
Как спарсить новости с любого новостного сайта? — Хабр Q&A
Но что, если RSS не указан на сайте, а любая попытка парсинга приводит к ошибкам?
Смириться. Это значит, что сайт не хочет тебе просто так отдавать новости. Это его право. Пора бы уже привыкнуть, что в интернете нет ничего дармового. И то, что сайт дает РСС, еще не значит, что можно публиковать его контент на своем ресурсе.
Или можешь нанять бригаду индусов, которые вручную будут копипастить. Но тогда тебе придется жить в постоянном ожидании иска или претензии от первоисточника.
Апдейт по поводу РСС.
Даже Лента, несмотря на наличие РСС, не разрешает без письменного разрешения публиковать их материалы у себя:
1.3. Использование материалов, размещенных на Сайте и в Специальных проектах, допускается только с письменного согласия Издания. Бесплатное использование материалов возможно только в случаях, прямо предусмотренных в пп. 2.2.1.-2.2.3. настоящих правил.
2.2. Использование на безвозмездной основе:2.2.1. Любые материалы Издания могут быть использованы без письменного согласия Издания и на безвозмездной основе при условии, что пользователь является физическим лицом, и такое использование осуществляется исключительно в личных целях. 2.2.2. Использование информационных текстовых материалов Издания религиозными и благотворительными организациями, а также любыми образовательными учреждениями на безвозмездной основе возможно только после получения письменного разрешения (согласия) Издания.
2.2.3. Новостные материалы Издания, расположенные по адресу lenta.ru/news/…, могут быть использованы любыми Пользователями без получения письменного разрешения Редакции и на безвозмездной основе при условии, что эти материалы не являются основным содержимым продукта, в котором используются. При этом Пользователи обязаны в каждом случае использования новостных материалов дать ссылку на источник и гиперссылку на сайт, с которого заимствованы указанные материалы.
https://lenta.ru/info/
qna.habr.com
Parser — парсер для профессионалов SEO
A-Parser — многопоточный парсер поисковых систем, сервисов оценки сайтов, ключевых слов, контента(текст, ссылки, произвольные данные) и других различных сервисов(youtube, картинки, переводчик…), всего A-Parser содержит более 70 парсеров
На сегодняшний день A-Parser развился в невероятный SEO комбаин, позволяющий покрыть огромное число задач для SEO-специалистов и вебмастеров любого уровня подготовки:
- Используйте встроенные парсеры чтобы с легкостью получать и анализировать любые данные
- Воспользуйтесь нашим каталогом парсеров и пресетов для расширения возможностей A-Parser и решения нестандартных задач
- Если вы продвинутый пользователь — создавайте свои собственные парсеры на основе
- Владеете JavaScript? Тогда A-Parser предлагает вам беспрецедентную возможность программировать свои собственные парсеры, используя всю мощь возможностей A-Parser!
- Для автоматизации мы предлагаем API позволяющий легко встроить A-Parser в ваши бизнес процессы, а также для создания сервисов любого уровня сложности на базе нашего парсера
Кроме этого мы предоставляем услуги по составлению заданий и написанию парсеров под ваши задачи, в кратчайшие сроки и по демократичной цене. Хотите спарсить целиком интернет магазин(Ozon, Amazon, AliExpress)? Проверить 100 миллионов сайтов по вашим признакам? Получить данные с любого сайта в структурированном виде(CSV, JSON, XML, SQL)? В решении этих задач поможет наша дополнительная платная поддержка
A-Parser полностью решает рутинные задачи по получению, обработке и систематизации данных, необходимых для работы в следующих областях:
- SEO-оптимизация сайтов и Web-аналитика
- Сбор баз ссылок для XRumer, A-Poster, AllSubmitter, ZennoPoster…
- Оценка сайтов и доменов по множеству параметров
- Мониторинг позиции любых сайтов в поисковых системах
- Сбор контента(текст, картинки, ролики) для генерации сайтов(дорвеев)
- Отслеживание обратных ссылок
- Сбор произвольной информации с любых сайтов(например телефоны/e-mails, сообщения с форумов, объявления…)
- Сбор и оценка ключевых слов
- Сбор списка обратных ссылок
- И многое другое
- Web-безопасность
- Сбор и фильтрация баз ссылок по признакам
- Определение CMS сайтов
- Формирование произвольных GET, POST запросов с одновременной фильтрацией ответа
- Сетевое администрирование
- Работа с DNS службой — резолвинг доменов в IP адреса
- Работа с Whois — дата регистрации и окончания регистрации доменов, name-cервера
Данный список включает лишь частые варианты применения парсера, A-Parser позволяет решать самые нестандартные задачи комбинируя его возможности, такие как:
A-Parser создавался и продолжает развиваться учитывая более чем 10 летний опыт разработки парсеров и многопоточных сетевых приложений, разработка ведется исключительно по следующим принципам:
- Быстродействие и производительность, прежде всего за счет многопоточной обработки запросов
- Максимальная эффективность использования ресурсов компьютера или сервера
- Функциональность и удобство использования, наш продукт ориентирован на пользователя
- Для каждой задачи выбирается лучший инструмент или алгоритм, предварительно прошедший тщательное тестирование
Для дальнейшего знакомства с A-Parser‘ом рекомендуется полноценно оценить его преимущества, ознакомится с отзывами пользователей, выбрать необходимую версию и перейти к оплате лицензии
a-parser.com
Учимся писать парсеры на примере парсера новостных сайтов
Парсеры новостных сайтов достаточно востребованы, например, если у вас новостой агрегатор, или, к примеру, вам нужно собирать местные новости из различных ресурсов для показа на своем сайте с географическим таргетированием, то вам необходим парсер. Также данные новостных агенств и СМИ часто используются для проведения исследований, машинного обучения и анализа. Распарсить новостую ленту на большинстве ресурсов, как правило, несложно, именно поэтому мы возьмем один из простых сайтов, а именно РИА Новости и научим вас писать парсеры самостоятельно.
Мы будем использовать Google Chrome как наш основной инструмент для работы с сайтом, и для начала мы советуем вам поставить расширение для Google Chrome: Quick Javascript Switcher — оно позволит вам быстро выключать и включать Javascript для сайтов. Это используется для того, чтобы быстро определить как именно данные выводятся на страницу: на стороне сервера или с помошью Javascript (это могут быть данные, внедренные в JS на странице, скрытый блок на странице, который включается JS или же данные забираются дополнительным XHR запросом).
