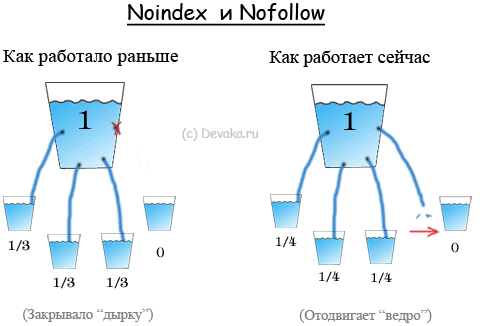
All in One SEO закрыть конкретную страницу noindex nofollow
Плагин All in One SEO большинство администраторов сайтов используют уже достаточно долгое время, однако, как говорит моя практика, вопросы по некоторым настройкам возникают снова и снова. Люди пишут на почту, задают много одних и тех же вопросов… Тратится попусту время… Я решил написать несколько коротеньких постов относительно важных настроек плагина (возможно, запишу и видеоролики, если тема будет достаточно актуальна, так что пишите комментарии и пр).
Дело в том, что не так уж давно, сей плагин претерпел большое обновление, все рычаги и инструменты управления были изменены до неузнаваемости. Некоторые пользователи были, мягко говоря, разочарованы!.. в их числе был и я … ну ладно…
Вот один из частых вопросов: как в All in One SEO закрыть конкретную страницу в noindex nofollow, куда пропали настройки.?.
Разделы статьи:
- плагин All in One SEO закрываем конкретную страницу в noindex
- опции All in One SEO в текстовом редакторе Advanced
- как скрыть в noindex nofollow отдельную запись, страницу
плагин All in One SEO закрываем конкретную страницу в noindex
Когда у меня спрашивают о том, как совершить ту или иную настройку, люди свои незнания мотивируют тем, что боятся что-то «поправить» и это окажется ошибочным (сайт сломается), а уж когда беда обнаружится, то окажется что напрочь забыл где и что мастерил в настройках — поправить как было нет возможности, и правки «где и что» на бумажку, к великому сожалению, не записал))
Вот из-за подобных опасений ошибок админы предпочитают переспрашивать — этот пост и будет ответом — одним для всех.
к оглавлению
опции All in One SEO в текстовом редакторе Advanced
Настройки индексации отдельной записи, страницы никуда не пропали. Нужно только быть немного повнимательнее, и тогда закрыть конкретную страницу от индексации запросто получится.
Сейчас, как и прежде, возможно скрыть по требованию в noindex nofollow любую отдельную страницу, запись, запись произвольного типа (подборка кода — произвольные типы) к которым привязано управление плагина.
Настройки: открываем в текстовом редакторе любую запись (я показываю на примере старого текстового редактора — в Gutenberg все точно так же), переходим в опции настроек плагина All in One SEO, открываем вкладку Advanced.
…во вкладке Advanced настроек All in One SEO нужно поработать в разделе «Настройка роботов» — как видите, если «Использовать настройки по умолчанию» (т.е. кнопка смещена вправо) никаких дополнительных регулировок нет: страница обрабатывается по умолчанию — открыта для поисковых роботов и пр.
к оглавлению
как скрыть в noindex nofollow отдельную запись, страницу
Для того, чтобы скрыть конкретную отдельную запись посредством All in One SEO — смещаем ползунок влево. В этом случае появятся дополнительные SEO настройки, а именно нужные нам по нашей теме возможности скрывать запись, страницу в noindex nofollow.
Помимо этих подстроек индексации/НЕ индексации в разделе есть и еще несколько полезных вариантов работы с индексом конкретно взятой страницы (фотка ниже).
Скрыть отдельно взятую страницу, запись, пост и пр. от индексации используя плагин All in One SEO, оказалось достаточно просто!
Желаю всяческих удач…
ОТКЛЮЧАЕМ ТУРБОСТРАНИЦЫ…
 youtube.com/embed/pgHTFbEoAKc?feature=oembed=0&showinfo=0″ allowfullscreen=»allowfullscreen»>
youtube.com/embed/pgHTFbEoAKc?feature=oembed=0&showinfo=0″ allowfullscreen=»allowfullscreen»>
…вопросы в комментариях — помогу, в чём дюжу…
mihalica.ru !
