Иногда возникают такие ситуации, когда надо поскорее сообщить поисковой системе об улучшении или изменении содержимого страницы: структуры, оптимизации или контента. Для этого у каждой поисковой системы есть свои инструменты, позволяющие принудительно пригласить поискового робота, чтобы он просканировал конкретный url. Для использования этих инструментов обязательно должны быть подтверждены вебмастера поисковиков. Особенностью их является то, что они помогают ускорить индексацию страниц только того сайта, владение которым верифицировано.
Переиндексация страниц в Google
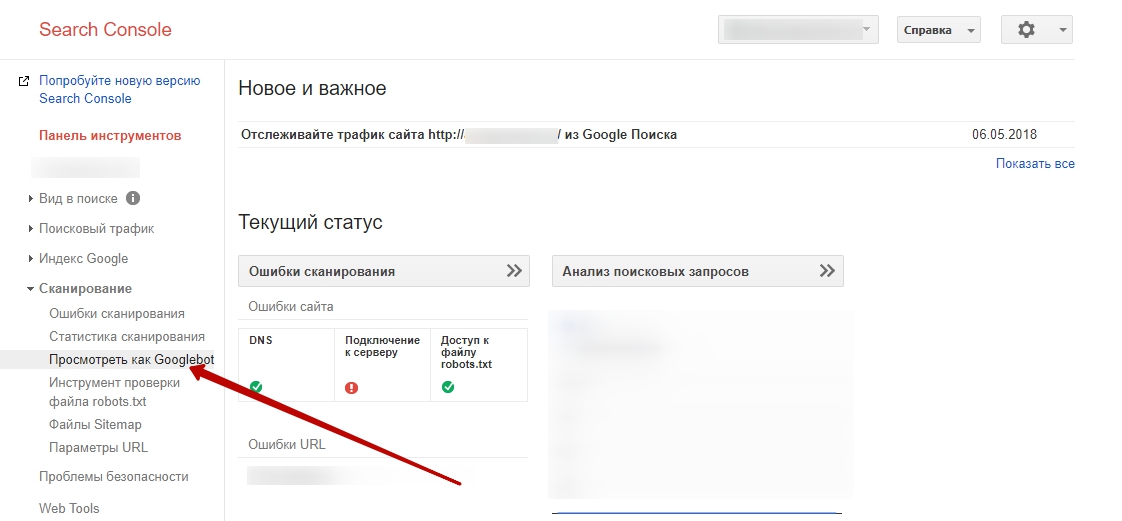
В Google это можно сделать в разделе Сканирование – Посмотреть как Googlebot. В последней версии вебмастера есть возможность выбрать, какую версию страницы нужно сканировать:
десктопную для ПК;
мобильную для смартфонов.
Также есть возможность выбрать тип сканирования:
“Сканировать” – это быстрое сканирование для получения кода ответа http страницы без обращения к ресурсам страницы;
“Получить и отобразить” – это полное сканирование страницы с получением кода ответа http, загрузкой контента, скриптов и изображений.
После того как вебмастер “получил и отобразил” страницу, её можно отправить на переиндексацию двумя вариантами:
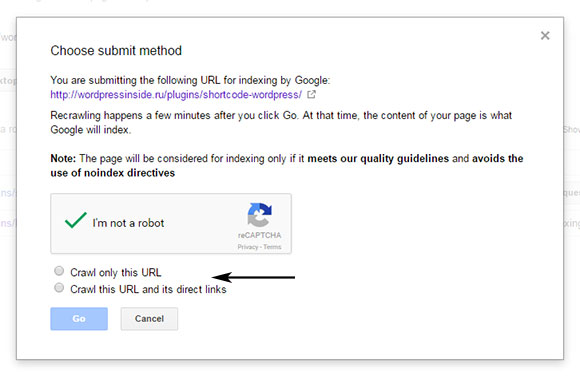
сканировать только указанный url;
сканировать указанный url и все прямые ссылки с него.
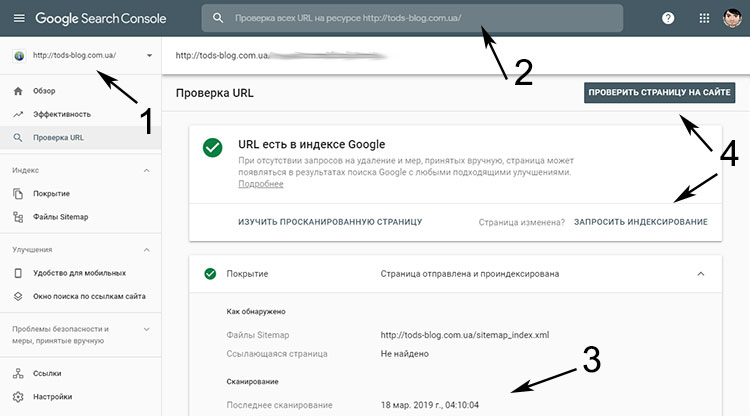
В новой версии Search Console Google адрес страницы достаточно вставить в поле проверки URL.
Больше о возможностях вебмастера Google можно узнать на SEO курсах.
Переиндексация страниц в Яндексе
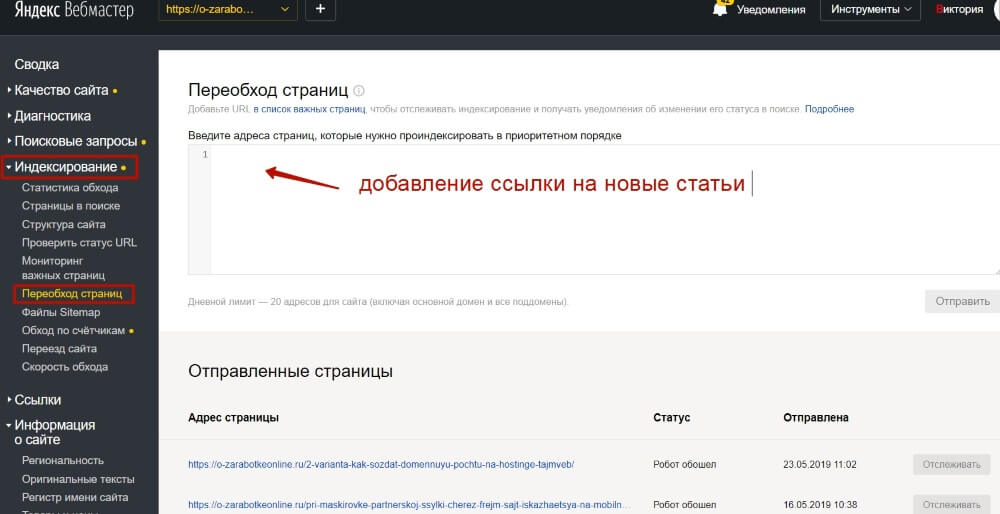
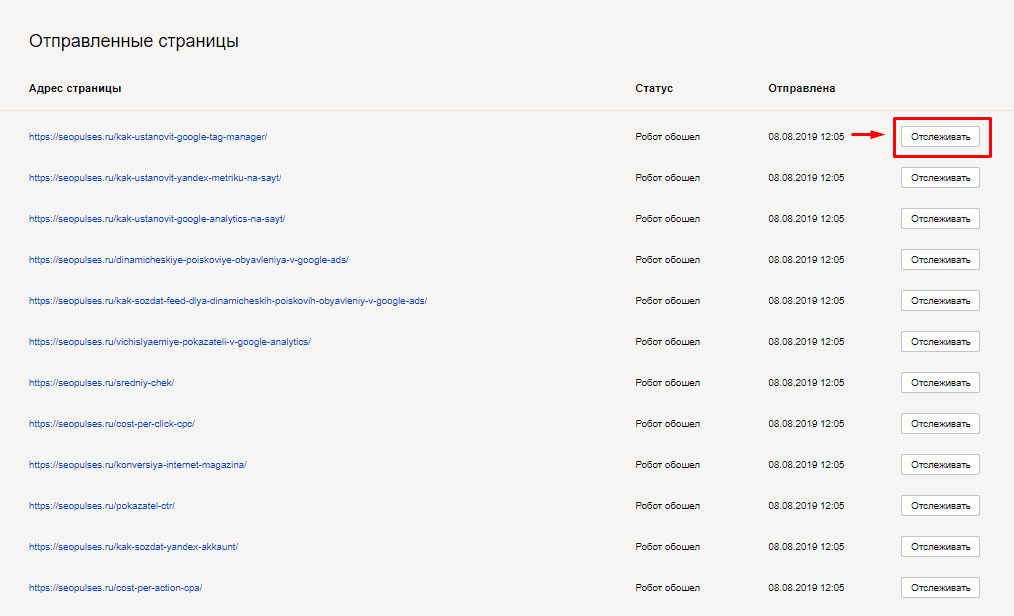
В Яндексе тоже доступна процедура принудительного вызова робота, для этого нужно зайти Индексирование – Переобход страниц.
