
KolchakA Blog Парсер Яндекс — KolchakA Blog
Парсер Яндекса имеет десятки модификаций и применений. Ниже мы опишем наиболее популярные варианты, которые нам приходилось реализовывать.
Парсер выдачи Яндекса
Чаще всего заказчикам требуется именно парсер выдачи. Зачем парсить выдачу Yandex? Вариантов очень много. Например SEO специалисты используют выдачу для оценки конкурентности ТОП по запросам. В последствии, опираясь на эту информацию, можно создать семантическое ядро сайта. SEOшники знают, что правильно подобранные запросы это уже полдела в продвижении сайта.
Кроме того, SEO специалисты могут найти в выдаче Yandex и самих своих конкурентов. Проанализировав конкурирующие сайты из ТОП3 – ТОП5, можно понять какие именно мероприятия лучше проводить, чтобы добиться таких же результатов. Опытные маркетологи могут также определить (исходя из анализа конкурентов) сколько времени и денег потребуется на продвижение по тому или иному запросу.
Некоторым заказчикам интересно не столько парсить ссылки Яндекса, сколько парсить адреса сайтов, которые выдаются сетью контекстной рекламы Яндекс Директ.
Бывают случаи, когда требуется парсинг определенных урлов из выдачи Яндекса – то есть адресов, соответствующих определенному формату (например site.blogspot.com). Здесь уже наверное понятно, что благодаря этому можно получить списки ресурсов по запросу, которые созданы на одном и том же движке. Как это использовать? Наверное, вы уже знаете сами)))
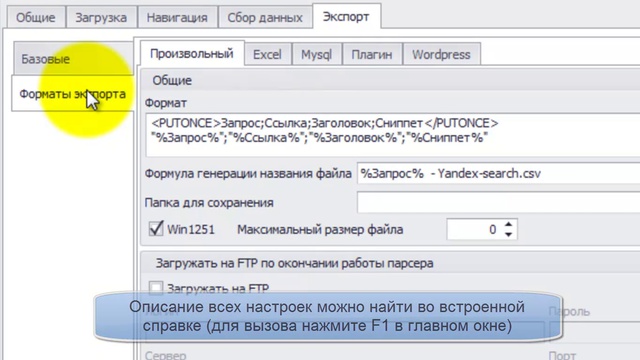
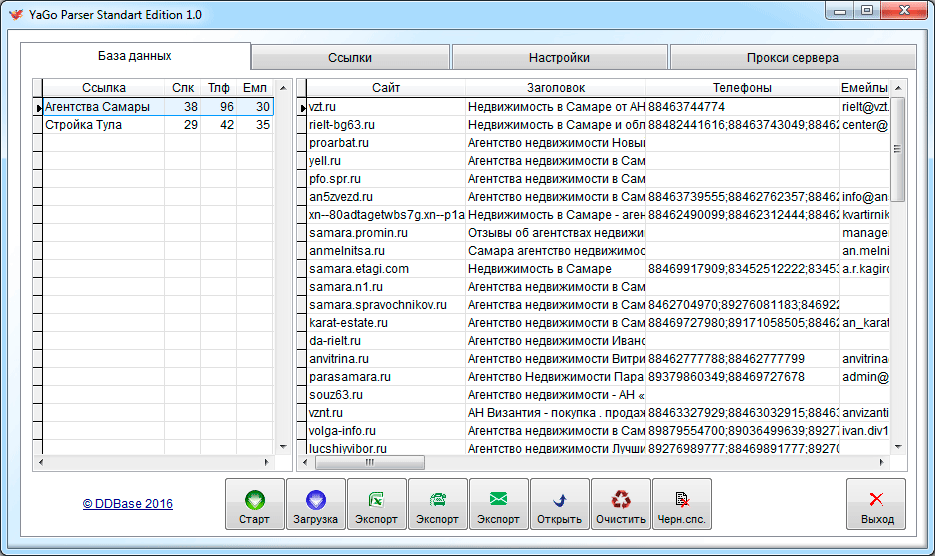
Сохранение ссылок из выдачи Яндекса обычно осуществляется в CSV, Excel или базу данных. В дальнейшем можно использовать стороннее программное обеспечение для последующего анализа собранных данных.
Ну и наконец – из результатов выдачи можно парсить подсказки Яндекса. Это больше относиться к сбору ключевиков, но тем не менее задача довольно распространенная.
