
Типы и виды поисковых запросов, их язык
4 мин — время чтения
Ноя 20, 2014
Поделиться
Поисковый запрос – это слово или словосочетание, которое вводит пользователь поисковой системы, желая получить определенную информацию. После получения запроса система автоматически выводит наиболее подходящие – по её мнению – страницы. Все запросы можно условно разделить на несколько видов и типов.
Для владельцев и оптимизаторов сайтов данная информация является обязательной к пониманию и изучению, т. к. основным источником трафика для большинства ресурсов по-прежнему остаются поисковики. Именно поэтому серьезное продвижение того или иного сайта требует серьезного подхода и ряда действий: составления семантического ядра и определения всех типов поисковых фраз, на которые стоит ориентироваться.
Виды поисковых запросов
Как уже говорилось выше, все поисковые запросы можно условно разделить на типы и виды. Виды выделяют в зависимости от следующих параметров: частотность, конкурентность, ценность, геозависомость. А к типам относят навигационные, информационные, мультимедийные, транзакционные и общие (нечеткие) запросы. Рассмотрим типы и виды запросов подробнее.
А к типам относят навигационные, информационные, мультимедийные, транзакционные и общие (нечеткие) запросы. Рассмотрим типы и виды запросов подробнее.
Виды поисковых запросов можно условно разделить на 4 категории.
1. По частотности
- ВЧ – высокочастотные. Слово «высокочастотный» уже дает точное определение данной подкатегории – высокая частота запроса. Высокочастотные запросы обычно состоят из 1–2 слов. Как правило, вывести сайт в ТОП по ВЧ очень сложно, т. к. конкуренция по ним высока.
- СЧ – среднечастотные. Среднечастотные запросы менее конкурентные, нежели ВЧ, но они также способны давать неплохую посещаемость. Что касается показателя конверсии, то он варьируется от среднего до высокого значения.
- НЧ – низкочастотные. НЧ – это редко запрашиваемые слова. Однако и они играют важную роль в оптимизации сайта, так как помогают продвинуть сайт по низкочастотным запросам и повысить целевой трафик. Наиболее любимы НЧ среди владельцев интернет-магазинов.


Существуют также «нулевые» или их ещё называют «супер низкочастотные запросы». Частота их колеблется в пределах 0–2 в месяц, а потому для продвижения они не имеют особой ценности.
2. По конкурентности
- ВК – высококонкурентные;
- СК – среднеконкурентные;
- НК – низкоконкурентные.
При работе над новым проектом предпочтение лучше отдать низко- и среднеконкурентным запросам. Как определить степень конкурентности, мы поговорим в следующих статьях.
3. По степени ценности
- Коммерческие. К данной категории относятся запросы, прямо или косвенно призывающие купить некоторый продукт.
- Некоммерческие. В противовес коммерческим, к покупке не побуждают, а носят скорее информационный характер. Соответственно, активно используются на информационных и развлекательных порталах.
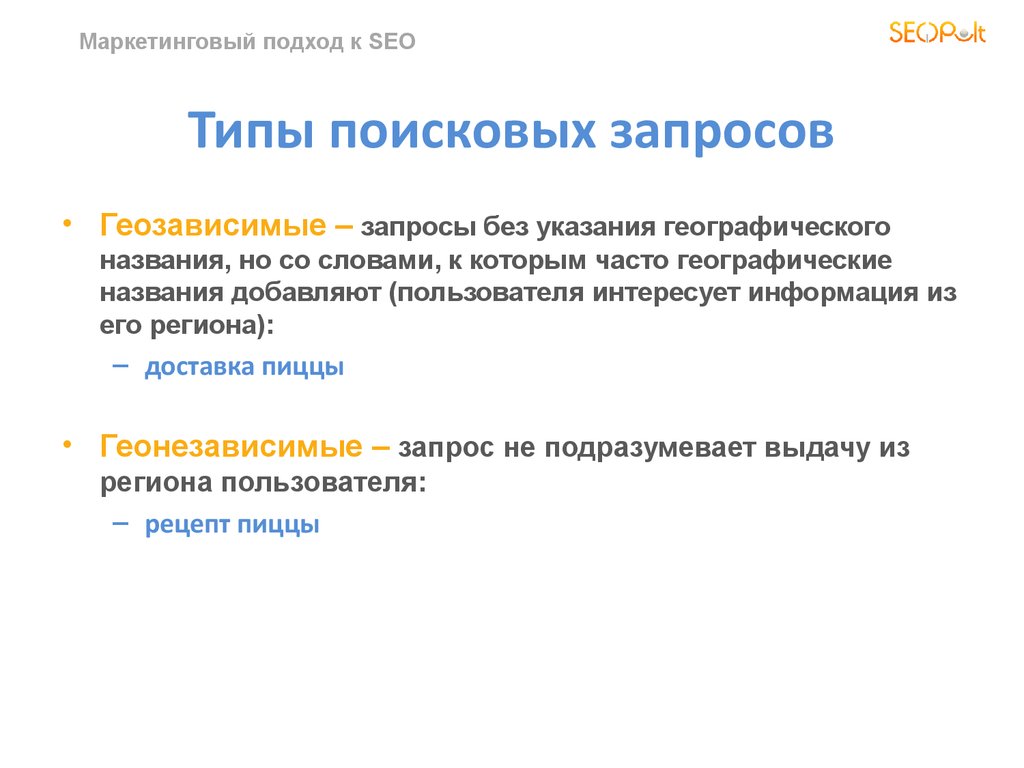
4. По геозависимости
- Геозависимые. Важная подкатегория, которая регулирует выдачу по географическому расположению. Например, «заказать пиццу». Поисковая система автоматически определяет ваше географическое расположение (например, Москва) и выдает результаты, которые относятся исключительно к московскому региону. Таким образом, поисковая выдача для разных регионов будет существенно отличаться.
