
Группировка запросов онлайн, кластеризация семантического ядра бесплатно – сервис Engine SEO Интеллект
За несколько минут мы превратим набор ключевых слов в полноценное СЯ. Вы сможете выбрать метод, глубину и степень кластеризации. Engine от SEO Интеллект предложит вам максимально точную и быструю кластеризацию.
Зачем нужна группировка запросов?
Экономия времени
Всего за несколько минут вы сможете автоматически сгруппировать до 10 000 ключевых слов.
Распределение ключей по страницам
Кластеризация поможет вам построить идеальную структуру ресурса, распределив ключевые слова по правильным страницам.

Повышение конверсии
Кластеризация СЯ позволит увеличить конверсию и повысить процент от продаж.

Основные преимущества кластеризации запросов
Уникальный алгоритм сбора информации
SEO Intellect предлагает самый точный алгоритм сбора информации. Вы сможете настроить кластеризацию таким образом, чтобы получить наилучший результат в вашей отрасли.
- Поддержка разных
языков
и регионов
Качество кластеризации остается одинаковым вне зависимости от вашего местонахождения.
Поддерживается более 70 языков. Высокая скорость группировки
За 15 минут мы сможем сгруппировать 10 000 ключевых слов.
 Поддерживается более 70 языков.
Поддерживается более 70 языков.Как работает группировка запросов
Вводите запрос в сервис.
Настраиваете кластеризацию в соответствии с вашими потребностями (точная частота, релевантная страница, количество главных страниц).
Получаете готовый список запросов.
-
Выбираете регион, метод кластеризации, ее глубину (топ-10, топ-20) и степень (от 1 до 9), а также поисковую систему (Яндекс или Google).
Настраиваете кластеризацию в соответствии с вашими потребностями (точная частота, релевантная страница, количество главных страниц).
Получаете готовый список запросов.

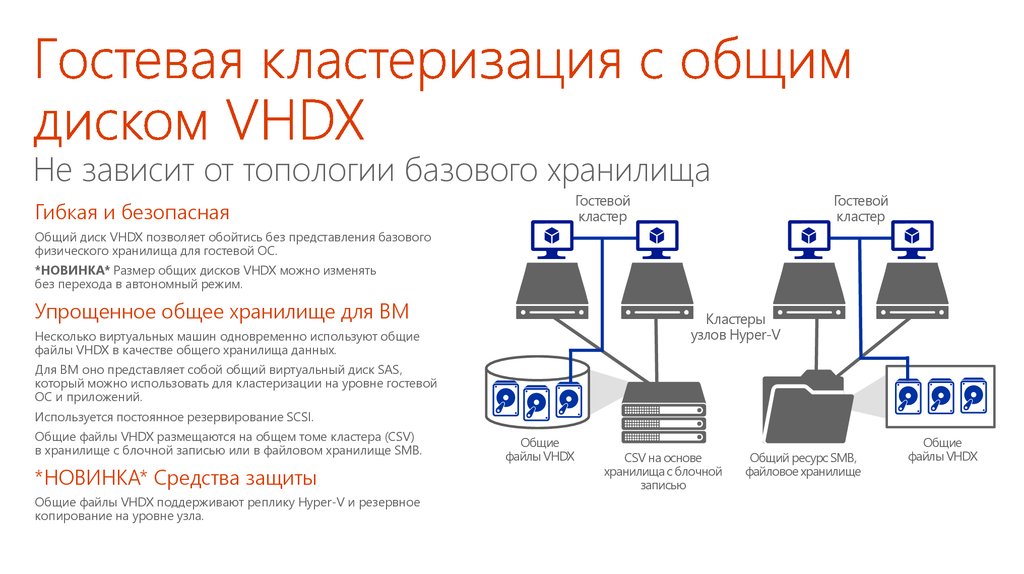
Engine SEO Интеллект
сервис анализа и продвижения сайтов
Отзывы специалистов
Долго искали с командой настоящих профессионалов своего дела и, наконец, нашли! Очень понравились специалисты Engine SEO Интеллект, все подробно рассказали, помогли разобраться с сервисом. Уже 4 месяца пользуемся кластеризацией запросов, за это время посещаемость сайта значительно возросла. Могу рекомендовать сервис Engine однозначно!
Сервис очень экономит время и позволяет нам, руководителям, избавиться от еще одной головной боли. Работает исправно вот уже полгода.
