
составляем правильный роботс для WordPress и других систем
Содержание статьи
- Что такое robots.txt
- Зачем закрывают какие-то страницы? Не проще ли открыть всё?
- Где находится Robots
- Для чего нужен этот файл
- Как работают поисковые роботы и как они обрабатывают данный файл
- По-разному ли Яндекс и Google воспринимают этот файл
- Чем может грозить неправильно составленный роботс
- Как создать файл robots.txt
- Пример правильного robots.txt для WordPress
- «Универсальный» роботс
- Роботс для Joomla
- Robots для Битрикса
- Как правильно составить роботс
- Что нужно закрывать в нем
- Как закрыть страницы от индексации и использовать Disallow
- Нужно ли использовать директиву Allow?
- Регулярные выражения
- Для чего нужна директива Host
- Что такое Crawl-delay
- Нужно ли указывать Sitemap в роботсе
- Прочие рекомендации к составлению
- Как запретить индексацию всего сайта
- Как проверить, правильно ли составлен файл
Вы знаете, насколько важна индексация — это основа основ в продвижении сайтов. Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Индексация сайта — это процесс, в ходе которого страницы вашего сайта попадают в Яндекс, Гугл или другой поисковик. И после этого пользователь может найти страницу вашего сайта по какому-нибудь запросу.
Управляете вы такой важной штукой, как индексация, именно посредством файла robots.txt. Начну с азов.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате . txt, который сможет открыть даже компьютер вашего деда.
txt, который сможет открыть даже компьютер вашего деда.
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
User-agent: * Allow: /
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.
Это корневой каталог, и в нем лежит роботс.
Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего нужен этот файл
А вот для чего:
- запрета на индексацию мусора — страниц и разделов, которые не содержат в себе полезный контент;
- разрешение индексации нужных страниц и разделов;
- чтобы давать разные задачи роботам разных поисковиков — то есть, например, Яндексу разрешить индексировать всё, а Рамблеру — ничего;
- можно также задавать роботам разные категории.
 Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта; - чтобы показать через директиву Host Яндексу, какое у сайта главное зеркало;
- еще некоторые вебмастера запрещают всяким нехорошим парсерам сканировать сайт с помощью этого файла;
 Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;То есть большую часть проблем по индексации он решает. Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Как работают поисковые роботы и как они обрабатывают данный файл
В большинстве случаев, очень упрощенно, они работают так:
- Обходят Интернет;
- Проверяют, какие документы разрешено индексировать, а какие запрещено;
- Включает разрешенные документы в базу;
- Затем уже другие механизмы решают, какие страницы достаточно полезны для включения в индекс.
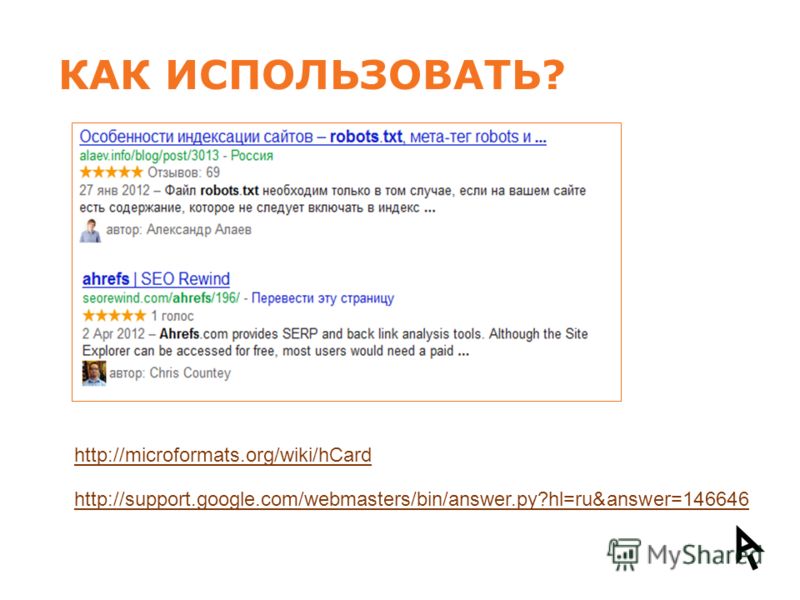
Вот ссылка на справку Яндекса о работе поисковых роботов, но там все довольно отдаленно описано.
Справка Google свидетельствует: robots – рекомендация. Файл создается для того, чтобы страница не добавлялась в индекс поисковой системы, а не чтобы она не сканировалась поисковыми системами. Гугл позволяет запрещенной странице попасть в индекс, если на нее направляется ссылка внутри ресурса или с внешнего сайта.
По-разному ли Яндекс и Google воспринимают этот файл
Многие прописывают для роботов разных поисковиков разные директивы. Даже если список этих директив ничем не отличается.
Наверное, это для того, чтобы выразить уважение к Господину Поисковику. Как там раньше делали — «великий князь челом бьет… и просит выдать ярлык на княжение». Других соображений по поводу того, зачем разным юзер-агентам прописывают одни и те же директивы, у меня нет, да и вебмастера, так делающие, дать нормальных объяснений своим действиям не могут.

