что это такое, как правильно использовать
Nofollow – это атрибут, который прописывается для определенной ссылки или всех ссылок на странице в мета-теге robots с целью запрета поисковым роботам на переход по ним.
Noindex – это атрибут, который закрывает от индексации текст на странице.
То есть, noindex отвечает за контент в документе и запрет на индексацию его, в то время как nofollow – за ссылку.
Правила применения и зачем нужен nofollow?
Как правильно прописать nofollow?
Robots Nofollow
Rel=»Nofollow»
Утекает ли вес ссылки через nofollow?
Стоит ли закрывать внутренние ссылки в nofollow?
Атрибут noindex: что это и чем отличается от nofollow?
Выводы
Правила применения и зачем нужен nofollow?
Чтобы понять, в каких случаях может вообще пригодиться этот атрибут,
рассмотрим, как к нему относятся популярнейшие поисковые системы.
- Яндекс. Когда на вашем ресурсе содержатся разделы, предназначенные специально для обсуждения записей, написания комментариев к статьям или форум, важно следить за тем, какие исходящие ссылки оставляют в них посетители. Желательно модерировать каждый комментарий. Благодаря этому владелец сайта сможет предотвратить размещение различных вредоносных ссылок от спамеров. Хотя поисковик и не учитывает их, спам сильно влияет на репутацию веб-ресурса и к нему может быть применен фильтр. В связи с этим следует проверять все комментарии, и если есть какие-то сомнения относительно качества размещаемой ссылки, пропишите для них атрибут rel=”nofollow”. Сейчас, в измененном руководстве Яндекс, данный текст был удален и осталось только правило применения rel=»nofollow» Руководство Яндекс о nofollow
- Google. Если у вашего сайта есть раздел, где пользователи могут комментировать записи, есть большой риск, что в комментариях появятся ссылки на вредоносные страницы.
 Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
 Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollowЭти сообщения взяты с официальных сайтов поисковиков. Как видите, в Яндекс и Google написаны аналогичные вещи: значение nofollow нужно использовать в тех случаях, когда вы хотите сообщить ботам о недоверии в отношении сайта, на который ведет ссылка.
Только в Яндекс упор делается, что ссылка с rel=»nofollow» не будет индексироваться поисковой системой, а в Google говорится о том, что робот не будет переходить по такой ссылке.
Рассмотрим более конкретный пример, когда для ссылки требуется прописать запрещающий атрибут:
Материал сомнительного качества. Если вам не нравится содержание страницы, на которую посетитель оставляет ссылку в комментарии, и вы не желаете жертвовать репутацией своего сайта, прописывайте в теги данной ссылки значение rel=”nofollow”.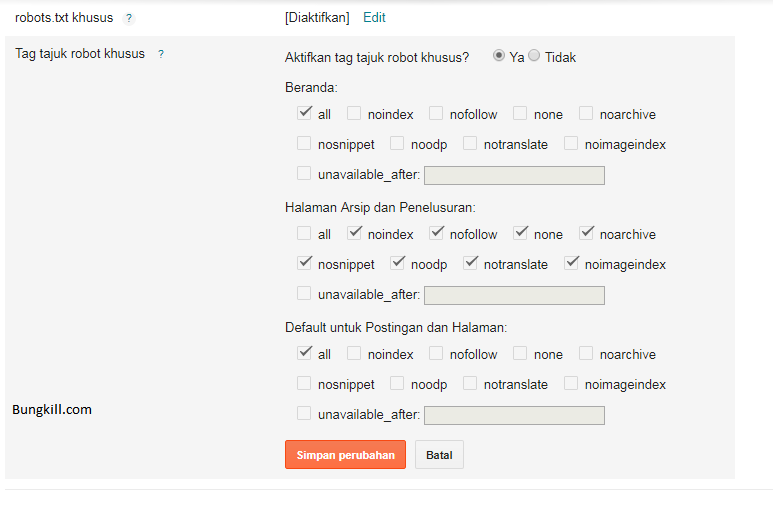 Спамеры, заметив на вашем ресурсе тенденцию, когда к непроверенным ссылкам добавляется блокирующий атрибут, вскоре прекратят попытки навредить сайту. Если же вы видите, что пользователь оставляет ссылку на качественный материал, вручную или автоматически nofollow можно удалить.
