
Анализ файлов robots.txt крупнейших сайтов / Хабр
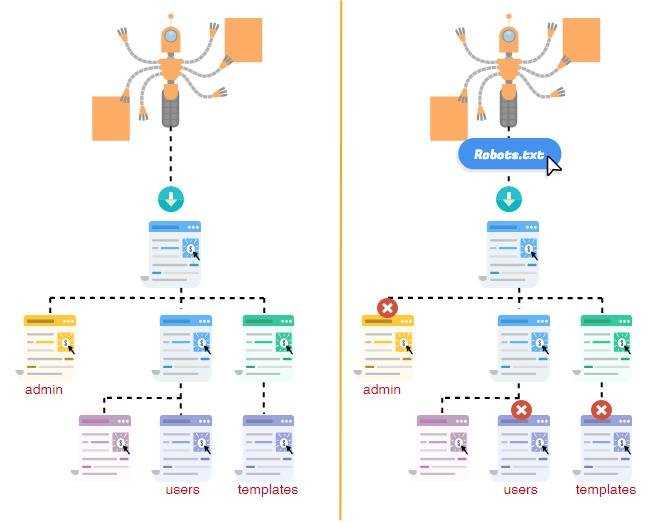
Robots.txt указывает веб-краулерам мира, какие файлы можно или нельзя скачивать с сервера. Он как первый сторож в интернете — не блокирует запросы, а просит не делать их. Интересно, что файлы robots.txt проявляют предположения веб-мастеров, как автоматизированным процессам следует работать с сайтом. Хотя бот легко может их игнорировать, но они указывают идеализированное поведение, как следует действовать краулеру.
По существу, это довольно важные файлы. Так что я решил скачать файл robots.txt с каждого из 1 миллиона самых посещаемых сайтов на планете и посмотреть, какие шаблоны удастся обнаружить.
Я взял список 1 млн крупнейших сайтов от Alexa и написал маленькую программу для скачивания файла robots.txt с каждого домена. После скачивания всех данных я пропустил каждый файл через питоновский пакет urllib.robotparser и начал изучать результаты.
Найдено в yangteacher.ru/robots. txt
txt
Среди моих любимых питомцев — сайты, которые позволяют индексировать содержимое только боту Google и банят всех остальных. Например, файл robots.txt сайта Facebook начинается со следующих строк:
Notice: Crawling Facebook is prohibited unless you have express written permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.php(Предупреждение: Краулинг Facebook запрещён без письменного разрешения. См. http://www.facebook.com/apps/site_scraping_tos_terms.php)
Это слегка лицемерно, потому что сам Facebook начал работу с краулинга профилей студентов на сайте Гарвардского университета — именно такого рода активность они сейчас запрещают всем остальным.
Требование письменного разрешения перед началом краулинга сайта плюёт в лицо идеалам открытого интернета. Оно препятствует научным исследованиям и ставит барьер для развития новых поисковых систем: например, поисковику DuckDuckGo запрещено скачивать страницы Facebook, а поисковику Google можно.![]()
В донкихотском порыве назвать и посрамить сайты, которые проявляют такое поведение, я написал простой скрипт, который проверяет домены и определяет тех, которые внесли Google в белый список тех, кому разрешено индексировать главную страницу. Вот самые популярные из этих доменов:
(В оригинальной статье указаны также аналогичные списки китайских, французских и немецких доменов — прим. пер.)
Я включил в таблицу пометку, позволяет ли сайт ещё DuckDuckGo индексировать свою заглавную страницу, в попытке показать, насколько тяжело приходится в наши дни новым поисковым системам.
У большинства из доменов в верхней части списка — таких как Facebook, LinkedIn, Quora и Yelp — есть одно общее. Все они размещают созданный пользователями контент, который представляет собой главную ценность их бизнеса. Это один из их главных активов, и компании не хотят отдавать его бесплатно. Впрочем, ради справедливости, такие запреты часто представляются как защита приватности пользователей, как в этом заявлении технического директора Facebook о решении забанить краулеры или глубоко в файле robots.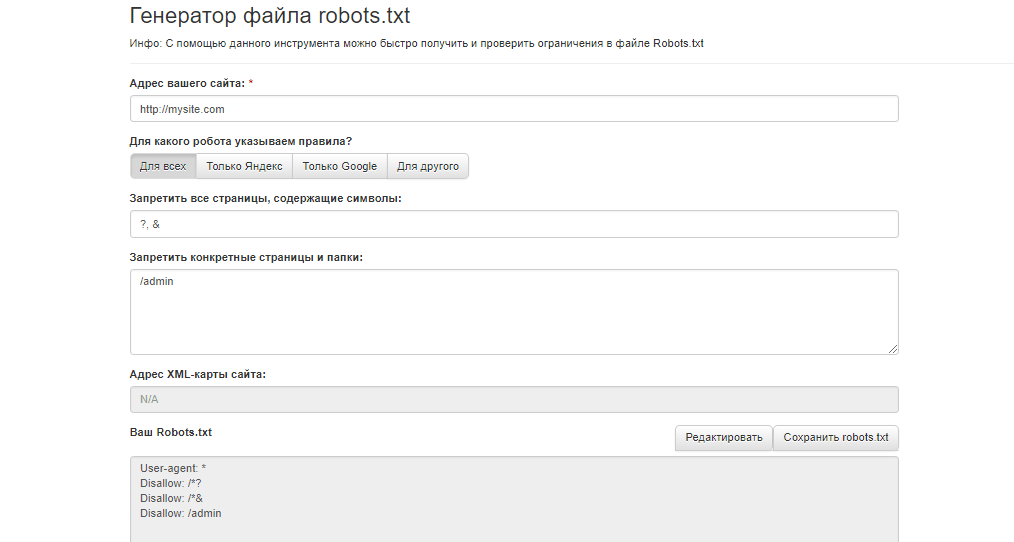
Далее по списку результаты становятся более противоречивыми — например, мне не совсем понятно, почему census.gov позволяет доступ к своему контенту только трём основным поисковым системам, но блокирует DuckDuckGo. Логично предположить, что данные государственных переписей принадлежат народу, а не только Google/Microsoft/Yahoo.
Хотя я не фанат подобного поведения, но вполне могу понять импульсивную попытку внести в белый список только определённые краулеры, если учесть количество плохих ботов вокруг.
Я хотел попробовать ещё кое-что: определить самые плохие веб-краулеры в интернете, с учётом коллективного мнения миллиона файлов robots.txt. Для этого я подсчитал, сколько разных доменов полностью банят конкретный useragent — и отранжировал их по этому показателю:
| user-agent | Тип | Количество |
|---|---|---|
| MJ12bot | SEO | 15156 |
| AhrefsBot | SEO | 14561 |
| Baiduspider | Поисковая система | 11473 |
| Nutch | Поисковая система | 11023 |
| ia_archiver | SEO | 10477 |
| WebCopier | Архивация | 9538 |
| WebStripper | Архивация | 8579 |
| Teleport | 7991 | |
| Yandex | Поисковая система | 7910 |
| Offline Explorer | Архивация | 7786 |
| SiteSnagger | Архивация | 7744 |
| psbot | Поисковая система | 7605 |
| TeleportPro | Архивация | 7063 |
| EmailSiphon | Спамерский скрапер | 6715 |
| EmailCollector | Спамерский скрапер | 6611 |
| larbin | Неизвестно | 6436 |
| BLEXBot | SEO | 6435 |
| SemrushBot | SEO | 6361 |
| MSIECrawler | Архивация | 6354 |
| moget | Неизвестно | 6091 |
Первая группа — краулеры, которые собирают данные для SEO и маркетингового анализа. Эти фирмы хотят получить как можно больше данных для своей аналитики — генерируя заметную нагрузку на многие сервера. Бот Ahrefs даже хвастается: «AhrefsBot — второй самый активный краулер после Googlebot», так что вполне понятно, почему люди хотят заблокировать этих надоедливых ботов. Majestic (MJ12Bot) позиционирует себя как инструмент конкурентной разведки. Это значит, что он скачивает ваш сайт, чтобы снабдить полезной информацией ваших конкурентов — и тоже на главной странице заявляет о «крупнейшем в мире индексе ссылок».
Вторая группа user-agents — от инструментов, которые стремятся быстро скачать веб-сайт для персонального использования в офлайне. Инструменты вроде WebCopier, Webstripper и Teleport — все они быстро скачивают полную копию веб-сайта на ваш жёсткий диск. Проблема в скорости многопоточного скачивания: все эти инструменты очевидно настолько забивают трафик, что сайты достаточно часто их запрещают.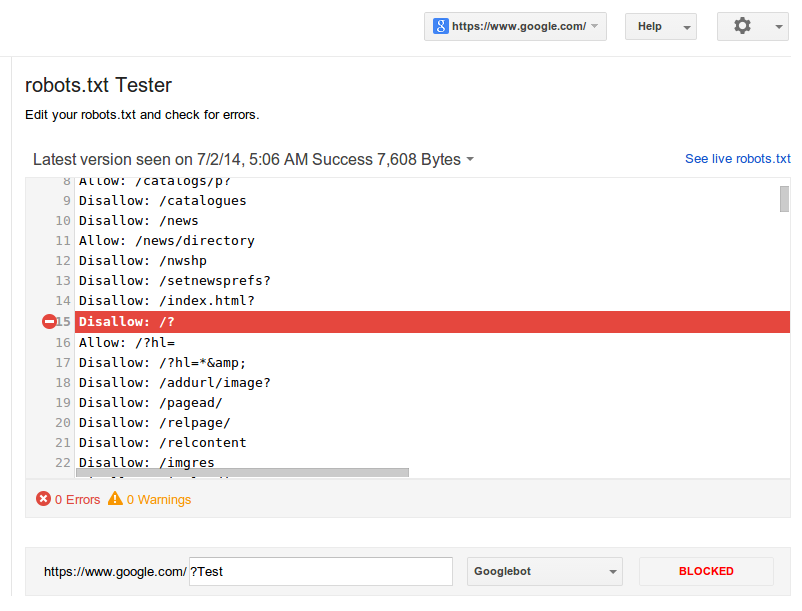
Наконец, есть поисковые системы вроде Baidu (BaiduSpider) и Yandex, которые могут агрессивно индексировать контент, хотя обслуживают только языки/рынки, которые не обязательно очень ценны для определённых сайтов. Лично у меня оба эти краулера генерируют немало трафика, так что я бы не советовал блокировать их.