…веб разработчик студии ATs media: помогу в создании, раскрутке, развитии и целенаправленном сопровождении твоего ресурса в сети… — заказы, вопросы… разработка…
HTTP-заголовок «X-Robots-Tag» не имеет значения «noindex, nofollow» — ℹ️ Поддержка
scgf 1
Я только что обновил установку Nextcloud до версии 26.0 и получил сообщение об ошибке «Заголовок HTTP X-Robots-Tag не имеет значения noindex, nofollow».
Я решил это, изменив/добавив эту строку в nextcloud/config/nginx/site-confs/default. conf:
conf:
add_header X-Robots-Tag «noindex, nofollow» всегда;
У меня Nextcloud работает в докере с использованием образов linuxserver.
Я разместил эту информацию здесь, потому что вчера я довольно долго пытался найти решение и не смог. Надеясь, что это поможет кому-то.
3 отметок «Нравится»
2
Это вчера уже обсуждалось здесь:
2 лайков
пассатиджи 3
Здравствуйте и спасибо, что поделились своим опытом.
Мой экземпляр имеет такое же предупреждение, но я не могу его исправить.
Он размещен на Truenas в тюремной среде.
Есть предложения?
Спасибо.
1 Нравится 4
Все, что я предлагаю, это найти папку site.confs и там вы должны увидеть файл default.conf.
Там уже должна быть строка add_header X-Robots-Tag, поэтому вам нужно отредактировать ее, а не просто добавить еще одну строку add_header X-Robots-Tag.
Кроме этого я понятия не имею.
1 Нравится
хенк
5 У нас такая же проблема и мы тоже не можем решить проблему. если мы протестируем наш сервер с помощью curl, мы увидим, что тег x-robots присутствует.
если мы протестируем наш сервер с помощью curl, мы увидим, что тег x-robots присутствует.
[/подробнее]
$ curl -v https://
- Перестроенный URL-адрес: https://
- Набор TCP_NODELAY
- порт 443 (#0)
- ALPN, предложение h3
- ALPN, предлагающий http/1.1
- успешно установил расположение проверки сертификата:
- CAfile: /etc/pki/tls/certs/ca-bundle.crt
CApath: нет - TLSv1.3 (OUT), рукопожатие TLS, приветствие клиента (1):
- TLSv1.3 (вход), рукопожатие TLS, приветствие сервера (2):
- TLSv1.3 (IN), рукопожатие TLS, [нет содержимого] (0):
- TLSv1.3 (IN), рукопожатие TLS, зашифрованные расширения (8):
- TLSv1.3 (IN), рукопожатие TLS, [нет содержимого] (0):
- TLSv1.3 (IN), рукопожатие TLS, сертификат (11):
- TLSv1.3 (IN), рукопожатие TLS, [нет содержимого] (0):
- TLSv1.3 (IN), рукопожатие TLS, проверка CERT (15):
- TLSv1.
 3 (IN), рукопожатие TLS, [нет содержимого] (0):
3 (IN), рукопожатие TLS, [нет содержимого] (0): - TLSv1.3 (IN), рукопожатие TLS, завершено (20):
- TLSv1.3 (OUT), изменение шифрования TLS, изменение спецификации шифрования (1):
- TLSv1.3 (OUT), рукопожатие TLS, [нет содержимого] (0):
- TLSv1.3 (OUT), квитирование TLS, завершено (20):
- SSL-соединение с использованием TLSv1.3/TLS_AES_256_GCM_SHA384
- ALPN, сервер принят для использования h3
- Сертификат сервера: Дата начала
- : 2 марта 06:27:26 2023 GMT
- срок действия: 31 мая 06:27:25 2023 GMT
- Проверка сертификата SSL в порядке.