- Геонезависимые. Данный вид запросов не привязывается к географическому расположению человека, запрашивающего информацию. Поисковая выдача будет с большой долей вероятности одинакова для разных стран и регионов.
 Например, «заказать пиццу». Поисковая система автоматически определяет ваше географическое расположение (например, Москва) и выдает результаты, которые относятся исключительно к московскому региону. Таким образом, поисковая выдача для разных регионов будет существенно отличаться.
Например, «заказать пиццу». Поисковая система автоматически определяет ваше географическое расположение (например, Москва) и выдает результаты, которые относятся исключительно к московскому региону. Таким образом, поисковая выдача для разных регионов будет существенно отличаться.Существуют также и другие виды поисковых запросов: сезонные, по времени суток и т.д. Но большинство оптимизаторов не выносит их в отдельную категорию при построении стратегии развития проекта.
Типы поисковых запросов
Тип поисковых запросов – это ещё одна важная классификация поисковых фраз. Вариант, который мы рассмотрим, был предложен в 2002 году Андреем Бродером в работе «A taxonomy of websearch». Согласно данной работе все поисковые запросы были разделены на 5 типов.
- Несущие информационный характер. Наиболее популярный в поисковых системах тип. Отвечает на вопросы «как», «для чего», «каким образом» и т. д. Например, «как правильно ухаживать за яблоней», «что делать, если болит желудок».
- Навигационные. Очень часто люди, которые с компьютером на «Вы» с помощью поисковой системы переходят на тот или иной сайт. Например, ищут, как перейти в Гугл, Вики и так далее. Аналогично могут разыскиваться сайты, когда пользователь забыл точный адрес или сомневается в варианте написания URL.
- Транзакционные. К данному типу относятся те, что предполагают совершение какого-либо действия. Например, «купить компьютер» или «заказать такси».
- Мультимедийные. Предполагают поиск мультимедийной информации: музыки, фильмов, изображений. Например, «новый клип Рианны», «посмотреть Comedy Club».
- Общие. К данному типу относятся запросы, которые тяжело однозначно отнести к любому из вышеописанных типов. Как правило, такие запросы состоят из 1–2 слов. Например, «мышка», «стиральная машинка», «холодильник» и другие.
 Например, «мышка», «стиральная машинка», «холодильник» и другие.
Например, «мышка», «стиральная машинка», «холодильник» и другие.Язык поисковых запросов
Каждая поисковая система имеет свой язык запросов. Это помогает более точно сформулировать свой вопрос и получить, соответственно, более точный на него ответ. Ниже приведены наиболее популярные операторы языка поиска Google.
Язык поисковых запросов Google| Назначение | Оператор |
| Поиск по определенному сайту или его страницах | Site:(url сайта) |
| Поиск обратных ссылок | link: |
| Поиск страниц с похожим или аналогичным содержанием | related: |
| Поиск по нескольким запросам. К примеру, Дата крещения Руси 988 OR899 | OR |
| Информация о ссылке | info: |
| Информация из кэша (последняя индексация сайта) | cache: |
Кроме того, Google предоставляет функцию расширенного поиска, где пользователь на интуитивном уровне может ввести дополнительные критерии: язык, регион, дата обновления и формат документа.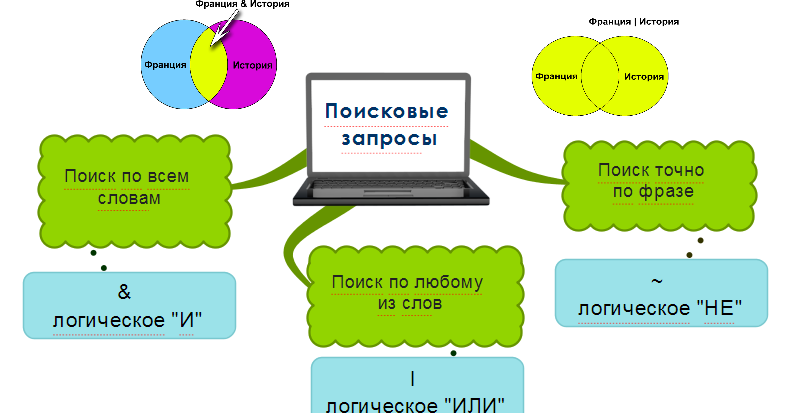
Кстати, проверить позиции своего сайта по запросам вы можете в SE Ranking.
