
Неканонические страницы теперь попадают в индекс- SEO-словарь веб-студии Муравейник
Автор статьи
Андрей Буйлов
Подробнее об авторе
4 июля Яндекс анонсировал, что теперь страницы, отмеченные как «неканонические» с помощью атрибута rel=«canonical», но которые он посчитает полезными, будут попадать в индекс, показываться в поиске.
Обычно страницы, помеченные этим атрибутом, в котором указана другая страница, по идее в индекс Яндекса никак не должны попадать. Однако теперь их будут сравнивать с указанной в rel=«canonical», и если отличия значительные, то может быть принято решение эту страницу из индекса не выбрасывать.
Если такое случилось с вашей страницей, то в Яндекс.Вебмастере придет сообщение о том, что «страница попала в поиск, поскольку во время сканирования роботом ее содержимое существенно отличалось от содержимого страницы по адресу, который указывался в rel=«canonical».
Какие могут быть негативные эффекты?
Чем это может быть чревато? В индекс могут попасть страницы, которые вы бы точно не хотели, чтобы туда попадали.
Но не стоит слишком паниковать. По тому, что демонстрирует Яндекс на данный момент, в тех случаях, когда приходили такие сообщения в Вебмастер, по факту оказывалось — там действительно страница имела некоторую самостоятельную ценностью.
То есть, когда применяется rel=«canonical»?
Например, на сайте есть страницы, которые создают дубль основной: с лишним слешем, с какими-то параметрами, с другим размером букв и т.д. И обычно в тех случаях, когда их не закрывают от поисковика другим способом — можно поставить редирект, например — то используют атрибут rel=«canonical». Для программистов это самый простой вариант, так действительно часто делают — и это нормальная ситуация.
И здесь Яндекс пока ни разу не ошибся. То есть в тех страницах, которые действительно полностью дублируют «родительскую», атрибут rel=«canonical» применялся правлиьно — закрывал от поиска.
Когда же приходит в Вебмастер это сообщение, в каких случаях страница добавляется обратно в индекс? В основном это страницы типа форумов либо постраничная пагинация в комментариях — то есть там, где отличия существенны. И важно посмотреть, действительно ли имеются какие-то посты на форуме, которые несут самостоятельную ценность и могут ранжироваться. Стоит отдельно посмотреть на пагинацию на сайтах (то есть там, где в рубриках есть постраничность). Здесь есть такой нюанс: если у вас страницы вроде как друг от друга никак не отличаются и по идее указанные в rel=«canonical» не должны выводится, следует учесть, что товары на них указаны разные. И Яндекс может посчитать, что такие страницы имеют самостоятельную ценность и индексировать их.
Чем это грозит?
Например, вы оптимизировали первую страницу рубрики, и у вас в остальные также подтянется и тайтл тот же самый, и h2 будет одинаковый, а в ряде случаев еще и тексты туда размножатся. Что в общем может создать негативный эффект: разные страницы рубрики будут мешаться друг другу, периодически может слетать релевантность с первой, перекидываясь на другую страницу пагинации, позиции в этот момент у первой страницы в большинстве случаев будут просаживаться. Поэтому стоит учесть этот момент и заранее проверить свои сайты.
Что делать?
Если у вас страницы пагинации стали залетать в индекс с таким статусом, то можно:
-
закрыть их от индексации более жестко;
-
попытался уникализировать настолько, чтобы они несли некоторую самостоятельную ценность. Сделать заголовки уникальными, тексты отдельные закидывать — то есть действительно оптимизировать под какую-то группу ключей, раз уж Яндекс посчитал их нормальными.


Но здесь опять же непонятно, под какую группу ключей тогда оптимизировать, потому что это же не подрубрика, а одна из страниц рубрики. То есть подобный вариант действий не оптимален. И скорее всего, если сайты с постраничностью начнут «влетать» под такое, то эти страницы лучше закрывать в robots, а может и в X-Robots-Tag, чтобы робот их не сканировал и не индексировал.
Стоит внимательно следить за этой ситуацией, за сайтами, потому как в любой момент может что-то пойти не так, «сбоинуть» и на позиции повлиять не лучшим образом.