- Используя HTTP2, сервер поддерживает многократное использование
- Состояние соединения изменено (HTTP/2 подтверждено)
- Копирование данных HTTP/2 из буфера потока в буфер соединения после обновления: len=0
- TLSv1.3 (OUT), данные приложения TLS, [нет содержимого] (0):
- TLSv1.3 (OUT), данные приложения TLS, [нет содержимого] (0):
- TLSv1. 3 (OUT), данные приложения TLS, [нет содержимого] (0):
- Использование идентификатора потока: 1 (простой дескриптор 0x55af4c34e6d0)
- TLSv1.3 (OUT), данные приложения TLS, [нет содержимого] (0):
 3 (IN), рукопожатие TLS, [нет содержимого] (0):
3 (IN), рукопожатие TLS, [нет содержимого] (0): 3 (OUT), данные приложения TLS, [нет содержимого] (0):
3 (OUT), данные приложения TLS, [нет содержимого] (0):GET / HTTP/2
Хост:
Агент пользователя: curl/7.61.1
Принять: /
- TLSv1.3 (IN), рукопожатие TLS, [нет содержимого] (0):
- TLSv1.3 (IN), рукопожатие TLS, Билет на выпуск новостей (4):
- TLSv1.3 (IN), рукопожатие TLS, [нет содержимого] (0):
- TLSv1.3 (IN), рукопожатие TLS, Билет на выпуск новостей (4):
- TLSv1.3 (IN), данные приложения TLS, [нет содержимого] (0):
- Состояние соединения изменено (MAX_CONCURRENT_STREAMS == 128)!
- TLSv1.3 (OUT), данные приложения TLS, [нет содержимого] (0):
- TLSv1.3 (IN), данные приложения TLS, [нет содержимого] (0):
- TLSv1.3 (IN), данные приложения TLS, [нет содержимого] (0):
< HTTP/2 302
< сервер: nginx
< дата: пн, 27 марта 2023 г. 14:57:40 по Гринвичу
< тип содержимого: текст/html; charset=UTF-8
< location: https:///login
< set-cookie: oc_sessionPassphrase=4%2BY6mBPQJmt5ClRR8bQsza%2FnvbqVul21h6FuxEt2LJDOFYG91Ylr695NPSKYyIh3fGsed7VZ5xwlxd0h4%2F pEvMGJJ%2BBFLv7zypuRm%2F3HN6yfodX80id3WCgMLb8ke12I; путь=/; безопасный; Только HTTP; SameSite=Lax
< политика безопасности контента: default-src ‘self’; script-src ‘self’ ‘nonce-bllQQ3JWUlpCZ2l3dDh3N0lSdm9WUHpTM3EvNnpJTXVuZ0JaUm55WlRwST06NWZPMzNpVWpjRUtKMDZDaGRXcVBIYnJsdC8rTHVxaDd0V01BY2tyd0Rmbz0=’; style-src «я» «небезопасно-встроенный»; кадр-источник *; img-src * данные: blob:; данные font-src «я»:; медиа-источник *; подключить-источник ; объект-источник «нет»; база-ури «я»;
< set-cookie: __Host-nc_sameSiteCookielax=true; путь=/; только http;безопасный; expires=пт, 31 декабря 21:00 23:59:59 по Гринвичу; SameSite=lax
< set-cookie: __Host-nc_sameSiteCookiestrict=true; путь=/; только http;безопасный; expires=пт, 31 декабря 21:00 23:59:59 по Гринвичу; SameSite=strict
< set-cookie: ocinrae3olnk=p53ooh0otb0skj9q8posle6bqh; путь=/; безопасный; Только HTTP; SameSite=Lax
< срок действия: четверг, 19 ноября 1981 г. , 08:52:00 по Гринвичу
< прагма: без кэша
< политика разрешений: геолокация = (я), полноэкранный режим =
< тег x-robots: noindex, nofollow
< политика реферера: нет реферера
< x-content-type- опции: nosniff
< x-download-options: noopen
< x-frame-options: SAMEORIGIN
< x-permitted-cross-domain-policies: none
< x-xss-protection: 1; mode=block
< x-robots-tag: noindex, nofollow
< strict-transport-security: max-age=31622400; включать поддомены; предварительная загрузка
< интерфейс-https: на
<
 14:57:40 по Гринвичу
14:57:40 по Гринвичу  , 08:52:00 по Гринвичу
, 08:52:00 по Гринвичу ДжиммиКатер 6
Чтобы вести обсуждение в одном месте, я предлагаю перейти к «X-Robots-Tag»-HTTP-Header, не настроенному с «noindex, nofollow» начиная с NC 26.
, и продолжить обсуждение там, как я собираюсь закрыть эту тему здесь, сейчас.
a BIIIIG Спасибо @scgf за ваши усилия и хорошую работу!