Бесплатный тестовый доступ
631 views
Всемирная паутина как информационное хранилище. Страница 5
Планирование уроков на учебный год (ФГОС)
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 7 классы | Планирование уроков на учебный год (ФГОС) | Всемирная паутина как информационное хранилище
Содержание урока
1.3.1. Что такое WWW
1.3.2. Поисковые системы
1.3.3. Поисковые запросы
1.3.4. Полезные адреса Всемирной паутины
Вопросы и задания
Электронное приложение к учебнику
Единая коллекция цифровых образовательных ресурсов
Практическая часть урока
Практическая работа №1. Задание 1
Задание 1
Практическая работа №1. Задание 2
Практическая работа №1. Задание 3
Практическая работа №1. Задание 4
Вопросы и задания
САМОЕ ГЛАВНОЕ
Свободный доступ к информации, невзирая на границы и расстояния, стал возможен благодаря World Wide Web — всемирному информационному хранилищу, существующему на технической базе сети Интернет.
Перемещаться пользователю по «паутине» помогают специальные программы, которые называются браузерами. Поиск нужного документа в WWW может происходить: путём указания адреса документа; путём перемещения по паутине гиперсвязей; путём использования поисковых систем.
Существует множество поисковых систем. В большинстве из них есть три основных типа поиска: по любому из слов; по всем словам; точно по фразе.
Вопросы и задания
1. Ознакомьтесь с материалами презентации к параграфу, содержащейся в электронном приложении к учебнику. Что вы можете сказать о формах представления информации в презентации и в учебнике? Какими слайдами вы могли бы дополнить презентацию?
Что вы можете сказать о формах представления информации в презентации и в учебнике? Какими слайдами вы могли бы дополнить презентацию?
2. Выполните дословный перевод словосочетания «World Wide Web».
3. Опишите в общих чертах организацию WWW.
4. Что обеспечивают гиперссылки в плане навигации по информационным ресурсам Всемирной паутины? Какие элементы нелинейной навигации вы встречали в книгах, справочниках, словарях?
5. Представим, что текст этого параграфа размещён на web-сайте. Какие слова из текста можно выбрать в качестве ключевых, чтобы наиболее точно передать его смысл? Перечислите до 10 таких слов.
6. Знаете ли вы адрес сайта вашей школы? Какие сайты вы рекомендовали бы посетить своим одноклассникам? Приведите адреса 3-4 таких сайтов.
7. Каким браузером вы пользуетесь в школе?
8. Какие поисковые системы вам известны?
9. Перечислите основные типы поисковых запросов.
10. Найдите во Всемирной паутине информацию о количестве пользователей самых распространённых поисковых систем.
Найдите во Всемирной паутине информацию о количестве пользователей самых распространённых поисковых систем.
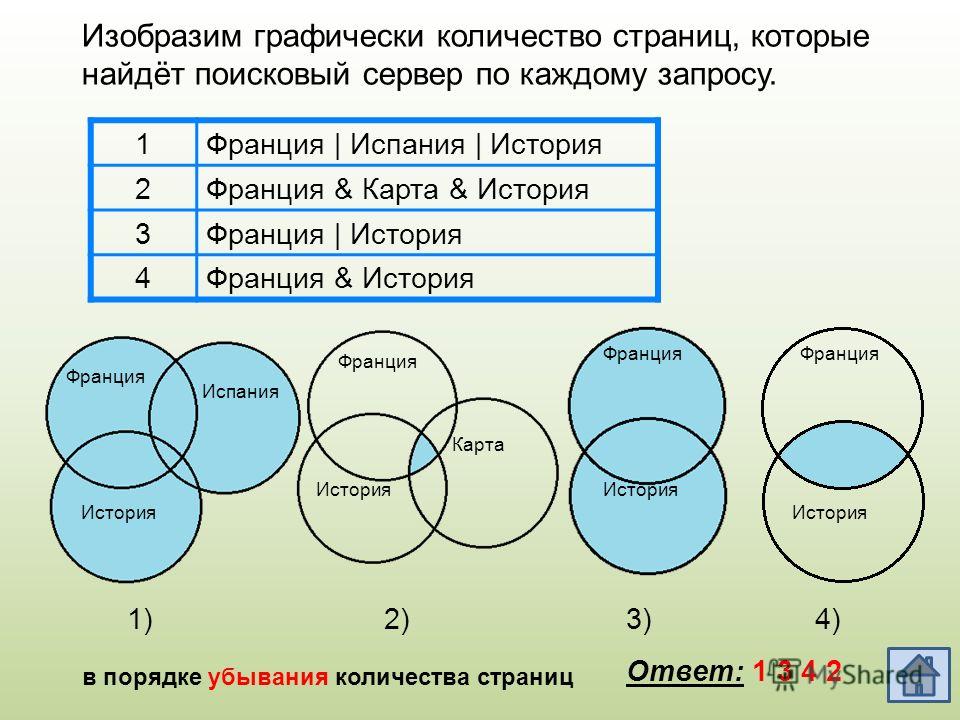
11. Даны запросы к поисковой системе:
а) чемпионы | (бег & плавание)
б) чемпионы & плавание
в) чемпионы | бег | плавание
г) чемпионы & Европа & бег & плавание
Представьте результаты выполнения этих запросов графически с помощью кругов Эйлера. Укажите обозначения запросов в порядке возрастания количества документов, которые найдёт поисковая система по каждому запросу.