Спамеры, заметив на вашем ресурсе тенденцию, когда к непроверенным ссылкам добавляется блокирующий атрибут, вскоре прекратят попытки навредить сайту. Если же вы видите, что пользователь оставляет ссылку на качественный материал, вручную или автоматически nofollow можно удалить.
Как правильно прописать nofollow?
Это сейчас nofollow позволяет управлять каждой ссылкой отдельно, но когда-то данное значение можно было задействовать только в мета-теге, который закрывал от поисковой системы абсолютно все ссылки на странице. И для запрета перехода по отдельным ссылкам вебмастерам приходилось блокировать их URL в robots.txt.
Robots Nofollow
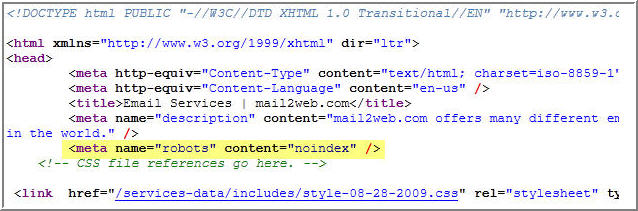
Эти мета-теги так и остались по сей день. Если вы хотите закрыть от индексации все ссылки, содержащиеся на определенной странице, то на этой странице нужно прописать такой код:
<meta name=”robots” content=”nofollow” />
Важно не путать данный тег с двумя нижеприведенными кодами, content=»none» и content=”noindex, nofollow” блокируют доступ ботов ко всей странице, а не только к ее ссылкам. Поэтому, если вы хотите чтобы страницы индексировались, то ни в коем случае не прописывайте для них два вот этих тега:
Поэтому, если вы хотите чтобы страницы индексировались, то ни в коем случае не прописывайте для них два вот этих тега:
<meta name=”robots” content=”none” />
<meta name =”robots” content=”noindex, nofollow” />
Rel=»Nofollow»
Выше мы рассмотрели варианты, как запретить переход поисковых роботов по всем ссылкам на страницах. Но еще можно назначить запрет на переход к конкретной ссылке.
Чтобы запретить для индексации и переход робота по ссылке, к ней надо прописать атрибут rel=”nofollow”, в коде это выглядит так:
<a href=”URL” rel=”nofollow”>анкор гиперссылки</a>
Утекает ли вес ссылки через nofollow?
Хотя Google в своих заявлениях позиционирует применение атрибута nofollow как переход по ссылке. И это подтвердило обращение бывшего главы компании по борьбе с поисковым спамом, Мэтта Катса. Он заявил, что «Google может учитывать ссылки из социальных сетей, даже несмотря на nofollow».
 youtube.com/embed/ofhwPC-5Ub4″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»» frameborder=»0″/>
youtube.com/embed/ofhwPC-5Ub4″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»» frameborder=»0″/>А вот с Яндексом вопрос не явный. Он четко пишет в своей документации, что данный атрибут запрещает индексацию таких ссылок.
А если мы перейдем в описание атрибута robots nofollow, то здесь уже видим запрет на переход, и не слово про индексацию.
Но, раньше можно было это проверить, если применить в поиске такую конструкцию url: ваш урл << inlink:(“анкор ссылки”), и Яндекс нам отображал только те страницы, где содержится наш искомый анкор ссылки. Сейчас же этот метод не работает, поисковая система Яндекс запретила использовать такую конструкцию в поиске. Поэтому можно с большей долью вероятностью сказать, что Яндекс может учитывать такие ссылки, потому что они появляются в Яндекс Вебмастер.
Видно, например, что Яндекс учитывает ссылки с Твиттера, даже если они отдаются через редирект и закрыты nofollow.
В целом можно сказать, что применение данного атрибута для поисковых роботов не всегда является запретом, если особенно сайт авторитетный.
Стоит ли закрывать внутренние ссылки в nofollow?
