Понимает ли Яндекс noindex и nofollow
Бывают ситуации, когда необходимо разместить на сайте ссылку на сторонний ресурс, но при этом совсем не радует такой факт, что со страницы будет утекать вес.
Или другая проблема: надо закрыть от индексации какую-либо часть текста. Что делать в таком случае?
Как закрыть внешние ссылки
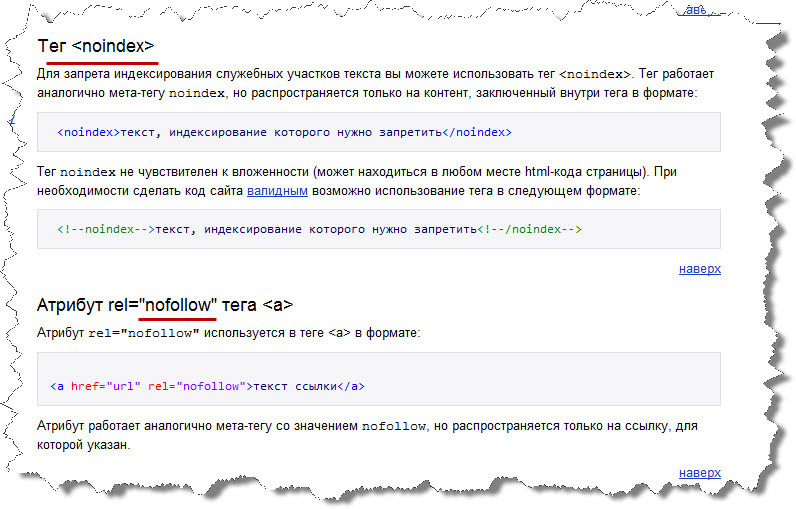
Оказывается, есть выход. Введенный Яндексом парный тег <noindex></noindex> запрещает поисковому роботу индексировать часть кода, заключенного внутри.
Данный тег является командой для ботов Яндекса и Рамблера, но для Google он ничего не значит.
Отсюда вывод, что если мы закроем часть кода noindex, то Яндекс его не будет индексировать, а Гугл будет.
Рассмотрим, к примеру: <noindex><a href=http://seitostroenie.ru>Создание и раскрутка сайта</noindex>.
Данный пример показывает, что мы закрыли от индексации анкор «Создание и раскрутка сайта», но саму ссылку поисковик будет учитывать и по ней будет утекать вес.
Валидность кода
Необходимо учесть такой факт, что закрыв от бота участок текста тегом <noindex>, приведет к тому, что:
- будет нарушена валидность кода. Причина в том, что такой код, кроме Яндекса и Рамблера другие системы не понимают;
- некоторые визуальные редакторы его не воспринимают и даже удаляют, например wordpress.
Чтобы исключить ошибки валидатора, связанные с тегом, можно текст закомментировать следующим образом: <!—noindex—><!—/noindex—>. Данный вариант устроит все поисковые системы, его распознает Яндекс, а валидатор не будет выдавать ошибку. К сожалению Google не понимает его и не придумал ничего аналогичного.
Польза тега noindex
Тег может быть незаменим в следующих случаях:
- если на сайте есть какой-то текст, который нужно спрятать от глаз поисковых роботов;
- чтобы спрятать от индексации код счетчика;
- при наличии неуникального контента, чтобы поисковик его не индексировал.


Напомню, что это правило действует только для Яндекса.
Если надо закрыть от индексации всю страницу
Если прописать мета-тег <meta name=»robots» content=»noindex»>, то вся страница не будет проиндексирована и роботы не смогут переходить по ссылкам. Запретить индексацию и переход по линкам можно также в файле robots.txt.
Как закрыть индексацию контента от Гугла
Атрибут rel=”nofollow” работает со всеми поисковиками и полностью является валидным.
Использование данного атрибута позволяет:
- закрыть ссылку от индексации;
- повлиять на перераспределение веса между всеми ссылками, которые есть на странице;
- закрыть ссылки в комментариях.
Атрибут rel=”nofollow” можно использовать в файле robots.txt, когда нужно запретить индексацию страницы и переходы по ссылкам.
Если одна ссылка оформлена тегами nofollow и noindex, то такое сочетание позволяет удержать вес страницы и спрятать анкор от Яндекса.
Новые правила для robots.txt от Google: какие изменения ожидаются?
С 1 сентября 2019 года ожидаются существенные изменения правил протокола Robots Exclusion Protocol (REP), на основе которого разрабатываются директивы для поисковых краулеров. В дальнейшем они отображаются в файле robots.txt.
REP-протокол в течение последних 25 лет был одним из ключевых инструментов, которыми пользовались поисковые оптимизаторы. Его применение позволяло ограничивать доступ роботам на какие-то определенные страницы сайта. Сейчас же компания Google вносит существенные изменения в данный протокол, ключевое из них – отказ от поддержки директивы noindex.