Это знак времени, что файлы, которые предназначены для чтения роботами, часто содержат объявления о найме на работу разработчиков программного обеспечения — особенно специалистов по SEO.
В каком-то роде это первая в мире (и, наверное, единственная) биржа вакансий, составленная полностью из описаний файлов robots.txt. (В оригинальной статье представлены тексты всех 67 вакансий из файлов robots.txt — прим. пер.).
Есть некоторая ирония в том, что Ahrefs.com, разработчик второго среди самых забаненных ботов, тоже поместила в своём файле robots.txt объявление о поиске SEO-специалиста. А ещё у pricefalls.com объявление о работе в файле robots. txt следует после записи «Предупреждение: краулинг Pricefalls запрещён, если у вас нет письменного разрешения».
txt следует после записи «Предупреждение: краулинг Pricefalls запрещён, если у вас нет письменного разрешения».
Весь код для этой статьи — на GitHub.
Правильный файл robots.txt для сайта
Автор Алексей На чтение 15 мин Просмотров 13к. Опубликовано Обновлено
Robots.txt – это специальный файл, расположенный в корневом каталоге сайта. Вебмастер указывает в нем, какие страницы и данные закрыть от индексации от поисковых систем. Файл содержит директивы, описывающие доступ к разделам сайта (так называемый стандарт исключений для роботов). Например, с его помощью можно установить различные настройки доступа для поисковых роботов, предназначенных для мобильных устройств и обычных компьютеров. Очень важно настроить его правильно.
Содержание
- Нужен ли robots.txt?
- Где лежит файл Robots.txt?
- Как создать правильный robots.
 txt
txt - Директивы Disallow и Allow
- Использование спецсимволов * и $
- Директива Sitemap
- Директива Crawl-delay
- Директива Clean-param
- Синтаксис директивы
- Директива HOST
- Правильный robots.txt: настройка
- Правильный Robots.txt пример для WordPress
- Robots.txt пример для Joomla
- Robots.txt пример для Bitrix
- Robots.txt пример для MODx
- Robots.txt пример для Drupal
- Проверить robots.txt
- Проверка robotx.txt для поискового робота Яндекса
- Проверка robotx.txt для поискового робота Google
- Генераторы robots.txt
 txt
txtНужен ли robots.txt?
После того, как вы добавите свой сайт в Google и Яндекс, ПС начнут индексировать все, абсолютно все, что находится в вашей папке с сайтом на сервере. Это не очень хорошо с точки зрения продвижения, ведь в папке содержится очень много лишнего для ПС «мусора», что негативно скажется на позициях в поисковой выдаче.
Именно правильно настроенный файл robots. txt запрещает индексирование документов, папок и ненужных страниц.
txt запрещает индексирование документов, папок и ненужных страниц.
С помощью robots.txt можно:
- запретить индексирование похожих и ненужных страниц, чтобы не тратить краулинговый лимит (количество URL, которое может обойти поисковый робот за один обход). Т.е. робот сможет проиндексировать больше важных страниц.
- скрыть изображения из результатов поиска.
- закрыть от индексации неважные скрипты, файлы стилей и другие некритичные ресурсы страниц.
Если это помешает сканеру Google или Яндекса анализировать страницы, не блокируйте файлы.
Где лежит файл Robots.txt?
Если вы хотите просто посмотреть, что находится в файле robots.txt, то просто введите в адресной строке браузера: site.ru/robots.txt.
Физически файл robots.txt находится в корневой папке сайта на хостинге. У меня хостинг beget.ru, поэтому покажу расположения файла robots.txt на этом хостинге.
У меня хостинг beget.ru, поэтому покажу расположения файла robots.txt на этом хостинге.
- Заходите на хостинг beget.ru и авторизуетесь (или регистрируетесь, если нет аккаунта).
- После выбираете Файловый менеджер.
- Находите домен вашего сайта. Далее откройте папку public_html.
- В папке должен лежать robots.txt.
Как создать правильный robots.txt
Файл robots.txt состоит из одного или нескольких правил. Каждое правило блокирует или разрешает индексирование пути на сайте.
- В текстовом редакторе создайте файл с именем robots.txt и заполните его в соответствии с представленными ниже правилами.
- Файл robots.txt должен представлять собой текстовый файл в кодировке ASCII или UTF-8. Символы в других кодировках недопустимы.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать индексацию всех страниц сайта
http://www., файл robots.txt следует разместить по адресу example.com/http://www.example.com/robots.txt. Он не должен находиться в подкаталоге (например, по адресуhttp://example.com/pages/robots.txt). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги. - Файл robots.txt можно добавлять по адресам с субдоменами (например,
http://website.example.com/robots.txt) или нестандартными портами (например,http://example.com:8181/robots.txt). - Проверьте файл в сервисе Яндекс.Вебмастер и Google Search Console.
- Загрузите файл в корневую директорию вашего сайта.
 example.com/
example.com/Вот пример файла robots.txt с двумя правилами. Ниже есть его объяснение.
User-agent: Googlebot Disallow: /nogooglebot/ User-agent: * Allow: / Sitemap: http://www.
 example.com/sitemap.xml
example.com/sitemap.xml
Объяснение
- Агент пользователя с названием Googlebot не должен индексировать каталог
http://example.com/nogooglebot/и его подкаталоги. - У всех остальных агентов пользователя есть доступ ко всему сайту (можно опустить, результат будет тем же, так как полный доступ предоставляется по умолчанию).
- Файл Sitemap этого сайта находится по адресу http://www.example.com/sitemap.xml.
Директивы Disallow и Allow
Чтобы запретить индексирование и доступ робота к сайту или некоторым его разделам, используйте директиву Disallow.
Примеры:
User-agent: Yandex
Disallow: / # блокирует доступ ко всему сайту
User-agent: Yandex
Disallow: /cgi-bin # блокирует доступ к страницам,
# начинающимся с '/cgi-bin'В соответствии со стандартом перед каждой директивой User-agent рекомендуется вставлять пустой перевод строки.
Символ # предназначен для описания комментариев. Все, что находится после этого символа и до первого перевода строки не учитывается.
Все, что находится после этого символа и до первого перевода строки не учитывается.
Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow
Примеры:
User-agent: Yandex Allow: /cgi-bin Disallow: / # запрещает скачивать все, кроме страниц # начинающихся с '/cgi-bin'
Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow.
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
# Исходный robots.txt: User-agent: Yandex Allow: /catalog Disallow: / # Сортированный robots.txt: User-agent: Yandex Disallow: / Allow: /catalog # разрешает скачивать только страницы, # начинающиеся с '/catalog'
# Исходный robots.
 txt:
User-agent: Yandex
Allow: /
Allow: /catalog/auto
Disallow: /catalog
# Сортированный robots.txt:
User-agent: Yandex
Allow: /
Disallow: /catalog
Allow: /catalog/auto
# запрещает скачивать страницы, начинающиеся с '/catalog',
# но разрешает скачивать страницы, начинающиеся с '/catalog/auto'.
txt:
User-agent: Yandex
Allow: /
Allow: /catalog/auto
Disallow: /catalog
# Сортированный robots.txt:
User-agent: Yandex
Allow: /
Disallow: /catalog
Allow: /catalog/auto
# запрещает скачивать страницы, начинающиеся с '/catalog',
# но разрешает скачивать страницы, начинающиеся с '/catalog/auto'.При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.
Использование спецсимволов * и $
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
Примеры:
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает '/cgi-bin/example.aspx'
# и '/cgi-bin/private/test.aspx'
Disallow: /*private # запрещает не только '/private',
# но и '/cgi-bin/private'Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Директива работает только с роботом Яндекса.