Очень удобно, что сервис поддерживает сразу несколько языков, так как у нас многонациональная команда специалистов.Engine здорово помог мне, когда я не имела достаточно опыта для самостоятельного формирования СЯ. Однако я настолько привыкла к этому сервису, что теперь не могу без него. Это настолько быстро, удобно и, что самое главное для любого руководителя, результативно. Еще один плюс отмечу – комфортный интерфейс, работать с ним легко и приятно.

Выберите ваш тариф
Скидки при подписке больше чем на два месяца
-10% 3 месяца
-15% 6 месяцев
-25% 12 месяцев
Кластеризация поисковых запросов – это определение ключевых запросов по сегментам, которые будут
применяться
для оптимизации определенных страниц сайта или добавления новых.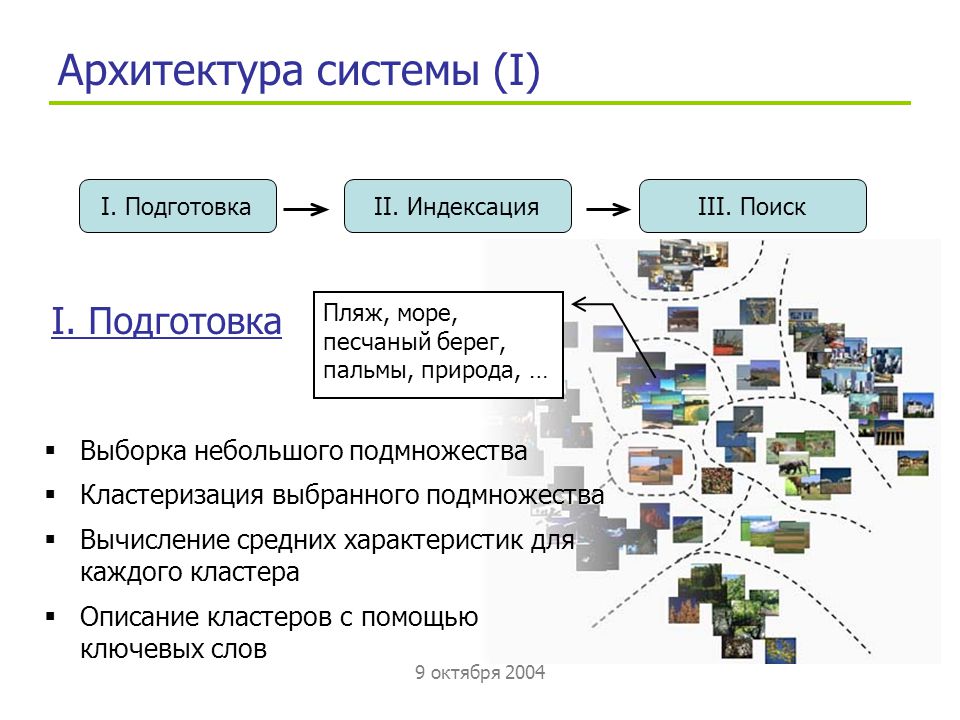
- Чтобы понять, какие ключевые слова нужно продвигать вместе, в группе, а какие – по отдельности.
- Чтобы привязать целые группы ключей к страницам сайта и добиться максимально результативного продвижения ресурса.
- Чтобы большое количество слов из семантического ядра грамотно структурировать и придать им логичности.
Что важно учитывать при группировке запросов?
В ходе кластеризации учитывают интент поиска. Это потребность пользователя, которая заключена в
запросе.
Интент необходим для того, чтобы в СЯ не было лишних слов, по которым будет происходить продвижение
страницы.
Методы группировки запросов
1. По интенту.
Кластеризацию по интенту проводят в соответствии с потребностями пользователей. Это точный метод группировки запросов, так как он помогает распределить ключи различным страницам ресурса.
2. По схожести семантики.
