Что такое ТИЦ и Pagerank, алгоритм расчета пузомерок
Разобравшись с типичными ошибками при коррекции текстов веб-страниц попробуем ответить на вопрос, как определить, какой сайт является авторитетным, а какой нет?
Здесь нет точного ответа, как и нет ответа на вопрос о принципах ранжирования, о них мы можем судить лишь по косвенным признакам.
Тем не менее, для оценки веса сайта в российском интернете служат показатели:
- ТИЦ — тематический индекс цитирования сайта «Яндекса»;
- PageRank — характеристика цитируемости страницы, определяемая Google (показатель перестал быть публичным с 2016 года).
Что такое ТИЦ?
Для начала рассмотрим «официальное» определение терминов «ИЦ» и «ТИЦ».
«Индекс цитирования» (или ИЦ) — принятая в научном мире мера «значимости» трудов какого-либо ученого. Величина индекса определяется количеством ссылок на этот труд (или фамилию) в других источниках.
Однако для действительно точного определения значимости научных трудов важно не только количество ссылок на них, но и качество этих ссылок. Так, на работу может ссылаться авторитетное академическое издание, популярная брошюра или развлекательный журнал. Значимость у таких ссылок разная.
Так, на работу может ссылаться авторитетное академическое издание, популярная брошюра или развлекательный журнал. Значимость у таких ссылок разная.
Наш тематический индекс цитирования (ТИЦ) определяет «авторитетность» интернет-ресурсов с учетом качественной характеристики ссылок на них с других сайтов.
Эту качественную характеристику мы называем «весом» ссылки. Рассчитывается она по специально разработанному алгоритму.
Большую роль играет тематическая близость ресурса и ссылающихся на него сайтов. Само по себе количество ссылок на ресурс также влияет на значение его ТИЦ и успех в продвижении сайта. Но ТИЦ определяется не количеством ссылок, а суммой их весов.
ТИЦ как средство определения авторитетности ресурсов призван обеспечить релевантность расположения ресурсов в рубриках каталога Яндекса. ТИЦ не является чисто количественной характеристикой, поэтому мы показываем некоторые округленные значения, которые помогают ориентироваться в «значимости» («авторитетности») ресурсов в каждой области (теме)».
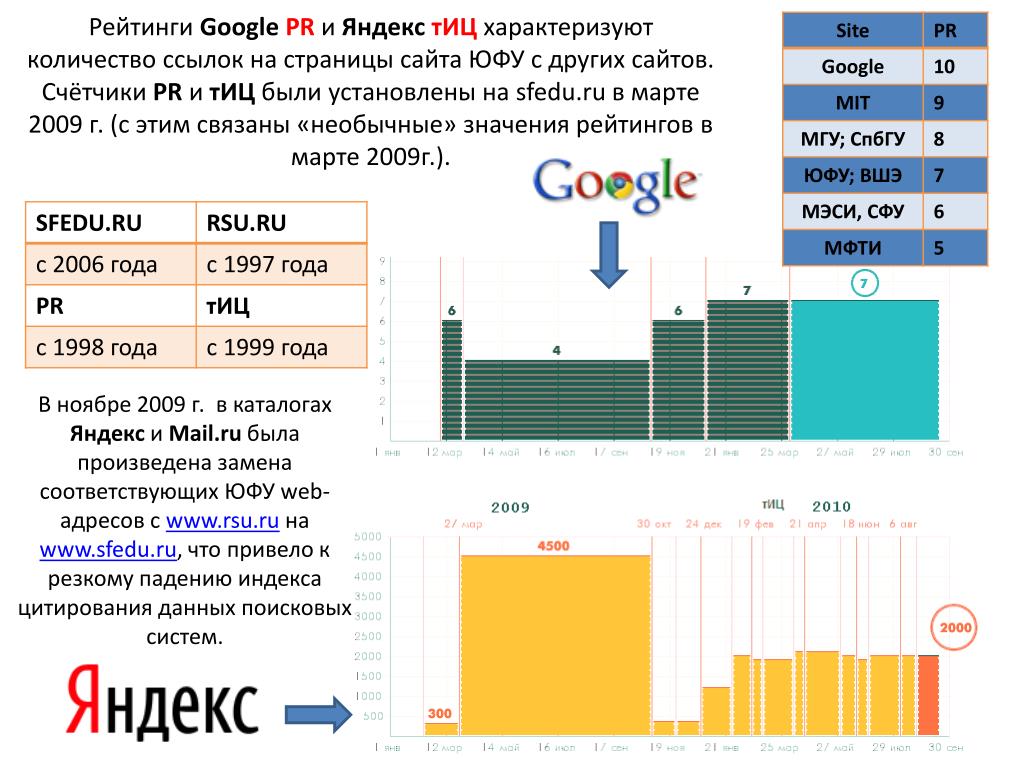
Как узнать значение тИЦ? Для этого нужно ввести в адресную строку браузера запрос вида http://www.yandex.ru/cycounter?my_site.ru, где вместо my_site. ru следует подставить адрес главной страницы интересующего вас сайта.
Минимальное отображаемое значение — 10 единиц, а максимальное не ограничено. Значение ТИЦ периодически пересчитывается исходя из изменения количества и качества внешних ссылок, а также изменений в порядке расчета.
Тематика ссылающегося сайта определяется по каталогу «Яндекса», поэтому наибольший разовый прирост индекса можно ожидать после регистрации сайта в «Яндекс. Каталоге».
Показатель PageRank
Согласно представлениям Google, если Страница А ссылается на страницу В, то Страница А считает, что Страница В — важная страница. При этом PageRank — это число, характеризующее исключительно голосующую способность всех входящих ссылок на страницу и то, как сильно они рекомендуют эту страницу.
Каждая уникальная страница сайта, проиндексированная Google, имеет определенный показатель PageRank. Причем внутренние ссылки сайта также учитываются при расчете PageRank.
Причем внутренние ссылки сайта также учитываются при расчете PageRank.
Под термином PageRank понимают не только числовой показатель, но и алгоритм расчета важности страницы.
Увидеть показатель PageRank можно было с помощью панели инструментов Google (GoogLe toolbar, панель инструментов для браузера). К сожалению, на данный момент показатель перестал быть публичным и его нельзя увидеть в браузере.
PageRank варьируется от 0 до 10. Минимальное значение показателя означает нулевую вероятность появления посетителя на веб-странице и наоборот, максимальное значение говорит об очень высокой вероятности посещения страницы сайта, а значит о её высоком авторитете.
Показатели авторитетности сайта от поисковых систем: ТИЦ, ВИЦ и PageRank
1. Введение
2. PageRank
3. тИЦ
4. Заключение
5. Материалы по теме
1. Введение
Цель данного мастер-класса:
— Расставить все точки над «i» в отношении показателей авторитетности сайтов – PR и тИЦ.
— Структурировать информацию по данной теме, коротко и ясно ее изложить.
