Парсинг частотности ключей в Яндекс Wordstat для Семантического Ядра за 500 руб., исполнитель Алексей (1lnmail) – Kwork
Бесконечные бесплатные правки в рамках технического задания и условий заказа. Платить нужно только за те изменения, которые выходят за рамки первоначального заказа. Подробнее
1lnmail
- 4.3
- (52)
Об этом кворке
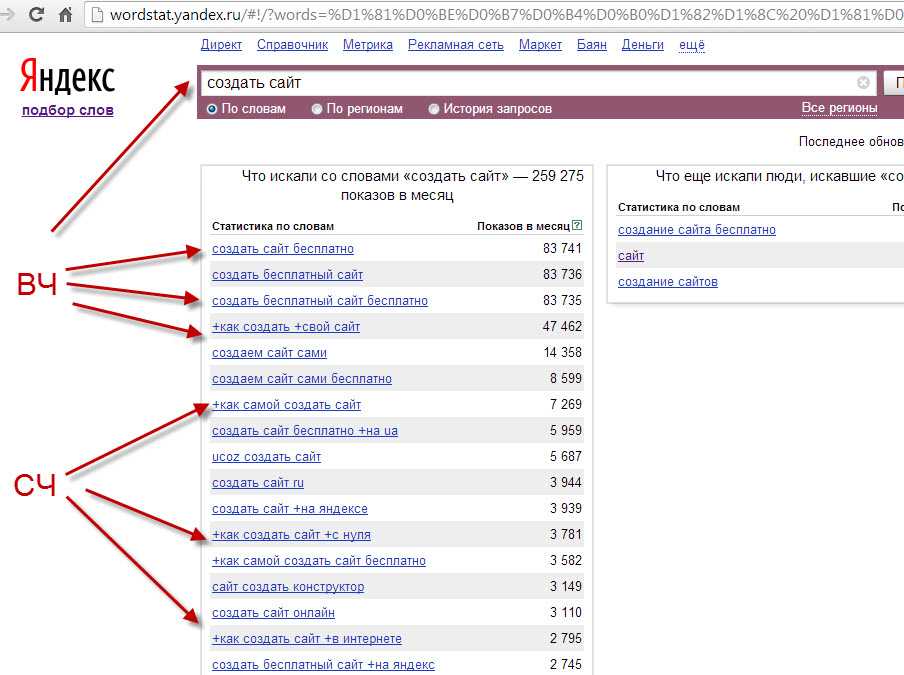
Парсинг и сбор частотности ключевых слов в Яндекс Wordstat по Вашему региону.
— базовые (количество показов за 30 дней)
— «» (количество запросов слово-формы)
— «!» (количество запросов по точному вхождению)
… … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … . . .
Сбор по левой колонке вордстат, возможен по двум (уточняйте в ТЗ)
В стоимость кворка входит сбор до 100 базовых масок (от 2х слов) из одной тематики
— Без сортировки.
— Без кластеризации.
Результат в файле .csv или .xls
… … … … … … … … … … … … … … … … … … … … … … … … … … … … . .
В примере по ТЗ:
- Базовая маска: «купить шоколад»
- Парсинг Яндекс Wordstat : левая колонка
- ГЕО: Москва и Московская обл.
Собрано: 2049 запросов
… … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … . . .
<p>Парсинг и сбор частотности ключевых слов в Яндекс Wordstat по Вашему региону.</p><p>- <strong>базовые</strong> (количество показов за 30 дней)</p><p>- <strong>»»</strong> (количество запросов слово-формы)</p><p>- <strong>»!»</strong> (количество запросов по точному вхождению)</p><p>… … … … … … … … … … . .. … … … … … … … … … … … … … … … … … … … … … … … … . . .</p><p>Сбор по левой колонке вордстат, возможен по двум (уточняйте в ТЗ)</p><p>В стоимость кворка входит сбор до 100 базовых масок (от 2х слов) из одной тематики</p><p>- Без сортировки.</p><p>- Без кластеризации.</p><p>Результат в файле .csv или .xls</p><p>… … … … … … … … … … … … … … … … … … … … … … … … … … … … . .</p><p><strong>В примере по ТЗ: </strong></p><ol><li>Базовая маска: «купить шоколад»</li><li>Парсинг Яндекс Wordstat : левая колонка</li><li>ГЕО: Москва и Московская обл. </li></ol><p><strong>Собрано:</strong> 2049 запросов</p><p>… … … … … … … … … … … … … … … … … … … … … … … … … … … … ..