А те, кто может ответить, аргументируют это так: мол, Google не воспринимает директиву Host и поэтому её нужно указывать только для Яндекса, и вот почему, мол, для яндексовского юзер-агента нужны отдельные директивы. Но я скажу так: если какой-то робот не воспринимает какую-то директиву, то он её просто проигнорирует. Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Чем может грозить неправильно составленный роботс
Некоторые при создании сайта на WordPress ставят галочку, чтобы система закрывала сайт от индексации (и забывают потом убрать её). Тогда Вордпресс автоматом ставит вам такой роботс, чтобы поисковики не включали ваш сайт в индекс, и это — самая страшная ошибка. Те страницы, на которые вы намерены получать трафик, обязательно должны быть открыты для индексации.
Потом, если вы не закрыли ненужные страницы от индексации, в индекс может попасть, как я уже говорил выше, очень много мусора (ненужных страниц), и они могут занять в индексе место нужных страниц.
Вообще, если вкратце, неправильный роботс грозит вам тем, что часть страниц не попадет в поиск и вы лишитесь части посетителей.
Как создать файл robots.txt
В Блокноте или другом редакторе создаем файл с расширением .txt, чтобы он в итоге назывался robots.txt. Заполняем его правильно (дальше расскажу, как) и загружаем в корень сайта. Готово!
Вот тут разработчик сайта Loftblog создает файл с нуля в режиме реального времени и делает настройку роботс:
Пример правильного robots.txt для WordPress
Составить правильный robots.txt для сайта WordPress проще всего. Я сам видел очень много таких роботсов (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Sitemap: https://znet.ru/sitemap.xml
 php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
Host: znet.ru
User-agent: Googlebot
Disallow: /wp-admin
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
User-agent: Mail.Ru
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.
php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
Host: znet.ru
User-agent: Googlebot
Disallow: /wp-admin
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
User-agent: Mail.Ru
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.Этот роботс для WordPress довольно проверенный. Большую часть задач он выполняет — закрывает версию для печати, файлы админки, результаты поиска и так далее.
«Универсальный» роботс
Если вы ищете какое-то решение, которое подойдет для всех сайтов на всех CMS (или для лендинга), «волшебную таблетку» — такой нет. Для всех CMS одинаково хорошо подойдет лишь решение, при котором вы говорите разрешить все для индексации:User-agent: * Allow: /
В остальном — нужно отталкиваться от системы, на которой написан ваш сайт. Потому что у каждой из них уникальная структура и разные разделы/служебные страницы.
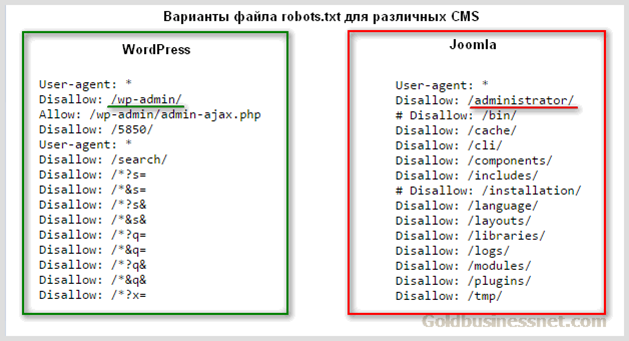
Роботс для Joomla
Joomla — ужасный движок, вы ужасный человек, если до сих пор им пользуетесь. Дублей страниц там просто дофига. В основном нормально работает такой код (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: https://znet.ru/sitemap.xml User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml

Но я вам настоятельно советую отказаться от этого жестокого движка и перейти на WordPress (а если у вас интернет-магазин — на Opencart или Bitrix). Потому что Joomla — это жесть.
Robots для Битрикса
Как составить robots.txt для Битрикс (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php$ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
 php
Disallow: /e-store/affiliates/
Disallow: /club/$
Disallow: /club/messages/
Disallow: /club/log/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /*/search/
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=yes
Disallow: /*forgot_password=yes
Disallow: /*change_password=yes
Disallow: /*login=yes
Disallow: /*logout=yes
Disallow: /*auth=yes
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*print_course=Y
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*index.
php
Disallow: /e-store/affiliates/
Disallow: /club/$
Disallow: /club/messages/
Disallow: /club/log/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /*/search/
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=yes
Disallow: /*forgot_password=yes
Disallow: /*change_password=yes
Disallow: /*login=yes
Disallow: /*logout=yes
Disallow: /*auth=yes
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*print_course=Y
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*index.
Как правильно составить роботс
У каждой поисковой системы есть свой User-Agent. Когда вы прописываете юзер-эйджент, то вы обращаетесь к какой-то определенной поисковой системе. Вот названия ботов поисковых систем:
Google: Googlebot
Яндекс: Yandex
Мэйл.ру: Mail.Ru
Yahoo!: Slurp
MSN: MSNBot
Рамблер: StackRambler
Это основные, которые включают ваш сайт в текстовые индексы поисковиков. А вот их вспомогательные роботы:
Googlebot-Mobile — это юзер-агент для мобильных
Googlebot-Image — это для картинок
Mediapartners-Google — этот робот сканирует содержание обьявлений AdSense
Adsbot-Google — это для качества целевых страниц AdWords
MSNBot-NewsBlogs – это для новостей MSN
Сначала в любом нормальном роботсе идет указание юзер-агента, а потом директивы ему. Юзер-агента мы указываем в первой строке, вот так:
User-agent: Yandex
Это будет обращение к роботу Яндекса. А вот обращение ко всем роботам всех систем сразу:
А вот обращение ко всем роботам всех систем сразу:
User-agent: *
После юзер-агента идут указания, относящиеся именно к нему. Пример:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
Сначала мы прописываем директивы для всех интересующих нас юзер-агентов. Затем дополняем их тем, что нас интересует, и заканчиваем обычно ссылкой на XML-карту сайта:
Sitemap: https://znet.ru/sitemap.xml
А вот что прописывать в директивах — это для каждой CMS, как я уже писал выше, по-разному. Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Что нужно закрывать в нем
Всю эту хрень нужно закрыть от индексации:
- Страницы поиска. Обычно поиск генерирует очень много страниц, которые нам не будут нести трафика;
- Корзина и страница оформления заказа. Обычно они не должны попадать в индекс;
- Страницы пагинации. Некоторые мастера знают, как получать с них трафик, но если вы не профессионал, лучше закройте их;
- Фильтры и сравнение товаров могут генерировать мусорные страницы;
- Страницы регистрации и авторизации. На этих страницах вводится только конфиденциальная информация;
- Системные каталоги и файлы. Каждый ресурс включает в себя административную часть, таблицы CSS, скрипты. В индексе нам это все не нужно;
- Языковые версии, если вы не продвигаетесь в других странах и они нужны вам чисто для информации;
- Версии для печати.
