
Самые распространенные ошибки файла robots.txt
Представляем вашему вниманию наиболее распространенные ошибки файла robots.txt, которые допускают вебмастеры в своей работе.
Перечень ошибок, возникающих при анализе файла robots.txt.
| Ошибка | Расширение Яндекса | Описание |
|---|---|---|
| Правило начинается не с символа / и не с символа * | Да | Правило может начинаться только с символа / или *. |
| Найдено несколько правил вида User-agent: * | Нет | Допускается только одно правило такого типа. |
| Найдено несколько директив Host | Да | Допускается только одна директива Host. |
| Превышен допустимый размерrobots.txt | Да | Количество правил в файле превышает 2048. |
| Перед правилом нет директивыUser-agent. | Нет | Правило должно всегда следовать за директивой User-agent. Возможно, файл содержит пустую строку после User-agent. |
| Слишком длинное правило | Да | Правило превышает допустимую длину (1024 символа). |
| Некорректное имя главного зеркала сайта | Да | Имя главного зеркала сайта в директиве Host содержит синтаксическую ошибку. |
| Некорректный формат URL файла Sitemap | Да | В качестве URL файла Sitemap должен быть указан полный адрес, включая протокол. Например,https://www.example.com/sitemap.xml |
| Некорректный формат директивы Crawl-delay | Да | Время в директиве Crawl-delay указано неверно. |
| Найдено несколько директив Crawl-delay | Да | Допускается только одна директива Crawl-delay. |
| Некорректный формат директивы Clean-param | Да | В директиве Clean-param указывается один или несколько параметров, которые робот будет игнорировать, и префикс пути. Параметры перечисляются через символ & и отделяются от префикса пути пробелом. |
Предупреждения
Перечень предупреждений, возникающих при анализе файла robots.txt.
| Предупреждение | Расширение Яндекса | Описание |
|---|---|---|
| Возможно, был использован недопустимый символ | Да | Обнаружен спецсимвол, отличный от * и $. |
| Обнаружена неизвестная директива | Да | Обнаружена директива, не описанная в правилах использования robots.txt. Возможно, эта директива используется роботами других поисковых систем. |
| Синтаксическая ошибка | Да | Строка не может быть интерпретирована как директиваrobots.txt. |
| Неизвестная ошибка | Да | При анализе файла возникла неизвестная ошибка. Обратитесь в службу поддержки. |
Ошибки проверки URL
Перечень ошибок проверки URL в Анализаторе robots.txt.
| Ошибка | Описание |
|---|---|
| Синтаксическая ошибка | Ошибка синтаксиса URL. |
| Этот URL не принадлежит вашему домену | Заданный URL не принадлежит сайту, для которого производится анализ файла. Возможно, вы указали адрес одного из зеркал вашего сайта или допустили ошибку в написании имени домена. |
Также стоит прочитать
Файл robots.txt – правила индексации, как создать, закрыть и проверить на ошибки
1 год назад
У вас больше контроля над поисковыми системами, чем вы думаете. Это правда! Вы можете манипулировать тем, кто сканирует и индексирует ваш сайт, вплоть до отдельных страниц. Чтобы управлять этим, вам нужно будет использовать файл robots.txt.
Robots.txt — это простой текстовый файл, который находится в корневом каталоге вашего сайта. Он сообщает роботам поисковых систем о страницах, которые нужно сканировать, и которые не нужно посещать.
Хотя это не совсем то, что вам нужно. Вы наверняка поняли, что это довольно мощный инструмент, и позволит вам представить свой сайт поисковикам как вы хотите. Поисковые системы – это судьи с суровым характером, поэтому важно произвести на них большое впечатление. Robots.txt при правильном использовании может улучшить частоту сканирования, что может повлиять на ваши усилия в SEO.
Итак, как его создать? Как им пользоваться? Чего нужно избегать? Прочтите эту статью, чтобы найти ответы на все эти вопросы.
Что такое файл Robots.txt?
Раньше, когда интернет был просто ребенком, способным делать великие вещи, разработчики придумали способ ползать и индексировать свежие страницы в интернете. Они назвали это «роботами» или «пауками».
Иногда эти маленькие ребята блуждали по сайтам, которые не предназначались для обхода и индексирования, например, сайты, которые проходят техническое обслуживание. Создатель первой в мире поисковой системы, Aliweb, рекомендовал решение – всевозможный ориентир, которому должны следовать все роботы.
