Парсер выдачи Яндекса | Datacol
Парсер выдачи Яндекса
Собирайте поисковую выдачу Яндекса (запросы, заголовки, ссылки и сниппеты) и сохраняйте в удобном формате (EXCEL, CSV, MySQL и др.) для последующей обработки.
https://www.youtube.com/watch?v=O5JvDeYO3yUVideo can’t be loaded because JavaScript is disabled: Автоматическое наполнение и обновление магазина Opencart с помощью Datacol (https://www.youtube.com/watch?v=O5JvDeYO3yU)
SEO анализ выдачи Яндекса
Собирайте информацию из поисковой выдачи Яндекса по продвигаемым запросам и учитывайте результаты при построении стратегии поискового продвижения.
Анализ поисковых трендов
Отслеживайте поисковую выдачу по вашей тематике и корректируйте стратегию в зависимости от потребностей и запросов пользователей.
Расширение бизнеса
Анализируйте поисковые запросы пользователей, выдачу конкурентов и вы сможете найти новые точки роста для вашего бизнеса или идеи для запуска новых проектов.
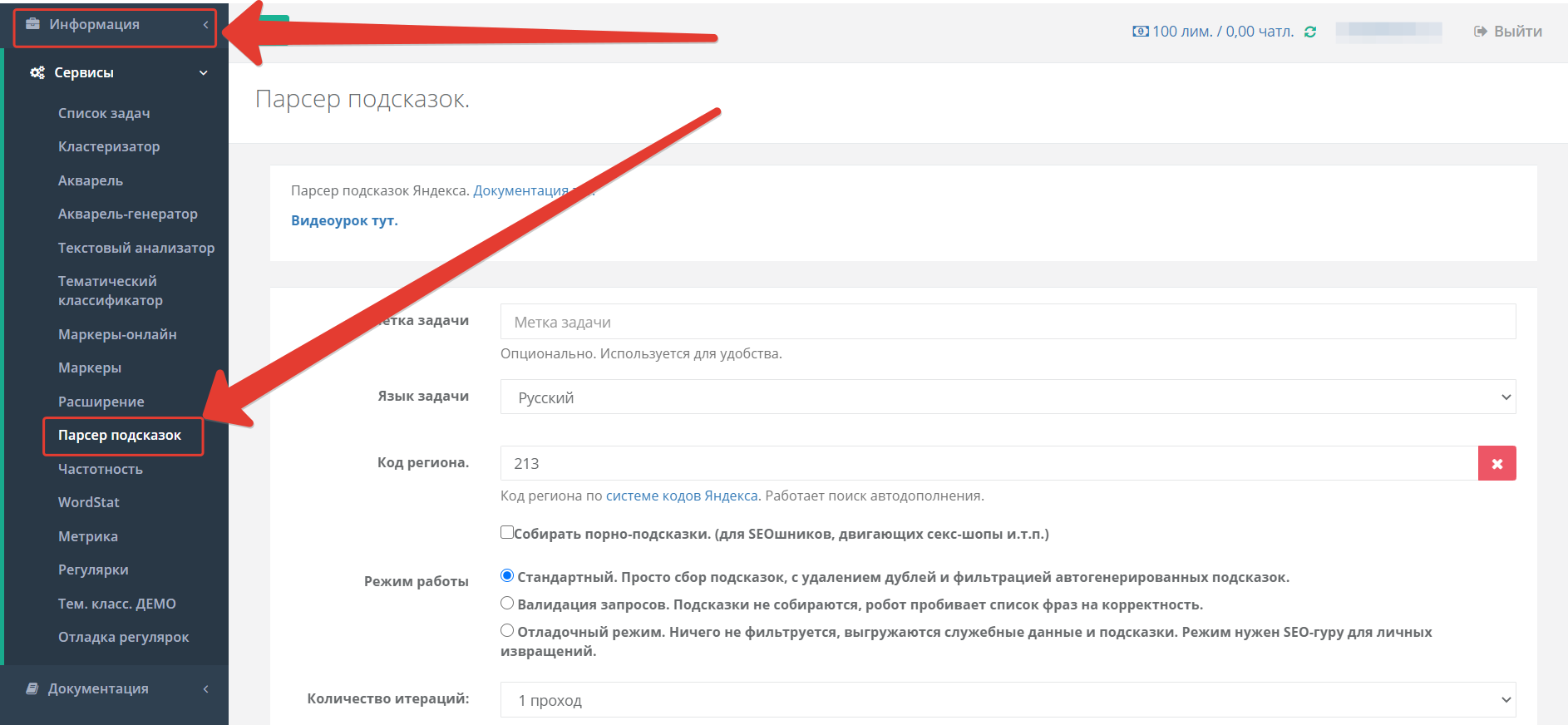
Как протестировать Datacol
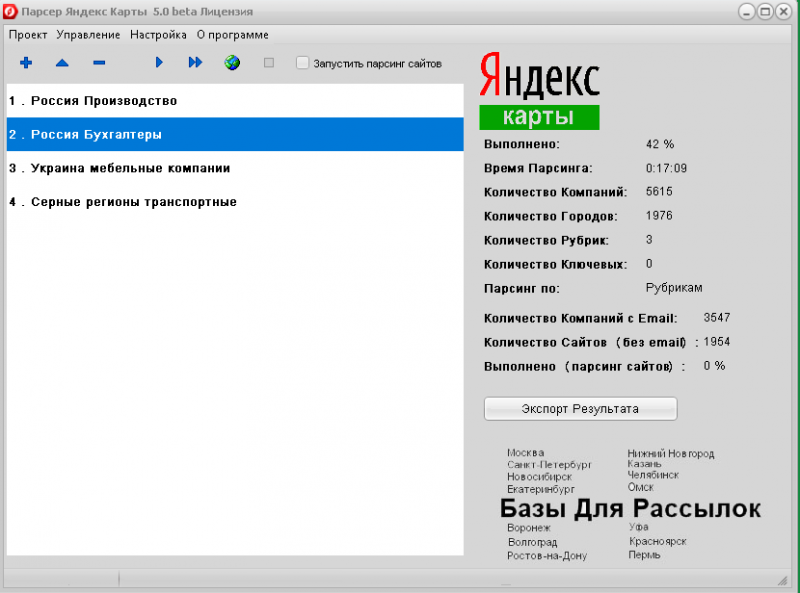
1. Установите демо-версию программы Datacol. Демо-версия программы имеет все возможности платной, но сохраняет только первые 25 результатов парсинга.
2. В дереве кампаний присутствует кампания seo-parsers/yandex-search.par. Выберите ее и нажмите кнопку Запуск (Play). Перед запуском вы можете отредактировать Входные данные, чтобы изменить набор ссылок, которые необходимо спарсить.
3. Дождитесь появления результатов работы парсера Яндекс. После появления результатов можно принудительно остановить парсинг (нажав кнопку Стоп).
4. После окончания/принудительной остановки парсера в папке Мои документы можно найти файл yandex-search.xlsx:
FAQ (Часто задаваемые вопросы)
Почему программа собрала только 25 результатов?В демо версии программа собирает только первые 25 результатов парсинга. Вы можете купить лицензию. После активации Datacol будет собирать данные без каких-либо ограничений с нашей стороны.
Вы можете купить лицензию. После активации Datacol будет собирать данные без каких-либо ограничений с нашей стороны.
Если сайт-источник забанит ваш IP-адрес (обычно в результате этого перестают собираться данные), задействуйте прокси или VPN.
Как разобраться в Datacol?Начните первое знакомство с программой с этой статьи. Хотите попробовать свои силы в самостоятельной настройке? Ознакомьтесь, пожалуйста, с видеоуроками по Datacol (хотя бы первые 3-5 уроков). Если при дальнейшей настройке программы у вас возникнут вопросы, задайте их нам. Поддержка Datacol отвечает с понедельника по пятницу.
Какие условия покупки Datacol?Все условия приобретения программы приведены здесь.