Как закрыть страницы от индексации и использовать Disallow
Вот чтобы закрыть от индексации какой-то тип страниц, нам потребуется она. Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
Disallow: /page.html
А если мне нужно закрыть все страницы, которые начинаются с https://znet.ru/instrumenty/? То есть страницы https://znet.ru/instrumenty/1.html, https://znet.ru/instrumenty/2.html и другие? Тогда я добавляю такую строку в роботс:
Disallow: /instrumenty/
Короче, это самая нужная директива.
Нужно ли использовать директиву Allow?
Крайне редко ей пользуюсь. Вообще, она нужна для того, чтобы разрешать роботу индексировать определенные страницы. Но он индексирует все, что не запрещено. Так что Allow я почти не использую. За исключением редких случаев, например, таких:
Допустим, у меня в роботсе закрыта категория /instrumenty/. Но страницу https://znet.ru/instrumenty/44.html я должен открыть для индексации. Тогда у меня в роботс тхт будет написано так:
Disallow: /instrumenty/ Allow: /instrumenty/44.
 html
htmlВ таком случае проблема будет решена. Как пишет Яндекс, «При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow». Короче, Allow я использую тогда, когда нужно перебить требования какой-то из директив Disallow.
Регулярные выражения
Когда прописываем директивы, мы можем использовать спецсимволы * и $ для создания регулярных выражений. Для чего они нужны? Давайте на практике рассмотрим:
User-agent: Yandex Disallow: /cgi-bin/*.aspx
Такая директива запретит Яндексу индексировать страницы, которые начинаются на /cgi-bin/ и заканчиваются на .aspx, то есть вот эти страницы:
/cgi-bin/loh.aspx
/cgi-bin/pidr.aspx
И подобные им будут закрыты.
А вот спецсимвол $ «фиксирует» запрет какой-то конкретной страницы. То есть такой код:
User-agent: Yandex Disallow: /example$
Запретит индексировать страницу /example, но не запрещает индексировать страницы /example-user, /example. html и другие. Только конкретную страницу /example.
html и другие. Только конкретную страницу /example.
Для чего нужна директива Host
Если сайт доступен сразу по нескольким адресам, директива Host указывает главное зеркало одного ресурса. Эту директиву распознают только роботы Яндекса, остальные поисковики забивают на нее болт. Пример:
User-agent: Yandex Disallow: /page Host: znet.ru
Host используется в robots только один раз. Если же их будет указано несколько, учитываться будет только первая директива.
Что такое Crawl-delay
Директива Crawl-delay устанавливает минимальное время между завершением загрузки роботом страницы 1 и началом загрузки страницы 2. То есть если у вас в роботсе добавлено такое:
User-agent: Yandex Crawl-delay: 2
То таймаут между загрузками двух страниц составит две секунды.
Это нужно, если ваш сервер плохо выдерживает запросы на загрузку страниц. Но я скажу так: если это так и есть, то ваш сервер — говно, и тут не Crawl-delay нужно устанавливать, а менять сервер.
Нужно ли указывать Sitemap в роботсе
В конце роботса нужно указывать ссылку на сайтмап, да. Я вам скажу, что это очень круто помогает индексации.
Был у меня один сайт, который хреново индексировался месяца полтора, когда я еще только начинал в SEO. Я не мог никак понять, в чем причина. Оказалось, я просто не указал путь к сайтмапу. Когда я это сделал — все нужные страницы через 1 апдейт уже попали в индекс.
Указывается путь к сайтмапу так:
Sitemap: https://znet.ru/sitemap.xml
Это если ваша карта сайта открывается по этому адресу. Если она открывается по другому адресу — прописывайте другой.
Прочие рекомендации к составлению
Рекомендую соблюдать:
- В одной строке — одна директива;
- Без пробелов в начале строк;
- Директива будет работать, только если написана целиком и без лишних знаков;
- Как пишет сам Яндекс, «Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке»;
- Правильный код роботс должен содержать как минимум одну директиву Dissallow.

А вот еще видео для продвинутых с вебмастерской Яндекса:
Как запретить индексацию всего сайта
Вот этот код поможет закрыть сайт от индексации:
User-agent: * Disallow: /
Пригодиться это может, если вы делаете новый сайт, но он еще не готов, и поэтому его лучше закрыть, чтобы он во время доработки не попал под какой-нибудь фильтр АГС.
