
Операторы Wordstat (ВордСтат) — как правильно использовать операторы, хитрости и фишки статистики запросов
Содержание
Базовые операторы WordStat
Вспомогательные приёмы и операторы
Примеры использования
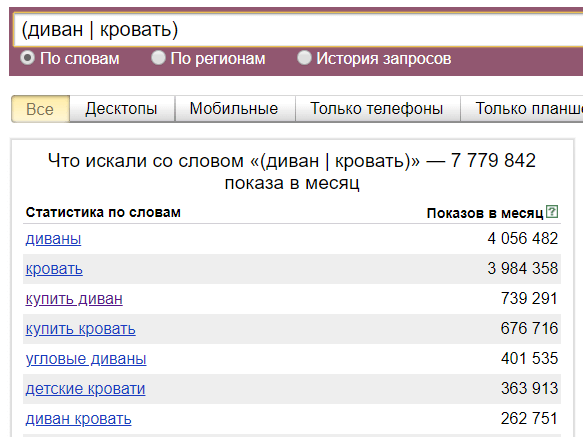
«Или»
«Квадратные скобки» и получение точной частоты запроса
«Плюс»
«Минус»
«Группировка» и более сложный запрос
Дополнительные возможности
История запроса
Частота в заданном регионе
Сбор (парсинг) запросов заданной длинны
Детальный анализ словоформ для ВЧ-запросов
Выводы
Размер текста:
Сервис подбора слов ВордСтат создан для оценки пользовательского интереса в рамках той или иной тематики, а также подбора ключевых запросов рекламодателями Яндекс.Директа. WordStat хранит подробную статистику запросов к поисковой системе Яндекс за последние 30 дней.
Для грамотной работы со статистикой поисковых запросов WordStat нам потребуется изучить и применить на практике два базовых и пять вспомогательных операторов. Данную статью можно рассматривать как инструкция по применению Яндекс.Вордстат.
Данную статью можно рассматривать как инструкция по применению Яндекс.Вордстат.
Если просто ввести интересующий нас запрос в статистику Яндекса по адресу https://wordstat.yandex.ru/, то будет представлена частота, которая отражает общее число показов результатов выдачи за предыдущей отчетный период в ответ на все запросы с содержанием заданной фразы. Так, число рядом со словом «магазин» отражает суммарную частоту показов по всем запросам со словом «магазин» — «интернет-магазин», «магазин сотовой техники», «статистика магазина», «как правильно выбрать магазин для покупок» и так далее.
В большом числе случаев, это не очень информативные и не самые полезные данные и требуется применять ряд вспомогательных операторов и приёмов о которых и пойдет речь в данной статье.
Данные операторы используются для целого ряда задач — прогнозирования трафика из органического поиска и спецразмещения, прогнозирования отдачи от SEO и других. В ряде сервисах имеются удобные инструменты парсинга данных из статистики.
Базовые операторы WordStat
К базовым операторам, без использования которых невозможно правильное понимание результатов работы статистики ВордСтат мы отнесем операторы «Кавычки» и «Восклицательный знак». Их определение и использование представлены ниже.
Как видно из примера, с помощью оператора «Восклицательный знак» можно быстро найти запросы с нужной нам словоформой одного или нескольких слов из фразы.
Совместное использование операторов «Кавычки» и «Восклицательный знак» позволяет получить так называемую «Точную частоту запроса» исходя из которой и строится прогноз трафика на сайт из контекста или органической выдачи. Требуется лишь верно предсказать показатель CTR (число кликов на 100 показов) для выбранной или занимаемой позиции.
Вспомогательные приёмы и операторы
Ещё большие возможности при работе с WordStat от Яндекса открываются с применением пяти дополнительных операторов. Это:
Оператор «Или» — задается скобками и символом «|».

Оператор «Квадратные скобки» — задается символами «[]» между которым заключена фраза. Позволяет зафиксировать порядок следования слов в запросе. Важен для оценки популярности близких фраз, особенно по частотным запросам.
Оператор «Плюс» — задается символом «+» и полезен, когда требуется найти поисковые запросы со стоп-словами (предлогами, союзами, частицами).
Оператор «Минус» — задается символом «-» и полезен, когда требуется исключить запросы с использованием ряда слов.
