
Робот Яндекса проиндексировал ненужную страницу. Закрыл в robots, поставил тег noindex, удалял в вебмастере, она всё ещё в поиске. Как быть?
Популярное
Сообщества
По мере освоения SEO узнал, что сайт в разработке нужно закрыть от индексации, а уже проиндексированные страницы удалить из поиска. С Google разобрался, а в Яндексе осталась одна страница, которую я никак не могу удалить. Вебмастер почему-то отклоняет удаление. Как быть?
Поисковые системыЯндекс вебмастерИндексация сайтов
Никита Грибков
·
1,2 K
ОтветитьУточнитьЛучший
Firemarketing
504
🖥 Разработка и продвижение сайтов · 12 нояб 2020 · firemarketing. ru
ru
Отвечает
Дмитрий Титов
Вы сделали все необходимое (disallow в robots и тег noindex). Остальное за роботом. Ему нужно это увидеть.
Заказать продвижение
Перейти на firemarketing.ruКомментировать ответ…Комментировать…
Антон Величко
Маркетинг
1,1 K
SEO аналитик. Нравится помогать — это развивает меня самого! · 17 нояб 2020 · antonvelichko.ru
> Что будет, если в файле robots.txt запретить доступ к контенту с тегом noindex?
Google не сможет увидеть директиву noindex, потому что он не будет сканировать страницу.
Какой получим результат: страница останется в выдаче Google и не выпадет из нее.
Вы будете продолжать видеть в выдаче Google сниппеты страниц, где отобразится заголовок страницы, в описании будет.
SEO e-commerce, услуг, статейников, наставничество и консультации:
Перейти на antonvelichko.ruКомментировать ответ…Комментировать…
Дмитрий Данилов
Менеджмент
607
Управляющий партнер. Агентство «Webpage Profy» · 9 нояб 2020 · webpage-profy.ru
У Яндекса может доходить до 2-3 недель ожидание, пока страница наконец выпадет из индекса. Часто подобная проблема бывает с техническими страницами, генерируемые движками согласно шаблону структуры страниц. Я бы посоветовал подождать, если срок прошел небольшой. Ещё одна причина индексации закрытой в роботе страницы может заключаться в наличие ссылки на эту страницу… Читать далее
Разработка и продвижение сайтов под ключ
Комментировать ответ…Комментировать…
Hot Heads
68
Студия правильного интернет-маркетинга HotHeads · 18 нояб 2020 · hotheads. su
su
Отвечает
Роман
Дополнительно проверьте есть ли данная страница в xml карте. Есть ее обнаружите, то удалите ее оттуда и направьте карту на переобход
И как все советуют подождите некоторое время и страница пропадет из поиска
Делаем только то, что приносит пользу бизнесу наших клиентов https://hotheads.su
Перейти на hotheads.suКомментировать ответ…Комментировать…
Вы знаете ответ на этот вопрос?
Поделитесь своим опытом и знаниями
Войти и ответить на вопрос
Noindex – это | Что такое Noindex
Что такое Noindex?
Noindex — имя тега, предназначенного для включения в него текста, который не должен быть проиндексирован поисковыми системами (Яндекс и Rambler).
Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш.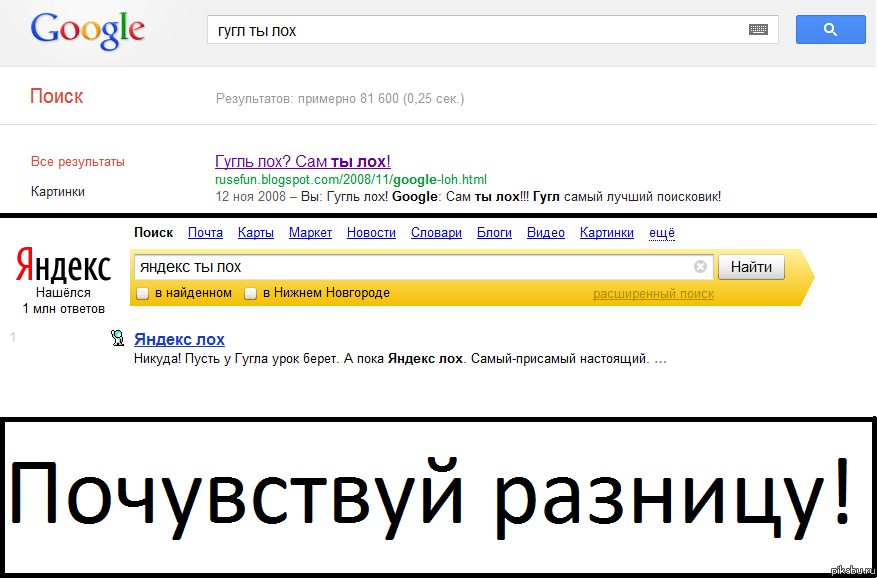 Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
Часто у тех, кто использует этот тег, существует убеждение, что если поместить часть какого-либо текста между открывающимся и закрывающимся тегом noindex, то робот Яндекса не станет читать и анализировать этот текст. Но это не так. Этот тег запрещает помещение содержимого в индексную базу, а его содержимое будет прочитано и проанализировано роботом в любом случае.
В чем отличие между noindex и nofollow
Существенное отличие их в том, что первый был введен ранее для Google, а второй — только для Яндекс и Rambler. В настоящее время Яндекс также научился распознавать Nofollow, который работает только для ссылок. А Noindex — для любого кода сайта.
Применение
Пример 1:
<noindex>Текст, запрещенный к индексированию</noindex>
Яндекс не индексирует текст, но читает его
Пример 2:
<noindex><a href=»http:// … . ru/»>Текст ссылки</a>
ru/»>Текст ссылки</a>
Яндекс не индексирует анкор, но учитывает ссылку на сайт и передает по ней вес
При работе с Noindex существует вероятность того, что снизится валидность кода, так как данный тег знает только российский поисковик. Некоторые HTML-редакторы не воспринимают его, поскольку он не является валидным. К примеру, визуальный редактор в WordPress его попросту удаляет. Поэтому рекомендуется следующий вариант написания:
<!—Noindex—> Весь текст, который надо скрыть <!—/Noindex—>.
При этом другие поисковые системы просто его пропустят, а валидность кода останется неизменной.
Не стоит путать тег Noindex с метатегом, имеющим такое же название. Последний прописывают в начале страницы. Они служат для разных целей. Если взять метатег <meta name=»robots» content=»noindex,nofollow»>, то он запрещает индексирование всей страницы и переход по ссылкам. Этот запрет можно также прописать в файле robots.
Категории
SEO (search engine marketing)
Внутренняя оптимизация
Теги
Метатеги
Title
Description
Альт теги
Микроразметка
Теги-заголовки
Nofollow
Noindex
Контент
Копирайтинг
Robots.txt
Семантическое ядро сайта
Внешняя оптимизация
Биржа ссылок
Аудит сайта
Яндекс.
 Вебмастер
Вебмастер
См. также
Хлебные крошки на сайте
Зеркало сайта
XML карта
Страница заблокирована от индексации
Опубликовано • Обновлено
Содержание
- Как обеспечить сбой аудита индексации Lighthouse
- 2 может сканировать вашу страницу
- Добавить дополнительный элемент управления (необязательно)
- Ресурсы
Поисковые системы могут отображать страницы в результатах поиска только в том случае, если эти страницы явно не блокируют индексацию сканерами поисковых систем. Некоторые заголовки HTTP и метатеги сообщают поисковым роботам, что страницу не следует индексировать.
Блокировать индексирование только того контента, который вы не хотите отображать в результатах поиска.
