
Массовая проверка robots.txt на доступность страниц для Google
Попробуйте бесплатно
Как проверить правила в robots.txt для каждой из страниц
Если у вас большое количество страниц с обратными ссылками которые вы хотели бы проверить на доступность для поисковых систем и наличие директив noindex и nofollow в файле robots.txt, то в ручном режиме это займет уйму времени. HyperChecker предлагает автоматизировать этот процесс и получить результаты проверки за несколько минут.
Для проверки правил файла robots.txt мы предлагаем два инструмента.
Первый инструмент — Массовая проверка страниц. Это простая одноразовая проверка страниц по ключевым СЕО параметрам:
- Директивы nofollow/noindex в Meta Tag и X-Robots-Tag;
- Количество исходящих ссылок;
- Статус индексации страниц в Google;
- Запрет на показ страницы через жалобы DMCA;
- Интегрированные данные из Ahrefs;
- Top-Level-Domain, IP адрес и страна размещения веб-сайта;
- Http статус код.


Второй инструмент — автоматический мониторинг обратных ссылок. Сюда входят те же проверки что и в первом случае, но еще добавлен поиск обратных ссылок на странице на ваш веб-сайт. В отчете вы увидите сколько и каких анкоров имеется у вашего проекта и доступны ли они для поисковых систем в атрибуте rel(nofollow/dofollow/sponsored и т.д.).
В настройках проекта можно настроить частоту проверки обратных ссылок чтобы всегда быть в курсе того, какие ссылки пропали, стали недоступны для поисковых систем или получили запрет на сканирование и индексацию для поисковых роботов согласно правил файла robots.txt.
Для чего линкбилдеру проверять правила файла robots.txt
Для проверки noindex nofollow в файле robots.txt есть несколько причин.
Оптимизация бюджета и восстановление работы обратных ссылок
Вебмастера, которые размещают гостевые посты на своих сайтах, часто вносят технические изменения в его работу. Не редки случаи когда по ошибке, либо намеренно, страница с вашим гостевым постом может получить запрет на сканирование и индексацию в файле robots. txt. Такая страница обязательно выпадет из поиска и перестанет передавать вес, что в дальнейшем приведет к понижению позиций вашего основного сайта в поисковых системах.
txt. Такая страница обязательно выпадет из поиска и перестанет передавать вес, что в дальнейшем приведет к понижению позиций вашего основного сайта в поисковых системах.
Пользы от таких гостевых постов — ноль, а деньги будут потрачены в пустую. Необходимо регулярно и вовремя выявлять страницы которые запрещены в robots.txt и писать вебмастерам, чтобы они вернули исходные параметры страниц с вашими обратными ссылкам. В таком случае вы минимизируете негативный эффект на продвижение своего проекта. Если же вебмастер не идет на контакт, вы можете открыть диспут и затребовать возврат потраченных денег. Это отлично работает в денежной системе PayPal.
Повторение ссылочной массы как у конкурентов
Если вы хотите разместить обратные ссылки на тех же площадках, на которых размещаются конкуренты, то здесь инструмент HyperChecker подойдет как никогда. Обратные ссылки конкурента могут быть заблокированы в файле robots.txt либо иметь запрет на индексацию в мета тегах или X-Robots-Tag.
Чтобы отсеять такие ссылки, необходимо загрузить их в чекер HyperChecker, и отфильтровать все то, что не разрешено в robots.txt и мета тегах. При желании можно воспользоваться фильтром по данным Ahrefs, исходящим ссылкам, по статусу индексации и т.д.
В итоге, вы не потратите деньги на безполезные гостевые посты и получите только те площадки, на которых ваши обратные ссылки будут приносить пользу для вашего проекта.
Попробуйте бесплатно
использование noindex, nofollow, robots и др.
На индексацию веб-страниц можно влиять по-разному. Кроме задания специальных директив в файле robots.txt используются noindex, nofollow, robots и др. элементы в коде веб-страницы.