Давайте откроем страницу с лентой https://ria.ru/lenta/ в нашем браузере и отключим JS для сайта с помощью расширения которое мы поставили ранее:
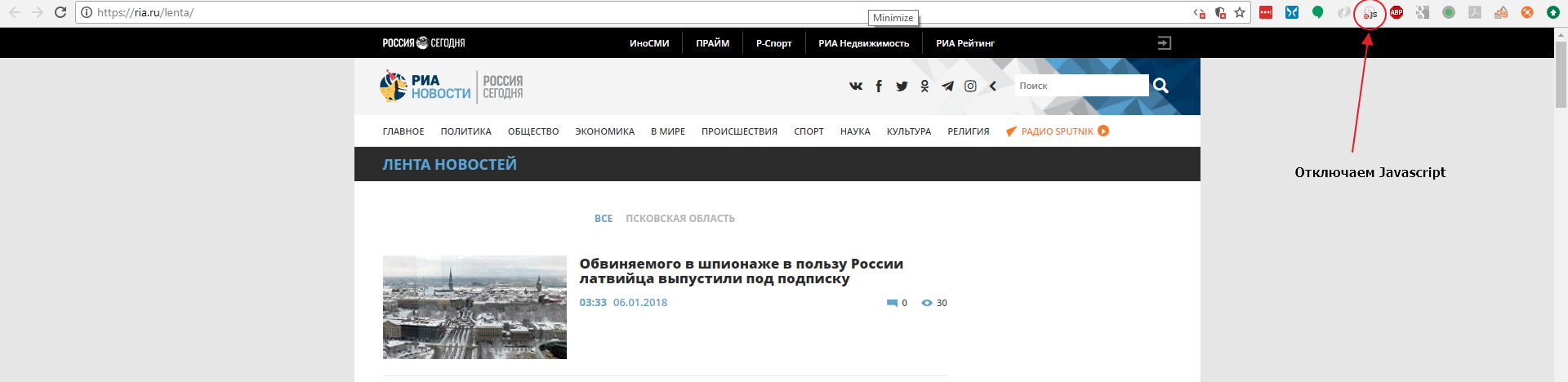
Мы увидим что данные ленты отображаются в браузере. Это означает, что новостная лента формируется на стороне сервера и мы сможем забрать данные просто загрузив страницу в парсер. Однако на странице показано только 20 последних заголовков и что же нам делать если нужно забирать 200 последних? Нам придется изучить механизм работы пагинатора. На разных сайтах пагинаторы работают по разному, поэтому не существует универсального решения и для каждого сайта вам придется разбираться в механизме его работы.
Откроем Chrome Dev Tools — инструменты для разработчика, которые встроены в Google Chrome. Для этого кликнем правой кнопкой мыши в любом месте страницы и выберем опцию «Показать код»:

После этого у вас откроется интерфейс разработчика:
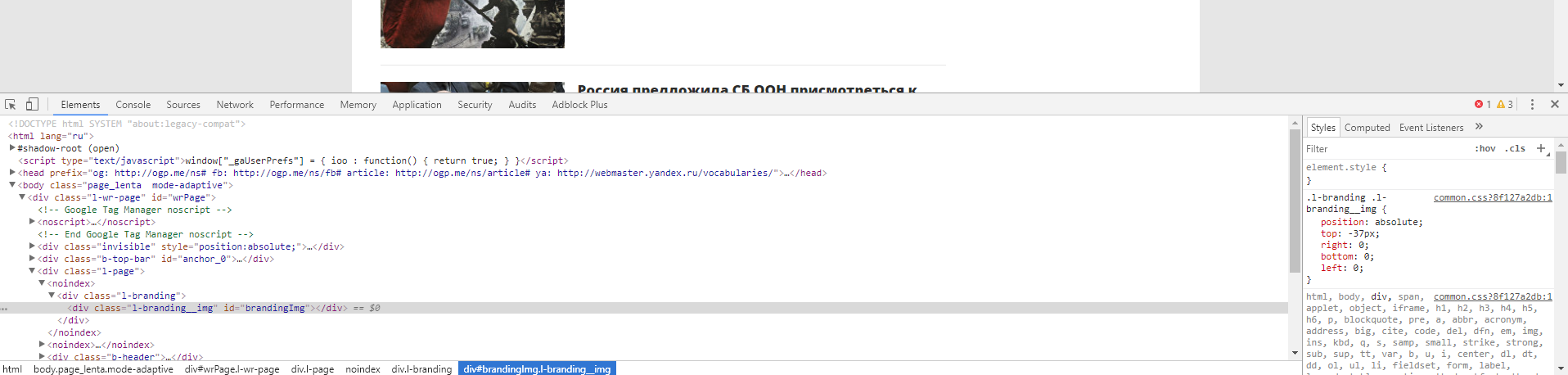
В основном мы будем взаимодействовать с вкладками Elements и Network. Elements — поможет нам работать с DOM структурой, находить элементы страницы, проверять CSS селекторы, искать CSS селекторы и содержимое, и так далее. Во вкладке Network мы можем изучать запросы, которые делает браузер к серверу. Это потребуется нам для нахождения XHR или JS запросов, или же если нам нужно изучить структуру какого-либо запроса (заголовки, куки и тд) для точной имитации его в парсере. Если вы незнакомы с инструментами для разработчика, мы рекомендуем вам посмотреть следующее обзорное видео: Chrome DevTools. Обзор основных возможностей веб-инспектора.
Сейчас нам нужно добраться до конца страницы и найти там пагинатор. Мы видим что здесь он организован как одна кнопка «ЗАГРУЗИТЬ ЕЩЕ», которая подгружает следующие 20 записей используя XHR (Ajax) запрос, то есть если вы кликните на кнопку, ничего не произойдет, поскольку мы выключили Javascript для этого сайта.