.. … … … … … … … … … … … … … … … … … … … … … … … … . . .</p><p>Сбор по левой колонке вордстат, возможен по двум (уточняйте в ТЗ)</p><p>В стоимость кворка входит сбор до 100 базовых масок (от 2х слов) из одной тематики</p><p>- Без сортировки.</p><p>- Без кластеризации.</p><p>Результат в файле .csv или .xls</p><p>… … … … … … … … … … … … … … … … … … … … … … … … … … … … . .</p><p><strong>В примере по ТЗ: </strong></p><ol><li>Базовая маска: «купить шоколад»</li><li>Парсинг Яндекс Wordstat : левая колонка</li><li>ГЕО: Москва и Московская обл. </li></ol><p><strong>Собрано:</strong> 2049 запросов</p><p>… … … … … … … … … … … … … … … … … … … … … … … … … … … … .. . … … . . .</p>Файлы
. … … . . .</p>Файлы
образец.xlsx
Язык перевода:
Объем услуги в кворке: 10 000 ключей
Развернуть Свернуть
Гарантия возврата
Средства моментально вернутся на счет,
если что-то пойдет не так. Как это работает?
Расскажите друзьям об этом кворке
Как собрать семантическое ядро из Wordstat с помощью Key Collector
Открываю серию материалов по работе с Key Collector для маркетолога. В этой статье рассмотрим процесс сбора поисковых фраз из Яндекс Вордстат.
Мы уделим работе с Key Collector несколько материалов в которых не будем касаться тайных знаний и описывать тонкости работы с инструментом. Цель в другом — показать основные функции, которые будут полезны интернет-маркетологу для решения задач по работе с семантикой.
KeyCollector никогда не являлся инструментом моей ежедневной работы. Семантическое ядро для подготовки рекламных кампаний за годы я привык собирать руками. Так значительно глубже понимаешь предметную область и оцениваешь возможные резервы.
Так значительно глубже понимаешь предметную область и оцениваешь возможные резервы.
Для решения сео-задач у нас есть команда seo-специалистов, которые как раз и являются экспертами в KeyCollector. И всё бы ничего, но бывают задачи, как например анализ спроса или массовый сбор позиций сайта, а сеошники заняты на других проектах. В такие моменты лучше всё сделать самому.
Начнем рассказ про возможность массового сбора ключевых фраз из Yandex.Wordstat по маскам. Для этого потребуется открыть программу и выполнить ряд несложных действий:
- Выберите вкладку Парсинг;
- В правой части в блоке Управление группами создайте новую группу, куда будут добавлены все собранные фразы;
- В левой верхней части нажмите на иконку Вордстата.
В модальном окне выберете регион по которому будут собираться фразы и добавьте основные маски для парсинга. Рекомендую выбрать регион Россия или оставить поле пустым.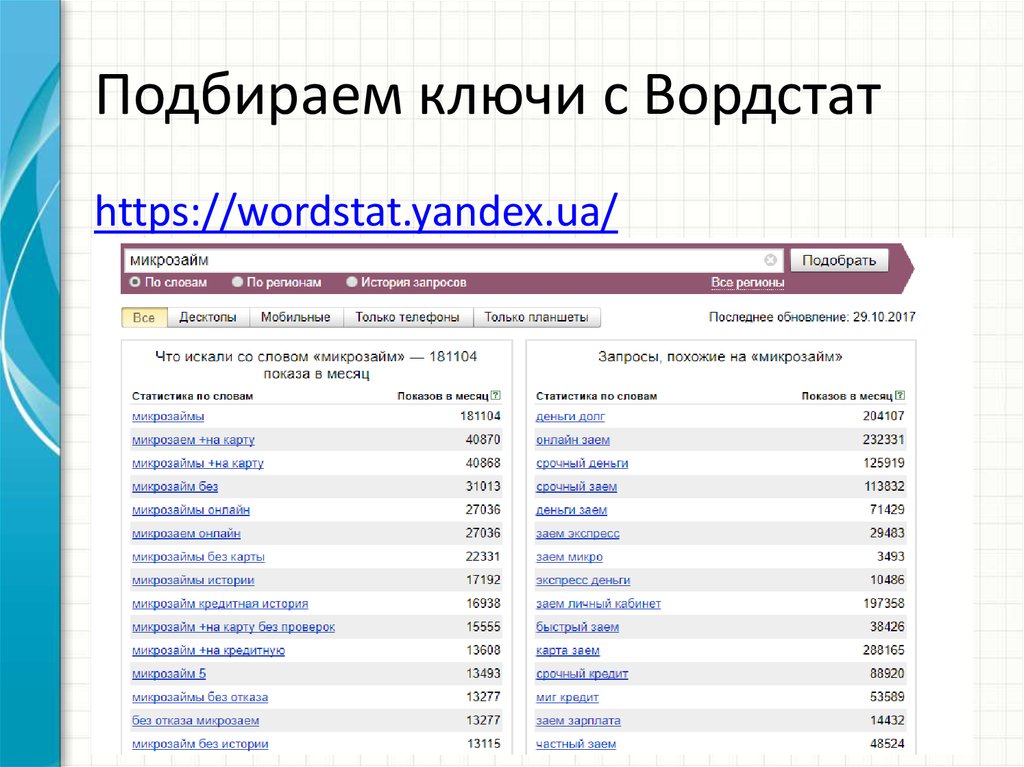 Так получиться собрать значительно больше фраз.