Схожесть семантики включает себя и потребности пользователей, и морфологию слова.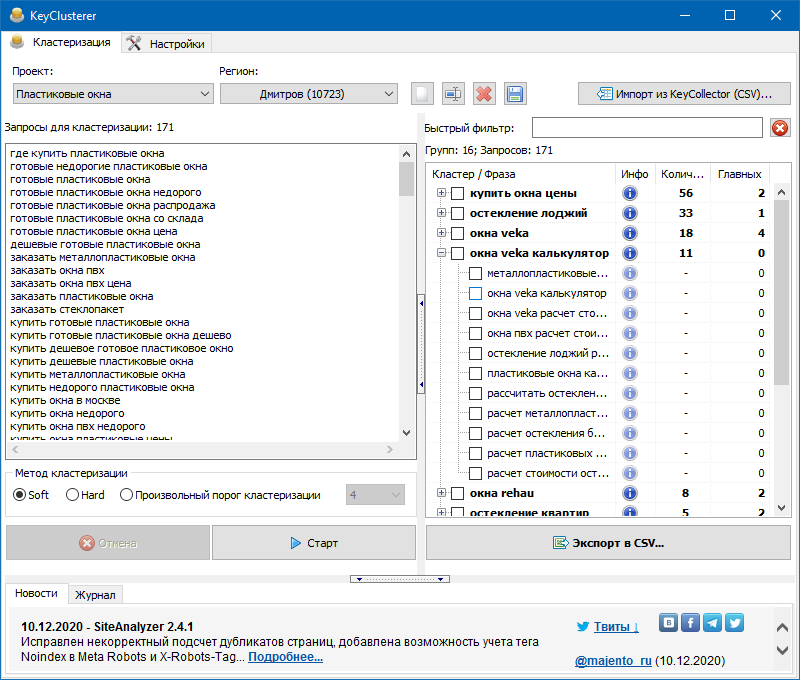 Например, сбор
семантического ядра по теме «пошив/шитье платья», в нем могут быть следующие поисковые запросы:
Например, сбор
семантического ядра по теме «пошив/шитье платья», в нем могут быть следующие поисковые запросы:
- пошив платья;
- шитье платьев на заказ;
- пошить платья.
Морфологически запросы немного отличаются между собой, хотя по интенту относятся к одной группе. Морфологически ключи можно разделить на две группы – пошив платья и шитье платья.
3. По ТОПам.
Группировка ключевых слов проводится на основе ТОПа выдачи и региона, в котором вы продвигаете свой ресурс. Сервис самостоятельно анализирует поисковые запросы и создает для общих ключей группу.Кластеризация по выдаче осуществляется двумя методами:
- Soft. Запросы проходят сравнение с высокочастотными. Метод Soft подойдет для
информационных
порталов со
статьями, коммерческих региональных ресурсов с небольшой конкуренцией.
- Hard. Запросы проходят сравнение не только с высокочастотными, но и друг с другом. На выходе получается много сегментов с определенными потребностями. При данном методе шанс того, что человек попадет на необходимую страницу гораздо выше, чем при использовании Soft. Можно использовать для всех ресурсов, имеющих большое количество конкурентов в нише.
 Метод Soft подойдет для
информационных
порталов со
статьями, коммерческих региональных ресурсов с небольшой конкуренцией.
Метод Soft подойдет для
информационных
порталов со
статьями, коммерческих региональных ресурсов с небольшой конкуренцией.Преимущества кластеризации по методу ТОПов:
- Быстрое определение запросов, которые должны продвигаться на одну страницу и, наоборот, никогда
не
окажутся на одной странице.
- Учет форм слова и синонимов. При данном методе кластеризации запросов корректно учитываются такие запросы как «винный магазин», «магазин вина», «магазины вина» и т. д.
- Быстрая скорость группировки. В отличие от ручного разбора, автоматические сервисы выполняют данную процедуру за считаные минуты, а не дни.

Группировать запросы в SEO Intellect
Наша компания предлагает автоматизированный сервис по кластеризации ключевых слов. Мы постарались
сделать
данную программу максимально удобной, точной и быстрой, чтобы решение подошло компании из любой
отрасли.
Обращаясь к нам, вы получите быстрое формирование семантического ядра, простой и понятный любому
сотруднику
интерфейс, обширную настройку сервиса под ваши потребности.
Инструменты для SEO-специалистов
Кластеризация
Перейти к инструменту
Текстовый анализатор
Перейти к инструменту
Проверка позиций
Перейти к инструменту
LSI-слова
Перейти к инструменту
Поиск конкурентов
Перейти к инструменту
Проверка переоптимизации
Перейти к инструменту
Возраст сайта/страницы
Перейти к инструменту
Лемматизатор
Перейти к инструменту
Выгрузка ТОП-10
Перейти к инструменту
SEO-текст
Перейти к инструменту
Парсинг h2-H6
Перейти к инструменту
Яндекс.
WordstatПерейти к инструменту
Проверка ссылок
Перейти к инструменту
Индексация страниц
Перейти к инструменту
 Wordstat
WordstatКластеризация запросов семантического ядра. Сервис автоматической кластеризации поисковых запросов онлайн
Составление семантического ядра на основе конкурентов и его кластеризация за минуту
Зачем нужна кластеризация запросов?
