
Парсинг сайтов в Excel в 2023: пошаговая инструкция
Парсить сайты в Excel достаточно просто если использовать облачную версию софта Google Таблицы (Sheets/Doc), которые без труда позволяют использовать мощности поисковика для отправки запросов на нужные сайты.
- Подготовка;
- IMPORTXML;
- IMPORTHTML;
- Обратная конвертация.
Видеоинструкция
Подготовка к парсингу сайтов в Excel (Google Таблице)
Для того, чтобы начать парсить сайты потребуется в первую очередь перейти в Google Sheets, что можно сделать открыв страницу:
https://www.google.com/intl/ru_ru/sheets/about/
Потребуется войти в Google Аккаунт, после чего нажать на «Создать» (+).
Теперь можно переходить к парсингу, который можно выполнить через 2 основные функции:
- IMPORTXML. Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
- IMPORTHTML. Позволяет получить данные из таблиц и списков.
Однако, все эти методы работают на основе ссылок на страницы, если таблицы с URL-адресами нет, то можно ускорить этот сбор через карту сайта (Sitemap). Для этого добавляем к домену сайта конструкцию «/robots.txt». Например, «seopulses.ru/robots.txt».
Здесь открываем URL с картой сайта:
Нас интересует список постов, поэтому открываем первую ссылку.
Получаем полный список из URL-адресов, который можно сохранить, кликнув правой кнопкой мыши и нажав на «Сохранить как» (в Google Chrome).
Теперь на компьютере сохранен файл XML, который можно открыть через текстовые редакторы, например, Sublime Text или NotePad++.
Чтобы обработать информацию корректно следует ознакомиться с инструкцией открытия XML-файлов в Excel (или создания), после чего данные будут поданы в формате таблицы.
Все готово, можно переходить к методам парсинга.
IPMORTXML для парсинга сайтов в Excel
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – в формате XPath.
С примером можно ознакомиться в:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit#gid=0
Примеры использования IMPORTXML в Google Doc
Парсинг названий
Для работы с парсингом через данную функцию потребуется знание XPATH и составление пути в этом формате. Сделать это можно открыв консоль разработчика. Для примера будет использоваться сайт крупного интернет-магазина и в первую очередь необходимо в Google Chrome открыть окно разработчика кликнув правой кнопкой мыли и в выпавшем меню выбрать «Посмотреть код» (сочетание клавиш CTRL+Shift+I).
После этого пытаемся получить название товара, которое содержится в h2, единственным на странице, поэтому запрос должен быть:
//h2
И как следствие формула:
=IMPORTXML(A2;»//h2″)
Важно! Запрос XPath пишется в кавычках «запрос».
Парсинг различных элементов
Если мы хотим получить баллы, то нам потребуется обратиться к элементу div с классом product-standart-bonus поэтому получаем:
//div[@class=’product-standart-bonus’]
В этом случае первый тег div обозначает то, откуда берутся данные, когда в скобках [] уточняется его уникальность.
Для уточнения потребуется указать тип в виде @class, который может быть и @id, а после пишется = и в одинарных кавычках ‘значение’ пишется запрос.