Как я получу программу после ее оплаты?После поступления оплаты за лицензию вы получите код активации программы и информацию о сроках действия вашей лицензии на адрес электронной почты, указанный при покупке. Инструкцию по активации можно посмотреть здесь.
Инструкцию по активации можно посмотреть здесь.
Парсинг поисковой выдачи Google и Яндекс: какие прокси лучше выбрать
Чтобы собрать нужную информацию для анализа, специалист делает запросы при помощи специального софта. Этот процесс называется парсингом. Вручную охватить такой объем информации невозможно. Популярные запросы, которые пользователи вводят в поисковую строку Google и Yandex, собираются программами. Затем проводится комплексный анализ, чтобы найти оптимальные запросы для подготовки контента. Чтобы специальный софт работал корректно, нужно использовать прокси для парсинга Google и Яндекс.
Парсинг поисковой выдачи Google и Яндекс
Обработать огромные массивы информации и получить точные, достоверные результаты можно при помощи специальных программ. Они ищут и извлекают данные, сохраняют ее и упорядочивают. Выборка составляется в соответствии с заданными параметрами поиска. При помощи парсинга можно получить цены конкурентов, контакты, отзывы, описания товаров, отзывы и другое.
Если нужно собрать и обработать большой объем данных, специалисты используют софт для парсинга. Популярными программами являются:
- Netpeak Checker. Софт позволяет анализировать трафик ваших конкурентов, работать в направлении линкбилдинга. Программа агрегирует данные из топовых сервисов SEO, выполняет комплексное сравнение сайтов.
- Key Collector. Сервис используется для сбора и организации семантического ядра. Программа организует большие массивы данных, готовит структуру по выбранным параметрам. Это позволяет отрабатывать лучшие варианты.
- KeyAssort. Программа используется для кластеризации запросов поисковой выдачи. Программа используется для сборки семантического ядра.
Перечисленные сервисы позволяют найти и выделить нужные данные для продвижения бизнеса в интернете. Эти программы используются в самых разных направлениях деятельности. Чтобы парсер мог работать со специальным софтом, заходить в сеть нужно через мобильные прокси.
Капча от Google и Яндекс
Система защиты ReCAPTCHA используются как в Гугл, так и в Яндекс. Представленные API не позволяют выполнять ряд автоматических процессов. Система проверяет, делает ли запрос человек или машина. Во втором случае запросы будут отсеиваться.
Представленные API не позволяют выполнять ряд автоматических процессов. Система проверяет, делает ли запрос человек или машина. Во втором случае запросы будут отсеиваться.
API ReCAPTCHA предлагает указать верные варианты изображений или ввести комбинацию из букв и цифр с картинки.
Для многих направлений бизнеса важно, чтобы на сайт заходили люди. Поэтому автоматические запросы сразу отметаются. Чтобы обойти защиту ReCAPTCHA, используется специальный софт и мобильные прокси. Это позволяет парсить без ограничений в любом объеме.
Какие прокси лучше выбрать
Профессиональные парсеры знают, насколько важно использовать специальные прокси для входа в интернет. Это ip-адреса, с которых посылаются запросы в сеть. Существует 2 вида прокси:
- Обычные. Это стационарный ip-адрес, который присваивается компьютеру обслуживающим датацентром. Это стационарные прокси, которые остаются неизменными в течение всего срока работы специалиста.
 Так как с одного ip подается множество автоматических запросов, это привлекает внимание защитных механизмов. В таких условиях специальный софт не может работать корректно.
Так как с одного ip подается множество автоматических запросов, это привлекает внимание защитных механизмов. В таких условиях специальный софт не может работать корректно. - Мобильные. Это прокси, которые используют операторы мобильной сети. В отличие от стационарных ip-адресов, мобильные прокси динамичные. Они меняются с установленной скоростью, обеспечивая анонимный, защищенный вход в интернет. Софт работает стабильно, выполняя все свои функции.
 Так как с одного ip подается множество автоматических запросов, это привлекает внимание защитных механизмов. В таких условиях специальный софт не может работать корректно.
