Граббер email-адресов. Законно ли это и какие сервисы можно использовать
Что такое парсинг Почему в большинстве случаев парсинг — не вариант Можно ли парсить и использовать email-адреса Программы и сервисы для парсинга Что в итоге
Читайте наc в Telegram
Разбираемся, что происходит в мире рассылок и digital-маркетинга. Публикуем анонсы статей, обзоры, подборки, мнения экспертов.
Смотреть канал
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Для запуска любой email-рассылки необходима база подписчиков. Чтобы собрать электронные адреса, можно пойти стандартным путём — вовлекать аудиторию в общение, рассказывать о потенциальной пользе, собирать контакты в обмен на что-то ценное.
Парсер выглядит простым вариантом, но на деле все совсем непросто — особенно, если вы захотите собрать email-адреса.
Что такое парсинг
Представьте, что пользователь посещает различные сайты, копирует с них данные и сортирует их с учётом нужных критериев. Так работает парсинг, только вместо пользователей по сайтам ходят специальные роботы. Сервис-парсер обращается к страницам целевого сайта, получает HTML-код, ищет в нём нужные данные и сохраняет их в собственной базе.
Парсить можно самые разные данные. Например, можно собирать телефоны, прайсы, каталоги товаров, структуру сайтов и многое другое. В том числе можно парсить email-адреса. Для этого в настройках сервиса (или в скрипте) указывают параметры отслеживания — элементы, составляющие электронный адрес («@», «email»). Как только парсер находит совпадения, он отправляет данные в базу.
Преимущества парсинга очевидны:
- сбор данных полностью автоматизирован;
- параметры поиска можно настраивать;
- можно собрать большой объём данных в кратчайшие сроки.
Применение парсинга выглядит очень удобным. Но вот с законностью есть проблемы.
Почему в большинстве случаев парсинг — не вариант
В ФЗ №149 «Об информации…» сказано, что «К общедоступной информации относятся общеизвестные сведения и иная информация, доступ к которой не ограничен». Поскольку в большинстве случаев парсер собирает открытые данные, опубликованные в общем доступе, это не запрещено законом. Но есть нюансы. Парсинг признают легальным инструментом, если он не нарушает какой-либо закон. Рассмотрим, причиной каких нарушений может стать парсинг.
Нарушение авторских и смежных прав
У любого контента в интернете есть автор или правообладатель, даже если это не указано в подписи к материалу. Нормы об авторском праве в некоторых случаях позволяют использовать чужой контент без разрешения владельца: при использовании цитирования, в информационных или образовательных целях. Однако если авторские произведения используют с целью получения дохода, видоизменяют либо присваивают авторство — это признают нарушением авторских прав. Нарушителя ждёт административный штраф.
Нормы об авторском праве в некоторых случаях позволяют использовать чужой контент без разрешения владельца: при использовании цитирования, в информационных или образовательных целях. Однако если авторские произведения используют с целью получения дохода, видоизменяют либо присваивают авторство — это признают нарушением авторских прав. Нарушителя ждёт административный штраф.
Например, нельзя парсить чужой контент и публиковать его от своего имени — это нарушение авторских прав.
Вывод
Парсинг любой информации для получения коммерческой выгоды запрещён.
Неправомерный доступ к компьютерной информации
Закон запрещает неправомерный доступ к информации, если это повлекло за собой уничтожение, блокировку, изменение или копирование сведений. Нарушителя могут оштрафовать, отправить на, исправительные или принудительные работы или лишить свободы.
Если даже парсинг никак не влияет на контент, парсер в любом случае копирует информацию. Не понятно, что понимать под неправомерным доступом. Можно предположить, что это любая попытка неавторизованного входа, когда доступ к информации ограничен, защищён или запрещён. Например, для использования сайта требуется регистрация пользователя. К незаконным методам можно отнести и обход технической блокировки парсинга.
Можно предположить, что это любая попытка неавторизованного входа, когда доступ к информации ограничен, защищён или запрещён. Например, для использования сайта требуется регистрация пользователя. К незаконным методам можно отнести и обход технической блокировки парсинга.
Вывод
Нельзя парсить данные, доступ к которым требует дополнительных действий со стороны пользователя. То есть, запрещено обходить блокировку парсинга, взламывать пароли, получать доступ к закрытым сведениям.
Использование гражданских прав для ограничения конкуренции
В законе есть такое понятие, как злоупотребление правом. Например, любой пользователь имеет право пользоваться общедоступной информацией, но только если это не вредит другим лицам. Кроме того, запрещено использовать гражданские права с целью навредить конкурентам.
Получается, что если парсинг причиняет вред конкурентам, это незаконно. Пострадавшее лицо может потребовать возместить убытки. К примеру, парсер собирает закрытые базы данных конкурирующих организаций, чтобы использовать их для обхода конкурентов.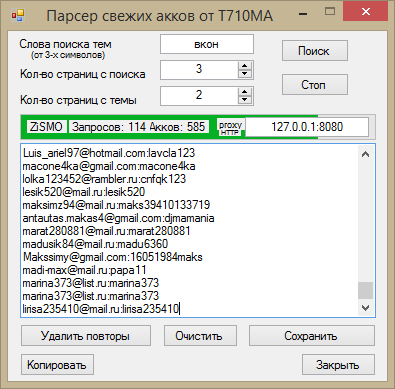
Вывод
Нельзя использовать парсинг с целью навредить конкурентам или обрести доминирующее положение на рынке благодаря определённым сведениям.
Разглашение коммерческой тайны
Запрещено собирать сведения, которые представляют коммерческую тайну. За это могут оштрафовать, отправить на исправительные или принудительные работы и даже лишить свободы. При разглашении или использовании коммерческих сведений без согласия владельца наказание увеличивают.
Коммерческой тайной могут быть списки клиентов и поставщиков, методы сбыта, исходные коды и прочее. Основные критерии — ограниченный доступ и получение экономической выгоды от использования данных.
Вывод
Запрещено применять парсинг для доступа к закрытой коммерческой информации, даже если впоследствии эта информация не будет использована.
Незаконное обращение с персональными данными
Без разрешения владельца нельзя собирать, обрабатывать и использовать персональные данные. Причём не имеет значения то, что человек сам разместил свои данные в открытом доступе. Это не делает их общедоступными.
Причём не имеет значения то, что человек сам разместил свои данные в открытом доступе. Это не делает их общедоступными.
При парсинге бывает сложно определить, что можно считать персональными данными. По закону это любая информация, которая прямо или косвенно относится к определяемому физическому лицу. При этом не существуют унифицированного перечня видов данных. К персональной информации можно отнести любые сведения, которые позволяют идентифицировать человека.
Например, парсер собирает телефоны пользователей без ФИО. Но каждый номер закреплён за человеком по договору с оператором. Теоретически пользователя можно идентифицировать и телефонные номера можно признать персональными данными.
Вывод
Нельзя парсить персональные данные.
Приведу несколько ситуаций, в которых парсинг не запрещен и может быть полезен владельцам сайтов и маркетологам:
- Исследование рынка и анализ конкурентов. Например, чтобы узнать структуру сайта у компаний из вашей сферы.

- Поиск ошибок на собственном ресурсе. Например, чтобы найти битые ссылки или цепочки редиректов.
- Сбор семантики. Какие запросы популярны среди ваших клиентов? Какие странички на сайте нужно внедрить?
- Изучение контента. Например, чтобы узнать миссию и ценности других компаний из вашей ниши.
Можно ли парсить и использовать email-адреса
Получается, что, парсинг законом разрешён как инструмент. Но имеет значение, что именно парсить и для каких целей.
Какие email-адреса можно парсить
Не всегда ясно, можно ли признать email-адреса персональной информацией. Сам по себе адрес электронной почты — это обезличенный набор букв и цифр. По нему сложно определить конкретного владельца. Например, [email protected] или [email protected]. Такие адреса нельзя считать персональными данными и, соответственно, их можно парсить.
А вот если вместе с теми же адресами парсят ФИО владельцев, то это уже незаконный сбор персональных данных. Пример: Иван Иванов — [email protected], Маша Петрова — [email protected].
Пример: Иван Иванов — [email protected], Маша Петрова — [email protected].
Адреса электронной почты могут стать персональными данными, если в них есть информация, которая помогает идентифицировать человека: имя, фамилия, отчество, город проживания, год рождения. К примеру, [email protected], [email protected]. Парсинг таких адресов будет нарушением закона.
Ещё один нюанс в принадлежности email. В законе о персональных данных говорится о принадлежности информации физическому лицу. Соответственно, если электронный адрес принадлежит юридическому лицу, то он не признаётся персональной информацией.
То есть, если с помощью граббера собирают email-адреса компаний, даже в сочетании с названиями организаций, это не считается нарушением закона. Исключение — парсинг списков email-адресов организаций, которые составляют коммерческую тайну и/или защищены от несанкционированного доступа.
Кстати, без согласия рассылать письма компаниям можно только через личную почту. Например, можно со своей почты отправить на корпоративную почту коммерческое предложение или запрос интересующей информации. Но если делать это регулярно и большими объёмами, то легко попасть под спам-фильтры почтовых сервисов.
Например, можно со своей почты отправить на корпоративную почту коммерческое предложение или запрос интересующей информации. Но если делать это регулярно и большими объёмами, то легко попасть под спам-фильтры почтовых сервисов.
Вывод
Можно парсить email физических лиц, по которым невозможно идентифицировать владельцев. Также можно парсить электронные адреса компаний, опубликованные в открытом доступе.
Как использовать спарсенные email-адреса для рассылок
Независимо от того, можно ли считать адреса электронной почты персональными данными или нет, необходимо соблюдать правила обработки информации. Если захотите использовать email-адреса для создания базы подписчиков и запуска рассылки, нужно взять согласие владельцев.
Теоретически, можно сделать рассылку по списку спарсенных адресов и в первом письме запросить согласие владельцев. Всех согласившихся адресатов можно добавить в базу email, а проигнорировавших письмо — просто удалить. Но сервисы email-рассылок не позволят рассылать письма без согласия получателей.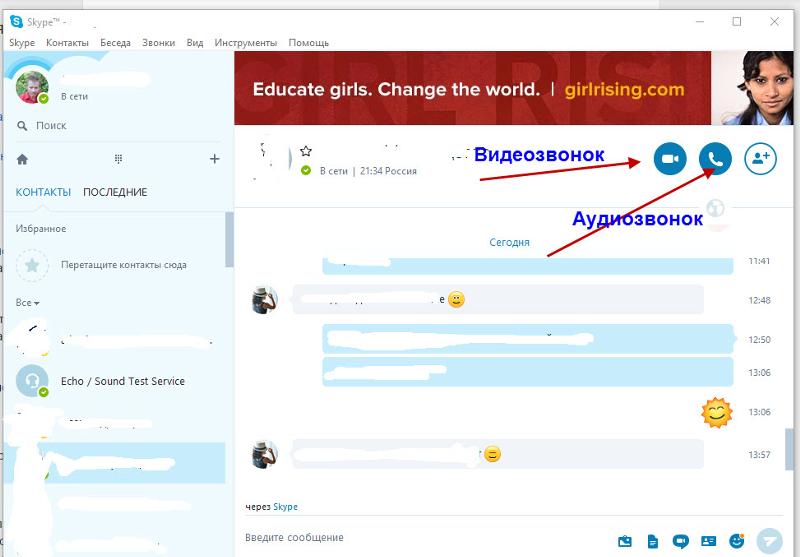 А при ручной рассылке большого объёма писем без согласия владельцев почтовые сервисы отправят сообщения в спам.
А при ручной рассылке большого объёма писем без согласия владельцев почтовые сервисы отправят сообщения в спам.
Выходом может стать отправка по спарсенным email не более 1-3 писем в день в общем и постепенное расширение легальной базы после получения согласия на рассылку. Но это потребует много времени и не факт, что адресаты принадлежат к целевой аудитории и дадут согласие. Более оптимально — применять законные способы сбора email.
Вывод
Использовать парсинг для легальных рассылок малоэффективно. Гораздо эффективнее применять законные способы сбора базы адресов. Например, через форму подписки на сайте либо предлагать подписку текущим клиентам.
Для чего ещё применяют спарсенные email кроме рассылок
Списки спарсенных email можно применять для запуска рекламы. Например, можно настроить таргетинг на потенциальных клиентов в ВКонтакте, Facebook*, Instagram* и в сети MyTarget (проекты mail.ru). Для этого список электронных адресов нужно загрузить в выбранную рекламную систему и настроить кампанию с нужными условиями.
Данный метод довольно популярен, поскольку позволяет быстро собрать аудиторию и запустить рекламную кампанию. При этом рекламные системы пока не могут проверять законность сбора email и относят этот этап к личной ответственности рекламодателя. Но в целом, такой способ использования спарсенных электронных адресов тоже нарушает закон. К тому же, таргетинг на незаинтересованных пользователей — это просто слив рекламного бюджета.
Программы и сервисы для парсинга
- Hunter — Email Finder Extension. Расширение для браузера, которое умеет извлекать электронные адреса с сайтов. Также может собирать дополнительную информацию — имя, должность, профиль в соцсети, телефон.
- EmailDrop. Программа для сбора электронных адресов с нужной веб-страницы и экспорта их в файл.
- Skrapp.io. Расширение браузера, которое ищет электронные адреса сотрудников B2B-компаний на сайтах и в Linkedin.
- Email Extractor.
- Barkov.net. Сборщик email-адресов пользователей «ВКонтакте».
- Scrapebox Email Scraper. Сервис для парсинга email-адресов в разных поисковых системах, на разных сайтах и из локальных файлов. При экспорте можно сохранять URL-адрес, с которого получен email.
- LetsExtract. Программа для поиска электронных адресов в Skype, Facebook* и Twitter. Также есть поиск email по ключевым словам в разных поисковых системах. Можно просто запустить парсер на любом сайте и собрать необходимые данные.

Что в итоге
Получается, сам по себе парсинг законом разрешён. Но имеет значение, какие данные парсят и с какой целью. В частности, запрещено собирать email-адреса, если их можно признать персональными данными. Парсинг не запрещён, если объектом сбора выступают email-адреса компаний и организаций при условии отсутствия коммерческой тайны, вреда конкурентам и ограниченного доступа.
Спарсенные email-адреса нельзя использовать для запуска честной рассылки — владельцы не давали на это согласия. Электронные адреса, собранные с помощью парсинга, нередко применяют для запуска таргетированной рекламы, но и это незаконно.