Однако, нужное нам значение находиться глубже в теге span, поэтому добавляем /span и вводим:
//div[@class=’product-standart-bonus’]/span
В документе:
Парсинг цен без знаний XPath
Если нет знаний XPath и необходимо быстро получить информацию, то требуется выбрав нужный элемент в консоли разработчика кликнуть правой клавишей мыши и в меню выбрать «Copy»-«XPath». Например, при поиске запроса цены получаем:
//*[@id=»showcase»]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div/div[1]
Важно! Следует изменить » на одинарные кавычки ‘.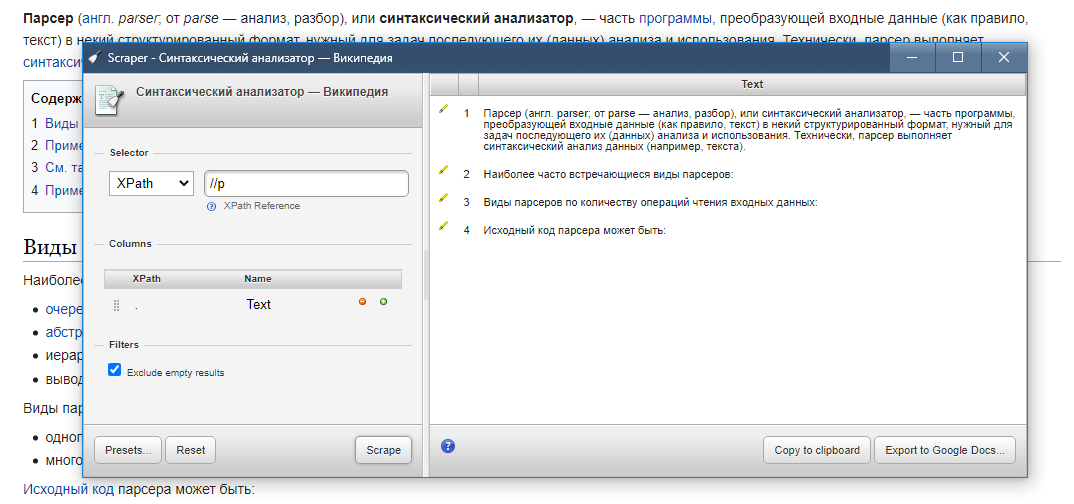
Далее используем ее вместе с IMPORTXML.
Все готово цены получены.
Простые формулы с IMPORTXML в Google Sheets
Чтобы получить title страницы необходимо использовать запрос:
=IMPORTXML(A3;»//title»)
Для вывода description стоит использовать:
=IMPORTXML(A3;»//description»)
Первый заголовок (или любой другой):
=IMPORTXML(A3;»//h2″)
IMPORTHTML для создания парсера веи-ресурсов в Эксель
Синтаксис IMPORTXML в Google ТаблицеДля того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос;Индекс)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – может быть в формате «table» или «list», выгружающий таблицу и список, соответственно.
- Индекс – порядковый номер элемента.
С примерами можно ознакомиться в файле:
https://docs.google.com/spreadsheets/d/1GpcGZd7CW4ugGECFHVMqzTXrbxHhdmP-VvIYtavSp4s/edit#gid=0
Пример использования IMPORTHTML в Google DocПарсинг таблицВ примерах будет использоваться данная статья, перейдя на которую можно открыть консоль разработчика (в Google Chrome это можно сделать кликнув правой клавишей мыши и выбрав пункт «Посмотреть код» или же нажав на сочетание клавиш «CTRL+Shift+I»).
Теперь просматриваем код таблицы, которая заключена в теге <table>.
Данный элемент можно будет выгрузить при помощи конструкции:
=IMPORTHTML(A2;»table»;1)
- Где A2 ячейка со ссылкой;
- table позволяет получить данные с таблицы;
- 1 – номер таблицы.
Важно! Сам запрос table или list записывается в кавычках «запрос».
Парсинг списковПолучить список, заключенный в тегах <ul>…</ul> при помощи конструкции.
=IMPORTHTML(A2;»list»;1)
В данном случае речь идет о меню, которое также представлено в виде списка.
Если использовать индекс третей таблицы, то будут получены данные с третей таблицы в меню:
Формула:
=IMPORTHTML(A2;»list»;2)
Все готово, данные получены.
Обратная конвертация
Чтобы превратить Google таблицу в MS Excel потребуется кликнуть на вкладку «Файл»-«Скачать»-«Microsoft Excel».
Все готово, пример можно скачать ниже.
Пример:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit
|
DDBase
Профессиональная разработка компьютерных программ по умеренным расценкам на главную | Задать вопрос / Оценить заказ Поздравляем! Всем кто попал так или иначе на эту страницу, предоставляется возможность абсолютно бесплатно получить парсер телефонов и емайлов с сайтов ContactGrabber XE 3.0. Для получения бесплатного парсера обращайтесь по указанным на сайте контактам и вы сможете осуществлять парсинг при помощи нашей программы абсолютно бесплатно. Также прадлагаем ознакомиться с предложением готовых разработок нашей команды: Примеры готовых парсеров
Для мониторинга объявлений, Вы сможете использовать бесплатную программу — Advert Monitor Вас заинтересовало наше предложение? Пишите в скайп: DD-Base или на емайл: [email protected] для обсуждения деталей сотрудничества.