У Яндекса нет такого расширенного функционала для ручной отправки страниц на переиндексацию. Здесь вы просто в столбец указываете все нужные страницы и отправляете. Когда робот их переобойдёт, в отчёте ниже это будет указано.
У Яндекса есть ограничение в 20 страниц в день.
Комплексная раскрутка сайтов в Днепре доступна по контактам внизу страницы.
Аддурилка – добавление новых страниц в поиск Яндекс и Google
Аддурилка (адурилка) – устоявшееся в среде SEO-оптимизаторов жаргонное название, которое происходит от фразы «add URL» – добавить URL. Означает инструменты поисковых систем Яндекс и Google, позволяющие принудительно добавить страницы сайта в поисковую базу (принудительная индексация страниц).
Точнее, есть два момента:
В свою базу поисковая система добавляет страницы сама после их обхода своими роботами, что происходит регулярно, но с определёнными интервалами. Аддурилка же даёт поисковым роботам сигнал о том, что указанную веб-страницу надо проиндексировать быстро – в приоритетном порядке.
Если страница имеет глубокий уровень вложенности (больше 3), поисковики могут просто её проигнорировать при обходе сайта: слишком глубоко. Аддурилка же позволяет гарантированно направить поисковые роботы на эти страницы – «загнать» страницы в поиск.
Добавить страницу в Яндекс
В вебмастере Яндекса (Яндекс.Вебмастер) аддурилка – это инструмент «Переобход страниц», расположенный в разделе «Индексирование». Он используется как для добавления новых, так и для ускоренной переиндексации старых страниц, если на них изменился контент.
Если Вы только запускаете сайт, т.е. недавно сформировали на нём xml-карту (общ. назв. – sitemap.xml) или добавили новую xml-карту (их может быть несколько), то эту(и) карту(и) также следует указать для поисковой системы, т.к. это в целом файл(ы), в котором(ых) как раз и отражён перечень страниц сайта, предназначенных для индексации. Указывать карту следует, если она содержит новый URL (страницу), предназначенный для индексации. В Яндекс.Вебмастере это делается с помощью инструмента «Файлы Sitemap» в разделе «Индексирование». При переиндексации нового контента на старой странице указание xml-карты не требуется, т.к. URL страницы остаётся прежним, т.е. уже присутствует в ранее указанной для поисковика xml-карте.
Добавление страниц в аддурилку также помогает защитить контент от воровства. Точнее, физически от воровства контент аддурилка не защищает. Но приоритетная индексация с помощью аддурилки закрепляет за сайтом оригинальность контента. Если аналогичный контент позже появится на другом сайте, он уже будет признан поисковой системой как дубль и не получит высокие позиции (может наоборот получить санкции, т.е. понижение позиций в выдаче). Не во всех случаях это 100%-но срабатывает, но в целом является полезным инструментом.
В Яндекс.Вебмастере существует ещё один инструмент для защиты контента от воровства – «Оригинальные тексты». Он расположен в разделе «Информация о сайте». В поле этого инструмента вставляются текстовые блоки с сайта (изображения и прочий медийный контент не учитываются). То есть в данном случае нет привязки контента к конкретному URL, а также Яндекс не гарантирует, что контент 100%-но закрепится за сайтом как авторский. Видимо, разработчики сделали этот инструмент как страховочный. Но использовать его также рекомендуется – вместе с другими инструментами индексации контента.
То есть стандартно при создании новой страницы сайта следует добавить её URL в аддурилку («Переобход страниц»), если нужно – указать xml-карту («Файлы Sitemap») и указать Яндексу свежий текстовый контент страницы («Оригинальные тексты»).
Инструмент «Переобход страниц» позволяет индексировать страницы по одной. Для ускоренной массовой индексации страниц следует воспользоваться инструментов «Файлы Sitemap».
Добавить страницу в Google
На данный момент (декабрь 2018) вебмастер Гугла (Google Search Console) работает в двух версиях – старой и новой. В обеих есть два инструмента принудительной (пере)индексации страниц.
Первый инструмент – это сервис «Просмотреть как Googlebot», расположенный в разделе «Сканирование». В нём задаётся URL страницы, указывается формат (ПК или мобильный), и выбирается одна из двух опций: «Сканировать» или «Получить и отобразить». При «Сканировании» вебмастер прочитает и отобразит HTML-код страницы, как его видит поисковая система. Опция «Получить и отобразить» выдаёт снимки страницы, как её видит система (Googlebot) и посетитель. В обоих случаях после обработки запроса появляется дополнительная опция «Запросить индексирование».
Это и есть аддурилка. В таком режиме страницы можно индексировать только по одной и в ограниченном количестве (как и в «Переобходе страниц» Яндекс.Вебмастера).
Массовая индексация страниц в старой версии Google Search Console делается с помощью инструмента «Файлы Sitemap», находящегося в разделе «Сканирование». Этот инструмент аналогичен одноимённому инструменту Яндекс.Вебмастера (см. выше).
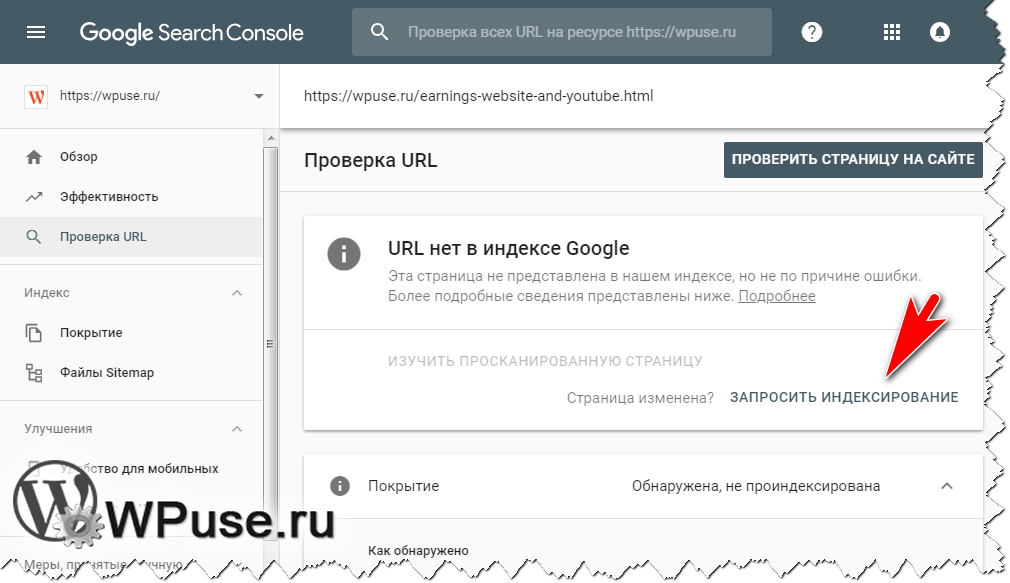
В новой версии Google Search Console аддурилка представлена инструментом «Проверка URL». При выборе этого инструмента появляется поле, в которое следует ввести адрес страницы. После обработки запроса появится опция «Запросить индексирование». Данный инструмент может использоваться для принудительного индексирования как новых, так и старых страниц, если на них изменился контент. То есть он аналогичен инструменту «Переобход страниц» Яндекс.Вебмастера (см. выше).
В новой версии Google Search Console также сохраняется инструмент пререобхода и добавления xml-карт(ы), который имеет прежние функционал и название – «Файлы Sitemap».
Замечания
При принудительном добавлении страниц в поисковую систему следует убедиться, что эти страницы доступны для индексации в файле robots.txt. Яндекс.Вебмастер и Google Search Console предоставляют специальные инструменты для проверки данного файла, его обновления и проверки доступности в нём отдельных страниц сайта.
Действия с сайтом через Яндекс.Вебмастер и Google Search Console может выполнять только администратор сайта, который изначально должен добавить веб-ресурс в эти сервисы (подтвердить права на сайт).
Вышеописанные вопросы касаются поискового продвижения сайтов (SEO), в котором существует немало других вопросов – порой достаточно сложных и требующих хорошей экспертизы. Если у Вас стоят задачи по эффективному продвижению вашего сайта в поисковых системах, или имеются отдельные вопросы по SEO, мы рекомендуем Вам обращаться в нашу компанию. Мы окажем Вам любую помощь вплоть до комплексного продвижения Ваших веб-ресурсов.
