Парсер контента вконтакте | Сервис поиска аудитории ВКонтакте vk.barkov.net
Наш Сервис поиска целевой аудитории предоставляет в ваше использование огромный набор парсеров (специальных инструментов), с помощью которых вы сможете найти ответ на все ваши поисковые запросы ВКонтакте.Парсер контента ВКонтакте доступен по ссылке ниже.
В поле поиска укажите ссылки на группы ВКонтакте по одной ссылке на строку, задайте количество постов для просмотра.
Из предложенных форматов вывода данных выберите тот, который наиболее точно соответствует вашим требованиям.
Запустите парсер в работу, он просмотрит указанное вами количество постов на стенах пользователей и сообществ ВК, соберет их тексты и выведет в искомом формате.
А если вы ищите тексты постов с определенным словом или хэштегом, выполняйте это парсером по ссылке https://vk.barkov.net/newsfeed.aspx
Запустить скрипт для решения вопроса
Полезный небольшой видеоурок по этой теме
О сервисе поиска аудитории ВКонтакте
vk. barkov.net — это универсальный набор инструментов, который собирает самые разнообразные данные из ВКонтакте в удобном виде.
barkov.net — это универсальный набор инструментов, который собирает самые разнообразные данные из ВКонтакте в удобном виде.Каждый инструмент (скрипт) решает свою задачу:
Например, есть скрипт для получения списка всех подписчиков группы.
А вот тут лежит скрипт для сбора списка всех людей, поставивших лайк или сделавших репост к конкретному посту на стене или к любым постам на стене.
Ещё есть скрипт для получения списка аккаунтов в других соцсетях подписчиков группы ВКонтакте.И таких скриптов уже более 200. Все они перечислены в меню слева. И мы регулярно добавляем новые скрипты по запросам пользователей.
Запустить скрипт для решения вопроса
Полезные ответы на вопросы по этому же функционалу для сбора данных из ВКонтакте
Сбор текстов постов ВК
Тексты постов со стен ВКонтакте
Собирать тексты постов по ссылкам ВК
Возможно ли находить комментарии под записями (постами) групп ВКонтакте?
Сбор на комментарии ВКонтакте
По списку ссылок на посты ВК загрузить их тексты и ключевые показатели
Бесплатные парсеры комментов ВК
Спарсить сами тексты постов и фото ВКонтакте
Собирать тексты постов ВКонтакте без ограничения по длине
Парсер текстов вконтакте
Инструмент сбора текстов постов ВКонтакте
Сборщик текстов ВКонтакте
Спарсить записи со стен групп ВК
Тексты самих постов ВКонтакте спарсить
Ввести список групп ВК и со всех собрать тексты постов в файл
Сбор текстов постов со стен ВКонтакте
Бесплатные парсеры контента ВК
Собрать тексты из постов ВКонтакте
Готовые тексты для постов в вк
Как скачать тексты постов ВК, а еще и количество лайков и репостов для каждого поста, чтобы потом можно было их отсортировать по лайкам и репостам?
Как использовать парсеры для анализа своей группы ВКонтакте — Маркетинг на vc.
 ru
ruЕсли вы слышите слово «парсер», в голове обычно всплывает ассоциация с таргетированной рекламой. Да, в парсерах действительно можно находить тематические сообщества, настраивать автоимпорт новых подписчиков для настройки рекламы, применять фильтры, но мало кто знает, как использовать парсер для анализа своего сообщества.
2272 просмотров
Например, вы запустили рекламу и хотите проанализировать вступивших в вашу группу людей, узнать их пол, возраст место жительство и т. д. Или вы сделали рекламные посевы в нескольких группах и хотите увидеть сколько и откуда (из каких источников) людей вступило к вам.
В этой статье мы разберемся в способах применения парсеров для анализа своего сообщества ВКонтакте. Делать обзор будем на примере парсера Pepper.Ninja.
Как проанализировать ядро подписчиков и узнать, какие паблики они любят
Как узнать сколько людей регулярно взаимодействует с вашей группой и кто они? Человек может регулярно заходить в группу, читать все посты, но никак не показывать свой интерес.
