
Как работать с Wordstat?| Основные функции и операторы Яндекс Вордстат
1. ОПРЕДЕЛЕНИЕ ТЕРМИНОВ
1.1. В настоящей Политике конфиденциальности используются следующие термины:
1.1.1. «Администрация сайта» – уполномоченные сотрудники на управления сайтом, действующие от имени ООО «Третий Путь», которые организуют и (или) осуществляет обработку персональных данных, а также определяет цели обработки персональных данных, состав персональных данных, подлежащих обработке, действия (операции), совершаемые с персональными данными.
1.1.2. «Персональные данные» — любая информация, относящаяся прямо или косвенно к определяемому физическому лицу (субъекту персональных данных).
1.1.3. «Обработка персональных данных» — любое действие (операция) или совокупность действий (операций),
совершаемых с использованием средств автоматизации или без использования таких средств с персональными
данными, включая сбор, запись, систематизацию, накопление, хранение, уточнение (обновление, изменение),
извлечение, использование, передачу (распространение, предоставление, доступ), обезличивание, блокирование,
удаление, уничтожение персональных данных.
1.1.4. «Конфиденциальность персональных данных» — обязательное для соблюдения Организацией или иным получившим доступ к персональным данным лицом требование не допускать их распространения без согласия субъекта персональных данных или наличия иного законного основания.
1.1.5. «Пользователь сайта (далее Пользователь)» – лицо, имеющее доступ к Сайту, посредством сети Интернет и использующее Сайт Организации.
1.1.6. «IP-адрес» — уникальный сетевой адрес узла в компьютерной сети, построенной по протоколу IP.
1.1.7. «Cookies» — небольшой фрагмент данных, отправленный веб-сервером и хранимый на компьютере пользователя, который веб-клиент или веб-браузер каждый раз пересылает веб-серверу в HTTP-запросе при попытке открыть страницу соответствующего сайта.
2. ОБЩИЕ ПОЛОЖЕНИЯ
2.1. Порядок ввода в действие и изменения Политики конфиденциальности:
2.1.1. Настоящая Политика конфиденциальности (далее – Политика конфиденциальности) вступает в силу с момента
его утверждения приказом Руководителей Организации и действует бессрочно, до замены его новой Политикой
конфиденциальности.
2.1.2. Изменения в Политику конфиденциальности вносятся на основании Приказов Руководителей Организации.
2.1.3. Политика конфиденциальности персональных данных действует в отношении информации, которую ООО «Третий Путь» (далее – Организация) являясь владельцем сайтов, находящихся по адресам: 3put.ru, а также их поддоменах (далее – Сайт и/или Сайты), может получить от Пользователя Сайта при заполнении Пользователем любой формы на Сайте Организации. Администрация сайта не контролирует и не несет ответственность за сайты третьих лиц, на которые Пользователь может перейти по ссылкам, доступным на Сайтах.
2.1.4. Администрация сайта не проверяет достоверность персональных данных, предоставляемых Пользователем.
2.2. Порядок получения согласия на обработку персональных данных и их обработки:
2.2.1. Заполнение любой формы Пользователем на Сайте означает дачу Организации согласия на обработку его
персональных данных и с настоящей Политикой конфиденциальности и условиями обработки персональных данных
Пользователя, так как заполнение формы на Сайте Пользователем означает конклюдентное действие Пользователя,
выражающее его волю и согласие на обработку его персональных данных.
2.2.2. В случае несогласия с условиями Политики конфиденциальности и отзывом согласия на обработку персональных данных Пользователь должен направить на адрес эл. почты и/или на почтовый адрес Организации заявление об отзыве согласия на обработку персональных данных.
2.2.3. Согласие Пользователя на использование его персональных данных может храниться в Организации в бумажном и/или электронном виде.
2.2.4. Согласие Пользователя на обработку персональных данных действует в течение 5 лет с даты поступления персональных данных в Организацию. По истечении указанного срока действие согласия считается продленным на каждые следующие пять лет при отсутствии сведений о его отзыве.
2.2.5. Обработка персональных данных Пользователя без их согласия осуществляется в следующих случаях:
- Персональные данные являются общедоступными.
- По требованию полномочных государственных органов в случаях, предусмотренных федеральным законом.

- Обработка персональных данных осуществляется для статистических целей при условии обязательного обезличивания персональных данных.
- В иных случаях, предусмотренных законом.

2.2.6. Кроме персональных данных при посещении Сайта собираются данные, не являющиеся персональными, так как
их сбор происходит автоматически веб-сервером, на котором расположен сайт, средствами CMS (системы управления
сайтом), скриптами сторонних организаций, установленными на сайте. К данным, собираемым автоматически,
относятся: IP адрес и страна его регистрации, имя домена, с которого Пользователь осуществил перехода на сайты
организации, переходы посетителей с одной страницы сайта на другую, информация, которую браузер Посетителя
предоставляет добровольно при посещении сайта, cookies (куки), фиксируются посещения, иные данные, собираемые
счетчиками аналитики сторонних организаций, установленными на сайте.
2.2.7. Порядок обработки персональных данных:
К обработке персональных данных Пользователей могут иметь доступ только сотрудники Организации, допущенные к
работе с персональными данными Пользователей и подписавшие соглашение о неразглашении персональных данных
Пользователей.
Перечень сотрудников Организации, имеющих доступ к персональным данным Пользователей, определяется приказом
Руководителей Организации.
Обработка персональных данных Пользователей может осуществляться исключительно в целях установленных настоящей
политикой и при условии соблюдения законов и иных нормативных правовых актов Российской Федерации.
3. ПРЕДМЕТ ПОЛИТИКИ КОНФИДЕНЦИАЛЬНОСТИ
3.1. Настоящая Политика конфиденциальности устанавливает обязательства Администрации сайта по неразглашению и обеспечению режима защиты конфиденциальности персональных данных, которые Пользователь предоставляет при заполнении любой формы на Сайте.
3.2. Персональные данные, разрешённые к обработке в рамках настоящей Политики конфиденциальности, предоставляются Пользователем путём заполнения регистрационной формы на Сайте и включают в себя следующую информацию:
3.2.1. фамилию, имя, отчество Пользователя.
3.2.2. контактный телефон Пользователя.
3.2.3. адрес электронной почты (e-mail).
3.3. Любая иная персональная информация неоговоренная выше подлежит надежному хранению и нераспространению, за исключением случаев, предусмотренных п. 2.5. настоящей Политики конфиденциальности.
4. ЦЕЛИ СБОРА ПЕРСОНАЛЬНОЙ ИНФОРМАЦИИ ПОЛЬЗОВАТЕЛЯ
4.1. Персональные данные Пользователя Администрация сайта может использовать в целях:
4. 1.1. Установления с Пользователем обратной связи, включая направление уведомлений, запросов, касающихся
использования Сайта, оказания услуг, обработка запросов и заявок от Пользователя.
1.1. Установления с Пользователем обратной связи, включая направление уведомлений, запросов, касающихся
использования Сайта, оказания услуг, обработка запросов и заявок от Пользователя.
4.1.2. Осуществления рекламной деятельности с согласия Пользователя.
4.1.3. Регистрации Пользователя на Сайтах Организации для получения индивидуальных сервисов и услуг.
4.1.4. Совершения иных сделок, не запрещенных законодательством, а также комплекс действий с персональными данными, необходимых для исполнения данных сделок.
5. СПОСОБЫ И СРОКИ ОБРАБОТКИ ПЕРСОНАЛЬНОЙ ИНФОРМАЦИИ
5.1. Обработка персональных данных Пользователя осуществляется без ограничения срока, любым законным способом, в том числе в информационных системах персональных данных с использованием средств автоматизации или без использования таких средств.
5.2. При утрате или разглашении персональных данных Администрация сайта информирует Пользователя об утрате
или разглашении персональных данных.
5.3. Администрация сайта принимает необходимые организационные и технические меры для защиты персональной информации Пользователя от неправомерного или случайного доступа, уничтожения, изменения, блокирования, копирования, распространения, а также от иных неправомерных действий третьих лиц.
6. ОБЯЗАТЕЛЬСТВА СТОРОН
6.1. Пользователь обязан:
6.1.1. Предоставить информацию о персональных данных, необходимую для пользования Сайтом.
6.1.2. Обновить, дополнить предоставленную информацию о персональных данных в случае изменения данной информации.
6.2. Администрация сайта обязана:
6.2.1. Использовать полученную информацию исключительно для целей, указанных в п. 4 настоящей Политики конфиденциальности.
6.2.2. Обеспечить хранение конфиденциальной информации в тайне, не разглашать без предварительного
письменного разрешения Пользователя, а также не осуществлять продажу, обмен, опубликование, либо разглашение
иными возможными способами переданных персональных данных Пользователя, за исключением случаев, указанных в п. 2.5. настоящей Политики Конфиденциальности.
2.5. настоящей Политики Конфиденциальности.
6.2.3. Принимать меры предосторожности для защиты конфиденциальности персональных данных Пользователя согласно порядку, обычно используемого для защиты такого рода информации в существующем деловом обороте.
6.2.4. Осуществить блокирование и/или удаления персональных данных, относящихся к соответствующему Пользователю, с момента обращения или запроса Пользователя или его законного представителя либо уполномоченного органа по защите прав субъектов персональных.
7. ОТВЕТСТВЕННОСТЬ СТОРОН
7.1. Администрация сайта, не исполнившая свои обязательства, несёт ответственность в соответствии с действующим законодательством Российской Федерации, за исключением случаев, предусмотренных п.2.5. и 7.2. настоящей Политики
Конфиденциальности.
7.2. В случае утраты или разглашения Конфиденциальной информации Администрация сайта не несёт ответственность, если данная конфиденциальная информация:
7. 2.1. Стала публичным достоянием до её утраты или разглашения.
2.1. Стала публичным достоянием до её утраты или разглашения.
7.2.2. Была получена от третьей стороны до момента её получения Администрацией сайта.
7.2.3. Была разглашена с согласия Пользователя.
8. РАЗРЕШЕНИЕ СПОРОВ
8.1. До обращения в суд с иском по спорам, возникающим из отношений между Пользователем сайта и Администрацией сайта, обязательным является предъявление претензии (письменного предложения о добровольном урегулировании спора).
8.2. Получатель претензии в течение 30 календарных дней со дня получения претензии, письменно уведомляет заявителя претензии о результатах рассмотрения претензии.
8.3. При не достижении соглашения спор будет передан на рассмотрение в судебный орган в соответствии с действующим законодательством Российской Федерации.
8.4. К настоящей Политике конфиденциальности и отношениям между Пользователем и Администрацией сайта
применяется действующее законодательство Российской Федерации.
9. ДОПОЛНИТЕЛЬНЫЕ УСЛОВИЯ
9.1. Администрация сайта вправе вносить изменения в настоящую Политику конфиденциальности без согласия Пользователя.
9.2. Новая Политика конфиденциальности вступает в силу с момента ее размещения на Сайте, если иное не предусмотрено новой редакцией Политики конфиденциальности.
9.3. Действующая Политика конфиденциальности размещена на страницах сайтов находящихся по адресам: 3put.ru, а также на их поддоменах.
как пользоваться и как установить Wordstat Helper
Содержание статьи
- Зачем нужен Вордстат
- Как правильно пользоваться Вордстатом
- По регионам
- История запроса
- Какие операторы полезны при работе с Wordstat
- Базовые операторы
- Вспомогательные операторы
- Плагины
- Yandex Wordstat Assistant
- Yandex Wordstat Helper
- Парсеры Вордстата
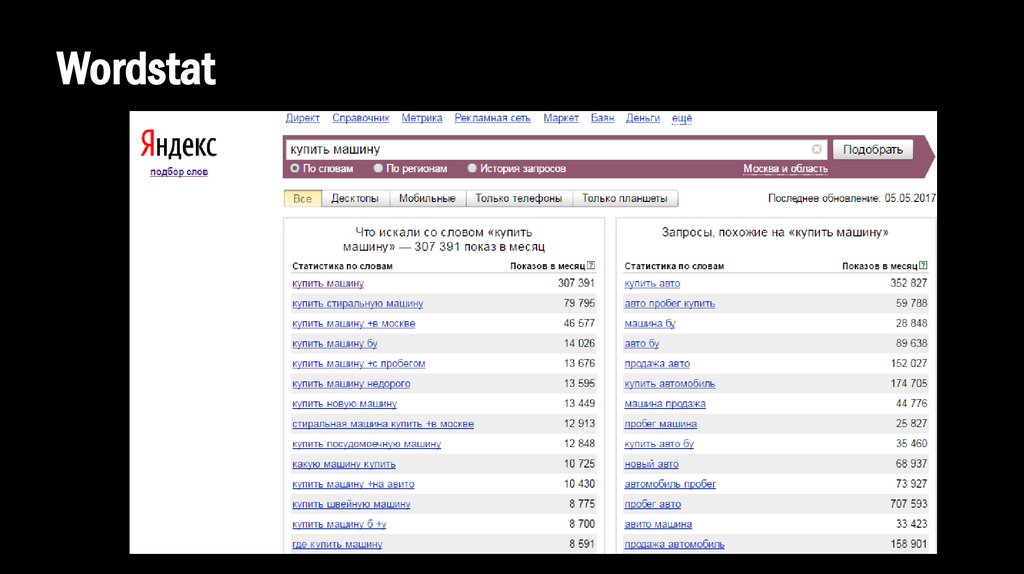
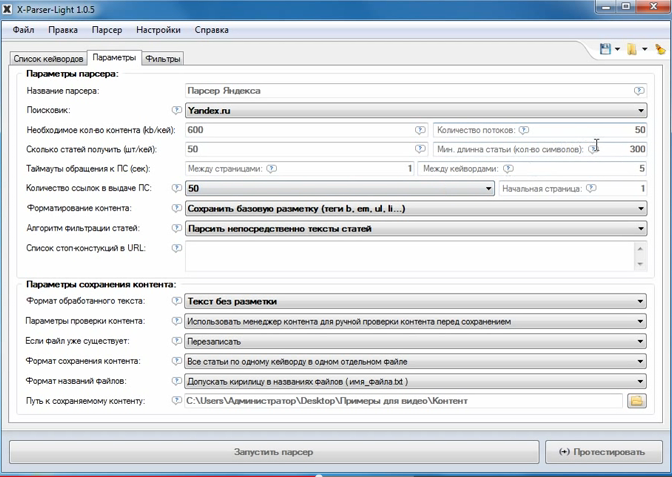
Яндекс Вордстат – это сервис компании Яндекс, используемый для подбора ключевых слов путем анализа поисковых запросов пользователей.
Зачем нужен Вордстат
В основном он применяется для составления семантического ядра. Wordstat бесплатен, он является многофункциональным инструментом, но настолько простым, что разобраться сможет даже новичок. С помощью Вордстата возможно узнать подробную статистику запросов в системе Яндекс за последний месяц, и составить не только структуру целого сайта, но и отдельных его страниц. В практике сервис применяется для решения следующих проблем:
- Сбор наиболее полной семантики за счет расширений запросов;
- Проверка частотности запросов, в том числе и региональной;
- Проверка сезонности запросов.
Это самое основное, но есть конечно и более мелкие задачи, которые помогает решить Wordstat.
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
Также важно, чтобы в вашем профиле в Яндексе был указан ваш регион, по которому вы и собираетесь смотреть статистику запроса.
 Иначе, если вы будете искать, сколько клиентов для вашего бизнеса вводят в ваших Нижних Васюках слово «удочки», а у вас стоит регион Москва, то вам может выдать, что сотни тысяч людей ищут удочки. Вы накупите их сотню тысяч, а в Нижних Васюках их ищут всего-то пара калек.
Иначе, если вы будете искать, сколько клиентов для вашего бизнеса вводят в ваших Нижних Васюках слово «удочки», а у вас стоит регион Москва, то вам может выдать, что сотни тысяч людей ищут удочки. Вы накупите их сотню тысяч, а в Нижних Васюках их ищут всего-то пара калек.После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:
Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
В основном с Вордстатом работают через специальные сервисы и программы. Тысячи их! Самая известная — Кей Коллектор. Все эти программы повышают удобство работы с этим инструментом в разы.
Напрямую с вордстатом работают очень редко, однако я слышал офигенные истории, что в студии Ашманова, одной из самых крутых SEO-студий, сидят мартышки, которые каждый запрос вводят в Вордстат руками и копируют выдачу в .txt-файл. Я сразу представил сотню рабов, которые за день работы выполняют такой же объем, как один сеошник с Кей Коллектором.
Давайте теперь смотреть остальные функции интерфейса:
В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.
В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.
А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.
В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.
В блоке 4 — выбираем регион/регионы.
По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:
А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:
История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:
Но самое профессиональное начинается, когда вы работаете с операторами.
Какие операторы полезны при работе с Wordstat
Надо знать, как пользоваться операторами Яндекс Вордстата, чтобы наиболее эффективно работать в интерфейсе.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.
А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:
Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
Он кстати позволяет провести сравнение двух запросов, для этого я его в основном и использую.
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».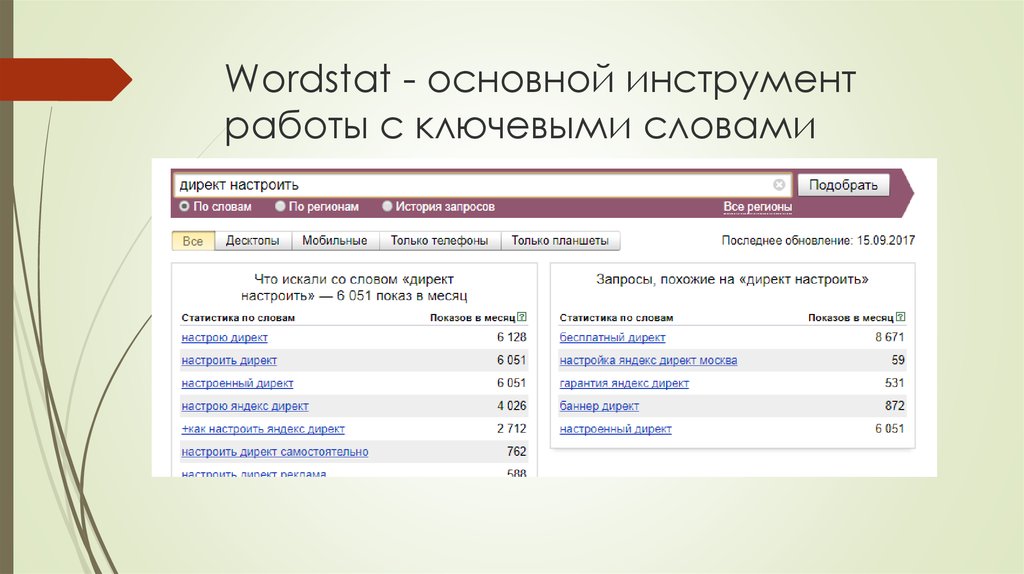
Круглые скобки «()» — группирует использование нескольких операторов.
Квадратные скобки «[]» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:
Как видим, с неправильным порядком фразу почти никто не вводит:
Плагины
Работать с голым Яндекс Wordstat в целом неудобно. Чтобы облегчить свой труд, можно установить себе в браузер специальный плагин, предназначенный для работы в Wordstat. Плагины для браузеров Хромиума (Яндекса, Мейла, Амиго, Оперы и Гугл Хрома) одинаковые, а вот для Мозилы идет отдельный плагин, все являются бесплатными и доступными для скачивания, устанавливать их можно сразу из браузера. Наиболее популярные — плагины Wordstat Assistant и Yandex Wordstat Helper.
Yandex Wordstat Assistant
Пожалуй, самый лучший плагин для wordstat. yandex.ru. Я сам им пользуюсь. Он удобен в использовании, практичен и не мешает, когда вы работаете на других сайтах. Установленный wordstat assistant запускается только в случае перехода на страницу Вордстата. Путем нажатия на плюсики, требуемое ключевое слово можно добавить в список (он находится слева). В ассистант есть возможность отсортировать выбранные ключевики, а ненужные удалить. Получившийся список просто скопируйте в буфер обмена, и перенесите в Excel для последующей обработки. Кстати, удобность использования плагина еще и в том, что когда вы добавляете в список уже находящиеся там фразы, дубли автоматически удаляются, что существенно сокращает работу.
yandex.ru. Я сам им пользуюсь. Он удобен в использовании, практичен и не мешает, когда вы работаете на других сайтах. Установленный wordstat assistant запускается только в случае перехода на страницу Вордстата. Путем нажатия на плюсики, требуемое ключевое слово можно добавить в список (он находится слева). В ассистант есть возможность отсортировать выбранные ключевики, а ненужные удалить. Получившийся список просто скопируйте в буфер обмена, и перенесите в Excel для последующей обработки. Кстати, удобность использования плагина еще и в том, что когда вы добавляете в список уже находящиеся там фразы, дубли автоматически удаляются, что существенно сокращает работу.
Yandex Wordstat Helper
Этот плагин попроще, чем предыдущий, но не менее популярен, его также можно устанавливать прямо с браузера. Хелпер сделан в виде виджета, который добавляется на страницу вордстата сразу после установки, нужно просто обновить страницу и можно начинать работу. Его функции:
Хелпер сделан в виде виджета, который добавляется на страницу вордстата сразу после установки, нужно просто обновить страницу и можно начинать работу. Его функции:
- Возможность автоматической сортировки в алфавитном порядке;
- Проверяет наличие дублей, удаляя последние;
- Есть возможность обработки разных запросов в нескольких вкладках браузера. Нужные слова добавляются в один и тот же список;
- Есть счетчик слов;
- Возможность копирования уже готового списка в Excel, собрав всё воедино по начальным фразам.
Прежде чем решить, какой плагин использовать, попробуйте в действии и тот и другой, это позволит вам сделать правильный выбор.
Парсеры Вордстата
Для экономии времени при подборе ключевых слов часто пользуются специально предназначенными для этого автоматическими программами – парсерами, которые могут быть как платными, так и бесплатными.
Некоторые пацаны заказывают парсеры и чисто под свои нужды.
Лучший платный парсер Wordstat – KeyCollector. Используют его в основном те, кто профессионально занимается составлением семантики. Бесплатным аналогом КейКоллектора является программа Словоеб. Функции его урезаны, но составлять небольшие ядра с его помощью вполне реально.
Используют его в основном те, кто профессионально занимается составлением семантики. Бесплатным аналогом КейКоллектора является программа Словоеб. Функции его урезаны, но составлять небольшие ядра с его помощью вполне реально.
Магадан тоже достаточно популярный парсер Вордстат, который тоже можно бесплатно скачать. Подбирает и анализирует запросы, есть поддержка регионов, предназначен для парсинга фраз Яндекс Директа.
Под конец хочу отметить, что Вордстат дает только те данные, которыми располагает Яндекс. Поэтому например частотность в Гугле и других поисковиках может быть совсем другая.
Яндекс Вордстат — полезные статьи
Яндекс Вордстат – это один из бесплатных сервисов Яндекса. Создан он для помощи в подборе словосочетаний, ключевых слов. Данный сервис облегчает SEO – продвижение. Помощь в написании оптимизированных статей – не единственная функция Яндекс Вордстат. Он помогает не только собирать семантическое ядро. Это многоопционный инструмент. Он обладает многими важными функциями. Разберём их по порядку.
Как правильно пользоваться Яндекс Вордстат
Многие люди задаются вопросом, как правильно пользоваться Яндекс Вордстат. В работе с ним нет ничего сложного. При правильном использовании данного сервиса, Вы сможете облегчить работу по продвижению сайта. Yandex Wordstat можно использовать как с компьютера, так и с мобильного телефона или планшета. Работать с этим помощником могут только пользователи Яндекс почты. Если Вы ещё не зарегистрированы, то сделайте это. Регистрация очень проста и займёт всего пару минут.
- Откройте Яндекс браузер
- Найдите значок Почта
- Выберете значок «зарегистрироваться»
- Зарегистрируйтесь
- Войдите в свою почту
Далее определим, как пользоваться яндекс вордстат. Пошаговая инструкция
- Войдите в Яндекс почту
- Пройдите по ссылке
- В поисковую строку впишите нужное слово и нажмите «Подобрать»
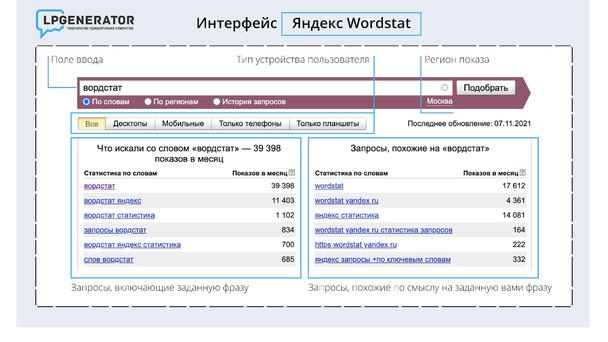
В результате он выдаёт подбор словосочетаний и слов, которые искали пользователи в интернете. Вордстат показывает число поисковых запросов с тем словом, которое вы выбрали в качестве ключевого. В запросе выдаются слова не только в исходном виде, но и в видоизменённых формах (падежах, числах). Например, вбив в поисковую строку запрос «оконные системы», вы получите видоизменённые запросы по этой теме: «оконных системах», «оконными системами», «оконную систему». Яндекс.Wordstat выдаёт общую статистику запросов по стране. Если Вам необходимо уточнить регион, то кликните по значку «все регионы». Кроме того, можно посмотреть статистику только с мобильных устройств.
Вордстат показывает число поисковых запросов с тем словом, которое вы выбрали в качестве ключевого. В запросе выдаются слова не только в исходном виде, но и в видоизменённых формах (падежах, числах). Например, вбив в поисковую строку запрос «оконные системы», вы получите видоизменённые запросы по этой теме: «оконных системах», «оконными системами», «оконную систему». Яндекс.Wordstat выдаёт общую статистику запросов по стране. Если Вам необходимо уточнить регион, то кликните по значку «все регионы». Кроме того, можно посмотреть статистику только с мобильных устройств.