12. Найдите во Всемирной паутине ответы на следующие вопросы.
• Кто такой Норберт Винер и какова его роль в исследовании информационных процессов?
• Кто такой Клод Шеннон и чем он знаменит?
• Кем и когда был введён термин «гипертекст»?
• Кого считают изобретателем WWW и когда это произошло?
• Кто такой Эйлер, в честь которого названа графическая схема, иллюстрирующая отношения между множествами?
Поиск в структуре данных — объяснение различных методов поиска
Новичок Программирование Python
Эта статья была опубликована в рамках блога Data Science Blogathon
Введение В современном мире сеть связи расширяется очень быстро. Компании переходят на цифровые технологии, чтобы повысить эффективность управления. Объем данных, генерируемых в Интернете, увеличивается, и в результате наборы данных становятся все более сложными. Важно тщательно и эффективно организовывать, управлять, получать доступ и анализировать данные, структура данных является наиболее полезным методом, и статья посвящена ему
Компании переходят на цифровые технологии, чтобы повысить эффективность управления. Объем данных, генерируемых в Интернете, увеличивается, и в результате наборы данных становятся все более сложными. Важно тщательно и эффективно организовывать, управлять, получать доступ и анализировать данные, структура данных является наиболее полезным методом, и статья посвящена ему
В информатике структуры данных служат основой для абстрактных типов данных (АТД), где АТД — это логическая форма типов данных. Физический дизайн типов данных реализован с использованием структур данных. различные типы структур данных используются для различных типов приложений; некоторые специализируются на конкретных задачах.
Структуры данных называются набором значений данных и взаимосвязей между ними, функциями и операциями, применимыми к данным. чтобы пользователи могли легко получать доступ к данным и эффективно изменять их.
Структуры данных помогают нам управлять большими объемами данных, такими как огромные базы данных.
В этой статье рассматриваются концепции поиска в структуре данных, а также его методы.
Что такое поиск в структуре данных?Поиск в структуре данных относится к процессу поиска необходимой информации из набора элементов, хранящихся в виде элементов в памяти компьютера. Эти наборы элементов представлены в различных формах, таких как массив, связанный список, график или дерево. Другой способ определить поиск в структурах данных — найти нужный элемент с определенными характеристиками в наборе элементов.
Изображение 1Методы поиска

Эти алгоритмы классифицируются в соответствии с типом операции поиска, которую они выполняют, например:
Эти методы оцениваются на основе времени, затрачиваемого алгоритмом на поиск элемента, соответствующего элементу поиска в наборах данных, и определяются по формуле 9.0003
- Лучшее время
- Среднее время
- Время наихудшего случая
Основные проблемы связаны с временем наихудшего случая, которое обеспечивает гарантированные прогнозы производительности алгоритма, а также его легче вычислить, чем среднее время.
Чтобы проиллюстрировать концепции и примеры в этой статье, мы предполагаем «n» элементов в сборе данных в любом формате данных. Для облегчения анализа и сравнения алгоритмов используются доминантные операции. Сравнение — основная операция поиска в структуре данных, обозначаемая O() и произносимая как «большой-О» или «О».
Существует множество алгоритмов поиска в структуре данных, таких как линейный поиск, двоичный поиск, поиск с интерполяцией, поиск по списку, экспоненциальный поиск, поиск с переходом, поиск Фибоначчи, вездесущий двоичный поиск, рекурсивная функция для поиска подстрок, неограниченный, двоичный поиск и рекурсивная программа для линейного поиска элемента в заданном массиве. Статья включает алгоритмы линейного поиска, бинарного поиска и интерполяционного поиска и принципы их работы.
Статья включает алгоритмы линейного поиска, бинарного поиска и интерполяционного поиска и принципы их работы.
Рассмотрим подробнее линейный и бинарный поиск в структуре данных.
Линейный поиск
Алгоритм линейного поиска итеративно просматривает все элементы массива. Он имеет лучшее время выполнения одного и худшее время выполнения n, где n — общее количество элементов в массиве поиска.
Это простейший алгоритм поиска в структуре данных, который проверяет каждый элемент в наборе элементов до тех пор, пока он не совпадет с искомым элементом до конца сбора данных. Когда данные не отсортированы, алгоритм линейного поиска предпочтительнее других алгоритмов поиска.
Сложности линейного поиска приведены ниже:
Космос Сложность:
Поскольку линейный поиск не требует дополнительного пространства, его пространственная сложность равна O(n), где n — количество элементов в массиве.
Время Сложность:
- В лучшем случае сложность = O(1) имеет место, когда искомый элемент присутствует в первом элементе массива поиска.
- В худшем случае сложность = O(n) имеет место, когда требуемый элемент находится в конце массива или вообще отсутствует.
