
Заменяем диск в zfs raidz
Эта запись встает на место одноименной записи от 2013 г. С тех пор много воды утекло, старую я не удаляю. Тем более, что настоящая запись — про замену диска в zfs массиве на именованных gpt разделах. А старая — про другие варианты.Запись подробна до деталей. Я только что провел всю процедуру на своем NAS и аккуратно документировал все команды и их выхлоп, сопроводив комментариями.
Версия xigmanas 2.1.0.4 — Ingva (revision 7728)
FreeBSD 12.1-RELEASE-p8
1) Итак исходное состояние — у нас выпал из массива один из дисков. Раньше он назывался /dev/gpt/D_ZFN0PARZ — и это имя я ему когда-то дал неспроста. ZFN0PARZ — последние несколько символов серийного номера. Когда диск возьму в руки можно будет убедиться, что не ошибся и не ломаю систему, вместо того, чтобы чинить. И, строго говоря, это не имя диска — это имя раздела, так как zfs пул у меня на разделах. Имена дисков свободно меняются при добавлени новых и отключении старых. А имена разделов — постоянны
17637550633201844329 — уникальный zfs ID старого диска. По нему можно будет указывать его в операции замены. Подобные ID есть и у пула и много еще у чего — но не полезем в дебри.
По нему можно будет указывать его в операции замены. Подобные ID есть и у пула и много еще у чего — но не полезем в дебри.
NB Давайте еще раз большими буквами НЕ СПЕШИТЕ ЗАМЕНЯТЬ ДИСК в подобном случае. По опыту более 90% подобных случаев — проблемы в проводах. Замените SATA кабель, попробуйте переподключить питание. Попробуйте подключить на другой SATA порт. Нет свободного — поменяйте с одним из рабочих дисков этого же пула. Потом верните обратно. Да, от капитана — ВСЕ КОММУТАЦИИ ТОЛЬКО НА ОБЕСТОЧЕННОМ ЖЕЛЕЗЕ. Желательно — вынуть кабель из розетки. А то, знаете, ли — вся электроника работает на белом дыме. Если он выйдет из железки — она больше на работает.
Итак, как выглядит статус нашего массива на именованных GPT разделах при одном отвалившемся диске
nas4free: ~# zpool status Pool
pool: Pool
state: DEGRADED
status: One or more devices could not be opened. Sufficient replicas exist for
the pool to continue functioning in a degraded state.
action: Attach the missing device and online it using 'zpool online'. see: http://illumos.org/msg/ZFS-8000-2Q
scan: resilvered 1.56G in 0h2m with 0 errors on Mon Sep 7 13:20:58 2020
config:
NAME STATE READ WRITE CKSUM
Pool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gpt/D_Z300V843 ONLINE 0 0 0
gpt/D_Z300W3TK ONLINE 0 0 0
gpt/D_W300DZ5A ONLINE 0 0 0
gpt/D_W300E0RC ONLINE 0 0 0
gpt/D_Z30053GL ONLINE 0 0 0
gpt/D_Z300PRXX ONLINE 0 0 0
17637550633201844329 UNAVAIL 0 0 0 was /dev/gpt/D_ZFN0PARZ
gpt/D_Z300V7AV ONLINE 0 0 0
errors: No known data errors
see: http://illumos.org/msg/ZFS-8000-2Q
scan: resilvered 1.56G in 0h2m with 0 errors on Mon Sep 7 13:20:58 2020
config:
NAME STATE READ WRITE CKSUM
Pool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gpt/D_Z300V843 ONLINE 0 0 0
gpt/D_Z300W3TK ONLINE 0 0 0
gpt/D_W300DZ5A ONLINE 0 0 0
gpt/D_W300E0RC ONLINE 0 0 0
gpt/D_Z30053GL ONLINE 0 0 0
gpt/D_Z300PRXX ONLINE 0 0 0
17637550633201844329 UNAVAIL 0 0 0 was /dev/gpt/D_ZFN0PARZ
gpt/D_Z300V7AV ONLINE 0 0 0
errors: No known data errors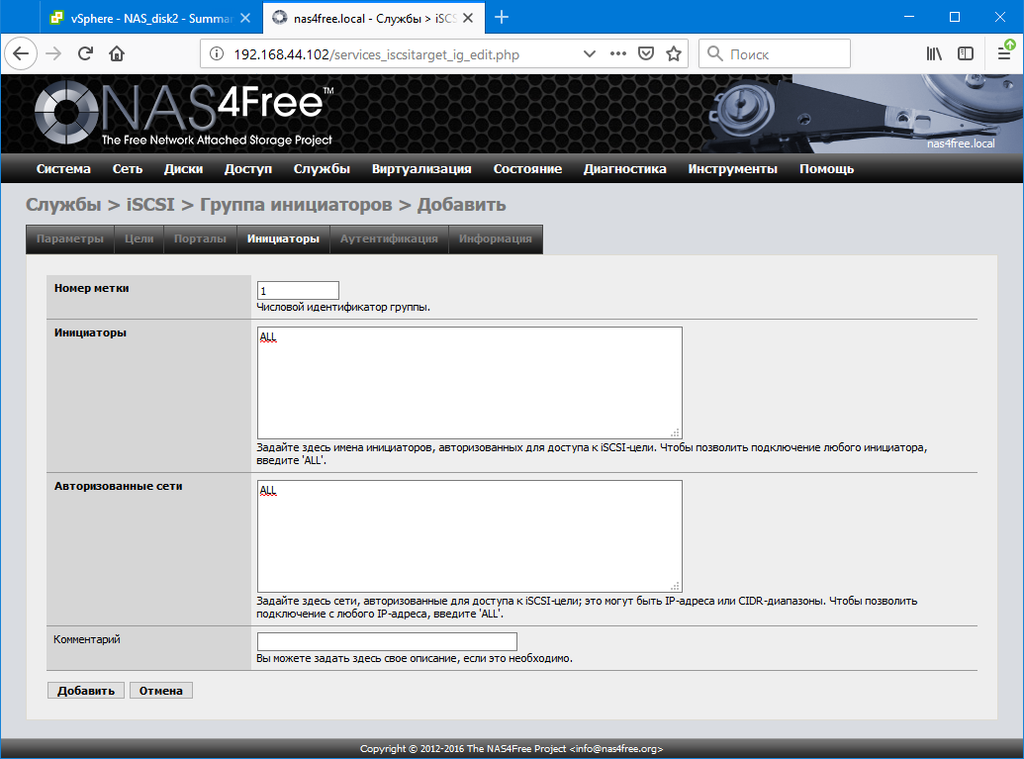 see: http://illumos.org/msg/ZFS-8000-2Q
scan: resilvered 1.56G in 0h2m with 0 errors on Mon Sep 7 13:20:58 2020
config:
NAME STATE READ WRITE CKSUM
Pool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gpt/D_Z300V843 ONLINE 0 0 0
gpt/D_Z300W3TK ONLINE 0 0 0
gpt/D_W300DZ5A ONLINE 0 0 0
gpt/D_W300E0RC ONLINE 0 0 0
gpt/D_Z30053GL ONLINE 0 0 0
gpt/D_Z300PRXX ONLINE 0 0 0
17637550633201844329 UNAVAIL 0 0 0 was /dev/gpt/D_ZFN0PARZ
gpt/D_Z300V7AV ONLINE 0 0 0
errors: No known data errors
see: http://illumos.org/msg/ZFS-8000-2Q
scan: resilvered 1.56G in 0h2m with 0 errors on Mon Sep 7 13:20:58 2020
config:
NAME STATE READ WRITE CKSUM
Pool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gpt/D_Z300V843 ONLINE 0 0 0
gpt/D_Z300W3TK ONLINE 0 0 0
gpt/D_W300DZ5A ONLINE 0 0 0
gpt/D_W300E0RC ONLINE 0 0 0
gpt/D_Z30053GL ONLINE 0 0 0
gpt/D_Z300PRXX ONLINE 0 0 0
17637550633201844329 UNAVAIL 0 0 0 was /dev/gpt/D_ZFN0PARZ
gpt/D_Z300V7AV ONLINE 0 0 0
errors: No known data errors2) Меняем диск физически НА ХОЛОДНУЮ. Отключаем тот что мертвый, серийный номер -ZFN0PARZ (если он жив — отключить может стоит и потом. Но это дилема. Если диск жив здоров и портов хватает — то точно потом. Если он тормозит и сыплется — то его наличие может очень сильно затормозить процесс замены)
