
Что такое парсинг? — Глоссарий Интернет-маркетинга
Что такое парсинг?
Парсинг (от англ. parse — «разбор») — обработка интернет-ресурсов с целью сбора какой-либо информации.
Парсинг означает разбор содержимого страницы на отдельные составляющие. Это можно делать и вручную, но намного чаще процесс является автоматическим — при задействии специальных программ («парсеров»). Объектом парсинга может быть справочник, интернет-магазин, форум, блог и абсолютно любой интернет-ресурс.
Отличный пример парсера — это поисковые системы. Их роботы буквально считывают информацию с сайтов и хранят данные об их содержимом в своих базах. И тогда стоит ввести поисковый запрос в специальную строку — они выдают самые подходящие и актуальные сайты.
Парсинг сайтов — это отличный способ автоматизировать процесс сбора и хранения информации. С помощью парсинга можно создавать и обновлять сайты, схожие по оформлению, содержанию и структуре. Задачи могут быть самые разные — например, скопировать все статьи из Википедии или достать все телефонные номера, которые есть на доске объявлений.
Задачи могут быть самые разные — например, скопировать все статьи из Википедии или достать все телефонные номера, которые есть на доске объявлений.
Как используют парсинг в интернет-маркетинге
В SEO парсинг чаще используют для получения контента для дальнейшего рерайта или репостинга, или для поиска каких-либо веб-ресурсов — форумов, блогов, e-mail-адресов. Также популярен парсинг внешних ссылок для анализа сайтов-конкурентов и обнаружения доступных трастовых сайтов.
Парсинг существенно ускоряет процесс работы с ключевыми словами. Настроив работу, можно оперативно подобрать необходимые для продвижения запросы. После кластеризации по страницам можно подготовить SEO-контент с учетом максимального количества ключей.
Интерфейс парсера Netpeak Spider
Кроме этого парсинг необходим для оценки технической стороны сайта. Он выявляет большинство технических ошибок, находит битые ссылки, неисправные редиректы, показывает, правильно ли настроен robots.
Интернет-магазины иногда используют парсинг для первичного наполнения сайта. В парсер загружают прайс-лист поставщика. Затем программа сканирует, например, Яндекс.Маркет, производя лингвистический анализ товаров, сравнивая товары поставщика и товары, которые есть на Яндекс.Маркете. Товары, которые были идентифицированы, парсер сохраняет в свою базу. А потом их выгружают на сайт интернет-магазина.
Особенности парсинга
Программа-парсер может быть написана на любом языке программирования (PHP, C++, Delphi и других), где присутствует поддержка регулярных выражений. Это набор метасимволов, используемых для поиска необходимых данных.
Сохранение данных происходит в формате, заданном программистом. Это может быть табличный документ, XML-, SQL-, TXT- или другой файл.
Популярные программы для парсинга:
- Screaming Frog SEO Spider 9.2
- ComparseR 1.0.129
- Netpeak Spider 3.
 0
0 - Xenu’s Link Sleuth
- WildShark SEO Spider
- Majento SiteAnalayzer
 0
0
См. также
Анкор
Биржа ссылок
Дублированный контент
Саттелит
Индекс цитируемости
Канибализация трафика
что это и где применяется — Сервисы на vc.ru
{«id»:13984,»url»:»\/distributions\/13984\/click?bit=1&hash=7d1145cad225b33ea22bcbd631a1999830a41712fb42e4cc382d48b13499574e»,»title»:»\u0421\u043e\u0437\u0434\u0430\u0442\u044c \u0431\u043e\u0442\u0430, \u043d\u0435 \u0431\u0443\u0434\u0443\u0447\u0438 \u043f\u0440\u043e\u0433\u0440\u0430\u043c\u043c\u0438\u0441\u0442\u043e\u043c. \u0421\u043f\u043e\u0439\u043b\u0435\u0440: \u043c\u0430\u0433\u0438\u044f \u043d\u0435 \u043d\u0443\u0436\u043d\u0430″,»buttonText»:»\u0410 \u043a\u0430\u043a?»,»imageUuid»:»aec8892e-a16f-5278-8a7c-f04dc5b866f4″}
Как известно, время – деньги, поэтому чем меньше времени у вас будет уходить на решение той или иной задачи, тем лучше это скажется на развитии бизнеса. Парсинг – незаменимый помощник в решении этого вопроса. Этот инструмент дает возможность относительно быстро структурировать огромный объем данных, который даст понять, как привести свой бизнес к лучшему результату.