Неканонические страницы в поиске Яндекса
Ранее приоритетными для поисковых систем всегда были только канонические страницы. Сейчас положение вещей изменилось. Теперь Яндекс чаще отображает по ключевикам неканонические. Когда это происходит? Только если их информация полнее соответствует полученному запросу. Содержание неканонической страницы при этом существенно отличается от аналогичного канонической. Причин для подобного обновления несколько. Основная – качественное улучшение релевантности демонстрируемых веб-страниц заявленному в поисковой строке Яндекса требованию пользователя.
Причин для подобного обновления несколько. Основная – качественное улучшение релевантности демонстрируемых веб-страниц заявленному в поисковой строке Яндекса требованию пользователя.
Содержание:
- Атрибуты rel=«canonical» в новых условиях
- Польза акцентирования неосновных страничек
- Важные советы
Атрибут rel=«canonical» в новых условиях
Атрибут rel=«canonical» всегда помогал вебмастерам указывать поисковикам приоритетные для показа странички среди нескольких с одинаковым содержанием или очень похожих по контенту. Только интернет-страница с таким тегом могла быть индексирована и отобразиться в нужный момент по запросу пользователя. Все неканонические аналоги попросту игнорировались поисковыми механизмами. Вебмастер самостоятельно выбирал, какую вкладку предложить Яндекс поиску в качестве основной.
Аналитики компании Yandex провели детальное исследование этого вопроса. Практический опыт профессионалов и результаты анализа показали, что для некоторых ключевых фраз релевантными часто оказываются не приоритетные, а неканонические страницы. Они приносят больше пользы, чем основные. Поэтому Яндекс-служба стала слегка «подстраховывать» сайты, предлагая все чаще именно такие версии.
Они приносят больше пользы, чем основные. Поэтому Яндекс-служба стала слегка «подстраховывать» сайты, предлагая все чаще именно такие версии.
Польза акцентирования неосновных страничек
Приоритетные для показа странички не всегда оказываются наилучшим выбором. Всегда найдутся ключевые запросы, для которых они будут проигрышным вариантом. Нужной информации там не найти. И вот тогда новшество от Яндекса придет на помощь. Демонстрация неканонических страниц по некоторым ключевым словам – это одновременно:
- повышение качества обслуживания пользователей;
- возможность ответить на запрос более полно и развернуто;
- пользователь сразу попадает на нужное место, что сокращает время поиска;
- разбитое на части литературное произведение или длинная статья онлайн теперь находится гораздо быстрее, чем ранее.
Теперь поисковые механизмы ориентируются не на атрибут rel=«canonical», а на релевантность запрашиваемой информации.
Важные советы
Неканоническая страница будет показана вместо канонической только при существенной разнице по содержанию и большем соответствии запросу. Об этом следует помнить, подбирая и формируя контент. Яндекс теперь показывает не только статус «no-canonical», но для всех отображаемых поиском страничек – «каноническая» или дополнительно «каноническая страница не указана».
Что касается листингов, здесь уместно в качестве canonical веб-странички продолжать указывать первую. Неканонические будут отображаться в случае нужного запроса. Если это нежелательно, то можно воспользоваться директивой Clean-param. Инструмент поможет предотвратить появление no-canonical страничек в качестве ответа на поисковый запрос.
Как исправить неканонические страницы в карте сайта
Часто бывает, что несколько URL-адресов ведут на одну и ту же страницу или на похожие, например, на десктопную и мобильную версии. Для нас это одна и та же страница с одинаковым контентом, но поисковые системы видят кучу разных URL, которые перенаправляют на разные «уникальные» страницы.
Для нас это одна и та же страница с одинаковым контентом, но поисковые системы видят кучу разных URL, которые перенаправляют на разные «уникальные» страницы.
Поэтому важно указать, какая страница считается канонической. Так вы будете уверены, что пользователи увидят правильный URL в результатах поиска, а робот Googlebot не потеряется среди дубликатов страниц. В противном случае Google сделает этот выбор за вас, и в результате могут возникнуть нежелательные проблемы со сканированием и индексацией.
Если вы хотите узнать больше о факторах, на которые ориентируются поисковые системы при выборе канонического URL, вы можете посмотреть это видео.
Что такое неканонический URL-адрес в карте сайта?
Неканонические URL-адреса в карте сайта вводят в заблуждение поисковые системы. Это происходит, когда URL-адрес страницы не соответствует каноническому URL-адресу. В результате роботы индексируют страницы, адреса которых отличаются от их канонических версий. Чтобы избежать этих проблем, всегда следует помещать тег на предпочтительный URL-адрес. Например, если к одной и той же странице можно получить доступ как с WWW, так и без него, вы должны пометить ту, которую поисковые системы должны проиндексировать.
