
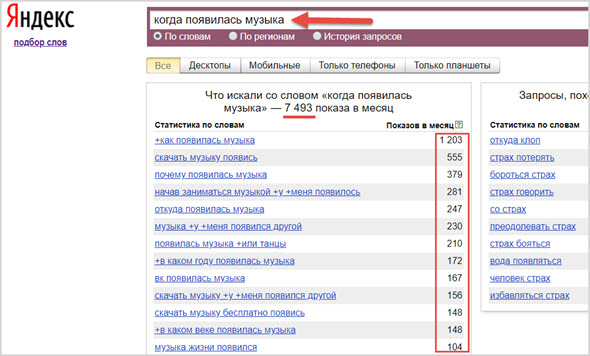
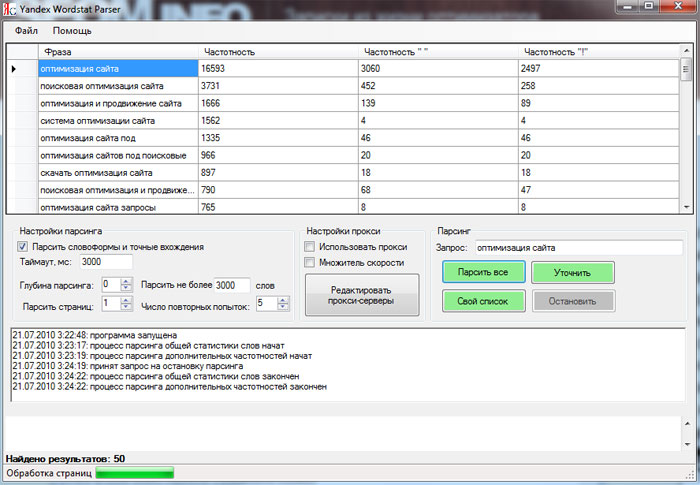
yandex.wordstat
- Цены
- Преимущества
- О нас
- Парсеры
- Партнерка
Например you
yandex.wordstat
Цена за 1000 запросов:
30.00
Калькулятор
Расчет стоимости запросов для парсера — yandex.wordstat
Доступен для использования по запросу
Для запроса на парсер, необходима регистрация
- 15 131
- wordstat
- yandex.
 ru
ru
 ru
ruОписание
Парсинг wordstat.yandex
Использование
Использование:
Параметры
Входящие параметры
| Название | Код по API | Тип | Описание |
| ID* | id | Строка | |
| Фраза | phrase | Строка | |
| Регион(ID) | region_id | Число | |
| Тип | type | Строка |
* уникальный параметр внутри одного задания
Результат
| Название | Код по API | Тип | Описание |
| Фраза | phrase | Строка | поисковый запрос, которому соответствует фраза |
| Колво просмотров | shows | Число | Количество поисковых запросов за прошедший месяц. |
| Тип | type | Строка | тип With/Also — Статистика поисковых запросов, соответствующих фразе. SearchedAlso Статистика других поисковых запросов, которые также делали потребители, искавшие фразы из массива |
* уникальный параметр у всего задания
Интеграция с Вашей системой(API)
Языки програмирования для интеграции с «yandex.wordstat»
Парсер Yandex.XML позволяет получать информацию о позициях сайта по определенным фразам через официальный XML поисковика.
yandex.xml
20.
- yandex.ru
- 11 424
Парсер Yandex позволяет получать информацию о позициях сайта по определенным фразам
YandexSerp
50.00
- yandex.ru
- позиции
- Удобный граббер для получения основных сведений из результатов выдачи популярного браузера от ведущего поисковика Рунета.
yandex.browser
1 000.00
- yandex.ru
- Javascript
- 10 706
Для наполнения и успешного продвижения сайта большое значение имеет качественный контент, его текстовое и графическое содержание. На поиск картинок всегда уходит много времени.
yandex.images
80.00
- yandex.ru
- Картинки
- 12 943
- yandex.ru
- 12 714
Яндекс.Директ — это система размещения поисковой и тематической контекстной рекламы. Она показывает ваши объявления людям, которые уже ищут похожие товары или услуги на Яндексе и тысячах других сайтов.
Yandex.Direct
30.00
- yandex. ru
- 11 394
- yandex.
yandex.add
400.00
- yandex.ru
- Индексация
- 11 256
Получение страницы из кеша яндекса
Получение Кеша Яндекса
400.
00 - yandex.ru
- Кеш
- seo
- 11 172
Парсер для массовой проверки индексации сайта
yandex.index
50.00
- yandex.ru
- 10 483
- yandex.ru
- подсказки
- 10 189
рефераты с referats.yandex.ru
vesna.yandex.ru
80.00
- yandex.ru
- 10 118
 org/Product» itemscope=»»>
org/Product» itemscope=»»>Скрипт сканирования объявлений, размещаемые в Yandex.Direct для каждой из переданных на анализ фразы.