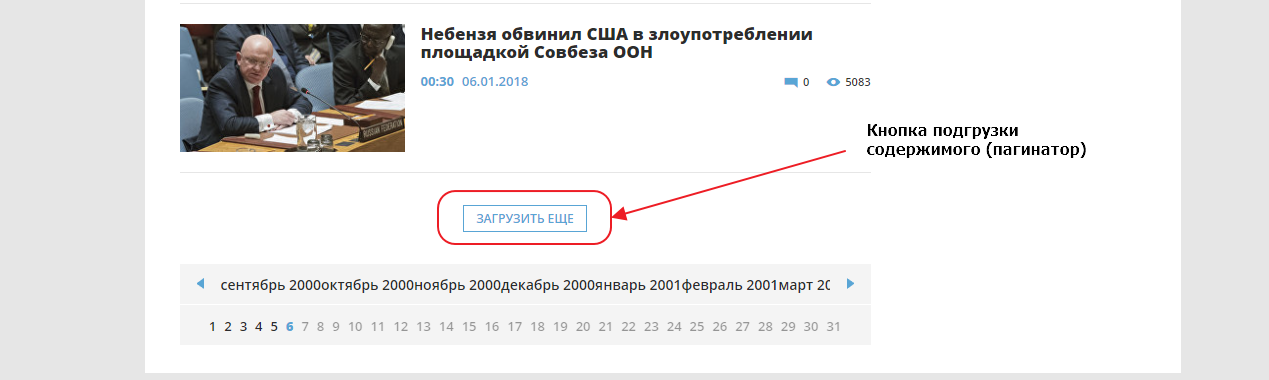
Первым делом найдем эту кнопку в элементах. Для того, чтобы это сделать быстро, можно воспользоваться специальным инструментом для выбора элемента на странице:
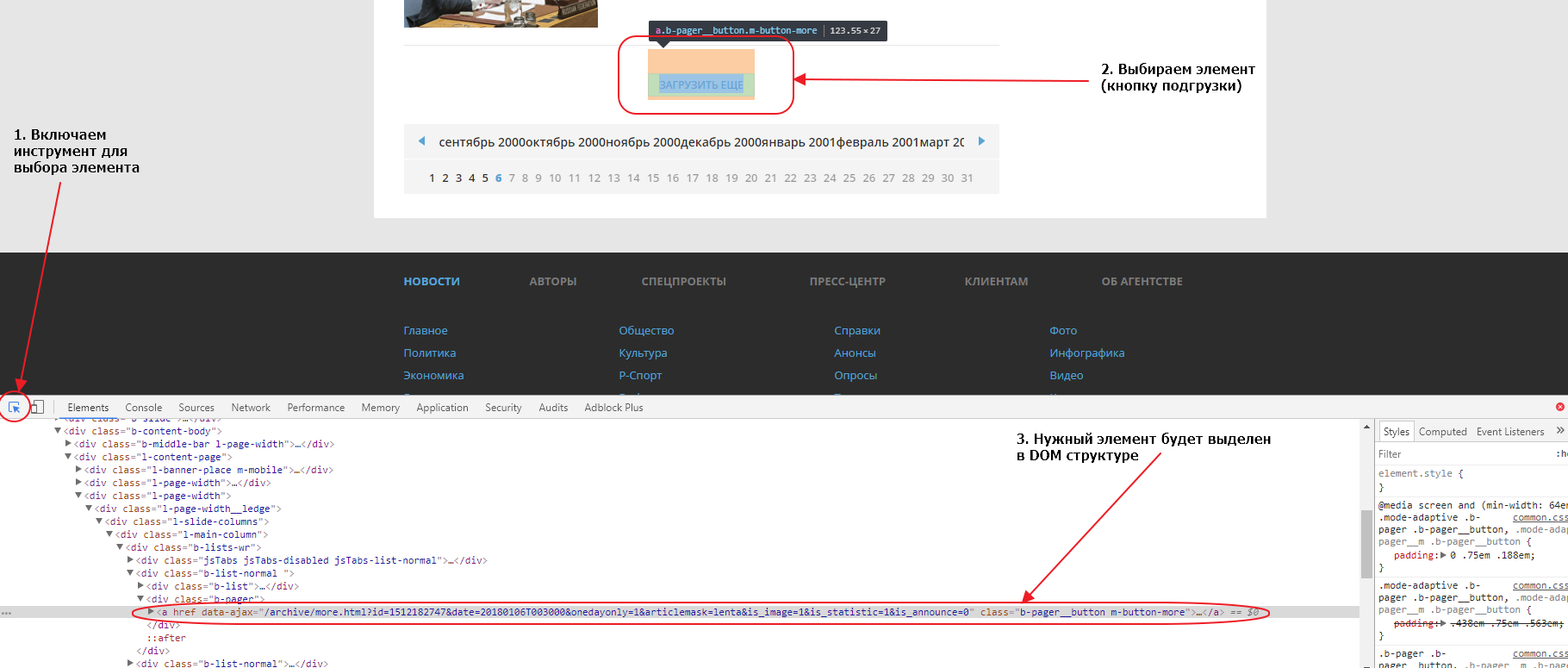
Если мы внимательно посмотрим на элемент, мы увидим что атрибут href у него пустой. Именно поэтому ничего не происходит при нажатии на линк, если отключен Javascript. Однако, мы видим что URL, используемый для подгрузки, указан в атрибуте data-ajax, именно этот URL и используется JS для подгрузки следующих 20 записей при нажатии на кнопку. Так как URL нам известен, нам совершенно не нужно анализировать запросы во вкладке Network. Соответсвенно, чтобы забрать следующие 20 записей, нам нужно забрать парсером этот URL:
https://ria.ru/archive/more.html?id=1512199556&date=20180106T154008&onedayonly=1&articlemask=lenta&is_image=1&is_statistic=1&is_announce=0
Если загрузить в новой вкладке браузера этот URL мы получим следующие 20 записей и увидим что там тоже есть кнопка для загрузки следующих записей. Теперь нам нужно найти селектор (CSS селектор) для этого элемента. Сделаем это во второй вкладке, в которой у нас загружены вторые 20 записей. Также открываем в этой вкладке инструменты разработчика и выбираем элемент-ссылку «Загрузить еще», так, чтобы элемент выделился в DOM структуре. Теперь нужно кликнуть правой кнопкой мыши на элементе, затем выбрать опцию Copy и следом опцию Copy selector:
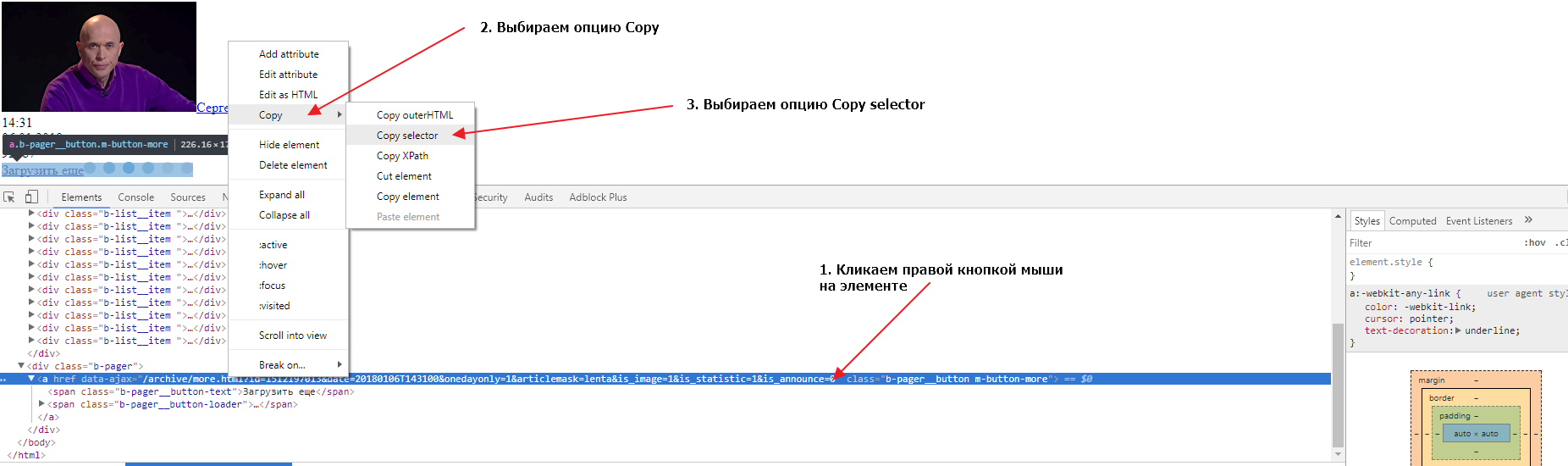
Давайте проверим, выбирает ли наш селектор ровно один элемент во второй и первой вкладке браузера. Для этого нужно в инструментах разработчика сделать активной вкладку Elements, нажать сочетание клавиш CTRL + F и в открывшуюся форму вставить наш селектор:

Мы видим, что селектор выбирает только один элемент, что очень хорошо. Если бы селектор выбирал несколько элементов, нам бы пришлось проверить все выбранные элементы и, либо подкорректировать селектор, так чтобы он выбирал только один элемент, либо в парсере брать срез найденных по селектору элементов, поскольку нам нужен только один элемент.