Оператор «Группировка» — задается символами скобки «()» и полезен, когда требуется сгруппировать использование описанных выше операторов.
Примеры использования
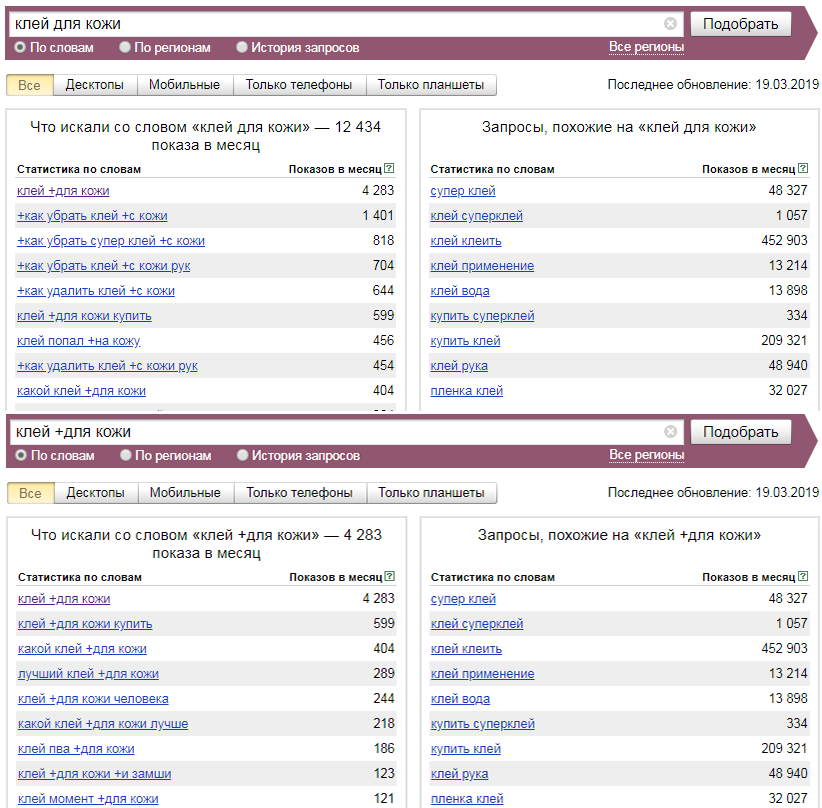
Приведем примеры использования каждого из операторов, код запроса в WordStat для самостоятельного задания и таблицу поисковых запросов до и после из применения.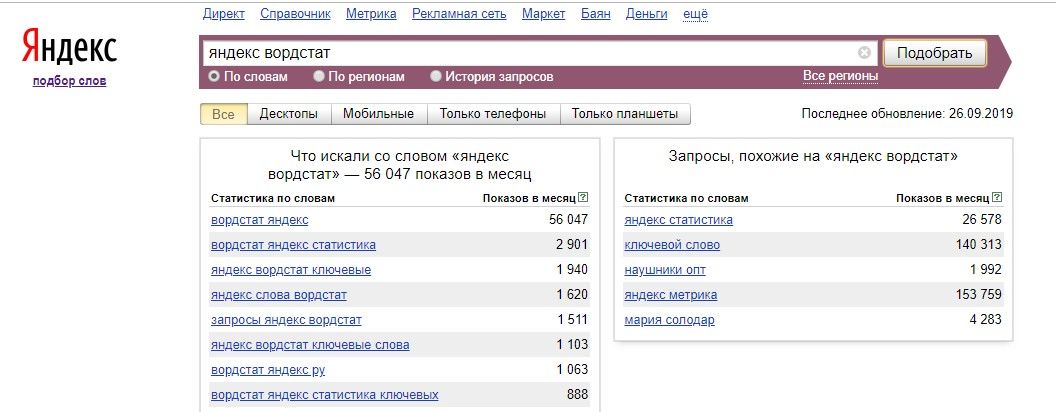
«Или»
Пример кода:
(шпаклевка | шпатлевка)
«Квадратные скобки» и получение точной частоты запроса
Пример кода:
«[!офисная !мебель]»
«Плюс»
Пример кода:
дела +на
«Минус»
Пример кода:
окна -пластиковые
«Группировка» и более сложный запрос
Пример кода:
(ворд стат | вордстат | wordstat | word stat) (операторы | приёмы | +какие | фишки | правила | +как)
Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки».