Парсинг можно применять для исследования рынка, анализа конкурентов, поиска ошибок на собственном ресурсе, сбора семантики, изучения контента. Но собирать электронные адреса лучше законными методами и только с согласия владельцев.
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся шутить, но получается не всегда
Оставляя свой email, я принимаю Политику конфиденциальностиКак запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
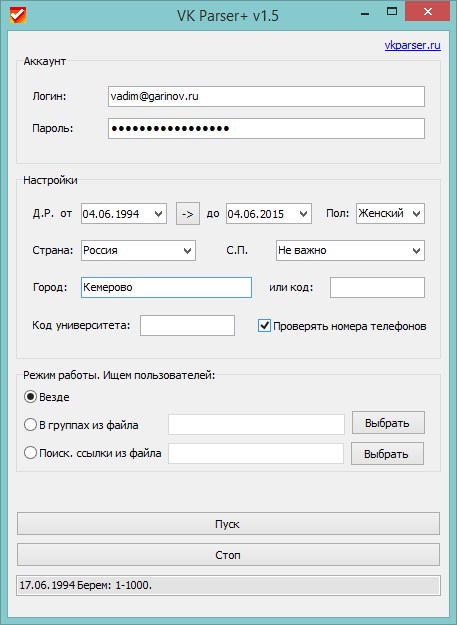
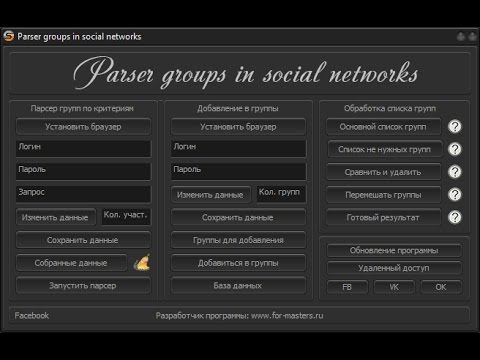
Разработка парсера ВК и ОК MegaParser
Задачи
- Создание парсера для для парсинга групп, которые продают товары через соцсети вконтакте и одноклассники.
Решение
К нам обратился клиент с просьбой создать парсер, который будет собирать информацию из групп и альбомов соцсетей вконтакте и одноклассники. Есть ряд крупных групп в данных соцсетях, которые продают оптом товары. Мелкие продавцы для своих групп вручную собирают у них данные о товарах (изображения, описания товаров и цену) и делают свою наценку (это основная целевая аудитория).
На этапе проектирования было решено не использовать CMS и PHP фрейвороков, так как функционал специфический и их использование избыточно. Поэтому парсер делался на чистом PHP. Для оформления использовался bootstrap, так как клиенту нужен был строгий дизайн без излишеств. Информация подтягивается парсером в основном через API ВК и ОК, но в некоторых местах не хватало их возможностей и приходилось парсить информацию напрямую.
Так выглядит главная страница для незарегистрированных пользователей. Дизайн решили делать минималистичный: оставить только шапку с логотипом и кнопками входа через ВК и одноклассники.
Данная страница появляется при входе через соцсети. Парсер даёт возможность получить информацию из группы, альбома или стены пользователя. Кроме этого вы можете выбрать определённый диапазон дат для выгрузки. Так как у API ВК и одноклассников есть свои лимиты в выгрузке информации, в шапке отображаются лимиты на выгрузку изображений за час и сутки.
Так выглядит выгрузка парсера для группы ВК за один день. Если не выбирать даты выгрузки, то появятся первые 10 карточек выгрузки парсера и кнопки предыдущая и следующая страница для парсинга следующих записей группы. Пагинация была сделана для ускорения работы с парсером, так как если выгрузить, например, 100 карточек, то пользователь будет ждать около минуты.
В некоторых публикациях групп может быть 2 и более фото, поэтому было решено выгружать все фото, а не только первое с одинаковым описанием у каждого, так как в соцсети оно общее для всех фото.
Изображение было решено растянуть по вертикали и горизонтали, не обрезая, чтобы было его видно полностью, так как на некоторых изображениях может быть водяной знак. При нажатии на лупу изображение открывается в выпадающем окне с оригинальным размером.

Заказчику нужны были инструменты для работы над информацией, полученной в процессе парсинга. Это было реализовано в виде панели фильтров, где можно изменить цену и описание карточек, полученных парсером. Для цен была сделана наценка в процентах и рублях и округление цен на величину кратную 10, 50 и 100. Для описаний реализовано удаление всех ссылок, номеров телефонов, самого описания, добавление текста в начало и конец описания, и поиск и замена текста. С технической стороны данный функционал было реализовать не просто, так как пришлось писать большое количество регулярных выражений, чтобы выделить из описания телефоны, цены и ссылки.
Следующий за парсингом этап – выгрузка фотографий в альбом группы. Здесь все выбранные галочкой фото будут выгружены в выбранную группу и альбом пользователя. Для удобства можно выбрать добавлять описания к выгруженным фото или нет.
После нажатия кнопки загрузить откроется выпадающее окно с миниатюрами фотографий, и по мере выгрузки будут подсвечиваться фото, которые уже были выгружены в альбом соцсети. Такое решение было выбрано для удобства и чтобы пользователь видел сколько и какие фото уже были выгружены в альбом.
Такое решение было выбрано для удобства и чтобы пользователь видел сколько и какие фото уже были выгружены в альбом.
Результат выгрузки в альбоме ВК.
В данной панели находятся дополнительные фишки парсера, которые выделяют его среди конкурентов. Первая из них – тёмная тема, это настройка цветовой гаммы сайта, чтобы глаза меньше уставали, так как целевая аудитория зачастую проводит несколько часов в день за парсером, поскольку продают огромный ассортимент товаров. Следующая опция – добавление водяного знака для защиты от копирования фото.
Кнопка «добавить ссылку» нужна для ускорения работы с парсером.
Автозагрузка по времени нужна для того, чтобы делать автоматическую выгрузку из соцсетей в определённое время.
Результат
В результате получился продвинутый и удобный парсер соцсетей, который позволяет в кратчайшие сроки выгружать информацию из соцсетей ВК и ОК в альбомы пользователя. Но для полноценного запуска пока не хватает системы оплаты за пользование парсером, сейчас пользоваться им может любой пользователь. У клиента есть своя аудитория, которая пользуется данным решением, поэтому было принято решение отложить полномасштабный запуск программы.
У клиента есть своя аудитория, которая пользуется данным решением, поэтому было принято решение отложить полномасштабный запуск программы.
Другие проекты
У вас есть проект?
Давайте обсудим его. Продумаем. И сделаем!
Как боты парсят ваши сайты и обходят защиту? Рассказываем в деталях — Сервисы на vc.ru
Меня зовут Максим Кульгин и моя компания xmldatafeed занимается парсингом сайтов в России порядка четырех лет. Ежедневно мы парсим более 500 крупнейших интернет-магазинов в России и на выходе мы отдаем данные в формате Excel/CSV и делаем готовую аналитику для маркетплейсов.
15 441 просмотров
Хочу показать некоторые достаточно простые приемы, с помощью которых можно обходить защиту на сайтах и парсить данные более-менее успешно.
Почему «более-менее»? Дело в том, что есть разные способы защитить свои данные от парсинга (или несанкционированного сбора). За много лет мы сталкивались с большим количеством решений, которые можно ранжировать от «безумных» (например, сайт отдает 30 страниц, а дальше IP — адрес блокирует на сутки, сильно замедляя парсинг), до очень простых, когда сайт может иногда попросить решить капчу. К каждому сайту нужен свой подход, но еще не встречались сайты, которые вообще нельзя парсить. Другое дело, что парсинг можно усложнить настолько, что вы просто физически в разумное время не сможете собрать данные, особенно если их много. Сразу подчеркну, что я за «человеческий» парсинг, который собирает данные, но не создает на сайте неподъёмной нагрузки по типу ddos. Статья ниже ориентирована на людей, которые сами не занимаются парсингом профессионально, но хотят понять основные механизмы, которые лежат в его основе.
К каждому сайту нужен свой подход, но еще не встречались сайты, которые вообще нельзя парсить. Другое дело, что парсинг можно усложнить настолько, что вы просто физически в разумное время не сможете собрать данные, особенно если их много. Сразу подчеркну, что я за «человеческий» парсинг, который собирает данные, но не создает на сайте неподъёмной нагрузки по типу ddos. Статья ниже ориентирована на людей, которые сами не занимаются парсингом профессионально, но хотят понять основные механизмы, которые лежат в его основе.
Парсинг сайтов — задача, к которой нужно подходить ответственно, — чтобы парсинг не оказывал негативного влияния на целевые сайты. Парсеры могут извлекать данные гораздо быстрее и тщательнее людей, поэтому плохие методы парсинга могут в некоторой степени влиять на производительность сканируемого сайта. Хотя у большинства сайтов могут отсутствовать (и чаще всего так и есть) средства защиты от парсинга, некоторые из сайтов используют меры, препятствующие ему, поскольку их владельцы или администраторы не считают себя приверженцами идеи открытого и неограниченного доступа к данным. В этой статье мы не будем рассматривать этическую сторону парсинга, а с точки зрения закона отмечу, что если вы не нарушаете авторские права (например, собирая название товара и цену), то парсинг не запрещен в России.
В этой статье мы не будем рассматривать этическую сторону парсинга, а с точки зрения закона отмечу, что если вы не нарушаете авторские права (например, собирая название товара и цену), то парсинг не запрещен в России.
Если парсер выполняет более одного запроса в секунду и скачивает объемные файлы, не обладающему достаточной мощностью серверу будет трудно успевать обрабатывать запросы, исходящие от множества сканеров. Поскольку веб-сканеры, парсеры или «пауки» (эти слова нередко используются в качестве синонимов) фактически не обеспечивают сайту настоящий, «человеческий» трафик и, судя по всему, влияют на производительность сайта, некоторые администраторы сайтов не любят «пауков» и пытаются заблокировать им доступ к данным на сайте.
Далее представлены лучшие подходы, которые вы можете использовать, чтобы не нарваться на запрет доступа к сайту в процессе парсинга.
Старайтесь учитывайть содержимое файла Robots.txt
Лучше всего, если при парсинге «пауки» придерживаются файла robot. txt соответствующего сайта. В нем прописаны конкретные правила «примерного поведения», как например: насколько часто вы можете запрашивать данные, на каких веб-страницах разрешается собирать их, а на каких это запрещено. Некоторые сайты разрешают поисковику Google собирать данные, не разрешая делать это кому-то еще. Эта мера противоречит открытой природе Интернета и может казаться несправедливой, но владельцы сайтов имеют право прибегать к ней.
txt соответствующего сайта. В нем прописаны конкретные правила «примерного поведения», как например: насколько часто вы можете запрашивать данные, на каких веб-страницах разрешается собирать их, а на каких это запрещено. Некоторые сайты разрешают поисковику Google собирать данные, не разрешая делать это кому-то еще. Эта мера противоречит открытой природе Интернета и может казаться несправедливой, но владельцы сайтов имеют право прибегать к ней.
Вы можете найти примеры файла robot.txt на различных сайтах. Обычно этот файл находится в корневой директории сайта, например в http://example.com/robots.txt.
Если в нем присутствуют строки наподобие указанных ниже, то это значит, что владельцы сайта не хотят, чтобы на нем собирали данные, и им бы это не понравилось.
User-agent: *
Disallow:/
Однако поскольку большинство владельцев сайтов хотели бы, чтобы их сайты присутствовали в поисковой выдаче Google или Яндекса, — пожалуй, крупнейших в мировом масштабе парсеров сайтов, они всё-таки открывают ботам и «паукам» доступ к сайтам.
Что делать, если вам нужны какие-либо данные, доступ к которым запрещен в robots.txt? Вы всё равно можете собрать эти данные. Большинство инструментов для защиты от парсинга противодействуют ему, когда вы собираете данные на веб-страницах, автоматический доступ к которым не разрешен в robots.txt.
Является ли пользователь сайта ботом или реальным посетителем, — вот что стремятся выяснить эти инструменты. И как они это делают? Они ищут несколько показателей, которые характерны для живых пользователей, но не характерны для ботов. Люди ведут себя бессистемно в отличие от ботов. Люди непредсказуемы в отличие от ботов.
Вот несколько очевидных признаков, по которым бот, парсер или веб-сканер обнаруживает себя:
- Чрезмерно частое запрашивание данных, находящихся на слишком большом количестве веб-страниц, то есть чаще, чем их мог бы просматривать живой пользователь сайта.
- Следование одной и той же модели поведения при сканировании веб-страниц. Например, просмотр всех страниц результатов поиска и переход на каждый результат только после сбора ссылок на них. Ни один человек никогда не пойдет на такое.
- Слишком много запросов от одного и того же IP-адреса за очень короткий период.
- Парсер не определяется как один из популярных браузеров. Вы можете исключить этот признак, указывая заголовок User-Agent.
- Использование User-Agent очень старого браузера.
 Например, просмотр всех страниц результатов поиска и переход на каждый результат только после сбора ссылок на них. Ни один человек никогда не пойдет на такое.
Например, просмотр всех страниц результатов поиска и переход на каждый результат только после сбора ссылок на них. Ни один человек никогда не пойдет на такое.Нижеследующие рекомендации должны помочь вам обходить большинство основных и вспомогательных защитных мер, используемых сайтами.
Замедлите сбор данных, не перегружайте сервер, хорошо «обращайтесь» с сайтами
Боты, предназначенные для парсинга данных, собирают их очень быстро, но сайт легко может обнаружить ваш парсер, так как люди не могут с такой скоростью просматривать веб-страницы. Чем быстрее вы сканируете и собираете данные, тем сильнее всем портите жизнь. Сайт может перестать отвечать на запросы, если получит их больше, чем может обработать.
Сайт может перестать отвечать на запросы, если получит их больше, чем может обработать.
Сделайте своего «паука» похожим на реального пользователя, имитируя действия человека. Поместите несколько случайных программных периодов бездействия между запросами, добавьте несколько задержек после сбора небольшого количества веб-страниц и выберите как можно меньшее число параллельно отправляемых запросов. Будет идеально добавить задержку в 10–20 секунд между программными кликами и не слишком сильно нагружать сайт, обращаясь с ним по-человечески.