Если диск жив здоров и портов хватает — то точно потом. Если он тормозит и сыплется — то его наличие может очень сильно затормозить процесс замены)
ЗАПИСЫВАЕМ НА БУМАЖКУ СЕРИЙНЫЙ НОМЕР нового диска, вставляем его, включаем.
3) Теперь нам надо понять какой номер стал у нового диска
Первым делом вызываем gpart show с ключом -l. Он позволит нам увидеть метки разделов. На старых дисках метки по серийным номерам на месте, но новом — метки если и есть — не такие.
Прим. Портянка вылезает длинная, я ее сокращаю
nas4free: ~# gpart show -l
=> 40 3907029088 ada0 GPT (1.8T)
40 4194304 1 gptswap (2.0G)
4194344 41943040 2 sparepartition (20G)
46137384 3860891736 3 D_WCAZAA099483 (1.8T)
3907029120 8 - free - (4.0K)
=> 34 7814037101 da0 GPT (3.6T)
34 6 - free - (3.0K)
40 7814037088 1 D_Z300V843 (3.6T)
7814037128 7 - free - (3. 5K)
=> 34 7814037101 da1 GPT (3.6T)
34 6 - free - (3.0K)
40 7814037088 1 D_Z300W3TK (3.6T)
7814037128 7 - free - (3.5K)
(...)
=> 34 7814037101 da7 GPT (3.6T)
34 262144 1 Microsoft reserved partition (128M)
262178 2014 - free - (1.0M)
264192 7813771264 2 Basic data partition (3.6T)
7814035456 1679 - free - (840K)
=> 63 15728577 da8 MBR (7.5G)
63 15165297 1 (null) [active] (7.2G)
15165360 563280 - free - (275M)
=> 0 15165297 da8s1 BSD (7.2G)
0 8129 - free - (4.0M)
8129 15155200 1 (null) (7.2G)
15163329 1968 - free - (984K) 5K)
=> 34 7814037101 da1 GPT (3.6T)
34 6 - free - (3.0K)
40 7814037088 1 D_Z300W3TK (3.6T)
7814037128 7 - free - (3.5K)
(...)
=> 34 7814037101 da7 GPT (3.6T)
34 262144 1 Microsoft reserved partition (128M)
262178 2014 - free - (1.0M)
264192 7813771264 2 Basic data partition (3.6T)
7814035456 1679 - free - (840K)
=> 63 15728577 da8 MBR (7.5G)
63 15165297 1 (null) [active] (7.2G)
15165360 563280 - free - (275M)
=> 0 15165297 da8s1 BSD (7.2G)
0 8129 - free - (4.0M)
8129 15155200 1 (null) (7.2G)
15163329 1968 - free - (984K)
5K)
=> 34 7814037101 da1 GPT (3.6T)
34 6 - free - (3.0K)
40 7814037088 1 D_Z300W3TK (3.6T)
7814037128 7 - free - (3.5K)
(...)
=> 34 7814037101 da7 GPT (3.6T)
34 262144 1 Microsoft reserved partition (128M)
262178 2014 - free - (1.0M)
264192 7813771264 2 Basic data partition (3.6T)
7814035456 1679 - free - (840K)
=> 63 15728577 da8 MBR (7.5G)
63 15165297 1 (null) [active] (7.2G)
15165360 563280 - free - (275M)
=> 0 15165297 da8s1 BSD (7.2G)
0 8129 - free - (4.0M)
8129 15155200 1 (null) (7.2G)
15163329 1968 - free - (984K)Пациент — da7 Я его проверял полным форматированием виндах, он несет виндовые разделы.
Проверяем еще раз — 7 раз отмерь, как говорится
nas4free: ~# gpart show -l da7 => 34 7814037101 da7 GPT (3.Точно он! Но не вредно проветить еще раз — смотрим физические диски
 6T)
34 262144 1 Microsoft reserved partition (128M)
262178 2014 - free - (1.0M)
264192 7813771264 2 Basic data partition (3.6T)
7814035456 1679 - free - (840K)
6T)
34 262144 1 Microsoft reserved partition (128M)
262178 2014 - free - (1.0M)
264192 7813771264 2 Basic data partition (3.6T)
7814035456 1679 - free - (840K)nas4free: ~# camcontrol devlist
{ATA ST4000DM000-1F21 CC52} at scbus0 target 4 lun 0 (pass0,da0)
{ATA ST4000DM000-1CD1 CC43} at scbus0 target 5 lun 0 (pass1,da1)
{ATA ST4000DM000-1F21 CC52} at scbus0 target 6 lun 0 (pass2,da2)
{ATA ST4000DM000-1F21 CC52} at scbus0 target 7 lun 0 (pass3,da3)
{ATA ST4000DM000-1F21 CC51} at scbus0 target 8 lun 0 (pass4,da4)
{ATA ST4000DM000-1F21 CC52} at scbus0 target 9 lun 0 (pass5,da5)
{ATA ST4000DM000-1F21 CC52} at scbus0 target 11 lun 0 (pass6,da6)
{ATA ST4000VX000-2AG1 CV11} at scbus0 target 15 lun 0 (pass7,da7)
{WDC WD20EARS-00MVWB0 51.0AB51} at scbus1 target 0 lun 0 (pass8,ada0)
{AHCI SGPIO Enclosure 1. 00 0001} at scbus2 target 0 lun 0 (ses0,pass9)
{SMI USB DISK 1100} at scbus3 target 0 lun 0 (pass10,da8)Видно, что da7 действительно другой модели. И вы ее должны знать, тк диск только что купили. 00 0001} at scbus2 target 0 lun 0 (ses0,pass9)
{SMI USB DISK 1100} at scbus3 target 0 lun 0 (pass10,da8)
00 0001} at scbus2 target 0 lun 0 (ses0,pass9)
{SMI USB DISK 1100} at scbus3 target 0 lun 0 (pass10,da8)NB. У меня диски сидят на SAS контроллере, поэтому они daX. У вас, скорее всего — на SATA, поэтому будут adaX, как мой WDC WD20EARS
NB Движок ЖЖ не выносит угловых скобок — выше я руками заменил их на фигурные
4) Теперь, трижды убедившись, что работаем именно над нужным диском (ошибка — потеряданных) подготавливаем его? создав раздел с нужным именем.
