
Почему бывает так трудно попасть в индекс Google?
В видео на Youtube, статьях о SEO продвижении, на конференциях говорят о том, как важна полная и быстрая индексация страниц сайта. Она может стать вашим конкурентным преимуществом в SEO-гонке. Пока остальные будут биться над попаданием в топ-100, вы, возможно будете уже собирать первые переходы по низкочастотным запросам.
Но тут начинаются сложности! Вы создать и отправить sitemap, десять раз проверить robots, сделать всё, как учили на курсах по SEO, но сложности останутся! Больше того! Проблемы с индексацией могут появиться на сайте, где их раньше не было!
Давайте разберемся, почему бывает так трудно проиндексировать сайт в Google.
Размеры сайта и индексация, приоритеты
Есть прямая связь между размером сайта, количеством страниц и индексацией. Чем больше URL адресов, тем выше шансы, что какие-то из них не попадут в индекс. По данным Ziptie в среднем 26% страниц каждого сайта не попадают в индекс. И дело даже не в том, что SEOшник делает что-то неправильно. В игру вступает ограниченность ресурсов.
И дело даже не в том, что SEOшник делает что-то неправильно. В игру вступает ограниченность ресурсов.
Существует понятие краулинговый бюджет сайта. Это ресурс, который может быть потрачен Google на сканирование страниц сайта за определенный период времени. Возьмем условные цифры. За один заход на сайт, поисковый робот может просканировать X страниц и заходить на сайт он может не больше Y раз в месяц. Ваша задача в том, чтобы за эти визиты он просканировал и оценил самые важные для продвижения страницы. Чем сайт больше, тем сложнее выбрать такие URL и спланировать индексацию.
Для примера. На собственном сайте digitalowl.top как приоритетные из 103 записей и нескольких страниц я выделил три адреса:
- статья Востребованные профессии на фрилансе
Очень объемный и подробный материал о том как происходит запуск, оптимизация интернет-магазина и его продвижение (статья огромная, но рекомендую, там только полезное)
страница с витриной курсов по SEO.
О проблемах с краулинговым бюджетом речь пока не идет. Но именно эти страницы в перспективе принесут больше всего трафика.
Но именно эти страницы в перспективе принесут больше всего трафика.
Чем раньше вы найдете такие ключевые URL тем лучше. На них желательно перераспределять вес страниц, направлять внешние и внутренние ссылки. Так вы получите лучшее ранжирование и больше переходов.
Также рекомендую почитать руководство Google по управлению краулинговым бюджетом для крупных сайтов.
Чаще всего от плохой индексации страдают e-commerce проекты. Поэтому дальше в статье будем говорить в основном о них. Итак, типичные проблемы с индексацией и способы их исправить.
1. «Просканировано — в данный момент не проиндексировано»
Это означает, что Google посетил страницу, но не проиндексировал ее.
В большинстве таких случаев проблема в качестве контента. Учитывая бум электронной коммерции, который сейчас происходит, Google становится более требовательным в отношении качества. Поэтому, если вы заметили, что страницы «просканированы — в настоящее время не проиндексированы», убедитесь, что контент на этих страницах имеет уникальную ценность:
- Используйте уникальные заголовки, описания и копии на всех индексируемых страницах.

- Избегайте копирования описаний продуктов из внешних источников, если товары сложные, как например дизайнерская мебель, техника, создайте подробные текстовые описания.
- Используйте канонические теги для объединения повторяющегося контента.

2. «Обнаружено — в данный момент не индексируется»
Эту ситуацию «обожают» все опытные SEOшники. Тут проблема может быть в чем угодно от неправильного расходования краулингового бюджета до перелинковки и некачественного контента. С таким часто сталкиваются крупные магазины и маркетплейсы. Но они компенсируют ситуацию за счет брендового трафика и товарной рекламы. Иногда под такой сигнал попадают тысячи адресов на одном сайте.
В качестве решения вы сами можете выбрать, какие страницы и разделы интернет-магазина не нужно индексировать. Запретите сканирование тегом noindex и в файле robots.txt.
Чтобы справиться с этой проблемой, требуется опыт, детальная аналитика и немало терпения. Обнаружили, что ваши страницы «обнаружены — в настоящее время не проиндексированы»? сделайте следующее:
- Найдите и опишите, какие типичные страницы попали в эту группу. Может быть, проблема связана с определенной категорией товаров, а вся категория не имеет внутренней связи? Или, может быть, огромная часть страниц продуктов ожидает в очереди на индексирование? Описав проблемные страницы, вы быстрее увидите решение.
- Оптимизируйте свой краулинговый бюджет. Ищите страницы низкого качества, на которые Google тратит краулинговый бюджет сайта. Это могут быть динамические фильтры, незаполненные страницы товаров и пр. Страницы фильтров по двум и более параметрам лучше закрыть от индексации, а страницы с товарами улучшить или даже удалить.
 Может быть, проблема связана с определенной категорией товаров, а вся категория не имеет внутренней связи? Или, может быть, огромная часть страниц продуктов ожидает в очереди на индексирование? Описав проблемные страницы, вы быстрее увидите решение.