Сбор информации о конкурентах
500.00
 ru
ru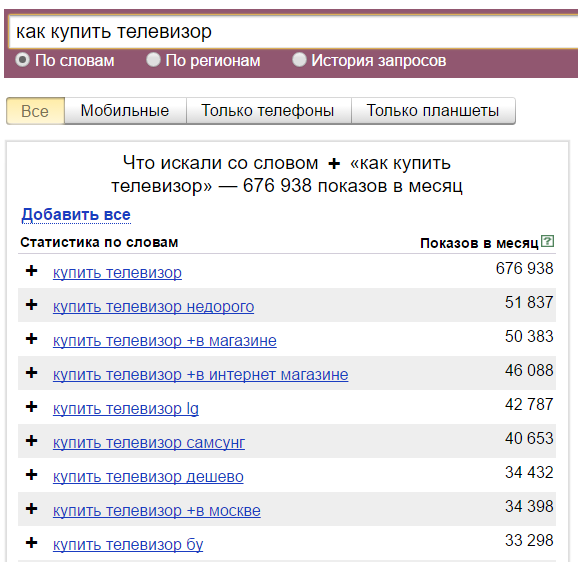 00
00 
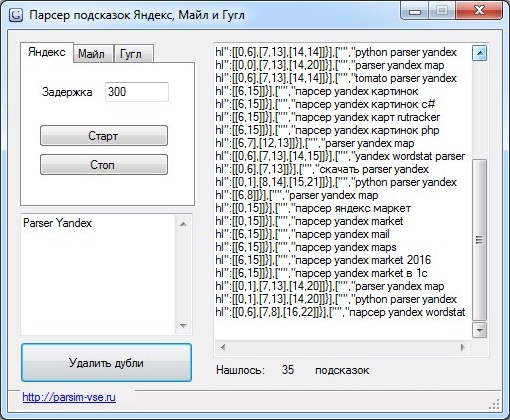
Парсер подсказок Yandex
подсказки yandex
80.00
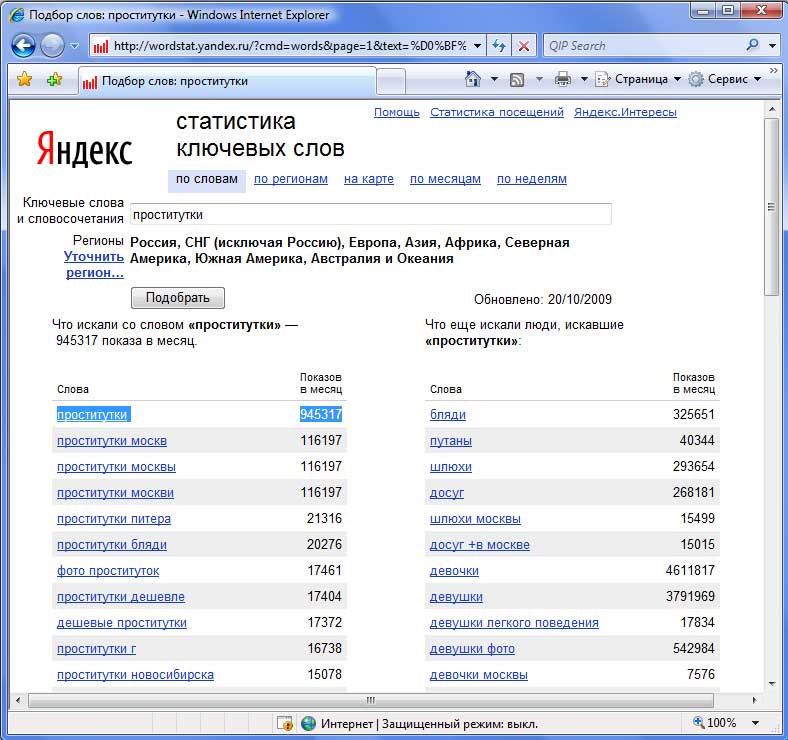
PHP парсер wordstat Яндекс — Сборная солянка
Простой и бесплатный пример PHP парсера (parser) статистики ключевых слов с wordstat Яндекс.
Понятно, что перед тем как продвигать сайт, нужно определиться с ключевиками. Подбор ключевых слов это не сложный, но кропотливый труд. Для того же чтоб найти что-то стоящее, нужно перелопатить кучу данных. Поэтому здесь не обойтись без средств автоматизации процесса. В данной заметке я хочу остановиться на создании PHP парсера данных wordstat Яндекс.
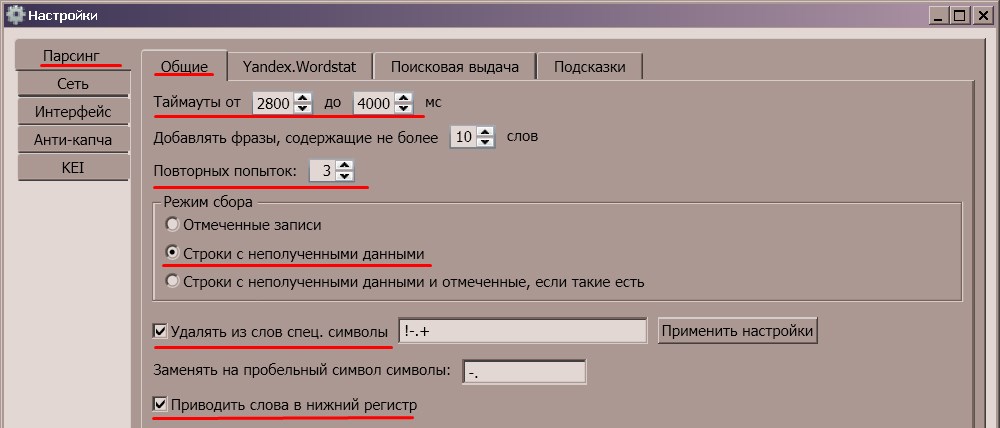
И так. Основная проблема при парсинге данных с сервиса статистики ключевых слов wordstat Яндекс заключается в наличии капчи. Обойти ее не так уж и сложно. Достаточно передать в запросе куку fuid01, генерируемую при обработки капчи. Другими словами, вам понадобится зайти на сервис, сделать запрос, указав символы с картинки и получить содержание требуемой куки.
Как получить содержание куки fuid01 в браузере Firefox?
Т.к. я не собираюсь замахиваться на эпосы и прочие великие труды человечества, то опишу лишь процесс получения содержания куки fuid01 в браузере Firefox (использую версию 8.0). В общем, запускаем Firefox. Считаем, что запрос в wordstat уже сделан и кука создана. Жмем кнопку «Firefox» в левом верхнем углу окна браузера. В меню выбираем: Настройки > Настройки (я ничего не путаю).
Считаем, что запрос в wordstat уже сделан и кука создана. Жмем кнопку «Firefox» в левом верхнем углу окна браузера. В меню выбираем: Настройки > Настройки (я ничего не путаю).
В открывшемся окне «Настройки», переходим на вкладку «Приватность». Здесь нас интересует блок «История». Выбираем в списке Firefox «будет использовать ваши настройки хранения истории» и жмем появившуюся кнопку «Показать куки…».
В окне «Куки», в поле «Поиск» введите имя интересующей нас куки, т.е. «fuid01». В списке должно отобразиться найденное. Выберите одну из предложенных кук и в поле информации, выделите и скопируйте ее «Содержимое».
Как работать с PHP парсером wordstat Яндекс
Бесплатно скачать PHP парсер wordstat Яндекс можно здесь. Сразу скажу, что это лишь пример, работа которого заключается в парсинге ключевых слов и выводе их на экран, но все по порядку.