Итак, все подписки человека формируются в порядке частоты взаимодействия с сообществом. Постоянные переходы в группы или частая активность в них поднимут паблик в топе подписок. Чтобы посмотреть самые популярные группы у ваших подписчиков, зайдите в «Быстрый парсинг», вставьте ссылку на страницу и выберите «Пользователи – Сообщества».
«Быстрый парсинг» – это «волшебная» кнопка, куда можно вставить любую ссылку из ВКонтакте и парсер сам покажет, что из нее можно собрать. Например, с помощью нее можно искать посты по ключам, парсить по ГЕО – все находится в одном месте и не обязательно переходить по вкладкам меню Pepper.Ninja.
Например, проанализируем топ-5 подписок группы о вышивании.
Как настроить сбор статистики по топам сообществ у подписчиков
После завершения анализа вы получите список самых популярных групп у аудитории, а в графе ЦА будет указано, у скольких людей группа находится в топе.
Для более точного анализа – примените фильтр по числу подписчиков сообщества и исключите группы с аудиторией более 500 тысяч. Так вы исключите группы о новинках кино, музыки и другие паблики, в которых может состоять практически любой человек.
В итоге вы сможете узнать, сколько людей чаще всего взаимодействуют с вашим контентом и на каких конкурентов подписаны. Это поможет как при настройке таргета, так и при проработке контент-стратегии.
Результат анализа по топу сообществ
Отдельно можно получить список подписчиков, у которых ваша группа находится в топе подписок. Это поможет получить портрет заинтересованной аудитории, узнать ее пол, возраст, ГЕО и многое другое.
Для поиска таких людей перейдите в «Быстрый парсинг», вставьте ссылку на страницу и выберите «Пользователи – Топ». Дополнительно можно применить фильтры к аудитории, например, посмотреть число учащихся или тех, кто указал информацию о детях в профиле.
Настройка фильтра
Еще один вариант использования этого инструмента – создать сбор новых участников группы в «Мониторинге общества» и, например, раз в неделю изучать в каких пабликах состоят новые подписчики.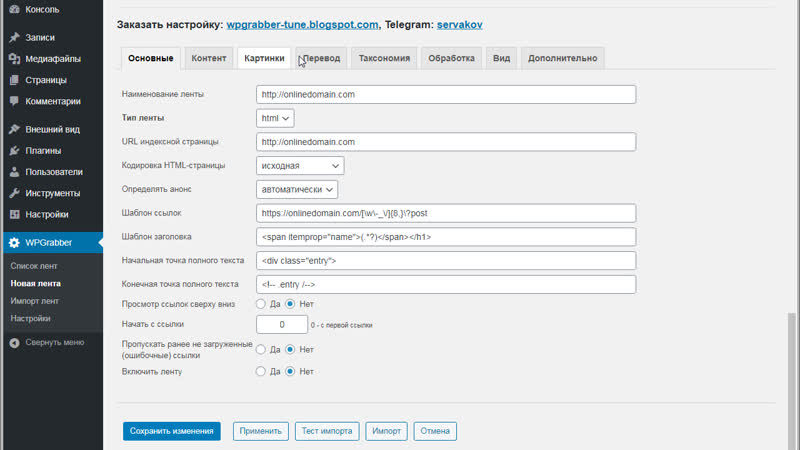
Наконец, если вы разместили посевы в нескольких группах, то сможете получить список недавно вступивших, проанализировать их подписки и посчитать сколько людей и из какого сообщества пришло. Полезно для выбора оптимальной рекламной стратегии и составления отчета.
Как узнать активность каждого подписчика
Если вам интересно посмотреть активность конкретного человека, в этом случае вы сможете посмотреть подробный отчет за любые даты. Пригодится, если вы проводите конкурс активности и хотите найти участника с большим числом комментариев или просто получить статистику по каждому человеку.
Зайдите в «Быстрый парсинг», вставьте ссылку на сообщество и выберите раздел «Пользователи – Активных», укажите период сбора активности и их число. Если хотите получить подробный отчет по всем – задайте от 1 активности.
Затем активируйте «Аналитику активных пользователей».