Так получиться собрать значительно больше фраз.
Например, можно указать такую конструкцию (унф) (купить|тариф|цена|стоимость). Это значит, что программа соберет в Вордстате все фразы с упоминанием программы «унф» в связке со словами «купить», «тариф», «цена» и «стоимость».
Нажимаем на кнопку Начать, чтобы запустить пакетный режим сбора. Если ваш Key Collector настроен корректно, то парсинг начнется в течение ближайших секунд. Смотреть статус можно во вкладе Процесс в нижней части экрана. Во вкладе Журнал можно следить за статусом выполнения задачи.
Выгрузить полученный список ключей с частотностью можно во вкладе Файл → Экспорт → Фразы и статистика → Экспортировать. Далее можно выбрать формат сохраняемого документа — xlsx или csv.
Добавлю, что Кейколлектор не испытывает сложности в работе с операторами «()[]!+», но есть некоторый нюанс с оператором «-». Сначала надо создать новый список стоп-слов, а уже потом его применить к парсингу.
В следующих статьях мы продолжим рассматривать важные для маркетолога функции кей коллектора и поговорим про сбор частотности в широком и фразовом соответствии, а также затронем кластеризацию запросов.
Что важного в диджитал на этой неделе?
Каждую субботу я отправляю письмо с новостями, ссылками на исследования и статьи, чтобы вы не пропустили ничего важного в интернет-маркетинге за неделю.
Узнать подробнее →
Метки #keycollector, #инструменты
Опубликовано Рубрики Материалы, ПрактикумHowto eas{y|ier} отладить ошибки синтаксического анализа grok — Logstash
stefws (Штеффен Винтер Соренсен) 1
Уже несколько часов пытаюсь найти сбой разбора grok, хотя, похоже, я получаю требуемые поля и задаюсь вопросом, как люди занимаются отладкой таких сбоев, кроме старого интерпретируемого языкового метода вставки операторов печати.
У меня есть несколько пользовательских шаблонов в /etc/logstash/patterns/owm:
LOGTIME %{YEAR}%{MONTHNUM2}%{MONTHDAY} %{HOUR}%{MINUTE}(?>[0-9]){2}(?>[0-9]){3}%{ISO8601_TIMEZONE}
STATBASE %{LOGTIME:logtime} %{HOSTNAME:host} %{WORD} %{POSINT};%{WORD:stat}(%{POSINT}/%{POSINT})
STATRATE %{INT:rate}/sec %{INT:stim} мс [%{INT:pn}] %{INT:t1n1}/%{INT:t1n2}/%{INT:t1n3} %{INT:t2n1}/%{INT:t2n2}/% {INT:t2n3}
СТАТЗНАЧЕНИЕ {INT:value}
получил такой фильтр:
filter {
# Вся статистика OWM имеет префикс с датой+временем хоста и т.д. > «\A%{STATBASE} *%{GREEDYDATA:message}\Z» }add_tag => [«owmstat»]
tag_on_failure => [«grok1»]
}
if «owmstat» в [tags] {
grok {
pattern_dir => «/etc/logstash/patterns»
overwrite => [«message»]
match => { «message» => «\A%{STATRATE}%{GREEDYDATA:message}\Z» }
tag_on_failure => [«grok2»]
}
grok {
pattern_dir => «/etc/logstash/patterns»
перезапись => [«сообщение»]
совпадение => { «сообщение» => «\A%{ STATVALUE}%{GREEDYDATA:message}\Z» }
tag_on_failure => [«grok3»]
}
# стандартизировать отметку времени по Гринвичу
date {
target => «@timestamp»
match => [«logtime», » YYYYMMdd HHmmssSSSZ»]
remove_field => [«logtime»]
}
# Удаление лишних/бесполезных полей
mutate {
remove_field => [«type», «beat», «count», «fields», «input_type», «смещение», «источник»]
remove_tag => [«shipper-filebeat», «owmstat»]
}
}
}
который при получении такого сообщения:
20151206 142648504+0100 fep1 imapserv 29448;StatFepResolveMS(77/523) 0/сек 0 мс [0] 0/0/0 0/0/0
даст мне ниже результат с ошибкой синтаксического анализа, но как определить, почему?
