
Метатег robots и HTTP-заголовок X-Robots-Tag
Вы можете указать роботам правила загрузки и индексирования определенных страниц сайта одним из способов:прописать метатег robots в HTML-коде страницы в элементе head;
настроить HTTP-заголовок X-Robots-Tag для определенного URL на сервере вашего сайта.
Примечание. Если страница запрещена в файле robots.txt, то директива метатега или заголовка не действует.
По умолчанию метатег и заголовок учитываются поисковыми роботами. Можно указать директивы для определенных роботов.
- Поддерживаемые Яндексом директивы
- Указание нескольких директив
- Указания для определенных роботов
| Директива | Описание | Метатег robots | Заголовок X-Robots-Tag |
|---|---|---|---|
| noindex | Не индексировать текст страницы. | ||
| nofollow | Не переходить по ссылкам на странице. Робот не перейдет по ссылкам при обходе сайта, но может узнать о них из других источников. Например, на других страницах или сайтах. | ||
| none | Соответствует директивам noindex, nofollow. | ||
| noarchive | Не показывать ссылку на сохраненную копию в результатах поиска. | ||
| noyaca | Не использовать сформированное автоматически описание. | — | |
| index | follow | archive | Отмена соответствующих запрещающих директив. | — | |
| all | Соответствует директивам index и follow — разрешено индексировать текст и ссылки на странице. |
Разрешающие директивы используются роботом по умолчанию, поэтому их можно не указывать, если нет других директив. В сочетании с запрещающими директивами разрешающие имеют приоритет. Пример.
Роботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Пример:
Запись, которая запрещает индексирование страницы.
<html>
<head>
<meta name="robots" content="noindex" />
</head>
<body>...</body>
</html>HTTP-ответ, где заголовок запрещает индексирование страницы.
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT X-Robots-Tag: noindex
Вы можете указать директивы через запятую.
<meta name="yandex" content="noindex, nofollow" />
Вы можете передать несколько заголовков в одном ответе, а также перечислить директивы через запятую.
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT X-Robots-Tag: noindex, nofollow X-Robots-Tag: noarchive
Если для робота Яндекса указаны противоречивые директивы, то он учтет положительное значение. Пример с директивами метатега:
<meta name="robots" content="all"/> <meta name="robots" content="noindex, follow"/> <!--Робот выберет значение all, текст и ссылки будут проиндексированы.--> <meta name="robots" content="all"/> <meta name="robots" content="noarchive"/> <!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки на сохраненную копию страницы.-->
 -->
<meta name="robots" content="all"/>
<meta name="robots" content="noarchive"/>
<!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки
на сохраненную копию страницы.-->
-->
<meta name="robots" content="all"/>
<meta name="robots" content="noarchive"/>
<!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки
на сохраненную копию страницы.-->Указать директиву только для роботов Яндекса можно с помощью метатега robots. Пример:
<meta name="yandex" content="noindex" />
Если вы перечислите общие директивы и директивы для роботов Яндекса, то поисковая система учтет все указания.
<meta name="robots" content="noindex" /> <meta name="yandex" content="nofollow" />
Такие директивы робот Яндекса воспримет как noindex, nofollow.
Если страницы долгое время не попадают в результаты поиска или были исключены, в форме приведите примеры таких страниц.
Plugins categorized as yandex | Page 2 of 4
Maps for WP
A handy plugin for inserting Yandex and Google maps using shortcode.
Maxim Glazunov 700+ active installations Tested with 6.1.3 Updated 2 months ago
Yandex Mail
This plugin gives you the easiest way to send emails through the Yandex SMTP server…Gaiaz Iusipov 600+ active installations Tested with 4.6.26 Updated 7 years ago
Import from YML
Import products from YML-feed to WooCommerce.
Maxim Glazunov 600+ active installations Tested with 6.2.2 Updated 2 months ago
DL Yandex Webmaster
Яндекс Вебмастер для вашей консоли WordPress
Dyadya Lesha ([email protected]) 500+ active installations Tested with 4.8.22 Updated 6 years ago
Loginza – Плагин авторизации ВКонтакте, OpenID, Yandex, Google и др.
Плагин позволяет использовать аккаунты Вконтакте, Yandex, Google, OpenID и тп. , для авторизации в блоге.
, для авторизации в блоге.
