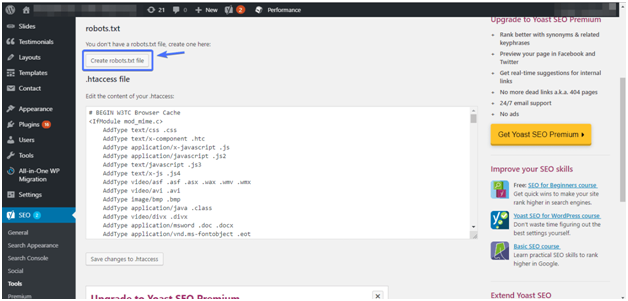
Что такое Robots.txt и как его настроить
robots.txt — это текстовый файл с инструкциями для поисковиков.
В этом файле можно закрыть сайт от поисковых систем или же закрыть отдельные страницы / разделы сайта. Можно прописывать правила как для конкретного поисковика, так и для всех поисковиков сразу.
Найти роботс можно по адресу: https://site.ru/robots.txt (где site.ru — это ваш домен).
robots.txt — это обязательный файл. Его отсутствие или кривая настройка могут вырасти в нереальный геморрой и сильно усложнить продвижение сайта.
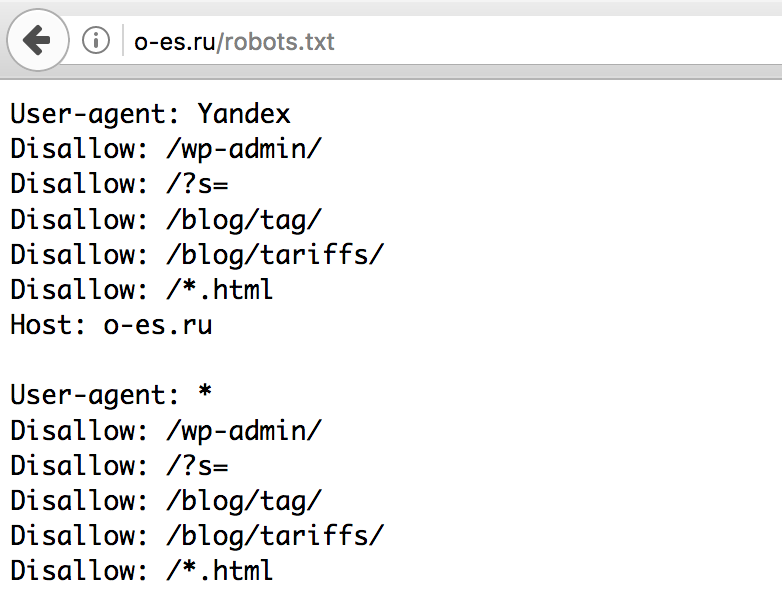
Пример robots.txt моего сайта
Разберем базовые директивы:
- User-agent: обращаемся к поисковому роботу по имени, либо ко всем роботам сразу
- Disallow: нужен для закрытия от индексации страниц, разделов, либо всего сайта
- Allow: разрешить индексацию отдельного раздела или страницы сайта
- Sitemap.
 xml: указать место расположения xml карты сайта
xml: указать место расположения xml карты сайта
 xml: указать место расположения xml карты сайта
xml: указать место расположения xml карты сайтаДополнительные директивы для яндекса:
- Clean-param: очистить адреса от параметров (динамических переменных)
- Crawl-delay: поставить задержку при ответе поисковому роботу (если вдруг ваш сервак не справляется и поисковик кладёт сайт).
Как настраивать robots.txt
1. Создаем .txt файл с именем robots.txt и вписываем первой строкой:
User-agent: *
Эта директива указывает на то, что любой поисковой робот может воспользоваться ниже указанными правилами, если не найдет определенных правил, конкретно для себя.
2. Скрываем от поисковиков технические страницы:
- Панель администрирования сайта
- Поиск по сайту
- Страницы с неуникальной информацией (политика конфиденциальности и т.д.)
В моем случае, нужно закрыть:
- Disallow: /register
- Disallow: /password/reset
- Disallow: /login
Просто подставьте свои адреса вместо адресов из примера. По необходимости добавьте еще несколько директив Disallow (если таких страниц у вас больше 3-х)
По необходимости добавьте еще несколько директив Disallow (если таких страниц у вас больше 3-х)
3. Закрываем от индексации URL с параметрами:
URL с параметрами — это страницы, в адрес которых дописываются атрибуты в результате работы сортировок, фильтров, и других элементов.