Ограничение доступа роботов осуществлялось по различным причинам, но основная – снижение нагрузки на сайт, ведь через robots.txt удавалось отсечь ненужных роботов. В результате таких действий скорость открытия веб-ресурсов повышалась и одновременно требовались меньшие расходы на поддержку пропускного канала.
Действия самых известных поисковых систем, включая Google, Bing и Yandex, всегда осуществлялись строго с правилами, что были указаны в файле robots.
Компания Google приняла решение официально задокументировать REP, следствием чего стало направление стандарта в организацию IETF. Эти действия корпорации нацелены на решение следующих задач:
- Расширить базу функциональных возможностей для того, чтобы создать возможность установки более конкретных правил;
- Определить понятные стандарты для исключения вероятности возникновения спорных вариантов по применению, то есть в итоге все связи причины/следствия по вопросам применения файла robots.txt должны стать одинаковыми и понятными для всех пользователей.
Каких изменений следует ожидать?
Можно выделить 4 наиболее важных изменений:
- Обеспечение возможности использования директивы для любого URI. Так, кроме HTTP/HTTPS правила теперь будут распространяться, например, и на CoAP, и на FTP.
- Все файлы, размещаемые в директиве, будут подвергаться кешированию. Данное введение необходимо для отсечения лишних запросов, которые посылаются на сервера. Кеширование планируется проводить на срок до 24 часов, что позволит поисковому оптимизатору в приемлемые сроки обновлять файл. Предусмотрена и возможность самостоятельно устанавливать значения по кешированию, для чего предполагается использование директивы кеширования с помощью заголовка Cache-Control.
- Поисковые краулеры теперь обязаны проводить сканирование первых 513 кб файла. При этом роботы могут сканировать и весь файл, но они это не обязаны делать для больших по размеру файлов. Также роботы могут отказаться от сканирования файла при нестабильном соединении.
- В случае недоступности файла директивы будут продолжать функционировать. Это означает, что если поисковый краулер не может получить доступ к файлу robots. txt, то правила, которые указаны выше, будут действовать еще в течение длительного отрезка времени.
 Так, кроме HTTP/HTTPS правила теперь будут распространяться, например, и на CoAP, и на FTP.
Так, кроме HTTP/HTTPS правила теперь будут распространяться, например, и на CoAP, и на FTP. txt, то правила, которые указаны выше, будут действовать еще в течение длительного отрезка времени.
txt, то правила, которые указаны выше, будут действовать еще в течение длительного отрезка времени.Также был произведен пересмотр директив, которым предоставляется доступ в файле robots.txt. Кроме того, открыт и исходный код парсера robots.txt, применяемый краулером Google для проведения парсинга данных из robots.txt.
Отмечается, что правила, не вошедшие в стандарт, с 01.09.2019 не будут поддерживаться Google, что исключает реализацию поддержки правил noindex, что, в свою очередь, негативно скажется на продвижении сайта, если не внести в него соответсвующие корректировки.
Как реализовать noindex?
После вступления в силу изменений для использования директивы noindex можно ее указывать в мета-теге robots либо задавать в HTTP заголовках.
Если планируется задействовать HTTP-заголовок, то надо записывать таким образом: X-Robots-Tag. Это означает, что для закрытия страницы от индексации надо написать X-Robots-Tag: noindex.
В случаях, когда имеется только доступ к шаблону веб-ресурса, то уже потребуется применять мета-тег robots. Для запрета индексации страниц записывается следующий код:
Для запрета индексации страниц записывается следующий код:
<meta name=»robots» content=»noindex»>.
Такой вариант используется для всех поисковых систем. Если требуется заблокировать заход ботов google, в name записывается значение googlebot, а не значение robots.
В то же время для исключения из индекса поисковой системы каких-либо страниц сайта надо работать с кодом ответа. Если проставляется код ответа 404 или 410, то это позволяет быстро решить проблему.
Для того чтобы задать время для кеширования файла robots.txt, требуется применять заголовок Cache-Control. Запись будет выглядеть следующим образом: Cache-Control: max-age=[ n секунд].
С помощью данной директивы задается отрезок времени, когда предоставляется возможность повторно использовать скачанный ответ. Отсчет будет начинаться с момента отправки запроса.
На что еще обратить внимание?
Инструмент Google Robots.txt Tester предлагается использовать для проверки настроек robots.txt. С его помощью проверяются директивы на валидность, а также выявляются ошибки в синтаксисе.
Стоит помнить, что все ссылки, помещенные в файл robots.txt, воспринимают большой и малый регистр.
Также надо учитывать следующие особенности:
- В поисковиках Bing и «Яндекс» не реализована поддержка директивы noindex в файле, поэтому «Яндекс» рекомендует применять noindex в X-Robots-Tag либо в метатеге robots.