Настройка поиска активных людей в сообществе
В разделе «Задания» появится число найденной аудитории, а также кнопка отчета.
Собранный отчет
В отчете можно сортировать людей по числу лайков, репостов (доступно для админов группы), комментариев или сумме активностей, а самая правая кнопка откроет список постов, в которых человек совершил активность.
Статистика действий собранной аудитории
Дополнительно вы сможете применить фильтры и оставить людей, поставивших определенное число лайков, исключить профили без аватара и многое другое.
Фильтр позволит отсеять собранную аудиторию более точно
Если вы награждаете самых активных комментаторов сообщества призами (не используете продвинутую геймификацию) и используете парсер при поиске аудитории для таргета, то с использованием Pepper.Ninja, вам не придется искать отдельный сервис для выявления самых активных пользователей. Обе задачи можно решать прямо здесь.
Как узнать больше информации о подписчиках других пабликов
В Pepper.
Способ 1. Выбираем инструмент «Аналитика ретаргета и сообществ». Он работает для групп от 2 000 подписчиков и получает аналитику прямо из рекламного кабинета.
Визуализация статистики из рекламного кабинета
Помимо таких базовых показателей, как пол, возраст и ГЕО аудитории, будут показаны основные интересы из рекламного кабинета, т. е. то, как сам ВКонтакте видит подписчиков. Плюс можно посмотреть устройства и браузеры, которые используют пользователи для входа ВКонтакте.
Список интересов подписчиков из проанализированной группы
Способ 2. Собираем подписчиков группы (можно через «Быстрый парсинг») и запускаем аналитику найденной аудитории. Ее можно применить к любой собранной базе, будь то просто сбор всех участников групп или сбор людей, проявивших активность в постах; недавно вступивших в группу и т.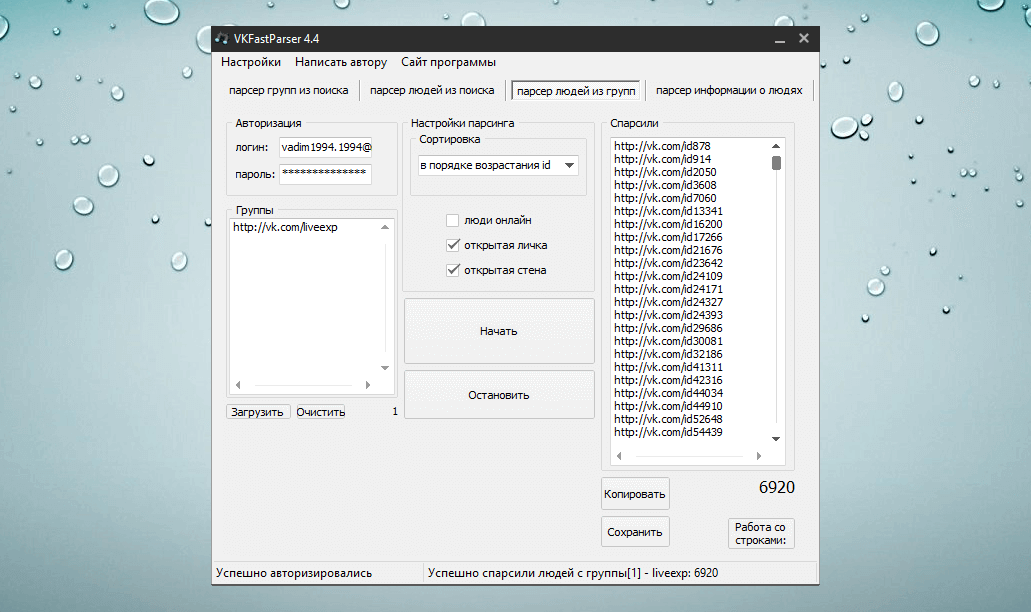
Помимо основных показателей, здесь можно посмотреть и музыкальные предпочтения (будут показаны песни, добавленные вашей аудиторией). Если вы добавляете музыку в посты, то сможете изучить любимые треки подписчиков и подбирать музыку, которая будет пересекаться с интересами участников группы.
