-страниц.
Пример установки тега на странице пагинации:
5. Установке тега «meta name=»robots» content=»noindex, nofollow»» — решение для печатных версий, табов с отзывами на товарах.
ЗаключениеЧасто решение проблемы кроется в настройке самого движка, а потому основной задачей оптимизатора является не столько устранение, сколько выявление полного списка частичных и полных дублей и постановке грамотного ТЗ исполнителю.
Запомните следующее:
1. Полные и частичные дубли могут понизить позиции сайта в выдаче не только в масштабах URL, а и всего домена.
2. Полные дубли — это когда одна и та же страница размещена по 2-м и более адресам.Частичные дубли — это когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
3. Полные дубликаты нетрудно найти и устранить. Чаще всего причина их появления зависит от особенностей CMS сайта и навыков SEO разработчика сайта.
4. Частичные дубликаты найти сложнее и они не приводят к резким потерям в ранжировании, однако делают это постепенно и незаметно для владельца сайта.
5. Чтобы найти частичные и полные дубли страниц, можно использовать мониторинг выдачи с помощью поисковых операторов, специальные программы-парсеры, поисковую консоль Google и ручной поиск на сайте.
6. Избавление сайта от дублей сводится к их физическому удалению, запрещению индексации дублей в файле «robots.txt», настройке 301 редиректов, установке тегов «rel=canonical» и «meta name=»robots» content=»noindex, nofollow»».
Имея достаточно полный перечень основных проблемных зон, а также рекомендации по инструментарию, который можно использовать для их анализа, вам будет несложно провести поиск дубликатов на ресурсе и сделать первый шаг в сторону их полного устранения.
Я желаю вам успехов на этом пути!
Статься опубликована на ресурсе https://serpstat.com/
Поделиться:
Если вы хотите работать с нами,
давайте начнем с обсуждения задачи Получить консультацию
Киев, Украина
+380 44 333-69-73
пн–пт. 1000–1900
01033, г. Киев,
ул. Семьи Праховых, 50,
Харьков, Украина
+380 57 752-54-62
пн–пт. 1000–1900
61072, г. Харьков,
ул. Отакара Яроша, 18
Львов, Украина
пн–пт.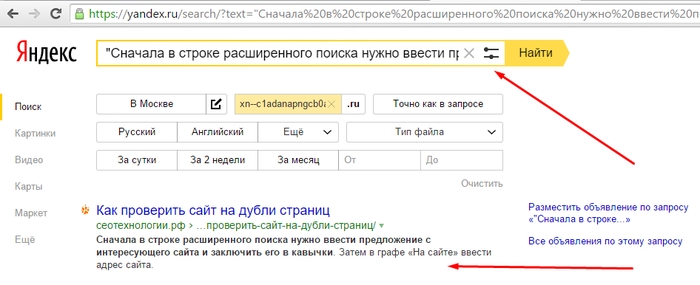 1000–1900
1000–1900
79041, г. Львов,
ул. Героев УПА 73,
корпус 10
Линкольн,
Англия
Алматы, Казахстан
Таллин, Эстония
Киев, Украина ул.
+380 44 333-69-73
Харьков, Украина ул. Отакара Яроша, 18
+38 057 752-54-62
Львов, Украина ул.
Героев УПА 73,корпус 10,

 Героев УПА 73,
Героев УПА 73,Лас-Вегас, США
Линкольн, Англия
Алматы, Казахстан
Таллин, Эстония
Мы в соцсетях
© 2004–2022 «Промодо»
7 инструментов, которые помогут вам найти повторяющийся контент на веб-сайте
Аудит веб-сайта
17 ноября 2017 г.
Наличие дублированного контента на вашем веб-сайте может привести к снижению рейтинга в поисковых системах. Наиболее важные поисковые системы, такие как Google и Bing, используют сложную и проницательную стратегию вознаграждения веб-страниц.
С высочайшим качеством уникального контента путем добавления их в свои индексы. При удалении веб-страниц с точным или «заметно похожим» контентом из поисковой выдачи.
В следующей статье представлен обзор дублированного содержимого. Как это может повлиять на вашу позицию в списках поисковой системы .