Тег noindex
Используется для запрета индексации части страницы, но учитывается только
поисковыми роботами Яндекса и Рамблера (Google его игнорирует)
<noindex>то, что нужно скрыть</noindex>
Атрибут rel=»nofollow»
Это атрибут тега <a>. Он не влияет на индексацию ссылки. Большинство поисковиков (кроме Google) по ней не переходит. Используется для того, чтобы сообщить поисковой системе, что рейтинг со страницы, на которой ссылка размещена, не должен передаваться по этой ссылке.
Он не влияет на индексацию ссылки. Большинство поисковиков (кроме Google) по ней не переходит. Используется для того, чтобы сообщить поисковой системе, что рейтинг со страницы, на которой ссылка размещена, не должен передаваться по этой ссылке.
<a href="http://site.ru" rel="nofollow">Текст ссылки</a>
Это значит, что «закрывать» ссылку нужно так:
<noindex><a href="http://site.ru" rel="nofollow">Текст ссылки</a></noindex>
meta-тег
На странице meta-тег «robots» (как и все meta-теги) находится между тегами <head> и </head>. Он позволяет управлять индексацией всей страницы.
Инструкция для всех роботов:
<meta name="robots" content="значение">
Атрибут content может иметь значение
- noindex — не индексировать
- index -индексировать
- nofollow- не следовать по ссылкам
- follow- следовать по ссылкам
- all — индексировать и следовать по ссылкам
- none — не индексировать и не следовать по ссылкам
- noimageindex — запретить индексирование картинок
- noarchive — запретить выводить ссылку «Сохранено в кэше» (поисковики будут по-прежнему индексировать страницу и выводить ее фрагмент)
- nosnippet — выводить выводить
фрагменты страницы ( это текст, который поисковики показывают под названием страницы в результатах поиска ). При удалении фрагментов удаляются также и сохраненные в кэше страницы.
 При удалении фрагментов удаляются также и сохраненные в кэше страницы.
При удалении фрагментов удаляются также и сохраненные в кэше страницы.Допустимо указывать несколько значений через запятую:
<meta name="robots" content="noindex, nofollow">
Инструкция для робота Google
<meta name="googlebot" content="noimageindex">
Атрибут alt
Атрибут alt тега <a> задает альтернативный текст для изображения, который отображается в браузере, если не удается показать само изображение
<a href="http://site.ru"><img src="http://www.mysite.ru/image.gif" alt="Мой рисунок"/></a>
Поисковые системы запоминают значение атрибута alt при индексации страницы, но не используют его при ранжировании результатов поиска.
Известно, что Google учитывает текст атрибута alt только тех изображений, которые являются ссылками на другие страницы.
Когда используется зеркало сайта
Для того чтобы в поисковиках не было дублирования страниц с зеркала сайта, следует задать в meta-теге URL абсолютный адрес страницы, а на зеркале – абсолютный адрес страницы основного сайта.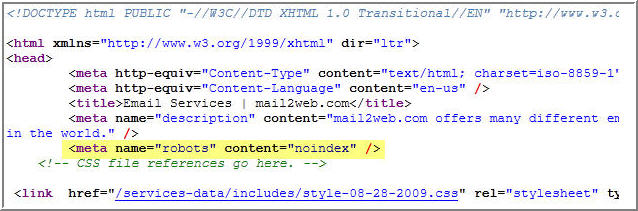
<meta name="URL" content="абсолютный адрес страницы">
Просмотров: 1494
Google откажется от поддержки Crawl-delay, nofollow и noindex в robots.txt
Главная > Новости Google > Google SEO > Google откажется от любой поддержки Crawl-delay, nofollow и noindex в robots.txt
Сегодня утром Google сообщил, что собирается прекратить неофициальную поддержку директив noindex, nofollow и crawl-delay в файлах robots.txt. Google говорил не делать этого в течение многих лет и намекал, что это произойдет очень скоро, и теперь оно здесь.