- Средняя сложность = средний случай возникает, когда искомый элемент находится где-то в середине массива.
Псевдокод алгоритма линейного поиска
процедура linear_search (список, значение)
для каждого элемента в списке
если элемент соответствия == значение
вернуть местонахождение предмета
конец, если
конец для
завершение процедуры Пример,
Возьмем следующий массив элементов: 45, 78, 15, 67, 08, 29, 39, 40, 12, 99 Чтобы найти «29» в массиве из 10 элементов, приведенном выше, как мы знаем, алгоритм линейного поиска будет последовательно проверять каждый элемент, пока его указатель не укажет на 29 в пространстве памяти. Требуется O(6) времени, чтобы найти 29 в массиве. Чтобы найти 15 в приведенном выше массиве, требуется O (3), тогда как для 39 требуется O (7) времени.Бинарный поиск

Этот алгоритм находит определенные элементы, сравнивая самые средние элементы в наборе данных. Когда совпадение найдено, он возвращает индекс элемента. Когда средний элемент больше элемента поиска, он ищет центральный элемент левого подмассива. Если, с другой стороны, средний элемент меньше элемента поиска, он ищет средний элемент в правом подмассиве. Он продолжает искать элемент, пока не найдет его или пока размер подмассивов не достигнет нуля.
Двоичный поиск требует отсортированного порядка элементов массива. Он работает быстрее, чем алгоритм линейного поиска. Бинарный поиск использует принцип «разделяй и властвуй».
Сложность во время выполнения = O(log n)
Сложности бинарного поиска приведены ниже:
- Сложность двоичного поиска в наихудшем случае составляет O(n log n).
- Средняя сложность случая в бинарном поиске составляет O(n log n)
- Сложность в лучшем случае = O (1)
Псевдокод алгоритма двоичного поиска
Процедура binary_search
A ← отсортированный массив
n ← размер массива
x ← значение для поиска
Установить нижнюю границу = 1
Установить верхнюю границу = n
пока х не найден
если верхняя граница < нижняя граница
ВЫХОД: x не существует.
установить midPoint = нижняя граница + (верхняя граница - нижняя граница) / 2
если A[средняя точка] x
установить верхнюю границу = midPoint - 1
если А[средняя точка] = х
ВЫХОД: x найдено в точке midPoint
конец, пока
окончание процедуры  установить midPoint = нижняя граница + (верхняя граница - нижняя граница) / 2
если A[средняя точка] x
установить верхнюю границу = midPoint - 1
если А[средняя точка] = х
ВЫХОД: x найдено в точке midPoint
конец, пока
окончание процедуры
установить midPoint = нижняя граница + (верхняя граница - нижняя граница) / 2
если A[средняя точка] x
установить верхнюю границу = midPoint - 1
если А[средняя точка] = х
ВЫХОД: x найдено в точке midPoint
конец, пока
окончание процедуры Пример,
Возьмем отсортированный массив из 08 элементов: 09, 12, 26, 39, 45, 61, 67, 78
- Чтобы найти 61 в массиве вышеуказанных элементов,
- Алгоритм разделит массив на два массива: 09, 12, 26, 39 и 45, 61, 67, 78
- Поскольку 61 больше 39, он начнет поиск элементов в правой части массива.
- Он далее разделит число на два, например 45, 61 и 67, 78
- Поскольку 61 меньше 67, поиск начнется слева от этого подмассива.
- Этот подмассив снова делится на два как 45 и 61.
- Поскольку 61 — это число, соответствующее элементу поиска, будет возвращен порядковый номер этого элемента в массиве.
- Он сделает вывод, что элемент поиска 61 расположен на 6-й позиции в массиве.

Двоичный поиск сокращает время вдвое, так как количество сравнений значительно уменьшается по сравнению с алгоритмом линейного поиска.
Интерполяционный поискЭто улучшенная версия алгоритма бинарного поиска, который фокусируется на проверке позиции элемента поиска. Он работает только с отсортированным сбором данных, подобно алгоритмам бинарного поиска.
Сложности интерполяционного поиска приведены ниже:
Когда середина (наша аппроксимация) является желаемой клавишей, интерполяционный поиск работает лучше всего. В результате временная сложность в лучшем случае составляет O (1).
Если набор данных отсортирован и распределен равномерно, средняя временная сложность интерполяционного поиска составляет O(log2(log2n)), где n обозначает общее количество элементов в массиве.
В худшем случае нам придется пройти весь массив, что займет O(n) времени.
Поиск с интерполяцией используется, когда местоположение целевого элемента известно в наборе данных. Если вы хотите найти номер телефона Рахула в телефонной книге, вместо использования линейного или двоичного поиска вы можете напрямую обратиться к хранилищу памяти, где имена начинаются с «R».
Если вы хотите найти номер телефона Рахула в телефонной книге, вместо использования линейного или двоичного поиска вы можете напрямую обратиться к хранилищу памяти, где имена начинаются с «R».