Это решение было окончательно доработано в июне 1994 года группой интернет-специалистов по технике безопасности и названо «Протокол исключения роботов».
Файл robots.txt — это реализация этого протокола. Протокол определяет правила, которыми должен следовать каждый настоящий робот. Включая ботов Яндекс и Google. Некоторые незаконные роботы, например, вредоносное ПО, шпионские программы и т.п., по определению, действуют вне этих правил. Вы можете заглянуть за завесу любого веб-сайта, введя любой URL-адрес и добавив: /robots.txt в конце.
Пример файла:
User-agent: *
Disallow: /index.php
Где найти файл Robots.txt
Ваш файл robots.txt будет храниться в корневом каталоге вашего сайта. Чтобы найти его, зайдите на FTP, и вы сможете найти файл в своем каталоге public_html.
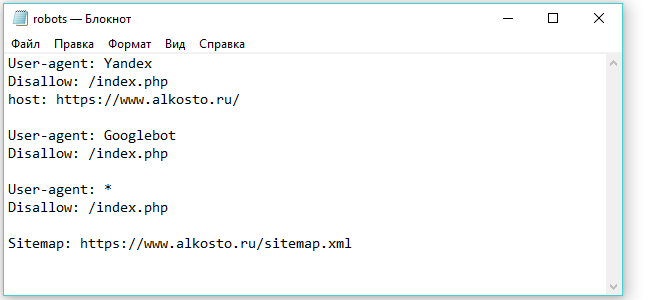
В нем нет ничего такого, чтобы он много весил, вероятно, всего несколько сотен байт. После того как вы откроете файл в текстовом редакторе, вы увидите что-то вроде этого:
Если вы не можете найти файл в корневом каталоге вашего сайта, тогда вам придется создавать свой собственный.
Как создать файл Robots.txt
Robots.txt — это базовый текстовый файл, поэтому его просто создать. Все, что вам понадобится, это простой текстовый редактор, например, «Блокнот». Откройте лист и сохраните пустую страницу как «robots.txt».
Теперь войдите на хостинг и найдите папку public_html для доступа к корневому каталогу сайта. Как только она будет открыта, перетащите файл в неё.
Наконец, необходимо убедиться, что установлены правильные разрешения для файла. В принципе, как владелец, вы должны иметь права на запись, чтение и редактирование файла, но никто другой не должен иметь таких прав. Файл должен отображать код разрешения «0644».
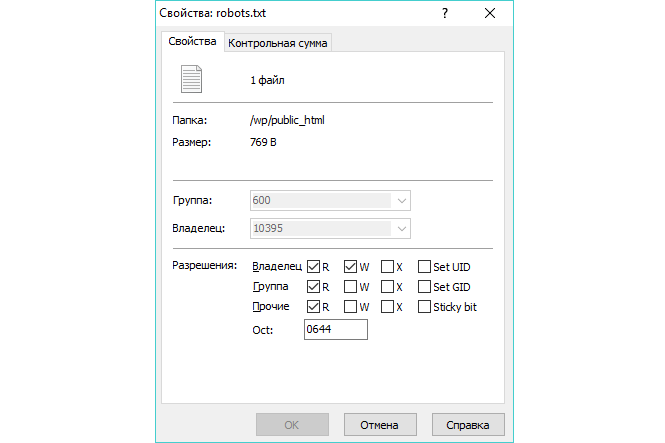
Если права отличаются от «0644», вам нужно будет изменить их, поэтому нажмите на файл и выберите «свойства». Вуаля! У вас есть файл Robots.txt.
Синтаксис Robots.txt
Файл robots.txt состоит из нескольких разделов «директив», каждый из которых начинается с указания User-agent. User-agent — это имя конкретного робота, к которому обращается код.
Доступны два варианта:
- Вы можете использовать звездочку (*) для одновременного обращения ко всем поисковым системам.
- Вы можете обращаться к конкретным поисковым системам по отдельности.
Когда бот готов для обхода веб-сайта, он будет обращаться к блокам, которые вызывают его.