Сначала убиваем остатки zfs пула — если был когда то на этом диске
nas4free: ~# zpool labelclear da7 failed to read label from /dev/da7Как видим — следов zfs на диске не найдено
Теперь убиваем таблицу разделов на нем. Причем форсированно, так как таблица не пустая. И создаем новую.
nas4free: ~# gpart destroy -F da7 da7 destroyed nas4free: ~# gpart create -s GPT /dev/da7 da7 createdСоздаем раздел во весь диск с правильной меткой, взятой и серийного номера нашего диска.

Номер можно было посмотреть на этикетке (если забыли — не проблема — импортировать диски через вебгуй и в информационной секции посмотреть серийный номер — исполняем п 6 прямо сейчас, потом придется повторить тк диск еще не zfs)
и сразу проверяем что получилось
40 7814037088 da7 GPT (3.6T)
40 7814037088 1 D_WDH04N0T (3.6T)</pre>
5) Замена
Нам осталась всего одна команда до замены. Но процесс очень длительный и я
NB настоятельно рекомендую давать эту команду, когда NAS подключен к источнику беспербойного питания. Я сам этим пренебрег — и получил сеанс плясок с бубном и материал для отдельного поста 🙂
Итак готовы? Поехали!
Здесь длинное число 17637550633201844329 мы узнали в п 1. А имя раздела — только что задали сами.
nas4free: ~# zpool replace Pool 17637550633201844329 /dev/gpt/D_WDH04N0TНачинается длинный процесс. Его можно изредка посматривать и в гуе и в командной строке. Длительность зависит от скорости и объема дисков, заполнения пула, скорости процессора.
nas4free: ~# zpool status
pool: Pool
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Mon Sep 7 10:55:40 2020
20.0T scanned at 881M/s, 18.9T issued at 832M/s, 24.9T total
2.31T resilvered, 75.81% done, 0 days 02:06:43 to go
config:
NAME STATE READ WRITE CKSUM
Pool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gpt/D_Z300V843 ONLINE 0 0 0
gpt/D_Z300W3TK ONLINE 0 0 0
gpt/D_W300DZ5A ONLINE 0 0 0
gpt/D_W300E0RC ONLINE 0 0 0
gpt/D_Z30053GL ONLINE 0 0 0
gpt/D_Z300PRXX ONLINE 0 0 0
replacing-6 DEGRADED 0 0 0
17637550633201844329 UNAVAIL 0 0 0 was /dev/gpt/D_ZFN0PARZ
gpt/D_WDH04N0T ONLINE 0 0 0
gpt/D_Z300V7AV ONLINE 0 0 0
errors: No known data errors Наконец, процесс завершенnas4free: ~# zpool status pool: Pool state: ONLINE status: Some supported features are not enabled on the pool.
 The pool can
still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(7) for details.
scan: resilvered 3.05T in 0 days 14:15:38 with 0 errors on Tue Sep 8 01:11:18 2020
config:
NAME STATE READ WRITE CKSUM
Pool ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/D_Z300V843 ONLINE 0 0 0
gpt/D_Z300W3TK ONLINE 0 0 0
gpt/D_W300DZ5A ONLINE 0 0 0
gpt/D_W300E0RC ONLINE 0 0 0
gpt/D_Z30053GL ONLINE 0 0 0
gpt/D_Z300PRXX ONLINE 0 0 0
gpt/D_WDH04N0T ONLINE 0 0 0
gpt/D_Z300V7AV ONLINE 0 0 0
errors: No known data errors
The pool can
still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(7) for details.
scan: resilvered 3.05T in 0 days 14:15:38 with 0 errors on Tue Sep 8 01:11:18 2020
config:
NAME STATE READ WRITE CKSUM
Pool ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gpt/D_Z300V843 ONLINE 0 0 0
gpt/D_Z300W3TK ONLINE 0 0 0
gpt/D_W300DZ5A ONLINE 0 0 0
gpt/D_W300E0RC ONLINE 0 0 0
gpt/D_Z30053GL ONLINE 0 0 0
gpt/D_Z300PRXX ONLINE 0 0 0
gpt/D_WDH04N0T ONLINE 0 0 0
gpt/D_Z300V7AV ONLINE 0 0 0
errors: No known data errors
6) Идем в вебгуй и видим, что у нас диск сменился (кстати, он уже da6 — не обращаем внимание, эти номера зависят от погоды на Марсе и при подключении-отключении дисков менются)
чистить конфиг — потом трачу несколько минут на восстановления параметров дисков — какой у них APM, AAM и чтобы диски показывали SMART (под гаечным ключем это).
Вероятно, можно и не нажимать галочку — так ни разу и не проверил
Система говорит — все поняла, готова исполнить — то есть дает вам возможность еще раз все проверить
Соглашаемся и видим нормальную картину. Кстати, именно здесь можно смотреть серийные номера дисков
Замена жесткого диска входящего в ZFS Stripe
- Status
- Not open for further replies.
djonik1562
Explorer
- #1

У меня при первоначальной настройки были 2 жестких диска по 320 гб. Я из них сделал ZFS Stripe раздел. Получился общим объемом 574,5 Гб.
Вот скриншот
Теперь я хочу один жесткий диск заменить другим, более большим по размеру — 600гб’ным. Я правильно понял, что могу это сделать через команду Replace?
Вот тут
Т.е. я когда подключу этот новый жесткий диск, он тут будет в списке? И я смогу его таким образом заменить? А 320гб жесткий диск вытащить с сервера и вставить себе в комп?
djonik1562
Explorer
- #2
Только что получилось сделать какие запланировал. Все отработало хорошо, только долго, 3 с лишним часа.