Используйте средства ограничивающего регулирования, которые будут автоматически понижать скорость сбора данных в зависимости от нагрузки как на «паука», так и на сайт, на котором осуществляется сбор данных. Подберите оптимальную скорость «паука» после его нескольких пробных запусков. Периодически повторяйте эту настройку скорости, потому что обстановка со временем действительно меняется.
Не используйте одну и ту же схему сбора данных
Как правило, люди не выполняют повторяющиеся задачи, так как просматривают сайт, действуя непредсказуемо.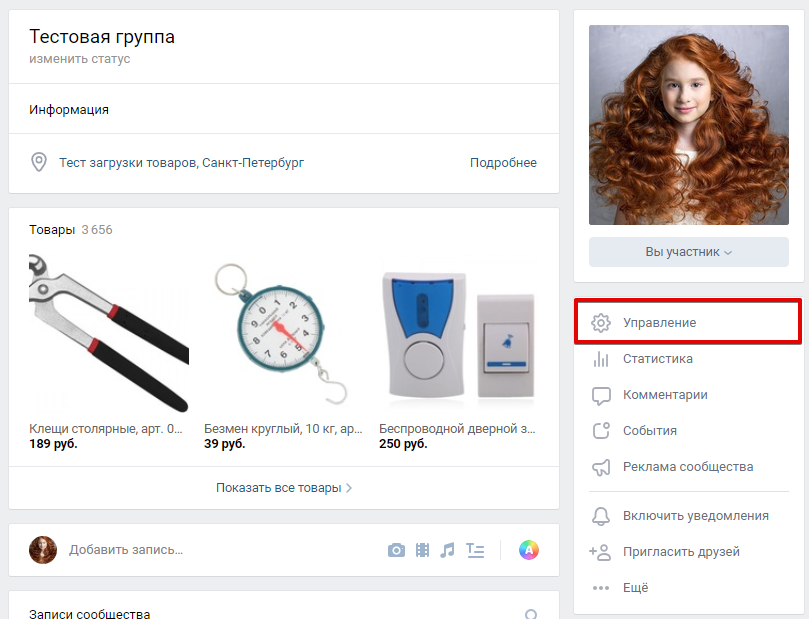 У ботов для сбора данных обычно одна и та же модель поведения при сканировании и сборе данных, потому что они так запрограммированы, если только в них не заложены какие-либо уникальные алгоритмы действий. Сайты с интеллектуальными средствами защиты от сбора данных могут легко обнаруживать «пауков», выявляя закономерности в их действиях и таким образом препятствуя парсингу данных.
У ботов для сбора данных обычно одна и та же модель поведения при сканировании и сборе данных, потому что они так запрограммированы, если только в них не заложены какие-либо уникальные алгоритмы действий. Сайты с интеллектуальными средствами защиты от сбора данных могут легко обнаруживать «пауков», выявляя закономерности в их действиях и таким образом препятствуя парсингу данных.
Включите в состав операций парсера случайные клики по веб-странице, передвижения курсора и бессистемные действия, которые сделают его похожим на человека.
Отправляйте запросы через прокси-серверы и при необходимости выполняйте их ротацию
При парсинге ваш IP-адрес может быть виден. Сайт будет знать о ваших действиях и о том, занимаетесь ли вы сбором данных. Сайты могут считывать такие данные, как закономерности в поведении пользователей или пользовательский опыт, если они зашли на сайт впервые.
Многочисленные запросы, исходящие из одного и того же IP-адреса, приведут к тому, что вы окажетесь без доступа к данным, поэтому нужно использовать более одного IP-адреса.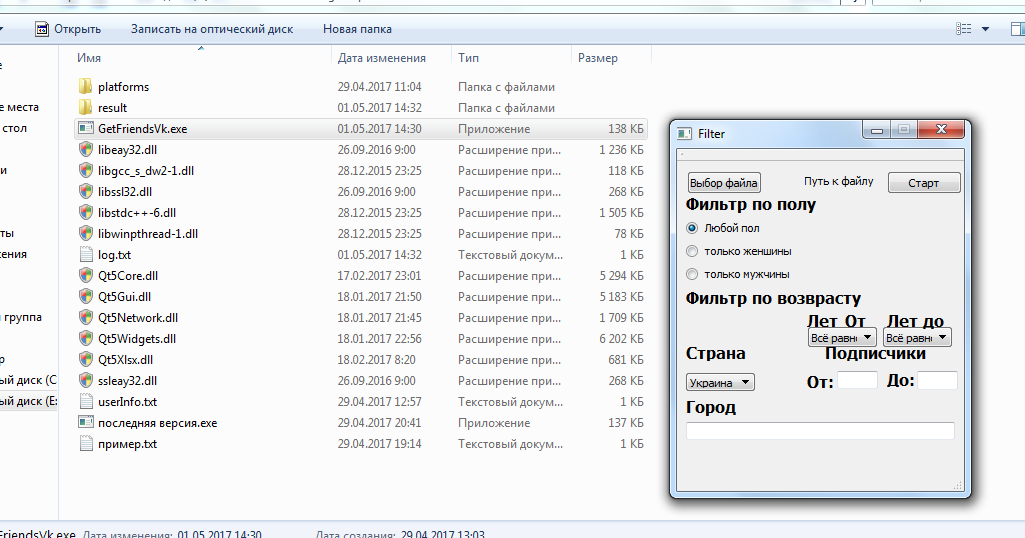 При отправке запросов через прокси-сервер целевой сайт не будет знать, из какого IP-адреса были отправлены исходные запросы, что усложняет обнаружение парсера.
При отправке запросов через прокси-сервер целевой сайт не будет знать, из какого IP-адреса были отправлены исходные запросы, что усложняет обнаружение парсера.
Создайте пул доступных для использования IP-адресов и используйте для каждого запроса случайный IP-адрес из этого пула. При этом нужно распределить несколько запросов по множеству IP-адресов.
Есть несколько методов изменения вашего IP-адреса, с которого отправляются запросы на целевой сайт:
- TOR (это легко обнаруживается)
- Виртуальные частные сети (VPN’ы).
- Бесплатные прокси-серверы.
- Общие («shared») прокси-серверы — самые дешевые и совместно используются множеством пользователей. Высокая вероятность блокировки доступа к целевому сайту.
- Приватные прокси-серверы — обычно используются только одним человеком. Меньшая вероятность возникновения блокировки при парсинге, если поддерживать низкую частоту обращений к целевому сайту.
- Серверные (датацентровые) прокси — если вам нужно большое количество IP-адресов, более быстрые прокси-серверы и более вместительные пулы IP-адресов. Они дешевле резидентных прокси-серверов, но сайты могут легко их обнаружить.
- Резидентные прокси-серверы — если вы делаете очень много запросов к сайтам, которые активно обнаруживают парсеры и запрещают им доступ к данным. Такие прокси-серверы очень дороги и могут работать медленнее, так как представляют собой реальные устройства. Перед тем как использовать резидентные прокси-серверы, попробуйте все остальные варианты.

Вдобавок различные коммерческие поставщики также предоставляют услуги по автоматической ротации IP-адресов. Сегодня есть много компаний, которые предоставляют резидентные IP-адреса, позволяющие еще существеннее упростить парсинг, но большинство из них дороги.
Циклично меняйте пользовательские агенты (строки заголовка User-Agent) и соответствующие HTTP-заголовки у разных запросов
Пользовательский агент — инструмент, который сообщает серверу о том, какой браузер используется.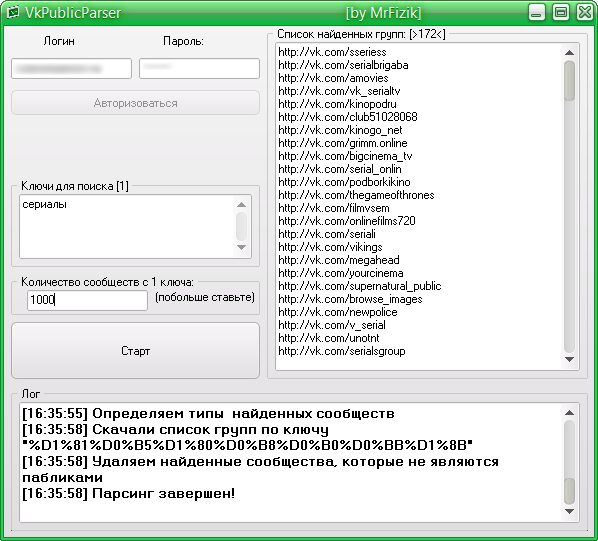 Если пользовательский агент не задан, сайты не позволят вам просматривать контент. Любой запрос, отправленный с помощью браузера, содержит заголовок User-Agent, и постоянное использование одного и того же пользовательского агента ведет к тому, что бот будет обнаружен. Чтобы узнать свой заголовок User-Agent, вы можете набрать в поисковике Google соответствующий запрос. Единственный способ сделать свой User-Agent более похожим на User-Agent реального пользователя и таким образом избежать обнаружения — это подделать его. По умолчанию у большинства парсеров нет пользовательский агента, и вам нужно будет добавить его самостоятельно.
Если пользовательский агент не задан, сайты не позволят вам просматривать контент. Любой запрос, отправленный с помощью браузера, содержит заголовок User-Agent, и постоянное использование одного и того же пользовательского агента ведет к тому, что бот будет обнаружен. Чтобы узнать свой заголовок User-Agent, вы можете набрать в поисковике Google соответствующий запрос. Единственный способ сделать свой User-Agent более похожим на User-Agent реального пользователя и таким образом избежать обнаружения — это подделать его. По умолчанию у большинства парсеров нет пользовательский агента, и вам нужно будет добавить его самостоятельно.
Вы даже можете прикидываться поисковым роботом Google — Googlebot/2.1, если хотите немного поразвлечься (http://www.google.com/bot.html)!
Итак, одна только лишь отправка заголовков User-Agent позволила бы вам обойти большинство простых скриптов и инструментов для обнаружения ботов. Если вы обнаружите, что ваших ботов заблокировали даже после добавления в них актуальной строки заголовка User-Agent, следует добавить другие HTTP-заголовков.
Большинство браузеров отправляют сайтам, помимо User-Agent’а, и другие заголовки. Например, ниже представлен набор заголовков, которые браузер отправил на комплект онлайн-тестов «Scrapeme.live». Оптимально будет отправлять в том числе и эти распространенные заголовки запросов.
Самыми основными считаются:
- User-Agent.
- Accept.
- Accept-Language.
- Referer.
- DNT.
- Updgrade-Insecure-Requests.
- Cache-Control.
Не отправляйте файлы cookie, если только они не нужны для обеспечения работы вашего парсера.
Вы можете найти подходящие значения для них, просматривая свой трафик с помощью инструментов разработчика в Chrome или инструмента вроде MitmProxy или Wireshark. Также вы можете скопировать из этих инструментов команду curl и использовать ее для своего запроса. Например:
Инструмент наподобие https://curl. trillworks.com может конвертировать вам эту команду в код на любом языке программирования. Вот в какой код на Python она была преобразована:
trillworks.com может конвертировать вам эту команду в код на любом языке программирования. Вот в какой код на Python она была преобразована:
Вы можете создавать подобные сочетания заголовков для нескольких браузеров и начать циклично менять эти заголовки для каждого запроса, чтобы снизить вероятность того, что ваш процесс сбора данных будет обнаружен и остановлен.
Используйте инструмент вроде Puppeteer, Selenium или Playwright для управления браузером в headless-режиме
Если ни один из перечисленных выше методов не сработал, сайт, должно быть, проверяет, является ли источник ваших HTTP-запросов настоящим браузером.
Для этого ему проще всего проверить, может ли клиент сайта (браузер) выполнить блок кода на языке JavaScript. Если клиент сайта на это не способен, то сайт фактически помечает такого посетителя как бота. Хотя можно запретить запуск JavaScript-кода в браузере, почти все сайты в Интернете окажутся в таком случае непригодными для использования, а значит в большинстве браузеров эта функция будет включена.
Как только имеет место такая защита от парсинга, чаще всего необходим настоящий браузер, чтобы собирать нужные вам данные. Существуют библиотеки для автоматического управления браузером, как например:
- Selenium.
- Puppeteer и Pyppeteer.
- Playwright.
Антипарсинговые инструменты сообразительны и становятся еще умнее с каждым днем, так как боты подают много данных на вход искусственному интеллекту этих инструментов, что позволяет им обнаруживать ботов. Наиболее продвинутые сервисы для защиты от ботов используют более сложные методы считывания «цифровых отпечатков» браузера, обнаруживая с помощью них ботов на стороне клиента, а не просто проверяют, можете ли вы выполнять JavaScript-код.
Инструменты обнаружения ботов ищут любые признаки, которые могут сообщить им, что браузер управляется библиотекой автоматизации:
- Присутствие признаков, специфических для ботов и демаскирующих их.
- Поддержка браузером нестандартных возможностей.
- Признаки использования популярных инструментов автоматизации, как например Selenium, Puppeteer или Playwright.
- Характерные для человека события, как например произвольные движения мыши, клики, прокрутка веб-страницы, переключения вкладок.

Вся эта информация объединяется, чтобы сформировать уникальный цифровой отпечаток на стороне клиента, который позволяет определить, является ли посетитель сайта ботом или человеком.
Вот несколько обходных вариантов решения проблемы или инструментов, которые могли бы помочь вашему парсеру, основанному на использовании браузера в headless-режиме, избежать обнаружения и блокировки.
- Puppeteer Extra – плагин puppeteer-extra-plugin-stealth, предназначенный для предотвращения обнаружения.
- Patching Selenium/ Phantom JS – ответ на Stack OverFlow на тему исправления Selenium с драйвером Chrome.
- Ротация цифровых отпечатков — статья от Microsoft на тему ротации цифровых отпечатков.

Но несложно догадаться, что, как и боты, разработчики инструментов для их обнаружения тоже становятся умнее. Они улучшают свои модели искусственного интеллекта и ищут переменные, операции, события и другие признаки, которые всё так же свидетельствуют об использовании библиотеки автоматизации, что в итоге приводит к остановке и предотвращению процесса парсинга.
Опасайтесь приманок (traps)
Приманки, или ловушки в виде приманок, — это системы, созданные для привлечения злоумышленников и обнаружения любых их попыток получения несанкционированного доступа к информации. Обычно приманка — это приложение, имитирующее поведение реальной системы. Некоторые сайты размещают приманки, представляющие собой ссылки, невидимые для нормальных пользователей, но отображаемые для парсеров веб-ресурсов.