«+», «-», «!» — символы, помогающие уточнить поисковый запрос
Вордстат схож с поисковым браузером тем, что в нём тоже можно использовать синтаксис. Это помогает уточнять поисковые запросы. Если перед нужным словом поставить знак «-», то система уберёт из списка все словосочетания с ним. Например, пишем в поисковике «коррекция бровей – видео». У нас отфильтруются такие запросы: «видео коррекции бровей», «коррекция бровей видео» и другие. Если вместо минуса поставить «+», то Яндекс. Wordstat выдаст запросы обязательно с этим словом. Данная функция очень полезна тем, что в значимые слова можно добавлять союзы и предлоги. В обычной работе сервис их игнорирует. Если перед словом поставить восклицательный знак «!», то система выдаст только запросы с точным вхождением фразы, включая число и падеж.
Если вместо минуса поставить «+», то Яндекс. Wordstat выдаст запросы обязательно с этим словом. Данная функция очень полезна тем, что в значимые слова можно добавлять союзы и предлоги. В обычной работе сервис их игнорирует. Если перед словом поставить восклицательный знак «!», то система выдаст только запросы с точным вхождением фразы, включая число и падеж.
Возможность подборки по регионам
Работа с данным помощником проста и информативна. Рассмотрим подробнее использование функции выбора региона. Нажимаем на значок «Все регионы». Ниже появится окно, в котором выделяем необходимые пункты. Вордстарт предлагает опцию «Быстрый выбор». Она значительно облегчает работу. С помощью этой клавиши можно сразу выбрать более распространённые регионы. В них входят: Московская область, Москва, Россия, Украина, Петербург, Ленинградская область, Грузия, СНГ.
Работа с низкочастотными запросами
Если Вы хотите перейти в полученном списке на последнюю страницу, сделать это в один клик не получится. К сожалению, дойти до конца страниц можно только перелистывая их по одной. Например, на двадцатую страницу можно перейти, нажав «далее» 19 раз. Если Вы очень быстро будете их листать, то система может заподозрить в Вас робота. Появится капча. Нужно будет ввести код с картинки в всплывшем окне. Если вы правильно введёте цифры и буквы, можно продолжать листать. Низкочастотные запросы появятся в конце списка. Иногда требуется сохранить полученную статистику популярных и низкочастотных запросов в Excel. Для этого нужно выполнить следующие шаги:
К сожалению, дойти до конца страниц можно только перелистывая их по одной. Например, на двадцатую страницу можно перейти, нажав «далее» 19 раз. Если Вы очень быстро будете их листать, то система может заподозрить в Вас робота. Появится капча. Нужно будет ввести код с картинки в всплывшем окне. Если вы правильно введёте цифры и буквы, можно продолжать листать. Низкочастотные запросы появятся в конце списка. Иногда требуется сохранить полученную статистику популярных и низкочастотных запросов в Excel. Для этого нужно выполнить следующие шаги:
- Нажать сочетание клавиш Ctrl+C
- Выделить необходимые поля в браузере
- Открыть Excel
- Нажать правую кнопку мыши
- Выбрать: «вставить текст без форматирования»
- Все данные вставятся в таблицу. Работать с ней будет удобнее
Работа с очень популярными и похожими запросами
В случае работы с очень популярными запросами Вордстат не покажет информацию дальше сороковой страницы. Например, если ввести «новости сегодня», то в выдаче будет более миллиона вариантов. Таким образом, до конца очереди добраться невозможно. Яндекс решил эту проблему. И создал сторонние программы для Yandex Wordstat. Их называют парсерами. Среди них: Yandex Wordstat Assistant, Yandex Key Parser, Yandex Wordstat Helper, Key Collector. Как пользоваться Яндекс Вордстат ассистент и другими программами мы расскажем подробнее в следующих статьях.
Таким образом, до конца очереди добраться невозможно. Яндекс решил эту проблему. И создал сторонние программы для Yandex Wordstat. Их называют парсерами. Среди них: Yandex Wordstat Assistant, Yandex Key Parser, Yandex Wordstat Helper, Key Collector. Как пользоваться Яндекс Вордстат ассистент и другими программами мы расскажем подробнее в следующих статьях.
Программа показывает не только информацию по искомым словам. Она автоматически даёт обзор на словосочетания и слова, которые будут полезны пользователю. Например, на он ищет не только «похудеть за неделю», но и «быстро сбросить вес». Таким образом, можно найти похожие статьи на интересующую тему. Эта опция бывает полезной не в 100% случаев. Но игнорировать её не стоит.
запросов». Она помогает узнавать об изменении запросов по сезонам. С её помощью пользователь может определить изменения в популярных словах за месяц, неделю, год.
Основные возможности Вордстарта
Теперь вы знаете, как пользоваться Яндекс Вордстат Сonvert Monster.
Определим его основные преимущества:
- Это бесплатный помощник
- С его помощью можно продвигать SEO – статьи для сайта
- Использование Яндекс Вордстат доступно только пользователям ЯндексПочты
- Он позволяет подбирать ключевые слова для текстов
- Популярность запросов меняется регулярно
- «По словам» — не единственный раздел программы
Исследуйте популярные запросы. С помощью полученных знаний, Вы сможете легче продвигать свои сайты. Yandex Wordstat станет неоценимым помощником в Вашей работе.
Парсер Яндекс Wordstat онлайн бесплатно
Заказать
Wordstat стал незаменимым помощником seo-оптимизаторов и всех, кто приобщен к созданию сайтов. Этот бесплатный сервис помогает вести статистику по основным запросам, выбирать ниши для построения бизнеса, собирать ключевые слова для написания статей. Бесспорно, Вордстат удобен в использовании, но у новичков, владельцев большого и среднего бизнеса просто нет времени сидеть и вбивать вручную огромное количество запросов.
Поэтому для оптимизации процессов, уменьшения затрат времени постоянно появляется новый софт. Команда yandex-wordstat создала удобный инструмент, чтобы помочь как опытным SEO-оптимизаторам, интернет-маркетологам, так и владельцам бизнеса, активным блогерам всех социальных сетей, – всем, кто часто пользуется Вордстатом.
С помощью парсера Wordstat от yandex-wordstat вы сможете:
- приступить к созданию семантического ядра сайта;
- подобрать ключевые слова, чтобы оформить и запустить контекстную рекламу;
- изучить количество запросов по нужной тематике, товару или услуге, без стоп-слов и словесного мусора;
- подобрать тему статьи для поста в социальных сетях, блоге;
- составить структуру будущего проекта с учетом потребностей клиента;
- проанализировать популярность услуги, товара по регионам, сезонам;
- получить готовую информацию в виде таблицы xlsx, xls.

Сбор частотности & сезонности из Яндекс Wordstat
Заполните форму и отправьте в наш сервис
Преимущества работы с yandex-wordstat
Можно настроить условия работы: разные тарифные планы и возможность подобрать индивидуальный тариф. Кроме этого, клиенты получают:
поддержку оптимизаторов и возможность задать вопрос;
использование всего комплекса инструментов для оптимизации.
понятный интерфейс и подсказки системы.
Основное преимущество инструмента от yandex-wordstat в том, что не нужно докупать антикапчи и прокси, нет сложных дополнительных настроек. Справиться с этим парсером Вордстат сможет пользователь начального уровня.
А благодаря продуманному сервису можно не только работать с запросами, но и совершать массу других полезных действий:
- проверять индексацию и позиции сайта в Яндекс;
- сделать кластеризацию;
- пользоваться текстовым анализатором и собирать поисковые подсказки;
- искать, восстанавливать информацию в Webarchive;
- бороться со спамом;
- провести аудит сайта и мониторить конкурентов.

Вордстат от сервиса yandex-wordstat с многозадачным функционалом — это находка для оптимизаторов.
Хотите бесплатный аудит сайта ?
Заполните форму и получите консультацию
Чем же отличается встроенный Wordstat yandex-wordstat от обычного сервиса Yandex?
Сервис от yandex-wordstat собрал все необходимые инструменты для оптимизаторов в одном месте. Вордстат претерпел изменения, стал более удобным.
Что изменилось:
- Робот отсеивает нецелевые, стоп-слова. Теперь не нужно вручную создавать документ Excel и прописывать перечень запросов, которые выдал Яндекс, при этом удалять ненужные слова (б/у, спб, екб). Чтобы получить конкретный ответ достаточно ввести основную фразу и указать регион. Система самостоятельно все отфильтрует, при этом не удалит запросы наподобие «мебель б/у Питер».
- Применение операторов аналогично обычному Вордстат. Для бывалых оптимизаторов и людей, непосвященных в тонкости сбора и анализа запросов, инструмент поможет вникнуть в «тему» без лишних вопросов.
- Все под рукой. Удобный интерфейс позволяет пользоваться всеми преимуществами сервиса. Например, создавать папки с проектами и работать над ними без перехода на сторонние сайты. Здесь есть не только вкладка для работы с Вордстатом. Но и другие инструменты для сбора статистики, ее анализа, и создания на базе более продвинутых, оптимизированных сайтов.

Если же вы хотите продвигать сайт с помощью специалистов — SEO-оптимизаторов, маркетологов, обращайтесь к команде yandex-wordstat.
Как собрать семантическое ядро?
Чтобы не упустить поисковой трафик, обеспечить сайту соответствие основным запросам, необходимо грамотно собрать семантическое ядро. Благодаря этому можно:
создать сайт, который будет попадать в топ выдачи и привлекать большее количество посетителей;
улучшить уже существующую страницу с точки зрения поисковых роботов;
определить последующую стратегию развития сайта;
увеличить конверсию сайта за счет грамотного распределения контента;
найти новые темы для взаимодействия с клиентами;
настроить сайт под популярные запросы
в Яндексе и Google.
Составление семантического ядра невозможно представить без аналитики запросов и подсказок в поисковых системах Яндекс, Google, YouTube. С инструментом от yandex-wordstat вы сможете:
- Создать маркерные запросы на основании анализа позиций конкурентов, проработки Яндекс.Метрики и Google Console Search.
- Собрать список запросов и подсказок из сервисов Вордстат, Adwords, очистить их от стоп-слов.
- Определить частотность основных запросов и запустить проект.
- Кластеризовать слова по смыслу и совместимости.
- Подготовить задачи копирайтерам с помощью текстового анализатора.
- Проверить позиции сайта.
Этот сервис с упорядоченными инструментами ускорит продвижение сайтов, поможет их сделать информативными, полезными и релевантными.
Статистика поиска из Google в сервисе yandex-wordstat
Поисковая система Яндекс — не единственный сервис, который помогает искать нужные запросы и настраивать контекстную рекламу. У Google также есть такая разработка под названием Adwords. Она помогает найти целевую аудиторию для бизнеса по основным запросам.
У Google также есть такая разработка под названием Adwords. Она помогает найти целевую аудиторию для бизнеса по основным запросам.
Сервис yandex-wordstat работает и с Google Adwords. Инструмент достаточно простой в управлении, но результативный, потому что показывает основные фразы и слова, их частотность.
Чтобы получить нужную статистику по товарам или услугам, следуйте инструкции:
- Во вкладке Adwards создайте задачу.
- Внесите основные данные для поиска по запросам: основную фразу или слово, регион, язык выдачи.
- Настройте сбор информации. Это может быть поиск основных словосочетаний из Google Keywords Planner или сбор частотности популярных запросов.
- Все данные, которые нашла система, переносятся в файл xlsx, xls. Запросы уже очищены от стоп-слов. Теперь можно приступить к следующему шагу.
- Инструмент обрабатывает полученную информацию. Отследить статус можно в личном кабинете.
- Скачайте ответ в файле с отсортированными по частотности запросами.
С помощью такого алгоритма можно собрать нужную статистику с Google.
Как работать с Вордстатом
Wordstat в поисковой системе Яндекс работает следующим образом:
- В строке поиска прописываете ключевое слово или фразу. Яндекс выдает все похожие запросы, которые смог найти за определенное время — 30 дней. Можно задать регионы (только Россия, конкретный город), временной промежуток — сбор данных за месяц, неделю. Можно отобрать пользователей по типу устройств — десктопные (ноутбук, компьютер), мобильные (смартфон, планшет).
- Чтобы поиск в Вордстат был более конкретный, используйте операторы — символы, которые выдадут нужный запрос. К операторам относят кавычки, восклицательный знак. Прописывают ключевые словосочетания, слова в именительном падеже.
- Система выдаст статистику показов по запросу. Поисковик находит только те, что запрашивают в Яндексе.
- На страницу Вордстата выносится две колонки. В левой отображается точное количество запросов с указанной ключевой фразой. В правой колонке система показывает синонимы, которые похожи с введенным ключом.
 Поисковик находит только те, что запрашивают в Яндексе.
Поисковик находит только те, что запрашивают в Яндексе.Сделать глубокий анализ помогает история запросов, которая предлагает статистику (абсолютную или относительную) за последние 1,5–2 года.
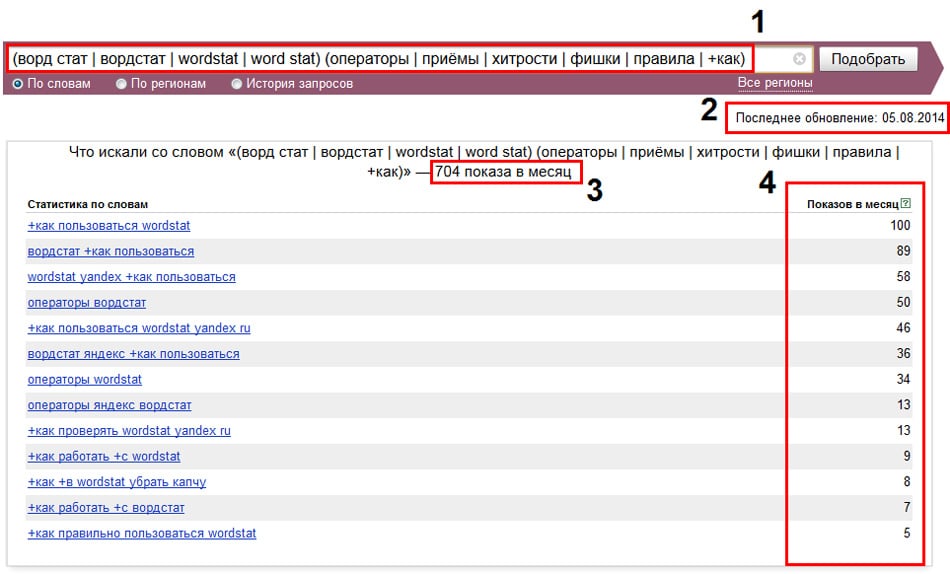
Описание операторов Вордстат
Символы, которые вводят в начале и конце основного запроса, помогают более точно найти частотность. Каждый из символов ориентирует Яндекс на определенный поиск.
Восклицательный знак — фиксируется окончание слова «!».
Квадратные скобки — фиксируют порядок слов в запросе. «[ ]».
Кавычки — выдает количество показов по заданной фразе. При этом могут меняться окончания слов и порядок.
Знаки:
а) «+» подбирает словосочетания с союзами и предлогами;
б) «-» удаляет стоп-слова.
«Или» (вертикальная полоска |) — помогает оформить запрос с несколькими условиями. Например, генеральный штаб или генштаб.
() — применяют при регулярной проверке с запросами, которые содержат комбинированные условия.
Полученная статистика зависит от правильности прописанных основных и дополнительных запросов.
Принцип работы парсера Вордстат от yandex-wordstat
Понимание принципов работы Вордстата от Яндекса — это залог успешного поиска запросов.
Алгоритм работы:
- Вводим основной запрос с операторами или название сайта, а также регион, в котором будем искать информацию. Операторами могут быть знаки + или -, кавычки, восклицательный знак, круглые скобки, вертикальная полоска.
- Настраиваем сбор — будете искать ключевую фразу в левой колонке Вордстата, ее частотность, или в правой колонке. Стандартная глубина – до 40 страниц.
- Сервис выдает частотность запросов за 30 дней. Для получения более ранней информации следует непосредственно работать с Яндексом.
- Тип частотности может быть разным: базовым, с частичным вхождением, с учетом порядка слов, точным.
- В парсере от yandex-wordstat можно убирать списки стоп-слов (система их просто вырезает), что позволяет экономить время и собирать более точные данные по запросу. Кстати, такие слова разбиты по тематикам и направлениям. Клиенты, которые работают с редкой тематикой, могут создавать собственные списки стоп-слов для кластеризации, подбора подсказок.
- Загрузить список запросов можно отдельным файлом в формате xlsx, xls с учетом первой строки или без нее.
- Вы не потеряете нужные слова, благодаря «эксперту опций».
- Для контроля поданной заявки на личной странице высвечивается статус обработки.

Данные после кластеризации используют по своему усмотрению. Чаще всего для сбора семантического ядра.
100% точные данные
Масштабируемость
Безопасность
как парсить максимальное число ключевых фраз и их частотность с помощью Wordstat
В этой статье я хочу поделиться своими методами повышения эффективности использования времени и получения качественных результатов. Мы разберем ряд инструментов и я кратко опишу их плюсы. Погнали..
Мы разберем ряд инструментов и я кратко опишу их плюсы. Погнали..
Совсем недавно открыл для себя инструмент word-keeper.ru, позволяющий собрать частотности с Wordstat без задержек и на большой скорости. Из явных плюсов могу отметить, что сервис имеет бесплатный тариф и собирает до 2000 ключей за раз в течение 1 минуты. Тот же платный Key Collector с данной задачей справляется значительно дольше и приходится ждать, покупать анти-капчу и прокси.
Для примера, решил проверить скорости сбора частностей через сервис и Кей Коллектор:
- Через Кей Коллектор сбор занял 2 минуты 46 секунд, затрачено 15 капчей;
- Через сервис — 30 секунд;
Автор проекта — замечательный специалист, ведет свой блог и регулярно выкладывает обновления.
Из дополнительных “плюшек” можно отметить постоянно расширяющийся функционал:
- Удобный стеммер, который показывает наиболее частые слова в вашем ядре;
- Возможность создания групп ключей;
- Область заметок для ваших записей и т. д.
 д.
д.Сервис крутой, годно использовать в своей работе!
«Если ты не сдашься, то ты победишь»
Всем нам понятно, что чем больше мы соберем качественных ключей с хорошей частотностью, тем более высокий результат мы сможем получить при продвижении.
Wordstat не дает возможности собрать семантику глубже 41 страницы, и при этом теряется большой объем ключей. Приходится использовать нестандартные средства, чтобы выкручиваться из этой ситуации, так как дальше 41 страницы скрыто еще множество запросов.
Решать эту проблему помогают специальные операторы: !, -, “”.
Но, для этого нужно подготовить колоссальную вариативную лестницу с разными падежами и операторами у исходного запроса.
Например, соберем ключи по запросу «собака»:
!собака
!собаки
!собаке
!собаку
!собакой
!собакою
!собак
!собакам
!собаками
!собаках
«!собака»
«!собака собака»
«!собака собака собака»
«!собака собака собака собака»
«!собака собака собака собака собака»
«!собака собака собака собака собака собака»
«!собака собака собака собака собака собака собака»
«собака»
«собака собака»
«собака собака собака»
«собака собака собака собака»
«собака собака собака собака собака»
«собака собака собака собака собака собака»
«собака собака собака собака собака собака собака»
собака -!собака
собака -!собака -!собаки
собака -!собака -!собаки -!собаке
собака -!собака -!собаки -!собаке -!собаку
собака -!собака -!собаки -!собаке -!собаку -!собакой
собака -!собака -!собаки -!собаке -!собаку -!собакой -!собакою
собака -!собака -!собаки -!собаке -!собаку -!собакой -!собакою -!собак
собака -!собака -!собаки -!собаке -!собаку -!собакой -!собакою -!собак -!собакам
собака -!собака -!собаки -!собаке -!собаку -!собакой -!собакою -!собак -!собакам -!собаками
собака -!собака -!собаки -!собаке -!собаку -!собакой -!собакою -!собак -!собакам -!собаками -!собаках
«!собаки собака»
«!собаки собака собака»
«!собаки собака собака собака»
«!собаки собака собака собака собака»
«!собаки собака собака собака собака собака»
«!собаки собака собака собака собака собака собака»
«!собаки собака собака собака собака собака собака собака»
«!собаке собака»
«!собаке собака собака»
«!собаке собака собака собака»
«!собаке собака собака собака собака»
«!собаке собака собака собака собака собака»
«!собаке собака собака собака собака собака собака»
«!собаке собака собака собака собака собака собака собака»
«!собаку собака»
«!собаку собака собака»
«!собаку собака собака собака»
«!собаку собака собака собака собака»
«!собаку собака собака собака собака собака»
«!собаку собака собака собака собака собака собака»
«!собаку собака собака собака собака собака собака собака»
«!собакой собака»
«!собакой собака собака»
«!собакой собака собака собака»
«!собакой собака собака собака собака»
«!собакой собака собака собака собака собака»
«!собакой собака собака собака собака собака собака»
«!собакой собака собака собака собака собака собака собака»
«!собакою собака»
«!собакою собака собака»
«!собакою собака собака собака»
«!собакою собака собака собака собака»
«!собакою собака собака собака собака собака»
«!собакою собака собака собака собака собака собака»
«!собакою собака собака собака собака собака собака собака»
«!собак собака»
«!собак собака собака»
«!собак собака собака собака»
«!собак собака собака собака собака»
«!собак собака собака собака собака собака»
«!собак собака собака собака собака собака собака»
«!собак собака собака собака собака собака собака собака»
«!собакам собака»
«!собакам собака собака»
«!собакам собака собака собака»
«!собакам собака собака собака собака»
«!собакам собака собака собака собака собака»
«!собакам собака собака собака собака собака собака»
«!собакам собака собака собака собака собака собака собака»
«!собаками собака»
«!собаками собака собака»
«!собаками собака собака собака»
«!собаками собака собака собака собака»
«!собаками собака собака собака собака собака»
«!собаками собака собака собака собака собака собака»
«!собаками собака собака собака собака собака собака собака»
«!собаках собака»
«!собаках собака собака»
«!собаках собака собака собака»
«!собаках собака собака собака собака»
«!собаках собака собака собака собака собака»
«!собаках собака собака собака собака собака собака»
«!собаках собака собака собака собака собака собака собака»
Чтобы сформировать ключи с операторами на основе главного запроса уходит очень много времени. Поэтому я использую автоматический генератор, доступный по адресу https://content.2seo.pro/generator
Поэтому я использую автоматический генератор, доступный по адресу https://content.2seo.pro/generator
Данный инструмент написан экспертом о работе с семантикой Анастасией Ледневой.
Рассмотрим, как же им пользоваться:
- Берем нужное слово для парсинга и вставляем в генератор.
2. Выставляем количество повторов на 7, так как Wordstat не отдаст нам ключи, в составе которых больше 7 слов.
3. Вводим капчу и жмем “Генерировать”
4. Полученный из генератора результат вставляем прямо в Кей Коллектор.
5. Запускаем парсинг и получаем тысячами слов, которые иначе мы могли бы упустить.
6. В результате получаем следующую разницу — новых ключей получилось на 35731 больше чем, полученных без сервиса!
Сравнив результаты, получил то, что были упущены ряд ключей, например «маленькая собака» с частотностью 230245.
Без сервиса найдено 26 ключей:
С сервисом дополнительно собрались еще 519, конечно есть ряд мусора, но в целом ключей гораздо больше:
Вот ряд инструментов, которые Я использую в своей работе. Буду периодически делиться с Вами также и своими наработками, ведь главный девиз для профессионала — это правильное использование своего времени!
Буду периодически делиться с Вами также и своими наработками, ведь главный девиз для профессионала — это правильное использование своего времени!
Программное обеспечение для анализа текста и майнинга | Простой в использовании контент-анализ
WordStat — это гибкое и простое в использовании программное обеспечение для анализа текста — нужны ли вам инструменты анализа текста для быстрого извлечения тем и тенденций или тщательное и точное измерение с помощью современных инструментов количественного анализа контента. WordStat может использоваться всеми, кому необходимо быстро извлекать и анализировать информацию из больших объемов документов. Наше программное обеспечение для контент-анализа и интеллектуального анализа текста можно использовать во многих приложениях, таких как анализ открытых ответов, бизнес-аналитика, контент-анализ новостей, обнаружение мошенничества и многое другое. Полная интеграция WordStat с SimStat — наш инструмент для анализа статистических данных — QDA Miner — наше программное обеспечение для качественного анализа данных — и Stata — комплексное статистическое программное обеспечение от StataCorp, обеспечивающее беспрецедентную гибкость при анализе текста и сопоставлении его содержания со структурированной информацией, включая числовую. и категориальные данные.
и категориальные данные.
СКАЧАТЬ БЕСПЛАТНУЮ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ ЗАПРОСИТЬ ВЕБ-ДЕМО
ИССЛЕДОВАНИЕ СОДЕРЖИМОГО ДОКУМЕНТА С ИСПОЛЬЗОВАНИЕМ ИНТЕРФЕЙСА ТЕКСТА
• Анализ больших объемов неструктурированной информации с помощью WordStat. Программное обеспечение может обрабатывать 25 миллионов слов в минуту, быстро извлекать темы и автоматически определять закономерности, используя кластеризацию, многомерное масштабирование, диаграммы близости и многое другое.
БЫСТРОЕ ИЗВЛЕЧЕНИЕ ЗНАЧЕНИЯ В РЕЖИМЕ ПРОВОДНИКА
• Быстро и легко извлекайте смысл из больших объемов текстовых данных с помощью режима Проводника, специально созданного для тех, у кого мало опыта в анализе текста. Одним щелчком мыши вы можете извлечь наиболее часто встречающиеся слова, фразы и самые важные темы в ваших документах.
ИМПОРТ ИЗ МНОГИХ ИСТОЧНИКОВ
• Импорт Word, Excel, HTML, XML, SPSS, Stata, NVivo, PDF-файлов, а также изображений. Подключайтесь и напрямую импортируйте данные из социальных сетей, электронной почты, платформ веб-опросов и инструментов управления ссылками.
Подключайтесь и напрямую импортируйте данные из социальных сетей, электронной почты, платформ веб-опросов и инструментов управления ссылками.
ИЗВЛЕЧЕНИЕ НАИБОЛЕЕ ЗНАЧИМЫХ ТЕМ С ПОМОЩЬЮ ТЕМАТИЧЕСКОГО МОДЕЛИРОВАНИЯ
• Получите краткий обзор наиболее важных тем из очень больших текстовых коллекций, используя современное автоматическое извлечение тем на основе слов, фраз и родственных слов (включая орфографические ошибки).