Экономия времени
Сервис автоматической кластеризации позволяет выполнить сортировку до 10.000 ключевых слов за несколько минут
Повышение конверсии
Кластеризация семантического ядра поможет сформировать логическую структуру, распределить ключевые слова по целевым страницам, повысить конверсию, увеличить % продаж с сайта
Конкурентное преимущество
Используйте кластеризацию поисковых запросов, отвечайте на интенты пользователей, получайте преимущество в поиске!
Преимущества кластеризации запросов
Вы хотите
Привести трафик из поиска на сайт
Ошибка
Лендинг создаётся под несовместимые между собой запросы и пользователь уходит
Решение
Кластеризовать запросы при помощи инструмента MegaIndex кластеризация запросов
Результат кластеризации запросов
Пользователь остаётся на странице, потому что он нашёл именно то, что искал. | |
| Повышается конверсия в лид | |
| Понижается процент отказов | |
| Сайт ранжируется выше за счёт ПФ |
Пользователь остаётся на странице, потому что он нашёл именно то, что искал.
Повышается конверсия в лид
Понижается процент отказов
Сайт ранжируется выше за счёт ПФ
+7 (495) 565-31-75
+7 (495) 565-31-75
Кластеризовать до 1000 запросов БЕСПЛАТНО!
Получите доступ ко всем инструментам
Сразу после кластеризации ваших ключевых фраз вы можете проверить своё присутствие по запросам в выдаче через сервис проверки видимости и сравнить свою видимость с конкурентами, а также автоматически кластеризировать запросы!
У Вас еще нет сайта? Введите адрес сайта Вашего конкурента!
[PDF] Кластеризация пользовательских запросов поисковой системы title={Кластеризация пользовательских запросов поисковой системы}, автор = {Цзи-Ронг Вэнь, Цзянь-Юнь Ни и ХунЦзян Чжан}, booktitle={Веб-конференция}, год = {2001} }
- Ji-Rong Wen, Jian-Yun Nie, HongJiang Zhang
- Опубликовано в The Web Conference 1 мая 2001 г.
- Информатика
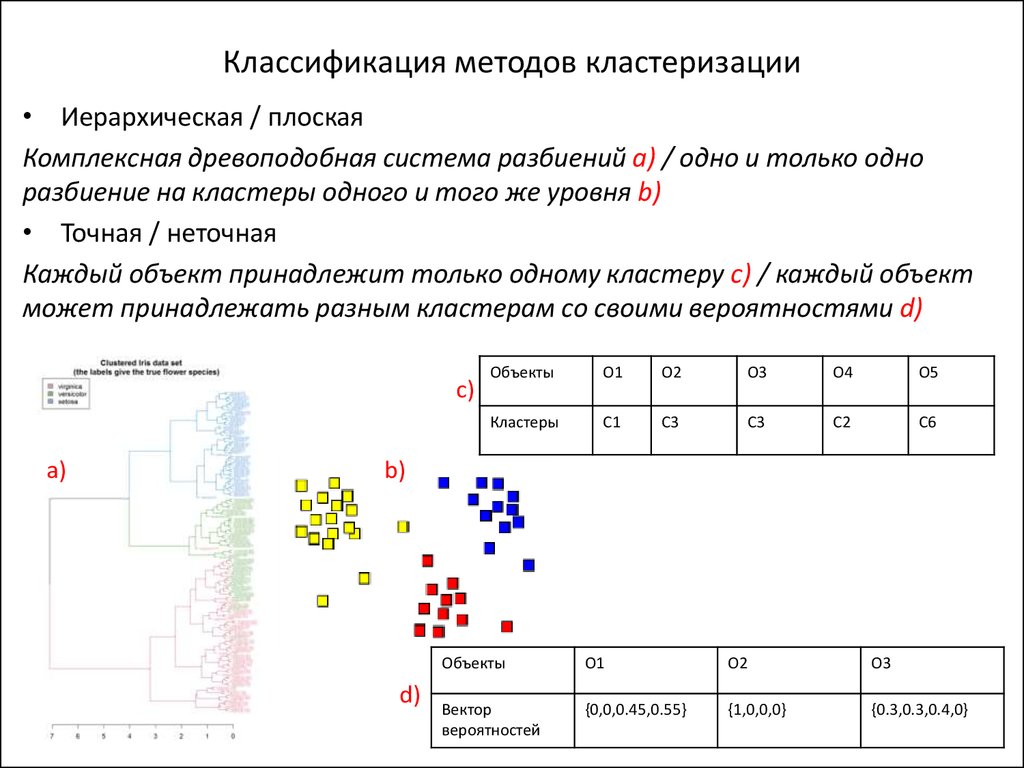
Для повышения точности поиска некоторые новые поисковые системы предоставляют проверенные вручную ответы на часто задаваемые вопросы (FAQ). Основной задачей является выявление часто задаваемых вопросов. В этой статье описывается наша попытка сгруппировать похожие запросы в соответствии с их содержанием, а также журналами пользователей. Наши предварительные результаты показывают, что полученные кластеры предоставляют полезную информацию для идентификации часто задаваемых вопросов.