Как проверить, правильно ли составлен файл
В Яндекс Вебмастере и Гугл Вебмастере есть инструмент, который поможет вам понять, правильно ли составлен роботс. Рекомендую обязательно проверять файл в этих сервисах перед размещением. В Яндекс Вебмастере вы также сможете добавить список страниц, чтобы проверить, разрешены ли они к индексации роботом.
что это такое, зачем нужен индексный файл и как его настроить – примеры роботс тхт
Если вы хоть немного интересовались вопросом внутренней оптимизации сайтов, то наверняка встречали термин robots txt. Как раз ему и посвящена наша сегодняшняя тема.
Сейчас вы узнаете, что такое robots txt, как он создается, каким образом веб-мастер задает в нем нужные правила, как обрабатывается файл robots.txt поисковыми роботами и почему отсутствие этого файла в корне веб-ресурса — одна из самых серьезных ошибок внутренней оптимизации сайта. Будет интересно!
Что такое robots.txt
Технически robots txt — это обыкновенный текстовый документ, который лежит в корне веб-сайта и информирует поисковых роботов о том, какие страницы и файлы они должны сканировать и индексировать, а для каких наложен запрет. Но это самое примитивное описание. На самом деле c robots txt все немного сложнее.
Файл robots txt — это как «администратор гостиницы». Вы приходите в нее, администратор выдает вам ключи от номера, а также говорит, где ресторан, SPA, зона отдыха, кабинет управляющего и прочее. А вот в другие номера и помещения для персонала вход вам заказан. Точно так же и с robots txt. Только вместо администратора — файл, вместо клиента — поисковые роботы, а вместо помещений — отдельные веб-страницы и файлы. Сравнение грубое, но зато доступное и понятное.
А вот в другие номера и помещения для персонала вход вам заказан. Точно так же и с robots txt. Только вместо администратора — файл, вместо клиента — поисковые роботы, а вместо помещений — отдельные веб-страницы и файлы. Сравнение грубое, но зато доступное и понятное.
Для чего нужен файл robots.txt
Без этого файла поисковики будут хаотично блуждать по сайту, сканировать и индексировать буквально все подряд: дубли, служебные документы, страницы с текстами «заглушками» (Lorem Ipsum) и тому подобное.
Правильный robots txt не дает такому происходить и буквально ведет роботов по сайту, подсказывая, что разрешено индексировать, а что необходимо упустить.
Существуют специальные директивы robots txt для данных задач:
- Allow — допускает индексацию.
- Disallow — запрещает индексацию.
Кроме того, можно сразу прописать, каким конкретно роботам разрешено или запрещено индексировать заданные страницы. Например, чтобы запретить индексацию директории /private/ поисковым роботам «Гугл», в роботс необходимо прописать User-agent:
Например, чтобы запретить индексацию директории /private/ поисковым роботам «Гугл», в роботс необходимо прописать User-agent:
User-agent: Google
Disallow: /private/
Также вы можете указать основное зеркало веб-сайта, задать путь к Sitemap, обозначить дополнительные правила обхода через директивы и прочее. Возможности robots txt достаточно обширны.
И вот мы разобрались, для чего нужен robots txt. Дальше сложнее — создание файла, его наполнение и размещение на сайте.
Как создать файл robots.txt для сайта?
Итак, как создать файл robots txt?
Создать и изменять файл проще всего в приложении «Блокнот» или другом текстовом редакторе, поддерживающим формат .txt. Специальное ПО для работы с robots txt не понадобится.
Создайте обычный текстовый документ с расширением .txt и поместите его в корень веб-ресурса. Для размещения подойдет любой FTP-клиент. После размещения обязательно стоит проверить robots txt — находится ли файл по нужному адресу. Для этого в поисковой строке браузера нужно прописать адрес:
Для этого в поисковой строке браузера нужно прописать адрес:
имя_сайта/robots.txt
Если все сделано правильно, вы увидите во вкладке данные из robots txt. Но без команд и правил он, естественно, работать не будет. Поэтому переходим к более сложному — наполнению.
Символы в robots.txt
Помимо упомянутых выше функций Allow/Disallow, в robots txt прописываются спецсимволы:
- «/» — указывает, что мы закрываем файл или страницу от обнаружения роботами «Гугл» и т. д.;
- «*» — прописывается после каждого правила и обозначает последовательность символов;
- «$» — ограничивает действие «*»;
- «#» — позволяет закомментировать любой текст, который веб-мастер оставляет себе или другим специалистам (своего рода заметка, напоминание, инструкция). Поисковики не считывают закомментированный текст.
Синтаксис в robots.
 txt
txtОписанные в файле robots.txt правила — это его синтаксис и разного рода директивы. Их достаточно много, мы рассмотрим наиболее значимые — те, которые вы, скорее всего, будете использовать.
User-agent
Это директива, указывающая, для каких search-роботов будут действовать следующие правила. Прописывается следующим образом:
User-agent: * имя поискового робота
Примеры роботов: Googlebot и другие.
Allow
Это разрешающая индексацию директива для robots txt. Допустим, вы прописываете следующие правила:
User-agent: * имя поискового робота
Allow: /site
Disallow: /
Так в robots txt вы запрещаете роботу анализировать и индексировать весь веб-ресурс, но запрет не касается папки site.