Все отработало хорошо, только долго, 3 с лишним часа.
en.sem
Explorer
- #3
Спасибо за пост, будем знать.
- Status
- Not open for further replies.
Замена неисправного диска в Zpool
- Meandr21
- Russian — Русский
- Replies
- 3
- Views
- 4K
shubert
Что лучше RAID массив или ZFS массив
- djonik1562
- Russian — Русский
- Replies
- 17
- Views
- 3K
djonik1562
Клонировал диск на новый диск бОльшего размера. Как добавить в pool этого же диска его нераспределённое пространство?
Как добавить в pool этого же диска его нераспределённое пространство?
- denis_photographer
- Russian — Русский
- Replies
- 1
- Views
- 721
mav@
Проблемы с подключением второго диска
- Freewa1lker
- Russian — Русский
- Replies
- 1
- Views
- 771
mav@
Подскажите про Raid1 на FreeNAS 8. 0.4
0.4
- sergeyk2005
- Russian — Русский
- Replies
- 0
- Views
- 1K
sergeyk2005
Share:Facebook Twitter Reddit Pinterest Tumblr WhatsApp Email Share Link
Сбой замены диска во время nas4free ZFS resilver
ID# НАЗВАНИЕ_АТРИБУТА ЗНАЧЕНИЕ ФЛАГА ХУДШИЙ ТИП ПОРОГА ОБНОВЛЕНО WHEN_FAILED RAW_VALUE 5 Reallocated_Sector_Ct 0x0033 001 001 005 До отказа Всегда FAILING_NOW 0 197 Current_Pending_Sector 0x0022 001 001 000 Old_age Всегда - 2000
Мне кажется, у тебя лимон. Такие вещи случаются; RMA диск и получите замену. При недавней покупке, предположительно низком количестве часов работы и сбоях, указанных SMART, это не должно быть проблемой. Если реселлер поднимает шумиху по этому поводу, найдите другого реселлера и начните делать покупки у него.
Такие вещи случаются; RMA диск и получите замену. При недавней покупке, предположительно низком количестве часов работы и сбоях, указанных SMART, это не должно быть проблемой. Если реселлер поднимает шумиху по этому поводу, найдите другого реселлера и начните делать покупки у него.
1) Как отключить плохой диск? Так же, как я всегда делаю?
Вы всегда можете отключить диск, используя zpool offline . Просто будьте осторожны, чтобы оставаться выше порога избыточности пула. (Я не думаю, что ZFS позволит вам без принуждения удалить диск, из-за которого пул станет ниже порога избыточности, и может даже не сделать этого, но легко попасть в ловушку добавления -f не задумываясь о последствиях.)
2) Остановит ли «автономный режим» плохой диск процесс восстановления?
Так и должно быть, поскольку теперь нет необходимости выполнять повторное серебрение. Однако обратите внимание, что у вас не будет никакой избыточности, поэтому любые сбои (даже ошибки ввода-вывода на уровне сектора), пока пул находится в этой конфигурации, могут быть критическими.
3) После замены неисправного диска и выполнения команды zpool replace запустится ли resilver снова автоматически?
Вам может понадобиться zpool online новый диск, так как старый был взят offline , но я так не думаю. Концептуально, zpool replace — это то же самое, что и zpool attach , за которым следует zpool detach (но вы не можете присоединить/ отсоединить устройства в рейдз-вдеве).
Что касается ZFS, то для замены нового диска потребуется resilver, поэтому будет запущен resilver.
Тем не менее, эта часть вашего вопроса мне запомнилась:
четыре диска по 2 ТБ RaidZ1. Раз в год я делаю полную резервную копию, отключаю самый старый диск, заменяю его новым диском и запускаю команду «zpool replace mytank /dev/ada0»,
Я бы посоветовал вам не удалять старый диск перед установкой нового, особенно , если он работает сносно. (у меня диск начал извергать ошибки от простого думал размещения на нем ввода-вывода, и в таком случае разумным выбором может быть отключение или удаление проблемного диска.) Вместо этого подключите новый диск вместе со старым и
(у меня диск начал извергать ошибки от простого думал размещения на нем ввода-вывода, и в таком случае разумным выбором может быть отключение или удаление проблемного диска.) Вместо этого подключите новый диск вместе со старым и zpool replace . Делая это, вы получаете преимущество избыточности в пуле; затем, если какой-либо из других дисков столкнется с проблемой во время резервного копирования, шансы на то, что система сможет справиться с этим изящно и без потери данных, намного выше.
По крайней мере, очень , выполните очистку zpool до завершения в пуле непосредственно перед отключением заменяемого диска.
Понимание и устранение сбоя диска ZFS
Этот документ предназначен для администраторов и тех, кто знаком с вычислительными аппаратными платформами и концепциями хранения, такими как RAID. Если вы уже знакомы с общим процессом отказа, вы можете сразу перейти к замене диска и восстановлению пула.
Степени детализации
Когда диск выходит из строя или имеет ошибки, в SmartOS доступен большой объем данных журнала. Мы можем углубиться более подробно, чтобы помочь нам найти основную причину сбоя диска. В порядке убывания эти команды будут отображать причину сбоя диска в возрастающей степени детализации:
* `zpool status`
* `iostat -en`
* `iostat -En`
* `fmadm неисправен`
* `fmdump -et {n}дней`
* `fmdump -eVt {n}days` Команда zpool status предоставит нам общее представление о состоянии пула.
iostat предоставит нам высокоуровневое количество ошибок и особенности рассматриваемых устройств.
fmadm failed сообщит нам более конкретно, какое событие привело к сбою диска. ( fmadm также можно использовать для устранения временных ошибок; это, однако, выходит за рамки данного документа. Дополнительную информацию см. на справочной странице fmadm.) fmdump является еще более конкретным, предоставляя нам журнал событий сбоя за последние {n} дней. Эта информация часто не нужна для замены неисправных дисков, но если проблема более сложна, чем простой отказ одного диска, она чрезвычайно полезна для выявления основной причины.
Эта информация часто не нужна для замены неисправных дисков, но если проблема более сложна, чем простой отказ одного диска, она чрезвычайно полезна для выявления основной причины.
Общий процесс сбоя
ZFS не является первым компонентом в системе, который узнает о сбое диска. Когда диск выходит из строя, становится недоступным или имеет функциональную проблему, происходит следующий общий порядок событий:
- FMA обнаруживает неисправный диск и регистрирует его.
- Диск удален операционной системой.
- ZFS видит измененное состояние и реагирует, выдавая ошибку устройства.