Тоже самое нужно сделать для другой вкладки, там где у нас открыта начальная страница. Сделать это нужно, чтобы удостовериться, что селекторы одинаковые на основной странице и на странице подгрузки. Иметь одну логику работы всегда лучше чем несколько, поэтому принцип унификации очень важен, в том числе и для подбора CSS селекторов. Если мы попробуем поискать наш селектор, мы обнаружим, что ничего не найдено. Дело в том, что элемент div.b-pager > a не находится в руте ноды body. Если мы уберем из пути body > и оставим только div.b-pager > a, то наш элемент будет найден в обеих вкладках и только один раз.
Мы определили, что для организации подгрузки данных в парсере, после загрузки страницы, мы должны найти элемент div.b-pager > a, забрать содержимое атрибута data-ajax и пройти по этому URL. Поскольку на страницах с подгрузкой структура элементов такая же, мы можем использовать единый логический блок. А для организации переходов по страницам мы можем использовать пул линков. Изначально мы поместим в пул только первый URL https://ria.ru/lenta/ и затем на каждой итерации мы будем добавлять в пул новый URL, который мы будем извлекать с загруженной страницы. Так мы организуем пагинацию в нашем парсере.
Теперь нам нужно определить как нам забирать новости со страниц, для этого нам нужно найти главный элемент блока в который обернута каждая новость. Сделать это мы можем точно так же, как мы делали это для кнопки подгрузки данных:
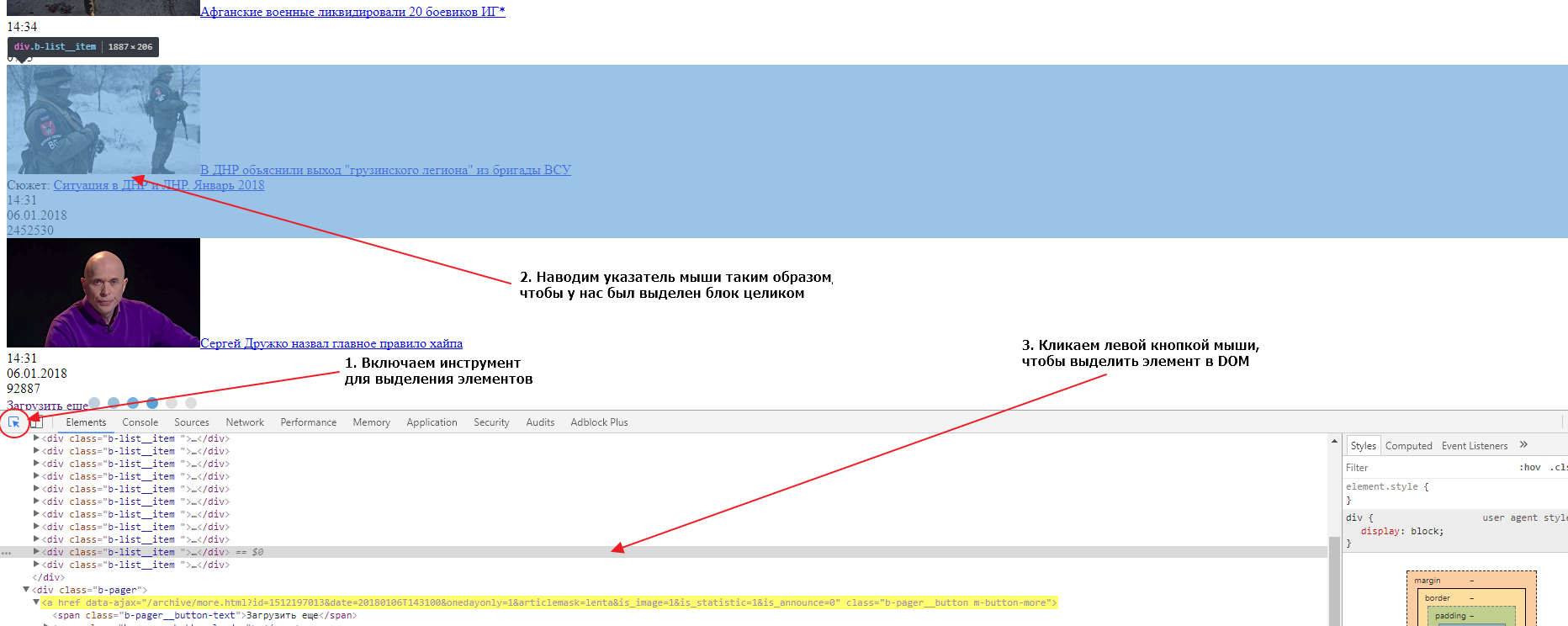
Если вы внимательно посмотрите на DOM структуру, вы увидите, что каждая новость обернута в элемент div с классом b-list__item. Таких элементов на странице ровно 20. Это и есть элемент, который нам нужен и CSS селектор для него будет div.b-list__item. Давайте сейчас проверим, насколько верно мы определили селектор для обеих вкладок (страницы с подгрузкой и основной страницы). Делаем мы это так же как мы проверяли валидность селектора для кнопки подгрузки. На обеих страницах селектор найдет по 20 элементов, значит наш селектор верен и мы можем его использовать.
Наш парсер на каждой странице должен находить этот селектор, и затем для каждого найденного элемента создавать новый объект данных, проходить в дочерние элементы, извлекать данные и записывать их в поля этого объекта данных, записывать объект данных в базу данных.
Давайте откроем один из элементов. Посмотрим какие у него есть дочерние элементы и какие данные нам нужны:

URL до страницы с новостью — находится просто в теге a, у этого тега нет класса или других атрибутов, кроме href. Поэтому единственный селектор, который мы можем использовать — a. Обратите внимание, что селекторы мы строим относительно родительского блока, поскольку мы в нем находимся, а не относительно всей страницы. Однако при таком селекторе если в блоке новости друг окажется еще один тег a в наших данных будет записан только последний, а нам нужен первый, поэтому мы можем брать срез элементов (элемент с номером 0) или же мы можем проверять в нашем a наличие дочернего элемента span с классом b-list__item-title. В последнем случае наш селектор будет выглядеть как a:haschild(span.b-list__item-title).