Заказать поисковое продвижение
Неуникальными карточки товаров и что с ними делать?
Что делать с неуникальными карточками товаров: прятать или улучшать?
Конкуренция среди интернет-магазинов с каждым годом растет. Но несмотря на это, ассортимент у них схож: одни и те же товары, характеристики к ним и даже описание. Например, информация о смартфоне Samsung A51 на разных сайтах:
Как видите, тексты практически идентичные. Ладно, само описание можно подкорректировать и добавить уникальности, но технические характеристики уникализировать никак не получится. Поэтому у владельцев сайтов возникает вопрос – не накажут ли поисковые системы за подобный контент и что вообще делать с такими карточками товаров?
Руководитель отдела PR агентства 1PS. RU Ксения Захарова рассказала, как уникализировать карточки товаров и дала 4 полезных совета владельцам интернет-магазина (и тем, кто пишет карточки).
Отношение поисковиков к неуникальным карточкам товаров
На самом деле поисковые системы понимают, что невозможно сделать карточки товаров полностью уникальными, поэтому серьезных санкций для сайта не будет.
Например, Яндекс просто исключает из индекса карточки, которые не проходят по уникальности, и присваивает им статус в Яндекс.Вебмастер как «Малоценная и маловостребованная страница». Если увидите у себя данную пометку, то такие страницы необходимо уникализировать, чтобы Яндекс вернул их в поиск.
Чтобы посмотреть, какие страницы попали под алгоритм, достаточно зайти в Яндекс.Вебмастер, затем на вкладку «Индексирование» и выбрать «Страницы в поиске».
После переходим на вкладку «Исключенные страницы» и настраиваем фильтрацию по статусу «Малоценная и маловостребованная страница».
После того, как поработаете над неуникальными страницами, отправьте их на переиндексацию. Это можно сделать в разделе «Индексирование», далее «Переобход страниц».
В Google дела обстоят по-другому. Прямого указания на то, почему страница была исключена из поиска из-за неуникального контента, вы не найдете. Максимум, что увидите – это статус в Google Search Console, что она обнаружена, но не проиндексирована, или страница просканирована, но пока не проиндексирована.
Но по итогу Гугл также с пониманием относится к неуникальным карточкам товаров.
С восприятием неуникальных карточек товаров поисковиками разобрались, теперь можно перейти к вариантам решения проблемы. И начнем мы не с лучших способов.
Стоит ли прятать неуникальные карточки товаров?
Использовать тег <meta name=»robots» content=»noindex,nofollow» />
Данный тег позволяет закрыть от индексации неуникальные страницы. Но это не выход, так как поисковые роботы не будут видеть страницу, а значит, и товар не смогут найти пользователи.
Как минимум такие необдуманные действия грозят тем, что вы потеряете львиную долю трафика на свой сайт. Поэтому если у вас большое количество товаров, описание которых было взято с сайта производителя, то этим вариантом лучше не пользоваться.
Использовать тег <noindex>
Данный тег помогает спрятать часть текста от поисковых роботов. Он был предложен Яндексом в качестве альтернативы атрибуту nofollow. Но минус в том, что полностью игнорируется Google. Поэтому получается, что Гугл этот текст все равно проиндексирует.
Давайте немного разберемся, как это работает. В коде страницы, если мы укажем текст между тегами и , то поисковые роботы Яндекса проиндексируют ее, но этот текст не будет ими учтен.
Пример:
<noindex> текст, который мы хотим скрыть от поисковика </noindex>
Но обращаем внимание еще раз, что данный тег учитывает только Яндекс. Все остальные поисковые системы его полностью игнорируют. Из-за этого при валидации может возникнуть ошибка. Чтобы этого избежать, стоит прописать тег в следующем виде:
<!—noindex—>текст, который мы хотим скрыть от поисковика <!—/noindex—>
Отказаться от контента
И такое тоже бывает. Некоторые владельцы сайта думают, что нет контента, а значит, нет и проблем. Но это в корне неверно.
Тексты на сайте в первую очередь нужны пользователям, чтобы понимать, что они приобретают, какими характеристиками обладает товар и чем вообще одна модель отличается от другой. И если на сайте нет текстов, то о покупке речи быть не может, ведь потребителю проще уйти к конкуренту, чем покупать кота в мешке.
После того как разобрались с вредными советами, можно перейти к способам уникализации карточек товаров.
Как сделать карточку товара уникальной?Совет №1. Писать уникальные тексты
Понимаю, что на такое заявление хочется сказать только «Спасибо, Кэп». Однако это одно из лучших решений. Да, технические характеристики вы не сможете придумать и уникализировать, но все остальное – вполне.
Такой совет будет рабочим, если у вас в интернет-магазине не так много товаров, но если их количество переваливает за тысячи, то ручками тут уже уникальное описание не попишешь. Чтобы решить эту проблему, специалисты используют маски товаров внутри CMS или размножают текст для определенной категории продукции.
Помимо этого, рекомендуем оптимизировать Title и h2. Можно прописывать модель, цвет, технические характеристики, артикул и другие параметры. Самое главное, чтобы информация смотрелась гармонично и давала пользователю представление о товаре.
Чтобы написать привлекательное описание для своего товара, сделайте следующее:
Определите целевую аудиторию и подумайте, почему она должна купить ваш продукт
Выделите достоинства товара перед другими моделями и постарайтесь их описать. Здесь можно даже покреативить и придумать что-то новенькое и необычное.
Совет №2. Используйте дополнительный контент
Если сделать уникальное описание никак не получится, то используйте дополнительные блоки в карточке товаров. Например, такие:
С этим товаром покупают
Похожие товары
Смотрите также
Возможно, вас заинтересует
Рекомендуем набор
Так вы разбавите неуникальный текст, к тому же блоки положительно влияют на конверсию сайта, на поведенческие факторы и позволят сделать допродажи. Поэтому пренебрегать этим разделом ни в коем случае не стоит.
Совет №3. Отзывы, комментарии и вопросы
Дайте возможность пользователям делиться своим мнением о товаре. Отзывы – это тоже контент, и контент уникальный. И если люди напишут комментарий к вашему товару, то это будет только плюсом при ранжировании.
Еще у отзывов есть дополнительное достоинство, которое влияет на продажи – это доверие. Чем больше положительных оценок товара, тем больше доверие к продукту у потенциальных покупателей.
Но стоит отметить, что если у вас на сайте отзывы подгружаются через сторонние сервисы, то толку от них никакого не будет. Дело в том, что поисковые роботы не увидят комментарии, так как они по факту принадлежат сервису, а не самому сайту, где размещен отзыв.
Что касается блока вопросов, то он тоже весьма полезный. Позволяет создавать дополнительный контент, который бы раскрыл преимущества товара. Смотрите сами: посетитель сайта задает свой вопрос, а менеджер или другие пользователи отвечают на него и рассказывают о самом продукте. Таким образом получается произвольная генерация контента.
Совет №4. Дополнительная информация
Безусловно, делать уникальное описание товара довольно сложно, поэтому стоит разбавить текст такими блоками, как:
Это позволит сделать карточку товара более уникальной.
Стоит отметить, что эта информацию нужна не только для того, чтобы уникализировать карточку товара, но и для того, чтобы у пользователя не осталось вопросов о схеме и сроках получения своего заказа. Чем будет больше информации о нюансах работы, тем лучше.
Вывод
Уникализация контента – дело непростое и весьма трудозатратное. Но несмотря на то, что от поисковиков сайт не получит страшных санкций, вы можете потерять трафик на определенные позиции. Это не критично, но есть большой минус – если этот товар на рынке популярен, а карточка вылетела из поиска, то ваш продукт пользователи просто не найдут в выдаче. Отсюда получается следующее: нет трафика – значит, нет и продаж.
Поэтому если вы не хотите, чтобы подобное произошло, поработайте над уникальностью контента за счет описаний, дополнительных блоков и других фишек, которые мы описали в статье. К тому же это будет полезно для конверсии, поведенческих факторов, а также может косвенно повлиять и на средний чек заказа.
как добавить, проверить, исправить ошибки
Вы решили создать сайт. Выбрали перспективную тематику, придумали доменное имя и развернули ресурс на хостинге. Что делать дальше? Следующий шаг — добавление сайта в Google и Яндекс. Это очень важно, поскольку пока о сайте не узнают поисковые роботы, пользователи не смогут находить вас через поиск. Ресурс будет нормально работать, но не сможет получать самое ценное — органический трафик.