При переходе по ссылкам всегда убеждайтесь в том, что у ссылки задана подходящая видимость и нет тега nofollow. У некоторых ссылок-приманок, предназначенных для обнаружения парсеров, будет задан CSS-стиль display: none, или они будут спрятаны благодаря использованию цвета, который сливается с цветом фона веб-страницы.
У некоторых ссылок-приманок, предназначенных для обнаружения парсеров, будет задан CSS-стиль display: none, или они будут спрятаны благодаря использованию цвета, который сливается с цветом фона веб-страницы.
Такой способ обнаружения парсеров, очевидно, непрост и требует значительного объема работы, связанной с программированием, чтобы успешно его реализовать. Как следствие, этот прием не используется широко как на стороне сервера, так и на стороне бота или парсера.
Проверяйте, меняет ли сайт разметку
Некоторые сайты отправляют немного разные варианты HTML-разметки, чтобы усложнить парсерам задачу сбора данных.
Например, на сайте 1–20 веб-страниц будут отображать одну разметку, а остальные страницы могут отображать другую. Чтобы справиться с этой проблемой, убедитесь в том, что парсинг данных выполняется с использованием XPath’ов или селекторов CSS. Если это не так, проверьте, как именно отличается разметка, и добавьте в свой программный код условие, согласно которому сбор данных на таких веб-страницах осуществляется по-другому.
Не собирайте данные, будучи в роли авторизованного пользователя сайта
Вход на сайт, или авторизация, — это, по сути, разрешение на получение доступа к данным, размещенным на веб-страницах. Некоторые сайты, как например Indeed и Facebook, не дают такого разрешения.
Если для полноценного просмотра веб-страницы необходимо пройти авторизацию, парсеру придется отправлять некоторую информацию или файлы cookie вместе с каждым запросом, чтобы получить доступ к данным на веб-странице. Благодаря наличию авторизации, сайту легко обнаруживать запросы, поступающие из одного и того же IP-адреса. Администраторы сайта могут удалить ваши данные для входа в систему или забанить вашу учетную запись, а это, в свою очередь, может привести к тому, что ваши попытки собрать там данные будут пресечены.
Как правило, предпочтительнее избегать сбора данных на сайтах, на которых нужно для сбора данных проходить авторизацию, потому что вы легко можете нарваться на запрет доступа к данным. Но вы можете, например, имитировать браузеры настоящих пользователей, и, когда необходимо пройти авторизацию, вы получите нужные вам целевые данные.
Но вы можете, например, имитировать браузеры настоящих пользователей, и, когда необходимо пройти авторизацию, вы получите нужные вам целевые данные.
Используйте сервисы для решения капч
Многие сайты используют меры, направленные против парсинга данных. Если вы собираете большие объемы данных на каком-то сайте, то в конечном итоге вам запретят к ним доступ. Вы начнете видеть веб-страницы с капчей, а не с данными. Существуют веб-сервисы, как например 2Captcha или Anticaptcha, позволяющие обходить эти ограничения.
Если вам необходимо парсить сайты, которые используют капчу, то лучше прибегнуть к помощи подобных сервисов. Услуги ервисов для решения капч относительно дешевы, что будет полезно при масштабном парсинге.
Как сайт может выявить и пресечь парсинг?
Сайты могут использовать различные механизмы, чтобы определить, что пользователь сайта — парсер, или «паук». Некоторые из этих подходов:
- Обнаружение чрезмерного объема трафика или высокой частоты обращения к данным, особенно от одного клиента сайта или IP-адреса за короткий отрезок времени.
- Обнаружение повторяющихся операций, выполняемых на сайте по одной и той же характерной «схеме» просмотра веб-страниц. Этот признак основан на том, что живой пользователь не будет всё время выполнять одни и те же повторяющиеся операции.
- Проверка на то, используете ли вы для отправки запросов к сайту настоящий браузер, будучи реальным пользователем. Простой тест — выполнение JavaScript-кода. Более продвинутые инструменты могут пойти намного дальше и проверять ваши видеокарты и центральные процессоры 😉, чтобы убедиться, что ваши запросы поступают от браузера настоящего пользователя.
- Обнаружение посредством использования приманок, которые обычно представляют собой ссылки, отображаемые только для парсера и скрытые от обычного пользователя. Когда парсер пытается получить доступ к ссылке, срабатывает «сирена».

Как быть с таким методом обнаружения и избежать остановки работы парсера?
Сначала уделите некоторое время исследованию антипарсинговых механизмов, используемых сайтом, а затем соответствующим образом разработайте или откорректируйте парсер. Такой прием в долгосрочной перспективе принесет более качественные результаты и увеличит «срок годности» и надежность вашей работы.
Такой прием в долгосрочной перспективе принесет более качественные результаты и увеличит «срок годности» и надежность вашей работы.
Как узнать, что сайт заблокировал или забанил вас?
Можно отметить следующие признаки обнаружения или противодействия вашей деятельности сайтом, на котором вы собираете данные:
- Веб-страницы с капчами.
- Большие задержки в получении контента.
- Частое получение HTTP-ответа с ошибками 404, 301 или 50x.
Частое появление следующих кодов состояния HTTP-запросов тоже свидетельствует о запрете доступа к данным:
- 301 Moved Permanently («перемещен на постоянной основе»).
- 401 Unauthorized («для получения ответа необходима авторизация»).
- 403 Forbidden («доступ запрещен»).
- 404 Not Found («не найден»).
- 408 Request Timeout («истекло время ожидания»).
- 429 Too Many Requests («слишком много запросов»).
- 503 Service Unavailable («веб-сервис недоступен»).

Вот что Amazon.com сообщает в случае запрета доступа к данным:
Чтобы обсудить автоматический доступ к данным Amazon, пожалуйста, свяжитесь с нами по адресу [email protected]Для получения информации о переходе на наши API, обратитесь к нашему онлайн-магазину API по адресу <ссылка> или к нашему Product Advertising API по адресу <ссылка> в случаях, связанных с рекламой. Извините! Что-то пошло не та! Далее следуют изображения милого пса Amazon.
Также вы можете взглянуть на ответ или сообщение от сайта. Популярные анти-парсинговые инструменты отправляют, например, такие:
Мы хотим убедиться, что имеем дело действительно с вами, а не с роботом.Пожалуйста, щелкните по кнопке-флажку ниже, чтобы получить доступ к сайту.<рекапча>Зачем вообще необходимо это подтверждение? Наше внимание привлекло что-то в поведении вашего браузера. Этому есть различные возможные объяснения:1. Вы просматриваете сайт и делаете щелчки мышью со скоростью, гораздо большей, чем можно было бы ожидать от человека.2. Что-то мешает выполнению JavaScript-кода на вашем компьютере.3. В той же сети, что и у вас, (на том же IP-адресе) замечен робот.Сталкиваетесь с проблемами доступа к сайту? Свяжитесь со службой поддержки или сделайте так, чтобы ваш робот прошел аутентификацию.
Этому есть различные возможные объяснения:1. Вы просматриваете сайт и делаете щелчки мышью со скоростью, гораздо большей, чем можно было бы ожидать от человека.2. Что-то мешает выполнению JavaScript-кода на вашем компьютере.3. В той же сети, что и у вас, (на том же IP-адресе) замечен робот.Сталкиваетесь с проблемами доступа к сайту? Свяжитесь со службой поддержки или сделайте так, чтобы ваш робот прошел аутентификацию.
или
Пожалуйста, докажите, что вы человек.<капча>В доступе к этой веб-странице было отказано, потому что мы считаем, что вы используете инструменты автоматизации для просмотра нашего сайта.Это могло случиться из-за того, что:1. Выполнение JavaScript-кода отключено или заблокировано расширением, например блокировщиками рекламы.2. Ваш браузер не поддерживает файлы cookie.Пожалуйста, убедитесь, что выполнение JavaScript-кода и файлы cookie включены в вашем браузере и что вы не препятствуете их загрузке.
или
Извините, что прерываем. Пока вы просматривали <наименование сайта>, что-то, связанное с вашим браузером, дало нам повод думать, что вы бот. Это могло случиться по нескольким причинам:1. Вы активный пользователь сайта, перемещающийся по нему со сверхчеловеческой скоростью.2. Вы отключили JavaScript в своем браузере.3. Сторонний плагин браузера, как например Ghostery или NoScript, препятствует выполнению JavaScript-кода. Дополнительная информация доступна в этой статье службы поддержки.После успешного решения представленной ниже капчи вы сразу снова получите доступ к <наименование сайта>.
Пока вы просматривали <наименование сайта>, что-то, связанное с вашим браузером, дало нам повод думать, что вы бот. Это могло случиться по нескольким причинам:1. Вы активный пользователь сайта, перемещающийся по нему со сверхчеловеческой скоростью.2. Вы отключили JavaScript в своем браузере.3. Сторонний плагин браузера, как например Ghostery или NoScript, препятствует выполнению JavaScript-кода. Дополнительная информация доступна в этой статье службы поддержки.После успешного решения представленной ниже капчи вы сразу снова получите доступ к <наименование сайта>.
или
Ошибка 1005 Ray ID: <контрольная сумма (хэш)> • <время>.В доступе отказано.Что произошл? Владелец этого сайта (<наименование сайта>) запретил номеру в автономной системе (ASN’у) <номер>, по которому располагается ваш IP-адрес, доступ к этому сайту.
Полный список HTTP-кодов ответа сервера, свидетельствующих об успешных и неудачных запросах к нему, можно увидеть здесь. Вам стоит уделить время, чтобы просмотреть эти коды и получить о них представление.
Вам стоит уделить время, чтобы просмотреть эти коды и получить о них представление.
Где сайты могут обнаружить ботов?
Обнаружение может произойти на стороне клиента, то есть в работающем на вашем компьютере браузере, на стороне сервера, то есть на веб-сервере, или через встроенные технологии защиты от ботов, защищающие трафик сайта путем его перехвата. Также возможно сочетание обоих вариантов. Веб-серверы либо используют встроенные программные продукты для обнаружения подобного поведения клиентов сайта еще до того, как их запросы дойдут до веб-сервера, либо они используют облачные сервисы, которые действуют до момента получения трафика сайтом или встроены в веб-сервер и опираются на стороннюю обработку трафика, чтобы обнаруживать и блокировать трафик ботов. Проблема заключается в том, что это обнаружение, как и все остальные средства защиты, характеризуется ложноположительными срабатываниями и приводит к обнаружению и блокировке живых добропорядочных пользователей, ошибочно считая их ботами. Или же оно оказывает непроизводительную нагрузку на сервер, делая сайт медленным и непригодным для использования. Подобные технологии действительно затратны с финансовой и технической точек зрения, а также обладают преимуществами и недостатками, которые следует учитывать.
Или же оно оказывает непроизводительную нагрузку на сервер, делая сайт медленным и непригодным для использования. Подобные технологии действительно затратны с финансовой и технической точек зрения, а также обладают преимуществами и недостатками, которые следует учитывать.
Вот некоторые из мест и ситуаций, при которых парсер может быть обнаружен:
- При считывании цифрового отпечатка на стороне сервера с помощью поведенческого анализа.
- При считывании цифрового отпечатка на стороне клиента или браузера с помощью поведенческого анализа.
- Сочетание этих двух вариантов на многочисленных доменах и в датацентрах.
Обнаружение на стороне сервера
Это обнаружение ботов начинается на серверном уровне, то есть на веб-сервере сайта или на устройствах облачных сервисов, которые находятся «перед» сайтом на пути следования запросов к нему, отслеживают трафик, а также выявляют и блокируют ботов. Методы считывания цифровых отпечатков, подразделяемые на несколько типов, обычно используются в сочетании и преследуют цель обнаружения ботов на стороне сервера.
Методы считывания цифровых отпечатков, подразделяемые на несколько типов, обычно используются в сочетании и преследуют цель обнаружения ботов на стороне сервера.
Считывание цифрового отпечатка в целом пагубно влияет на конфиденциальность данных посетителей сайта, позволяя без проблем отслеживать активность отдельных пользователей по всему Интернету, но это уже отдельная тема.
Считывание цифрового HTTP-отпечатка
Считывание цифрового HTTP-отпечатка осуществляется путем анализа трафика, который посетитель сайта отправляет на веб-сервер. Почти вся соответствующая информация доступна веб-серверу и некоторую ее часть также можно увидеть в журналах (логах) веб-сервера. Такой цифровой отпечаток может предоставить сайту основную информацию о посетителе, как например:
- User-Agent, сообщающий о том какой браузер и какой версии использует пользователь, как например Chrome, Firefox, Edge, Safari.
- Заголовки запроса, как например Referer, Cookie, принимаемая браузером кодировка, принимает ли он сжатие gzip и так далее. Всё это представляет собой дополнительные фрагменты данных, которые браузер отправляет серверу.
- Порядок перечисленных выше заголовков.
- IP-адрес, через который посетитель отправляет запрос или в конечном итоге обращается к веб-серверу в том случае, если посетитель использует NAT-адрес интернет-провайдера или прокси-серверы.
 Всё это представляет собой дополнительные фрагменты данных, которые браузер отправляет серверу.
Всё это представляет собой дополнительные фрагменты данных, которые браузер отправляет серверу.Считывание цифрового отпечатка данных, связанных со стеком TCP/IP
Данные, которые посетитель отправляет на серверы, приходит на них в качестве пакетов по протоколам TCP/IP. Цифровой отпечаток данных, связанных с TCP, включает в себя следующие подробные данные:
- Исходный размер пакета (16 битов).
- Исходный TTL (8 битов).
- Размер окна (16 битов).
- Максимальный размер сегмента (16 битов).
- Величина масштабирования окна (8 битов).
- Флаг «don’t fragment», то есть «не разбивать на фрагменты» (1 бит).
- Флаг «sackOK» (1 бит).
- Флаг «nop» (1 бит).
Эти переменные объединяются в данные в виде цифровой подписи компьютера посетителя сайта, которая позволяет уникальным образом идентифицировать посетителя и определить, бот он или человек. Инструменты с открытым исходным кодом, как, например, p0f, могут сообщить о том, подделан ли User-Agent. Такой инструмент даже может определить, находится ли посетитель сайта за сетью NAT, или у него прямое подключение к Интернету. Также он может узнать текущие настройки браузеров, например языковые настройки.