Изображение — нам нужно забрать URL до зображения, который находится в атрибуте src тега img. У этого тега есть атрибут itemprop=»associatedMedia», который выглядит достаточно надежным признаком для выборки нужного тега img. Поэтому мы можем использовать его в CSS селекторе: img[itemprop=»associatedMedia»].
Заголовок — здесь нет никаких подводных камней, наш заголовок находится в элементе span с классом b-list__item-title, поэтому CSS селектор будет таким: span.b-list__item-title.
Время и Дата — так же просто как и заголовок, получаем селекторы div.b-list__item-time и div.b-list__item-date соответственно.
Количество комментариев и Количество просмотров — находятся в элементах span с классом b-statistic__number, то так как в текущем блоке по такому селектору будут найдены оба элемента, то мы можем либо использовать срезы для выбора определенного элемента, либо использовать родительский элемент как часть селектора. В первом случае родительский элемент — это тег span с классом m-comments, и наш селектор получается таким span.m-comments > span.b-statistic__number. Во втором случае, родительский тег span с классом m-views формирует CSS селектор: span.m-views > span.b-statistic__number.
Вот мы и определили все селекторы для выбора полей которые нам надо собрать. Также давайте ограничим количество забираемых новостей, сделаем так чтобы парсер забирал 200 первых новостей (или 10 страниц). Мы можем организовать это с помощью счетчика, будем считать количество загруженных страниц и если счетчик примет значение более 9, просто не будем добавлять новый линк в пул. Займемся теперь написанием конфигурации парсера:
---
config:
debug: 2
agent: Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14
do:
# Устанавливаем счетчик страниц равным 1
- counter_set:
name: pages
value: 1
# Добавляем начальный URL в пул
- link_add:
url:
- https://ria.ru/lenta/
# Начинаем итерацию по пулу с последовательной загрузкой страниц из пула
- walk:
to: links
do:
# Делаем паузу 2 секунды для уменьшения нагрузки на сервер источника
- sleep: 2
# Находим кнопку подгрузки
- find:
path: div.b-pager > a
do:
# Считываем в регистр значение счетчика pages
- counter_get: pages
# проверяем если значение регистра больше 9
- if:
type: int
gt: 9
else:
# если значение меньше 9 - парсим значение аттрибута data-ajax текущего элемента в регистр
- parse:
attr: data-ajax
# делаем нормализацию значения в регистре, убираем лишние пробелы, унифицируем пробельные символы в ASCII пробелы
- space_dedupe
# удаляем все ведущие и завершающие пробелы значения в регистре, если они есть
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: \w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и добавляем линк в пул
- normalize:
routine: url
- link_add
# Находим все блоки с новостями и начинаем итерировать по найденным элементам
- find:
path: div.b-list__item
do:
# создаем новый объект данных с именем item
- object_new: item
# находим элемент с URL к странице с новостью
- find:
path: a:haschild(span.b-list__item-title)
do:
# парсим значение атрибута href в регистр
- parse:
attr: href
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: \w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле url объекта item
- normalize:
routine: url
- object_field_set:
object: item
field: url
# находим элемент с заголовком новости
- find:
path: span.b-list__item-title
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле headline объекта item
- object_field_set:
object: item
field: headline
# находим элемент с изображением
- find:
path: img[itemprop="associatedMedia"]
do:
# парсим значение атрибута src текущего элемента в регистр
- parse:
attr: src
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: \w+
do:
- normalize:
routine: url
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле image объекта item
- object_field_set:
object: item
field: image
# находим элемент с временем
- find:
path: div.b-list__item-time
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле time объекта item
- object_field_set:
object: item
field: time
# находим элемент с датой
- find:
path: div.b-list__item-date
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле date объекта item
- object_field_set:
object: item
field: date
# находим элемент с количеством комментариев
- find:
path: span.m-comments > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле comments объекта item
- object_field_set:
object: item
field: comments
# находим элемент с количеством просмотров
- find:
path: span.m-views > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле views объекта item
- object_field_set:
object: item
field: views
# сохраняем объект данных item в базу данных
- object_save:
name: item
# увеличиваем значение счетчика pages на 1
- counter_increment:
name: pages
by: 1Вам осталось создать новый диггер на платформе Diggernaut, перенести в него этот сценарий и запустить. Надеемся что этот материал был полезен и помог вам в изучении нашего мета-языка.
Удачного парсинга!
www.diggernaut.ru
парсинг статей / Mail.ru Group corporate blog / Habr
Для меня всегда было некоей магией то, как Getpocket, Readability и Вконтакте парсят ссылки на страницы и предлагают готовые статьи к просмотру без рекламы, сайдбаров и меню. При этом они практически никогда не ошибаются. А недавно подобная задача назрела и в нашем проекте, и я решил копнуть поглубже. Сразу скажу, что это «белый» парсинг, вебмастеры сами добровольно пользуются нашим сервисом.
В идеальном мире вся информация на страницах должна быть семантически размечена. Умные люди придумали много полезных штук типа Microdata, OpenGraph, тэги Article, Nav …etc, но полагаться на сознательность вебмастеров в плане семантики я бы не спешил. Достаточно самим посмотреть код страниц популярных сайтов. Open Graph кстати самый востребованный формат, всем хочется красиво выглядеть в соц. сетях
Вычленение заголовка статьи и картинки остается за рамками моего поста, так как заголовок обычно берется из title или og, а картинка если она не берется из og:image – это отдельный рассказ.
Переходим к самому интересному – вычленению тела статьи.
Оказывается, есть вполне себе научные paper’ы посвященные этой проблеме (в том числе от сотрудников Гугла). Есть даже соревнование CleanEval с набором тестовых страниц из которых надо извлечь данные, и алгоритмы соревнуются в том кто сделает это точнее.
Выделяются следующие подходы:
- Извлечение данных пользуясь только html документом (DOM и текстовый уровень). Именно эту технику мы обсудим ниже
- Извлечение данных используя отрендеренный документ с помощью computer vision. Это очень точный алгоритм, но и самый сложный и прожорливый. Посмотреть как работает можно например вот здесь: www.diffbot.com (проект ребят из Стэнфорда).
- Извлечение данных на уровне сайта целиком, сравнивая однотипные страницы и находя различия между ними (различающиеся блоки это по сути и есть нужный контент). Этим занимаются большие поисковики.
Нас сейчас интересуют подходы к извлечению статьи имея на руках лишь один html документ. Параллельно мы можем решить проблему определения страниц со списками статей с пагинаций. В данной статье мы говорим о методах и подходах, а не окончательном алгоритме.
