
Как парсить ключевые слова для контекстной рекламы: краткое руководство
Яндекс.Директ, Яндекс Маркет, Google Adwords, Google Merchant, Ремаркетинг

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Для запуска поисковой контекстной рекламы необходимо создать объявления, интересные потенциальным клиентам. Чтобы вызвать интерес, нужно знать по каким запросам аудитория ищет ваш товар или услугу. Если вы указываете ключевые слова наугад, то рискуете «слить» бюджет впустую. На ручной подбор вы потратите недели и месяцы упорного труда. Оптимальным вариантом является использование парсеров и вспомогательных SEO-инструментов. Поговорим о том, как парсить ключевые фразы для контекстной рекламы.
Как работает контекстная реклама
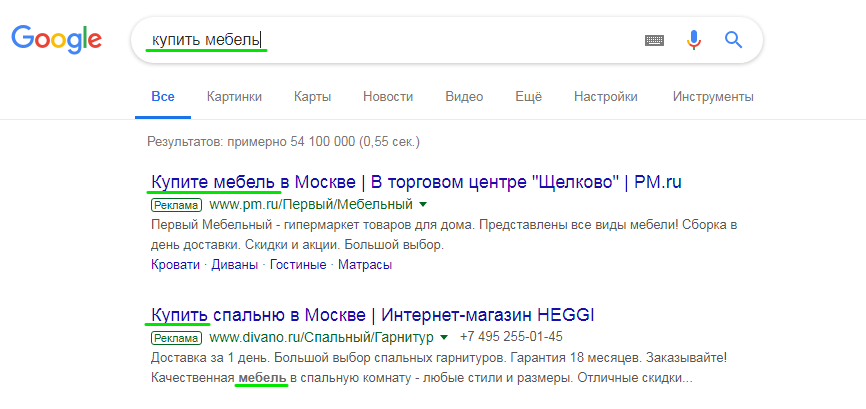
Контекстная реклама направлена непосредственно на людей, которые искали/ищут ваш товар/услугу. Пользователь вводит запрос в поисковую строку и в первых строках выдачи видит релевантное рекламное объявление.
Объявления контекстной рекламы содержат фразы, соответствующие конкретным запросам потенциальных клиентов. Следовательно, для их создания нужно собрать ключевые слова, которые может использовать ваша целевая аудитория.
Как парсеры помогают в подборе коммерческих запросов
Парсеры – это программы или скрипты, которые автоматически собирают необходимые данные с указанных источников. Они изучают содержимое веб-страниц, выбирают нужную информацию и сохраняют в виде готового отчета.
При подборе ключевых фраз парсеры анализируют запросы пользователей в поисковых системах, тематические сайты и статистические данные. На основе анализа формируется список заданных и похожих фраз с указанием частотности показа. Из полученного перечня рекламодатель может выбрать наиболее релевантные словосочетания для создания объявлений. Рассмотрим все этапы сбора ключевых запросов.
Пошаговое руководство: как парсить ключевые слова для контекстной рекламы
Подготовку к запуску рекламной кампании в поиске начать следует с анализа вашего предложения: что вы предлагаете, почему клиентам это может быть интересно, чем вы отличаетесь от конкурентов и прочее. Эта информация поможет понять, что могут искать ваши потенциальные клиенты. Начинаем парсить.
# 1 Подбираем основные ключевые фразы
В первую очередь определяем базовые запросы. Это популярные ключевые слова, которые характеризуют ваш товар/услугу.
Для подбора базовых фраз используйте:
- «мозговой штурм» – соберите все идеи и ассоциации, связанные с тематикой вашего предложения;
- анализ топ-выдачи – посмотрите результаты, которые поисковики выдают по вашим запросам, и соберите ключевые слова из сниппетов;
- Яндекс.Метрика/Google Search Console – при наличии сайта посмотрите данные статистики и выберите ключи, по которым больше всего переходов с поиска.