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).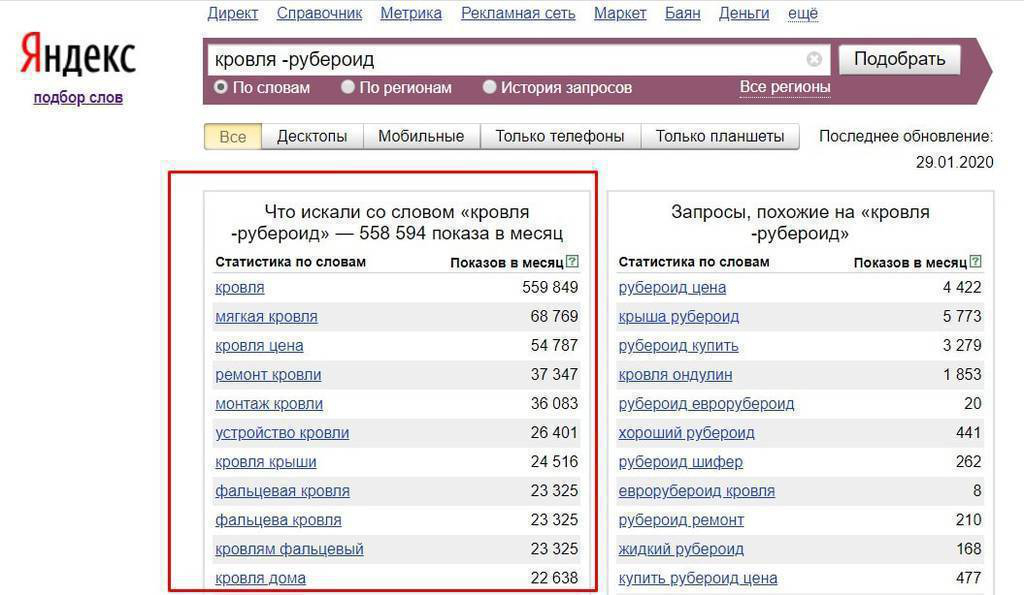
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу [Новый год]. Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«[!продвижение !сайтов]», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Выводы
Мы рассмотрели все основные функциональные возможности сервиса статистики WordStat. Теперь вам остается лишь правильно применить полученные знания на практике для своих проектов.
Мы оставим «в рукаве» ещё две интересных и скрытых возможности ВордСтат для наших подписчиков. Хотите узнать их? Тогда оформите подписку на обновления проекта «Продвижение самостоятельно». Удачи!
Автор
Дмитрий Севальнев
Подписывайтесь
на рассылку
Операторы WordStat с примерами использования
Широкое соответствиеОператор кавычкиКоличество слов в запросеОператор знак восклицанияОператор порядок словОператор илиОператор группировкаОператор минусОператор плюсСтоп словаСписок русских стоп словСписок английских стоп словКомбинирование операторовОператоры в других функциях wordstat
Операторы Вордстат (https://wordstat.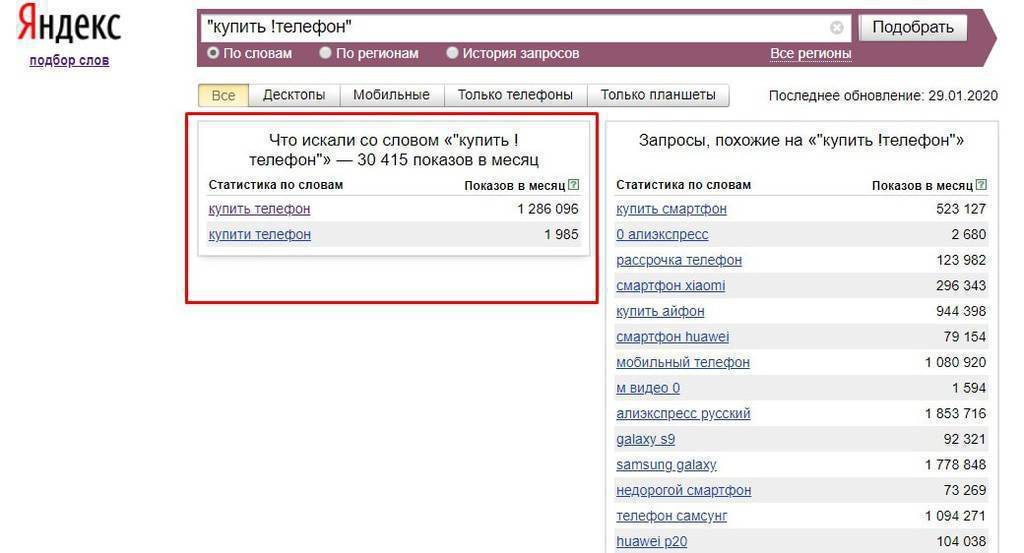 yandex.ru/) – это специальные символы применяемые при подборе слов в сервисе wordstat с целью уточнения её смысла.
