
Тег noindex и атрибут nofollow: что это такое
Тег noindex введен поисковой системой Яндекс. Он предназначен для закрытия от индексации роботами ссылки или части html кода на странице. Имеет следующую структуру:
<noindex> ссылка или часть кода, которые необходимо скрыть, </noindex>
Данный тег не чувствителен к вложенности и может быть размещен в любой части кода. Поисковые машины, кроме Яндекса, воспринимают команду в качестве невалидной. Если валидность кода важна, тег оформляется следующим образом:
<!—noindex—> текст <!—/noindex—>
Функции:
Тег noindex позволяет:
- повысить релевантность страницы поисковым запросам за счет уменьшения доли второстепенной информации и увеличения плотности ключевых слов,
- скрыть дублирующийся контент, за использование которого может последовать пессимизация сайта в выдаче Яндекса,
- сохранять статический вес страниц и управлять его передачей, так как закрытие одних ссылок пропорционально увеличивает вИЦ оставшихся,
- улучшить сниппет.
 Если в ходе раскрутки сайта в его текстовое описание в выдаче попадает ненужная информация со страницы, ее закрывают от индексации,
Если в ходе раскрутки сайта в его текстовое описание в выдаче попадает ненужная информация со страницы, ее закрывают от индексации, - скрыть от роботов лишние данные (коды счетчиков, ссылки на сайты с постоянно изменяющейся информацией и т.д.).
 Если в ходе раскрутки сайта в его текстовое описание в выдаче попадает ненужная информация со страницы, ее закрывают от индексации,
Если в ходе раскрутки сайта в его текстовое описание в выдаче попадает ненужная информация со страницы, ее закрывают от индексации,Nofollow
Атрибут nofollow не оказывает влияния на индексацию ссылок, но сообщает поисковым роботам, что вес данного линка равен нулю. При продвижении сайта это позволяет сохранить его PR и тИЦ, которые на указанную страницу не передаются. Поисковые боты (кроме googlebot) по ссылке переходят. Атрибут поддерживают Google, Yahoo и Яндекс (с 30 апреля 2010 года). Структура написания параметра следующая: анкор ссылкиАтрибут nofollow используют для ссылок на все сайты, которым не требуется передавать TrustRank ресурса-донора. Для внутренней перелинковки прием не применяется.
Noindex и nofollow позволяют закрыть от индексацию не только отдельную ссылку, но и всю страницу (прописываются внутри нее или в файле robots. txt):
txt):
<Meta name=”robot” content=”noindex, nofollow”>
или
<html>
<head>
<title>Заголовок данной страницы</title>
</head>
Nofollow и noindex могут использоваться совместно:
<noindex><a rel=»nofollow» href=»http://example.ru»> анкор ссылки</a></noindex>.
В таком случае поисковый робот Google ссылку проигнорирует, а Яндекса не увидит.
Другие термины на букву «N»
Совпадений не найдено
Все термины SEO-ВикипедииТеги термина
Что такое nofollow ссылка? Всё что вам нужно об этом знать
Тег rel=”nofollow” — один из самых простых HTML-тегов и один из самых важных для понимания, если вы занимаетесь SEO-оптимизацией. В этом руководстве вы узнаете о ссылках с атрибутом nofollow всё, что нужно, и даже больше.
Ссылки с атрибутом nofollow не новы. Они существуют уже 14 лет.
Если вам важен успех сайта в поисковых системах, то знать, когда стоит использовать ссылки с nofollow, а когда нет — не просто важно, а необходимо.
В этом руководстве я объясню, как появились ссылки nofollow, как они помогают в SEO и при правильном использовании защитят ваш сайт от фильтров Google.
Давайте сперва поговорим об основах.
Что такое nofollow ссылки?
Ссылки nofollow — это гиперссылки с атрибутом rel со значением “nofollow.”
Такие ссылки не влияют на ранжирование страниц на которые ведут, потому что Google не передаёт PageRank или анкорный текст через них. На самом деле, поисковый бот Google даже не посещает подобные страницы.
Рекомендуем к прочтению: Google PageRank не умер: почему он всё ещё имеет значение
Ссылки nofollow vs. dofollow ссылки
Ссылки с и без атрибута nofollow для среднестатистического пользователя выглядят одинаково.
Синий текст в этом предложении — это dofollow ссылка. А синий текст в этом предложении — nofollow. Разница между ними становится заметна только если покопаться в HTML-коде.
Ссылка dofollow:
<a href="https://ahrefs.com">Синий текст</a>
Ссылка nofollow:
<a href="https://ahrefs.com" rel="nofollow">синий текст</a>
Они идентичны, за исключением того, что во второй ссылке появляется тег rel=”nofollow”.
Можно сделать так, чтобы все ссылки на странице стали ссылками nofollow — просто добавьте тег в header страницы. Однако, тег rel=”nofollow” используется чаще, поскольку он позволяет добавлять атрибут nofollow только к определенным ссылкам на странице, а не ко всем.
Не уверены зачем это вообще нужно? Пришло время для небольшого экскурса в историю.
История возникновения
rel=”nofollow”В 2005 году компания Google представила тег nofollow, позиционируя его как инструмент для борьбы со спамом в комментариях.
Если вы блогер (или читатель блога), вам, вероятно, до боли знакомы люди, которые пытаются поднять позиции своих сайтов в поисковых системах через комментарии со ссылками, например, “Заглядывайте на мой сайт со скидками на лекарства”. Это называется спам в комментариях, и нам он тоже не нравится, поэтому мы тестируем новый тег, который его блокирует. С этого момента, когда Google видит атрибут (rel=“nofollow”) на гиперссылках, они не получают никакой пользы при ранжировании сайта в результатах поиска. Это не влияет на сайт, на котором был размещен этот самый комментарий, это всего лишь способ убедиться в том, что спамеры не получат выгоды от злоупотребления попыткой пропиариться в публичных пространствах типа комментариев в блоге, трекбеках и списках сайтов источников переходов.
Вскоре после этого Yahoo, Bing и несколько других поисковых систем также объявили о поддержке тега nofollow.
ВАЖНО
В разных поисковых системах определения тега nofollow немного отличаются. Вот таблица, демонстрирующая эти различия
Вот таблица, демонстрирующая эти различия В настоящее время WordPress, как и многие другие CMS, по умолчанию добавляет тег nofollow к ссылкам в комментариях. Так что даже если раньше вы никогда не слышали о ссылках с атрибутом nofollow, можете быть уверены, что любой спам-комментатор в вашем блоге, скорее всего, не получит никакой SEO-выгоды, несмотря на приложенные усилия.
Тем не менее, если вы переживаете, что к вашим комментариям не применяется атрибут nofollow, то вот простой способ это перепроверить:
- Найдите комментарий
- Щёлкните правой кнопкой мыши на ссылку
- Нажмите “Проверить”
- Посмотрите на выделенный HTML-код.
Если вы видите тег rel=nofollow, то ссылка nofollow, а если нет, то, соответственно, dofollow
Не хочется копаться в HTML-кодах? Установите расширение “nofollow” для Chrome, которое будет выделять все ссылки nofollow при просмотре веб-страниц.
Есть? Отлично. А теперь вернёмся к нашему уроку истории.
2009: Google ведёт борьбу с накруткой PageRank
PageRank передаётся по сайту через внутренние ссылки (ссылки с одной страницы сайта на другую).
Например, часть веса PageRank этой статьи перетекает на другие страницы этого сайта по гиперссылкам, подобным этой. И в целом, более высокий PageRank означает более высокое место при ранжировании. Гари Илш подтвердил эту информацию ещё несколько лет назад.
DYK that after 18 years we’re still using PageRank (and 100s of other signals) in ranking?
Wanna know how it works?https://t.co/CfOlxGauGF pic.twitter.com/3YJeNbXLml
— Gary “鯨理” Illyes (@methode) 9 February 2017
Однако, PageRank передаётся только по ссылкам dofollow.
Так было всегда, но с годами способ распределения PageRank между follow ссылками на странице изменился.
До 2009 года всё работало следующим образом:
Если у вас было три ссылки на странице, и одна из них — nofollow, то общий PageRank делился между двумя ссылками dofollow.
К сожалению, некоторые люди начали использовать это как возможность влиять на ранжирование путём наращивания PageRank для своих сайтов.
Другими словами, они перестали размещать ссылки на менее важные страницы, чтобы обеспечить максимальный приток PageRank на продающие страницы.
В 2009 году Google объявил об изменениях, направленных на пресечение подобной практики на корню.
Так что же всё-таки произойдет, если у вас будет страница с десятью “баллами” PageRank и десятью исходящими ссылками, где пять из них — nofollow? […] Первоначально пять ссылок без nofollow получили бы по два “балла” PageRank каждая […] А более года назад Google изменили это, и теперь PageRank проходит по ссылкам таким образом, что пять ссылок без nofollow получают только по одному значению PageRank.
Вот наглядный пример того, как это выглядело до и после:
ВАЖНО
PageRank — зверь очень загадочный и непростой. Прошло больше десяти лет с тех пор, как в Google внесли эти изменения. И хотя в последние годы от них не было слышно о каких-либо дальнейших изменениях, связанных с работой PageRank, вполне вероятно, что негласно они всё же происходили.
И хотя в последние годы от них не было слышно о каких-либо дальнейших изменениях, связанных с работой PageRank, вполне вероятно, что негласно они всё же происходили.
И хотя накрутка PageRank больше не практикуется, добавление атрибута nofollow к некоторым внутренними ссылками поможет с приоритетом сканирования, потому что, как было сказано ранее, поисковый бот Google даже не переходит по подобным ссылкам.
Поисковые боты не могут войти или зарегистрироваться на вашем сайте в качестве пользователя, поэтому нет смысла приглашать Google-бота переходить на страницы регистрации и авторизации. Использование тега nofollow даёт возможность боту Google сканировать другие более важные для вас страницы, которые и попадут в индекс Google.
Однако, это немного другая и более сложная тема, поэтому не будем углубляться в неё сегодня.
Рекомендуем к прочтению: Crawl budget for SEO: the ultimate reference guide
2013 год и далее: Google борется с проплаченными ссылками
Покупка и продажа ссылок, которые передают PageRank нарушают Руководство для вебмастеров.
Таким образом, все проплаченные ссылки должны быть nofollow.
Так было на протяжении многих лет, даже задолго до 2013 года.
Однако, судя по всему, с этого времени Google все больше беспокоится о влиянии проплаченных ссылок на алгоритм ранжирования.
Мэтт Каттс рассуждает о разоблачени таких ссылок в видео от 2013 года:
Подытожим: Google хочет поощрять заработанные, а не проплаченные ссылки.
Люди относятся к ссылкам как к рекомендациям от редакторов. Они ставят ссылки на что-то, что их вдохновляет. На что-то интересное. Они делятся ссылками с друзьями. Значит, есть причина, по которой они хотят выделить эту конкретную ссылку.
Проблема заключается в том, что некоторые “проплаченные” ссылки ничем не отличаются от заслуженных. Подумайте о том, какая разница между ссылками в проплаченном обзоре и независимом обзоре.
На первый взгляд обе ссылки будут выглядеть одинаково. Поэтому у Google должен быть способ обозначить “проплаченные” ссылки.
Поэтому у Google должен быть способ обозначить “проплаченные” ссылки.
Думайте об этом в следующем ключе: Есть два способа получить Оскар:
Вариант #1: Жить ради актёрского искусства, постоянно оттачивать навыки, совершенствовать своё мастерство в течение долгих лет.
Вариант #2: Купить сразу 6 штук на Амазоне всего за $8.97…
Тег nofollow (на “проплаченных ссылках”) для Google — все равно Что ценник в $8.97 на обратной стороне вашего фальшивого Оскара: признак того, что вы не заслужили такую награду.
Помогают ли ссылки с атрибутом nofollow для SEO?
Давайте вкратце вспомним, что говорит Google о том, как они работают с nofollow-ссылками:
Google не передаёт PageRank и не учитывает анкорный текст по таким ссылкам.
Вроде всё понятно, пока вы не прочитаете предыдущее предложение:
Обычно мы не переходим по таким ссылкам. Это означает, что Google не передаёт по ним PageRank или анкорный текст.

Выражение “обычно” довольно размыто и абстрактно, как по мне. Оно подразумевает, что в некоторых случаях они всё же по таким ссылкам переходят.
Что это могут быть за случаи — остаётся только догадываться.
Некоторые считают, что все без исключения ссылки всё еще передают PageRank. Некоторые считают, что Google передаёт PageRank по ссылкам с атрибутом nofollow, но не по всем. Другие полагают, что некоторые слишком вчитываются в текст, который не менялся в течение добрых семи лет.
Ранее в этом году мы изучили 44,589 поисковых выдач на предмет корреляции между ранжированием в Google и различными атрибутами ссылок — одной из метрик было количество dofollow ссылок.
Вот что мы выяснили:
Корреляция обратных ссылок dofollow несколько слабее корреляции с общим количеством обратных ссылок.
Вот что на этот счёт говорит Тим:
Это может указывать на то, что Google ценит nofollow ссылки с “сильных” страниц больше, чем dofollow ссылки со “слабых” страниц.
 #ктознает
#ктознает Но отнеситесь к этому скептически. Основной целью данного исследования не являлся анализ влияния ссылок nofollow vs. dofollow как таковой. Поэтому мы не изучали этот фактор в отдельности.
Но даже если предположить, что ссылки nofollow не оказывают прямого влияния на SEO, косвенно они все равно могут иметь влияние, поскольку:
1. Они помогают разнообразить ваш ссылочный профиль
Естественные ссылочные профили содержат разные ссылки.
Некоторые dofollow ссылки, а некоторые — nofollow. Это неизбежно, потому что кто-то обязательно будет ссылаться на вас через ссылки nofollow… как бы вы вам это не хотелось это изменить.
Более того, большинство обратных ссылок, которые вы получаете из следующих мест, автоматически будут ставиться в nofollow:
- Социальные сети (Facebook, Twitter, YouTube, и т.д.)
- Форумы (Reddit, Quora, и т.д.)
- Пресс-релизы
- Гостевые книги (привет, 1998 год!)