Парсинг – незаменимый помощник в решении этого вопроса. Этот инструмент дает возможность относительно быстро структурировать огромный объем данных, который даст понять, как привести свой бизнес к лучшему результату.
206 просмотров
Что такое парсинг?
Парсинг – это процесс сбора с различных сайтов информации, которая является ценной для выстраивания бизнес-процессов, планирования стратегий развития и внедрения новых продуктов. Парсингом занимаются специально разработанные для этого программы – парсеры. Благодаря таким сервисам значительно сокращается, во-первых, количество времени на обработку информации, во-вторых, возможность допущения ошибки в этом процессе. Итогом парсинга является документ, в котором содержатся все необходимые данные по заранее установленным фильтрам. Одной из таких программ является парсер “Compass Gooru”, который качественно отличается от других по многим критериям. Этот сервис позволяет выгружать информацию не только в отдельный файл, но и в социальные сети.
Сферы применения парсинга
Использование парсера в своем бизнесе поможет в решении множества важных проблем:
- ценовая разведка для маркетолога и анализ конкурентной среды – парсинг ассортимента товаров, их цен, количества продаж и других данных дает возможность держать руку на пульсе и оперативно реагировать на изменения ценовой политики по определенным позициям, внося корректировки в собственный интернет-магазин;
- анализ собственного сайта или интернет-магазина – внедряя парсинг в работу с собственным сайтом, можно проверить его на ошибки и вовремя их устранить;
- сбор баз данных клиентов – парсеру доступна и информация о пользователях сайта: номера телефонов и адреса электронной почты, которые можно в дальнейшем использовать для холодных обзвонов или email-рассылок. Сбор этих данных не противоречит законодательству при соблюдении определенных правил:информация должна лежать в открытом доступе;информация не должна являться коммерческой тайной;парсинг не затрагивает авторские права;парсер не мешает работе сайта.
- получение идей для создания нового контента – парсинг может проанализировать информацию и о самых популярных и непопулярных темах для создания собственного контента и планирования контент-плана, что даст возможность рассказывать своей аудитории о том, что ее действительно интересует.
 Сбор этих данных не противоречит законодательству при соблюдении определенных правил:информация должна лежать в открытом доступе;информация не должна являться коммерческой тайной;парсинг не затрагивает авторские права;парсер не мешает работе сайта.
Сбор этих данных не противоречит законодательству при соблюдении определенных правил:информация должна лежать в открытом доступе;информация не должна являться коммерческой тайной;парсинг не затрагивает авторские права;парсер не мешает работе сайта.Парсинг позволяет быстро и качественно перенимать ценный опыт конкурентов и обдуманно внедрять новшества в свой бизнес на основе данных анализа. Но, как и во всем, результат сильно зависит от используемого инструмента: чем мощнее вы выберете парсер, тем быстрее и качественнее получите итог. Парсер “Compass Gooru” обладает всеми необходимыми свойствами, чтобы обеспечить вам скорость и удобство работы. Вам всего лишь нужно настроить выборку по предпочтениям, все остальное мы берем на себя: подберем ресурсы под ваши задачи, систематизируем информацию и отправим все в ваш личный кабинет.
Если хотите использовать наш инструмент для оптимизации своего бизнеса, оставляйте заявку на сайте, и мы вам поможем. Наша компания гарантирует качественный парсинг в сжатые сроки. Совершенствуйте свой бизнес с Compas Pro!
Разбор. Ищете четкое определение того, что такое «токенизатор», «парсер» и «лексер», и как они связаны друг с другом и используются?