Состояние устройства ZFS (и виртуального устройства)
Общее состояние пула, о котором сообщает zpool status , определяется совокупным состоянием всех устройств в пуле. Вот несколько определений, которые помогут внести ясность в этот документ.
ONLINE
Все устройства могут (и должны при оптимальной работе) находиться в состоянии ONLINE. Сюда входят пул, VDEV верхнего уровня (группы четности типа зеркало, рейдз{1,2,3}) и сами диски. Временные ошибки могут по-прежнему возникать без изменения состояния привода.
Сюда входят пул, VDEV верхнего уровня (группы четности типа зеркало, рейдз{1,2,3}) и сами диски. Временные ошибки могут по-прежнему возникать без изменения состояния привода.
OFFLINE
Только устройства нижнего уровня (диски) могут быть OFFLINE. Это ручное административное состояние, и исправные диски можно вернуть в оперативный режим и активировать в пуле.
UNAVAIL
Данное устройство (или VDEV) не может быть открыто. Если VDEV имеет значение UNAVAIL , пул будет недоступен или не сможет быть импортирован. НЕДОСТУПНЫЕ устройства также могут сообщать о НЕИСПРАВНОСТИ в некоторых сценариях. С точки зрения эксплуатации НЕДОСТУПНЫХ дисков примерно эквивалентны НЕИСПРАВНЫМ дискам.
DEGRADED
Произошла ошибка в устройстве, затронувшая все VDEV над ним. Пул по-прежнему работает, но в VDEV может быть потеряна избыточность.
УДАЛЕНО
Устройство было физически удалено во время работы системы. Обнаружение удаления устройства зависит от оборудования и может поддерживаться не на всех платформах.
FAULTED
Все компоненты (основные и резервные VDEV и диски) пула могут находиться в состоянии FAULTED. НЕИСПРАВНЫЙ компонент полностью недоступен. Серьезность ДЕГРАДИРОВАННОГО устройства во многом зависит от того, какое это устройство.
INUSE
Этот статус зарезервирован для запасных частей, которые использовались для замены неисправного диска.
Благодаря интегрированным характеристикам управления томами сбои на разных уровнях ZFS в разной степени влияют на состояние системы и общее состояние пула.
Сам пул
Это наихудший возможный сценарий, обычно возникающий в результате потери большего количества дисков из резервируемой группы, чем группа была рассчитана. В самом пуле нет понятия избыточности, вместо этого он полагается на целостность, которая должна поддерживаться с помощью отдельных RAIDZ или зеркальных VDEV. Например, потеря 2 дисков из RAIDZ приведет к тому, что и VDEV, и пул (VDEV верхнего уровня) станут НЕИСПРАВНЫМИ.
Следует отметить, что в этом случае все еще может быть возможно перевести пул в режим ONLINE в редких случаях, например, вызванных сбоем контроллера, когда большое количество дисков выходит из строя как второстепенная причина. В большинстве сценариев пул FAULTED не подлежит восстановлению, и его данные необходимо будет воссоздать из резервной копии.
Группы избыточности
Если в группе избыточности потеряно больше дисков, чем существует избыточность (2 из 2 дисков в зеркале, 3 диска из RAIDZ-2 или 2 из RAIDZ), избыточность станет НЕИСПРАВНОЙ. Состояние FAULTED на уровне VDEV приведет к состоянию FAULTED пула: каждую группу резервирования следует рассматривать как защиту верхнего уровня от потери данных, а сам пул служит для чередования данных по группам резервирования.
Отказ отдельного диска
Отказ отдельных дисков не представляет проблемы для пула или группы резервирования, если выходит из строя меньше дисков, чем существует резервирование. Например, 2 диска в RAIDZ-2 VDEV могут выйти из строя без каскадирования вверх.
Например, 2 диска в RAIDZ-2 VDEV могут выйти из строя без каскадирования вверх.
На высоком уровне замена конкретного неисправного диска включает следующие шаги:
- Идентификация
НЕИСПРАВНЫЙилиНЕДОСТУПНЫЙдиск -
zpool заменитьрассматриваемый диск - Подождите, пока закончится переосмысление
-
zpool удалитьзамененный диск -
zpool offlineудаленный диск - Выполнить любую необходимую очистку
Эти шаги могут несколько различаться в зависимости от конкретного уровня резервирования и конфигурации оборудования.
Подробные шаги по замене диска
Давайте начнем с примера сценария с несколькими неисправными и деградировавшими дисками:
[root@headnode (dc-example-1) ~]# zpool status
бассейн: зоны
состояние: ДЕГРАДАЦИЯ
статус: Одно или несколько устройств вышли из строя из-за постоянных ошибок.
Существует достаточное количество реплик, чтобы пул мог продолжать функционировать в
деградированное состояние.
Действие: замените неисправное устройство или используйте команду «zpool clear», чтобы пометить устройство.
отремонтировано.
сканирование: повторное серебро 7.64G за 0h6m с 0 ошибками в пятницу, 26 мая, 10:45:56 2017
конфигурация:
ИМЯ СОСТОЯНИЕ ЧТЕНИЕ ЗАПИСЬ CKSUM
зоны ДЕГРАДАЦИЯ 0 0 0
зеркало-0 ОНЛАЙН 0 0 0
c1t0d0 ОНЛАЙН 0 0 0
c1t1d0 ОНЛАЙН 0 0 0
зеркало-1 ДЕГРАДАЦИЯ 0 0 0
c1t2d0 ОНЛАЙН 0 0 0
c1t3d0 FAULTED 0 0 0 неисправность внешнего устройства
зеркало-2 ОНЛАЙН 0 0 0
c1t4d0 ОНЛАЙН 0 0 0
c1t5d0 ОНЛАЙН 0 0 0
зеркало-3 ДЕГРАДАЦИЯ 0 0 0
1173487 НЕДОСТУПЕН 0 0 0 был /dev/dsk/c1t16d0
c1t6d0 ОНЛАЙН 0 0 0
зеркало-4 ОНЛАЙН 0 0 0
c1t7d0 ОНЛАЙН 0 0 0
c1t8d0 ОНЛАЙН 0 0 0
зеркало-5 ДЕГРАДАЦИЯ 0 0 0
запасной-0 ДЕГРАДИРОВАННЫЙ 0 0 0
c1t10d0 УДАЛЕНО 0 0 0
c1t11d0 ОНЛАЙН 0 0 0
c1t9d0 FAULTED 0 0 0 неисправность внешнего устройства
зеркало-6 ОНЛАЙН 0 0 0
c1t12d0 ОНЛАЙН 0 0 0
c1t13d0 ОНЛАЙН 0 0 0
журналы
c1t14d0 ОНЛАЙН 0 0 0
запчасти
c1t15d0 INUSE используется в настоящее время
c1t16d0 ОНЛАЙН 0 0 0
ошибки: нет известных ошибок данных  Действие: замените неисправное устройство или используйте команду «zpool clear», чтобы пометить устройство.