Skype: DD-Base
, Email: develop@ddbase. © DDBASE 2012-2023 |


 ru
, Тел: 8(937) 452-51-53 +7 937 881 60 15
, ОГРНИП: 316732500093816
ru
, Тел: 8(937) 452-51-53 +7 937 881 60 15
, ОГРНИП: 316732500093816
6 бесплатных инструментов веб-скрейпинга для сбора больших данных
Веб-скрейпинг — один из самых важных навыков, которые вам необходимо отточить как специалисту по данным; вам нужно знать, как искать, собирать и очищать ваши данные, чтобы ваши результаты были точными и содержательными. Если вы хотите выбрать инструмент для парсинга в Интернете, вам необходимо учитывать некоторые факторы, такие как интеграция API и масштабируемость парсинга. В этой статье представлены шесть инструментов, которые можно использовать для различных проектов по сбору данных.
6 БЕСПЛАТНЫЕ Инструменты для скребки веб -скрещин
- Common Crawl
- Crawly
- Content Grabber
- Webhose.io
- Parsehub
- Scrapingbee
Хорошая новость — это то, что Web Scraping не должно быть Tedious; вам даже не нужно тратить много времени на это вручную. Использование правильного инструмента может помочь вам сэкономить много времени, денег и усилий. Более того, эти инструменты могут быть полезны для аналитиков или людей без большого (или вообще никакого) опыта программирования.
Использование правильного инструмента может помочь вам сэкономить много времени, денег и усилий. Более того, эти инструменты могут быть полезны для аналитиков или людей без большого (или вообще никакого) опыта программирования.
Стоит отметить, что законность веб-скрапинга была поставлена под сомнение, поэтому, прежде чем мы углубимся в инструменты, которые могут помочь в ваших задачах по извлечению данных, давайте удостоверимся, что ваша деятельность полностью легальна. В 2020 году суд США полностью легализовал парсинг общедоступных данных. То есть, если кто-то может найти данные в Интернете (например, в статьях Wiki), то их можно очистить.
Законен ли ваш веб-скрейпинг?
- Не используйте повторно и не публикуйте данные с нарушением авторских прав.
- Соблюдайте условия обслуживания сайта, который вы пытаетесь очистить.
- Иметь разумную скорость сканирования.
- Не пытайтесь парсить частные разделы сайта.
Если вы не нарушаете ни одно из этих условий, ваша деятельность по очистке веб-страниц должна быть законной.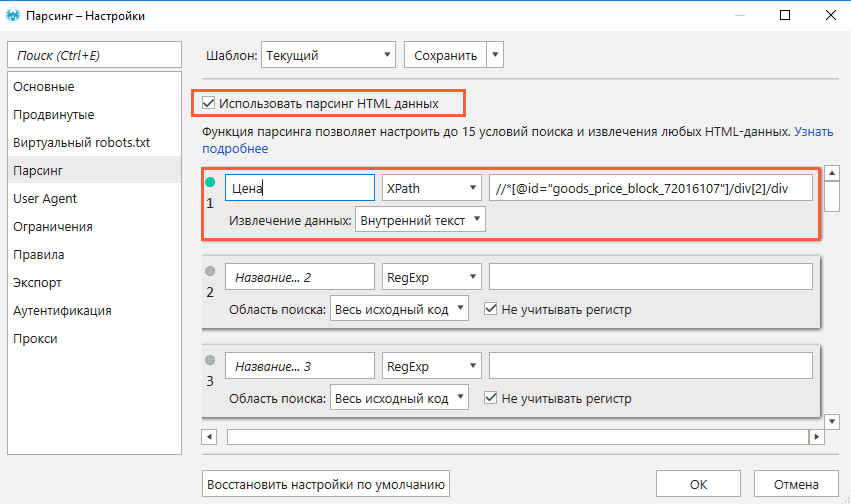 Но не верьте мне на слово.
Но не верьте мне на слово.