Может быть, проблема связана с определенной категорией товаров, а вся категория не имеет внутренней связи? Или, может быть, огромная часть страниц продуктов ожидает в очереди на индексирование? Описав проблемные страницы, вы быстрее увидите решение.- Дубли контента
Особенно острая проблема! О ней пишут сотни статей. Сложность в том, что существуют частичные и полные дубли и каждая из этих категорий неоднородна. Дубли могут возникать по нескольким причинам:
- Неправильно реализованная мультиязычность и не расставленные атрибуты ;
- Отсутствие тегов canonical;
- Дублирование контента внутри сайта;
- Контент с других сайтов;
- Повторяющиеся title и description.
Проверьте все эти варианты, чтобы методом исключения найти решение проблемы. Удалить дубли можно с помощью редиректов, удаления страницы или редактирования контента.
Как найти проблемы с индексацией?
Проверить индексацию страниц проще всего с помощью отчета Покрытие в Google Search Console.
Сначала посмотрите на количество исключенных страниц, потом разберитесь в причинах. Далеко не всегда исключение страницы из индекса это плохо.
Удачи вам в продвижении, следите за следующими статьями!
▷ Як правильно заманити пошукових роботів на сайт. Працюємо з Google Search Console
Проблема індексації посадкових сторінок — одна з основних, з якою стикається майже кожен власник сайту. Індексація — додавання інформації про ваш сайт в базу даних пошукових систем. Сторінки, яких немає в індексі, користувачі не зможуть знайти, отже — трафіку на них не буде.
Пошукові системи сканують сайти в інтернеті на предмет якісних документів, що задовольняють попит користувачів. Пошуковики зацікавлені, щоб база сайтів була максимально повною та актуальною, тому регулярно сканують всі, відомі їм, сайти в пошуках нового контенту. Є цілі сайти і / або окремі документи, які рідко сканують пошукові системи або які не скануються зовсім. У статті ми розберемо основні моменти, що впливають на швидкість індексації документів.
Пошуковики зацікавлені, щоб база сайтів була максимально повною та актуальною, тому регулярно сканують всі, відомі їм, сайти в пошуках нового контенту. Є цілі сайти і / або окремі документи, які рідко сканують пошукові системи або які не скануються зовсім. У статті ми розберемо основні моменти, що впливають на швидкість індексації документів.
Причини поганої індексації сайту
Щоб розібратися, чому сайт погано індексується, потрібно визначитися з поняттями «краулінга» і «краулінгового бюджету».
Краулінг — це процес сканування сторінок ботами пошукових систем. Основна мета краулінга — знайти якомога більше корисних і актуальних документів.
Краулінговий бюджет — це ліміт, який виділяється кожному сайту на сканування. Іншими словами це обмеження кылькості сторінок, які пошуковий робот може просканувати в певний проміжок часу. Краулінговий бюджет розраховується для кожного сайту окремо, виходячи з частоти оновлення контенту, якості ресурсу, відповіді сервера, розміру сторінок та інших параметрів.
Логічно, якщо на сайті 10 сторінок і нічого не змінюється роками — роботи рейтингів не будуть сканувати такі сайти часто. Немає сенсу витрачати ресурси на це завдання.
Виходячи з поняття «краулінга» і нашого SEO-досвіду розглянемо помилки та способи їх виправлення.
Як дізнатися, що сайт погано індексується?
Сайт або сторінка рідко індексується, якщо дата збереженої копії (кешу) понад два тижні. Перевіряємо дату кешу документа в Google через оператор cache: cache:inweb.ua
Примітка. Подивитися дату індексації сторінки можна за допомогою букмарклету.
Якщо даті кешованої копії понад місяць — з індексацією серйозні проблеми. Результати сканування вашого сайту пошуковими системами можна подивитися в спеціальних звітах Google і Яндекс. Для пошукової системи Google даний звіт доступний в сервісі Search Console. Ось що пише Google про свій звіт:
Приклад звіту в Google Search Console:
Такого ж типу звіт є і в Яндексі. Доступний він в Яндекс Вебмайстері. Візуалізація звіту:
Доступний він в Яндекс Вебмайстері. Візуалізація звіту:
Найчастіше, проблема краулінга стосується тільки дуже великих сайтів. Якщо ваш сайт має до 1000 сторінок і вони індексуються раз на місяць або рідше, основна причина поганої індексації десь на самих сторінках. Розглянемо основні помилки, що впливають на сканування та індексування сторінок.
Закриття сайту або окремих сторінок у файлі robots.txt, noindex, X-Robots tag
Окремі сторінки або сайт в цілому можуть бути закритими від індексації всіх пошукових систем або якоїсь конкретної. В такому випадку сайт не буде скануватися, потрібні сторінки потрапляти в індекс, підсумок — ви не зможете ранжуватися в пошуку.
Приклад закритого сайту від індексації у файлі robots.txt:
Приклад закритої сторінки від індексації за допомогою метатегу noindex:
Приклад закритої для індексації сторінки за допомогою X-Robots tag:
Фільтр, санкції від пошукових систем
Щоб надавати користувачам якісний контент, Google і Яндекс створили алгоритми для обчислення якісних сайтів.
Якщо ваш ресурс добре росте тільки в одній пошуковій системі, а в інший трафіку майже немає, можливо на сайт було накладені санкції (перевірити можна в Google Analytics, Search Console або Яндекс.Вебмайстер).Неякісний контент (неунікальний, неінформативний, дубльований) і дублі сторінок
Дублі сторінок — це сторінки, оптимізовані під однакові запити, але на різних url-адресах. Загальний обсяг сайту збільшується шляхом таких дублів, боти, своєю чергою, витрачають більше часу на індексацію цих «сміттєвих» сторінок, тим самим неефективно витрачаючи краулінговий бюджет сайту, а якісні сторінки можуть зовсім не потрапити в індекс.