Первое, что вам надо понять – все данные представлены в кодировке UTF-8. Так что если что не забудьте сконвертировать данные. Более того, на некоторых серверах с этим может возникнуть проблема, подробней читайте тут. Следующий нюанс заключается в том, что для работы скрипта понадобится поддержка cURL. В остальном все достаточно просто.
Более того, на некоторых серверах с этим может возникнуть проблема, подробней читайте тут. Следующий нюанс заключается в том, что для работы скрипта понадобится поддержка cURL. В остальном все достаточно просто.
Содержание куки fuid01 мы присваиваем переменной $fuid01. По сути, это значение задается в curl_setopt() через CURLOPT_COOKIE, но для удобства я вывел его отдельно. Далее нас интересует массив $params — это переменные, передаваемые в запросе к wordstat Яндекс. В качестве примера я ограничился простейшим вариантом, так что обошлось без динамики. В частности, парсится только первая страница выдачи: 'page' => 1, значение text получается через GET, ну а для региона выбрана Москва: 'geo' => 1.
Понятно, что идентификатор региона, в случае если нужен другой, придется уточнять. Для этого заходим на wordstat Яндекс, кликаем ссылку «Уточнить регион…» и выбираем требуемое.
Сделав запрос, в URL надо посмотреть значение требуемого параметра. Следует отметить, что если выбрано более одного региона, их идентификаторы будут перечислены через запятую.
Дальше идет запрос к сервису статистики и парсинг данных wordstat Яндекс. Последнее имеет один небольшой нюанс. Дело в том, что wordstat Яндекс выводит статистику в виде двух таблиц: «что искали со словом…» и «что еще искали люди, искавшие…» — я же использовал только первую. Впрочем, там нет ничего сложного. Регулярные выражения достаточно простые. Думаю, разберетесь. Удачи!
Краткое руководство • Quanteda
Источник: виньетки/quickstart.Rmd
quickstart.Rmd
Поскольку Quanteda
можно установить с помощью пакетов RUI или GUI, установка доступна через CRAN. :
install.packages("quanteda") См. инструкции на https://github.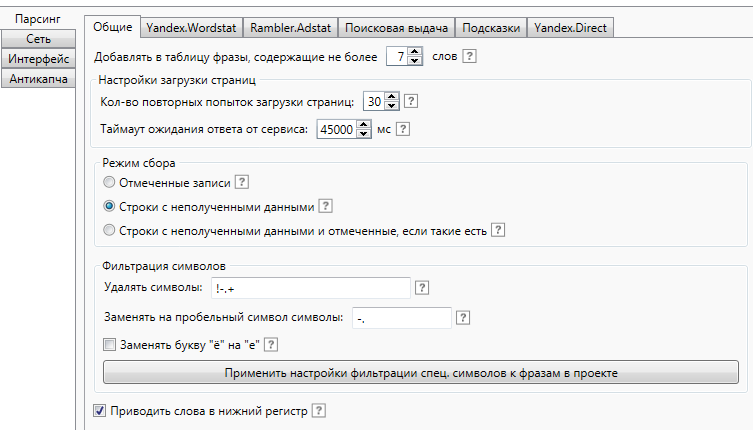 com/quanteda/quanteda, чтобы установить (разрабатываемую) версию GitHub.
com/quanteda/quanteda, чтобы установить (разрабатываемую) версию GitHub.
Вы загружаете пакет для доступа к функциям и данным в пакете.
Доступные в настоящее время исходники корпуса
Quanteda имеет простой и мощный сопутствующий пакет для загрузки текстов: readtext . Основная функция в этом пакете, readtext() , берет файл или набор файлов с диска или URL-адреса и возвращает тип data.frame, который можно использовать непосредственно с функцией конструктора corpus() для создания Quanteda Корпус объекта.
readtext() работает с:
- текстовые (
.txt) файлы; - файлов с разделителями-запятыми (
.csv); - Данные в формате XML;
- данные из Facebook API в формате JSON;
- данные из Twitter API в формате JSON; и
- общие данные JSON.
Команда конструктора корпуса corpus() работает непосредственно с:
- вектором символьных объектов, например, которые вы уже загрузили в рабочую область с помощью других инструментов;
- a
VCorpusкорпусный объект из пакета tm . - data.frame, содержащий текстовый столбец и любые другие метаданные уровня документа.
Построение корпуса из вектора символов
Простейшим случаем является создание корпуса из вектора текстов, уже хранящихся в памяти R. Это дает продвинутому пользователю R полную гибкость в выборе текстовых входов, поскольку существует почти бесконечное количество вариантов ввода. способы получить вектор текстов в R.
Если у нас уже есть тексты в таком виде, мы можем напрямую вызвать функцию конструктора корпуса. Мы можем продемонстрировать это на встроенном символьном объекте текстов об иммиграционной политике, извлеченных из предвыборных манифестов политических партий Великобритании 2010 г. (названных data_char_ukimmig2010 ).
corp_uk <- corpus(data_char_ukimmig2010) # собрать новый корпус из текстов summary(corp_uk)
## Корпус, состоящий из 9 документов, показывающий 9 документов: ## ## Типы текста Токены Предложения ## БНП 1125 3280 88 ## Коалиция 142 260 4 ## Консервативный 251 499 15 ## Зелень 322 677 21 ## Рабочая сила 298 680 29 ## ЛибДем 251 483 14 ## ПК 77 114 5 ## СНП 88 134 4 ## UKIP 346 722 26
Если бы мы захотели, мы могли бы добавить некоторые переменные уровня документа — то, что Quanteda называет docvars — в этот корпус.