Парсер Яндекс каталога
Реже заказчиков интересует выгрузка Яндекс каталога. Результаты выполнения данной задачи необходимы для поиска хороших ссылочных доноров (если вы SEO специалист, то понимаете о чем я). Понятно, что если сайт находится в Яндекс каталоге, то поисковик считает его трастовым, а если получить ссылку с трастового сайта, то она с большой вероятностью даст эффект в ссылочном ранжировании.
Результаты выполнения данной задачи необходимы для поиска хороших ссылочных доноров (если вы SEO специалист, то понимаете о чем я). Понятно, что если сайт находится в Яндекс каталоге, то поисковик считает его трастовым, а если получить ссылку с трастового сайта, то она с большой вероятностью даст эффект в ссылочном ранжировании.
К вышеописанной задаче можно подходить с другой стороны. Например, у нас есть список сайтов (с которых можно получить ссылки), и нам нужно определить те из них, которые есть в Яндекс каталоге. Таким образом парсер должен осуществить проверку на присутствие в Яндекс каталоге по списку URL.
Парсер Яндекс картинок
Создание мультимедийных порталов просто невозможно без большого количество картинок. Самый простой вариант получения большого количества тематических изображений – это парсинг Яндекс картинок по ключевым запросам. Только не стоит забывать, что поисковик уже умеет отслеживать уникальность картинок, поэтому обычно в такой парсер дорабатывается модуль изменения метатегов изображений, а также их размера.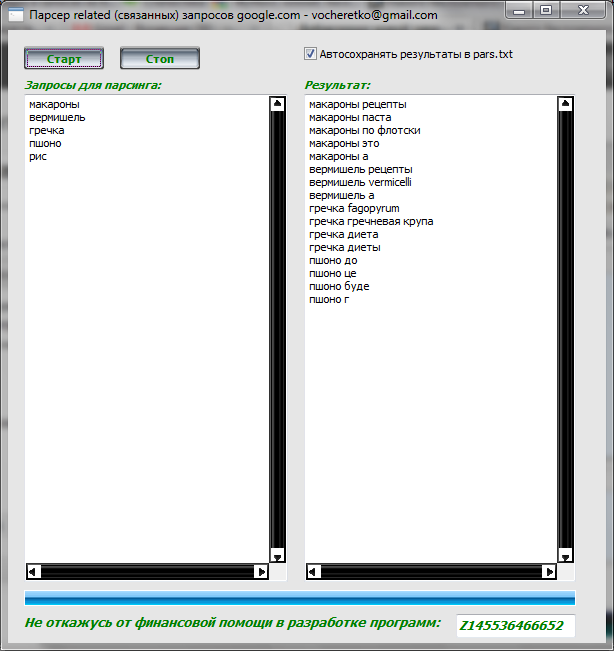
Парсер email из Yandex
Еще одно интересное применение Yandex парсера. Допустим мы хотим предлагать свою услугу владельцам строительных компаний. Как вариант можно спарсить выдачу Яндекса, и на собранных сайтах попытаться найти emailы компаний. Затем (уже после окончания сбора контактов парсером email из Яндекса) можно сделать рассылку по собранным адресам с нашим предложением.
Парсера дополнительных сервисов Яндекса
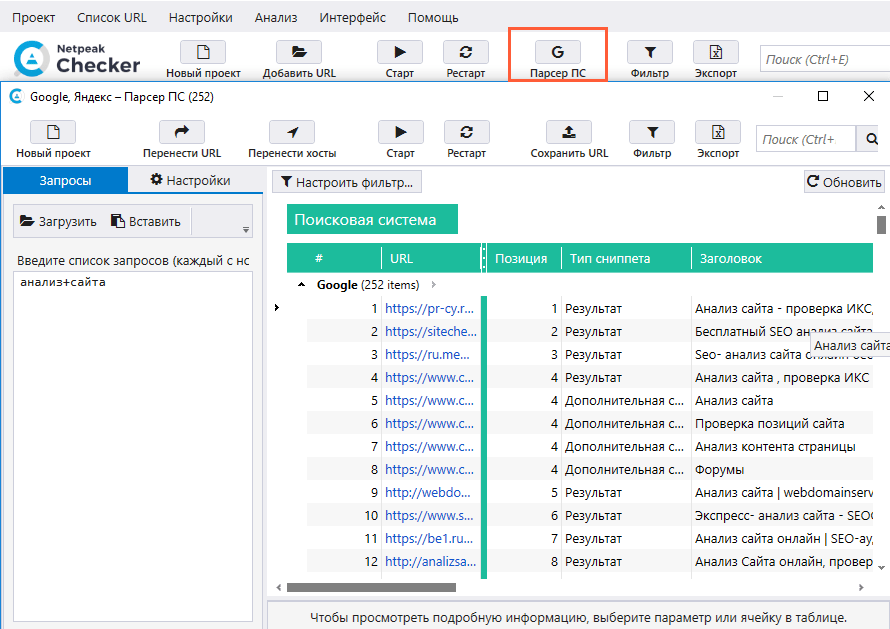
Кроме основных типов парсеров (описанных выше), рунетовцев часто интересуют следующие их разновидности: парсер Яндекс организаций, парсер Яндекс почты, парсер карт, парсер отчетов Яндекс Вебмастер. И конечно же – отдельный разговор – это парсер статистики запросов Яндекс Директ (его нюансы мы опишем в последующих статьях).