yandex.ru/) – это специальные символы применяемые при подборе слов в сервисе wordstat с целью уточнения её смысла.
Операторы Вордстат представлены в виде символов, которые приписывают к словам и фразам для:
- для уточнения условий показа по ключевому слову в Яндекс.Директ
- для корректной формулировки запроса в поисковой система Яндекс
- для получения более точных результатов подбора слов в wordstat.yandex.ru
Последнее наиболее ярко отражает работу операторов Вордстат и их значение.
Видео о том, как это сильно влияет на показ объявлений в Яндекс.Директ при использовании ключевых слова без операторов.👇
Словоформа – это (в понимании Яндекса) приставка + корень, без окончания, но это не совсем так. Чаще всего это число, падеж и время. И в этой статье определимся, что
- слово – это 1 слово (без пробелов)
- фраза – это несколько слов через пробелы
То есть при подборе выдаются фразы, которые содержат указанные слова, и фразы могут содержать указанные фразы (фраза + еще слова, которые употреблялись с фразой).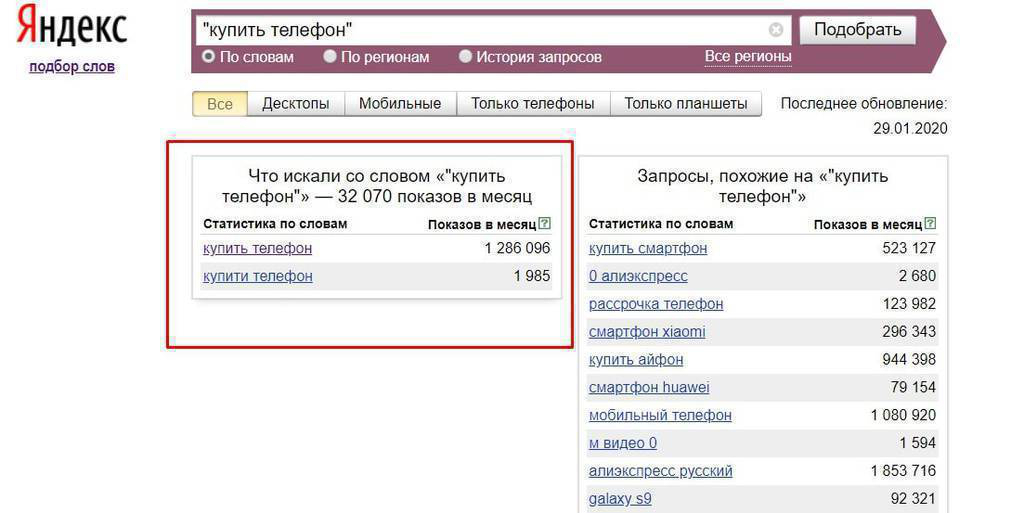
При подборе фраз без использования специальных символов в левой колонке wordstat будут все фразы
- включающие эту фразу
- по всем словоформам
- без учёта порядка слов в запросе.
- без фиксации стоп-слов
Пример: вордстат
Именно в случае отсутствия любых операторов люди, которые никогда ранее не работали с wordstat не верно воспринимают результаты подбора и не корректно оценивают увиденное, и стало быть делают неправильные выводы.
Оператор кавычки” ” – при заключении в кавычки фразы или слова фиксирует количество слов в запросе, при использовании этого оператора исключаются все фразы включающие эту фразу. То есть
- будет показан запрос и его частотность без суммы частотностей фраз включающих ключевую фразу
- не будет учитываться словоформа
- не будет учитываться порядок слов
- не фиксирует стоп-слова
Пример: ”вордстат”
Обратите внимание, что при использовании такого оператора у слова или фразы отсутсвует так называемый “хвост”, то есть фразы, которые содержат искомое слово.