Мы можем сделать это, используя функцию R name() , чтобы получить имена вектора символов data_char_ukimmig2010 и назначьте его переменной документа ( docvar ).
docvars(corp_uk, "Party") <- имена(data_char_ukimmig2010) docvars(corp_uk, "Год") <- 2010 summary(corp_uk)
## Корпус, состоящий из 9 документов, показывающий 9 документов: ## ## Типы текста Токены Предложения Партия Год ## млрд НП 1125 3280 88 млрд НП 2010 ## Коалиция 142 260 4 Коалиция 2010 ## Консервативный 251 499 15 Консервативный 2010 ## Зелень 322 677 21 Зелень 2010 ## Труд 298 680 29 труда 2010 ## LibDem 251 483 14 LibDem 2010 ## ПК 77 114 5 ПК 2010 ## СНП 88 134 4 СНП 2010 ## УКИП 346 722 26 УКИП 2010
Загрузка файлов с помощью пакета readtext
require(readtext)
# Твиттер json
dat_json <- readtext("~/Dropbox/QUANTESS/социальные сети/зомби/tweets.json")
corp_twitter <- корпус (dat_json)
резюме (corp_twitter, 5)
# универсальный json - требуется спецификатор текстового поля
dat_sotu <- readtext("~/Dropbox/QUANTESS/Рукописи/коллокации/Corpora/sotu/sotu. json",
текстовое поле = "текст")
резюме (корпус (dat_sotu), 5)
# текстовый файл
dat_txtone <- readtext("~/Dropbox/QUANTESS/corpora/project_gutenberg/pg2701.txt",
кеш = ЛОЖЬ)
резюме (корпус (dat_txtone), 5)
# несколько текстовых файлов
dat_txtmultiple1 <- readtext("~/Dropbox/QUANTESS/corpora/inaugural/*.txt", cache = FALSE)
сводка (корпус (dat_txtmultiple1), 5)
# несколько текстовых файлов с docvars из имен файлов
dat_txtmultiple2 <- readtext("~/Dropbox/QUANTESS/corpora/inaugural/*.txt", docvarsfrom = "имена файлов",
sep = "-", docvarnames = c("Год", "Президент"))
сводка (корпус (dat_txtmultiple2), 5)
# XML-данные
dat_xml <- readtext("~/Dropbox/QUANTESS/quanteda_working_files/xmlData/plant_catalog.xml",
текстовое поле = "ОБЩИЙ")
сводка (корпус (dat_xml), 5)
# CSV-файл
write.csv(data.frame(inaug_speech = as.character(data_corpus_inaugural), docvars(data_corpus_inaugural)),
файл = "/tmp/inaug_texts.csv", row.names = FALSE)
dat_csv <- readtext("/tmp/inaug_texts.csv", textfield = "inaug_speech")
резюме (корпус (dat_csv), 5)  json",
текстовое поле = "текст")
резюме (корпус (dat_sotu), 5)
# текстовый файл
dat_txtone <- readtext("~/Dropbox/QUANTESS/corpora/project_gutenberg/pg2701.txt",
кеш = ЛОЖЬ)
резюме (корпус (dat_txtone), 5)
# несколько текстовых файлов
dat_txtmultiple1 <- readtext("~/Dropbox/QUANTESS/corpora/inaugural/*.txt", cache = FALSE)
сводка (корпус (dat_txtmultiple1), 5)
# несколько текстовых файлов с docvars из имен файлов
dat_txtmultiple2 <- readtext("~/Dropbox/QUANTESS/corpora/inaugural/*.txt", docvarsfrom = "имена файлов",
sep = "-", docvarnames = c("Год", "Президент"))
сводка (корпус (dat_txtmultiple2), 5)
# XML-данные
dat_xml <- readtext("~/Dropbox/QUANTESS/quanteda_working_files/xmlData/plant_catalog.xml",
текстовое поле = "ОБЩИЙ")
сводка (корпус (dat_xml), 5)
# CSV-файл
write.csv(data.frame(inaug_speech = as.character(data_corpus_inaugural), docvars(data_corpus_inaugural)),
файл = "/tmp/inaug_texts.csv", row.names = FALSE)
dat_csv <- readtext("/tmp/inaug_texts.csv", textfield = "inaug_speech")
резюме (корпус (dat_csv), 5)
json",
текстовое поле = "текст")
резюме (корпус (dat_sotu), 5)
# текстовый файл
dat_txtone <- readtext("~/Dropbox/QUANTESS/corpora/project_gutenberg/pg2701.txt",
кеш = ЛОЖЬ)
резюме (корпус (dat_txtone), 5)
# несколько текстовых файлов
dat_txtmultiple1 <- readtext("~/Dropbox/QUANTESS/corpora/inaugural/*.txt", cache = FALSE)
сводка (корпус (dat_txtmultiple1), 5)
# несколько текстовых файлов с docvars из имен файлов
dat_txtmultiple2 <- readtext("~/Dropbox/QUANTESS/corpora/inaugural/*.txt", docvarsfrom = "имена файлов",
sep = "-", docvarnames = c("Год", "Президент"))
сводка (корпус (dat_txtmultiple2), 5)
# XML-данные
dat_xml <- readtext("~/Dropbox/QUANTESS/quanteda_working_files/xmlData/plant_catalog.xml",
текстовое поле = "ОБЩИЙ")
сводка (корпус (dat_xml), 5)
# CSV-файл
write.csv(data.frame(inaug_speech = as.character(data_corpus_inaugural), docvars(data_corpus_inaugural)),
файл = "/tmp/inaug_texts.csv", row.names = FALSE)
dat_csv <- readtext("/tmp/inaug_texts.csv", textfield = "inaug_speech")
резюме (корпус (dat_csv), 5) Как работает квантовый корпус
Принципы корпуса
Корпус представляет собой «библиотеку» исходных документов, которые были преобразованы в обычный текст в кодировке UTF-8 и сохранены вместе с метаданными на уровне корпуса и на уровне документа. У нас есть специальное имя для метаданных уровня документа: docvars . Это переменные или функции, описывающие атрибуты каждого документа.
У нас есть специальное имя для метаданных уровня документа: docvars . Это переменные или функции, описывающие атрибуты каждого документа.
Корпус представляет собой более или менее статичный контейнер текстов с точки зрения обработки и анализа. Это означает, что тексты в корпусе не предназначены для внутреннего изменения посредством (например) очистки или этапов предварительной обработки, таких как определение основы или удаление пунктуации. Скорее, тексты могут быть извлечены из корпуса как часть обработки и присвоены новым объектам, но идея состоит в том, что корпус останется исходной эталонной копией, чтобы можно было проводить другие анализы, например те, в которых требовались основы и пунктуация. например, анализ индекса легкости чтения — может выполняться на том же корпусе.