Посмотреть на ACM
www10.orgИсследование и внедрение истории поиска пользователей
- С. Шейк, Б. Кумар
Информатика
- 2013
В этом документе предлагается эффективный механизм кластеризации для группировки запросов аналогичного типа, который помогает в организации требований поиска пользователей.
Рекомендации по улучшению результатов поиска
- Хамада М. Захера, Гамаль Ф. Эль Хади
Информатика
 Захера, Гамаль Ф. Эль Хади
Захера, Гамаль Ф. Эль Хадипроцесс кластеризации, в котором обнаруживаются группы семантически схожих запросов.
Рекомендации по автоматическим запросам с использованием данных Click-Through
- G. Dupret, Marcelo Mendoza
Информатика
IFIP PPAI
- 2006 7 A 90 , на основе данных о переходах по клику, которые с помощью экспериментов с реальными данными покажут, что выявление лучших запросов полезно для устранения неоднозначности запросов и специализации запросов.
- Carlos Ruiz, Ernestina Menasalvas Ruiz, M. Spiliopoulou
Информатика
AWIC
- 2007
- М. Хоссейни, Х. Абольхассани
Информатика
CSICC
- 2008
- Шуй-Лунг Чуанг, Ли-Фэн Чиен
Информатика
Онлайн инф.
- 2003
- G. Dupret, Marcelo Mendoza
Компьютерные науки
SPIRE
- 2005
- Р. Умаганди, А. Кумар
Информатика
- 2013
- V. Kulyukin, K. Hammond, R. Burke
Computer Science
AAAI/IAAI
- 1998
- D. Lewis, W. Bruce Croft
Информатика
SIGIR ’90
- 1989 9003 предварительные эксперименты с созданием кластеров фраз и показывают небольшое улучшение эффективности поиска в результате использования кластеров фраз.
- M. Ester, H. Kriegel, J. Sander, Xiaowei Xu
Информатика
KDD
- 1996
- M. Ester, H. Kriegel, J. Sander, M. Wimmer, Xiaowei Xu
Computer Science
VLDB
- 1998
- Дуг Биферман, А. Бергер
Информатика
KDD ’00
- 2000
- Г. Солтон, М. Макгилл
Медицина
- 1983
- R. NG, Jiawei Han
Компьютерные науки
VLDB
- 1994
- Г. Миллер, Р. Беквит, К. Феллбаум, Дерек Гросс, К. Миллер
Лингвистика
- 1990
- М. Портер
Лингвистика
Программа
- 1980
- Д. Гасфилд
Информатика
- 1997
- Нечеткое сопоставление в Power BI и Power Query; Сопоставление на основе порога схожести
- Нечеткое группирование в Power BI с использованием Power Query
Кластеризация запросов на основе ограничений
Это исследование применяет ограничение качества кластеров на основе запросов и алгоритм кластеризации C-DBSCAN, основанный на ограничениях. , что приводит к более однородным и надежным группам.
Журнал кластеризации поисковой системы для рекомендаций по запросам
В этом документе представлен метод помощи пользователям поисковых систем в получении необходимой информации путем предложения некоторых запросов, связанных с запросами, отправленными пользователями, чтобы направить их к цели.
Автоматическое создание таксономии запросов для приложений поиска информации
Результаты предварительного эксперимента показали потенциал предлагаемого подхода в создании таксономий для запросов, которые могут быть полезны в различных приложениях для поиска информации в Интернете.
Рекомендовать лучшие запросы из данных о клике
Метод, чтобы помочь пользователю Redefine на основе пользователя, основанных на пользовательских пользователях, на основе последних пользователей. данные о кликах, записанные поисковой системой, которые эффективны при определении специализации запроса или подтем, поскольку учитывают совместное появление документов в отдельных сеансах запросов.
данные о кликах, записанные поисковой системой, которые эффективны при определении специализации запроса или подтем, поскольку учитывают совместное появление документов в отдельных сеансах запросов.
Улучшение поисковых систем путем кластеризации запросов
Представлена структура для кластеризации запросов веб-поисковых систем, целью которой является определение групп запросов, используемых для поиска аналогичной информации в Интернете, на основе новой векторной модели запросов, которая объединяет пользователя. выборки и содержимое выбранных документов, извлеченных из журналов поисковой системы.