Если вы когда-либо создавали проект по науке о данных с использованием Python, то вы, вероятно, использовали BeatifulSoup для сбора данных и Pandas для их анализа. В этой статье вы познакомитесь с шестью инструментами веб-скрейпинга, которые не включают BeatifulSoup, но помогут вам бесплатно собрать данные, необходимые для вашего следующего проекта.
Другие бесплатные инструменты для обработки и анализа данных5 Библиотеки машинного обучения с открытым исходным кодом, которые стоит попробовать исследовать и анализировать окружающий мир, чтобы выявить закономерности. Они предлагают высококачественные данные, которые ранее были доступны только для крупных корпораций и исследовательских институтов, любому любопытному уму бесплатно для поддержки сообщества открытого исходного кода.
Это означает, что если вы студент университета, человек, ориентирующийся в науке о данных, исследователь, ищущий интересующую вас тему, или просто любознательный человек, который любит выявлять закономерности и находить тенденции, вы можете использовать Common Crawl без беспокоясь о сборах или любых других финансовых сложностях.
Common Crawl предоставляет открытые наборы данных необработанных данных веб-страниц и извлечения текста. Он также предлагает поддержку вариантов использования, не основанных на коде, и ресурсы для преподавателей, обучающих анализу данных.
Еще от Sara A. MetwalliПсевдокод: что это такое и как его написать для извлечения данных в формате CSV, чтобы вы могли анализировать их без написания кода.
Все, что вам нужно сделать, это ввести URL-адрес, ваш адрес электронной почты (чтобы они могли отправить вам извлеченные данные) и формат, в котором вы хотите свои данные (CSV или JSON). Вуаля! Собранные данные находятся в вашем почтовом ящике для использования. Вы можете использовать формат JSON, а затем анализировать данные на Python с помощью Pandas и Matplotlib или на любом другом языке программирования.
Хотя Crawly идеален, если вы не программист или только начинаете заниматься наукой о данных и парсингом веб-страниц, у него есть свои ограничения. Crawly может извлекать только ограниченный набор HTML-тегов, включая заголовок, автора, URL-адрес изображения и издателя.
Ищете дополнительные ресурсы по науке о данных? We Got YouBuilt In Learning Lab for Data Science
3. Content Grabber
Content Grabber — один из моих любимых инструментов веб-скрейпинга, потому что он очень гибкий. Если вы хотите очистить веб-страницу и не хотите указывать какие-либо другие параметры, вы можете сделать это, используя их простой графический интерфейс (графический пользовательский интерфейс). Однако, если вы хотите иметь полный контроль над параметрами извлечения, Content Grabber также дает вам возможность сделать это
Одним из преимуществ Content Grabber является то, что вы можете запланировать автоматическое извлечение информации из Интернета. Как мы все знаем, большинство веб-страниц регулярно обновляются, поэтому регулярное извлечение контента может быть весьма полезным.
Content Grabber также предлагает широкий выбор форматов для извлеченных данных, от CSV до JSON, SQL Server или MySQL.
Подробнее о SQLПочему SQLZoo — лучший способ практиковать SQL
4. Webhose.io
Webhose.io — веб-скрапер, который позволяет извлекать данные корпоративного уровня в режиме реального времени из любого онлайн-ресурса. Данные, собранные Webhose.io, структурированы, чисты, содержат настроения и распознавание объектов и доступны в различных форматах, таких как XML, RSS и JSON.
Webhose.io предлагает полный охват данных для любого общедоступного веб-сайта. Кроме того, он предлагает множество фильтров для уточнения извлеченных данных, чтобы вы могли выполнять меньше задач по очистке и сразу переходить к этапу анализа.
Бесплатная версия Webhose.io обеспечивает 1000 HTTP-запросов в месяц. Платные планы предлагают больше звонков, более мощные данные и дополнительные преимущества, такие как аналитика изображений, геолокация и архивные данные за 10 лет.
Связанные материалы из сети экспертов-участников9 Всеобъемлющие памятки по науке о данных
5. ParseHub
ParseHub — это мощный инструмент для очистки веб-страниц, который каждый может использовать бесплатно. Он предлагает надежное и точное извлечение данных одним нажатием кнопки. Вы также можете запланировать время парсинга, чтобы держать ваши данные в актуальном состоянии.