# Как проваливается аудит индексации Lighthouse
Lighthouse помечает страницы, которые поисковые системы не могут индексировать:
Lighthouse проверяет только заголовки или элементы, которые блокируют все сканеров поисковых систем.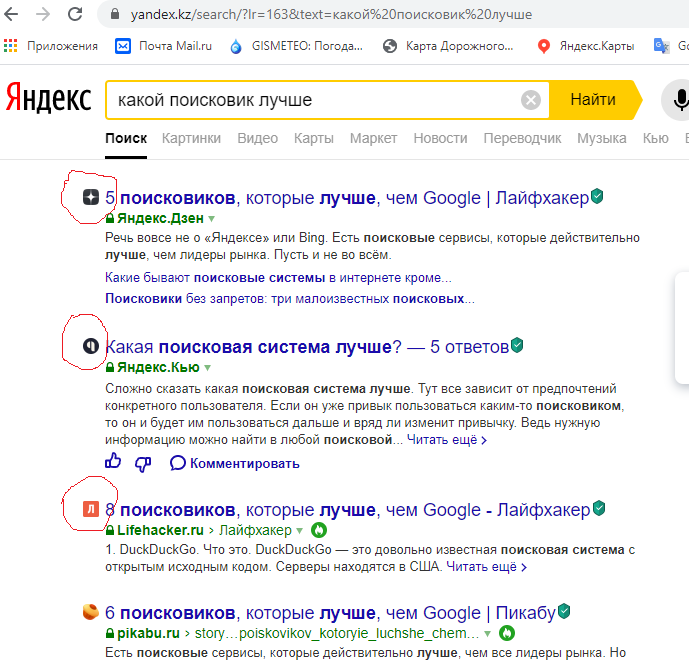 Например, приведенный ниже элемент
Например, приведенный ниже элемент запрещает всем сканерам поисковых систем (также известным как роботы) доступ к вашей странице:
Этот заголовок ответа HTTP также блокирует все поисковые роботы:
X-Robots-Tag: noindex
У вас также могут быть элементы , которые блокируют определенные поисковые роботы, например:
Lighthouse не проходит проверку на наличие таких директив для поисковых роботов, но они все же могут затруднить обнаружение вашей страницы, поэтому используйте их с осторожностью. Lighthouse выдаст предупреждение, если директива, специфичная для сканера, блокирует обычного индексирующего бота.
Каждый SEO-аудит имеет одинаковый вес в рейтинге Lighthouse SEO Score, за исключением , проведенного вручную. Структурированные данные действительны. аудит. Узнайте больше в Руководстве по подсчету очков Lighthouse.
# Как убедиться, что поисковые системы могут сканировать вашу страницу
Сначала убедитесь, что вы хотите, чтобы поисковые системы индексировали страницу. Некоторые страницы, такие как карты сайта или юридический контент, вообще не должны индексироваться. (Имейте в виду, что блокировка индексации не препятствует доступу пользователей к странице, если они знают ее URL-адрес.)
Для страниц, которые вы хотите проиндексировать, удалите все заголовки HTTP или элементы , которые блокируют сканеры поисковых систем. В зависимости от того, как вы настроили свой сайт, вам может потребоваться выполнить некоторые или все из следующих шагов:
- Удалить заголовок ответа HTTP
X-Robots-Tag, если вы настроили заголовок ответа HTTP:
X -Robots-Tag: noindex
- Удалите следующий метатег, если он присутствует в заголовке страницы:
- Избегайте метатегов, которые блокируют определенные поисковые роботы, если эти теги присутствуют в заголовке страницы.
 Например:
Например:
 Например:
Например:# Добавить дополнительный элемент управления (необязательно)
Возможно, вам потребуется больше контроля над тем, как поисковые системы индексируют вашу страницу. Например, возможно, вы не хотите, чтобы Google индексировал изображения, но вы хотите, чтобы индексировалась остальная часть страницы.