Sergey Arsenichev 400+ active installations Tested with 3.3.2 Updated 11 years ago
SAPE Links
This plugin is in Russian language only.
ram108 400+ active installations Tested with 4.2.35 Updated 8 years ago
Metrika
Metrika allow you insert counter code for YandexMetrika and Google Google Analytics to your blog.
Aleksander Novikov 400+ active installations Tested with 5.2.18 Updated 4 years ago
Ya Turbo
Yandex Turbo модуль позволяет гибко настроить RSS 2.0. выгрузку для сервиса «Яндекс Турбо» страницы (https://yandex.ru/)…
hardkod 400+ active installations Tested with 4.9.23 Updated 5 years ago
Fix sitemap.xml Yoast SEO for Yandex
Eng/Rus
mojWP 300+ active installations Tested with 4.
 7.26
Updated 6 years ago
7.26
Updated 6 years agoYandex Maps for Gutenberg
The plugin adds a simple Yandex Maps to your page. Do not forget to install…
al5dy 300+ active installations Tested with 5.0.19 Updated 4 years ago
ZMSEO
WordPress plugin for SEO analytic – ZMSEO. KPI and page’s requests directly in your personal…
Sergey F 300+ active installations Tested with 5.1.16 Updated 4 years ago
Easy Ya.Turbo Pages
Add rss channel for Yandex Turbo pages (Яндекс турбо страниц). URL of rss channel for…
ConsultApp 200+ active installations Tested with 5.4.13 Updated 3 years ago
Yandex Speller Application
Проверка правописания в TinyMCE, используя Яндекс.Спеллер.
Dmitry Ponomarev 200+ active installations Tested with 3.3.

Yandex.Zen PostGrid
The plugin allows you to display the last record from your ZEN channel
Popov Vladimir 200+ active installations Tested with 6.1.3 Updated 6 months ago
Addurilka
Plugin for verify a link indexing and adding it to the search engines.
jon4god 200+ active installations Tested with 4.5.29 Updated 7 years ago
Noindex Links
Плагин заключает любые ссылки в комментариях в теги <noindex></noindex>.
Flector 200+ active installations Tested with 6.1.3 Updated 7 months ago
YML Turbo Pages for WooCommerce
Plugin generates the YML file necessary for Yandex services.
Gleb Varganov 100+ active installations Tested with 5.2.18 Updated 4 years ago
Yandex Webmaster
This plugin shows information from Yandex Webmaster.
TIgor 100+ active installations Tested with 3.2.1 Updated 11 years ago
ACF: Yandex Maps Field
ACF: Yandex Maps Field
Roman Bondarenko 100+ active installations Tested with 6.1.3 Updated 4 months ago
Fast Yandex Metrika
Plugin for configuring the counter and Yandex Metrica goals.
Sergey Parshin 90+ active installations Tested with 5.8.7 Updated 1 year ago
плагинов, отнесенных к категории роботов | Страница 2 из 3
БД Robots.txt
БД Robots.txt автоматически создает виртуальный файл robots.txt со специальными правилами для Google и Яндекс.…
Денис Бистейнов 200+ активных установок Протестировано с 6.2.2 Обновлено 3 недели назад
Disable WP Robots
 7.
7.Джефф Старр 200+ активных установок Протестировано с 6.2.2 Обновлено 3 месяца назад
Advanced Robots.txt Optimizer & Editor
Плагин WordPress «Advanced Robots.txt Optimizer & Editor» улучшает функциональность веб-сайта, SEO и управление трафиком…
Большие технари 100+ активных установок Протестировано с 6.1.3 Обновлено 1 месяц назад
410 Удалить страницы SEO
Принудительно 410 Состояние HTTP на перечисленных страницах или только на статьях/страницах, которых больше не существует.
Марк Меллер 100+ активных установок Протестировано с 5.4.13 Обновлено 3 года назад
Простые SEO-улучшения
Легкое SEO-решение для улучшения вашего веб-сайта.
Марчин Петшак 100+ активных установок Протестировано с 6.2.2 Обновлено 3 недели назад
Magic robots.txt
Этот плагин автоматически создает robots.txt, анализируя ваш сайт, чтобы улучшить ваш рейтинг в Google и…
ABCДатос 100+ активных установок Протестировано с 6.
 2.2 Обновлено 4 месяца назад
2.2 Обновлено 4 месяца назадРазблокировать CSS и JS для робота Googlebot
Изменяет файл robots.txt, чтобы разрешить роботу Googlebot доступ к файлам JS и CSS.