Disallow
Это противоположная директива, которая закрывает от индексации только прописанные страницы или файлы. Чтобы запретить индексировать определенную папку, нужно прописать:
Disallow: /folder/
Также можно запретить сканировать и индексировать все файлы выбранного расширения. Например:
Например:
Disallow: /*.css$
Sitemap
Данная директива robots txt направляет поисковых роботов к описанию структуры вашего ресурса. Это важно для SEO. Вот пример:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site.com/sitemap1.xml
Sitemap: http://site.com/sitemap2.xml
Crawl-delay
Директива ограничивает частоту анализа сайта и тем самым снижает нагрузку на сервер. Здесь прописывается время в сек. (третья строчка):
User-agent: *
Disallow: /site
Crawl-delay: 4
Clean-param
Запрещает индексацию страниц, сформированных с динамическими параметрами. Суть в том, что поисковые системы воспринимают их как дубли, а это плохо для SEO. О том, как найти дубли страниц на сайте, мы уже рассказывали. Вам нужно прописывать директиву:
Clean-param: p1[&p2&p3&p4&. .&pn] [Путь к динамическим страницам]
.&pn] [Путь к динамическим страницам]
Примеры Clean-param в robots txt:
Clean-param: kol_from1&price_to2&pcolor /polo.html # только для polo.html
или
Clean-param: kol_from1&price_to2&pcolor / # для всех страниц сайта
Кстати, советуем прочесть нашу статью «Как просто проверить индексацию сайта» — в ней много полезного по этой теме. Плюс есть информативная статья «Сканирование сайта в Screaming Frog». Рекомендуем ознакомиться!
Особенности настройки robots.txt для «Гугла»
На практике синтаксис файла robots.txt для этих систем отличается незначительно. Но есть несколько моментов, которые мы советуем учитывать.
Google не рекомендует скрывать файлы с CSS-стилями и JS-скриптами от сканирования. То есть правило должно выглядеть так:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *. css
css
Allow: *.js
Host: www.site.com
Примеры настройки файла robots.txt
Каждая CMS имеет свою специфику настройки robots txt для сканирования и индексации. И лучший способ понять разницу — рассмотреть каждый пример robots txt для разных систем. Так и поступим!
Пример robots txt для WordPress
Роботс для WordPress в классическом варианте выглядит так:
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *. css # открыть все файлы стилей
css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ua/sitemap.xml
Sitemap: http://site.ua/sitemap1.xml
Пример robots.txt для «Битрикс»
Одна из главных проблем «Битрикс» — по дефолту поисковые системы считывают и проводят индексацию служебных страниц и дублей. Но это можно предотвратить, правильно прописав robots txt:
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter. php
php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo.png
Allow: /personal/cart/
Sitemap: https://site.ua/sitemap.xml
Пример robots.txt для OpenCart
Рассмотрим пример robots txt для платформы электронной коммерции OpenCart:
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *. css
css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site. ua/sitemap.xml
ua/sitemap.xml
Пример robots.txt для Joomla
В «Джумле» роботс выглядит так:
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www. site.ua/sitemap.xml
site.ua/sitemap.xml
Пример robots.txt для Drupal
Для Drupal:
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: *register*
Disallow: *login*
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index. php
php
Allow: /*?page=
Disallow: /*?
Sitemap: http://путь к вашей карте XML формата
Выводы
Файл robots txt — функциональный инструмент, благодаря которому веб-разработчик дает инструкции поисковым системам, как взаимодействовать с сайтом. Благодаря ему мы обеспечиваем правильную индексацию, защищаем веб-ресурс от попадания под фильтры поисковых систем, снижаем нагрузку на сервер и улучшаем параметры сайта для SEO.
Чтобы правильно прописать инструкции файла robots.txt, крайне важно отчетливо понимать, что вы делаете и зачем вы это делаете. Соответственно, если не уверены, лучше обратитесь за помощью к специалистам. В нашей компании настройка robots txt входит в услугу внутренней оптимизации сайта для поисковых систем.
Кстати, в нашей практике был случай, когда клиент обратился за услугой раскрутки сайта, в корне которого файл robots txt попросту отсутствовал и индексация происходила некорректно. Почитайте, там много интересных моментов: «SEO-Кейс: Продвижение сайта медицинских справок».
Почитайте, там много интересных моментов: «SEO-Кейс: Продвижение сайта медицинских справок».
FAQ
Что такое файл robots.txt?
Robots txt — это документ, содержащий правила индексации вашего сайта, отдельных его файлов или URL поисковиками. Правила, описанные в файле robots.txt, называются директивами.
Зачем нужен файл robots.txt?
Robots txt помогает закрыть от индексации отдельные файлы, дубли страниц, документы, не несущие никакой пользы для посетителей, а также страницы, содержащие неуникальный контент.
Где находится файл robots.txt?
Он размещается в корневой папке веб-ресурса. Чтобы проверить его наличие, достаточно в URL-адрес вашего веб-ресурса дописать /robots.txt и нажать Enter. Если он на месте, откроется его страница. Так можно просмотреть данный файл на любом сайте, даже на стороннем. Просто добавьте к адресу /robots.txt.
У Вас остались вопросы?
Наши эксперты готовы ответить на них. Оставьте ваши контактные данные. Будем рады обсудить ваш проект!
Оставьте ваши контактные данные. Будем рады обсудить ваш проект!
Получить консультацию
Наш менеджер свяжется с Вами в ближайшее время
Что такое файл robots.txt и как его создать?
Поделиться
Содержание
- 1 Что такое robots.txt?
- 2 Как работает файл robots.txt
- 3 Какие инструкции используются в файле robots.txt?