Считывание TLS-отпечатка
Когда к сайту кто-то обращается безопасным образом по протоколу HTTPS, браузер и веб-сервер генерируют цифровой TLS-отпечаток в процессе рукопожатия SSL. Большинство клиентских User-Agent’ов, например различные браузеры и приложения (Dropbox, Skype и прочие), будут уникальным образом инициировать запрос на рукопожатие SSL, что позволяет считать цифровой отпечаток такой попытки получения доступа к данным.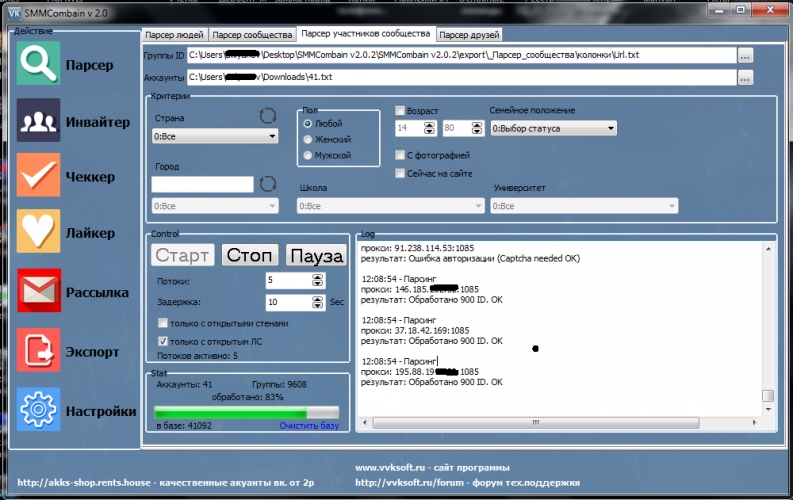
JA3 — библиотека с открытым исходным кодом для считывания цифрового TLS-отпечатка, собирает десятичные значения байтов по следующим полям в пакете (сообщении) Client Hello во время рукопожатия SSL:
- Версия SSL.
- Принимаемые шифры.
- Список расширений.
- Эллиптические кривые.
- Форматы эллиптических кривых.
Затем она объединяет эти значения по порядку, используя запятую в качестве разделителя между полями и короткую черту для отделения значения каждого поля от его наименования. Далее эти строки хэшируются по алгоритму MD5, чтобы получить в результате 32-символьный цифровой отпечаток, который легко использовать и которым легко обмениваться. Так формируется цифровой SSL-отпечаток клиента в библиотеке JA3. Хэши MD5 также обладают преимуществом в скорости генерации и сравнения значений. Кроме того, их уникальность находится на очень высоком уровне.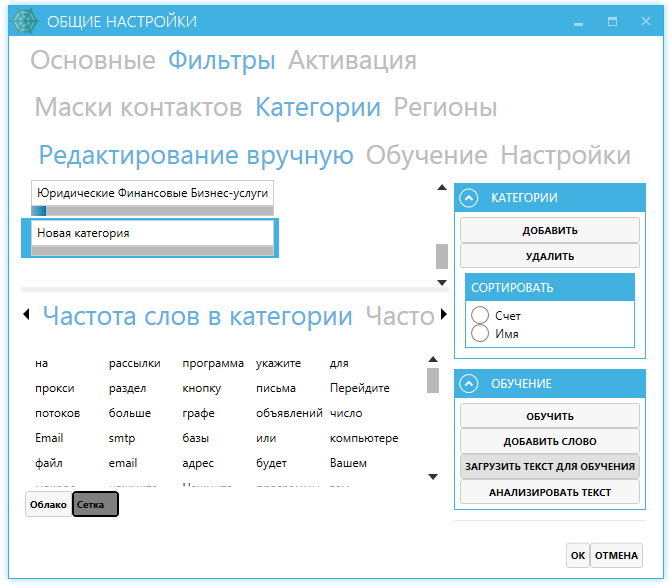
Поведенческий анализ и обнаружение шаблонных действий
Как только уникальный цифровой отпечаток будет сформирован из всех перечисленных выше элементов, инструменты обнаружения ботов смогут отслеживать поведение посетителя на сайте или на множестве сайтов, если они пользуются услугами по обнаружению ботов от того же поставщика таких услуг. Эти инструменты проводят поведенческий анализ того, как пользователи просматривают сайт. Обычно этот анализ учитывает:
- Какие страницы были посещены.
- Порядок, в котором они были посещены.
- Перекрестное сопоставление HTTP-заголовка Referer с ранее посещенной страницей.
- Количество запросов, отправленных на сайт.
- Частота запросов к сайту.
Эти признаки позволяют программным продуктам, предназначенным для борьбы с ботами, определять, является ли посетитель сайта ботом или человеком, основываясь на данных, которые они прочитали ранее.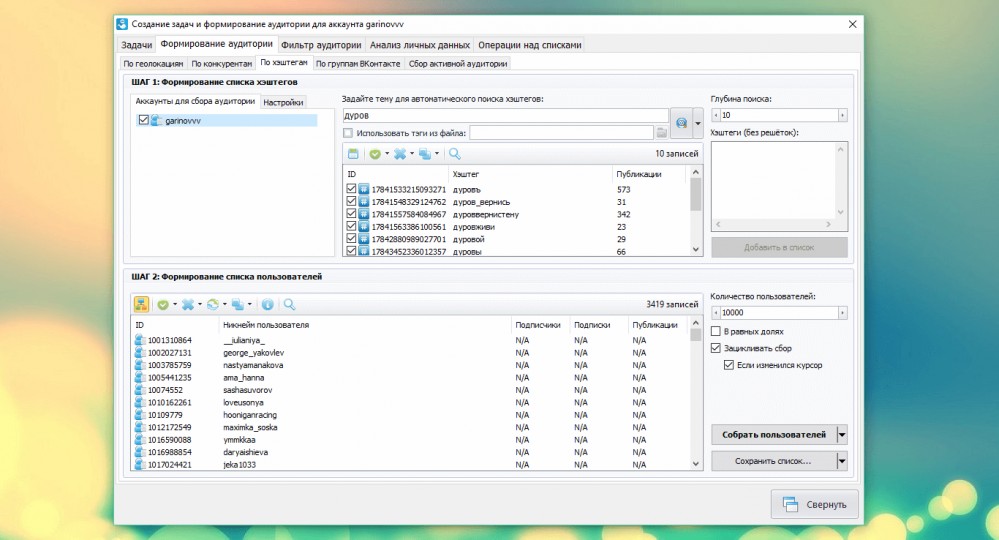 Также в некоторых случаях подобные инструменты отправляют пользователю задачу, которую он должен решить, например капчу. Если посетитель решит капчу, то система может принять его за настоящего пользователя, а если решение капчи завершится провалом, что типично для большинства ботов, которые не ожидают появления капчи, то такого «посетителя» система пометит как бота и запретит ему доступ к сайту.
Также в некоторых случаях подобные инструменты отправляют пользователю задачу, которую он должен решить, например капчу. Если посетитель решит капчу, то система может принять его за настоящего пользователя, а если решение капчи завершится провалом, что типично для большинства ботов, которые не ожидают появления капчи, то такого «посетителя» система пометит как бота и запретит ему доступ к сайту.
Таким образом, любые запросы к сайтам с одним и тем же сервисом обнаружения ботов, которые поступают от посетителей с такими цифровыми отпечатками, например отпечатками HTTP, TCP, TLS или IP-адреса, будут требовать от посетителей доказать, что они люди, а не боты. Посетитель или его IP-адрес обычно помещается в черный список на определенный период, а затем удаляется из списка, если больше за ним не замечена активность, характерная для ботов. Иногда IP-адреса, которые постоянно проявляют характерную для ботов активность, бессрочно добавляются во всеобщий черный список, и им запрещают заходить на многие сайты, использующие такие первичные черные списки.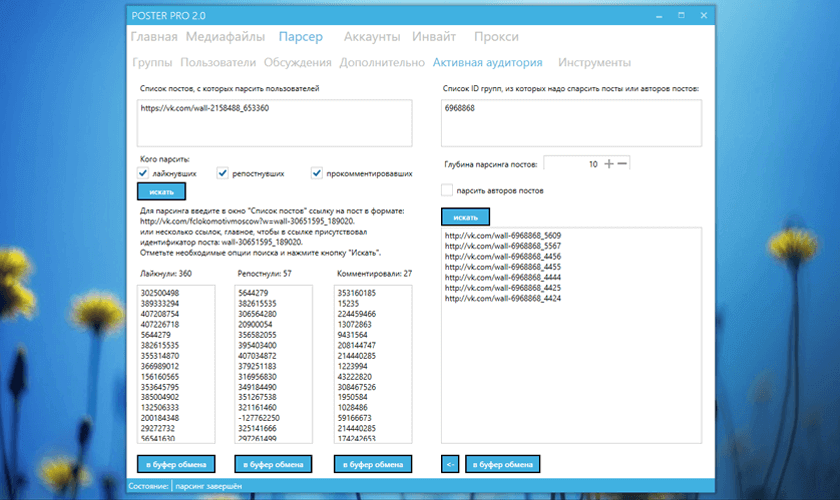
Парсерам веб-ресурсов сравнительно легче избежать обнаружения на стороне сервера, если они хорошо настроены на работу с теми сайтами, на которых они собирают данные.
Совет от профессионалов 🙂 — лучший способ понять каждый аспект данных, которые перемещаются между клиентом и сервером в качестве части веб-запроса, — это использовать прокси-сервер, расположенный между ними, как, например, MITM, или же посмотреть на содержимое вкладки Network («Сеть») на панели браузера с инструментами разработчика, которая чаще всего доступна через F12. Для более глубокого анализа, который выходит за рамки протокола HTTP к более низкому уровню — стеку TCP/IP, вы можете воспользоваться Wireshark, чтобы проверить фактически передающиеся пакеты, заголовки и все эти данные, которые курсируют между браузером и сайтом. Любой фрагмент этих данных можно использовать для идентификации посетителя сайта и таким образом облегчить считывание его цифрового отпечатка.
Обнаружение на стороне клиента (браузера)
Почти все сервисы для обнаружения используют комбинацию инструментов для обнаружения ботов на стороне браузера в сочетании с инструментами их обнаружения на стороне сервера, чтобы более безошибочно препятствовать деятельности ботов.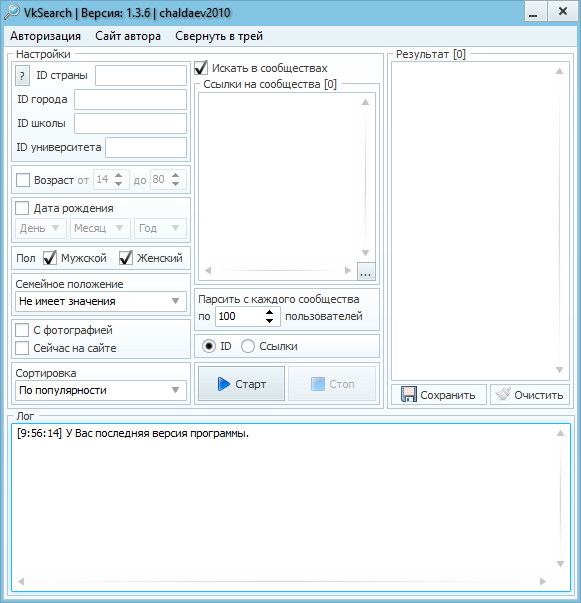
Первое, что предпринимает сайт в начале процесса обнаружения ботов на стороне клиента, — немедленная блокировка всех парсеров, которые не являются браузерами реальных пользователей.
Для этого ему проще всего проверить, может ли клиент сайта (браузер) выполнить блок кода на языке JavaScript. Если клиент этого сделать не может, средство обнаружения с высокой вероятностью пометит такого клиента в качестве бота. Хотя можно запретить запуск JavaScript-кода в браузере, почти все сайты в Интернете окажутся в таком случае непригодными для использования, а значит в большинстве браузеров эта функция будет включена.
Как только имеет место такая защита от парсинга, чаще всего необходим настоящий браузер, чтобы собирать нужные вам данные. Существуют библиотеки для автоматического управления браузером, как например:
- Selenium.
- Puppeteer и Pyppeteer.
- Playwright.
Средства обнаружения ботов на стороне браузера обычно предусматривают формирование цифрового отпечатка путем обращения через браузер к самой разнообразной информации системного уровня.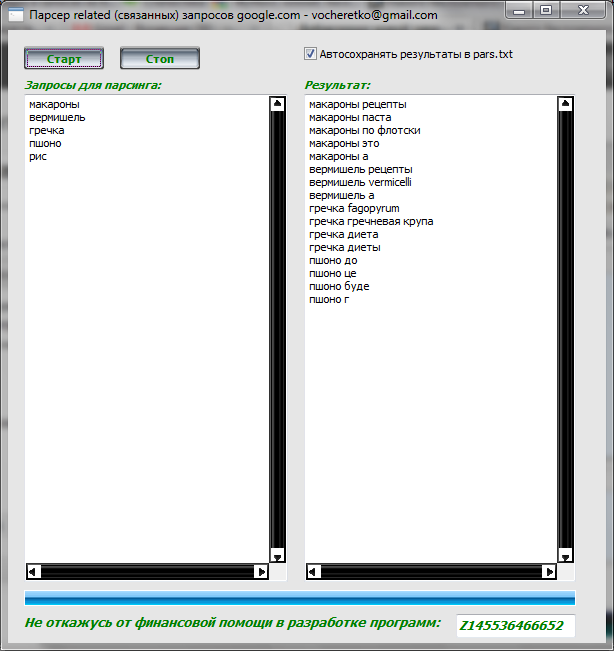 Как правило, такие средства прибегают к использованию отслеживающего JavaScript-файла, который выполняет в браузере обнаруживающий ботов код и отправляет обратно для дальнейшего анализа информацию о браузере и соответствующем компьютере, где этот браузер установлен и функционирует.
Как правило, такие средства прибегают к использованию отслеживающего JavaScript-файла, который выполняет в браузере обнаруживающий ботов код и отправляет обратно для дальнейшего анализа информацию о браузере и соответствующем компьютере, где этот браузер установлен и функционирует.
Например, объект браузера «navigator» показывает много информации о компьютере, на котором работает браузер. Вот как в раскрытом состоянии выглядит объект «navigator» браузера Safari:
Некоторые из распространенных характерных признаков, используемых для формирования цифрового отпечатка браузера:
- User-Agent.