В прошлом, seo оптимизаторы сильно злоупотребляли rel=»nofollow» тем самым манипулирую передаваемым весом внутри сайта. Поэтому поисковая система Google заявила, что все внутренние ссылки отмеченные rel=»nofollow» будут отдавать вес вникуда https://www.mattcutts.com/blog/pagerank-sculpting/.
То есть со страницы где стоит такая ссылка будет уходить вес, но на страницу на которую стоит ссылка он не будет передаваться, получается он будет обнуляться.
Об этом в видео говорит бывший руководитель поиска в Google. Видео на английском, поэтому включите русские субтитры.
Атрибут noindex: что это и чем отличается от nofollow?
Многие начинающие вебмастера ломают голову, не понимая, чем noindex отличается от nofollow. Все просто:
Все просто:
- nofollow — применяется к ссылкам
- noindex — применяется к тексту
Если вы хотите запретить текст на всей странице сайта для индексации, но при этом учитывать ссылки, на странице нужно прописать следующий код:
<meta name=”robots” content=”noindex, follow: />
Если вы хотите закрыть часть текста, то в Google нет такого атрибута, но в Яндексе это возможно. Тег noindex был внедрен поисковиком Яндекс, так как раньше он не понимал nofollow, а ненужные ссылки нужно было как-то закрывать от роботов.
Но в 2010 году поисковая система начала работать с атрибутом rel=”nofollow”, при этом noindex не исчез, а остался отвечать за скрытие текста. Теперь, если вы хотите закрыть от индексации текст или например анкор ссылки, пропишите команду:
<noindex><a href=”url”>анкор ссылки</a></noindex>
Сама ссылка будет открыта для перехода роботами поисковых систем, не учтется только ее текст (анкор).
Например это удобно было, когда Яндекс ввел новый алгоритм Баден-Баден, который накладывал санкции за seo тексты. Стоило закрыть портянки текста в noindex, и можно было выйти из под этого фильтра, причем не потерять позиции в Google, так как поисковая система Google не учитывает тег <noindex></noindex>.
Выводы
Nofollow отвечает за переход поисковых систем по этим ссылкам, как на всей странице, так и для определенной ссылки. Ранее noindex тоже выполнял аналогичную функцию, но только по отношению к Яндексу, который со временем начал понимать nofollow, в результате чего значением noindex начали закрывать от индексации контент на странице.
Владелец сайта должен грамотно использовать атрибут nofollow и понимать, в каких именно случаях это делать:
- Когда ссылка ведет на веб-ресурсы с некачественным контентом.
- Когда вы размещаете на странице коммерческий контент.
По атрибуту nofollow ссылка может индексироваться и передавать свой вес, если она стоит на качественный ресурс.
Главная задача использования nofollow — помочь указать приоритетные для сканирования ссылки, разделить продающие статьи от информационных, а также защитить сайт от спама, который, если не контролировать, может привести к снижению ранжирования или куда хуже, вылету ресурса из индекса.
Для всех других ситуаций можете смело применять dofollow ссылки, открытые для поисковых роботов. Репутация сайта ничуть не ухудшится, а даже улучшится, если вы будете оставлять ссылки на полезные для вашей целевой аудитории страницы. И никакой вес ваши документы не потеряют, а наоборот даже могут приобрести за счет обратного PageRank.