Повертаємося в поняття «краулінговий бюджет», де пошукові роботи витрачають на сканування сайту n часу. Якщо робот «бачить», що контент регулярно повторюється, індексація буде проводитися значно довше або може зовсім припинитися. Пошуковик вважатиме контент неякісним, не побачить сенсу його взагалі або часто сканувати.
Дублюватися можуть не тільки сторінки, а й контент.
Дублі контенту — повторювані матеріали на різних сторінках сайту (часто зустрічаються на сторінках пагінації, фільтрів або сортуваннях). Ось приклад дубльованого контенту на сторінках, які не закриті від індексації: http://smoke-gadgets.com.ua/kalyany/kalyany_cwp_razor/filter/hit-is-recommend/apply/Той самий контент на сторінці категорії: http://smoke-gadgets.com.ua/kalyany/kalyany_cwp_razor/
Помилки в коді сайту
Пошуковий робот повинен обробити HTML-код. Якщо сторінки зроблені на JavaScript, то пошуковий бот не зможе розпізнати їх, обробити й додати в кеш пошукової системи. Щоб перевірити кеш сторінки, потрібно додати до неї cache: і переглянути текстову версію:
Неправильна відповідь сервера на потрібні сторінки
Сторінка, що доступна для індексації, має віддавати код відповіді сервера 2хх. Якщо цього немає, не буде й індексації. Для пошукових роботів кожна група відповідей сервера дає вказівки, що потрібно робити:
3хх означає, що потрібний контент розташовано за іншою адресою;
4хх — сторінка не доступна;
5хх — проблема з сервером;
і тільки група відповіді сервера 2хх означає, що сторінка доступна за поточною адресою, отже її можна сканувати та індексувати. Якщо сервер дає невірний код відповіді потрібної сторінки, сторінка не потрапить в індекс.Великий рівень вкладеності
Від вкладеності залежить пріоритетність сторінок під час індексування пошуковими ботами. Чим більше рівень вкладеності, тим менше у неї пріоритет: якщо ви створили нову сторінку або нову категорію, але для того, щоб до неї дістатися користувач повинен зробити більше 3-х кліків — швидкість індексації такої сторінки буде не високою. Наприклад: https://remshop.com.ua/p1007251549-kryshka-blendernoj-chashi.html
Щоб дістатися до карток товару на сторінці «Крышка чаши» нужно:
- Зайти на сайт.
- Перейти в категорію «Для кухонних комбайнів».
- Далі — на підкатегорію «Кришка чаші».
І тільки після цього можна буде перейти на потрібну картку товару. Погодьтеся, не швидко.
Повільна швидкість сайту
Швидкість завантаження сторінок умовно складається з трьох складових:
- швидкість завантаження контенту;
- швидкість завантаження зображень;
- швидкість відповіді сервера.
Чим менше у вас розмір контенту, зображень і вище швидкість завантаження сервера, тим швидше бот просканує сторінку та додасть її в індекс.
Відсутність мобільної версії
Здавалося б, до чого тут мобільна або адаптивна версія сайту до швидкості індексації сторінок пошуковою системою. Але з 1 липня 2019 року пошукова система віддала пріоритет мобільному контенту. Якщо сторінки відсутні в мобільній або адаптивній версії вашого сайту, пошукова система їх може будь-коли побачити.
Чи не регулярне оновлення контенту сайту
Частота оновлення контенту сигналізує пошуковому боту про її регулярність. Якщо на сайті давно нічого не публікувалося або не додавати нові товари, робот не буде ставити в пріоритет сканування та індексування вашого сайту. Наприклад, ви створили інтернет-магазин, наповнили його товарами, контентом і всіма необхідними даними. Тут можна подумати, що робота над сайтом закінчена і потрібно просто акцентувати на посилальному профілі.
І ось ви регулярно розширюєте його, а результату немає. У чому ж проблема? У тому, що сайт без постійного оновлення контенту (асортименту), здається пошуковому боту «мертвим», а отже — час витрачати на нього не варто.Відсутність внутрішнього перелінкування
Перехід за внутрішнім посиланням сприяє прискоренню індексації нових сторінок. Чим більше лінків веде на сторінку, тим більшу вагу вона набуває, тобто стає більш значущою для пошукових систем. Наприклад, на цю сторінку веде тільки одне посилання з переліку статей: http://eco-food.com.ua/articles/sushi-is-popular/
 Якщо ваш ресурс добре росте тільки в одній пошуковій системі, а в інший трафіку майже немає, можливо на сайт було накладені санкції (перевірити можна в Google Analytics, Search Console або Яндекс.Вебмайстер).
Якщо ваш ресурс добре росте тільки в одній пошуковій системі, а в інший трафіку майже немає, можливо на сайт було накладені санкції (перевірити можна в Google Analytics, Search Console або Яндекс.Вебмайстер). Дублі контенту — повторювані матеріали на різних сторінках сайту (часто зустрічаються на сторінках пагінації, фільтрів або сортуваннях). Ось приклад дубльованого контенту на сторінках, які не закриті від індексації: http://smoke-gadgets.com.ua/kalyany/kalyany_cwp_razor/filter/hit-is-recommend/apply/
Дублі контенту — повторювані матеріали на різних сторінках сайту (часто зустрічаються на сторінках пагінації, фільтрів або сортуваннях). Ось приклад дубльованого контенту на сторінках, які не закриті від індексації: http://smoke-gadgets.com.ua/kalyany/kalyany_cwp_razor/filter/hit-is-recommend/apply/ Якщо сервер дає невірний код відповіді потрібної сторінки, сторінка не потрапить в індекс.