Рекомендации по поисковым запросам с использованием гибридного профиля пользователя с журналами запросов
Техника рекомендаций по запросам предоставляет пользователю альтернативные запросы для создания значимого и релевантного запроса в будущем и быстро удовлетворяет их информационные потребности.
Кластеризация запросов в веб-контексте
Проанализировано несколько мотивов и применений кластеризации запросов — обнаружение часто задаваемых вопросов, выбор индексного термина и переформулировка запроса.
ПОКАЗАНЫ 1-10 ИЗ 22 ССЫЛОК
SORT BYRelevanceMost Influenced PapersRecency
Answering Questions for an Organization Online
This work developed an approach to создание встроенных в организацию посредников для ответа на вопросы, называемых системами обмена информацией, которые используют свои знания о структуре организации, чтобы отвечать на вопросы клиентов и приобретать новый опыт от экспертов организации.
Группировка терминов синтаксических фраз

Алгоритм на основе плотности для обнаружения кластеров в больших пространственных базах данных с шумом
DBSCAN, новый алгоритм кластеризации, основанный на плотности кластеров, не основанный на плотности кластеров для обнаружения кластеров произвольной формы, который требует только один входной параметр и помогает пользователю определить для него подходящее значение.
Инкрементная кластеризация для интеллектуального анализа данных в среде хранилища данных
, которая применима к любой базе данных, содержащей данные из метрического пространства, например, к пространственной базе данных или к базе данных WWW-журнала.
Агломеративная кластеризация журнала запросов поисковой системы
 Бергер
Бергер!# $% ‘&( ) ) * + ! ‘ , * ‘ * ‘ . ./0’ 1 * . ‘&*’ % 2 ) *!3 $% ) 4 ‘» + $% ) * 65 7189 :, » !; * $4 ) @ & A B C D E . * . ! F ‘ G H ‘ IJ K L * M & + *) N~ z’cC g) ‘ & p : q : r…
Введение в современный поиск информации
Чтение – это одновременно и потребность, и хобби, и именно это условие заставит вас почувствовать, что вы должны читать.
Эффективные и эффективные методы кластеризации для добычи пространственных данных
Анализ и эксперименты показывают, что с помощью Clahans, двое, два альгана. очень эффективны и могут привести к открытиям, которые трудно найти с помощью современных алгоритмов интеллектуального анализа пространственных данных.
Введение в WordNet: интерактивная лексическая база данных
Стандартные алфавитные процедуры для организации лексической информации соединяют слова с одинаковым написанием и разбрасывают слова или связанные значения случайным образом в списке.…
Алгоритм удаления суффиксов
Описан алгоритм удаления суффиксов, реализованный в виде короткой быстрой программы на языке BCPL и работающий немного лучше, чем гораздо более сложная система, с которой его сравнивали.
Алгоритмы строк, деревьев и последовательностей: информатика и вычислительная биология
редактирование строк, выравнивание и динамическое программирование, а также более глубокий взгляд на классические методы точного сопоставления строк.
Нечеткая кластеризация в Power BI с использованием Power Query: поиск схожих значений
Нечеткая кластеризация в Power Query и Power BIНа данный момент я написал две статьи о нечетких операциях в Power BI и Power Query; нечеткое сопоставление в Power BI и нечеткое группирование. вышеприведенные методы включают преобразование данных с помощью нечеткой операции. Однако иногда хочется просто узнать сходство значений, или скажем другими словами; найти кластеры. Поиск кластеров может помочь вам в дальнейшей трансформации. Эту операцию можно выполнить с помощью нечеткой кластеризации в Power Query внутри Power BI. Посмотрим, как это работает.
Видео
Пример ввода и требования
Допустим, у нас есть таблица, как показано ниже;
«исходная» таблица, в которой находятся данные сотрудников и их отделов. Обратите внимание, что в поле «Отдел» есть проблемы с качеством данных. у нас есть значения отдела, такие как «Продажи» и «Продажи». Или другой пример — «Managmnt» и «Management».
Обратите внимание, что в поле «Отдел» есть проблемы с качеством данных. у нас есть значения отдела, такие как «Продажи» и «Продажи». Или другой пример — «Managmnt» и «Management».
Мы хотим узнать, насколько значения похожи друг на друга, или, скажем,; сколько кластеров похожих значений у нас есть.