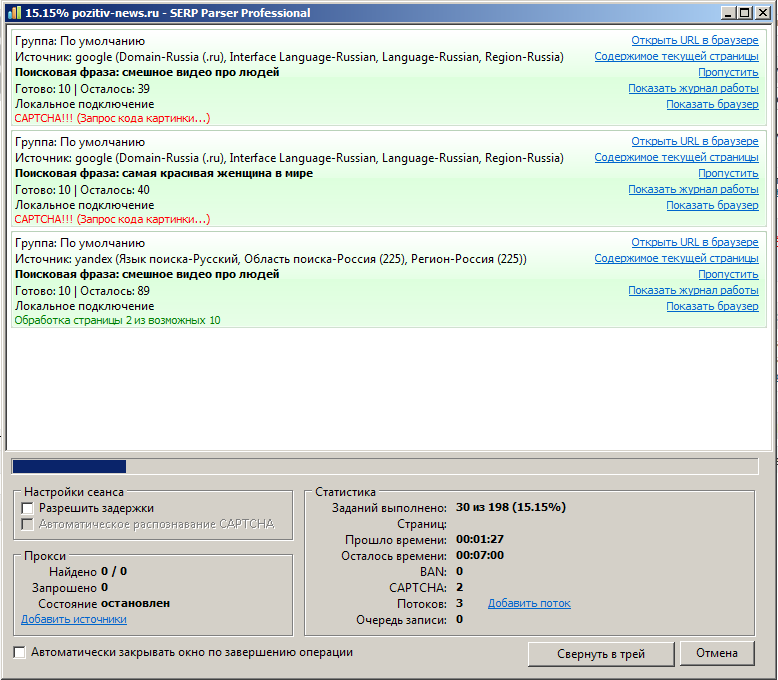
Для любого парсера страниц Яндекс обязательно используются прокси и сервисы автоматического распознавания капчи. Это позволяет избежать бана при парсинге Яндекс. Парсер Яндекса с прокси позволяет собирать практически неограниченное количество результатов.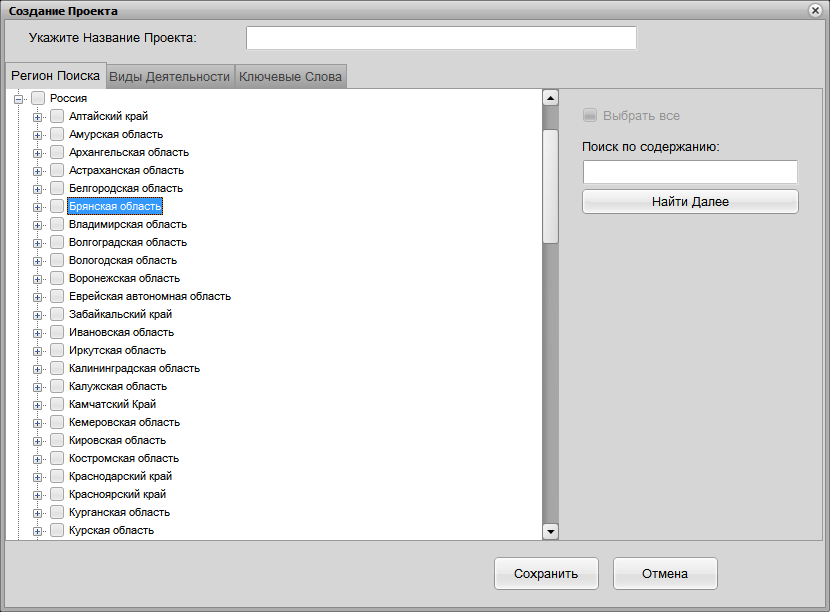
Если вас интересует создание парсера Яндекса, вы можете связаться с нами прямо сейчас.