ВПСОС 100+ активных установок Протестировано с 4.4.30 Обновлено 7 лет назад
Noindex by Path
Попросить поисковые системы не индексировать отдельные страницы по относительному пути — что означает…
Марчин Киджак 80+ активных установок Протестировано с 4.7.26 Обновлено 6 лет назад
Блокировать ресурсы электронной коммерции через robots.txt
Блокировать некоторые ресурсы WooCommerce и страницы поиска, которые не следует индексировать через robots.txt
Апасионадос, Апасионадос-дель-Маркетинг 60+ активных установок Протестировано с 6.2.2 Обновлено 2 месяца назад
Экспорт и удаление данных Seo Crawlytics
Экспортирует все записи Seo Crawlytics и дает вам возможность удалить записи…
Apasionados.es 50+ активных установок Протестировано с 6.
 1.3 Обновлено 6 месяцев назад
1.3 Обновлено 6 месяцев назадЖурнал роботов WP
Журнал посещений вашего веб-сайта роботами поисковых систем.取得搜索引擎的蜘蛛訪問網站的記錄
Арфлай 50+ активных установок Протестировано с 3.7.41 Обновлено 9 лет назад
Noindex Login
Добавляет метатег noindex на страницу входа в WordPress. Если в вашем блоге WordPress есть…
Джонатан Кемп 20+ активных установок Протестировано с 2.7.1 Обновлено 14 лет назад
Блокировать ленту новостей и комментарии через robots.txt
Блокировать некоторые ресурсы лент и комментариев, чтобы избежать спам-ботов
Апасионадос, Апасионадос-дель-Маркетинг 20+ активных установок Протестировано с 6.2.2 Обновлено 2 месяца назад
Simple Noindex
Добавляет тег noindex ко всем URL-адресам
Ресницы Арианы 20+ активных установок Протестировано с 4.8.22 Обновлено 5 лет назад
Block Chat GPT через robots.txt
Блокирует бота ChatGPT-User, который используется плагинами в ChatGPT для сканирования веб-сайтов через…
Апасионадос, Апасионадос-дель-Маркетинг 20+ активных установок Протестировано с 6.
 2.2 Обновлено 2 месяца назад
2.2 Обновлено 2 месяца назадRRZE-Robots-Txt
Ermöglich die Bearbeitung des robots.txt Inhalts um weitere Direktiven hinzuzufügen. Мультисайтовая совместимость.
рвдфорст 10+ активных установок Протестировано с 3.5.2 Обновлено 10 лет назад
Thin Content Manager
Просмотрите количество слов в основном тексте, чтобы идентифицировать страницы с тонким содержимым, затем выберите страницы для…
мссвободно 10+ активных установок Протестировано с 3.7.41 Обновлено 9 лет назад
Роботы «noindex,follow» метатег
Добавить метатеги robots «noindex,follow» в архивы, страницы тегов и страницы категорий, чтобы…
родхомор 10+ активных установок Протестировано с 4.95 Обновлено 5 лет назад
докажи, что ты человек! (RUH) Плагин Captcha на основе изображений
RUH Captcha помогает отфильтровывать все попытки роботов зарегистрироваться/комментировать.
Гордиевский Дмитрий Васильевич 10+ активных установок Протестировано с 3.
 2.1 Обновлено 11 лет назад
2.1 Обновлено 11 лет назадRobots.txt Extender
Динамический robots.txt для мультисайтов! Изменять или не изменять параметры для каждого сайта вашей сети без…
Умберто «Бетто» Адами 10+ активных установок Протестировано с 5.0.19 Обновлено 3 года назад
Окончательное объяснение статусов отчета об индексировании
Отчет об индексировании в Google Search Console позволяет вам проверять статусы индексирования ваших страниц и показывает любые проблемы с индексированием, с которыми Google столкнулся на вашем веб-сайте.
Регулярный мониторинг этих статусов чрезвычайно важен. Это позволяет вам быстро обнаружить любые проблемы, которые могут помешать вашим страницам попасть в индекс Google, и принять меры для их решения.
Но чтобы действовать, нужно понимать, что означает каждый статус.
Документация по отчету о покрытии индекса, предоставленная Google, не всегда ясна и не охватывает распространенные сценарии и все возможные причины данного состояния. Вот почему я создал эту статью, чтобы обобщить статусы отчетов об индексировании и предоставить вам информацию о том, что означает каждый статус.