Учтите, что базовых запросов может быть много. Старайтесь максимально их конкретизировать и сузить. Преимущественно выбирайте ключи из 1-2 слов. Длинные фразы чаще всего используют для редких товаров, брендированных запросов или как дополнение к основным. Вместе с тем отсеивайте короткие ключи слишком общего характера, чтобы не спарсить кучу нерелевантных фраз.
Итогом этого этапа станут 5-10-20 базовых словосочетаний. Они станут «каркасом» будущего списка ключей.
# 2 Дополняем базу ключевых запросов
Для Рунета основным источником ключевых слов выступает поисковая система Яндекс и бесплатный сервис подбора слов Wordstat Yandex. Он показывает количество и частоту запросов по заданной фразе в Яндексе. Ключи отображаются в разных падежах. Дополнительно показаны похожие фразы. Фразы можно искать по регионам и типам устройств. Есть возможность просмотреть историю запроса за 2 года. При помощи специальных операторов можно максимально точно сформулировать проверяемый запрос и исключить лишние фразы.
Введите в строку ввода Яндекс.Вордстат базовый запрос из ранее созданного списка. Система выдаст все запросы за последние 30 дней. Выберите подходящие фразы. Аналогично поработайте со всеми базовыми ключами. При необходимости укажите регион поиска, тип устройства, точность словосочетания и минус-слова.

Если ниша узкая или нужно собрать максимально широкую базу ключей, дополнительно примените бесплатный Планировщик ключевых слов Google. Он показывает статистику по словам и прогнозирует эффективность ключей по заданной ставке.
Откройте Планировщик и выберите раздел «Найдите новые ключевые слова». Введите базовый запрос. Система выдаст список релевантных фраз с указанием частотности, уровня конкуренции и вариации ставок для показа. Проработайте весь список базовых ключей и выберите самые подходящие фразы.

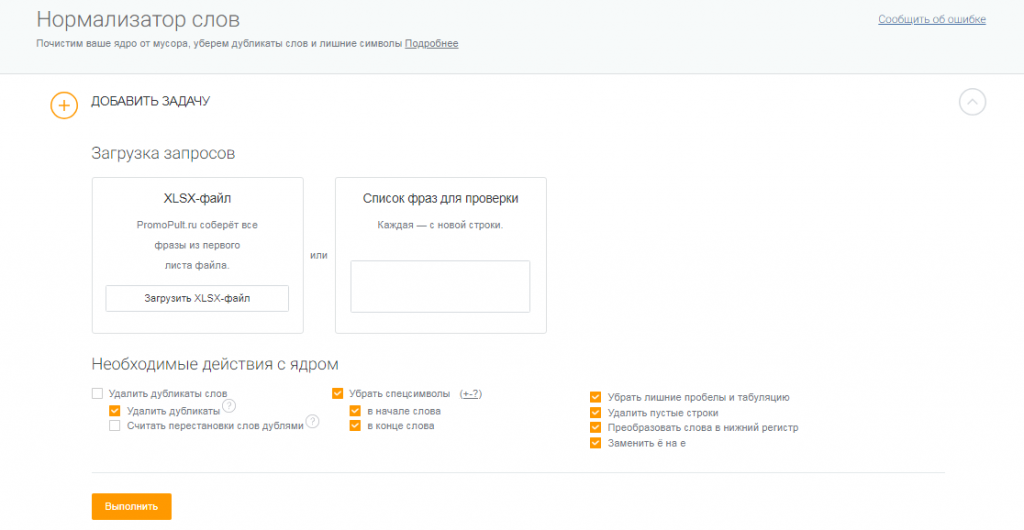
Все собранные ключевые слова добавьте в общий Excel-файл. Однако учтите, что на этом этапе в базе могут присутствовать дубли, нерелевантные фразы, ключи с нулевой частотностью. Их нужно удалить.
Нерелевантные запросы придется удалять вручную. Для очистки семантического ядра от мусорных фраз и дублей используйте специальные инструменты. Например, бесплатный сервис от PromoPult «Нормализатор слов» автоматически чистит базу и не ограничен количеством запросов.
Собранное ядро желательно расширить дополнительными фразами. Для этого используем сторонние парсеры.