Чтобы извлечь текст из корпуса, мы просто приводим его к простому символьному типу, используя as.character() .
as.character(data_corpus_inaugural)[2]
## 1793-Вашингтон ## «Сограждане, я снова призван голосом моей страны выполнять функции ее главного магистрата.
 Когда для этого наступит подходящий случай, я постараюсь выразить высокое чувство, которое я питаю к этой выдающейся чести, и о доверии, которое было оказано мне народом объединенной Америки.\n\nПеред исполнением любого официального акта президента Конституция требует присяги. Эту присягу я сейчас собираюсь принять, и в ваше присутствие: что, если будет обнаружено, что во время моего управления правительством я в каком-либо случае сознательно или намеренно нарушил его предписания, я могу (помимо того, что понесу конституционное наказание) подвергнуться упрекам всех, кто в настоящее время является свидетелями настоящего торжественная церемония.\n\n "
Когда для этого наступит подходящий случай, я постараюсь выразить высокое чувство, которое я питаю к этой выдающейся чести, и о доверии, которое было оказано мне народом объединенной Америки.\n\nПеред исполнением любого официального акта президента Конституция требует присяги. Эту присягу я сейчас собираюсь принять, и в ваше присутствие: что, если будет обнаружено, что во время моего управления правительством я в каком-либо случае сознательно или намеренно нарушил его предписания, я могу (помимо того, что понесу конституционное наказание) подвергнуться упрекам всех, кто в настоящее время является свидетелями настоящего торжественная церемония.\n\n " Чтобы обобщить тексты из корпуса, мы можем вызвать метод summary() , определенный для корпуса.
summary(data_corpus_inaugural, n = 5)
## Корпус, состоящий из 59 документов, показывающий 5 документов: ## ## Типы текста Токены Предложения Год Президент Имя ## 1789-Вашингтон 625 1537 23 1789 Вашингтон Джордж ## 1793-Вашингтон 96 147 4 1793 Вашингтон Джордж ## 1797-Адамс 826 2577 37 1797 Адамс Джон ## 1801-Джефферсон 717 1923 41 1801 Джефферсон Томас ## 1805-Джефферсон 804 2380 45 1805 Джефферсон Томас ## Партия ## никто ## никто ## Федералист ## демократ-республиканец ## Demo-Republican
Мы можем сохранить вывод сводной команды в виде фрейма данных и построить базовую описательную статистику с этой информацией:
tokeninfo <- summary(data_corpus_inaugural)
tokeninfo$Year <- docvars(data_corpus_inaugural, "Год")
if (require(ggplot2)) ggplot(data = tokeninfo, aes(x = Year, y = Tokens, group = 1)) +
geom_line() + geom_point() + scale_x_continuous(labels = c(seq(1789), 2017, 12)),
breaks = seq(1789, 2017, 12)) + theme_bw() ## Загрузка требуемого пакета: ggplot2
# Самый длинный инаугурационный адрес: Уильям Генри Харрисон tokeninfo[what.
 max(tokeninfo$Tokens), ]
max(tokeninfo$Tokens), ] ## Типы текста Токены Предложения Год Президент Имя Партия ## 14 1841-Харрисон 1898 9123 210 1841 Харрисон Уильям Генри Виг
Инструменты для работы с объектами корпуса
Добавление двух корпусных объектов вместе
Оператор + обеспечивает простой метод объединения двух объектов корпуса. Если они содержат разные наборы переменных уровня документа, они будут объединены таким образом, чтобы гарантировать, что никакая информация не будет потеряна. Метаданные уровня корпуса также объединяются.
corp1 <- corpus(data_corpus_inaugural[1:5]) corp2 <- corpus(data_corpus_inaugural[53:58]) corp3 <- corp1 + corp2 summary(corp3)
## Корпус, состоящий из 11 документов, показывающий 11 документов: ## ## Типы текста Токены Предложения Год Президент Имя ## 1789-Вашингтон 625 1537 23 1789 Вашингтон Джордж ## 1793-Вашингтон 96 147 4 1793 Вашингтон Джордж ## 1797-Адамс 826 2577 37 1797 Адамс Джон ## 1801-Джефферсон 717 1923 41 1801 Джефферсон Томас ## 1805-Джефферсон 804 2380 45 1805 Джефферсон Томас ## 1997-Клинтон 773 2436 111 1997 Клинтон Билл ## 2001-Буш 621 1806 97 2001 Буш Джордж У.
 ## 2005-Буш 772 2312 99 2005 Буш Джордж У.
## 2009-Обама 938 2689 110 2009 Обама Барак
## 2013-Обама 814 2317 88 2013 Обама Барак
## 2017-Трамп 582 1660 88 2017 Трамп Дональд Дж.
## Партия
## никто
## никто
## Федералист
## демократ-республиканец
## демократ-республиканец
## Демократичный
## республиканец
## республиканец
## Демократичный
## Демократичный
## Республиканский
## 2005-Буш 772 2312 99 2005 Буш Джордж У.
## 2009-Обама 938 2689 110 2009 Обама Барак
## 2013-Обама 814 2317 88 2013 Обама Барак
## 2017-Трамп 582 1660 88 2017 Трамп Дональд Дж.
## Партия
## никто
## никто
## Федералист
## демократ-республиканец
## демократ-республиканец
## Демократичный
## республиканец
## республиканец
## Демократичный
## Демократичный
## Республиканский Подмножество объектов корпуса
Существует метод функции corpus_subset() , определенный для объектов корпуса, где новый корпус может быть извлечен на основе логических условий, примененных к документам :
summary(corpus_subset(data_corpus_inaugural, Year > 1990 ))
## Корпус из 8 документов, показывающий 8 документов: ## ## Типы текста Жетоны Предложения Год Президент Имя Сторона ## 1993-Клинтон 642 1833 81 1993 Клинтон Билл демократ ## 1997-Клинтон 773 2436 111 1997 Клинтон Билл демократ ## 2001-Буш 621 1806 97 2001 Буш Джордж У.