отремонтировано.
сканирование: повторное серебро 7.64G за 0h6m с 0 ошибками в пятницу, 26 мая, 10:45:56 2017
конфигурация:
ИМЯ СОСТОЯНИЕ ЧТЕНИЕ ЗАПИСЬ CKSUM
зоны ДЕГРАДАЦИЯ 0 0 0
зеркало-0 ОНЛАЙН 0 0 0
c1t0d0 ОНЛАЙН 0 0 0
c1t1d0 ОНЛАЙН 0 0 0
зеркало-1 ДЕГРАДАЦИЯ 0 0 0
c1t2d0 ОНЛАЙН 0 0 0
c1t3d0 FAULTED 0 0 0 неисправность внешнего устройства
зеркало-2 ОНЛАЙН 0 0 0
c1t4d0 ОНЛАЙН 0 0 0
c1t5d0 ОНЛАЙН 0 0 0
зеркало-3 ДЕГРАДАЦИЯ 0 0 0
1173487 НЕДОСТУПЕН 0 0 0 был /dev/dsk/c1t16d0
c1t6d0 ОНЛАЙН 0 0 0
зеркало-4 ОНЛАЙН 0 0 0
c1t7d0 ОНЛАЙН 0 0 0
c1t8d0 ОНЛАЙН 0 0 0
зеркало-5 ДЕГРАДАЦИЯ 0 0 0
запасной-0 ДЕГРАДИРОВАННЫЙ 0 0 0
c1t10d0 УДАЛЕНО 0 0 0
c1t11d0 ОНЛАЙН 0 0 0
c1t9d0 FAULTED 0 0 0 неисправность внешнего устройства
зеркало-6 ОНЛАЙН 0 0 0
c1t12d0 ОНЛАЙН 0 0 0
c1t13d0 ОНЛАЙН 0 0 0
журналы
c1t14d0 ОНЛАЙН 0 0 0
запчасти
c1t15d0 INUSE используется в настоящее время
c1t16d0 ОНЛАЙН 0 0 0
ошибки: нет известных ошибок данных
Действие: замените неисправное устройство или используйте команду «zpool clear», чтобы пометить устройство.
отремонтировано.
сканирование: повторное серебро 7.64G за 0h6m с 0 ошибками в пятницу, 26 мая, 10:45:56 2017
конфигурация:
ИМЯ СОСТОЯНИЕ ЧТЕНИЕ ЗАПИСЬ CKSUM
зоны ДЕГРАДАЦИЯ 0 0 0
зеркало-0 ОНЛАЙН 0 0 0
c1t0d0 ОНЛАЙН 0 0 0
c1t1d0 ОНЛАЙН 0 0 0
зеркало-1 ДЕГРАДАЦИЯ 0 0 0
c1t2d0 ОНЛАЙН 0 0 0
c1t3d0 FAULTED 0 0 0 неисправность внешнего устройства
зеркало-2 ОНЛАЙН 0 0 0
c1t4d0 ОНЛАЙН 0 0 0
c1t5d0 ОНЛАЙН 0 0 0
зеркало-3 ДЕГРАДАЦИЯ 0 0 0
1173487 НЕДОСТУПЕН 0 0 0 был /dev/dsk/c1t16d0
c1t6d0 ОНЛАЙН 0 0 0
зеркало-4 ОНЛАЙН 0 0 0
c1t7d0 ОНЛАЙН 0 0 0
c1t8d0 ОНЛАЙН 0 0 0
зеркало-5 ДЕГРАДАЦИЯ 0 0 0
запасной-0 ДЕГРАДИРОВАННЫЙ 0 0 0
c1t10d0 УДАЛЕНО 0 0 0
c1t11d0 ОНЛАЙН 0 0 0
c1t9d0 FAULTED 0 0 0 неисправность внешнего устройства
зеркало-6 ОНЛАЙН 0 0 0
c1t12d0 ОНЛАЙН 0 0 0
c1t13d0 ОНЛАЙН 0 0 0
журналы
c1t14d0 ОНЛАЙН 0 0 0
запчасти
c1t15d0 INUSE используется в настоящее время
c1t16d0 ОНЛАЙН 0 0 0
ошибки: нет известных ошибок данных В приведенном выше примере есть два неисправных устройства и одно недоступное. С административной точки зрения эти два состояния функционально идентичны: вы хотите заменить их известными рабочими дисками.
С административной точки зрения эти два состояния функционально идентичны: вы хотите заменить их известными рабочими дисками.
ZFS будет знать, когда диск достигнет предела количества ошибок, и автоматически исключит его из пула. Это может произойти при любом типе отказа. Для оператора все, что имеет значение, это неисправность привода; производитель может определить, почему это произошло, когда вы RMA его.
Определите физическое местонахождение НЕИСПРАВНОГО или НЕДОСТУПНОГО диска
Используйте diskinfo для получения этой информации.
Например, zpool status показал c1t3d0 ошибка:
ИМЯ СОСТОЯНИЕ ЧТЕНИЕ ЗАПИСЬ CKSUM
зоны ДЕГРАДАЦИЯ 0 0 0
[...]
зеркало-1 ДЕГРАДАЦИЯ 0 0 0
c1t2d0 ОНЛАЙН 0 0 0
c1t3d0 FAULTED 0 0 0 ошибка внешнего устройства diskinfo -cH покажет, где находится c1t3d0 . Например:
$ diskinfo -cH === Вывод из 00000000-0000-0000-0000-003590935999 (имя хоста): <фрагмент> SCSI c1t4d0 HITACHI HUS723030ALS640 YHK16Z7G 2794,52 ГиБ ---- [0] Слот 02 SCSI c1t13d0 HITACHI HUS723030ALS640 YHJZMU7G 2794,52 ГиБ ---- [0] Слот 03 <фрагмент> SCSI c1t3d0 HITACHI HUS723030ALS640 YHK08JHG 2794.
 52 GiB ---- [1] Слот 05 <--- здесь
52 GiB ---- [1] Слот 05 <--- здесь Мигание рассматриваемого диска
Для мигания диска потребуется сторонний инструмент для контроллера(ов) хранения. В большинстве случаев, когда используются карты LSI, вам понадобится sas2ircu для Solaris. Расположение диска на других платформах здесь не рассматривается.
Установите sas2ircu в нужное место, а затем запустите его примерно так:
p /opt/custom/bin/sas2ircu 0 locate 1:5 ON
Приведенная выше команда зажжет светодиод на 5-м слоте на второй ([1]) расширитель через первый (0) HBA.
диск, о котором идет речь
Теперь, когда диск FAULTED/UNAVAIL определен для замены, существует несколько различных способов замены диска.