# 3 Расширяем семантику
Для расширения ядра потребуется собрать поисковые подсказки, а также «длиннохвостые» ключи. В работе пригодятся такие инструменты, как:
- Key Collector – платная десктоп-программа. Собирает данные с популярных ресурсов. Учитывает региональность и глубину поиска. Можно применять для чистки семантического ядра.

- СловоЁБ – бесплатный парсер, практически аналогичный Key Collector. Отличием выступает некоторое ограничение в источниках.

- Keyword Tool – частично бесплатный парсер, собирающий поисковые подсказки из Google, YouTube и англоязычных ресурсов.

- Букварикс – бесплатный онлайн-инструмент с платным вариантом для десктопа. Собирает ключи по запросам и доменам сайтов.

Выбираем подходящий сервис и проверяем фразы, собранные с помощью Вордстата и Планировщика. Изучаем ключи, полученные в результате парсинга, и наиболее релевантные добавляем в общий список.
На данном этапе у нас получится довольно большой перечень ключей. Он может содержать дубликаты фраз, словосочетания с переставленными словами и схожие словоформы. Некоторые парсеры позволяют проанализировать базу. Например, Букварикс поможет убрать из загруженного списка слов морфологические дубликаты и дубликаты-перестановки.
После завершения работы целесообразно будет проанализировать конкурентов, чтобы знать, как продвигаются они.
# 4 Парсим запросы конкурентов
По поводу парсинга ключей конкурентов для контекстной рекламы мнения специалистов противоречивы. Кто-то считает, что этот способ позволяет собрать самые оптимальные фразы для Яндекс Директ и Google Ads. Другие обоснованно полагают, что использование чужих ключевиков не всегда целесообразно.
Во-первых, вы не знаете маркетинговых целей конкурентов. Их задачи могут отличаться от ваших и не соответствовать вашей стратегии. Возможно, что цель конкурента заключается в продвижении бренда и максимальном охвате аудитории, а вам нужны реальные продажи. К тому же, вы не знаете рекламный бюджет конкурента, который может в разы отличаться от вашего.
Во-вторых, рекламу конкурента мог настроить начинающий специалист. При копировании вы можете повторить все совершенные ошибки кампании. Поэтому логично использовать запросы конкурентов для проверки своего семантического ядра.
Для анализа конкурентов пригодятся следующие инструменты:
- Serpstat – анализирует домены конкурентов, объявления, посадочные страницы. Также ищет страницы с высокими показателями видимости в выдаче, показывает фразы ранжирования конкурентов из топ-10, отображает частотность фраз и проверяет уровень конкуренции. Есть ограниченная бесплатная версия.
- SpyWords – собирает ключевые слова конкурентов, тексты объявлений, трафик, бюджет, рекламные позиции. Платный инструмент.

- AdvSpider – находит объявления в РСЯ по ключевым запросам с учетом региональности показов и типа устройств. Есть демо-версия.
Выберите одного или нескольких конкурентов с максимальной схожестью. Спарсите ключи, по которым они запускают контекстную рекламу. Затем сравните собранные фразы со своими ключевыми словами. Может быть, вы упустили некоторые словосочетания и сможете дополнить ими собственную семантику.
После завершения всех вышеуказанных этапов у вас будет готовая база ключевых слов для создания объявлений контекстной рекламы. Однако в ней перемешаны разные типы запросов, отличающиеся по намерениям, степени схожести и т. д. Потому заключительным этапом подбора ключей выступает создание сегментов.
# 5 Сегментируем ключевые слова для контекстной рекламы
Сегментация базы ключевых слов для контекстной рекламы подразумевает осуществление кластеризации – разбивку семантического ядра на кластеры и группирование схожих фраз. Каждый кластер объединяет похожие ключевые слова.
Для кластеризации можно использовать сервис Rush Analytics. Для его использования нужно просто загрузить собранные ключи в одну колонку Excel, а в другой колонке документа – указать частотность . Далее вы отправляете ядро на кластеризацию, а сервис сортирует данные, создавая набор кластеров.