- Википедия (подсказка “почему”: любой может отредактировать страницу в Википедии)
- Пингбэки
- Каталоги
Короче говоря, если у веб-сайта есть только dofollow ссылки то это подозрительно.
Чтобы проверить количество dofollow ссылок и nofollow воспользуйтесь отчетом Overview в Сайт Эксплорере Ahrefs.
Site Explorer > введите любой домен, URL, или вложенную папку > Overview
Мы видим, что 85% ссылающихся доменов на блог Ahrefs это dofollow ссылки.
Хорошо это или плохо? Пока есть разнообразие, это хорошо.
Но если увидите 100% dofollow ссылок или около того, то это явный признак ссылочных манипуляций. Исходя из опыта, я бы сказал, что 60–90% — это вполне нормально, но этот диапазон не является каким-либо абсолютом оценивания. Если кажется, что что-то нечисто, копните немного глубже.
2. Они приводят трафик, а трафик даёт dofollow ссылки
Ссылки полезны не только для SEO. Это ещё и источник реферального трафика.
Вот почему мы так активны на Quora.
Если вы никогда ранее не слышали о Quora, это сайт вопросов и ответов, на котором каждый может ответить на вопросы, которые задают другие люди. Quora позволяет вставлять в ответах ссылки на соответствующие ресурсы.
Quora позволяет вставлять в ответах ссылки на соответствующие ресурсы.
Вот недавний ответ нашего менеджера по маркетингу Ребекки Бек, где она оставила ссылку на блог Ahrefs:
К сожалению, все исходящие ссылки на Quora являются nofollow. И эта ссылка прямо не повлияет на SEO.
Но вот что интересно:
Если мы проверим отчет по Backlinks (обратным ссылкам) в Сайт Эксплорере Ahrefs для ahrefs.com и поставим фильтр только на ссылки dofollow, то вот одна из многих обратных ссылок, которые мы увидим:
А теперь давайте рассмотрим ссылающуюся страницу (страницу, с которой идёт dofollow ссылка):
Единственная причина, по которой мы получили dofollow ссылку заключается в том, что автор этой статьи наткнулся на ответ Ребекки на Quora. Другими словами, nofollow ссылка косвенно привела к ссылке dofollow.
Поэтому стоит запомнить следующее: чтобы кто-то мог оставить на вас ссылку, следующие три события должны произойти в таком порядке::
- Люди должны увидеть ваш контент
- Он должен им понравиться
- Они рекомендуют его другим (через другие ссылки на сайте).
Поскольку ссылки с атрибутом nofollow могут помочь выполнить первый шаг, они часто являются катализаторами последующих ссылок.
3. Они могут защитить от санкций со стороны Google
Иногда есть справедливые основания для того, чтобы платить за ссылки.
Если сайт получает кучу трафика, есть смысл заказать рекламный пост на этом сайте. И если вы платите хорошие деньги за размещение, то вы, вероятно, захотите оставить обратную ссылку на ваш сайт, чтобы читатели могли легко на него выйти.
Проблема? Google утверждает, что использование платных ссылок противоречит Руководству для вебмастеров.
Учитывая сказанное, SEO-коммьюнити, как правило, делится на два лагеря:
- Те, кто считает, что Google может точно определить платные ссылки алгоритмически.
- Те, кто считает, что Google не может точно определить платные ссылки алгоритмически.
Кто из них прав — уже совсем другой вопрос.
Пока что предположим, что лагерь под номером 2 прав, и Google действительно с трудом определяет подобные ссылки. Это значит, что вы можете не беспокоиться и спокойно продавать и покупать ссылки на контент, который вам нравится, верно? Не спешите.
Это значит, что вы можете не беспокоиться и спокойно продавать и покупать ссылки на контент, который вам нравится, верно? Не спешите.
У Google есть инструмент, позволяющий любому пожаловаться на сайт, который покупает или продаёт ссылки..
Инструмент Google для жалоб на “проплаченные” ссылки.
Перевожу: возможно следует бояться не Google, а конкурентов.
Подумайте сами: Если конкурент видит, что вы хорошо ранжируетесь по его целевому запросу и использует такой инструмент, как Сайт Эксплорер Ahrefs для поиска ваших ссылок и находит dofollow ссылки вроде этой:
Пример “проплаченной” ссылки.
Почему бы ему на вас не пожаловаться?
Если благодаря этой жалобе команда, занимающейся веб-спамом в Google увидит сайт, найдёт проплаченные ссылки и применит ручные меры, то на одного конкурента в выдаче станет меньше.
И это подводит нас к следующему пункту:
Как проверить сайт на наличие проблем с nofollow ссылками
Рискованно иметь dofollow ссылки, которые противоречат Руководству для вебмастеров от Google.
То же самое относится и к исходящим ссылкам на вашем сайте, которые должны иметь атрибут nofollow.
Но дело не только в гневе Google (т.е. санкциях). Может случиться так, что некоторые внутренние ссылки nofollow будут ухудшать SEO.
Дальше мы научимся проводить беглый анализ, который поможет выявить и устранить любые подобные проблемы.
1. Ищите dofollow ссылки с вхождениями запросов в анкорных текстах
Чаще всего, ссылаясь на ваш сайт, люди не будут использовать точное вхождение запроса в анкорном тексте. Поэтому dofollow ссылки с точным вхождением обычно служат признаком манипуляций со ссылками.
Чтобы их найти, воспользуйтесь отчетом Anchors (Анкоры) в Сайт Эксплорере Ahrefs.
Site Explorer > введите свой домен > Anchors > фильтр dofollow
Здесь мы видим, что большинство анкоров этого сайта брендированные или общие (размытые с целью конфиденциальности), но есть также девятнадцать веб-сайтов (ссылающихся доменов), которые ссылаются, используя в качестве анкора фразу “кредиты”.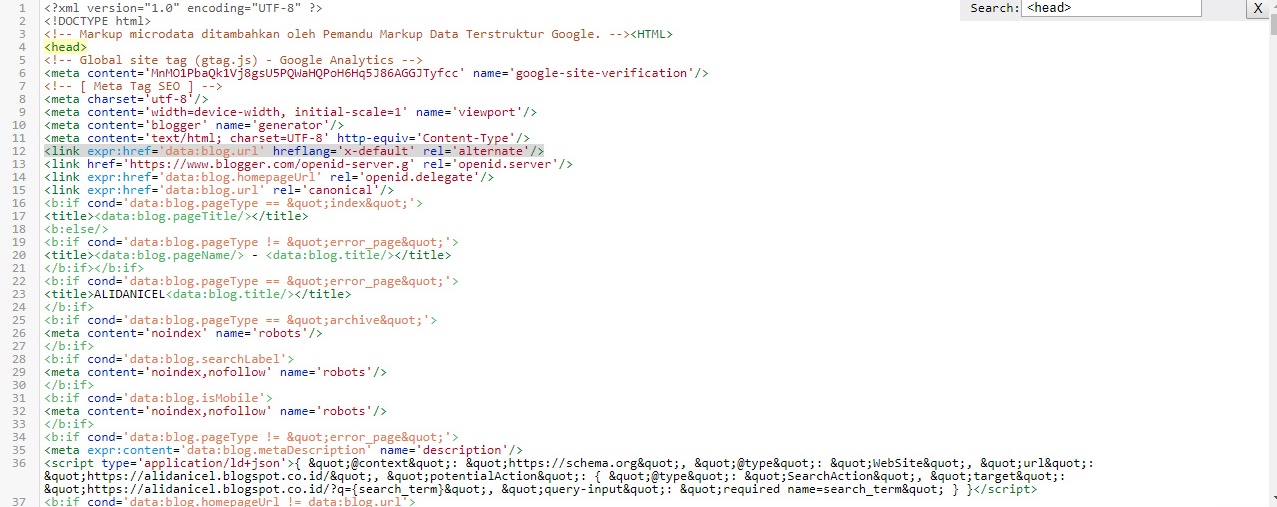
Если нажать на выпадающий список, а затем выбрать Referring domains (Ссылающиеся домены), мы сможем увидеть, что это за сайты.
Затем, если еще раз нажмем на выпадающий список, то увидим окружающий текст всех ссылок с каждого домена.
Вот некоторые рекомендации по работе с различными типами ссылок:
- Покупные ссылки на некачественных сайтах. Попросите убрать ссылку на ваш сайт (желательно) или добавить к ней атрибут nofollow. В противном случае, просто отклоните ссылки на уровне домена или страницы.
- Ссылки из блока об авторе в гостевых постах. Вы когда-нибудь оставляли ссылки с точным вхождением в блоке автора в гостевых постах? Попросите поставить ссылку на бренд, а не ключевое слово. А если хотите оставить ссылку с вхождением, то поставьте nofollow
- Ссылки c виджетов. Измените HTML вашего виджета так, чтобы ссылка была nofollow. Попросите того, кто уже встроил виджет, добавить к ссылке атрибут nofollow.
- “Сквозные” ссылки. Попросите поменять анкор с ключевого слова на бренд.

Обратите внимание, что точное вхождение ключевых слов в dofollow ссылках не всегда говорит о том, что сайт низкого качества или ссылка “проплачена”. Такие ссылки могут появляться и естественным образом.
Поэтому, прежде чем отклонять обратные ссылки или просить добавить к ним тег nofollow, стоит тщательно их изучить.
Если этого не делать, в конечном счёте можно нанести больше вреда, чем пользы.
СОВЕТ
Во вкладке с отчётами Anchors крупных сайтов может быть огромное количество различных анкоров.
Так что вот небольшая хитрость:
Сначала экспортируйте полный список всех анкоров.
Site Explorer > введите свой домен > Anchors > добавьте фильтр dofollow > Export > CSV
Затем скопируйте и вставьте их в Ahrefs Keywords Explorer пачками по 10000 за раз.
Нажмите на поиск, чтобы сгенерировать отчёт, затем отсортируйте по CPC от большего к меньшему.
Поскольку обычно анкоры с высоким CPC спамятся чаще, они будут вверху списка.
В отчёте Anchors в Сайт Эксплорере введите спамные анкоры в поисковую строку и исследуйте дальше.
2. Ищите проплаченные обратные ссылки follow
Обратные ссылки из проплаченных постов всегда должны иметь атрибут nofollow.
Потому что вы фактически платите за ссылку и она не должна передавать PageRank.
Чтобы найти такие ссылки, введите слово “sponsored” в поиск в отчёте Backlinks по вашему сайту, используя Сайт Эксплорер Ahrefs.
Site Explorer > Backlinks > поиск по слову “sponsored” > фильтр dofollow
Разберитесь с ними и попросите сделать такие ссылки nofollow.
3. Ищите на своём сайте исходящие ссылки с вхождениями ключевых слов
Знаете ли вы, что Forbes сделал все исходящие ссылки на сайте nofollow ещё в 2017 году?
Это произошло после того, как они обнаружили, что некоторые из их авторов продавали ссылки со своих статей. И поскольку авторов у них очень много, они решили, что проверять каждую ссылку будет очень долго, и воспользовались “ленивым” вариантом, чтобы не пропустить ни одной.
И поскольку авторов у них очень много, они решили, что проверять каждую ссылку будет очень долго, и воспользовались “ленивым” вариантом, чтобы не пропустить ни одной.
Как это относится к вам?
Если вы когда-либо публиковали гостевые публикации на своём сайте или у вас есть UGC контент, вы можете столкнуться с аналогичной проблемой.
Чтобы это выяснить, посмотрите на исходящие анкоры в Сайт Эксплорере Ahrefs.
Site Explorer > введите свой домен > Outgoing links > Anchors > фильтр dofollow
Ищите подозрительные слова и фразы, которые не ожидаете увидеть на своём сайте, и удаляйте или ставьте тег nofollow везде, где ссылка может показаться неестественной (например, анкоры с точными или частичными вхождениями ключевых слов в блоке автора в гостевых постах и т.д.).
Google лучше всех может объяснить почему это важно:
Если вы не можете или не хотите поручиться за содержание страниц, на которые ссылаетесь, например, комментарии или записи в “гостевой книге”, лучше сделать эти ссылки nofollow.
 Это может отбить у спамеров охоту использовать в своих корыстных целях ваш сайт, и поможет уберечь его от непреднамеренной передачи PageRank.
Это может отбить у спамеров охоту использовать в своих корыстных целях ваш сайт, и поможет уберечь его от непреднамеренной передачи PageRank. Нашли много анкоров?
Воспользуйтесь советом из пункта #1.
4. Ищите проплаченные follow ссылки на своём сайте
Вы когда-нибудь публиковали на сайте посты за деньги? А убедились, что ссылки обернуты в nofollow?
Если нет, то проверьте.
Для этого вбейте в строку Google <code>site:yourwebsite.com “sponsored post”</code>
Открывайте результаты один за другим и ищите эти самые ссылки.
Если вы установили расширение для Хрома nofollow, все ссылки с атрибутом nofollow на странице будут выделены, соответственно, спонсируемая ссылка тоже должна быть выделена. А если нет, то это dofollow ссылка.
Убедитесь в этом наверняка, проверив HTML код. Щёлкните правой кнопкой мыши по ссылке, нажмите “Inspect”и найдите тег <code>rel=”nofollow”<code>—HTML—
Если его нет, то это dofollow ссылка и вам следует добавить к ней тег nofollow.
5. Ищите внутренние nofollow ссылки
Ни одна внутренняя ссылка не должна быть nofollow если она не указывает на маловажные страницы или те, которые вы хотите исключить из индекса поисковых систем.
Чтобы найти внутренние nofollow ссылки, используйте отчёт Best by Links в Ahrefs Site Explorer.
Site Explorer > введите свой домен > Best by Links > переключите на Internal > сортировать по nofollow
Если вы видите страницы с внутренними nofollow ссылками, нажмите на цифру с их количеством, чтобы увидеть где они появились и разбирайтесь подробнее. Возможно, они там нужны (например, если есть внутренние nofollow ссылки на страницу входа в систему).
Однако, если очевидной причины для добавления атрибута nofollow нет, просто удалите его.
У нас тоже есть такое. По какой-то причине у нас появилась nofollow ссылка с одной записи в блоге на другую.
СОВЕТ
Для более детального аудита проблем, связанных с внутренними nofollow ссылками, запустите последнюю версию Ahrefs Site Audit.