Забегая вперед отметим, что первые полгода-год рассчитывать на поток органики нет смысла. Молодой сайт по умолчанию попадает в песочницу и его видимость в поиске ограничена. Больше о том, что такое песочница и как из нее быстрее выйти — читайте здесь.
В добавлении в индекс нет ничего сверхсложного. Если коротко: нужно создать учетные записи в вебмастерках Google и Яндекса и подтвердить в них права на владение сайтом; далее создаем карту сайта в xml-формате и забрасываем ее в соответствующие разделы каждого из сервисов. Теперь наглядно и более детально, как это делать. По ходу дела будем давать ответы на самые животрепещущие вопросы, возникающие у новичков.
Вам также может быть интересен наш курс молодого seo-бойца, как создать и по-белому продвинуть сайт, имея скромный бюджет:
Выбираем тематику, оцениваем перспективность ниши, анализируем конкурентов, собираем семантику Проводим стартовые работы по внутреннему и внешнему SEO
Индексируем сайт в Google
Основной способ добавить ресурс в поиск Google — сделать это посредством Google Search Console. Вы можете встретить и другие варианты, но связываться с ними мы бы категорически не советовали, ниже расскажем почему.
Google Search Console — это бесплатный сервис для вебмастеров, через который отслеживают все жизненно важные параметры сайта в поисковой системе Google. О назначении и основных фишках консоли можно почитать здесь. Ну, или просто поверьте на слово, что привязка сайта к этому сервису — мастхэв для любого вебмастера, конечно, если вы не намерены пренебрегать трафиком из Гугла.
Подтверждаем права на сайт в Google Search Console
Для начала вам понадобится — аккаунт в Google. Он создается за пару минут здесь. Далее переходим на страницу сервиса и привязываем к нему свой сайт. Но сначала нужно пройти верификацию, что вполне логично, т.к. система должна убедиться, что права на сайт принадлежат вам.
Так приветствует Search Console. Начинаем верификацию. Мы покажем самый популярный (да, он не один) способ подтверждения прав — с помощью DNS.
Сначала указываем сайт. Можно ввести либо просто доменное имя (слева), либо URL ресурса (справа). Подробные подсказки даны в каждом из полей.
Прописав имя сайта, и нажав продолжить, появится окно с перечнем вариантов, каким именно способом вы желаете подтвердить права на сайт. Выбираем «Добавление записи DNS в конфигурацию домена». Вам будет доступно окно, изображенное на скриншоте. Сгенерированная TXT-запись – это персональный ключ верификации, который нужно добавить в конфигурацию DNS домена в панели управления хостингом.
Давайте посмотрим, как это сделать на примере самой популярной панели управления веб-хостингом cPanel. В блоке «Домены» переходим в Zone Editor, выбираем нужный домен (если он не один) и нажимаем «Управлять».
Откроется новое окно.
В нем еще раз выбираем интересующий нас домен (в поле «имя»), а в графу «запись» вводим скопированный TXT-ключ. Нажимаем «Добавить запись».
Права на сайт подтверждены, но нужно подождать несколько часов пока обновится DNS.
Есть и другие способы подтверждения прав в Google Search Console. Возможно, они и несколько сложней для новичков, но хороши тем, что позволяют пользоваться консолью сразу после верификации. Это может быть удобно, когда по каким-то причинам нет времени ждать обновления DNS. Подробно об остальных способах верификации — читайте в справке Google.
Отправляем запрос на индексирование
После того как мы добавили сайт в вебмастерку и прошли верификацию, отправляем запрос на индексирование. Для этого:
1. Переходим во вкладку «Проверка URL».
2. В поисковой строке консоли вбиваем адрес ресурса (или новой страницы).
3. Запрашиваем индексирование.
Если указанный URL доступен для сканирования поисковыми роботами (их также называют краулерами), страница попадает в очередь на индексирование, о чем вас уведомят следующим сообщением.
Но это еще не все.
Создаем и добавляем sitemap.xml
Чтобы помочь краулерам Google корректно проиндексировать сайт, в вебмастерку необходимо загрузить карту сайта. Начинающие вебмастера почему-то думают, что это очень сложно. Расслабьтесь, это не так. Все просто, но давайте по порядку. Sitemap.xml — это список XML-документов, в которые вшиты служебные данные. Вся эта информация — своего рода ориентиры, необходимые поисковым системам для удобной и эффективной индексации всех страниц сайта.
Выглядит sitemap.xml вот так:
Сгенерировать sitemap.xml можно при помощи специальных программ и даже онлайн-сервисов. С сайтами на WordPress, все еще проще: можно использовать плагины Yoast или Google XML Sitemaps, которые сделают большую часть работы сами.
Сгенерировав файл sitemap.xml, далее его нужно загрузить на сервер. Обратите внимание, это актуально, если вы создавали карту сайта с помощью сервисов или программ. В cPanel это делают через «Диспетчер файлов», доступный в блоке «Файлы» на стартовой странице.
Если использовались плагины для WordPress, файл sitemap.xml подтянется на сервер автоматически.
Остался финальный аккорд — забрасываем карту сайта в соответствующий раздел Google Search Console: Индекс → Файлы Sitemap
Добавляем Sitemap и нажимаем отправить
Об альтернативных способах индексирования
На форумах вебмастеров можно встретить дискуссии, на тему альтернативных способов отправки страниц в индекс. Например, многие оптимизаторы уверены, что если прогрузить в браузере Google Chrome главную или новые страницы сайта, они автоматически залетят в гугловский индекс. Или, что если добавить на непроиндексированные страницы код счетчика Google Analytics, поиск автоматически получит информацию о появлении новых документов, которые необходимо просканировать.
Эти способы, не требующие практически никаких усилий, могут показаться привлекательными для начинающих вебмастеров. Но связываться с ними мы бы категорически НЕ рекомендовали. Нет убедительных оснований считать, что Google Chrome и GA каким-либо образом влияют на индексирование страниц. Это подтверждено, в том числе, экспериментально1. В самом Google также никогда официально не высказывались на этот счет.
Поэтому пользуйтесь только общепризнанным алгоритмом добавления в индекс Google. Еще раз, теперь уже вкратце, подытожим, что нужно делать:
Создаем аккаунт в Google и добавляем свой сайт в Search Console.
Подтверждаем права на сайт. Самый простой способ — с помощью DNS.
Отправляем запрос на индексирование.
Создаем файл sitemap.xml и добавляем его сначала на сервер, а затем в соответствующий раздел консоли. Если sitemap генерировался через плагины WordPress, загрузка на сервер не нужна.
Добавляем сайт в поиск Яндекса
Чтобы страницы нового сайта начали отображаться в поиске Яндекса их также нужно добавить в индекс. Механика процесса идентична поисковой системе Google. Добавление ресурса в поиск осуществляют через консоль Яндекс.Вебмастер. При этом есть и другие способы (о них мы расскажем ниже), но наиболее рабочим считается именно этот. Возможности вебмастерки Яндекса в целом аналогичны Search Console. Более подробно об этом сервисе можно почитать здесь.
Добавление в Яндекс.Вебмастер и подтверждение прав на сайт
Для привязки сайта к вебмастерке понадобится учетная запись в Яндексе. Если она есть, что вероятнее всего, т. к. многие пользуются почтой и другими яндексовскими сервисами, переходим сюда и указываем адрес сайта.
Как и в случае с гугловской консолью, дальше нужно пройти верификацию и подтвердить права. Сделать это можно по-разному:
создав HTML-файл с уникальным идентификатором, и поместив его в корневой каталог сайта;
разместив в HTML-коде главной страницы специальный метатег;
добавив DNS-запись с идентификатором;
подтвердив электронный адрес из WHOIS-записи (этот способ не рекомендуется даже самим Яндексом).
Для подтверждения прав удобнее всего использовать первый способ — через HTML-файл. Указав сайт и перейдя во вкладку, отмеченную на скриншоте, система сгенерирует файл с уникальным именем и содержимым. Его нужно скачать и разместить в корневом каталоге сайта. Далее проверяем, что файл открывается по указанной ссылке. Нажимаем кнопку «Проверить». Если все сделано правильно, панель инструментов слева станет кликабельной.
Добавляем сайт в индекс
После верификации и получения доступа к функционалу вебмастерки, выполняем следующие действия.
Переходим во вкладку «Индексирование» → «Переобход страниц»
Добавляем главную страницу и основные разделы сайта — нажимаем «Отправить». Обратите внимание, в Яндексе установлен лимит на количество индексируемых страниц.
