
индексация — noindex следует в Robots.txt
спросил
Изменено 3 года, 9 месяцев назад
Просмотрено 2к раз
У меня есть сайт wordpress, который проиндексирован поисковыми системами.
Я отредактировал файл robots.txt, чтобы исключить определенные каталоги и веб-страницы из поискового индекса.
Я умею использовать только разрешения и запреты, но не знаю, как использовать подписку и nofollow в файле Robots.txt.
Во время гугления я где-то читал, что у меня могут быть веб-страницы, которые не будут проиндексированы в Google, но будут просканированы для рангов страниц. Этого можно добиться, запретив веб-страницы в файле Robots.txt и используя подписку для веб-страниц.
Пожалуйста, дайте мне знать, как использовать follow и nofollow в файле Robots.
Спасибо
Сумить
- indexing
- search-engine
- robots.txt
- robot
- nofollow
тег мета-роботов на странице (устанавливает правила для этой конкретной страницы)
Дополнительная информация о мета-роботах
b.) Google не будет сканировать запрещенные страницы, но может индексировать их в поисковой выдаче (используя информацию из внешних ссылок). или каталоги веб-сайтов, такие как Dmoz).
Сказав это, вы не можете получить от этого никакого PR.
Дополнительная информация о поведении Googlebot при индексировании
Google действительно распознает директиву Noindex: внутри robots.txt. Об этом говорит Мэтт Каттс: http://www.mattcutts.com/blog/google-noindex-behavior/
Если вы поместите «Запретить» в robots.txt для страницы, которая уже находится в индексе Google, вы обычно обнаружите, что страница остается в индексе, как призрак, лишенная своих ключевых слов. Я полагаю, это потому, что они знают, что не будут его сканировать, и им не нужен индекс, содержащий битовую гниль.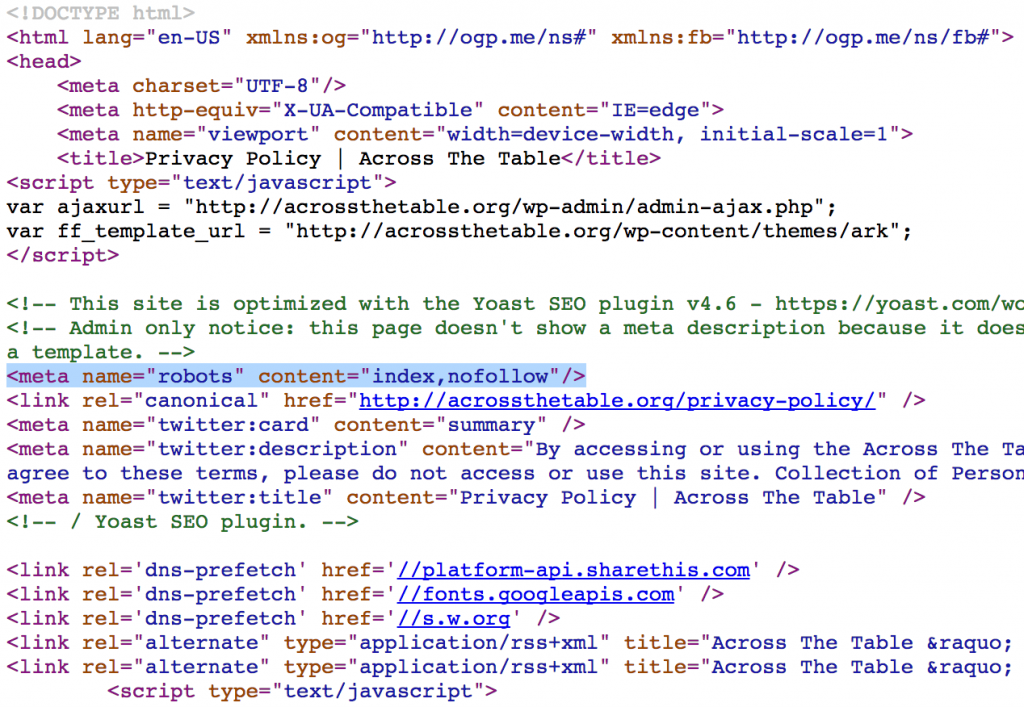
Итак, проблема остается: как нам удалить эту ссылку из Google, так как «Запретить» не работает? Как правило, вы хотите использовать метатег robots noindex на рассматриваемой странице, потому что Google фактически удалит страницу из индекса, если увидит это обновление, но с этой директивой Disallow в вашем файле robots они никогда не узнают об этом.
Таким образом, вы можете удалить правило Disallow этой страницы из файла robots.txt и добавить метатег robots noindex в заголовок страницы, но теперь вам придется ждать, пока Google вернется и просмотрит страницу, о которой вы сказали им забыть. .
Вы можете создать новую ссылку на него со своей домашней страницы в надежде, что Google поймет подсказку, или вы можете избежать всего этого, просто добавив это правило Noindex непосредственно в файл robots.txt. В сообщении выше Мэтт говорит, что это приведет к удалению ссылки.