Noindex Tag / Ноиндекс Тег
TL;DR
Ноиндекс представляет собой тег, который можно разместить на странице сайта, чтобы избежать его видимости в результатах поиска. Он используется для контроля над проиндексированными страницами сайта, и это легко сделать, поместив на страницу кусок кода, например, мета-тег или заголовок HTTP-ответа.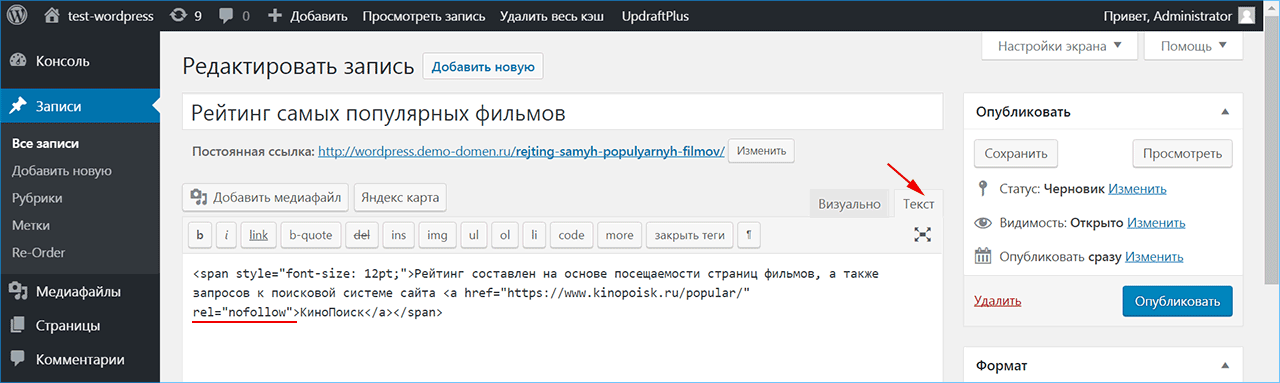
Что такое тег noindex?
Ноиндекс представляет собой метатег, который можно легко добавить на сайт, чтобы исключить определенные страницы из индексации поисковых систем.
Почему веб-сайт должен использовать тег Noindex?
Ноиндексный тег предоставляет гибкость всем владельцам сайтов в отношении того, какой тип контента должен отображаться в поисковых системах, а также позволяет контролировать доступ к сайту по страницам.
Как только тег Noindex добавляется к определенной странице, паук поисковой системы (например, Googlebot) сканирует эту страницу и видит этот тег; он полностью удаляет эту страницу из результатов поиска Google.
Какие страницы могут иметь ноиндекс, не влияя на рейтинг сайта? Если тег «noindex» не добавляется на нужную страницу (или добавляется неправильно), нежелательная информация может оказаться в результатах (или весь сайт может оказаться невидимым в поисковой системе, в зависимости от того, как это было реализовано). Итак, вот некоторые страницы, которые может не захотелось индексировать:
- Описания авторов: если на сайте есть только один автор (или несколько активных), то каждый раз, когда публикуется сообщение, их описание также может быть добавлено на страницу, и это может быть воспринято как дубликат контента ползунами. Опция go-to — не индексировать страницу/описание автора.
- Пользовательские страницы или скрытые страницы: Если вы создали какой-то ограниченный контент для определенной аудитории, то, возможно, вы захотите сохранить его только для нее и не делать видимым в поисковых системах.
- Отказ от страницы подписки или страницы благодарности: это страницы, на которые люди должны попасть только один раз, и их содержание не является ценным или релевантным с точки зрения содержания. Некоторые сайты также предпочитают не индексировать страницы входа или регистрации.
- Внутренние результаты поиска. Если у сайта есть строка поиска, и для каждого поискового запроса, есть сгенерированная страница, которая индексируется; это может закончиться разрушением ранга сайта. Таким образом, шумоподавление может быть хорошей идеей.
 Опция go-to — не индексировать страницу/описание автора.
Опция go-to — не индексировать страницу/описание автора.Как реализовать ноиндекс?
Есть два способа реализации ноиндекса: в виде метатега и в виде заголовка ответа HTTP, исходя из того, что удобнее для сайта.
Чтобы большинство поисковых роботов не смогли проиндексировать страницу сайта, поместите следующий метатег в раздел <head> страницы: <meta name=»robots» content=»noindex»>.
Некоторые поисковые веб-краулеры могут интерпретировать директиву noindex по-разному. Поэтому настоятельно рекомендуется искать рекомендации по noindex в каждой поисковой системе, в которой заинтересованы пользователи, чтобы убедиться, что их страницы не будут отображаться в результатах поиска.
Важное замечание! По мнению Google, для того, чтобы тег noindex был эффективен, страница не должна быть заблокирована файлом robots.txt, потому что гусеничный просмотрщик никогда не увидит директиву noindex, и страница все равно может появиться в результатах поиска.
php — Добавить «noindex» в ссылку на pdf
спросил
Изменено 7 месяцев назад
Просмотрено 2к раз
У меня есть веб-сайт, на котором есть ссылки на php-скрипт , где я генерирую pdf-файл с библиотекой mPdf, и он отображается в браузере или загружается, в зависимости от конфигурации.