Наример, когда вы переходите по пагинации на моем сайте.
Наример, — когда вы переходите по пагинации на моем сайте.
В синий прямоугольник я выделил постоянный адрес,
а в красный — подставляемые параметры при переходе по пагинации.
Чтобы закрыть от индексации всю пагинацию на моем сайте, нужно воспользоваться следующей директивой:
Disallow: *page=*
Символ * указывает роботу, что нет значения, что идет перед началом и концом записи нашей константы.
URL, которые будут закрыты в результате работы директивы:
- https://kondrashov.online/?page=любой_текст
- https://kondrashov. online/любой_текст?page=3/любой_текст
- https://kondrashov.online/любой_текст/?page=21231231
 online/любой_текст?page=3/любой_текст
online/любой_текст?page=3/любой_текстЕсли робот найдет в адресе страницы фрагмент «page=«, то он не станет индексировать эту страницу. Сама же страница может быть любого уровня вложенности.
Рассмотрим работу переменных в интернет магазине
Возьмем случайный интернет магазин, отправимся на страницу каталога и кликнем в какую-нибудь сортировку товаров:
По умолчанию у нас статические адрес страницы, без переменных в адресе.
При использовании каких-либо сортировок и фильтраций адрес начинает меняться. К нему добавляются переменные (красный прямоугольник на скриншоте).
Страница при этом остается прежней, на ней меняется только порядок товаров.
Такие страницы не являются полезными для поисковика, они воспринимаются как дубли основной страницы.
- Подробнее читайте тут: некачественные страницы yandex
- И еще тут: поиск и удаление дублей на сайте
Наша задача — понять, какие есть способы образования таких страниц, и закрыть их от индексирования!
В моем примере я отсортировал товары по актуальности, и адрес изменился.
В нем появился вот такой тест: ?sort=ACTIVE_TO&order=asc
Параметры генерируются через переменную ?sort. Понимая это, я могу дописать в наш robots.txt новую директиву:
Disallow: *?sort*
Тем самым я закрою от индексации все страницы, в которых встречается переменная ?sort, по аналогии с первым примером.
Любые динамические адреса генерируются через символы: ?, $, &, =, %
Если закрыть все адреса, в которых встречаются эти символы, то мы избавимся от всех дублей страниц с параметрами.
- Disallow: *?*
- Disallow: *$*
- Disallow: *&*
- Disallow: *%*
Но такая глобальная зачистка может зацепить и важные страницы сайта!
4. Открываем доступ к файлам стилей сайта CSS
Директива: Allow: *css* решит проблему доступности всех CSS файлов на сайте.
Адреса до CSS файлов могут содержать параметры. Есть риск, что при закрытии дублей страниц, мы можем закрыть и доступ к CSS. Поэтому после закрытия динамических страниц дописываем директиву Allow: *css*.
Есть риск, что при закрытии дублей страниц, мы можем закрыть и доступ к CSS. Поэтому после закрытия динамических страниц дописываем директиву Allow: *css*.
5. Указываем ссылку на Sitemap.xml
Самый простой пункт настройки — нужно поставить ссылку на карту сайта через директиву:
Sitemap: https://site.ru/sitemap.xml
Где site.ru — домен вашего сайта.
Все! Настройка закончена.
Мы настроили базовый robots.txt, который подойдет для любой CMS системы.
Если есть вопросы, пишите в комменты, разберем 😉
Некоторые важные моменты про robots.txt
- Robots.txt кешируется поисковиками, краткосрочно, но все же кешируется!
- Кодировка для robots.txt — UTF8
- Размер файла — не более 500кб.
- Код ответа сервера должен быть 200. Проверить можно тут: https://webmaster.yandex.ru/tools/server-response/
- Использование кириллицы запрещено в файле robots. txt и HTTP-заголовках сервера. Для указания имен доменов в зоне РФ используйте Punycode!