Основные моменты, которые будут затронуты в мастер-классе:
1. История возникновения показателей
2. Методы расчета показателей
3. Влияние показателей на релевантность сайта
4. Учет показателей при покупке ссылок
2. PageRank
Теория
PageRank — это метод вычисления веса страницы путем подсчета важности ссылок на нее.
PageRank – самый часто употребляемый термин в среде оптимизаторов. Не в последнюю очередь и потому, что PR связан с понятием «релевантность», а повышение релевантности — фактически цель работы по продвижению сайта.
Самое главное, что нужно знать о расчете классического PageRank это:
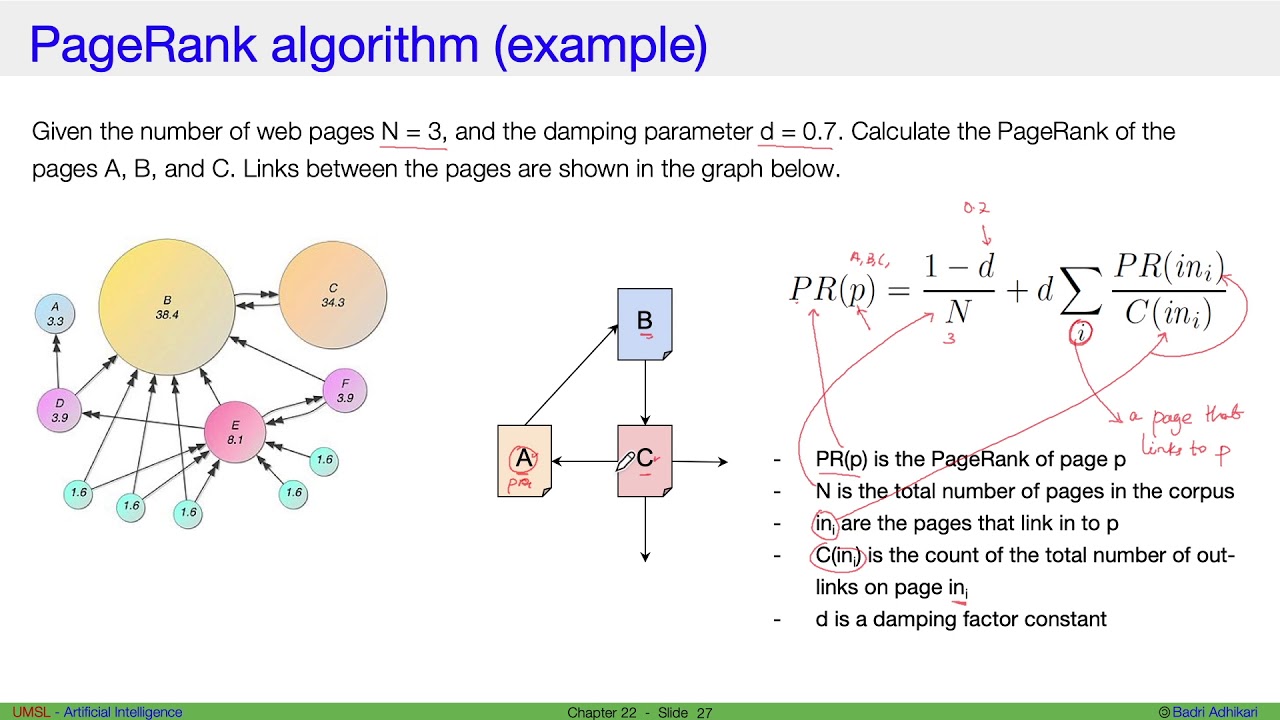
 Формула расчета: где PRp1 – PageRank анализируемой страницы, p1,p2,…,pN – рассматриваемые страницы, M(pi) множество страниц, которые ссылаются на pi, L(pj) число исходящих ссылок на странице pj, N – общее количество страниц, d – понижающий коэффициент.
Формула расчета: где PRp1 – PageRank анализируемой страницы, p1,p2,…,pN – рассматриваемые страницы, M(pi) множество страниц, которые ссылаются на pi, L(pj) число исходящих ссылок на странице pj, N – общее количество страниц, d – понижающий коэффициент. 2. В расчете участвуют страницы (документы), а не сайты. Т.е. такого понятия как «сайт» в принципе не существует. Соответственно, учитываются внутренние ссылки на сайте. Как следствие, чем больше страниц на сайте, тем выше PageRank сайта. (см. статью)
3. В расчете не участвуют тексты ссылок, тематика ссылающегося сайта тоже не принимается во внимание.
PageRank и вИЦ Яндекса
У Яндекса существует собственный показатель, напоминающий по технологии расчета PageRank. Это «взвешенный индекс цитирования» — вИЦ. Конечно же, у него есть отличия от классического PR.
 Это отчетливо наблюдалось, когда по результатам эксперимента решающее значение сыграло количество ссылающихся сайтов, а не страниц. По итогам эксперимента первые места в сравнительной выдаче заняли сайты с 2-3 ссылками, но с разных сайтов, а не сайты с 7-10 ссылающимися, но с одного домена. Ссылающиеся страницы были примерно одинаковыми по весу.
Это отчетливо наблюдалось, когда по результатам эксперимента решающее значение сыграло количество ссылающихся сайтов, а не страниц. По итогам эксперимента первые места в сравнительной выдаче заняли сайты с 2-3 ссылками, но с разных сайтов, а не сайты с 7-10 ссылающимися, но с одного домена. Ссылающиеся страницы были примерно одинаковыми по весу. Косвенно различия в учете ссылок при подсчете вИЦ подтверждает еще и тот факт, что в выдачу Яндекса по одному запросу не могут попасть 2 страницы с одного и того же сайта, только самая релевантная из них – остальные будут скрыты за ссылкой «еще с сайта».
На практике разница вИЦ и PR выражается в вопросе: насколько близко значение PR к значению вИЦ? Если переформулировать его с позиции исследователя: если у двух страниц PR равен 2 и 5 соответственно, то означает ли это, что и значения виЦ отличаются примерно в такой же пропорции?
В первую очередь, ответ надо искать в технологиях расчетов и формате отображаемых результатов.
 Начнем с последнего. Посмотрим на следующую таблицу:
Начнем с последнего. Посмотрим на следующую таблицу: | Если действительный вес PageRank между | То тулбар показывает | Среднее значение интервала |
| 0,00000001 и 5 | 1 | 2,5 |
| 6 и 25 | 2 | 15,5 |
| 26 и 125 | 3 | 75,5 |
| 126 и 625 | 4 | 375,5 |
| 626 и 3125 | 5 | 1875,5 |
| 3126 и 15625 | 6 | 9375,5 |
| 15626 и 78125 | 7 | 46875,5 |
| 78126 и 390625 | 8 | 234375,5 |
| 390626 и 1953125 | 9 | 1171876 |
| больше 1953126 | 10 | — |
 Соответственно, если мы возьмем две страницы с PR=3 и PR=6, то отличия могут быть минимум в 3126/125=25 раз, максимум – в 600 раз (15625/26), ну а в среднем – в 125 раз.