{
«сообщение» => «0/сек 0 мс [0] 0/0/0 0/0/0»,
«@version» => «1»,
«@timestamp» => «2015- 12-06Т13:11:48.500З»,
«tags» => [
[0] «output-stdout»,
[1] «_grokparsefailure»,
[2] «grok3»
],
«host» => «fep1»,
«stat» = > «StatFepResolveMS»,
«скорость» => «0»,
«стим» => «0»,
«pn» => «0»,
«t1n1» => «0»,
«t1n2» = > «0»,
«t1n3» => «0»,
«t2n1» => «0»,
«t2n2» => «0»,
«t2n3» => «0»,
«@metadata» => {
«бит» => «файлбит»,
«тип» => «журнал»
}
}
 500З»,
500З», советы приветствуются, TIA
STATBASE %{LOGTIME:logtime} %{HOSTNAME:host} %{WORD} %{POSINT};%{WORD:stat}(%{POSINT}\/%{POSINT})
Убедитесь, что вы экранируете круглые скобки (но вы можете не экранировать косую черту). Это одна из причин, по которой он не работает, которую я сразу заметил.
Для более общего вопроса о том, как отлаживать выражения grok, я предлагаю начать с самого простого возможного выражения и увеличивать сложность, постепенно добавляя больше исходного выражения, пока вы снова не получите _grokparsefailure ). В этом случае, начиная с
%{STATBASE}
не поможет, поскольку проблема, похоже, скрыта внутри определения STATBASE (это одна из причин, по которой я думаю, что шаблоны grok, определенные вне файла конфигурации Logstash, являются PITA). Разверните STATBASE в его определение,
%{LOGTIME:logtime} %{HOSTNAME:host} %{WORD} %{POSINT};%{WORD:stat}(%{POSINT}\/%{POSINT})
и уменьшить его:
%{LOGTIME:logtime}
Это работает? Хорошо — добавьте %{HOSTNAME:host} и так далее.
продукты (Штеффен Винтер Соренсен) 3
Верно, также, как я его построил в первую очередь, снизу вверх и между прочим, STATBASE должен работать, так как он обрезает сообщение в первом grok1, а сбой синтаксического анализа, похоже, возникает в grok3 или.
I’ ll один раз (на самом деле несколько раз) снова раздеться задом наперёд…
продукты (Штеффен Винтер Соренсен) 4
Вы правы, внешние паттерны могут быть PITA, но «нормализация» паттернов упрощает их обслуживание в случае, например, PITA. вы измените свои форматы ввода, как и все предопределенные
1 Нравится
(Штеффен Винтер Соренсен) 5
Используя этот шаблон:
STATRATE %{INT:rate}/sec %{INT:stim} мс [%{INT:pn}] %{INT:t1n1}/%{INT:t1n2}/%{INT:t1n3} %{INT:t2n1 }/%{INT:t2n2}/
оставляет, как и ожидалось, мое последнее целое число в сообщении:
{
«сообщение» => «0»,
«@версия» => «1»,
«@timestamp» => «2015-12-06T21:23:48.
«теги» => [
[0] «выходной стандартный вывод»,
[1] «_grokparsefailure»
],
«host» => «fep1»,
«stat» => «StatFepResolveMS»,
«rate» => «0»,
«stim» => «0»,
«pn» => «0»,
«t1n1» => «0»,
«t1n2» => «0»,
«t1n3» => «0»,
«t2n1» => «0»,
«t2n2» => «0»,
«@metadata» => {
«beat» => «filebeat»,
«type» => «log»,
«logts» => «20151206 222348624+0100» ,
«esindex» => «filebeat»
}
}
 624Z»,
624Z», Странно, поскольку grokconstructor указывает, что я также должен иметь возможность подобрать последнее число, почему F… не при запуске в logstash тогда (извините за мой французский 🙂
система (система) Закрыто 6
Общие вопросы / PROXY6.net
- Зачем использовать прокси?
- Сколько времени ждать получения прокси после оплаты?
- Чем отличаются ваши прокси от прокси конкурентов?
- Как обновить прокси?
- Порт 25 открыт?
- Можно ли через прокси зайти на сайты из реестра запрещённых сайтов Роскомнадзора?
- Qiwi и Paypal доступны через прокси?
- Доступен ли Steam через прокси?