Проблема в том что я не хочу что бы он индексировался в гугл . Я уже поставил ссылку rel="nofollow" с тем, что больше не индексируется, но как мне dexindexe то, что уже есть?
С rel="noindex, nofollow" не работает.
Придется делать это только по php или какой-то html тег
- php
- html
- mpdf
1
Как Google должен что-то деиндексировать, если вы запретили его роботу доступ к ресурсу? 😉 Сначала это может показаться нелогичным.
Удалите rel="nofollow" в ссылках, а в сценарий, обслуживающий файлы PDF, включите заголовок X-Robots-Tag: none . Google сможет зайти на ресурс, и увидит, что индексировать данный конкретный ресурс запрещено и удалит запись из индекса.
После завершения деиндексации добавьте Запретить правило для файла robots., как упоминает @mtr.web, чтобы роботы больше не истощали ваш сервер. txt
txt
Если у вас есть файл robots.txt, вы можете запретить Google индексировать какой-либо конкретный файл, добавив к нему правило. В вашем случае это будет примерно так:
User-agent: * запретить: /path/to/PdfIdontWantIndexed.pdf
После этого все, что вам нужно сделать, это убедиться, что вы отправляете файл robots.txt в Google, и вскоре после этого Google прекратит его индексацию.
Примечание:
Также может быть целесообразно удалить ваш URL-адрес из существующего индекса Google, потому что это будет быстрее в случае, если он уже был просканирован Google.
Самый простой способ: Добавьте robots.txt в корень и добавьте это:
User-agent: * Запретить: /*.pdf$
Примечание. Если к URL-адресу добавлены параметры (например, ../doc.pdf?ref=foo ), то этот подстановочный знак не будет препятствовать сканированию, поскольку URL-адрес больше не заканчивается на «. pdf»
pdf»
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как добавить «noindex» или «nofollow» к ссылке в WordPress | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы были помещены в режим только для чтения .
В результате ваши впечатления от просмотра будут уменьшены, и вы были помещены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
- Дом
- Техническое SEO
- Как добавить «noindex» или «nofollow» к ссылке в WordPress
Эта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
-
Давненько я не занимался SEO-оптимизацией сайта WordPress. Как добавить «nofollow» или «noindex» к определенным ссылкам? Выделяю анкорный текст в текстовом редакторе, нажимаю кнопку «ссылка».
Могу поклясться, что раньше во всплывающем диалоговом окне была опция.
-
Привет, Рахул,
На самом деле это не ссылка, которую нужно запретить индексировать, а URL-адрес, на который указывает ссылка.
Для этого просто используйте старый добрый плагин Yoast SEO: http://yoast.
com/wordpress/seo/Peter
Плагин отлично подходит для nofollow, но ничего не делает для noindex.
-
Добро пожаловать, Рахул.
Я лично не использовал плагин для этой цели, но этот плагин, похоже, справляется со своей задачей: http://wordpress.org/extend/plugins/nofollow/.
Петр
-
Спасибо, Питер.
Можете ли вы порекомендовать плагин?
-
Привет, Рахул,
Вам нужно будет сделать это, переключившись на «текстовый» вид и добавив нужные атрибуты в html, без установки плагина невозможно сделать это с помощью визуального редактора.
Питер
 com/wordpress/seo/
com/wordpress/seo/
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией All CategoriesAffiliate MarketingAlgorithm UpdatesAPIBrandingCommunityCompetitive ResearchContent DevelopmentConversion Rate OptimizationDigital MarketingFeature RequestsGetting StartedImage & Video OptimizationIndustry EventsIndustry NewsIntermediate & Advanced SEOInternational SEOJobs and OpportunitiesKeyword ExplorerKeyword ResearchLink BuildingLink ExplorerLocal ListingsLocal SEOLocal Website OptimizationMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn-Page OptimizationOther SEO ToolsPaid Search MarketingProduct SupportReporting & AnalyticsResearch & TrendsReviews and RatingsSearch BehaviorSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Связанные вопросы
 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»> Привет, ребята!