Соответственно, если мы возьмем две страницы с PR=3 и PR=6, то отличия могут быть минимум в 3126/125=25 раз, максимум – в 600 раз (15625/26), ну а в среднем – в 125 раз. В итоге, может сложиться интересная ситуация. Например, при покупке ссылки мы оцениваем 2 площадки:
1. PR=4, исходящих ссылок – 5.
2. PR=5, исходящих ссылок – 30.
В итоге вес, передаваемый ссылкой с первого сайта будет равен (375/5)*0,85=63,835 у.е., вес ссылки со второго сайта = 53,139 у.е. Хотя изначально казалось, что второй сайт привлекательнее.
Однако так вот напрямую использовать PR в расчетах не стоит, т.к. база проиндексированных сайтов у двух поисковых сильно различается, соответственно в расчетах PR и вИЦ участвуют несколько отличающиеся группы сайтов, и численное значение показателей будет также отличаться.
3. тИЦ
История
Показатель тИЦ – «тематический индекс цитирования» — появился 2 августа 1999 года. Изначально он задумывался как показатель авторитетности интернет-ресурса, т. е. мы видим здесь прямую аналогию с Google и его PageRank.
е. мы видим здесь прямую аналогию с Google и его PageRank.
18 октября 2000 года появился Яндекс Каталог и тИЦ начал использоваться, в том числе как показатель, на основе которого ранжировались сайты в рубриках каталога.
Яндекс не заставил себя долго ждать и сообщил в конце 2004 года интернет-общественности, что, во-первых, проблема искусственной накрутки тИЦ существует и в Яндексе ведутся исследовательские работы, направленные на решение проблемы. Во-вторых, было чётко озвучено, что тИЦ влияет только на ранжирование сайтов в каталоге и никак не влияет на основную выдачу.
Теория
Сегодня мы на «официальном Яндексе» можем прочитать следующее: «тИЦ как средство определения авторитетности ресурсов призван обеспечить релевантность расположения ресурсов в рубриках каталога Яндекса».
Из этого же официального источника можно выбрать следующие тезисы:
1. тИЦ рассчитывается для сайта целиком, поэтому внутренняя перелинковка страниц сайта не влияет на тИЦ.
2. Аналогично, учитывается только лишь факт наличия ссылки с внешнего ресурса. Т.е. ссылается на вас другой сайт одной ссылкой или десятью – влияние на тИЦ вашего сайта будет одинаковым. Исходя из первого и второго пункта, тИЦ можно назвать этаким «PR для сайтов», учитывающим еще и тематику сайтов.
3. Учитывается только русскоязычный сегмент интернета.
4. тИЦ не переходит с домена на поддомен одного и того же сайта, только если поддомен самостоятельно не зарегистрирован в каталоге Яндекса.
5. При подсчете тИЦ сайта не берутся в расчет ссылки с досок объявлений, форумов, немодерируемых каталогов и прочих ресурсов, в которые есть возможность добавления ссылок без контроля со стороны владельца ресурса.

Также некоторая информация про тИЦ доступна из заявлений официальных лиц Яндекса:
1. На ТИЦ влияют только ссылки с доменов 2-го уровня (с небольшим списком исключений) а также ресурсы из каталога\.
2. «тИЦ — показатель всего сайта и поэтому тема учитывается для сайта в целом. тИЦ зависит исключительно от ссылок на сайт и с него, от темы сайта; на него не влияют другие внутренние факторы».
3. Ссылки с сайта, расположенного в каталоге Яндекса учитываются как ссылки с «авторитетных сайтов».
Влияние тИЦ на релевантность
Из перечисленного выше видно, что тИЦ на позицию сайта в основной выдаче не влияет. Докажем это на конкретном примере — первой десяткой сайтов по запросу «пластиковые окна» (по состоянию на 02.08.07):
| Позиция | Сайт | тИЦ |
| 1 | http://www.okna-new.ru/ | 325 |
| 2 | http://divnie.ru/ | 650 |
| 3 | http://www. | 650 |
| 4 | http://www.oknastar.ru/ | 325 |
| 5 | http://www.academokna.ru/ | 1200 |
| 6 | http://www.fabrikaokon.ru/ | 1100 |
| 7 | http://okna-feba.ru/ | 700 |
| 8 | http://www.oknarosta.ru/ | 1600 |
| 9 | http://www.victory.ru/ | 700 |
| 10 | http://www.eurookna.ru/ | 1600 |

В последнее время данное рассуждение может быть не всегда верным, так как, с развитием различных сервисов по покупке/продаже ссылок с внутренних страниц, большинство бирж ссылок позволяет выбирать при покупке ссылок тематику сайтов, с которых будут проставлены ссылки. Поэтому, как следствие покупки тематичных ссылок, у сайта может быть высокий тИЦ.
тИЦ и покупные ссылки
Теперь расскажем немного о влиянии тИЦ сайта на цену покупных ссылок. Проанализируем распространенную формулу, используемую в некоторых сервисах по оценке площадки (Smile Seo Tools, YandexTools и т.д.) – см. формулу на странице http://vface.controlstyle.ru/calc.htm. Формула выведена на основании выборки цен сервиса SAPE.RU и поэтому реально (хотя и с погрешностью 30%) оценивает стоимость площадки.
Теперь составим график, который покажет зависимость цены ссылки с площадки от тИЦ сайта, т.е. проанализируем следующую часть формулы:

Видим из графика, что при увеличении тиЦ с 1000 до 5000 (при неизменном PR) придется приплатить еще 31 у.е. (разница между 41 у.е. и 10 у.е.).
Вопрос: «А как увеличение тИЦ с 1000 до 5000 отразится на результате? Площадка с большим тИЦ принесет пользу?». Однозначно ответить сложно… С одной стороны большой тИЦ говорит об авторитетности сайта в своей области, об естественности его ссылочной массы и, как следствие, о качестве приобретаемой ссылки с сайта. С другой стороны, Яндексу ничего не стоит поместить и такой сайт под непот- фильтр (см. мастер-класс «Выявление непот-фильтра, или непот где-то рядом»), учитывая то, что фильтр накладывается автоматом и поэтому не оглядывается на авторитетность сайта. (Например, на сайт «Независимой газеты» с параметрами тИЦ = 15000, PR=7 был наложен и до сих пор еще не снят непот-фильтр)
тИЦ и Яндекс.Каталог
Еще будет небезынтересно посмотреть, раз уж тИЦ влияет на позицию сайта в каталоге, то сколько посетителей может привести этот самый каталог? Найти сайт с общедоступной статистикой не так легко, но все же…
Сайт 3dnews. ru, занимающий 4 место в рубрике «Компьютеры».
ru, занимающий 4 место в рубрике «Компьютеры».