Вот почему я создал эту статью, чтобы обобщить статусы отчетов об индексировании и предоставить вам информацию о том, что означает каждый статус.
Прежде чем я перейду к объяснению статусов отчета об индексировании, я хотел бы уделить немного времени обсуждению названий статусов.
Различные статусы могут указывать на одну и ту же проблему, но они отличаются только тем, как Google обнаружил URL-адрес. В частности, слово «Отправлено» указывает, что Google нашел вашу страницу в вашей карте сайта (простом текстовом файле со списком всех страниц, которые вы хотите проиндексировать поисковыми системами) .
Например, оба статуса «Заблокировано robots.txt» и «Отправленный URL заблокирован robots.txt» означают, что Google не может получить доступ к странице, поскольку она заблокирована robots.txt (я объясню этот статус позже). Однако вы явно попросили Google проиндексировать вашу страницу, поместив ее в свою карту сайта в последнем случае.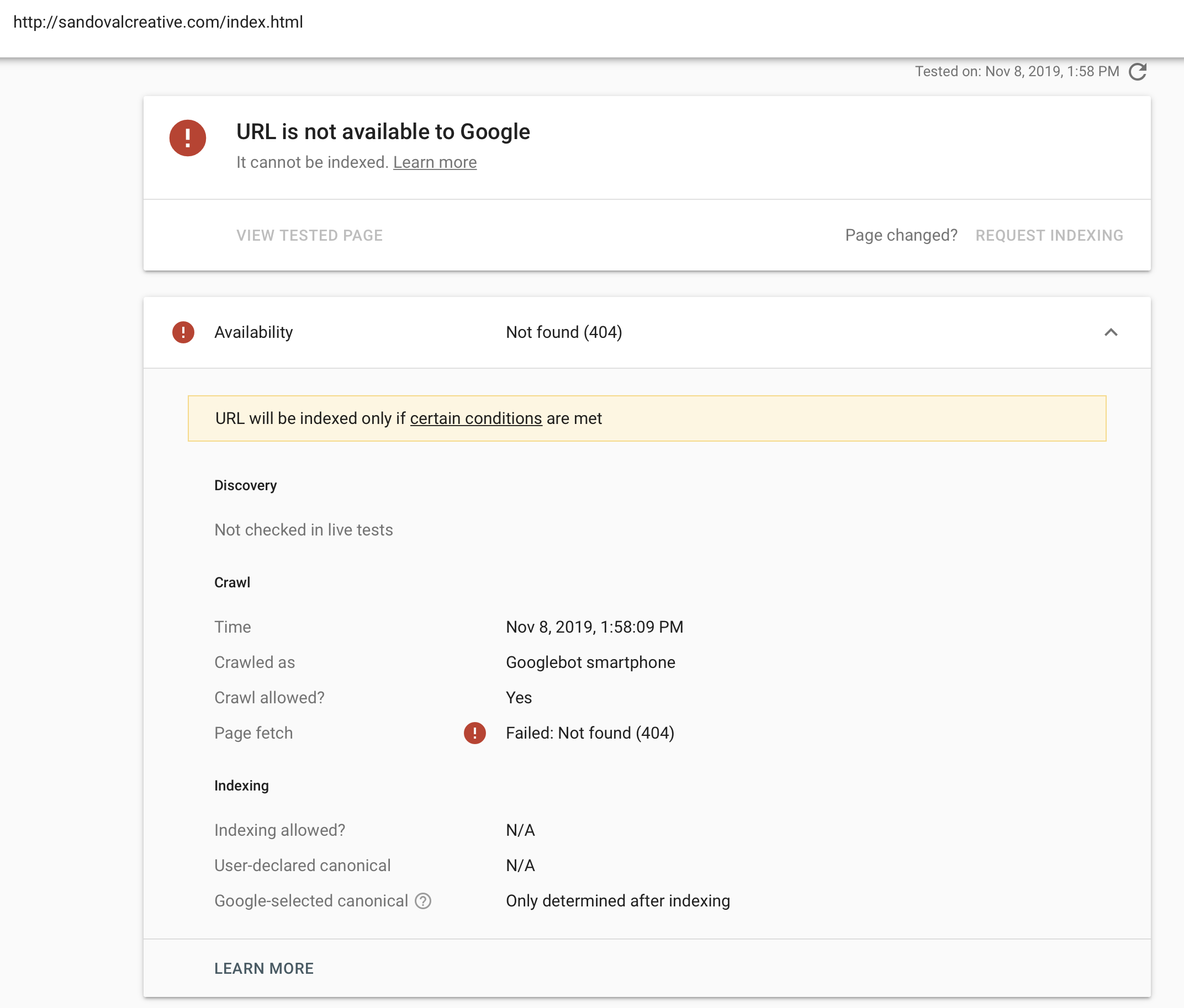
Если ваша страница сообщает о статусе со словом «Отправлено», у вас есть два варианта: решить проблему или удалить URL-адрес из карты сайта. В противном случае вы просите Google посетить и проиндексировать страницу, которую невозможно проиндексировать. Эта ситуация может привести к впустую краулинговый бюджет.