Парсить будем страницу http://habrahabr.ru/post/198982/
Список кандидатов на то чтобы стать статьей
Берем все элементы разметки структуры страницы (для простоты — div) и текст который в них содержится (если он есть). Наша задача получить плоский список DIV элемент –> текст в нем
Например блок меню на Хабре:
Дает нам элемент содержащий текст «посты q&a события хабы компании»
При наличии вложенных div элементов, их содержание отбрасывается. Дочерние div будут обработаны в свою очередь. Пример:
Мы получим два элемента, в одном текст ©habrahabr.ru, а во втором Служба поддержки Мобильная версия
Мы предполагаем что в 21 веке элементы которые семантически предназначены для разметки структуры (div), не используют для разметки параграфов в тексте, и это на топ 100 новостных сайтов действительно так.
В итоге из дерева у нас получается плоский набор:
И так, у нас есть набор в котором надо классифицировать статью. Далее, с помощью различных довольно простых алгоритмов каждому элементу мы будем понижать или повышать коэффициент вероятности наличия в нем статьи.
DOM дерево мы не выкидываем, оно нам понадобится в алгоритмах.
Находим повторяющиеся паттерны.
Во всех элементах DOM дерева мы находим элементы с повторяющимися паттернами в атрибутах (class, id..). Например если приглядится к комментариям:
Становится понятно, что такое повторяющийся паттерн:
- Одинаковый набор классов у элементов
- Одинаковая текстовая подстрока в id
Все эти элементы и их «детишек» мы пессимизируем, то есть ставим некоторый понижающий коэффициент в зависимости от количества найденных повторений.
Когда я говорю про «детишек» я имею ввиду, что все вложенные элементы (включая те которые попали в наш набор для классификации) получат пессимизацию. Вот, например, элемент с текстом комментария тоже попадает под раздачу:
Соотношение ссылок и обычного текста в элементе.
Идея понятна – в меню и в колонках мы видим сплошные ссылки, что явно не похоже на статью. Пробегаемся по элементам из нашего набора и каждому проставляем коффициент.
Например, текст в элементах в блоке Фрилансим (он у нас уже получили минус за повторяющийся класс), получают минус в догонку за некрасивое соотношение ссылок к тексту равное единице. Понятно, что чем меньше этот коэффициент, тем больше текст похож на осмысленную статью:
Соотношение элементов разметки текста к тексту
Чем больше в блоке всякой разметки (списки, переносы, span…), тем меньше шанс, что это статья. Например, реклама вероятно уважаемой SEO компании, не очень похожа на статью, так как целиком представляет собой список. Чем ниже значение соотношения разметки к тексту тем лучше.
Количество точек (предложений) в тексте.
Здесь мы уже почти заползли на территорию численной лингвистики. Дело в том, что в заголовках и меню точки практически не ставятся. А вот в теле статьи их много.
Если какие-то меню и списки новых материалов на сайте еще пролезли через предыдущие фильтры, то можно добить подсчетом точек. Не очень-то их много в блоке лучшее:
Чем больше точек, тем лучше, и мы повышаем шансы данному элементу на получения гордого звания статьи
Количество блоков с текстом примерно одинаковой длины
Много блоков с текстом примерно одной длины это плохой признак, особенно если текст короткий. Мы такие блоки пессимизируем. Идея хорошо сработает на подобной верстке:
В примере не Хабр, так как данный алгоритм лучше работает на более строгих сетках. На комментариях на Хабре сработает к примеру не очень хорошо.
Длина текста в элементе
Здесь прямая зависимость – чем длиннее текст в элементе, тем больше шансов на то, что это статья.
Причем вклад этого параметра в итоговую оценку элемента очень существенен. 90% случаев парсинга статьи можно решить одним этим методом. Все предыдущие изыскания поднимут этот шанс до 95%, но при этом скушают львиную долю процессорного времени.
Однако представьте: комментарий размером с саму статью. Если просто определять статью по длине текста случится конфуз. Но есть высокий шанс, что предыдущие алгоритмы немного подрежут крылья нашему комментатору-графоману, так как элемент будут пессимизирован за повторяющийся паттерн в id или классе.
Или еще один случай — увесистое выпадающее меню сделанное с применением
Готовые алгоритмы для вашего языка можно найти по запросам «boilerplate algorithm», «readability algorithm»
habr.com
Парсер новостей WordPress | Datacol
Если вы запустили информационный сайт или блог, то по прошествии некоторого времени становится понятно, что для успешной работы ресурса регулярно требуется новый контент. Но писать статьи самому не всегда позволяет время. Где же брать новый контент? В данной ситуации вы можете использовать парсер, который будет автоматически публиковать нужный контент на ваш сайт.
Парсер контента WordPress
Если основная цель вашего сайта — это предоставление информации, то он будет пользоваться интересом у пользователей только когда количество контента на нем будет внушительным. Парсер контента WordPress, настроенный в рамках программы Datacol – отличное решение для данной задачи. Благодаря парсеру вы сможете очень быстро перегнать конкурентов, увеличив количество информации на вашем ресурсе.
Парсер контента будет полезен при выполнении множества задач, перечислим наиболее популярные:
- первоначальное наполнение сайта с нуля до необходимого объема;
- автоматически наполняемый сайт для удержания аудитории на длительный срок;
- добавление контента на сайт “по расписанию” с помощью встроенного планировщика.
Парсер новостей WordPress
Базовый функционал программы Datacol позволит вам опубликовать собранную информацию в WordPress сайт. Публиковать можно новости, статьи, товары, информацию из соц. сетей и т. п. Выгрузку данных можно настроить почти с любого вебресурса.
Парсер позволяет сделать процесс наполнения довольно быстрым и исключает возможность появления ошибок, причиной которых является человеческий фактор. Настройка прямого экспорта контента на WordPress сайт продемонстрирована на видео.
При необходимости собранные данные можно уникализировать благодаря автопереводу и синонимизации. Данные возможности становятся доступны после подключения дополнительных плагинов.
Парсер новостей WordPress позволит сэкономить время и силы, которые вы бы потратили на ручное наполнение вашего сайта. У вас появится возможность не только автоматизировать сбор контента, но и повысить эффективность вашей работы.