Я только что завершил простую миграцию старого домена -> нового домена. Все перенаправления были сделаны 7 февраля. Я отправил запрос на смену домена 7 февраля. Все выглядело нормально, как видно из прикрепленного файла.
Сегодня 19 марта, а наши друзья из GSC все еще говорят, что миграция домена продолжается. У меня никогда раньше это не занимало так много времени; 2-3 дня максимум. Их результаты ухудшаются, так как я не могу выполнить геотаргетинг, а другие функции в GSC не работают, поскольку они «заблокированы» из-за этой миграции (я просто получаю экран, как показано в прикрепленном файле). Мысли? Рискну ли я отозвать запрос и начать заново? Старое «выключи и снова включи»?
Спасибо!
hJXKC
Мысли? Рискну ли я отозвать запрос и начать заново? Старое «выключи и снова включи»?
Спасибо!
hJXKC
Техническое SEO | | tonyatfat
0
Формат моего URL-адреса по умолчанию, оканчивающийся на «.html», я знаю, что это не проблема. Но работают обе ссылки с «.html» и без него. Это критическая проблема или нет? и как это решить?
Техническое SEO | | Мохамед_Самер
0
 org/ListItem»> Как Google может интерпретировать все ссылки «hreflag» в код HTML
org/ListItem»> Как Google может интерпретировать все ссылки «hreflag» в код HTML Я нашел решение. Проблема заключалась в том, что в HTML-код не помещался закрывающий тег….
Техническое SEO | | Red_educativa
0
Недавно запустили сайт для клиента, использующего WP/WooCommerce, чтобы заменить его устаревший сайт корзины покупок, и столкнулись с тысячами ошибок «Отсутствует тег мета-описания». Исследовал и попробовал несколько разных подходов, но, похоже, ничто не решает эту проблему.
Я рад продолжить исследования, но никогда не сталкивался с этой проблемой раньше. Кто-нибудь еще сталкивался с подобным? Если да, то как вы исправили? С каких ресурсов начать?
2ВКДРВx
Исследовал и попробовал несколько разных подходов, но, похоже, ничто не решает эту проблему.
Я рад продолжить исследования, но никогда не сталкивался с этой проблемой раньше. Кто-нибудь еще сталкивался с подобным? Если да, то как вы исправили? С каких ресурсов начать?
2ВКДРВx
Техническое SEO | | двенадцать.net
0
Здравствуйте!
После обновления пингвина мой сайт медленно терял трафик. а теперь с ежедневных 15к-18к он упал до 8к. (6к по выходным)
Я пытался выяснить, каковы причины, но мне не повезло еще несколько месяцев. Я заметил это изменение в GWT, хотя:
Не выбрано в индексе, статус значительно поднялся вверх. см. прикрепленное изображение.
Мой сайт Designzzz
я постоянно исправляю ошибки и проблемы, показанные в инструментах semoz pro.
Если вы, ребята, можете потратить несколько минут, чтобы оценить, что может быть причиной такого падения, я буду благодарен :}
ваше здоровье
6xtkp.jpg
Я заметил это изменение в GWT, хотя:
Не выбрано в индексе, статус значительно поднялся вверх. см. прикрепленное изображение.
Мой сайт Designzzz
я постоянно исправляю ошибки и проблемы, показанные в инструментах semoz pro.
Если вы, ребята, можете потратить несколько минут, чтобы оценить, что может быть причиной такого падения, я буду благодарен :}
ваше здоровье
6xtkp.jpg
Техническое SEO | | wickedsunny1
0
Привет, ребята!
Один из наших сайтов имеет обширные страницы категорий номеров, поэтому мы внедрили теги rel=»next» и rel=»prev» для этих страниц (как предложено Google ниже). Однако мы все еще видим повторяющиеся ошибки метаданных в SEOMoz. отчеты о сканировании, а также в инструментах Google для веб-мастеров. Проверяет ли инструмент сканирования SEOMoz правильность использования тегов rel=»next» и «prev» и не перечисляет ли ошибки метаданных, если теги реализованы правильно?