спросил
Изменено 5 месяцев назад
Просмотрено 47 тысяч раз
Я ищу четкое определение того, что такое «токенизатор», «парсер» и «лексер» и как они связаны друг с другом (например, использует ли парсер токенизатор или наоборот)? Мне нужно создать программу, которая будет проходить через исходные файлы c/h для извлечения объявлений и определений данных.
Я искал примеры и могу найти некоторую информацию, но я действительно изо всех сил пытаюсь понять основные понятия, такие как правила грамматики, деревья синтаксического анализа и абстрактное синтаксическое дерево, и то, как они взаимосвязаны друг с другом. В конечном итоге эти концепции должны быть сохранены в реальной программе, но 1) как они выглядят, 2) существуют ли общие реализации.
Я просматривал Википедию по этим темам и таким программам, как Lex и Yacc, но никогда не изучал класс компилятора (основной EE), поэтому мне трудно полностью понять, что происходит.
- разбор
- лексер
- токенизация
Токенизатор разбивает поток текста на токены, обычно ища пробелы (табуляции, пробелы, новые строки).
Лексер — это, по сути, токенизатор, но обычно он добавляет к токенам дополнительный контекст: этот токен — это число, этот токен — строковый литерал, этот другой токен — оператор равенства.
Синтаксический анализатор берет поток токенов из лексера и превращает его в абстрактное синтаксическое дерево, представляющее (обычно) программу, представленную исходным текстом.
Последнее, что я проверял, лучшей книгой по этому вопросу была «Компиляторы: принципы, методы и инструменты», обычно известная просто как «Книга дракона».
12Пример:
int x = 1;
Лексер или токенизатор разделит это на токены ‘int’, ‘x’, ‘=’, ‘1’, ‘;’.
Парсер возьмет эти токены и использует их для понимания:
- у нас есть утверждение
- это определение целого числа
- целое число называется ‘x’
- ‘x’ должен быть инициализирован значением 1
Я бы сказал, что лексер и токенизатор в основном одно и то же, и они разбивают текст на составные части («токены»). Затем синтаксический анализатор интерпретирует токены, используя грамматику.
Я бы не стал слишком зацикливаться на точном терминологическом употреблении — люди часто используют «парсинг» для описания любого действия по интерпретации куска текста.
( добавление к данным ответам )
- Токенизатор также удалит любые комментарии и вернет лексеру только токенов .
- Lexer также определит области действия для этих токенов (переменные/функции)
- Парсер затем создаст структуру кода/программы
Использование
«Принципы, методы и инструменты компиляторов, 2-е изд.». (WorldCat) Ахо, Лам, Сетхи и Ульман, также известная как Книга Пурпурного Дракона
мой связанный ответ В чем разница между токеном и лексемой?
Как и в случае с другим моим ответом, такие вопросы имеют больше смысла, когда желательна конкретная цель.
В вашем случае конкретная цель
Create Программа будет просматривать исходные файлы c/h для извлечения объявлений и определений данных.
Если целью является создание абстрактных синтаксических деревьев (AST), то они создаются с использованием синтаксического анализатора , а синтаксический анализатор обычно передает список токенов из лексера . Обратите внимание, что Tokenizer намеренно не упоминается.
Обратите внимание, что Tokenizer намеренно не упоминается.
Другой способ представить отношения между лексером и синтаксическим анализатором состоит в том, что лексер создает линейную структуру (список/поток лексем), а синтаксический анализатор преобразует лексемы в древовидную структуру (абстрактное синтаксическое дерево).
Если вы читали книгу «Дракон», вы заметите, что слово Анализ встречается часто, что означает, что анализ является одной из ключевых функций на различных этапах. Это связано с тем, что при работе с лексерами и синтаксическими анализаторами они предназначены для работы с формальными языками, и необходимо определить, соответствует ли входная информация формальному языку.
Со страницы 5
поток символов
|
В
Лексический анализатор
(поток токенов)
|
В
Анализатор синтаксиса
(синтаксическое дерево)
|
В
Семантический анализатор
(синтаксическое дерево)
|
В
. ..