1
Нет, нельзя. Вы можете указать, какие каталоги вы хотите заблокировать и какие боты, но вы не можете установить nofollow с помощью robots.txt Используйте метатег robots на страницах, чтобы установить nofollow.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Website Robots.
 txt, Noindex, Nofollow and Canonical
txt, Noindex, Nofollow and Canonical
|
A1 Website Search Engine
Онлайн-справка
Покупка
Обновление
Загрузки
Скриншоты
Видео
A1 Website Search Engine имеет дополнительную поддержку подчинения текстового файла robots, notagslink.
 low и inflow, inflow и nofol Поисковая система для веб-сайтов и фильтры сканирования веб-мастеров
low и inflow, inflow и nofol Поисковая система для веб-сайтов и фильтры сканирования веб-мастеров Сканер веб-сайтов в поисковой системе A1 Website Search Engine имеет множество инструментов и опций, позволяющих сканировать сложные веб-сайты. Некоторые из них включают полная поддержка текстового файла robots, noindex и nofollow в метатегах и nofollow в тегах ссылок.
Совет: Загрузка robots.txt часто заставляет веб-серверы и аналитическое программное обеспечение идентифицировать вас как робота для сканирования веб-сайтов.
Большинство из этих параметров можно найти на веб-сайте Scan | Фильтры для веб-мастеров.
В связи с этим вы также можете контролировать их применение:
- Отключить сканирование веб-сайта | фильтры для веб-мастеров | После остановки сканирования веб-сайта: удалите URL-адреса с noindex/disallow.


Если вы используете функции приостановки и возобновления сканирования, вы можете избежать повторного сканирования одних и тех же URL-адресов, сохраняя их все между сканированиями.
HTML-код для Canonical, NoIndex, NoFollow и др.- Canonical:
Это полезно в случаях, когда два разных URL-адреса дают один и тот же контент. Подумайте о том, чтобы прочитать о повторяющиеся URL-адреса, поскольку могут быть лучшие решения, чем использование канонических инструкций, например. перенаправляет. Поддержка этого управляется опцией: Сканировать сайт | фильтры для веб-мастеров | Соблюдать тег «ссылка» «rel» канонический. - NoFollow:
неверная ссылка и
Поддержка этого управляется опциями: Сканировать сайт | фильтры для веб-мастеров | Соблюдайте тег «a» «rel» nofollow и Сканировать сайт | фильтры для веб-мастеров | Подчиняйтесь «мета» тегу «роботы» nofollow. - NoIndex:
Поддержка этого управляется опциями: Сканировать сайт | фильтры для веб-мастеров | Подчиняйтесь «мета» тегу «роботы» noindex. - Мета-перенаправление:
Поддержка этого управляется опцией: Сканировать сайт | Опции сканера | Рассмотрим 0-секундное метаобновление для перенаправления. - Ссылки и ссылки Javascript:
Поддержка этого управляется опциями:- Скан веб-сайта | Опции сканера | Попробуйте поискать внутри Javascript.
- Сканировать сайт | Опции сканера | Попробуйте выполнить поиск внутри JSON.
Совет. Кроме того, вы можете выбрать сканер с поддержкой AJAX в Сканировать веб-сайт | Гусеничный двигатель.
Вы можете прочитать больше в нашей интерактивной справке для A1 Website Search Engine, чтобы узнать о
анализ
и
выход
фильтры.
Поведение поискового робота веб-сайта, используемого поисковой системой веб-сайта A1, похоже на поведение большинства поисковых систем.
Поддержка подстановочных знаков в файле robots.txt:
- Стандарт: соответствие от начала до длины фильтра.
gre будет соответствовать: greyfox, greenfox и green/fox. - Подстановочный знак *: соответствует любому символу, пока не станет возможным другое совпадение.
gr*fox будет соответствовать: greyfox, Grayfox, рычащий лис и зеленый/лис.
Совет. Фильтры подстановочных знаков в файле robots.txt часто настроены неправильно и являются источником проблем при сканировании.
Сканер в нашем инструменте поисковой системы веб-сайта будет подчиняться следующим идентификаторам пользовательского агента в файле robots. txt:
txt:
- Точное совпадение с пользовательским агентом, выбранным в: Общие параметры и инструменты | Поисковый робот | Идентификатор пользовательского агента.
- Агент пользователя: поисковая система веб-сайта A1, если название продукта находится в вышеупомянутой строке пользовательского агента HTTP.
- User-agent: miggibot, если имя поискового движка находится в вышеупомянутой строке пользовательского агента HTTP.
- Агент пользователя: *.
Все найденные инструкции по запрету в robots.txt внутренне конвертируются в оба анализ и выход фильтры в поисковой системе А1.
Проверка результатов после сканирования веб-сайта Просматривайте все флаги состояния всех URL-адресов, обнаруженные сканером — для этого используются параметры, установленные в фильтрах для веб-мастеров, фильтрах анализа и фильтрах вывода.