Бюджет сканирования показывает, сколько страниц на вашем веб-сайте Google может и хочет сканировать. Если у вас есть большой веб-сайт, вам нужно убедиться, что Google тратит ваш краулинговый бюджет на ценный контент. Отслеживая статусы, содержащие слово «Отправлено», вы можете быть уверены, что не тратите свой краулинговый бюджет на страницы, которые не должны быть проиндексированы.
Теперь давайте подробно поговорим о статусах отчета Index Coverage.
Две наиболее распространенные проблемы с индексацией
В 2021 году я исследовал наиболее часто возникающие проблемы с индексацией. Оказалось, что эти два статуса были особенно распространены:
- Просканировано – пока не проиндексировано,
- Обнаружен — в настоящее время не проиндексирован.

Оба статуса указывают на то, что ваша страница не проиндексирована. Разница заключается в том, посещал ли Google уже вашу страницу или нет. В таблице ниже приведены различия между этими статусами:
| Статус | Обнаружено | Посетил | Индексировано |
| Просканировано – в настоящее время не проиндексировано | Да | Да | № |
| Обнаружено – в настоящее время не проиндексировано | Да | № | № |
Теперь давайте подробнее рассмотрим каждый из этих статусов.
Просканировано — в настоящее время не проиндексировано
Статус Просканировано — в настоящее время не проиндексировано указывает, что Google нашел и просканировал вашу страницу, но решил ее не индексировать.
Причин появления этого состояния может быть много. Например, это может быть просто задержка индексации, и Google скоро проиндексирует страницу, но это также может указывать на проблему с вашей страницей или всем веб-сайтом.
В моем руководстве «Как исправить сканирование — в настоящее время не проиндексировано» я перечислил возможные причины этого состояния и способы их устранения. Короче говоря, основные причины статуса «Просканировано — в настоящее время не проиндексировано» включают в себя:
- Страница не соответствует стандартам качества — если ваша страница низкого качества, Google, скорее всего, проигнорирует ее. Чтобы решить эту проблему, улучшите качество контента. Вы можете заглянуть в Руководство Google по оценке качества, чтобы понять, на что обращает внимание поисковая система при оценке качества страниц.
- Страница деиндексирована — если страница была проиндексирована в прошлом, но была деиндексирована, она сообщит о статусе Просканировано — в настоящее время не проиндексирована. Может быть много причин, по которым он выпал из индекса. Скорее всего, она была заменена более качественной страницей, и для решения проблемы нужно улучшить ее качество.
- Плохая структура веб-сайта в целом — Google использует внутреннюю структуру ссылок для оценки важности ваших страниц. Если внутренних ссылок, указывающих на данную страницу, недостаточно, Google может решить, что страница недостаточно важна для ее индексации.
 Может быть много причин, по которым он выпал из индекса. Скорее всего, она была заменена более качественной страницей, и для решения проблемы нужно улучшить ее качество.
Может быть много причин, по которым он выпал из индекса. Скорее всего, она была заменена более качественной страницей, и для решения проблемы нужно улучшить ее качество.Обнаружено – в настоящее время не проиндексировано
Статус Обнаружено – в настоящее время не проиндексировано означает, что Google нашел вашу страницу, но не просканировал и не проиндексировал ее.