- 4 Какую роль robots.txt играет в поисковой оптимизации?
- 5 Ссылки по теме
- 6 Аналогичные изделия
Что такое robots.txt?
Рисунок: Robots.txt — Автор: Seobility — Лицензия: CC BY-SA 4.0
Robots.txt — это текстовый файл с инструкциями для ботов (в основном сканеров поисковых систем), пытающихся получить доступ к веб-сайту. Он определяет, к каким областям сканеров сайта разрешен или запрещен доступ. Вы можете легко исключить целые домены, целые каталоги, один или несколько подкаталогов или отдельные файлы из сканирования поисковыми системами с помощью этого простого текстового файла. Однако этот файл не защищает от несанкционированного доступа.
Однако этот файл не защищает от несанкционированного доступа.
Robots.txt хранится в корневом каталоге домена. Таким образом, это первый документ, который сканеры открывают при посещении вашего сайта. Однако файл не только контролирует сканирование. Вы также можете интегрировать ссылку в свою карту сайта, которая дает поисковым роботам обзор всех существующих URL-адресов вашего домена.
Robots.txt Checker
Проверьте файл robots.txt вашего веб-сайта
Как работает robots.txt
В 1994 году был опубликован протокол под названием REP (стандартный протокол исключения роботов). Этот протокол предусматривает, что все сканеры поисковых систем (пользовательские агенты) должны сначала найти файл robots.txt в корневом каталоге вашего сайта и прочитать содержащиеся в нем инструкции. Только после этого роботы смогут начать индексировать вашу веб-страницу. Файл должен находиться непосредственно в корневом каталоге вашего домена и должен быть написан строчными буквами, поскольку роботы читают файл robots. txt и его инструкции с учетом регистра. К сожалению, не все роботы поисковых систем следуют этим правилам. По крайней мере, файл работает с наиболее важными поисковыми системами, такими как Bing, Yahoo и Google. Их поисковые роботы строго следуют инструкциям REP и robots.txt.
txt и его инструкции с учетом регистра. К сожалению, не все роботы поисковых систем следуют этим правилам. По крайней мере, файл работает с наиболее важными поисковыми системами, такими как Bing, Yahoo и Google. Их поисковые роботы строго следуют инструкциям REP и robots.txt.
На практике robots.txt можно использовать для разных типов файлов. Если вы используете его для файлов изображений, он предотвращает появление этих файлов в результатах поиска Google. Неважные файлы ресурсов, такие как файлы сценариев, стилей и изображений, также можно легко заблокировать с помощью файла robots.txt. Кроме того, вы можете исключить из сканирования динамически сгенерированные веб-страницы с помощью соответствующих команд. Например, могут быть заблокированы страницы результатов внутренней функции поиска, страницы с идентификаторами сеанса или действия пользователя, такие как корзины покупок. Вы также можете контролировать доступ сканера к другим файлам, не являющимся изображениями (веб-страницам), с помощью текстового файла. Таким образом, вы можете избежать следующих сценариев:
Таким образом, вы можете избежать следующих сценариев:
- поисковые роботы сканируют множество похожих или неважных веб-страниц
- ваш краулинговый бюджет тратится напрасно
- ваш сервер перегружен поисковыми роботами
В этом контексте, однако, обратите внимание, что файл robots.txt не гарантирует, что ваш сайт или отдельные подстраницы не будут проиндексированы. Он контролирует только сканирование вашего сайта, но не индексацию. Если веб-страницы не должны индексироваться поисковыми системами, вам необходимо установить следующий метатег в заголовке вашей веб-страницы:
Однако не следует блокировать файлы, имеющие высокую релевантность для поисковых роботов. Обратите внимание, что файлы CSS и JavaScript также должны быть разблокированы, так как они используются для сканирования, особенно мобильными роботами.
Какие инструкции используются в файле robots.txt?
Ваш robots. txt должен быть сохранен как текстовый файл UTF-8 или ASCII в корневом каталоге вашей веб-страницы. Должен быть только один файл с таким именем. Он содержит один или несколько наборов правил, структурированных в удобном для чтения формате. Правила (инструкции) обрабатываются сверху вниз, при этом различаются прописные и строчные буквы.
txt должен быть сохранен как текстовый файл UTF-8 или ASCII в корневом каталоге вашей веб-страницы. Должен быть только один файл с таким именем. Он содержит один или несколько наборов правил, структурированных в удобном для чтения формате. Правила (инструкции) обрабатываются сверху вниз, при этом различаются прописные и строчные буквы.
В файле robots.txt используются следующие термины:
- user-agent: обозначает имя сканера (имена можно найти в базе данных роботов)
- disallow: предотвращает сканирование определенных файлов, каталогов или веб-страниц
- разрешить: перезаписывает запрет и разрешает сканирование файлов, веб-страниц и каталогов Карта сайта
- (необязательно): показывает расположение карты сайта .
- *: означает любое количество символов
- $: означает конец строки
Инструкции (записи) в robots.txt всегда состоят из двух частей. В первой части вы определяете, для каких роботов (пользовательских агентов) применяется следующая инструкция. Вторая часть содержит инструкцию (запретить или разрешить). «user-agent: Google-Bot» и инструкция «disallow: /clients/» означают, что боту Google не разрешен поиск в каталоге /clients/. Если поисковый бот не должен сканировать весь сайт, запись: «user-agent: *» с инструкцией «disallow: /». Вы можете использовать знак доллара «$», чтобы заблокировать веб-страницы с определенным расширением. Оператор «disallow: /* .doc$» блокирует все URL-адреса с расширением .doc. Точно так же вы можете заблокировать определенные форматы файлов robots.txt: «disallow: /*.jpg$».