- Не закрывайте страницы пагинации от индексации в robots.txt (в своем примере я делаю в точности наоборот, но у меня есть свои причины на это). Для закрытия страниц пагинации используйте теги: noindex, follow или rel=»canonical».
 txt и HTTP-заголовках сервера. Для указания имен доменов в зоне РФ используйте Punycode!
txt и HTTP-заголовках сервера. Для указания имен доменов в зоне РФ используйте Punycode!Robots.txt Generator — Online Robots.txt Generator Tool Free | SEOToolsNet
Robots.txt Generator
| По умолчанию — все роботы: | РазрешаетсяОтказалась | |
| Crawl-Delay: | По умолчанию — без задержки5 Seconds10 Seconds20 Seconds60 seconds120 Seconds | |
| Карта сайта: (оставьте пустым, если у вас нет) | ||
| Поиск роботов: | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Google Image | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Google Mobile | То же, что по умолчаниюРазрешаетсяОтказалась | |
| MSN Search | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Yahoo | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Yahoo MM | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Yahoo Blogs | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Ask/Teoma | То же, что по умолчаниюРазрешаетсяОтказалась | |
| GigaBlast | То же, что по умолчаниюРазрешаетсяОтказалась | |
| DMOZ Checker | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Nutch | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Alexa/Wayback | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Baidu | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Naver | То же, что по умолчаниюРазрешаетсяОтказалась | |
| MSN PicSearch | То же, что по умолчаниюРазрешаетсяОтказалась | |
| Ограниченные каталоги: | Путь относительно корня и должен содержать косую черту «/» | |
Теперь создайте файл robots. txt в корневом каталоге. Скопируйте текст выше и вставьте в текстовый файл.
txt в корневом каталоге. Скопируйте текст выше и вставьте в текстовый файл.
About Robots.txt Generator
Robot.txt Generator: Robot.txt generator one of the fantastic tool for its users. This provides the benefit of keeping data secure. As sometimes users forget to keep their data confidential, then this tool helps them out for securing their content.Robot.txt Generator is very advantageous to its users as it helps its users to tell them about necessary data. In simple words, sometimes web admins forget to preserve their data safe then this assists them by telling which information should be kept confidential which not.
A robots.txt file is a simple text file that is used to instruct search engine crawlers on which pages or sections of a website should not be indexed or followed. The file is placed in the root directory of a website and can be easily created using a robots.txt generator tool.
Robots.txt is not a method for keeping a web page out of Google, but rather a means for website owners to tell Google which pages or sections of a website should not be crawled. This can be useful for preventing duplicate content, blocking sensitive pages, or simply keeping your website organized.
This can be useful for preventing duplicate content, blocking sensitive pages, or simply keeping your website organized.
In this article, we will be discussing the importance of a robots.txt file and how to use a free robots.txt generator tool to create one for your website.
Why is a robots.txt file important?
A robots.txt file is important for a number of reasons. For one, it can help prevent search engines from crawling and indexing duplicate content on your website. This can be especially useful for large websites with a lot of similar content.
Additionally, a robots.txt file can be used to block sensitive pages from being indexed by search engines. This can include pages such as login pages, admin pages, and other pages that should not be publicly accessible.
Lastly, a robots.txt file can be used to help keep your website organized. By blocking certain sections of your website from being indexed, you can ensure that search engines are only focusing on the most important pages.
How to create a robots.txt file
Creating a robots.txt file is easy, and can be done using a free robots.txt generator tool. Here are the steps to creating a robots.txt file:
- Go to a free robots.txt generator tool such as SeoToolsNet.
- Enter the URL of your website in the «Website URL» field.
- Select the pages or sections of your website that you want to block from being indexed.
- Click the «Create Robots.txt» button to create your robots.txt file.
- Download the file and upload it to the root directory of your website.
It’s important to note that when creating a robots.txt file, you should only block pages or sections of your website that you do not want to be indexed. Blocking too many pages can actually harm your search engine rankings.
In conclusion, a robots.txt file is an important tool for website owners to use in order to control how search engines crawl and index their websites. By using a free robots. txt generator tool, it is easy to create and implement a robots.txt file for your website. Remember to only block pages or sections of your website that you do not want to be indexed, as blocking too many pages can harm your search engine rankings.
txt generator tool, it is easy to create and implement a robots.txt file for your website. Remember to only block pages or sections of your website that you do not want to be indexed, as blocking too many pages can harm your search engine rankings.