После сегментации собранных баз определите, какие предложения можно составить на основе каждого кластера . На основании своих выводов создайте объявления, релевантные запросам потенциальных клиентов, и запустите рекламу.
Используя парсеры, собрать ключевые запросы для контекстной рекламы сможет даже новичок. Чем точнее будут ваши ключи, тем эффективнее пройдет кампания. Но помните, что «волшебных» фраз не существует. Анализируйте результаты показов, выбирайте лучшие объявления и определяйте наиболее эффективные фразы для вашего бизнеса.
semantica.in
Парсер объявлений Яндекс Директ | Datacol
Задача Тестирование Обработка и экспорт данных Загрузка в CMS/магазин/ сайт Задать вопросПарсер Яндекс Директ – это настройка Datacol, которая автоматически получает объявления из из Яндекс Директа по заданным ключевым словам.
С помощью этой настройки вы сможете:
- С помощью парсера объявлений Яндекс Директ Вы сможете собрать информацию об интересующих Вас объявлениях;
- Вам нужно указать только список ключевых слов;
- Сохраняйте собранную информацию в любом удобном формате (Excel, TXT, WordPress, MySQL и т. д.).
В результате работы парсера Директа генерируется XLSX файл для последующего открытия в Excel:
кликните на изображении для увеличения
Проверить работу парсера объявлений Яндекс Директа можно бесплатно в демо-версии программы.
Основные преимущества парсера Директа на базе Datacol это:
- Возможность донастройки парсера объявлений Директа конкретно под ваши нужды (вами либо нами на платной основе).
- Возможность переводить, уникализировать, дополнительно обработать собранные данные с помощью плагинов а также загружать их в различные форматы и CMS.
- Возможность цикличного запуска кампаний. Когда результаты выполнения первой задачи парсинга будут входными данными для второй задачи по сбору данных. Подробнее смотрите здесь.
Варианты использования парсера объявлений Яндекс Директ
Яндекс Директ — одна из крупнейших и наиболее эффективных сетей мобильной рекламы в русскоязычном интернете. Многие предприниматели используют именно Директ, чтобы продвинуть свои товары и услуги. Чтобы получить список конкурентов, которые рекламируются по нашим запросам в Яндекс Директе, можно задействовать Datacol.
Дополнительная информация о парсере объявления Яндекс Директ
Настройка объявлений Яндекс Директ собирает запрос, название сайта, объявление и ссылку на сайт. Эта информация будет актуальна для быстрого исследования своей ниши.
Тестирование парсинга объявлений Яндекс Директ
Чтобы протестировать работу парсера объявлений с Яндекс Директ:
Шаг 1. Установите демо-версию программы Datacol. Демо-версия программы имеет все возможности платной, но сохраняет только первые 25 результатов парсинга.
Скачать Демо-версию Datacol
Шаг 2. В дереве кампаний присутствует кампания direct.yandex.ru.par. Выберите ее и нажмите кнопку Запуск (Play). Перед запуском вы можете отредактировать Входные данные. Так вы сможете задать список ключевых слов, информацию о которых вы хотите отпарсить.
кликните на изображении для увеличения
Шаг 3. Дождитесь появления результатов работы парсера Яндекс Директ. После появления результатов можно принудительно остановить парсинг (нажав кнопку Стоп).
кликните на изображении для увеличения
Шаг 4. После окончания/принудительной остановки парсера в папке Мои документы можно найти файл direct.yandex.ru.xlsx:
кликните на изображении для увеличения
Блокировка парсера со стороны сайта источника »
Если сайт-источник забанит ваш IP адрес (обычно в результате этого перестают находиться новые результаты), задействуйте прокси.
Обработка и экспорт данных
Способы обработки данных, собранных парсером объявлений Яндекс Директ:
Форматы экспорта данных, собранных парсером объявлений Яндекс Директ:
Загрузка в CMS/магазин/сайт
Если у вас не получается самостоятельно загрузить собранные данные в свою CMS/интернет магазин/сайт, оставьте заявку и мы постараемся Вам помочь.