Есть много причин, которые могут вызвать этот статус. Госия Подденбняк объяснила их все в своей статье «Как исправить «Обнаружено — в настоящее время не проиндексировано» в Google Search Console», а также рассказала о решениях каждой проблемы. К основным факторам, вызывающим этот статус, относятся:
- Проблема с краулинговым бюджетом . Если у вас большой веб-сайт, но ваш краулинговый бюджет не позволяет сканировать все страницы, Google может обнаружить вашу страницу, но не будет ее сканировать. Если вы хотите узнать больше об оптимизации краулингового бюджета, посетите Полное руководство по оптимизации краулингового бюджета.
- Плохая внутренняя перелинковка — как я уже упоминал, внутренняя перелинковочная структура помогает Google определить важность страницы. Если никакие внутренние ссылки не ведут на вашу страницу, Google, скорее всего, проигнорирует ее, чтобы сэкономить свои ресурсы и сосредоточиться на более важных.
- Google обнаружил шаблоны в вашем URL-адресе — Google анализирует шаблоны в ваших URL-адресах, например, для обнаружения дублированного контента и исключения страницы из процесса сканирования при обнаружении URL-адресов.
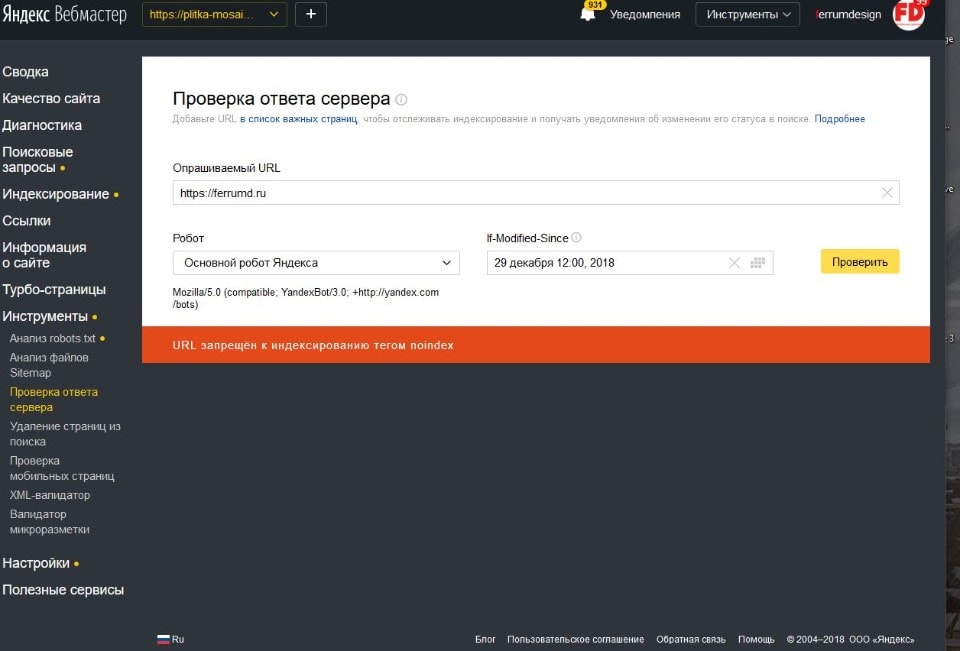 Если у вас большой веб-сайт, но ваш краулинговый бюджет не позволяет сканировать все страницы, Google может обнаружить вашу страницу, но не будет ее сканировать. Если вы хотите узнать больше об оптимизации краулингового бюджета, посетите Полное руководство по оптимизации краулингового бюджета.
Если у вас большой веб-сайт, но ваш краулинговый бюджет не позволяет сканировать все страницы, Google может обнаружить вашу страницу, но не будет ее сканировать. Если вы хотите узнать больше об оптимизации краулингового бюджета, посетите Полное руководство по оптимизации краулингового бюджета.Статусы, связанные с дублирующимся контентом
Google хочет индексировать страницы с отдельной информацией, чтобы предоставить своим пользователям наилучшие возможные результаты и не тратить свои ресурсы на дублированный контент. Вот почему, когда он обнаруживает, что две страницы идентичны, он выбирает только одну из них для индексации.
Вот почему, когда он обнаруживает, что две страницы идентичны, он выбирает только одну из них для индексации.
В отчете «Покрытие индекса» есть два основных статуса, связанных с дублирующимся контентом:
- Дублирование без выбранного пользователем канонического и
- Дубликат, Google выбрал другой канонический, чем пользователь.