Все новые страницы, которые в дальнейшем будут добавляться на сайт, отправляют на переиндексацию по аналогичной схеме.
Дополнительно в Яндекс.Вебмастер необходимо добавить файл sitemap.xml. Здесь работает та же механика, что и в Google. Сначала необходимо создать саму карту. Если это сделано не через плагин — размещаем sitemap на сервере. Далее в разделе «Индексирование» → Файлы Sitemap вписываем в поле URL, по которому доступен файл. Нажимаем «Добавить».
После добавления файл будет какое-то время обрабатываться. Это происходит не быстро, и может занять до двух недель. По завершении обработки напротив файлов должен отображаться статус «OK». Если присутствует статус «Редирект», «Ошибка» или «Не проиндексирован», необходимо определить причину некорректной индексации, исправить ее, после чего сообщить роботам об обновлении.
Индексируем страницы через Яндекс.Метрику
Существует еще один способ сообщить краулерам Яндекса о новых страницах сайта — через Метрику. Этот вариант менее удобен, чем первый, но знать о нем вебмастеру не помешает. Для этого на сайте должен быть добавлен и настроен счетчик Яндекс.Метрики. В любом случае рано или поздно его придется добавить, конечно, если вы намерены серьезно заниматься продвижением своего проекта.
Итак, чтобы роботы Яндекса подтягивали сведения о новых страницах из данных Метрики, нужно разрешить обход страниц, на которых установлен счетчик. Для этого выполняем следующие действия.
Индексирование → Обход по счетчикам→ Обход «включен»
Активировав эту опцию, во вкладке Привязка к Яндекс.Метрике отобразится статус «Связан с сайтом в Вебмастере».
Настройки → Привязка к Яндекс.Метрике
Сколько ждать попадания в индекс?
В индекс Google новый сайт залетает в среднем спустя неделю. В Яндексе — это может занимать до двух недель. Эти сроки актуальны, если на сайте не создано никаких препятствий для обхода поисковыми роботами. Важно понимать, попадание в индекс не означает, что страницы со старта получат высокие позиции в поиске. В первое время, скорее всего, они будут на задворках выдачи — на второй-третьей странице. И только постепенно начнут укреплять свои позиции. Также они могут вовсе не отображаться по основным поисковым запросам (находясь при этом в индексе). Второй сценарий больше актуален для молодых сайтов, пребывающих в песочнице.
Как быстро проверить индексацию?
Узнать, попал ли сайт в индекс, вы можете по-разному. Основной способ — через панель вебмастера.
В Google SC сведения представлены в отчете Индекс → Покрытие. Количество страниц, попавших в индекс, доступно в зеленой графе.
Здесь же красным цветом будет отображаться количество страниц с ошибками. Перейдя по вкладке, можно ознакомиться с расширенным отчетом: что конкретно за ошибка и когда она была обнаружена.
В яндексовской вебмастерке интересующая нас информация находится в разделе Индексирование → Проверить статус URL.
Перейдя в отчет «Страницы в поиске» можно ознакомиться со всеми проиндексированными страницами, посмотреть их распределение по разделам, узнать, что исключено из индекса.
Второй способ быстро проверить индексацию в Google и Яндексе — через операторы расширенного поиска. Вбиваем в поисковую строку команду site:+название домена, и получаем сведения о количестве страниц в индексе.
Аналогичным образом можно проверить не только весь сайт, но и конкретную страницу. Для этого вместо доменного имени достаточно ввести URL нужной страницы.
Найден один результат — страница в индексе
Аналогичным образом оператор работает в выдаче Яндекса.
Вообще, операторы расширенного поиска — очень полезная и недооцененная штука. Больше о том, какую пользу они могут принести сеошникам и вебмастерам — читайте здесь.
Почему не индексируется ресурс?
Прошло недостаточно времени. Владельцам новых сайтов, нужно запастись терпением. Нередко попадание в индекс растягивается больше, чем на две недели.
Не добавлена карта сайта. Если вы решили проигнорировать sitemap.xml, возвращайтесь наверх и читайте, как это исправить.
Запрет на индексацию в файле robots.txt. Некоторые страницы сайта советуют закрывать от индексации. Это делают через прописывание специальных директив в служебном файле robots.txt. Здесь нужно быть предельно аккуратным. Лишний символ — и можно закрыть то, что должно быть доступным для поисковых роботов. В этом случае будут проблемы.
Ошибка с метатегом “robots”. Этот элемент кода сообщает поисковым краулерам о запрете на индексацию страницы. Он помещен между тегами <head> </head>, и выглядит следующим образом:
Метатег может появиться там, где не нужно. Часто это случается при изменении настроек движка или хостинга.
Запрет на индексацию в файле .htaccess. В этом файле прописаны правила работы сервера, и через него также можно закрыть сайт от индексирования.
Тег rel=”canonical”. Этот тег используют на страницах с дублированным содержимым, указывая с его помощью поисковым роботам адрес основного документа. Если страницы не попадают в индекс, причиной может быть наличие этого тега.
X‑Robots-Tag. В файле конфигурации сервера может быть прописана директива X Robots-Tag, запрещающая индексирование документов.
Долгий или неверный ответ сервера. Критически низкий отклик сервера создает сложности поисковым роботам при обходе сайта, из-за чего часть страниц может не залететь в индекс.
Некачественный контент на страницах. Плагиат, дубли, ссылочный переспам, автоматически сгенерированные тексты — все это также создает потенциальные риски.
Как видим, причин, по которым возможны проблемы с индексированием, довольно много. Но не переживайте, все это не нужно тестить вручную. Вебмастерки регулярно оповещают о возникших ошибках. Ваша задача — следить за уведомлениями в Яндекс.Вебмастере и Google Search Console и своевременно исправлять ошибки.
Можно ли индексировать пустой сайт? Или сначала лучше наполнить его контентом?
Мы отправили на индексацию не один десяток сайтов, и убедились, что особой разницы нет. Если сайт новый.
Вы можете сделать 5-10 стартовых страниц, наполнить их контентом и забросить сайт на индексацию. А можете добавить сайт пустым, и не спеша наполнять его контентом. Это не должно отразиться на скорости и качестве индексирования. Конечно, если не растягивать наполнение этих 5-10 страниц на месяцы. А вот с чем можно повременить на первых порах — оттачивание дизайна, создание перелинковки, размещение виджетов и пр. Это не так принципиально, если вы не планируете сразу же лить рекламный трафик на сайт.
Что нужно, чтобы сайт попал в поисковики Яндекс и Google
Продвижение в поисковых системах по сей день остается одним из наиболее эффективных инструментов привлечения на сайт целевых клиентов. Огромный плюс органического трафика – его бесплатность. Чем больше людей заходит на страницы, тем выше конверсия и вероятность получить желаемый результат.
Рано или поздно поисковые роботы найдут ваш молодой ресурс, однако это может занять недели, а то и месяцы. Чтобы ускорить индексацию, целесообразно добавить сайт в поисковики самостоятельно с помощью специальных сервисов, также регулярно отслеживать процесс и использовать дополнительные ресурсы.
Яндекс.Вебмастер и Google Search Console – это сервисы, с помощью которых можно добавить ресурс в поисковые системы и видеть, как он сканируется поисковыми роботами. Они позволяют:
видеть, как сайт индексируется в системах поиска;
оценить трафик, в том числе с мобильных устройств;
выявить проблемы с индексацией;
проанализировать ссылочную массу;
узнавать, какие источники ссылаются на ресурс.
Сервисы лишь показывают, как сайт представлен в результатах поиска, но не влияют на них. Далее рассмотрим подробнее, как настроить Вебмастер и Серч Консоль, и расскажем, каким образом можно влиять на индексацию.
Бесплатно проконсультируем, подготовим подробный медиаплан и коммерческое предложение в течение 1 дня по SEO-продвижению в Google и Яндекс. Обращаться по контактам.
Добавляем сайт в поисковую систему Яндекса
Добавить сайт в Вебмастере несложно, просто нажмите «Начать работу» и выберите на открывшейся странице «Добавить сайт».
Затем введите url (адрес) своего сайта, например, fireseo.ru
Вам интересны интернет-маркетинг и продвижение бизнеса в интернете? Подписывайтесь на наш Telegram-канал!
Вторым шагом станет «Подтверждение прав на сайт». Яндекс. Вебмастер сам предложит вам 4 варианта подтверждения прав на ваш ресурс, среди которых:
Мета-тег на главной странице: необходимо добавить в HTML-код главной страницы сайта (в элемент head) специальный мета-тег.