Так как с одного ip подается множество автоматических запросов, это привлекает внимание защитных механизмов. В таких условиях специальный софт не может работать корректно.Обычные прокси стоят меньше, но работать с них парсеры не могут. Только мобильные ip-адреса способны обеспечить нормальные условия для автоматического поиска данных.
search_engine_parser.core package — документация Search Engine Parser 0.6.1
search_engine_parser.core package — документация Search Engine Parser 0.6.1Подпакеты
- Пакет search_engine_parser.core.engines
- Подмодули
- модуль search_engine_parser.core.engines.aol
- модуль search_engine_parser. core.engines.ask
- модуль search_engine_parser.core.engines.baidu
- модуль search_engine_parser.core.engines.bing
- модуль search_engine_parser.core.engines.coursera
- модуль search_engine_parser.core.engines.duckduckgo
- модуль search_engine_parser.core.engines.github
- модуль search_engine_parser.core.engines.google
- модуль search_engine_parser.core.engines.googlescholar
- модуль search_engine_parser.core.engines.myanimelist
- модуль search_engine_parser.core.engines.stackoverflow
- модуль search_engine_parser.core.engines.yahoo
- модуль search_engine_parser.core.engines.youtube
- Содержимое модуля
 core.engines.ask
core.engines.askПодмодули
модуль search_engine_parser.core.base
@desc Базовый класс, наследуемый каждой поисковой системой
- класс
search_engine_parser. core.base. BaseSearch[источник] Основания:
объект-
async_search( запрос = нет , страница = 1 , кэш = True , ** kwargs ) [источник] Запрос поисковой системы, но в асинхронном режиме
Параметры: - query ( str ) – запрос на поиск
- страница ( int ) — страница для отображения, по умолчанию 1
Возвратов: словарь. Содержит заголовки, ссылки, netlocs и описания.
-
cache_handler
-
clear_cache( all_cache=False )[источник] Запускает функцию очистки кэша для определенного движка
Параметры: all_cache — если True, удаляет для всех движков
-
get_cache_handler()[источник] Возврат обработчика кэша для использования
-
get_params( query = None , page = None , offset = None , ** kwargs ) [источник] Эта функция должна быть перезаписана, чтобы возвращать словарь параметров запроса
-
get_results( суп , **kwargs )[источник] Получить результаты супа
-
get_search_url( запрос = нет , страница = нет , **kwargs )[источник] Возвращает отформатированный URL-адрес поиска
-
get_soup( url , кэш )[источник] Получить html суп запроса
Тип возврата: bs4. element.ResultSet
-
get_source( url , cache=True )[источник] Возвращает исходный код веб-страницы. Также устанавливает _cache_hit, если использовался кеш
Тип возврата: строка Параметры: url — URL для извлечения исходного кода Возвращает: html исходный код заданного URL.
-
имя= нет
-
parse_result( результатов , **kwargs )[источник] Пропускает каждую запись на странице через parse_single_result
Параметры: результатов (список[ bs4. element.ResultSet ]) – Результат основного поиска для извлечения отдельных результатовВозвращает: словарь. Содержит списки заголовков, ссылок, описаний и других возможных возвратов. Тип возвращаемого значения: dict
-
parse_single_result( single_result , return_type= Каждый div/span, содержащий результат, передается сюда для извлечения название , ссылка и описание
-
parse_soup( суп )[источник] Определяет результаты, содержащиеся в супе
-
поиск( запрос = Нет , страница = 1 , кэш = True , **kwargs )[источник] Запрос в поисковой системе
Параметры: - query ( str ) – запрос на поиск
- страница ( int ) — страница для отображения, по умолчанию 1
Возвращает: словарь.
Содержит заголовки, ссылки, netlocs и описания.
-
search_url= Нет
-
сводка= нет
-
 core.base.
core.base.  element.ResultSet
element.ResultSet  element.ResultSet ]) – Результат основного поиска для извлечения отдельных результатов
element.ResultSet ]) – Результат основного поиска для извлечения отдельных результатов Содержит заголовки, ссылки, netlocs и описания.