Это не только даст вам на 100% свежие данные, но и предупредит о множестве специфических проблем, связанных с внутренними и внешними ссылками nofollow.
Пример проблем, которые могут возникнуть со внутренними ссылками nofollow в Ahrefs Site Audit
Узнайте, как настроить первое сканирование в Site Audit в этом видео:
Заключительные мысли
Ссылки nofollow играют огромную роль в SEO.
Надеюсь, это руководство вооружит вас знаниями, необходимыми для того, чтобы ссылки nofollow работали на вас… а не против вас.
Прежде чем закончить, хочу поделиться заключительной и, возможно, довольно очевидной мыслью: если вы активно создаёте ссылки на сайт, то стоит отдать предпочтение созданию dofollow ссылок. Через них передаётся PageRank и они оказывают непосредственное влияние на SEO.
В Site Explorer все наши отчёты по обратным ссылкам имеют фильтры dofollow и nofollow.
Так проще выбирать нужное при анализе ссылочных профилей конкурентов, или при создании списка для методики “skyscraper” и т.д.
Всё ещё остались вопросы? Спросите в комментариях ниже или в Twitter.
Перевел Дмитрий Попов, владелец Affilimarketer.com
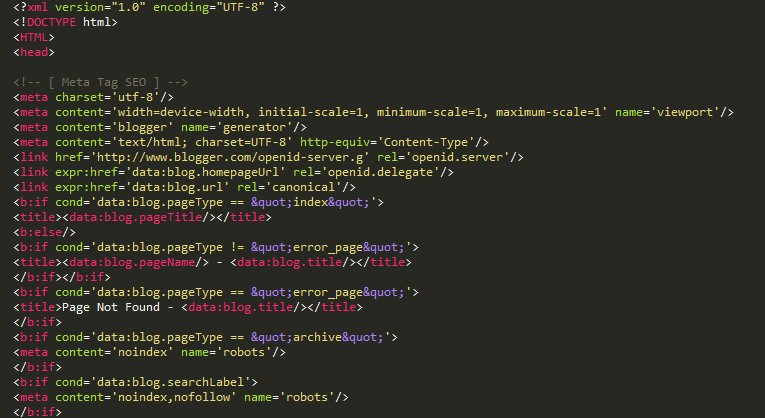
Используем rel=nofollow и noindex для Yandex » WPbloging
В апреле, поисковик Yandex, обрадовал рунетовских веб-мастеров, включением поддержки атрибута rel=»nofollow» в ссылках. Какую пользу это нам — блоггерам принесет? Как правильно прописать атрибут rel=»nofollow» в ссылках и что теперь будет с <noindex>?Давайте попробуем разобраться в этих новинках Яндекса .
Небольшая предыстория атрибута rel=nofollow
Что такое rel=nofollow?
Rel=» « — атрибут в ссылке <a>, указывающий отношение ссылки к целевой странице. Также, есть еще атрибут Rev=» «, указывающий отношение целевой страницы к ссылке, например (ссылка с rev=»sponsor» указывает, что это спонсорская ссылка). Но об этом в следующей статье.
Nofollow — статус, говорящий о том,что вы не одобряете данную ссылку.
Исходя из вышесказанного:
Rel=nofollow — определяет отношение вашей ссылки к целевой странице как не одобряемое. Применительно к поисковикам, данный атрибут указывает индексирующим роботам, что по данной ссылке не следует переходить на целевую страницу.
Rel=nofollow был введен и стандартизирован в 2005 году, в ответ на многочисленный ссылочный спам, присутствующий в блогах. Инициатором введения была поисковая система Google, источник.
Google, встречая ссылку с данным атрибутом, не следует по данной ссылке и не передает вес PR целевым страницам. Также, данные ссылки не учитывались в расчетах распределения ссылочного веса по ссылкам страницы. Но, так было до 2010 года. На данный момент, Google, также не передает ссылочный вес и не следует по ссылкам с rel=»nofollow», но вот ссылочный вес, внутри страницы, стал распределятся и на эти ссылки но впустую. То есть, если у вашей страницы PR-10 и 10 ссылок на странице, где 5 из них закрыты, то каждая открытая ссылка передавала по 2PR на целевую страницу. Теперь каждая открытая ссылка будет передавать 1PR по открытым ссылкам и по 1PR в пустоту по закрытым. Но эта статья не о Google, вернемся к Яндексу.
Yandex, до апреля месяца 2010г., не учитывал данный статус. В рекомендациях Яндекса находим нашумевший тег <noindex>, который позволял сделать тоже самое и больше. Теперь там и nofollow.
В чем разница rel=nofollow и <noindex>
Так в чем же проблема?
Зачем Яндексу понадобилось вводить поддержку rel=»nofollow»?
<!--noindex-->Блок вашего закрываемого текста<!--/noindex-->
Еще одна проблема тега <noindex> в том, что зарубежные веб-мастера, не ведая о данном теге, не используют его в разработках своих плагинов к WordPress. Приходится данные плагины адаптировать под Яндексовскую реальность.
Если в комментариях блога ссылки были закрыты атрибутом rel=»nofollow», то для Яндекса эти ссылки были открыты. Это означало, что роботу приходилось путешествовать по всем ссылкам указанным в комментариях.
Атрибут со статусом rel=»nofollow» стандартизирован и используется во всем мире для указания поисковикам, что ссылка не одобрена автором и по ней не нужно следовать.
Например, если закрыть служебную страницу от индексации в robots.txt, а ссылку оставить открытой, робот проследует на данную страницу, но не проиндексирует ее. Зачем тогда тратить ресурсы робота на переходы по ненужным страницам? Еще есть один нюанс, если на вашу служебную страницу ведут открытые ссылки с других внешних источников, то ваша, как бы закрытая страница, попадет в поиск, даже если она закрыта в robots.txt. Об этом также расскажу в следующих статьях.
Исходя из всего этого, по многочисленным просьбам и жалобам веб-мастеров, Яндекс ввел поддержку стандартизированного W3C атрибута со статусом rel=»nofollow». Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст.
Зачем нужен <noindex>?
Тег <noindex> очень важен, если вы хотите, чтобы часть текста, со всеми анкорами ссылок и т.д., не индексировалась и не попала в поисковую базу Yandex.
Например, у вас на странице может быть служебная информация, или блок текста с сайта, который используется как негативный пример. Вы не хотите, чтобы поисковик связал ваш сайт с данным текстом или индексировал служебную информацию и сохранил у себя в базе. Для этого данный блок обрамляется тегом <noindex>.
К сожалению, такого инструмента для Google не существует. Вполне возможно, что Google или консорциум W3C в будущем обратят внимание на данный тег или придумают свой, и веб-мастера получат в свой инструментарий еще один полезный инструмент.
Как правильно прописать rel=nofollow и <noindex>
- Для закрытия ссылок от индексации, с помощью rel=»nofollow», используется простая схема:
<a rel=»nofollow» href=»http://www.site.com» title=»Подсказка»>Ссылка на сайт</a>
перехода по ссылке не будет. - Для закрытия блока текста тегом <noindex>, со всем содержимым, в том числе и с анкорами ссылок, используется схема:
<!--noindex-->Блок вашего закрываемого текста<!--/noindex-->данный текстовый блок не будет проиндексирован в Яндекс, со всеми текстами ссылок. - Для закрытия блока текста тегом и ссылок в блоке, используется схема:
<!--noindex-->Блок вашего закрываемого текста <a rel="nofollow" href="http://www.site.com" title="Подсказка">Текст анкор ссылки</a> Блок вашего закрываемого текста<!--/noindex-->данный блок не будет проиндексирован в Яндекс, со всеми ссылками содержащимся в данном блоке.
Что изменилось с вводом поддержки rel=nofollow?
- Для тех, кто ведет ресурсы для людей и не использует спам-продвижения, почти ничего не изменится. Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
- Для тех, кто использовал в продвижении ссылочный спам (спам в комментариях, спам в форумах, соц. сетях, Википедии и т.д), и у кого основная ссылочная масса, дающая ТИЦ, состояла из таких ссылок, будет существенное снижение ТИЦ и как правило, проседание в поисковой выдаче Yandex.
Источник
Кратко, о новинках апреля 2010 года в Яндекс:
- У страницы поисковой выдачи Яндекс теперь фиксированная ширина.
- Появились в выдаче навигационные цепочки, у некоторых сниппетов и даты публикации.
- Появился колдунщик видео.
- В панели веб-мастера появилась возможность просмотра статистики по собственным ключевым словам.
P.S. Теперь осталось дождаться включения поддержки Яндексом канонического атрибута rel=»canonical», о котором я писал в статье о дублированном контенте, и многие блогеры вздохнут с облегчением.
Хорошая новость, в конце мая 2011г. Яндекс стал учитывать атрибут rel=»canonical». Принесет это облегчение или нет, покажет время.
Нашел ошибку в тексте? Выдели ее мышкой и нажми
Noindex, nofollow — чек лист для работы
Noindex и nofollow зачастую называют некорректно: тегами, метатегами, атрибутами. На самом деле noindex — это тег, а nofollow — атрибут внутри тега.
Метатеги — это теги, которые относятся ко всей странице: <meta name=»robots» content=»noindex, nofollow» />
Тег <noindex> создает конструкцию: <noindex> … </noindex>;
атрибут rel=”nofollow” может появляться в конструкции тега.
С помощью этих параметров можно и нужно указывать поисковым роботам Google, Яндекс или других систем, как именно нужно взаимодействовать с контентом, находящимся внутри этих параметров.
Где и как использовать noindex и nofollow
Эти атрибуты могут располагаться в заголовке страницы, и тогда они будут правилом для всего контента. А могут ограждать конкретный текстовый фрагмент, ссылку или изображение.
Для страниц метатеги noindex и nofollow закрывают от индексации:
- страницы регистрации;
- служебные страницы;
- страницы авторов комментариев;
- другие «вредные» для индексации страницы;
Для контента теги noindex и атрибут nofollow закрывают от индексации:
- «вредные» ссылки;
- цитаты из различных источников;
- повторяющийся контент
Чтобы закрыть от индексации страницы — метатеги noindex и nofollow
Когда нужно чтобы страница и контент на ней индексировались, а поисковый робот не переходил по ссылкам. В таком случае используем конструкцию:
<meta name="robots" content="index, nofollow"/>
Когда надо закрыть страницу от индексации, а переходы по ссылкам разрешить, вставляем
<meta name="robots" content="noindex, follow"/>
Чтобы индексировались и ссылки, и сама страница, в заголовке применяем метатег
<meta name="robots" content="index, follow"/>
Для полного закрытия страницы и ссылок на ней от индексации:
<meta name="robots" content="noindex, nofollow"/>
Для примера приведем заголовок страницы, в которой используются метатеги с полным закрытием страницы и ссылок для индексации ее роботом поисковой системы (noindex, nofollow):
<html> <head> <meta name="robots" content="noindex,nofollow"> <meta name="description" content="Description для данной странички"> <title>…</title> </head> <body>
Для контента и ссылок тег noindex и атрибут nofollow
Чтобы скрыть от индексации фрагмент текста (работает только для Яндекс и Рамблер), используем следующее решение:
<!--noindex--> (текст, который нужно скрыть) <!--/noindex-->
Чтобы скрыть от индексации ссылку, используем:
<a href="https://mysite.com/" rel="nofollow">Текст ссылки </a>
Чтобы скрыть ссылку от индексации и Яндекс, и Google, применяем
<noindex><a href="http://mysite.com/" rel="nofollow">текст ссылки</a></noindex>
Google в данной конструкции принимает только rel=»nofollow», а для Яндекса действуют и noindex, и rel=»nofollow».
<noindex> — неофициальный тег
<noindex>…</noindex> используется поисковыми системами Яндекс и Rambler. Цель — скрыть от индексации указанный контент.
Google на данный тег не обращает внимание, ибо он не является принятым тегом разметки html.
rel=”nofollow
rel=”nofollow” запрещает поисковым системам переходить по указанной ссылке. Конструкция:
<a href="signin.php" rel="nofollow">Войти</a>
Как сообщается в ответе поддержки Google для веб-мастеров, поисковая система не переходит по ссылке и не использует для перехода по ней краулинговый бюджет. Но это не значит, что робот туда не заглянет и не проверит. То есть дальнейшая судьба данной ссылки такая: мы про тебя знаем, но молчим, пока это безопасно.
Если нужно скрыть от индексации страницы только для Google, можно использовать <meta name=»googlebot» content=»noindex» />.
Если нужно закрыть от индексации только для Яндекс – <meta name=»yandex» content=»noindex»/>.
Закрытие индексации через файл robots.txt
Метатеги, описанные ранее <meta name=»robots» content=»noindex, nofollow»> появляются только после открытия роботом страницы и прочтения заголовка.
Закрытие же страницы через файл robots.txt запрещает даже заходить на страницу.
Если поисковая система раньше проиндексировала эту страницу, то она будет находится в индексе поисковых систем (даже после закрытия в файле robots.txt). А в description нам сообщат, что описание для данной страницы отобразить невозможно, ведь она закрыта от индексации в файле robots.txt.
# robots.txt for http://www.w3.org/ User-agent: W3C-gsa Disallow: /Out-Of-Date User-agent: W3T_SE Disallow: /Out-Of-Date User-agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT; MS Search 4.0 Robot) Disallow: / # W3C Link checker User-agent: W3C-checklink Disallow: User-agent: Applebot Disallow: /People/domain/ # the following settings apply to all bots User-agent: * # Blogs - WordPress # https://codex.wordpress.org/Search_Engine_Optimization_for_WordPress#Robots.txt_Optimization Disallow: /*/wp-admin/ Disallow: /*/wp-includes/ Disallow: /*/wp-content/plugins/ Disallow: /*/wp-content/cache/ Disallow: /*/wp-content/themes/ Disallow: /blog/*/trackback/ Disallow: /blog/*/feed/ Disallow: /blog/*/comments/ Disallow: /blog/*/category/*/* Disallow: /blog/*/*/trackback/ Disallow: /blog/*/*/feed/ Disallow: /blog/*/*/comments/ Disallow: /blog/*/*?
Поэтому для непроиндексированных страниц можно использовать как вариант закрытия через метатеги в заголовке, так и через файл роботс.тхт.