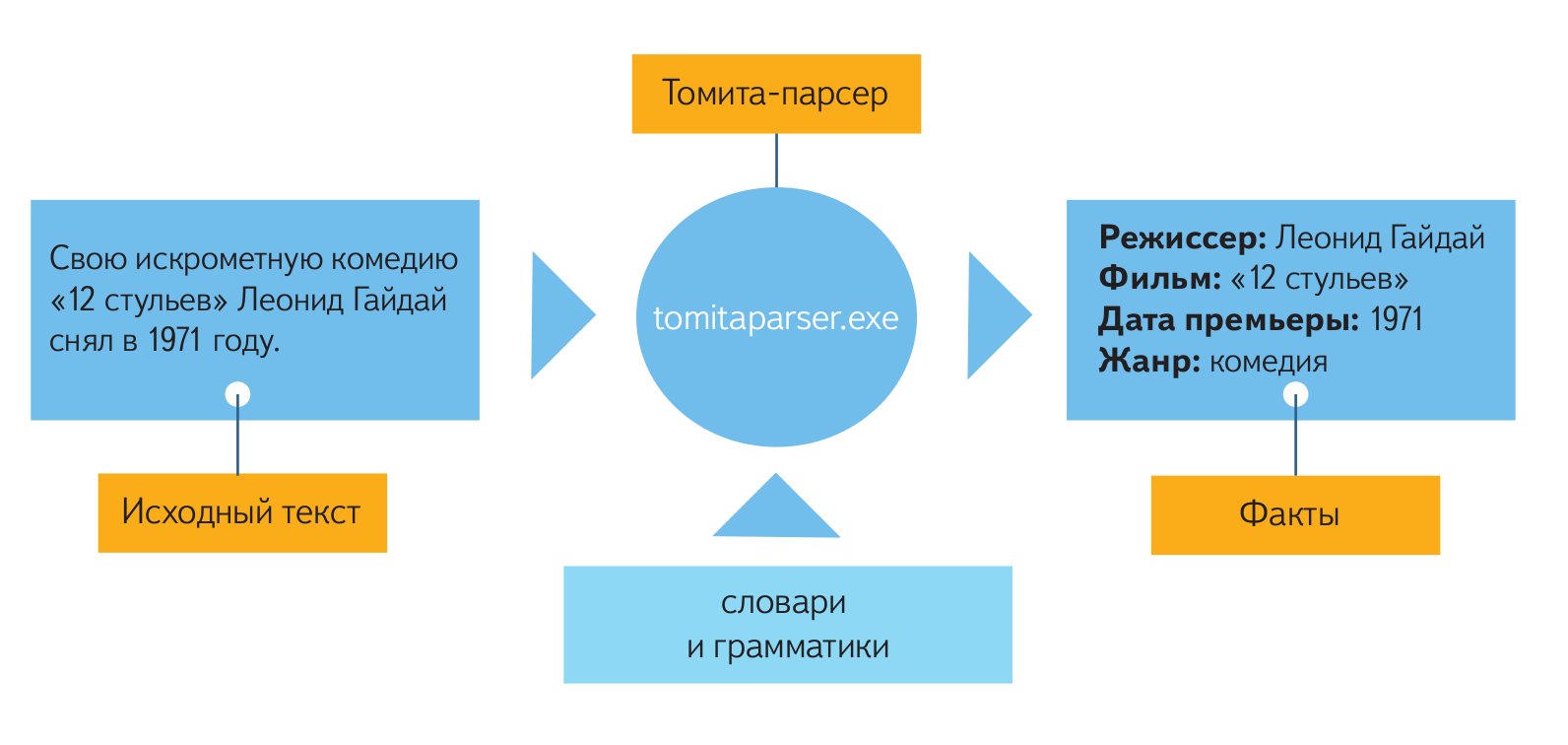 ..
..
На приведенной выше диаграмме Lexer связан с Lexical Analyzer , и я бы связал Syntax Analyzer и Semantic Analyzer с Parser, но YMMV.
AFAIK Tokenizer не имеет официального определения в книге Dragon и даже не упоминается в указателе. У меня нет электронной копии книги, поэтому я не могу выполнить автоматический поиск.