Якщо сервер дає невірний код відповіді потрібної сторінки, сторінка не потрапить в індекс.
 І ось ви регулярно розширюєте його, а результату немає. У чому ж проблема? У тому, що сайт без постійного оновлення контенту (асортименту), здається пошуковому боту «мертвим», а отже — час витрачати на нього не варто.
І ось ви регулярно розширюєте його, а результату немає. У чому ж проблема? У тому, що сайт без постійного оновлення контенту (асортименту), здається пошуковому боту «мертвим», а отже — час витрачати на нього не варто.Як дізнатися, що сайт погано індексується
Спосіб №1
В адмін панелі дивимося загальну кількість сторінок вашого сайту, а потім в пошуковому рядку до домену додаємо site: Приклад: site: https:/домен.org
Під пошуковим рядком ви побачите кількість результатів, які знайшла пошукова система у видачі з вашим доменом. Далі потрібно зробити порівняння кількості сторінок в адмін панелі з кількістю сторінок у видачі. З різниці робимо висновок, скільки сторінок ще не проіндексовано.
З різниці робимо висновок, скільки сторінок ще не проіндексовано.
Спосіб №2
Порівнюємо кількість сторінок з адмін панелі з даними з Search Console або Яндекс.Вебмайстер.
Приклад: Всього проіндексованих сторінок в Search Console:
Також можна подивитися звіт “Статистика сканування”
Яндекс.Вебмайстер, звіт “Сторінки в пошуку”
Потім завантажуємо таблицю
Дивимося кількість сторінок, що проіндексовані пошуковою системою:
Спосіб №3
Можна подивитися, чи є конкретна сторінка у видачі, використовуючи той самий алгоритм, що і в способі №1. В цьому випадку потрібно додати site: з конкретною url-адресою. Приклад:
12 методів прискорення індексації сайту
Підсумовуючи вище описане, ми підготували 12 дієвих методів для поліпшення індексації сайту пошуковими системами Яндекс або Google.
- Оновлення поточного контенту.Один зі способів привернути пошукових роботів — це регулярне оновлення контенту на вашому сайті. Оновлення контенту може відбуватися шляхом перепису старого контенту або його окремих частин, наприклад, шляхом написання нових відгуків на старі сторінки сайту.
- Додавання нового контенту. Домогтися залучення уваги пошукових роботів до вашого інтернет-ресурсу можна шляхом додавання нового контенту на сайт. Для цього можна регулярно писати нові статті на блог, додавати нові товари, категорії або інформаційні сторінки.
- Відсутність дублікатів і сміттєвих сторінок. Як ми писали вище, на сканування кожного сайту виділяється n часу пошукового робота. Відсутність дублів і / або сміттєвих сторінок сайту збільшить кількість часу пошукових роботів на сканування потрібних сторінок. Як визначити, то що на сайті є сміттєві або дублі сторінок? Почніть з самого простого: перевірте коректність оптимізації сторінок пагінації, фільтрів і сортувань на сайті. Перевірте доступність сторінок з /, www і без. Якщо у вас зроблена ця оптимізація, проскануйте сайт спеціальними SEO-програмами, наприклад Netpeak Spider чи Screaming Frog, зверніть увагу на дублі метатегів.
Сторінки, оптимізовані під однакові запити, також є дублями в «очах» пошукової системи.
- Створити коректний і автообновлювальний Sitemap.xml.
Для прискорення індексації сайту, створіть коректну xml-карту і додайте її в файл robots.txt і Веб-майстер. Вона буде, свого роду, навігатором вашим сайтом для пошукових систем. А додавання в неї Last-Modified вкаже ботам дату останнього оновлення конкретної сторінки та скануватиме сторінки з новим контентом швидше.
- Зовнішні ресурси. Розміщення посилань на сторонніх ресурсах або лiнкбилдiнг не тільки допомагає збільшити контрольну вагу сайту в цілому або конкретної його сторінки, а й залучає пошукового бота для поліпшення індексації. Кілька способів розміщення посилання на ваш сайт на сторонніх ресурсах:
- форуми;
- рейтинги;
- статті;
- довідники;
- отзовікі.
У поточній рекомендації важливо вибрати якісні інтернет-ресурси з хорошими показниками, такими як відвідуваність майданчиків, кількість вхідних і вихідних посилань, основні ключові слова ранжирування сайту і приналежність до регіону, в якому ви рухаєтеся.
- HTML-карта сайту для категорій, а також для підтвердження бронювання.
Карта сайту в форматі HTML — це, свого роду, каталог усіх розділів сайту з категоріями та підкатегоріями, розміщених відповідно до їх ієрархії. Наявність html-карти сайту показує пошуковій системі, які сторінки є основними та зменшує рівень вкладеності для підкатегорії.
- HTML-карта сайту для карток товару.
Цей спосіб покращення індексації добре підходить для великих інтернет-магазинів: всі картки з товарами знаходяться в одному місці та є, свого роду, путівником для пошукової системи за асортиментом.