Если страница уже была проиндексирована, рекомендуем вставить в заголовок, в секцию <head> метатег <meta name=»robots» content=»noindex, nofollow» />. Это исключит ее из индексации и предотвратит последующее попадание в нее.
В данном файле есть несколько блоков. Первый — User-agent — команда для определения робота, к которому относится последующие директивы. В коде файла роботс.тхт, что представлен выше — для робота W3C-gsa, W3T_SE, Mozilla/4.0, W3C-checklink, Applebot. А звездочка ( * ) после команды User-agent — говорит что последующие директивы относятся ко всем поисковым роботам.В большинстве случаев нам понадобиться заголовок в файле robots.txt следующего стандартного вида:
User-agent: * # applies to all robots
Последующие директивы позволяют исключить как отдельные страницы, так и целые папки со страницами. Код будет выглядеть так:
Disallow: / # disallow indexing of all pages
В случае, если в данной папке есть одна или несколько страниц, которые должны быть проиндексированы поступаем следующим образом:
User-agent: * Disallow: /help #запрещает страницы к индексированию, которые находятся в каталоге, например: /help.html и /help/index.html Disallow: /help/ #запрещает только те страницы, которые находятся на уровень ниже каталога help, а те, что в этом каталоге - остаются открытыми, например: /help/index.html закрыт, но /help.html - открыт
В файле robots.txt обязательно должно быть хотя бы одно поле Disallow. Как же поступить если нам не нужно закрывать ни одной страницы? Оставляем поле пустым:
Disallow: #если после директивы оставить поле пустым - считается что все страницы сайта остаются открытыми для индексирования
Распространенные ошибки:
- Попытка закрыть от индексации ссылку следующей комбинацией: <nofollow><a href=»index.php»>Перейти</a></nofollow>
- Попытка закрыть ссылку от индексации с помощью тега <noindex>. Таким образом можно закрыть только анкор (текст ссылки, а не саму ссылку), и только для Яндекс.
Тег <noindex> для разметки html является неофициальным; в официальной разметке есть только атрибут rel или метатег со значением nofollow.
Выводы
Для экономии краулингового бюджета важно закрывать от индексации лишние ссылки, вес которых не существенен для продвижения.
Для поисковых систем ссылки nofolow выглядят естественно, а их наличие является нормальным. Однако большое количество исходящих ссылок на сайте может оказаться и минусом, несмотря на то, что они были закрыты от индексации.
Заказать сайт
сколько их должно быть — SEO на vc.ru
Разбираем, для чего нужны ссылки nofollow, если они не передают вес, сколько их должно быть и какое соотношение dofollow и nofollow должно быть на странице.
9377 просмотров
Какие ссылки должны быть на сайте? pr-cy.ru
Nofollow и dofollow ссылки — что это такое
Несмотря на то, что с 2014 года Google отменил Page Rank, один из алгоритмов определения авторитетности страниц, ссылочный вес все еще передается и имеет значение для сайта. Поисковые боты анализируют все ссылки страниц при сканировании сайта. Веб-мастер решает, нужно ли передавать вес по ссылкам — для этого используют dofollow и nofollow, значения атрибута rel тега «a».
Ссылки dofollow
Ссылки со значением dofollow передают PR и анкор, это значение атрибута сообщает поисковому боту, что по ссылке можно перейти и индексировать ее:
<a href=»url» rel=»dofollow»>текст ссылки</a>
Все ссылки, где не задан этот параметр, по умолчанию считаются dofollow. С dofollow все относительно понятно — они индексируются, анкоры учитываются, вес передается. Разберемся в особенностях ссылок с nofollow.
Ссылка с nofollow
Когда не нужно передавать PR, в теге rel прописывают nofollow. Вот так:
<a href=»url» rel=»nofollow»>текст ссылки</a>
Как Google относится к nofollow
В справке Google для веб-мастеров сказано, что значение nofollow не дает поисковым ботам переходить по ссылкам. Такие ссылки не передают ссылочный вес, поэтому не учитываются при расчете ссылочного веса акцепторов. Также в справке говорится, что атрибут rel=»nofollow» не дает передавать PR.
«Если вы блогер(или читатель блога), вы встречали комментарии людей, которые пытаются повысить рейтинг своих сайтов, оставляя ссылки по типу «Посетите мой фармацевтический сайт». Это называется спамом, и нам это тоже не нравится. Мы протестировали новый тег, который блокирует его. Отныне, когда Google видит атрибут rel=«nofollow» в гиперссылках, эти ссылки не получают веса».
Стоит обратить внимание, что Справке написано: «Как правило, переход не производится» — можно сделать вывод, что боты рассматривают nofollow как рекомендацию, а не как строгий запрет. К тому же, в Search Console в отчете «Ссылки на ваш сайт» можно найти и nofollow ссылки, то есть поисковик их все равно воспринимает. Значит, вес не будет передаваться, но боты могут по этим ссылкам переходить.
Атрибуты для рекламных и пользовательских ссылок
Осенью 2019 года Google ввел новые атрибуты для рекламных ссылок:
- rel=»sponsored» – обозначает рекламные и спонсорские ссылки;
- rel=»ugc» – обозначает ссылки в пользовательском контенте, например, в комментариях.
По словам представителей Google, эти атрибуты нужны для того, чтобы поисковым ботам было проще определять природу появления ссылок. По сути, они отчасти заменяют nofollow. Поддержка обновления уже работает, но Google не настаивает на замене атрибутов в старых ссылках.
Также поисковая система сообщает, что к одной ссылке можно применить сразу несколько атрибутов, но с 1 марта 2020 года может игнорировать любые запретительные атрибуты, то есть любые ссылки могут повлиять на позиции в выдаче.
Подробнее о рекламных атрибутах можно прочитать в статье.
Как Яндекс относится к nofollow
Раньше у Яндекса был только собственный тег noindex как альтернатива nofollow, который закрывал часть текста страницы от индексирования, но с 2010 года поисковая система стала поддерживать nofollow тоже — для запрета индексирования отдельных ссылок. Noindex работал только в Яндекс и Рамблер, Google его не поддерживал, что вызывало много неудобств у веб-мастеров.
Noindex можно использовать в сочетании с nofollow, это ограничит передачу веса ссылки и поисковые боты не обратят на нее внимание. В разделе Яндекс.Помощи об индексировании сказано, что атрибут rel=»nofollow» запрещает боту переход и индексирование ссылки.
Согласно исследованию Алексея Трудова, если использовать оператор inlink для поиска по анкор-листу, окажется, что все анкоры ссылок nofollow Яндекс учитывает. Можно сделать вывод, что вес передается, но нет точных данных о вычете передаваемого веса.
Ссылки из поисковых систем
Ссылки из ВКонтакте, Facebook, Twitter и других социальных сетей содержат nofollow, поэтому не должны влиять на ранжирование в Яндекс и в Google.
«…Если там что-то и передается, то поведенческие от тех пользователей, которые по этой ссылке кликнут».
Ссылки из соцсетей не передают вес, но учитываются в панели Вебмастера в Яндексе. Сергей Devaka Кокшаров в 2015 году провел эксперимент и выяснил, что ссылки из Twitter учитываются в панели Вебмастера, несмотря на nofollow и 301 редирект. Из Одноклассников не учитываются, потому что закрыты для индексации. Из Youtube появляются ссылки из закрытых nofollow описаний к видео и из аккаунтов пользователей, которые его недавно лайкали. ВКонтакте не ставит прямые ссылки на сайты в постах, а всегда использует 302 редирект, поэтому Яндекс отображает конструкции vk.com/away.php.
Сергей также сообщал, что всегда учитываются и отображаются ссылки из настроек публичных страниц, у которых нет параметра«post» в URL.
В любом случае, если ссылки из соцсетей не передают вес, они служат для поисковых систем сигналом о том, что страницы сайтов, на которые ведут эти ссылки, интересны пользователям. Например, в 2010 году Мэтт Катс из Google заявил, что поисковая система обращает внимание на ссылки из соцсетей.
Cсылки nofollow — влияние на SEO
Зачем нужны nofollow:
- Закрыть служебные ссылки. Закрывают ссылки на страницы входа, в личный кабинет и прочие страницы, которые незачем показывать поисковому боту.
- Избавиться от негативного влияния SEO-ссылок. Раньше, до введения рекламных ссылочных атрибутов, Google рекомендовал все рекламные ссылки закрывать nofollow, чтобы не получить санкции из-за качества доноров и чрезмерно большого количества ссылок. Теперь любая ссылка может повлиять на позиции.
- Уменьшить количество спама. В некоторых CMS все пользовательские ссылки по умолчанию имели nofollow, чтобы спамные комментарии не влияли на сайт.
- Не передавать PR на сторонние сайты. Многие веб-мастеры ставили ссылки на свои сайты на ресурсы вроде Википедии, чтобы получить ссылочный вес. По словам сотрудника Google Мэтта Каттса, это бессмысленно: ссылки в Википедии имеют nofollow. Единственная польза от такой ссылки — возможный трафик.
Соотношение dofollow и nofollow на сайте
Четких рекомендаций по количеству и соотношению нет. Все, что говорят поисковики: меньше спама и коммерческих анкоров. Ссылки плохого качества лучше удалять, SEO-ссылки закрывать nofollow для Яндекса или новыми рекламными атрибутами Google. За переспам ссылками можно получить санкции.
Яндекс: санкции за ссылки
«Минусинск» — снижает позиции за переспам ссылками на страницах, если количество ссылок с коммерческими анкорами превышает 40% от общей ссылочной массы или на сайте всего более 500 покупных ссылок.
«Непот» закрывает учет покупных ссылок. Советуют ставить не более пяти внешних ссылок в одном блоке, чтобы не получить санкции.
Google: санкции за ссылки
«Пингвин» отменяет вес покупных ссылок.Фильтр
«Ссылочная помойка(Links)» наказывает за беспорядочную продажу ссылок со своих страниц. Допустимое количество ссылок — не более пяти на страницу.
Какие ссылки не передают вес
Польский специалист Макс Сайрек три месяца проводил эксперимент, который показал, что ссылочный вес не передается по ссылкам через JavaScript —, хотя краулеры их воспринимают и переходят по ним.
Аналогично со ссылками через JavaScript-функцию — data-url=»page9.html». В этом случае почему-то страницу, на которую вела ссылка, краулер посещал чаще других в этой категории.
Бот Google игнорировал ссылки через JavaScript-функцию с закодированными данными — data-url=»cGFnZTEwLmh0bWw=» и ссылки с динамическим параметром — page2.html?parameter=1.
Также не передавала вес ссылка с якорем — page2.html#testhash, по запросу анкора в индексе страница не появилась.
Краткие рекомендации:
- размещайте на страницах только тематические ссылки;
- задавайте nofollow всем ссылкам, которым не хотите передавать PR;
- ссылок с коммерческими анкорами на сайте не должно быть больше 40%;
- размещайте менее пяти внешних ссылок в одном блоке;
- обращайте внимание на тематику и dofollow-ссылок;
- задайте sponsored или ugs всем рекламным и пользовательским ссылкам в комментариях.
Noindex, nofollow для Google — как и когда использовать с пользой для SEO продвижения
Noindex – это директива для поисковых систем, которая запрещает отображать страницу либо часть текста в результатах поиска. Давайте рассмотрим подробнее – где и в каких случаях используется эта директива?
Mетатег “robots” со значением “noindex”
Чтобы не допустить определенную страницу к индексированию поисковыми системами используется метатег robots с добавлением значения “noindex”.
В разделе <head> страницы размещается следующая конструкция:
<head>
<meta name="robots" content="noindex" />
…
</head>
Данный метатег распространяется на всех роботов поисковых систем. Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
<meta name="googlebot" content="noindex" />
Пример: Вы не хотите, чтобы ваши изображения были найдены через поиск по изображениям и использованы кем-то в личных целях.
Решение: Можно запретить индексацию страницы с данными изображениями только в поиске по изображениям, используя робот Googlebot-Image:
<meta name="googlebot-image" content="noindex" />
Таким образом, страница появится в результатах обычного поиска, но её содержимое не будет индексироваться для поиска по изображениям.
Тег <noindex> – для закрытия от индексации части контента
Для того, чтобы закрыть от индексации часть текста используется тег <noindex>, который может быть помещен в любые элементы html-кода страницы:
<noindex>текст, который будет запрещен к индексированию</noindex>
Однако, данный тег будет восприниматься только поисковиком Яндекс, так как он не является стандартизированным и был введен только этой поисковой системой.
Если мы разместим текст внутрь тега, то он не будет индексироваться при сканировании роботом Яндекс и при этом будет попадать в индекс всех остальных поисковиков.
Валидность
Так как тег <noindex> не является стандартизированным, то могут возникать ошибки валидации. Чтобы код оставался валидным, рекомендуется использование тега в таком виде:
<!--noindex-->текст, который будет запрещен к индексированию<!--/noindex-->
Варианты использования meta robots noindex
Мета-тег “Robots” содержит директивы, разделенные запятыми:
- Index/Noindex задает правило индексации страницы;
- Follow/Nofollow разрешает или запрещает переходить по ссылкам со страницы. Значения по умолчанию – Index и Follow.
Существуют следующие варианты использования метатега:
| <meta name=“robots” content=“index,follow”> | Разрешено индексировать страницу и переходить по ссылкам на ней. |
| <meta name=“robots” content=“noindex,follow”> | Запрещено индексировать страницу, но можно переходить по ссылкам на ней. |
| <meta name=“robots” content=“index,nofollow”> | Разрешено индексировать страницу, но нельзя переходить по ссылкам на странице. |
| <meta name=“robots” content=“noindex,nofollow”> | Запрещено индексировать страницу и переходить по ссылкам на ней. |
Как показывает практика (см. эксперимент С. Кокшарова), Google обычно корректно воспринимает данные правила. Что касается Яндекс, то он может не всегда следовать правилу “noindex, nofollow” и переходит по ссылкам, чтобы проверить их качество (под такими директивами иногда прячутся недобросовестные сайты).
Отличия meta robots noindex от noindex в robots.txt
Есть 2 способа скрыть страницу от индексирования:
- Закрыть страницу в robots.txt с помощью Disallow.