Вторая часть содержит инструкцию (запретить или разрешить). «user-agent: Google-Bot» и инструкция «disallow: /clients/» означают, что боту Google не разрешен поиск в каталоге /clients/. Если поисковый бот не должен сканировать весь сайт, запись: «user-agent: *» с инструкцией «disallow: /». Вы можете использовать знак доллара «$», чтобы заблокировать веб-страницы с определенным расширением. Оператор «disallow: /* .doc$» блокирует все URL-адреса с расширением .doc. Точно так же вы можете заблокировать определенные форматы файлов robots.txt: «disallow: /*.jpg$».
Например, файл robots.txt для веб-сайта https://www.example.com/ может выглядеть так:
Агент пользователя: * Запретить: /логин/ Запретить: /карта/ Запретить: /фото/ Запретить: /temp/ Запретить: /поиск/ Запретить: /*.pdf$ Карта сайта: https://www.example.com/sitemap.xml
Какую роль robots.txt играет в поисковой оптимизации?
Инструкции в файле robots.txt оказывают сильное влияние на SEO (поисковую оптимизацию), поскольку этот файл позволяет вам управлять поисковыми роботами. Однако, если пользовательские агенты слишком сильно ограничены инструкциями запрета, это может негативно сказаться на рейтинге вашего сайта. Вы также должны учитывать, что вы не будете ранжироваться с веб-страницами, которые вы исключили, запретив в robots.txt.
Однако, если пользовательские агенты слишком сильно ограничены инструкциями запрета, это может негативно сказаться на рейтинге вашего сайта. Вы также должны учитывать, что вы не будете ранжироваться с веб-страницами, которые вы исключили, запретив в robots.txt.
Перед тем, как сохранить файл в корневом каталоге вашего веб-сайта, вы должны проверить синтаксис. Даже незначительные ошибки могут привести к тому, что поисковые роботы будут игнорировать правила запрета и сканировать сайты, которые не должны быть проиндексированы. Такие ошибки также могут привести к тому, что страницы больше не будут доступны для поисковых роботов, а целые URL-адреса не будут проиндексированы из-за запрета. Вы можете проверить правильность файла robots.txt с помощью Google Search Console. В разделе «Текущее состояние» и «Ошибки сканирования» вы найдете все страницы, заблокированные инструкциями по запрету.
Правильно используя robots.txt, вы можете гарантировать, что поисковые роботы просканируют все важные части вашего веб-сайта. Следовательно, важный контент вашей страницы может быть проиндексирован Google и другими поисковыми системами.
Следовательно, важный контент вашей страницы может быть проиндексирован Google и другими поисковыми системами.
Ссылки по теме
- https://support.google.com/webmasters/answer/6062608?hl=ru
- https://support.google.com/webmasters/answer/6062596?hl=ru
Похожие статьи
- Canonical Tag
- hreflang
Как исправить ошибку «Проиндексировано, но заблокировано robots.txt» » Rank Math как показано ниже, то в этой статье базы знаний мы покажем вам, как устранить и исправить предупреждение.
Содержание
- Что означает ошибка «Проиндексировано, но заблокировано Robots.Txt»?
- Экспорт отчета из Google Search Console
- страниц для индексации
- страниц не для индексации
- Заключение — проверка исправления в Google Search Console
1 Что означает ошибка «Проиндексировано, но заблокировано Robots.Txt»?
Ошибка просто означает, что
- Google нашел вашу страницу и проиндексировал ее в результатах поиска.
- Но с другой стороны, он также нашел правило в robots.txt, предписывающее игнорировать страницу при сканировании.

Теперь, когда Google не знает, индексировать страницу или нет, он просто выдает предупреждение в Google Search Console. Чтобы вы могли разобраться в этом и выбрать план действий.
Когда вы заблокировали страницу с намерением предотвратить ее индексацию, вы должны знать, что хотя Google в большинстве случаев уважает файл robots.txt, сам по себе он не может предотвратить индексацию страницы. Может быть множество причин, например, внешний сайт ссылается на вашу заблокированную страницу и в конечном итоге заставляет Google проиндексировать страницу с небольшим количеством доступной информации.
С другой стороны, если страница должна быть проиндексирована, но случайно заблокирована файлом robots.txt, вам следует разблокировать страницу из файла robots.txt, чтобы поисковые роботы Google могли получить к ней доступ.
Теперь вы понимаете основную идеологию этого предупреждения, практических причин этого может быть много, учитывая CMS и техническую реализацию. Следовательно, в этой статье мы рассмотрим комплексный способ отладки и исправления этого предупреждения.
Следовательно, в этой статье мы рассмотрим комплексный способ отладки и исправления этого предупреждения.
2 Экспорт отчета из Google Search Console
Для небольших веб-сайтов под этим предупреждением может быть только несколько URL-адресов. Но самые сложные веб-сайты и сайты электронной коммерции должны иметь сотни или даже тысячи URL-адресов. Хотя использовать GSC для просмотра всех ссылок невозможно, вы можете экспортировать отчет из Google Search Console, чтобы открыть его в редакторе электронных таблиц.
Для экспорта просто щелкните предупреждение, которое будет доступно в разделе Панель управления Google Search Console > Покрытие > Действительны с предупреждениями .