Power Query Online
На момент написания этой статьи этот параметр был доступен только в Power Query Online. В будущем он наверняка будет доступен в других вариантах Power Query для настольных компьютеров, таких как Power BI Desktop и Excel. Но если вы хотите попробовать это, а онлайн — единственный вариант, это означает, что вам нужно создать для него новый поток данных внутри организационного рабочего пространства;
создание потока данных в службе Power BIПосле создания потока данных вы можете использовать добавление новой таблицы
определение новых таблиц в потоке данных Power BI Это даст вам возможность получить данные для подключения к любым источникам данных, которые вы хотите.
Нечеткая кластеризация
Выполнение нечеткой кластеризации очень похоже на нечеткую группировку с той разницей, что выходные данные не группируются.
Для выполнения нечеткой кластеризации; перейдите к разделу «Добавить столбцы» в редакторе Power Query и выберите значения кластера. Помните, что вам нужно заранее выбрать столбец, для которого вы хотите выполнить кластеризацию.
Добавьте столбец нечеткого кластера в Power QueryЗатем вы можете просто задать имя для этого нового столбца и нажать OK.
Нечеткое имя столбца кластераЭто просто дает вам вывод, как показано ниже, с новым столбцом, показывающим значения кластера; Столбец значения кластера
добавлен в таблицу. Я выделил цветом приведенный выше результат, чтобы вам было проще его понять. В столбце «Кластеры отдела» есть три значения кластера; Информационные технологии, менеджмент и продажи. Power Query обнаруживает, что значения в столбце «Отдел» аналогичны этим трем основным кластерам.
Алгоритм подобия
Это возможно, потому что нечеткая кластеризация использует алгоритм для нахождения порога подобия текстовых значений. Алгоритм основан на индексе Жаккара , описание которого приведено здесь.
Аспект производительности
Будьте осторожны при использовании нечеткого слияния, нечеткой группировки или нечеткой кластеризации. Любая нечеткая операция над набором данных окажет огромное влияние на производительность обработки данных. Причина в том, что каждое текстовое значение должно сравниваться с любым другим текстовым значением в таблице, должен быть рассчитан порог подобия двух (на основе алгоритма выше). Этот процесс занимает очень много времени. Особенно с большим количеством строк в таблице данных вы почувствуете это гораздо сильнее.
Параметры нечеткой кластеризации
Если вы хотите настроить параметры нечеткой кластеризации, вы можете развернуть нечеткие параметры.
Опции нечеткой кластеризацииПоказать оценки подобия
Эта опция, пожалуй, самая полезная в нечеткой кластеризации.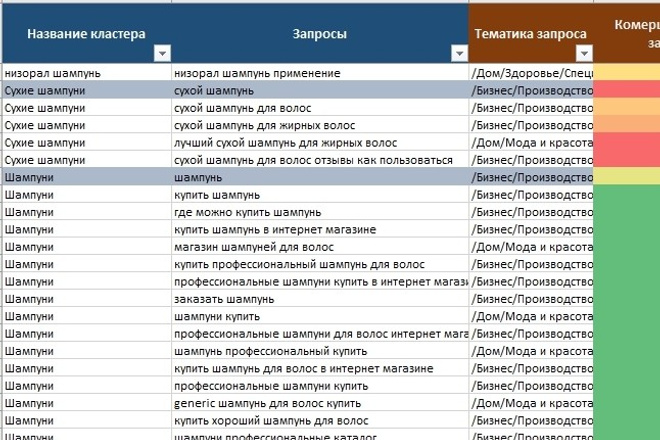 Вам нравится знать значения кластера, но самое главное, вам нравится знать сходство каждого значения со значением кластера. Вот почему показатель сходства шоу подойдет.
Вам нравится знать значения кластера, но самое главное, вам нравится знать сходство каждого значения со значением кластера. Вот почему показатель сходства шоу подойдет.
Он добавит новый столбец к вашему выводу с оценкой сходства от 0 до 1.
Показатели сходства, основанные на нечеткой кластеризацииПоказатели сходства очень полезны. Это поможет вам точно настроить следующий порог сходства на основе ваших значений данных. Я сам часто использую эту опцию перед применением нечеткого слияния или нечеткой группировки.
Порог подобия
Порог по умолчанию для нечеткой кластеризации равен 0,8, что означает 80% сходства.
Порог подобия для нечеткой кластеризации в Power QueryВы можете изменить такие параметры, как Игнорировать регистр или Порог сходства. Например, если я изменю порог сходства на 1, это означает 100% совпадение.