Вот пример:
User-agent: Yandex
Disallow: /index.phpUser-agent: Googlebot
Disallow:User-agent: *
Disallow: /
Директива User-Agent
Первая строка в каждом блоке — это «user-agent», в котором указывается конкретный бот. «User-agent» будет соответствовать определенному имени бота, например:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)Итак, если вы хотите сказать роботу Google что делать, например, начните с:
User-agent: Googlebot
Поисковые системы всегда стараются точно определить конкретные директивы, которые наиболее тесно связаны с ними. Так, например, если у вас есть две директивы, одна для Googlebot и одна для Yandex. Бот, который приходит вместе с user-agent «Yandex», будет следовать его инструкциям, тогда как бот «Googlebot» пройдет через это и отправится на поиски более конкретной директивы. В большинстве поисковых систем есть несколько разных ботов, вот списки ботов Яндекса и Google.
Директива Host
Директива host до недавнего времени поддерживалась только Яндексом (было объявлено о прекращении поддержки), хотя существуют некоторые предположения, что Google поддерживал или поддерживает её. Эта директива позволяет вебмастеру решить показывать www перед URL-адресом. Для этого используется этот блок:
Host: site.ru
Так как официально обе поисковые системы отказались от использования директивы Host, то для указания главного зеркала рекомендуется использовать 301 редирект.
Директива Disallow
Более конкретно рассмотрим эту директиву чуть позже. Вторая строка в блоке директив — Disallow. Вы можете использовать её, чтобы указать, какие разделы сайта не должны быть доступны ботами. Пустое значение Disallow означает, что сайт является доступным для всех, и боты могут ходить где угодно.
Директива Sitemap
Используя директиву sitemap, вы указываете поисковым системам, где можно найти файл Sitemap в формате XML. Однако, наиболее правильным было бы отправить каждый файл в формате XML в поисковые системы через специальные инструменты в панели веб-мастеров поисковых систем. Это связано с тем, что в панели вы можете узнать много ценной информации о вашем веб-сайте.
Однако, если у вас мало времени, директива sitemap является жизнеспособной альтернативой.
Директива Crawl-Delay
Google, Yahoo, Bing и Яндекс могут немного нагрузить ваш сайт, когда дело доходит до обхода, но они действительно реагируют на директиву crawl-delay, которая сдерживает их некоторое время. Допишите эту строку к вашему блоку:
Crawl-delay: 10
Это означает, что вы можете заставить поисковые системы ждать десять секунд, прежде чем снова обходить сайт, т.е. поисковый робот делает паузу между обходами вашего сайта.
Зачем использовать Robots.txt
Теперь вы знаете об основных принципах и о том, как использовать несколько директив, вы можете собрать свой файл. Robots.txt не является существенным элементом успешного веб-сайта, на самом деле ваш сайт все еще может правильно функционировать и занимать хорошие позиции без него.
Однако есть несколько ключевых преимуществ, о которых вы должны знать:
- Приватная информация: запрещайте ботам посещать ваши личные данные, это значительно усложнит их индексирование и появление в открытом доступе в поисковой выдаче.
- Держите ресурсы под контролем: каждый раз, когда бот сканирует ваш сайт, он тратит пропускную способность и другие ресурсы сервера. Например, сайты с тоннами контента и большим количеством страниц, например, на сайтах электронной коммерции могут иметь тысячи страниц, и эти ресурсы могут быть быстро истощены. Вы можете использовать robots.txt, чтобы затруднить доступ ботов к отдельным скриптам и изображениям; это сохранит ценные ресурсы сервера для реальных посетителей.
Вы, конечно, хотите, чтобы поисковые системы находили путь к наиболее важным страницам вашего сайта. Вы можете контролировать, какие страницы дать в приоритет поисковикам, но не забудьте полностью блокировать от них определенные страницы.
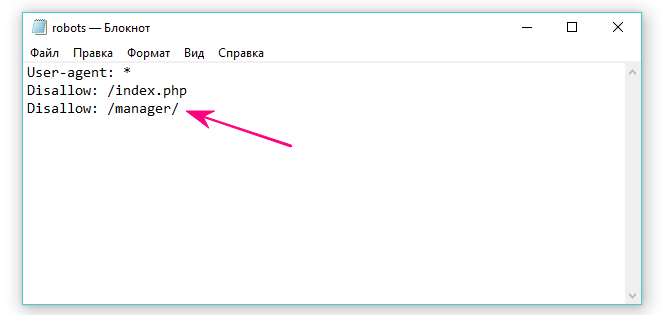
Например, если мы посмотрим на файл robots, мы увидим, что URL-адрес www.alkosto.ru/manager/ не разрешен к индексации.