- Добавить на страницу в <head> метатег:
<meta name="robots" content="noindex" />
Основные отличия:
- В robots.txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
- <meta name=”robots” content=”noindex, follow”> позволяет закрывать страницы точечно, а также передавать ссылочный вес.
Если необходимо закрыть определенную страницу, лучше все-же воспользоваться метатегом чтобы не перегружать robots.txt лишними строками. Кроме того, выше вероятность того, что правило сработает (по сравнению с robots.txt).
Помните, что robots.txt – это всего лишь рекомендации, то есть поисковые системы могут игнорировать его — индексировать и сканировать запрещенные URL. Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Распространенные ошибки
Страница закрыта через метатег, но все равно находится в поиске
Возможные причины:
- Страница закрыта также robots.txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
- Робот еще не успел посетить страницу (на сайте много страниц).
Решение: Чтобы закрыть страницу через метатег, необходимо, чтобы она была открыта в robots.txt. Если на сайте много страниц, а страницу нужно срочно закрыть – лучше воспользоваться панелью вебмастера.
Внедрение одновременно noindex и rel canonical на страницах (например, пагинации)
Это частая ошибка вебмастеров, ведь эти два тега противоречат друг другу. Google дает четкий ответ по этому поводу тут: https://www.seroundtable.com/noindex-canonical-google-18274.html .
Решение для страниц пагинации:
- canonical не использовать,
- на страницах пагинации прописать: <meta name=”robots” content=”noindex, follow” />, а также link rel=”prev” и link rel=”next”.
На сайте есть не закрытые метатегом служебные страницы – версии страниц «для печати», а также служебные/шаблонные страницы, которые создаются динамически. Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Решение: Google советует закрыть такого рода страницы через метатег <meta name="robots" content="noindex, nofollow" />.
Атрибут rel-nofollow
Значение rel=”nofollow” запрещает поисковой системе переходить по конкретной ссылке.
Пример использования: <a href="test.com" rel="nofollow">Ссылка</a>
Google утверждает: «…Как правило, переход не производится. Это означает, что по этим ссылкам Google не передает ни PageRank, ни текст ссылки…»
Однако, «как правило» предполагает, что бывают исключения. Также, например, ссылки с nofollow могут быть проиндексированы, если на страницу ссылаются другие сайты без использования nofollow, либо страница есть в Sitemap.
Как и где использовать
Рекомендуется использовать rel=”nofollow”:
- для закрытия ссылок на некачественный контент или контент, которому вы не доверяете,
- для закрытия неуникального контента,
- для закрытия платных ссылок,
- для корректной индексации (например, чтобы скрыть технические страницы и не тратить ресурсы робота на их сканирование).
Помимо этих случаев, многие оптимизаторы используют rel=”nofollow”, когда хотят, чтобы внешняя ссылка не передавала вес.
Передает ли nofollow вес
По словам Google, rel=”nofollow” не передает ссылочный вес. Однако, есть свидетельства, что Google учитывает ссылки социальных сетей Facebook, Twitter не смотря на nofollow.
Что касается Яндекс, то с 2010 года он не учитывает ссылки с nofollow и, соответственно ссылка не передает вес. Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Как бы там ни было, ваш ссылочный профиль должен быть разнообразным и рекомендуется разбавлять анкор-лист ссылками с rel=”nofollow”.
Распространенные ошибки
Использование rel=”nofollow” для внутренней перелинковки.
Google так делать не советует (https://www.searchengines.ru/mett_katts_ne_nofollow_int_links.html )
Использовать rel nofollow на каждый язык языковой версии чтобы «сегментировать» их, не передавая вес друг-другу.
Не нужно с помощью rel nofollow пытаться манипулировать весом. Если сайт целостный, все равно в рамках внутренней перелинковки вес будет переходить. Как уже говорилось выше – Google не приветствует rel nofollow для внутренней перелинковки. Но не забудьте об использовании hreflang.
Использовать rel nofollow для ссылок на страницы фильтра.
Рекомендуется не использовать атрибут nofollow, а реализовать фильтры с помощью JS или закрывать страницы метатегом noindex, nofollow.
Надеемся, что данная статья ответила на основные вопросы по использованию тегов noindex, nofollow. Желаем успешного продвижения!
Что это за теги Nofollow и Noindex, в чем разница и как правильно прописывать
Выясняем, как работают тег noindex и атрибут nofollow. Подробно рассмотрим сценарии использования и узнаем, как прописывать теги для роботов в зависимости от поставленных задач.
Теги и атрибуты
Их еще называют дескрипторами. Это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфичные визуальные характеристики…
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
<a href=“page.html” rel=“nofollow”>Гиперссылка</a>
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше.
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Я уже упомянул выше, что за тегом <noindex> частенько прячут контактную информацию, но не пояснил зачем. Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике.
- Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования. Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
Выше мы использовали <noindex> и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком. Посмотрим, как разрешить для роботов весь контент и все ссылки:
<meta name="robots" content="index, follow"/>
А это полный запрет на контент и ссылки:
<meta name="robots" content="noindex, nofollow"/>
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.txt, который отвечает за «исключение» страниц из индексации.
Но способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots.txt заносите новые ссылки, неизвестные для Google и Яндекс.
Итоги
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow. С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.
noindex vs. nofollow — Справочный центр Siteimprove
Модуль Siteimprove SEO уведомляет пользователей о страницах, исключенных noindex / nofollow. Эта статья предназначена для объяснения разницы между метатегами noindex и nofollow, когда их использовать и как эти теги влияют на веб-индексирование и страницы результатов поисковой системы (SERP).
Как noindex, так и nofollow являются частью протокола исключения роботов (REP) , стандарта для управления индексированием веб-страниц на вашем сайте.Давайте рассмотрим несколько примеров noindex и nofollow и то, как они контролируют доступ и индексацию вашего веб-сайта Google и другими поисковыми системами.
Что такое noindex и когда его использовать?
Обычно, когда робот Googlebot находит страницу, он читает все ссылки на этой странице, а затем выбирает эти страницы и индексирует их. Это основной процесс, с помощью которого робот Googlebot «сканирует» Интернет. Это полезно, поскольку позволяет Google включать все страницы вашего сайта, если они связаны друг с другом.Что делать, если вы не хотите, чтобы некоторые страницы вашего сайта отображались в индексе Google? Здесь применяется метатег noindex.
Когда вы добавляете метатег «noindex» к веб-странице, он сообщает поисковой системе, что она не может добавить страницу в свой поисковый индекс, даже если поисковая система может сканировать страницу.
Noindex, пример
статей в разделе «Последние новости» CNN могут появиться только в течение нескольких часов, прежде чем они будут обновлены и перемещены в раздел «Статьи». В этом случае CNN захочет проиндексировать все статьи, а не раздел последних новостей с короткой частью полной статьи.
Таким образом, вы можете добавить тег noindex к статьям, которые в настоящее время находятся в разделе «Последние новости», и удалить этот тег, как только статья больше не будет актуальной.
Чтобы превратить обычные ссылки в ссылки noindex, добавьте «noindex» в HTML-код:
Текст ссылки
Что такое nofollow и когда его использовать?
Nofollow — это атрибут HTML, который предписывает большинству поисковых систем воздерживаться от перехода по ссылке и тем самым передавать значение странице, на которую ведет ссылка.Некоторые эксперты по SEO интерпретируют это как способ сообщить поисковым системам, что вы не доверяете или не можете поручиться за содержание ссылки, на которую ведет ссылка. Короче говоря, если вы хотите, чтобы поисковая машина проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице; добавьте на свою страницу тег nofollow.
Чтобы превратить обычные ссылки в ссылки nofollow, добавьте «nofollow» в HTML-код *:
Текст ссылки
* Вы можете добавить код вручную, но многие CMS вставляют его автоматически, когда это необходимо.Обратитесь за советом к своему веб-мастеру.
Nofollow, пример
Когда пользователи ищут в Google фразы, связанные с новостями, CNN хочет, чтобы разделы их статей (со статьями) занимали первые места в поисковой выдаче, потому что статьи являются наиболее ценным активом CNN.
Не имеет смысла располагать их раздел входа наверху.
Чтобы сообщить Google, что статьи важнее входа в систему, CNN добавит тег nofollow к своей ссылке для входа.
Примечание. Сканер Siteimprove не учитывает «noindex» или «nofollow» при определении содержания для сканирования.Сканируем на основе настроек сканирования.
квалифицированных исходящих ссылок для SEO
Для определенных ссылок на вашем сайте вы можете сообщить Google о своих отношениях с
связанная страница. Для этого вы должны использовать один из следующих rel значения атрибутов в теге .
Для обычных ссылок, по которым, как вы ожидаете, Google будет следовать без какой-либо квалификации, вам не нужно
чтобы добавить атрибут rel . Пример: «Моя любимая лошадь — паломино . «
Для других ссылок используйте одно или несколько из следующих значений:
отн. значений | |
|---|---|
rel = "спонсируемый" | Отметьте ссылки, которые являются рекламными или платными
ссылки ) со спонсируемым nofollow был
ранее
рекомендуется для этих типов ссылок и по-прежнему является приемлемым способом пометить
их, хотя и спонсируемые предпочтительнее. |
rel = "ugc" | Мы рекомендуем отмечать ссылки пользовательского контента (UGC), такие как комментарии и форум.
сообщений со значением Если вы хотите распознавать и вознаграждать надежных участников, вы можете удалить это атрибут из ссылок, размещенных участниками или пользователями, которые постоянно делали качественный вклад с течением времени. Узнать больше о избегать спама в комментариях. |
rel = "nofollow" | Используйте значение |
| Несколько значений | Вы можете указать несколько значений |
Ссылки, отмеченные этими атрибутами rel , обычно не используются. Помнить
что связанные страницы могут быть найдены другими способами, такими как карты сайта или ссылки с других
сайты, и поэтому они все еще могут сканироваться.Эти атрибуты rel используются только в тегов (потому что Google
может переходить только по ссылкам, указанным тегом ), кроме nofollow , который также доступен в виде роботов
метатег.
Если вам нужно запретить Google переходить по ссылке на страницу вашего собственного сайта, используйте robots.txt Правило запрета.
Чтобы запретить Google индексировать страницу, разрешите сканирование и используйте noindex правило роботов.
с помощью noindex
Вы можете запретить отображение страницы в поиске Google, указав noindex метатег в HTML-коде страницы или путем возврата заголовка noindex в HTTP
отклик. Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, он сбросит
эта страница полностью из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
noindex вступила в силу, страница не должен блокировать файлом robots.txt, иначе это должно быть
доступный для краулера. Если страница заблокирована
robots.txt или он не может получить доступ к странице, поисковый робот никогда не увидит noindex , и страница по-прежнему может отображаться в результатах поиска, например
если на него ссылаются другие страницы. Использование noindex полезно, если у вас нет root-доступа к вашему серверу, так как он
позволяет вам контролировать доступ к вашему сайту на постраничной основе.
Реализация
noindex Есть два способа реализовать noindex : как метатег и как HTTP-ответ.
заголовок. У них такой же эффект; выберите способ, который удобнее для вашего сайта.
Тег
Чтобы запретить большинству поисковых роботов индексировать страницу вашего сайта, поместите
следующий метатег в раздел вашей страницы:
Чтобы запретить только веб-сканерам Google индексировать страницу:
Вы должны знать, что некоторые поисковые роботы могут интерпретировать noindex иначе.В результате возможно, что ваша страница
по-прежнему появляются в результатах других поисковых систем.
Узнайте больше о метатеге noindex .
Вместо метатега вы также можете вернуть заголовок X-Robots-Tag со значением
либо noindex , либо none в вашем ответе. Вот пример
HTTP-ответ с X-Robots-Tag , инструктирующий сканеры не индексировать страницу:
HTTP / 1.1 200 ОК (…) X-Robots-Tag: noindex (…)
Узнайте больше о заголовке ответа noindex .
Помогите нам определить ваши метатеги
Нам необходимо просканировать вашу страницу, чтобы увидеть метатеги и заголовки HTTP. Если страница все еще появляется в результатах, вероятно, потому, что мы не сканировали страницу с тех пор, как вы добавили тег. Вы можете запросить у Google повторное сканирование страницы с помощью Инструмент проверки URL.Другая причина также может заключаться в том, что файл robots.txt блокирует URL-адрес из сети Google. сканеры, поэтому они не видят тег. Чтобы разблокировать свою страницу от Google, вы должны отредактировать свой файл robots.txt. Вы можете редактировать и тестировать свой robots.txt, используя Тестер robots.txt инструмент.
seo — это хорошая идея использовать имя в этой ситуации?
nofollow
nofollow означает, что бот не должен переходить по этой ссылке.Если вас беспокоит только Google (как предполагает ваш тег), это, вероятно, поможет:
Как Google обрабатывает nofollow-ссылки?
Как правило, мы им не следуем. Это означает, что Google не передавать PageRank или якорный текст по этим ссылкам. По сути, использование nofollow заставляет нас отбрасывать целевые ссылки из нашего общего граф сети. Однако целевые страницы могут по-прежнему отображаться в нашем index, если другие сайты ссылаются на них без использования nofollow, или если URL-адреса отправляются в Google в файле Sitemap.Также важно обратите внимание, что другие поисковые системы могут немного обрабатывать nofollow различные пути. [Источник]
Однако добавление этого атрибута ни в коем случае не является жестким ограничением, стандарта нет, и некоторые боты могут его вообще игнорировать. Кроме того, поисковые системы могут по-прежнему помечать страницу как сайт для построения ссылок в зависимости от соотношения содержания / ссылки.
noindex
noindex не используется в ссылках Google (про другие не знаю).Он предназначен для атрибута robots в заголовке html и применяется ко всей странице. Так что это, скорее всего, бесполезно для вас. Пример:
линкбилдинг
Однако200 ссылок также не очень удобны для пользователя. Вам следует серьезно подумать о сокращении количества ссылок, (например) выбрав те, которые имеют схожую тему.
Пока вы это читаете, смотрите направо, да, здесь, на Stack Overflow, есть «Коробка» под названием Related .Вот как вы это делаете. Представьте, что они помещают туда каждой отдельной темы, когда-либо созданной … Не очень полезно.