Псевдокод алгоритма интерполяционного поиска
A → Список массивов
N → Размер A
X → Целевое значение
Процедура Интерполяция_Поиск()
Установить Lo → 0
Установите среднее значение → -1
Установить Привет → N-1
Пока X не совпадает
если Lo равно Hi ИЛИ A[Lo] равно A[Hi]
ВЫХОД: Ошибка, цель не найдена
конец, если
Установить Mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
если A[Mid] = X
ВЫХОД: Успех, цель найдена в середине.
еще
если A[Mid] X
Установите Hi на Mid-1
конец, если
конец, если
Конец пока
Завершить процедуру Заключение Поиск заданного элемента в массиве из n элементов называется поиском в структурах данных. В поиске есть два типа: последовательный поиск и интервальный поиск. Почти каждый алгоритм поиска попадает в одну из этих двух категорий. Линейный и бинарный поиск — это два простых и удобных в реализации алгоритма, причем бинарные алгоритмы работают быстрее, чем линейные алгоритмы.
В поиске есть два типа: последовательный поиск и интервальный поиск. Почти каждый алгоритм поиска попадает в одну из этих двух категорий. Линейный и бинарный поиск — это два простых и удобных в реализации алгоритма, причем бинарные алгоритмы работают быстрее, чем линейные алгоритмы.
Хотя линейный поиск является самым простым, он проверяет каждый элемент, пока не найдет совпадение с элементом поиска, что делает его эффективным, когда сбор данных не отсортирован должным образом. Однако бинарный поиск выполняется быстрее, если набор данных отсортирован, а длина массива велика.
При работе с наборами данных структура данных является неотъемлемой частью компьютерного программирования. Программисты и разработчики должны постоянно обновлять и улучшать свои навыки в технике компьютерного программирования.
Об автореПрашант Шарма
Надеюсь, вам понравилась статья. Если вы хотите связаться со мной, вы можете подключиться по телефону:
LinkedIn или по любым другим вопросам, вы также можете отправить мне письмо
Источник изображения
- Изображение 1 – https://www. google.com/imgres?imgurl=https%3A%2F%2Fwww.onely.com%2Fwp-content%2Fuploads%2Fblog%2F2019%2Fwhat-happened-to-meta-search -engines%2F0.-meta-search-engines-hero-image.jpg&imgrefurl=https%3A%2F%2Fwww.onely.com%2Fblog%2Fwhat-happened-to-meta-search-engines%2F&tbnid=UU4vh4iiGokd4M&vet=12ahUKEwjB0vm7_dvyAhWaM7cAHSC4BhgQMyhSC. .i&docid=Bg0uMeChoXFo7M&w=1920&h=1080&q=search&ved=2ahUKEwjB0vm7_dvyAhWaM7cAHSC4BhgQMyhTegUIARCjAQ
 google.com/imgres?imgurl=https%3A%2F%2Fwww.onely.com%2Fwp-content%2Fuploads%2Fblog%2F2019%2Fwhat-happened-to-meta-search -engines%2F0.-meta-search-engines-hero-image.jpg&imgrefurl=https%3A%2F%2Fwww.onely.com%2Fblog%2Fwhat-happened-to-meta-search-engines%2F&tbnid=UU4vh4iiGokd4M&vet=12ahUKEwjB0vm7_dvyAhWaM7cAHSC4BhgQMyhSC. .i&docid=Bg0uMeChoXFo7M&w=1920&h=1080&q=search&ved=2ahUKEwjB0vm7_dvyAhWaM7cAHSC4BhgQMyhTegUIARCjAQ
google.com/imgres?imgurl=https%3A%2F%2Fwww.onely.com%2Fwp-content%2Fuploads%2Fblog%2F2019%2Fwhat-happened-to-meta-search -engines%2F0.-meta-search-engines-hero-image.jpg&imgrefurl=https%3A%2F%2Fwww.onely.com%2Fblog%2Fwhat-happened-to-meta-search-engines%2F&tbnid=UU4vh4iiGokd4M&vet=12ahUKEwjB0vm7_dvyAhWaM7cAHSC4BhgQMyhSC. .i&docid=Bg0uMeChoXFo7M&w=1920&h=1080&q=search&ved=2ahUKEwjB0vm7_dvyAhWaM7cAHSC4BhgQMyhTegUIARCjAQМатериалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
blogathonПоиск в структуре данных
Содержание
Лучшие ресурсы
Скачать приложение
Мы используем файлы cookie на веб-сайтах Analytics Vidhya для предоставления наших услуг, анализа веб-трафика и улучшения вашего опыта на сайте. Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Принять
Политика конфиденциальности и использования файлов cookie
Станьте полноценным специалистом по данным
Продвигайтесь вперед в своей карьере в области машинного обучения искусственного интеллекта | Предварительных условий не требуетсяЗагрузить брошюруЧто такое запрос? Исследуйте запросы к базе данных и многое другое
Управление даннымиПо
- Эндрю Золя
- Адам Хьюз
Запрос — это вопрос или запрос информации, выраженный в формальной форме. В компьютерных науках запрос — это, по сути, то же самое, с той лишь разницей, что ответ или извлекаемая информация поступает из базы данных.
В компьютерных науках запрос — это, по сути, то же самое, с той лишь разницей, что ответ или извлекаемая информация поступает из базы данных.