- Директивы robots.txt касаются только верхнего уровеня хоста, поэтому отдельные правила для поддоменов в robots.txt можно не прописывать.
- Скрипты JavaScript и файлы CSS не следует закрывать в robots. Это связано с тем, что поисковая система используется рендеринг сайта, который осуществляется перед ранжированием. И в случае закрытия доступа к скриптам и стилям все равно будет проведен рендеринг веб-ресурса. Однако в этом случае нельзя ожидать корректного результата, а это, соответственно, негативно отразится на позициях ресурса в поисковой выдаче.
- Запрет robots.txt не распространяется на краулинговый бюджет, ведь он зависит преимущественно от пропускной способности сервера, а также авторитетности доменного имени.

В результате фиксация директив robots.txt в качестве стандарта позволяет устранить все ранее существовавшие неопределенности и установить понятные правила для различных поисковых систем.
Будет полезно знать: «Как искать и увеличивать количество клиентов с помощью инструментов Yandex»
Остались ещё вопросы?
Метатег с noindex — Конфигурация сервера — Форумы SitePoint
javascript7
17 февраля 2018 г., 22:13#1
У меня проблемы с тем, что Яндекс посещает мой сайт тысячами в течение 10 минут. Я читал, что могу использовать это:
meta name=»Яндекс» content=»noindex»
Кто-нибудь знает, работает ли это?
Также я читал об использовании файла robots.txt в корне, но я не совсем понимаю, так как я не использовал его раньше. У кого-нибудь есть текст, который я могу скопировать и вставить для «Яндекса», который я могу использовать для этого файла? Я понимаю, что он чувствителен к пробелам и правильной формулировке, поэтому я немного растерялся.
У кого-нибудь есть текст, который я могу скопировать и вставить для «Яндекса», который я могу использовать для этого файла? Я понимаю, что он чувствителен к пробелам и правильной формулировке, поэтому я немного растерялся.
Будем признательны за любую помощь.
Надеюсь, я размещаю это в правильном месте.
Спасибо
#2
Не уверен насчет специфичного для Яндекса метатега; это не то, с чем я сталкивался.
Вы можете указать пользовательские агенты в файле robots.txt, но директивы robots носят только рекомендательный характер: боты могут их игнорировать, хотя авторитетные боты, такие как Google, будут уважать их. Это в равной степени относится к метатегам robots и к файлу robots.txt.
Альтернативой может быть блокировка Яндекса с помощью файла . htaccess, если вы уверены, что хотите полностью предотвратить его сканирование.
htaccess, если вы уверены, что хотите полностью предотвратить его сканирование.
1 Нравится
JavaScript7
17 февраля 2018 г., 23:14#3
Знаете ли вы, что если метатег (вверху страницы), характерный для Яндекса, сработает, не помешает ли им остальная часть страницы, где у меня есть код для регистрации активности?
Я не возражаю против бота, но что мне не нравится, так это то, что он становится записью журнала в базе данных, что затем делает журналы нечитаемыми для реальных пользователей. Поэтому я надеялся, что метатег остановит это, но не уверен, что это произойдет.
ТехноМедведь
#4
Возможно, вам также потребуется добавить «nofollow», чтобы гарантировать, что он не переходит ни по каким ссылкам на этой странице.
1 Нравится
JavaScript7
#5
Спасибо за это. Я тоже пробовал это вчера, и похоже, что метатег не работает.
Гэндальф
#6
Интересно, почему бот Яндекса так сильно бьет ваш сайт. Я всегда считал, что это хороший бот. Конечно, это может быть что-то еще, просто притворяющееся Яндексом. 9Яндекс [NC,OR] Правило перезаписи .* — [F]
1 Нравится
JavaScript7
#7
Спасибо, я изучу это.
ТехноМедведь
#8
В качестве альтернативы, если проблемные боты используют узкий диапазон IP-адресов, их может быть проще заблокировать. Таким образом, если это это плохой бот подделывает яндекс, настоящую не заблокируешь. (Вы должны иметь возможность проверить, действительно ли IP-адреса принадлежат Яндексу.)
2 лайка
javascript7
#9
Да, будем разбираться. Спасибо!
Спасибо!
1 Нравится
система закрыто
#11
Эта тема была автоматически закрыта через 91 день после последнего ответа. Новые ответы больше не допускаются.
Яндекс.Вебмастер Отзывы и цены 2022
Аудитория
Компании, бренды и веб-мастера заинтересованы в решении статистики поисковых запросов для мониторинга своих сайтов.