Замените дисковод запасным
Это предпочтительный метод, так как он менее подвержен человеческим ошибкам. Однако если в шасси нет места для запчастей, это будет невозможно.
zpool replace zone
Например, используя приведенный выше пример, мы могли бы сделать zpool replace zone c1t3d0 c1t16d0 , используя другой доступный резерв.
После того, как диск был заменен, и вы убедились, что диск резервируется ( zpool status ), неисправный диск в автономном режиме:
автономные зоны zpool c1t3d0
Даже в состоянии FAULTED диски должны быть отключены перед удалением.
Чтобы затем удалить отключенный диск:
zpool remove zone c1t3d0
При таком подходе к замене у вас также есть возможность дождаться завершения восстановления перед удалением диска. Однако будьте осторожны, чтобы это не привело к забытым неисправным дискам.
Продолжить и выполнить необходимую очистку.
Замените диск на другой в том же слоте (с помощью cfgadm)
Чтобы заменить диск в том же слоте, что и неисправный диск, его необходимо удалить из пула и деконфигурировать из ОС, прежде чем можно будет установить новый диск. вставлен.
Следующие шаги описывают общую процедуру:
- Offline
c1t3d0, заменяемый диск. Вы не можете деконфигурировать диск, который используется. - Используйте
cfgadm, чтобы определить диск, который нужно деконфигурировать, и деконфигурировать его (т. е.c1t3d0). Пул по-прежнему будет доступен, хотя он будет деградировать из-за того, что диск теперь находится в автономном режиме. - Физически заменить диск. Индикатор готовности к удалению должен загореться до того, как вы физически извлечете неисправный диск.
- Переконфигурировать
c1t3d0. - Подключите к сети новый
c1t3d0. - Запустите команду
zpool replace, чтобы заменить диск.
 Вы не можете деконфигурировать диск, который используется.
Вы не можете деконфигурировать диск, который используется.В следующем примере показаны шаги по замене диска в пуле хранения ZFS на диск в том же слоте.
# автономная зона zpool c1t3d0 # cfgadm | grep c1t3d0 диск sata1/3::dsk/c1t3d0 подключен настроен нормально # cfgadm -c деконфигурировать sata1/3 Отмените настройку устройства по адресу: /devices/pci@0,0/pci1022,7458@2/pci11ab,11ab@1:3.
 Эта операция приостановит работу на устройстве SATA.
Продолжить (да/нет)? да
# cfgadm | grep сата1/3
диск sata1/3 подключен, не настроен, все в порядке
<Физически заменить неисправный диск c1t3d0>
# cfgadm -c настроить sata1/3
# cfgadm | grep сата1/3
sata1/3::dsk/c1t9диск d0 подключен настроен нормально
# онлайн-зона zpool c1t3d0
# zpool заменить зону c1t3d0
#зона состояния zpool
бассейн: зоны
состояние: ОНЛАЙН
скраб: resilver завершен после 0h0m с 0 ошибками во вторник, 2 февраля, 13:17:32 2010
конфигурация:
ИМЯ СОСТОЯНИЕ ЧТЕНИЕ ЗАПИСЬ CKSUM
зоны ОНЛАЙН 0 0 0
зеркало-0 ОНЛАЙН 0 0 0
c1t0d0 ОНЛАЙН 0 0 0
c1t1d0 ОНЛАЙН 0 0 0
зеркало-1 ОНЛАЙН 0 0 0
c1t2d0 ОНЛАЙН 0 0 0
c1t3d0 ОНЛАЙН 0 0 0
зеркало-2 ОНЛАЙН 0 0 0
c1t4d0 ОНЛАЙН 0 0 0
c1t5d0 ОНЛАЙН 0 0 0
ошибки: Нет известных ошибок данных
Эта операция приостановит работу на устройстве SATA.
Продолжить (да/нет)? да
# cfgadm | grep сата1/3
диск sata1/3 подключен, не настроен, все в порядке
<Физически заменить неисправный диск c1t3d0>
# cfgadm -c настроить sata1/3
# cfgadm | grep сата1/3
sata1/3::dsk/c1t9диск d0 подключен настроен нормально
# онлайн-зона zpool c1t3d0
# zpool заменить зону c1t3d0
#зона состояния zpool
бассейн: зоны
состояние: ОНЛАЙН
скраб: resilver завершен после 0h0m с 0 ошибками во вторник, 2 февраля, 13:17:32 2010
конфигурация:
ИМЯ СОСТОЯНИЕ ЧТЕНИЕ ЗАПИСЬ CKSUM
зоны ОНЛАЙН 0 0 0
зеркало-0 ОНЛАЙН 0 0 0
c1t0d0 ОНЛАЙН 0 0 0
c1t1d0 ОНЛАЙН 0 0 0
зеркало-1 ОНЛАЙН 0 0 0
c1t2d0 ОНЛАЙН 0 0 0
c1t3d0 ОНЛАЙН 0 0 0
зеркало-2 ОНЛАЙН 0 0 0
c1t4d0 ОНЛАЙН 0 0 0
c1t5d0 ОНЛАЙН 0 0 0
ошибки: Нет известных ошибок данных Обратите внимание, что предыдущий вывод zpool может отображать как новый, так и старый диски под замещающим заголовком. Например:
Например:
вместо DEGRADED 0 0 0 c1t3d0s0/o ОШИБКА 0 0 0 c1t3d0 ONLINE 0 0 0
Это нормально и не должно вызывать беспокойства. Статус , заменяющий , останется до завершения замены.
Замена диска в том же слоте (с devfsadm)
devfsadm -Cv также можно использовать вместо вышеуказанных команд cfgadm для восстановления файлов устройства.
Этот процесс является более простым, чем описанный выше процесс с использованием cfgadm, и не требует установки нового сменного диска в том же слоте.
- отключен неисправный диск
- физически удалить неисправный диск
- запустите
devfsadm -Dv, чтобы деконфигурировать старый диск - вставить новый диск
- запустить
devfsadm -Dvеще раз, чтобы настроить новый диск. - онлайн диск как указано выше
- заменить диск (также как указано выше)
Выполните любую необходимую очистку
Выключите индикатор уведомления диска
При выключении индикатора уведомления диска на корпусе обязательно используйте те же идентификаторы слота и корпуса, что и при его включении.
'''$ p /opt/custom/bin/sas2ircu 0 locate 1:5 OFF'''
Запасная замена
Обязательно отследите и извлеките неисправный диск и замените запасной в пуле, если он есть был использован.
Проверка
Используйте команду zpool status , чтобы убедиться, что:
- Статус пула ONLINE
- Имеется один или несколько запасных дисков (если они используются в вашей среде).