HTML-файл в корневом каталоге: необходимо создать HTML-файл с заданным уникальным именем и содержимым, и разместить его в корневом каталоге сайта.
TXT-запись в DNS: необходимо добавить в DNS записи сайта запись типа TXT, содержащую указанное уникальное значение.
Электронный адрес из данных WHOIS: необходимо подтвердить электронный адрес, указанный в WHOIS на странице Адреса электронной почты.
Используйте этот способ, если ваш сайт является доменом второго уровня и находится не в доменной зоне RU или РФ. Рекомендуем вам самый простой способ решить ситуацию – добавить мета-тег. Это можно сделать самостоятельно через FTP. Также несложным будет и 4 вариант подтверждения прав на ресурс – добавьте лишь запись о почте в whols! Теперь вы знаете,что нужно сделать , чтобы сайт попал в поисковик Яндекс и,если сделали все согласно инструкциям, теперь вам доступна вся общая информация по сайту. Подождите окончания процедуры проверки прав, которая занимает обычно несколько секунд, и приступайте к полноценной работе с массой полезных инструментов Вебмастера.
Далее зайдите в раздел “Переобход страниц” Яндекс. Вебмастера и добавьте адреса основных страниц сайта. Вот здесь:
Если сайт сложнее, чем лендинг, с особым вниманием поработайте в Вебмастере над файлом robots.txt, который содержит параметры индексирования сайта для роботов поисковых систем. Создайте файл, заполните его в соответствии с требованиями (в Вебмастере есть хорошее видео на эту тему), проверьте файл в сервисе Яндекс. Вебмастер и загрузите его в корневую директорию сайта. А поможет вам вот это видео.
Итак, если у вас на сайте больше 1 страницы, то рекомендуем вам для более быстрой индексации остальные страницы также добавить в Переобход страниц Яндекс Вебмастера.
Но, помните! Существует дневной лимит по добавлению адресов. В день можно увеличить количество таких страниц не более 10. Вместе с тем, вы можете воспользоваться созданием и настройкой файла Sitemap, который будет содержать информацию о страницах сайта, подлежащих индексированию. В Яндекс. Вебмастер представлена подробная информация и инструкции к работе с этим файлом. Ознакомиться с ней можно здесь.
А для увеличения посещаемости сайта советуем подумать о контекстной рекламе. При помощи этого эффективного инструмента для продвижения сайта, размещения объявлений ваших товаров или услуг в Яндекс. Директ, в результатах поиска на конкретный запрос пользователям будет представлен именно ваш сайт. Ваши клиенты будут приятно удивлены! Да, и не забудьте добавить свою организацию в Яндекс. Справочник
Заполните форму с указанием названия, адреса, контактных данных и вида деятельности вашей организации. Несколько несложных манипуляций, и вас легко найдут! Особенно, если будут искать по локальному признаку, например “парикмахерская в Перово”. Поздравляем! Теперь Ваш сайт найдут все пользователи в поисковике Яндекс!
Добавляем сайт в Google
Для того, чтобы добавить свой сайт в Google, сначала вам тоже нужно зарегистрироваться или войти под своим логином в систему, и вы увидите:
С помощью бесплатного сервиса Google Search Console вы сможете не только добавить свой сайт для индексации в Google, но и оптимизировать его согласно предпочтениям системы, улучшить его для повышения позиций в поиске. Сам сервис довольно простой и понятный в управлении. Укажите url своего сайта в адресной строке и нажмите кнопку «Добавить ресурс», Процедура добавления аналогична действиям в Яндекс. Вебмастер (как, например, с мета-тегами). Google также сам предложит вам следующий список действий, среди которых будет:
Анализируйте переходы к вашему контенту из Google Поиска.
Получайте оповещения о проблемах или критических ошибках.
Проверяйте, верно ли Googlebot обработал контент.
Этот замечательный сервис поможет оптимизировать ваш сайт, улучшить его контент в зависимости от запросов пользователей, сделать его понятным и привлекательным и многое другое – все, что позволит найти новых потенциальных клиентов и заручиться доверием уже имеющейся аудитории. Главное в этом деле, как вы наверняка знаете – всегда работать над улучшением сайта и стремиться к совершенству! 😉 Еще один эффективный сервис, который поможет вам в этом, Google бизнес. Данный сервис является аналогом Яндекс. Справочника и предназначен для поиска ближайших организаций.
Зарегистрируйте свою компанию, указав ее название, адрес, основные контакты и другую необходимую информацию. Дальше – вы всегда сможете размещать актуальные данные о своей организации, добавлять фото и другой контент, следить за отзывами и статистикой посещения вашего сайта.
Заголовок – это важно!
Рекомендуем вам прописать заголовок (title) вашего сайта. Зачем? С помощью этого заголовка страницы, который выглядит как специальный тег в начале html кода внутри конструкции, вы продвинете свой веб-проект. Например, это может выглядеть так:
Такой тайтл «СЕО агентство» был выбран нами неслучайно. Во-первых, мы хотим, чтобы большинство пользователей при вводе запроса «СЕО агентство в Москве или «СЕО агентство», переходили именно к нам на сайт. К тому же, эти слова дают хорошее описание деятельности нашей компании и помогают пользователям найти нас через поисковик.
Также и вы, формулируя заголовок, помните, что тайтл – это один из краеугольных камней успешного продвижения сайтов, и, создавая его, поработайте над правильным оформлением, лаконичным и понятным для клиентов. При работе над этим атрибутом учитывайте, что он будет отображаться и при распространении в соцсетях, и в результатах поиска. Именно поэтому ваш тайтл должен быть кратким и максимально содержательным. Такие несложные манипуляции позволят вашему сайту появляться в поисковых системах, помогая пользователям найти вас.
После того, как вы успешно добавили сайт в поисковые системы Яндекс и Google, можете приступать к дальнейшей оптимизации сайта.
Как улучшить индексацию
Чтобы заставить робота-индексатора чаще посещать сайт, увеличить количество проиндексированных страниц, видеть как можно скорее появившиеся публикации, используйте дополнительные способы продвижения.
Регулярно добавляйте новый уникальный контент. Поисковые роботы быстрее сканируют ресурсы с обновляемой информацией, нежели те, которые не обновляются;
Настройте внутреннюю перелинковку;
Проверьте структуру веб-ресурса. Устраните дубли страниц на сайте. Если ошибок в структуре нет и на каждую страницу будет хотя бы одна внутренняя ссылка, боты быстрее доберутся до страниц и занесут их в свою базу;
Позаботьтесь о внешних ссылках. Займитесь их закупкой, публикуйте посты в соцсетях, размещайте ссылки на форумах. Наращивание ссылочной массы ускорит сканирование страниц сайта поисковиком;
Используйте пинг-сервисы, которые устанавливаются на движки и уведомляют поисковых роботов о появлении обновлений на сайте (CS YZZLE, Pingxpert, PingFarm и другие).
Безусловно, вы вполне можете не регистрировать свой сайт в Яндекс.Вебмастер и Google Search Concole, поисковики все равно его проиндексируют. Однако для улучшения позиций и ускорения индексации эти сервисы, а также другие инструменты обязательны.
Подпишитесь на рассылку FireSEO
и получайте подборки статей, полезных сервисов, анонсы и бонусы. Присоединяйтесь!
AddUrl: что такое АддУрл в Яндекс и Google
Addurl (англ. add url – «добавить УРЛ», жарг. «аддурилка») – сервисы, при помощи которых можно сообщать поисковым системам о появлении новых ресурсов и через форму добавлять их в базу для последующей индексации.
Добавление сайта или страницы в индекс поисковых систем через «аддурл» существенно ускоряет заход на нее поискового робота. Самостоятельное нахождение нового сайта машиной может занять достаточно большой промежуток времени.
Принцип работы формы Addurl
В особую форму следует ввести адрес главной страницы ресурса, заполнить капчу и нажать на кнопку «добавить». После этого могут появиться следующие ответы:
Ресурс добавлен. Это значит, что площадка была принята системой и поставлена в очередь на индексацию.
Хостинг не отвечает. В данном случае следует попробовать добавить ваш сайт позже.
URL запрещен для индексации. Такая надпись свидетельствует о том, что ресурс был забанен системой или скрыт от индексации в настройках файла robots.txt.
Ускорение индексации сайта
Для ускорения индексации страниц или каких-либо изменений есть дополнительный функционал:
При внесении изменений на страницы сайта и для ускорения индексации в Яндекс.Вебмастере разработан специальный функционал «Переобход страниц», где можно добавлять определенное количество URL. Лимит страниц устанавливается в зависимости количества страниц на сайте. Минимальное значение – 20 адресов можно добавить за один день.