- Хлібні крихти.
Елемент інтерфейсу в веб-сайтах, що показує шлях від п
 Оновлення контенту може відбуватися шляхом перепису старого контенту або його окремих частин, наприклад, шляхом написання нових відгуків на старі сторінки сайту.
Оновлення контенту може відбуватися шляхом перепису старого контенту або його окремих частин, наприклад, шляхом написання нових відгуків на старі сторінки сайту.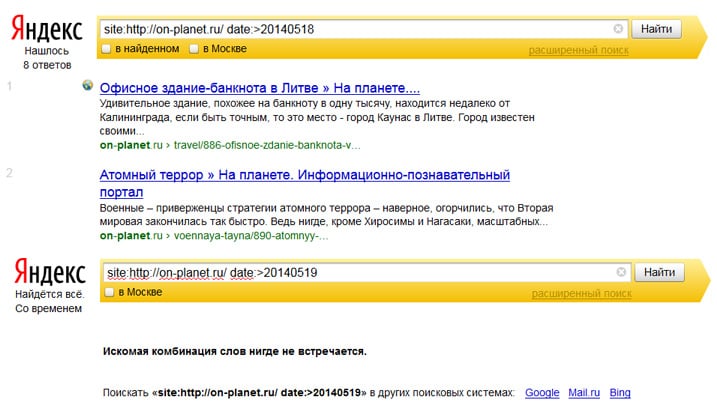

Почему 100% индексация невозможна и почему это допустимо
Когда речь заходит о таких темах, как краулинговый бюджет, историческая риторика всегда сводилась к тому, что это проблема крупных веб-сайтов (по классификации Google — более 1 миллиона веб-страниц).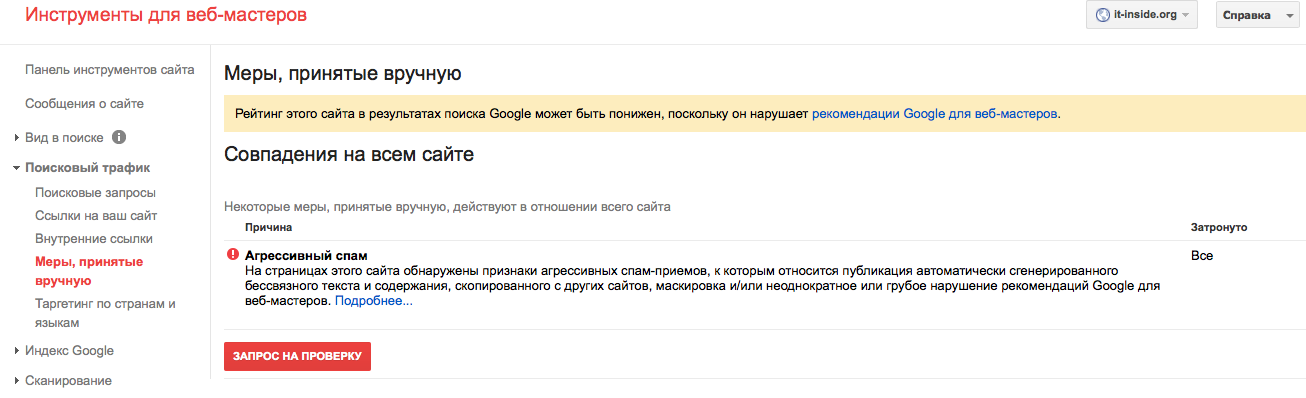 ) и веб-сайты среднего размера с высокой частотой смены контента.
) и веб-сайты среднего размера с высокой частотой смены контента.
Однако в последние месяцы сканирование и индексирование стали более распространенными темами на форумах SEO и в вопросах, заданных сотрудникам Google в Twitter.
По моему собственному неподтвержденному опыту, с ноября веб-сайты разного размера и с разной частотой изменений претерпевают большие колебания и сообщают об изменениях в Google Search Console (как в статистике сканирования, так и в отчетах о покрытии), чем это было раньше.
Ряд крупных изменений покрытия, свидетелем которых я был, также коррелировали с неподтвержденными обновлениями Google и высокой волатильностью датчиков/наблюдателей SERP. Учитывая, что ни один из веб-сайтов не имеет слишком много общего с точки зрения стека, ниши или даже технических проблем, является ли это признаком того, что 100% индексация (для большинства веб-сайтов) сейчас невозможна, и это нормально?
Это имеет смысл.
Google в своих собственных документах отмечает, что сеть расширяется такими темпами, которые намного превосходят ее собственные возможности и средства сканирования (и индексации) каждого URL-адреса.
Получайте ежедневный информационный бюллетень, на который полагаются поисковые маркетологи.
В той же документации Google описывает ряд факторов, влияющих на их способность сканирования, а также спрос на сканирование, в том числе:
- Популярность ваших URL-адресов (и контента).
- Это затхлость.
- Насколько быстро сайт отвечает.
- Знание Google (воспринимаемый перечень) URL-адресов на нашем веб-сайте.
Из разговоров с Джоном Мюллером из Google в Твиттере известно, что популярность вашего URL не обязательно зависит от популярности вашего бренда и/или домена.
Имея непосредственный опыт крупного издателя, не индексирующего контент на основе его уникальности по сравнению с аналогичным контентом, уже опубликованным в Интернете, — как будто он падает ниже порога качества и не имеет достаточно высокого значения включения SERP.
