
Google Search Console: отправленный URL-адрес отмечен как ‘noindex’ | Центр Поддержки
Если вы отправили страницу на индексирование в Google и получили сообщение об ошибке Submitted URL Marked ‘noindex’, это означает, что Google определил, что ваша страница не должна индексироваться и отображаться в результатах поиска.
Тег noindex — это метатег, который вы можете добавить в HTML-код страницы, чтобы предотвратить ее отображение в результатах поиска. Однако это сообщение об ошибке не обязательно означает, что в вашем коде есть тег noindex. У этой ошибки могут быть разные причины, которые вы можете легко проверить и исправить.
Если вы получаете сообщение об ошибке Submitted URL Marked ‘noindex’, попробуйте выполнить следующие действия:
Шаг 1 | Проверьте URL
Убедитесь, что вы правильно указали URL-адрес страницы, когда отправляли ее для индексирования.
Также убедитесь, что URL соответствует существующей странице вашего сайта, которая не возвращает ошибку 404 или ошибку 5xx.
Шаг 2 | Убедитесь, что поисковые системы могут индексировать страницу и сайт
Проверьте на страницах сайта, что поисковым системам разрешено их индексировать. Иначе страница будет иметь тег «noindex» в коде, и Google не будет включать ее в результаты поиска.
Как проверить, могут ли поисковые системы индексировать ваши страницы:
- Редактор Wix
- Editor X
Также нужно проверить настройки сайта, чтобы убедиться, что поисковые системы могут его проиндексировать.
Шаг 3 | Проверьте, не защищена ли страница паролем
Убедитесь, что ваша страница не защищена паролем. В противном случае страница будет иметь тег «noindex» в коде, и Google не будет включать ее в результаты поиска.
Подробнее о страницах, защищенных паролем:
- Редактор Wix
- Editor X
Шаг 4 | Убедитесь, что страница не предназначена только для пользователей
Проверьте, что страница не предназначена только для зарегистрированных пользователей. Страницы только для пользователей по умолчанию исключаются из результатов поиска.
Страницы только для пользователей по умолчанию исключаются из результатов поиска.
Подробнее о страницах только для пользователей:
- Редактор Wix
- Editor X
Шаг 5 | Используйте инструмент проверки URL
Если индексирование страницы разрешено, она не является страницей только для пользователей и не защищена паролем, следует проверить ее URL-адрес с помощью инструмента проверки URL Google.
Инструмент проверки URL позволяет отправлять отдельные страницы в Google и симулировать, как Google сканирует и отображает URL-адрес вашего сайта. Вы можете использовать инструмент для диагностики ошибок, которые препятствуют индексированию страницы. Подробнее
Шаг 6 | Проверьте дату последнего сканирования
Проверьте дату под Last read в отчете по файлам Sitemap в Google Search Console. Если стоит дата больше месяца назад, сообщение об ошибке, скорее всего, больше не актуально.
Шаг 7 | Запросите в Google индексирование страницы
Если вы проверили все вышеперечисленное, но страница все еще не индексируется, запросите индексирование в Google, нажав Запросить индексирование в инструменте проверки URL.
Скрытие меню в noindex вредно или полезно? Использование noindex и AJAX для нежелательных ссылок в Яндексе и Google
Данный вопрос — приоритетный!
Степан:
Дмитрий, привет!
Яндекс рекомендует оборачивать тех. информацию, и контент нежелательный к индексации в тег <noindex>. Например, на Я.Маркете сквозные блоки (шапка, меню под шапкой, подвал) как раз обернуты в noindex.
Есть рекомендации прятать подобный контент через AJAX, убирать совсем из тела страницы. Так как всё-таки правильно скрывать от индексации массивные блоки, которые вшиты в шаблон и повторяются на всех страницах сайта? Интересуют рекомендации для интернет-магазинов и агрегаторов?
В чём мои сомнения:
- Если использовать AJAX, поисковые системы не увидят, что на сайте есть отличное удобное меню, формы обратной связи, информативный, полезный подвал и т.д.
Т.е. они это конечно увидят, через счетчики (ту же Метрику), через информацию из собственных браузеров, различные бары и т.
- Если использовать <noindex>, это как полумера — работает в Яндексе, но в Google бесполезна.
Если на сайте массивное меню, noindex не поможет убрать передаваемый ссылками меню вес внутри сайта.

И по внутренним ссылкам в продолжение еще вопрос — актуально ли в нынешних реалиях (отключение внешнего ссылочного Яндексом) заморачиваться с ссылочным внутренним, с распределением ссылочного веса, с закрытием ненужных ссылок в AJAX и т.д.?