- Заданный язык.
- Статус «Do Not Track», то есть «не отслеживать».
- Поддерживаемые возможности HTML5.
- Поддерживаемые CSS-правила.
- Поддерживаемые возможности JavaScript.
- Установленные в браузере плагины.
- Разрешение экрана и глубина цвета.
- Временная зона.
- Операционная система.
- Количество ядер центрального процессора.
- Производитель GPU и браузерный модуль отображения (rendering engine).
- Максимальное количество одновременных касаний тачпада.
- Различные типы хранения данных, поддерживаемые браузером.
- Контрольная сумма холста HTML5.
- Список установленных на компьютере шрифтов.
Помимо этих технических приемов инструменты обнаружения ботов также ищут любые признаки, которые могут сообщить им о том, что браузер пользователя управляется с помощью библиотеки автоматизации:
- Присутствие признаков, специфических для ботов и демаскирующих их.
- Поддержка нестандартных возможностей браузера.
- Признаки использования популярных инструментов автоматизации, как например Selenium, Puppeteer или Playwright.
- Также учитываются характерные для человека события, как например: произвольные движения мыши, клики, прокрутка веб-страницы, переключения вкладок.

Вся эта информация объединяется, чтобы сформировать уникальный цифровой отпечаток на стороне клиента, который позволяет определить, является ли посетитель сайта ботом или человеком.
Spark Parse JSON из столбца String | Текстовый файл
В этой статье Spark вы узнаете, как анализировать или читать строку JSON из файла TEXT/CSV и преобразовывать ее в несколько столбцов DataFrame, используя примеры Scala.
Предположим, у вас есть текстовый файл с данными JSON или файл CSV со строкой JSON в столбце. Чтобы прочитать эти файлы, проанализировать JSON и преобразовать в DataFrame, мы используем функцию from_json() , предоставленную в Spark SQL. .
1. Чтение и разбор JSON из TEXT-файла
В этом разделе мы увидим анализ строки JSON из текстового файла и преобразование ее в столбцы Spark DataFrame с помощью встроенной функции from_json() Spark SQL.
Ниже представлены данные JSON в текстовом файле,
{"Почтовый индекс": 704, "ZipCodeType": "СТАНДАРТ", "Город": "ПАРК-ПАРК", "Штат": "PR"}
{"Почтовый индекс": 704, "ZipCodeType": "СТАНДАРТ", "Город": "ПАСЕО КОСТА-ДЕЛЬ-СУР", "Штат": "PR"}
{"Почтовый индекс": 709, "ZipCodeType": "СТАНДАРТ", "Город": "BDA SAN LUIS", "Штат": "PR"}
{"Почтовый индекс": 76166, "ZipCodeType": "УНИКАЛЬНЫЙ", "Город": "CINGULAR WIRELESS", "Штат": "TX"}
{"Почтовый индекс": 76177, "ZipCodeType": "СТАНДАРТ", "Город": "ФОРТ-УЭРТ", "Штат": "TX"}
{"Почтовый индекс": 76177, "ZipCodeType": "СТАНДАРТ", "Город": "FT WORTH", "Штат": "TX"}
{"Почтовый индекс": 704, "ZipCodeType": "СТАНДАРТ", "Город": "URB EUGENE RICE", "Штат": "PR"}
{"Почтовый индекс": 85209,"ZipCodeType":"СТАНДАРТ","Город":"MESA","Штат":"AZ"}
{"Почтовый индекс": 85210, "ZipCodeType": "СТАНДАРТ", "Город": "MESA", "Штат": "AZ"}
{"Почтовый индекс": 32046, "ZipCodeType": "СТАНДАРТ", "Город": "ХИЛЛИАРД", "Штат": "Флорида"}
мы можем легко прочитать этот файл с помощью метода read. json(), однако мы игнорируем это и читаем его как текстовый файл, чтобы объяснить использование функции from_json().
json(), однако мы игнорируем это и читаем его как текстовый файл, чтобы объяснить использование функции from_json().
// Чтение строки JSON из текстового файла
val dfFromText:DataFrame = spark.read.text("src/main/resources/simple_zipcodes.txt")
dfFromText.printSchema()
Это чтение строки JSON из текстового файла в столбец значения DataFrame , как показано на схеме ниже.
корень |-- значение: строка (nullable = true)
2. Преобразование столбца JSON в несколько столбцов
Теперь давайте преобразуем столбец значений в несколько столбцов с помощью from_json(). Эта функция принимает столбец DataFrame со строкой JSON и схемой JSON в качестве аргументов. Итак, во-первых, давайте создадим схему, представляющую наши данные.
//Определяем схему структуры JSON
импортировать org.apache.spark.sql.types.{StringType, StructType}
схема val = новый StructType()
.add("Почтовый индекс", StringType, правда)
.add("ZipCodeType", StringType, true)
. add("Город", StringType, правда)
.add("Состояние", StringType, правда)
 add("Город", StringType, правда)
.add("Состояние", StringType, правда)
add("Город", StringType, правда)
.add("Состояние", StringType, правда)
Наконец, используйте функцию from_json() , которая возвращает структуру столбца со всеми столбцами JSON, и мы разбиваем структуру, чтобы сгладить ее.
// преобразовать столбец json в несколько столбцов
импортировать org.apache.spark.sql.functions.{col,from_json}
val dfJSON = dfFromText.withColumn ("jsonData", from_json (столбец ("значение"), схема))
.выбрать("jsonData.*")
dfJSON.printSchema()
dfJSON.show(ложь)
Урожайность ниже выпуска
корень |-- Почтовый индекс: строка (можно обнулить = истина) |-- ZipCodeType: строка (можно обнулить = истина) |-- Город: строка (nullable = true) |-- Состояние: строка (nullable = true) +-------+-----------+-----+-----+ |Почтовый индекс|ZipCodeType|Город |Штат| +-------+-----------+-----+-----+ |704 |СТАНДАРТ |ПАРК ПАРК |PR | |704 |СТАНДАРТ |ПАСЕО-КОСТА-ДЕЛЬ-СУР|PR | |709|СТАНДАРТ |BDA САН-ЛУИС |PR | |76166 |УНИКАЛЬНЫЙ |CINGULAR WIRELESS |TX | |76177 |СТАНДАРТ |ФОРТ-УЭРТ |TX | |76177 |СТАНДАРТНЫЙ |ФУТОВАЯ СТОИМОСТЬ |TX | |704 |СТАНДАРТ |URB ЮДЖИН РАЙС |PR | |85209 |СТАНДАРТ |MESA |AZ | |85210 |СТАНДАРТ |MESA |AZ | |32046 |СТАНДАРТ |ХИЛЬЯРД |FL | +-------+-----------+-----+-----+
В качестве альтернативы вы также можете написать приведенный выше оператор, используя select.
// альтернативно используя выбор
val df5 = dfFromText.select(from_json(col("значение"), схема).as("данные"))
.select("данные.*").show(false)
3. Считайте и проанализируйте строку столбца JSON из CSV
Аналогичным образом мы также можем проанализировать JSON из файла CSV и создать DataFrame.
//Чтение из файла CSV
val dfFromCSV:DataFrame = spark.read.option("заголовок",true)
.csv("источник/основной/ресурсы/simple_zipcodes.csv")
dfFromCSV.printSchema()
dfFromCSV.show (ложь)
Это загружает всю строку JSON в столбец JsonValue и дает схему ниже.
корень |-- Идентификатор: строка (nullable = true) |-- JsonValue: строка (можно обнулить = истина)
Теперь давайте проанализируем столбец JsonValue и преобразуем его в несколько столбцов с помощью функции from_json() .
// Преобразование JsonValue в несколько столбцов
val dfFromCSVJSON = dfFromCSV.select(col("Id"),
from_json(col("JsonValue"),схема). as("jsonData"))
.выбрать("Идентификатор","jsonData.*")
dfFromCSVJSON.printSchema()
dfFromCSVJSON.show (ложь)
 as("jsonData"))
.выбрать("Идентификатор","jsonData.*")
dfFromCSVJSON.printSchema()
dfFromCSVJSON.show (ложь)
as("jsonData"))
.выбрать("Идентификатор","jsonData.*")
dfFromCSVJSON.printSchema()
dfFromCSVJSON.show (ложь)
Выход ниже выхода
корень |-- Идентификатор: строка (nullable = true) |-- Почтовый индекс: строка (можно обнулить = истина) |-- ZipCodeType: строка (можно обнулить = истина) |-- Город: строка (nullable = true) |-- Состояние: строка (nullable = true) +---+-------+-------------+-----+----- + |Id |Почтовый индекс|ZipCodeType|Город |Штат| +---+-------+-------------+-----+----- + |1 |704 |СТАНДАРТ |ПАРК ПАРК |PR | |2 |704 |СТАНДАРТ |ПАСЕО-КОСТА-ДЕЛЬ-СУР|PR | |3 |709|СТАНДАРТ |BDA САН-ЛУИС |PR | |4 |76166 |УНИКАЛЬНЫЙ |CINGULAR WIRELESS |TX | |5 |76177 |СТАНДАРТ |ФОРТ-УЭРТ |TX | |6 |76177 |СТАНДАРТ |ФУТОВ |TX | |7 |704 |СТАНДАРТ |URB EUGENE RICE |PR | |8 |85209 |СТАНДАРТ |MESA |AZ | |9 |85210 |СТАНДАРТ |MESA |AZ | |10 |32046 |СТАНДАРТ |ХИЛЬЯРД |FL | +---+-------+-------------+-----+----- +
4. Преобразование строки JSON в столбцы DataFrame
Если у вас есть JSON в строке и вы хотите преобразовать или загрузить в Spark DataFrame, используйте spark. , эта функция принимает Dataset[String] в качестве аргумента. read.json()
read.json()
//Чтение json из строки
импортировать spark.implicits._
val jsonStr = """{"Почтовый индекс":704,"ZipCodeType":"СТАНДАРТ","Город":"ПАРК-ПАРК","Штат":"PR"}"""
val df = spark.read.json(Seq(jsonStr).toDS())
df.show (ложь)
Урожайность ниже выпуска
+-----------+-----+------------+-------+ |Город |Штат|ZipCodeType|Почтовый индекс| +-----------+-----+------------+-------+ |ПАРК ПАРК|PR |СТАНДАРТ |704 | +-----------+-----+------------+-------+
5. Преобразование RDD[String] в JSON
spark.read.json() также имеет другую устаревшую функцию для преобразования RDD[String], которая содержит строку JSON, в Spark DataFrame
// из RDD[String]
// устарело
val rdd = spark.sparkContext.parallelize(
""" {"Почтовый индекс":704,"ZipCodeType":"СТАНДАРТ","Город":"ПАРК-ПАРК","Штат":"PR"} """ :: Nil)
val df2 = spark.read.json(rdd)
df2.show()
Это дает тот же результат, что и выше.
6. Полный пример синтаксического анализа JSON из строки в DataFrame
пакет com.sparkbyexamples.spark.dataframe
импортировать org.apache.spark.sql.{DataFrame, SparkSession}
импортировать org.apache.spark.sql.functions._
импортировать org.apache.spark.sql.types._
объект ReadJsonFromString расширяет приложение {
val spark: SparkSession = SparkSession.builder()
.мастер("местный[1]")
.appName("SparkByExamples.com")
.getOrCreate()
spark.sparkContext.setLogLevel("ОШИБКА")
// Чтение строки JSON из текстового файла
val dfFromText:DataFrame = spark.read.text("src/main/resources/simple_zipcodes.txt")
dfFromText.printSchema()
//Определяем схему структуры JSON
схема val = новый StructType()
.add("Почтовый индекс", StringType, правда)
.add("ZipCodeType", StringType, true)
.add("Город", StringType, правда)
.add("Состояние", StringType, правда)
// Преобразование столбца JSON в несколько столбцов
val dfJSON = dfFromText.withColumn ("jsonData", from_json (столбец ("значение"), схема))
. выбрать("jsonData.*")
dfJSON.printSchema()
dfJSON.show(ложь)
//Альтернативно используя выбор
val dfJSON2 = dfFromText.select(from_json(col("значение"), схема).as("jsonData"))
.выбрать("jsonData.*")
// Чтение строки JSON из файла CSV
val dfFromCSV:DataFrame = spark.read.option("заголовок",true)
.csv("источник/основной/ресурсы/simple_zipcodes.csv")
dfFromCSV.printSchema()
dfFromCSV.show (ложь)
val dfFromCSVJSON = dfFromCSV.select(col("Id"),
from_json(col("JsonValue"),схема).as("jsonData"))
.выбрать("Идентификатор","jsonData.*")
dfFromCSVJSON.printSchema()
dfFromCSVJSON.show (ложь)
//Чтение json из строки
импортировать spark.implicits._
val jsonStr = """{"Почтовый индекс":704,"ZipCodeType":"СТАНДАРТ","Город":"ПАРК-ПАРК","Штат":"PR"}"""
val df = spark.read.json(Seq(jsonStr).toDS())
df.show (ложь)
// из RDD[String]
// устарело
val rdd = spark.sparkContext.parallelize(
""" {"Почтовый индекс":704,"ZipCodeType":"СТАНДАРТ","Город":"ПАРК-ПАРК","Штат":"PR"} """ :: Nil)
val df2 = spark. read.json(rdd)
df2.show()
}
 выбрать("jsonData.*")
dfJSON.printSchema()
dfJSON.show(ложь)
//Альтернативно используя выбор
val dfJSON2 = dfFromText.select(from_json(col("значение"), схема).as("jsonData"))
.выбрать("jsonData.*")
// Чтение строки JSON из файла CSV
val dfFromCSV:DataFrame = spark.read.option("заголовок",true)
.csv("источник/основной/ресурсы/simple_zipcodes.csv")
dfFromCSV.printSchema()
dfFromCSV.show (ложь)
val dfFromCSVJSON = dfFromCSV.select(col("Id"),
from_json(col("JsonValue"),схема).as("jsonData"))
.выбрать("Идентификатор","jsonData.*")
dfFromCSVJSON.printSchema()
dfFromCSVJSON.show (ложь)
//Чтение json из строки
импортировать spark.implicits._
val jsonStr = """{"Почтовый индекс":704,"ZipCodeType":"СТАНДАРТ","Город":"ПАРК-ПАРК","Штат":"PR"}"""
val df = spark.read.json(Seq(jsonStr).toDS())
df.show (ложь)
// из RDD[String]
// устарело
val rdd = spark.sparkContext.parallelize(
""" {"Почтовый индекс":704,"ZipCodeType":"СТАНДАРТ","Город":"ПАРК-ПАРК","Штат":"PR"} """ :: Nil)
val df2 = spark.