Вот почему, работая со всеми веб-сайтами определенного размера или типа (например, электронной коммерции), я с первого дня заявляю, что 100% индексация не всегда является показателем успеха.
Уровни и сегменты индексации
Google довольно откровенно объяснил, как работает их индексация.
Они используют многоуровневую индексацию (некоторый контент на лучших серверах для более быстрого доступа) и что у них есть индекс обслуживания, хранящийся в нескольких центрах обработки данных, который, по сути, хранит данные, обслуживаемые в поисковой выдаче.
Еще больше упрощая:
Содержимое документа веб-страницы (документа HTML) затем токенизируется и сохраняется в сегментах, а сами сегменты индексируются (как глоссарий), чтобы их можно было быстрее и проще запрашивать по определенным ключевым словам. (когда пользователь ищет).
В большинстве случаев в проблемах с индексированием обвиняют техническое SEO, и если у вас есть отсутствие индекса или проблемы и несоответствия, мешающие Google индексировать контент, то это технические проблемы, но чаще всего это проблема ценностного предложения.
Полезная цель и значение включения в поисковую выдачу
Когда я говорю о ценностном предложении, я имею в виду две концепции из рекомендаций Google по оценке качества (QRG), а именно:
- Полезная цель
- Качество страницы
В совокупности они создают то, что я называю значением включения в поисковую выдачу.
Обычно по этой причине веб-страницы попадают в категорию «Обнаруженные — в настоящее время не проиндексированные» в отчете о покрытии Google Search Console.
В QRG Google делает следующее заявление:
Помните, что если страница не имеет полезной цели, ей всегда следует присвоить рейтинг «Самое низкое качество страницы», независимо от рейтинга страницы «Удовлетворены потребности» или от того, насколько хорошо оформлена страница.
Что это значит? Чтобы страница могла ориентироваться на правильные ключевые слова и ставить правильные галочки. Но если он обычно повторяется в другом контенте и не имеет дополнительной ценности, Google может не индексировать его.
Здесь мы сталкиваемся с порогом качества Google, концепцией того, соответствует ли страница необходимому «качеству» для индексации.
Ключевой момент в том, как работает этот порог качества, заключается в том, что он работает почти в реальном времени и плавно.
Гэри Иллиес из Google подтвердил это в Твиттере, где URL-адрес может быть проиндексирован при первом обнаружении, а затем удален при обнаружении новых (лучших) URL-адресов или даже получить временное повышение «свежести» за счет ручной отправки в GSC.
Определение наличия проблемы
Первое, что нужно определить, — это если вы видите, что количество страниц в отчете о покрытии Google Search Console перемещается из включенных в исключенные.
Одного этого графика, вырванного из контекста, достаточно, чтобы вызвать беспокойство у большинства маркетологов.
Но сколько из этих страниц вам нужно? Сколько из этих страниц приносят пользу?
Вы сможете определить это по своим коллективным данным. Вы увидите, уменьшаются ли трафик и доход/лиды в вашей аналитической платформе, и вы заметите в сторонних инструментах, если вы потеряете общую видимость на рынке и рейтинг.
После того, как вы определили, что ценные страницы выпадают из индекса Google, следующие шаги заключаются в том, чтобы понять, почему, и Search Console разбивает исключенные на дополнительные категории. Основные из них, которые вам нужно знать и понимать, это:
Просканировано — в настоящее время не проиндексировано
Это то, с чем я сталкивался чаще в электронной коммерции и недвижимости, чем в любой другой вертикали.
В 2021 году количество регистраций новых бизнес-приложений в США побило предыдущие рекорды, и, поскольку все больше компаний конкурируют за пользователей, публикуется много нового контента, но, вероятно, не так много новой и уникальной информации или перспектив.
Обнаружено — в настоящее время не проиндексировано
При отладке проблем с индексацией я часто обнаруживаю это на веб-сайтах электронной коммерции или веб-сайтах, которые используют значительный программный подход к созданию контента и публикуют большое количество страниц одновременно.
Основные причины, по которым страницы попадают в эту категорию, могут быть связаны с краулинговым бюджетом, поскольку вы только что опубликовали большое количество контента и новых URL-адресов и экспоненциально увеличили количество сканируемых и индексируемых страниц на сайте, а также краулинговый бюджет который Google определил для вашего сайта, не предназначен для такого количества страниц.
Вы мало что можете сделать, чтобы повлиять на это. Тем не менее, вы можете помочь Google с помощью карт сайта в формате XML, карт сайта в формате HTML и хороших внутренних ссылок, чтобы передать рейтинг страницы с важных (проиндексированных) страниц на эти новые страницы.
Тем не менее, вы можете помочь Google с помощью карт сайта в формате XML, карт сайта в формате HTML и хороших внутренних ссылок, чтобы передать рейтинг страницы с важных (проиндексированных) страниц на эти новые страницы.
Вторая причина, по которой контент может попасть в эту категорию, связана с его качеством, и это часто встречается на сайтах программного контента или электронной коммерции с большим количеством продуктов и PDP, которые являются похожими или вариативными продуктами.
Google может идентифицировать шаблоны в URL-адресах, и если он посещает определенный процент этих страниц и не находит никакой ценности, он может (и иногда будет) делать предположение, что HTML-документы с похожими URL-адресами будут такого же (низкого) качества, и он решит не сканировать их.