Для получения информации о настройке вашего Элементы и заголовки HTTP для конкретных поисковых систем см. Спецификации метатега Google Robots и заголовка HTTP X-Robots-Tag
Обновлено • Улучшить статью
Яндекс Вакансии за февраль 2023
Хочу нанять Я хочу работать
О Яндекс Yandex NV — многонациональная компания, ориентированная преимущественно на русских и русскоязычных пользователей, предоставляющая 70 интернет-продуктов и услуг, включая транспортные, поисковые и информационные услуги, электронную коммерцию, навигацию, мобильные приложения и интернет-рекламу.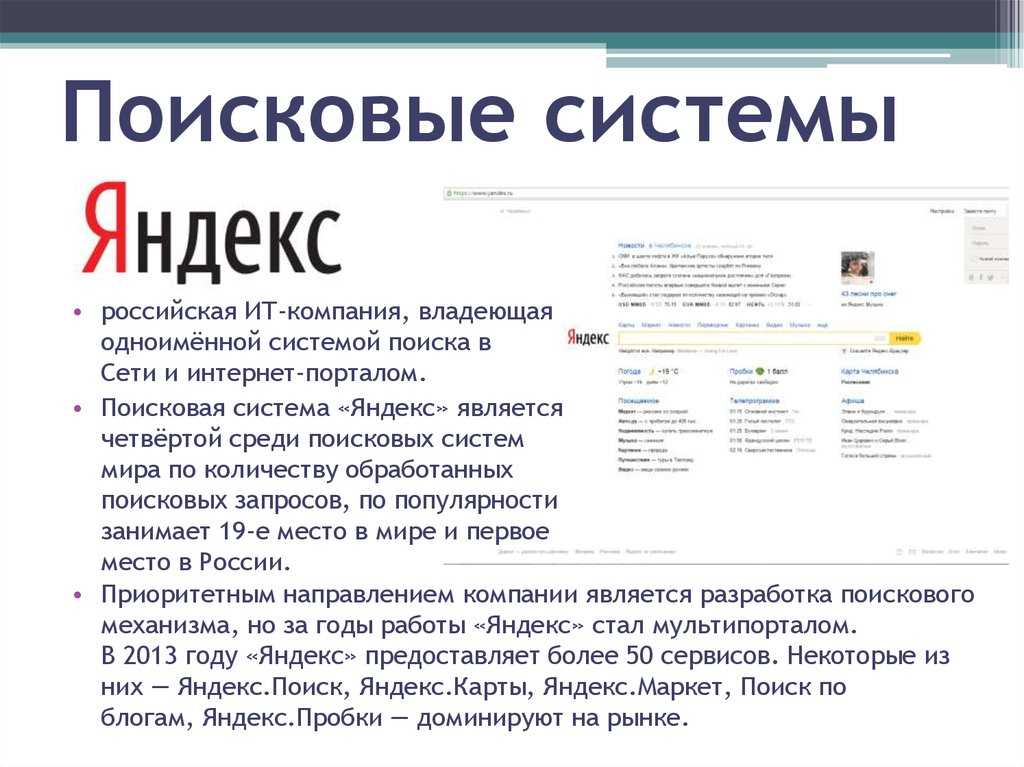
По 3 отзывам клиенты оценивают нашу
Яндекс Эксперты
5 из 5 звезд.
Поиск по ключевому слову
Где ?
Мои недавние поиски
Фильтровать по:
Бюджет
Проекты с фиксированной ценой
Почасовые проекты
Продолжительность Все ПродолжительностьМеньше 1 неделиОт 1 недели до 4 недельОт 1 месяца до 3 месяцевОт 3 месяцев до 6 месяцевСвыше 6 месяцев / ПродолжаетсяНе указано
Конкурсы
Тип
- Местные вакансии
- Рекомендуемые вакансии
- Рекрутер Вакансии
- Полная занятость
Навыки
введите навыки
Языки
введите языки
рекомендуемых статей специально для вас
Полное руководство по найму веб-разработчика в 2021 году
Если вы хотите оставаться конкурентоспособными в 2021 году, вам нужен качественный веб-сайт.