Чем ниже порог сходства, тем больше совпадений непохожих значений. Например, порог сходства 0,92 даст мне значение ниже
, устанавливающее порог сходства для нечеткой группировки. Если вы хотите установить другие настройки для нечеткой кластеризации, вот что они означают;
Если вы хотите установить другие настройки для нечеткой кластеризации, вот что они означают;
| Опция | Приемлемое значение | Описание |
| Пороговое значение | Значения от 0,00 до 1.00 | , если похоже, по сравнению с аналогичной жизнью. Значение 1.00 означает точное совпадение. |
| Игнорировать регистр | true/false | Если вы хотите, чтобы алгоритм подобия работал независимо от прописных или строчных букв, выберите этот параметр. |
| Группировка путем объединения частей текста | true/false | Если вы хотите, чтобы алгоритм подобия работал независимо от количества пробелов в тексте, выберите этот вариант. |
| Таблица преобразования | таблица | Это похоже на таблицу отображения, давайте проверим ее чуть позже в этом посте. Это дает вам возможность использовать собственную таблицу сопоставления. В этой таблице должно быть как минимум два столбца «Кому» и «От». |
В дополнение к опции, добавленной в графический интерфейс Power Query, у нас также есть функция Power Query, которая выполняет нечеткую кластеризацию:
Table.AddFuzzyClusterColumn
Если вы используете эти две функции напрямую в сценарии M вам нужно будет установить некоторые параметры;
Функция Table.AddFuzzyClusterColumn в MТаблица преобразования
Иногда в операции слияния вам нужна таблица сопоставления. Эта таблица называется здесь таблицей преобразования. Вот пример таблицы сопоставления:
Обратите внимание, что в этой таблице должно быть как минимум два столбца «Кому» и «От». И не забывайте, что Power Query чувствителен к регистру!
Теперь вы можете выбрать эту таблицу в операции слияния в нечеткой конфигурации, как показано ниже;
Этот процесс похож на слияние «исходной» таблицы, которая является первой таблицей в нашем слиянии, с таблицей «Отдел» на основе столбца «Отдел», а затем «Название отдела», а затем слияние с «отображением» таблицы на основе столбца «Кому» и «Название отдела». На выходе появится столбец «Кому» таблицы сопоставления. Вот пример вывода:
На выходе появится столбец «Кому» таблицы сопоставления. Вот пример вывода:
Нечеткая кластеризация — это обычно шаг, который я делаю сам перед нечеткой группировкой или нечетким сопоставлением. отображение показателей подобия может помочь вам точно настроить порог сходства, а затем использовать его для выполнения дальнейших операций. Нечеткая кластеризация проста в применении, однако требует снижения производительности. В идеале вы должны убедиться, что данные чистые, прежде чем выполнять преобразование. Это означает применение правильного процесса для получения чистых данных. Однако иногда, когда вам нужно преобразование, вы можете его использовать. В этой статье и видео вы узнали об этом. Я настоятельно рекомендую вам также прочитать две другие статьи ниже:
Реза Рад
Тренер, консультант, наставник
Реза Рад — региональный директор Microsoft, автор, тренер, спикер и консультант. Он имеет степень бакалавра вычислительной техники; он имеет более чем 20-летний опыт работы в области анализа данных, бизнес-аналитики, баз данных, программирования и разработки, в основном на технологиях Microsoft. Он является Microsoft Data Platform MVP в течение девяти лет подряд (с 2011 года по настоящее время) за свою приверженность Microsoft BI. Реза — активный блоггер и соучредитель RADACAD. Реза также является соучредителем и соорганизатором конференции Difinity в Новой Зеландии.
Он имеет степень бакалавра вычислительной техники; он имеет более чем 20-летний опыт работы в области анализа данных, бизнес-аналитики, баз данных, программирования и разработки, в основном на технологиях Microsoft. Он является Microsoft Data Platform MVP в течение девяти лет подряд (с 2011 года по настоящее время) за свою приверженность Microsoft BI. Реза — активный блоггер и соучредитель RADACAD. Реза также является соучредителем и соорганизатором конференции Difinity в Новой Зеландии.
Его статьи о различных аспектах технологий, особенно о MS BI, можно найти в его блоге: https://radacad.com/blog.
Он написал несколько книг по MS SQL BI, а также пишет несколько других. Он также был активным участником технических онлайн-форумов, таких как MSDN и Experts-Exchange, был модератором форумов MSDN SQL Server, а также является MCP, MCSE, и MCITP BI. Он является лидером группы пользователей Новозеландской бизнес-аналитики. Он также является автором очень популярной книги Power BI от новичка до рок-звезды, которая содержит более 1700 страниц контента и архитектуру Power BI Pro, опубликованную Apress.