Мы также составили исчерпывающий список инструментов, которые вы можете использовать, чтобы убедиться, что ваш сайт пользуется популярностью. Руководству поисковой системы и предоставляет пользователям аутентичный контент.
Что такое дублированный контент и почему он важен?
В статье « Дублированный контент » в Справочном центре Google Search Console говорится, что:
«Дублированный контент относится к основным блокам контента внутри или между доменами.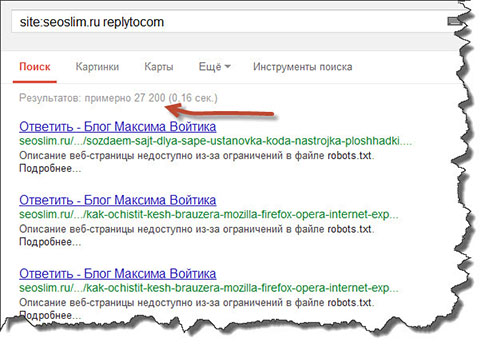 Они либо полностью соответствуют другому контенту, либо заметно похожи».
Они либо полностью соответствуют другому контенту, либо заметно похожи».
Дублирование частей контента, таких как блочное цитирование текста из другого источника (как сделано выше) или веб-сайтов электронной коммерции, цитирующих поставщиков, предоставляющих общие описания продуктов, неизбежно.
Однако серьезные опасения возникают, когда на значительном количестве веб-страниц вашего сайта размещено содержимое, аналогичное другим страницам в Интернете.
Хотя Google не налагает штрафов за дублированный контент, это влияет на позицию вашего веб-сайта в поисковых системах из-за некоторых факторов:
а) Поисковые системы не отображают несколько версий одного и того же материала; вместо этого они выбирают текст, который они считают наиболее подходящим в отношении запроса. Это ослабляет видимость вашей страницы
б) Входящие ссылки, которые могут указывать на ваш контент, вместо этого делятся на дубликаты, уменьшающие вес ссылок. Это разбавление влияет на рейтинг вашего веб-сайта, поскольку входящие ссылки являются основным решающим фактором для видимости сайта 9.0005
Это разбавление влияет на рейтинг вашего веб-сайта, поскольку входящие ссылки являются основным решающим фактором для видимости сайта 9.0005
В большинстве случаев дублированный контент создается не намеренно владельцами веб-сайтов. Несмотря на это, исследование, проведенное Raven Tools, показало, что 29% сайтов сталкиваются с проблемами дублированного контента.
Ниже приведены несколько способов, которые приводят к непреднамеренному созданию дублированного контента:
Варианты URL-адресов
Иногда одна и та же страница вашего веб-сайта находится в нескольких местах. Например, на веб-сайте электронной коммерции страница представлена. Найден предмет женской одежды со скидкой — как в разделе «Женская одежда», так и в разделе «Распродажа».
Идентификаторы сеансов — еще одна причина дублирования контента. Различные веб-сайты электронной коммерции используют идентификаторы сеансов для отслеживания поведения пользователей. Однако, когда каждому пользователю назначается другой идентификатор сеанса. Он создает дубликат основного URL-адреса страницы, на которой был применен идентификатор сеанса.
Однако, когда каждому пользователю назначается другой идентификатор сеанса. Он создает дубликат основного URL-адреса страницы, на которой был применен идентификатор сеанса.
Если у вашего сайта есть две разные версии, одна с префиксом www, а другая без префикса www, и каждая версия имеет одинаковое содержание, обе они конкурируют друг с другом за ранжирование в поисковых системах.
Скопированный контентЕсть несколько веб-сайтов, которые могут заниматься плагиатом, копируя сообщения в блогах или публикуя редакционные материалы. Практика, которая привела к дублированию контента и нахмурилась.
Однако различные веб-сайты электронной коммерции также создают дублированный контент. Когда они продают те же продукты на других сайтах, используйте стандартное описание продукта, предоставленное производителем.
Как исправить проблемы с дублированием?
Ниже приведены несколько технических решений для решения проблемы дублирования:
Канонический URL-адрес
Использование Канонического URL-адреса на каждой дублированной странице помогает поисковой системе идентифицировать исходную страницу, которая должна быть проиндексирована, и предотвращает дублирование URL-адресов. зарегистрирован. Следовательно, все ссылки, показатели контента и другие факторы ранжирования относятся к исходной странице.