Проанализируем статистику переходов – за месяц из каталога Яндекса перешло чуть более 7000 человек, что на порядок меньше, чем количество переходов с Rambler’s Top100 (67000) и в 53 раза меньше, чем всего переходов с Яндекса — 376 054. Конечно, при таком раскладе уделять дополнительные силы на продвижение в каталоге Яндекса не стоит.
Статистику см. по адресу http://www.liveinternet.ru/stat/3dnews.ru/catalogs.html?period=month
А вот у сайта www.euro-football.ru, размещающегося в рубрике «Футбол» картина совершенно противоположная!
Переходы (суммарно за июль):
| Каталог Яндекса | 211,432 |
| Rambler’s Top100 | 151,076 |
| Переходы с закладок | 479,920 |
| yandex.ru | 38,931 |
 ru и euro-football.ru можно объяснить тем, что:
ru и euro-football.ru можно объяснить тем, что: — во-первых, сайт 3dnews.ru – 4-й в каталоге, а euro-football.ru – первый.
— во-вторых, у сайта 3dnews.ru лучшая видимость, много посетителей приходят с поисковика по различным запросам компьютерной тематики, а на сайт euro-football.ru попасть по каким-либо запросам сложно.
4. Заключение
Итак, подведем черту.
тИЦ влияет только на выдачу в каталоге Яндекса, однако все же косвенно показывает качество сайта. При покупке ссылок не стоит надеяться, что ссылка с сайта с высоким тИЦ принесет счастья – непот-фильтр безжалостен даже к известным сайтам.
С помощью PR можно только косвенно оценить русскоязычный сайт. При использовании показателя PR для оценки площадки (при покупке ссылки) надо обращать внимание на разницу показателей ссылающихся на площадку согласно данным Яндекса и Google.
5. Материалы по теме
«официальном Яндексе»
Рулев Д. Морозов М. «Битва за индекс цитирования»
Морозов М. «Битва за индекс цитирования»
Трофименко Е. «PageRank: начала анализа»
Статья о PageRank в Википедиии (на англ.)
Патент на PageRank
Спадовский А. «Растолкованный PageRank, или Все, что вы всегда хотели знать о PageRank»
Наука о графических данных с помощью Python/NetworkX
Мы завалены данными. Постоянно расширяющиеся базы данных и электронные таблицы изобилуют скрытой бизнес-аналитикой. Как мы можем анализировать данные и делать выводы, когда их так много? Графики (сети, а не гистограммы) обеспечивают элегантный подход.
Мы часто используем таблицы для общего представления информации. Но графы используют специализированную структуру данных: вместо строки таблицы узел представляет собой элемент. Край соединяет два узла, чтобы указать их отношения.
Эта структура графических данных позволяет нам наблюдать за данными под уникальными углами, поэтому наука о графовых данных используется во всех областях, от молекулярной биологии до социальных наук:
Левое изображение предоставлено: TITZ, Björn, et al. «Интерактом бинарного белка бледной трепонемы…» PLoS One, 3, no. 5 (2008).
«Интерактом бинарного белка бледной трепонемы…» PLoS One, 3, no. 5 (2008).Право на изображение предоставлено: ALBANESE, Federico, et al. «Прогнозирование смены людей с помощью интеллектуального анализа текста и графического машинного обучения в Twitter». (24 августа 2020 г.): arXiv: 2008.10749.[cs.SI]
Так как же разработчики могут использовать науку о графовых данных? Давайте обратимся к наиболее используемому языку программирования для науки о данных: Python.
Приступая к работе с «теорией графов» Графики в Python
Разработчикам Python доступно несколько библиотек данных графов, таких как NetworkX, igraph, SNAP и graph-tool. Помимо плюсов и минусов, у них очень похожие интерфейсы для визуализации графов Python и управления структурой.
Мы будем использовать популярную библиотеку NetworkX. Он прост в установке и использовании и поддерживает алгоритм обнаружения сообщества, который мы будем использовать.
Создать новый граф NetworkX очень просто:
импортировать networkx как nx G = nx.График()
 График()
График()
Но G еще не совсем граф, поскольку он лишен узлов и ребер.
Как добавить узлы в график
Мы можем добавить узел в сеть, объединив возвращаемое значение Graph() с .add_node() (или .add_nodes_from() для нескольких узлов в список). Мы также можем добавлять к узлам произвольные характеристики или атрибуты, передавая словарь в качестве параметра, как показано на примере 9.0027 узел 4 и узел 5 :
G.add_node("узел 1")
G.add_nodes_from(["узел 2", "узел 3"])
G.add_nodes_from([("узел 4", {"abc": 123}), ("узел 5", {"abc": 0})])
печать (G.узлы)
print(G.nodes["node 4"]["abc"]) # доступ как к словарю
Это выведет:
['узел 1', 'узел 2', 'узел 3', 'узел 4', 'узел 5'] 123
Но без ребер между узлами они изолированы, и набор данных ничем не лучше простой таблицы.
Как добавить ребра к графику
Подобно технике для узлов, мы можем использовать . с именами двух узлов в качестве параметров (или  add_edge()
add_edge() .add_edges_from() для нескольких ребер в списке) и дополнительно включить словарь атрибутов:
G.add_edge("узел 1", "узел 2")
G.add_edge ("узел 1", "узел 6")
G.add_edges_from([("узел 1", "узел 3"),
("узел 3", "узел 4")])
G.add_edges_from([("узел 1", "узел 5", {"вес" : 3}),
("узел 2", "узел 4", {"вес" : 5})])
Библиотека NetworkX поддерживает подобные графы, где каждое ребро может иметь вес. Например, в графе социальной сети, где узлы — это пользователи, а ребра — взаимодействия, вес может означать, сколько взаимодействий происходит между данной парой пользователей — очень важный показатель.
NetworkX перечисляет все ребра при использовании G.edges , но не включает их атрибуты. Если нам нужны атрибуты ребра, мы можем использовать G[node_name] , чтобы получить все, что подключено к узлу или G[node_name][connected_node_name] для получения атрибутов определенного ребра:
print(G.
 nodes)
печать (G.edges)
печать (G ["узел 1"])
print(G["узел 1"]["узел 5"])
nodes)
печать (G.edges)
печать (G ["узел 1"])
print(G["узел 1"]["узел 5"])
Это выведет:
['узел 1', 'узел 2', 'узел 3', 'узел 4', 'узел 5', 'узел 6']
[('узел 1', 'узел 2'), ('узел 1', 'узел 6'), ('узел 1', 'узел 3'), ('узел 1', 'узел 5'), ( 'узел 2', 'узел 4'), ('узел 3', 'узел 4')]
{'узел 2': {}, 'узел 6': {}, 'узел 3': {}, 'узел 5': {'вес': 3}}
{'вес': 3}
Но читать наш первый график таким образом нецелесообразно. К счастью, есть гораздо лучшее представление.
Как генерировать изображения из графиков (и взвешенных графиков)
Визуализация графика очень важна: она позволяет нам быстро и четко увидеть отношения между узлами и структуру сети.