Поскольку эта страница сделана только для того, чтобы мы вошли в панель управления системой, нет смысла позволять ботам тратить свое время и энергию на её сканирование.
Noindex
Итак, мы говорили о директиве Disallow, как будто это ответ на все наши проблемы. Тем не менее, это не всегда препятствует индексированию страницы. Вы можете потенциально запретить страницу к обходу, и она все равно может оказаться где-то в результатах поисковой выдачи. Нам поможет тэг noindex. Он работает в тандеме с командой disallow, чтобы боты не обошли определенные страницы и не проиндексировали их.
Вот пример того, как это делается:
Disallow: /page/
Noindex: /page/
После того, как вы указали эти инструкции, выбранная страница не окажется в результатах поиска … или, мы просто так думаем. Экспериментальные результаты разнятся на этот счет, каким-то сайтам это помогало, а каким-то нет.
Что следует избегать
Мы немного поговорили о том, что вы можете сделать, и о том, как вы можете управлять своим robots.txt, но мы немного углубимся в каждый пункт этого раздела и объясним, как каждый параметр может превратиться в катастрофу для вашего SEO, если не используется должным образом.
Чрезмерное использование Crawl-Delay
Мы уже объяснили, что делает директива Crawl-Delay с задержкой, но вы должны избегать слишком частого ее использования, так как вы ограничиваете роботов сканировать страницы вашего сайта. Для некоторых сайтов это неплохо, но, если у вас есть огромный веб-сайт, вы можете тем самым выстрелить себе в ногу и препятствовать хорошему ранжированию и постоянному обновлению вашего сайта поисковыми системами.
Использование для предотвращения индексирования
Мы уже немного рассмотрели этот момент. Как уже было сказано, Disallow для страницы — лучший способ попытаться не допустить, чтобы боты сканировали ее напрямую. Но это не сработает в следующих случаях:
- Если страница была связана с внешним источником (например, ссылки на сторонних ресурсах), боты все равно будут попадать на страницу и индексировать ее.
- Нелегальные боты будут игнорировать robots.txt и индексировать контент.
Использование для защиты приватной информации
Некоторые личные материалы, такие как PDF-файлы или страницы с благодарностью, могут индексироваться, даже если вы запретили ботам это делать. Один из лучших методов, которому следует придерживаться помимо директивы disallow, заключается в том, чтобы поместить всю вашу личную информацию за регистрацию.
Конечно, это добавляет трудностей для ваших посетителей (регистрация), но ваш контент останется в безопасности.
Использование для скрытия повторяющегося содержимого
Дублируемый контент иногда является необходимым злом — например, страницы для печати. Однако поисковые системы достаточно умны и знают, когда вы пытаетесь скрыть что-то. Вот три способа решения такого рода проблемы:
- Переписывайте контент. Создание захватывающего и полезного контента побудит поисковые системы просматривать ваш сайт в качестве надежного источника информации.
- 301 редирект — сообщает поисковым системам, что страница перенесена в другое место. Добавьте 301 на страницу с дублирующимся контентом и переадресуйте посетителей на исходный контент на сайте.
- Rel = «canonical» — это тег, который сообщает о первоначальном местоположении дублированного контента. Это особенно важно для веб-сайта электронной коммерции, где CMS часто генерирует повторяющиеся версии одного и того же URL-адреса.
Момент истины: проверка файла Robots.txt
Настало время проверить ваш файл, чтобы убедиться, что все работает так, как вы этого хотите. В Инструментах для веб-мастеров Яндекс и Google есть раздел проверки robots.txt.