зарегистрирован. Следовательно, все ссылки, показатели контента и другие факторы ранжирования относятся к исходной странице.
На каждой дублированной странице помогает поисковой системе определить исходную страницу, которую следует проиндексировать, и предотвращает регистрацию повторяющихся URL-адресов. Следовательно, все ссылки, показатели контента и другие факторы ранжирования относятся к исходной странице.
301 перенаправление
В большинстве случаев реализация 301 перенаправления является наиболее подходящим вариантом для предоставления приоритета исходной странице. Постоянный редирект 301. Пользователи и поисковые системы переходят на исходную страницу независимо от URL-адреса, который они вводят в браузере.
Применение перенаправления 301 на самую ценную страницу. Помимо всего прочего, дублированные страницы не позволяют разным страницам конкурировать друг с другом за ранжирование. А также усиливает фактор релевантности исходной страницы.
Мета Noindex, след.
Включив метатег Noindex follow Meta в HTML-заголовок страницы, вы можете предотвратить индексацию страницы поисковой системой. Поисковые системы могут сканировать страницу при обнаружении тега или заголовка. Они удалят страницу, чтобы она не попала в поисковую выдачу.
Перезапись контента
Простой способ выделить ваш контент. В частности, описания продуктов с других веб-сайтов электронной коммерции должны дополнять общую историю вашей формулировкой.
Это нацелено на определенную аудиторию и ее проблемы. Включите свое уникальное торговое предложение в контент, описывающий продукт, чтобы побудить пользователей покупать у вас.
Чтобы получить более полное представление о том, как создается дублированный контент и как предотвратить его создание или как исправить проблемы, прочитайте этот блог Нила Пателя, эксперта по маркетингу, консультанта и докладчика.
Инструменты для обнаружения дублированного контента
Прежде чем вы сможете внедрить решения для противодействия последствиям дублирования контента, вам необходимо проверить содержимое вашего веб-сайта, чтобы определить, что необходимо исправить.
Обнаружение повторяющихся материалов может быть интенсивным и трудоемким процессом; следующие инструменты могут упростить процесс и помочь вам найти дублирующийся контент на вашем веб-сайте:
Инструмент сканирования сайта MozMoz — широко известное имя в области SEO, входящего маркетинга, контент-маркетинга и построение ссылок. В дополнение к этим услугам Moz также предлагает Инструмент Site Crawl , который очень полезен для выявления дублирующегося содержимого страниц на веб-сайте.
Инструмент распознает дублированный контент как проблему с высоким приоритетом, поскольку повышенное соотношение дублированного контента к уникальному может значительно снизить доверие к веб-сайту в индексе поисковых систем .
Инструмент также позволяет экспортировать страницы с дублирующимся материалом, что упрощает определение неизменяемого, что необходимо реализовать.
Инструмент Moz является платным инструментом с 30-дневным бесплатным пробным периодом.
Siteliner
Siteliner — это фантастический инструмент для глубокого анализа дублирующихся страниц и близости их родства. Устройство идентифицирует не только скопированные страницы, но и конкретные области реплицированных текстов.
Эта функция удобна в некоторых случаях, когда большие объемы текстов дублируются, а вся страница не может быть реплицирована. Он также предлагает быстрый способ получить представление о страницах, которые содержат больше всего внутреннего дублированного контента.
Copyscape
Copyscape — один из старейших инструментов борьбы с плагиатом, который в основном важен для аудита контента веб-сайта с целью выявления внешнего редакционного дублирования контента.
Он сканирует карту сайта веб-сайта и сравнивает существующий URL-адрес по отдельности с индексом Google, чтобы проверить наличие дубликатов на ваших страницах.
Экспортирует данные в виде CSV-файла и ранжирует страницы по дублированному содержимому, при этом самой реплицируемой странице присваивается наивысший приоритет.
Вы также можете приобрести подписку на инструмент за символическую плату для проверки на плагиат содержимого, которое вы создаете в документе Word.