Вопрос интересует с точки зрения улучшения видимости сайта в выдаче и роста трафика после данных манипуляций.
Приветствую, Степан.
Отдельное спасибо за понятную и подробную постановку вопроса.
С точки зрения корректности использования тега <noindex> — мы не рекомендовали бы его применять по следующим причинам:
Скрывается только текстовый контент.
Сам факт наличия ссылок и передача по ним статического веса (PR) — сохраняется.Тег интерпретируется только Яндексом. В результате его использования информация с которой работает Яндекс и Google начинает различаться (порой значительно), что осложняет дальнейший анализ позиций проекта и работу с ним.
 Сам факт наличия ссылок и передача по ним статического веса (PR) — сохраняется.
Сам факт наличия ссылок и передача по ним статического веса (PR) — сохраняется.Правда, существует два положительных случаев локального использования тега <noindex>:
Снятие фильтров Переспам или Переоптимизация, в том случае, когда позиции в Google просто отличные (ТОП-3), а в Яндексе документ попал под фильтр.
Как промежуточная мера, пока реализуются более длительные технические доработки.
Почему иногда меню закрывают в noindex?
Что касается Яндекса и тех его сервисов, которые вы назвали, то основная причина скрытия меню тегом <noindex> состоит в желании исключить текст из меню и сквозных блоков из поиска. То есть, данные блоки, при использовании поиска по сайту (и основного поиска) могут приводить к появлению нерелевантных результатов.
Это наглядно продемонстрировано ниже. На иллюстрациях видно, что в Google документ с камерой Sony Alpha (http://market.yandex.ru/product/9279446/) ранжируется по запросу [техника для кухни], а в Яндексе — нет, что в целом весьма корректно.
Ко второму, дополнительному эффекту от скрытия, можно отнести повышение процентного содержимого релевантного запросу контента (за счёт неучёта обвязки, меню и т.д.).
Есть ли отрицательное влияние скрытие меню в noindex?
Как известно, Яндекс старается понижать важность текста анкора, который встречается на заданном сайте (ведущий на одну и ту же страницу) два и большее число раз.
Для нас это означает, что текст (анкор) из меню используются ≃ 1 раз для ранжирования. При условии, что сами ссылки продолжают передавать статический вес, большого влияния на ранжирование скрытие меню тегом ноуиндекс не оказывает (достаточно в каком-то 1 месте оставить меню открытым, скажем, на главной странице).
Итого, стоит ли убирать меню через ноуиндекс или AJAX?
На наш взгляд — нет, это избыточная мера.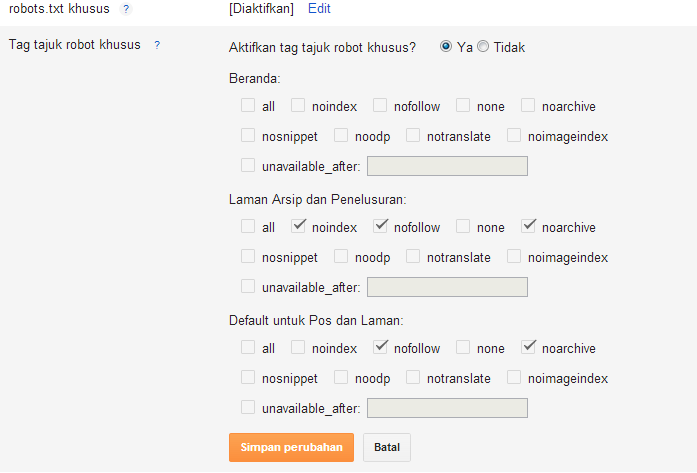 Наоборот, для ряда запросов большое число релевантных документов на сайте будет оказывать положительное влияние, а использование скрытия через скрипт (AJAX) — нарушит распределение статического веса на сайте.
Наоборот, для ряда запросов большое число релевантных документов на сайте будет оказывать положительное влияние, а использование скрытия через скрипт (AJAX) — нарушит распределение статического веса на сайте.
Скрытие ряда ссылок с помощью AJAX
Использование методов AJAX для скрытия сквозных или просто нежелательных ссылок — штука полезная. Стоит привлекать её, когда статический вес (PR) перераспределяется на те страницы, на которых вы его скапливать не хотите, скажем: Лицензионное соглашение, О нас, Онлайн-заявка и т.д.