Также, если вы сделаете это с некоторой логикой, как я предложил выше, а не просто случайным образом выбирая N ссылок из списка, вы, вероятно, можете удалить nofollow , поскольку ссылки станут полезными, а Google любит полезные ссылки.
Затем вы также можете добавить «прожектор» для сайтов с низким трафиком (хотя им, вероятно, понадобится nofollow).
Что это такое и как их использовать?
Три слова, приведенные выше, могут звучать как SEO gobbledegook, но эти слова стоит знать, поскольку понимание того, как их использовать, означает, что вы можете управлять роботом Googlebot.Это весело.
Итак, начнем с основ: есть три способа контролировать, какие части вашего сайта будут сканироваться поисковыми системами:
- Noindex: указывает поисковым системам не включать ваши страницы в результаты поиска.
- Disallow: запрещает сканирование ваших страниц.
- Nofollow: говорит им не переходить по ссылкам на вашей странице.
Что такое метатег Noindex?
Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный метод запрета индексации страницы — это добавить тег в заголовок HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница не должна быть заблокирована (запрещена) в файле robots.txt. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы поисковые системы не индексировали вашу страницу, просто добавьте следующее в раздел:
Вторая часть тега содержимого здесь указывает, что необходимо переходить по всем ссылкам на этой странице, которые мы обсудим ниже.
В качестве альтернативы тег noindex можно использовать в теге X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Дополнительную информацию см. В сообщении разработчиков Google о спецификациях метатега Robots и HTTP-заголовка X-Robots-Tag.
Как использовать Noindex в файле Robots.txt?
Тег noindex в файле robots.txt также сообщает поисковым системам не включать страницу в результаты поиска, но это более быстрый и простой способ не индексировать сразу много страниц, особенно если у вас есть доступ к вашим роботам.txt файл. Например, вы не можете индексировать любые URL-адреса в определенной папке.
Вот пример директивы noindex, которую можно поместить в файл robots.txt:
Noindex: / robots-txt-noindexed-page /
Однако Google не рекомендует использовать этот метод: Джон Мюллер заявил, что «не следует полагаться на него».
Что такое запретительная директива?
Запрещение страницы означает, что вы указываете поисковым системам не сканировать ее, что должно быть сделано в robots.txt вашего сайта. Это полезно, если у вас много страниц или файлов, которые бесполезны для читателей или поискового трафика, поскольку это означает, что поисковые системы не будут тратить время на сканирование этих страниц.
Чтобы добавить запрет, просто добавьте в файл robots.txt следующую строку:
Запретить: / your-page-url /
Если на странице есть внешние ссылки или канонические теги, указывающие на нее, ее все равно можно проиндексировать и ранжировать, поэтому важно сочетать запрет с тегом noindex, как описано ниже.
Предупреждение: запрещая страницу, вы фактически удаляете ее со своего сайта.
Запрещенные страницы не могут передавать PageRank куда-либо еще — поэтому любые ссылки на этих страницах фактически бесполезны с точки зрения SEO — а запрещение страниц, которые должны быть включены, может иметь катастрофические последствия для вашего трафика, поэтому будьте особенно осторожны при написании запрещающих директив.
Как совместить Noindex и Disallow?
Noindex (страница) + Disallow: Disallow не может сочетаться с noindex на странице, потому что страница заблокирована, и поэтому поисковые системы не будут сканировать ее, чтобы знать, что они не должны оставлять страницу вне индекс.
Noindex (robots.txt) + Disallow : предотвращает появление страниц в индексе, а также предотвращает сканирование страниц. Однако помните, что через эту страницу не может пройти PageRank.
Чтобы объединить запрет с noindex в файле robots.txt, просто добавьте обе директивы в файл robots.txt:
Запрещено: / example-page-1/
Запрещено: / example-page-2/
Noindex: / example-page-1/
Noindex: / example-page-2/
Что такое тег Nofollow?
Тег nofollow в ссылке указывает поисковым системам не использовать ссылку для определения важности связанных страниц (PageRank) или обнаружения дополнительных URL-адресов на том же сайте.
Обычно nofollows использует ссылки в комментариях и другом контенте, который вы не контролируете, платные ссылки, встраиваемые элементы, такие как виджеты или инфографику, ссылки в гостевых сообщениях или что-нибудь не по теме, на которое вы все еще хотите связать людей.
Исторически сложилось так, что оптимизаторы поисковых систем также избирательно исключали переход по ссылкам, чтобы направлять внутренний PageRank на более важные страницы.
Теги Nofollow могут быть добавлены в одном из двух мест:
- страницы (для nofollow всех ссылок на этой странице):
- Код ссылки (для nofollow отдельной ссылки): пример страницы
nofollow не предотвратит полное сканирование связанной страницы; он просто предотвращает сканирование по этой конкретной ссылке. Наши и другие тесты показали, что Google не будет сканировать URL-адрес, который он находит в ссылке nofollowed.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница отображается в файле Sitemap, эта страница может по-прежнему отображаться в результатах поиска. Точно так же, если это URL, о котором уже знают поисковые системы, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и представил два новых атрибута ссылки, а именно:
- rel = «sponsored» — Атрибут sponsored следует использовать для идентификации ссылок, предназначенных для рекламных целей, при наличии соглашений о спонсорстве и компенсации.
- rel = «ugc» — В качестве атрибута для пользовательского контента это значение рекомендуется для ссылок на сайтах с пользовательским контентом, например для сообщений на форумах и комментариев в блогах.
Кроме того, все ссылки, помеченные как nofollow, sponsored или ugc, теперь обрабатываются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как раньше использовалось для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, который также охватывает их влияние и мнения экспертов.
Что такое Noindex Nofollow?
Как упоминалось выше, добавление тега nofollow к странице не препятствует ее полному сканированию.Поэтому, чтобы предотвратить индексирование, вам также нужно не индексировать страницу. Это позволит Google сканировать страницу, но она не будет отображаться в индексе. Страницы, которые вы, вероятно, захотите включить в noindex; страницы администратора / входа, внутренние результаты поиска и страницы регистрации. Чтобы Google полностью прекратил сканирование страницы, вам также следует запретить это (см. Выше).
Другие директивы: Canonical Tags, Pagination и Hreflang
Есть и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса:
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать.Канонизированные (т. Е. Вторичные страницы, которые направляют поисковые системы к первичной версии) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на свои настольные.
- Разбиение на страницы группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента предназначены для какого региона, чтобы они могли определить приоритетность правильной версии для каждой аудитории.Все эти версии останутся в индексе.
Сколько времени вам следует потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны для SEO эффективность сканирования и бюджет сканирования, и хотя общепринято запрещать и не индексировать большие группы страниц, которые не имеют никакой пользы для поисковых систем или читателей (например, back -end кода, который используется только для работы сайта или некоторых типов дублированного контента), решение о том, скрывать ли много отдельных страниц, вероятно, не лучший вариант использования времени и усилий.
Google любит индексировать как можно больше URL-адресов, поэтому, если нет особой причины скрыть страницу от поисковых систем, обычно можно оставить решение на усмотрение Google. В любом случае, даже если вы скроете страницы от поисковых систем, Google все равно будет проверять, изменились ли эти URL-адреса. Это особенно актуально, если есть ссылки, указывающие на эту страницу; даже если Google забыл об URL-адресе, он может снова обнаружить его в следующий раз, когда на него будет найдена ссылка.
Тестирование с помощью Search Console, DeepCrawl и Robotto
Тестовые роботы.txt с помощью Search Console
Инструмент robots.txt Tester в Search Console (в разделе «Сканирование») — популярный и в значительной степени эффективный способ проверить новую версию вашего файла на наличие ошибок до того, как он будет опубликован, или проверить конкретный URL, чтобы убедиться, что он заблокирован:
Однако этот инструмент не работает точно так же, как Google, с некоторыми небольшими различиями в конфликтующих правилах разрешения / запрета, которые имеют одинаковую длину.
Инструмент тестирования robots.txt сообщает, что это разрешено, однако Google сказал: «Если результат не определен, robots.txt могут разрешить или запретить сканирование. По этой причине не рекомендуется полагаться на то, что какой-либо из результатов будет использоваться повсеместно ».
Подробнее читайте в этом обсуждении на справочном форуме в Центре веб-мастеров.
Найти все неиндексируемые страницы с помощью DeepCrawl
Запустите универсальное сканирование без каких-либо ограничений (но с применением условий robots.txt), чтобы DeepCrawl мог вернуть все ваши URL-адреса и показать вам все индексируемые / неиндексируемые страницы.
Если у вас есть параметры URL, которые были заблокированы для робота Google с помощью Search Console, вы можете имитировать эту настройку для сканирования, используя поле «Удалить параметры» в разделе Расширенные настройки> Перезапись URL .
Затем вы можете использовать следующие отчеты, чтобы убедиться, что сайт настроен так, как вы ожидали при первом сканировании, а затем объединить их со встроенными журналами изменений при последующих сканированиях.
Индексация> Страницы Noindex
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, HTTP-заголовке или файле robots.txt файл.
Индексация> Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за запрещающего правила в файле robots.txt. На панели управления вашего отчета есть цифры для обоих этих отчетов:
Используйте наши интуитивно понятные отчеты в каждом из наших отчетов, чтобы проверить определенные папки и выявить шаблоны в URL-адресах, которые в противном случае вы могли бы пропустить:
Протестируйте новый файл robots.txt с помощью DeepCrawl
Используйте роботов DeepCrawl.txt Функция перезаписи в расширенных настройках для замены живого файла на пользовательский.
Затем при следующем запуске сканирования вы можете использовать тестовую версию вместо активной.
В отчетах о добавленных и удаленных запрещенных URL-адресах будет показано, какие именно URL-адреса были затронуты измененным файлом robots.txt, что упростит оценку.
Для получения дополнительной информации прочтите наше руководство по управлению изменениями robots.txt с помощью DeepCrawl.
Хотите больше такого?
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации о noindex, nofollow и disallow для управления сканированием вашего сайта.
Вы можете узнать больше об этих темах в нашей Технической библиотеке SEO или, если вы хотите узнать, как проводить технический SEO-аудит, прочитайте наше руководство.
Кроме того, если вы заинтересованы в том, чтобы быть в курсе последних обновлений Google и рекомендациями по передовому опыту, почему бы не заглянуть в наши электронные письма?
Loop Me In!
Автор
Сэм Марсден
Сэм Марсден — менеджер по поисковой оптимизации и контенту DeepCrawl.Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых публикаций, таких как Search Engine Journal и State of Digital.
Теги
Управление роботами
Какие страницы на вашем сайте использовать noindex или nofollow? • Yoast
Михиэль ХеймансМихиэль был одним из наших первых сотрудников и раньше был партнером Yoast. Начните оптимизацию своего сайта с его статей!
Некоторые страницы вашего сайта служат определенной цели, но эта цель не состоит в ранжировании в поисковых системах и даже не в привлечении трафика на ваш сайт.Эти страницы должны быть там, как клей для других страниц, или просто потому, что правила требуют, чтобы они были доступны на вашем веб-сайте. Если вы регулярно читаете наш блог, вы знаете, как noindex или nofollow могут помочь вам справиться с этими страницами. Однако, если вы новичок в этих условиях, пожалуйста, продолжайте читать и позвольте мне объяснить, что они из себя представляют и к каким страницам они могут применяться!
Что такое noindex nofollow?
noindex означает, что веб-страница не должна индексироваться поисковыми системами и, следовательно, не должна отображаться на страницах результатов поиска. nofollow означает, что пауки поисковых систем не должны переходить по ссылкам на этой странице. Вы можете добавить эти значения в свой метатег robots. Мета-тег robots — это фрагмент кода в разделе заголовка веб-страницы. Он сообщает поисковым системам, как сканировать и индексировать ли страницу.
Наше полное руководство по метатегу robots — отличное чтение, если вы хотите немного глубже погрузиться в эту тему.
Вкратце:
- Метатег robots в большинстве случаев выглядит следующим образом:
- VALUE1 и VALUE2 установлены на индекс
, по умолчанию используется, что означает данная страница может быть проиндексирована поисковыми системами, и по ссылкам на этой странице можно переходить для сканирования страниц, на которые они ссылаются. - VALUE1 и VALUE2 могут иметь значение
noindex, nofollowили другую комбинацию, например индекс, nofollow.
Но пусть вас не пугает этот код. Yoast SEO поможет вам! Если вы хотите узнать, как noindex пост в WordPress супер-простым способом, вы должны прочитать этот пост: Как noindexировать пост в WordPress: простой способ.
Но когда какое значение использовать?
Страниц для установки noindex
Авторский архив в блоге одного автора
Если вы единственный, кто пишет для своего блога, страницы ваших авторов, вероятно, на 90% совпадают с домашней страницей вашего блога.Это бесполезно для Google и может рассматриваться как дублированный контент. Чтобы предотвратить такое дублирование контента, вы можете полностью отключить авторский архив. Вот как легко включить или отключить его с помощью Yoast SEO. Если по какой-то причине вы хотите сохранить его на своем сайте, но не в результатах поиска, вы можете noindex его. К счастью, с Yoast SEO это тоже не сложно; просто проверьте, как нельзя индексировать архив автора.
Определенные (настраиваемые) типы сообщений
Иногда плагин или веб-разработчик добавляют пользовательский тип сообщения, который вы не хотите индексировать.Например, в Yoast мы используем персонализированные страницы для наших продуктов, поскольку мы не являемся типичным интернет-магазином, продающим физические продукты. Таким образом, нам не нужно изображение продукта, фильтры, такие как размеры и технические характеристики, на вкладке рядом с описанием. Поэтому мы не индексируем обычные страницы продуктов, которые выводит WooCommerce, и используем наши собственные страницы. Действительно, у нас noindex тип сообщения о продукте.
Соответственно, мы видели решения для электронной коммерции, которые также добавляли такие характеристики, как размеры и вес, в качестве настраиваемого типа сообщений.Эти страницы считаются некачественным контентом. Вы поймете, что эти страницы бесполезны ни для посетителей, ни для Google, поэтому их тоже нужно держать подальше от страниц результатов поиска.