На следующей странице вы сможете экспортировать все URL-адреса, относящиеся к этому предупреждению, щелкнув параметр Экспорт , доступный в правом верхнем углу. Из списка параметров экспорта вы можете загрузить и открыть файл в редакторе электронных таблиц по вашему выбору.
Теперь, когда вы экспортировали URL-адреса, самое первое, что вы должны выяснить, просмотрев эти URL-адреса, — следует ли индексировать страницу или нет. И дальнейшие действия будут зависеть только от вашего ответа.
3 Страницы для индексации
Если вы обнаружите, что страница должна быть проиндексирована, вам следует проверить файл robots.txt и определить, существует ли какое-либо правило, препятствующее сканированию страницы роботом Googlebot.
Чтобы отладить файл robots.txt, выполните точно описанные ниже действия.
3.1 Откройте тестер robots.txt
Сначала перейдите к тестеру robots.txt. Если ваша учетная запись Google Search Console связана с несколькими веб-сайтами, выберите свой веб-сайт из списка сайтов, показанного в правом верхнем углу. Теперь Google загрузит файл robots.txt вашего сайта. Вот как это будет выглядеть.
3.2 Введите URL-адрес вашего сайта
В нижней части инструмента вы найдете возможность ввести URL-адрес вашего веб-сайта для тестирования. Здесь вы добавите URL-адрес из электронной таблицы, которую мы скачали ранее.
Здесь вы добавите URL-адрес из электронной таблицы, которую мы скачали ранее.
3.3 Выберите пользовательский агент
В раскрывающемся списке справа от текстового поля выберите пользовательский агент, который вы хотите имитировать ( Googlebot в нашем случае ).
3.4 Validate Robots.txt
Наконец, нажмите Test 9Кнопка 0148.
Сканер немедленно проверит, есть ли у него доступ к URL-адресу на основе конфигурации robots.txt, и, соответственно, тестовая кнопка превратится в ACCEPTED или BLOCKED .
Редактор кода, доступный в центре экрана, также выделит правило в файле robots.txt, которое блокирует доступ, как показано ниже.
3.5 Редактирование и отладка
Если тестер robots.txt обнаружит какое-либо правило, запрещающее доступ, вы можете попробовать отредактировать правило прямо в редакторе кода, а затем снова запустить тест.
Вы также можете обратиться к нашей специальной статье базы знаний о robots. txt, чтобы узнать больше о принятых правилах, и было бы полезно отредактировать правила здесь.
txt, чтобы узнать больше о принятых правилах, и было бы полезно отредактировать правила здесь.
Если получится исправить правило, то отлично. Но обратите внимание, что это инструмент отладки, и любые внесенные вами изменения не будут отражены в robots.txt вашего веб-сайта, если вы не скопируете и не вставите содержимое в robots.txt своего веб-сайта.
Если у вас возникнут трудности при редактировании robots.txt, обратитесь в службу поддержки.
3.6 Экспорт Robots.txt
Итак, чтобы добавить измененные правила в ваш robots.txt, перейдите в раздел Rank Math > General Settings > Edit robots.txt в административной области WordPress. Если эта опция недоступна для вас, убедитесь, что вы используете расширенный режим в Rank Math.
В редакторе кода, расположенном посередине экрана, вставьте код, скопированный из файла robots.txt. Tester, а затем нажмите кнопку Сохранить изменения , чтобы отразить изменения.
4 Страницы не должны быть проиндексированы
Ну, если вы определили, что страница не должна быть проиндексирована, но Google проиндексировал страницу, то это может быть одной из причин, которые мы обсуждали ниже.
4.1 Неиндексируемые страницы, заблокированные с помощью robots.txt
Если страница не должна индексироваться в результатах поиска, это должно быть указано в директиве Robots Meta, а не в правиле robots.txt.
Файл robots.txt содержит только инструкции для сканирования. Помните, что сканирование и индексирование — это два отдельных процесса.
Предотвращение сканирования страницы ≠ Предотвращение индексации страницы
Таким образом, чтобы предотвратить индексацию страницы, вы можете добавить No Index Robots Meta с помощью Rank Math.
Но тогда, если вы добавите метаданные No Index Robots и одновременно заблокируете поисковую систему от сканирования этих URL-адресов, технически вы не позволите роботу Googlebot сканировать и знать, что страница имеет метаданные No Index Robots.
В идеале вы должны разрешить роботу Googlebot сканировать эти страницы, и на основании метаданных No Index Robots Google исключит страницу из индекса.
Примечание: Используйте robots.txt только для блокировки файлов (таких как изображения, PDF, фиды и т. д.), где невозможно добавить No Index Robots Meta.
4.2 Внешние ссылки на заблокированные страницы
Страницы, которые вы заблокировали с помощью файла robots.txt, могут иметь ссылки с внешних сайтов. Затем Googlebot в конечном итоге попытается проиндексировать страницу.
Поскольку вы запретили ботам сканировать страницу, Google проиндексирует страницу с ограниченной информацией, доступной на связанной странице.
Чтобы решить эту проблему, вы можете обратиться к внешнему сайту и запросить изменение ссылки на более подходящий URL-адрес на вашем веб-сайте.
5 Заключение. Подтвердите исправление в Google Search Console
После устранения проблем с URL-адресами вернитесь к предупреждению Google Search Console и нажмите кнопку Проверить исправление . Теперь Google повторно просканирует эти URL-адреса и закроет проблему, если ошибка устранена.