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.example.
 com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123
com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123
Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn] [path]
В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots. txt. В случае, если директив указано несколько, все они будут учтены роботом.
txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.php
означает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php Clean-param: sid&sort /forum/*.php Clean-param: someTrash&otherTrash
Директива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots. txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т. д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта  д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогичноRobots.
 txt пример для Joomla
txt пример для JoomlaUser-agent: *Disallow: /administrator/Disallow: /cache/Disallow: /includes/Disallow: /installation/Disallow: /language/Disallow: /libraries/Disallow: /media/Disallow: /modules/Disallow: /plugins/Disallow: /templates/Disallow: /tmp/Disallow: /xmlrpc/Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для Bitrix
User-agent: *Disallow: /*index.php$Disallow: /bitrix/Disallow: /auth/Disallow: /personal/Disallow: /upload/Disallow: /search/Disallow: /*/search/Disallow: /*/slide_show/Disallow: /*/gallery/*order=*Disallow: /*?print=Disallow: /*&print=Disallow: /*register=Disallow: /*forgot_password=Disallow: /*change_password=Disallow: /*login=Disallow: /*logout=Disallow: /*auth=Disallow: /*?action=Disallow: /*action=ADD_TO_COMPARE_LISTDisallow: /*action=DELETE_FROM_COMPARE_LISTDisallow: /*action=ADD2BASKETDisallow: /*action=BUYDisallow: /*bitrix_*=Disallow: /*backurl=*Disallow: /*BACKURL=*Disallow: /*back_url=*Disallow: /*BACK_URL=*Disallow: /*back_url_admin=*Disallow: /*print_course=YDisallow: /*COURSE_ID=Disallow: /*?COURSE_ID=Disallow: /*?PAGENDisallow: /*PAGEN_1=Disallow: /*PAGEN_2=Disallow: /*PAGEN_3=Disallow: /*PAGEN_4=Disallow: /*PAGEN_5=Disallow: /*PAGEN_6=Disallow: /*PAGEN_7=Disallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*PAGE_NAME=searchDisallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*SHOWALLDisallow: /*show_all=Sitemap: http://путь к вашей карте XML формата
Robots.
 txt пример для MODx
txt пример для MODxUser-agent: *Disallow: /assets/cache/Disallow: /assets/docs/Disallow: /assets/export/Disallow: /assets/import/Disallow: /assets/modules/Disallow: /assets/plugins/Disallow: /assets/snippets/Disallow: /install/Disallow: /manager/Sitemap: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *Disallow: /database/Disallow: /includes/Disallow: /misc/Disallow: /modules/Disallow: /sites/Disallow: /themes/Disallow: /scripts/Disallow: /updates/Disallow: /profiles/Disallow: /profileDisallow: /profile/*Disallow: /xmlrpc.phpDisallow: /cron. php
phpDisallow: /update.phpDisallow: /install.phpDisallow: /index.phpDisallow: /admin/Disallow: /comment/reply/Disallow: /contact/Disallow: /logout/Disallow: /search/Disallow: /user/register/Disallow: /user/password/Disallow: *register*Disallow: *login*Disallow: /top-rated-Disallow: /messages/Disallow: /book/export/Disallow: /user2userpoints/Disallow: /myuserpoints/Disallow: /tagadelic/Disallow: /referral/Disallow: /aggregator/Disallow: /files/pin/Disallow: /your-votesDisallow: /comments/recentDisallow: /*/edit/Disallow: /*/delete/Disallow: /*/export/html/Disallow: /taxonomy/term/*/0$Disallow: /*/edit$Disallow: /*/outline$Disallow: /*/revisions$Disallow: /*/contact$Disallow: /*downloadpipeDisallow: /node$Disallow: /node/*/track$Disallow: /*&Disallow: /*%Disallow: /*?page=0Disallow: /*sectionDisallow: /*orderDisallow: /*?sort*Disallow: /*&sort*Disallow: /*votesupdownDisallow: /*calendarDisallow: /*index. php
phpAllow: /*?page=Disallow: /*?Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер, еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список – выберите Анализ robots.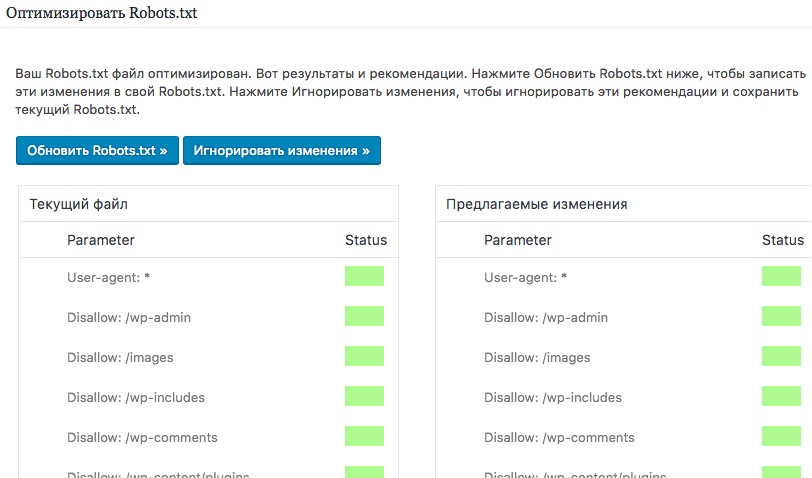 txt или по ссылке http://webmaster.yandex.ru/robots.xml
txt или по ссылке http://webmaster.yandex.ru/robots.xml
Вариант 2:
Этот вариант подразумевает, что ваш сайт добавлен в Яндекс Вебмастер и в корне сайта уже есть robots.txt.
Слева выберите Инструменты — Анализ robots.txt
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.

Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru.С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru.В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots. txt и загрузить в корневой каталог вашего сайта.
 txt и загрузить в корневой каталог вашего сайта.
txt и загрузить в корневой каталог вашего сайта.Как использовать файл robots.txt
В начале лета интернет-маркетологи отметили юбилей: файлу robots.txt исполнилось 20 лет. В честь этого Google расширил функциональность инструментов для веб-мастеров, добавив в набор средство проверки файла robots.txt. Опытные маркетологи прекрасно знают, что это за файл и как с ним работать. А начинающие специалисты получат базовую информацию из этой статьи.
Не любите читать? Посмотрите видео
Еще больше полезных видео — на нашем YouTube-канале. Подписывайтесь 😉
А теперь переходим к тексту.
Зачем необходим файл robots.txt
В файле robots.txt содержится информация, которую используют при сканировании сайта поисковые роботы. В частности, из robots.txt краулеры узнают, какие разделы сайта, типы страниц или конкретные страницы не следует сканировать. С помощью файла вы исключаете из индекса поисковых систем контент, который не хотите показывать поисковикам. Также вы можете запретить индексирование дублированного контента.
Также вы можете запретить индексирование дублированного контента.
Если вы используете robots.txt неправильно, это может стоить вам дорого. Ошибочный запрет на сканирование исключит из индекса важные разделы, страницы или даже весь контент целиком. В этом случае вам сложно рассчитывать на успешное продвижение сайта.
Как работать с файлом robots.txt
Текстовый файл robots.txt содержит инструкции для роботов поисковых системы. Обычно его используют для запрета сканирования служебных разделов сайта, дублированного контента или публикаций, которые не предназначены для всей аудитории.
Если у вас нет необходимости закрывать от сканирования какой-либо контент вам можно не заполнять robots.txt. В этом случае запись в файле выглядит так:
User-agent: *
Disallow:
Если вы по каким-то причинам собираетесь полностью заблокировать сайт для поисковых роботов, запись в файле будет выглядеть так:
User-agent: *
Disallow: /
Чтобы правильно использовать robots. txt, вы должны иметь представление об уровнях директив:
txt, вы должны иметь представление об уровнях директив:
- Уровень страницы. В этом случае директива выглядит так: Disallow: /primerpage.html.
- Уровень папки. На этом уровне директивы записываются так: Disallow: /example-folder/.
- Уровень типа контента. Например, если вы не хотите, чтобы роботы индексировали файлы в формате .pdf, используйте следующую директиву: Disallow: /*.pdf.
Будьте осторожны
Помните о наиболее распространенных ошибках, встречающихся при составлении robots.txt:
- Полный запрет индексации сайта поисковыми роботами
В этом случае директива выглядит так:
User-agent: *
Disallow: /
Зачем создавать сайт, если вы не разрешаете поисковикам его сканировать? Использование этой директивы уместно на стадии разработки или глобального усовершенствования ресурса.
- Запрет на сканирование индексируемого контента
Например, веб-мастер может запретить сканировать папки с видео и изображениями:
Disallow: /images/
Disallow: /videos/
Сложно представить ситуацию в которой запрет на сканирование индексируемого контента был бы оправданным. Обычно такие действия лишают сайт части трафика.
Обычно такие действия лишают сайт части трафика.
- Использование атрибута allow
Это действие не имеет никакого смысла. Поисковые системы по умолчанию сканируют весь доступный контент. С помощью файла robots.txt можно запретить сканирование, однако разрешать что-либо индексировать не нужно.
Инструмент проверки файла robots.txt
В середине июля Google представил инструмент проверки файла robots.txt, доступный в панели для веб-мастеров. Чтобы найти его, воспользуйтесь меню «Панель инструментов сайта – сканирование – инструмент проверки файла robots.txt».
Новый инструмент решает следующие задачи:
- Отображение текущей версии файла robots.txt.
- Редактирование и проверка корректности файла robots.txt непосредственно в панели для веб-мастеров.
- Просмотр старых версий файла.
- Проверка заблокированных URL.
- Просмотр сообщений об ошибках файла robots.txt.
Если Google не индексирует отдельные страницы или целые разделы вашего сайта, новый инструмент поможет вам в течение нескольких секунд проверить, связано ли это с ошибками файла robots. txt. По данным эксперта Google Асафа Арнона, инструмент подсвечивает конкретную директиву, которая приводит к блокировке индексирования контента.
txt. По данным эксперта Google Асафа Арнона, инструмент подсвечивает конкретную директиву, которая приводит к блокировке индексирования контента.
Вы можете внести изменения в robots.txt и проверить его корректность. Для этого достаточно указать интересующий вас URL и нажать кнопку «Проверить».
Представитель Google Джон Миллер рекомендует всем владельцам сайтов проверить файл robots.txt с помощью нового инструмента. По мнению эксперта, потратив несколько секунд на проверку, веб-мастер может выявить критические ошибки, которые препятствуют краулерам Google.