- Какой минимальный срок аренды прокси?
- Для каких сайтов подходят прокси IPv6?
- Подходят ли прокси-серверы IPv6 для синтаксического анализа?
- Чем IPv6 хуже, чем IPv4?
- Как выглядят прокси-серверы IPv6?
- Какова скорость прокси?
- Какие существуют форматы прокси?
- Как работает авторизация?
- Как проверить работоспособность прокси?
- Как проверить, работает ли сайт или сервис с IPv6?
- Можно ли заменить прокси?
- Возврат денег
Зачем использовать прокси?
Изменение IP и DNS — Вы можете скрыть свой реальный IP адрес и DNS просто подключив прокси;
Анонимность в сети — Анонимное и безопасное использование интернета, сокрытие интернет-активности от вашего провайдера;
Обход блокировок — Снятие сервисных ограничений по IP, GEO данным, порту и протоколу. Ваш интернет становится бесплатным;
Ваш интернет становится бесплатным;
Защита от хакеров — Атаки хакеров попадают на наш прокси сервер. Злоумышленники не смогут узнать настоящий IP.
Сколько времени ждать получения прокси после оплаты?
Вы получаете прокси автоматически после оплаты.
Если прокси не отображается в личном кабинете, обратитесь в нашу техподдержку.
Чем отличаются ваши прокси от прокси конкурентов?
Наши прокси предоставляются индивидуально каждому клиенту и не для публичного использования.
Мы заверяем, что вы являетесь единственными пользователями IP-адресов, которые вы покупаете у нас, и эти IP-адреса используются только для ваших целей.
Наши прокси можно использовать для разных социальных сетей без ограничений.
Наши прокси расположены на не перегруженных серверах, поэтому скорость отклика на порядок выше, чем у конкурентов, что немаловажно при сборе и фильтрации информации.
Как обновить прокси?
В личном кабинете перейдите на вкладку « Мои прокси », выберите нужные вам прокси, нажмите кнопку « Продлить » и выберите период продления и произведите оплату выбранных вами прокси.
Порт 25 открыт?
Нет, 25 порт закрыт. Доставка электронной почты отключена.
Можно ли через прокси зайти на сайты из реестра запрещённых сайтов Роскомнадзора?
№ , с 1 ноября 2017 года доступ к ним через прокси закрыт .
Qiwi и Paypal доступны через прокси?
Нет, в нашей сети не работает Qiwi и Paypal.
Доступен ли Steam через прокси?
Нет, Steam заблокирован в наших сетях.
Какой минимальный срок аренды прокси?
Минимальный срок аренды прокси IPv6 3 дня
Минимальный срок аренды IPv4/IPv4 Shared прокси 30 дней
Для каких сайтов подходят прокси IPv6?
Прокси протокола IPv6 можно использовать только для сайтов, поддерживающих протокол IPv6, таких как:
instagram.com, facebook.com, youtube.com, plus.google.com и других сайтов, поддерживающих ipv6
Подходят ли прокси IPv6 для парсинга ?
Прокси-серверы IPv6 не подходят для анализа wordstat и программного обеспечения, такого как keycollector, поскольку wordstat не поддерживает протокол IPv6
IPv6 хуже, чем IPv4?
Нет , только не все сайты поддерживают протокол IPv6
Как выглядят прокси IPv6?
Прокси IPv6 сделаны как туннель от IPv4 до IPv6 . Туннель используется, чтобы программное обеспечение правильно получало прокси. Сайты не видят туннель, только IPv6, скрытый в порту туннеля. Уникальный индивидуальный IPv6-адрес находится на каждом порту туннеля.
Туннель используется, чтобы программное обеспечение правильно получало прокси. Сайты не видят туннель, только IPv6, скрытый в порту туннеля. Уникальный индивидуальный IPv6-адрес находится на каждом порту туннеля.
Пример IPv4 — 164.0.32.25:3229
Пример IPv6 скрыт за портом — fabc:de12:3456:7890:ABCD:EF98:7654:3210
Какова скорость прокси?
IPv4 — 10 Мбит/с
IPv4 Shared — 10 Мбит/с
IPv6 — 30 Мбит/с
Какие существуют форматы прокси?
Прокси форматов HTTPS и SOCKS5 поддерживаются практически любым ПО.
В личном кабинете вы можете легко переключать выбранные форматы прокси с HTTPS на SOCKS5 и обратно.
Как работает авторизация?
Авторизация прокси может производиться с использованием логина и пароля или с использованием IP .
Как проверить работоспособность прокси?
Соблюдайте лимиты и не используйте слишком много учетных записей в пределах 1 прокси.