Это не операторы Вордстат, но помогает сузить смысл используемой фразы за счёт ограничения количества слов во фразе. Работает только с оператором кавычки ” ” и использованием одинаковых слов в запросе.
Пример: ”вордстат вордстат вордстат вордстат”Оператор знак восклицания
! – оператор фиксирует слово и его форму точно в том числе, роде, падеже и времени. При использовании этого оператора подбор фраз будет наиболее точным в плане смысла и окончания.
- будет показан запрос и частотность и сумма частотностей всех запросов включающих ключевую фразу в этой словоформе
- будут показаны все фразы включающие эту фразу в этой словоформе
- не будет учитываться порядок слов
- если поставить знак перед стоп-словом, то фиксирует стоп слово как оператор +
Пишется вплотную к слову, словоформу которого надо зафиксировать без пробела. Применяется к каждому слову во фразе, а не к фразе целиком.
Применяется к каждому слову во фразе, а не к фразе целиком.
Пример: !МосквуОператор порядок слов
Оператор квадратные скобки.
[ ] – при заключении в квадратные скобки фразы или слова фиксирует порядок слов в запросе. Тот случай когда именно порядок слов в предложении или запросе имеет ключевой смысл. При использовании этого оператора
- будут показаны запросы и их частотность, содержащие ключевые слова фразы именно в том порядке, который указан при подборе
- будут показаны все фразы включающие эту фразу в этой словоформе и с этим порядком слов
- при использовании квадратных скобок будут учтены стоп слова в запросе
Пример: [питер москва]Оператор или
| – используется между словами или целыми фразами для получения выдачи подбора по нескольким отличным друг от друга фразам или словам.
Это вспомогательный оператор, который не несёт смысловой нагрузки на слова и используется для сравнения одновременно в выдаче частотности различных слов или целых фраз. Используется только вместе с оператором круглые скобки ( )
Используется только вместе с оператором круглые скобки ( )
Пример: (шары | шарики)Оператор группировка
( ) – при указании в круглых скобках фраз или слов, подбор слов водстат покажет их как единую смысловую единицу. Это вспомогательный оператор и используется с оператором “или | ” для более точной группировки единых по смыслу, но различных по написанию слов.
Пример: (мерседес | mercedes) (купить | цена | стоимость)Оператор минус
– данный оператор нужен для исключения из выдачи вордстат ненужных результатов с использованием этого слова. Активно применяется в рекламных кампаниях Яндекс Директ для показа по нужным ключевым словам. Может применяться в при запросе в поисковую систему Яндекс.
Чтобы сработало надо после пробела от ключевой фразы или слова вплотную (без пробела) приписать к ненужному слову оператор –
Пример: ремонт квартиры -фото -своими -руками - самому -планОператор плюс
+ – это вспомогательный оператор для принудительного учёта стоп-стоп слов при запросе подбора в вордстат, использования в рекламных кампаниях Яндекс. Директ.
Директ.
Стоп слова – это различные союзы, предлоги и междометия которые могут как не нести смысловой нагрузки, так и повлиять на смысл запроса. Полный список стоп-слов читайте ниже.
Для использования необходимо вплотную (без пробела) приписать к стоп-слову в запросе.
Пример: +на завтраСтоп слова
Служебные части речи и местоимения, а также любые слова, не несущие дополнительного смысла, которые автоматически исключаются из запроса пользователя при отборе объявлений для показа.
Так определяет Яндекс стоп слова в своей справке. Стоит уточнить, что эти стоп слова сами по себе нее несут смысла и что они исключаются при выдаче, если вы не указали перед ними специальный оператор + и конечно же это справедливо не только для отбора объявлений Яндекс Директ, но и для подбора в Wordstat.
Пример: +так +же +и +также правило
Список ниже постоянно пополняется Яндексом и может быть не актуален на момент прочтения статьи, но это официальный список из справки.