Задать вопрос
Если у вас возник вопрос по парсингу Директа:
Популярные вопросы:
Как разобраться в Datacol? »
Пожалуйста ознакомьтесь с базовыми справочными материалами. После ознакомления воспользуйтесь нашей поддержкой на форуме. Поддержка отвечает с понедельника по пятницу.
Какие условия покупки Datacol? »
Все условия приобретения программы приведены здесь.
Как я получу программу после ее оплаты? »
После поступления оплаты за лицензию на адрес электронной почты, указанный при покупке, Вы получите код активации программы и информацию о сроках действия Вашей лицензии. Инструкцию по активации можно посмотреть здесь.
Можно ли купить ОПРЕДЕЛЕННОЕ РЕШЕНИЕ? »
Вы можете приобрести Datacol и в рамках него настроить необходимую компанию (либо воспользоваться базовой настройкой, если таковая имеется). Перед покупкой вы можете описать нам свою задачу, чтобы мы могли ознакомиться с ней и подтвердить что она реализуема в рамках Datacol. Задачу необходимо описать СТРОГО по данному плану — обязательно со скриншотами!
web-data-extractor.net
2 урок сбора семантики — Парсинг ключей
Мы собрали наши маски и сохранили в файл для удобства, теперь переходим к парсингу наших ключевых фраз. Я покажу два способа парсинга платный и бесплатный.
Бесплатный способ парсинга
Устанавливаем расширение для браузера Yandex Wordstat Assistant. Для Яндекс браузера и Оперы можно скачать по ссылке, для Хрома здесь. Это приложение позволяет собирать ключи из Вордстата в полуавтоматическом режиме.
Заходим в Вордстат. Теперь в правой части страницы у нас появилось приложение в котором и будут сохранятся наши фразы, а в верхней части левого столбца кнопка “добавить все”.

Кнопка “добавить все” обведена в круг. Стрелка указывает на “wordstat assistant”
Теперь по одной вводим наши маски в строку поиска Вордстата и собираем все ключевые фразы с помощью кнопки “добавить все”. Фразы добавляются только с одной страницы, поэтому листаем дальше и повторяем процесс, пока не дойдем до последней страницы с ключевыми фразами. Это необходимо проделать с каждой маской.

кнопка для перехода на следующую страницу
После того как наши ключевые фразы добавлены в Yandex Wordstat Assistant, нажимаем копировать и добавляем результат в файл эксель или блокнот.

Платный способ парсинга
Тут все просто, регистрируемся в сервисе Мутаген, выбираем массовый парсинг, как на скрине.

массовый парсинг
Затем создаем задание, выбираем “новое масс задание”
Выбираем новое масс задание
Вводим все наши маски, выбираем парсер “Wordstat 2000”, нажимаем отправить на проверку.
Через какое то время парсер закончит свою работу и мы сможем скачать готовый список с ключевыми фразами и частотностью. На этом этапе мы собрали ключевые фразы для нашего семантического ядра. Далее нам предстоит отфильтровать нерелевантные фразы и сделать сортировку.
Смотрите также:
direct-settings.ru
Парсер объявлений Яндекс-Директа | Сок Сайтов
Яндекс-Директ является самой большой рекламной сетью. Поэтому для тех, кто ищет контакты платежеспособных рекламодателей, Яндекс-Директ является самым лучшим источником данных. Часть объявлений в Директе содержат контакты рекламодателя (сайт, адрес, телефон, электронная почта). Наша программа — парсер объявлений Директа, позволяет получать выгрузки из объявлений по заданному списку ключевых слов, и заданному списку регионов.
Предлагаемая нами программа-парсер контактов Яндекс.Директа, позволяет собирать следующую информацию:
- Регион
- Запрос (ключевое слово)
- Позиция объявления
- Заголовок объявления
- Сайт компании
- Название компании
- Страна
- Город
- Адрес
- Код телефона
- Номер телефона
- Адрес электронной почты (email)
Программа позволяет задать интервал между запросами к сервису, для предотвращения блокировки. Кроме того, имеется возможность выгружать не все объявления, а только первые 10 по каждому ключевому слову.