Screaming Frog
Screaming Frog — это лягушка, которая очень известна среди продвинутых SEO-специалистов, поскольку, помимо прочего, для дублирования контента она выявляет потенциальные технические проблемы, неправильное перенаправление и сообщения об ошибках. .
Создает подробный отчет о сканировании вашего сайта и отображает все заголовки, URL-адреса, код состояния и количество слов, что упрощает просмотр и сравнение заголовков и URL-адресов для выявления дубликатов.
Страницы с низким количеством слов могут быть рассмотрены на предмет качества и переписаны в случае низкого качества, а столбец состояния может помочь определить страницы с ошибками 404, которые необходимо удалить.
Консоль поиска Google
Консоль поиска Google можно использовать для обнаружения различных проблем с дублированием контента:
1. Она определяет определенные URL-адреса с повторяющимися тегами заголовков и мета-описанием
Она определяет определенные URL-адреса с повторяющимися тегами заголовков и мета-описанием
2. В статусе индекса , необычно высокий объем индекса для вашего сайта может указывать на проблемы с дублированным содержимым
3. Раздел параметров URL может помочь вам определить, возникают ли у Google проблемы со сканированием и индексированием вашего сайта, которые ссылаются на технически созданные повторяющиеся URL-адреса предоставляется другими поисковыми системами, такими как Bing. Однако, по сравнению с Screaming Frog, он предлагает ограниченные возможности и отсутствие дополнительной информации. Услуга бесплатна для установки на вашем сайте.
Duplichecker — один из лучших бесплатных инструментов для проверки на плагиат, который позволяет выполнять полезный поиск по тексту и URL-адресам, чтобы исключить плагиат в вашем тексте.
Инструмент разрешает неограниченные поиски после регистрации и разрешает один бесплатный пробный поиск.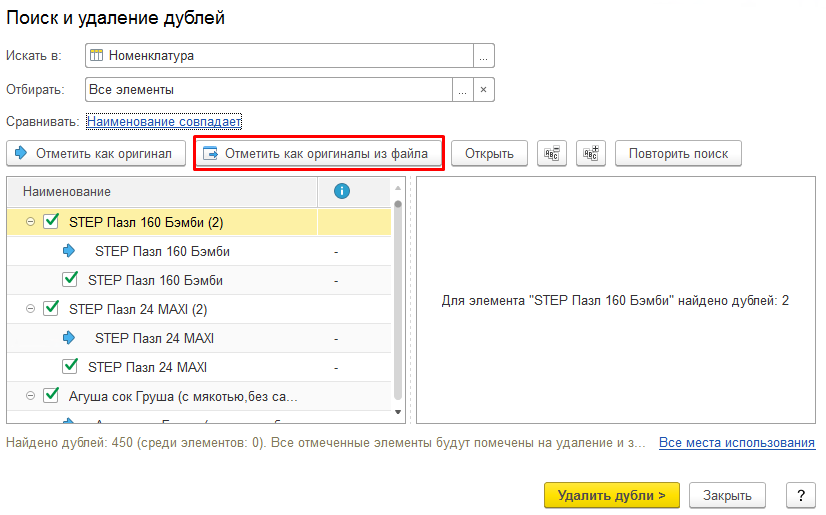 Весь процесс сканирования проводится за короткое время; однако время зависит от длины текста и размера файла.
Весь процесс сканирования проводится за короткое время; однако время зависит от длины текста и размера файла.
Это качество инструмента уступает продвинутым платным инструментам, таким как предоставленный Moz.
Plagspotter
Plagspotter — еще один бесплатный инструмент для борьбы с плагиатом. Поиск URL-адресов, осуществляемый этим устройством, является тщательным и быстрым и дает источники дублированного контента для дальнейшего просмотра.
В дополнение к бесплатному поиску URL-адресов, он также предлагает множество ценных функций в доступной платной версии, включая полное сканирование сайта, мониторинг плагиата и пакетный поиск. Вы также можете подписаться на их бесплатную 7-дневную пробную версию.