Чтобы правильно использовать…
… файл robots.txt, необходимо понимать его практический смысл. Этот файл служит для ограничения доступа к сайту для поисковых систем. Если вы хотите запретить роботам сканировать страницу, раздел сайта или тип контента, внесите соответствующую директиву a robots.txt. Проверяйте корректность использования файла с помощью нового инструмента доступного в панели для веб-мастеров Google.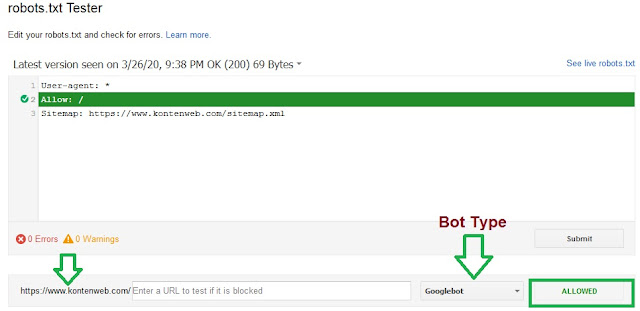 Это поможет вам быстро обнаружить и устранить ошибки, а также внести в robots.txt необходимые изменения.
Это поможет вам быстро обнаружить и устранить ошибки, а также внести в robots.txt необходимые изменения.
Читайте также:
- Анализ контента. Часть 1. Сбор метрик с помощью плагина Seo Tools
- Google начал шифровать 100% поисковых запросов: что делать?
- 6 советов по использованию Google Analytics для продвинутых пользователей
Robots.txt и SEO: полное руководство (2022)
Robots.txt — это простой, но важный файл, который может определить судьбу вашего веб-сайта на страницах результатов поисковой системы (SERP).
Ошибки Robots.txt являются одними из наиболее распространенных ошибок SEO, которые вы обычно обнаруживаете в отчете аудита SEO. На самом деле, даже самые опытные SEO-специалисты подвержены ошибкам robots.txt.
Вот почему важно глубже понять, как работает robots.txt.
Поняв основы, вы сможете создать идеальный файл robots. txt, облегчающий поисковым системам сканирование и индексирование ваших страниц.
txt, облегчающий поисковым системам сканирование и индексирование ваших страниц.
В этом руководстве мы рассмотрим:
- Что такое robots.txt
- Почему файл robots.txt важен
- Как найти файл robots.txt
- Синтаксис robots.txt
- Как создать файл robots.txt
- Как проверить, работает ли ваш robots.txt
- Robots.txt передовой опыт
К концу этого поста у вас будет SEO-оптимизированный файл robots.txt для вашего веб-сайта.
Давайте начнем.
Что такое Robots.txt?Robots.txt — это текстовый файл, созданный владельцами веб-сайтов, который инструктирует поисковые системы о том, как сканировать страницы на вашем веб-сайте. Иными словами, файл robots.txt сообщает поисковым системам, где они могут и не могут находиться на вашем сайте.
По данным Google:
Robots.txt используется в основном для управления трафиком поисковых роботов на вашем сайте и обычно для защиты страницы от Google, в зависимости от типа файла.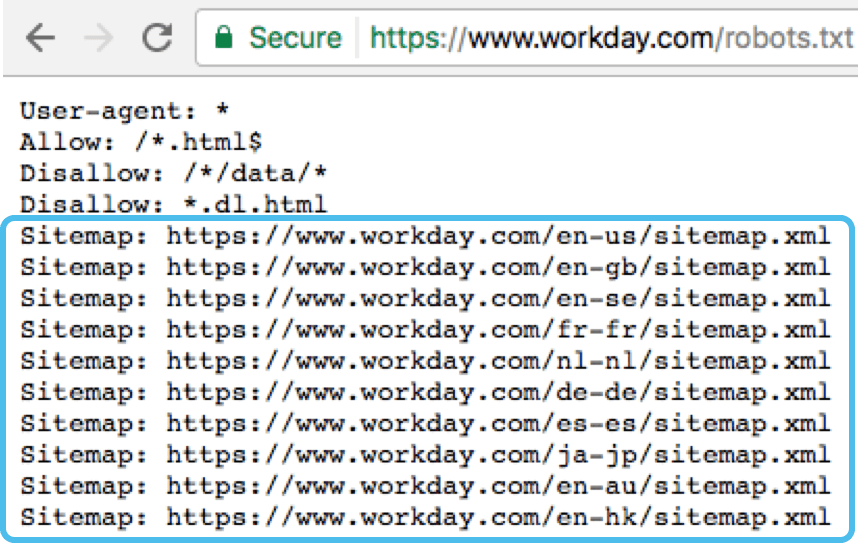
Например, если на вашем сайте есть определенная страница, которую вы не хотите индексировать Google, вы можете использовать robots.txt, чтобы заблокировать Googlebot (веб-сканер Google) от сканирования этой страницы.
Почему файл robots.txt важен?Вопреки распространенному мнению, файл robots.txt необходим не для всех веб-сайтов.
Если на вашем сайте очень мало страниц, вам не нужно создавать файл robots.txt для вашего сайта.
Google достаточно развился, чтобы узнать, какие страницы индексировать, а какие игнорировать на вашем сайте.
Тем не менее, лучше всего использовать файл robots.txt, даже если у вас небольшой веб-сайт.
Почему?
Потому что это дает вам больше контроля над тем, какие страницы вы хотите, чтобы поисковые роботы индексировали.
Давайте подробнее рассмотрим 5 основных причин, по которым вы хотите создать файл robots.txt для своего веб-сайта:
- Заблокировать личные страницы от сканеров поисковых систем: Вы можете использовать robots. txt для блокировки личных страниц на вашем сайте. Ваша страница входа или промежуточные версии страниц на вашем сайте должны быть недоступны для широкой публики. Здесь вы можете использовать robots.txt, чтобы другие люди не попадали на эти страницы.
- Оптимизируйте бюджет сканирования: Бюджет сканирования — это количество страниц, которые робот Googlebot будет сканировать в любой день. Если у вас возникли проблемы с индексацией всех важных страниц, возможно, вы столкнулись с проблемой краулингового бюджета. Это тот случай, когда вы можете использовать robots.txt, чтобы оптимизировать свой краулинговый бюджет, заблокировав доступ к неважным страницам.
- Предотвратить сканирование дублированного контента: Если у вас один и тот же контент появляется на нескольких страницах, вы можете использовать robots.txt, чтобы предотвратить ранжирование повторяющихся страниц в поисковой выдаче. Это распространенная проблема, с которой сталкиваются веб-сайты электронной коммерции, и ее можно легко предотвратить, добавив простые директивы в файл robots. txt.
- Предотвращение появления файлов ресурсов в поисковой выдаче: Robots.txt может помочь вам предотвратить индексирование файлов ресурсов, таких как PDF-файлы, изображения и видео.
- Предотвратить перегрузку сервера: Вы можете использовать файл robots.txt, чтобы указать задержку сканирования, чтобы избежать перегрузки сайта запросами.
 txt для блокировки личных страниц на вашем сайте. Ваша страница входа или промежуточные версии страниц на вашем сайте должны быть недоступны для широкой публики. Здесь вы можете использовать robots.txt, чтобы другие люди не попадали на эти страницы.
txt для блокировки личных страниц на вашем сайте. Ваша страница входа или промежуточные версии страниц на вашем сайте должны быть недоступны для широкой публики. Здесь вы можете использовать robots.txt, чтобы другие люди не попадали на эти страницы. txt.
txt.Если у вас уже есть файл robots.txt, найти его очень просто.
Просто введите yoursitename.com/robots.txt в вашем браузере, и если на вашем сайте есть файл robots.txt, он должен выглядеть примерно так:
Если на вашем сайте нет файла robots.txt, вы найдете пустую страницу.
Синтаксис файла robots.txt Перед созданием файла robots.txt необходимо ознакомиться с синтаксисом, используемым в файле robots.txt. Вот 4 наиболее часто встречающихся компонента в файле robots. txt:
txt:
- User-agent: Это имя поискового робота, которому вы даете инструкции по сканированию. У каждой поисковой системы свое имя пользовательского агента. Пример: Googlebot — это имя пользовательского агента Google.
- Disallow: Это директива, используемая для указания агенту пользователя не сканировать определенный URL-адрес.
- Разрешить: Эта директива используется для указания агенту пользователя сканировать страницу, даже если ее родительская страница запрещена.
- Карта сайта: Эта директива используется для указания местоположения вашей карты сайта XML для поисковых систем.
Если на вашем сайте нет файла robots.txt, его легко создать. Вы можете использовать любой текстовый редактор для создания файла robots.txt.
Если вы используете Mac, вы можете создать файл robots.txt с помощью приложения TextEdit.
Откройте текстовый документ и начните вводить директивы.
Например, если вы хотите, чтобы Google проиндексировал все ваши страницы и просто скрыл страницу администратора, создайте файл robots.txt, который выглядит следующим образом:
User-agent: * Disallow: /wp-admin/
Когда вы закончите вводить все директивы, сохраните файл как «robots.txt».
Вы также можете использовать этот бесплатный генератор robots.txt от SEOptimer для создания файла robots.txt.
Если вы хотите избежать синтаксических ошибок при создании файла robots.txt, я настоятельно рекомендую вам использовать генератор robots.txt. Даже небольшая синтаксическая ошибка может привести к деиндексации вашего сайта, поэтому убедитесь, что файл robots.txt настроен правильно.
Когда файл robots.txt будет готов, загрузите его в корневой каталог вашего веб-сайта.
Используйте FTP-клиент, например Filezilla, чтобы поместить текстовый файл в корневой каталог домена. Например, файл robots.txt из yoursitename.com должен быть доступен по адресу yoursitename.com/robots.txt .
Например, файл robots.txt из yoursitename.com должен быть доступен по адресу yoursitename.com/robots.txt .