Robots Проверка текстовых файлов | ПейджДарт
Воспользуйтесь нашей программой проверки файла robots.txt ниже, чтобы проверить, работает ли ваш файл robots.txt.
Скопируйте и вставьте файл robots.txt в текстовое поле ниже. Вы можете найти файл robots, добавив /robots.txt на свой веб-сайт. Например, https://example.com/robots.txt .
Строка: ${error.index}
`; список результатов.innerHTML += ли; } если (ошибки.длина > 0) { resultsTitle.innerHTML = errors.length + «Ошибки» результаты.скрытый = ложь; } еще { resultsTitle.innerHTML = «Нет ошибок» результаты.скрытый = ложь; } вернуть ложь; } window.onload = функция () { document. getElementById(«отправить»).onclick = проверить;
}
getElementById(«отправить»).onclick = проверить;
}Для создания этого инструмента мы проанализировали более 5000 файлов robots. В ходе нашего исследования мы обнаружили 7 распространенных ошибок.
Как только мы обнаружили эти ошибки, мы научились их исправлять. Ниже вы найдете подробные инструкции о том, как исправить все ошибки.
Продолжайте читать, чтобы узнать, почему мы создали этот инструмент и как мы завершили исследование.
Почему мы создали инструмент
Когда поисковый робот посещает ваш сайт, например Googlebot, он читает файл robots.txt, прежде чем просматривать любую другую страницу.
Он будет использовать файл robots.txt, чтобы проверить, куда он может пойти, а куда нет.
Он также будет искать вашу карту сайта, в которой будут перечислены все страницы вашего сайта.
Каждая строка в файле robots.txt — это правило, которому должен следовать сканер.
Если в правиле есть ошибка, сканер проигнорирует это правило.
Этот инструмент предоставляет простой способ быстро проверить наличие ошибок в файле robots.txt.
Мы также даем вам список того, как это исправить.
Более подробно о том, насколько важен файл robots.txt, можно прочитать в публикации Robots txt для SEO.
Как мы проанализировали более 5000 файлов robots.txt
Мы получили список из 1 миллиона лучших веб-сайтов по версии Alexa.
У них есть CSV-файл со списком всех URL-адресов, который вы можете скачать.
Мы обнаружили, что не на каждом сайте есть или нужен файл robots.txt.
Чтобы получить более 5000 файлов robots.txt, нам пришлось просмотреть более 7500 веб-сайтов.
Это означает, что из 7541 самых популярных веб-сайтов в Интернете 24% сайтов не имеют файла robots.txt.
Из 5000+ файлов robots.txt, которые мы проанализировали, мы обнаружили 7 распространенных ошибок:
- Шаблон должен быть пустым, начинаться с «/» или «*»’
- «$» следует использовать только в конце шаблона
- Пользовательский агент не указан
- Неверный протокол URL-адреса карты сайта
- Неверный URL-адрес карты сайта
- Неизвестная директива
- Синтаксис не понят
Мы рассмотрим каждую из этих ошибок и способы их исправления ниже.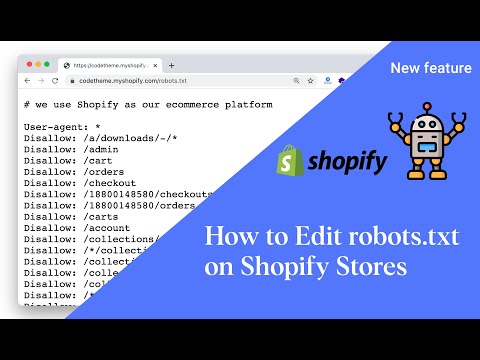
Но вот что мы обнаружили в результате нашего анализа.
Из 5732 проанализированных нами файлов robots.txt только 188 содержали ошибки.
Мы также обнаружили, что в 51 % случаев было более одной ошибки. Часто повторялась одна и та же ошибка.