Одним из распространенных справочников, в которых упоминается Tokenizer, является Anatomy of a Compiler, но многие в этой области предпочитают книги Dragon.
Однако, если вашей единственной целью является создание списка токенов, а затем выполнение чего-то другого, кроме семантического анализа, тогда вызов модуля/функции/… токенизатора может быть правильным именем.
Я использую Lexer с Parser и не использую Tokenizer с Parser.
Еще одна мысль, о которой следует помнить, заключается в том, что при преобразованиях не должна теряться полезная информация. Другими словами, если одной из ваших целей является воссоздание входных данных из AST, тогда AST необходимо захватить постороннюю информацию, такую как пробелы, что означает, что Lexer также должен захватить постороннюю информацию. Одной из причин таких усилий является создание полезных сообщений об ошибках или редактирование кода и продолжение отладки.
Другими словами, если одной из ваших целей является воссоздание входных данных из AST, тогда AST необходимо захватить постороннюю информацию, такую как пробелы, что означает, что Lexer также должен захватить постороннюю информацию. Одной из причин таких усилий является создание полезных сообщений об ошибках или редактирование кода и продолжение отладки.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаОбязательно, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Что означает парсинг HTML?
В отличие от того, что сказал Спадли, синтаксический анализ в основном состоит в том, чтобы разложить (предложение) на составные части и описать их синтаксические роли.
Согласно Википедии, синтаксический анализ или синтаксический анализ — это процесс анализа строки символов либо на естественном языке , либо на компьютерных языках , в соответствии с правилами формальной грамматики. Термин синтаксический анализ происходит от латинского pars (orationis), что означает часть (речи).
В вашем случае синтаксический анализ HTML в основном заключается в следующем: получение HTML-кода и извлечение соответствующей информации, такой как заголовок страницы, абзацы на странице, заголовки на странице, ссылки, полужирный текст и т. д.
Парсеры:
Компьютер программа, анализирующая содержимое, называется синтаксическим анализатором. В целом существует 2 типа синтаксических анализаторов:
В целом существует 2 типа синтаксических анализаторов:
Анализ сверху вниз — Анализ сверху вниз можно рассматривать как попытку найти самые левые производные входного потока путем поиска деревьев анализа с использованием расширения сверху вниз заданных правил формальной грамматики. Токены потребляются слева направо. Инклюзивный выбор используется для устранения двусмысленности путем расширения всех альтернативных правых частей правил грамматики.
Синтаксический анализ снизу вверх — Анализатор может начать с ввода и попытаться переписать его в начальный символ. Интуитивно синтаксический анализатор пытается найти самые основные элементы, затем элементы, содержащие их, и так далее. Парсеры LR являются примерами восходящих парсеров. Другой термин, используемый для этого типа синтаксического анализатора, — синтаксический анализ Shift-Reduce.
Несколько примеров парсеров:
Нисходящие парсеры:
- Парсер рекурсивного спуска
- Парсер LL (слева направо, крайнее левое производное)
- Парсер Эрли
Анализаторы «снизу вверх»:
- Анализатор приоритета
- Анализатор приоритета операторов
- Простой синтаксический анализатор приоритетов
- BC (ограниченный контекст) синтаксический анализ Анализатор
- LR ( L слева направо, R крайнее правое производное)
- Простой синтаксический анализатор LR (SLR)
- Парсер LALR
- Канонический синтаксический анализатор LR (LR(1))
- Анализатор GLR
- CYK парсер
- Парсер рекурсивного восхождения
Пример синтаксического анализатора:
Вот пример синтаксического анализатора HTML в python:
из HTMLParser import HTMLParser # создать подкласс и переопределить методы обработчика класс MyHTMLPaser (HTMLPaser): def handle_starttag (я, тег, атрибуты): print "Встретил начальный тег:", тег def handle_endtag (я, тег): print "Обнаружен конечный тег :", тег def handle_data (я, данные): print "Обнаружены некоторые данные:", data # создаем экземпляр парсера и передаем ему HTML-код синтаксический анализатор = MyHTMLPaser() parser.