Многие из этих страниц были созданы преднамеренно с целью привлечения клиентов, например, программные страницы местоположения или страницы сравнения, ориентированные на нишевых пользователей, но поиск по этим запросам осуществляется с низкой частотой, они, скорее всего, не привлекут много внимания, а содержание может быть недостаточно уникальным по сравнению с другими программными страницами, поэтому Google не будет индексировать контент с низкой ценностью, когда доступны другие альтернативы.
В этом случае вам необходимо оценить и определить, могут ли цели быть достигнуты в рамках ресурсов и параметров проекта без избыточных страниц, которые забивают сканирование и не считаются ценными.
Дублированный контент
Дублированный контент является одним из самых простых и часто встречается в электронной коммерции, издательском деле и программатике.
Если основной контент страницы, содержащий ценностное предложение, дублируется на других веб-сайтах или внутренних страницах, Google не будет вкладывать ресурсы в индексирование контента.
Это также связано с ценностным предложением и концепцией полезной цели. Я сталкивался с многочисленными примерами, когда на крупных авторитетных веб-сайтах контент не индексировался, потому что он такой же, как и другой доступный контент — не предлагает уникальных перспектив или уникальных ценностных предложений.
Принимаем меры
Для большинства крупных веб-сайтов и веб-сайтов среднего размера добиться 100%-ной индексации будет только сложнее, поскольку Google должен обрабатывать весь существующий и новый контент в Интернете.
Если вы обнаружите, что качество ценного контента ниже порогового, какие действия следует предпринять?
- Улучшение внутренней перелинковки со страниц с «высокой ценностью» : Это не обязательно означает страницы с наибольшим количеством обратных ссылок, но те страницы, которые ранжируются по большому количеству ключевых слов и имеют хорошую видимость, могут передавать положительные сигналы через описательные привязки к другим страницам.
- Удаление некачественного и малоценного контента. Если страницы, исключаемые из индекса, имеют низкую ценность и не приносят никакой ценности (например, просмотров страниц, конверсий), их следует удалить. Наличие их в реальном времени просто тратит впустую ресурсы сканирования Google, когда он решает их сканировать, и это может повлиять на их предположения о качестве, основанные на сопоставлении шаблонов URL и предполагаемом инвентаре.
Мнения, высказанные в этой статье, принадлежат приглашенному автору и не обязательно принадлежат Search Engine Land. Штатные авторы перечислены здесь.
Штатные авторы перечислены здесь.
Добавьте Search Engine Land в свою ленту новостей Google.
Похожие статьи
Новое в поисковой системе
Об авторе
Консоль поиска Google: как исправить проблемы, связанные с тем, что «в настоящее время не проиндексировано»
Вы когда-нибудь смотрели отчет Google Search Console и задавались вопросом, почему Google просканировал ваш сайт, но не проиндексировал определенные страницы?
Что такое ошибки индексации в Google?Нажав Узнать больше в отчете о покрытии, вы найдете объяснения ошибок индексации Google в справочном документе GSC:
- Просканировано – в настоящее время не проиндексировано не индексируется. Google также заявляет, что нет необходимости повторно отправлять URL-адреса, поскольку они могут быть проиндексированы в будущем.
- Обнаружено – в настоящее время не проиндексировано: Google присваивает эту категорию URL-адресам, которые еще не просканированы (но будут просканированы позже), вероятно, потому, что это может привести к перегрузке сайта во время последнего сканирования. Таким образом, дата последнего сканирования отсутствует в отчете для этих URL-адресов.

Отчет о покрытии GSC: проблемы с индексацией (и сколько ваших страниц они затронуты)
Совет для профессионалов: Учитывая приведенные выше статусы, нет необходимости вручную запрашивать повторную индексацию страницы, поскольку Google утверждает, что в конечном итоге он будет переоценен.
Вот что думает Джон Мюллер:
Помимо справочного документа GSC, мы также можем раскрыть подсказки от старшего аналитика тенденций Google для веб-мастеров Джона Мюллера, который делится в Интернете своими ответами на часто задаваемые вопросы о Google SEO.
Отвечая на вопрос о том, что делать со статусом Обнаружено — в настоящее время не проиндексировано во время видеовстречи в Центре веб-мастеров Google в рабочее время, Джон заявил, что наиболее вероятной причиной того, что Google не сканирует или не индексирует веб-страницу, может быть одна из следующих:
- Веб-страница автоматически генерирует слишком много вариантов URL.
- Веб-страница имеет плохую структуру внутренних ссылок.
С этой целью он советует свести количество веб-страниц к минимуму (то есть качество важнее количества), чтобы улучшить общее качество сайта.
Что касается Crawled — в настоящее время не проиндексированной проблемы , Джон сказал, что для Google нормально не индексировать все веб-страницы на веб-сайте, сославшись на то, что невозможно заставить поисковый робот Google проиндексировать конкретную страницу.
Если на веб-странице есть эта проблема, скорее всего, это проблема всего сайта, а не отдельная проблема этой страницы, поэтому крайне важно оптимизировать структуру сайта и обеспечить его высочайшее качество.
Для всех URL-адресов с ошибками Google четко указывает, что необходимо исправить, и помогает повторно проверить ту же проблему после ее устранения.
В ожидании повторной проверки Google вот три обязательных действия, которые необходимо выполнить, чтобы проверить индексацию вашего сайта, прежде чем оценивать наилучший подход к решению ваших проблем с индексацией — или нужно ли вам их решать вообще.