Парсер вордстат — онлайн сервис Engine SEO Интеллект
Сервис позволит вам с максимальной скоростью собирать все ключевые слова и разные виды частотностей Wordstat. Это гораздо удобнее, чем заниматься поиском данных вручную.
В чем преимущества данного сервиса?
Сбор информации из левой колонки Wordstat
Сервис способен обнаружить стоп-слова, ключевые слова на любую глубину от 1 до 40 страниц, а также автоматически удалить спец-символы.
Все виды информации
Работа со всеми видами частотности.

Исторический индекс
• Парсинг истории поисковых запросоы.

Возможности инструмента парсинга
Как работает сервис?
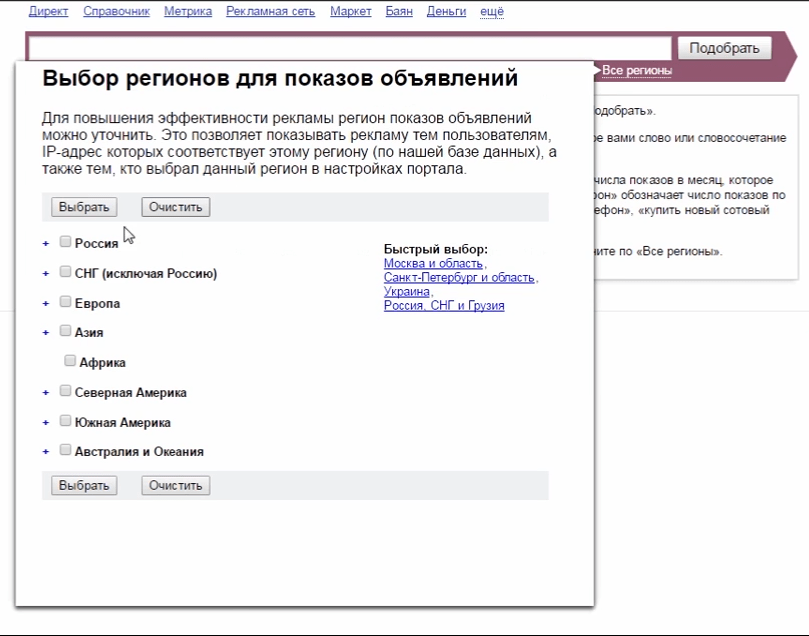
Выберите свой регион.
Выберите тип выдачи (мобильная, десктопная, только телефоны, только планшеты).
Укажите, какую информацию будете собирать – ключевые слова из левой колонки Wordstat или частотность.
-
Загрузите ключевые слова.
Их можно ввести вручную или загрузить в формате таблице Excel.
 Их можно ввести вручную или загрузить в формате таблице Excel.
Их можно ввести вручную или загрузить в формате таблице Excel.Engine SEO Интеллект
сервис анализа и продвижения сайтов
Отзывы специалистов
Инструмент значительно облегчает работу моих SEO-оптимизаторов. Очень нравится, что можно выбрать разные форматы выгрузки результатов и просматривать их на планшете, телефоне и ноутбуке. Я не всегда в офисе, поэтому часто просматриваю данные с мобильника.
Я работаю копирайтером и часто использую разные сервисы.
Этот – мой любимый! Очень
удобно, что сервис поддерживает все частотности Вордстата, а также, что я могу
выбирать любой регион. Я работаю с клиентами со всей России.Наверное, лучший инструмент для парсинга частотности запросов. Он поддерживает абсолютно любую частотность Yandex.Wordstat. Работать стало гораздо легче и удобнее. Еще, кстати, очень удобно, что интерфейс понятный и простой.
 Этот – мой любимый! Очень
удобно, что сервис поддерживает все частотности Вордстата, а также, что я могу
выбирать любой регион. Я работаю с клиентами со всей России.