Unknown block type: child_database
Список английских стоп словUnknown block type: child_database
Комбинирование операторовПрактически все приведенные выше операторы Вордстат можно комбинировать друг с другом для получения нужной именно Вам информации с максимальной точностью. Вот несколько примеров такого использования
(услуга | услуга) +наПример использования операторов когда нужно выяснить повод (причину), направленность, к чему используется товар или услуга.
Пример: заказать (шары | шарики) +на
(товар | товар) (+с | +из)Пример поиска слов с комплектацией товара, когда нужно сегментировать или понять с чем чаще всего или из чего должен состоять товар
заказать (цветов|букетов) (+из|+с) -доставка
Точный спрос по фразеПример для поиска абсолютной точности запроса и получение частотности только этих слов в этой словоформе и в этом порядке. Не автобуса, не из Тулы в Москву, а именно в таком порядке и с такими окончаниями
Не автобуса, не из Тулы в Москву, а именно в таком порядке и с такими окончаниями
Пример:[!автобус !тула !москва]
Операторы в других функциях wordstatЗдесь мы рассматривали операторы вордстат только для левой колонки этого сервиса. На правую колонку мы не можем повлиять операторами. Так же следует отметить что операторы работают только для таких вкладок
- по словам
- по регионам
Для вкладки история запросов работает только оператор плюс «+»
О том как работает правая колонка yandex.wordstat, о функциях, ограничениях и правильного понимания выдачи подбора по запросам в других вкладках читайте в следующей статье.
Классификация документов с использованием обработки естественного языка
Процессы количественной оценки текста WordStat Интеллектуальный анализ текста, выполняемый WordStat, включает некоторую форму количественной оценки текстовых данных. Такая количественная оценка достигается за счет применения методов обработки естественного языка (стемминг, лемматизация, удаление стоп-слов и т. д.), статистических критериев отбора, а также группировки слов и фраз в понятия с использованием либо таксономий, либо словарей пользовательского содержания. Все эти процедуры можно комбинировать для извлечения чисел, отражающих наличие или частотность важных ключевых слов или ключевых понятий. Мы называем это процесс классификации . WordStat также поддерживает другую форму количественной оценки: автоматическую классификацию документов, , по которой документы распределяются по одному из нескольких взаимоисключающих классов с использованием той или иной формы машинного обучения.
Такая количественная оценка достигается за счет применения методов обработки естественного языка (стемминг, лемматизация, удаление стоп-слов и т. д.), статистических критериев отбора, а также группировки слов и фраз в понятия с использованием либо таксономий, либо словарей пользовательского содержания. Все эти процедуры можно комбинировать для извлечения чисел, отражающих наличие или частотность важных ключевых слов или ключевых понятий. Мы называем это процесс классификации . WordStat также поддерживает другую форму количественной оценки: автоматическую классификацию документов, , по которой документы распределяются по одному из нескольких взаимоисключающих классов с использованием той или иной формы машинного обучения.
Процессы категоризации и классификации выполняются WordStat, который предлагает графический пользовательский интерфейс, позволяющий пользователю создавать, проверять и уточнять эти процессы, применять их к различным текстовым коллекциям, выполнять сравнения, исследовать, связывать и создавать графические и табличные отчеты.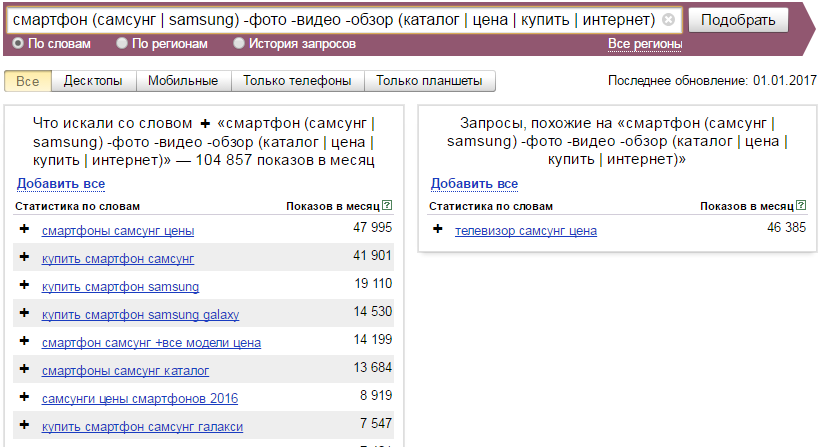 Хотя модели категоризации и классификации можно сохранить на диск и повторно применить к другому набору документов, для выполнения этих анализов по-прежнему требуется человек-оператор, что ограничивает возможность полной автоматизации анализа текста и операций отчетности.