ИССЛЕДУЙТЕ СОЕДИНЕНИЯ
• Исследуйте отношения между словами или понятиями и извлекайте текстовые сегменты, связанные с определенными соединениями.
СВЯЗАТЬ ТЕКСТ СО СТРУКТУРИРОВАННЫМИ ДАННЫМИ
• Исследовать отношения между неструктурированным текстом и структурированными данными, такими как даты, числа или категориальные данные, для выявления временных тенденций или различий между подгруппами или для оценки отношений с рейтингом или другими видами категориальных или числовых данных со статистическими и графические инструменты (анализ соответствия, тепловые карты, пузырьковые диаграммы и др. ).
).
КАТЕГОРИЗАЦИЯ ТЕКСТОВЫХ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ СЛОВАРОВ
• Автоматизируйте полнотекстовый анализ с помощью существующих словарей или создайте собственную модель категоризации со словами, фразами, правилами близости и т. д.
ПОЛУЧИТЕ УНИКАЛЬНУЮ ПОДДЕРЖКУ ДЛЯ СОЗДАНИЯ СЛОВАРОВ
• Создавайте свой словарь быстрее с помощью инструментов для извлечения общих фраз и технических терминов, а также для быстрого выявления в вашей текстовой коллекции орфографических ошибок, синонимов, антонимов и родственных слов.
КАТЕГОРИЗАЦИЯ ТЕКСТОВЫХ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ МАШИННОГО ОБУЧЕНИЯ
• Разрабатывайте и оптимизируйте модели автоматической классификации документов с использованием наивного байесовского метода и алгоритма K-ближайших соседей.
ВОЗВРАТ К ИСХОДНОМУ ДОКУМЕНТУ В ОДИН ЩЕЛЧОК
• Проверяйте или углубляйтесь в свой анализ, возвращаясь к тексту почти любой характеристики, диаграммы или графика. Вы можете использовать функции поиска ключевых слов или ключевых слов в контексте для поиска предложений, абзацев или целых документов. Это особенно полезно при построении таксономий или для устранения неоднозначности смысла слов. Вы также можете прикрепить коды QDA Miner к извлеченным сегментам.
ВЫПОЛНЕНИЕ КАЧЕСТВЕННОГО КОДИРОВАНИЯ
• Объедините WordStat с современным инструментом качественного кодирования (QDA Miner) для более точного исследования данных или более глубокого анализа конкретных документов или извлеченных текстовых сегментов, когда это необходимо.
ПРЕОБРАЗОВАНИЕ НЕСТРУКТУРИРОВАННОГО ТЕКСТА В ИНТЕРАКТИВНЫЕ КАРТЫ (ОТОБРАЖЕНИЕ ГИС)
• Связывайте неструктурированные текстовые данные с географической информацией и создавайте интерактивные графики точек данных, тематических карт и тепловых карт, а также веб-службу геокодирования для преобразования названий местоположений, почтовых индексов и IP-адресов в широту и долготу.
АВТОМАТИЧЕСКОЕ ИЗВЛЕЧЕНИЕ ИМЕНОВАННЫХ ОБЪЕКТОВ
• Автоматическое извлечение именованных объектов, которые можно добавить в словарь категорий с помощью простой операции перетаскивания.
ЭКСПОРТ РЕЗУЛЬТАТОВ
• Простой экспорт результатов анализа текста в распространенные отраслевые форматы файлов, такие как Excel, SPSS, ASCII, HTML, XML, MS Word, а также графики, такие как PNG, BMP и JPEG.
ПРЕОБРАЗОВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ СКРИПТОВ PYTHON
• Используйте скрипты Python и полный спектр библиотек с открытым исходным кодом для предварительной обработки или преобразования текстовых документов для анализа в WordStat.
Мы пришли к выводу, что WordStat является самым мощным инструментом текстовой аналитики, доступным для бизнес-приложений.
Д-р Джон М. Аарон
Магистерская программа профессора Элмхерстского колледжа по науке о данных
WordStat может легко выполнять широкий спектр анализа текста. Он имеет множество удобных возможностей, которые делают его намного проще в использовании, чем другие продукты.
Д-р Грант Бланк
Научный сотрудник, Оксфордский университет
Анализ ключевых слов — Топвизор
Попробуй бесплатно
Инструмент исследования ключевых слов для SEO, PPC и создания контента
У каждого интернет-бизнеса должен быть набор ключевых слов, на которые они ориентируются при таргетинге своего веб-сайта для получения конверсий. Ключевое слово — это одно слово, несколько слов или фраза, которые имеют отношение к содержимому веб-сайта и влияют на рейтинг веб-сайта. Каждая веб-страница может соответствовать ключевому слову или группе ключевых слов, связанных с вашей целевой аудиторией.
Идеи ключевых слов могут быть взяты из всех доступных источников исследования ключевых слов: Google (Планировщик ключевых слов, Search Console, Analytics), Bing
(Вебмастер), Яндекс (Wordstat, Метрика, Вебмастер), Mail. ru (Вебмастер) инструменты и поисковые подсказки (Google, Bing, Yahoo,
Ютуб, Яндекс и Mail.ru).
ru (Вебмастер) инструменты и поисковые подсказки (Google, Bing, Yahoo,
Ютуб, Яндекс и Mail.ru).
Инструменты исследования ключевых слов обеспечивают рабочую структуру ключевых слов, сегментированную на группы, и все готово для распространения по веб-страницам. Извлекайте эффективные идеи ключевых слов из всех доступных источников, используйте удобные инструменты и функции для получения ценной информации, управляйте и анализируйте ключевые слова, применять автоматизированные инструменты кластеризации и группировки, чтобы создать полную структуру ключевых слов за пару минут.
Исследование ключевых слов
Обогатите свой веб-сайт идеями ключевых слов из всех доступных источников
Ключевые слова — это релевантные слова и фразы, описывающие тему веб-страницы, бизнеса, продуктов или услуг, которые веб-сайт обеспечивает.
Получите эффективные идеи ключевых слов из всех доступных источников: Google Keyword Planner, Webmaster Bing, Yandex.Wordstat или Webmaster Mail. ru.
ru.
Autocomplete Suggestions
Сбор предложений поиска с уровнями вложенности и поддержкой расширенных методов
Использовать предложения автозаполнения Google, Bing, Yahoo, Youtube, Yandex и Mail.ru в качестве другого источник релевантных и эффективных ключевых слов для вашего сайта.
Инструмент подсказок ключевых слов — это идеальный источник ценных идей ключевых слов, созданный для того, чтобы сделать ваш веб-сайт, богатый ключевыми словами с поисковыми запросами реальных пользователей.
Magnet Tool
Варианты ключевых слов из Google Analytics, Google Search Console, Yandex Metrica и Yandex.Webmaster
Magnet — это бесплатный и удобный инструмент, который автоматически извлекает ключевые слова из информационных панелей и инструментов популярных поисковых систем.
Соберите все ключевые слова, которые привлекли посетителей на ваш веб-сайт, и множество дополнительных сведений за указанный период.
Инструменты для повышения эффективности ключевых слов
Используйте все доступные инструменты и функции для исследования, управления и группировки ключевых слов. Извлеките важные сведения и проанализируйте каждое ключевое слово перед добавлением его на ваш сайт. Исследуйте и прогнозируйте эффективность ключевых слов: отслеживайте объем поиска, чтобы убедиться, что ваши ключевые слова эффективны.
Применяйте инструменты автоматической группировки ключевых слов: кластеризация ключевых слов или группировка ключевых слов по релевантности страницы сэкономит ваше время, управляйте и создавайте полную структуру ключевых слов на основе Google и Яндекс. результаты поиска в течение нескольких минут.
Количество ключевых слов
Среднее количество поисковых запросов в месяц
Расширение
Объем ключевых слов относится к среднему количеству поисковых запросов, которые происходят для прикладного поискового термина за период, такой как
как один месяц. Используйте объем поиска, чтобы предсказать количество поисковых запросов, которые вы можете получить, если выберете этот поисковый запрос.
в качестве целевого ключевого слова для вашего веб-сайта. Объем поиска — один из ключевых показателей, на который полагаются SEO-специалисты при планировании своей работы.
кампания.
Используйте объем поиска, чтобы предсказать количество поисковых запросов, которые вы можете получить, если выберете этот поисковый запрос.
в качестве целевого ключевого слова для вашего веб-сайта. Объем поиска — один из ключевых показателей, на который полагаются SEO-специалисты при планировании своей работы.
кампания.
Статистику поисковых запросов можно получить из следующих источников:
Яндекс.Директ (Яндекс.Wordstat) все локации;
Google Ads (Планировщик ключевых слов) все местоположения;
Адреса Mail.ru для вебмастеров не поддерживаются.
Группировка ключевых слов
Кластеризация ключевых слов и группировка по релевантности страницы
Expand
Каждая страница вашего веб-сайта может быть релевантна одному или нескольким ключевым словам (группе ключевых слов). Автоматизированное ключевое слово
группировка — это простой способ получить рабочую структуру ключевых слов и быстро повысить производительность вашего сайта.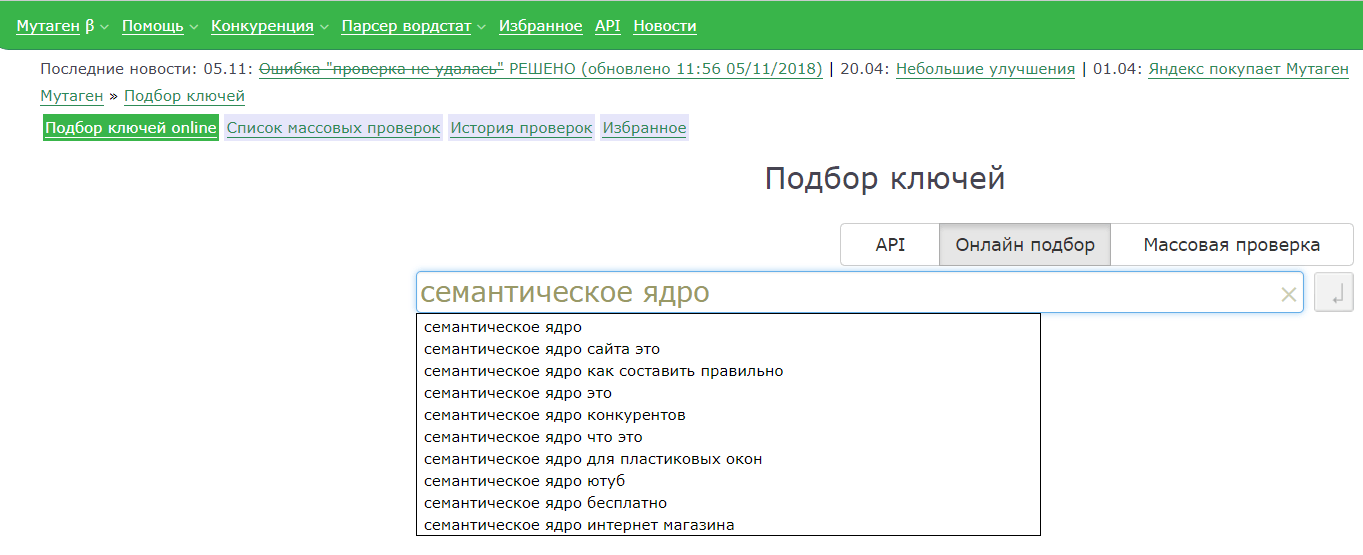
Группировка ключевых слов по релевантности страницы мгновенно распределяет ключевые слова по страницам веб-сайта точно так же, как они ранжируются и отображаются в прикладной поисковая система и местоположение.
Примените инструмент группировки ключевых слов или используйте оба инструмента, чтобы получить полную структуру ключевых слов для вашего веб-сайта.
Рекомендован экспертами
Александр Буракс Глава SEO Discover Cars Топвизор — лучшее решение для многих задач:
— Поиск возможностей путем сканирования Google;
— Проверка алгоритмических фильтров с помощью операторов Google для списка доменов;
— Быстрая проверочная индексация;
— Отслеживание изменений и мониторинг конкурентов;
В принципе, это лучший сервис для парсинга больших файлов Google (100 МБ + экспорт csv).
Энстине Муки SEO-блогер EnstineMuki.com Обладая более чем 3 флагманскими функциями, Topvisor рассматривает общие элементы SEO с точки зрения, которая дает больше результатов, чем вы можете получить где-либо еще.
Структура ценообразования является наиболее гибкой в цифровом мире на сегодняшний день. Вы можете хотеть платить, как вы идете. Переведите средства на свой счет и только
используйте их каждый раз, когда есть действие.
Томас Харви Консультант ThomasHarvey.me После использования Topvisor в течение нескольких месяцев я считаю, что это один из лучших инструментов для отслеживания позиций. Поддержка со стороны команды не имеет себе равных.
Очень отзывчив на предложения.
Я использую с клиентами всех размеров, более 20 000 ключевых слов вплоть до 10, очень доступный и стоит своих денег.
Иван Браун Основатель Icons8 Мы много заплатили за различные инструменты SEO. По анализу ключевых слов мы не нашли ничего похожего на Топвизор. Во-первых, он находит связанные ключевые слова, поскольку никто
еще. Во-вторых, у него потрясающая кластеризация; единственный, кому мы можем доверять.
Наконец, нам нравится план Topvisor с оплатой по мере использования. Кроме того, мы должны балансировать между ограничениями плана; у них есть много, даже для «безлимитных» планов.
Кроме того, мы должны балансировать между ограничениями плана; у них есть много, даже для «безлимитных» планов.
Кристапс Рог Директор и владелец Ideaspool Topvisor был важен для нас, помогая нашим клиентам продвигаться по карьерной лестнице Google. После использования Топвизор более года могу сказать с уверенность в том, что он предоставляет важные для бизнеса данные быстро и точно. Это помогло нам сэкономить значительную сумму денег, ориентируясь на только те ключевые слова, которые приносят прибыль, и поиск новых вариантов для лучшего бизнеса завтра.
Алекс Чимпока Начальник отдела SEO в МКОР Использование Topvisor — это прекрасный опыт для меня, так как мне не нужно платить ежемесячную плату за отслеживание моего рейтинга. Интерфейс прост и простой. Рекомендую сервис всем, кто хочет посмотреть, как у них дела в Google.
Наши клиенты
Выберите план, который вам подходит, и сэкономьте до 30%
ВЫ ЭКОНОМИТЕ
Инструмент трекера рейтинга
/100 Ключевые слова
Инструмент исследования ключевых слов
/100 Ключевые слова
Инструмент поиска
/100 Ключевые слова
Инструмент поиска
/100 Ключевые слова
/100 страниц
Наблюдатель за сайтом
/100 страниц
Менеджер ставок
/1000 корректировок
Тарифный план
в месяц
Вы экономите
XS
$ 0
per month
Rank tracker tool
/100 keywords
$ 0. 15
15
Keyword research tool
/100 keywords
$ 2.5
Search suggestions tool
/100 keywords
$ 1,5
Инструмент поиска по объему
/100 Ключевые слова
$ 0,052
Кластеризационная инструмент
/100 Ключевые слова
$ 0,8
Seo Audit Tool $ 0,8
Seo Audit Tool $ 0,8
SEO AUDIT Tool .0081 /100 pages
$ 1.5
Website watcher
/100 pages
$ 0.25
Bid manager
/1000 adjustments
$ 0.025
S
$ 29
per месяц
Инструмент отслеживания позиций
/100 ключевых слов
$ 0,135
Инструмент исследования ключевых слов
/100 ключевых слов
$ 2,25 9008 ключевых слов 9008 предложений
9
$ 1.35
Search volume tool
/100 keywords
$ 0. 047
047
Keyword clustering tool
/100 keywords
$ 0.72
SEO audit tool
/100 pages
$ 1,35
Webser Watcher
/100 страниц
$ 0,225
Диспетчер ставок
/1000 Корректировки
$ 0,0225
M
$ 89
M
$ 89
M
$ 89
M
$ 89
M
$ 89
M
$ 89
в месяц
Инструмент трекера рейтинга
/100 Ключевые слова
$ 0,1275
Инструмент исследования ключевых слов
/100 Ключевые слова
$ 2.125
Инструмент для поиска
/100177777777777777777777777777777777777777777777777777777777777
Инструмент объема поиска
/100 ключевых слов
$ 0,044
Инструмент кластеризации ключевых слов
/100 ключевых слов
$ 0,68
098 Инструмент аудита SEO10009
$ 1. 275
275
Website watcher
/100 pages
$ 0.2125
Bid manager
/1000 adjustments
$ 0.02125
L
$ 299
per month
Rank Инструмент отслеживания
/100 ключевых слов
$ 0,12
Инструмент исследования ключевых слов
/ 100 ключевых слов
$ 2
Инструмент поисковых подсказок
/ 900 ключевых слов0009
$ 1,2
Инструмент поиска по объему
/100 Ключевые слова
$ 0,042
Кластеризации
/100 Ключевые слова
$ 0,649999969.
9000 21610101010101010101010101010101010101016 9000 9000 2 SE
$ 0,64
SE
долл. 1.2
Website watcher
/100 pages
$ 0.2
Bid manager
/1000 adjustments
$ 0.02
XL
$ 599
per month
Rank tracker tool
/100 keywords
$ 0.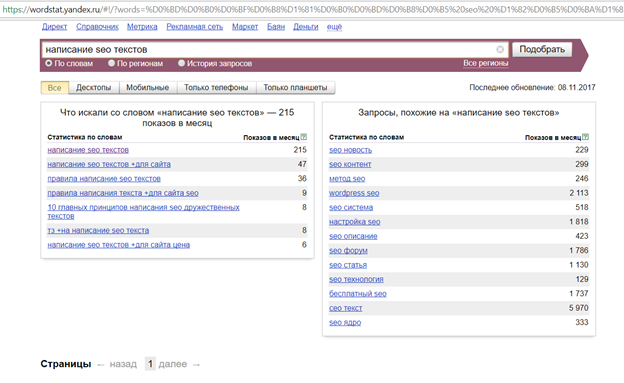 105
105
Keyword research tool
/100 keywords
$ 1.75
Search suggestions tool
/100 keywords
$ 1.05
Инструмент объема поиска
/100 ключевых слов
$ 0,036
Инструмент кластеризации ключевых слов
/ 100 ключевых слов
$ 0,56
Инструмент SEO-аудита 1
/0009
$ 1.05
Website watcher
/100 pages
$ 0.175
Bid manager
/1000 adjustments
$ 0.0175
View full pricing
лучших альтернатив WordStat и конкурентов
ThinkAutomation
Parker Software
Разработайте автоматизацию, которая работает на вас. С ThinkAutomation вы получаете открытую студию для создания любого автоматизированного рабочего процесса, который вам может понадобиться. Все без ограничений по объему и без оплаты за процесс, лицензию или «робота».
Все без ограничений по объему и без оплаты за процесс, лицензию или «робота».
Semeon Analytics
Semeon Analytics
Semeon может помочь вам понять и расставить приоритеты в крупномасштабных данных обратной связи сотрудников, клиентов и торговых площадок из любого места, таких как социальные сети, опросы, обзоры и данные CRM. Наша платформа автоматически извлекает из ваших данных наиболее релевантные понятия, состоящие из нескольких слов, измеряет настроения и создает информативные информационные панели. Доступно более чем на 10 родных языках. Государственные учреждения, агентства безопасности и обороны, бренды и организации по всему миру полагаются на технологии Semeon, чтобы улучшить качество обслуживания клиентов и жизнь граждан, снизить эксплуатационные расходы и стимулировать рост.
teX.
 ai
aiteX.ai
Учитывая море контента, ваша компания быстро, точно и эффективно генерирует, идентифицирует и обрабатывает только интересующий вас текст. Независимо от ваших бизнес-потребностей, оперативной гибкости, более быстрых решений, получения информации о клиентах или многого другого, teXai, признанная Forbes компания по текстовой аналитике, поможет вам использовать текст для продвижения вашего бизнеса. Мощный настраиваемый препроцессор teXai идентифицирует и извлекает интересующие вас объекты из электронных писем вашей организации, текстовых сообщений, таблиц, веб-сайтов, социальных сетей, архивов или любых документов по вашему выбору. Его интеллектуальное настраиваемое лингвистическое приложение определяет жанр текста, группы, похожий контент и создает краткие сводки, чтобы ваши бизнес-группы могли получить правильный контекст из правильного текста. Простое в использовании программное обеспечение для анализа текста извлекает суть вашего текста и упрощает процесс принятия решений.
PolyAnalyst
Megaputer Intelligence
PolyAnalyst — это программное обеспечение для анализа данных, используемое крупными организациями в различных отраслях (страхование, производство, финансы и т. д.). Некоторые из его наиболее заметных функций и возможностей включают использование визуального компоновщика для моделирования сложного анализа данных, а не для кодирования / программирования. Он объединяет структурированные и полиструктурированные формы данных для унифицированного анализа (например, вопросы с несколькими вариантами ответов и открытые ответы) и может обрабатывать текстовые данные на более чем 16 различных языках. PolyAnalyst имеет множество функций, отвечающих потребностям комплексного анализа данных, таких как загрузка данных, очистка и подготовка данных для анализа, развертывание методов машинного обучения и контролируемого анализа, а также создание отчетов, которые могут использовать неаналитики для получения информации.
Semantria
Lexalytics
Semantria — это API-интерфейс обработки естественного языка (NLP) от Lexalytics, лидера в области корпоративного анализа настроений и текстовой аналитики с 2004 года. обобщение в легко интегрируемом пакете RESTful API.
Semantria полностью настраивается с помощью графических инструментов настройки, поддерживает 24 языка и может быть развернута в частных, общедоступных и гибридных облаках. Semantria легко масштабируется от отдельных серверов до целых центров обработки данных и обратно, чтобы удовлетворить ваши потребности в обработке по требованию.
Интегрируйте Semantria, чтобы добавить мощные и гибкие возможности анализа текста и обработки естественного языка в свои облачные продукты для анализа данных или корпоративную инфраструктуру бизнес-аналитики. Или добавьте инструменты хранения и визуализации Lexalytics, чтобы создать полную платформу бизнес-аналитики для хранения, управления, анализа и визуализации текстовых документов.
MonkeyLearn
MonkeyLearn
MonkeyLearn упрощает очистку, маркировку и визуализацию отзывов клиентов — все в одном месте. Работает на передовом искусственном интеллекте. Универсальная студия анализа текста и визуализации данных. Получите мгновенную информацию, когда вы проводите анализ своих данных. Используйте готовые модели машинного обучения или создавайте и обучайте свои собственные — без написания кода. Откройте для себя наши шаблоны, адаптированные для различных бизнес-сценариев и оснащенные готовыми моделями анализа текста и информационными панелями. Определите темы и интересы, наиболее важные для целевых рынков. Применяйте стратегии формирования спроса и продаж на основе точного анализа мнений и чувств клиентов. Разделяйте ответы на опросы по запросам, намерениям и настроению. Увидеть больше, чем предполагал опрос.
 org/ListItem»>
7
org/ListItem»>
7MeaningCloud
MeaningCloud
MeaningCloud — это самый простой, самый мощный и самый доступный способ извлечь смысл из неструктурированного контента: документов, статей, социальных бесед, веб-контента и т. д.
Мы предоставляем продукты текстовой аналитики для извлечения наиболее точной информации из любого контента на многих языках. И мы делаем это SaaS и On-prem. Мы работаем для различных отраслей (фармацевтика, финансы, СМИ, розничная торговля, гостиничный бизнес, телекоммуникации и т. д.), разрабатывая персонализированные и отраслевые решения.
Наши сценарии включают в себя:
* Извлечение информации
* Анализ голоса клиента, сотрудника, гражданина или пациента. (Аналитика пользовательского или клиентского опыта в целом.)
* Интеллектуальная автоматизация документов
Вы можете использовать наши API бесплатно (20 000 вызовов API в месяц). Загрузите наши надстройки для таблиц Excel и Google. Используйте наши интеграции с Dataiku, RapidMiner и Automation Anywhere, а также наши SDK для PHP, Python, Java, JavaScript и т. д.
д.
Clarabridge
Clarabridge
Платформа Clarabridge объединяет все данные VoC, взаимодействие с клиентами и отзывы на единой платформе. Мы используем анализ речи и текста на базе искусственного интеллекта с лучшим в отрасли пониманием естественного языка (NLU) для оценки ежедневных разговоров ваших клиентов и сотрудников по телефону, в чатах, личных сообщениях и в социальных сетях. Clarabridge даст вам своевременные ответы о простоте ведения бизнеса (усилия), лояльности клиентов и эмоциях, основных причинах изменения NPS, оттока клиентов или большом объеме контактов и многом другом. Инсайты Clarabridge помогают принимать решения, действовать быстро и отслеживать результаты. Сотрудничайте с Clarabridge, чьи решения специально созданы для обслуживания клиентов и поддерживаются лучшим в своем классе механизмом текстовой аналитики на базе искусственного интеллекта, чтобы перейти от сложности к ясности и по-настоящему понять каждое взаимодействие с клиентом. Clarabridge — единственная платформа, предоставляющая высокоэффективные средства фиксации того, что говорят клиенты.
Clarabridge — единственная платформа, предоставляющая высокоэффективные средства фиксации того, что говорят клиенты.
Keatext
Keatext
Keatext — это платформа текстовой аналитики на основе искусственного интеллекта, которая мгновенно обрабатывает отзывы клиентов, опросы и заявки в службу поддержки из нескольких источников, чтобы помочь вам найти то, что требует немедленного внимания для улучшения качества обслуживания клиентов.
Вы можете загружать данные в Keatext в виде файла CSV или напрямую интегрировать их с Zendesk, Intercom, Surveymonkey и более чем 400 другими платформами. Сэкономьте часы своей команды на ручном анализе и используйте функцию plug and play Keatext всего за 10 минут.
Ключевая особенность:
— Многоканальный анализ
— Анализ мнений и настроений
— Многоязычная обработка
— Расширенная фильтрация данных
— Расширенный статистический анализ
— Обнаружение тренда
— Общие наборы фильтров
— Детальное сравнение времени
— Автоматическая группировка
— Экспортируемая аналитика
— Резюме темы и мнения
— Корреляции
Keatext используется брендами в более чем 10 отраслях, включая American Express, Orange, Brother International и Bain Consulting.