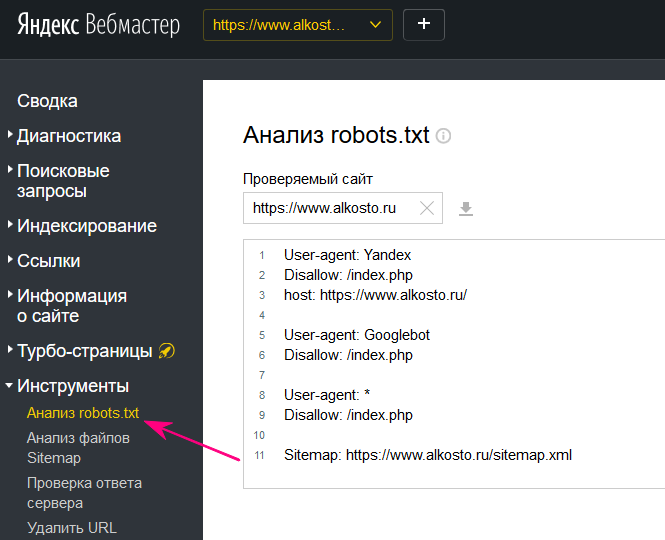
Если проверка дала положительный результат, то вы получили полностью работоспособный файл robots.txt. Создание правильного файла robots.txt, означает, что вы улучшаете своё SEO и не позволяете поисковым системам показывать в результатах выдачи ненужные страницы.
Если у вас возникли трудности в оптимизации или необходимо продвижение сайта, то наши специалисты обязательно вам помогут. Звоните!
Robots.txt и его оптимизация и поиск ошибок. 100 советов от профи.
3. Перепутанные инструкции
Одна из самых распространённых ошибок в robots.txt – перепутанные между собой инструкции. Например:
Disallow: Yandex
Правильно писать вот так:
User-agent: Yandex
Disallow: /
4. Указание нескольких каталогов в одной инструкции disallow
Многие владельцы сайтов пытаются поместить все запрещаемые к индексации каталоги в одну инструкцию Disallow:
Disallow: /css/ /cgi-bin/ /images/
Такая запись нарушает стандарт, и невозможно угадать, как ее обработают разные роботы. Правильно надо писать так:
Disallow: /css/
Disallow: /cgi-bin/
Disallow: /images/
5. Пустая строка в user-agent
Так неправильно:
User-agent:
Disallow:
Так правильно:
User-agent: *
Disallow:
6. Зеркала сайта и URL в директиве Host
 Чтобы указать, какой сайт является главным, а какой — зеркалом (дублем), для Google используются 301 редирект и внесение информации в Google Search Console, а для Яндекса — директива host. Правда эта директива была отменена весной 2018 года, но многие продолжают её использовать.
Чтобы указать, какой сайт является главным, а какой — зеркалом (дублем), для Google используются 301 редирект и внесение информации в Google Search Console, а для Яндекса — директива host. Правда эта директива была отменена весной 2018 года, но многие продолжают её использовать.
С точки зрения поисковых систем http://www.site.ru , http://site.ru , https://www.site.ru и https://site.ru — четыре разных сайта. Несмотря на то что визуально для людей это одно и то же, поисковая система принимает решение самостоятельно, какой сайт отображать в результатах выдачи, а какой — нет. Казалось бы, в чем проблема? Их может быть несколько:
- поисковик Яндекс принял решение оставить у себя в индексе сайт с www, a Google решил оставить без www;
- ссылки с других ресурсов, которые имеют влияние на ранжирование, ссылаются на сайт с www, а в индексе поисковика остался сайт без www.
Чтобы таких проблем не возникло, на этапе технической оптимизации принудительно сообщаем поисковикам, какой вариант сайта — с www или без, с https или без него — для нас предпочтительнее, и избавляем себя от возможных проблем в дальнейшем.
Итак, для протокола http следует писать без аббревиатуры протокола передачи гипертекста, то есть без http:// и без закрывающего слеша /
Неправильно:
User-agent: Yandex
Disallow: /cgi-bin
Host: http://www.site.ru/
Правильно:
User-agent: Yandex
Disallow: /cgi-bin
Host: www.site.ru
Однако, если ваш сайт с https, то правильно писать вот так:
User-agent: Yandex
Disallow: /cgi-bin
Host:https:// www.site.ru
Директива host Является корректной только для робота Яндекса, межсекционной. Поэтому, желательно, секцию Яндекса описывать после всех других секций.
Напомню еще раз, директива host стала необязательной. Теперь главное зеркало можно установить в Яндекс вебмастере.
7. Использование в Disallow символов подстановки
Иногда хочется написать что-то вроде:
User-agent: *
Disallow: file*.html
для указания все файлов file1.html, file2.html, file3.html и т.д. На сегодняшний день — это вполне допустимо как для робота Яндекс так и Google.