Чтобы избежать этих проблем, всегда следует помещать тег на предпочтительный URL-адрес. Например, если к одной и той же странице можно получить доступ как с WWW, так и без него, вы должны пометить ту, которую поисковые системы должны проиндексировать.
Что вызывает эту проблему?
Вот наиболее распространенные причины канонических проблем:
- Существует несколько URL-адресов, ведущих на страницы с идентичным или похожим содержанием. В то же время не указывается версия URL по умолчанию. Приводит к дубликату одной и той же страницы: с WWW и без и т.д.
- Если к веб-сайту можно получить доступ с помощью HTTP и HTTPS, существует дубликат каждой страницы.
- Ваш сайт имеет мобильную и десктопную версии.
- Вы неправильно настроили переадресацию. В результате вы отправляете сканерам смешанные сигналы.
- Веб-сайты электронной коммерции часто имеют разные URL-адреса для одной и той же страницы в зависимости от применяемых фильтров.

Проанализируйте не только неканоническую страницу в карте сайта, но и весь сайт!
Проведите полный аудит, чтобы выяснить и исправить ваше техническое SEO, чтобы улучшить результаты поисковой выдачи.
Почему это важно?
Если поисковые системы получают вводящие в заблуждение сигналы от вашей XML-карты сайта, существует риск того, что они будут игнорировать ваш сайт в будущем. Кроме того, проблемы с дублированием контента могут вызвать проблемы с SEO. Для правильной индексации ваша карта сайта должна содержать только канонические URL-адреса. Так вы информируете сканеры о наиболее важных страницах сайта. Без исправления канонических проблем вы не сможете должным образом отслеживать трафик вашего сайта.
Как это проверить
Чтобы понять, есть ли у вас какие-либо проблемы с канонизацией, вы можете ввести разные версии имени вашего сайта, то есть те, которые начинаются с HTTP или HTTPS и WWW или не WWW. Если какой-либо из этих вариантов не ведет к вашему предпочтительному URL-адресу, у вас проблемы с неканоническими страницами.
Другим вариантом может быть сканирование всех страниц вашего веб-сайта с помощью таких инструментов, как Screaming Frog, SiteAnalyzer и других. Некоторые программы умеют находить дубликаты страниц и канонические проблемы. Это избавит вас от необходимости просматривать каждый URL-адрес вручную.
Как решить проблему
Ваша цель — удалить все неканонические URL-адреса из вашей XML-карты сайта. После выбора и отправки канонических файлов вам также следует повторно отправить карту сайта в Google Search Console.
Эти рекомендации расскажут вам больше о том, что нужно и что нельзя делать в процессе канонизации.
Что еще можно сделать:
- Создать переадресацию 301 для повторяющихся URL-адресов. Таким образом, Google поймет, какая страница является предпочтительной. Вы можете реализовать перенаправления на веб-сервере (Apache или Nginx) или обратиться в службу поддержки вашего хост-сервиса.
- Добавьте на каждую страницу тег rel=»canonical» (также известный как каноническая ссылка). Обычно у CMS есть собственный способ или плагин для упрощения процесса без необходимости вручную помечать страницы одну за другой. Так вы указываете предпочитаемую страницу среди ее дубликатов. Это деликатная версия 301 редиректа.
- Используйте HTTP-заголовок rel=»canonical», если у вас есть доступ к серверу. Это полезно, когда вам нужно исправить ссылку на файл PDF.
 Обычно у CMS есть собственный способ или плагин для упрощения процесса без необходимости вручную помечать страницы одну за другой. Так вы указываете предпочитаемую страницу среди ее дубликатов. Это деликатная версия 301 редиректа.
Обычно у CMS есть собственный способ или плагин для упрощения процесса без необходимости вручную помечать страницы одну за другой. Так вы указываете предпочитаемую страницу среди ее дубликатов. Это деликатная версия 301 редиректа.Иван Палий
Маркетолог
Иван работает специалистом по маркетингу продуктов в Sitechecker. Увлекается аналитикой и созданием бизнес-стратегии для продуктов SaaS.