После завершения работы программы файл с результатами автоматически открывается в Excel (если установлен MS Office) или Calc (если установлен OpenOffice). Файл имеет имя вида results-***.csv. Результатом сбора являются такие файлы: пример файла с выгрузкой объявлений Директа.
Файл Excel с данными, собранными с Яндекс.Директ
Программа очень проста в использовании и имеет интуитивно понятный интерфейс.
Программа умеет приостанавливать свою работу, и продолжать её. Паузу можно включать вручную, а если отключится интернет — программа поставит себя на паузу автоматически. Если во время сбора на сайте возникнет ошибка, и программа не сможет получить данные — она поставит себя на паузу на некоторое время, затем автоматически проснется и сделает еще несколько попыток получить те же данные.
Два индикатора показывают ход выполнения работы. Синий показывает прогресс по списку заданных регионов, зеленый индикатор показывает прогресс по списку заданных ключевых слов.
Стоимость парсера сегодня: 5.000Р 3000р!
Чтобы приобрести нашу программу для выгрузки объявлений Яндекс.Директа по списку запросов, укажите в данной форме имя, email, и способ оплаты (Webmoney / ЯД / Paypal / Liqpay / Qiwi / Visa / Mastercard / наличные / другое). После нажатия кнопки «Заказать!» вы получите на указанный ящик ДЕМО-версию и все подробности об условиях приобретения программы, о процедуре оплаты, о техподдержке и обновлениях.
Хотите заказать подобную программу для других сайтов — закажите у нас создание парсера.
Заказать разработку парсера!soksaitov.ru
Как составить семантическое ядро запросов. Как расширить
Как парсить? Расширение базовой семантики. 2 шаг в Директе.Reviewed by Владислав Челпаченко on Sep 9Rating: 5.0
Здравствуйте, уважаемые коллеги и друзья!
Что такое парсинг и как этим правильно заниматься? Как расширить ваше семантическое ядро в сотни и тысячи раз?
В этой статье мы разберём два способа расширения семантического ядра.
Как составить семантическое ядро?
В прошлой статье мы познакомились с составлением басовой семантики. У вас получился набор слов, из которого можно составить более 50 фраз.
Теперь я расскажу каким образом увеличить это число в 10, а может и в 1000 раз в зависимости от ниши. Сбор ключевиков, или составление семантического ядра, называется парсингом.
Я предлагаю два способа расширения семантики, оба из них подходят под определенные задачи:- Assistant. Это модуль для браузера, который помогает одним нажатием кнопки отправить в буфер обмена все фразы на странице вордстата.
- KeyCollector. Это программа, которая за вас собирает 40 страниц выдачи в вордстате.
Далее, для каждого сервиса мы разберём принцип составления семантики.
Wordstat Assistant
Я покажу на примере браузера Mozilla. Для начала необходимо установить сам модуль. Сделать это можно в разделе «Дополнения» в главном меню (правый верхний угол).
В поиске напишите «Wordstat» и установите плагин «Yandex Wordstat Assistant». Перезапустите браузер.
Теперь, когда вы будете искать ключевые фразы в вордстате, то рядом будет окошко данного плагина, который позволяет одним нажатием мышки добавлять только подходящие вам фразы.
Фразы, которые получились при пересечении базовых слов, нужно вписывать в вордстат и взять оттуда только необходимые ключевики. Лучше всего для этого создать excel-таблицу, в которой под каждой составляющей скелета вписать найденные ключевики.
Какую программу использовать для сбора семантического ядра?
KeyCollector или Словарёк?
Эта программа является платной, но существует бесплатная версия, которой хватит для составления семантики. Скачать ееё можно на этом сайте. После установки нужно создать проект и, программа сразу предложит его сохранить.
Перед тем, как собирать семантику настроим программу:
- В предыдущей статье мы составили «скелет» базовой семантики, теперь необходимо по нему составить разнообразные ключевики. Сделать это можно с помощью сервиса генератора фраз. Под каждую составляющую скелета создаём свою группу.