Более того, Яндекс по умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *. Пример:
User-agent: Yandex
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с ‘/cgi-bin’
Disallow: /cgi-bin # то же самое
Чтобы отменить * на конце правила, можно использовать спецсимвол $, например:
User-agent: Yandex
Disallow: /example$ # запрещает ‘/example’,
# но не запрещает ‘/example.html’
User-agent: Yandex
Disallow: /example # запрещает и ‘/example’,
# и ‘/example.html’
Спецсимвол $ не запрещает указанный * на конце, то есть:
User-agent: Yandex
Disallow: /example$ # запрещает только ‘/example’
Disallow: /example*$ # так же, как ‘Disallow: /example’
# запрещает и /example.html и /example
8. Редирект на страницу 404-й ошибки
Довольно часто, на сайтах без файла robots.txt при запросе этого файла делается переадресация на другую страницу.
Иногда такая переадресация происходит без отдачи статуса 404 Not Found. Пауку самому приходится разбираться, что он получил – robots.txt или обычный html-файл. Эта ситуация вряд ли создаст какие-то проблемы, но все-таки лучше всегда класть в корень сайта пустой файл robots.txt.
9. Заглавные буквы — это плохой стиль
USER-AGENT: GOOGLEBOT
DISALLOW:
Хотя по стандарту robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий. Кроме того, написание robots.txt сплошь заглавными буквами считается плохим стилем.
10. Перечисление всех файлов
Еще одной ошибкой является перечисление каждого файла в директории:
User-agent: *
Disallow: /AL/Alabama.html
Disallow: /AL/AR.html
Disallow: /Az/AZ.html
Disallow: /Az/bali.html
Disallow: /Az/bed-breakfast.html
Вместо этого можно просто закрыть от индексации директорию целиком:
User-agent: *
Disallow: /AL/
Disallow: /Az/
11.Использование дополнительных директив в секции *
Некоторые роботы могут неправильно отреагировать на использование дополнительных директив. Это значит, что не стоит использовать дополнительные директивы в секции «*».
То есть рекомендуется создавать специальные секции для нестандартных директив, таких как host.
Так неправильно:
User-agent: *
Disallow: /css/
Host: www.example.com
А вот так – правильно:
User-agent: *
Disallow: /css/
User-agent: Yandex
Disallow: /css/
Host: www.example.com
12. Отсутствие инструкции Disallow
Даже если мы хотим просто использовать дополнительную директиву и не хотим ничего запрещать, лучше всего указать пустой Disallow. По стандарту инструкция Disallow является обязательной, и робот может «неправильно вас понять».
Так неправильно:
User-agent: Yandex
Host: www.example.com
Так правильно:
User-agent: Yandex
Disallow:
Host: www.example.com
13. Отсутствие слешей при указании директории
Как в этом случае поступит робот?
User-agent: Yandex
Disallow: john
По стандарту, он не будет индексировать файл с именем «john» и директорию с именем «john». Для указания только директории надо писать так:
User-agent: Yandex
Disallow: /john/
14. Неправильный HTTP-заголовок
Сервер должен возвращать в HTTP-заголовке для robots.txt «Content-Type: text/plain» а, например, не «Content-Type: text/html». Неправильный заголовок может привести к тому, что некоторые роботы не обработают файл.
15. Логические ошибки
 Зачастую при разветвленной структуре сайта возникают логические ошибки в определении того, что и как нужно блокировать от индексации.
Зачастую при разветвленной структуре сайта возникают логические ошибки в определении того, что и как нужно блокировать от индексации.
Для Google: На уровне группы, в частности для директив allow и disallow, самое строгое правило, учитывающее длину записи [путь], будет важнее менее строгого и более короткого правила. Порядок очередности правил с подстановочными знаками не определен.
Яндекс: Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом.