OpenText Magellan
OpenText
Платформа машинного обучения и прогнозной аналитики. Расширьте возможности принятия решений на основе данных и ускорьте бизнес с помощью передового искусственного интеллекта на предварительно созданной платформе машинного обучения и аналитики больших данных. OpenText Magellan использует технологии искусственного интеллекта для предоставления предиктивной аналитики в удобной и гибкой визуализации данных, которая максимизирует ценность бизнес-аналитики. Программное обеспечение искусственного интеллекта устраняет необходимость ручной обработки больших данных, предоставляя ценную информацию о бизнесе в доступной форме, связанной с наиболее важными задачами организации. Дополняя бизнес-процессы с помощью специально подобранного набора возможностей, включая прогнозное моделирование, инструменты обнаружения данных, методы интеллектуального анализа данных, аналитику данных Интернета вещей и многое другое, организации могут использовать свои данные для улучшения процесса принятия решений на основе реальной бизнес-аналитики и аналитики.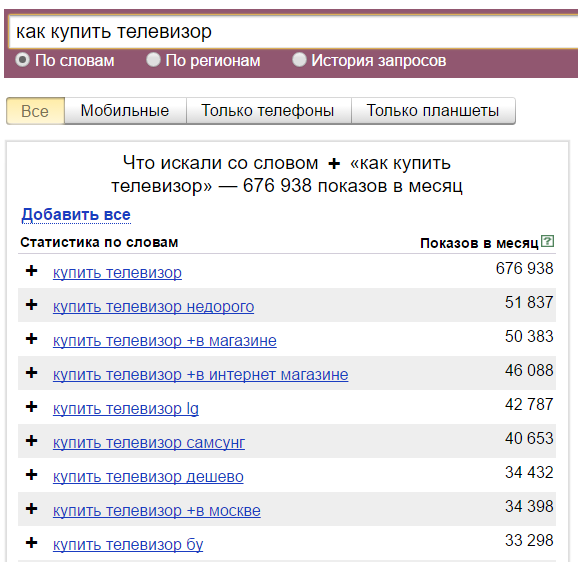
TAS Insight Engine
Precognox
Обнаружение, извлечение, извлечение и нахождение ценности в корпоративных данных — это все, что нужно для получения информации. TAS Insight Engine предоставляет вам всю необходимую информацию, которая поможет вам принять правильное бизнес-решение. Получение информации означает своего рода извлечение информации из корпоративных данных с целью поддержки принятия бизнес-решений. Очевидно, почему получение информации играет важную роль в наши дни, поскольку понимание ваших данных и получение результатов и ответов необходимы для решения проблем современного делового мира. Во всех областях или секторах, всегда. Чтобы сделать это возможным, TAS Insight Engine сочетает в себе последние достижения, такие как преимущества текстовой аналитики, обработки естественного языка (NLP) и машинного обучения (ML).
 org/ListItem»>
12
org/ListItem»>
12Cognitive Workbench
ExB Group
ExB предлагает платформу автоматизации когнитивных процессов на основе искусственного интеллекта и машинного обучения, которая позволяет страховым компаниям преобразовывать любую форму текста в полезную информацию и идеи для управления вводом данных и автоматизации процессов. Страховщики могут внедрить готовые к использованию предварительно обученные модули управления полисами, управления претензиями, интеллектуального анализа текста в отчетах и модулей оценки счетов, попросить нас обучить специальные модели для своих уникальных бизнес-процессов или напрямую использовать нашу Cognitive Workbench для самостоятельного создания и обучать любые модели интеллектуального анализа текста и сквозного управления вводом.
Cx Moments
Cx MOMENTS
Мгновенная информация из разговоров с клиентами. Узнайте, что больше всего беспокоит ваших клиентов и вредит вашему бизнесу. Всего за несколько кликов классифицируйте и определяйте тенденции для 100 000 обращений в службу поддержки, заявок и чатов в реальном времени. Маркировка заявок вручную обременительна и ненадежна, а агенты по обслуживанию клиентов часто не могут классифицировать важные детали запросов клиентов. Они даже могут оставить до 60% ваших обращений в службу поддержки непомеченными. Cx Moments AI помечает заявки лучше и быстрее, чем ваши агенты, независимо от того, насколько сложной и детальной должна быть ваша категоризация. Мы также будем автоматически применять новые теги или категории ко всей истории ваших билетов. Cx Moments автоматически суммирует ваши запросы клиентов по областям. Теперь вы можете показать каждому отделу проблемы клиентов, которыми они владеют. Одним щелчком мыши вы увидите, какие драйверы контактов находятся в тренде и требуют особого внимания. Узнайте, в каких областях ваши агенты борются больше всего и в каких областях им может потребоваться обучение.
Всего за несколько кликов классифицируйте и определяйте тенденции для 100 000 обращений в службу поддержки, заявок и чатов в реальном времени. Маркировка заявок вручную обременительна и ненадежна, а агенты по обслуживанию клиентов часто не могут классифицировать важные детали запросов клиентов. Они даже могут оставить до 60% ваших обращений в службу поддержки непомеченными. Cx Moments AI помечает заявки лучше и быстрее, чем ваши агенты, независимо от того, насколько сложной и детальной должна быть ваша категоризация. Мы также будем автоматически применять новые теги или категории ко всей истории ваших билетов. Cx Moments автоматически суммирует ваши запросы клиентов по областям. Теперь вы можете показать каждому отделу проблемы клиентов, которыми они владеют. Одним щелчком мыши вы увидите, какие драйверы контактов находятся в тренде и требуют особого внимания. Узнайте, в каких областях ваши агенты борются больше всего и в каких областях им может потребоваться обучение.
 org/ListItem»>
14
org/ListItem»>
14DiscoverText
Texifter
Совместная текстовая аналитика для человеческого и машинного обучения. Мы предоставляем десятки многоязычных функций, интеллектуального анализа текста, науки о данных, аннотирования человеком и машинного обучения. DiscoverText предлагает ряд простых и продвинутых облачных программных инструментов, позволяющих пользователям быстро и точно оценивать большие объемы текстовых данных. Наши клиенты сортируют неструктурированный свободный текст, распространенный в исследованиях рынка, а также связанные метаданные, которые также можно найти на платформах обратной связи с клиентами, CRM, чатах, электронной почте, крупномасштабных HR или других опросах, публичных комментариях для государственных учреждений, Твиттере, RSS-каналах и т. д. формы текстовых данных. Узнайте, почему мы занимаем первое место в рейтинге поддержки анализа текста, метаданных и социальных сетей, и нам доверяют сотни академических исследовательских групп. Наши просеиватели с машинным обучением создаются за часы или всего за несколько минут с использованием краудсорсинга.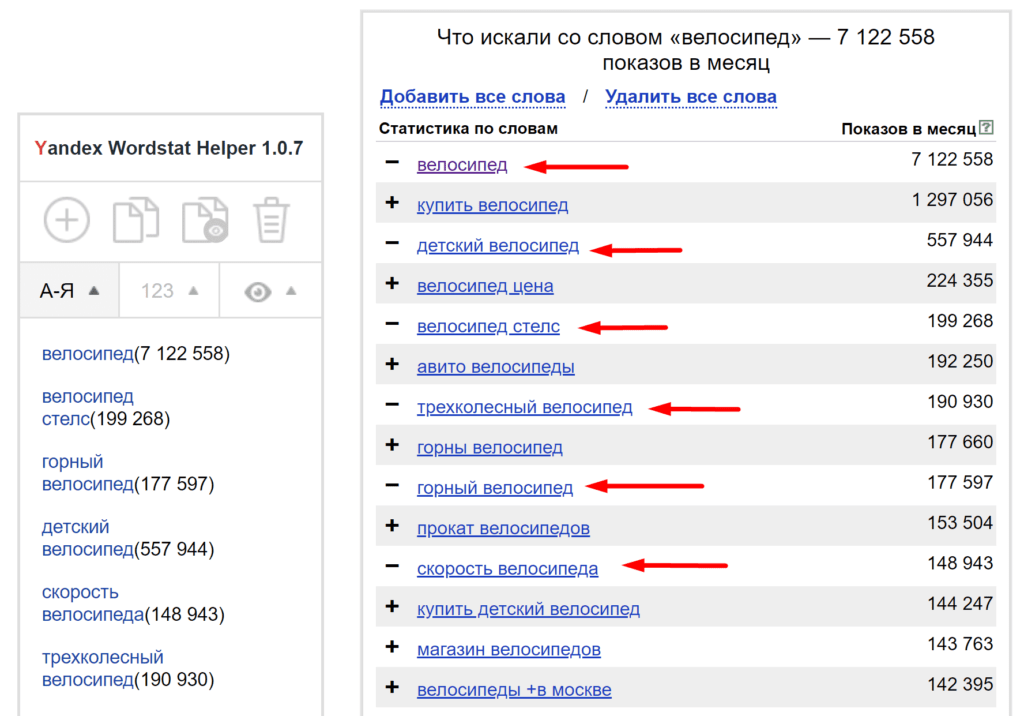 Мы предлагаем API и поддерживаем техническую интеграцию с Twitter и SurveyMonkey.
Мы предлагаем API и поддерживаем техническую интеграцию с Twitter и SurveyMonkey.
Luminoso
Luminoso Technologies Inc.
Luminoso превращает неструктурированные текстовые данные в важную для бизнеса информацию. Используя здравый смысл искусственного интеллекта для понимания языка, мы даем организациям возможность обнаруживать, интерпретировать и действовать в соответствии с тем, что им говорят люди. Не требуя настройки, обслуживания, обучения или ввода данных, Luminoso сочетает в себе ведущую в мире технологию понимания естественного языка с обширной базой знаний для изучения слов из контекста — как это делают люди — и точного анализа текста за считанные минуты, а не месяцы. Наше программное обеспечение обеспечивает встроенную поддержку более чем дюжины языков, поэтому руководители могут исследовать взаимосвязи в данных, анализировать отзывы и сортировать запросы для быстрого увеличения ценности. Luminoso является частной компанией со штаб-квартирой в Бостоне, штат Массачусетс.
Luminoso является частной компанией со штаб-квартирой в Бостоне, штат Массачусетс.
SAS Text Miner
SAS Institute
Извлечение информации из набора текстовых документов и раскрытие скрытых в них тем и концепций. SAS Text Miner позволяет комбинировать количественные переменные с неструктурированным текстом и тем самым объединять интеллектуальный анализ текста с другими традиционными методами интеллектуального анализа данных. SAS Text Miner является компонентом SAS® Enterprise Miner. SAS Enterprise Miner должен быть установлен на том же компьютере. SAS High-Performance Text Mining работает в компьютерной сетке или на одной компьютерной системе с несколькими процессорами. Текстовые алгоритмы являются многопоточными и обрабатывают в памяти, что повышает скорость отклика и параллелизм, снижая нагрузку на ввод-вывод. Он доступен как узлы в среде SAS High-Performance Data Mining или как две процедуры PROC HPTMINE и PROC HPTMSCORE. Изучите технологию SAS быстро и эффективно, пройдя курс от экспертов по аналитике.
Изучите технологию SAS быстро и эффективно, пройдя курс от экспертов по аналитике.
VizRefra
VizRefra
Анализ текста с помощью визтекста 2D и 3D сопоставление Анализ текста Тематическое моделирование, анализ тональности, облако слов. Уникальный алгоритм машинного обучения для визуализации тем в тексте, который вы хотите обнаружить. Анализ текста обеспечивает тематическое моделирование с навигацией по 2D/3D картам. Использует справочную структуру для проведения логического реляционного тематического анализа с функциями увеличения и уменьшения масштаба на 2D- и 3D-картах, включая красочное облако слов. Анализ уровня настроений в тексте с круговой диаграммой соотношения положительных, отрицательных и нейтральных. Отображает основные объекты в тексте в процентах, а также выделяет в тексте тип объекта: правительство, человек, организация и т. д. Просто перетащите, загрузите текстовый файл или вставьте текст из Интернета или сообщений в социальных сетях или введите HTTP-адрес для веб-сайт, содержащий текстовую статью, которую вы хотите проанализировать.
Professional Document Analyzer
Scion Analytics
Модернизированный Professional Document Analyzer использует технологию обработки естественного языка AI (NLP) для улучшенного анализа контента и повышения удобочитаемости. Наш недавний редизайн упрощает взаимодействие с пользователем (UX) с помощью общего пользовательского интерфейса (UI), предоставляет расширенные настройки для создания и обслуживания, а также обеспечивает повышенную гибкость и упрощение для расширения возможностей как обычных пользователей, так и суперпользователей. Анализирует (разбирает / измельчает) ваши запросы предложений на такие слова, как «должен», «должен», «будет» и ваши пользовательские ключевые слова / фразы — поддерживает 6 типов файлов. Создайте матрицу соответствия двумя щелчками мыши в шаблоне Excel или документе MS Word. Панель «Результаты анализа» — манипулируйте результатами анализа, разделяя, комбинируя, комментируя и фильтруя. Поделитесь своей матрицей соответствия и отчетами в 2 клика.
Поделитесь своей матрицей соответствия и отчетами в 2 клика.
Medallia
Medallia
Medallia позволяет вдумчиво и систематически привлекать пользователей с помощью целевых, актуальных опросов в цифровых и традиционных точках взаимодействия. Наши легко внедряемые решения для опросов гарантируют, что вы будете собирать актуальные и полезные данные, чтобы оказать ощутимое влияние на клиентов. После сбора данных опроса клиентов технология искусственного интеллекта Medallia использует машинное обучение для анализа структурированных и неструктурированных данных, чтобы выявить настроения, найти общие черты, предсказать поведение, предвидеть потребности и предписать действия для улучшения опыта. Создавайте наиболее эффективные опросы для ваших клиентов. Быстро управляйте изменениями и инновациями в каждом аспекте вашей программы управления опытом — от дизайна до электронных писем, вопросов и переводов — с помощью сложной логики таргетинга, гибкой настройки и распространения. Опросы Medallia позволяют вам
Опросы Medallia позволяют вам
Цветная капуста
Цветная капуста
Будь то услуга или продукт, моментальный снимок или мониторинг с течением времени — Cauliflower обрабатывает отзывы и комментарии из различных областей применения. Используя искусственный интеллект (ИИ), Cauliflower определяет наиболее важные темы, их актуальность, оценку и взаимосвязь. Модели машинного обучения собственной разработки для извлечения контента и оценки настроений. Интуитивно понятные информационные панели с параметрами фильтрации и детализацией. Используйте включенные переменные для языка, веса, идентификатора, времени или местоположения. Определите свои собственные переменные фильтра в раскрывающемся списке. При необходимости Cauliflower переводит результаты на единый язык. Определите общекорпоративный язык отзывов клиентов вместо того, чтобы читать их спорадически и цитировать отдельные мнения.
BytesView
Algodom Media
BytesView — это передовой инструмент машинного обучения и анализа текста на основе НЛП. Он может легко компилировать и анализировать большие объемы текстовых данных из нескольких источников информации. Различные модели извлечения и анализа текста могут помочь проанализировать и извлечь ценную информацию из неструктурированного текста. BytesView также предлагает услуги API, которые могут помочь вам обучать пользовательские модели анализа данных с данными, характерными для вашей организации, для повышения точности и эффективности.
Etuma
Etuma
Служба анализа текста Etuma превращает все открытые отзывы клиентов в согласованную и полезную информацию. Вы получаете большое количество комментариев в открытом тексте из разных каналов, и вам сложно систематически и своевременно превращать их в ценную информацию. Вручную читать и классифицировать все комментарии медленно, дорого и непоследовательно. Вы попробовали анализ ключевых слов, но он не дает статистически значимой или полезной информации. Результаты обратной связи из разных процессов и каналов не агрегируются, поэтому много ценной информации теряется в организационных хранилищах, где ее могут использовать только те, у кого есть к ней доступ. У Etuma есть существующие коннекторы для десятков опросов, управления клиентским опытом и платформ контакт-центров. Вы также можете подключить любой канал спонтанной обратной связи, такой как электронная почта или веб-формы.
Вручную читать и классифицировать все комментарии медленно, дорого и непоследовательно. Вы попробовали анализ ключевых слов, но он не дает статистически значимой или полезной информации. Результаты обратной связи из разных процессов и каналов не агрегируются, поэтому много ценной информации теряется в организационных хранилищах, где ее могут использовать только те, у кого есть к ней доступ. У Etuma есть существующие коннекторы для десятков опросов, управления клиентским опытом и платформ контакт-центров. Вы также можете подключить любой канал спонтанной обратной связи, такой как электронная почта или веб-формы.
Archeo
Общение
Быстро находите сообщения, связанные с вашим бизнесом, и получайте полный обзор в удобном веб-интерфейсе. Archeo предоставляет информацию, которая позволяет вам контролировать свой бизнес-процесс. Легко находите свои сообщения, когда весь записанный текстовый контент доступен для поиска на основе произвольного текста. Запишите всю информацию в REST API в Azure. Доступен из всех ваших приложений и интеграций. Быстро находите сообщения, связанные с вашим бизнесом, и получайте полный обзор в удобном веб-интерфейсе. Archeo предоставляет информацию, которая позволяет вам контролировать свой бизнес-процесс. Запишите всю информацию в REST API в Azure. Доступен из всех ваших приложений и интеграций. Создавайте настраиваемые графики и информационные панели, которые предоставят вам полный обзор ваших потоков и транзакций. Пусть любой в вашей организации использует приложение, а конечные пользователи используют Archeo для управления своими бизнес-процессами.
Запишите всю информацию в REST API в Azure. Доступен из всех ваших приложений и интеграций. Быстро находите сообщения, связанные с вашим бизнесом, и получайте полный обзор в удобном веб-интерфейсе. Archeo предоставляет информацию, которая позволяет вам контролировать свой бизнес-процесс. Запишите всю информацию в REST API в Azure. Доступен из всех ваших приложений и интеграций. Создавайте настраиваемые графики и информационные панели, которые предоставят вам полный обзор ваших потоков и транзакций. Пусть любой в вашей организации использует приложение, а конечные пользователи используют Archeo для управления своими бизнес-процессами.
WinAutomation
Softomotive
WinAutomation предоставляет преимущества роботизированной автоматизации процессов на вашем рабочем столе. Он предлагает самое мощное, надежное и простое в использовании программное обеспечение на базе Windows, которое позволяет автоматизировать рутинные и повторяющиеся задачи. WinAutomation помогает сократить расходы и повысить общую скорость и точность бизнес-процессов.
WinAutomation помогает сократить расходы и повысить общую скорость и точность бизнес-процессов.
NaturalText
NaturalText
NaturalText А.И. помогает вам получить больше от ваших данных.
Выявляйте отношения, создавайте коллекции и раскрывайте скрытые идеи в документах и других текстовых данных.
Натуральный текст ИИ использует новую технологию искусственного интеллекта для выявления скрытых взаимосвязей в данных.
Программное обеспечение использует различные современные методы для понимания контекста, анализа закономерностей и выявления идей — и все это в понятной для человека форме.
Выявляйте идеи, скрытые в ваших данных
Найти все, что скрыто в ваших текстовых данных, — сложная, если не невозможная задача. С помощью традиционного поиска вы можете найти только информацию, относящуюся к документу. С другой стороны, искусственный интеллект NaturalText находит новую информацию в миллионах документов, включая научные работы и патенты. Используйте искусственный интеллект NaturalText. чтобы раскрыть информацию о ваших данных, которых вам сейчас не хватает.
Используйте искусственный интеллект NaturalText. чтобы раскрыть информацию о ваших данных, которых вам сейчас не хватает.
Tisane
Tisane Labs
Tisane — это API NLU, ориентированный на оскорбительный контент и нужды правоохранительных органов. Тизан обнаруживает: * разжигание ненависти * киберзапугивание * преступная деятельность * сексуальные домогательства * попытки установить внешний контакт и более. Tisane классифицирует фактическую проблему и точно определяет оскорбительный фрагмент текста; дополнительно может быть предоставлено пояснение для проверки работоспособности или аудита. Tisane поддерживает 30 языков, даже если текст содержит сленг и запутанность.
uCrawler
uCrawler
uCrawler — это облачный сервис для сбора новостей на основе искусственного интеллекта. Добавляйте последние новости на свой веб-сайт или в приложение через экспорт API или ElasticSearch, MySQL или Postgres. Если у вас нет веб-сайта, вы можете использовать наш шаблон новостного веб-сайта. Получите готовый новостной сайт за 1 день с uCrawler CMS! Создавайте собственные новостные ленты, отфильтрованные по ключевым словам, для мониторинга новостей и аналитики. Скрапинг данных. Мы извлекаем данные из файлов PDF, Word, Excel, PowerPoint на веб-страницах и каналах Telegram.
Добавляйте последние новости на свой веб-сайт или в приложение через экспорт API или ElasticSearch, MySQL или Postgres. Если у вас нет веб-сайта, вы можете использовать наш шаблон новостного веб-сайта. Получите готовый новостной сайт за 1 день с uCrawler CMS! Создавайте собственные новостные ленты, отфильтрованные по ключевым словам, для мониторинга новостей и аналитики. Скрапинг данных. Мы извлекаем данные из файлов PDF, Word, Excel, PowerPoint на веб-страницах и каналах Telegram.
Text Analyzer
online-utility.org
Бесплатная утилита, позволяющая находить наиболее часто встречающиеся фразы и частоты слов. Поддерживаются тексты не на английском языке. Он также подсчитывает количество слов, символов, предложений и слогов.
Repustate
Repustate
Repustate обеспечивает семантический поиск, анализ тональности и текстовую аналитику мирового класса для организаций по всему миру. Это дает предприятиям возможность расшифровывать терабайты информации и находить ценную, полезную бизнес-аналитику с большей проницательностью, чем когда-либо. От наших уважаемых клиентов в отрасли здравоохранения до признанных лидеров в области образования, банковского дела или управления, Repustate обеспечивает постоянное глубокое погружение в сложные интегрированные данные в различных отраслях.
Наше решение обеспечивает анализ тональности и текстовую аналитику для прослушивания социальных сетей, голоса клиента (VOC) и анализа видеоконтента (VCA) на разных платформах. Он включает в себя множество сленгов, смайликов и аббревиатур, заменяющих правила формального языка в социальных сетях. Будь то данные с Youtube, IGTV, Facebook, Twitter или TikTok, или ваши собственные форумы отзывов клиентов, опросы сотрудников или EHR, вы можете точно определить критические аспекты своего бизнеса.
Это дает предприятиям возможность расшифровывать терабайты информации и находить ценную, полезную бизнес-аналитику с большей проницательностью, чем когда-либо. От наших уважаемых клиентов в отрасли здравоохранения до признанных лидеров в области образования, банковского дела или управления, Repustate обеспечивает постоянное глубокое погружение в сложные интегрированные данные в различных отраслях.
Наше решение обеспечивает анализ тональности и текстовую аналитику для прослушивания социальных сетей, голоса клиента (VOC) и анализа видеоконтента (VCA) на разных платформах. Он включает в себя множество сленгов, смайликов и аббревиатур, заменяющих правила формального языка в социальных сетях. Будь то данные с Youtube, IGTV, Facebook, Twitter или TikTok, или ваши собственные форумы отзывов клиентов, опросы сотрудников или EHR, вы можете точно определить критические аспекты своего бизнеса.
PrediCX
Warwick Analytics
Ваш контакт-центр — один из самых больших неиспользованных активов. Это место, где клиенты постоянно обучают ваш бизнес. PrediCX — это платформа искусственного интеллекта, которая раскрывает эту ценность с помощью прогностического анализа и автоматизации по всем каналам, чтобы оптимизировать как клиентский опыт, так и обслуживание клиентов. Используйте искусственный интеллект, чтобы получить прогнозную информацию из каждого разговора и взаимодействия с клиентом — независимо от канала. Рекомендуемые действия для повышения прибыльности и качества обслуживания клиентов. Получайте ранние предупреждения о проблемах, автоматическое обучение и контроль качества ваших агентов для всех их взаимодействий. Быстро отслеживайте любые срочные запросы или жалобы и направляйте своих клиентов к лучшему доступному каналу или ресурсу. ИИ использует понятия, а не ключевые слова, для классификации входящих отзывов, поэтому анализ является точным, проницательным и не предопределен заранее. Ни одна обратная связь с клиентом не остается без внимания. Автоматическая сортировка запросов из цифровых каналов, автоматическая классификация и помощь агентам, а также улучшение чат-ботов.
Это место, где клиенты постоянно обучают ваш бизнес. PrediCX — это платформа искусственного интеллекта, которая раскрывает эту ценность с помощью прогностического анализа и автоматизации по всем каналам, чтобы оптимизировать как клиентский опыт, так и обслуживание клиентов. Используйте искусственный интеллект, чтобы получить прогнозную информацию из каждого разговора и взаимодействия с клиентом — независимо от канала. Рекомендуемые действия для повышения прибыльности и качества обслуживания клиентов. Получайте ранние предупреждения о проблемах, автоматическое обучение и контроль качества ваших агентов для всех их взаимодействий. Быстро отслеживайте любые срочные запросы или жалобы и направляйте своих клиентов к лучшему доступному каналу или ресурсу. ИИ использует понятия, а не ключевые слова, для классификации входящих отзывов, поэтому анализ является точным, проницательным и не предопределен заранее. Ни одна обратная связь с клиентом не остается без внимания. Автоматическая сортировка запросов из цифровых каналов, автоматическая классификация и помощь агентам, а также улучшение чат-ботов.