 Республиканец
## 2005-Буш 772 2312 99 2005 Буш Джордж У. Республиканец
## 2009-Обама 938 2689 110 2009 Обама Барак Демократическая
## 2013-Обама 814 2317 88 2013 Обама Барак Демократическая
## 2017-Трамп 582 1660 88 2017 Трамп Дональд Дж. Республиканец
## 2021-Байден 811 2766 216 2021 Байден Джозеф Р. Демократическая партия
Республиканец
## 2005-Буш 772 2312 99 2005 Буш Джордж У. Республиканец
## 2009-Обама 938 2689 110 2009 Обама Барак Демократическая
## 2013-Обама 814 2317 88 2013 Обама Барак Демократическая
## 2017-Трамп 582 1660 88 2017 Трамп Дональд Дж. Республиканец
## 2021-Байден 811 2766 216 2021 Байден Джозеф Р. Демократическая партия summary(corpus_subset(data_corpus_inaugural, President == "Adams"))
## Корпус, состоящий из 2 документов, показывающий 2 документа: ## ## Типы текста Токены Предложения Год Президент Имя ## 1797-Адамс 826 2577 37 1797 Адамс Джон ## 1825-Адамс 1003 3147 74 1825 Адамс Джон Куинси ## Партия ## Федералист ## Республиканско-демократический
Изучение корпусных текстов
Функция kwic (ключевые слова в контексте) выполняет поиск слова и позволяет нам просматривать контексты, в которых оно встречается:
data_tokens_inaugural <- токены (data_corpus_inaugural) kwic(data_tokens_inaugural, pattern = "terror")
## Ключевое слово в контексте с 8 совпадениями.
 ## [1797-Адамс, 1324] мошенничество или насилие, | террор |
## [1933-Рузвельт, 111] безымянный, необоснованный, неоправданный | террор |
## [1941-Рузвельт, 285] казался замороженным фаталистическим | террор |
## [1961-Kennedy, 850] изменить этот неустойчивый баланс | террор |
## [1981-Рейган, 811] освобождение всех американцев от | террор |
## [1997-Clinton, 1047] Они подпитывают фанатизм | террор |
## [1997-Клинтон, 1647] поддерживать сильную защиту от | террор |
## [2009-Обама, 1619] продвигают свои цели, побуждая | террор |
##
## , интриги или продажность
## что парализует необходимые усилия по
## , мы доказали, что это
## который держит руку
## безудержных расходов на проживание.
## . И они мучают
## и разрушение. Наши дети
## и убивая невинных, мы
## [1797-Адамс, 1324] мошенничество или насилие, | террор |
## [1933-Рузвельт, 111] безымянный, необоснованный, неоправданный | террор |
## [1941-Рузвельт, 285] казался замороженным фаталистическим | террор |
## [1961-Kennedy, 850] изменить этот неустойчивый баланс | террор |
## [1981-Рейган, 811] освобождение всех американцев от | террор |
## [1997-Clinton, 1047] Они подпитывают фанатизм | террор |
## [1997-Клинтон, 1647] поддерживать сильную защиту от | террор |
## [2009-Обама, 1619] продвигают свои цели, побуждая | террор |
##
## , интриги или продажность
## что парализует необходимые усилия по
## , мы доказали, что это
## который держит руку
## безудержных расходов на проживание.
## . И они мучают
## и разрушение. Наши дети
## и убивая невинных, мы kwic(data_tokens_inaugural, pattern = "terror", valuetype = "regex")
## Ключевое слово в контексте с 12 совпадениями. ## [1797-Адамс, 1324] мошенничество или насилие, | террор | ## [1933-Рузвельт, 111] безымянный, необоснованный, неоправданный | террор | ## [1941-Рузвельт, 285] казался замороженным фаталистическим | террор | ## [1961-Kennedy, 850] изменить этот неустойчивый баланс | террор | ## [1961-Кеннеди, 972] науки вместо ее | ужасы | ## [1981-Рейган, 811] освобождение всех американцев от | террор | ## [1981-Рейган, 2186] понятны тем, кто практикует | терроризм | ## [1997-Clinton, 1047] Они подпитывают фанатизм | террор | ## [1997-Клинтон, 1647] поддерживать сильную защиту от | террор | ## [2009-Обама, 1619] продвигают свои цели, побуждая | террор | ## [2017-Трамп, 1117] цивилизованный мир против радикальных исламистов | терроризм | ## [2021-Байден, 544], превосходство белых, внутренний | терроризм | ## ## , интриги или продажность ## что парализует необходимые усилия по ## , мы доказали, что это ## который держит руку ## .
 Вместе давайте исследовать
## безудержных расходов на проживание.
## и охотятся на своих соседей
## . И они мучают
## и разрушение. Наши дети
## и убивая невинных, мы
## , который мы искореним
## которым мы должны противостоять и
Вместе давайте исследовать
## безудержных расходов на проживание.
## и охотятся на своих соседей
## . И они мучают
## и разрушение. Наши дети
## и убивая невинных, мы
## , который мы искореним
## которым мы должны противостоять и kwic(data_tokens_inaugural, pattern = "communist*")
## Ключевое слово в контексте с 2 совпадениями. ## [1949-Truman, 832] действия, вытекающие из | коммунист | ## [1961-Kennedy, 510] требуется - не потому, что | коммунисты | ## ## философия представляет угрозу для ## может так и делать,
Используя фразу () , мы также можем искать многословные выражения.
kwic(data_tokens_inaugural, шаблон = фраза("США")) %>%
head() # показать контекст первых шести вхождений «США» ## Ключевое слово в контексте с 6 совпадениями. ## [1789-Вашингтон, 433:434] народа | США | ## [1789-Вашингтон, 529:530] больше, чем у | США | ## [1797-Адамс, 524:525] увидел Конституцию | США | ## [1797-Адамс, 1716:1717] к Конституции | США | ## [1797-Адамс, 2480:2481] поддерживают Конституцию | США | ## [1805-Джефферсон, 441:442] видит сборщика налогов | США | ## ## правительство, созданное ими самими ## .
 Каждый шаг, которым
## в чужой стране.
## и добросовестная решимость
## , я не сомневаюсь
## ? Эти вклады позволяют нам
Каждый шаг, которым
## в чужой стране.
## и добросовестная решимость
## , я не сомневаюсь
## ? Эти вклады позволяют нам В приведенном выше резюме Год и Президент являются переменными, связанными с каждым документом. Мы можем получить доступ к таким переменным с помощью функции docvars() .
# проверить переменные уровня документа head(docvars(data_corpus_inaugural))
## Год Президент Имя Партия ## 1 1789 Вашингтон Джордж нет ## 2 1793 Вашингтон Джордж нет ## 3 1797 Адамс Джон Федералист ## 4 1801 Джефферсон Томас Демократический республиканец ## 5 1805 Джефферсон Томас Демократический республиканец №6 1809Мэдисон Джеймс Демократический республиканец
Дополнительные корпуса доступны в пакете quanteda.corpora.