выбрать("jsonData.*")
dfJSON.printSchema()
dfJSON.show(ложь)
//Альтернативно используя выбор
val dfJSON2 = dfFromText.select(from_json(col("значение"), схема).as("jsonData"))
.выбрать("jsonData.*")
// Чтение строки JSON из файла CSV
val dfFromCSV:DataFrame = spark.read.option("заголовок",true)
.csv("источник/основной/ресурсы/simple_zipcodes.csv")
dfFromCSV.printSchema()
dfFromCSV.show (ложь)
val dfFromCSVJSON = dfFromCSV.select(col("Id"),
from_json(col("JsonValue"),схема).as("jsonData"))
.выбрать("Идентификатор","jsonData.*")
dfFromCSVJSON.printSchema()
dfFromCSVJSON.show (ложь)
//Чтение json из строки
импортировать spark.implicits._
val jsonStr = """{"Почтовый индекс":704,"ZipCodeType":"СТАНДАРТ","Город":"ПАРК-ПАРК","Штат":"PR"}"""
val df = spark.read.json(Seq(jsonStr).toDS())
df.show (ложь)
// из RDD[String]
// устарело
val rdd = spark.sparkContext.parallelize(
""" {"Почтовый индекс":704,"ZipCodeType":"СТАНДАРТ","Город":"ПАРК-ПАРК","Штат":"PR"} """ :: Nil)
val df2 = spark. read.json(rdd)
df2.show()
}
read.json(rdd)
df2.show()
}
Этот пример также доступен для справки в проекте GitHub.
7. Заключение
В этой статье Spark вы узнали, как читать и анализировать строку JSON из текстовых и CSV-файлов, а также научились преобразовывать столбцы строки JSON в несколько столбцов в DataFrame на примерах Scala.
EXA2PRO, DQRA и HiCMA-PaRSE Frameworks & More
В этой регулярной рубрике HPCwire освещаются недавно опубликованные исследования в области высокопроизводительных вычислений и смежных областях. От параллельного программирования до эксафлопсных и квантовых вычислений — подробности здесь.
EXA2PRO: основа для высокой производительности разработки на гетерогенных вычислительных системах
В этой статье группа международных исследователей (Афинский национальный технический университет, Греция; Центр исследований и технологий Hellas, Институт химических процессов и энергетических ресурсов, Греция ; Университет Линчепинга, Швеция; Центр исследований и технологий Hellas, Институт химических процессов и энергетических ресурсов, Греция; Maison de la Simulation, CEA, CNRS, Франция; Université de Pau et des Pays de l’Adour, Франция; Университет Бордо, Франция Центр исследований и технологий Hellas, Институт информационных технологий, Греция) продемонстрировал ключевые компоненты платформы EXA2PRO, целью которой является повышение «производительности разработчиков приложений, предназначенных для гетерогенных вычислительных систем». Эта структура «основана на передовых моделях программирования и абстракциях, которые инкапсулируют низкоуровневые оптимизации для конкретных платформ, и поддерживается средой выполнения, которая обрабатывает развертывание приложений на разнородных узлах». Исследователи «применили платформу EXA2PRO к четырем приложениям для высокопроизводительных вычислений и продемонстрировали, как ее можно использовать для автоматического развертывания и оценки приложений в самых разных разнородных кластерах».
Эта структура «основана на передовых моделях программирования и абстракциях, которые инкапсулируют низкоуровневые оптимизации для конкретных платформ, и поддерживается средой выполнения, которая обрабатывает развертывание приложений на разнородных узлах». Исследователи «применили платформу EXA2PRO к четырем приложениям для высокопроизводительных вычислений и продемонстрировали, как ее можно использовать для автоматического развертывания и оценки приложений в самых разных разнородных кластерах».
Авторы: Лазарос Пападопулос, Димитриос Судрис, Кристоф Кесслер, Август Эрнстсон, Йохан Альквист, Никос Василас, Афанасиос И. Пападопулос, Панос Сеферлис, Шарль Прувёр, Матьё Хефеле, Самуэль Тибо, Афанасиос Кефелиша Саламанис, Теодорос Иоакишамисиодис
Глубокое обучение с подкреплением для вычислительной гидродинамики в системах HPC
Исследователи из Института аэродинамики и газовой динамики Штутгартского университета, Hewlett Packard Enterprise (HPE), Центра высокопроизводительных вычислений Штутгартского университета и Лаборатория гидродинамики и технических потоков Магдебургского университета имени Отто фон Герике описывает разработанную ими структуру Relexi. Relexi «преодолевает разрыв между рабочими процессами машинного обучения и современными решателями вычислительной гидродинамики (CFD) в системах HPC, предоставляя обоим компонентам свое специализированное оборудование». Это «масштабируемая структура обучения с подкреплением (RL)… построенная с учетом модульности и позволяющая легко интегрировать различные решатели высокопроизводительных вычислений посредством передачи данных в памяти, предоставляемой библиотекой SmartSim». В этой статье исследователи продемонстрировали, что «инфраструктура Relexi может масштабироваться до сотен параллельных сред на тысячах ядер». По словам исследователей, эта возможность позволит ресурсам высокопроизводительных вычислений решать масштабные проблемы или сокращать время выполнения проектов. Наконец, исследователи продемонстрировали «потенциал CFD-решателя, дополненного RL, найдя стратегию управления для оптимального выбора вязкости вихря в моделировании больших вихрей».
Relexi «преодолевает разрыв между рабочими процессами машинного обучения и современными решателями вычислительной гидродинамики (CFD) в системах HPC, предоставляя обоим компонентам свое специализированное оборудование». Это «масштабируемая структура обучения с подкреплением (RL)… построенная с учетом модульности и позволяющая легко интегрировать различные решатели высокопроизводительных вычислений посредством передачи данных в памяти, предоставляемой библиотекой SmartSim». В этой статье исследователи продемонстрировали, что «инфраструктура Relexi может масштабироваться до сотен параллельных сред на тысячах ядер». По словам исследователей, эта возможность позволит ресурсам высокопроизводительных вычислений решать масштабные проблемы или сокращать время выполнения проектов. Наконец, исследователи продемонстрировали «потенциал CFD-решателя, дополненного RL, найдя стратегию управления для оптимального выбора вязкости вихря в моделировании больших вихрей».
Авторы: Мариус Курц, Филипп Оффенхаузер, Доминик Виола, Александр Щербаков, Майкл Реш, Андреа Бек
DQRA: агент глубокой квантовой маршрутизации для запутанной маршрутизации в квантовых сетях Государственный университет Кеннесо в Мариетте, штат Джорджия, занимается маршрутизацией в квантовых сетях с помощью «модели квантовой маршрутизации на основе машинного обучения для квантовых сетей» под названием Deep Quantum Routing Agent (DQRA). В этой статье авторы подробно описывают схему маршрутизации с глубоким подкреплением DQRA, в которой используется «эмпирически разработанная глубокая нейронная сеть, которая наблюдает за текущими состояниями сети для удовлетворения требований сети, которые затем соединяются с помощью алгоритма кратчайшего пути с сохранением кубитов». По словам исследовательской группы, «процесс обучения DQRA управляется функцией вознаграждения, которая направлена на максимальное количество обработанных запросов в каждом окне маршрутизации». Они демонстрируют, что в среднем «DQRA может поддерживать уровень успешно маршрутизируемых запросов на уровне выше 80 процентов в сети с ограниченным числом кубитов и примерно на уровне 60 процентов в экстремальных условиях».
В этой статье авторы подробно описывают схему маршрутизации с глубоким подкреплением DQRA, в которой используется «эмпирически разработанная глубокая нейронная сеть, которая наблюдает за текущими состояниями сети для удовлетворения требований сети, которые затем соединяются с помощью алгоритма кратчайшего пути с сохранением кубитов». По словам исследовательской группы, «процесс обучения DQRA управляется функцией вознаграждения, которая направлена на максимальное количество обработанных запросов в каждом окне маршрутизации». Они демонстрируют, что в среднем «DQRA может поддерживать уровень успешно маршрутизируемых запросов на уровне выше 80 процентов в сети с ограниченным числом кубитов и примерно на уровне 60 процентов в экстремальных условиях».
Авторы: Линь Ле и Ту Н. Нгуен
Фреймворк для использования разреженности данных в низкоранговой факторизации Холецкого
Эта статья многопрофильной группы исследователей из Лаборатории инновационных вычислений Университета Теннесси, Исследовательский центр экстремальных вычислений, Отделение компьютерных, электрических и математических наук и инженерии в Университете науки и технологий имени короля Абдуллы, Окриджская национальная лаборатория и Манчестерский университет предлагают программную «инфраструктуру, которая сочетает в себе систему времени выполнения PaRSEC. и числовая библиотека HiCMA для решения сложных задач с ограниченным объемом 3D-данных». В этой статье исследователи демонстрируют «эффективность и масштабируемость HiCMA-PaRSE». Результаты производительности, проведенные исследователями, показали, что внедрение их инфраструктуры HiCMA-PaRSE продемонстрировало «до 7-кратного увеличения на Shaheen II и 9в несколько раз превосходит производительность Fugaku в ситуациях, когда приложение деформации трехмерной неструктурированной сетки визуализирует матричный оператор с низкой плотностью». Кроме того, программная среда «решает формально плотную 3D-задачу с 52 млн точек сетки на 65 тыс. ядрах примерно за полчаса».
и числовая библиотека HiCMA для решения сложных задач с ограниченным объемом 3D-данных». В этой статье исследователи демонстрируют «эффективность и масштабируемость HiCMA-PaRSE». Результаты производительности, проведенные исследователями, показали, что внедрение их инфраструктуры HiCMA-PaRSE продемонстрировало «до 7-кратного увеличения на Shaheen II и 9в несколько раз превосходит производительность Fugaku в ситуациях, когда приложение деформации трехмерной неструктурированной сетки визуализирует матричный оператор с низкой плотностью». Кроме того, программная среда «решает формально плотную 3D-задачу с 52 млн точек сетки на 65 тыс. ядрах примерно за полчаса».
Авторы: Цинлей Цао, Рабаб Аломайри, Ю Пей, Джордж Босилка, Хатем Лтаиф, Дэвид Киз и Джек Донгарра
Суперкомпьютер The Summit.Моделирование рабочих нагрузок параллельного ввода-вывода до Exascale AMR с помощью прокси-приложений
В этой статье ученые-компьютерщики из Ок-Риджской национальной лаборатории в Теннесси и Технологического института Джорджии в Джорджии углубляются в «моделирование предэкзафлопсных рабочих нагрузок ввода/вывода (I/O) при моделировании Adaptive Mesh Refinement (AMR) с помощью простое прокси-приложение».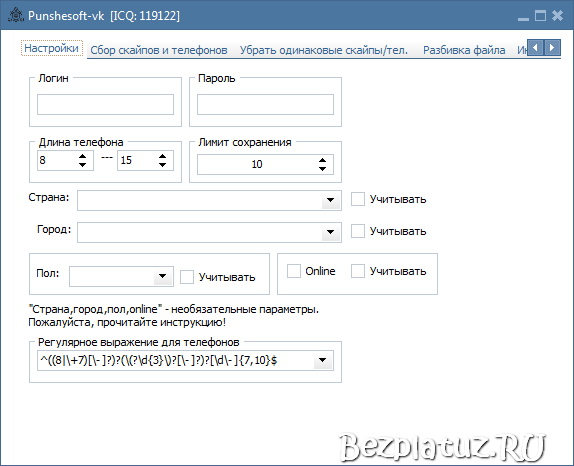 По словам авторов, конечная цель этого исследования — «обеспечить начальный уровень понимания рабочих нагрузок ввода-вывода AMR с помощью моделей облегченных прокси-приложений, чтобы облегчить стратегии управления данными с автоматической настройкой в преддверии экзафлопсных систем». Используя суперкомпьютер Summit, ученые собрали данные из структуры AMReX Castro «для широкого диапазона масштабов и разделов сетки для гидродинамического случая Седова в качестве основы, чтобы обеспечить достаточное покрытие сформулированной прокси-модели». Результаты этого исследования показали, что «MACSio может моделировать реальные нелинейные «статические» рабочие нагрузки ввода-вывода AMReX с определенной степенью уверенности на суперкомпьютере Summit, используя существующую методологию».
По словам авторов, конечная цель этого исследования — «обеспечить начальный уровень понимания рабочих нагрузок ввода-вывода AMR с помощью моделей облегченных прокси-приложений, чтобы облегчить стратегии управления данными с автоматической настройкой в преддверии экзафлопсных систем». Используя суперкомпьютер Summit, ученые собрали данные из структуры AMReX Castro «для широкого диапазона масштабов и разделов сетки для гидродинамического случая Седова в качестве основы, чтобы обеспечить достаточное покрытие сформулированной прокси-модели». Результаты этого исследования показали, что «MACSio может моделировать реальные нелинейные «статические» рабочие нагрузки ввода-вывода AMReX с определенной степенью уверенности на суперкомпьютере Summit, используя существующую методологию».
Авторы: Уильям Ф. Годой, Дженна Делозье и Грегори Р. Уотсон
HPC-расширения конвейера обработки OpenKIM
Группа исследователей из отдела аэрокосмической техники и механики Миннесотского в Суперкомпьютерном центре Сан-Диего при Калифорнийском университете в Сан-Диего разработать расширения конвейера обработки OpenKIM, чтобы обеспечить эффективное использование высокопроизводительных вычислительных ресурсов с помощью открытой базы знаний межатомных моделей (OpenKIM). OpenKIM — это «научный шлюз NSF, который архивирует полнофункциональные компьютерные реализации межатомных моделей (потенциалы и силовые поля) и коды моделирования, которые используют их для вычисления свойств материалов. Межатомные модели сочетаются с совместимыми кодами моделирования и выполняются полностью автоматически с помощью конвейера обработки OpenKIM, облачной вычислительной платформы». Однако предыдущие исследования показали, что использование конвейера недостаточно для поддержки крупномасштабных вычислений. Поэтому в этой статье исследователи подробно описывают расширения конвейера обработки OpenKIM для достижения лучших результатов с использованием высокопроизводительных вычислительных ресурсов.