Заключение
Дублированный контент, будь то внутренний или внешний, может оказать существенное влияние на ваш рейтинг в поисковых системах и общую видимость вашего веб-сайта. Поэтому крайне важно создавать аутентичный, надежный, привлекательный и уникальный контент в меру своих возможностей.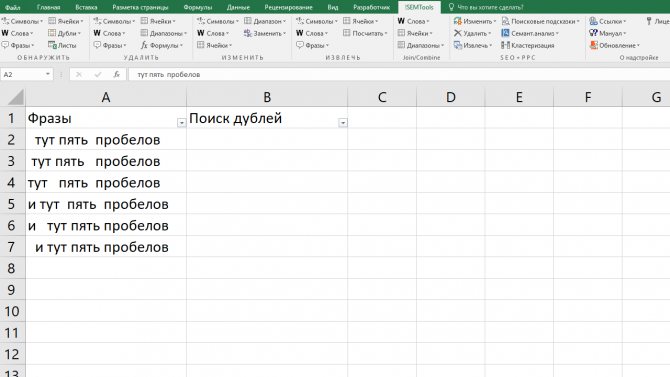
Несмотря на опыт Google в обнаружении непреднамеренного дублирования, наилучшей практикой является защита вашего контента от плагиата посредством периодического аудита контента веб-сайта с помощью творческих инструментов и последующего исправления обнаруженных проблем.
RoboAuditor — это встраиваемый инструмент SEO-аудита, , который генерирует в 4 раза больше потенциальных клиентов с уже имеющимся у вас трафиком.
Теги: Скопированное содержимое, Поиск повторяющегося содержимого
Автор
Автоматическое определение дубликатов документов во время обработки
До четырех поля документа могут быть использованы для выявления дубликатов документы в интерпретации на основе текущей соответствующей информации в базе данных для ранее обработанных документы. Идентифицированные таким образом документы затем помещаются в папку Дубликаты в Входящие в Verify. Это настроено в два этапа:
- Определите, какие поля используются для идентификации повторяющихся документы
- Создать папку для дубликатов документы в папке «Входящие»
Определите, какие поля используются для идентификации повторяющихся документы
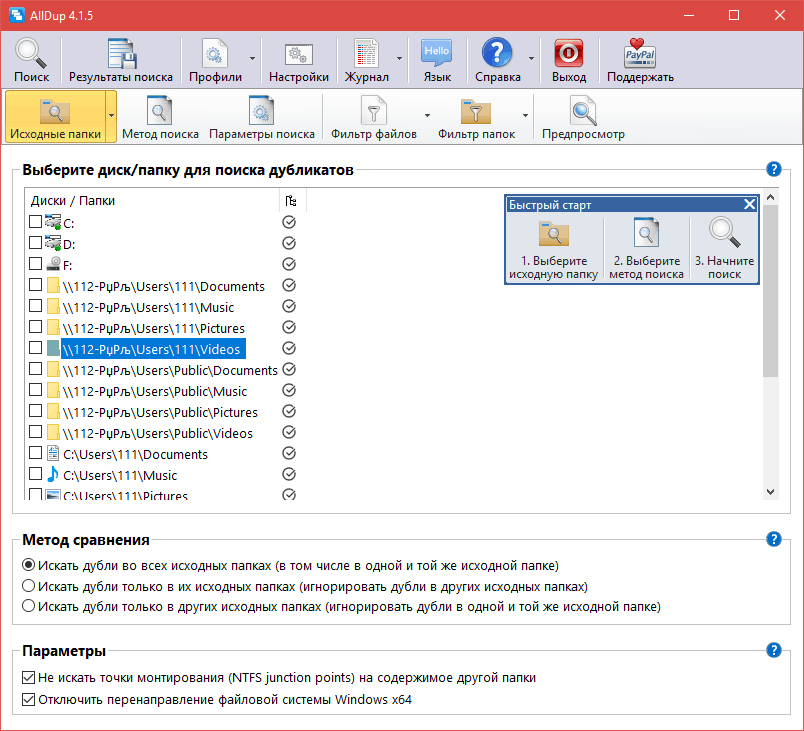
Примечания:
- В приложении «Менеджер» нажмите «Настройки» > «Входящие». конфигурации, а затем щелкните
Настроить
дубликаты документов.