Фейсбук Линкедин
Объяснение проблемы «Ссылки, указывающие на неканонический URL»
Перейти к основному содержанию Центр помощиДата изменения: пн, 20 сентября 2021 г., 11:12
В этой статье объясняется, как решить проблему «Ссылки, указывающие на неканонический URL», когда они выделены в Siteimprove SEO.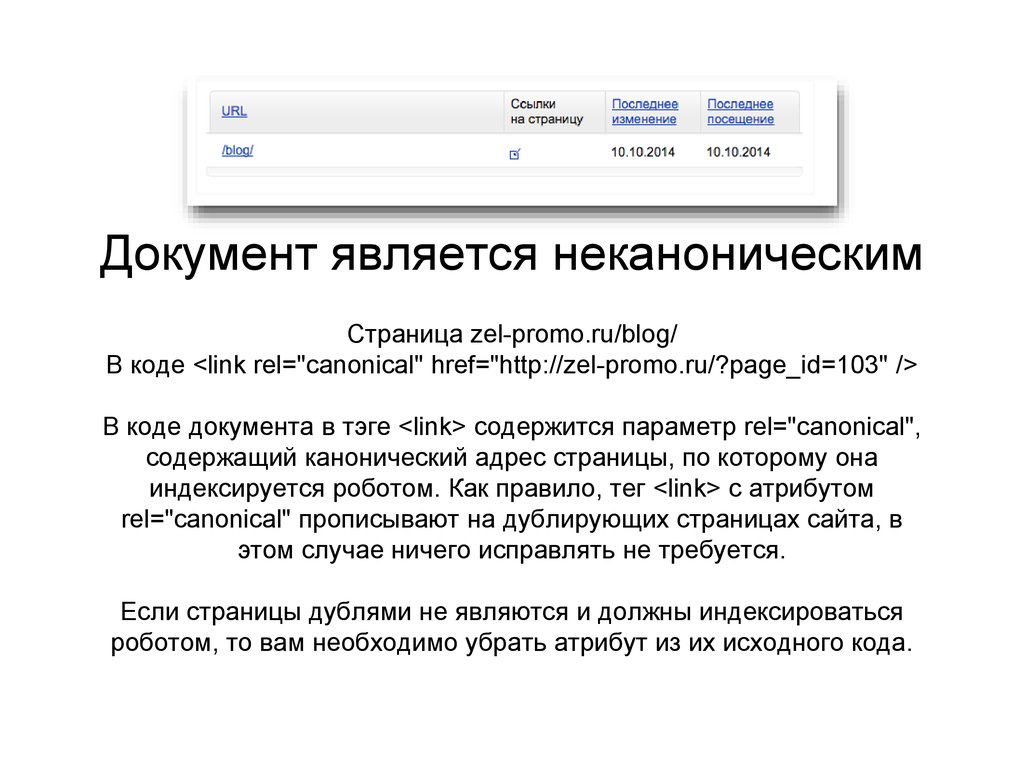
Канонический тег можно использовать для указания того, какую страницу вы хотите, чтобы поисковая система (например, Google) индексировала, если на вашем веб-сайте есть несколько страниц с очень похожим/идентичным содержанием.
Например, если две приведенные ниже страницы имеют очень похожее содержание и вы предпочитаете, чтобы первая страница отображалась в результатах поиска, вы можете добавить этот канонический код тега на вторую страницу.
1. https://www.mysite.com/shoes 2. https://www.mysite.com/shoes?page=1
Страница с «каноническим» тегом, указывающим на другую страницу, часто называется «неканонической» страницей.
Если на сайте используется канонический тег, рекомендуется убедиться, что URL-адрес внутри канонического тега используется только на сайте.
Example:
let’s say
www.example.com/test/product-A/
has a canonical tag pointing to
www.example.com/product-A/
Лучше всего убедиться, что все другие страницы вашего сайта также ссылаются на
www.example.com/product-A/
(канонический URL), а не неканонический URL,
www.example.com/test/product-AВ пределах
58 вопрос «Ссылки, указывающие на неканонический URL», вы увидите 3 столбца.
- Неканонический URL-адрес
- Канонический целевой URL-адрес
- Ссылающиеся страницы.
Проверка показывает, что все ссылающиеся страницы содержат ссылку на неканонический URL-адрес где-то на странице.
Решение состоит в том, чтобы найти неканоническую ссылку на странице перехода и заменить ее каноническим URL-адресом.
Взгляните на предыдущий пример:
www.example.com(ссылающаяся страница) имеет ссылку на главной странице на
www.