Здесь стоит обратить своё внимание, на то, что Google индексирует уже давно не исходный код документа, а сначала рендерит страницу и исполняет JS и параллельно ругается, если ли скрыли от него важные скрипты в файле robots.txt. Тем не менее, скрипт, с помощью которого вы скрываете ссылки, должен быть не самым банальным и недоступным для индексации и воспроизведения пауку Googlebot.
Также, применение грамотной внутренней перелинковки с разными анкорами и распределение статического веса на страницы, на которые ведут более частотные и конкурентные поисковые запросы — позволяет повысить поисковый трафик. Так что данные работы, по прежнему остаются актуальными.
Так что данные работы, по прежнему остаются актуальными.
В первую очередь, при работе с внутренней перелинковкой, уделите внимание:
- Уровню вложенности документов.
- Числу входящих на раскручиваемые страницы ссылок (по отношению к общему числу страниц в индексе).
- Использованию различных анкоров для перелинковки.
Удачи в работе с проектом и грамотной самостоятельной перелинковке!
Дата ответа:
Автор ответа:
Дмитрий Севальнев
Как я могу проверить, действителен ли индекс? — Часто задаваемые вопросы по Python
jephos249 1
Вопрос
В контексте этой задачи кода, как я могу проверить, действителен ли индекс?
Ответ
Индекс списка действителен, только если к этому индексу можно получить доступ из списка, не вызывая какой-либо ошибки.
Обычно это означает, что индекс должно быть целым числом , и оно должно быть меньше длины списка , поскольку любой индекс, превышающий длину списка, выходит за пределы допустимого диапазона. Кроме того, для этого упражнения мы можем предположить, что передаются только положительные значения, но чтобы гарантировать это, мы можем проверить, что оно должно быть больше или равно 0.
Используя вышеизложенное, мы можем проверить, является ли индекс допустимым. как следующее условие:
, если индекс >= 0 и индекс < len(list)
Это будет работать только для положительных значений индекса, поэтому в качестве задачи вы можете попробовать реализовать его так, чтобы он принимал допустимые отрицательные значения индекса, где -1 — индекс последнего элемента, -2 — индекс предпоследнего элемента и так далее.
10 лайков
мтф 2
В Python мы можем писать выражения неравенства с отношениями по обе стороны от переменной.
, если 0 <= x < len(lst)
Это устраняет необходимость в логической операции.
Все допустимые индексы находятся между отрицательной длиной списка, включительно, и длиной списка, исключая.
если -len(lst) <= x < len(lst)
и находится в списке, сгенерированном для этого диапазона.
, если x в диапазоне (-len(lst), len(lst))
>>> лст = [1, 2, 3, 4, 5, 6, 7, 8, 9] >>> х = 9 >>> x в диапазоне (-len(lst), len(lst)) ЛОЖЬ >>> х = -9 >>> x в диапазоне (-len(lst), len(lst)) Истинный >>>
8 лайков
математика755344839 3
Поскольку недопустимый индекс вызывает ошибку, я использовал try/except для решения этой проблемы
3 лайков
4
Привет, теперь я знаю, как должно выполняться упражнение, но я хотел убедиться, что мое решение также жизнеспособно. Вот как я это сделал:
по определению double_index(lst, index):
пытаться:
лст[индекс] = лст[индекс] * 2
кроме IndexError:
вернуть список
Похоже, это работает на моей стороне и проще/чище. Есть ли что-то еще, что мне не хватает, что делает это плохим решением?
9 отметок «Нравится»
мтф 5
Это вполне жизнеспособное решение, если мы понимаем другие методы проверки входных данных. Цель новичка — изучить все возможные решения, а не только самые простые или лучшие. Часто мы не замечаем других подходов, когда зацикливаемся на превосходной степени.
5 лайков
6
Спасибо за быстрый ответ, это справедливое замечание. Я бы не стал сразу думать о методе, ожидаемом в упражнении, поэтому я рад, что научился делать это двумя разными способами.
1 Нравится
paulo_rayner 7
Привет, я тоже застрял в вызове. Я решил это, но, проверив решение, я увидел, что команда возвращает список. Так что неважно, что вы делаете, он всегда возвращает список вместо двойного индекса.
Как может быть правильно, если ответ на вызов равен -20?