Сходства между текстами
библиотека("quanteda.textstats")
dfmat_inaug_post1980 <- corpus_subset (data_corpus_inaugural, год > 1980) %>%
токены (remove_punct = TRUE) %>%
tokens_wordstem (language = "en") %>%
tokens_remove(стоп-слова("en")) %>%
дфм()
tstat_obama <- textstat_simil(dfmat_inaug_post1980, dfmat_inaug_post1980[c("2009-Обама",
"2013-Обама"), ], margin = "документы", method = "косинус")
как. list(tstat_obama)
dotchart(as.list(tstat_obama)$"2013-Obama", xlab = "Косинусное сходство", pch = 19)  list(tstat_obama)
dotchart(as.list(tstat_obama)$"2013-Obama", xlab = "Косинусное сходство", pch = 19)
list(tstat_obama)
dotchart(as.list(tstat_obama)$"2013-Obama", xlab = "Косинусное сходство", pch = 19) Мы можем использовать эти расстояния для построения дендрограммы, объединяющей президентов.
Сначала загрузите некоторые данные.
data_corpus_sotu <- readRDS(url("https://quanteda.org/data/data_corpus_sotu.rds"))
dfmat_sotu <- corpus_subset(data_corpus_sotu, Date > as.Date("1980-01-01")) %>%
токены (remove_punct = TRUE) %>%
tokens_wordstem (language = "en") %>%
tokens_remove(стоп-слова("en")) %>%
дфм()
dfmat_sotu <- dfm_trim(dfmat_sotu, min_termfreq = 5, min_docfreq = 3) Теперь мы вычисляем кластеры и строим дендрограмму:
# иерархическая кластеризация - получаем расстояния на нормализованном dfm tstat_dist <- textstat_dist (dfm_weight (dfmat_sotu, схема = "реквизит")) # иерархическая кластеризация удаленного объекта pres_cluster <- hclust(as.dist(tstat_dist)) # метка с именами документов pres_cluster$labels <- имена документов (dfmat_sotu) # график в виде дендрограммы plot(pres_cluster, xlab = "", sub = "", main = "Евклидово расстояние на нормализованной частоте токена")
Мы также можем посмотреть на сходство терминов:
tstat_sim <- textstat_simil(dfmat_sotu, dfmat_sotu[ c("справедливость", "здоровье", "ужас")],
метод = "косинус", поле = "функции")
lapply(as. list(tstat_sim), head, 10)  list(tstat_sim), head, 10)
list(tstat_sim), head, 10) ## $fair ## раз лучше далеко стратеги нас нижняя длинная практика онли ## 0,8266617 0,8135324 0,8036487 0,8002557 0,8000581 0,7995066 0,7977770 0,7949795 0,7944127 0,7899963 ## ## $здоровье ## система issu privat нуждается в расширении поддержки реформы hous dramat mani ## 0,9232094 0,9229859 0,9175231 0,9145142 0,9118901 0,9072380 0,9072374 0,9063870 0,9051588 0,51 ## ## $террор ## террорист Коалит Чейни злая родина либерти 11 внезапный режим сентябрь ## 0,8539894 0,8179609 0,8175618 0,7949619 0,7878223 0,7697739 0,7603221 0,7556575 0,7533021 0,7502925
Масштабирование позиций документа
Вот демонстрация неконтролируемого масштабирования документа в сравнении с моделью Wordfish:
if (require("quanteda.textmodels") && require("quanteda.textplots")) {
dfmat_ire <- dfm (токены (data_corpus_irishbudget2010))
tmod_wf <- textmodel_wordfish (dfmat_ire, dir = c (2, 1))
# построить оценки Wordfish по партиям
textplot_scale1d (tmod_wf, groups = docvars (dfmat_ire, «вечеринка»))
} ## Загрузка необходимого пакета: quanteda.
 textmodels
textmodels Тематические модели
Quanteda позволяет очень легко подобрать тематические модели, например:
quant_dfm <- tokens(data_corpus_irishbudget2010, remove_punct = TRUE, remove_numbers = TRUE) %>%
tokens_remove(стоп-слова("en")) %>%
дфм()
quant_dfm <- dfm_trim(quant_dfm, min_termfreq = 4, max_docfreq = 10)
quant_dfm ## Матрица признаков документа: 14 документов, 1263 признака (разреженность 64,52%) и 6 докваров. ## Особенности ## docs дополнительный отчет за апрель сказал период тяжелый сегодня ## Ленихан, Брайан (FF) 7 1 1 2 3 96 ## Брутон, Ричард (ФГ) 0 1 0 0 0 6 5 ## Бертон, Джоан (ЛАБ) 0 0 4 2 0 13 1 ## Морган, Артур (SF) 1 3 0 3 0 4 0 ## Коуэн, Брайан (FF) 0 0 0 4 1 3 2 ## Кенни, Энда (ФГ) 1 4 4 1 0 2 0 ## Особенности ## документы трудности месяцев пути ## Ленихан, Брайан (FF) 6 11 2 ## Брутон, Ричард (ФГ) 0 0 1 ## Бертон, Джоан (LAB) 1 3 1 ## Морган, Артур (SF) 1 4 2 ## Коуэн, Брайан (FF) 1 3 2 ## Кенни, Энда (ПБ) 0 2 5 ## [ достигнуто max_ndoc .
 .. еще 8 документов, достигнуто max_nfeat ... еще 1253 функции ]
.. еще 8 документов, достигнуто max_nfeat ... еще 1253 функции ] Теперь мы можем подобрать модель темы и построить ее:
set.seed(100)
если (требовать ("stm")) {
my_lda_fit20 <- stm(quant_dfm, K = 20, verbose = FALSE)
сюжет (my_lda_fit20)
} ## Загрузка требуемого пакета: stm
## stm v1.3.6 успешно загружен. Обратитесь за помощью к ?stm. ## Документы, ресурсы и другие материалы на сайтеstructuretopicmodel.com
Общие вопросы / PROXY6.net
- Зачем использовать прокси?
- Сколько времени ждать получения прокси после оплаты?
- Чем отличаются ваши прокси от прокси конкурентов?
- Как обновить прокси?
- Порт 25 открыт?