После загрузки файла robots.txt в корневой каталог вы можете проверить его с помощью средства проверки robots.txt в Google Search Console.
Средство проверки robots.txt проверит правильность работы файла robots.txt. Если вы заблокировали сканирование каких-либо URL-адресов в файле robots.txt, инструмент Tester проверит, действительно ли определенные URL-адреса блокируются поисковыми роботами.
То, что ваш файл robots.txt проверен один раз, не означает, что он всегда будет безошибочным.
Ошибки robots.txt встречаются довольно часто. Плохо настроенный файл robots.txt может повлиять на возможность сканирования вашего сайта. Поэтому вам нужно следить за проблемами и убедиться, что ваш файл robots.txt не содержит ошибок.
Самый эффективный способ проверить файл robots. txt на наличие проблем — использовать Google Search Console. Войдите в свою учетную запись Google Search Console и перейдите к отчету «Покрытие» в разделе «Индекс».
txt на наличие проблем — использовать Google Search Console. Войдите в свою учетную запись Google Search Console и перейдите к отчету «Покрытие» в разделе «Индекс».
Если есть какие-либо ошибки и предупреждения, связанные с вашим файлом robots.txt, вы найдете их в отчете «Покрытие».
Вы также можете использовать такой инструмент, как SEMrush, для проверки файла robots.txt на наличие ошибок.
Если у вас есть действующая подписка на SEMrush, регулярно проводите аудит своего сайта, чтобы поддерживать его техническое SEO-здоровье, а также выявлять и исправлять ошибки robots.txt.
Чтобы проверить файл robots.txt на наличие ошибок, откройте последний обзорный отчет об аудите сайта и найдите « 9Виджет 0043 Robots.txt Updates» . Вы увидите, смог ли SEMrushBot просканировать ваш файл robots.txt.
Если вы внесли какие-либо изменения в файл robots.txt, SEMrush отобразит количество изменений, внесенных в него с момента последнего сканирования.
Что еще более важно, SEMrush также выявит проблемы с вашими файлами robots. txt и предоставит рекомендации по их устранению, чтобы улучшить возможности сканирования и индексации вашего веб-сайта.
txt и предоставит рекомендации по их устранению, чтобы улучшить возможности сканирования и индексации вашего веб-сайта.
Примечание: SEMrush — это мощное программное обеспечение для SEO, которое может помочь вам не только в техническом SEO-анализе. Вы можете использовать его для исследования ключевых слов, анализа обратных ссылок, изучения конкурентов и многого другого. Попробуйте SEMrush Pro бесплатно в течение 30 дней.
Передовые методы работы с robots.txtТеперь, когда вы знаете основы robots.txt, давайте кратко рассмотрим некоторые рекомендации, которым необходимо следовать:
1. Robots.txt чувствителен к региструИмя файла robots.txt чувствительно к регистру. Поэтому убедитесь, что файл называется robots.txt (а не robots.TXT, ROBOTS.TXT, Robots.Txt и т. д.)
2. Поместите файл Robots.txt в главный каталог Ваши роботы Файл .txt должен быть размещен в основной директории вашего сайта. Если ваш файл robots.txt находится в подкаталоге, он не будет найден.
Если ваш файл robots.txt находится в подкаталоге, он не будет найден.
Плохо:
YoursiteName.com/page/robots.txt
Хорошо:
YoursiteName.com/ROBOTS.TXT
3. Использование. Веб-сайтВ файле robots.txt можно использовать два подстановочных знака — подстановочный знак (*) и подстановочный знак ($). Использование этих подстановочных знаков robots.txt помогает вам контролировать, как поисковые системы сканируют ваш сайт. Давайте рассмотрим каждый из этих подстановочных знаков:
(*) Подстановочный знакВы можете использовать подстановочный знак (*) в файле robots.txt для обращения ко всем агентам пользователя (поисковым системам). Например, если вы хотите запретить всем поисковым роботам сканировать вашу страницу администратора, ваш файл robots.txt должен выглядеть примерно так:
User-agent: * Запретить: /wp-admin/($) Подстановочный знак
Подстановочный знак ($) указывает на конец URL-адреса. Например, если вы хотите запретить поисковым роботам индексировать все PDF-файлы на вашем сайте, ваш файл robots.txt должен выглядеть примерно так:
Например, если вы хотите запретить поисковым роботам индексировать все PDF-файлы на вашем сайте, ваш файл robots.txt должен выглядеть примерно так:
Агент пользователя: * Disallow: /*.pdf$4. Используйте комментарии для дальнейшего использования
Комментарии в файле robots.txt могут быть полезны разработчикам и другим членам команды, имеющим доступ к файлу. Их также можно использовать для дальнейшего использования.
Чтобы добавить комментарии к файлу robots.txt, введите решетку (#) и введите свой комментарий.
Вот пример:
# Блокирует роботу Googlebot сканирование yoursitename.com/directory1/ Агент пользователя: googlebot Запретить: /directory1/
Поисковые роботы игнорируют строки, содержащие хэш.
5. Создайте отдельный файл robots.txt для каждого субдомена Для каждого субдомена требуется свой файл robots.txt. Таким образом, если у вас есть раздел вашего сайта, размещенный на другом субдомене, вам необходимо создать два отдельных файла robots. txt.
txt.
Например, блог HubSpot размещен на поддомене и имеет собственный файл robots.txt:
Заключительные мыслиRobots.txt может быть простым текстовым файлом, но это мощный инструмент SEO. Оптимизированный файл robots.txt может улучшить индексируемость ваших страниц и повысить видимость вашего сайта в результатах поиска.
Для получения дополнительной информации о том, как создать идеальный файл robots.txt, вы можете обратиться к этому руководству robots.txt от Google.
Если вы нашли эту статью полезной, поделитесь ею в Твиттере, используя ссылку ниже:
Примечание редактора: Эта статья была впервые опубликована 3 декабря 2020 года и с тех пор регулярно обновляется для обеспечения актуальности и полноты.
Статьи по теме
- Как создать XML-карту сайта для вашего веб-сайта (и отправить ее в Google)
- Контрольный список технического SEO: 10 советов по техническому SEO для мгновенного увеличения трафика
- Semrush Site Audit: 10 самых недооцененных функций
Как создать идеальный файл robots.
 txt для SEO (с примерами)
txt для SEO (с примерами)Внедрение файла robots.txt на ваш веб-сайт является одним из самых простых технических методов SEO, но вы также можете легко испортить его. .
Простая опечатка, неверный URL-адрес или неверно истолкованное правило могут привести к катастрофическим последствиям для результатов поиска ваших веб-сайтов. В худшем случае это может даже привести к полному исчезновению ключевых страниц вашего сайта из Google!
Тем не менее, правильно реализованный файл robots.txt может дать вашему веб-сайту, особенно крупным сайтам с дублирующимся содержимым, возможность управлять тем, как боты и поисковые роботы, такие как Google и Bing, индексируют ваш сайт.
В этой статье мы дадим вам:
Полное изложение того, что такое файл robots.txt и почему он может повлиять на сайт вашего бренда.
Более того, мы опишем полные пошаговые инструкции по созданию файла robots.txt, удобного для поисковых роботов.
Плюс все инструменты и хитрости по тестированию и оптимизации.

Ну что же мы ждем? Давайте дадим вам инструменты и инструкции, необходимые для взлома кода идеального файла robots.txt.
Что такое Robots.txt?
Robots.txt — это обычный текстовый файл, размещенный на вашем веб-сайте, который сообщает поисковым системам и поисковым роботам, таким как Google, куда они могут или не могут идти. Следуя набору веб-стандартов, называемых протоколом исключения роботов, файлы robots.txt дают поисковым системам четкие указания, куда им следует идти, «разрешая» или «запрещая» части вашего сайта.
Проще говоря, думайте о файлах robots.txt как о путеводителе по природному парку, который сообщает вам, где в парке вам разрешено и где запрещено совершать приключения.
Вот очень простой пример файла robots.txt:
«Пользовательский агент» указывает, какой веб-сканер или поисковая система должны подчиняться последующим директивам, в данном случае подстановочный знак означает всех веб-ботов. Косая черта после слова «запретить» сообщает роботу, что не следует посещать все страницы всего сайта.
Косая черта после слова «запретить» сообщает роботу, что не следует посещать все страницы всего сайта.
Вот еще один пример:
В данном случае файл robots.txt сообщает агенту пользователя «Googlebot» не посещать какие-либо страницы «/блог/» на всем сайте.
Почему файл robots.txt важен?
Это все хорошо, и все, что вы знаете, что текстовый файл может сделать, но как это распространено на вашем сайте? Ну…
Небольшая вещь, называемая краулинговым бюджетом
Если у вас есть веб-сайт электронной коммерции или если ваш сайт запущен и работает в течение длительного времени, у вас, скорее всего, есть приличное количество страниц с контентом. Когда появятся поисковые системы, такие как Google, они начнут сканировать и индексировать каждую вещь на вашем сайте в своем вечном стремлении предоставить наилучшие результаты для пользователей в Интернете.
Вот в чем проблема: если на вашем веб-сайте слишком много страниц, поисковым системам, естественно, потребуется больше времени для завершения сканирования, что, в свою очередь, негативно повлияет на рейтинг ваших ключевых слов.
Это так называемый «краулинговый бюджет»; количество страниц, которые поисковая система может просканировать и проиндексировать на вашем сайте за определенный период времени. Сумма краулингового бюджета, которую вы будете иметь, зависит от ряда факторов, включая скорость сайта, популярность URL-адресов и многое другое. Поэтому не забудьте позаботиться о своем сайте с помощью тщательно продуманной оптимизации скорости страницы и различных других стратегий SEO, чтобы максимально увеличить свой бюджет.