Или необходимо по-прежнему использовать уникальные мета-заголовки и мета-описания на каждой странице, даже если мы используем теги rel=»next» и «prev», как рекомендует Google?
Спасибо, Джордж Реализация rel=»next» и rel=»prev» Если вы предпочитаете вариант 3 (выше) для своего сайта, давайте начнем! Допустим, у вас есть контент, разбитый на страницы по URL-адресам:
http://www.example.com/article?story=abc&page=1
Однако мы все еще видим повторяющиеся ошибки метаданных в SEOMoz. отчеты о сканировании, а также в инструментах Google для веб-мастеров. Проверяет ли инструмент сканирования SEOMoz правильность использования тегов rel=»next» и «prev» и не перечисляет ли ошибки метаданных, если теги реализованы правильно?
Или необходимо по-прежнему использовать уникальные мета-заголовки и мета-описания на каждой странице, даже если мы используем теги rel=»next» и «prev», как рекомендует Google?
Спасибо, Джордж Реализация rel=»next» и rel=»prev» Если вы предпочитаете вариант 3 (выше) для своего сайта, давайте начнем! Допустим, у вас есть контент, разбитый на страницы по URL-адресам:
http://www.example.com/article?story=abc&page=1
http://www.example.com/article?story=abc&page=2
http://www.example.com/article?story= abc&page=3
http://www.example.com/article?story=abc&page=4
На первой странице, http://www.example.com/article?story=abc&page=1, вы должны включить в раздел:
На второй странице http://www. example.com/article?story=abc&page=2:
На третьей странице http://www.example.com/article?story=abc&page=3:
И на последней странице http://www.example.com/article?story=abc&page=4:
Несколько моментов, чтобы упомянуть:
Первая страница содержит только разметку rel=»next» и не содержит разметки rel=»prev».
Страницы со второй до предпоследней должны быть дважды связаны с разметкой rel=»next» и rel=»prev».
Последняя страница содержит только разметку для rel=»prev», а не rel=»next».
Значения rel=»next» и rel=»prev» могут быть как относительными, так и абсолютными URL-адресами (как разрешено тегом). А если вы добавите в документ ссылку
example.com/article?story=abc&page=2:
На третьей странице http://www.example.com/article?story=abc&page=3:
И на последней странице http://www.example.com/article?story=abc&page=4:
Несколько моментов, чтобы упомянуть:
Первая страница содержит только разметку rel=»next» и не содержит разметки rel=»prev».
Страницы со второй до предпоследней должны быть дважды связаны с разметкой rel=»next» и rel=»prev».
Последняя страница содержит только разметку для rel=»prev», а не rel=»next».
Значения rel=»next» и rel=»prev» могут быть как относительными, так и абсолютными URL-адресами (как разрешено тегом). А если вы добавите в документ ссылку  Например, http://www.example.com/article?story=abc&page=2&sessionid=123 может содержать:
rel=»prev» и rel=»next» служат подсказками для Google, а не абсолютными директивами.
При неправильной реализации, например при пропуске ожидаемого обозначения rel=»prev» или rel=»next» в серии, мы продолжим индексировать страницы и полагаться на собственные эвристики для понимания вашего контента.
Например, http://www.example.com/article?story=abc&page=2&sessionid=123 может содержать:
rel=»prev» и rel=»next» служат подсказками для Google, а не абсолютными директивами.
При неправильной реализации, например при пропуске ожидаемого обозначения rel=»prev» или rel=»next» в серии, мы продолжим индексировать страницы и полагаться на собственные эвристики для понимания вашего контента.
Техническое SEO | | gkgrant
0
Привет, ребята, небольшой вопрос. Теряет ли страница ссылочный вес, когда она дает ссылочный вес? Если я дам ссылку на внешний сайт, потеряю ли я столько же ссылочного веса, или он просто применяется к этому сайту, а не удаляется с моего? Я понимаю, что ссылка на конкурента, в свою очередь, может помочь ему и навредить мне (если он будет считаться более релевантным, чем я, для Google), но имеет ли это прямое отношение к повреждению/удалению ссылочного веса моей страницы? Надеюсь, все это имеет смысл.