web-data-extractor.net
| Парсеры поисковых систем | Описание |
|---|---|
 SE::Google SE::Google | Парсер поисковой выдачи Google |
 SE::Yandex SE::Yandex | Парсер поисковой выдачи Яндекса |
 SE::AOL SE::AOL | Парсер поисковой выдачи search.aol.com |
 SE::Bing SE::Bing | Парсер поисковой выдачи Bing |
 SE::Baidu SE::Baidu | Парсер поисковой выдачи Baidu |
 SE::Dogpile SE::Dogpile | Парсер поисковой выдачи Dogpile |
 SE::DuckDuckGo SE::DuckDuckGo | Парсер поисковой выдачи DuckDuckGo |
 SE::MailRu SE::MailRu | Парсер поисковой выдачи Mail.ru |
 SE::Seznam SE::Seznam | Парсер чешской поисковой системы seznam.cz |
 SE::Yahoo SE::Yahoo | Парсер поисковой выдачи Yahoo |
 SE::YouTube SE::YouTube | Парсер поисковой выдачи YouTube |
 SE::Ask SE::Ask | Парсер американской поисковой выдачи Google через Ask.com |
 SE::Rambler SE::Rambler | Парсер поисковой выдачи Рамблера |
 SE::Startpage SE::Startpage | парсер выдачи startpage.com |
| Парсеры позиций в поисковых системах | Описание |
 SE::Google::position SE::Google::position | Проверка позиций сайтов по ключевым словам в Google |
 SE::Bing::position SE::Bing::position | Проверка позиций сайтов по ключевым словам в Bing |
 SE::MailRu::position SE::MailRu::position | Проверка позиций сайтов по ключевым словам в Mail.ru |
 SE::Yandex::position SE::Yandex::position | Проверка позиций сайта по ключевым словам в Яндексе |
| Парсеры подсказок поисковых систем | Описание |
 SE::AOL::Suggest SE::AOL::Suggest | Парсер подсказок AOL |
 SE::Google::Suggest SE::Google::Suggest | Парсер подсказок Google |
 SE::Yandex::Suggest SE::Yandex::Suggest | Парсер подсказок Yandex |
 SE::Bing::Suggest SE::Bing::Suggest | Парсер подсказок Bing |
 SE::Yahoo::Suggest SE::Yahoo::Suggest | Парсер подсказок Yahoo |
 SE::Youtube::Suggest SE::Youtube::Suggest | Парсер подсказок Youtube |
| Парсеры кейвордов | Описание |
 SE::Yandex::WordStat SE::Yandex::WordStat | Парсер ключевых слов и статистики показов с сервиса wordstat.yandex.ru |
 SE::Yandex::WordStat::ByDate SE::Yandex::WordStat::ByDate | Парсер статистики показов WordStat по месяцам и неделям |
 SE::Yandex::WordStat::ByRegion SE::Yandex::WordStat::ByRegion | Парсер статистики ключевых слов по регионам и городам в WordStat |
 SE::Yandex::Direct::Frequency SE::Yandex::Direct::Frequency | Проверка частотности ключевых слов через Яндекс.Директ |
 SE::Google::Trends SE::Google::Trends | Парсер популярных кейвордов по версии Google |
| Сбор ключевых слов по домену из Букварикса | |
| Сбор ключевых слов по кейворду из Букварикса | |
| Регистрация аккаунтов | Описание |
 SE::Yandex::Register SE::Yandex::Register | Регистрирует аккаунты в Yandex |
| Парсеры параметров сайтов и доменов | Описание |
 SE::Google::TrustCheck SE::Google::TrustCheck | Проверка сайта на trust (доверие) гугла(дополнительный блок ссылок в выдаче) |
 SE::Google::Compromised SE::Google::Compromised | Проверка наличия надписи This site may be hacked в гугле |
 SE::Google::SafeBrowsing SE::Google::SafeBrowsing | Проверка домена в блеклисте гугла (подпись harm в выдачи) |
 SE::Yandex::SafeBrowsing SE::Yandex::SafeBrowsing | Проверка домена в блеклисте Yandex |
 SE::Bing::LangDetect SE::Bing::LangDetect | Определение языка сайта через поисковик Bing |
 SE::Yandex::SQI SE::Yandex::SQI | Проверка Индекса качества сайта в Яндексе |
 Net::Whois Net::Whois | Определяет зарегистрирован ли домен, дату создания домена, а так же дату окончания регистрации и NS сервера |
 Net::DNS Net::DNS | Парсер резолвит домены в IP адреса |
| Определение более 600 видов CMS на основе признаков. Определяет все популярные форумы, блоги, CMS, гестбуки, вики и множество других типов движков | |
| Парсер Alexa Rank | |
| Быстрый чекер алексы через API | |
| Парсер даты первого и последнего кэширования сайта в веб архиве(archive.org) | |
| Парсер беклинков и статистики с сервиса linkpad.ru(бывший solomono) | |
| Парсер количества бек-линков с сервиса majesticseo.com | |
| Парсер оценки трафика на сайте, также стоимости и рейтинга домена | |
| Проверяет рейтинг SEMrush | |
| Парсер социальных сигналов | |
| Парсер каталога curlie.org | |
| Парсинг данных SerpStat по доменам/ссылкам | |
| Парсинг данных SerpStat по ключевым словам | |
| Парсер Ahrefs | |
| Парсеры различных сервисов | Описание |
 SE::Bing::Translator SE::Bing::Translator | Переводчик текста через сервис www.bing.com/translator/ |
 SE::Google::Translate SE::Google::Translate | Переводчик через сервис Google |
 SE::Yandex::Translate SE::Yandex::Translate | Переводит текст через переводчик Яндекса |
 SE::Bing::Images SE::Bing::Images | Парсер картинок с поисковика Bing |
 SE::Google::Images SE::Google::Images | Парсер картинок Google Images по ключевым словам |
 SE::Google::ByImage SE::Google::ByImage | Парсер картинок Google Images по ссылке |
 SE::Yandex::Images SE::Yandex::Images | Парсер Яндекс Картинок |
 SE::DuckDuckGo::Images SE::DuckDuckGo::Images | Парсер картинок из DuckDuckGo |
 SE::Dogpile::Images SE::Dogpile::Images | Парсер картинок из Dogpile |
 SE::Yandex::Direct SE::Yandex::Direct | Парсер объявлений по кейворду через сервис direct.yandex.ru |
 Util::AntiGate Util::AntiGate | Распознавание каптчи через сервисы поддерживающие AntiGate API |
 Util::YandexRecognize Util::YandexRecognize | Парсер для распознавания каптчи |
 Util::ReCaptcha2 Util::ReCaptcha2 | Парсер для распознавание рекаптчи |
 SEO::ping SEO::ping | Массовая отправка Ping запросов в сервисы поддерживающие Weblog API(Google Blog Search, Feed Burner, Ping-o-Matic и т.п.) |
 Check::RosKomNadzor Check::RosKomNadzor | Проверка сайта в базе Роскомнадзора |
 SE::Yandex::Speller SE::Yandex::Speller | Проверка страниц на ошибки в тексте через Яндекс.Спеллер |
 GooglePlay::Apps GooglePlay::Apps | Парсер приложений Google Play |
 Social::Instagram::Post Social::Instagram::Post | Парсер данных о постах в Instagram |
 Social::Instagram::Profile Social::Instagram::Profile | Парсер данных из профилей в Instagram |
 Social::Instagram::Tag Social::Instagram::Tag | Парсер постов по тегам в Instagram |
 Social::Instagram::Geo Social::Instagram::Geo | Парсер постов в Instagram в указанной локации |
 Telegram::GroupScraper Telegram::GroupScraper | Парсер данных из публичных групп в Телеграм |
 API::Server::Redis API::Server::Redis | Работа с A-Parser через Redis |
| Парсеры магазинов | Описание |
 Shop::Amazon Shop::Amazon | Парсер поисковой выдачи amazon.com |
 Shop::Yandex::Market Shop::Yandex::Market | Парсер Яндекс.Маркет |
 Shop::AliExpress Shop::AliExpress | Парсер поисковой выдачи AliExpress |
 Shop::eBay Shop::eBay | Парсер поисковой выдачи Ebay |
| Парсеры карт | Описание |
 Maps::Google Maps::Google | Парсер Google карт |
 Maps::Yandex Maps::Yandex | Парсер Яндекс карт |
| Парсеры контента | Описание |
 Check::BackLink Check::BackLink | Проверяет нахождение обратной ссылки(ссылок) по базе сайтов |
 HTML::LinkExtractor HTML::LinkExtractor | Парсер внешних и внутренних ссылок с указанного сайта, может проходить по внутренним ссылкам до выбранного уровня |
 HTML::TextExtractor HTML::TextExtractor | Парсер текстовых блоков, позволяет собирать контент с произвольных сайтов |
 HTML::TextExtractor::LangDetect HTML::TextExtractor::LangDetect | Определение языка страницы, без использования сторонних сервисов |
 HTML::EmailExtractor HTML::EmailExtractor | Парсер e-mail адресов со страниц сайтов |
 Net::HTTP Net::HTTP | Загружает данные по заданной ссылке, на основе этого парсера можно создавать любые парсеры используя регулярные выражения для извлечения информации |
a-parser.com
Урок №3. Парсинг анонсов новостей блога
В этом видео я покажу пример настройки кампании Datacol, которая поможет вам быстро собрать заголовки и анонсы новостей блога. Для лучшего восприятия информации, советую перед просмотром ознакомиться с видео пошаговой настройки интернет магазина.