Хотя модели категоризации и классификации можно сохранить на диск и повторно применить к другому набору документов, для выполнения этих анализов по-прежнему требуется человек-оператор, что ограничивает возможность полной автоматизации анализа текста и операций отчетности.
Комплект разработки программного обеспечения WordStat (SDK) предоставляет решение, позволяющее использовать модели, разработанные с помощью настольного инструмента WordStat, в других приложениях, написанных на других компьютерных языках, таких как C++, Delphi, C#, VB.Net и т. д.
Примером такой интеграции может быть применение модели категоризации в системе сбора данных отзывов клиентов компании для автоматического измерения ссылок на определенные темы и классификации этих отзывов как положительных, отрицательных или нейтральных.
Применение SDK Все настройки анализа и преобразования текста, установленные в WordStat, хранятся на диске в файлах модели (стемминг, лемматизация, правила категоризации, критерии выбора и т. д.). Это значительно упрощает интеграцию такой обработки текста в другие приложения, сокращая применение процесса анализа текста до четырех простых шагов:
д.). Это значительно упрощает интеграцию такой обработки текста в другие приложения, сокращая применение процесса анализа текста до четырех простых шагов:
- Загрузить файл модели категоризации или классификации
- Получить текст для категоризации или классификации
- Применить модель к тексту
- Получить соответствующую информацию (частоты, вероятности, предсказанные классы и т. д.)
Модель нужно загрузить только один раз, а шаги с 2 по 4 можно повторять сколько угодно раз.
В настоящее время в DLL отсутствуют функции создания отчетов или построения графиков, поэтому дальнейшая обработка полученной информации является задачей программиста. Как правило, числовые значения либо хранятся в базе данных, либо накапливаются для создания отчетов, информационных панелей и т. д.
SDK состоит из Windows DLL, доступной как в 32-разрядной, так и в 64-разрядной версиях. DLL безопасна в многопоточном режиме , что позволяет проводить количественную оценку текста нескольких документов одновременно. Он также поддерживает одновременное применение нескольких моделей категоризации и классификации , что позволяет выполнять несколько количественных оценок одних и тех же документов.
Он также поддерживает одновременное применение нескольких моделей категоризации и классификации , что позволяет выполнять несколько количественных оценок одних и тех же документов.
SDK поставляется с образцом проекта с исходными файлами, иллюстрирующими, как можно добиться интеграции. Этот пример проекта в настоящее время доступен в Delphi, C# и VB.NET. Свяжитесь с нами, если вам нужна помощь в использовании SDK с другими компьютерными языками.
Заинтересованы?Если вы заинтересованы в получении дополнительной информации о SDK, в получении пробной версии (с документацией и примерами приложений) или в ее покупке, свяжитесь с нами по *защищенному адресу электронной почты*.
WordStat 5 Новые возможности
СТРАНИЦА СЛОВАРОВ
- Новая опция предварительной обработки позволяет создавать собственный текст
предварительная обработка EXE или DLL (пример стеммера английского портера и n-граммы
трансформация включена).
- Новый диалог мониторинга лемматизации позволяет просматривать замены, переопределение существующих путем создания пользовательских замен.
- Правила устранения неоднозначности с логическими значениями (И, ИЛИ, НЕ) и близостью операторы (РЯДОМ, ПОСЛЕ, ДО) теперь могут быть добавлены к категоризации словари (нажмите на миниатюру, чтобы увидеть снимок экрана).
- Настройка уровня «Как показано» позволяет настроить категоризацию уровень к тому, как отображается дерево словаря.
- Возможность создавать неразрывные категории (отменяя уровень параметр).
- Словари категорий теперь можно распечатать или экспортировать в XML.
- Возможность объединения существующих словарей.
- Улучшенные контекстные меню для более быстрого редактирования словаря.

СТРАНИЦА ОПЦИИ
- Новая опция позволяет включать наблюдения с отсутствующими значениями для независимых переменных (переопределить существующее исключение по списку).
- Функция выбора переменной для взвешивания случаев.
- Новый порог для удаления элементов, встречающихся более чем в указанном % случаев.