Приведенные выше статусы указывают на то, что страница не проиндексирована, поскольку Google выбрал для индексации другую версию. Единственная разница заключается в том, пытались ли вы сообщить Google, какая версия является вашей предпочтительной, используя канонический тег (тег HTML, указывающий, какая версия является вашей предпочтительной, если существует более одной версии), или вы не оставили подсказок, и Google обнаружил дублированный контент и выбрал каноническая версия сама по себе.
| Проверенная страница | Проиндексированная страница | Вы объявили канонический тег? | Почему проверяемая страница не индексируется? | |
| Дублировать без выбранного пользователем канонического | Страница А | Страница Б | № | Google самостоятельно решил, что страницы А и Б дублируются, и выбрал страницу Б в качестве канонической. |
| Дубликат, Google выбрал другой канонический, чем пользователь | Страница А | Страница Б | Да — страница B имеет канонический тег, указывающий на страницу A. | Ваш канонический тег не был принят. Google решил, что Страница B является канонической. |
Дубликат, Google выбрал другой канонический, чем пользователь
Тег канонический является лишь подсказкой, и Google не обязан его соблюдать.
Дубликат, Google выбрал другой канонический статус, чем статус пользователей, указывает на то, что Google не согласен с вашим каноническим тегом и вместо этого выбрал другую версию страницы для индексации.
Если версии страницы идентичны, выбор Google версии, отличной от вашей, может не иметь никаких последствий для вашего бизнеса. Однако, если между версиями была существенная разница, и Google выбрал неправильную версию, это может уменьшить ваш органический трафик, отображая неправильную версию для пользователей.
Одной из основных причин статуса является несогласованная сигнализация , например, вы добавили канонический тег к одной версии страницы, но внутренние ссылки и карта сайта указывают, что канонической является другая версия. В этом случае Google должен угадать, какая страница является настоящей канонической, и может проигнорировать ваш канонический тег. Вот почему так важно убедиться, что вы последовательны, и что все сигналы указывают на одну версию.
Вы можете найти больше возможных причин и решений для дублирования, Google выбрал другой канонический, чем пользователь, в статье моего коллеги, как исправить «Дублировать, Google выбрал другой канонический, чем пользователь» в Google Search Console.
Дублировать без канонического, выбранного пользователем
Дублировать без канонического, выбранного пользователем означает, что ваша страница не проиндексирована, поскольку Google считает, что это дублированный контент, и вы не включили тег канонического.
Я рассматриваю этот отчет как возможность увидеть, какой тип страниц определяет Google как дублирующийся контент. Это позволяет вам действовать и объединять контент, например, перенаправляя все версии на одну страницу или используя канонический тег.
В отчете о покрытии индекса также есть статус «Дубликат», отправленный URL-адрес не выбран в качестве канонического. Это указывает на ту же проблему, что и дубликат без канонического, выбранного пользователем, но, как я упоминал в начале, страница с сообщением о дублирующемся отправленном URL-адресе, не выбранном в качестве канонического, была обнаружена внутри карты сайта.
Статусы, указывающие на то, что вы не хотите, чтобы ваша страница была проиндексирована
Статусы в этой главе указывают на то, что страница не проиндексирована, потому что вы явно сказали Google не индексировать их, и поисковая система уважила ваше желание.
Исключено тегом noindex
Тег noindex — очень мощный инструмент в руках владельца веб-сайта. Это фрагмент HTML, используемый для того, чтобы сообщить поисковым системам, что URL-адрес не следует индексировать.
Это фрагмент HTML, используемый для того, чтобы сообщить поисковым системам, что URL-адрес не следует индексировать.
Noindex — это директива, поэтому Google должен ей подчиняться. Если Google обнаружит тег, он не будет индексировать страницу и пометит ее как исключенную тегом «noindex» (или отправленный URL-адрес с пометкой «noindex», если вы включили эту страницу в карту сайта).
В ситуации, когда страница с отчетом Excluded by noindex действительно не должна быть проиндексирована, никаких действий предпринимать не нужно. Однако иногда разработчик или SEO-специалист ошибочно добавляет тег noindex к важным URL-адресам, в результате чего эти страницы выпадают из индекса Google. Я рекомендую вам внимательно просмотреть список всех страниц, сообщающих об исключении тегом «noindex», чтобы убедиться, что ни одна ценная страница не была ошибочно помечена как noindex.