Этот – мой любимый! Очень
удобно, что сервис поддерживает все частотности Вордстата, а также, что я могу
выбирать любой регион. Я работаю с клиентами со всей России.Выберите ваш тариф
Скидки при подписке больше чем на два месяца
-10% 3 месяца
-15% 6 месяцев
-25% 12 месяцев
Парсер Wordstat от компании Engine SEO Интеллект
Yandex. Wordstat – одна из основных программ, которую используют SEO-оптимизаторы. Для чего он нужен?
Прежде всего, для поиска ключевых слов разной частоты (высокой, средней и низкой). Вы сможете также
проверить частоту уже имеющихся запросов, чтобы избавиться от переспамленности и «нулевых» слов.
Wordstat – одна из основных программ, которую используют SEO-оптимизаторы. Для чего он нужен?
Прежде всего, для поиска ключевых слов разной частоты (высокой, средней и низкой). Вы сможете также
проверить частоту уже имеющихся запросов, чтобы избавиться от переспамленности и «нулевых» слов.
Если вам нужно проверить сотни или тысячи слов на частотность, будет легче делать этот не вручную, а при помощи автоматизированных сервисов.
Почему десктопные программы не смогут справиться с этой задачей:
- Яндекс.Вордстат хорошо защищен от автоматического парсинга. Если вы будете проверять частотность вручную или при помощи десктопных программ, ваш IP-адрес могу забанить, а в ответ на запросы просить ввести капчу.
- Для качественного парсинга вам понадобится несколько IP-адресов.
- Для работы вам придется много раз вводить капчу, тратить время и силы.
- Большинство подобных программ не защищены от потери конфиденциальных данных.
Парсинг Яндекс.Ворстат при помощи сервиса от Engine SEO Интеллект
Наша компания предлагает качественный надежный парсер для проверки частотности запросов в Яндекс.Wordstat и сборе ключевых фраз. Сервис максимально устойчив к максимальному количеству проблем.
Преимущества онлайн-сервиса:
- Отсутствие капчи и бане прокси. Вам не придется постоянно вводить капчу, предлагаемую Яндексом. Достаточно загрузить ключевые слова и дождаться файла с результатами.
- Высокая скорость. Мы используем оптимальную схему подключения адресов IP, чтобы максимально
повысить скорость сбора ключевых слов.
- Сохранность информации. После загрузки файла со словами вы можете быть спокойны, что он не удалится, и вы сможете скачать его с любого устройства.
- Поддержка всех регионов. Вы сможете проверять необходимые вам показатели не только в России, но и Беларуси, Украине и других регионах.
Инструменты для SEO-специалистов
Кластеризация
Перейти к инструменту
Текстовый анализатор
Перейти к инструменту
Проверка позиций
Перейти к инструменту
LSI-слова
Перейти к инструменту
Поиск конкурентов
Перейти к инструменту
Проверка переоптимизации
Перейти к инструменту
Возраст сайта/страницы
Перейти к инструменту
Лемматизатор
Перейти к инструменту
Выгрузка ТОП-10
Перейти к инструменту
SEO-текст
Перейти к инструменту
Парсинг h2-H6
Перейти к инструменту
Яндекс.
WordstatПерейти к инструменту
python — Clickhouse Не удается разобрать ввод: ожидается \t до
спросил
Изменено 1 год, 6 месяцев назад
Просмотрено 4к раз
Пытаюсь вставить данные в clickhouse с помощью yandex logs api (https://github.com/yndx-metrika/logs_api_integration)
Он использует запрашивает как библиотеку для отправки запроса.