Быстрый вызов nx.draw(G) — это все, что нужно:
Давайте сделаем более тяжелые ребра соответственно толще с помощью нашего вызова nx.draw() :
weights = [1 if G[u][v] == {} else G[u][v]['weight'] для u,v в G.edges()]
nx.draw(G, ширина=вес)
Мы указали толщину по умолчанию для невесомых ребер, как видно из результата:
Наши методы и алгоритмы графов станут более сложными, поэтому для нашего следующего примера NetworkX/Python мы будем использовать более известный набор данных.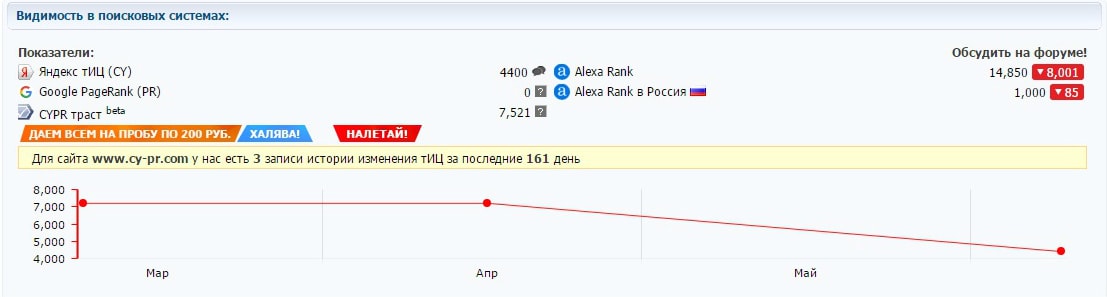
Наука о графических данных с использованием данных из фильма
Звездные войны: Эпизод IVЧтобы упростить интерпретацию и понимание наших результатов, мы будем использовать этот набор данных. Узлы представляют важные персонажи, а ребра (которые здесь не взвешиваются) означают совместное появление в сцене.
Примечание. Набор данных предоставлен Габасовой Э. (2016). Звездные войны социальная сеть. DOI: https://doi.org/10.5281/zenodo.1411479.
Сначала мы визуализируем данные с помощью nx.draw(G_starWars, with_labels = True) :
Персонажи, которые обычно появляются вместе, такие как R2-D2 и C-3PO, кажутся тесно связанными. Напротив, мы видим, что Дарт Вейдер не делится сценами с Оуэном.
Макеты визуализации Python NetworkX
Почему каждый узел расположен там, где он находится на предыдущем графике?
Это результат стандартного алгоритма spring_layout . Он имитирует силу пружины, притягивающей соединенные узлы и отталкивающей разъединенные. Это помогает выделить хорошо связанные узлы, которые оказываются в центре.
Это помогает выделить хорошо связанные узлы, которые оказываются в центре.
NetworkX имеет другие макеты, которые используют другие критерии для размещения узлов, например round_layout :
pos = nx.circular_layout(G_starWars) nx.draw(G_starWars, pos=pos, with_labels = True)
Результат:
Этот макет нейтрален в том смысле, что расположение узла не зависит от его важности — все узлы представлены одинаково. (Круговая компоновка может также помочь визуализировать отдельные связанных компонентов — подграфов, имеющих путь между любыми двумя узлами, — но здесь весь граф представляет собой один большой компонент связности.)
Оба макета, которые мы видели, имеют степень визуальный беспорядок, потому что края могут свободно пересекать другие края. Но Камада-Каваи, другой силовой алгоритм, такой как spring_layout размещает узлы так, чтобы минимизировать энергию системы.
Это уменьшает пересечение ребер, но имеет свою цену: он медленнее, чем другие макеты, и поэтому не рекомендуется для графов с большим количеством узлов.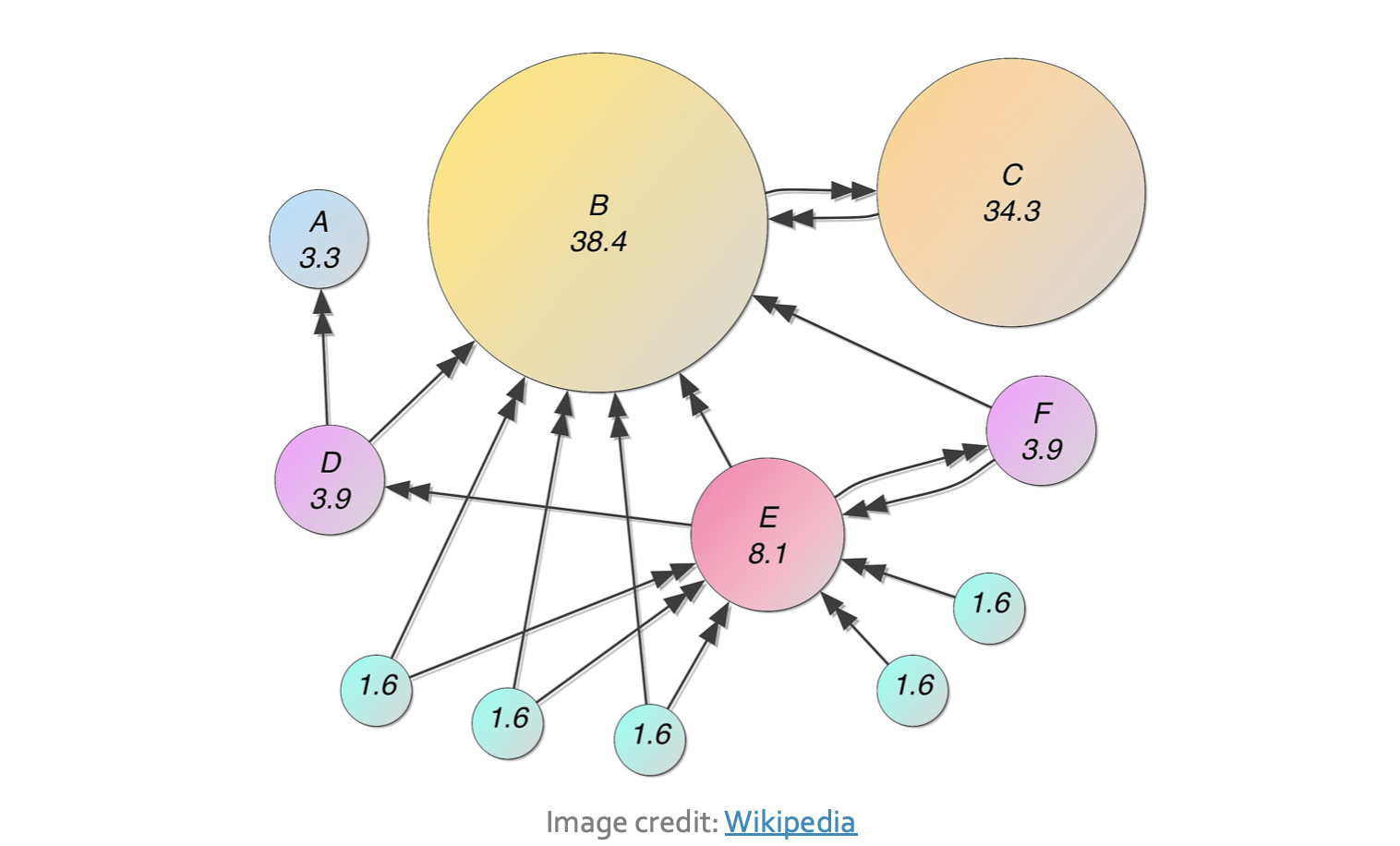
У этого есть специальная функция рисования:
nx.draw_kamada_kawai(G_starWars, with_labels = True)
Вместо этого получается следующая форма:
Без какого-либо специального вмешательства алгоритм поместил главных персонажей (таких как Люк, Лея и C-3PO) в центр, а менее заметных (таких как Кейми и генерал Додонна) — на границу.