- Выбираем регион/город/район показов. Если вы собираетесь продавать свой товар или услугу только в Москве, то нет смысла брать семантику по всей России. Таким образом вы устраняете из будущей семантики лишний мусор.
- Настройка программы. Здесь нас интересует всего 1 раздел, о котором поговорим чуть ниже.
- Вписывание получившихся фраз и начало сбора семантики.
В 3 пункте нас интересует раздел с аккаунтами яндекса, с помощью которых программа будет пользоваться вордстатом. Программа работает достаточно быстро, и система яндекса может воспринять это как атаку на свои сервера, поэтому ни в коем случае не вписывайте туда свой личный аккаунт, создайте 7-10 сторонних аккаунтов.
Теперь программа готова к запуску. Возвращаемся к 4 пункту и жмём на кнопку с красной иконкой. Перед нами откроется окно, выставите настройки такие же, как на скриншоте:
Впишите в окошки составленные пересечённые слова и нажмите на кнопку «начать сбор». В зависимости от вашей базовой семантики сбор может длится от 1 часа до нескольких дней. Компьютер при этом нельзя выключать, иначе закроется программа.
На этом методика парсинга закончена. В следующей статье я разберу тему минусация — как очистить составленную семантику и не показываться по ненужным запросам.
Если вы до сих пор не знаете, что такое контекстная реклама, то обязательно прочтите эту статью, а если вам требуется срочно запустить директ, то я показываю, как это сделать в статье «Как быстро запустить Яндекс.Директ?».
Также напоминаю, что вы можете пройти курс по Яндекс.Директу, если появилось желание профессионально изучить директ.
Пишите в комментариях ваши трудности по настройке директа, на все вопросы обязательно ответят. Успехов!
P.S. Понравилась статья? Подпишитесь на обновления блога, чтобы не пропустить следующую.
www.chelpachenko.ru
Инструкция по настройке Key Collector для эффективного парсинга. Яндекс директ парсинг
Как составить семантическое ядро запросов. Как расширить
Как парсить? Расширение базовой семантики. 2 шаг в Директе.Reviewed by Владислав Челпаченко on Sep 9Rating: 5.0
Здравствуйте, уважаемые коллеги и друзья!
Что такое парсинг и как этим правильно заниматься? Как расширить ваше семантическое ядро в сотни и тысячи раз?
В этой статье мы разберём два способа расширения семантического ядра.
Как составить семантическое ядро?
В прошлой статье мы познакомились с составлением басовой семантики. У вас получился набор слов, из которого можно составить более 50 фраз. Теперь я расскажу каким образом увеличить это число в 10, а может и в 1000 раз в зависимости от ниши. Сбор ключевиков, или составление семантического ядра, называется парсингом. Я предлагаю два способа расширения семантики, оба из них подходят под определенные задачи:- Assistant. Это модуль для браузера, который помогает одним нажатием кнопки отправить в буфер обмена все фразы на странице вордстата.
- KeyCollector. Это программа, которая за вас собирает 40 страниц выдачи в вордстате.
Далее, для каждого сервиса мы разберём принцип составления семантики.
Wordstat Assistant
Я покажу на примере браузера Mozilla. Для начала необходимо установить сам модуль. Сделать это можно в разделе «Дополнения» в главном меню (правый верхний угол).
В поиске напишите «Wordstat» и установите плагин «Yandex Wordstat Assistant». Перезапустите браузер.
Теперь, когда вы будете искать ключевые фразы в вордстате, то рядом будет окошко данного плагина, который позволяет одним нажатием мышки добавлять только подходящие вам фразы.
Фразы, которые получились при пересечении базовых слов, нужно вписывать в вордстат и взять оттуда только необходимые ключевики. Лучше всего для этого создать excel-таблицу, в которой под каждой составляющей скелета вписать найденные ключевики.
Какую программу использовать для сбора семантического ядра?KeyCollector или Словарёк?
Эта программа является платной, но существует бесплатная версия, которой хватит для составления семантики. Скачать ееё можно на этом сайте. После установки нужно создать проект и, программа сразу предложит его сохранить.