OpenKIM — это «научный шлюз NSF, который архивирует полнофункциональные компьютерные реализации межатомных моделей (потенциалы и силовые поля) и коды моделирования, которые используют их для вычисления свойств материалов. Межатомные модели сочетаются с совместимыми кодами моделирования и выполняются полностью автоматически с помощью конвейера обработки OpenKIM, облачной вычислительной платформы». Однако предыдущие исследования показали, что использование конвейера недостаточно для поддержки крупномасштабных вычислений. Поэтому в этой статье исследователи подробно описывают расширения конвейера обработки OpenKIM для достижения лучших результатов с использованием высокопроизводительных вычислительных ресурсов.
Авторы: Дэниел С. Карлс, Стивен М. Кларк, Брендон А. Уотерс, Райан С. Эллиот и Эллад Б. Тадмор
Таксономия источников ошибок в моделях машинного обучения ввода-вывода HPC
В этом В статье исследовательская группа из нескольких институтов анализирует наборы данных с суперкомпьютера ALCF Theta и суперкомпьютера NERSC Cori, чтобы лучше понять моделирование пропускной способности ввода-вывода.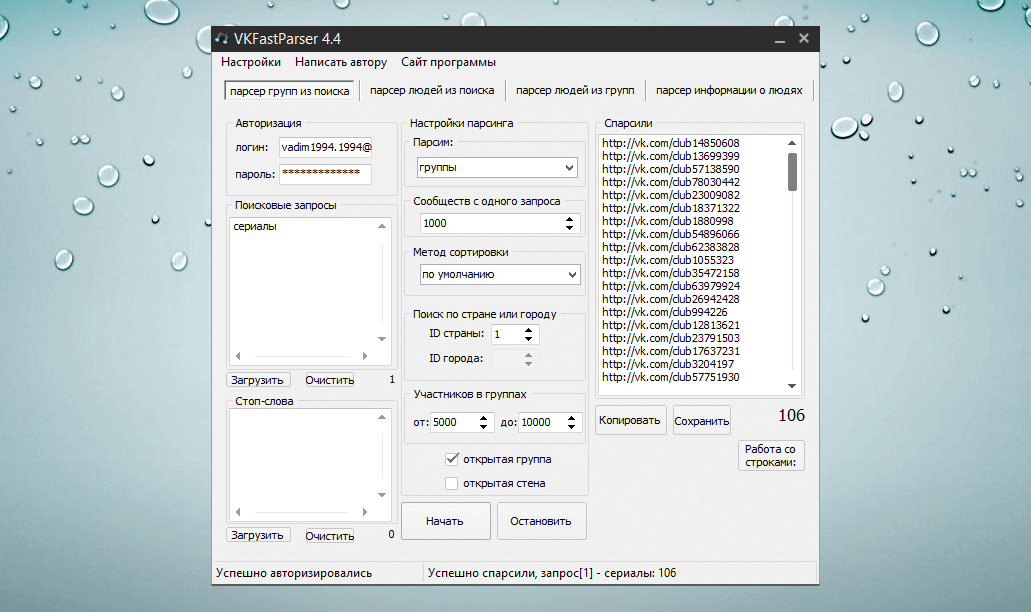 «Мы изучаем, почему модели ML пропускной способности ввода-вывода могут совершенно неверно предсказывать производительность заданий HPC. В большинстве случаев [это происходит из-за] плохих моделей или недостаточного обучения, но мы обнаружили, что в игру вступают несколько других эффектов — недиагностированное переобучение, конфликты между рабочими местами, системный шум и т. д.», — сказал ведущий автор Михайло Исаков (Arizona State Университет) в Твиттере. Исаков также сообщил, что статья была принята Суперкомпьютерной конференцией (SC22). В настоящее время он доступен в виде препринта Arxiv.
«Мы изучаем, почему модели ML пропускной способности ввода-вывода могут совершенно неверно предсказывать производительность заданий HPC. В большинстве случаев [это происходит из-за] плохих моделей или недостаточного обучения, но мы обнаружили, что в игру вступают несколько других эффектов — недиагностированное переобучение, конфликты между рабочими местами, системный шум и т. д.», — сказал ведущий автор Михайло Исаков (Arizona State Университет) в Твиттере. Исаков также сообщил, что статья была принята Суперкомпьютерной конференцией (SC22). В настоящее время он доступен в виде препринта Arxiv.
Авторы: Михайло Исаков, Микаэла Карриер, Элиакин дель Росарио, Сандип Мадиредди, Прасанна Балапракаш, Филип Карнс, Роберт Б. Росс, Гленн К. Локвуд, Мишель А. Кинси
Знаете ли вы об исследованиях, которые должны быть включенным в список следующего месяца? Если да, отправьте нам электронное письмо по адресу [email protected]. Мы с нетерпением ждем ответа от вас.
Темы: Exascale, Networks, Quantum, Research, Systems
Секторы: Академия и исследования
Метки: исследования, наука
Джанаи Нельсон
Джанаи С. Нельсон является президентом и директором-юрисконсультом Фонда правовой защиты NAACP (LDF). Ведущая национальная организация по защите гражданских прав, борющаяся за расовую справедливость и равенство. LDF была основана в 1940 году легендарным адвокатом по гражданским правам и первым в стране чернокожим судьей Верховного суда Тергудом Маршаллом и стала отдельной организацией от NAACP в 1957 году. Юристы Фонда правовой защиты разработали и реализовали правовую стратегию, которая привела к Знаменательное решение Верховного суда в Браун против Совета по образованию , широко признанное самым преобразующим и монументальным судебным решением 20-го века.
Нельсон ранее занимал должность заместителя директора-юрисконсульта, а также члена группы LDF по судебным разбирательствам и политике. Она также занимала должность временного директора Института Тергуда Маршалла LDF и занимала различные другие руководящие должности в LDF. Нельсон был одним из ведущих юрисконсультов в деле Veasey v. Abbott (2018 г.), успешном федеральном оспаривании закона Техаса об удостоверении личности избирателя, и ведущим архитектором NUL против Трампа (2020 г.), в котором пытались объявить указ президента Трампа, запрещающий разнообразие, равенство и инклюзивное обучение на рабочем месте, неконституционным, прежде чем он был позже отменен. До прихода в LDF в июне 2014 года Нельсон была заместителем декана по стипендии факультета и заместителем директора Центра гражданских прав и экономического развития Рональда Х. Брауна на юридическом факультете Университета Св. Иоанна, где она также была профессором права и работала в группе старшего руководства юридической школы.
Она также занимала должность временного директора Института Тергуда Маршалла LDF и занимала различные другие руководящие должности в LDF. Нельсон был одним из ведущих юрисконсультов в деле Veasey v. Abbott (2018 г.), успешном федеральном оспаривании закона Техаса об удостоверении личности избирателя, и ведущим архитектором NUL против Трампа (2020 г.), в котором пытались объявить указ президента Трампа, запрещающий разнообразие, равенство и инклюзивное обучение на рабочем месте, неконституционным, прежде чем он был позже отменен. До прихода в LDF в июне 2014 года Нельсон была заместителем декана по стипендии факультета и заместителем директора Центра гражданских прав и экономического развития Рональда Х. Брауна на юридическом факультете Университета Св. Иоанна, где она также была профессором права и работала в группе старшего руководства юридической школы.
Известный ученый в области избирательного права и избирательного права, Нельсон продолжает готовить передовые исследования в области внутреннего и сравнительного избирательного права, расы и теории демократии. Публикация Нельсона Анализ пристрастности: подход к партизанскому мошенничеству и расе была опубликована в NYU Law Review (октябрь 2021 г.) и предлагает Верховному суду вариант рассмотрения исков о гибридном расовом и партийном мошенничестве, несмотря на то, что он пришел к выводу, что партийное мошенничество не подлежит судебному преследованию. . Она также опубликовала Изменение подсчета: обеспечение инклюзивной переписи цветных сообществ , 119 Colum. L. Rev. (2019 г.), в котором продвигается теория репрезентативного равенства, согласно которой все жители США «должны учитываться — и служить — как избирателям», и которая центрирует перепись и точный подсчет наиболее уязвимых групп населения страны в функционировании нашей демократии. Две другие ее основополагающие научные публикации: Причинный контекст разнородного отказа в голосовании , 54 г. до н.э. Л. Откр. 579(2013), в котором исследуется раздел 2 Закона об избирательных правах как несоизмеримый стандарт воздействия и расовые аспекты современного отказа в голосовании, и Первая поправка, равная защита и лишение избирательных прав преступников: новая точка зрения , 64 Fl.
Публикация Нельсона Анализ пристрастности: подход к партизанскому мошенничеству и расе была опубликована в NYU Law Review (октябрь 2021 г.) и предлагает Верховному суду вариант рассмотрения исков о гибридном расовом и партийном мошенничестве, несмотря на то, что он пришел к выводу, что партийное мошенничество не подлежит судебному преследованию. . Она также опубликовала Изменение подсчета: обеспечение инклюзивной переписи цветных сообществ , 119 Colum. L. Rev. (2019 г.), в котором продвигается теория репрезентативного равенства, согласно которой все жители США «должны учитываться — и служить — как избирателям», и которая центрирует перепись и точный подсчет наиболее уязвимых групп населения страны в функционировании нашей демократии. Две другие ее основополагающие научные публикации: Причинный контекст разнородного отказа в голосовании , 54 г. до н.э. Л. Откр. 579(2013), в котором исследуется раздел 2 Закона об избирательных правах как несоизмеримый стандарт воздействия и расовые аспекты современного отказа в голосовании, и Первая поправка, равная защита и лишение избирательных прав преступников: новая точка зрения , 64 Fl. L. Rev. 111 (2013 г.), в котором исследуется пересечение Первой поправки и положения о равной защите при пересмотре конституционности лишения избирательных прав преступников в Соединенных Штатах. Нельсон вел курсы по избирательному праву и политическому участию, сравнительному избирательному праву, избирательным правам, профессиональной ответственности и конституционному праву, а также семинар по стратегиям расового равенства, а также читал лекции в юридических школах по всей стране. Нельсон также является лауреатом премии Деррика А. Белла 2013 года от секции по группам меньшинств Американской ассоциации юридических школ (AALS) и был назван одним из 50 профессоров из числа представителей меньшинств до 50 лет, внесенных организацией Lawyers of Color в юридическое образование.
L. Rev. 111 (2013 г.), в котором исследуется пересечение Первой поправки и положения о равной защите при пересмотре конституционности лишения избирательных прав преступников в Соединенных Штатах. Нельсон вел курсы по избирательному праву и политическому участию, сравнительному избирательному праву, избирательным правам, профессиональной ответственности и конституционному праву, а также семинар по стратегиям расового равенства, а также читал лекции в юридических школах по всей стране. Нельсон также является лауреатом премии Деррика А. Белла 2013 года от секции по группам меньшинств Американской ассоциации юридических школ (AALS) и был назван одним из 50 профессоров из числа представителей меньшинств до 50 лет, внесенных организацией Lawyers of Color в юридическое образование.
До поступления в академию Нельсон была стипендиатом Фулбрайта в Центре юридических ресурсов в Аккре, Гана, где она исследовала политическое лишение избирательных прав лиц с уголовными судимостями и продвижение демократии в Гане. Ее исследование в качестве стипендиата программы Фулбрайта легло в основу публикации под названием « Справедливая мера права голоса: сравнительная перспектива обеспечения соблюдения избирательных прав в развивающейся демократии» ,18 Cardozo J. Comp. и международный 425 (2010). До получения премии Фулбрайта Нельсон была директором Группы политического участия LDF, где она курировала все судебные процессы и вопросы, связанные с голосованием, рассматривала права голоса и дела о перераспределении избирательных округов, а также работала над вопросами уголовного правосудия от имени афроамериканцев и других малообеспеченных слоев населения. сообщества. Находясь в LDF, она выступала в полном составе перед Вторым округом и работала ведущим адвокатом в Хайден против Патаки , дело о лишении избирательных прав преступника, в котором оспаривались законы штата Нью-Йорк, отказывающие в праве голоса людям, находящимся в заключении и условно-досрочно освобожденным за уголовное преступление.
Ее исследование в качестве стипендиата программы Фулбрайта легло в основу публикации под названием « Справедливая мера права голоса: сравнительная перспектива обеспечения соблюдения избирательных прав в развивающейся демократии» ,18 Cardozo J. Comp. и международный 425 (2010). До получения премии Фулбрайта Нельсон была директором Группы политического участия LDF, где она курировала все судебные процессы и вопросы, связанные с голосованием, рассматривала права голоса и дела о перераспределении избирательных округов, а также работала над вопросами уголовного правосудия от имени афроамериканцев и других малообеспеченных слоев населения. сообщества. Находясь в LDF, она выступала в полном составе перед Вторым округом и работала ведущим адвокатом в Хайден против Патаки , дело о лишении избирательных прав преступника, в котором оспаривались законы штата Нью-Йорк, отказывающие в праве голоса людям, находящимся в заключении и условно-досрочно освобожденным за уголовное преступление. Она также входила в группу адвокатов по гражданским правам, представляющих афро- и гаитянских избирателей в деле NAACP против Худа (коллективный иск, возникший в результате всеобщих выборов 2000 г.) и одним из адвокатов, представляющих заключенного, приговоренного к смертной казни. чей приговор был смягчен в 2003 году Верховным судом США в Бэнкс против Дретке .
Она также входила в группу адвокатов по гражданским правам, представляющих афро- и гаитянских избирателей в деле NAACP против Худа (коллективный иск, возникший в результате всеобщих выборов 2000 г.) и одним из адвокатов, представляющих заключенного, приговоренного к смертной казни. чей приговор был смягчен в 2003 году Верховным судом США в Бэнкс против Дретке .
Нельсон начал заниматься юридической практикой, получив в 1998 году стипендию NAACP LDF/Fried Frank Fellowship. Она получила степень бакалавра искусств. Нью-Йоркского университета и степень доктора права юридического факультета Калифорнийского университета в Лос-Анджелесе, где она работала редактором статей в UCLA Law Review, редактором-консультантом журнала National Black Law Journal и помощником редактора женского юридического журнала UCLA. После окончания юридического факультета Нельсон работал секретарем достопочтенного Теодора Макмиллиана в Апелляционном суде Соединенных Штатов по восьмому округу (19 лет).