Google написал: «Открывая исходный код нашей библиотеки синтаксического анализа, мы проанализировали использование правил robots.txt. В частности, мы сосредоточились на правилах, не поддерживаемых интернет-проектом, таких как задержка сканирования, nofollow и noindex. Поскольку эти правила никогда не документировались Google, естественно, их использование по отношению к роботу Googlebot очень редко.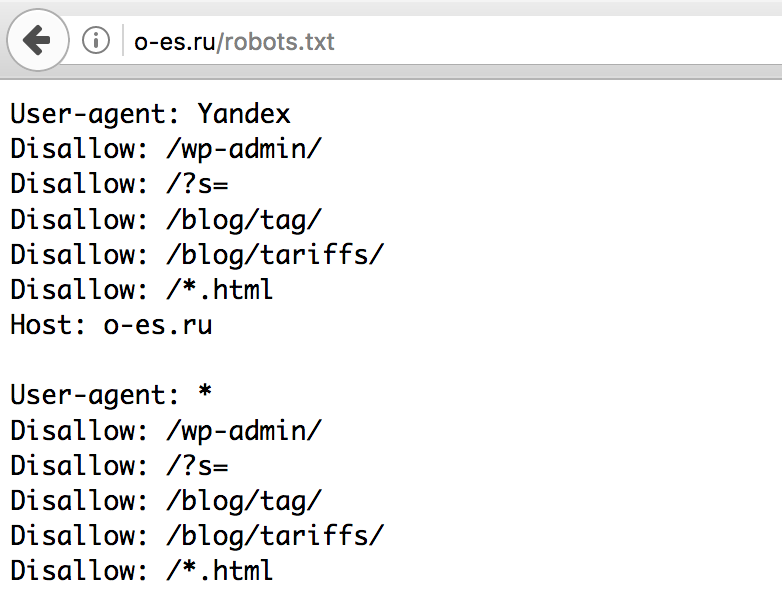
Короче говоря, если вы упомянете задержку сканирования, nofollow и noindex в файле robots.txt, Google с 1 сентября 2019 года прекратит их учитывать. В настоящее время они соблюдают некоторые из этих реализаций, даже несмотря на то, что они являются «неподдерживаемыми и неопубликованными правилами», но перестанут это делать 1 сентября 2019 года.
Google может отправлять уведомления через Google Search Console, если вы используете эти неподдерживаемые команды в своем файлы robots.txt.
Звучит как хорошая идея. Вы читаете нашу электронную почту?
/медленно поворачивается, чтобы осмотреть комнату — 🍌 John 🍌 (@JohnMu) 2 июля 2019 г.

Как я уже говорил выше, Google советует веб-мастерам и SEO-специалистам не использовать noindex в robots.txt:
Что ж, мы уже много лет говорим не полагаться на него :).
— 🍌 Джон 🍌 (@JohnMu) 2 июля 2019 г.
Вы понимаете, что мы уже много лет говорим людям не полагаться на это?
— 🍌 John 🍌 (@JohnMu) 2 июля 2019 г.
Google сообщил нам, что это изменение в конечном итоге произойдет:
Как и обещал несколько недель назад, я провел анализ noindex в robotstxt. Количество сайтов, которые наносили себе вред, очень велико. Я искренне верю, что это к лучшему для экосистемы, и те, кто использовал ее правильно, найдут лучшие способы добиться того же. https://t.co/LvdhsN2pIE
— Гэри «鯨理» Иллиес (@methode) 2 июля 2019 г.
В этом виноват Гэри Иллис:
Заранее извините.
— Гэри «鯨理» Иллиес (@methode) 2 июля 2019 г.
 .. 😶 pic.twitter.com /IhT8zUzhK1
.. 😶 pic.twitter.com /IhT8zUzhK1Он сказал, что искренне сожалеет:
Честно… Прямо сейчас… Да
— Гэри «鯨理» Иллиес (@methode) 2 июля 2019 г.
Но Google посмотрел и проанализировал влияние, и так небольшое влияние, если оно есть. Фактически, они не будут вносить изменения в течение нескольких месяцев и, как я уже сказал выше, могут отправить электронное письмо тем, кого это затронет:
Да! Мы действительно не делаем такие изменения волей-неволей :-).
— 🍌 John 🍌 (@JohnMu) 2 июля 2019 г.