Моя ошибка:
Код: 27, e.displayText() = DB::Exception: Невозможно проанализировать ввод: ожидается \t до: \n33\t55\t2017-05-05\n33\t55\t2017-05 -05\n33\t55\t2017-05-05\n33\t55\t2017-05-05 (версия 19.16.4.12)
Пока я отправляю запрос, мои параметры запроса:
{u'query': u'INSERT INTO db. table FORMAT TabSeparatedWithNames ', u'input_format_allow_errors_num': 99999, u'input_format_tsv_empty_as_default': 1, u'errorsput_formatio_allow_ : 1}
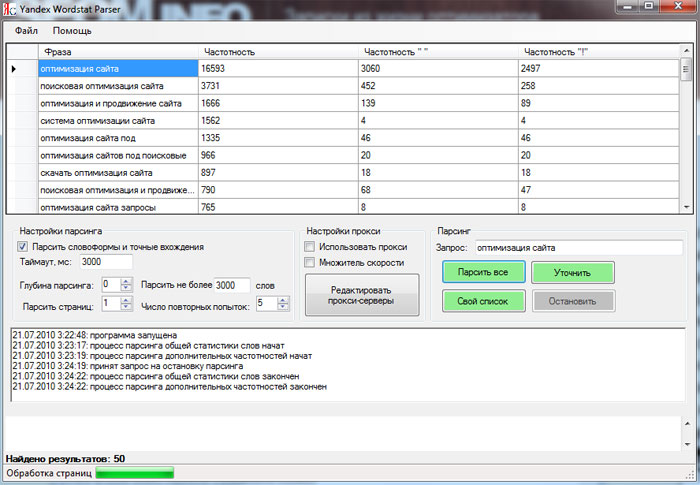 table FORMAT TabSeparatedWithNames ', u'input_format_allow_errors_num': 99999, u'input_format_tsv_empty_as_default': 1, u'errorsput_formatio_allow_ : 1}
table FORMAT TabSeparatedWithNames ', u'input_format_allow_errors_num': 99999, u'input_format_tsv_empty_as_default': 1, u'errorsput_formatio_allow_ : 1}
движок MergeTree()
столбцы не могут быть нулевыми
Мои данные
ClientID CounterID Дата 55 33 2017-05-05 55 33 2017-05-05 55 33 2017-05-05 55 33 2017-05-05 55 33 2017-05-05 55 33 2017-05-05 55 33 2017-05-05 55 33 2017-05-05
- python
- clickhouse
При использовании TabSeparatedWithNames необходимо передать заголовок (имена столбцов):
запросы на импорт
CH_USER = 'по умолчанию'
CH_ПАРОЛЬ = ''
SSL_VERIFY = Ложь
хост = 'http://localhost:8123'
дб = 'дб'
таблица = 'стол'
содержимое = 'КлиентИД\tCounterID\tДата' \
'\n33\t55\t2017-05-05' \
'\n33\t55\t2017-05-05' \
'\n33\t55\t2017-05-05' \
'\n33\t55\t2017-05-05' \
'\n33\t55\t2017-05-05'
контент = контент.кодировать('utf-8')
запрос_дикт = {
'запрос': 'ВСТАВИТЬ В ' + db + '. ' + таблица + 'ФОРМАТ TabSeparatedWithNames'
}
r = Requests.post(хост, данные=контент, params=query_dict, auth=(CH_USER, CH_PASSWORD), verify=SSL_VERIFY)
печать (р.текст)
 ' + таблица + 'ФОРМАТ TabSeparatedWithNames'
}
r = Requests.post(хост, данные=контент, params=query_dict, auth=(CH_USER, CH_PASSWORD), verify=SSL_VERIFY)
печать (р.текст)
' + таблица + 'ФОРМАТ TabSeparatedWithNames'
}
r = Requests.post(хост, данные=контент, params=query_dict, auth=(CH_USER, CH_PASSWORD), verify=SSL_VERIFY)
печать (р.текст)
Схема тестовой таблицы:
Таблица CREATE TABLE
(
`Идентификатор клиента` Int32,
`CounterID` Int32,
`дата` дата
)
ДВИГАТЕЛЬ = дерево слияния
ЗАКАЗАТЬ ПО Дата
Убедитесь, что количество столбцов (и самих имен/типов столбцов), которые вы пытаетесь вставить, совпадают с таблицей назначения
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Написание парсеров 2022 : разработка, тестирование
Парсеры — это скрипты для быстрой обработки веб-страниц и получения необходимых данных.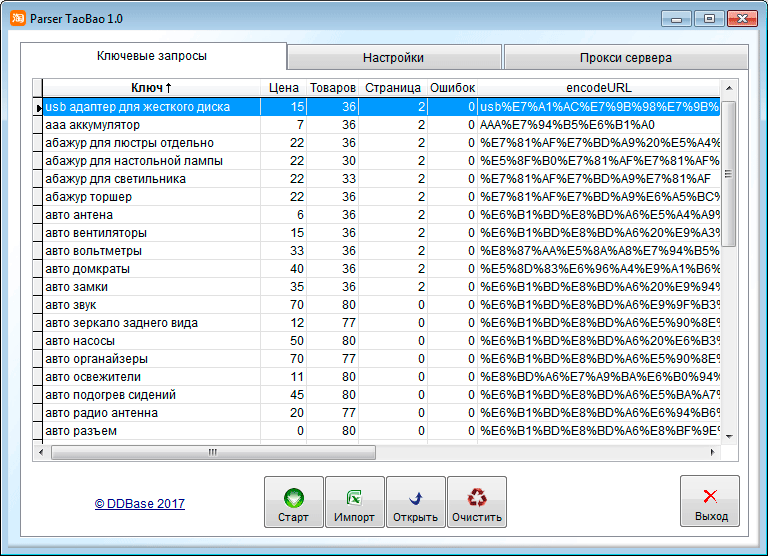 Такие программы могут собирать контакты, фотографии, цены и другую информацию.