Альтернативная страница с правильным каноническим тегом
Альтернативная страница с правильным каноническим тегом означает, что Google не проиндексировал эту страницу, потому что он соблюдал ваш канонический тег.
Что это значит для вас?
В большинстве случаев никаких действий предпринимать не нужно. В основном это информация о том, что с этим URL все работает корректно. Однако есть два случая, когда этот отчет не стоит пропускать:
- Иногда вы вводите канонические теги по ошибке, т.е. все страницы канонизируются в одну. Стоит следить за этим отчетом и проверять теги, чтобы убедиться в отсутствии ошибок.
- Тег canonical является подсказкой и может не соблюдаться Google. Если в этом отчете почти нет страниц, это может указывать на то, что ваши канонические теги не соблюдаются.
Статусы, указывающие на то, что Google не может просканировать вашу страницу
Прежде чем Google сможет проиндексировать вашу страницу, ему необходимо разрешить сканирование, чтобы увидеть ее содержимое.
Сканирование может быть заблокировано по многим причинам. Вы можете сделать это намеренно, чтобы уберечь поисковые системы от определенного контента и сэкономить краулинговый бюджет, но это также может быть следствием ошибки или неисправности.
В приведенной ниже таблице вы можете найти статусы отчета об индексировании, указывающие на проблему, которая приводит к блокировке сканирования.
Soft 404
Компания Google стремится обеспечить высокое качество страниц, которые она показывает пользователям Google. Для выполнения этой миссии он использует передовые алгоритмы, такие как мягкий детектор 404.
Google помечает страницы как программные 404, когда обнаруживает, что страница не существует, даже если код состояния HTTP не указывает на это.
Если страница определяется как soft 404, она не попадет в индекс Google. В таких случаях Google пометит его как:
- Soft 404 или .
- Представленный URL-адрес, похоже, является программным 404.
Однако, как и любой механизм, детектор программных ошибок 404 подвержен ложным срабатываниям , что означает, что ваши страницы могут быть ошибочно классифицированы как программные 404 и в конечном итоге деиндексированы. Общие причины такой ситуации включают в себя:
Общие причины такой ситуации включают в себя:
- Нерелевантные перенаправления — если Google обнаружит, что страница перенаправлена на нерелевантную, он не будет следовать за перенаправлением и рассматривать страницу как мягкую 404. Вот почему вы всегда должны перенаправлять на релевантную страницу.
- Много слов, подобных 404, на странице — примером может быть страница электронной коммерции, содержащая такие фразы, как «продукт недоступен». В этом случае Google может ошибочно предположить, что страницы вообще не существует. Чтобы решить эту проблему, вы можете удалить слова, похожие на 404, или заменить их другими.
- Отсутствие контента или проблема с отображением . Если на странице мало контента или его нет (например, пустые списки продуктов) или Google не может отобразить контент, он может предположить, что страница не существует. Вот почему вы всегда должны следить за тем, чтобы на ваших страницах был уникальный контент (или добавлять тег noindex к пустым страницам). Кроме того, вы можете использовать инструмент проверки URL-адресов, чтобы увидеть, как отображается ваша страница, и уведомить своих разработчиков в случае возникновения каких-либо проблем.
 Кроме того, вы можете использовать инструмент проверки URL-адресов, чтобы увидеть, как отображается ваша страница, и уведомить своих разработчиков в случае возникновения каких-либо проблем.
Кроме того, вы можете использовать инструмент проверки URL-адресов, чтобы увидеть, как отображается ваша страница, и уведомить своих разработчиков в случае возникновения каких-либо проблем.Если вам интересно узнать больше о мягких ошибках 404, я рекомендую вам ознакомиться со статьей Каролины Бронишевской о мягких ошибках 404 в SEO, где она подробно рассмотрела эту тему.
Подведение итогов
Понимание отчета о покрытии индексом необходимо для повышения шансов индексации ваших страниц.
К сожалению, документация Google не содержит всей информации, необходимой для диагностики и решения проблем на вашем веб-сайте. Не всегда понятно, требует ли статус вашего немедленного внимания или это просто информация о том, что все идет хорошо.
Надеюсь, моя статья помогла вам понять, как смотреть отчет о покрытии индексов, и немного упростила анализ статусов. Помните, что регулярный мониторинг отчета является ключом к быстрому выявлению технических проблем SEO и предотвращению потери органического трафика вашим бизнесом.