- Ожидаемое количество устройств журнала
Зеркала — особые замечания
Управление зеркалами отличается от работы с элементами RAIDZ{123}, поскольку, в отличие от RAIDZ, здесь нет четности. Из-за этого зеркальные элементы могут быть «отсоединены» там, где вы обычно удаляете их в RAIDZ.
Зоны отсоединения zpool c1t3d0
Отсоединение устройства возможно только при наличии действительных реплик данных.
Работа с запасными частями
Диски горячей замены можно добавлять с помощью команды zpool add и удалять с помощью команды zpool remove .
zpool добавить зоны <диск> zpool remove zone
После инициирования резервной замены в конфигурации создается новый «запасной» VDEV, который будет оставаться там до тех пор, пока исходное устройство не будет заменено. В этот момент «горячий» резерв снова становится доступным, если другое устройство выйдет из строя.
Выполняемую замену можно отменить, отсоединив горячую замену. Это можно сделать только в том случае, если исходное неисправное устройство еще не было отсоединено. Если диск, который он заменяет, был удален, то его место в конфигурации занимает «горячий» резерв.
Зоны отключения zpool
Запасные части не могут заменить устройства журналирования.
Работа с журналами ZIL
Устройства журналов ZIL представляют собой особый случай в ZFS. Они «передают» синхронную запись в пул: более медленные синхронизирующие записи помещаются в пул и эффективно кэшируются в быстром временном хранилище, чтобы позволить потребителям хранилища продолжать работу, с механизмами ZIL для сброса транзакций из журнала в постоянное хранилище в пакетах.
Это фактически делает ZIL опасной единственной точкой отказа для пула в определенных ситуациях. Например, если одно устройство журнала выходит из строя, оно фактически обрезает середину конвейера данных, теряя при этом любые транзакции в процессе: данные, которые уже были записаны в пул и представлены в журнале, но еще не зафиксированы в постоянном хранилище, будет потерян.
Настоятельно рекомендуется запускать зеркальные устройства журналов ZIL, поскольку они устраняют эту единственную точку отказа. Работа с зеркалами журналов ZIL контекстуально идентична другим зеркалам VDEV: вы используете detach для удаления члена зеркала.
Если имеется только одно устройство журнала ZIL, оно удаляется, а не отсоединяется:
zpool remove zone c1t3d0
Обратите внимание, что удаление журнала ZIL является потенциально разрушительным действием и должно выполняться только во время низкое окно обслуживания ввода-вывода.
Работа с L2 ARC
Устройства L2 ARC можно добавить в пул, чтобы обеспечить вторичное кэширование ARC для первичных и метаданных. Независимо от того, добавлено ли одно или несколько устройств L2 ARC, они будут использоваться более «чередующимся» образом. Это не зеркальные устройства, поскольку данные, которые они содержат, являются временными.
Независимо от того, добавлено ли одно или несколько устройств L2 ARC, они будут использоваться более «чередующимся» образом. Это не зеркальные устройства, поскольку данные, которые они содержат, являются временными.
Чтобы добавить кеш-устройство:
zpool add zone cache
Замена во многом аналогична зеркалам: отдельные устройства могут быть сразу удалены в случае отказа и добавлены новые.
Одно существенное предостережение относительно L2ARC заключается в том, что эти устройства не являются свободными для системы: их метаданные хранятся в первичном ARC, который, в свою очередь, связан с системной памятью. При добавлении устройств L2ARC необходимо учитывать использование памяти.
Ошибки контрольной суммы
Ошибки контрольной суммы могут возникать временно на отдельных дисках или на нескольких дисках. Наиболее вероятными виновниками являются битовая гниль или временные ошибки подсистемы хранения — такие странности, как потеря сигнала из-за солнечных вспышек и так далее.
В ZFS они не представляют особого беспокойства, но необходима некоторая степень профилактического обслуживания для предотвращения накопления сбоев.
Время от времени вы можете видеть вывод zpool status , подобный этому:
ИМЯ СОСТОЯНИЕ ЧТЕНИЕ ЗАПИСЬ CKSUM
зоны ОНЛАЙН 0 0 0
зеркало-0 ОНЛАЙН 0 0 0
c1t0d0 ОНЛАЙН 0 0 23
c1t1d0 ONLINE 0 0 0 Обратите внимание на «23» в столбце CKSUM.
Если это число значительно велико или быстро растет, накопитель, вероятно, находится в состоянии, предшествующем отказу, и вскоре выйдет из строя, а в противном случае (в данном случае) это может поставить под угрозу избыточность VDEV.
Следует отметить, что ошибки контрольной суммы на отдельных дисках время от времени являются нормальным и ожидаемым поведением (если не оптимальным). Как и многие ошибки на отдельных дисках, которые вот-вот выйдут из строя. Многие сбои контрольной суммы на нескольких дисках могут указывать на серьезную проблему с подсистемой хранения: поврежденный кабель, неисправный HBA или даже проблемы с питанием. Если это замечено, рассмотрите возможность обращения в службу поддержки за помощью в идентификации.
Если это замечено, рассмотрите возможность обращения в службу поддержки за помощью в идентификации.
Совет. Вы можете проверить работоспособность пула во всем центре обработки данных с головного узла с помощью: sdc-oneachnode -c 'zpool status -x'
Resilver
zpool resilver — это операция по восстановлению четности в пуле из-за ухудшения состояния устройства (например, диск может временно исчезнуть и его необходимо «наверстать упущенное») или только что замененное устройство. Другими словами, перемещение данных с одного устройства (испорченного/старого диска) на новое устройство.
Одновременно в нескольких VDEV может выполняться несколько операций восстановления.
Обратите внимание, что резервные копии могут снизить производительность в загруженном пуле. Соответственно планируйте прогнозы производительности.
Ресилверы работают автоматически. Они не могут (и не должны) прерываться за исключением физического удаления или отказа устройства.
Scrub
Scrub проверяет все данные в указанных пулах, чтобы убедиться, что они правильно вычисляют контрольные суммы. Для реплицированных (зеркальных или рейдовых) устройств ZFS автоматически восстанавливает любые повреждения, обнаруженные во время очистки. Команда zpool status сообщает о ходе очистки и резюмирует результаты очистки после ее завершения.
Чтобы запустить скраб:
зоны очистки zpool
Чтобы остановить очистку:
зоны очистки zpool -s
Если zpool resilver находится в процессе, его нельзя будет запустить до завершения восстановления.
Параллелизм очистки и восстановления
Очистка и повторное преобразование — очень похожие операции. Разница заключается в том, что при повторном серебрении проверяются только те данные, которые ZFS считает устаревшими (например, при подключении нового устройства к зеркалу или замене существующего устройства), а при очистке проверяются все данные для обнаружения скрытых ошибок из-за сбоев оборудования или диска.