Вот еще одна проблема: если общее количество ваших страниц превышает лимит краулингового бюджета, робот Googlebot вообще не будет индексировать вашу страницу. По сути, некоторый контент, на оптимизацию которого вы потратили бесчисленное количество часов для SEO, вообще не будет ранжироваться.
Мы хотим убедиться, что ваш краулинговый бюджет расходуется разумно, поэтому создание файла robots.txt поможет обеспечить сканирование и индексирование действительно важных страниц.
Предотвращение доступа общественности к частному контенту
Хотя вы, вероятно, захотите проиндексировать большую часть своего веб-сайта, некоторые страницы могут быть скрыты от просмотра.
Например, у вас, вероятно, будет страница входа для сотрудников, чтобы получить доступ к серверной части. Могут быть целевые страницы, содержащие секретную или конфиденциальную информацию. Возможно, вы разрабатываете новый дизайн веб-сайта для своего бренда.
Используя robots.txt, вы можете запретить индексацию этих страниц и предотвратить случайное попадание публики на страницу, которую им не следует делать.
Важно отметить, что, как и путешественники, которые предпочитают не слушать гида в природном парке, некоторые поисковые системы могут игнорировать некоторые или все правила в файлах robots.txt. К счастью, Google — хороший бот, который, как правило, подчиняется всем вашим инструкциям.
Готовы создать файл robots.txt, который почти улучшит вашу поисковую оптимизацию? Давайте начнем!
Поиск файла robots.
 txt
txtНайти файл robots.txt на самом деле довольно просто, если вы просто ищете, существует ли он. Более того, это то, что вы можете сделать на большинстве крупных веб-сайтов в Интернете, если хотите быстро изучить конкурентов в файлах robots.txt.
Чтобы просмотреть страницу robots.txt, просто введите URL-адрес в строке поиска и добавьте в конце /robots.txt.
Скорее всего, вы столкнетесь с одним из следующих сценариев:
1. Есть полный файл robots.txt, как у нас!
2. Файл robots.txt есть, но он пустой! Например, у Disney нет файла на их сайте здесь.
3. robots.txt отсутствует, и страница возвращает сообщение об ошибке 404 (страница не существует), как и Burger King.
После проверки существования вашего файла robots.txt вы можете получить доступ к фактическому файлу и отредактировать его, обратившись к корневому каталогу вашего веб-сайта с помощью вашего FTP-инструмента, такого как cPanel.
Если вы не уверены, что сможете открыть серверную часть своего веб-сайта и получить доступ к корневому каталогу, мы рекомендуем привлечь SEO-агентство или кого-то, кто разбирается в управлении сайтом, чтобы найти и отредактировать файл robots. txt.
txt.
Как создать файл Robots.txt (используя передовой опыт)
Чтобы создать файл robots.txt, мы начинаем с открытия любого текстового редактора, такого как Блокнот, Sublime Text или TextEdit, если вы работаете на Mac. Хотя вы можете создавать файлы robots.txt с помощью текстовых процессоров, таких как Microsoft Word или Google Docs, и сохранять их в виде текстового файла, программа может добавить дополнительный код в ваш robots.txt и привести к проблемам несовместимости. Так что будь проще!
Независимо от того, есть ли на вашем сайте в настоящее время файл robots.txt, мы рекомендуем начать с пустого файла. Таким образом вы создаете файл robots.txt, который полностью понимаете.
Прежде чем мы начнем, вам нужно понять некоторые основные синтаксические конструкции, используемые для обеспечения того, чтобы каждое размещаемое вами правило работало должным образом.
Вот краткое описание общего синтаксиса:
User-agent: Роботы поисковых систем (например, Google), которые будут сканировать ваш сайт.
Например: User-agent: Googlebot
Disallow: команда, которая сообщает пользовательскому агенту не обращаться к определенному URL-адресу или пути URL-адреса.
Например: Запретить: /reviews/
Разрешить: команда, которая сообщает пользовательскому агенту, что возможен доступ к определенному дочернему URL-адресу запрещенного родительского URL-адреса.
Например: Позволяет: /reviews/product/
Карта сайта: описывает расположение файла (или файлов) карты сайта xml на вашем веб-сайте.
Например: Карта сайта: https://www.examplesite.com.au/sitemap.xml
*: Известный как подстановочный знак, его можно использовать в любой из вышеперечисленных директив , кроме карты сайта .
Например: User-agent: * означает, что все боты придерживаются следующих правил.
Для более подробного ознакомления с правилами и синтаксисом robots. txt мы настоятельно рекомендуем ознакомиться с объяснением Google.
txt мы настоятельно рекомендуем ознакомиться с объяснением Google.
Теперь, когда вы разобрались с синтаксисом, давайте шаг за шагом рассмотрим, как создать файл robots.txt!
Сначала создайте текстовый файл и назовите его robots.txt. Убедитесь, что вы не называете его как-либо иначе, так как любая форма опечатки или использование верхнего регистра не будет рассматриваться сканером вообще как действительный файл. Затем откройте его с помощью текстового редактора.
Затем вам нужно указать агент пользователя, для простоты давайте сделаем так, чтобы эти директивы влияли на все поисковые роботы следующим образом:
Далее, в новой строке под запретить правило следующим образом:
Важно, чтобы каждую вновь написанную директиву мы писали с новой строки, чтобы Googlebot не запутался. На данный момент, поскольку мы не хотим ничего запрещать (пока), мы оставим это поле пустым.
Далее мы свяжем файл robots.txt с вашим XML-файлом карты сайта. Вы можете сделать это в новой строке, отделенной от пользовательского агента, и запретить правила, введя:
Вы можете сделать это в новой строке, отделенной от пользовательского агента, и запретить правила, введя:
Если на вашем веб-сайте есть более одной карты сайта, обязательно добавьте их.
Поздравляю! Вы создали базовый файл robots.txt, который позволяет каждой поисковой системе сканировать каждую страницу вашего сайта. Теперь давайте сделаем еще один шаг и превратим этот изящный маленький инструмент в инструмент, который повысит ваш рейтинг SEO.
Оптимизация Robots.txt для SEO
Прежде чем вы начнете добавлять другую команду, очень важно, чтобы вы нашли время и провели надлежащий аудит каждой страницы на своем веб-сайте. Нет ничего хуже, чем создать команду запрета для определенного URL-адреса, а через некоторое время узнать, что одна из его подстраниц жизненно важна для вашего SEO!
Важно отметить, что мы не используем файл robots.txt для явного блокирования страниц на вашем сайте из поискового робота, мы просто предоставляем четкую карту или руководство для поисковых роботов, таких как Googlebot.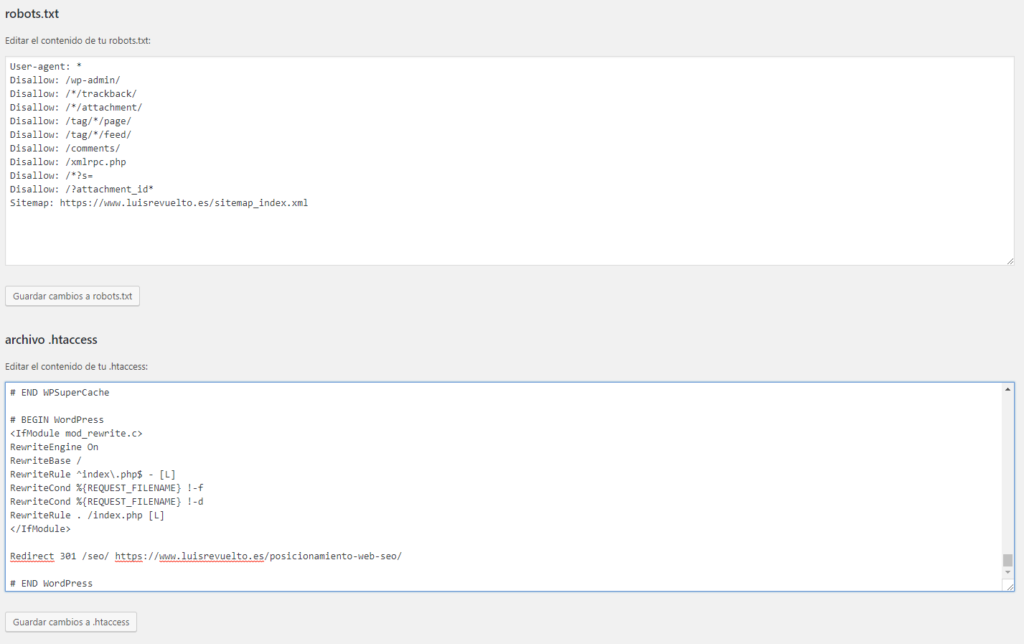 В то время как Google обычно следует каждой команде в текстовом файле, другие боты могут игнорировать их и в любом случае получать доступ к каталогам.
В то время как Google обычно следует каждой команде в текстовом файле, другие боты могут игнорировать их и в любом случае получать доступ к каталогам.
Лучше всего начать с определения того, какие разделы вашего сайта не показываются (или не должны быть) общедоступными.
Например, веб-сайты, использующие WordPress, могут подумать о запрете входа на страницу входа в серверную часть.
Точно так же, если вы хотите запретить любую другую страницу веб-сайта, это так же просто, как это:
Более того, если вы хотите разрешить доступ к определенной подстранице из каталога «страница», вы должны добавьте следующую команду:
Теперь, когда мы изучили основы, вот несколько страниц, которые вы можете добавить в директивы disallow.