Watson Natural Language Understanding
IBM
Watson Natural Language Understanding — это облачный продукт, который использует глубокое обучение для извлечения метаданных из текста, таких как сущности, ключевые слова, категории, настроения, эмоции, отношения и синтаксис. Получите представление о темах, упомянутых в ваших данных, с помощью анализа текста для извлечения ключевых слов, понятий, категорий и многого другого. Анализируйте свои неструктурированные данные на более чем тринадцати языках. Готовые модели машинного обучения для интеллектуального анализа текста обеспечивают высокую степень точности вашего контента. Разверните Watson Natural Language Understanding за брандмауэром или в любом облаке. Обучите Watson понимать язык вашего бизнеса и извлекать индивидуальную информацию с помощью Watson Knowledge Studio. Сохраняйте право собственности на свои данные с гарантией того, что ваши данные в безопасности.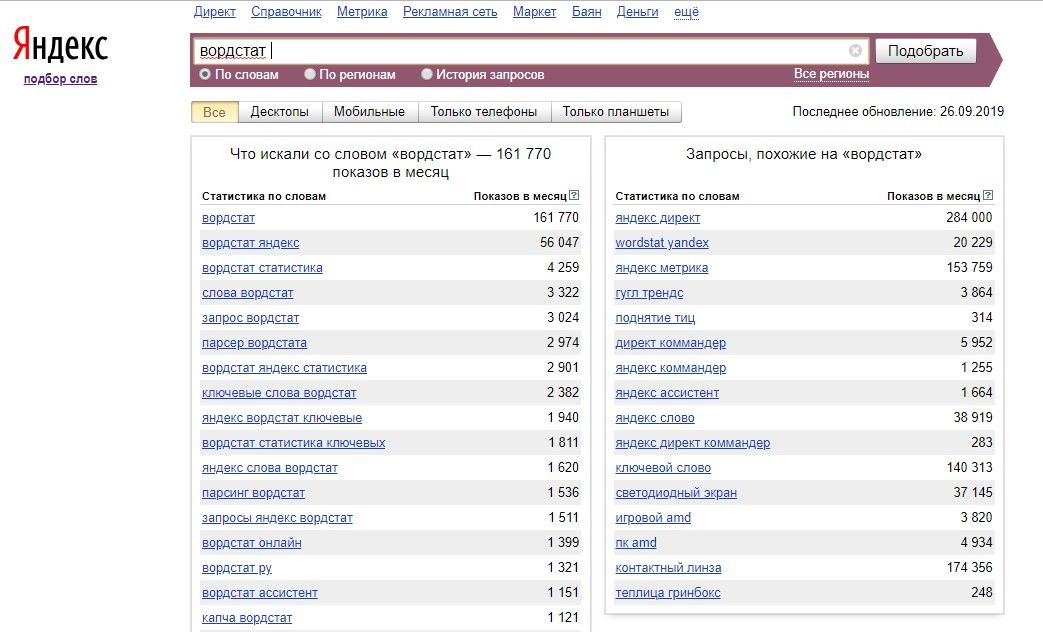 IBM не будет собирать или хранить ваши данные. С помощью нашего расширенного сервиса обработки естественного языка (NLP) мы предоставляем разработчикам инструменты для обработки и извлечения ценных сведений из неструктурированных данных.
IBM не будет собирать или хранить ваши данные. С помощью нашего расширенного сервиса обработки естественного языка (NLP) мы предоставляем разработчикам инструменты для обработки и извлечения ценных сведений из неструктурированных данных.
NetOwl TextMiner
NetOwl
NetOwl TextMiner сочетает в себе наш удостоенный наград NetOwl Extractor с Elasticsearch для предоставления уникального программного обеспечения для анализа текста. TextMiner использует все аспекты возможностей NetOwl и идеально подходит для поддержки анализа «что, если», обнаружения, расследования с быстрым ответом и детального исследования. NetOwl TextMiner объединяет все возможности текстовой аналитики NetOwl Extractor, включая извлечение сущностей, отношений и событий, анализ настроений, категоризацию текста и геотеги во всеобъемлющее программное обеспечение для анализа текста. Выходные данные экстрактора сохраняются в Elasticsearch для различных интеллектуальных поисковых и аналитических возможностей. Сочетание Elasticsearch и NetOwl обеспечивает быстрый и масштабируемый анализ текста в режиме реального времени для больших данных. Веб-интерфейс TextMiner — это простой в использовании и настраиваемый инструмент текстовой аналитики для различных сценариев анализа, который позволяет пользователям получать быстрый доступ ко всей и только ценной информации, полученной из огромного количества текстов.
Сочетание Elasticsearch и NetOwl обеспечивает быстрый и масштабируемый анализ текста в режиме реального времени для больших данных. Веб-интерфейс TextMiner — это простой в использовании и настраиваемый инструмент текстовой аналитики для различных сценариев анализа, который позволяет пользователям получать быстрый доступ ко всей и только ценной информации, полученной из огромного количества текстов.
Amenity Analytics
Amenity Analytics
Наше НЛП извлекает информацию из текста в масштабе с точностью, которая не имеет себе равных в отрасли, и с гибкостью, позволяющей интегрировать его в конкретные требования вашего бизнеса и рабочего процесса. Достигайте значимых, воспроизводимых результатов. Многие из наших моделей в производстве достигают точности более 90% точности и отзыва. По сравнению со средним показателем по отрасли, составляющим 68%, неудивительно, что НЛП Amenity доверяют некоторые из крупнейших игроков в различных отраслях. Извлекайте релевантный текст, игнорируя при этом шум. Наш NLP извлекает, очищает и структурирует текст из миллионов документов, превращая его в полезную информацию для бизнеса. Он определяет контекст и значение текста и то, как они могут меняться от фразы к абзацу. Преобразуйте любой источник текста в отраслевой анализ и настроения, связанные с деловыми событиями, с четким представлением о том, «почему» стоит за результатами. Здесь нет черных ящиков. Наше НЛП настраивается на то, что вам нужно и где вам это нужно.
Извлекайте релевантный текст, игнорируя при этом шум. Наш NLP извлекает, очищает и структурирует текст из миллионов документов, превращая его в полезную информацию для бизнеса. Он определяет контекст и значение текста и то, как они могут меняться от фразы к абзацу. Преобразуйте любой источник текста в отраслевой анализ и настроения, связанные с деловыми событиями, с четким представлением о том, «почему» стоит за результатами. Здесь нет черных ящиков. Наше НЛП настраивается на то, что вам нужно и где вам это нужно.
TextRazor
TextRazor
API TextRazor поможет вам извлечь и понять кто, что, почему и как из ваших новостей с беспрецедентной точностью и скоростью. Извлечение сущностей, устранение неоднозначности и связывание. Извлечение ключевой фразы. Автоматическая пометка тем и классификация. Все на 12 языках. Глубокий анализ вашего контента для извлечения отношений, типизированных зависимостей между словами и синонимами, что позволяет использовать мощные контекстно-зависимые семантические приложения. Быстро извлекайте пользовательские продукты, компании и создавайте правила для конкретных проблем для маркировки вашего контента собственными категориями. TextRazor предлагает полную облачную или автономную инфраструктуру для анализа текста. Мы сочетаем современные методы обработки естественного языка с обширной базой знаний фактов из реальной жизни, чтобы помочь быстро извлечь пользу из ваших документов, твитов или веб-страниц.
Быстро извлекайте пользовательские продукты, компании и создавайте правила для конкретных проблем для маркировки вашего контента собственными категориями. TextRazor предлагает полную облачную или автономную инфраструктуру для анализа текста. Мы сочетаем современные методы обработки естественного языка с обширной базой знаний фактов из реальной жизни, чтобы помочь быстро извлечь пользу из ваших документов, твитов или веб-страниц.
Relative Insight
Relative Insight
Благодаря опыту защиты детей в Интернете наша платформа сравнительного анализа текстов извлекает коммерческую ценность из ваших текстовых данных. Технология Relative Insight помогает специалистам по маркетингу и специалистам по брендам извлекать больше пользы из уже имеющихся текстовых данных. Используя сравнительный подход, наша платформа помогает вам быстро и масштабно получать ценные сведения об аудитории. Это добавляет сложности и научности вашему качественному анализу. Обладая уникальными маркетинговыми знаниями, бренды могут разрабатывать более четкие коммуникации, улучшать позиционирование бренда и проводить более резонансные кампании. Наша платформа поможет вам расшифровать и использовать ваши неструктурированные данные и сократить время, необходимое для анализа. Этот же подход можно использовать для анализа других расшифровок первичных исследований, включая видео, интервью и фокус-группы, вы сидите на золотой жиле данных! Relative Insight позволяет сравнить сообщения вашего бренда с сообщениями конкурентов.
I2E
Linguamatics
Приложение Linguamatics I2E зарекомендовало себя в предоставлении лучших в своем классе возможностей анализа текста в широком диапазоне областей применения. Его гибкий характер позволяет настраивать стратегии запросов для обеспечения точности и отзыва, необходимых для конкретных задач, но в масштабе предприятия. I2E — это гибкое и интерактивное приложение для анализа текста для извлечения и анализа информации. Благодаря лежащей в основе технологии обработки естественного языка (NLP), I2E особенно сильна в своей способности отвечать на широкий круг вопросов, от, казалось бы, простых открытых вопросов до вопросов, требующих расширенной лингвистической аналитики. I2E может ускорить многие исследования, разработки и клинические процессы. Задачи, на выполнение которых раньше уходили месяцы или которые ранее были невыполнимы с помощью ручных методов, теперь можно выполнять за часы или минуты. По словам клиентов, I2E дает полезные результаты как минимум в 10 раз быстрее, чем традиционный поиск по ключевым словам.
Dcipher Analytics
Dcipher Analytics
Dcipher Analytics — это современная сквозная платформа текстовой аналитики без кода, основанная на SaaS, которая делает текстовую аналитику доступной для общего эксперта в предметной области. Платформа ускоряет получение информации, обучение модели и автоматизацию рабочих процессов для всех аналитиков и специалистов по анализу данных. Уникальная архитектура и собственный язык запросов, адаптированный для вложенных структур данных, таких как текст, являются основой решения. Dcipher Analytics — ведущее в мире комплексное решение для извлечения выгоды из неструктурированных текстовых данных. Ищете ли вы инструмент, API или чистую информацию, вы попали в нужное место. Анализируйте электронные письма, обзоры и журналы чатов клиентов, чтобы обнаруживать проблемы и укреплять успех клиентов. Создавайте более релевантные часто задаваемые вопросы и быстрее обучайте чат-ботов. Исследуйте социальные сети, чтобы понять потребности и проблемы потребителей и определить новые тенденции. Используйте для маркетинга и разработки продукта.
Gavagai
Gavagai
Наша технология обработки естественного языка на основе искусственного интеллекта может собирать, анализировать и визуализировать информацию из каждого канала общения с клиентами. Расшифровки звонков, чаты, электронные письма, билеты в службу поддержки, заявки на возврат, социальные сети и опросы. Все на 47 языках! С Explorer любой может анализировать открытые текстовые ответы за считанные минуты. Explorer имеет API, который позволяет интегрировать неструктурированные текстовые данные в экосистему бизнес-аналитики. Опыт сотрудников — это область анализа и определения факторов, которые делают сотрудников счастливыми и мотивированными. Наши продукты помогают компаниям обрабатывать, анализировать и понимать большие объемы неструктурированных данных на естественном языке за короткий промежуток времени. Интуитивно понятная платформа для создания собственных ботов, полностью соответствующих потребностям вашего бизнеса, без необходимости кодирования. Минуты для немедленного повышения эффективности. API Gavagai — это набор инструментов семантического анализа, поддерживающий 47 языков. Немедленный доступ к нашим простым в использовании конечным точкам.
Scraawl
Scraawl
Scraawl — это набор инструментов для анализа данных, предназначенных для того, чтобы вы могли извлечь больше пользы из своих данных. Независимо от того, сосредоточен ли ваш набор задач на общедоступных данных, изображениях и видео, неструктурированном тексте или на всем вышеперечисленном, в Scraawl есть мощные инструменты для улучшения вашего анализа. Scraawl использует самые современные методы искусственного интеллекта и машинного обучения, чтобы предоставлять полезную информацию с помощью аналитики. Наша команда представляет собой междисциплинарную группу разработчиков, исследователей и специалистов по обработке и анализу данных, стремящихся предоставить пользователям передовую аналитику. Scraawl SocL® — это простой в использовании веб-инструмент для прослушивания и аналитики PAI корпоративного уровня. Scraawl SocL® ищет, анализирует и визуализирует онлайн-разговоры и данные новостей, предоставляя пользователю подробный всесторонний анализ.
Biz7
Luma7
Различные бизнес-операции часто создают большое количество документов, но часто возникают проблемы с отслеживанием всего и поиском похожей или связанной информации для каждого документа, контекста или фразы. Luma7 решает эти проблемы, автоматически создавая ссылки между документами, независимо от ключевых слов, метаданных или тегов. Наши алгоритмы способны находить все возможные связи между документами, обрабатывая весь текст в каждом из них и понимая основные связи. Отслеживание всех созданных документов, ссылки на несколько источников документации, полностью автоматизированное создание ссылок между несколькими документами, отношения между концепциями, отношения между концепциями и документами. Автоматическая маркировка каждого документа, включая связанные ключевые слова, отсутствующие в тексте, автоматизированные процессы соединений по всему архиву статей, распознавание сущностей в документах, поддержка нескольких языков и многое другое.
Canvs
Canvs
Canvs AI — это информационная платформа, которая преобразует открытый текст из опросов, социальных сетей, расшифровок стенограмм, обзоров продуктов и т. д. в разговорную информацию о том, что люди чувствуют и почему. Canvs используется некоторыми из самых уважаемых мировых брендов, исследовательскими агентствами, а также медиа- и развлекательными компаниями для ускорения получения информации, углубления понимания аудитории и снижения стоимости анализа. Автоматизируйте анализ открытого текста, чтобы быстро получить информацию о потребителях с глубоким, нюансированным эмоциональным контекстом и высокой аналитической достоверностью. Быстро исследуйте, фильтруйте и сравнивайте результаты и создавайте потрясающие визуализации данных с помощью интуитивно понятного и простого в использовании портала Canvs. Упростите анализ открытых вопросов в тестах вашего бренда и концепции и автоматизируйте кодирование вопросов о неконтролируемой осведомленности, отзыве и атрибутах. Быстро определяйте и классифицируйте настроения и эмоции, связанные с ответами и респондентами.
Leximancer
Leximancer
Мощь вашего анализа. Leximancer автоматически анализирует ваши текстовые документы, чтобы определить концепции высокого уровня, предоставляя ключевые идеи и практические идеи, которые вам нужны, с помощью мощных моделей, интерактивных визуализаций и экспорта данных. Leximancer поддерживает обработку текста различных форматов и языков. Поддерживаются отдельные или большие коллекции документов. выйти за рамки текста, найти смысл. Текст — это больше, чем набор слов. Текст рассказывает историю. Идеи, концепции и отношения скрыты в словах. Быстрое и эффективное определение понятий является ключом к использованию того, что на самом деле говорит текст. Опросы клиентов, опубликованные статьи, стенограммы интервью, подробные отчеты, веб-страницы, формы обратной связи, твиты и многое другое. Узнайте, что на самом деле говорится. Основные возможности лексимансера. Текстовое моделирование. Минимальная настройка. Никаких обучающих наборов или словарей ключевых терминов. Отсутствие человеческого фактора в анализе Находит концепции в контексте, а не по ключевым словам. Полезные результаты быстро.
Atomic Intelligence
Atomic Intelligence
Atomic Intelligence предоставляет веб-сервис для автоматического анализа текстового контента. Мы отслеживаем большие объемы контента, такого как новости, социальные сети и нормативные документы, и выявляем мнения, высказанные вместе с упоминаниями названий компаний, продуктов и тем. Наш сервис используется инвестиционными фирмами, которые используют данные как часть своих собственных торговых стратегий, компаниями по производству потребительских товаров, которым необходимо понимать, что говорят их клиенты, и технологическими компаниями, которые хотят передать текстовый анализ на аутсорсинг. Atomic Intelligence сканирует текст, чтобы найти упоминания о компаниях, продуктах, настроениях, темах и многом другом. Обработка естественного языка и машинное обучение используются для выявления важных упоминаний, которые могут быть явными или неявными в тексте. Atomic Intelligence работает с любым типом неструктурированного контента. Загружайте файлы через веб-интерфейс или через API или настройте Atomic для выполнения автоматической загрузки по расписанию из выбранных вами источников.
Rosette
Basis Technology
Адаптируемая платформа для анализа и обнаружения текста. Создан для самых требовательных приложений текстовой аналитики и разработан для обеспечения высокой точности без ущерба для скорости. Полностью адаптируемая платформа, которая является идеальной основой для приложений обработки естественного языка. Основы текстовой аналитики для подготовки данных к анализу. Языковые инструменты для токенизации, тегирования частей речи, лемматизации, декомпозиции и чтения на китайском и японском языках для вашего ввода. Каждый язык, включая английский, ставит перед поисковыми приложениями уникальные и сложные задачи по выдаче релевантных и точных результатов. Rosette® Base Linguistics (RBL) позволяет корпоративным приложениям эффективно искать или обрабатывать текст на многих языках, предоставляя полный набор лингвистических услуг. RBL обогащает исходный текст на его родном языке для лучшей в своем классе обработки естественного языка, повышая скорость и точность.
Sphinx iQ3
Le Sphinx
Sphinx iQ 3 — это интуитивно понятное и эффективное многоканальное решение для проведения опросов, которое поможет вам на каждом этапе ваших проектов: от разработки анкет до анализа результатов и их передачи. Сочетая количественные и качественные подходы к визуализации данных, Sphinx iQ 3 заставляет ваши данные говорить, чтобы получить видение результатов, которые являются настолько же синтетическими, насколько богатыми и точными. Sphinx iQ 3 — это инновационное решение, позволяющее получить максимальную отдачу от учебы и помочь вам в принятии решений. Индивидуализируйте свои пригласительные сообщения. Разработайте свои индивидуальные формы (дизайн, количество вопросов на странице, типы вопросов, сообщение с благодарностью и т. д.). Задайте правильный вопрос нужному контакту, написав форму с условными вопросами и рекомендациями. Распространяйте динамические и интерактивные анкеты с отображением, адаптированным к различным носителям, компьютерам, планшетам, смартфонам и т. д. для лучшего взаимодействия с пользователем (адаптивный дизайн).
Verint Text Analytics
Verint
Извлекайте полезную бизнес-аналитику из неструктурированных данных в веб-чате, электронной почте, социальных сетях и заметках о звонках, чтобы лучше понять качество обслуживания клиентов (CX). Используйте многоканальную аналитику, чтобы лучше понять своих многоканальных клиентов. Ваши клиенты теперь многоканальны, и в результате ваша аналитика клиентов и сотрудников также должна быть многоканальной. В то время как голос остается важным каналом, клиенты все чаще выбирают цифровые каналы обслуживания клиентов, такие как чат, электронная почта и социальные сети. Добавление Text Analytics дает вам целостный анализ вашей стратегии взаимодействия с клиентами.
Deep Talk
Deep Talk
Deep Talk — это самый быстрый способ превратить текст из чатов, электронных писем, опросов, обзоров, социальных сетей в настоящую бизнес-аналитику. Узнайте, что внутри общения с клиентами, с помощью нашей простой в использовании платформы искусственного интеллекта. Неконтролируемые модели глубокого обучения для анализа неструктурированных текстовых данных. Deepers — это предварительно обученные модели глубокого обучения для получения пользовательских обнаружений внутри ваших данных. Используйте API «Deepers» для анализа текста в режиме реального времени и пометки текста или разговоров. Обратитесь к людям, которым нужен продукт, запросите новую функцию или выскажите жалобу. Deep Talk предлагает облачные модели глубокого обучения в качестве услуги. Вам просто нужно загрузить свои данные или интегрировать одну из служб поддержки, чтобы извлечь все идеи и информацию из WhatsApp, разговоров в чате, электронных писем, опросов или социальных сетей
Pienso
Pienso
Создание тематической модели с нуля требует передовых знаний в области программирования. Этот опыт стоит дорого и заменяет самое важное знание: знакомство с вашими данными. Маркировка ваших собственных обучающих данных — процесс медленный, утомительный и дорогостоящий. Передача его работникам с низкой заработной платой быстрее и дешевле, но ставит под угрозу точность и нюансы. В любом случае вы застрянете с фиксированной таксономией, которую трудно развивать. Пора перестать ставить теги. Предоставьте экспертам в предметной области возможность моделировать и анализировать собственные данные. У вас есть горы текстовых данных, наполненных идеями, которые только и ждут, чтобы их извлекли. И Пиенсо здесь, чтобы помочь. Pienso предназначен для обучения моделей с вашими собственными данными, потому что мы знаем, что это работает лучше всего. Независимо от того, являются ли ваши данные неструктурированными или полуструктурированными, длинными или короткими, Pienso может помочь вам проанализировать их и получить представление.
Infinia ML
Infinia ML
Обработка документов сложна, но не обязательно. Представляем интеллектуальную платформу обработки документов, которая понимает, что вы пытаетесь найти, извлечь, классифицировать и отформатировать. Infinia ML использует машинное обучение для быстрого понимания контента в контексте, понимая не только слова и диаграммы, но и отношения между ними. Независимо от того, является ли ваша цель автоматизацией процессов, прогностическим анализом, пониманием взаимосвязей или системой семантического поиска, мы можем построить ее с помощью наших комплексных возможностей машинного обучения. Используйте машинное обучение, чтобы принимать лучшие бизнес-решения. Мы настраиваем ваш код для решения вашей конкретной бизнес-задачи, выявляя неиспользованные возможности, раскрывая скрытые идеи и генерируя точные прогнозы, чтобы помочь вам добиться успеха. Наши интеллектуальные решения для обработки документов — не волшебство. Они основаны на передовых технологиях и многолетнем практическом опыте.
Emotics
Adoreboard
Emotics — это платформа для анализа эмоций, которая превращает текстовые данные из отзывов клиентов и сотрудников в бизнес-ответы. Emotics распределяет эмоции и темы по сильным и слабым сторонам, возможностям и угрозам, чтобы вы могли получить стратегическое представление о клиенте или сотруднике. Автоматически создает эталонные показатели, чтобы получить представление о том, как вы сравниваетесь с конкурентами, и о конкретных аспектах CX, которые вам необходимо улучшить или оптимизировать. Дает представление о причинах эмоциональных реакций, предоставляя систему предупреждения об эмоциях, провоцирующих действия. Измеряйте интенсивность эмоций, выражаемых клиентами, по 8 индексам эмоций и 24 эмоциям, чтобы точно определить эмоции, вызывающие темы, которые наносят ущерб или улучшают восприятие CX. Обеспечивает 360-градусное представление о клиенте благодаря подключению к NPS, CSAT, обзорам продуктов, социальным данным и таким инструментам, как SurveyMonkey и Zendesk. Смайлики делают анализ настроений излишним и идут дальше, чем NPS.
10 Лучшее программное обеспечение для анализа контента: инструменты для анализа текстовых данных
В нашу эпоху больших данных лучшее программное обеспечение для анализа контента программы (также называемые инструментами для анализа документов или программами для анализа текстовых данных) более чем важны.
Они помогут вам изучить практически любой тип неструктурированных текстовых данных, таких как деловые документы, электронные письма, социальные сети, чаты, комментарии, новости, блоги, веб-сайты конкурентов, вопросы маркетинговых опросов, отзывы клиентов, обзоры продуктов, стенограммы колл-центра и даже научные документы.
Они бывают разных форм: платные или бесплатные онлайн-инструменты для анализа текста, локальное программное обеспечение для анализа документов для MAC и Windows и т. д.
На этой странице мы собрали 10 лучших программ для анализа контента, чтобы вы могли получить ценную информацию из большого количества неструктурированных данных.
1. Word Stat
WordStat — это гибкий и очень простой в использовании программный инструмент для анализа контента и анализа текста, предназначенный для обработки больших объемов данных. Он помогает быстро извлекать темы, шаблоны и тенденции, а также анализировать неструктурированные и структурированные данные из многих типов документов.
Вы можете использовать Word Stat для широкого спектра действий по изучению контента, таких как: анализ стенограмм интервью или фокус-групп, анализ конкурентных веб-сайтов, бизнес-аналитика, извлечение информации из жалоб клиентов и т. д.
Кроме того, Word Stat может анализировать освещение новостей или научная литература или может помочь вам в обнаружении мошенничества, патентном анализе и установлении авторства.
Основные преимущества и функции:
- Обработка текста возможности.
- Интегрированные средства анализа пояснительного текста и средства визуализации , такие как кластеризация, диаграммы близости и многое другое.
- Связывает неструктурированные со структурированными данными , такими как даты, числа или категориальные данные, для выявления временных трендов.
- Одномерный частотный анализ ключевых слов.
- Функция поиска ключевых слов и анализ совпадения ключевых слов.
- Анализ сходства дел или документов.
- Автоматическая классификация текстов и многое другое.
Операционные системы: Microsoft Windows XP, 2000, Vista, Windows 7, 8 и 10, Mac OS, Linux.
Веб-сайт: https://provalisresearch.com/
2. Lexalytics
Когда речь идет о лучшем программном обеспечении и инструментах для анализа контента, Lexalytics определенно занимает здесь первое место.
Lexalytics производит облачные и локальные решения для анализа текста и настроений, которые помогают вам преобразовывать мысли и разговоры клиентов в ценную и полезную информацию.
Продукты Lexalytics SaaS Semantria и локальная Salience интегрированы в платформы для мониторинга социальных сетей, анализа опросов, управления репутацией, маркетинговых исследований и многих других действий по анализу контента.
Основные преимущества и функции:
- Извлечение именованных объектов для идентификации именованных текстовых фигур, таких как люди, места и бренды, конкретные сокращения, адреса улиц, номера телефонов и все, что вы хотите.
- Темы для работы с многозначными словами.
- Категории.
- Такие намерения, как «Купить», «Продать», «Рекомендовать» и «Выйти».
- Анализ настроений , чтобы показать вам, как потребители относятся к своему предмету.
- Механизм обработки естественного языка.
Salience доступен для серверов Microsoft Windows и Linux. Semantria API предназначен для анализа документов в облаке.
Веб-сайт: https://www.lexalytics.com
3. DiscoverText
Они какие-то новаторы. DiscoverText сочетает адаптивные программные алгоритмы с кодированием, основанным на человеческом факторе, для проведения крупномасштабного анализа.
Программное обеспечение может объединять неструктурированные данные из разных источников. Примерами неструктурированных данных являются различные документы и текстовые файлы, открытые ответы на опросы, электронные письма и другие офлайн- и онлайн-источники текста.
С помощью одной платформы вы можете поддерживать показатели качества данных, собирать, фильтровать, удалять дубликаты, выполнять поиск, кластеризацию, человеческий код и машинную классификацию большого количества небольших текстовых единиц.
Основные преимущества и возможности:
- Усовершенствованный многофункциональный инструмент для анализа текста.
- Запланировать повторную выборку прямых трансляций через API.
- Классификация посредством автоматизации и ручного обучения.
- Прикрепляйте заметки к документам и наборам данных.
- Редактировать конфиденциальную информацию.
- Подключайтесь и работайте с командой через браузер.
- Создание общей сводки.
- Создание тематических моделей для автоматизации.