Изучив видео Вы сможете собирать анонсы всех новостей, которые находятся на главной странице или странице раздела новостного сайта или блога. Видеоурок будет особенно полезен людям, которые используют Datacol для работы с контентом.
Напомним, что в Datacol Вы так-же найдете уже готовые парсера:
Обратите внимание, в отличие от примера с интернет магазином, сейчас нужная информация расположена непосредственно на исходной странице. Кроме того, с одной страницы необходимо собирать сразу несколько групп данных, ведь анонсов на странице более одного.
Уточню, группой данных мы называем одну строку в таблице результатов, которая в нашем случае включает в себя заголовок и анонс новости.
В виду необходимости сбора сразу нескольких групп данных с одной страницы, для настройки потребуется задействовать Продвинутый мастер создания новой кампании.
Запускаем мастер.
Вводим название кампании.
Задаем входные данные.
Сейчас это ссылка на главную страницу блога, с которого мы хотим собрать анонсы новостей. Datacol начинает обход сайта в поиске нужных данных именно с этой ссылки .
Поскольку анонсы новостей присутствуют на главной странице, казалось бы, нам нет необходимости настраивать сбор ссылок. Однако, нам нужно проложить маршрут программы до каждого конкретного анонса, даже если он расположен не на первой странице выдачи. Для этого мы должны собрать ссылки пагинации. Для тех кто не знает, пагинация – это порядковая нумерация страниц каталога или выдачи материалов сайтов, которая обычно находится вверху или внизу вебстраницы. Так мы покажем Datacol , как переходить на другие страницы выдачи анонсов новостей.
Для этого мы будем использовать Xpath выражения. Xpath выражения — это адреса различных частей вебдокумента. Благодаря им Datacol находит нужные ссылки и данные. Для быстрого подбора Xpath выражений мы запускаем Datacol Picker.
Чтобы подобрать Xpath для ссылок пагинации, просто кликаем по одной из них левой кнопкой мышки. Моментально в блоке Подбор Xpath появляется подобранное Xpath выражение. Оно автоматически сохраняется в список Варианты Xpath. Именно этот список будет использоваться при работе программы. Справа , в блоке ссылки , можно увидеть набор ссылок, которые соберет Datacol используя текущий Xpath.
В некоторых случаях может понадобится следовать по страницам выдачи последовательно. Для этого можно вместо Xpath для получения всех доступных ссылок пагинации, подобрать Xpath ссылки на следующую страницу.
Осталось нажать кнопку Сохранить, чтобы подобранные Xpath выражения сохранились в конфигурации нашей новой кампании.
Теперь, когда Datacol знает как добраться до нужных данных, ему необходимо пояснить что именно требуется собирать.
При этом мы помним, что на странице у нас расположено сразу несколько групп данных, то есть несколько пар заголовок-анонс. Для таких случаев в Datacol предусмотрен специальный механизм, которые называется парсинг с помощью диапазонов. Для его использования нам нужно задать области страницы, в рамках которых расположены отдельные группы данных. Эти области мы называем диапазонами. Для поиска диапазонов Datacol также использует Xpath выражения. Запускаем Picker для их подбора.
Чтобы подобрать Xpath выражения для диапазонов, сначала кликаем на одном из полей данных, например на заголовке новости.
После этого нажимаем кнопку с ножницами (которые смотрят в левую сторону), чтобы расширить область, адресуемую Xpath выражением. Нажимаем ее до тех пор, пока выделение не охватит все поля данных одной группы. В нашем случае — это заголовок и анонс.
Правильность подбора Xpath подтверждает тот факт, что области, содержащие остальные группы данных на странице, оказались также выделены.
Теперь нажмем кнопку Сохранить, чтобы сохранить подобранные Xpath выражения.
Наконец, переходим к настройке сбора данных.
Для начала задаем перечень полей данных, которые мы хотим сохранять.
Запускаем Picker для подбора Xpath полей данных.
Обратите внимание, что диапазоны (Xpath для которых мы подбирали ранее), выделены синим цветом. Заметим, что сейчас мы можем производить подбор Xpath для полей данных только в рамках этих областей.
Итак, нам нужно подобрать Xpath выражение для сбора заголовка новости. Для этого кликаем на заголовке левой кнопкой мышки. В блоке Подбор Xpath сразу же появляется подобранное Xpath выражение, которое автоматически сохраняется в список варианты Xpath. Обратите внимание, что заголовок автоматически выделяется красной рамкой не только в первом диапазоне, но и во всех остальных. Правильноcть подбора Xpath подтверждает исходный Html код найденного блока. Он отображается в поле “Найденные соответствия”.
По аналогии с заголовком можно подобрать Xpath выражение для сохранения анонса.
Остается нажать кнопку Сохранить.
Таким образом мы завершили настройку сбора данных. Теперь закрываем мастер и переходим к тестированию.
Нажимаем кнопку “Запуск”.
Через некоторое время мы видим как начинают появляться результаты.
После завершении работы кампании все выгруженные данные будут сохранены в Excel файл. По умолчанию он генерируется в папке Мои документы.
Название файла соответствует названию новой кампании.
Формат и место сохранения результатов можно изменять. Об этом мы расскажем в последующих видео.
web-data-extractor.net