СТРАНИЦА ЧАСТОТ
- Возможность создавать файлы норм частоты ключевых слов и сравнение существующих частот к ранее сохраненным файлам норм.
- Полностью
новый диалог поиска ключевых слов позволяет извлекать документы,
абзацы или предложения с определенной пользователем комбинацией ключевых слов.
Извлеченные текстовые сегменты могут быть дополнительно помечены с помощью QDA Miner.
коды (нажмите на миниатюры ниже, чтобы увидеть снимки экрана).

- Полная категоризация процесс теперь может быть сохранен на диске и применен к документам с использованием автономная служебная программа (WS Document Classifier) или дополнительная DLL и программа командной строки.
- Дополнительный цветной линии сетки.
- Включенные элементы могут быть временно удалены из дальнейшего анализа.
- Добавлен столбец TF*IDF (частота термина x обратная частота документа).
АВТОМАТИЧЕСКАЯ КЛАССИФИКАЦИЯ ДОКУМЕНТОВ
- Применение наивного байесовского метода и метода k-ближайших соседей по встречаемости, частоте, проценту слов и т. д.
- Выбор признаков и взвешивание признаков.
- Методы перекрестной проверки (исключение одного, n-кратность, разделение выборки).
- Модуль пакетного эксперимента и диаграммы истории для оптимизации модели.
- Классификация документов по отдельным текстам, спискам документов или база данных.
- Модель классификации может храниться на диске и применяться к внешние документы с помощью отдельной служебной программы (WS Document Classifier) или дополнительную DLL и программу командной строки,

- Дополнительно цветные линии сетки.
- Включенные элементы могут быть временно удалены из дальнейшего анализа.
СТРАНИЦА КОНТЕКСТНОГО КЛЮЧЕВОГО СЛОВА
- Страница KWIC теперь может быть отсоединена и отображаться как непрерывная диалог.
СТРАНИЦА ИЗВЛЕЧЕНИЯ ФУНКЦИЙ
- Страница поиска фраз перемещена на извлечение функций страница.
- Новый поисковик неизвестных слов позволяет быстро находить орфографические ошибки
слова, аббревиатуры, технические слова, имена собственные и либо заменить,
игнорировать или назначать их словарю категоризации.
КЛАСТЕРНЫЙ АНАЛИЗ
- Добавлены вероятностные версии Жаккара и Соренсена (или Дайса) коэффициенты.
- Добавлена кластеризация ключевых слов второго порядка (на основе схожести моделей совпадений, а не просто совпадений).
- Возможность выбора одного кластера и извлечения связанных документов.
- Новая опция для скрытия кластеров отдельных элементов в дендрограммах и многомерных масштабирование сюжетов.
PROXIMITY PLOT
- Новая опция для извлечения документов или текстовых сегментов, содержащих два конкретных ключевых слова.
ДРУГИЕ
- Мастер преобразования документов теперь может извлекать текст из PDF файлы.
- Модели категоризации и правила классификации могут быть сохранены
на диске.
- линий «Привязка к полу» на 3D графиках (МДС и корреспонденция сюжет).
- WS Document Classifier, небольшое автономное приложение для применения ранее сохраненные модели категоризации и классификации во внешние документы.
- Отдельно продаваемые версии WordStat для DLL и командной строки для автономный контент-анализ и автоматическая классификация документов (пока недоступно).
- Значительные улучшения скорости. В таблице ниже указана скорость сравнения между v4 и v5. Этот тест был выполнен на частоте 1,2 ГГц. Компьютер Пентиум 3.

ЗАДАНИЕ | ВЕРСИЯ | ВЕРСИЯ | СКОРОСТЬ |
| Частота слов в 11 314 сообщениях группы новостей (3 249 029 слов) | 5м 52с | 2м 59с | x2,0 |
| — с лемматизацией и стоп-листом | 6м 45с | 3м 11с | x2,1 |
| — классифицированы с использованием Словаря регрессивных изображений (РИД) | 10м 4с | 2м 24с | x4,2 |
| — классифицировано с использованием лингвистического исследования и Количество слов (LIWC) | 10 м 52 с | 2м 52с | x3,8 |
 0*
0* * Повышение скорости может отличаться на других компьютерах и в финальной версии
выпуск v5.