Просмотр популярных треков у проанализированной группы
Как найти самые популярные посты, отсортировать их по просмотрам и активностям
Допустим, вы публикуете один пост в день и по итогам месяца хотите посмотреть отчет по активности аудитории в постах. Полученная информация пригодится в будущем, чтобы сделать акцент на рубриках, которые лучше заходят у аудитории и посмотреть записи, которые привлекают меньше внимания.
Поиск лучших постов в сообществе
Итак, для поиска постов вставьте ссылку на группу в быстрый парсинг и выберите «Посты – Популярные посты», если надо найти хештег, то укажите его в поле для ключевых слов, например #мпстудия . Потом выберите даты для поиска постов, можно задать фильтры по типу вложения и ключевым словам в посте, но их можно применить и при просмотре результатов.
Потом выберите даты для поиска постов, можно задать фильтры по типу вложения и ключевым словам в посте, но их можно применить и при просмотре результатов.
Фильтрация поиска
В задаче будет показан список постов, их можно отфильтровать по лайкам, комментариям, ключевым и минус-словам, наличию опроса или видео в посте и т. д. Также записи можно сортировать по популярности – от большего к меньшему по числу лайков, комментариев и т. д.
Найденный пост
Как узнать больше о зрителях прямых эфиров
Если вы проводите прямые трансляции, то Pepper.Ninja поможет изучить ваших зрителей, узнать сколько минут человек смотрел эфир, какого он пола и возраста. Достаточно вставить ссылку в «Парсер трансляций» и активировать «Мониторинг трансляций» (он будет собирать зрителей эфира каждую минуту), без выбора этого пункта найдутся зрители, смотрящие прямо сейчас.
Настройка парсера для зрителей прямых эфиров
После завершения эфира вы получите список зрителей, сможете применить к ним фильтрацию и сортировку по длительности просмотра. Например, увидеть число людей, смотревших более половины эфира.
Например, увидеть число людей, смотревших более половины эфира.
Это поможет узнать самых вовлеченных зрителей, так и пригодится если вы проводите конкурсы, условие которых – присутствие на трансляции и просмотр, как минимум, половины видео.
Список активных зрителей на трансляции
Используя Pepper.Ninja вы сможете не только собирать аудиторию для настройки таргетированной рекламы, но и анализировать участников вашей группы, узнавать их интересы, вовлеченность и многое другое. Пользуйтесь и применяйте все доступные функции для более качественной работы с контентом, рекламой и статистикой.
bash — Анализ JSON с помощью инструментов Unix
Существует ряд инструментов, специально разработанных для управления JSON из командной строки, и они будут намного проще и надежнее, чем делать это с помощью Awk, например jq :
curl -s 'https://api.github.com/users/lambda' | jq -r '.имя'
Вы также можете сделать это с помощью инструментов, которые, вероятно, уже установлены в вашей системе, таких как Python, используя модуль json , и, таким образом, избежать каких-либо дополнительных зависимостей, сохраняя при этом преимущества правильного парсера JSON. Далее предполагается, что вы хотите использовать кодировку UTF-8, в которой должен быть закодирован исходный JSON и которую также используют большинство современных терминалов:
Далее предполагается, что вы хотите использовать кодировку UTF-8, в которой должен быть закодирован исходный JSON и которую также используют большинство современных терминалов:
Python 3:
curl -s 'https://api.github.com/users/lambda' | \
python3 -c "импортировать sys, json; печать (json.load (sys.stdin) ['имя'])"
Python 2:
экспорт PYTHONIOENCODING=utf8
curl -s 'https://api.github.com/users/lambda' | \
python2 -c "импортировать sys, json; напечатать json.load(sys.stdin)['имя']"
Часто задаваемые вопросы
Почему не чистое решение оболочки?
Стандартная оболочка спецификации POSIX/Single Unix — это очень ограниченный язык, который не содержит средств для представления последовательностей (списков или массивов) или ассоциативных массивов (также известных как хэш-таблицы, карты, словари или объекты на некоторых других языках). . Это делает представление результата анализа JSON несколько сложным в переносимых сценариях оболочки. Есть несколько хакерских способов сделать это, но многие из них могут сломаться, если ключи или значения содержат определенные специальные символы.