Давайте посмотрим, сколько раз возникала каждая ошибка:
| Ошибка | Считать |
|---|---|
| Шаблон должен быть пустым, начинаться с «/» или «*»‘ | 11660 |
| «$» следует использовать только в конце шаблона | 15 |
| Пользовательский агент не указан | 461 |
| Неверный протокол URL карты сайта | 0 |
| Неверный URL-адрес карты сайта | 29 |
| Неизвестная директива | 144 |
| Синтаксис не понят | 146 |
Как видите, шаблон должен быть пустым, начинаться с "/" или "*". — самая распространенная ошибка.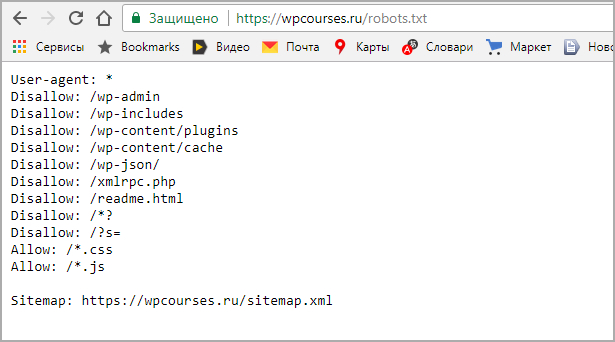
Получив данные, мы смогли понять и исправить ошибки.
Шаблон должен быть пустым, начинаться с «/» или «*»
Это была самая распространенная ошибка, которую мы обнаружили при анализе, и в этом нет ничего удивительного.
Эта ошибка относится к правилам Разрешить и Запретить . Эти правила чаще всего встречаются в файле robots.txt.
Если вы получаете эту ошибку, это означает, что первый символ после двоеточия не является «/» или «*».
Например, Разрешить: администратор вызовет эту ошибку.
Правильный способ форматирования: Разрешить: /admin .
Подстановочный знак (*) используется, чтобы разрешить все или запретить все. Например, часто можно увидеть это, когда вы хотите остановить сканирование сайта:
Запретить: *
Чтобы исправить эту ошибку, убедитесь, что после двоеточия стоит символ «/» или «*».
«$» следует использовать только в конце шаблона
В файле robots.txt может быть знак доллара.
Вы можете использовать это, чтобы заблокировать определенный тип файла.
Например, если мы хотим заблокировать сканирование всех файлов .xls , вы можете использовать:
Агент пользователя: * Запретить: /*.xls$
Знак $ сообщает сканеру, что это конец URL-адреса. Таким образом, это правило запрещает:
https://example.com/pink.xls
Но разрешить:
https://example.com/pink.xlsocks
Если у вас нет знака доллара в конце строки, например:
Агент пользователя: * Запретить: /*$.xls
Это вызовет это сообщение об ошибке. Для исправления переместите в конец:
Агент пользователя: * Запретить: /*.xls$
Так что используйте только знак $ в конце URL для соответствия типам файлов.
Пользовательский агент не указан
В файле robots.txt необходимо указать хотя бы один User-agent . Вы используете User-agent для идентификации и нацеливания на определенные поисковые роботы.
Если бы мы хотели настроить таргетинг только на поисковый робот Googlebot, вы бы использовали:
Агент пользователя: Googlebot Запретить: /
Используется довольно много сканеров:
- Гуглбот
- Бингбот
- Хлеб
- УткаУткаБот
- Байдуспайдер
- ЯндексБот
- фейсбот
- ia_archiver
Если вы хотите иметь разные правила для каждого, вы можете перечислить их следующим образом:
Агент пользователя: Googlebot Запретить: / Агент пользователя: Bingbot Разрешить: /
Вы также можете использовать «*», это подстановочный знак, означающий, что он будет соответствовать всем поисковым роботам.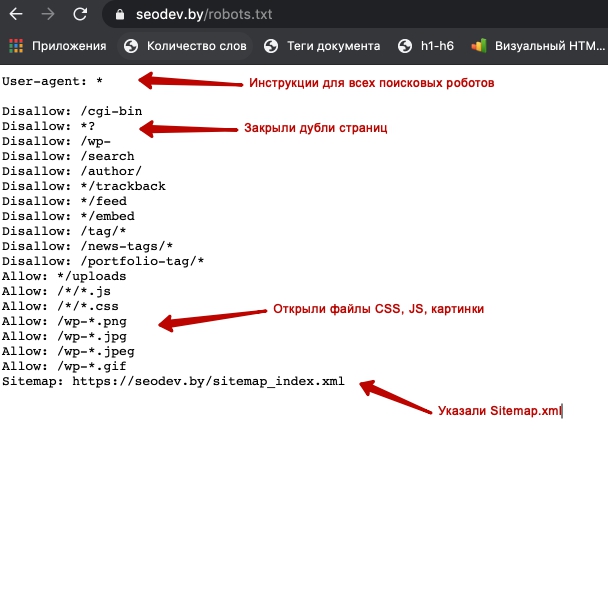
Агент пользователя: * Разрешить: /
Убедитесь, что у вас установлен хотя бы один User-agent .