Визуализация графика с определенной компоновкой может дать нам интересные качественные результаты. Тем не менее, количественные результаты являются жизненно важной частью любого анализа данных, поэтому нам необходимо определить некоторые показатели.
Анализ узлов: степень и PageRank
Теперь, когда мы можем ясно визуализировать нашу сеть, нам может быть интересно охарактеризовать узлы. Существует несколько метрик, описывающих характеристики узлов и, в нашем примере, персонажей.
Одной из основных метрик для узла является его степень : сколько у него ребер. Степень узла персонажа «Звездных войн » измеряет, со сколькими другими персонажами они делили сцену.
Функция Degree() может вычислить степень персонажа или всей сети:
print(G_starWars.grade["LUKE"]) печать (G_starWars.степень)
Вывод обеих команд:
15
[('R2-D2', 9), ('ЧУБАККА', 6), ('C-3PO', 10), ('ЛЮК', 15), ('ДАРТ ВЕЙДЕР', 4), ('КЭМИ' , 2), ('БИГГС', 8), ('ЛЕЯ', 12), ('БЕРУ', 5), ('ОВЕН', 4), ('ОБИ-ВАН', 7), ('МОТТИ' , 3), ('ТАРКИН', 3), ('ХАНЬ', 6), ('ДОДОННА', 3), ('ЗОЛОТО ЛИДЕР', 5), ('КЛИН', 5), ('КРАСНЫЙ ЛИДЕР' , 7), («КРАСНАЯ ДЕСЯТКА», 2)]
Сортировка узлов от высшего к низшему в зависимости от степени может быть выполнена с помощью одной строки кода:
print(sorted(G_starWars.degree, key=lambda x: x[1], reverse=True))
Вывод:
[('LUKE', 15), ('LEIA', 12), ('C-3PO', 10), ('R2-D2', 9), ('BIGGS', 8 ), ('ОБИ-ВАН', 7), ('КРАСНЫЙ ЛИДЕР', 7), ('ЧУБАККА', 6), ('ХАН', 6), ('БЕРУ', 5), ('ЗОЛОТОЙ ЛИДЕР' , 5), ('КЛИН', 5), ('ДАРТ ВЕЙДЕР', 4), ('ОВЕН', 4), ('МОТТИ', 3), ('ТАРКИН', 3), ('ДОДОННА', 3), ('CAMIE', 2), ('RED TEN', 2)]
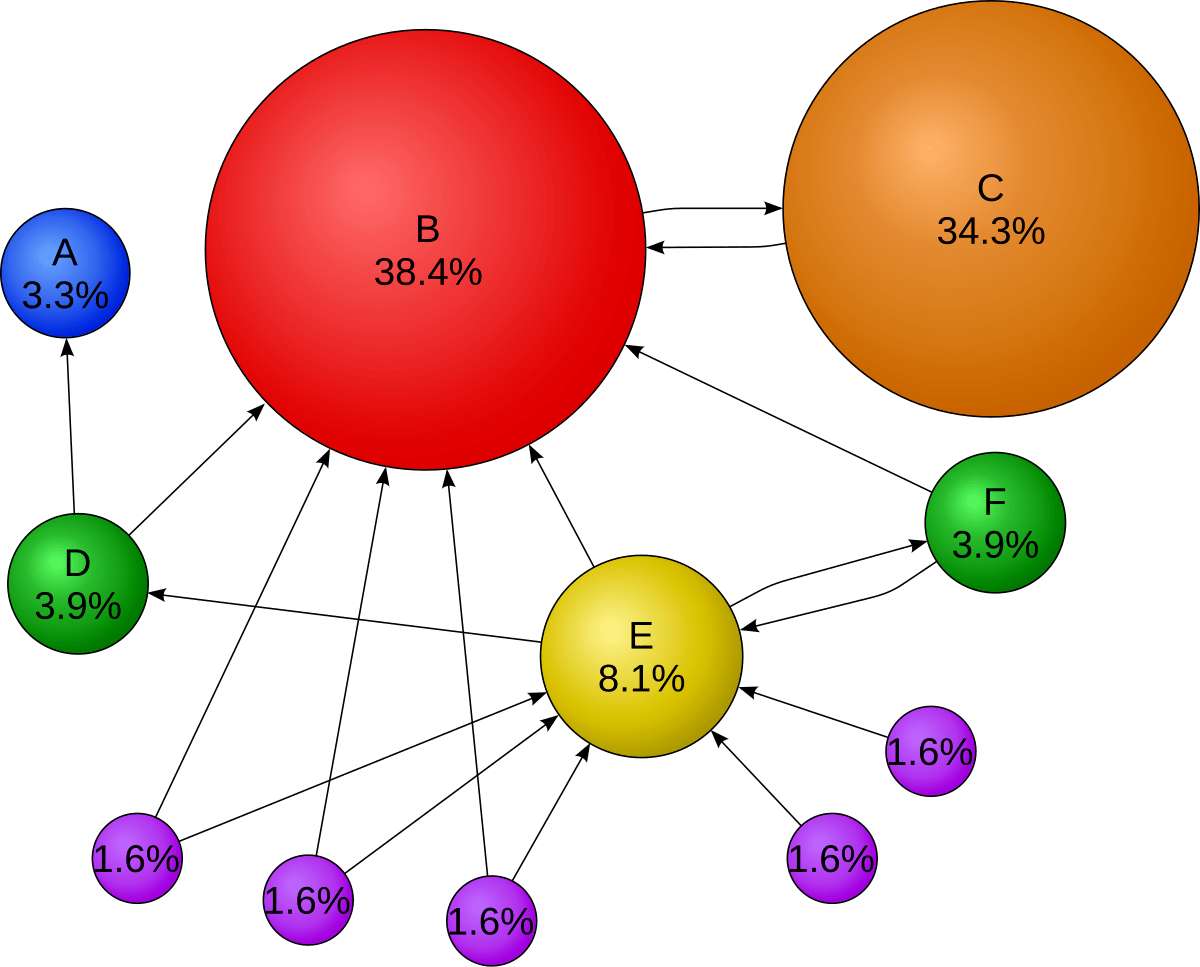
Будучи общей суммой, степень не учитывает детали отдельных ребер.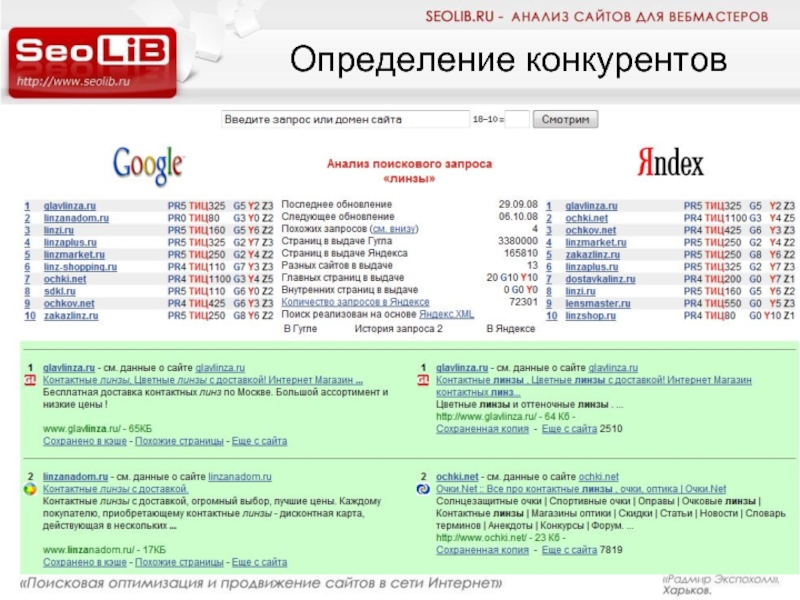 Соединяется ли данное ребро с изолированным узлом или с узлом, связанным со всей сетью? Алгоритм Google PageRank объединяет эту информацию, чтобы оценить, насколько «важным» является узел в сети.
Соединяется ли данное ребро с изолированным узлом или с узлом, связанным со всей сетью? Алгоритм Google PageRank объединяет эту информацию, чтобы оценить, насколько «важным» является узел в сети.