Запрос к базе данных является либо запросом действия, либо запросом выбора. Запрос на выборку — это запрос, который извлекает данные из базы данных. Запрос действия запрашивает дополнительные операции с данными, такие как вставка, обновление, удаление или другие формы манипулирования данными.
Это не означает, что пользователи просто вводят случайные запросы. Чтобы база данных понимала требования, она должна получать запрос на основе предопределенного кода. Этот код является языком запросов.
Что такое запрос в SQL? Языки запросов используются для выполнения запросов к базе данных, а Microsoft Structured Query Language (SQL) является стандартом. Примечание. SQL и MySQL — это не одно и то же, поскольку последний представляет собой расширение программного обеспечения, использующее SQL. Другие языковые расширения языка включают Oracle SQL и NuoDB.
Другие языковые расширения языка включают Oracle SQL и NuoDB.
Хотя Microsoft SQL является наиболее популярным языком, существует множество других типов баз данных и языков. К ним относятся базы данных NoSQL и графовые базы данных, язык запросов Cassandra (CQL), расширения интеллектуального анализа данных (DMX), Neo4j Cypher и XQuery.
Как работают запросы?Запросы могут выполнять несколько различных задач. В первую очередь запросы используются для поиска конкретных данных путем фильтрации явных критериев. Запросы также помогают автоматизировать задачи управления данными, суммировать данные и участвовать в вычислениях.
Другие примеры запросов включают добавление, перекрестную таблицу, удаление, создание таблицы, параметр, итоги и обновления.
Тем временем параметр запроса запускает варианты определенного запроса, предлагая пользователям вставить значение поля, а затем использовать это значение для создания критерия.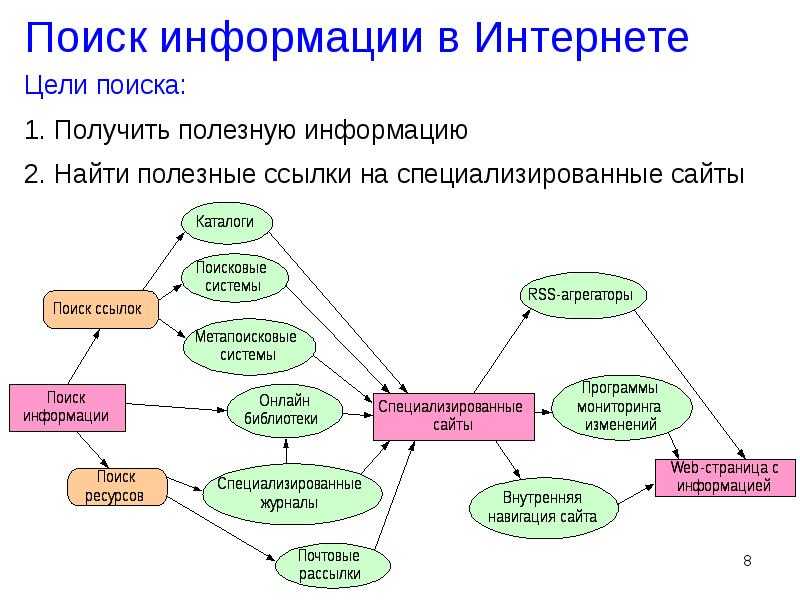 Итоговые запросы, с другой стороны, позволяют пользователям группировать и суммировать данные.
Итоговые запросы, с другой стороны, позволяют пользователям группировать и суммировать данные.
В реляционной базе данных, которая содержит записи или строки информации, запрос оператора SQL SELECT позволяет пользователям выбирать данные и возвращать их из базы данных в приложение. Результирующий запрос сохраняется в таблице результатов, которая называется набором результатов. Пользователи могут разбить оператор SELECT на другие категории, такие как FROM, WHERE и ORDER BY. Запрос SQL SELECT также может группировать и агрегировать данные для анализа или суммирования.
По сути, запрос подобен заказу чашки кофе в кафе. Вы подходите к баристе и делаете запрос, спрашивая: «Можно мне чашечку кофе?» Бариста понимает вашу просьбу и дает вам чашку кофе. Запросы работают так же.
Запрос придает смысл строкам кода, используемым в каждом языке запросов. Таким образом, и пользователь, и база данных обмениваются информацией, поскольку они оба «говорят» на одном языке. Однако запросы по языку — не единственный способ запросить информацию из базы данных. Другие популярные примеры включают пользователей, выполняющих запрос по образцу или с использованием доступных параметров.
Однако запросы по языку — не единственный способ запросить информацию из базы данных. Другие популярные примеры включают пользователей, выполняющих запрос по образцу или с использованием доступных параметров.
Для источников данных, таких как реляционные и нереляционные базы данных, такие как Active Directory, OData или Exchange, mashup-движок «переводит» с M Language — языка преобразования данных Power Query (инструмента mashup и преобразования данных) — на язык понимается базовым источником данных. Чаще всего этим языком будет SQL.
Когда сложные вычисления и преобразования передаются непосредственно в источник, Power Query использует надежные механизмы реляционных баз данных, разработанные для эффективной обработки больших объемов данных.