Исходный robots.txt:
User-agent: Yandex
Allow: /catalog
Disallow: /
Сортированный robots.txt:
User-agent: Yandex
Disallow: /
Allow: /catalog
# разрешает скачивать только страницы, начинающиеся с ‘/catalog’
Исходный robots.txt:
User-agent: Yandex
Allow: /
Allow: /catalog/auto
Disallow: /catalog
Сортированный robots.txt:
User-agent: Yandex
Allow: /
Disallow: /catalog
Allow: /catalog/auto
# запрещает скачивать страницы, начинающиеся с ‘/catalog’,
# но разрешает скачивать страницы, начинающиеся с ‘/catalog/auto’.
При конфликте между двумя директивами с префиксами одинаковой длины в Яндексе приоритет отдается директиве Allow, в Google — Disallow.
В любом случае протестируйте ваш robots.txt на конфликты в обоих вебмастерах.
Ошибки, часто встречающиеся в файле robots.txt — Robots.Txt по-русски
Непосредственно ошибки
Перепутанные инструкции
Одна из самых распространённых ошибок в robots.txt – перепутаные между собой инструкции. Например:
User-agent: /
Disallow: Yandex
Правильно писать вот так:
User-agent: Yandex
Disallow: /
Указание нескольких каталогов в одной инструкции Disallow
Многие владельцы сайтов пытаются поместить все запрещаемые к индексации каталоги в одну инструкцию Disallow.
Disallow: /css/ /cgi-bin/ /images/
Такая запись нарушает стандарт, и невозможно угадать, как ее обработают разные роботы. Некоторые могут «отбросить» пробелы и интерпретируют эту запись как «Disallow: /css/cgi-bin/images/». Некоторые могут использовать только первую или последнюю папки (/css/ или /images/ соответственно). Кто-то может просто отбросить непонятную инструкцию полностью.
Конечно, какие-то роботы могут обработать эту конструкцию именно так, как расчитывал веб-мастер, но расчитывать на это все же не стоит. Правильно надо писать так:
Disallow: /css/
Disallow: /cgi-bin/
Disallow: /images/
Имя файла содержит заглавные буквы
Файл должен называться robots.txt, а не Robots.txt или ROBOTS.TXT.
Использование файла robot.txt вместо robots.txt
Еще раз – файл должен называться robots.txt.
Пустая строка в User-agent
Так неправильно:
User-agent:
Disallow:
Так правильно:
User-agent: *
Disallow:
Url в директиве Host
Следует писать без аббревиатуры протокола передачи гипертекста, то есть без http:// и без закрывающего слеша /
Неправильно:
User-agent: Yandex
Disallow: /cgi-bin
Host: http://www.site.ru/
Правильно:
User-agent: Yandex
Disallow: /cgi-bin
Host: www.site.ru
Директива host Является корректной только для робота Яндекса
Использование в Disallow символов подстановки
Иногда хочется написать что-то вроде:
User-agent: *
Disallow: file*.html
для указания все файлов file1.html, file2.html, file3.html и т.д. Но нельзя, к сожалению (некоторые роботы поддерживают символы подстановки).
Плохой стиль
Комментарии на одной строке с инструкциями
По стандарту, такая запись вполне возможна:
Disallow: /cgi-bin/ #запрещаем роботам индексировать cgi-bin
В прошлом некоторые роботы не обрабатывали такие строки. Вероятно, сейчас ни у одной из основных поисковых систем уже нет такой проблемы, но стоит ли рисковать? Лучше помещать комментарии отдельно.
Редирект на страницу 404-й ошибки:
Довольно часто, на сайтах без файла robots.txt при запросе этого файла делается переадресация на другую страницу. Иногда такая переадресация происходит без отдачи статуса 404 Not Found. Пауку самому приходится разбираться, что он получил – robots.txt или обычный html-файл. Эта ситуация вряд ли создаст какие-то проблемы, но все-таки лучше всегда класть в корень сайта пустой файл robots.txt.
Заглавные буквы – это плохой стиль
USER-AGENT: GOOGLEBOT
DISALLOW:
Хотя по стандарту robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файов и директорий. Кроме того, написание robots.txt сплошь заглавными буквами считается плохим стилем.
User-agent: googlebot
Disallow:
Перечисление всех файлов
Еще одной ошибкой является перечисление каждого файла в директории:
User-agent: *
Disallow: /AL/Alabama.html
Disallow: /AL/AR.html
Disallow: /Az/AZ.html
Disallow: /Az/bali.html
Disallow: /Az/bed-breakfast.html
Вместо этого можно просто закрыть от индексации директорию целиком:
User-agent: *
Disallow: /AL/
Disallow: /Az/
Инструкции Allow не существует! [перевод устаревший]
Примечание: Не существовало на момент перевода данного текста, сейчас эта инструкция поддерживаетcя и Гуглом, и Яндексом. Уточняйте по использованию для других роботов.