Такие программы могут собирать контакты, фотографии, цены и другую информацию.
Парсеры нужны для быстрой обработки больших объемов информации и автоматизации рутинных задач. Такие программы незаменимы для сбора информации о товарах и быстрого наполнения крупных интернет-магазинов.
Наши программисты создают парсеры под задачи клиента.
Оставить заявку
Какие задачи решает разработка парсера?
Быстрая обработка информации
С помощью парсера можно быстро собрать и структурировать огромное количество данных. Как правило, это информация, необходимая для выполнения бизнес-задач или принятия решений.
Быстрое наполнение контентом
Торговым площадкам, агрегаторам и крупным интернет-магазинам требуется огромное количество контента. Парсер информации поможет собрать и отобразить ее на сайте.
Выгрузка данных
Собранные данные могут быть загружены в CSV, XML, SQL, XLSX или другом удобном формате.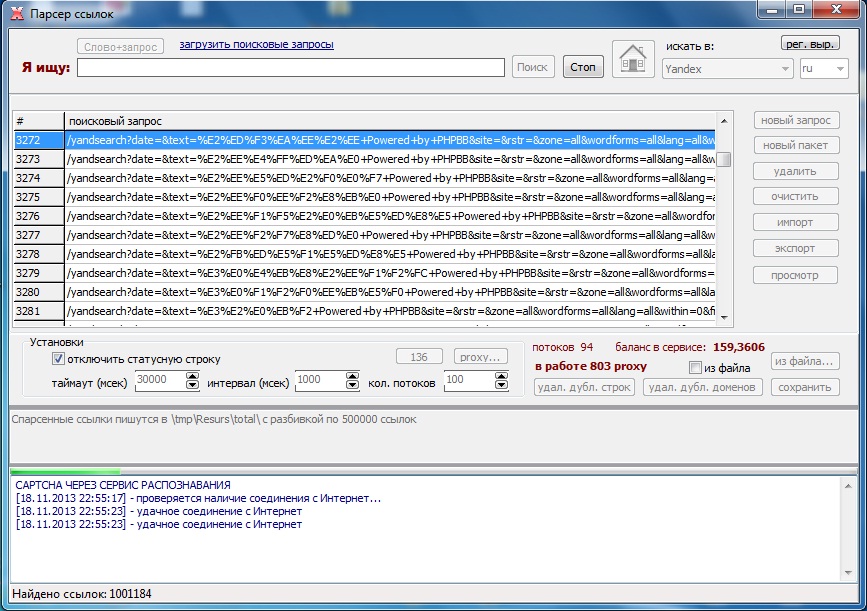 При загрузке информацию можно структурировать по нужным критериям.
При загрузке информацию можно структурировать по нужным критериям.
Парсинг в разных режимах
Часто нужны парсеры, которые работают в нескольких режимах, собирают разные наборы данных и срабатывают при определенных условиях. Такие сценарии мы создадим для заказчика.
Каковы преимущества использования синтаксических анализаторов?
- Экономия времени. Готовая программа позволяет автоматически и быстро собирать большие объемы информации. В то же время вы можете позаботиться о других задачах.
- Экономия денег. Парсеры особенно полезны при регулярном использовании. Чем дольше и чаще вы пользуетесь программой, тем заметнее будет эффект.
- Данные для работы и принятия решений. Правильно собранная и структурированная информация о ценах, товарах, контактах позволяет быстрее решать другие задачи.
- Мониторинг существенных изменений.