При внесении большого количества изменений на сайте (шаблонного внесения тегов, создание большого раздела), в Яндекс.Вебмастере в разделе «Файлы Sitemap» можно назначить переобход карты сайта.
Добавление сайта в систему Яндекс.
Яндекс «Файлы Sitemap»
Фильтры поисковых систем Google и Яндекс
Выше рассмотрены основные фильтры Google и Яндекса, которые определяют качество поиска и задают правила игры. Но помимо них есть и менее известные и узконаправленные санкции. Рассмотрим некоторые из них тезисно:
Спам в микроразметке Попытки отобразить в структурированных данных страницы информации, которая невидима пользователю. Например, в микроразметку отдается рейтинг и отзывы, которые показываются в поисковом сниппете, но на странице нет ни функционала проставления рейтинга, ни отзывов. Как следствие удаляются все расширенные сниппеты и понижаются позиции сайта.
Кликджекинг Применяется к сайтам, которые пользовательским кликам присваивают действия, которые они не совершали. Например, вы находитесь на странице интернет-магазина, а в соседней вкладке в браузере авторизованы Вконтакте. Вы кликаете на категорию товара и уходите с сайта, но тут же получаете личное сообщение Вконтакте от менеджера интернет-магазина с предложением вернуться. Как такое возможно? Технология использует данные авторизации Вконтакте и клик как лайк или подписку на группу интернет-магазина. Сами того не подозревая, вы оставили контакт продавцу. На данный момент технология легко вычисляется поисковыми системами и наказывается снижением позиций всего сайта.
Избыточная реклама и попапы Ограничения касаются тех, кто переусердствует со всплывающими окнами и навязчивой рекламой. Особенно актуально это для отображения на мобильных устройствах. Если видимая часть контента сайта без каких-либо действий пользователя закрывается рекламой, мешает взаимодействовать с сайтом — это будет четким сигналом для поисковых систем понизить сайт в выдаче.
Непот-фильтр Разновидность фильтра Яндекса, который наказывает за продажу ссылок. Обратная сторона Минусинска. В группе риска сайты, участвующие в биржах вечных и арендных ссылок, вебмастеры которых не заботятся о полезности той или иной ссылки.
Принимая во внимание вышеописанные фильтры, можно описать рецепт успеха сайта в органической поисковой выдаче простым напутствием: будьте профессионалами и делайте качественный продукт. Показатели качества же должны определяться не только поисковыми системами, но и здравым смыслом. Абсолютное большинство попыток обмануть поисковик приводит к тому, что на сайт накладываются фильтры. Очевидно, что проще предотвратить проблему до ее наступления, чем судорожно пытаться решить ее после.
Эпоха «черного seo» стремительно уходит в закат, а те оптимизаторы, которые пытаются ее догнать, получают справедливое наказание — фильтры и санкции от Google и Яндекс. Стратегически правильным будет решение следовать правилам поисковых систем и идти в ногу со временем, не упуская никаких нововведений и трендов постоянно меняющегося рынка.
Ссылка на первоисточник: https://i-market.ru
Как работает поиск Google | Центр поиска | Разработчики Google
Как работает гугл? Вот короткая версия и длинная версия.
Google получает информацию из множества различных источников, в том числе:
Веб-страницы,
Пользовательский контент, такой как пользовательские материалы в Google Мой бизнес и Карты,
Книжное сканирование,
Публичные базы данных в Интернете,
и многие другие источники.
Однако эта страница ориентирована на веб-страницы.
Укороченная версия
Google выполняет три основных шага для получения результатов с веб-страниц:
Ползание
Первый шаг — выяснить, какие страницы существуют в сети. Нет центрального реестра
все веб-страницы, поэтому Google должен постоянно искать новые страницы и добавлять их в свой список
известные страницы. Некоторые страницы известны, потому что Google уже посещал их раньше.Другие страницы
обнаруживаются, когда Google переходит по ссылке с известной страницы на новую. Еще другие страницы
обнаруживаются, когда владелец веб-сайта отправляет список страниц (карта сайта )
для сканирования Google. Если вы используете управляемый веб-хостинг, например Wix или Blogger, они могут
скажите Google сканировать любые обновленные или новые страницы, которые вы создаете.
Как только Google обнаруживает URL-адрес страницы, он посещает или сканирует страницу, чтобы выяснить, что
в теме. Google отображает страницу и анализирует как текстовое, так и нетекстовое содержание, а также в целом
визуальный макет, чтобы решить, где он должен отображаться в результатах поиска.Тем лучше, что Google может
понимаем ваш сайт, тем лучше мы сможем сопоставить его с людьми, которые ищут ваш контент.
Для улучшения сканирования вашего сайта:
Убедитесь, что Google может получить доступ к страницам вашего сайта и что они выглядят правильно. Google
получает доступ в Интернет как анонимный пользователь (пользователь без паролей или информации). Google
также должен иметь возможность видеть все изображения и другие элементы страницы, чтобы иметь возможность
поймите это правильно.Вы можете выполнить быструю проверку, введя URL своей страницы в поле
Удобство для мобильных
Контрольная работа.
Если вы создали или обновили одну страницу, вы можете отправить
индивидуальный URL-адрес в Google. Чтобы сообщить Google сразу о многих новых или обновленных страницах, используйте
карту сайта.
Если вы просите Google сканировать только одну страницу, сделайте ее своей домашней. Ваш
Домашняя страница — это самая важная страница на вашем сайте, с точки зрения Google. Поощрять
полное сканирование сайта, убедитесь, что ваша главная страница (и все страницы) содержат хороший сайт
система навигации, которая ссылается на все важные разделы и страницы вашего сайта; это помогает
пользователи (и Google) ориентируются на вашем сайте.Для небольших сайтов (менее 1000 страниц)
информировать Google только о вашей домашней странице — это все, что вам нужно, при условии, что Google может охватить все
ваши другие страницы, следуя пути ссылок, которые начинаются с вашей домашней страницы.
Свяжите свою страницу с другой страницей, о которой Google уже знает. Однако имейте в виду, что ссылки в рекламных объявлениях, ссылки, за которые вы платите на других сайтах, ссылки в
комментарии или другие ссылки, которые не следуют за Google
Google не будет следовать рекомендациям для веб-мастеров.
Google не принимает платежи за более частое сканирование сайта или за его ранжирование.
выше. Если кто-то говорит вам иное, он ошибается.
Индексирование
После того, как страница обнаружена, Google пытается понять, о чем она. Этот процесс
называется с индексом . Google анализирует содержание страницы, каталогизирует изображения и
видеофайлы, встроенные в страницу, и в противном случае пытается понять страницу. Эта информация
хранится в индексе Google , огромной базе данных, хранящейся на многих, многих (многих!) компьютерах.
Используйте заголовки страниц, которые передают тему страницы.
Используйте текст, а не изображения для передачи контента. Google может понимать некоторые изображения и видео,
но не так хорошо, как он может понимать текст. Как минимум, аннотируйте свой
видео и
изображения с замещающим текстом и др.
атрибуты в зависимости от обстоятельств.
Обслуживание (и рейтинг)
Когда пользователь вводит запрос, Google пытается найти наиболее релевантный ответ в его индексе.
основанный на многих факторах.Google пытается найти ответы наивысшего качества и учитывать
другие соображения, которые обеспечат лучший пользовательский опыт и наиболее подходящий ответ,
учитывая такие вещи, как местоположение пользователя, язык и устройство (настольный компьютер или телефон).
Например, поиск по запросу «мастерская по ремонту велосипедов» покажет пользователю разные ответы.
в Париже, чем пользователю в Гонконге. Google не принимает оплату за ранжирование страниц
выше, и ранжирование выполняется программно.
Для улучшения обслуживания и рейтинга:
Длинная версия
Хотите больше информации? Вот он:
Длинная версия
Ползание
Сканирование — это процесс, с помощью которого робот Google
посещает новые и обновленные страницы для добавления в индекс Google.
Мы используем огромный набор компьютеров для получения (или «сканирования») миллиардов страниц в сети. Программа
который выполняет выборку, называется Googlebot (также известный как робот, бот или паук).Googlebot
использует алгоритмический процесс, чтобы определить, какие сайты сканировать, как часто и сколько страниц
получать с каждого сайта.
Процесс сканирования Google начинается со списка URL-адресов веб-страниц, созданного в результате предыдущего сканирования.