Содержит заголовки, ссылки, netlocs и описания.- класс
search_engine_parser.core.base.Тип возврата[источник] Базы:
enum.EnumПеречисление.
-
ОПИСАНИЕ= «описание»
-
ПОЛНЫЙ= «полный»
-
ССЫЛКА= ‘ссылки’
-
НАЗВАНИЕ= «названия»
-
- класс
search_engine_parser.core.base.SearchItem[источник] Базы:
диктSearchItem — это список результатов, содержащий ключи (заголовки, описания, ссылки и т.
д.).
дополнительные ключи в зависимости от двигателя)
>>> результат 6a280> >>> результат[«описание»] Некоторое описание >>> результат[“описание”] То же описание
 д.).
дополнительные ключи в зависимости от двигателя)
>>> результат
д.).
дополнительные ключи в зависимости от двигателя)
>>> результат - класс
search_engine_parser.core.base.SearchResult[источник] Основания:
объектРезультаты поиска после поиска
>>> results = gsearch.search("проповедь хора", 1) >>> результаты6a280> Объект поддерживает получение отдельных результатов путем итерации только по типу >>> results[0] # Возвращает первый результат
>>> results[«descriptions»] # Возвращает список всех описаний из всех результатов Его можно повторять как обычный список, чтобы вернуть отдельный SearchItem
-
добавить( значение )[источник]
-
ключи()[источник]
-
модуль search_engine_parser.
 core.cli
core.cli@desc Использование парсера через cli
-
search_engine_parser.core.cli.create_parser()[источник] бегун, который обрабатывает логику синтаксического анализа
-
search_engine_parser.core.cli.дисплей( результаты , термин , аргументы )[источник] Отображает результаты поиска
-
search_engine_parser.core.cli.get_engine_class( двигатель )[источник] Возврат двигателя класса
-
search_engine_parser.core.cli.основной( аргументы )[источник] Выполняет логику из проанализированных аргументов
-
search_engine_parser.core.cli.show_summary( термин , engine_class )[источник] Показать сводную информацию о двигателе
модуль search_engine_parser.
 core.exceptions
core.exceptions@desc Исключения
- исключение
search_engine_parser.core.exceptions.Неправильное ключевое слово[источник] Базы:
ИсключениеКогда в функцию поиска передается неверный аргумент ключевого слова
- исключение
search_engine_parser.core.exceptions.NoResultsFound[источник] Базы:
Исключение
- исключение
search_engine_parser.core.exceptions.NoResultsOrTrafficError[источник] Базы:
ИсключениеКогда результаты не возвращаются или необычный трафик приводит к тому, что приложение возвращает пустые результаты
Содержимое модуля
Читать документы v: последний- Версии
- последний
- стабильный
- Загрузки
- HTML
- epub
- При прочтении документов
- Дом проекта
- Строит
Бесплатный хостинг документов предоставляется Read the Docs.

ClickHouse — Ревизия #11 — База данных баз данных
Просмотреть текущий Просмотр редакции № 11 от 17.04.2020 7:44
CilckHouse — это СУБД OLAP с открытым исходным кодом, ориентированная на столбцы. Он предназначен для обеспечения линейной масштабируемости запросов.
- https://en.wikipedia.org/wiki/ClickHouse
- https://clickhouse.yandex/
История
ClickHouse разработан российской компанией Яндекс. Он предназначен для нескольких проектов в рамках Яндекс. Яндексу нужна была СУБД для анализа больших объемов данных, поэтому они начали разрабатывать собственную СУБД, ориентированную на столбцы. Прототип ClickHouse появился в 2009 году, а выпущен он был в 2016 году.
- https://en.wikipedia.org/wiki/ClickHouse
Индексы
Лог-структурированное дерево слияния
ClickHouse поддерживает индексы первичных ключей. Механизм индексирования называется разреженным индексом. В MergeTree данные сортируются по первичному ключу лексикографически в каждой части. Затем ClickHouse выбирает несколько меток для каждой строки index_granualarity. Эти метки служат разреженными индексами, что позволяет выполнять эффективные запросы диапазона.