Итак, сейчас самое время провести аудит, чтобы убедиться, что ваши клиенты не зависят от этих неподдерживаемых команд в своих файлах robots.txt.
Вот что Google опубликовал с точки зрения альтернатив директивы noindex:
- Noindex в метатегах robots: Директива noindex, поддерживаемая как в заголовках ответов HTTP, так и в HTML, является наиболее эффективным способом удаления URL-адресов из индекса, когда сканирование разрешено.
- 404 и 410 Коды состояния HTTP: Оба кода состояния означают, что страница не существует, что приведет к удалению таких URL-адресов из индекса Google после их сканирования и обработки.
- Защита паролем:
- Запретить в robots.txt: Поисковые системы могут индексировать только известные им страницы, поэтому блокирование сканирования страницы обычно означает, что ее содержимое не будет проиндексировано. Хотя поисковая система также может индексировать URL-адрес на основе ссылок с других страниц, не видя самого контента, мы стремимся сделать такие страницы менее заметными в будущем.
- Инструмент для удаления URL-адресов в Search Console: Этот инструмент позволяет быстро и легко временно удалить URL-адрес из результатов поиска Google.

Обсуждение форума в Твиттере.
Как использовать Nofollow, Noindex и Robots.txt для SEO
Опубликовано Taylor De Luca 11 ноября 2008 г., 12:01:46 | Поделиться
Часто возникает путаница в отношении того, как следует использовать nofollow, noindex и robots.txt для хорошего SEO. Я собираюсь дать обзор трех, в том числе, когда, где и почему вы должны их использовать.
Что такое файл robots.txt
Во-первых, файл robots.txt — это просто файл, который вы можете разместить на своем веб-сервере и который будет давать роботам поисковых систем инструкции относительно того, какие разделы и страницы им не следует сканировать. . Это равносильно размещению таблички «Не беспокоить» на двери гостиничного номера. В то время как большинство будет подчиняться вашей просьбе, нет никаких гарантий. Причины, по которым роботы не могут посещать страницы и разделы сайта, различаются в зависимости от веб-сайта, но обычно связаны с тем, что поисковая система не хочет сканировать или индексировать отдельные страницы или разделы сайта.
Что делает метатег noindex?
Метатег noindex — это простой тег, который предписывает поисковой системе не отображать данную страницу в индексе поиска (результатах поиска). Этот тег часто используется, когда владелец веб-сайта не хочет, чтобы отдельные страницы отображались в поиске. Веб-сайты с проблемами дублирования контента часто используют эти теги для удаления дублирующегося контента из поискового индекса.
Размещение тега noindex на странице отличается от исключения этой страницы из файла robots.txt тем, что страница с noindex в заголовке все еще может быть просканирована поисковыми системами и может накапливать и передавать PageRank. Тег noindex просто сделает любую страницу невидимой для поисковиков.
Что делает тег nofollow?
Теги Nofollow могут быть вставлены в заголовок или прикреплены к ссылкам, чтобы указать поисковым системам, таким как Google, не сканировать данную ссылку. По сути, это предотвращает передачу PageRank с одной страницы на другую при использовании nofollow. Это делается по нескольким причинам:
Это делается по нескольким причинам:
- Сокращение спама. Большинство веб-сайтов позволяют пользователям каким-либо образом вносить свой вклад. Размещая ссылки nofollow на любых ссылках, добавленных пользователями, вы можете отговорить пользователей от явного спама на вашем веб-сайте, потому что ссылки не будут иметь ценности для SEO.
- Моделирование PageRank. Веб-мастера, заинтересованные в распределении PageRank по всему веб-сайту, могут размещать nofollow на ссылках, указывающих на несущественные страницы на их веб-сайте. Например, ссылка, ведущая на страницу вашей политики конфиденциальности, может использовать nofollow, потому что маловероятно, что эта страница очень важна для поисковых систем. Добавление nofollow ко всем ссылкам, указывающим на эту страницу, будет означать, что больше PageRank передается другим более важным страницам вашего сайта.
Использование robots.txt, nofollow и noindex при правильном использовании может оказать заметное влияние на результаты органического поиска.