Нет инструкции Allow, есть только Disallow. Файл robots.txt ничего не разрешает, только запрещает!
Отдельные роботы (например googlebot) понимают директиву Allow
Так неправильно:
User-agent: Yandex
Disallow: /john/
Allow: /jane/
А вот так – правильно:
User-agent: Yandex
Disallow: /john/
Disallow:
Использование дополнительных директив в секции *
Некоторые роботы могут неправильно отреагировать на использование дополнительных директив. Это значит, что не стоит использовать дополнительные директивы в секции «*».
То есть рекомендуется создавать специальные секции для нестандартных директив, таких как «Host».
Так неправильно:
User-agent: *
Disallow: /css/
Host: www.example.com
А вот так – правильно:
User-agent: *
Disallow: /css/User-agent: Yandex
Disallow: /css/
Host: www.example.com
Отсутствие инструкции Disallow
Даже если мы хотим просто использовать дополнительную директиву и не хотим ничего запрещать, лучше всего указать пустой Disallow. По стандарту интрукция Disallow является обязательной, и робот может «неправильно вас понять».
Так неправильно:
User-agent: Yandex
Host: www.example.com
Так правильно:
User-agent: Yandex
Disallow:
Host: www.example.com
Обсуждение этого вопроса на Searchengines.ru
Отсутствие слешей при указании директории
Как в этом случае поступит робот?
User-agent: Yandex
Disallow: john
По стандарту, он не будет индексировать файл с именем “john” и директорию с именем “john”. Для указания только директории надо писать так:
User-agent: Yandex
Disallow: /john/
Неправильный http-заголовок
Сервер должен возвращать в HTTP-заголовке для robots.txt «Content-Type: text/plain» а, например, не «Content-Type: text/html». Неправильный заголовок может привести к тому, что некоторые роботы не обработают файл.
Найдено несколько директив Host — есть ответ « Вопросы и ответы
Почему Яндекс выдает мне такую ошибку при проверке robots.txt? Вроде бы он составлен правильно:User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-content/uploads/2012/04/dogovor.doc
Disallow: /hip-young-woman
Disallow: /hello-world-2
Disallow: /hello-contact
Disallow: /wp-content/uploads/2012/04/license.pdf
Disallow: /feed
Disallow: */feed
Disallow: /*?*
Disallow: /*?
Disallow: /*.js$
Disallow: /*.inc$
Disallow: /*.css$
Disallow: /search/*/feed
Disallow: /search/*/*
Disallow: /tag/
Host: xn--e1af1aeqh.xn--p1ai
Sitemap: http://xn--e1af1aeqh.xn--p1ai/sitemap.xml
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-content/uploads/2012/04/dogovor.doc
Disallow: /hip-young-woman
Disallow: /hello-world-2
Disallow: /hello-contact
Disallow: /wp-content/uploads/2012/04/license.pdf
Disallow: /wp-trackback
Disallow: /wp-feed
Disallow: /wp-comments
Disallow: */trackback
Disallow: */feed
Disallow: */comments
Host: xn--e1af1aeqh.xn--p1ai
Sitemap: http://xn--e1af1aeqh.xn--p1ai/sitemap.xml
RPI.su — самая большая русскоязычная база вопросов и ответов. Наш проект был реализован как продолжение популярного сервиса otvety.google.ru, который был закрыт и удален 30 апреля 2015 года. Мы решили воскресить полезный сервис Ответы Гугл, чтобы любой человек смог публично узнать ответ на свой вопрос у интернет сообщества.
Все вопросы, добавленные на сайт ответов Google, мы скопировали и сохранили здесь. Имена старых пользователей также отображены в том виде, в котором они существовали ранее. Только нужно заново пройти регистрацию, чтобы иметь возможность задавать вопросы, или отвечать другим.
Чтобы связаться с нами по любому вопросу О САЙТЕ (реклама, сотрудничество, отзыв о сервисе), пишите на почту [email protected]. Только все общие вопросы размещайте на сайте, на них ответ по почте не предоставляется.