Механизм индексирования называется разреженным индексом. В MergeTree данные сортируются по первичному ключу лексикографически в каждой части. Затем ClickHouse выбирает несколько меток для каждой строки index_granualarity. Эти метки служат разреженными индексами, что позволяет выполнять эффективные запросы диапазона.
- https://medium.com/@f1yegor/clickhouse-primary-keys-2cf2a45d7324
Модель хранения
Модель хранения декомпозиции (столбцовая)
ClickHouse — это столбцовая СУБД, которая хранит данные по столбцам.
- https://clickhouse.yandex/reference_ru.html
- https://clickhouse.yandex/reference_ru.html
- https://clickhouse.yandex/reference_ru.html
- https://clickhouse.yandex/
- https://github.com/yandex/ClickHouse/blob/master/doc/developers/architecture.md
- https://github. com/yandex/ClickHouse/issues/11
- https://github.com/yandex/ClickHouse/issues/32
- https://groups.google.com/forum/#!topic/clickhouse/AsVXzqysxRQ
- https://en.wikipedia.org/wiki/ClickHouse
- https://github.com/yandex/ClickHouse/blob/master/doc/developers/architecture.md
Выполнение запроса
Векторизованная модель
Архитектура хранения
Дискоориентированный В памяти
ClickHouse имеет несколько типов движков таблиц. Тип механизма таблиц определяет, где хранятся данные, параллельный уровень, поддерживаются ли индексы и некоторые другие свойства. Механизмы таблиц, которые хранят данные на дисках, включают TinyLog и Log. Механизм памяти хранит данные в памяти, и этот механизм таблиц в основном используется для временных таблиц с внешними данными запроса. Данные модуля памяти исчезнут после перезапуска сервера.
Механизмы таблиц, которые хранят данные на дисках, включают TinyLog и Log. Механизм памяти хранит данные в памяти, и этот механизм таблиц в основном используется для временных таблиц с внешними данными запроса. Данные модуля памяти исчезнут после перезапуска сервера.
Интерфейс запросов
Пользовательский API SQL
ClickHouses предоставляет два типа синтаксических анализаторов: полный синтаксический анализатор SQL и синтаксический анализатор формата данных. Он использует синтаксический анализатор SQL для всех типов запросов и синтаксический анализатор формата данных только для запросов INSERT. Помимо языка запросов, он предоставляет несколько пользовательских интерфейсов, включая интерфейс HTTP, драйвер JDBC, интерфейс TCP, клиент командной строки и т. д.
Взгляды
Виртуальные представления Материализованные представления
ClickHouse поддерживает как виртуальные представления, так и материализованные представления. Материализованные представления хранят данные, преобразованные соответствующим запросом SELECT. Запрос SELECT может содержать DISTINCT, GROUP BY, ORDER BY, LIMIT и т. д.
Материализованные представления хранят данные, преобразованные соответствующим запросом SELECT. Запрос SELECT может содержать DISTINCT, GROUP BY, ORDER BY, LIMIT и т. д.
Компиляция запросов
Генерация кода
ClickHouse поддерживает генерацию кода во время выполнения. Код генерируется для каждого типа запроса на лету, удаляя всю косвенность и динамическую диспетчеризацию. Генерация кода во время выполнения может быть лучше, если она объединяет множество операций и полностью использует исполнительные блоки ЦП.
Хранимые процедуры
Не поддерживается
В настоящее время хранимые процедуры и UDF числятся открытыми проблемами в ClickHouse.
 com/yandex/ClickHouse/issues/11
com/yandex/ClickHouse/issues/11Присоединяется
Хэш-соединение
ClickHouse поддерживает только хеш-соединение, которое выполняется путем помещения правой части данных в хеш-таблицу в памяти. Хэш-соединение выполняется быстрее, но требует достаточно памяти.
Архитектура системы
Общий-Ничего
Система ClickHouse представляет собой кластер шардов. Он использует асинхронную репликацию с несколькими мастерами, и в системе нет единой точки состязания.
Модель данных
Относительный
ClickHouse использует модель реляционной базы данных.