Поэтому я изменил код на:
def double_index(lst, index):
if index < len(lst):
lst[index] = lst[index] * 2
И это работало хорошо, но если я вставлю число вне диапазона, оно вернет ошибку (я надеялся, потому что я ничего не использовал, чтобы с этим справиться).
def double_index(lst, index):
if index < len(lst):
lst[index] = lst[index] * 2
else:
lst[index ] = lst
return lst[index]
Если индекс находится в диапазоне, код выполняется правильно. Однако, если индекс выходит за пределы диапазона, он возвращает ошибку
. Моя логика верна? Чтобы построить код таким образом?
Что я пропустил с «еще»?
Спасибо
мтф 8
Учтите, что во всех случаях вы будете возвращать список.
по определению double_index(lst, index):
# код
вернуть список
Теперь вставьте только оператор if и действие для кода # без
paulo_rayner 9
Спасибо за помощь.
1 Нравится
arc4433623687 10
Это несправедливо. Как новичок, я просто потратил много времени, чтобы найти метод по всему содержанию, которому Codecademy научила меня раньше. Я думал, что будет лучшее решение, чем оператор IF, потому что в этом курсе Pro он не упоминается . Я думал, что смогу поверить Codecademy, но это оказалось не так.
дцыи 11
Привет, друзья,
Я только что снова пересмотрел это упражнение, и чтение комментариев (спасибо op и mtf) помогло мне найти еще 2 способа сделать это. Я надеюсь, что мое дополнение поможет тем, кто новичок и все еще не понимает этого.
Я надеюсь, что мое дополнение поможет тем, кто новичок и все еще не понимает этого.
# Действительно только для положительных индексов
def double_index (lst, индекс):
если индекс >= 0 и индекс < len(lst):
лст[индекс] = лст[индекс] * 2
вернуть список
печать (двойной_индекс ([3, 8, -10, 12], 2))
#отпечатки [3, 8, -20, 12]
печать (двойной_индекс ([3, 8, -10, 12], -1))
#prints [3, 8, -10, 12] << это исходный список, поскольку отрицательный индекс, такой как -1, рассматривается как недопустимый, исходный список возвращается функцией
---
# Метод 1 - действителен как для положительных, так и для отрицательных индексов
def double_index (lst, индекс):
если -len(lst) <= index < len(lst):
лст[индекс] = лст[индекс] * 2
вернуть список
печать (двойной_индекс ([3, 8, -10, 12], 2))
#отпечатки [3, 8, -20, 12]
печать (двойной_индекс ([3, 8, -10, 12], -1))
#отпечатки [3, 8, -10, 24]
#Метод 2 - Действителен как для положительных, так и для отрицательных индексов
def double_index (lst, индекс):
если индекс в диапазоне (-len(lst), len(lst)):
лст[индекс] = лст[индекс] * 2
вернуть список
печать (двойной_индекс ([3, 8, -10, 12], 2))
#отпечатки [3, 8, -20, 12]
печать (двойной_индекс ([3, 8, -10, 12], -1))
#отпечатки [3, 8, -10, 24]
8 лайков
орафаэльпорто 12
Я использую этот код, но он продолжает говорить, что я не определил, что делать, если «индекс слишком велик»
def double_index (lst, index):
new_index = lst[index]*2
lst_len = len(lst), если индекс > lst_len:
вернуть lst
иначе:
вернуть lst.append(new_index)
2 лайков
amiasshipley31815297 13
, если index > lst_len , все равно будет разрешен один индекс выше, чем содержит сам список; помните, они имеют нулевой индекс! Замена > на >= должна решить эту проблему.
2 лайка
14
Здравствуйте, кодеры,
Я перепробовал много решений в этом упражнении… мой мозг немного поджарился прямо сейчас… это было мое последнее решение, и я продолжаю получать сообщение Codecademy внизу: «Обязательно определите, что должно произойти, если ИНДЕКС слишком велик». Я не могу обойти это сообщение, и я действительно хотел бы решить эту функцию, не получая решения… любая помощь будет принята с благодарностью 🙂
def double_index(lst, index):
new_list = lst[index] * 2
if index < len(lst):
return new_list
elif index > len(lst):
return lst
print(double_index([ 3, 8, -10, 12], 2))
мтф 15
Общий подход заключается в проверке перед попыткой запуска кода на объекте. Если мы сначала запустим код, мы можем натолкнуться на индекс вне диапазона исключение до достижения строки проверки.
, если len(lst) >= index:
лст[индекс] *= 2
вернуть список
В обоих случаях список возвращается, но изменяется только в том случае, если индекс действителен.