- Наслаждайтесь облачным приложением.
- Делитесь проектами, повторно используйте модели и обновляйте результаты.
Веб-сайт: https://discovertext. com
4. Rapid Miner Text Extension
Если вы ищете лучшее бесплатное программное обеспечение для анализа контента , Rapid Miner Text Extension стоит рассмотреть. Это расширение популярной бесплатной программной платформы для обработки данных с открытым исходным кодом Rapid Miner.
Расширение Rapid Miner Text Extension имеет все необходимое для статистического анализа текста и обработки естественного языка (NLP). Он позволяет загружать тексты из различных источников данных и документов, преобразовывать их и легко анализировать контент.
Основные преимущества и функции:
- Поддерживает множество текстовых форматов , включая обычный текст, HTML или PDF.
- Предоставляет стандартные фильтры для токенизации, выделения корней, фильтрации стоп-слов или генерации n-грамм.
- Класс документов, в котором хранятся все документы в сочетании с дополнительной метаинформацией.
- Статистический анализ текста.
Вы должны быть членом сообщества RapidMiner, чтобы использовать их текстовое расширение. Вы можете присоединиться к сообществу и бесплатно использовать все расширения RapidMiner.
Веб-сайт: https://marketplace.rapidminer.com/
5. SAS Text Miner
Без сомнения, SAS является одним из самых громких имен в сфере бизнес-аналитики и интеллектуального анализа данных. Их продукт Text Miner может предоставить вам быстрое и глубокое понимание самых разных неструктурированных документов и других типов данных.
Программное обеспечение позволяет легко анализировать текстовые данные из Интернета, книг, полей комментариев и многих других текстовых источников. Инструмент автоматически считывает текстовые данные и предоставляет расширенные алгоритмы анализа, чтобы помочь вам выявлять тенденции и использовать новые возможности.
Основные преимущества и функции:
- Высокопроизводительный анализ текста , который поможет вам быстро оценить большое количество коллекций документов.
- Интерфейс обработки соответствует стандартам специальных возможностей Windows.
- Автоматическая генерация логических правил для легкой классификации содержимого.
- Профилирование терминов и тенденции.
- Обнаружение темы документа.
- Встроенная поддержка нескольких языков .
- Определите, что популярно, а что нет.
Веб-сайт: https://www.sas.com
6. Text2data
Text2data — отличный продукт для тех, кто ищет недорогое программное обеспечение для анализа текста и контента.
Это платформа NLP/глубокого обучения (обработка естественного языка) с запатентованными алгоритмами, которые предоставляют облачных служб текстовой аналитики для лучшего понимания ваших клиентов.
Независимо от того, хотите ли вы анализировать социальные сети, электронные письма, вопросы опроса с произвольным текстом или другие источники информации об опыте ваших клиентов, система поможет вам.
Основные преимущества и функции:
- Анализ тональности для выявления и извлечения субъективной информации в текстовом документе.
- Обобщение текста/документа.
- Классификация документов на основе предварительно обученных моделей данных.
- Извлечение сущностей, таких как имена лиц, организаций, мест и т. д.
- Обнаружение тем , что может значительно улучшить вывод контекста документа.
- Анализ документов по ключевым словам и присвоение им оценки тональности.
- Обнаружение цитирования.
- Обнаружение сленга.
Веб-сайт: http://text2data.org/
7. Etuma
Etuma Text Analysis – это один из лучших программных инструментов для анализа контента, способный превратить ваши открытые отзывы клиентов в полезную информацию.
Etuma обслуживает широкий спектр областей бизнеса, таких как управление качеством обслуживания клиентов, анализ конкурентов, анализ рынка и разведка, контакт-центры, анализ настроений, голос клиента (исследования), мониторинг социальных сетей, вовлечение сотрудников и анализ чатов.
Etuma в режиме реального времени узнает, что вашим клиентам нравится и не нравится в ваших продуктах. Etuma — это продукт SaaS, работающий в облаке.
Основные преимущества и особенности:
- Многоязычность — понимание нескольких языков — результаты на одном языке.
- Автоматическое программное обеспечение без участия человека. Он использует обработку естественного языка (NLP) и искусственный интеллект.
- Последовательный – актуальный отраслевая классификация .
- Обнаруживает в режиме реального времени что нравится и не нравится вашим клиентам.
- Может анализировать любой тип обратной связи.
- Простота интеграции — инструмент имеет разъемы для различных платформ для опросов, контакт-центров и управления качеством обслуживания клиентов, таких как Salesforce, Zendeck и т. д.
- Большое количество функций анализа текста и анализа текста, таких как синтаксический анализ , количество слов, корни токенизации, определение корня слова, определение конца предложения, идентификация частей речи (POS), исправление правописания, синонимы, семантическая тема, определение тональности и т. д.
Веб-сайт: www.etuma.com
8. Luminoso
Luminoso — это отличный инструмент для извлечения и анализа текста, который работает с большим количеством неструктурированных данных, позволяя вам быстро выявить ключевые темы, определить разговоры, которые важно, перейдите на вкладку обслуживания клиентов и отслеживайте тенденции с течением времени.
Этот простой в использовании инструмент позволяет быстро просматривать и анализировать такие данные, как открытые ответы на опросы, обзоры продуктов и стенограммы колл-центра.
Программное обеспечение использует новейшие методы искусственного интеллекта и понимания естественного языка, чтобы помочь вам в решении различных бизнес-задач, таких как понимание ключевых факторов, влияющих на показатели NPS, и классификация обращений в службу поддержки клиентов.
Основные преимущества и функции:
- Быстро находите ценных аналитических данных в текстовых данных.
- Может анализировать данные на 13 языках , включая английский, арабский, китайский, испанский и русский.
- В течение нескольких минут Luminoso Text Analytics выявляет ключевые темы, значимые связи и тенденции.
- Новейшие методы искусственного интеллекта и понимания естественного языка.
- Гибкие выходные данные и интуитивно понятные информационные панели, упрощающие отчетность и обмен данными
- Анализ данных контакт-центра.
- Раскройте связь между уровнем вовлеченности сотрудников и удовлетворенностью клиентов.
- Понимание потребностей в уходе путем анализа текстовых данных из интернет-сообществ.
Веб-сайт: https://luminoso.com
9. Pingar DiscoveryOne
Pingar DiscoveryOne — это программное обеспечение для анализа контента, позволяющее предприятиям обнаруживать возможности и риски, скрытые в тексте веб-данных и корпоративных данных.
Это может помочь вам сократить расходы на хранение и безопасность документов. Этот мощный механизм текстовой аналитики может отображать релевантные сводки статей, каналы социальных сетей, отчеты и даже входящие жалобы клиентов по электронной почте.
Pingar DiscoveryOne предназначен для выявления тенденций, тем и проблем, раскрытых в различных типах документов, сообщений, статей и электронных писем.
Ключевые преимущества и особенности:
- Решение Content Intelligence , которое быстро идентифицирует ключевые рыночные данные и выявляет тенденции во времени.
- Основано на машинном обучении и может быть уникально адаптировано для любой отрасли.
- Может ли постоянно сканировать Интернет , чтобы найти актуальную информацию для мониторинга конкурентов, новых тенденций и анализа целевых рынков.
- Улучшает поиск, обеспечивает безопасное удаление и идентифицирует риски безопасности документов.
- Показывает отчеты с графиками, отображающими важные отношения.
- Объединяет социальные сети, новости, блоги, форумы , чаты, электронные письма и документы в единый анализ.
- Может читать ваши документы и классифицировать их в соответствии с вашими потребностями.
- Может обнаруживать сети , отношения и их важность.
- Медиа и анализ настроений и т. д.
Веб-сайт: http://pingar.com/
10. MeaningCloud
MeaningCloud — одно из самых простых и доступных программ для анализа контента. публикации, электронные письма, статьи, деловые документы и т. д.
Вы можете анализировать отзывы клиентов по электронной почте, социальным сетям, колл-центру, опросам, твитам и комментариям, а также любым другим каналам связи. Вы можете заниматься публикацией контента, анализом социальных сетей, кодированием документов и управлением.
MeaningCloud — это облачное решение, которое не нужно устанавливать на компьютер.
Основные преимущества и функции:
- Сочетает в себе расширенные функции: анализ настроений на уровне функций, обработку языка социальных сетей и т. д.
- Очень прост в использовании и интеграции.
- Несколько языков — вы можете анализировать содержимое на английском, испанском, французском, португальском или итальянском языках.
- Доступно — вы платите только за то, чем пользуетесь.
- Инструмент автоматически классифицирует документы любого типа (медицинские карты, справки, претензии и т.д.).
- Программное обеспечение для анализа контента с широкими возможностями настройки.
- Голос клиента Анализ, управление клиентским опытом, публикация контента и монетизация.
Заключение:
Выбор лучшего программного обеспечения для анализа контента и инструментов для анализа текстовых данных для ваших нужд — непростая задача.
Несмотря на то, что на рынке доступно множество хороших вариантов, сочетающих в себе передовые технологии (например, искусственный интеллект и понимание естественного языка), единственного идеального решения может не быть.
Неструктурированные данные — одно из самых мощных орудий, которое может принести скрытую и даже неожиданную пользу вашему бизнесу.
Прежде чем выбрать программное решение для анализа текста, вы должны сначала изучить свои потребности в анализе контента. В зависимости от размера вашего бизнеса, это может быть значительный исследовательский проект.
Комплексный анализ текстовых данных добавляет высокий уровень интеллекта и дает вам поддержку принятия решений в любом масштабе, возможности, конкурентные преимущества и повышенную эффективность работы.
Итак, не торопитесь, изучите свои потребности и определите необходимые функции программного обеспечения, а затем приступайте к решению.
Каковы ваши предложения по хорошему программному обеспечению для инструментов анализа контента и извлечения текстовых данных? Поделитесь своими мыслями и опытом в комментариях ниже.
Rank Tracker 8.43.10 Скачать для Windows / Журнал изменений / FileHorse.
comЧто нового в этой версии:
Rank Tracker 8.43.10
— Обновлен алгоритм парсинга для мобильных и карт результатов в Rank Tracker
Rank Tracker 8.43.9
— Реализовано несколько улучшений производительности и исправлены некоторые незначительные проблемы в Rank Tracker
Rank Tracker 8.43.7
— Исправлен неверный статус сложности ключевого слова в Rank Tracker
Rank Tracker 8.43.5
— Обновлен рейтинг алгоритмы анализа результатов для мобильных и настольных компьютеров в Rank Tracker
Rank Tracker 8.43.4
— Несколько улучшений производительности реализованы в Rank Tracker
Rank Tracker 8.43.2
— Обновлены алгоритмы анализа рейтинга для мобильных и настольных результатов в Rank Tracker
Rank Tracker 8.43.1
— Исправлены проблемы с синтаксическим анализом для поисковых систем Google Mobile и Desktop в Rank Tracker
Rank Tracker 8.42.31
— Исправлены мелкие проблемы
Rank Tracker 8. 42.30
— Обновлен синтаксический анализ алгоритм для мобильных результатов SE в Rank Tracker
Rank Tracker 8.42.28
Разное:
— Обновленный алгоритм анализа для мобильных результатов SE и Keyword Planner в Rank Tracker
Rank Tracker 8.42.27
Разное:
– Обновленный алгоритм анализа мобильных результатов SE в Rank Tracker
Rank Tracker 8.42.26
– Исправлены повторяющиеся URL-адреса в Google Mobile, улучшена интеграция Google Ads в Rank Tracker , ссылки на сайты и результаты обзоров, исправлены пропущенные результаты Google Featured Snippet в Rank Tracker
Rank Tracker 8.42.24
Разное:
— Исправлены отсутствующие позиции Feature Snipped и Local Pack для мобильных устройств Google в Rank Tracker
Rank Tracker 8.42.23
— проблемы с синтаксическим анализом для проверок Google Mobile и отслеживания локальных пакетов в Rank Tracker
Rank Tracker 8.42.22
— проблемы с синтаксическим анализом были решены для проверок Google Mobile и отслеживания локальных пакетов; В Rank Tracker
Rank Tracker 8. 42.21
Разное:
— Реализовано несколько улучшений производительности в Rank Tracker
Rank Tracker 8.42.20
Разное:
— Фактор Alexa Rank был удален, обновлен синтаксический анализ результатов Google Mobile в Rank Tracker
Rank Tracker 8.42.19
Разное:
— Несколько незначительных проблем были решены в Rank Tracker
Rank Tracker 8.42.17
— Исправлены повторяющиеся URL-адреса для Google Mobile SERP, исправлена ошибка при перемещении ключевых слов из песочницы, реализовано несколько других незначительных улучшений парсера, обновлен дизайн кнопки SEO PowerSuite Cloud в Rank Tracker 9.0009
Rank Tracker 8.42.16
— Исправлена ошибка при сборе объема поиска в Rank Tracker
Rank Tracker 8.42.15
Разное:
— Обновлены внутренние библиотеки браузера для компьютеров Mac на базе ARM в Rank Tracker
Rank Tracker 8.42.14
— Обновлен алгоритм парсинга для Google Mobile в Rank Tracker
Rank Tracker 8. 42.13
— Исправлены ошибки при обновлении позиций в Yahoo! Mobile и Seznam: решено зависание окна браузера при обновлении данных SEO/PPC в Rank Tracker
Rank Tracker 8.42.12
Разное:
— Исправлены результаты без данных для Google Mobile, обновлен анализатор объема поиска в Rank Tracker
Rank Tracker 8.42.11
Разное:
— Исправлены пропущенные элементы SERP Featured Snippet в Rank Tracker
9 Rank Tracker Rank Tracker 8.42.10
Разное:
— Обновлен синтаксический анализатор Google Mobile и другие незначительные улучшения алгоритма, реализованные в Rank Tracker
Rank Tracker 8.42.9
Разное:
— Rank Tracker адаптирован к новым элементам в Планировщике ключевых слов Google Ads учетных записей, проверка ранга была адаптирована к поисковой выдаче Google и Google Mobile
Rank Tracker 8.42.8
Разное:
— в Rank Tracker было внесено несколько незначительных улучшений настроен для Google Mobile и поисковой выдачи Bing
Rank Tracker 8. 42.5
— В Rank Tracker выпущены новые расширенные фильтры рабочей области
Rank Tracker 8.42.4
Разное:
— Обновлена цифровая подпись для Rank Tracker
Rank Tracker 8.42.3
— Обновлен анализатор рейтинга для поисковых систем Google Mobile, Bing и Seznam в Rank Tracker. анализатор рангов для разделов Google Mobile, Google Reviews и Local Pack в Rank Tracker
Rank Tracker 8.42
— В Rank Tracker реализована новая версия JxBrowser 7, исправлены ошибки при обновлении количества поисковых запросов через личный кабинет, несколько других мелких проблем решено
Rank Tracker 8.41.9
Разное:
— Исправлена неправильная сортировка для столбца сложности ключевых слов, исправлены дублирующиеся URL-адреса на вкладке «Детали SERP» в Rank Tracker
Rank Tracker 8.41.8
— Обновлен парсер Google Mobile, добавлена поддержка для дополнительных шагов проверки, которые появляются при подключении личного аккаунта Google Ads к Rank Tracker
Rank Tracker 8. 41.7
— Обновлено несколько текстовых описаний интерфейса, исправлено отображение некорректных значений видимости в основной рабочей области проекта в Rank Tracker
Rank Tracker 8.41.6
— В Rank Tracker реализованы некоторые обновления и улучшения производительности
Rank Tracker 8.41.5
— В модуль Rank Tracker возвращена вкладка «Сложность ключевых слов», обновлен парсер для Yandex.by в Rank Tracker
Rank Tracker 8.41.4
— Парсер Google Mobile SERP был улучшен и обновлен в Rank Tracker
Rank Tracker 8.41.3
— В Rank Tracker 9 реализованы некоторые обновления и улучшения производительности.0009
Rank Tracker 8.41.2
— Журнал изменений недоступен для этой версии
Rank Tracker 8.41
— Исправлены раскрывающиеся раскрывающиеся списки для систем MacOs, обновлены библиотеки IP, решено неправильное копирование имен событий и другие мелкие проблемы, исправленные в Rank Tracker
Rank Tracker 8.40.13
— Внесено несколько незначительных улучшений и исправлены некоторые ошибки в Rank Tracker
Rank Tracker 8. 40.12
— Внесено несколько незначительных улучшений и исправлены некоторые ошибки в Rank Tracker
Rank Tracker 8.40.11
Разное:
— Улучшен анализатор Google Mobile, запланированные процессы задач оптимизированы, чтобы избежать ошибок нехватки памяти, обновлен график прогресса ранга со списком последних обновлений Google Core в Rank Tracker
Ранг Трекер 8.40.10
— Исправлена проблема с увеличением лимита памяти в системах Linux, исправлены невидимые цветовые маркеры для конкурентов в модуле Анализ SERP, другие мелкие улучшения выпущены в Rank Tracker
Rank Tracker 8.40.9
— Выпущен улучшенный синтаксический анализатор для Google Mobile, обновлен и улучшен метод исследования ключевых слов Ask Autocomplete, исправлены другие мелкие проблемы в Rank Tracker
Rank Tracker 8.40.7
— Журнал изменений недоступен для этой версии0009
Rank Tracker 8.40.4
— Реализованы некоторые обновления синтаксического анализатора результатов Google для ПК и мобильных устройств, добавлено автозаполнение ключевых слов для анализа SERP в Rank Tracker
Rank Tracker 8. 40.3
— Реализованы некоторые улучшения графического интерфейса
— исправлен синтаксический анализатор для связанных поисковых запросов Bing
Rank Tracker 8.40.2
— Несколько улучшений были реализованы для нового модуля анализа SERP и другие незначительные улучшения, примененные к Rank Tracker
Rank Tracker 8.40.1
Разное:
— Исправлено несколько незначительных проблем в Rank Tracker
Rank Tracker 8.40
— Новый модуль анализа SERP в Rank Tracker: получите подробные данные SERP и проверьте корреляции между факторами ранжирования и позициями SERP
Rank Tracker 8.39.14
— Журнал изменений недоступен для этой версии
Rank Tracker 8.39.13
— Исправлено несколько незначительных проблем в Rank Tracker
Rank Tracker 8.39.12
— Исправлены проблемы аутентификации со службой DeathByCaptcha в Rank Tracker
Rank Tracker 8.39.11
Разное:
— Несколько незначительных обновлений производительности были реализованы в Rank Tracker
Rank Tracker 8. 39.10
Разное:
— Несколько незначительных обновлений производительности были реализованы в Rank Tracker
Rank Tracker 8.39.8
— обновлены некоторые переменные шаблона экспорта SQL, реализовано несколько незначительных обновлений для проверки Google SERP в Rank Tracker
Rank Tracker 8.39.7
Разное:
— Исправлены некоторые незначительные технические проблемы и реализованы улучшения производительности Трекер рейтинга
Rank Tracker 8.39.6
— Исправлены некоторые мелкие технические проблемы и реализованы улучшения производительности в Rank Tracker
Rank Tracker 8.39.5
Разное:
— Обновлены библиотеки API для сервиса DeathByCaptcha, обновлен список обновлений Google Core для Rank Progress график, несколько других незначительных проблем были исправлены в Rank Tracker
Rank Tracker 8.39.4.
Rank Tracker 8.39.3
Разное:
— Несколько незначительных обновлений производительности были реализованы в Rank Tracker
Rank Tracker 8. 39.2
Разное:
— Несколько незначительных обновлений производительности были реализованы в Rank Tracker
Rank Tracker 8.39 .1
Разное:
— Исправлено некорректное определение https-сайтов в модуле Keyword Gap, исправлены дублирующиеся позиции для Google Mobile и другие мелкие проблемы были решены в Rank Tracker
Rank Tracker 8.38.14
Разное:
— Исправлено несколько проблем с парсингом функций SERP в Rank Tracker
Rank Tracker 8.38.13
Разное:
— Исправлена ошибка подключения учетной записи для Планировщика ключевых слов Google Ads в Rank Tracker
Rank Tracker 8.38.12
Разное:
— Несколько улучшений производительности были реализованы в Rank Tracker
Rank Tracker 8.38.11
Разное:
— Несколько улучшений производительности были реализованы в Rank Tracker
Rank Tracker 8.38.10
Разное:
— Внесено несколько незначительных улучшений для настройки Rank Tracker с некоторыми изменениями в интерфейсе Google Ads
Rank Tracker 8. 38.9
Разное:
— Несколько улучшений производительности Rank Tracker
Rank Tracker 8.38.8
— Исправлены проблемы с синтаксическим анализом для результатов «Люди также спрашивают» для Google Mobile, решена проблема дублирования ключевых слов для карты ключевых слов и несколько других мелких проблем, исправленных в Rank Tracker 9.0009
Rank Tracker 8.38.7
— В Rank Tracker выпущено несколько незначительных обновлений для новых изменений в интерфейсе Google Ads. Программное обеспечение было обновлено для работы с новым интерфейсом Google Ads.
Rank Tracker 8.38.4
Разное:
— В Rank Tracker выпущено несколько незначительных обновлений для нового интерфейса Google Ads
Rank Tracker 8.38.3
— Rank Tracker обновлен для сбора данных из нового интерфейса Google Ads. В настройки программного обеспечения добавлена новая возможность управления всплывающими уведомлениями.
Rank Tracker 8.38.2
— Исправлены проблемы со входом в учетные записи Google Ads, которые запрашивают капчи, когда Rank Tracker пытается войти в систему. Tracker 8.38
— в Rank Tracker 9 реализовано несколько незначительных улучшений производительности.0009
Rank Tracker 8.37.11
— Исправлена приостановка процесса сбора объемов поиска, когда в Rank Tracker выбраны All Locations
Rank Tracker 8.37.10
— Журнал изменений недоступен для этой версии журнал недоступен для этой версии
Rank Tracker 8.37.8
— исправлено отсутствие результатов для похожих запросов Google в Rank Tracker
Rank Tracker 8.37.7
— журнал изменений недоступен для этой версии
Rank Tracker 8.37.6
— В Rank Tracker реализовано несколько незначительных усовершенствований и улучшений производительности
Rank Tracker 8.37.5
— Журнал изменений недоступен для этой версии
Rank Tracker 8.37.4
Разное:
— Исправлен слишком маленький размер окна приложения, потому что в Rank Tracker
Rank Tracker 8.37.3
— исправлен слишком маленький размер окна приложения из-за сломанного файла свойств и другие мелкие улучшения реализованы в Rank Tracker
Rank Tracker 8. 37.2
— Исправлена ошибка парсера для Планировщика ключевых слов Google Ads в Rank Tracker
Rank Tracker 8.37.1
— Исправлена ошибка парсера для Планировщика ключевых слов Google Ads в Rank Tracker
Rank Tracker 8.37
— Несколько незначительных усовершенствования и улучшения производительности были реализованы в Rank Tracker
Rank Tracker 8.36.14
— несколько незначительных улучшений были реализованы в Rank Tracker
Rank Tracker 8.36.12
— несколько незначительных улучшений были реализованы в Rank Tracker
Rank Tracker 8.36.11
— Улучшено удобство использования мастера настройки проекта, обновлен график истории с основными обновлениями Google в Rank Tracker
Rank Tracker 8.36.10
— Несколько обновлений производительности реализовано в Rank Tracker
Rank Tracker 8.36.9
— Несколько обновлений производительности были реализованы в Rank Tracker
Rank Tracker 8.36.8
— Обновлен парсер Google SERP, исправлен запланированный экспорт данных в Rank Tracker
Rank Tracker 8. 36.7
Разное:
— Несколько обновлений производительности были реализованы в Rank Tracker
Rank Tracker 8.36.6
— Объявление осенней распродажи: скидка до 70% SEO PowerSuite
Rank Tracker 8.36.5
— Журнал изменений недоступен для этой версии
Rank Tracker 8.36.4
Разное:
— обновлен синтаксический анализатор функций Google SERP и исправлено несколько других незначительных проблем в Rank Tracker
Rank Tracker 8.36.3
— The ‘100 улучшен метод проверки ранга результатов на страницу, исправлен сброс настроек времени планировщика задач в Rank Tracker
Rank Tracker 8.36.2
— исправлен неработающий анализатор миниатюр Google, решено несколько других мелких проблем в Rank Tracker
Rank Tracker 8.36.1
— журнал изменений недоступен для этой версии
Rank Tracker 8.36
— Исправлена команда «Копировать все ключевые слова» для рабочей области проекта Rank Tracker, обновлен парсер для панели знаний Google Mobile и Google Mobile Video
Rank Tracker 8. 35.14
в трекере рангов
Rank Tracker 8.35.13
— Журнал изменений недоступен для этой версии
Rank Tracker 8.35.12
— Журнал изменений недоступен для этой версии
Rank Tracker 8.35.11
— Журнал изменений недоступен для этой версии
Rank Tracker 8.35.10
— Журнал изменений недоступен для этой версии
Rank Tracker 8.35.9
— Журнал изменений недоступен для этой версии
Rank Tracker 8.35.8
— Журнал изменений недоступен для этой версии
Rank Tracker 8.35.7
— Журнал изменений недоступен для этой версии
Rank Tracker 8.35.6
— Журнал изменений недоступен для этой версии Tracker
Rank Tracker 8.35.3
— Журнал изменений недоступен для этой версии
Rank Tracker 8.35.2
— Несколько незначительных обновлений были реализованы в Rank Tracker
Rank Tracker 8.35.1
— Улучшена проверка Google Mobile Результаты панели изображений, новостей и знаний в Rank Tracker
Rank Tracker 8. 35
— Новая функция в Rank Tracker: получать автоматические оповещения и уведомления, если обнаружены резкие изменения в рейтинге и видимости ваших ключевых слов
Rank Tracker 8.34.5
— Исправлены ошибки при обновлении результатов в локальных пакетах Google и избранные сниппеты в Rank Tracker
Rank Tracker 8.34.4
— Добавлена возможность отслеживать несколько избранных сниппетов на одной выдаче в Rank Tracker, исправлена ошибка при обновлении данных SEO/PPC
Rank Tracker 8.34.3
— Rank Tracker был скорректирован с учетом некоторых изменений в интерфейсе Google Ads Keyword Planner. исправлено несколько других незначительных проблем
Rank Tracker 8.34.1
— Интерфейс на французском языке был обновлен, и несколько других незначительных проблем были исправлены в Rank Tracker
Rank Tracker 8.34
— Исправлено: выбор файла Rank Tracker не просмотр файлов на MacOS Catalina. Виджет «Органический трафик» адаптирован для экранов с высоким разрешением
Rank Tracker 8. 33.6
— Исправлены ошибки при обновлении данных органического трафика в Rank Tracker
Rank Tracker 8.33.5
— Исправлены ошибки, связанные с получением трафика из GA для определенных аккаунтов, алгоритм парсинга избранных сниппетов Google был изменен обновлено в Rank Tracker
Rank Tracker 8.33.4
Разное:
— Исправлены мелкие ошибки для рабочих областей проекта в Rank Tracker
Rank Tracker 8.33.2
— Исправлено несколько мелких проблем
Rank Tracker 8.33.1
— Журнал изменений недоступен для этой версии
Rank Tracker 8.33
— Исправлено несколько мелких проблем двигатели были исправлены в Rank Tracker
Rank Tracker 8.32.8
— журнал изменений недоступен для этой версии Двухэтапная аутентификация, исправлена поисковая система Najdi.si
Rank Tracker 8.32.6
— Журнал изменений недоступен для этой версии
Rank Tracker 8.32.5
Исправлено:
— отрицательные значения для столбца Intersection в Domain Competitors
— проблема открытия проектов из SEO PowerSuite Cloud на Windows для Rank Tracker
Rank Tracker 8. 32.4
— Исправлено несколько мелких ошибок
Rank Tracker 8.32.3
— Исправлено несколько мелких ошибок фиксированный
Rank Tracker 8.32.1
— Исправлена проблема со сбором изображений для функций Google SERP
Rank Tracker 8.32
— Исправлено несколько мелких ошибок
Rank Tracker 8.30.5
— Добавлены новые страны SEO PowerSuite Keyword index: Эстония, Казахстан и некоторые другие. Исправлена проблема расчета силы домена для новых проектов и несколько других мелких ошибок.