- Можно ли через прокси зайти на сайты из реестра запрещённых сайтов Роскомнадзора?
- Qiwi и Paypal доступны через прокси?
- Доступен ли Steam через прокси?
- Какой минимальный срок аренды прокси?
- Для каких сайтов подходят прокси IPv6?
- Подходят ли прокси IPv6 для парсинга?
- IPv6 хуже, чем IPv4?
- Как выглядят прокси-серверы IPv6?
- Какова скорость прокси?
- Какие существуют форматы прокси?
- Как работает авторизация?
- Как проверить работоспособность прокси?
- Как проверить, работает ли сайт или сервис с IPv6?
- Можно ли заменить прокси?
- Возврат денег
Зачем использовать прокси?
Изменение IP и DNS - Вы можете скрыть свой реальный IP адрес и DNS просто подключив прокси;
Анонимность в сети - Анонимное и безопасное использование интернета, сокрытие интернет-активности от вашего провайдера;
Обход блокировок - Снятие сервисных ограничений по IP, GEO данным, порту и протоколу.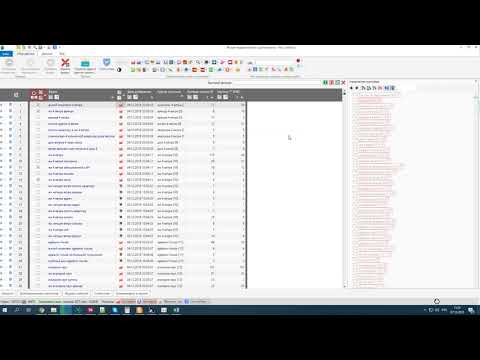 Ваш интернет становится бесплатным;
Ваш интернет становится бесплатным;
Защита от хакеров - Атаки хакеров попадают на наш прокси сервер. Злоумышленники не смогут узнать настоящий IP.
Сколько времени ждать получения прокси после оплаты?
Вы получаете прокси автоматически после оплаты.
Если прокси не отображается в личном кабинете, обратитесь в нашу техподдержку.
Чем отличаются ваши прокси от прокси конкурентов?
Наши прокси предоставляются индивидуально каждому клиенту и не для публичного использования.
Мы заверяем, что вы являетесь единственными пользователями IP-адресов, которые вы покупаете у нас, и эти IP-адреса используются только для ваших целей.
Наши прокси можно использовать для разных социальных сетей без каких-либо ограничений.
Наши прокси расположены на не перегруженных серверах, поэтому скорость отклика намного выше, чем у конкурентов, что немаловажно при сборе и фильтрации информации.
Как обновить прокси?
В личном кабинете нажмите « Мои прокси », выберите нужные вам прокси, нажмите кнопку « Продлить », выберите период продления и произведите оплату выбранных вами прокси.
Порт 25 открыт?
Нет, 25 порт закрыт. Доставка электронной почты отключена.
Можно ли через прокси зайти на сайты из реестра запрещённых сайтов Роскомнадзора?
№ , с 1 ноября 2017 года доступ к ним через прокси закрыт .
Qiwi и Paypal доступны через прокси?
Нет, в нашей сети не работает Qiwi и Paypal.
Доступен ли Steam через прокси?
Нет, Steam заблокирован в наших сетях.
Какой минимальный срок аренды прокси?
Минимальный срок аренды прокси IPv6 3 дня
Минимальный срок аренды прокси IPv4/IPv4 Shared 30 дней
Для каких сайтов подходят прокси IPv6?
Прокси-серверы протокола IPv6 можно использовать только для сайтов, поддерживающих протокол IPv6, например:
instagram.com, facebook.com, youtube.com, plus.google.com и другие сайты, поддерживающие ipv6
Подходят ли прокси IPv6 для парсинга?
Прокси-серверы IPv6 не подходят для анализа wordstat и программного обеспечения, такого как keycollector, поскольку wordstat не поддерживает протокол IPv6
IPv6 хуже, чем IPv4?
Нет , только не все сайты поддерживают протокол IPv6
Как выглядят прокси IPv6?
Прокси IPv6 сделаны как туннель от IPv4 до IPv6 . Туннель используется, чтобы программное обеспечение правильно получало прокси. Сайты не видят туннель, только IPv6, скрытый в порту туннеля. Уникальный индивидуальный IPv6-адрес находится на каждом порту туннеля.
Туннель используется, чтобы программное обеспечение правильно получало прокси. Сайты не видят туннель, только IPv6, скрытый в порту туннеля. Уникальный индивидуальный IPv6-адрес находится на каждом порту туннеля.
Пример IPv4 - 164.0.32.25:3229
Пример IPv6 скрыт за портом - fabc:de12:3456:7890:ABCD:EF98:7654:3210
Какая скорость прокси?
IPv4 — 10 Мбит/с
IPv4 Общий — 10 Мбит/с
IPv6 - 30 Мбит/с
Какие существуют форматы прокси?
Прокси форматов HTTPS и SOCKS5 поддерживаются практически любым ПО.
В личном кабинете вы можете легко переключать выбранные форматы прокси с HTTPS на SOCKS5 и обратно.
Как работает авторизация?
Авторизация прокси может производиться с помощью логина и пароля или с помощью IP .
Как проверить работоспособность прокси?
Соблюдайте ограничения и не используйте слишком много учетных записей в пределах 1 прокси. Несмотря на то, что прокси «чистые», ненадлежащее использование может привести к бану.
Несмотря на то, что прокси «чистые», ненадлежащее использование может привести к бану.
Адреса можно посмотреть здесь: yandex.ru/internet .
Сначала введите прокси в настройки браузера, затем попробуйте посетить этот сайт со своего IP и с прокси, чтобы увидеть разницу.
Или вы можете воспользоваться нашим онлайн прокси-чекером
Как проверить, работает ли сайт или сервис с IPv6?
Чтобы проверить, поддерживает ли сайт или служба протокол IPv6, посетите веб-сайт-ipv6-поддержка и введите адрес.
Можно ли заменить прокси?
Возможна замена в первый день после покупки по уважительной причине.
Возврат денег
1-дневная гарантия возврата денег, однако это не действует, если мы обнаружим, что вы использовали прокси. Мы возвращаем деньги только в случае ошибок (сервис не работает) или медленной/плохой работы сервиса .