описывает способность Power Query генерировать один оператор запроса для извлечения и преобразования исходных данных. Подсистема mashup-приложений Power Query пытается выполнять свертывание запросов для повышения эффективности, когда это возможно.
Пользователи также могут выполнять сотни различных преобразований данных с помощью Power BI, платформы бизнес-аналитики Microsoft, которая встроена в Power Query для выполнения свертки запросов. Power BI включает в себя инструменты для сбора, анализа, визуализации и обмена данными.
Поисковый запрос в Интернете Поисковый запрос в Интернете описывает, что ищут пользователи, когда они вводят вопрос или слово в поисковых системах, таких как Bing, Google или Yahoo. Запросы поисковых систем предоставляют информацию, которая сильно отличается от запросов SQL, поскольку они не требуют позиционных параметров или ключевых слов. Запрос поисковой системы по сути является запросом информации по определенной теме.
Поисковые системы используют алгоритм поиска и находят наиболее точные результаты по запросам. Они сортируют их по значимости и в соответствии с конкретной поисковой системой, детали которой публично не разглашаются.
Типы поисковых запросов включают навигационные, информационные и транзакционные. Навигационный поиск предназначен для поиска определенного веб-сайта, например ESPN.com; информационный поиск предназначен для охвата широкой темы, такой как сравнение нового iPhone и Android-устройства; а транзакционные поиски стремятся завершить транзакцию, например покупку нового свитера на Amazon.com.
Другие виды запросовНекоторые запросы не имеют ничего общего с вышеперечисленным; среди них querySelector() в JavaScript и ошибки запросов в Facebook.
JavaScript querySelector() помогает пользователям найти первый элемент, который соответствует определенному селектору CSS. Чтобы вернуть все совпадающие элементы, разработчики также используют метод querySelectorAll(). Всякий раз, когда селектор недействителен, процесс вызывает исключение SyntaxError. Если совпадений нет, querySelector() возвращает null.
Всякий раз, когда селектор недействителен, процесс вызывает исключение SyntaxError. Если совпадений нет, querySelector() возвращает null.
Ошибки запросов возникают на Facebook по ряду причин. Всякий раз, когда это происходит, пользователи получают сообщение типа «Ошибка выполнения запроса». Обычно это устраняется перезагрузкой устройства, обновлением страницы, выходом из системы и повторным входом в нее или очисткой кеша и файлов cookie.
Последнее обновление: май 2021 г.
Продолжить чтение О запросе- Основные преимущества баз данных с открытым исходным кодом для предприятий
- 10 проблем с большими данными и способы их решения
- Объяснение основных типов тестирования баз данных
- Графовая база данных и реляционная база данных: ключевые отличия
- Лучший способ запрашивать данные DynamoDB с помощью SQL
Как предотвратить внедрение SQL с помощью подготовленных операторов
Автор: Шэрон Ши
Как Fauna планирует продвигать технологию бессерверных баз данных
Автор: Шон Кернер
Учебник по языку запросов Kusto для ИТ-администраторов
Автор: Лиам Клири
InfluxDB Cloud обновляет механизм базы данных временных рядов
Автор: Шон Кернер
Бизнес-аналитика
- Инструменты аналитики AWS помогают французской коммунальной компании стать «зеленой»
Пакет гиганта облачных вычислений позволил Engie SA отказаться от ископаемого топлива и теперь помогает французской коммунальной.
.. - Поставщик ипотечных данных использует Qlik для создания аналитической платформы
Компания Polygon Research использовала инструменты поставщика аналитических услуг для разработки платформы SaaS, состоящей из девяти информационных панелей, которые …
- Генеральный директор Tableau Марк Нельсон уходит в отставку, преемник не назван
Нельсон занял руководящую должность в марте 2021 года после ухода Адама Селипски. Salesforce, которая приобрела …
 ..
..ПоискAWS
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Услуга автоматизирует…
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных.
Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу… - Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи
AWS сталкиваются с выбором при развертывании Kubernetes: запустить его самостоятельно на EC2 или позволить Amazon выполнить тяжелую работу с помощью EKS. См…
 Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу…
Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу…Управление контентом
- Как правильно выбрать PIM-систему для вашего бизнеса 9Системы 0002 PIM гарантируют, что каналы продаж отображают точную информацию о продукте. Чтобы найти правильную систему, лидеры электронной коммерции должны сначала …
- PIM и DAM: в чем разница?
Системы
PIM и DAM помогают розничным торговцам управлять информацией, но они сосредоточены на разных типах информации. Агрегат систем PIM …
- Генеральный директор OpenText по искусственному интеллекту контента, облачной стратегии и гибридной работе
Генеральный директор OpenText Марк Барренечи обсуждает состояние Magellan, крупное приобретение Micro Focus, метавселенную и многое другое в .
..
 ..
..ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная …
- Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь в …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, положив конец …
ПоискSAP
- Безопасность SAP требует определенных навыков, командной работы
Критические уязвимости SAP вызывают постоянную озабоченность, и их количество растет по мере того, как системы SAP становятся все более открытыми из-за цифровой трансформации и.