Страницы благодарности
Эта страница служит только для того, чтобы поблагодарить вашего клиента / подписчика на новостную рассылку / впервые комментирующего. Эти страницы обычно представляют собой страницы с тонким контентом, с опциями допродажи и обмена в социальных сетях, но они не представляют ценности для тех, кто использует Google для поиска полезной информации. Следовательно, этих страниц не должно быть на страницах результатов поиска.
Страницы администратора и входа в систему
Большинство страниц входа не должны находиться в Google. Но это так. Не допускайте попадания своего в индекс, добавив к нему noindex . Исключение составляют страницы входа в систему, которые обслуживают сообщество, например Dropbox или аналогичные службы. Просто спросите себя, стали бы вы гуглить одну из своих страниц входа в систему, если бы вы не работали в своей компании. В противном случае можно с уверенностью сказать, что Google не нужно индексировать эти страницы входа. К счастью, если вы используете WordPress, вы в безопасности, поскольку CMS не индексирует страницу входа на ваш сайт автоматически.
Результаты внутреннего поиска
Результаты внутреннего поиска — это в значительной степени последние страницы, на которые Google хотел бы отправлять своих посетителей. Если вы хотите испортить поиск, вы ссылаетесь на другие страницы поиска вместо фактического результата. Но ссылки на странице результатов поиска по-прежнему очень ценны, вы определенно хотите, чтобы Google следил за ними. Таким образом, необходимо переходить по всем ссылкам, а мета-настройка роботов должна быть:
Yoast SEO следит за тем, чтобы для ваших внутренних поисковых страниц по умолчанию было установлено значение noindex.Это одна из скрытых функций Yoast SEO. Это не редактируемый параметр, потому что это просто то, как это должно быть сделано в соответствии с рекомендациями Google, и мы полностью с ними согласны.
Только для разработчиков: если вы действительно хотите изменить это, это можно сделать с помощью одного из наших фильтров. Пример можно найти здесь.
Страниц для установки на nofollow
Для всех примеров, упомянутых выше, нет необходимости nofollow все ссылки на этих страницах.Вы не хотите, чтобы они отображались в результатах поиска, но вы хотите, чтобы Google переходил по ссылкам на странице. Теперь, когда следует добавить nofollow в метатег роботов?
Если вы установите для страницы значение nofollow с метатегом robots, ни одна из ссылок на этой странице не будет переходить. Google придумал nofollow, чтобы иметь возможность различать ссылки на ненадежный контент (или, позже, оплаченный, например, рекламу). На обычном веб-сайте, вероятно, очень мало страниц, на которых вы бы хотели, чтобы Google не переходил по по любой ссылке .
Пример: если у вас есть страница со списком книг по SEO с избытком партнерских ссылок Amazon, они могут быть полезны для вашего сайта для ваших пользователей. Но я бы nofollow всю страницу, если на странице нет ничего важного. Однако вы могли бы проиндексировать его. Просто убедитесь, что вы правильно скрываете свои ссылки.
Одинарные ссылки Nofollow
Если у вас есть сообщение или страница с несколькими ссылками, вы можете помочь поисковым системам квалифицировать их.В настоящее время вы можете nofollow для одной ссылки или даже установить для нее спонсируемый или пользовательский контент. Добавление правильных атрибутов rel к вашей ссылке позволяет вам это сделать. Например, ссылка на рекламу будет выглядеть так: пример ссылки . С Yoast SEO настроить эти атрибуты rel очень просто, как вы можете видеть в этом видео:
Заключение
Как мы видели, независимо от того, используется ли noindex страница или nofollow ссылка, сводится к двум вопросам: хотите ли вы, чтобы эта страница отображалась на страницах результатов поиска и , если поисковые системы переходят по ссылкам на эта страница? Например, для страниц с благодарностями или страниц входа в систему ответ на первый вопрос — «нет».Для страницы с множеством партнерских ссылок ответ на второй вопрос — «нет». Помните о примерах из этого поста, и у вас больше не будет проблем с поиском ответов для вашего собственного сайта!
PS. Вы noindex пост или страницу, хотя не хотели? Не беспокойтесь, вы можете легко исправить случайную ошибку noindex !
Подробнее: Как не индексировать сообщение »
Что такое ссылка Nofollow? Все, что вам нужно знать (без жаргона!)
Тег rel = ”nofollow” — один из простейших HTML-тегов, который очень важно понимать, если вы занимаетесь поисковой оптимизацией.Из этого руководства вы узнаете все, что вам нужно знать о ссылках без перехода.
В ссылках Nofollow нет ничего нового. Они существуют уже 14 лет.
Если вы заботитесь об эффективности своего сайта в поисковых системах, то знать, когда и когда не использовать nofollowed ссылки, не просто важно — это критически важно .
В этом руководстве я объясню, как появились nofollow-ссылки, как они помогают с SEO и как их правильное использование может защитить ваш сайт от страшного наказания Google.
Но сначала давайте рассмотрим основы.
Ссылки Nofollow — это гиперссылки с тегом rel = «nofollow».
Эти ссылки не влияют на рейтинг целевого URL в поисковых системах, поскольку Google не передает по ним PageRank или текст привязки. Фактически, Google даже не сканирует ссылки без перехода.
Рекомендуемая литература: Google PageRank НЕ мертв: почему это все еще имеет значение
Nofollow по сравнению со ссылками для перехода
Ссылки, по которым переходят или нет, выглядят идентично среднему пользователю сети.
Синий текст в этом предложении представляет собой ссылку , за которой последовали . Синий текст в этом предложении — это ссылка nofollowed . Разница между ними становится очевидной, только если вы углубитесь в HTML-код.
Читали:
синий текст
Nofollowed:
синий текст
HTML идентичен, за исключением добавления тега rel = «nofollow».
Можно исключить всех ссылок на веб-странице с помощью nofollow, поместив в заголовок метатег robots со значением «nofollow». Тем не менее, тег nofollow используется чаще, поскольку он позволяет отказаться от некоторых ссылок на странице, оставив при этом другие.
Не знаете, зачем вам это нужно? Пришло время для небольшого урока истории.
История
rel = «nofollow»Google впервые представил тег nofollow в 2005 году для борьбы со спамом в комментариях.
Если вы блоггер (или читатель блога), вы до боли знакомы с людьми, которые пытаются поднять рейтинг своих собственных веб-сайтов в поисковых системах, отправляя связанные комментарии в блогах, такие как «Посетите мой сайт со скидкой на лекарства». Это называется спамом в комментариях, он нам тоже не нравится, и мы тестировали новый тег, который его блокирует. С этого момента, когда Google видит атрибут (rel = «nofollow») в гиперссылках , эти ссылки не получают никакого кредита, когда мы оцениваем веб-сайты в результатах поиска .Это не голосование против сайта, на котором был опубликован комментарий; это просто способ убедиться, что спамеры не получат никакой выгоды от злоупотребления общедоступными областями, такими как комментарии в блогах, обратные ссылки и списки рефереров.
Вскоре после этого Yahoo, Bing и несколько других поисковых систем также объявили о своей приверженности тегу nofollow.
ВАЖНОЕ ПРИМЕЧАНИЕ
Интерпретация nofollow несколько различается между поисковыми системами. Вот таблица, показывающая различия.В настоящее время WordPress по умолчанию добавляет тег nofollow к ссылкам на комментарии, как и многие другие CMS.Поэтому, даже если вы никогда раньше не слышали о ссылке nofollow, будьте уверены, что любые комментаторы, рассылающие спам в вашем блоге, скорее всего, не получат от своих усилий каких-либо преимуществ для SEO.
Однако, если вы обеспокоены тем, что ваши комментарии могут быть недоступны, вот как дважды проверить:
- Найти комментарий
- Щелкните ссылку правой кнопкой мыши
- Нажмите «Проверить»
- Посмотрите на выделенный HTML-код код.
Если вы видите тег rel = nofollow, это значит, что это nofollow.В противном случае следовали.
Не удобно копаться в HTML-коде? Установите расширение nofollow для Chrome, которое визуально выделяет все ссылки nofollow, когда вы просматриваете веб-страницы.
Понял? Хорошо. Вернемся к нашему уроку истории.
2009: Google борется с формированием PageRank
PageRank обтекает веб-сайт через внутренние ссылки (ссылки с одной страницы сайта на другую).
Например, некоторые из PageRank этой статьи переходят на другие страницы нашего сайта через гиперссылки, подобные этой.В общем, более высокий PageRank означает более высокий рейтинг. Гэри Иллисес подтвердил это в прошлом году.
Знаете ли вы, что по прошествии 18 лет мы все еще используем PageRank (и сотни других сигналов) для ранжирования?
Хотите знать, как это работает? Https: //t.co/CfOlxGauGF pic.twitter.com/3YJeNbXLml
— Гэри «鯨 理» Иллиес (@methode) 9 февраля 2017 г.
Однако PageRank передается только через переходили по ссылкам, а не по ссылкам без перехода.
Так было всегда, но способ распределения PageRank между переходящими ссылками на странице с годами изменился.
До 2009 года это работало следующим образом:
Если у вас было трех ссылок на странице и одна из них не имела подписки, то общий PageRank был разделен между двумя ссылками, по которым переходили.
К сожалению, некоторые люди начали использовать эту техническую деталь, чтобы манипулировать рейтингом, формируя поток PageRank вокруг своих сайтов.
Другими словами, они не использовали ссылки nofollow на свои неважные страницы, чтобы обеспечить максимальный перенос PageRank на их «денежные» страницы.
Google объявил об изменениях, направленных на пресечение этой практики в зародыше в 2009 году:
Итак, что происходит, когда у вас есть страница с «десятью точками PageRank» и десятью исходящими ссылками, а пять из этих ссылок не содержат подписки? […] Первоначально пять ссылок без nofollow передавали бы по два пункта PageRank каждая […] Более года назад Google изменил порядок потоков PageRank, так что пять ссылок без nofollow будут передавать по одному пункту PageRank каждая.
Вот иллюстрация до и после:
ВАЖНОЕ ПРИМЕЧАНИЕ
PageRank — это сложный зверь.Прошло десять лет с тех пор, как Google внес это изменение. Хотя они публично не объявляли о каких-либо дальнейших изменениях в работе PageRank за последние годы, вполне вероятно, что по крайней мере некоторые изменения произошли за кулисами.
Хотя формирование PageRank больше не относится к категории , «nofollow» для некоторых внутренних ссылок может помочь с установлением приоритета сканирования, поскольку Google не сканирует ссылки nofollow.
Роботы поисковых систем не могут войти в систему или зарегистрироваться в качестве участников на вашем форуме, поэтому нет причин приглашать робота Googlebot перейти по ссылкам «зарегистрироваться здесь» или «войти».Использование nofollow для этих ссылок позволяет роботу Googlebot сканировать другие страницы, которые вы предпочитаете видеть в индексе Google.
Однако это несколько сложная тема, поэтому я не буду здесь углубляться в нее.
Рекомендуемая литература: Бюджет сканирования для SEO: полное справочное руководство
2013 г. и далее: Google борется с платными ссылками
Google классифицирует покупки или продажи ссылок, которые передают PageRank, как нарушение их рекомендаций для веб-мастеров.
Таким образом, для всех платных ссылок не должно быть никаких подписок.
Так было много лет, даже задолго до 2013 года.
Однако, насколько я могу судить, примерно в это время Google стал все больше беспокоиться о влиянии нераскрытых платных ссылок на их алгоритм… и с тех пор.
Мэтт Каттс более подробно описывает аргументы в пользу раскрытия платных ссылок в этом видео 2013 года:
https: // www.youtube.com/watch?v=1SmlsfSqmOw
Но резюмируем: Google хочет вознаградить заработанных ссылок, а не платных ссылок.
Люди воспринимают ссылки как голоса редакторов. Они ссылаются на что-то, потому что это вселяет в них страсть. Это что-то интересное. Они хотят поделиться этим с друзьями. Есть причина, по которой они хотят выделить именно эту ссылку.
Проблема в том, что некоторые платные ссылки ничем не отличаются от заработанных. Подумайте о разнице между ссылкой в платном обзоре иссылка в неоплачиваемом обзоре.
На первый взгляд, обе ссылки будут выглядеть одинаково. Вот почему должен быть способ сообщить Google о платном.
Подумайте об этом так: есть два способа получить Оскар:
Вариант № 1: Живите, чтобы действовать, постоянно оттачивайте свое мастерство и много лет трудитесь.
Вариант № 2: Купите 6 из них за 8,97 доллара на Amazon…
Тег nofollow (на платных ссылках) для Google то же самое, что наклейка за 8,97 доллара на нижней части вашего поддельного Оскара для ваших друзей: контрольный знак что вы заработали это незаконно и, следовательно, не заслуживаете похвалы за свои дурацкие манипулятивные усилия.
Помогают ли ссылки nofollow в SEO?
Давайте кратко напомним, что Google говорит о том, как они обрабатывают nofollowed ссылки:
Google не передает PageRank или текст привязки по этим ссылкам.
Все это кажется достаточно ясным, пока вы не прочитаете предшествующее ему предложение:
В общем, мы не следуем им. Это означает, что Google не передает PageRank или текст привязки по этим ссылкам.
В целом, , я думаю, что это утверждение более расплывчатое, чем должно быть, и подразумевает, что в некоторых случаях они переходят по ссылкам без подписки.
Какие это могут быть случаи, никто не знает.
Некоторые считают, что все ссылки без перехода по-прежнему передают некоторый PageRank. Некоторые думают, что Google передает PageRank некоторым, но не всем ссылкам, по которым нет перехода. Другие считают, что люди слишком много зацикливаются на формулировках, которые не менялись на протяжении большей части семи лет.
Ранее в этом году мы изучили 44 589 поисковых запросов, чтобы увидеть, есть ли какая-либо корреляция между рейтингом Google и различными атрибутами обратных ссылок, одним из которых было количество отслеживаемых обратных ссылок.
Вот что мы обнаружили:
Корреляция для количества обратных ссылок «dofollow» немного слабее, чем для общего количества обратных ссылок.
Вот что сказал по этому поводу Тим:
Это может быть показателем того, что Google ценит некоторые nofollow-ссылки с сильных страниц больше, чем переходы по ссылкам со слабых. #whoknows
Отнеситесь к этой находке с большой долей скептицизма. Основная цель этого исследования не состояла в том, чтобы проанализировать влияние nofollowed vs.переходили по ссылкам и поэтому не пытались изолировать этот фактор.