Дублированный контент
В общем, вы хотите свести к минимуму количество дублированного контента на вашем сайте. Дублированный контент может не только вызвать путаницу среди потенциальных клиентов, посещающих ваш сайт, но и негативно повлиять на ваши результаты SEO.
Тем не менее, в ситуации, когда должен существовать некоторый дублированный контент, добавление директивы disallow скажет любому боту сканировать только ту версию, которую вы хотите.
Частное содержимое
Некоторый контент на вашем сайте, такой как страницы благодарности, страница входа в систему WordPress или ресурсы, такие как изображения или PDF-файлы, может содержать важную и личную информацию, на которую вы бы не хотели натыкаться. Размещение правила запрета на этих страницах помогает защитить ваш более личный контент от легкого доступа в поисковой системе.
Указание агента пользователя
Думаете о создании набора команд для определенных агентов пользователя, таких как Googlebot? Все, что вам нужно сделать, это ввести этот конкретный пользовательский агент, а затем перечислить директивы, которым вы хотите, чтобы пользовательский агент следовал, например:
Обратите внимание, что каждый новый добавленный набор команд пользовательского агента отделяется разрывом строки. Это связано с тем, что каждый набор команд, упомянутых в этом наборе, разделенном строкой, будет применяться только для указанного пользовательского агента.
Это связано с тем, что каждый набор команд, упомянутых в этом наборе, разделенном строкой, будет применяться только для указанного пользовательского агента.
В приведенном выше примере, хотя оба агента пользователя запрещают URL-адрес входа в WordPress «wp-admin», роботу Googlebot запрещено сканировать URL-адрес «другая страница», в то время как все другие пользовательские агенты не могут сканировать URL-адрес «страница».
Кроме того, имейте в виду, что если пользовательский агент будет следовать только тем директивам, которые наиболее точно к нему применимы. Таким образом, если Facebot (собственный поисковый робот Facebook) столкнулся с приведенным выше примером, поскольку нет набора директив, в которых явно упоминается их пользовательский агент, он выберет следование подстановочному знаку.
Проверьте файл robots.txt
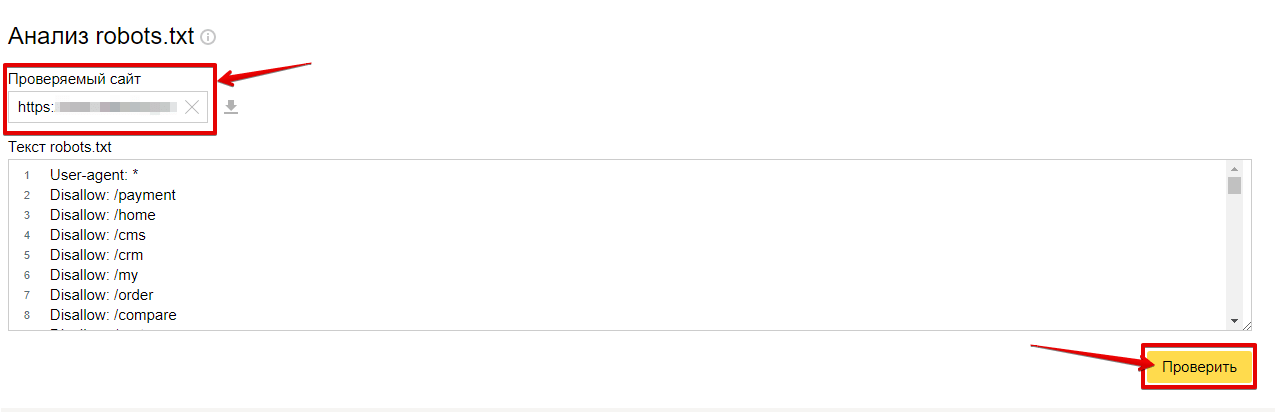
Теперь, когда файл robots.txt полностью оптимизирован, пришло время проверить его, чтобы убедиться, что все добавленное корректно и без ошибок. К счастью, у Google есть собственный инструмент для тестирования robots.txt, который вы можете использовать на своем сайте.
К счастью, у Google есть собственный инструмент для тестирования robots.txt, который вы можете использовать на своем сайте.
После входа в учетную запись веб-мастера, связанную с вашим веб-сайтом, перейдите на страницу тестирования, которая должна выглядеть следующим образом:
Этот фантастический инструмент также покажет ваш текущий файл robots.txt, который они нашли на веб-сайте. как любые ошибки и предупреждения, которые могут присутствовать. Просто замените текст новым файлом robots.txt, затем нажмите «Тест» в правом нижнем углу экрана.
Если ваш текст действителен, вы должны получить сообщение «Разрешено» зеленым текстом.
Теперь ваш изящный маленький файл robots.txt готов к загрузке в Интернет. Вернитесь в корневой каталог и загрузите файл robots.txt.
При загрузке файлов robots.txt убедитесь, что они размещены в корневом каталоге или папке верхнего уровня на вашем веб-сайте. Хотя вы можете подумать, что боты, такие как Googlebot, могут найти ваш robots.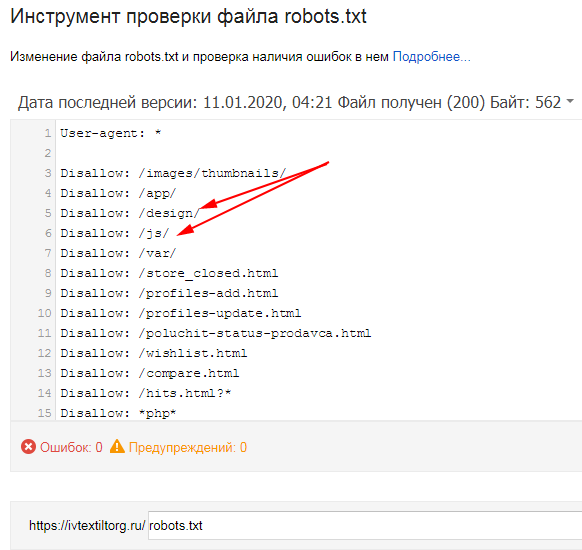 txt независимо от местоположения, это определенно 9.0035 не случай.
txt независимо от местоположения, это определенно 9.0035 не случай.
Когда робот посещает ваш сайт, чтобы начать индексирование, он будет искать только в корневом каталоге, в противном случае он решит, что ваш сайт не использует robots.txt, и просканирует весь ваш сайт с опрометчивой небрежностью. Итак, убедитесь, что ваша тяжелая работа окупается, поместив файл robots.txt в корневой каталог для быстрого доступа ботов и поисковых роботов.
Вуаля! Вы только что настроили свой веб-сайт с замечательным файлом robots.txt, который поможет вам быстро контролировать, какие страницы контента сканируются и индексируются ботами в Интернете, включая Google.
Вам слово
Несмотря на то, что вы успешно загрузили идеально оптимизированный файл robots.txt, теперь важно правильно поддерживать файл robots.txt, чтобы в долгосрочной перспективе ваш файл оставался актуальным с учетом последних изменений. у вас на сайте. Более того, поскольку поисковые системы, такие как Google, и поисковые роботы регулярно меняют методы сканирования и индексации, вам необходимо регулярно проверять файл robots. txt.
txt.
Хотя вы вполне можете сделать это самостоятельно, работа со специализированной командой может помочь значительно улучшить ваше техническое SEO наряду с другими каналами, включая социальные сети и контекстную рекламу. Вот куда мы входим!
Для подходящих предприятий наша команда опытных гуру с радостью проведет комплексный БЕСПЛАТНЫЙ цифровой аудит на 50+ страницах , охватывающий основные каналы, включая SEO, PPC, Facebook и другие.
Более того, мы проведем с вами фантастическую стратегическую сессию, а затем разработаем 6-месячный многоканальный план игры, в котором мы наметим пошаговые инструкции и инструменты, которые помогут вам добиться немедленного цифрового роста. Пришло время взять под контроль вашу цифровую стратегию и обеспечить долгосрочный рост вашего бренда. Работайте с гуру онлайн-маркетинга уже сегодня.
Что такое файл robots.txt и как его использовать
Файл robots.txt — это среда, которая позволяет вам общаться с ботами, сканирующими ваш сайт. Хотя указание роботам Google, что следует анализировать на странице, может быть полезным, для правильного выполнения этого требуется изучение языка, понятного поисковым роботам. Узнайте больше в этой статье!
Хотя указание роботам Google, что следует анализировать на странице, может быть полезным, для правильного выполнения этого требуется изучение языка, понятного поисковым роботам. Узнайте больше в этой статье!
Содержание:
- Robots.txt — что это такое?
- элементов, которые не следует сканировать
- Будьте осторожны!
- Файлы robots.txt являются только рекомендациями Генераторы
- Robots.txt — как создать файл?
- Конструкции
- Директивы для файлов robots.txt
- Настройка по умолчанию
- Размер букв
- Сила звездочки
- Конец последовательности символов
- Комментарии
- Еще несколько примеров
- Куда поместить файл robots.txt?
- Информация для Google
- Файл robots.txt — вынос
Каждый, кто создает веб-сайт, хочет быть видимым в Интернете. Вот почему все больше и больше людей решают выполнять SEO-мероприятия в соответствии с рекомендациями Google, чтобы гарантировать, что их сайты будут отображаться высоко в результатах обычного поиска.
Один из первых вопросов, который, вероятно, приходит вам на ум, : как Google или любая другая поисковая система узнает, что опубликовано на данной странице ?
Так называемые поисковые роботы проверяют бесконечные ресурсы онлайн-мира и анализируют контент на всех встречаемых веб-сайтах. Стоит убедиться, что как только роботы заходят на ваш сайт, они получают информацию о том, какие страницы должны быть просканированы, поскольку некоторые подстраницы не должны или даже не должны отображаться в результатах поиска — вот где роботов .txt пригодится.