Неверный протокол URL-адреса карты сайта
При ссылке на карту сайта из файла robot.txt необходимо указать полный URL-адрес.
Этот URL-адрес должен быть абсолютным URL-адресом, например https://www.example.com/sitemap.xml .
Протокол — это https часть URL-адреса. Для URL-адреса карты сайта вы можете использовать HTTPS , HTTP или FTP . Если у вас есть что-то еще, вы увидите эту ошибку.
Неверный URL-адрес карты сайта
Вы можете сделать ссылку на карту сайта из файла robots.txt. Это должен быть полный (абсолютный) URL. Например, https://www.example.com/sitemap.xml будет абсолютным URL.
Если у вас нет абсолютного URL-адреса, например:
Агент пользователя: * Позволять: / Карта сайта: /sitemap.
 xml
xml Это вызовет эту ошибку. Чтобы исправить это, измените абсолютный URL-адрес:
.Агент пользователя: * Позволять: / Карта сайта: https://www.example.com/sitemap.xml
Неизвестная директива
При написании правила вы можете использовать только фиксированное количество «директив». Это команды, которые вы вводите перед двоеточием «:». Разрешить и Запретить — обе директивы.
Вот список всех допустимых директив:
- Карта сайта
- Агент пользователя
- Разрешить
- Запретить
- Задержка сканирования
- Чистый параметр
- Хост
- Скорость запроса
- Время посещения
- Без индекса
Если у вас есть что-то еще за пределами списка выше, вы увидите эту ошибку.
Согласно нашему исследованию, наиболее распространенной причиной этой проблемы является опечатка в написании директивы.
Исправьте опечатку и повторите проверку.
Синтаксис не понят
Вы увидите эту ошибку, если в строке нет двоеточия.
В каждой строке должно стоять двоеточие, отделяющее директиву от значения.
Это вызовет ошибку:
Агент пользователя: * Разрешить /
Чтобы исправить, добавьте двоеточие (найдите разницу):
Агент пользователя: * Разрешить: /
Поместите двоеточие после директивы, чтобы устранить проблему.
Подведение итогов, программа проверки файлов txt для роботов
Этот инструмент может помочь вам проверить наличие наиболее распространенных ошибок в файлах robots.txt.
Скопировав и вставив файл robots.txt в указанный выше инструмент, вы можете проверить, не содержит ли он ошибок.
Проверяем на 7 ошибок в том числе:
- Шаблон должен быть пустым, начинаться с «/» или «*»’
- «$» следует использовать только в конце шаблона
- Пользовательский агент не указан
- Неверный протокол URL-адреса карты сайта
- Неверный URL-адрес карты сайта
- Неизвестная директива
- Синтаксис не понят
Как только вы узнаете, в какой строке ошибка, вы можете исправить ее, используя предоставленные советы.
Последние сообщения
В этом уроке мы добавим поиск Google на веб-сайт с помощью инструмента пользовательского поиска по сайту.
В этом уроке мы рассмотрим, как создать плагин WordPress.
Мы рассмотрим, как добавить строку поиска в HTML на ваш сайт и подключить поиск к поиску Google.
Что такое robots.txt? Узнайте все, что вам нужно знать сегодня!
Что делает robots.txt?Robots.txt позволяет блокировать части вашего сайта и индексировать другие части вашего сайта. Вы можете выбрать «Разрешить» или «Запретить» определенные страницы и папки на вашем веб-сайте.
Если вы разрешаете определенные страницы, вы разрешаете поисковым роботам заходить в эту конкретную область вашего веб-сайта и индексировать ее. И наоборот, запрет означает, что вы не хотите, чтобы пауки находили определенные страницы и области вашего сайта.