Но даже если мы предположим, что nofollowed ссылки не имеют прямого воздействия на SEO, они все равно могут иметь косвенное влияние , потому что:
1. Они помогают разнообразить ваш ссылочный профиль.
Естественные профили обратных ссылок разнообразны.
По некоторым ссылкам переходят, по другим нет. Этот факт неизбежен, потому что некоторые люди неизбежно будут ссылаться на вас через ссылки без перехода… как бы вы ни хотели, чтобы этого не было.
Кроме того, большинство обратных ссылок, которые вы получаете из следующих источников, не содержат ссылок:
- Социальные сети (Facebook, Twitter, YouTube и т. Д.)
- Форумы (Reddit, Quora и т. Д.)
- Пресс-релизы
- Гостевые книги ( привет, 1998!)
- Википедия (подсказка: любой, может редактировать страницу Википедии)
- Pingbacks
- Каталоги
Короче говоря, если веб-сайт следил только по обратным ссылкам или заметно высокий процент отслеживаемых обратных ссылок, то это явный признак того, что происходит что-то подозрительное.
Чтобы проверить соотношение последовательных и запрещенных ссылок для любого веб-сайта или веб-страницы, используйте отчет Overview в Ahrefs Site Explorer.
Site Explorer> введите любой домен, URL или подпапку> Обзор
Похоже, что 85% ссылающихся доменов (ссылающихся на веб-сайты) на блог Ahrefs отслеживаются.
Это хорошо или плохо? Честно говоря, если здесь есть какое-то разнообразие, это хороший знак.
То, что вы не хотите видеть, — это 100% dofollow или что-то подобное, потому что это явный признак манипуляции.По опыту я бы сказал, что от 60 до 90% нормально, но этот диапазон не является окончательным. Если вы подозреваете нечестную игру, копайте глубже.
2. Они привлекают трафик, а трафик приводит к переходу по ссылкам
Ссылки полезны не только для целей SEO. Они также привлекают реферальный трафик.
Вот почему мы так активны на Quora.
Если вы раньше не слышали о Quora, это сайт вопросов и ответов, где каждый может ответить на вопросы, которые публикуют. В этих ответах Quora позволяет ссылаться на соответствующие ресурсы.
Вот недавний ответ, опубликованный нашим менеджером по маркетингу Ребеккой Бек, где она ссылается на блог Ahrefs:
К сожалению, поскольку все исходящие ссылки на Quora запрещены, эта ссылка не имеет прямого SEO-эффекта.
Но вот интересная часть:
Если мы проверим отчет Backlinks в Ahrefs Site Explorer для ahrefs.com и отфильтруем только ссылки «dofollow», вот одна из многих обратных ссылок, которые мы видим:
Теперь давайте присмотритесь к соответствующей странице (страница, с которой идет ссылка):
Единственная причина, по которой мы получили эту ссылку после , заключается в том, что автор этой статьи наткнулся на ответ Ребекки на Quora.Другими словами, ссылка nofollow косвенно вела на ссылку, по которой читали.
Итак, помните: чтобы кто-то связался с вами, должны произойти три вещи в следующем порядке:
- Они видят ваш контент
- Им нравится ваш контент
- Они рекомендуют другим ссылки на своем сайте)
Поскольку ссылки nofollow могут помочь в этом первом шаге, они часто являются катализатором для следующих ссылок.
3. Они могут защитить от штрафов Google
Иногда есть законные причины платить за ссылки.
Если веб-сайт получает огромное количество трафика, покупка спонсируемого сообщения на этом сайте может иметь смысл. А если вы платите хорошие деньги за функцию, то, вероятно, вы захотите добавить обратную ссылку, чтобы читатели могли легко найти ваш сайт.
Проблема? Google заявляет, что переход по платным ссылкам противоречит их рекомендациям для веб-мастеров.
Тем не менее, сообщество SEO обычно делится на два лагеря:
- Те, кто считает, что Google может точно идентифицировать платные ссылки алгоритмически.
- Те, кто считает, что Google не может точно определять платные ссылки алгоритмически.
Какой лагерь правильный, мы обсудим в другой день.
А пока предположим, что лаг № 2 верен и что Google изо всех сил пытается идентифицировать все платные ссылки. Это означает, что покупать и продавать ссылки на то, что душе угодно, безопасно, верно? Не так быстро.
У Google есть инструмент, который позволяет любому сообщать о покупке или продаже ссылок на веб-сайте.
Инструмент Google для сообщения о платных ссылках.
Перевод: возможно, вам следует опасаться не Google, а ваших конкурентов.
Подумайте об этом: если конкурент видит, что вы занимаетесь хорошим рейтингом по их целевому ключевому слову, и использует такой инструмент, как Site Explorer от Ahrefs, чтобы вникнуть в ваши обратные ссылки, только для того, чтобы обнаружить следующие ссылки, подобные этой: сообщить вам?
Если в результате команда Google по борьбе со спамом просматривает ваш веб-сайт, обнаруживает платные ссылки и вводит штраф вручную, то у них на одного конкурента меньше, с которым они могут конкурировать в поисковой выдаче.
Что аккуратно подводит нас к:
Как проверить свой веб-сайт на наличие проблем, связанных с ссылками nofollow
Переходить по обратным ссылкам, нарушающим рекомендации Google для веб-мастеров, рискованно.
То же самое верно и для исходящих ссылок на вашем веб-сайте, для которых не следует переходить по ссылке.
Но дело не только в гневе Google (то есть штрафах). Также может случиться так, что некоторые внутренние ссылки nofollow снижают эффективность вашего SEO.
Далее следует быстрый аудит, который поможет выявить и устранить любые подобные проблемы.
1. Ищите отслеживаемые обратные ссылки с помощью якорей с множеством ключевых слов
По большей части люди не будут использовать якоря с точным соответствием при переходе по ссылке на ваш сайт. Вот почему переходы по ссылкам с точным соответствием якорей могут быть признаком манипулирования обратными ссылками.
Чтобы найти их, используйте отчет «Якоря» в Ahrefs Site Explorer.
Site Explorer> введите свой домен> Anchors> dofollow filter
Здесь мы видим, что большинство привязок этого веб-сайта являются брендированными или универсальными (размыты в целях конфиденциальности), но есть девятнадцать веб-сайтов (ссылающихся на домены), которые ссылаются с использованием фраза «ссуды до зарплаты» в качестве якоря.
Если мы нажмем на курсор, затем «Ссылающиеся домены», мы увидим, что это за веб-сайты.
Затем, если мы снова нажмем курсор, мы сможем увидеть контекст всех ссылок из каждого домена.
Вот некоторые приблизительные рекомендации по работе с различными типами ссылок, которые вы найдете здесь:
- Купленные ссылки на некачественных сайтах. Попросите удалить ссылку (желательно) или исключить подписку. Отклонить на уровне страницы или домена, если они этого не сделают.
- Гостевые посты, биографические ссылки. Использовали ли вы ранее якоря, содержащие ключевые слова, в биографии авторов гостевых постов? Попросите человека, отвечающего за этот сайт, заменить ссылку с большим количеством ключевых слов на фирменную. Или, если вы предпочитаете оставить привязанную ссылку, попросите, чтобы она не была подписана.
- Ссылки на виджет. Измените HTML-код виджета так, чтобы ссылка не переходила по ссылке. Попросите тех, кто уже встроил ваш виджет, не переходить по ссылке.
- Ссылки на сайт. Попросите, чтобы ссылка была отменена или заменена на фирменный якорь.
Обратите внимание, что ссылки с точным соответствием не всегда указывают на некачественные или платные ссылки. Такие ссылки могут появляться естественным образом и при законных обстоятельствах.
Вот почему вы всегда должны тщательно изучать ссылки, прежде чем отклонять их или просить запретить им подписываться.
Если вы этого не сделаете, вы можете в конечном итоге принести больше вреда, чем пользы.
PRO TIP
Для крупных веб-сайтов в отчете Anchors могут быть сотни или тысячи различных привязок.Просеивание всех из них может занять много времени.
Итак, вот небольшой трюк, который вы можете использовать:
Во-первых, экспортируйте полный список отслеживаемых привязок.
Site Explorer> введите свой домен> Якоря> добавьте фильтр «dofollow»> Экспорт> CSV
Затем скопируйте и вставьте их в Ahrefs Keywords Explorer партиями до 10 000 за раз.
Нажмите поиск, чтобы создать отчет, затем отсортируйте по столбцу CPC от большего к меньшему.
Поскольку якоря с высокой ценой за клик часто более склонны к рассылке спама, это должно привести к тому, что якоря со спамом окажутся в верхней части списка.
Наконец, поищите в отчете Anchors в Site Explorer любые якоря, выглядящие как спам, и исследуйте их дальше.
2. Ищите отслеживаемые спонсируемые обратные ссылки
Обратные ссылки из спонсируемых сообщений всегда должны быть без подписи.
Это потому, что вы фактически платите за ссылку, поэтому она не должна учитываться в PageRank.
Чтобы найти такие ссылки, выполните поиск по слову «спонсируемые» в отчете Обратные ссылки для вашего веб-сайта в Ahrefs Site Explorer.
Site Explorer> Обратные ссылки> поиск по запросу «спонсируемые»> фильтр по запросу «dofollow»
Свяжитесь с нами и попросите исключить любые такие ссылки.
3. Ищите на своем веб-сайте исходящие ссылки с большим количеством ключевых слов
Знаете ли вы, что Forbes заблокировал все исходящие ссылки в 2017 году?
Этот шаг был сделан после того, как они заметили, что некоторые из их участников продавали по ссылкам из их статей. Поскольку у них так много участников, они решили, что невозможно проверить все ссылки на сайте, и поэтому выбрали ленивый вариант, чтобы nofollow все.
Почему это актуально?
Потому что, если вы когда-либо принимали гостевые посты на своем сайте или имели какой-либо пользовательский контент, у вас могла быть такая же проблема.
Чтобы узнать, так ли это, взгляните на свои исходящие привязки в Ahrefs Site Explorer.
Site Explorer> введите свой домен> Исходящие ссылки> Якоря> добавьте фильтр «dofollow»
Ищите подозрительные слова и фразы, которые вы не ожидаете увидеть на своем сайте, и удалите или запретите всем, что кажется манипулятивным е.g., якоря, содержащие ключевые слова, в биографии гостевых постов и т. д.).
Что касается того, почему это важно, Google объясняет это лучше всего:
Если вы не можете или не хотите поручиться за содержание страниц, на которые вы ссылаетесь с вашего сайта — например, ненадежные комментарии пользователей или записи в гостевой книге — вы не должны переходить по этим ссылкам. Это может оттолкнуть спамеров от нацеливания на ваш сайт и поможет предотвратить непреднамеренную передачу рейтинга PageRank сайтам в плохие сети.
Вы видите много якорей?
Воспользуйтесь советом из шага №1.
4. Ищите на своем сайте следующие спонсорские ссылки.
Принимали ли вы когда-нибудь спонсируемое сообщение на своем сайте? Вы не пропустили ссылку?
Если вы не уверены, возможно, стоит проверить.
Для этого выполните поиск в Google по запросу site: yourwebsite.com "спонсируемое сообщение"
Откройте все результаты один за другим и найдите спонсируемую ссылку.
Если вы установили расширение nofollow для Chrome, все ссылки nofollow на странице будут выделены, поэтому спонсируемая ссылка обязательно должна быть выделена.Если это не так, это переход по ссылке.
Подтвердите это, покопавшись в HTML.
Щелкните ссылку правой кнопкой мыши, нажмите «Проверить» и найдите тег rel = «nofollow».
Если его нет, значит, это переходящая ссылка, и вам следует добавить тег nofollow.
5. Ищите внутренние ссылки nofollow
Никакие внутренние ссылки не должны быть nofollow, если они не указывают на неважные страницы или страницы, которые вы хотите исключить из индексов поисковых систем.
Чтобы найти внутренние ссылки без перехода, используйте отчет Best by Links в Ahrefs Site Explorer.
Site Explorer> введите свой домен> Best by Links> переключитесь на Internal> сортируйте по столбцу nofollow
Если вы видите какие-либо страницы с внутренними ссылками nofollow, нажмите номер, чтобы узнать, откуда эти ссылки, и исследуйте способствовать. Может случиться так, что они имеют смысл (например, внутренние ссылки nofollow на страницу входа).
Однако, если нет очевидной причины для запрета перехода по ссылкам, удалите тег nofollow.
Вот и все.По какой-то причине у нас есть ссылка nofollow с одного сообщения в блог на другой.
PRO TIP
Для более детальной разбивки проблем с внутренними ссылками nofollow на вашем веб-сайте запустите новое сканирование в Ahrefs Site Audit.
Это не только дает вам 100% свежие данные, но также предупреждает вас о множестве конкретных проблем, связанных с внутренними и внешними ссылками nofollow.
Пример проблем, связанных с внутренними ссылками nofollow в Ahrefs Site Audit
Узнайте, как настроить первое сканирование в Site Audit, из этого видео:
https: // www.youtube.com/watch?v=LjinWqfGyVE
Заключительные мысли
Ссылки Nofollow играют жизненно важную роль, когда дело доходит до SEO.
Надеюсь, это руководство успешно вооружило вас знаниями, необходимыми для того, чтобы ссылки nofollow работали для вас… а не против вас.
Прежде чем я подведу итоги, у меня есть еще один заключительный — вероятно, довольно очевидный — момент: если вы активно создаете ссылки на свой веб-сайт, тогда имеет смысл установить приоритеты создания ссылок, по которым вы переходите. Это те, которые учитывают PageRank и имеют прямое влияние на SEO.
В Site Explorer все наши отчеты, связанные с обратными ссылками, имеют фильтры «dofollow» и «nofollow».
Это упрощает расстановку приоритетов, когда вы анализируете профили обратных ссылок конкурентов на предмет воспроизводимых ссылок или составляете список потенциальных клиентов «небоскребов», или в любом другом случае.
У вас остались вопросы? Напишите мне в комментариях ниже или через Twitter.