Метрику PageRank можно интерпретировать как агент, перемещающийся случайным образом с одного узла на другой. Узлы с лучшими связями имеют больше путей, ведущих через них, поэтому агент будет чаще посещать их.
Такие узлы будут иметь более высокий PageRank, который мы можем рассчитать с помощью библиотеки NetworkX:
pageranks = nx.pagerank(G_starWars) # Словарь print(pageranks["LUKE"]) печать (отсортировано (страницы, ключ = лямбда x: x [1], реверс = True))
Это выводит ранг Люка и наших персонажей, отсортированных по рангу:
0,12100659993223405 ['ОВЕН', 'ЛЮК', 'МОТТИ', 'ДОДОННА', 'ЗОЛОТОЙ ЛИДЕР', 'БИГГС', 'ЧУБАККА', 'ЛЕЯ', 'БЕРУ', 'КЛИН', 'КРАСНЫЙ ЛИДЕР', 'КРАСНАЯ ДЕСЯТЬ' ', 'ОБИ-ВАН', 'ДАРТ ВЕЙДЕР', 'КЭМИ', 'ТАРКИН', 'ХАН', 'R2-D2', 'C-3PO']
Оуэн — персонаж с самым высоким PageRank, превосходящим Люка, имевшего самую высокую степень. Анализ: хотя Оуэн не является персонажем, который разделяет большинство сцен с другими персонажами, он является персонажем, который разделяет сцены со многими важными персонажами, такими как сам Люк, R2-D2 и C-3PO.
Анализ: хотя Оуэн не является персонажем, который разделяет большинство сцен с другими персонажами, он является персонажем, который разделяет сцены со многими важными персонажами, такими как сам Люк, R2-D2 и C-3PO.
В отличие от этого, C-3PO, символ с третьей по величине степенью, имеет самый низкий PageRank. Несмотря на то, что у C-3PO много связей, многие из них связаны с неважными персонажами.
Вывод: использование нескольких метрик может дать более глубокое представление о различных характеристиках узлов графа.
При выполнении анализа графа Python в сети может быть важно разделить сообществ : группы узлов, которые тесно связаны друг с другом, но минимально связаны с узлами за пределами своего сообщества.
Для этого существует несколько алгоритмов. Большинство из них встречаются в неконтролируемых алгоритмах машинного обучения, потому что они присваивают метку узлам без необходимости их предварительной маркировки.
Одним из самых известных является распространение метки .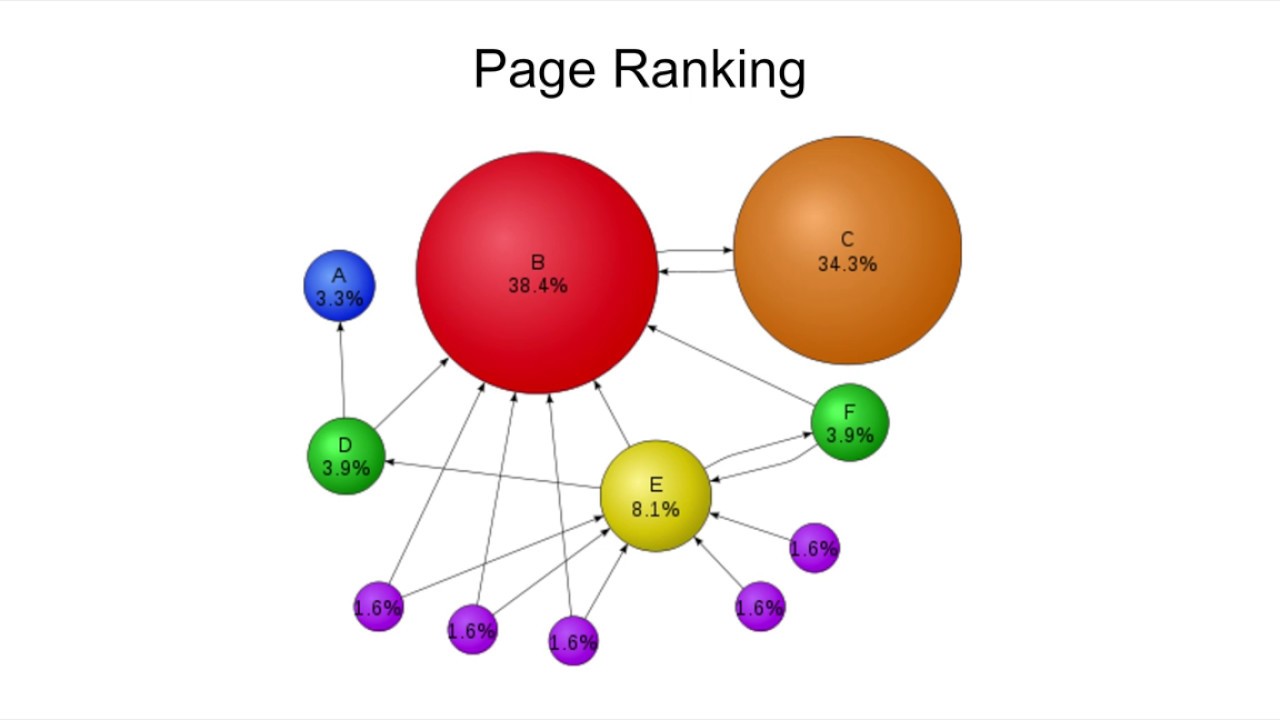 В нем каждый узел начинается с уникальной метки в сообществе из одного. Метки узлов итеративно обновляются в соответствии с большинством меток соседних узлов.