- в Настройте поля для диалогового окна дублирования счетов, определите до четырех полей, используя И или ИЛИ модификаторы для идентификации документы. Обратите внимание, что приоритет полей в диалоговом окне сверху вниз, и если Для поля не указано значение None, как для этого поля, так и для любых последующих полей, указанных в диалоговом окне. не будет учитываться при поиске дубликатов документы.
- Нажмите ОК, чтобы сохранить изменения.
 конфигурации, а затем щелкните
Настроить
дубликаты документов.
конфигурации, а затем щелкните
Настроить
дубликаты документов.- Примечания:
- Когда данные журнала процесса удаленный из базы данных с помощью плана обслуживания или очистив базу данных, не будет никаких документировать данные для сравнения с использованием этой функции до тех пор, пока не будет добавлено документы обработаны.
- Вы можете ограничить поля, доступные для выбора в
раскрывающиеся списки, перечисляя только нужные поля в
Раздел [DuplicateIdentifier]
Eiglobal.ini (дополнительную информацию см. в справке по файлу INI).
 в справке по файлу INI).
в справке по файлу INI).Создать папку для дубликата документы в папке «Входящие»
Для отображения документы, идентифицированные как дубликаты, для пользователей в папке «Входящие» в определенной папке, выполните следующие действия:
- В рамках процесса к создать или отредактировать почтовый ящик, в Входящие диалоговое окно конфигурации, нажмите Редактировать папки.
- в Изменить папку «Входящие» диалоговое окно папок, нажмите для создания корневого узла с именем Duplicates в иерархии выбора.
- В зависимости от того, что лучше для вашей ситуации, вы можете нажать один раз, чтобы создать один дочерний узел для всех дубликатов документы, или вы можете использовать его несколько раз, чтобы создать дочерний узел для каждого профиль документа, например.
- Щелкните дочерний узел, чтобы выбрать его, а затем щелкните
Примените критерии выбора к этой папке/группе справа на экране, чтобы отобразить критерии
которые можно указать для папки. Если было создано более одного дочернего узла, необходимо выполнить этот и следующие шаги.
сделано для каждого.
- На Профили документов нажмите кнопку профиль(и) документа, для которого вы хотите дублировать документы для размещения в дочернем узле.
- На Вкладка Статусы, нажмите Дублируйте, чтобы выбрать его, и снимите выделение любых других статусов, если таковые имеются.
- Необязательно: можно указать дополнительные критерии, если вы хотите, чтобы любой из этих дочерних узлов применялся к дубликату. документы для конкретных приемники, очереди или пользовательские переменные. Однако обратите внимание, что все указанные критерии должны быть соблюдены для документы должны быть помещены в соответствующую папку входящих сообщений.
- Нажмите ХОРОШО.
- Если вы хотите, чтобы эти папки видели только определенные пользователи, вы можете
создайте роли авторизации пользователей для этой цели, а затем свяжите соответствующих пользователей с
роль. Обратите внимание, что если выбранный вами пользователь
ограничено от просмотра
а
профиль документа, выбранный для роли, они не увидят дубликат
документы на это
профиль документа в папке в Верифицировать во время обработки.
- Когда закончите, нажмите ОК, чтобы сохранить изменения.
 Если было создано более одного дочернего узла, необходимо выполнить этот и следующие шаги.
сделано для каждого.
Если было создано более одного дочернего узла, необходимо выполнить этот и следующие шаги.
сделано для каждого.
Как это работает
При выявлении дубликатов документы настроены в соответствии с вышеизложенным, Вход Kofax ReadSoft проверяет указанные поля в Interpret и сравнивает их с информацией о дубликате счета-фактуры, найденной в база данных. Если потенциал найдены документы с совпадающими полями, им даются статус «Дублировать», и они помещаются в соответствующую папку «Дубликаты» в папке «Входящие» в разделе «Проверка» в зависимости от того, как он был настроен.
Только те документы, для которых все поля получают Полный статус, рассматриваются как потенциальный дубликат документы. Кроме того, если какое-либо поле на а документ имеет более одного предложенного значения, что документ не рассматривается как потенциальный дубликат документ, даже если поле получает Полный статус.
Если значения полей изменены в Verify for
а
документ, который ранее использовался для идентификации дубликатов
документы, обновленные значения используются для идентификации последующих дубликатов
документы в интерпретаторе.