Проанализируйте уязвимые URL-адреса
Как заявил Джон Мюллер, Google обычно не индексирует некоторые из ваших веб-страниц, поскольку его алгоритм обслуживает только наиболее релевантные результаты на странице результатов поисковой системы (SERP).
Таким образом, статус , не проиндексированный в настоящее время , не требует ваших немедленных действий, если только он не затрагивает страницы, которые считаются наиболее важными для вашего бизнеса, например целевую страницу регистрации, предназначенную для конверсии клиентов.
Чтобы решить, какие действия предпринять, вы можете экспортировать список уязвимых URL-адресов из GSC и установить приоритет для тех, которые вы хотите проиндексировать в Google. Классифицируя затронутые URL-адреса, вы также можете выявить закономерности того, где возникает проблема индексации на вашем сайте, и какие типы веб-страниц — например, URL-адреса блогов — обычно не индексируются.
Проверка правильности ошибки индексирования
Далее, вы всегда должны выполнять проверку статуса индекса для своих URL-адресов, поскольку URL-адреса, отмеченные Google как , исключены из , в конце концов, часто могут оказаться в его индексе.
Примечание : Статус исключено относится к страницам, которые либо являются дубликатами проиндексированных страниц, либо заблокированы от индексации каким-либо механизмом на вашем сайте.
Вы можете использовать оператор поиска по сайту Google, чтобы проверить, какие из ваших URL-адресов отображаются в его поисковой выдаче, а затем отфильтровать их по тому, были ли они проиндексированы или нет.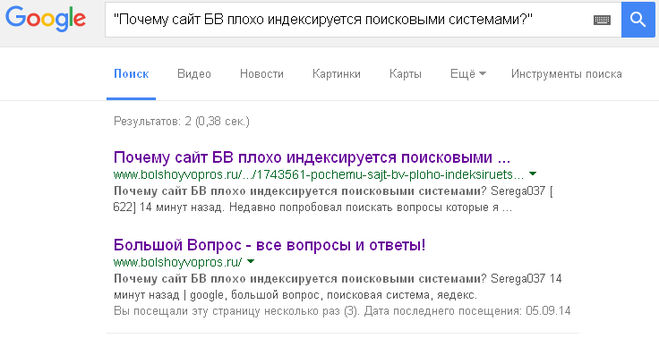
Проведите живое тестирование URL-адресов
Чтобы убедиться, что Google проиндексирует ваши высокоприоритетные URL-адреса в следующий раз при их сканировании, вам также следует провести живое тестирование URL-адресов в инструменте проверки URL-адресов Google, чтобы убедиться, что Google может индексировать ваши страницы без каких-либо проблем со сканированием.
Инструмент Google для проверки URL-адресов, проверяющий индексируемость URL-адреса
Как вы решаете C проблемы, которые в данный момент не индексируются ?Увеличение внутренних ссылок
Плохая структура ссылок затрудняет обнаружение Google ваших веб-страниц, которые необходимо просканировать. Таким образом, для высокоприоритетных страниц, которые вы хотите, чтобы Google сканировал, вы можете добавить больше внутренних ссылок со страниц, которые находятся выше в архитектуре вашего сайта.
Увеличение количества внутренних ссылок, ведущих на веб-страницу, помогает по двум причинам:
- Большее количество внутренних ссылок, ведущих на веб-страницу, означает, что сканерам поисковых систем будет легче найти страницу.
- Больше внутренних ссылок, ведущих на веб-страницу, свидетельствует о важности этой страницы для Google.
Улучшение качества контента
Решение Google не индексировать страницу также может свидетельствовать о том, что ее содержание не соответствует стандартам качества Google. Следовательно, вы должны создавать уникальный контент с релевантными, высокоэффективными ключевыми словами, чтобы увеличить шансы вашей веб-страницы на индексацию.
Вот несколько важных советов по оптимизации вашего контента:
- Создавайте оригинальный контент, уникальный для вашего бренда, нацеленный на высокоэффективные ключевые слова.
- Добавьте больше контекста, чтобы избежать неполноценного контента, который может повредить вашему рейтингу.
- Выделиться в поисковой выдаче, предоставляя контент, более ценный для пользователей, чем то, что могут предоставить ваши конкуренты в поисковой выдаче.
- Поймите, кто ваши посетители, и удовлетворите их поисковые запросы.

Выполнение обрезки контента
При запуске нового веб-сайта или проведении модернизации сайта вы можете обнаружить, что некоторые URL-адреса попадают в Discover — в настоящее время не проиндексированы 9Категория 0137 из-за перегрузки контента. Это означает, что ваш веб-сайт содержит гораздо больше контента, чем Google готов выделить для сканирования.
Перегрузка контента может произойти, когда сайт случайно автоматически генерирует много URL-адресов или имеет слишком много индексированных страниц с небольшой SEO-ценностью, таких как теги и страницы категорий.
Вот несколько способов решения проблемы перегрузки содержимым:
- Использование канонических тегов для объединения сигналов ранжирования и указания Google, какой URL-адрес представляет собой основную копию страницы.
- Обновите файл robots.txt, чтобы Google не сканировал низкоприоритетные страницы, по которым вы не хотите ранжироваться.
- Объединяйте и перепрофилируйте короткие статьи с похожим содержанием и темами в развернутые материалы.