О Яндекс.Вебмастере
Мы отслеживаем поисковые запросы, которые возвращают этот сайт. Сервис позволяет отслеживать изменения в показах, количестве кликов, сниппетах CTR и других показателях. Мы можем предложить предложения по улучшению сайта. Сравните его с ресурсами конкурентов и получите советы, как сделать сайт более полезным и привлекательным. Мы проверим, правильно ли отображается ваш сайт на смартфонах и планшетах. Например, мы посмотрим, содержит ли он какие-либо элементы, которые создают проблемы для мобильных браузеров. Мы будем уведомлять вас об ошибках сайта и давать рекомендации по их устранению. Яндекс Вебмастер автоматически проверяет сайт более чем по 30 параметрам. Мы сообщим вам обо всех нарушениях, обнаруженных на сайте. Информация собрана в специальном разделе. Когда все проблемы будут исправлены, вы можете сообщить об этом в Яндекс с помощью кнопки «Я все исправил». Мы будем уведомлять вас о новых отзывах о сайте, чтобы вы могли оперативно на них реагировать. Ваши комментарии будут помечены как официальные.
Мы проверим, правильно ли отображается ваш сайт на смартфонах и планшетах. Например, мы посмотрим, содержит ли он какие-либо элементы, которые создают проблемы для мобильных браузеров. Мы будем уведомлять вас об ошибках сайта и давать рекомендации по их устранению. Яндекс Вебмастер автоматически проверяет сайт более чем по 30 параметрам. Мы сообщим вам обо всех нарушениях, обнаруженных на сайте. Информация собрана в специальном разделе. Когда все проблемы будут исправлены, вы можете сообщить об этом в Яндекс с помощью кнопки «Я все исправил». Мы будем уведомлять вас о новых отзывах о сайте, чтобы вы могли оперативно на них реагировать. Ваши комментарии будут помечены как официальные.
Интеграции
Нет перечисленных интеграций.
Рейтинги/отзывы
Общий
0,0 / 5
простота
0,0 / 5
Особенности
0,0 / 5
дизайн
0,0 / 5
поддерживать
0,0 / 5
Это программное обеспечение еще не проверено.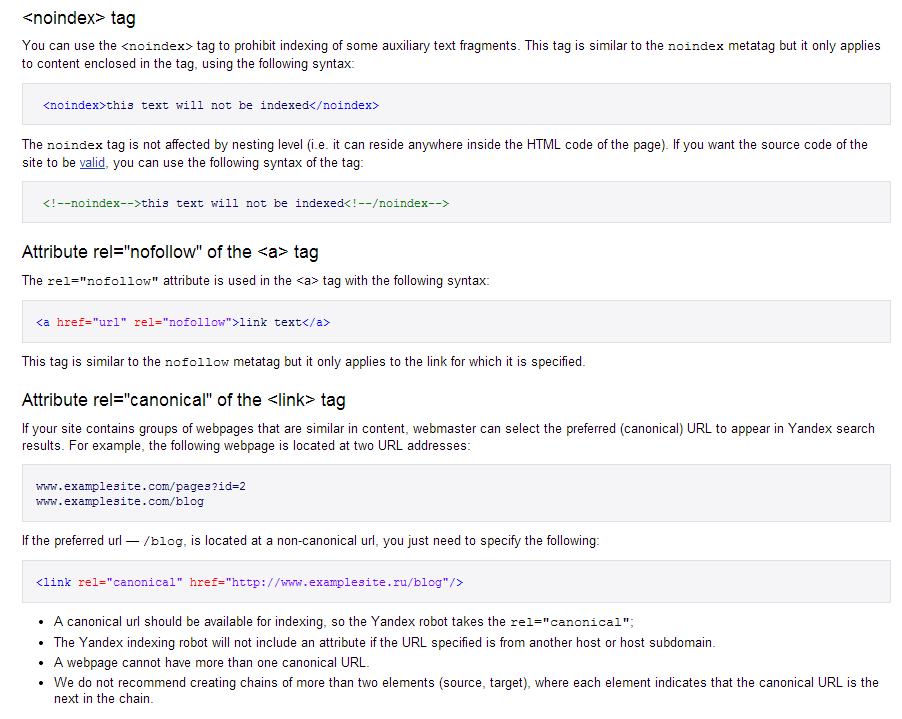 Будьте первым, кто оставит отзыв:
Будьте первым, кто оставит отзыв:
Обзор этого программного обеспечения
Информация о компании
Яндекс
Год основания: 2000
Россия
webmaster.yandex.com/welcome/
Видео и снимки экрана
monday.com | Новый способ работы
monday.com Work OS — это открытая платформа, на которой каждый может создавать инструменты, необходимые для выполнения всех аспектов своей работы.
Централизуйте всю свою работу, процессы, инструменты и файлы в одной рабочей ОС. Объединяйте команды, объединяйте разрозненные ресурсы и используйте единый источник достоверной информации в своей организации.
Подробнее
Подробная информация о продукте
Системные требования
Обучение
Документация
Поддержка
Онлайн
Часто задаваемые вопросы Яндекс.