1 Нравится
ДжиммиКатер Закрыто 7
Noindex и Nofollow — nopCommerce
- Главная >
- Форумы >
- Общие >
 org/ListItem»> Noindex и Nofollow
org/ListItem»> Noindex и Nofollow привет друзья,
я получил nopCommerce 4.4 со многими продуктами, сегодня Google просканировал его, но проиндексировал многие ссылки из плагинов или страницы входа,
Какое лучшее решение для установки Noindex или Nofollow для этих URL?
спасибо
MVP
Сертифицированный разработчик
Добавьте robots.custom.txt в корневую папку проекта nopCommerce и добавьте запрещенные пути, которым не нужно следоватьИли вы можете добавить запрещенные пути к исходному коду nopcommerce здесь
Полезная ссылка 1.https://www.nopcommerce.com/en/boards/topic/73298/how-to-edit-robotstxt
2.https://medium.com/@esty_c/robots-txt-in-asp -net-core-36007684ea02 Спасибо, Рашед Хан,
1- когда я проверил консоль поиска, я получил много ссылок от входа, регистрации, вложения, просмотра и …
я пишу образец Robots.txt и отправляю исходную ссылку из консоли поиска, спасибо проверить это правда или нет ? (URL-адрес вложения предназначен для изображения, я хочу проиндексировать его для изображения Google)
2- при поиске я обнаружил, что есть robot. txt и robot.Custom.txt и robot.addition.txt,
txt и robot.Custom.txt и robot.addition.txt,
, поэтому вопрос я должен использовать, какой из них и какая польза от каждого?
3- последний вопрос заключается в том, что с запретом на robot.txt, как мы можем использовать тег Follow для этого robot.txt? (я имею в виду, что хочу Noindex с подпиской)
Спасибо
Хамид
Индексированная ссылка:
https://farshstore.com/register?returnUrl=/contactus-2
https://farshstore.com/register?returnUrl= /shipping-delivery
https://farshstore.com/register?returnUrl=/conditions-of-use
https://farshstore.com/register?returnUrl=/
https://farshstore.com/register?returnUrl= /?attachment_id%3D14953
https://farshstore.com/productreviews/49
https://farshstore.com/productreviews/61
https://farshstore.com/productreviews/62
https://farshstore.com/login?returnUrl= /
https://farshstore.com/login?returnUrl=/filterSearch
https://farshstore.com/?attachment_id=14575
https://farshstore. com/?attachment_id=14552
com/?attachment_id=14552
https://farshstore.com /?attachment_id=14455
Мой robot.txt для этого URL:
User-agent: *
Disallow: /productreviews/
Disallow: /register?returnUrl=/
Запретить: /login?returnUrl=/
Запретить: /product-tag/
Запретить: /?attachment_id=*
Агент пользователя: Googlebot-Image
Разрешить: /?attachment_id=*
Карта сайта: https:// farshstore.com/sitemap.xml
MVP
Сертифицированный разработчик
h.jalalishad написал:
1- когда я проверил консоль поиска, я получил много ссылок из входа, регистрации, вложения, обзора и …
я пишу образец Robots.txt и отправляю исходную ссылку из консоли поиска, спасибо, проверьте, правда это или нет? (URL-адрес вложения предназначен для изображения, я хочу проиндексировать его для изображения Google)
h.jalalishad написал:
2- когда я искал, я обнаружил, что есть robot. txt и robot.Custom.txt и robot.addition.txt,
txt и robot.Custom.txt и robot.addition.txt,
, поэтому вопрос в том, какой из них я должен использовать и какая польза от каждого?
h.jalalishad написал:
3- последний вопрос заключается в том, что с запретом на robot.txt, как мы можем использовать тег Follow для этого robot.txt? (я имею в виду, что хочу Noindex с подпиской)
ссылка https://www.deepcrawl.com/blog/best-practice/noindex-disallow-nofollow/ Спасибо Rashed за ваше время,
, как вы просите, я нахожу robot.addition.txt здесь:
https://www.nopcommerce.com/en/boards/topic/40973/add-noindex-tag-in-a-specific-category
, как я проверил по ссылке, в robots.txt просто Disallow и Allow будут работать как функции, так как же можно управлять функциями Follow/Nofollow и Noindexing для любого страница или каталог? (против тега html, потому что у меня нет доступа к разработчику сайта, а я менеджер сайта)
я вижу, что здесь есть инструменты Google для тестирования robots.