В нем каждый узел начинается с уникальной метки в сообществе из одного. Метки узлов итеративно обновляются в соответствии с большинством меток соседних узлов.
Метки распространяются по сети до тех пор, пока все узлы не разделят метку с большинством своих соседей. Группы узлов, тесно связанных друг с другом, в конечном итоге имеют одинаковую метку.
С библиотекой NetworkX запуск этого алгоритма занимает всего три строки Python:
из networkx.algorithms.community.label_propagation import label_propagation_communities сообщества = label_propagation_communities(G_starWars) print([сообщество для сообщества в сообществах])
Вывод:
[{'R2-D2', 'КЭМИ', 'КРАСНАЯ ТЕН', 'КРАСНЫЙ ЛИДЕР', 'ОБИ-ВАН', 'ДОДОННА', 'ЛЕЯ', 'КЛИН', 'ХАН' , 'ОВЕН', 'ЧУБАККА', 'ЗОЛОТОЙ ЛИДЕР', 'ЛЮК', 'БИГГС', 'C-3PO', 'БЕРУ'}, {'ДАРТ ВЕЙДЕР', 'ТАРКИН', 'МОТТИ'}]
В этом списке наборов каждый набор представляет сообщество. Читатели, знакомые с фильмом, заметят, что алгоритму удалось идеально отделить «хороших парней» от «плохих парней», осмысленно различая персонажей без использования каких-либо истинных (общественных) ярлыков или метаданных.![]()
Intelligent Insights с использованием анализа графических данных в Python
Мы убедились, что начать работу с инструментами графического анализа данных проще, чем может показаться. Как только мы представим данные в виде графика с помощью библиотеки NetworkX в Python, несколько коротких строк кода могут пролить свет. Мы можем визуализировать наш набор данных, измерять и сравнивать характеристики узлов и узлов кластера разумно с помощью алгоритмов обнаружения сообщества.
Умение извлекать выводы и идеи из сети с помощью Python позволяет разработчикам интегрироваться с инструментами и методологией, которые обычно используются в конвейерах услуг по обработке и анализу данных. От поисковых систем до планирования полетов и электротехники — эти методы легко применимы к широкому спектру контекстов.
Рекомендуемая литература по науке о графовых данных
Алгоритмы обнаружения сообщества
Чжао Ян, Рене Альгешаймер и Клаудио Тессон. «Сравнительный анализ алгоритмов обнаружения сообщества в искусственных сетях». Научные отчеты, 6, вып. 30750 (2016).
«Сравнительный анализ алгоритмов обнаружения сообщества в искусственных сетях». Научные отчеты, 6, вып. 30750 (2016).
Глубокое обучение графов
Томас Кипф. «Графические сверточные сети». 30 сентября 2016 г.
Applications of Graph Data Science
Albanese, Federico, Leandro Lombardi, Esteban Feuerstein и Pablo Balenzuela. «Прогнозирование смены людей с помощью интеллектуального анализа текста и графического машинного обучения в Twitter». (24 августа 2020 г.): arXiv: 2008.10749.[cs.SI].
Коэн, Элиор. «Встреча PyData в Тель-Авиве: Node2vec». YouTube. 22 ноября 2018 г. Видео, 21:09. https://www.youtube.com/watch?v=828rZgV9t1g.
Понимание основ
Можно ли использовать Python для визуализации данных?
Да, можно. В Python есть несколько библиотек для визуализации данных, например, библиотека NetworkX.
Как графически отображать данные в Python?
Библиотеки визуализации графических данных Python, такие как NetworkX, igraph, SNAP и graph-tool, имеют встроенную функциональность.
Библиотека NetworkX полезна для визуализации узлов и границ сетей.Является ли Graph типом данных в Python?
Библиотека Python NetworkX предоставляет различные типы графов данных. Возможными типами, в зависимости от характеристик графика, являются Graph, DiGraph, MultiGraph и MultiDiGraph.
Используется ли теория графов в науке о данных?
Да. Библиотека NetworkX позволяет специалистам по данным Python легко использовать различные алгоритмы на основе теории графов, такие как PageRank и распространение меток.
Какая польза от NetworkX в Python?
NetworkX — это библиотека для представления графов в Python. Разработчики могут использовать его для создания, обработки и визуализации графиков, а также для невизуального анализа графических данных.
Когда следует использовать NetworkX?
Для анализа графов следует использовать простую в использовании библиотеку NetworkX; например, когда необходимы алгоритмы обнаружения сообществ или другие особенности.
Но в остальном его функциональность сравнима с другими библиотеками графов, такими как igraph, SNAP и graph-tool.Является ли NetworkX быстрой?
Для многих приложений NetworkX достаточно быстр, но другие библиотеки Python могут быть быстрее для крупномасштабных наборов графических данных, в зависимости от алгоритма(ов). Преимущество начала работы с NetworkX заключается в простоте использования и обширном сообществе разработчиков.
Что такое алгоритм обнаружения сообщества?
Алгоритм обнаружения сообщества ищет кластерные сетевые узлы в соответствии с их связностью. Распространение меток является широко используемым методом для этого и имеет реализацию в библиотеке Python NetworkX.
 Библиотека NetworkX полезна для визуализации узлов и границ сетей.
Библиотека NetworkX полезна для визуализации узлов и границ сетей. Но в остальном его функциональность сравнима с другими библиотеками графов, такими как igraph, SNAP и graph-tool.
Но в остальном его функциональность сравнима с другими библиотеками графов, такими как igraph, SNAP и graph-tool.тезис.dvi
%PDF-1.4
%
1 0 объект
>
эндообъект
6 0 объект
/Заголовок
/Предмет
/Автор
/Режиссер
/Ключевые слова
/CreationDate (D:20230507040200-00’00’)
/ModDate (D:20141020151350+02’00’)
>>
эндообъект
2 0 объект
>
эндообъект
3 0 объект
>
эндообъект
4 0 объект
>
эндообъект
5 0 объект
>
транслировать
2014-10-20T15:13:50+02:002014-10-20T15:13:50+02:00dvips(k) 5.