Robots.txt — что это такое?
Файл robots.txt является одним из элементов, используемых для связи с поисковыми роботами.
Роботы ищут этот конкретный файл сразу после входа на сайт. Он состоит из комбинации команд, соответствующих стандарту Robots Exclusion Protocol — «языку», понятному ботам.
Благодаря этому владельцы веб-сайтов могут управлять роботами и ограничивать их доступ к таким ресурсам, как графика, стили, скрипты или определенные подстраницы на веб-сайте, которые не нужно показывать в результатах поиска.
Элементы, которые не следует сканировать
Давно веб-сайты перестали быть простыми файлами, не содержащими ничего, кроме текста. Большинство интернет-магазинов содержат множество подстраниц, которые не представляют ценности с точки зрения результатов поиска или даже приводят к созданию внутреннего дублированного контента.
Чтобы узнать больше, ознакомьтесь с нашей статьей о дублирующемся контенте
Роботы не должны иметь доступа к таким элементам, как корзины покупок, внутренние поисковые системы, процедуры заказа или пользовательские панели.
Почему?
Потому что дизайн этих элементов может не только вызвать ненужную путаницу, но и негативно повлиять на видимость сайта в поисковой выдаче . Вам также следует рассмотреть возможность блокировки копий подстраниц, созданных CMS, поскольку они могут увеличить ваш внутренний дублированный контент.
Будьте осторожны!
Создание правил, позволяющих перемещаться по поисковым роботам , требует отличного знания структуры веб-сайта.
Использование неправильной команды может помешать роботам Google получить доступ ко всему содержимому веб-сайта или его важным частям. Это, в свою очередь, может привести к контрпродуктивным эффектам – ваш сайт может полностью исчезнуть из результатов поиска .
Поисковые роботы могут решить следовать вашим советам, однако по многим причинам вы не можете заставить их соблюдать какие-либо команды, размещенные в вышеупомянутом протоколе связи.
Во-первых, Googlebot — не единственный робот, сканирующий веб-сайты. Хотя создатели ведущей в мире поисковой системы следят за тем, чтобы их поисковые роботы соблюдали рекомендации владельцев веб-сайтов, другие боты не всегда так полезны. Кроме того, данный URL-адрес также может быть просканирован, когда на него ссылается другой проиндексированный веб-сайт.
В зависимости от ваших потребностей есть несколько способов защитить себя от такой ситуации. Например, вы можете применить метатег noindex или HTTP-заголовок «X-Robots-Tag».
Также можно защитить личные данные паролем, так как поисковые роботы не смогут его взломать. В случае с файлом robots.txt удалять данные из индекса поисковика не обязательно, достаточно просто скрыть.
Генераторы Robots.txt – Как создать файл?
Интернет изобилует генераторами robots.txt и очень часто CMS оснащены специальными механизмами, облегчающими пользователям создание таких файлов. Вероятность того, что вам придется готовить инструкции вручную, довольно мала. Однако стоит изучить базовые структуры протокола, а именно правила и команды, которые можно давать поисковым роботам.
Структуры
Начните с создания файла robots.txt . Согласно рекомендациям Google, следует применять системы кодировки символов ASCII или UTF-8. Держите все как можно проще. Используйте несколько ключевых слов, заканчивающихся двоеточием, чтобы давать команды и создавать правила доступа.
User-agent: — указывает получателя команды. Здесь вам нужно ввести имя поискового робота. Можно найти обширный список всех имен в Интернете (http://www.robotstxt.org/db.html), однако в большинстве случаев вы, вероятно, захотите общаться в основном с роботом Googlebot. Тем не менее, если вы хотите отдать команды всем роботам, просто используйте звездочку «*».
Здесь вам нужно ввести имя поискового робота. Можно найти обширный список всех имен в Интернете (http://www.robotstxt.org/db.html), однако в большинстве случаев вы, вероятно, захотите общаться в основном с роботом Googlebot. Тем не менее, если вы хотите отдать команды всем роботам, просто используйте звездочку «*».
Примерная первая строка команды для роботов Google выглядит так:
User-agent: Googlebot
Disallow: — здесь вы указываете URL-адрес, который не должен сканироваться ботами. Наиболее распространенные методы включают скрытие содержимого целых каталогов путем вставки пути доступа, заканчивающегося символом «/», например:
Disallow: /blocked/
или файлов:
Disallow: /folder/blockedfile.html
Разрешить: — Если какой-либо из ваших скрытых каталогов содержит контент, который вы хотите сделать доступным для поисковых роботов, введите путь к его файлу после «Разрешить»:
Разрешить: /blocked/unblockeddirectory/
Разрешить: /blocked/other/unblockedfile. html
html
Карта сайта: — позволяет указать путь к карте сайта. Однако этот элемент не является обязательным для файла robots.txt для правильной работы. Например:
Карта сайта: http://www.mywonderfuladdress.com/sitemap.xml
Директивы для файлов Robots.txt
Настройка по умолчанию
Прежде всего, помните, что 9Поисковые роботы 0579 предполагают, что им разрешено сканировать весь сайт . Итак, если ваш файл robots.txt должен выглядеть так:
User-agent: *
Allow: /
то включать его в каталог сайта не нужно. Боты будут сканировать сайт в соответствии со своими предпочтениями. Однако вы всегда можете вставить файл, чтобы предотвратить возможные ошибки при анализе сайта.
Size Of Letters
Как ни удивительно, роботы способны распознавать строчные и заглавные буквы . Поэтому они будут воспринимать file.php и File.php как два разных адреса.
Сила звездочки
Звездочка — *, упомянутая ранее, — еще одна очень полезная функция. В протоколе исключения роботов он сообщает, что разрешено размещать любую последовательность символов неограниченной длины (также нулевую) в заданном пространстве. Например:
В протоколе исключения роботов он сообщает, что разрешено размещать любую последовательность символов неограниченной длины (также нулевую) в заданном пространстве. Например:
Disallow: /*/file.html
будет применяться к обоим файлам в:
/directory1/file.html
и один в папке:
/folder1/folder2/folder36/file.html
Звездочка также может служить другим целям. Если вы поместите его перед определенным расширением файла, то правило применимо ко всем файлам этого типа. Например:
Disallow: /*.php
будет применяться ко всем файлам .php на вашем сайте (кроме пути «/», даже если он ведет к файлу с расширением .php), а правило:
Запретить: /folder1/test*
будет применяться ко всем файлам и папкам в папке 1, начиная со слова «тест».
Конец последовательности символов
Не забывайте об операторе «$», который указывает на конец адреса. Таким образом, используя правило:
User-agent: *
Disallow: /folder1/
Allow: /folder1/*. php$
php$
предлагает ботам не индексировать содержимое в folder1 но в то же время разрешает их для сканирования файлов .php внутри папки. Пути, содержащие загруженные параметры, такие как:
http://mywebsite.com/catalogue1/page.php?page=1
не сканируются ботами. Однако такие проблемы можно легко решить с помощью канонических URL-адресов.
Если созданный файл или ваш сайт сложный, рекомендуется добавить комментарии, поясняющие ваши решения . Это проще простого — просто вставьте «#» в начале строки, и поисковые роботы просто пропустят эту часть контента при сканировании сайта.
Еще несколько примеров
Вы уже знаете правило, открывающее доступ ко всем файлам, однако стоит также выучить правило, которое заставляет поисковые роботы покинуть ваш сайт.
User-agent: *
Disallow: /
Если ваш сайт не отображается в результатах поиска, проверьте, нет ли в файле robots.txt вышеуказанной команды.
На скриншоте ниже вы можете увидеть пример файла robots. txt , найденного на сайте интернет-магазина:
txt , найденного на сайте интернет-магазина:
Он содержит набор всех вышеперечисленных структур, за исключением карты сайта, которая не является обязательной.
Правила адресованы всем ботам. Например, каталог «environment» заблокирован, но поисковым роботам разрешен вход в путь «/environment/cache/images/». Более того, поисковая система не может получить доступ к корзине покупок, странице входа, копиям содержимого (индекс, полный) или внутренней поисковой системе и разделу комментариев.
Куда поместить файл robots.txt?
Если вы уже создали файл robots.txt , соответствующий всем стандартам, все, что вам нужно сделать, это загрузить его на сервер. Он должен быть размещен в вашем основном каталоге хоста . Любое другое место не позволит ботам найти его. Итак, примерный URL-адрес выглядит следующим образом:
http://mywebsite.com/robots.txt
Если на вашем веб-сайте есть несколько версий URL-адреса (например, с http, https, www или без www ), желательно применить соответствующие перенаправления к одному основному домену . Благодаря этому сайт будет сканироваться правильно.
Благодаря этому сайт будет сканироваться правильно.
Информация для Google
Правильно расположенный файл легко распознается роботами поисковых систем. Однако вы также можете облегчить им задачу.
Google позволяет пользователям Search Console проверять свои текущие файлы, проверять правильность работы запланированных изменений и загружать новые файлы robots.txt .
Ссылки в официальной документации Google перенаправляют на старую версию GSC, поэтому будем использовать и ее.
Источник: https://www.google.com/webmasters/tools/robots-testing-toolС помощью этого инструмента вы можете эффективно проверить, видны ли роботам определенные элементы вашего веб-сайта. Например, они не смогут получить доступ к адресу /wp/wp-admin/test.php из-за наложенных ограничений, отмеченных красным.
Вы можете сообщить Google, что ваш файл robots.txt был обновлен, используя опцию «отправить», и попросить его повторно просканировать ваш сайт.