Robots.txt позволяет вашему веб-сайту быть доступным для поисковых систем. Так, например, если у вас есть контактная страница на вашем веб-сайте, вы можете заблокировать эту страницу с помощью robots.txt, чтобы Google мог сканировать другие важные страницы на вашем веб-сайте и не тратить время на сканирование страницы. что вам все равно, имеют ли люди доступ к странице или нет из поисковой системы.
Делая это, вы говорите Google не сканировать содержимое вашей контактной страницы. Конечно, вы также можете полностью заблокировать свой сайт с помощью robots.txt, если хотите.
Как работает файл robots.txt? Существуют различные типы сканеров для разных поисковых систем и платформ. Обычно мы называем эти сканеры «User Agent». Поэтому, когда вы решите разрешить или запретить определенную область вашего веб-сайта, вы можете указать конкретный сканер, например, Googlebot (сканеры Google), в качестве агента пользователя, или вы можете просто использовать * и ссылаться на все поисковые роботы, обитающие во всемирной паутине.
С помощью файла robots.txt можно добиться очень высоких результатов. Например, вы можете заблокировать URL-адреса, каталоги или даже определенные параметры URL-адресов.
Тот же метод применяется к страницам, которые вы хотите просканировать Google и которым должно быть уделено особое внимание. Вы можете проиндексировать эти избранные страницы с помощью robots.txt.
Временные задержкиВ файл robots.txt можно включить временные задержки. Например, вы можете не захотеть, чтобы сканер сканировал ваш веб-сайт так быстро, поэтому вы можете установить временные задержки. Значение: вы говорите паукам сейчас сканировать ваш сайт до тех пор, пока не будет указана временная задержка.
Вы должны использовать временную задержку, чтобы сканеры не перегружали ваш веб-сервер.
Однако имейте в виду, что Google не поддерживает временные задержки. Если вы не хотите перегружать свой веб-сервер ботами Google, вместо этого вы можете использовать скорость сканирования. Вы можете выбрать предпочтительную скорость сканирования в Google Search Console и попытаться замедлить пауков.
Если вы не хотите перегружать свой веб-сервер ботами Google, вместо этого вы можете использовать скорость сканирования. Вы можете выбрать предпочтительную скорость сканирования в Google Search Console и попытаться замедлить пауков.
Если у вас более обширный веб-сайт, вы можете подумать о реализации сопоставления с образцом. Будь то Google или любая другая поисковая система, вы можете поручить этим поисковым системам просматривать и сканировать ваши страницы на основе набора правил.
Сопоставление с образцом подразумевает набор правил, которым должны следовать сканеры. Например, вы можете заблокировать URL-адреса со словом «веб-сайт».
Почему вы должны использовать robots.txt? Многие люди используют файл robots.txt, чтобы запретить третьим лицам сканировать их веб-сайты. Однако ваш сайт сканируют не только поисковые системы; другие третьи лица также постоянно пытаются получить доступ к вашему веб-сайту. Следовательно, все сканирование на вашем веб-сайте замедляет работу вашего веб-сайта и сервера, что отрицательно сказывается на работе пользователей. Кроме того, эти сторонние виджеты могут вызывать проблемы с сервером, которые необходимо решить.
Однако ваш сайт сканируют не только поисковые системы; другие третьи лица также постоянно пытаются получить доступ к вашему веб-сайту. Следовательно, все сканирование на вашем веб-сайте замедляет работу вашего веб-сайта и сервера, что отрицательно сказывается на работе пользователей. Кроме того, эти сторонние виджеты могут вызывать проблемы с сервером, которые необходимо решить.
Вы также можете использовать robots.txt, чтобы запретить третьим лицам копировать контент с вашего веб-сайта или анализировать изменения, которые вы вносите на свой веб-сайт. robots.txt — отличный способ заблокировать то, что вам не нужно на вашем сайте.
Имейте в виду, что если третьи лица очень заинтересованы в вашем веб-сайте, они могут использовать программное обеспечение, такое как Screaming Frog, которое позволяет им игнорировать «блокировку» и по-прежнему сканировать ваш веб-сайт. Таким образом, вы не должны на сто процентов полагаться на robots.txt, когда речь идет о защите определенных аспектов вашего сайта.