амиасшиплей31815297:
Нигде в предыдущем уроке я не узнал, что определенному индексу в списке может быть присвоено новое значение
Насколько я помню, в начале раздела о списках нам показывают, что списки mutable , что означает, что мы можем изменять значения, добавлять новые элементы и удалять элементы.
johnpaul1985:
Обязательно определите, что должно произойти, если ИНДЕКС слишком велик.
Функция должна удвоить значение элемента по адресу
indexизlstи вернуть новый список с удвоенным значением.Если
индексне является допустимым индексом, функция должна вернуть исходный список.

Я понял, что последняя инструкция означает ничего не делать со списком, просто вернуть его. Нет ожидаемого сообщения, только исходный список.
, если индекс действителен (то есть находится в пределах диапазона) затем измените элемент по этому индексу иначе ничего не делать в обоих случаях вернуть список.
2 лайка
data1249767510 16
Привет,
Я не могу понять предложенное решение:
def double_index(lst, index):
if index >= len(lst):
return lst
еще:
new_lst = lst[0:index]
new_lst.append(lst[index]*2)
new_lst = new_lst + lst[index+1:]
return new_lst
Что делает эта строка:
new_lst = new_lst + lst[index+1:]
Почему это index+1, а не index+2\3\4 и т. д... почему именно 1?
д... почему именно 1?
Спасибо
мтф 17
Добро пожаловать, @data1249767510,
К сожалению, это не может быть решением, так как в списке должно быть изменено только одно значение, а новые не должны добавляться.
После проверки параметра индекса нам нужно получить доступ к этому элементу и умножить его значение на два, а затем повторно вставить его в тот же индекс.
лст[индекс] = лст[индекс] * 2
Это все, что нужно сделать. Обязательно верните lst , а не new_lst .
нхаткуан94 18
Привет,
Я видел, как много людей обсуждали это упражнение, и когда дело доходит до проверки ошибок, все становится все сложнее и сложнее.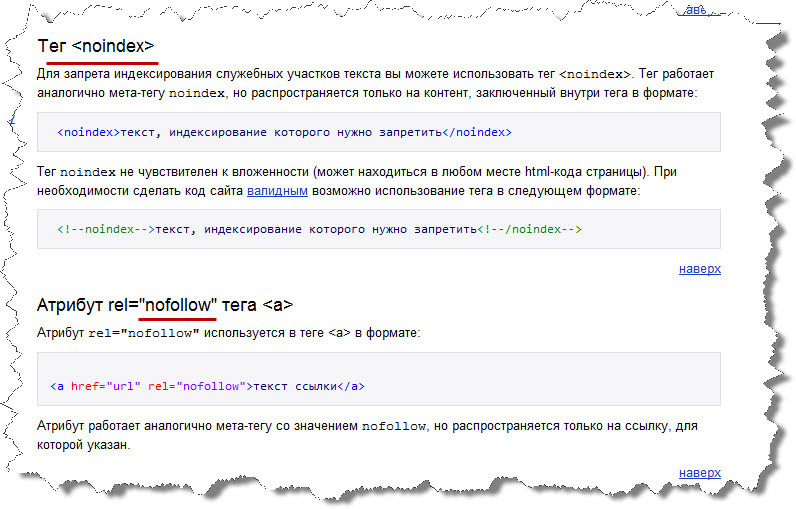 Очевидно, что предложенное Codecademy решение довольно простое и недостаточное.
Очевидно, что предложенное Codecademy решение довольно простое и недостаточное.
Мы обсуждаем отрицательный и положительный индекс, но представьте, что если бы мы ввели НАСТОЯЩЕЕ число вместо целого числа?
Использование try: и exclude: на IndexError будет работать, если мы ввели целое число, но если мы введем 1.2 вместо 1, 3, 4… что-то тогда произойдет ошибка типа. Нам также нужно проверить, является ли lst реалистом.
На данный момент я думаю, что мы должны поверить и попрактиковаться в использовании всего материала, который был предоставлен до сих пор, но я ожидаю, что в следующем уроке будет предоставлен более подробный код.
Поделюсь с вами моим решением, конечно, не идеальным и не может предсказать все сценарии ошибок, которые могут произойти: lst[index]*2)
new_lst = new_lst + lst[index+1:]
вернуть new_lst
, кроме IndexError:
вернуть «Ваш индекс недействителен»
кроме TypeError:
вернуть «Проверьте тип вашего списка или вашего индекса»
lilysha 19
Я придумал код ниже. У него меньше шагов для выполнения, поэтому с точки зрения времени выполнения он будет более эффективным. оно прошло испытание. Дайте мне знать, что вы думаете.