процессы, дополненные данными Sitemap, предоставленными владельцами веб-сайтов. Когда робот Googlebot посещает страницу
он находит ссылки на странице и добавляет их в свой список страниц для сканирования. Новые сайты, изменения в
Существующие сайты и мертвые ссылки отмечаются и используются для обновления индекса Google.
Во время сканирования Google отображает страницу с помощью последней версии Chrome. В рамках
В процессе рендеринга он запускает любые найденные скрипты страниц. Если на вашем сайте используются динамически генерируемые
содержание, убедитесь, что вы следуете
Основы JavaScript SEO.
Первичное сканирование / вторичное сканирование
Google использует два разных сканера для сканирования веб-сайтов: мобильный сканер и настольный компьютер.
гусеничный трактор. Каждый тип сканера имитирует посещение пользователем вашей страницы с помощью устройства этого типа.
Google использует один тип сканера (мобильный или настольный) в качестве основного поискового робота для вашего
сайт. Все страницы вашего сайта, которые сканирует Google, сканируются с помощью основного поискового робота.
Основным поисковым роботом для всех новых веб-сайтов является мобильный сканер.
Кроме того, Google повторно сканирует несколько страниц вашего сайта с помощью поискового робота другого типа (мобильного или
рабочий стол). Это называется вторичным сканированием и выполняется для проверки того, насколько хорошо ваш сайт
работает с другим типом устройств.
Как Google узнает, какие страницы не сканировать?
Страницы, заблокированные в robots.txt, не будут сканироваться, но все же могут быть проиндексированы, если на них ссылается
другая страница. (Google может определить содержание страницы по ссылке, указывающей на нее, и проиндексировать
страницу без разбора ее содержимого.)
Google не может сканировать страницы, недоступные анонимному пользователю. Таким образом, любой логин или другой
защита авторизации предотвратит сканирование страницы.
страниц, которые уже просканированы и считаются
дубликаты другого
страницы, сканируются реже.
Улучшите сканирование
Используйте эти методы, чтобы помочь Google находить нужные страницы на вашем сайте:



 Означает инструменты поисковых систем Яндекс и Google, позволяющие принудительно добавить страницы сайта в поисковую базу (принудительная индексация страниц).
Означает инструменты поисковых систем Яндекс и Google, позволяющие принудительно добавить страницы сайта в поисковую базу (принудительная индексация страниц).
 Он используется как для добавления новых, так и для ускоренной переиндексации старых страниц, если на них изменился контент.
Он используется как для добавления новых, так и для ускоренной переиндексации старых страниц, если на них изменился контент.
 Но приоритетная индексация с помощью аддурилки закрепляет за сайтом оригинальность контента. Если аналогичный контент позже появится на другом сайте, он уже будет признан поисковой системой как дубль и не получит высокие позиции (может наоборот получить санкции, т.е. понижение позиций в выдаче). Не во всех случаях это 100%-но срабатывает, но в целом является полезным инструментом.
Но приоритетная индексация с помощью аддурилки закрепляет за сайтом оригинальность контента. Если аналогичный контент позже появится на другом сайте, он уже будет признан поисковой системой как дубль и не получит высокие позиции (может наоборот получить санкции, т.е. понижение позиций в выдаче). Не во всех случаях это 100%-но срабатывает, но в целом является полезным инструментом.

 Мы окажем Вам любую помощь вплоть до комплексного продвижения Ваших веб-ресурсов.
Мы окажем Вам любую помощь вплоть до комплексного продвижения Ваших веб-ресурсов.
 RU Ксения Захарова рассказала, как уникализировать карточки товаров и дала 4 полезных совета владельцам интернет-магазина (и тем, кто пишет карточки).
RU Ксения Захарова рассказала, как уникализировать карточки товаров и дала 4 полезных совета владельцам интернет-магазина (и тем, кто пишет карточки). 
 Но это не выход, так как поисковые роботы не будут видеть страницу, а значит, и товар не смогут найти пользователи.
Но это не выход, так как поисковые роботы не будут видеть страницу, а значит, и товар не смогут найти пользователи. 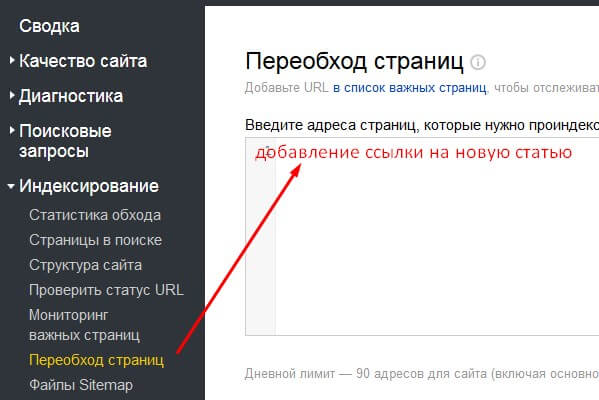 Все остальные поисковые системы его полностью игнорируют. Из-за этого при валидации может возникнуть ошибка. Чтобы этого избежать, стоит прописать тег в следующем виде:
Все остальные поисковые системы его полностью игнорируют. Из-за этого при валидации может возникнуть ошибка. Чтобы этого избежать, стоит прописать тег в следующем виде: 
 Здесь можно даже покреативить и придумать что-то новенькое и необычное.
Здесь можно даже покреативить и придумать что-то новенькое и необычное.  Поэтому пренебрегать этим разделом ни в коем случае не стоит.
Поэтому пренебрегать этим разделом ни в коем случае не стоит.  Смотрите сами: посетитель сайта задает свой вопрос, а менеджер или другие пользователи отвечают на него и рассказывают о самом продукте. Таким образом получается произвольная генерация контента.
Смотрите сами: посетитель сайта задает свой вопрос, а менеджер или другие пользователи отвечают на него и рассказывают о самом продукте. Таким образом получается произвольная генерация контента. Это не критично, но есть большой минус – если этот товар на рынке популярен, а карточка вылетела из поиска, то ваш продукт пользователи просто не найдут в выдаче. Отсюда получается следующее: нет трафика – значит, нет и продаж.
Это не критично, но есть большой минус – если этот товар на рынке популярен, а карточка вылетела из поиска, то ваш продукт пользователи просто не найдут в выдаче. Отсюда получается следующее: нет трафика – значит, нет и продаж. 
 Вы можете встретить и другие варианты, но связываться с ними мы бы категорически не советовали, ниже расскажем почему.
Вы можете встретить и другие варианты, но связываться с ними мы бы категорически не советовали, ниже расскажем почему.

 Начинающие вебмастера почему-то думают, что это очень сложно. Расслабьтесь, это не так. Все просто, но давайте по порядку. Sitemap.xml — это список XML-документов, в которые вшиты служебные данные. Вся эта информация — своего рода ориентиры, необходимые поисковым системам для удобной и эффективной индексации всех страниц сайта.
Начинающие вебмастера почему-то думают, что это очень сложно. Расслабьтесь, это не так. Все просто, но давайте по порядку. Sitemap.xml — это список XML-документов, в которые вшиты служебные данные. Вся эта информация — своего рода ориентиры, необходимые поисковым системам для удобной и эффективной индексации всех страниц сайта.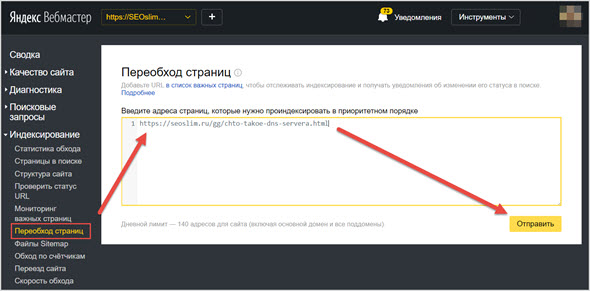 Например, многие оптимизаторы уверены, что если прогрузить в браузере Google Chrome главную или новые страницы сайта, они автоматически залетят в гугловский индекс. Или, что если добавить на непроиндексированные страницы код счетчика Google Analytics, поиск автоматически получит информацию о появлении новых документов, которые необходимо просканировать.
Например, многие оптимизаторы уверены, что если прогрузить в браузере Google Chrome главную или новые страницы сайта, они автоматически залетят в гугловский индекс. Или, что если добавить на непроиндексированные страницы код счетчика Google Analytics, поиск автоматически получит информацию о появлении новых документов, которые необходимо просканировать.
 к. многие пользуются почтой и другими яндексовскими сервисами, переходим сюда и указываем адрес сайта.
к. многие пользуются почтой и другими яндексовскими сервисами, переходим сюда и указываем адрес сайта.