Одной из сильных сторон ParseHub является то, что он может без проблем парсить даже самые сложные веб-страницы. Вы даже можете поручить ему искать формы, меню, входить на веб-сайты и даже нажимать на изображения или карты для дальнейшего сбора данных.
Вы также можете предоставить ParseHub различные ссылки и некоторые ключевые слова, и он извлечет соответствующую информацию в течение нескольких секунд. Наконец, вы можете использовать REST API для загрузки извлеченных данных для анализа в форматах JSON или CSV. Вы также можете экспортировать собранные данные в виде Google Sheet или Tableau.
Профессиональное развитие от Сары Метвалли5 Карьера в области квантовых вычислений и как ее достичь
6. Scrapingbee
Наш последний инструмент для очистки в списке — Scrapingbee. Scrapingbee предлагает API для парсинга веб-страниц, который обрабатывает даже самые сложные страницы JavaScript и превращает их в необработанный HTML для использования. Кроме того, у него есть специальный API для просмотра веб-страниц с использованием поиска Google.
Scrapingbee можно использовать одним из трех способов:
- Общий просмотр веб-страниц, например, извлечение цен на акции или отзывов клиентов
- Страница результатов поисковой системы (SERP), которую вы можете использовать для SEO или мониторинга ключевых слов
- Взлом роста, который может включать извлечение контактной информации или информации из социальных сетей
Scrapingbee предлагает бесплатный план, который включает 1000 кредитов и платные планы для неограниченного использования.

Сбор данных для ваших проектов — это, пожалуй, наименее увлекательный и наиболее утомительный этап рабочего процесса проекта по науке о данных. Эта задача может занять довольно много времени. Если вы работаете в компании или даже фрилансером, вы знаете, что время — деньги, а это всегда означает, что если есть более эффективный способ сделать что-то, вам лучше это сделать.
Бесплатные онлайн-курсы и сертификация по веб-скрейпингу
Все бесплатные курсы по веб-скрейпингу
Изучите базовые и расширенные возможности парсинга веб-страниц с помощью наших бесплатных онлайн-сертификатов и курсов. Станьте сертифицированным парсером сегодня!
Все курсы
Основы парсинга веб-страниц
11 уроков Бесплатно
Все курсы
ParseHub Web Scraping — сертификация для начинающих
8 уроков Бесплатно
Все курсы
Анализ веб-страниц ParseHub — промежуточная сертификация
10 уроков Бесплатно
Все курсы
Парсинг веб-страниц ParseHub — расширенная сертификация
8 уроков Бесплатно
Посмотреть другие курсы
Часто задаваемые вопросы о наших курсах веб-скрейпинга
- Сколько времени нужно, чтобы изучить веб-скрапинг?
Все зависит от тебя! Наши курсы обычно занимают 20–30 минут, так как они сопровождаются пояснениями и примерами, которые помогут вам практиковаться.
Хотя на то, чтобы стать экспертом по веб-парсингу, может уйти некоторое время, вы можете освоить основы всего за несколько минут! - Зачем вам изучать веб-скрапинг?
Веб-скрапинг позволяет извлекать ценные данные из Интернета всего за несколько минут! Многие специалисты по данным и аналитики данных используют методы парсинга веб-страниц для извлечения необработанных данных, чтобы помочь им принять решение о проблеме, с которой может столкнуться компания. По мере того, как веб-скрапинг продолжает расти, растет и спрос на этот навык. Вы сможете добавить это в свое резюме или предложить услуги веб-скрейпинга.
- Легко ли научиться веб-скрапингу?
Веб-скрапинг может показаться пугающим для некоторых людей. Особенно, если вы никогда в жизни не занимались кодированием.

 Хотя на то, чтобы стать экспертом по веб-парсингу, может уйти некоторое время, вы можете освоить основы всего за несколько минут!
Хотя на то, чтобы стать экспертом по веб-парсингу, может уйти некоторое время, вы можете освоить основы всего за несколько минут!