Перед тем, как собирать семантику настроим программу:
- В предыдущей статье мы составили «скелет» базовой семантики, теперь необходимо по нему составить разнообразные ключевики. Сделать это можно с помощью сервиса генератора фраз. Под каждую составляющую скелета создаём свою группу.
- Выбираем регион/город/район показов. Если вы собираетесь продавать свой товар или услугу только в Москве, то нет смысла брать семантику по всей России. Таким образом вы устраняете из будущей семантики лишний мусор.
- Настройка программы. Здесь нас интересует всего 1 раздел, о котором поговорим чуть ниже.
- Вписывание получившихся фраз и начало сбора семантики.
В 3 пункте нас интересует раздел с аккаунтами яндекса, с помощью которых программа будет пользоваться вордстатом. Программа работает достаточно быстро, и система яндекса может воспринять это как атаку на свои сервера, поэтому ни в коем случае не вписывайте туда свой личный аккаунт, создайте 7-10 сторонних аккаунтов.
www.consei.ru
Есть ли смысл парсить ключи конкурентов для контекстной рекламы?
Есть ли смысл парсить ключи конкурентов для контекстной рекламы?
Многие гуру в своих обучающих материалах пропагандируют парсинг ключей конкурентов. Идея очень проста, ты берёшь сайт своего конкурента и используя специальные сервисы получаешь все ключи, которые у него есть, по которым показывается его реклама в Яндекс Директ либо в Google Adwords.
И этот способ преподносится как некая панацея.
Как-будто такой подход решает все проблемы по сбору ключевых фраз для рекламы. А некоторые преподносится его некую супер фишку. Тем более что и сервисов предоставляющих подобные услуги развелось очень много.
Ну давайте разберемся в этом вопросе логически.
Есть ли практическая польза и если есть, то какая, от того что я заберу себе ключевые фразы по которым рекламируются мои конкуренты.
Ну, во-первых, Яндекс вордстат уже давно спалил все ключи и с этим не поспоришь, главное уметь им правильно пользоваться.
Далее, есть два интересных момента о которых стоит подумать.
Мы не знаем маркетинговые цели, которые преследуют наши конкуренты.
Они могут заниматься продвижение своего бренда, их маркетинговая стратегия это максимальный охват аудитории и для этой цели они могут брать ключевые фразы все подряд и холодные и теплые и горячие и какие угодно запросы.
А как правило для парсинга берут наиболее крупного, жирного конкурента с большими рекламным бюджетом, то и получается что у него большой бюджет и большое семантическое ядро, которое абсолютно не подойдёт тем у кого совсем другие маркетинговые задачи. Если нам нужно просто привлечь максимум целевой аудитории, а не охватить всех подряд то, что мы взяли у конкурента будет работать для нас неправильно и попросту сливать наш бюджет.
Второй момент, который нужно хорошо понимать.
Это-то что мы не можем знать насколько грамотный и адекватный специалист по контексту настраивал рекламу нашему конкуренту. То есть мы можем банально взять себе все ошибки, которые были допущены при создании его рекламной кампании.
А как же делать правильно?
Хороший вариант это собрать все свои ключи, выбрать для парсинга ближайшего, самого целевого, наиболее на вас похожего конкурента.
А потом просто сравнить свои ключи с его ключами, чтобы найти то что вы по каким-то причинам могли упустить, не заметить и таким образом вы можете дополнить свое семантическое ядро.
А брать что-то чужое, копировать себе чужую стратегию и чужие слова. это не самый надежный подход и он может привести к неэффективной работе рекламной кампании.
Также мне ещё непонятны люди, которые составляют искусственную семантику и тем самым получают огромное количество людей по которым 0 показов в месяц.
Это просто лишняя работа, от которой мало толку. Собственно поэтому Яндекс И придумал статус мало показов чтобы ограничить рекламодателей, которые нагружают рекламные компании тысячами пустых слов.
И в качестве завершения, небольшая памятка:
dramtezi.ru
dramtezi.ru













KeyCollector или Словарёк?