Rank Tracker 8.30.4
— В SEO PowerSuite Keyword index добавлена новая страна: Нигерия
Rank Tracker 8.30.3
— Новые страны были добавлены в указатель ключевых слов SEO PowerSuite: Панама и Турция
— Исправлено несколько мелких ошибок
Rank Tracker 8.30.2
— Добавлена новая поисковая система: Google Албания. Исправлено несколько незначительных проблем с производительностью.
Rank Tracker 8.30.1
— Новый модуль: Лучшие страницы в Rank Tracker. Найдите страницы, которые домен занимает в Google, проверьте статистику трафика страниц, найдите их ключевые слова с самым высоким рейтингом и соберите другую полезную статистику
Rank Tracker 8.29.3
— В модуль ключевых слов рейтинга добавлено более 30 новых регионов. Теперь вы можете собирать результаты по Норвегии, Греции, Ирландии, Венгрии и другим странам.
Rank Tracker 8.29.2
— Исправлена проблема с подключением личного аккаунта Google Ads Keyword Planner и несколько других мелких ошибок
Rank Tracker 8.29. 1
— Улучшена производительность внутреннего браузера в Rank Tracker. Исправлена ошибка, которая могла возникать в старых проектах, использующих цвета из старой палитры для обозначения конкурентов проекта
Rank Tracker 8.29
— В Rank Tracker добавлена новая функция «Исследование конкурентов»: исследуйте своих нишевых конкурентов, найдите конкурентов, которые уже ранжируются по тем же ключевым словам, что и ваш целевой домен
Rank Tracker 8. 28.2
— Проблема исправлено: решен сбор идей и объема поиска из Google Ads Keyword Planner
Rank Tracker 8.28.1
— Журнал изменений недоступен для этой версии
Rank Tracker 8.28
— Переработан раздел исследования ключевых слов: новый интерфейс, новое исследование режимы для Keyword Gap и Ranking Keywords — проверка по домену или точному URL, группировка по URL в разделе Карта ключевых слов
Rank Tracker 8.27.15
— Журнал изменений недоступен для этой версии
Rank Tracker 8.27.14
— В Rank Tracker добавлен новый метод подсказки ключевых слов: Люди также спрашивают.
— В раздел «Карта ключевых слов» добавлена колонка «Рейтинг».
Rank Tracker 8.27.13
— Исправлена проблема с несогласованностью результатов по объему поиска, взятых из Яндекс Вордстат, и проблема вмешательства прокси в модуль Keyword Gap
Rank Tracker. 8.27.12
— Новая функция «Разрыв ключевых слов» в Rank Tracker: сравните профили ключевых слов доменов ваших конкурентов, чтобы найти их уникальные и пересекающиеся ключевые слова
Rank Tracker 8. 27.11
— Исправлена проблема с отображением предпочтений местоположения в расширенных настройках поисковика, обновлена база данных Whois для IP-адресов доменов
Rank Tracker 8.27.10
— Исправлено несколько мелких ошибок
Rank Tracker 8.27.9
— Исправлена проблема некорректных условий фильтрации для расширенного фильтра, устранена ошибка сохранения проекта и ряд других мелких ошибок
Rank Tracker 8.27.8
— Исправлено несколько мелких ошибок
Rank Tracker 8.27.7
Разное:
— Исправлено несколько мелких ошибок: некорректный выбор поисковых систем по сложности ключевых слов, исключение ошибки при создании нового проекта для несуществующего ДВУ и несколько других ошибок.
Rank Tracker 8.27.5
— Добавлены мелкие исправления ошибок и улучшения стабильности
Rank Tracker 8.27.4
— Исправлена проблема с выполнением задачи проверки ранга для ключевых слов, которые были отмечены тегами, которые не были указаны в настройки запланированного задания
Rank Tracker 8. 27.3
— исправлено несколько незначительных ошибок и реализованы некоторые обновления производительности.
Rank Tracker 8.27.2 другие незначительные ошибки были исправлены
Rank Tracker 8.27.1
— Исправлено несколько проблем
Rank Tracker 8.27
— Разное: 10 новых регионов были добавлены в модуль Ranking Keywords. Теперь вы можете собирать результаты по Канаде, Великобритании, Германии, Франции и другим странам
Rank Tracker 8.26.11
— Исправлено несколько проблем в Rank Tracker: обновление силы домена, сбор универсальных результатов видео из Google, отключена опция распознавания Captcha и несколько других мелких проблемa
Rank Tracker 8.26.10
— Ошибка связанные с открытием проектов в Rank Tracker и несколько других мелких ошибок были исправлены. Обновлен импорт объема поиска
Rank Tracker 8.26.9
— исправлено подключение консоли Google Search, решена проблема подключения к профилям Google Analytics без свойства
Rank Tracker 8. 26.8
— В настройки Google Analytics в Rank Tracker добавлен новый элемент «свойства», чтобы помочь пользователям найти и подключить правильное представление
Rank Tracker 8.26.7
— параметры масштабирования интерфейса обновлены и исправлено несколько других мелких проблем
Rank Tracker 8.26.6
— исправлена ошибка шаблона экспорта для новых запланированных задач, устранено несколько незначительных проблем
Rank Tracker 8.26.5
— исправлено несколько проблем: некорректное определение типа «Ответы» в поисковой выдаче, устранена ошибка, связанная с созданием запланированных задач, и некоторые другие мелкие ошибки
Rank Tracker 8.26.4
— Улучшен процесс автообновления ПО для приложений с запланированными задачами, исправлена проблема отображения некорректных символов для названий проектов с кириллическими символами
Rank Tracker 8.26.3
— Число проблем было исправлено в Rank Tracker, в том числе проблемы с неправильными символами в сохраненных названиях проектов, сортировка по алфавиту для запланированных задач, прерывание фоновой задачи во время автообновления и многие другие мелкие улучшения
Rank Tracker 8. 26.2
— Добавлена новая поисковая система: Google Афганистан. Проблемы, исправленные в Rank Tracker: некорректное определение страны пользователя для Google Catalonia и несколько других мелких ошибок
Rank Tracker 8.26.1
— В LinkAssistant добавлена синхронизация проектных и глобальных настроек: синхронизация профилей клиентов и компаний, учетных записей Google, проектные и глобальные события в разных проектах и приложениях
Rank Tracker 8.25.3
— обновлена библиотека IP-адресов, исправлены некоторые проблемы, связанные с обновлением объема поиска и конкуренции
Rank Tracker 8.25.2
— Исправлено: функция ротации прокси
— Обновлены: шрифты для названий языков в модуле исследования ключевых слов Показатели силы в Rank Tracker. Исправлено несколько мелких проблем: сохранение отчета Истории рейтингов, ошибка шаблона экспорта и ряд других проблем. Метод Google Forecast и несколько других мелких проблем были исправлены
Rank Tracker 8. 23.22
— функция прогнозов Google обновлена для поддержки учетных записей Google Ads. Исправлено формирование отчетов в формате PDF
Rank Tracker 8.23.21
— Внутренний браузер улучшен и настроен для лучшего взаимодействия с Google re-captcha. Исправлено несколько других мелких проблем
Rank Tracker 8.23.20
— Исправлено несколько мелких проблем
Rank Tracker 8.23.19
— Обновлен алгоритм сбора конкурентов по фактору TF-IDF и несколько исправлены другие мелкие ошибки. Реализовано новое изменение для автоматических обновлений программного обеспечения: выпуски новых версий будут пропущены приложениями, у которых есть активные задачи, работающие в фоновом режиме
Rank Tracker 8.23.18
— В Rank Tracker добавлены новые функции: создавать запланированные задачи только для записей проектов, отмеченных определенными тегами; приостанавливать и возобновлять выполнение задач; в модуль «Ключевые слова рейтинга» добавлено новое диалоговое окно SERP, в котором отображается список рейтинговых веб-сайтов. теперь поддерживается Rank Tracker для функций SERP. В Rank Tracker исправлена проблема: URL-адреса с закодированными символами теперь корректно отображаются в проекте
Rank Tracker 8.23.15
— Rank Tracker был адаптирован к новому интерфейсу Google Ads и механизму проверки Google Search Console. Модуль песочницы: он содержит имена методов, из которых были собраны новые идеи ключевых слов. Столбец «Теги» теперь синхронизирован во всех модулях исследования ключевых слов
Rank Tracker 8.23.13
— Журнал изменений недоступен для этой версии
Rank Tracker 8.23.12
— Исправлено несколько мелких ошибок
Rank Tracker 8.23.11
— Исправлена проблема подсчета сложности ключевых слов для домена проекта
Rank Tracker 8.23.10
— Новый поиск добавлен движок Google.kg, исправлена проблема с подсчетом сложности ключевых слов в модуле исследования ключевых слов
Rank Tracker 8.23.9
— Исправлено несколько мелких ошибок подключение к учетной записи Google Adwords было обновлено в Rank Tracker
Rank Tracker 8. 23.7
— В Rank Tracker исправлена проблема с подсчетом общего числа посещений. Оптимизирован процесс подключения профилей GA с несколькими учетными записями.
Rank Tracker 8.23.6
— Журнал изменений недоступен для этой версии
Rank Tracker 8.23.5
— Изображения Google.ca добавлены в список поддерживаемых поисковых систем исправлены мелкие ошибки
Rank Tracker 8.23.3
— Исправлена проблема с выбором страны в инструменте Планировщика ключевых слов Google Adwords и несколько других ошибок.
Rank Tracker 8.23.2
— Исправлено несколько мелких ошибок уже ранжируется с помощью нового метода Ranking Keywords
Rank Tracker 8.22.9
— Исправлено несколько мелких ошибок
Rank Tracker 8.22.8
— Исправлено несколько мелких ошибок
Rank Tracker 8.22. 7
— Обновлена библиотека whois для проверки возраста домена
— Исправлена проблема со сбором результатов Яндекс Директ вместе с органическим ранжированием
Rank Tracker 8. 22.6
— Исправлено несколько мелких ошибок
Rank Tracker 8.22.5
— Исправлена проблема размытого интерфейса на дисплеях Retina
Rank Tracker 8.22.4
— Исправлено несколько мелких ошибок
Rank Tracker 8.22.3
— Исправлено несколько мелких ошибок
Rank Tracker 8.22 .2
— Исправлено несколько мелких ошибок
Rank Tracker 8.22.1
— Исправлено несколько мелких ошибок
Rank Tracker 8.22
— Решена проблема с расчетом средней цены за клик
Rank Tracker 8.21.7
— Исправлена проблема, связанная со сбором объема поиска через Google Прогноз
Rank Tracker 8.21.6
— Реализовано исправление для нового интерфейса Google Adwords Keyword Planner
Rank Tracker 8.21.5
— Несколько мелких ошибок фиксированный
Rank Tracker 8.21.4
— исправлено несколько незначительных ошибок
Rank Tracker 8.21.3
— исправлена проблема со сбором URL-адресов из Google Top Stories в результаты поиска ключевых слов
Rank Tracker 8. 21.2
— исправлена ошибка, приводившая к сбору неправильного количества конкурентов для вкладки «Сложность ключевого слова»
Rank Tracker 8.21.1
— Исправлено несколько мелких ошибок
Rank Tracker 8.21
— Исправлена проблема с некорректными результатами графика видимости для конкурентов проекта
Rank Tracker 8.20.5
— Исправлено дублирование записей для модуля «Карта ключевых слов», исправлена проблема с фильтрами для Яндекс Регионов под главным окном
Rank Tracker 8.20.3
— Улучшен UI для свернутого вида интерфейса и для экранов с низким разрешением, а также исправлены некоторые другие мелкие ошибки
Rank Tracker 8.20.2
— Фильтр времени из модуля исследования ключевых слов исправлено
Rank Tracker 8.20.1
— Новая версия Rank Tracker с улучшенным алгоритмом использования памяти для 64-битных машин Windows
Rank Tracker 8.20
— Исправлено несколько ошибок и реализованы улучшения пользовательского интерфейса в Rank Tracker
WordStat 2019 | Meta-Guide.
comПримечания:
WordStat — это дополнительный модуль анализа контента и извлечения текста из QDA Miner.
- Программное обеспечение CAQDA
- CAQDAS (компьютерный анализ качественных данных)
- компьютерный анализ контента
Ресурсы:
- atlasti.com .. мощное рабочее место для качественного анализа больших массивов текстовых данных
- dedoose.com .. кроссплатформенное приложение для анализа качественных и смешанных методов исследования с текстовыми данными
- lexicoder.com .. многоплатформенное программное обеспечение на основе Java для автоматизированного анализа содержания текста
- liwc.wpengine.com . золотой стандарт компьютерного анализа текста
- maxqda.com .. ПО для качественного анализа данных
- rstudio.com .. профессиональное программное обеспечение с открытым исходным кодом для r
- sas text miner .. программное обеспечение для анализа текста для более быстрого и глубокого анализа неструктурированных данных
- simstat . . альтернатива spss или аналогичному программному обеспечению для статистического анализа
- visualtext.com .. интегрированная среда разработки для построения систем извлечения информации
Википедия:
- Категория:Программное обеспечение QDA
- Компьютерное программное обеспечение для качественного анализа данных
- Контент-анализ
- Интердискурс
- MAXQDA
- Исследования Провалиса
- Майнер QDA
- Качественный анализ
- Количественный анализ
- Социальная информатика
- WordStat
Каталожные номера:
- Интеграция динамического развития информационных технологий в учебный процесс (2017)
- Использование методов интеллектуального анализа данных и интеллектуального анализа текста в образовательных исследованиях (2017)
- Анализ предметной области для организации знаний: инструменты для извлечения онтологий (2015)
- Кембриджский справочник по корпусной лингвистике английского языка (2015)
- Руководство по кодированию для качественных исследователей (2015 г. )
- Сравнительный анализ трех типичных программ для анализа текста (2014)
- Феномен телетона в Чили: лингвистическая перспектива (2014)
- Использование программного обеспечения в качественных исследованиях: пошаговое руководство (2014)
См. также:
100 лучших видеороликов RapidMiner | 100 лучших видео SPSS | 100 лучших статистических видео | Nvivo
Развитие интеллектуальных технологий ведения сельского хозяйства в Малайзии
GWW En, H Devanthran — TEST Engineering & Management, 2019 — iceiee.org
… публикации. Модуль Wordstat программного обеспечения QDA Miner был активирован для анализа названия, аннотации и ключевых слов выбранных публикаций для определения следующих значений параметров: i) частота (количество случаев в термине …
О пороке и добродетели: религиозная и моральная риторика в деловой прессе и экономический кризис
Э. Паттон — Журнал религии и деловой этики, 2019 г. — via. library.depaul.edu
… осторожное дело. Затем для извлечения и кодирования соответствующих слов использовалась программа Wordstat, компонент анализа контента и анализа текста QDA Miner. Для этого в Wordstat были импортированы предустановленные словари. Для религиозных …
СВОЙСТВА, КОТОРЫЕ СПОСОБСТВУЮТ УДОВЛЕТВОРЕННОСТИ ГОСТЕЙ: СРАВНИТЕЛЬНОЕ ИССЛЕДОВАНИЕ ОТЗЫВОВ, ОПУБЛИКОВАННЫХ НА BOOKING. COM И НА AIRBNB …
I Egresi, V Puiu, V Zotic, D Alexandru – 2019 – researchgate.net
… Мы использовали отзывы, опубликованные пользователями на booking.com (для клиентов отелей) и на платформе Airbnb в период с мая по ноябрь 2018 года, а также количественно и качественно проанализировали их с помощью QDA Miner и Wordstat, чтобы понять основные атрибуты, связанные с …
Парамилитаризм и музыка в Колумбии: анализ corridos paracos
Э.Б. Каро, Дж. Р. Суавита – Журнал языка и политики, 2019 г.– jbe-platform.com
… Трупы. Данные были обработаны с помощью Excel и SPSS для извлечения количественных результатов по текстам, а WordStat (QDA Miner) использовался для получения частот и создания графики полного текстового корпуса. Затем две матрицы …
ЧТО ДЕЛАЕТ ДИКИХ ТУРИСТОВ СЧАСТЛИВЫМИ И ЧТО ИХ РАЗОЧАРАЕТ? УЧИТЕСЬ ИЗ ОБЗОРОВ, РАЗМЕЩЕННЫХ НА TRIPADVISOR. GeoJournal of …
I Egresi, T Prakash – 2019 – gtg.webhost.uoradea.ro
… Программное обеспечение QDA Miner и Wordstat использовалось для качественного анализа контента и кодирования отзывов, размещенных иностранными туристами на TripAdvisor. Исследование показало, что подавляющее большинство посетителей остались довольны посещением национального парка Яла …
Удалось или нет? Оценка потенциала исследовательской ниши: тематическое исследование в области виртуального управления качеством
A Weckenmann, ? Боди, С. Попеску, М. Драгомир… — Устойчивое развитие, 2019 — mdpi.com
… в классификации, тегировании, разборе, семантическом анализе и сокращении объема информации до приемлемого размера [13,14,15], но в то же время время сохраняя связность, разборчивость и смысл анализируемого текста: WordStat; майнер QDA; Морковь 2 ; РапидМайнер; Тропы. 3,3 …
Что радует туристов, занимающихся дикой природой, и что их разочаровывает? Учимся на отзывах, размещенных на TripAdvisor.
И Эгреси, Т. Пракаш — GeoJournal of Tourism and Geosites, 2019 г. — cabdirect.org
Туризм в дикой природе является одним из самых быстрорастущих секторов туризма в мире и все чаще используется для продвижения туризма в некоторых странах. С 26 национальными парками и 61 заповедником дикой природы, покрывающими 13% площади суши, Шри-Ланка имеет большой потенциал стать одним из …
Потери и ущерб в Пятом оценочном отчете МГЭИК (Рабочая группа II): анализ текстовой информации /WordStat) был использован для извлечения предложений из 30 глав ДО5 РГII МГЭИК, а также РП и Технического резюме (ТР), содержащих слова убыток(и), потерянный, утерянный, утерянный, проигравший(ые), ущерб(я), поврежденный или нанести ущерб …
Количественные исследования в области образования и обучения взрослых
E Boeren – Mapping of the Research Field of Adult Education and …, 2019 – Springer
… Все журнальные статьи, включенные в анализ, были подвергнуты контекстному и текстовому анализу, проведенному с помощью программных пакетов QDA Miner и WordStat, продуктов разработана Provalis Research. QDA Miner …
Письма в редакцию в Колумбии: святилище общественных эмоций
MM Barrios, LM Gil – Письма в редакцию, 2019 – Springer
… Программное обеспечение для анализа смешанных данных – QDA Miner и WordStat – использовалось для обработки данные, используя его различные функции, такие как поиск ключевых слов в контексте. В соответствии с критериями Криппендорфа (2013) компьютерная помощь, предлагаемая QDA, считалась интерактивно-герменевтической …
Исследование основного состава основных блюд турецкой кухни
М. Чакмак, М. Сар????к – Anais Brasileiros de Estudos Turísticos …, 2019 – Periodos.ufjf.br
… Данные, полученные в это исследование было использовано для изучения с помощью программного обеспечения QDA MINER-WordStat с помощью анализа TF-IDF (частота терминов – обратная частота документов). Метод взвешивания TF-IDF — это термин «метод нормализации» в области IR …
ГЛАВА ШЕСТНАДЦАТАЯ ДИРЕКТИВЫ В БИЗНЕСЕ (ПРОДАЖИ) ДИСКУРС: BESCHLEUNIGUNG (УСКОРЕНИЕ)
A DANIELEWICZ-BETZ – Discourse, Communication and the …, 2019 – books. google.com
… Применяемый метод представляет собой смешанный качественный анализ данных с помощью QDA Miner и WordStat 7.0. 6, программный пакет для кодирования, аннотирования, извлечения и анализа коллекций документов и изображений … Анализ контента с помощью QDA Miner и WordStat 7.0 …
Facebook и виртуальная нация: социальные сети и сообщество арабских канадцев
A Al- Рави — ИИ и ОБЩЕСТВО, 2019 г.– Springer
… Собранные комментарии были проанализированы с помощью компьютерной программы под названием QDA Miner 4–Wordstat, которая подходит для анализа больших данных. В этом исследовании анализируется текстовый корпус путем выявления наиболее часто встречающихся слов и …
Подходы к совместной конфигурации в разработке линеек программных продуктов: систематическое картографическое исследование
S Edded, SB Sassi, R Mazo, C Salinesi… – Journal of Systems and … , 2019 — Elsevier
… Для этого мы импортировали сегмент «заголовок-аннотация-ключевое слово» каждой статьи в QDA Miner и WordStat 1, которые представляют собой инструменты анализа, которые могут не только определять наиболее часто встречающиеся термины, но и выявлять базовые отношения между этими терминами. …
Будущие онлайн-компетенции преподавателей: взгляды студентов
П. Дэвидсон — Международный журнал по электронному обучению, 2019 г. — Learntechlib.org
… вызов. Проблемы с орфографией и заглавными буквами вызвали некоторые проблемы. Использование QDA Miner v4.1.10 очень помогло. Wordstat v6.1.22 (надстройка с майнером QDA) также помог в обнаружении частоты слов и фраз. Независимо …
Сравнение существующих гибких подходов в контексте разработки мехатронных систем: возможности и ограничения в реализации
J Heimicke, M Niever, V Zimmermann… – Proceedings of the …, 2019 – cambridge.org
… (Provalis Research, QDA Miner 5) На первом этапе были отфильтрованы все отрывки, содержащие термины agile и/или agility. из бумаг. С помощью WordStat (Provalis Research, WordStat 6) — программного обеспечения для анализа контента и интеллектуального анализа текста — все соответствующие абзацы могут быть …
Болезни и эмоции: автоматизированный анализ содержания рассказов о здоровье в запросах в онлайн-консультационную службу по вопросам здоровья
SH Kessler, S Schmidt-Weitmann — Health Communication, 2019 — Taylor & Francis
… Метод Автоматизированный анализ содержания всех онлайн-запросов в службу онлайн-консультаций USZ с 08. 09.1999 по 07.06.2018 был проводится с использованием программного обеспечения WordStat с QDA-Miner. Полная выборка включала …
Использование медиа-информатики для эпиднадзора и понимания вспышек заболеваний
B Falade – South African Journal of Science, 2019 – scielo.org.za
… текст. Ежедневный формат был изменен на еженедельный, чтобы соответствовать еженедельным результатам Google. Для анализа данных использовалась программа QDA/Miner WordStat, которая работает на английском и португальском языках. Ограничения исследования. Secondary …
Модели сотрудничества как функция исследовательского опыта среди смешанных исследователей: библиометрическое исследование смешанного метода
MS Wachsmann, AJ Onwuegbuzie… – Качественный …, 2019 – search.proquest.com
… качественные данные и количественные данные, и как составлять отчеты об исследованиях смешанных методов с помощью серии так называемых блокнотов смешанных методов, в которых учащиеся используют компьютерное программное обеспечение для анализа данных смешанных методов [например, QDA Miner, WordStat] для облегчения …
Элемент комплекса маркетинга кофейни. Практический пример @ CoffeeBeanIndo
YHJ Sihite — Marketing, 2019 — pdfs.semanticscholar.org
… набор данных твитов. Кластерный анализ снижает сложность данных (Campbell, Pitt, Parent, & Berthon, 2011). Программное обеспечение Provalis Research состоит из двух программ: Wordstat и Simstat, которые называются QDA Miner. Это программное обеспечение …
Кризис фентанила и темная сторона социальных сетей
Аль-Рави – Телематика и информатика, 2019– Elsevier
… опасность злоупотребления наркотиками. Исследование данных Twitter было проведено с использованием компьютерной программы под названием QDA Miner-WordStat 8, поскольку набор данных Twitter намного больше, чем набор данных Instagram. Это программное обеспечение использовалось …
Повышение прозрачности и достоверности индуктивных исследований с помощью компьютерного программного обеспечения для качественного анализа данных
П. О’Кейн, А. Смит, М.П. Лерман – Организационные исследования …, 2019 г. – journals.sagepub.com
Многие ученые призвали к качественному исследованию, чтобы продемонстрировать прозрачность и надежность процесса анализа данных. Тем не менее, эти процессы, особенно в рамках индуктивных исследований, часто приводят к…
Женская природа, рогоносцы и простофили: понимание мужчин, идущих своим путем, как части Маносферы.