Есть несколько хакерских способов сделать это, но многие из них могут сломаться, если ключи или значения содержат определенные специальные символы.
Bash 4 и более поздние версии, zsh и ksh имеют поддержку массивов и ассоциативных массивов, но эти оболочки не являются общедоступными (macOS перестала обновлять Bash в Bash 3 из-за перехода с GPLv2 на GPLv3, в то время как многие системы Linux не поддерживают zsh установлен из коробки). Вполне возможно, что вы могли бы написать сценарий, который будет работать либо в Bash 4, либо в zsh, один из которых доступен в большинстве систем macOS, Linux и BSD в наши дни, но было бы сложно написать строку shebang, которая работала бы для такого полиглотский сценарий.
Наконец, написание полноценного синтаксического анализатора JSON в оболочке было бы достаточно важной зависимостью, поэтому вместо этого вы могли бы просто использовать существующую зависимость, например jq или Python. Это не будет однострочный или даже небольшой пятистрочный фрагмент для хорошей реализации.
Почему бы не использовать awk, sed или grep?
Эти инструменты можно использовать для быстрого извлечения из JSON с известной формой и форматированием известным способом, например, по одному ключу в строке. В других ответах есть несколько примеров предложений для этого.
Однако эти инструменты предназначены для форматов на основе строк или записей; они не предназначены для рекурсивного анализа совпадающих разделителей с возможными экранирующими символами.
Таким образом, эти быстрые и грязные решения с использованием awk/sed/grep, вероятно, будут хрупкими и сломаются, если какой-либо аспект входного формата изменится, например, свертывание пробелов или добавление дополнительных уровней вложенности к объектам JSON или экранированный цитата внутри строки. Решение, достаточно надежное для обработки всех входных данных JSON без нарушения, также будет довольно большим и сложным, и поэтому не слишком сильно отличается от добавления еще одной зависимости от 9. 0003 jq или Python.
0003 jq или Python.
Раньше мне приходилось сталкиваться с удалением больших объемов клиентских данных из-за плохого разбора входных данных в сценарии оболочки, поэтому я никогда не рекомендую быстрые и грязные методы, которые могут быть хрупкими в этом смысле. Если вы выполняете какую-то разовую обработку, см. другие ответы для предложений, но я все же настоятельно рекомендую просто использовать существующий проверенный анализатор JSON.
Исторические заметки
Этот ответ изначально рекомендовал jsawk, который все еще должен работать, но немного более громоздкий в использовании, чем jq и зависит от установленного автономного интерпретатора JavaScript, который встречается реже, чем интерпретатор Python, поэтому приведенные выше ответы, вероятно, предпочтительнее:
curl -s 'https://api.github.com/users/lambda' | jsawk -a 'вернуть это.имя'
В этом ответе также изначально использовался API Twitter из вопроса, но этот API больше не работает, что затрудняет копирование примеров для тестирования, а для нового API Twitter требуются ключи API, поэтому я переключился на использование GitHub API, который можно легко использовать без ключей API. Первый ответ на исходный вопрос будет:
Первый ответ на исходный вопрос будет:
curl 'http://twitter.com/users/username.json' | jq -r '.текст'
Страница не найдена — Qaru Переполнение стека
- О
- Для команд
- Переполнение стека Публичные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся личными знаниями с коллегами
- Талант Создайте свой бренд работодателя
- Реклама Свяжитесь с разработчиками и технологами по всему миру
- Лаборатории Будущее коллективного обмена знаниями
- О компании
Загрузка…
Этот вопрос был удален из Stack Overflow по соображениям модерации. Пожалуйста, обратитесь в справочный центр для возможных объяснений, почему вопрос может быть удален.
Вот несколько похожих вопросов, которые могут быть уместны:
- Что делает ключевое слово «доходность» в Python?
- Что делать, если __name__ == «__main__»: делать?
- Что такое метаклассы в Python?
- В чем разница между __str__ и __repr__?
- Доступ к индексу в циклах for
- Для чего нужен __init__.