Снимок экрана 22.10.2019, 25.05.05.png738×552 63,2 КБ
мтф 20
>>> а = [3, 8, -1, 12] >>> -1 в диапазоне (len(a)) ЛОЖЬ >>> -1 в диапазоне (len(a)-1) ЛОЖЬ >>> 4 в диапазоне(len(a)) ЛОЖЬ >>> 3 в диапазоне(len(a)) Истинный >>> 3 в диапазоне (len(a)-1) ЛОЖЬ >>>
Из вышеизложенного видно, что вычитание 1 из верхней границы диапазона приводит к False, хотя должно быть True.
Многие ошибочные решения ускользают от внимания SCT, но это не означает, что они верны.
Мы никогда никого не отговариваем от публикации, за исключением тех случаев, когда речь идет о публикации необъяснимых или ошибочных решений. Ни кому не помогает.
Ни кому не помогает.
Как исправить ошибку #Н/Д в функциях ИНДЕКС/ПОИСКПОЗ
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel для Windows Phone 10 Еще. ..Меньше
В этом разделе описываются наиболее распространенные причины появления ошибки "#Н/Д" в результате использования функций ИНДЕКС или ПОИСКПОЗ.
Примечание. Если вы хотите, чтобы функция ИНДЕКС или ПОИСКПОЗ возвращала осмысленное значение вместо #Н/Д, используйте функцию ЕСЛИОШИБКА, а затем вложите функции ИНДЕКС и ПОИСКПОЗ в эту функцию. Замена #N/A собственным значением только идентифицирует ошибку, но не устраняет ее. Итак, очень важно, прежде чем использовать ЕСЛИ ОШИБКА убедитесь, что формула работает правильно, как вы предполагали.
Проблема: нет данных для соответствия
Если функция ПОИСКПОЗ не находит значение поиска в массиве поиска, она возвращает ошибку #Н/Д.
Если вы считаете, что данные присутствуют в электронной таблице, но ПОИСКПОЗ не может найти их, возможно, причина в следующем:
В ячейке есть неожиданные символы или скрытые пробелы.
Ячейка может иметь неправильный формат данных. Например, в ячейке есть числовые значения, но она может быть отформатирована как Текст .
РЕШЕНИЕ : Чтобы удалить неожиданные символы или скрытые пробелы, используйте функцию ОЧИСТИТЬ или ОБРЕЗАТЬ соответственно. Кроме того, убедитесь, что ячейки отформатированы как правильные типы данных.
Вы использовали формулу массива, не нажимая Ctrl+Shift+Enter
При использовании массива в ИНДЕКС , ПОИСКПОЗ или комбинации этих двух функций необходимо нажать Ctrl+Shift+Enter на клавиатуре. Excel автоматически заключит формулу в фигурные скобки {}. Если вы попытаетесь ввести скобки самостоятельно, Excel отобразит формулу в виде текста.
Excel автоматически заключит формулу в фигурные скобки {}. Если вы попытаетесь ввести скобки самостоятельно, Excel отобразит формулу в виде текста.
Примечание: Если у вас есть текущая версия Microsoft 365, вы можете просто ввести формулу в выходную ячейку, а затем нажать ENTER , чтобы подтвердить формулу как формулу динамического массива. В противном случае формулу необходимо ввести как устаревшую формулу массива, сначала выбрав выходной диапазон, введя формулу в выходную ячейку, а затем нажав CTRL+SHIFT+ENTER для подтверждения. Excel вставляет фигурные скобки в начале и в конце формулы. Дополнительные сведения о формулах массива см. в разделе Рекомендации и примеры формул массива.
Проблема: несоответствие типа соответствия и порядка сортировки данных
При использовании MATCH должна быть согласованность между значением в аргументе match_type и порядком сортировки значений в массиве поиска. Если синтаксис отличается от следующих правил, вы увидите ошибку #N/A.
Если синтаксис отличается от следующих правил, вы увидите ошибку #N/A.
Если match_type равно 1 или не указано, значения в lookup_array должны быть в порядке возрастания. Например, -2, -1, 0 , 1 , 2…, A, B, C…, FALSE, TRUE, и это лишь некоторые из них.
Если match_type равно -1, значения в lookup_array должны быть в порядке убывания.
В следующем примере функция ПОИСКПОЗ равна
=ПОИСКПОЗ(40,B2:B10,-1)
Аргумент match_type в синтаксисе имеет значение -1, что означает, что порядок значений в B2:B10 должен быть в порядке убывания, чтобы формула работала.