Z Hunte – 2019 – diva-portal.org
… Фуко анализ дискурса. Контент-анализ был выполнен с помощью качественного и количественного программного обеспечения WordStat. Благодаря использованию этих инструментов было обнаружено, что женская природа, феминизм, мужественность, общество и самосовершенствование были общими темами в сообществе …
Страх перед музыкальным исполнением и воспринимаемые преимущества участия пожилых людей в музыкальных группах в общественных группах
AK Barbeau, R Mantie – Journal of Research in Music …, 2019 – journals.sagepub.com
Цель настоящего исследования состояла в том, чтобы изучить тревожность при исполнении музыки и причины, о которых сообщали сами члены сообщества пожилых людей для участия…
Предполагаемые целевые бренды европейских столичных городов и их позиционирование
S Hanna, J Rowley – Journal of Marketing Management, 2019 – Taylor & Francis
… За этим последовал анализ соответствия DBPL городов в качестве основы для исследования относительного положения этих городов на основе их размеров DBP. Сбор и анализ данных был облегчен благодаря использованию QDA Miner с WordStat …
Социальное предпринимательство: анализ сети Ashoka
E Bega – 2019 – tesi.cab.unipd.it
Страница 1. UNIVERSITA’ DEGLI STUDI DI PADOVA DIPARTIMENTO DI SCIENZE ECONOMICHE ED AZIENDALI “M.FANDILA LA URE CORSO MAGISTRALE IN BUSINESS ADMINISTRATION TESI DI LAUREA «СОЦИАЛЬНОЕ ПРЕДПРИНИМАТЕЛЬСТВО …
Агломерации, 1 кластеры и промышленные районы
M Гонсалес-Лоурейро, Ф. Слова в заголовке, ключевые слова, предоставленные авторами, и аннотация статьи стали объектом последующего контент-анализа. Мы использовали программное обеспечение QDA Miner (v. 4.1. 15), которое включает утилиту Wordstat (v. 7.0 …
Понимание больших данных в библиотечном деле
M Zhan, G Widén – Journal of Librarianship and Information …, 2019 – journals.sagepub.com
Большие данные широко обсуждаются. Разнообразное воздействие и потенциал больших данных были точно определены и эмпирически доказаны. Тем не менее, нет единого мнения…
Практичность и идентичность как функции образования в меннонитских и гуттеритовских общинах старого порядка
Дж. Циммерман — Журнал амишей и простых анабаптистов…, 2019– ideaexchange.uakron.edu
… Процесс начался с количественного анализа ключевых слов и фраз с использованием программного обеспечения QDA Miner™ и WordStat™. Этот процесс дал приблизительное определение тем и понятий, которые интервьюируемые считали наиболее важными …
Кто участвует а кто нет: Международное сообщество как средство (де)легитимации
М Митрани – law.ed.ac.uk
… конкретный я в Мы. Методы План эмпирического исследования состоит из двух этапов, на которых я применяю методы автоматизированного компьютеризированного дискурса и контент-анализа с использованием программного обеспечения QDA Miner и Wordstat3. Этап I …
Классификация переформулировок: применение машинного обучения и текстовой аналитики
BL Hayes, JE Boritz — 2019 — papers. ssrn.com
… Классификация была продублирована с использованием WordStat (версия 7.1.6) и загрузки текста объявлений о переформулировке в WordStat с помощью QDA Miner, еще одного исследовательского продукта Provalis. Электронная копия доступна по адресу: https://ssrn.com/abstract=2716166 Страница 14. 13 …
Подливаете масла в огонь? Политизация оценки политики ЕС в национальных парламентах
JM Hoerner — Politische Vierteljahresschrift, 2019 — Springer
… Словари затем применялись к документам для каждой страны/месяца с использованием программы QDA Miner/WordStat (Provalis Research, Монреаль, Канада). Примеры ключевых слов можно найти в онлайн-приложении …
Влияние СМИ на регулирование ГМО: пример из России
E Галата Бикелл – Российский коммуникационный журнал, 2019 – Taylor & Francis
… Затем использовалось автоматизированное программное обеспечение для непараметрического контент-анализа под названием QDA Miner и сопровождающий его пакет WordStat. И тон, и кадры были исследованы с помощью пакета WordStat …
Внедрение Индустрии 4.0: систематическое изучение литературы с использованием анализа текста
H Nayernia, H Bahemia, S Papagiannidis – 2019 – iceb.johogo.com
… 19-я Международная конференция по электронному бизнесу, Ньюкасл-апон-Тайн, Великобритания , 8-12 декабря 2019 г. 244 Интеллектуальный анализ текста и данных: После этапа предварительной обработки набор статей загружается в надстройку QDA miner под названием Wordstat для полнотекстового анализа …
Электронная библиотека АИС (AISeL)
H Nayernia, H Bahemia, S Papagiannidis – 2019 – aisel.aisnet.org
… 19-я Международная конференция по электронному бизнесу, Ньюкасл-апон-Тайн, Великобритания, 8-12 декабря 2019 г. На этапе обработки набор статей загружается в дополнительное программное обеспечение QDA Miner под названием Wordstat для полнотекстового анализа …
Маркеры агентства в предварительных учителях музыки: направленный анализ содержания письменной курсовой работы
Дж. Ратгебер, Р. Манти – Бюллетень Совет по исследованиям в области музыки …, 2019 г.– JSTOR
… Закодировано Этот контент загружен с 66.249.66.156 в субботу, 14 декабря 2019 г., 08:22:37 UTC. были проанализированы с помощью инструмента анализа текста QDA Miner, WordStat …
Cumulus-SDN-IxDA Report-Seattle Session 2019
M Manhaes, J Ball, MB Botero, I Sperano, A Hartman… – researchgate.net
… После расшифровки и анализируя материал, был проведен процесс кластеризации с применением автоматизированного метода компьютерного анализа текста с использованием программного обеспечения QDA Miner и WordStat (Mitrani, 2017; Provalis, 2014) …
Большие данные для прогнозирования: Патентный анализ – Патентование больших данных для прогнозного анализа
M Pejic-Bach, J Pivar, Ž Krsti? – Управление большими данными и …, 2019 г. – igi-global.com
… анализ, в частности анализ ассоциаций патентных областей МПК, извлечение ключевых терминов и кластеризация. Для этого использовались Statistica Text Miner 13.0 и Provalis Wordstat 8.0. Глава состоит из следующих разделов …
Призыв к повышению насыщенности на этапе анализа качественных данных за счет использования нескольких подходов к анализу качественных данных
AN Sechelski, AJ Onwuegbuzie — Качественный отчет, 2019 г. — search.proquest.com
… Для получения информации о том, как провести KWIC через WordStat, мы отсылаем вас к страницам 93–95 Руководства пользователя WordStat (Provalis Research, 1989-2014). Затем QDA Miner Version 4.1.33 (Provalis Research, 2014a) использовался для проведения классического контент-анализа (Berelson, 1952 …
Пересекающееся насилие: представления сомалийской молодежи в канадской прессе
Y Jiwani, A Al-Rawi – Журналистика, 2019– journals.sagepub.com
В этой статье исследуется освещение канадской молодежи сомалийского происхождения в канадской прессе с использованием двух методологических процедур. Диаграмма репутации…
«Единство — наша сила»: взгляды на набор и удержание афроамериканских студентов-мужчин социальной работы
M Nsonwu, C Welch-Brewer, OM Folarin… – Urban Social …, 2019 – connect. springerpub .com
… объем интервью (Теш, 1990). Программное обеспечение (QDA Miner 4 и WordStat 7) использовалось в качестве организационного инструмента для определения частотности слов, методов определения ключевых слов в контексте и извлечения цитат. Команда встретилась как группа, чтобы …
Социальная ответственность и ориентация на консенсус в государственном управлении: анализ содержания
N Tomaževi? – Central European Public Administration Review, 2019 – uprava.fu.uni-lj.si
… Благодаря функциям анализа текста QDA Miner предоставляет широкий спектр исследовательских инструментов для определения шаблонов в кодировании и взаимосвязей между присвоенными кодами и другими числовыми или категориальные переменные (Suerdem, 2014). Полная интеграция с WordStat, количественным …
Группа поддержки при алкоголизме на основе смартфона: влияние предоставления и получения эмоциональной поддержки на преодоление самоэффективности и рискованного употребления алкоголя
W Yoo, DV Shah, MY Chih… — Health Infomatics …, 2019 – journals. sagepub.com
Цель этого исследования состояла в том, чтобы изучить характер и последствия обмена эмоциональной поддержкой через группу поддержки на основе смартфона для пациентов с алкогольной зависимостью. Из 349 пациентов, которые…
Изучение социотехнических сценариев будущего в СМИ: дело о переходе на энергию в итальянских ежедневных газетах
F Neresini, P Giardullo, E Di Buccio, A Cammozzo — Quality & Quantity, 2019 — Springer
… Чтобы выбрать подкорпус статей, связанных с будущим, мы использовали автоматическую классификацию текста с помощью алгоритмов Wordstat 7 в сочетании с QDA- Майнер 5. Во-первых, среди статей, связанных с ET, мы выбрали образец, содержащий слова, которые явно относятся к FS (основные …
Визуализация онлайн- и офлайн-сетей турецкой диаспоры в трех европейских странах: проверка роли сети Структура и динамика в социальных …
RI Giglou, C. Ogan, L d’Haenens — researchgate.net
… Контент будет автоматически анализироваться с помощью QDA Miner и Wordstat. Сеть тем и будет отображена NodeXL, чтобы выяснить структуру диалогов турецкой диаспоры в Твиттере. 5. ССЫЛКИ [1] Burns, A., & Eltham, B. (2009) …
Война слов: British Gazette и британский рабочий во время всеобщей забастовки 1926 года
MD Harmon – Labor History, 2019 – Taylor & Francis
… Исследователь использовал QDA Miner и WordStat для анализа частотности определенных ключевых слов и фраз, а также для сравнения газет Gazette, Worker и общераспространенных газет на основе четырех «словарей» определенных терминов, связанных с забастовками …
Картирование будущего трансграничных слияний и поглощений: обзор и программа исследований
T Kiessling, B Vla?i?, M Dabi? – IEEE Transactions on …, 2019 – ieeexplore.ieee.org
… наша выборка дескрипторов, чтобы можно было сравнить их с общей картой поля. Мы приняли процедуру, представленную в [35]–[38], и закодировали предоставленные автором ключевые слова по основным категориям или темам, используя программное обеспечение QDA Miner v. 5 и Wordstat v.7…
Сопоставление экономических, социальных и технологических атрибуты экономики совместного потребления
Давлембаева Д, Папагианнидис С… – … Технологии и люди, 2019 – emerald.com
… включены в количественный анализ. QDA Miner с его расширением Wordstat использовался для анализа статей, поскольку было доказано, что он обеспечивает надежные результаты исследований в различных дисциплинах (Silver, 2014). Выбор …
Рассказ об использовании женщинами общественного туалета: исследование Варангала
Ю.М. Редди, С. Рагхаван… – Indian Journal of Gender …, 2019– journals.sagepub.com
Несмотря на повышенный акцент на повестке дня страны в области санитарии, обусловленной как международными, так и национальными целями развития, мало научных …
Неформальный и неформальный музыкальный опыт: сила, знания и обучение в музыке педагогическое образование в Чили
C Poblete, A Leguina, N Masquiarán… – … Journal of Music …, 2019 – journals. sagepub.com
Предыдущие исследования признают важность музыкального опыта для подготовки учителей музыки. Тем не менее, текущие усилия не дают всестороннего представления о т…
Воспринимаемые последствия киберзапугивания во взрослом возрасте на рабочем месте
ML Dark — 2019 — search.proquest.com
Страница 1. Воспринимаемые последствия киберзапугивания во взрослом возрасте на рабочем месте Рукопись диссертации частично представлена в Школу психологии Североцентрального университета Выполнение требований для получения степени ДОКТОРА ФИЛОСОФИИ МЕЛИССЫ ЛИ ДАРК …
Как иностранные первичные публичные предложения привлекают внимание инвесторов? Исследование влияния языка
DP Blevins, A Ingram, EWK Tsang… — Strategic …, 2019 — journals.sagepub.com
Язык получает все большее признание как способный формировать стратегические результаты. Чтобы понять влияние языка на предпринимательскую среду, мы изучаем язык…
Как следует подходить к анализу данных и отображению результатов?
Р. Кукси, Г. Макдональд — Выживание и процветание в аспирантуре…, 2019 г. — Springer
Основная цель всех форм анализа данных — извлечь смысл из необработанных данных и донести его до одной или нескольких конкретных аудиторий. В этой главе рассматриваются подходы к анализу данных, которые…
Латентный семантический анализ отчетов о корпоративной социальной ответственности (с приложением к фирмам Hellenic)
I Kountouri, E Manousakis, AE Tsekrekos – International Journal of …, 2019 – Springer
… Прежде чем покинуть этот подраздел предварительной обработки корпуса, несколько реализаций ноты в порядке. Во-первых, весь наш текстовый анализ в этой статье проводится с использованием программного обеспечения QDA Miner® и WordStat® компании Provalis Research. 11 …
Дополненная реальность и информатика здравоохранения: исследование, основанное на библиометрическом и контент-анализе научной коммуникации и социальных сетей
N Gupte – 2019 – digitalcommons. liu.edu
Страница 1. Университет Лонг-Айленда Digital Commons @ LIU Selected Full Text Dissertations, 2011- LIU Post 2019 Дополненная реальность и информатика здравоохранения: исследование, основанное на библиометрическом и контент-анализе научной коммуникации и социальные сети Nilish Gupte …
Закон Федеральной юстиции о борьбе с коррупцией на юге Бразилии
LM Madeira, L Geliski – Revista de Administração Pública, 2019 – SciELO Brasil
… Латиноамериканская политика и общество, 56(2), 27 -48. [Ссылки]. Исследования Провалиса. (2010). WordStat 6: модуль анализа контента для QDA Miner и SimStat. Руководство пользователя. Монреаль, Канада: Автор. [Ссылки]. Синоретто, Дж. (2014). Seletivide Penal e Acesso à Justiça …
Использование информации от заинтересованных сторон в Твиттере: тематическое исследование коротких перерывов в испанских туристических городах Закон о справедливости в борьбе с коррупцией на юге Бразилии.
L Mori Madeira, L Geliski – RAP: Revista Brasileira de …, 2019 – search. ebscohost.com
… 2019 RAP | Закон Федеральной юстиции о борьбе с коррупцией на юге Бразилии 989 (через ключевые категории) в программном обеспечении WordSTAT (Provalis Research, 2010 г.), поэтому все внимание сосредоточено на содержании судебных решений и профиле уголовного преследования по делам о коррупции …
Развитие быстрыми темпами: исследования Искусственный интеллект в высшей школе.
F ALTINAY, C KARAATMACA… – … & Software for …, 2019 – search.ebscohost.com
… QDA) QDA Miner — это простой в использовании программный пакет для качественного анализа данных для кодирования, аннотирования, извлечения и анализа небольших и большие коллекции документов и изображений. Полная интеграция программы с SimStat, инструментом статистического анализа данных, и WordStat…
Быстрое развитие: исследования искусственного интеллекта в высшем образовании
C Karaatmaca, G Dagli PhD — The International Scientific —…, 2019 — search.proquest.com
… QDA) QDA Miner — это простая в использовании программа Пакет программного обеспечения для качественного анализа данных для кодирования, аннотирования, извлечения и анализа небольших и больших коллекций документов и изображений. Полная интеграция программы с SimStat, инструментом статистического анализа данных, и WordStat …
15-я Международная научная конференция «Электронное обучение и программное обеспечение для образования», Бухарест, 11-12 апреля 2019 г.
F ALTINAY, C KARAATMACA, Z ALTINAY, G DAGLI – ceeol.com
… пакет программного обеспечения для анализа данных для кодирования, аннотирования, извлечения и анализа небольших и больших коллекций документов и изображений. Полная интеграция программы с SimStat, инструментом статистического анализа данных, и WordStat …
ОСНОВНЫЕ НАВЫКИ ДЛЯ ТРУДОУСТРОЙСТВА, ТРЕБУЕМЫЕ НАЛОГОВЫМИ БУХГАЛТЕРАМИ.
LINMEI TAN, F LASWAD – Австралазийский налоговый журнал …, 2019 – business.unsw.edu.au
… работа. B-анализ Мы использовали пакет программного обеспечения для анализа контента, QDA Miner© версии 5 и WordStat© версии 7, чтобы вычислить частоты конкретных категорий навыков, включенных в рекламу. 71 На основе …
Эмпирическое исследование роли занятости студентов в обучении лидерству
Дж. С. Льюис – Новые направления для студенческого лидерства, 2019 г. – Интернет-библиотека Wiley
… способствовал эффективной обработке более 67 000 открытых ответов; с таким большим количеством данных традиционные качественные методы были непрактичными и неэффективными (Ignatow & Mihalcea, 2017; Miner et al., 2012, стр. 30). С помощью программного обеспечения WordStat я исследовал …
Модель поведения туристов: образ места назначения, удовлетворенность посетителей и лояльность ИМИДЖ, УДОВЛЕТВОРЕНИЕ ПОСЕТИТЕЛЕЙ И ЛОЯЛЬНОСТЬ Виржиния Мария де Карвалью Диас Лопес Фигу Диссертация представлена как частичное требование для присвоения степени магистра в области управления Руководитель: проф …
Сетевые структуры в разговоре о перекрестных движениях: Демократия сейчас!, 2003-2013
А. Тофт — Исследования социальных движений, 2019 — Тейлор и Фрэнсис
… В исследовании используется программа корпусно-лингвистического анализа, подходящая для чтения и анализа больших объемы электронного текста (WordStat, версия 7. 1.6). Корпус, использованный для этого исследования, содержит все транскрибированные сюжеты, доступные на сайте Democracy Now …
EPL, 79 Поправка о равных правах (ERA), 13 Обзор европейских медиасистем, 17 Повседневные заботы, 124
D Рекламодатель, F Вестник — Сравнительные и исторические перспективы — Springer
… 111, 119, 120, 130, 131, 138, 139, 142, 143, 147, 148, 164 Общественная сфера, местная, 131, 138, 143 Удар , 132 Q QDA Miner, 71 Анкета, 9 … их дом, 26, 44, 45 Женские гражданские ассоциации (WCA), 30–34, 36, 37, 40, 44 Женская кооперативная гильдия, 27 WordStat, 71 Мир …
Стратегии корпоративных социальных сетей: изучение того, как совместные команды уменьшают потерю знаний в организации
DS Walker – 2019 – search.proquest.com
Страница 1. СТРАТЕГИИ ПРЕДПРИЯТИЯ В СОЦИАЛЬНЫХ СЕТЯХ: ИССЛЕДУЕМ, КАК СОВМЕСТНЫЕ КОМАНДЫ СМЯГЧАЮТ ОРГАНИЗАЦИОННЫЕ ПОТЕРИ ЗНАНИЙ Диссертация, представленная при частичном выполнении требований для получения степени доктора компьютерных наук …
Семантический анализ для обнаружения информационно-коммуникационных угроз пользователей онлайн-сервисов
Федушко С. , Бенова Е. – Procedia Computer Science, 2019 – Elsevier
… анализа компьютерного контента, Иванов О. [8] имеет три типа программ: полностью автоматизированные пакеты для контент-анализ (WordStat, Crawdad Text … С помощью программного обеспечения QDA Global, Catpac и BAAL специалисты имеют возможность сделать качественный анализ текста …
Показывают ли онлайн-обзоры удобство и удобство использования мобильных приложений? Случай с WhatsApp
P Weichbroth, A Baj-Rogowska — Федеративная конференция 2019 …, 2019 — ieeexplore.ieee.org
… Вычислительная платформа включает в себя три основных инструмента: • QDA Miner для качественного анализа данных, включая кодирование, аннотирование, извлечение анализ малых и больших коллекций документов и изображений; • WordStat для контент-анализа открытых ответов, интервью или …
Мать знает лучше: понимание влияния блогов мам на убеждения и привычки мам в отношении питания
M Kalaitzandonakes – 2019 – ecommons. cornell.edu
… Затем мы начали вручную кодировать разделы A&D, используя программный пакет QDA Miner и сопроводительный пакет, WordStat. После нескольких прогонов кодовая книга стала более надежной, и мы подготовили вторую …
Президентство и СМИ: традиционные и новые медиа как действующие лица американской большой политики
Я Белко – ??????. ?????????. ??????, 2019 — elibrary.ru
… Кроме того, WordStat имеет инструмент совпадений и позволяет искать совпадения словоупотреблений в пределах одного… Некоторые выводы стали возможными с помощью QDA Miner : кодирование непристойной/оскорбительной лексики и аргументов авторитетных лиц в соответствующие …
Анализ настроений в ходе пятого опроса производственных предприятий и услуг округа
S Pinto – Economic Quarterly, 2019 – papers.ssrn.com
… См., среди прочего, Nyman et al. (2018), Торсруд (2018) и Каломирис и Мамайский (2019). 8 Provalis Research, поставщик текстового аналитического программного обеспечения QDA Miner и WordStat, предоставляет общий словарь настроений на веб-сайте для загрузки …
Сила позитивных слов: общение, познание и организационная трансформация
SK Muthusamy — Journal of Organizational Change Management, 2019 — emerald. com
… 36 переменных друг к другу из 223 описательных утверждений, мы провели кластерный анализ с использованием программного обеспечения QDA Miner, чтобы определить основные организационные, социальные и когнитивные аспекты и отношения между ними, отраженные в утверждениях (Wordstat 7 , 2014) …
ОПРЕДЕЛЕНИЕ ЭМОЦИЙ ПОТРЕБИТЕЛЕЙ В СОЦИАЛЬНЫХ СЕТЯХ
P MADHALA – 2019 – researchgate.net
Страница 1. PRASHANTH MADHALA ОБНАРУЖЕНИЕ ПОТРЕБИТЕЛЬСКИХ ЭМОЦИЙ В СОЦИАЛЬНЫХ СЕТЯХ Факультет бизнеса и управления Страница магистра наук 2.0081 …
Изучение атрибутов качества услуг Airbnb и их асимметричного влияния на удовлетворенность клиентов
Y Ju, KJ Back, Y Choi, JS Lee – International Journal of Hospitality …, 2019– Elsevier
… Собранные необработанные текстовые данные были изучены, а частота и совпадение слов были проанализированы с помощью QDA Miner 5 … темы), которые охватывают ключевые слова, определенные в …
Расширение предоставления медицинских услуг в Сент-Марке, Гаити: пример наращивания потенциала и развития инфраструктуры в рамках формирующейся коалиции
SL Tolson – 2019 – search. proquest.com
Стр. 1. РЕФЕРАТ Название диссертации: РАСШИРЕНИЕ ПРЕДОСТАВЛЕНИЯ МЕДИЦИНСКИХ УСЛУГ В СЕНТ. Марк, Гаити: тематическое исследование в области наращивания потенциала и развития инфраструктуры в рамках развивающейся коалиции…
Транснациональные пропагандистские сети в Информационном обществе
DL Cogburn — Springer
Page 1. Деррик Л. Когберн Транснациональные сети в Общественном обществе Партнеры или пешки? ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ И ГЛОБАЛЬНОЕ УПРАВЛЕНИЕ Стр. 2. Редактор серии информационных технологий и глобального управления …
Использование приложений ИКТ в исследованиях аспирантами в Гане
S ANKAMAH – 2019 – researchgate.net
… Robey, 2008; Университет Нового Южного Уэльса, 2016 г.; ван Девентер и Пиенаар, 2012). Например, Мейер и Даттон (2009) определили некоторые передовые или специализированные приложения ИКТ, такие как Transana; Наблюдатель; Вордстат; согласование; веб-тренды; нетлого; Трапеза; УЦИНет; Atlas.ti и др. в их …
Редко, поверхностно и скоро исчезнет: освещение в телевизионных новостях беженцев в США, 2006–2015
SM Brandle, JE Reilly — Refugee Survey Quarterly, 2019 — Academic.oup.com
… 34 Стенограммы были импортированы в QDA Miner и очищены от дубликатов, омографов и того, были ли поисковые слова включены только в данные, предоставленные Lexis-Nexis , такой … В WordStat был проведен дополнительный анализ контента, включая частотность слов и категоризацию …
Новые 10 транснациональных корпораций в испанской гостиничной индустрии
B Marco-Lajara, E Claver-Cortés… – Economic Clusters …, 2019– books.google.com
Страница 200. Новые 10 транснациональных корпораций в гостиничном бизнесе Испании. Анализ теории туристических районов Бартоломе Марко-Лахара, Энрике Клавер-Кортес, Мерседес Убеда-Гарсия, Франсиско Гарсия-Лилло и Патросинио дель Кармен Сарагоса -Sáez 1. Введение …
Планирование сосуществования в сложном мире, где доминируют люди
С. Марчини, К. Ферраз, А. Циммерманн… – … : Превращение конфликта в …, 2019 – books.google.com
… сказал инструменты. средства программирования и в развертывании. Опции SAS Trackur Miner LanguageWare, заказ и R, ввод Социальный контент Visual MATLAB и машина UIMA Анализ и данные для сравнения, включая Интернет; Упомяните внутреннее обнаружение в Интернете WordStat …
Асимметричная информация
J Yeabsley – nzae.org.nz
Стр. 1. ВЫПУСК № 64, апрель 2019 г. Информационный бюллетень, способствующий обмену информацией, новостями и идеями между членами Новозеландской ассоциации экономистов (Inc). . http://www.nzae.org.nz Асимметричная информация, выпуск № 64, апрель 2019 г. | 1 …
Рекомендации криптовалютным компаниям для укрепления доверия к криптовалютным продуктам и услугам
Y Белявцев — 2019 — vdu.lt
… Теперь количество ежедневных криптовалютных транзакций огромно, поэтому вы, как отправитель, должны привлекать майнера к своей транзакции с комиссией, которая пойдет майнеру в качестве вознаграждения за транзакцию … Таким образом, первый майнер, который решает каждый новый блок (блок может содержать несколько транзакций ) получает всю награду …
Самовосприятие внештатных преподавателей об их ролях в избранной системе муниципальных колледжей В ИЗБРАННОЙ СИСТЕМЕ КОЛЛЕДЖА СООБЩЕСТВА _____ Диссертация, представленная на факультете Департамента лидерства в образовании Государственного университета Сэма Хьюстона …
Вычислительные международные отношения Что могут сделать программирование, кодирование и интернет-исследования для дисциплины?
HA Ünver — All Azimuth: A Journal of Foreign Policy and Peace, 2019 — dergipark.